

O Google eliminou o parâmetro num em setembro de 2025 sem aviso prévio. A renderização em JavaScript tornou-se obrigatória e as visões gerais de IA foram implementadas em 200 países e territórios. Se você estiver fazendo scraping do Google, suas solicitações HTTP brutas agora retornam respostas vazias ou degradadas, a paginação baseada em num está quebrada e o conteúdo gerado por IA empurra os resultados orgânicos para baixo da página.
Todas as URLs de pesquisa do Google contêm parâmetros após o ? (como q para sua consulta, gl para país, hl para idioma, tbs para filtros de tempo e dezenas de outros). Errar neles significa que seu Scraper retornará dados do país errado ou resultados vazios que são difíceis de depurar.
Abaixo estão todos os parâmetros importantes, com código testado e exemplos práticos. Todo o código foi executado na API SERP ao vivo da Bright Data.
TL;DR: O que você precisa saber para 2026:
- Rastreamento de classificação:
q=...&gl=us&hl=en&pws=0&udm=14&brd_json=1(não personalizado, sem visões gerais de IA)- Paginação:
start=10,start=20, etc. (10 resultados por página).numnão funciona mais- Filtros de tempo:
tbs=qdr:d(último dia),tbs=sbd:1(ordenar por data),tbs=li:1(literal)- Novo:
udmestendetbmcom modos comoudm=14(somente web, sem IA). Ambos funcionam hoje. Suporte ambos.- Necessário: renderização em JavaScript. As chamadas raw
requests.get()retornam resultados vazios desde janeiro de 2025
Exemplo mínimo funcional:
curl -X POST "https://api.brightdata.com/request"
-H "Content-Type: application/json"
-H "Authorization: Bearer <API_TOKEN>"
-d '{"zona":"<ZONA_NAME>","url":"https://www.google.com/search?q=tools de Scraping de dados&gl=us&hl=en&brd_json=1","format":"raw"}'(brd_json=1 na URL instrui a Bright Data a parsar o HTML do Google em JSON estruturado. O formato: raw no corpo da solicitação retorna a resposta tal como está da infraestrutura da Bright Data, que, neste caso, é o JSON parseado produzido por brd_json=1.)
Referência rápida: folha de dicas dos parâmetros de pesquisa do Google
| Parâmetro | O que faz | Status |
|---|---|---|
q |
Consulta de pesquisa | Ativo |
hl |
Idioma da interface (en, fr, de) |
Ativo |
gl |
Geolocalização/país (us, gb, in) |
Ativo |
lr |
Restringir resultados a idiomas específicos | Ativo |
cr |
Restringir os resultados a páginas hospedadas em países específicos | Ativo |
num |
Resultados por página | Inativo (setembro de 2025) |
Início |
Deslocamento de paginação | Ativo |
tbm |
Tipo de pesquisa (isch, nws, loja, vid) |
Ativo |
udm |
Filtro de modo de conteúdo (14, 2, 39, 50) |
Ativo (Novo) |
tbs |
Filtros de tempo e avançados (qdr:d, qdr:w) |
Ativo |
seguro |
Filtragem SafeSearch | Ativo |
filtro |
Filtragem de resultados duplicados | Ativo |
nfpr |
Desativar correção automática | Ativo |
pws |
Desativar resultados personalizados (pws=0) |
Ativo |
uule |
Localização codificada (segmentação por cidade) | Ativo |
sclient |
Identificador do cliente de pesquisa | Ativo (interno) |
kgmid |
ID da entidade do gráfico de conhecimento | Ativo |
si |
Guias do Gráfico de Conhecimento (cadeia codificada opaca; não construível pelo usuário) | Ativo (interno) |
ibp |
Controle de renderização (trabalhos, listagens comerciais) | Ativo |
ei, ved, sxsrf |
Rastreamento interno/tokens de sessão | Ativo (interno) |
Os operadores de pesquisa do Google (site:, filetype:, intitle:, etc.) são abordados na seção de operadores mais adiante.
Experimente pesquisas básicas na API SERP – não é necessário fazer login. Para obter o conjunto completo de parâmetros, use a API diretamente.
O que são parâmetros de pesquisa do Google?
Os parâmetros de pesquisa do Google controlam a consulta, a localização, o idioma e a filtragem dos resultados. Eles são importantes para o rastreamento de classificação de SEO, análise de concorrentes, monitoramento de anúncios e alimentação de resultados de pesquisa em aplicativos LLM.
Uma coisa que mudou em 2025: o Google anunciou em abril de 2025 que os ccTLDs (domínios de nível superior com código de país, como google.co.uk, google.de, google.ca) serão redirecionados para google.com. A implementação é gradual e alguns ccTLDs ainda apresentam resultados diretamente. De qualquer forma, use gl e hl para localização, não o domínio.
Parâmetros de pesquisa principais
Estes são os que você definirá em quase todas as solicitações: consulta, idioma, país e paginação.
q – consulta de pesquisa
Sua consulta de pesquisa vai em q.
https://www.google.com/search?q=bright+data+Scraping de dadosOs espaços na consulta são codificados como + ou %20. O parâmetro q também suporta os operadores de pesquisa do Google, por exemplo:
https://www.google.com/search?q=filetype:pdf+guia+de+scraping+de+dados+web
https://www.google.com/search?q=site:github.com+API+SERP
https://www.google.com/search?q=intitle:tutorial+de+rotacao+de+ProxyCodifique corretamente sua string de consulta, especialmente caracteres não latinos (chinês, árabe, japonês, coreano, etc.) – a falha na codificação desses caracteres é uma causa comum de resultados inesperados ou vazios. Se você estiver usando a API SERP da Bright Data, sempre coloque o parâmetro q em primeiro lugar na sua URL. A documentação da Bright Data exige isso. Colocar outros parâmetros antes do q pode resultar em respostas mais lentas e taxas de sucesso mais baixas.
Através do método Proxy da API SERP da Bright Data:
curl --proxy brd.superproxy.io:33335
--proxy-user brd-customer-<CUSTOMER_ID>-zone-<ZONE_NAME>:<PASSWORD> -k
"https://www.google.com/search?q=tools de Scraping de dados&brd_json=1"Se você precisar preservar o HTML bruto dentro do JSON, use brd_json=html em vez de brd_json=1. A API direta suporta formatos de saída adicionais, incluindo Markdown, capturas de tela e saída analisada leve.
A resposta JSON tem a seguinte aparência (aprimorada):
{
"general": {
"search_engine": "google",
"results_cnt": 33500000,
"search_time": 0.21,
"language": "en",
"mobile": false,
"search_type": "text"
},
"input": {
"original_url": "https://www.google.com/search?q=Ferramentas de Scraping de dados&brd_json=1"
},
"organic": [
{
"link": "https://www.reddit.com/r/automation/comments/1ncuv8k/best_web_scraping_tools_ive_tried_and_what_i/",
"title": "As melhores ferramentas de Scraping de dados que já experimentei (e o que aprendi com elas...)",
"description": "Playwright: Ótimo para automação estruturada e testes, embora um pouco pesado em termos de código para scraping leve.",
"rank": 1,
"global_rank": 5
}
]
}O JSON agrupa tudo por seção SERP. Os resultados orgânicos são separados de top_ads e bottom_ads, os painéis de conhecimento são separados de people_also_ask, os resultados locais estão em snack_pack e os recursos mais recentes, como ai_overview, estão em seus próprios campos. Há mais de uma dúzia de seções no total, dependendo da consulta.
hl – idioma do host
Abreviação de “host language” (idioma do host), o hl controla o idioma da interface do Google e como o Google interpreta sua consulta.
https://www.google.com/search?q=coffee&hl=en
https://www.google.com/search?q=coffee&hl=es
https://www.google.com/search?q=coffee&hl=jaOs valores são códigos ISO 639-1, como hl=en (inglês), hl=fr (francês), hl=de (alemão), ou tags de idioma BCP 47, como hl=en-gb (inglês britânico), hl=pt-br (português brasileiro), hl=es-419 (espanhol latino-americano).
Através da API SERP, a mesma pesquisa fica assim:
curl --proxy brd.superproxy.io:33335
--proxy-user brd-customer-<CUSTOMER_ID>-zone-<ZONE_NAME>:<PASSWORD> -k
"https://www.google.com/search?q=meilleurs+outils+de+scraping&hl=fr&gl=fr&brd_json=1"Isso busca resultados em francês para uma consulta em francês, como se você estivesse pesquisando na França.
gl – geolocalização
A localização da sua pesquisa afeta os resultados. O parâmetro gl simula sua geolocalização (o país de onde a pesquisa parece ter origem). Ele usa códigos de país de duas letras ISO 3166-1 alfa-2.
https://www.google.com/search?q=pizza+delivery&gl=us
https://www.google.com/search?q=pizza+delivery&gl=gb
https://www.google.com/search?q=pizza+delivery&gl=inCompare a mesma consulta em dois países:
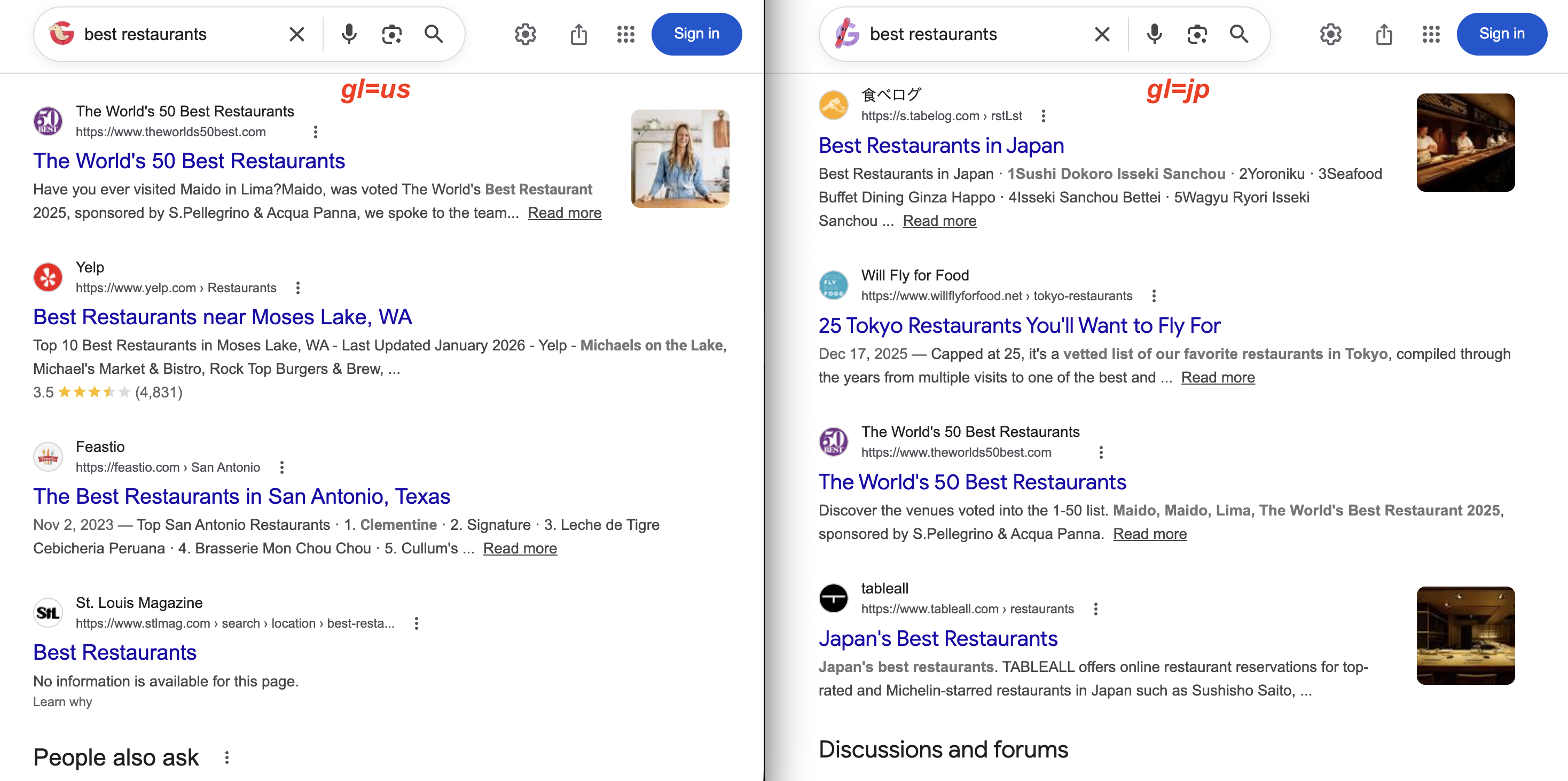
gl=us retorna o Yelp e revistas locais dos EUA. Com gl=jp, os resultados mostram 食べログ (Tabelog) e guias de restaurantes de Tóquio. A mesma consulta, resultados muito diferentes.
lr – restrição de idioma
Pesquisar por machine learning com hl=en ainda retorna artigos em chinês, japonês ou alemão, se o Google considerar que eles são relevantes. O parâmetro lr resolve isso. Ele restringe os resultados a páginas realmente escritas em idiomas específicos, não apenas à interface.
https://www.google.com/search?q=machine+learning&lr=lang_en
https://www.google.com/search?q=machine+learning&lr=lang_en|lang_frPrefixe o código do idioma com lang_ (portanto, inglês é lang_en, francês é lang_fr). Use o sinal | para combinar vários idiomas.
cr – restrição por país
Semelhante a lr, mas filtra por país de hospedagem em vez de idioma do conteúdo. Use cr=countryUS para um único país, cr=countryUS|countryGB para vários. A principal diferença em relação a gl: gl geolocaliza sua pesquisa como se você estivesse naquele país, cr filtra para páginas realmente hospedadas lá. Use os dois juntos se precisar de uma filtragem exata.
num – número de resultados
O parâmetro num era usado para controlar quantos resultados de pesquisa apareciam por página (por exemplo, num=20, num=50, num=100).
Se o seu Scraper começou a retornar apenas 10 resultados após setembro de 2025, essa alteração no parâmetro é o motivo. A partir de setembro de 2025, o Google desativou silenciosamente o parâmetro num. Agora ele é completamente ignorado. O Google retorna 10 resultados por página, independentemente do valor num que você passa, sem erro ou redirecionamento. Isso prejudicou as ferramentas de SEO e os fluxos de trabalho de scraping de SERP que dependiam dele. Um porta-voz do Google confirmou: “O uso desse parâmetro de URL não é algo que oferecemos suporte formalmente”. A seção de alterações de 2025–2026 aborda a solução alternativa usando o endpoint Top 100 Results da Bright Data.
Você pode verificar isso. num=100 está na URL, mas apenas 10 resultados são retornados:
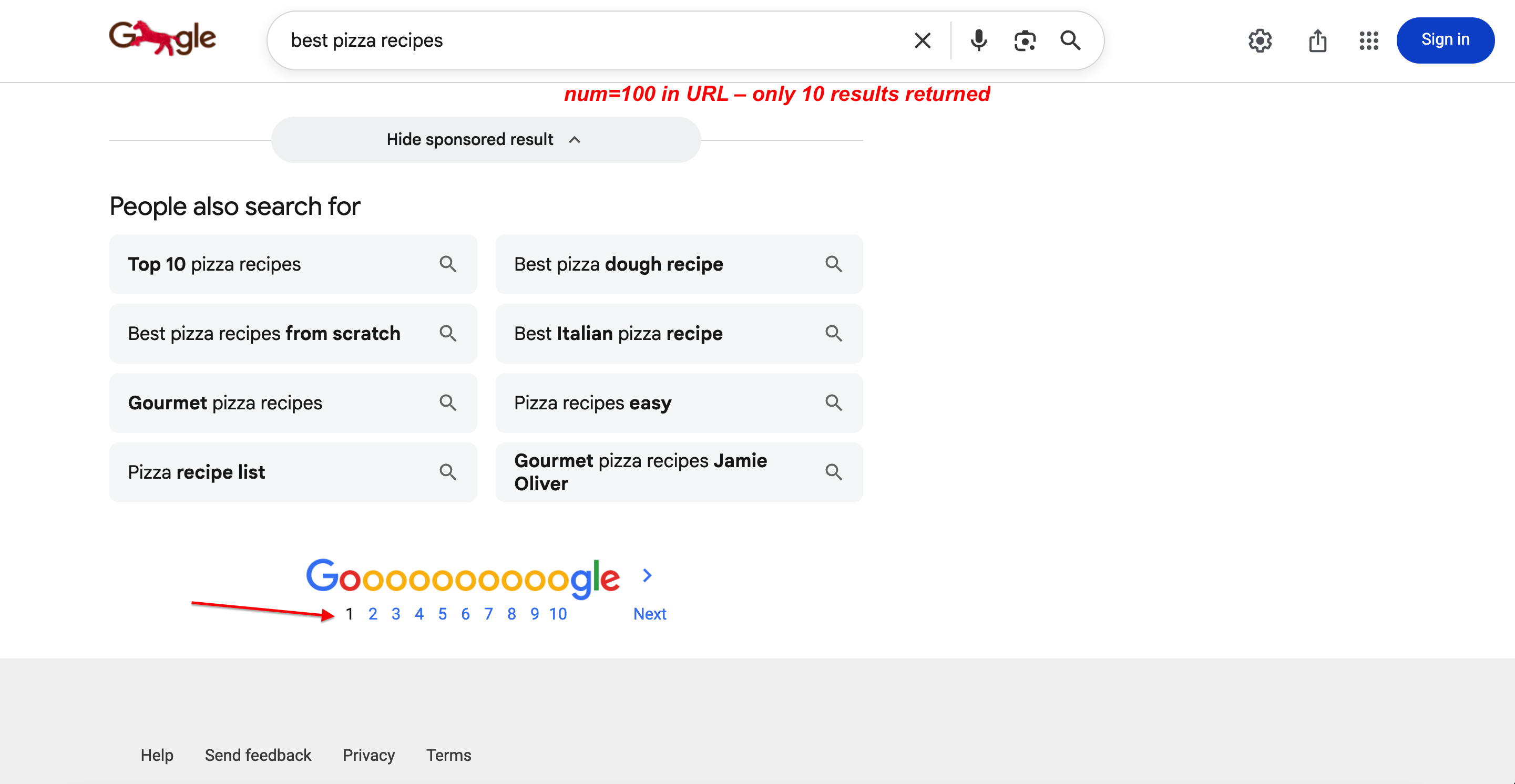
Pesquisando com num=100 na URL. O Google ainda retorna apenas 10 resultados por página com paginação completa. O parâmetro é completamente ignorado.
start – deslocamento do resultado (paginação)
Como o Google eliminou o num, o start é sua única opção de paginação nativa. Ele define o deslocamento do resultado, controlando a posição do resultado a partir da qual começar.
https://www.google.com/search?q=Scraping de dados&start=0
https://www.google.com/search?q=Scraping de dados&start=10
https://www.google.com/search?q=Scraping de dados&start=20start=0 é a página 1 (padrão), start=10 é a página 2, start=20 é a página 3.
Como o Google retorna 10 resultados por página, start=20 fornece os resultados 21–30, start=30 fornece 31–40 e assim por diante. Ao paginar em várias páginas, o Google pode retornar resultados sobrepostos ou ligeiramente reordenados entre as páginas. Desduplique por URL antes do processamento.
Paginação pela API SERP:
# Buscar a página 3 dos resultados
curl --proxy brd.superproxy.io:33335
--Proxy-user brd-customer-<CUSTOMER_ID>-Zona-<ZONA_NAME>:<PASSWORD> -k
"https://www.google.com/search?q=serp+scraping&start=20&brd_json=1"Parâmetros do tipo de pesquisa
O Google tem dois parâmetros para alternar entre verticais de pesquisa (imagens, notícias, compras, vídeo): tbm e udm.
tbm – tipo de conteúdo da pesquisa
O parâmetro tbm (comumente interpretado como “to be matched”, embora o Google nunca tenha confirmado a sigla) informa ao Google que tipo de resultados de pesquisa você deseja. Sem ele, o Google usa como padrão a pesquisa normal na web.
| Valor | Tipo de pesquisa | Exemplo |
|---|---|---|
| (vazio) | Pesquisa na web | q=café |
isch |
Pesquisa de imagens | tbm=isch&q=café |
vid |
Pesquisa de vídeo | tbm=vid&q=café |
nws |
Pesquisa de notícias | tbm=nws&q=café |
loja |
Pesquisa de compras | tbm=loja&q=café |
bks |
Pesquisa de livros | tbm=bks&q=café |
A mesma consulta em três tipos de pesquisa:
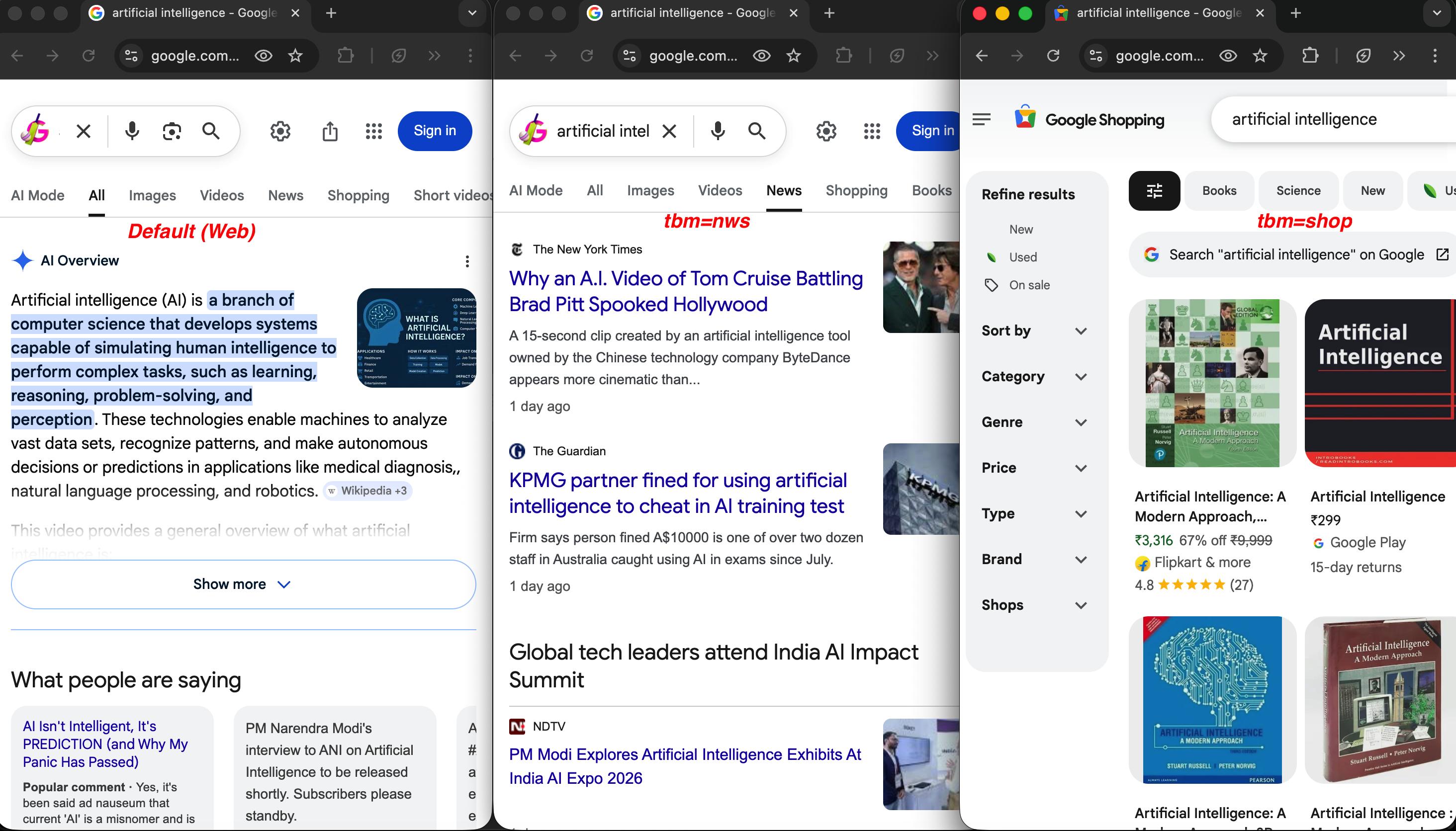
Mesma consulta, valores tbm diferentes: a pesquisa padrão na web (à esquerda) mostra uma visão geral da IA, tbm=nws (ao centro) retorna artigos de notícias do NYT e do The Guardian, e tbm=shop (à direita) mostra listas de produtos com preços e avaliações.
Uma pesquisa de notícias sobre inteligência artificial:
https://www.google.com/search?q=artificial+intelligence&tbm=nws&hl=en&gl=usUma pesquisa de compras por teclados mecânicos:
https://www.google.com/search?q=mechanical+keyboard&tbm=shop&gl=usTodos esses tipos de pesquisa funcionam nativamente. Ao realizar o Parsing da resposta JSON, os anúncios são separados nos campos top_ads e bottom_ads, e as listas de produtos aparecem em popular_products, todos distintos dos resultados orgânicos. Para monitoramento dedicado de anúncios, consulte o Scraper do Google Ads. Os parâmetros de viagem e hotel (hotel_occupancy, hotel_dates, brd_dates, brd_occupancy, brd_currency, etc.) são específicos da Bright Data e documentados na referência de parâmetros da API SERP.
udm – modo de exibição do usuário
O filtro de modo de conteúdo mais recente do Google é o udm, que amplia o tbm com tipos de resultados adicionais. Ele controla qual “modo” de resultados de pesquisa você vê. Nenhum dos valores udm está na documentação oficial do Google. Todos eles são revertidos pela comunidade de desenvolvedores por meio de testes. Os valores abaixo são estáveis e amplamente utilizados, mas o Google pode alterá-los sem aviso prévio.
| Valor | Modo de resultado | Descrição |
|---|---|---|
udm=2 |
Imagens | Resultados da pesquisa de imagens |
udm=7 |
Vídeos | Resultados de vídeo; equivalente mais recente de tbm=vid |
udm=12 |
Notícias | Resultados de notícias; equivalente mais recente de tbm=nws |
udm=14 |
Web | Resultados clássicos da web sem recursos de IA |
udm=18 |
Fóruns | Resultados de discussões e fóruns |
udm=28 |
Compras | Resultados de compras/produtos |
udm=36 |
Livros | Resultados de livros; equivalente mais recente de tbm=bks |
udm=39 |
Vídeos curtos | Conteúdo de vídeo de formato curto |
udm=50 |
Modo IA | Pesquisa conversacional com tecnologia de IA do Google |
O valor mais notável é udm=14. Ele força o Google a exibir resultados tradicionais da web sem visões gerais de IA ou outro conteúdo gerado por IA:
https://www.google.com/search?q=Scraping de dados&udm=14A diferença entre o padrão e udm=14 é visível imediatamente:
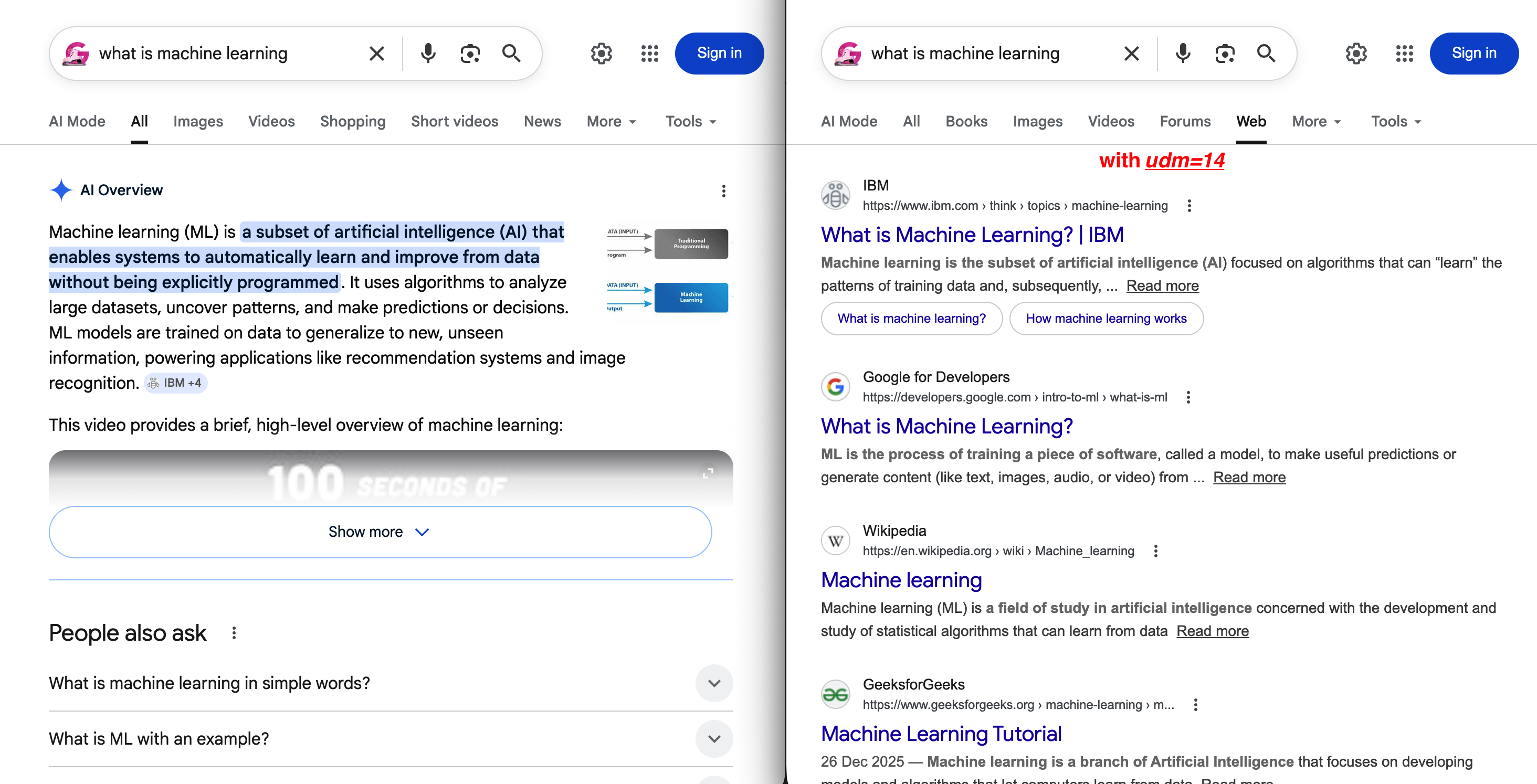
Esquerda: a SERP padrão com uma visão geral da IA empurrando os resultados orgânicos para baixo da página. Direita: udm=14 remove tudo isso e mostra uma guia “Web” limpa com links azuis tradicionais.
Para resultados de vídeos curtos, use udm=39 (não documentado pelo Google; o comportamento pode variar de acordo com a região):
https://www.google.com/search?q=coffee+recipes&udm=39O modo IA (udm=50) é um tipo de pesquisa muito diferente:
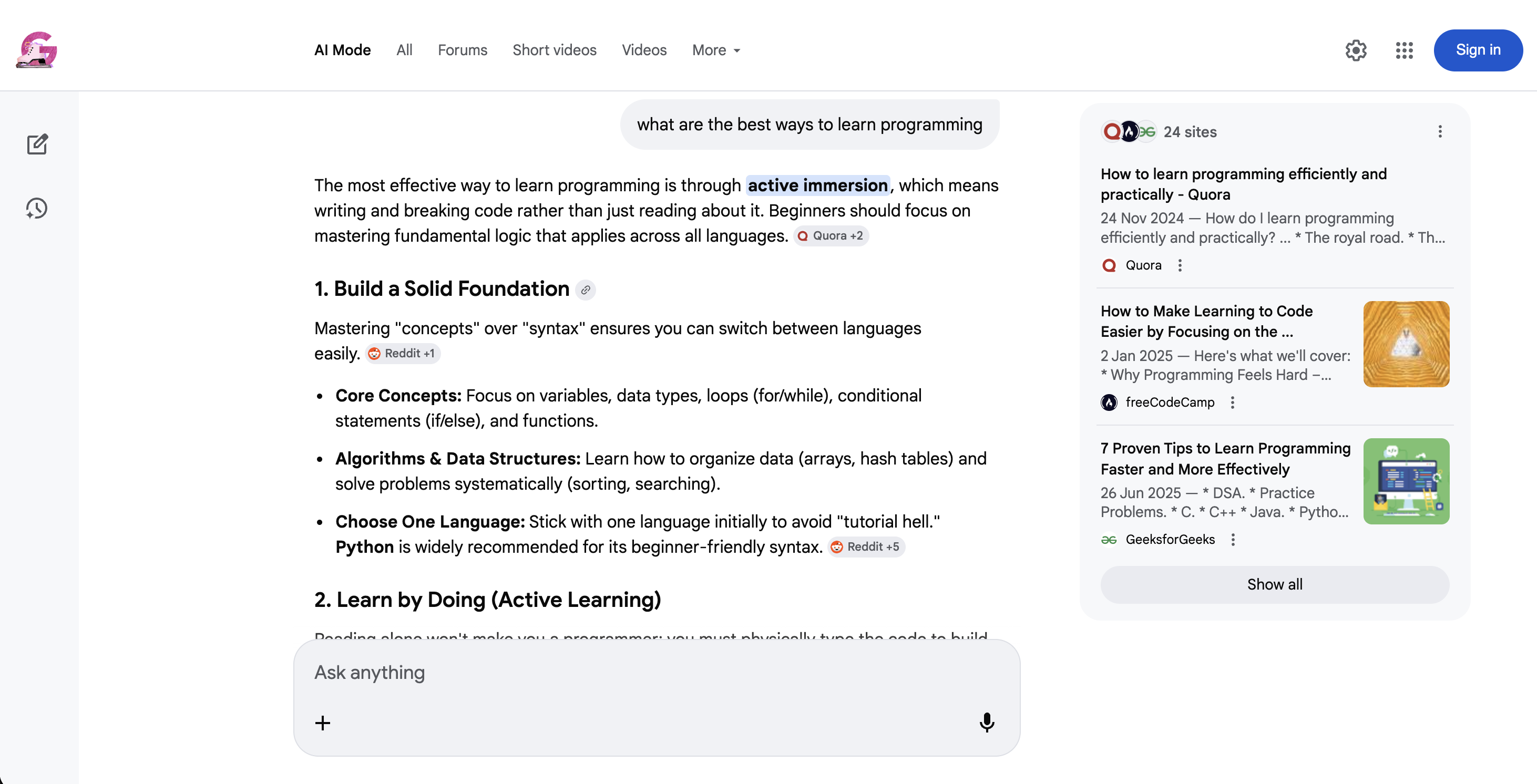
Modo IA do Google (udm=50): em vez dos resultados tradicionais, o Google retorna uma resposta de IA conversacional com citações de fontes embutidas e sugestões de perguntas complementares.
O tbm e o udm se sobrepõem para imagens, notícias e compras, mas o udm também abrange modos que o tbm não abrange (fóruns, vídeos curtos, modo IA, somente web). Ambos funcionam hoje. Se você estiver criando novos fluxos de trabalho de scraping, ofereça suporte a ambos os parâmetros para obter compatibilidade máxima.
Parâmetros de filtragem e classificação
tbs – filtros baseados em tempo e avançados
O parâmetro tbs (comumente interpretado como “a ser pesquisado”, embora nenhuma fonte oficial confirme isso) controla a filtragem por tempo, classificação por data e correspondência literal.
O uso mais comum é a filtragem por tempo com qdr (intervalo de datas da consulta):
| Valor | Intervalo de tempo |
|---|---|
tbs=qdr:h |
Última hora |
tbs=qdr:d |
Últimas 24 horas |
tbs=qdr:w |
Última semana |
tbs=qdr:m |
Último mês |
tbs=qdr:y |
Último ano |
Você também pode definir um intervalo de datas personalizado com tbs=cdr:1,cd_min:01/01/2025,cd_max:12/31/2025. Útil para acompanhar como os resultados da pesquisa mudam ao longo de um período específico.
Além da filtragem por tempo, o tbs tem dois outros modos úteis. tbs=sbd:1 força o Google a classificar os resultados por data (os mais recentes primeiro) em vez de relevância, o que é útil para monitorar menções recentes. E tbs=li:1 habilita a pesquisa literal. O Google pesquisa exatamente o que você digitou, sem correções automáticas, sinônimos ou termos relacionados.
Para monitorar notícias recentes sobre um tópico:
curl --proxy brd.superproxy.io:33335
--proxy-user brd-customer-<CUSTOMER_ID>-zone-<ZONE_NAME>:<PASSWORD> -k
"https://www.google.com/search?q=Scraping de dados&tbs=qdr:w&brd_json=1"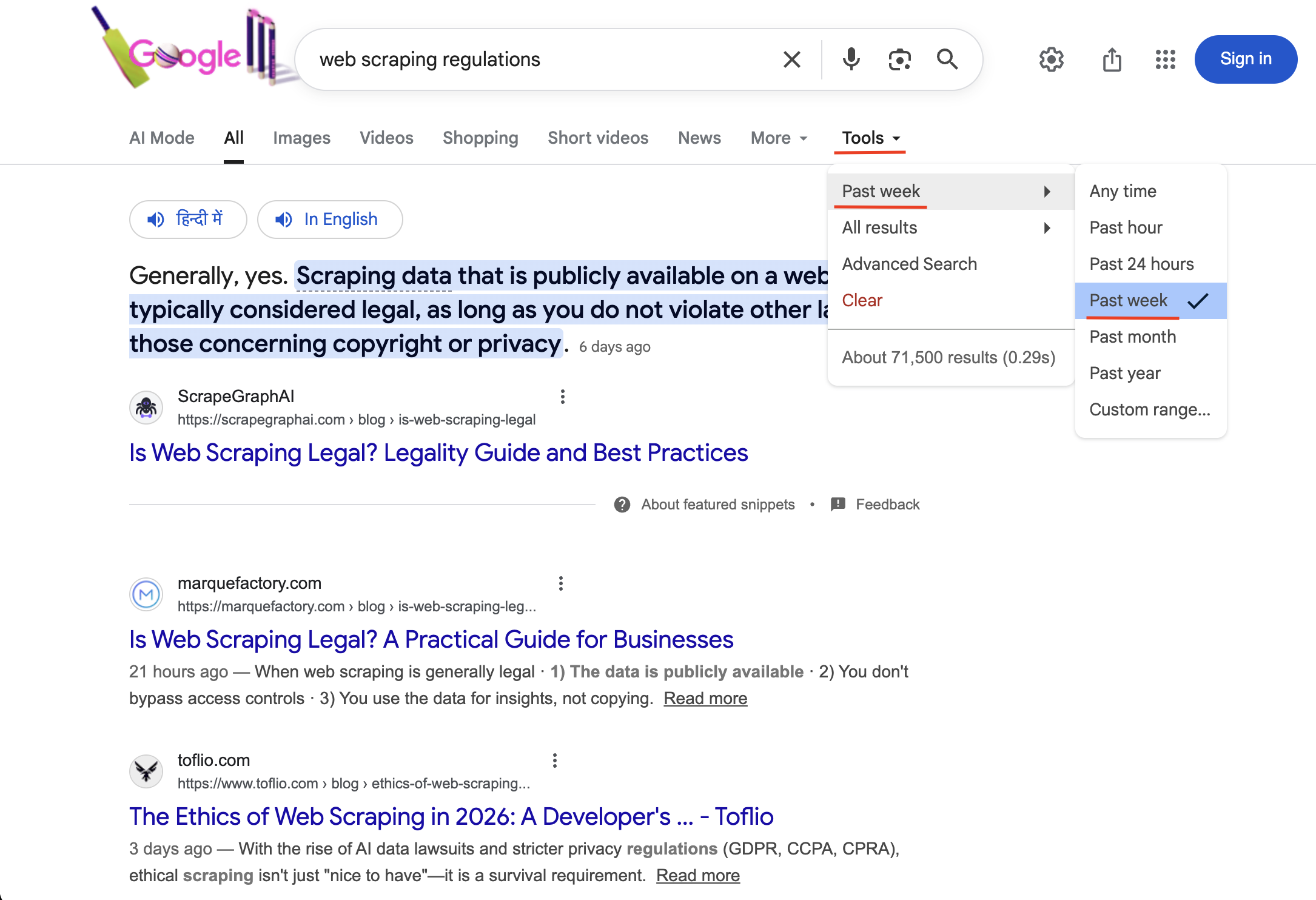
A pesquisa com tbs=qdr:w ativa o filtro de tempo “Última semana” (visível em Ferramentas com uma marca de seleção). Apenas os resultados publicados nos últimos 7 dias são retornados.
Dica: combine filter=0 com qualquer filtro de tempo tbs para obter todos os resultados. Sem isso, o Google agrupa páginas semelhantes e você pode perder coberturas relevantes.
safe – Filtragem SafeSearch
safe=active filtra conteúdo explícito, safe=off desativa a filtragem.
https://www.google.com/search?q=photography&safe=active
https://www.google.com/search?q=photography&safe=offfilter – filtragem de duplicatas
O parâmetro filter controla como o Google agrupa resultados semelhantes ou duplicados.
https://www.google.com/search?q=Scraping de dados&filter=0
https://www.google.com/search?q=Scraping de dados&filter=1filter=0 mostra todos os resultados, incluindo duplicatas. filter=1 (padrão) agrupa páginas semelhantes. Mais útil quando combinado com filtros de tempo (veja a dica tbs acima).
nfpr – sem correção automática
Defina nfpr=1 para impedir que o Google corrija automaticamente sua consulta.
https://www.google.com/search?q=scraping+brwser&nfpr=1Quando definido como 1, o Google pesquisará exatamente o que você digitou, sem sugerir “você quis dizer: Navegador de scraping”. Útil quando você está procurando intencionalmente por termos com erros ortográficos, nomes de marcas que o Google considera errados ou termos técnicos que o Google pode tentar corrigir. Observação: nfpr=1 apenas suprime a autocorreção. tbs=li:1 (modo literal) vai além, desativando também sinônimos, radicais e termos relacionados. Use os dois juntos para obter a correspondência mais rigorosa.
pws – pesquisa personalizada na web
O Google personaliza os resultados da pesquisa por padrão. pws controla se essa personalização está ativa.
https://www.google.com/search?q=Scraping de dados&pws=0Desativar a personalização (pws=0) é importante porque os resultados personalizados variam de acordo com o usuário, tornando os dados em massa inconsistentes. Para qualquer coleta séria de dados SERP, sempre inclua pws=0 para obter as classificações básicas e não personalizadas.
Parâmetros de localização
A maioria dos rastreamentos de classificação precisa apenas de segmentação em nível de país com gl. No entanto, para SEO local, você precisa de uma segmentação mais precisa.
uule – localização codificada
uule oferece precisão em nível de cidade quando gl não é granular o suficiente.
O valor uule é uma string codificada com base nas segmentações geográficas da API do Google Ads. Ele usa uma codificação de nome canônico (do banco de dados de segmentação geográfica do Google) ou uma codificação de coordenadas GPS (latitude/longitude).
https://www.google.com/search?q=best+restaurants&uule=w+CAIQICIGUGFyaXMGerar valores uule manualmente é complicado. Você precisa procurar o nome canônico do local na documentação do Geo Targets do Google e, em seguida, codificá-lo no formato específico esperado pelo Google.
Com a API SERP da Bright Data, você pode pular a codificação completamente e apenas passar o nome do local como uma string legível:
https://www.google.com/search?q=best+restaurants&uule=New+York,New+York,United+StatesA API lida com a pesquisa e a codificação automaticamente.
Use gl para segmentação em nível de país e uule quando precisar de precisão em nível de cidade. Para a maioria dos rastreamentos de classificação, gl é suficiente. Reserve uule para auditorias de SEO locais, nas quais os resultados diferem entre cidades do mesmo país.
Parâmetros de dispositivo e cliente
O Google retorna resultados diferentes para dispositivos móveis e computadores. Esses parâmetros controlam a emulação do dispositivo e a identificação do navegador.
sclient – cliente de pesquisa
Você verá sclient em quase todas as URLs de pesquisa do Google. Ele identifica o cliente de pesquisa que iniciou a pesquisa. Valores comuns: gws-wiz (pesquisa na web), gws-wiz-serp (iniciada por SERP), img (pesquisa de imagens), psy-ab (associado à pesquisa instantânea/preditiva do Google). É usado para análises internas do Google e não afeta seus resultados.
brd_mobile / brd_browser – emulação de dispositivo e navegador
A API SERP oferece brd_mobile para simular pesquisas a partir de dispositivos específicos:
| Valor | Dispositivo | Tipo de agente do usuário |
|---|---|---|
0 ou omitir |
Desktop | Desktop |
1 |
Celular | Celular |
iOS ou iPhone |
iPhone | iOS |
iPad ou tablet iOS |
iPad | Tablet iOS |
Android |
Android | Android |
Tablet Android |
Tablet Android | Tablet Android |
curl --proxy brd.superproxy.io:33335
--proxy-user brd-customer-<CUSTOMER_ID>-zone-<ZONE_NAME>:<PASSWORD> -k
"https://www.google.com/search?q=best+apps&brd_mobile=ios&brd_json=1"Se você encontrar erros
expect_bodyao usarbrd_mobilecom o método Proxy, tente o método Direct API. Ele tende a ser mais confiável para emulação de dispositivos. A integração LangChain também funciona bem aqui, pois passadevice_typepela Direct API automaticamente.
Você também pode controlar o tipo de navegador com brd_browser:
brd_browser=chrome(Google Chrome)brd_browser=safari(Safari)brd_browser=firefox(Mozilla Firefox, não compatível combrd_mobile=1)
Se não for especificado, a API escolhe um navegador aleatório. Combine os dois parâmetros para definir a combinação exata de dispositivo + navegador:
curl --proxy brd.superproxy.io:33335
--proxy-user brd-customer-<CUSTOMER_ID>-zone-<ZONE_NAME>:<PASSWORD> -k
"https://www.google.com/search?q=best+smartphones&brd_browser=safari&brd_mobile=ios&brd_json=1"Parâmetros avançados e internos
Você não precisa definir nenhum desses parâmetros. Eles são parâmetros internos do Google. No entanto, se você quiser saber o que significam ei, ved e sxsrf quando os vir em uma URL do Google, esta seção os explica.
kgmid – ID da máquina do Knowledge Graph
O parâmetro kgmid fornece resultados do Gráfico de Conhecimento do Google e pode substituir totalmente o parâmetro q.
https://www.google.com/search?kgmid=/m/07gyp7Isso carrega diretamente o painel do Knowledge Graph para o McDonald’s. Cada entidade tem um ID de máquina exclusivo, e passá-lo por meio do kgmid busca o painel dessa entidade.
O painel que o Google retorna para esse ID:
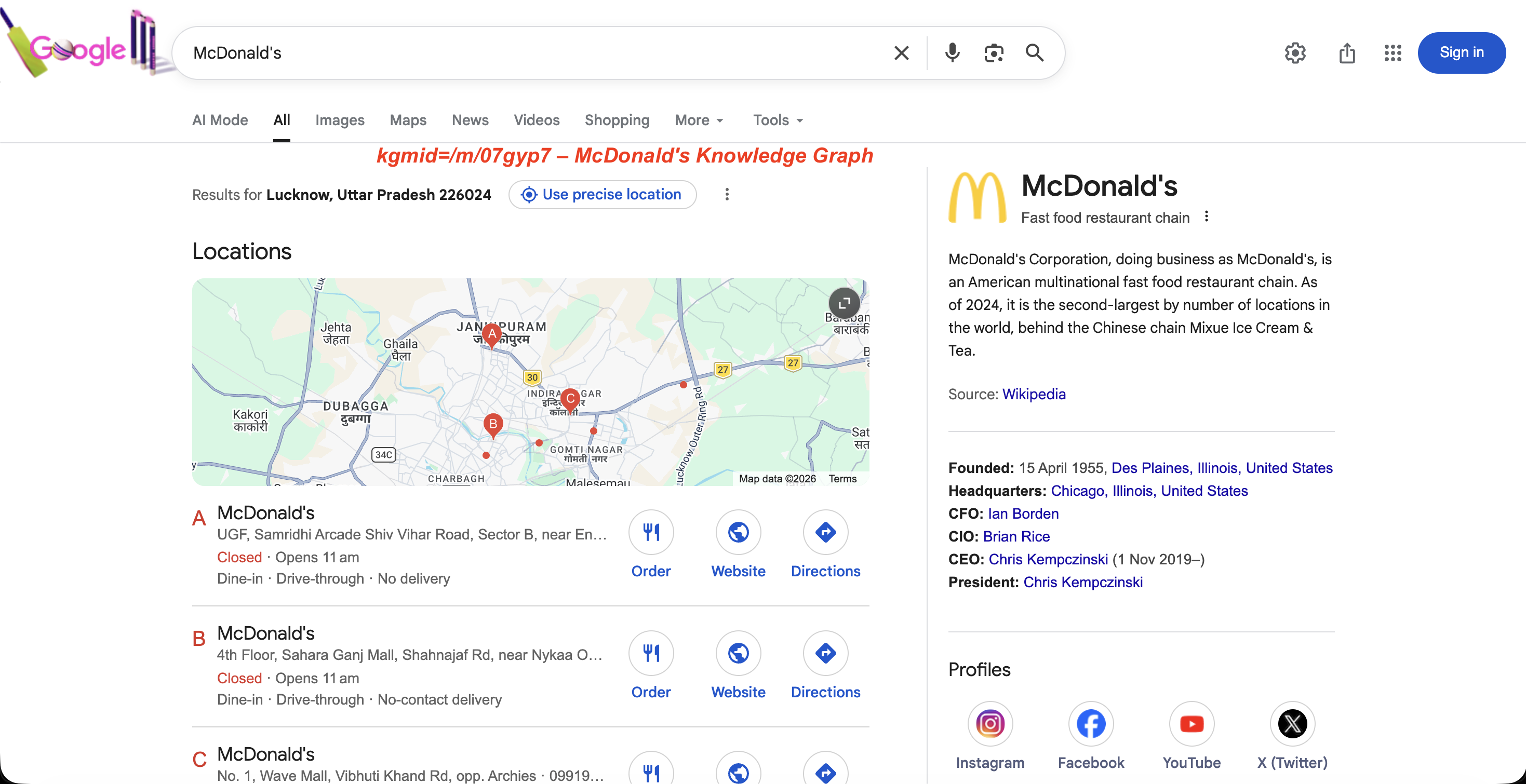
O painel do Gráfico de Conhecimento para kgmid=/m/07gyp7: descrição da entidade, data de fundação, liderança e perfis sociais.
As equipes de monitoramento de marca usam isso para acompanhar como o painel do Knowledge Graph do Google muda ao longo do tempo para sua empresa ou concorrentes.
ibp – controle de renderização
O Google não usa ibp para resultados de pesquisa regulares. Ele controla como certos elementos são renderizados no SERP, particularmente listagens do Google Business e Google Jobs.
https://www.google.com/search?ibp=gwp%3B0,7&ludocid=1663467585083384531Quando usado com o parâmetro ludocid (que é o ID exclusivo de uma listagem do Google Business), o ibp pode acionar visualizações de página inteira da listagem da empresa.
Para pesquisas de empregos, ibp=htl;jobs (codificado como ibp=htl%3Bjobs) aciona o painel do Google Jobs com listagens completas de empregos:
curl --proxy brd.superproxy.io:33335
--proxy-user brd-customer-<CUSTOMER_ID>-zone-<ZONE_NAME>:<PASSWORD> -k
"https://www.google.com/search?q=technical+copywriter&ibp=htl%3Bjobs&brd_json=1"O painel de empregos que ibp=htl%3Bjobs aciona:
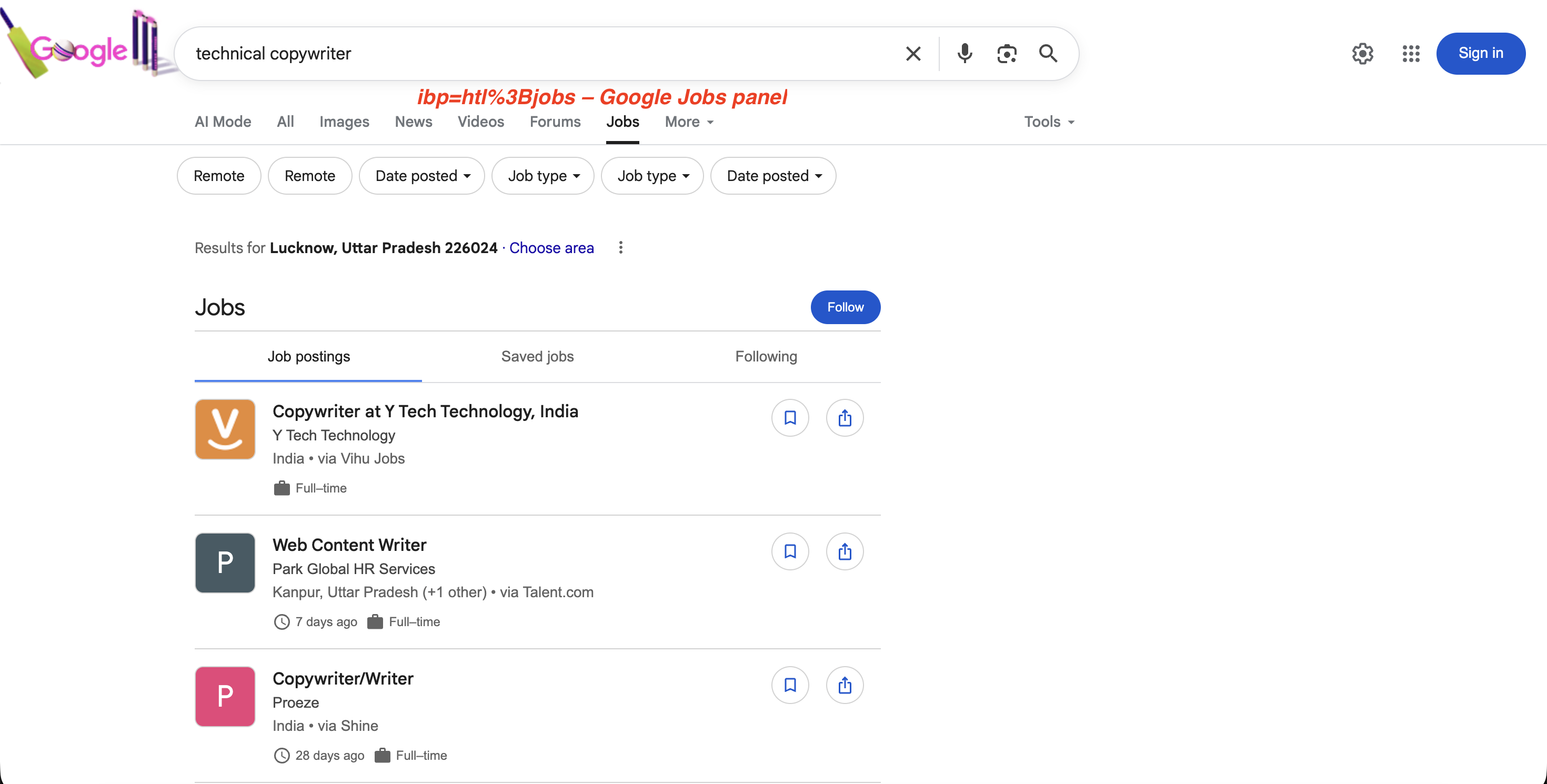
O parâmetro ibp=htl%3Bjobs aciona o painel de empregos dedicado do Google com anúncios de vagas, filtros e uma opção “Seguir”, todos extraíveis por meio da API SERP.
O ponto-e-vírgula em
htl;jobsdeve ser codificado como URL como%3B(ou seja,ibp=htl%3Bjobs) quando usado no curl ou em qualquer cliente HTTP. Sem a codificação adequada, a solicitação pode retornar resultados vazios.
ei, ved, sxsrf, oq, gs_lp – parâmetros de rastreamento internos
Nenhum deles afeta os resultados retornados. É seguro removê-los de suas URLs. Veja o que cada um deles faz:
| Parâmetro | Finalidade |
|---|---|
ei |
Identificador de sessão contendo um carimbo de data/hora Unix e valores opacos |
ved |
Rastreamento de cliques: codifica qual elemento SERP foi clicado, seu índice e tipo |
sxsrf |
Token CSRF com um carimbo de data/hora Unix codificado |
oq |
Consulta original conforme digitada antes da modificação pelo preenchimento automático (por exemplo, oq=web+scrap quando q=web+Scraping de dados+API) |
gs_lp |
Dados internos da sessão relacionados ao estado do cliente de pesquisa |
ie / oe |
Codificação de caracteres de entrada/saída (quase sempre UTF-8; pode ser ignorada) |
client |
Tipo de cliente de pesquisa (por exemplo, firefox-b-d, safari); identifica o navegador ou aplicativo |
fonte |
Identificador da fonte de pesquisa (por exemplo, hp para página inicial, lnms para mudança de modo) |
biw / bih |
Largura/altura interna do navegador em pixels; pode influenciar qual variante de layout SERP o Google exibe |
Operadores de pesquisa do Google
Os operadores de pesquisa são comandos especiais dentro do parâmetro q que filtram os resultados por domínio, tipo de arquivo, título, URL ou frase exata. O Google documenta alguns deles em sua página de ajuda sobre refinamento de pesquisa.
Eles são diferentes dos parâmetros de URL: os operadores ficam dentro do valor q, enquanto os parâmetros são pares de chave-valor separados na URL. Aqui estão os mais úteis para scraping e coleta de dados:
| Operador | Função | Exemplo |
|---|---|---|
site: |
Restringir a um domínio específico | site:github.com python Scraper |
tipo de arquivo: |
Restringir ao tipo de arquivo | filetype:pdf guia de Scraping de dados |
intitle: |
Pesquisar nos títulos das páginas | intitle:comparação de API SERP |
inurl: |
Pesquisar em URLs | inurl:documentação da API |
intext: |
Pesquisar no corpo da página | intext:rotação de Proxy |
allintitle: |
Todas as palavras no título | allintitle:Scraping de dados python |
allinurl: |
Todas as palavras na URL | allinurl:API docs scraping |
related: |
Encontrar sites semelhantes | related:brightdata.com |
OU |
Correspondência de qualquer termo | Scraping de dados OU web crawling |
"frase exata" |
Correspondência exata | “API SERP para python” |
- |
Excluir termo | Scraping de dados -selenium |
antes: / depois: |
Intervalo de datas | Visão geral da IA após: 2025-01-01 |
AROUND(n) |
Pesquisa por proximidade | scraping AROUND(3) python |
definir: |
Definição do dicionário | definir: Scraping de dados |
* |
Curinga | “melhor * para Scraping de dados” |
Todos eles também funcionam em solicitações de API. Por exemplo:
curl --proxy brd.superproxy.io:33335
--proxy-user brd-customer-<CUSTOMER_ID>-zone-<ZONE_NAME>:<PASSWORD> -k
"https://www.google.com/search?q=site:reddit.com+Ferramentas de Scraping de dados+2026&brd_json=1"Pesquisa especificamente no Reddit por discussões sobre ferramentas de Scraping de dados em 2026, com saída JSON estruturada.
O operador site:reddit.com restringe todos os resultados ao Reddit. Combinado com um termo de ano, ele mostra discussões recentes da comunidade sobre ferramentas de Scraping de dados.
Os operadores podem ser combinados:
site:github.com filetype:pdf machine learningretorna apenas arquivos PDF hospedados no GitHub que correspondem a “machine learning”.
as_* – parâmetros de pesquisa avançada
O formulário de pesquisa avançada do Google gera parâmetros com o prefixo as_ (as_q, as_epq, as_sitesearch, as_filetype, etc.) que correspondem aos operadores acima. A maioria dos engenheiros usa os operadores diretamente em q. Eles são úteis principalmente se você estiver criando uma interface de usuário para um formulário de pesquisa e quiser mapear campos do formulário para parâmetros de URL sem concatenar strings de operadores.
Mudanças de 2025-2026 que você precisa saber
O Google fez três alterações em 2025-2026 que quebraram as configurações de scraping existentes: renderização obrigatória de JavaScript (janeiro de 2025), remoção do parâmetro num (setembro de 2025) e expansão das visões gerais de IA para mais de 200 países.
O Google agora exige renderização em JavaScript
A partir de janeiro de 2025, o Google não exibirá resultados de pesquisa sem renderização JavaScript. Se você estiver executando um Scraper requests + BeautifulSoup, essa mudança é o motivo. Agora, todos os requests.get('https://google.com/search?q=...') retornam uma resposta vazia ou degradada. Você precisa de renderização completa do navegador ou de uma API SERP que faça isso por você.
A renderização JavaScript é automática com a API SERP, portanto, suas chamadas de API permanecem as mesmas.
O parâmetro num não funciona mais
Entre 12 e 14 de setembro de 2025, o Google desativou silenciosamente o num. O impacto foi amplo: 87,7% dos sites rastreados tiveram quedas de impressões no Google Search Console, de acordo com um estudo que abrangeu 319 propriedades.
Para obter mais de 10 resultados, a API SERP da Bright Data tem um endpoint Top 100 Results que retorna as posições 1 a 100 em uma única solicitação. Ela usa uma superfície de API diferente (/datasets/v3/trigger com o ID do Conjunto de dados gd_mfz5x93lmsjjjylob) e fornece os parâmetros start_page e end_page para controlar a profundidade da paginação:
curl -X POST "https://api.brightdata.com/conjuntos_de_datos/v3/trigger?dataset_id=gd_mfz5x93lmsjjjylob&include_errors=true"
-H "Authorization: Bearer <API_TOKEN>"
-H "Content-Type: application/json"
-d '[{
"url": "https://www.google.com/",
"keyword": "Scraping de dados",
"language": "en",
"country": "US",
"start_page": 1,
"end_page": 10
}]'Intervalos de páginas: 1..2 = 20 primeiros, 1..5 = 50 primeiros, 1..10 = 100 primeiros (10 resultados por página). A resposta inclui o texto da visão geral da IA (no campo aio_text ) quando o Google mostra um, e você pode adicionar "include_paginated_html": true para capturar o HTML bruto junto com os dados analisados. O processamento em lote também é suportado. Passe uma matriz de objetos de consulta para pesquisar várias palavras-chave em uma única solicitação.
Visão geral da IA nos resultados de pesquisa
As visões gerais da IA do Google (os resumos gerados por IA na parte superior dos resultados de pesquisa) agora estão disponíveis em mais de 200 países e mais de 40 idiomas. Em janeiro de 2026, o Google atualizou as visões gerais da IA para o Gemini 3. O Google também adicionou transições das visões gerais da IA para conversas no modo IA (udm=50). A captura desse conteúdo requer renderização em JavaScript e lógica de extração específica. Uma visão geral da IA em uma SERP ao vivo:
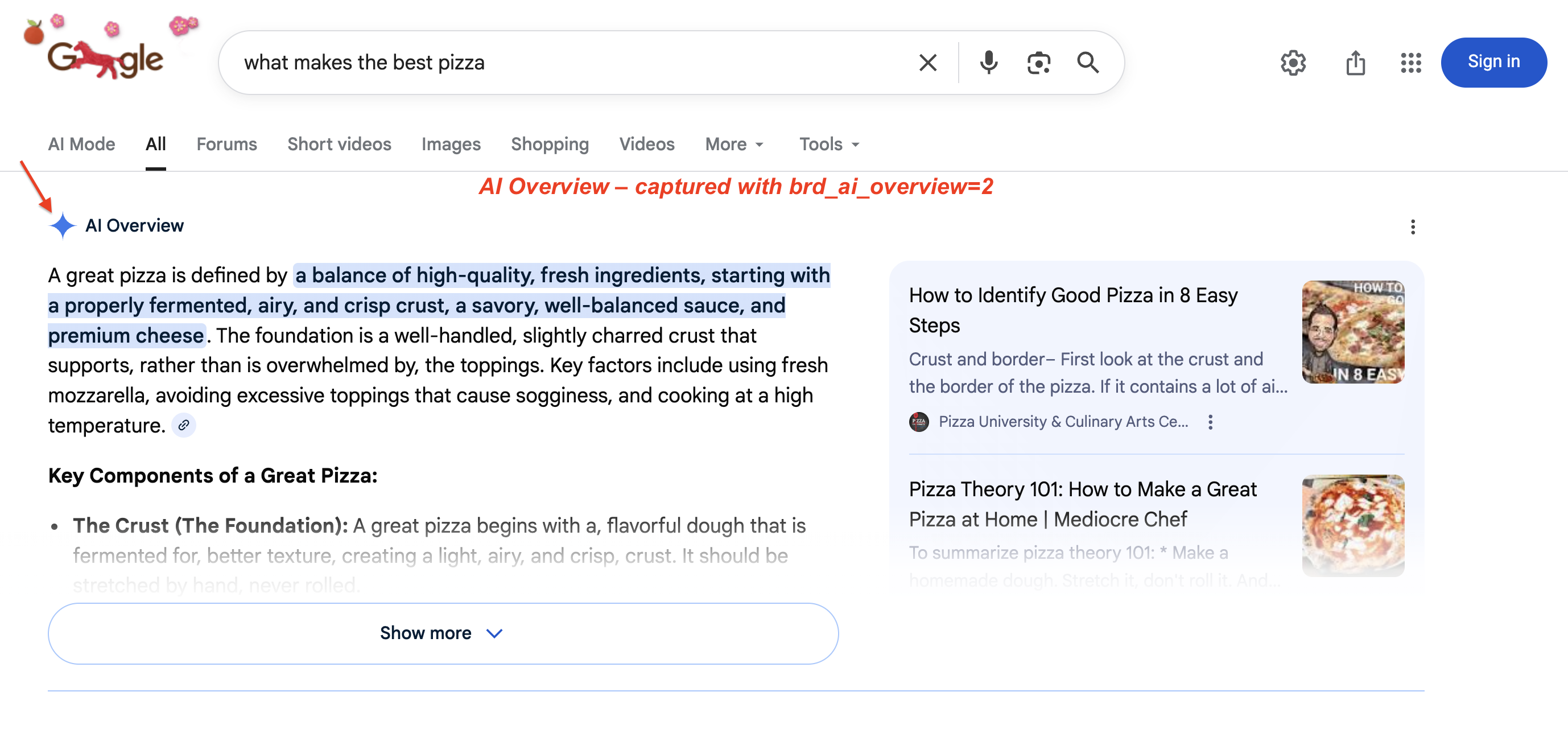
Uma visão geral típica da IA: o Google gera um resumo de vários parágrafos com frases-chave destacadas e cartões de fonte à direita. Esse bloco empurra os resultados orgânicos para baixo da tela. Use brd_ai_overview=2 para capturá-lo por meio da API SERP.
O Scraper da visão geral da IA funciona através do parâmetro brd_ai_overview. Defina brd_ai_overview=2 para aumentar a probabilidade de receber visões gerais geradas por IA nos seus resultados:
curl --proxy brd.superproxy.io:33335
--proxy-user brd-customer-<CUSTOMER_ID>-zone-<ZONE_NAME>:<PASSWORD> -k
"https://www.google.com/search?q=what+makes+the+best+pizza&brd_ai_overview=2&brd_json=1"Em nossos testes (consultas nos EUA), ativar a captura da visão geral da IA adicionou de 5 a 10 segundos ao tempo de resposta. A latência extra vem da espera pelo conteúdo de IA carregado dinamicamente pelo Google para terminar a renderização em um navegador headless.
Como usar os parâmetros de pesquisa do Google com uma API SERP
Se você estiver fazendo scraping em qualquer volume real, encontrará CAPTCHAs, bloqueios de IP, renderização obrigatória de JavaScript e alterações na infraestrutura do Google que silenciosamente quebram os analisadores. Testamos todos os métodos abaixo com a API ao vivo para confirmar se eles funcionam conforme documentado.
Quatro maneiras de usar esses parâmetros com a API SERP da Bright Data, da mais simples à mais avançada. Se você estiver apenas explorando, comece com o Método 1 (API direta). Se estiver integrando a uma base de código existente com cabeçalhos personalizados, opte pelo Método 2 (Proxy). Para fluxos de trabalho de agentes de IA, pule para o Método 4 (LangChain). O guia de introdução orienta você na configuração.
| Método | Ideal para | Resposta | Complexidade |
|---|---|---|---|
| API direta | Introdução, consultas únicas | Síncrono | Baixa |
| Roteamento de Proxy | Fluxos de trabalho HTTP existentes, cabeçalhos de solicitação personalizados | Síncrono | Baixo |
| Assíncrono em lote | Alto volume (mais de 1.000 consultas), varreduras de paginação | Em fila | Médio |
| LangChain | Agentes de IA, pipelines RAG, fluxos de trabalho com várias ferramentas | Síncrono | Baixo |
Método 1: solicitação direta de API
O método mais simples. Faça uma solicitação POST com sua URL de pesquisa e receba dados estruturados de volta:
import requests
import json
from urllib.parse import urlencode
# Crie a URL de pesquisa do Google com a codificação adequada (lida com caracteres não latinos e caracteres especiais)
params = urlencode({"q": "API de Scraping de dados", "gl": "us", "hl": "en", "brd_json": "1"})
search_url = f"https://www.google.com/search?{params}"
url = "https://api.brightdata.com/request"
headers = {
"Content-Type": "application/json",
"Authorization": "Bearer <API_TOKEN>"
}
payload = {
"zone": "<ZONE_NAME>",
"url": search_url,
"format": "raw"
}
response = requests.post(url, headers=headers, json=payload, timeout=30)
response.raise_for_status()
data = response.json()
# Validar resposta antes do processamento
if "organic" not in data or len(data.get("organic", [])) == 0:
print("Aviso: nenhum resultado orgânico retornado (possível bloqueio suave ou SERP vazio)")
print(json.dumps(data, indent=2))O nome padrão da zona é normalmente “serp”. A resposta analisada é retornada assim:
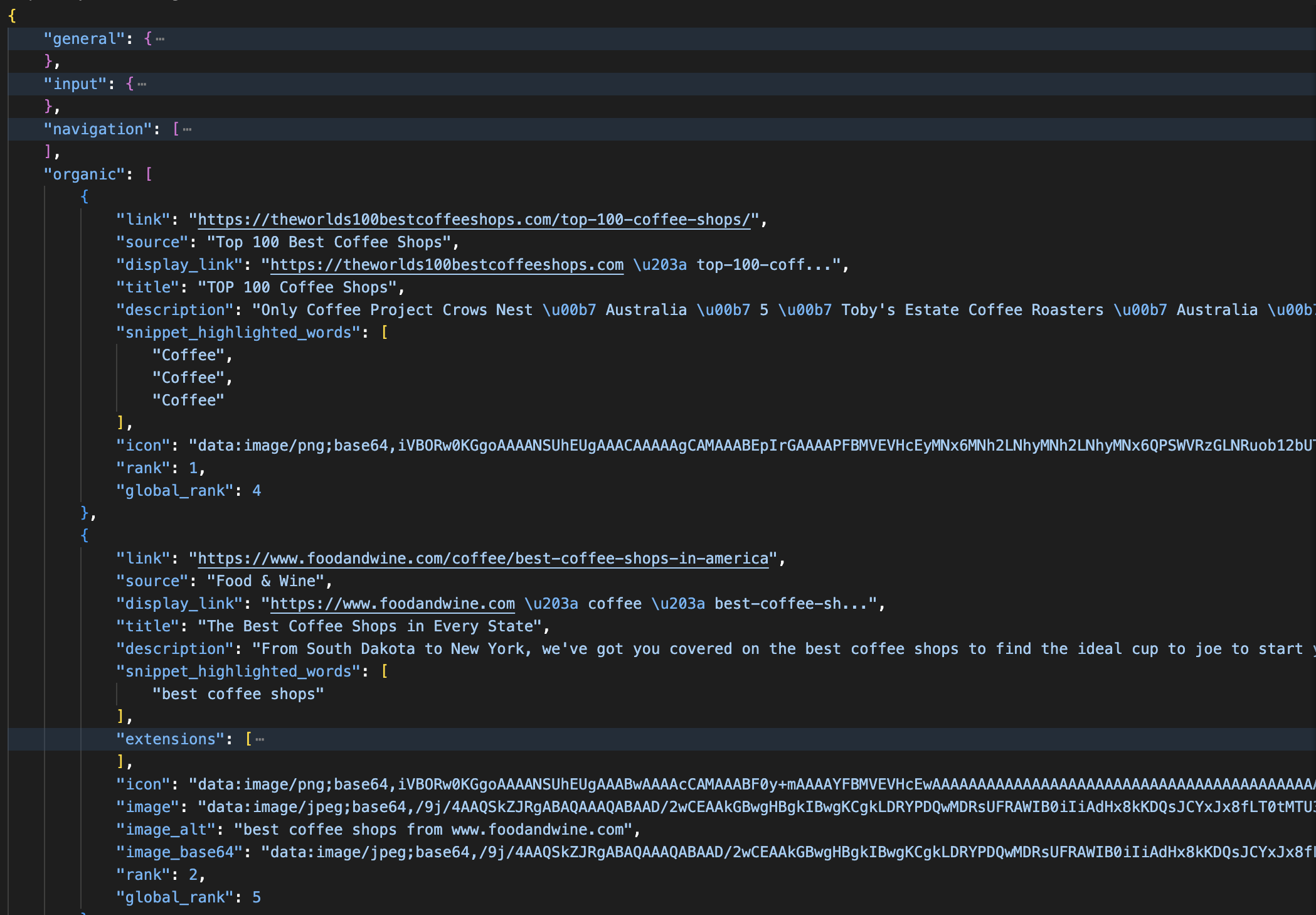
Uma resposta JSON analisada da API SERP: cada resultado orgânico inclui os campos título, link, descrição, classificação e classificação global. A resposta também separa anúncios, painéis de conhecimento e visões gerais de IA em seções nomeadas.
A API direta também aceita um campo de corpo “data_format” (separado de “format”): “markdown” para pipelines LLM/RAG (Retrieval-Augmented Generation), “screenshot” para uma captura PNG ou “parsed_light” apenas para os 10 principais resultados orgânicos. Use brd_json=html na URL se quiser que o HTML bruto seja preservado dentro do JSON.
countryno corpo não é o mesmo queglna URL.“country”: “us”controla o nó de saída do Proxy (a localização do IP da solicitação).gl=usinforma ao Google quais resultados do país devem ser exibidos. Para obter resultados geograficamente direcionados precisos, defina ambos.
Método 2: roteamento de Proxy
Encaminhe suas solicitações pela infraestrutura de Proxy da Bright Data. O Proxy lida com a renderização de JavaScript em seu lado, portanto, mesmo que seu código faça uma solicitação HTTP padrão, ele recebe resultados totalmente renderizados de volta. Isso funciona com qualquer cliente HTTP e permite que você defina cabeçalhos personalizados, cookies e opções no nível da solicitação que a API direta não expõe. Com a abordagem de Proxy, você controla o formato de saída por meio de parâmetros de URL: acrescente brd_json=1 para obter JSON analisado de volta em vez de HTML bruto:
import requests
# Use uma sessão para agrupamento de conexões (reutiliza conexões TCP entre solicitações)
session = requests.Session()
session.proxies = {
"http": "http://brd-customer-<CUSTOMER_ID>-zona-<ZONA_NAME>:<PASSWORD>@brd.superproxy.io:33335",
"https": "http://brd-customer-<CUSTOMER_ID>-zona-<ZONA_NAME>:<PASSWORD>@brd.superproxy.io:33335"
}
session.verify = False # para teste; carregue o certificado TLS/SSL da Bright Data em produção
url = "https://www.google.com/search?q=API SERP comparison&gl=us&hl=en&tbs=qdr:m&brd_json=1"
response = session.get(url, timeout=30)
response.raise_for_status()
print(response.json())As credenciais estão na guia “Detalhes de acesso” da Zona API SERP no seu painel. Sempre valide a resposta antes de processar. Um bloqueio suave do Google pode retornar JSON válido com conjuntos de resultados vazios ou reduzidos. Se general.results_cnt mostrar milhões de resultados estimados, mas a matriz orgânica estiver vazia ou tiver apenas 1–2 entradas, isso geralmente indica um bloqueio suave, em vez de um SERP genuinamente vazio.
O sinalizador
verify=False(ou-kno curl) ignora a verificação TLS/SSL, o que é adequado para testes. Para produção, carregue o certificado SSL da Bright Data.
Método 3: processamento em lote assíncrono
Para operações de alto volume (mais de 1.000 consultas), use o modo assíncrono. O modo assíncrono faz sentido quando você está paginando centenas de combinações de palavras-chave + localização usando os parâmetros start, gl e hl (por exemplo, rastreando 500 palavras-chave em 10 países). Você só é cobrado ao enviar a solicitação; a coleta da resposta é gratuita. Os tempos de retorno variam dependendo do volume e da carga de pico.
Primeiro, habilite a opção Solicitações assíncronas nas configurações avançadas da sua zona. Em seguida, use o endpoint /unblocker/req:
import requests
import json
import time
url = "https://api.brightdata.com/unblocker/req"
params = {"customer": "<CUSTOMER_ID>", "zone": "<ZONE_NAME>"}
headers = {
"Content-Type": "application/json",
"Authorization": "Bearer <API_TOKEN>"
}
payload = {
"url": "https://www.google.com/search?q=Ferramentas de Scraping de dados&gl=us&hl=en&brd_json=1",
"country": "us"
}
response = requests.post(url, params=params, headers=headers, json=payload, timeout=30)
response.raise_for_status()
response_id = response.headers.get("x-response-id")
print(f"Enfileirado. ID da resposta: {response_id}")
# Pesquise os resultados (para produção, configure uma URL webhook na configuração da sua zona)
# Janela total de pesquisa: 30 tentativas × 10s = 300s. Aumente range() para lotes grandes.
para tentativa em range(30):
time.sleep(10) # espere antes de verificar - os resultados nunca ficam prontos imediatamente
resultado = requests.get(
"https://api.brightdata.com/unblocker/get_result",
params={"customer": "<ID_DO_CLIENTE>", "zone": "<NOME_DA_ZONA>", "response_id": response_id},
headers={"Authorization": "Bearer <API_TOKEN>"},
timeout=30
)
if result.status_code == 200:
data = result.json()
if "organic" in data and len(data["organic"]) > 0:
imprimir(json.dumps(dados, indent=2))
else:
imprimir("Aviso: resposta retornada, mas não contém resultados orgânicos")
break
elif resultado.status_code == 202:
continuar # resultados ainda não estão prontos
else:
imprimir(f"Tempo limite após 300s aguardando response_id={response_id}")Em vez de fazer polling, você pode configurar uma URL de webhook (como padrão na configuração da sua zona ou por solicitação usando o parâmetro webhook_url ). A Bright Data envia uma notificação para o seu endpoint quando os resultados estão prontos (com o response_id e o status), então você não precisa fazer polling manualmente no endpoint /get_result. As respostas são armazenadas por até 48 horas.
Mesmo com uma API gerenciada, respeite os limites de taxa da sua zona. A configuração padrão lida com alto rendimento, mas enviar milhares de solicitações de sincronização simultâneas sem controle pode acionar respostas HTTP 429. O modo assíncrono evita isso, pois a API enfileira e controla as solicitações internamente.
Método 4: integração LangChain para fluxos de trabalho de IA
Se você estiver criando agentes de IA que precisam de dados de pesquisa em tempo real, existe uma integração oficial do LangChain (langchain-brightdata) para que você possa usar a pesquisa em tempo real como uma ferramenta nos fluxos de trabalho do agente:
pip install langchain-brightdatafrom langchain_brightdata import BrightDataSERP
serp_tool = BrightDataSERP(
bright_data_api_key="<API_TOKEN>",
zone="<ZONE_NAME>", # deve corresponder ao nome da zona no seu painel Bright Data
search_engine="google",
country="us",
language="en",
results_count=10,
parse_results=True)
# Substitua os padrões do construtor para esta solicitação específica:
results = serp_tool.invoke({
"query": "best web scraping tools 2026",
"country": "de",
"language": "de",
"search_type": "shop",
"device_type": "mobile",
})Algumas coisas a serem observadas nesta integração:
results_countmapeia paranumdo Google internamente. Comonumnão funciona mais (consulte a seção num), valores acima de 10 não têm efeito.countryelanguagecorrespondem aglehl(resultados de qual país e em que idioma). Ao contrário da API Direct, em que“country”controla o nó de saída do Proxy, o LangChain lida com o roteamento do Proxy automaticamente.Zonatem como padrão"serp". Se o nome da sua zona for diferente (por exemplo,"serp_api1"), defina-o explicitamente ou você receberá uma mensagem de erro “zona não encontrada”.
Além do LangChain, consulte os guias de integração para CrewAI, AWS Bedrock e Google Vertex AI. Para coleta de dados que não sejam de pesquisa, consulte as ferramentas de acesso à web de IA da Bright Data.
Para obter a lista completa de parâmetros: Documentação da API SERP
Por que usar uma API SERP gerenciada?
A API SERP lida com renderização JavaScript, Proxy rotativo, Resolução de CAPTCHA e segmentação geográfica:
Você mesmo poderia criar isso com Playwright, Selenium ou a própria API do navegador da Bright Data. Mas manter um Scraper do Google significa lidar com CAPTCHAs, bloqueios de IP, Proxies residenciais, renderização de JavaScript e Parsing de HTML que quebra sempre que o Google atualiza sua marcação. Consulte scraping gerenciado vs. baseado em API para uma comparação das duas abordagens.
Com a API SERP, você envia uma URL de pesquisa e recebe um JSON estruturado de volta. Ela funciona no Google, Bing, DuckDuckGo, Yandex e outros. Consulte a página de preços para ver as taxas atuais.
O API SERP Playground permite que você execute pesquisas básicas sem código, e o espaço de trabalho do Postman tem solicitações pré-construídas. Aqui está o Playground:
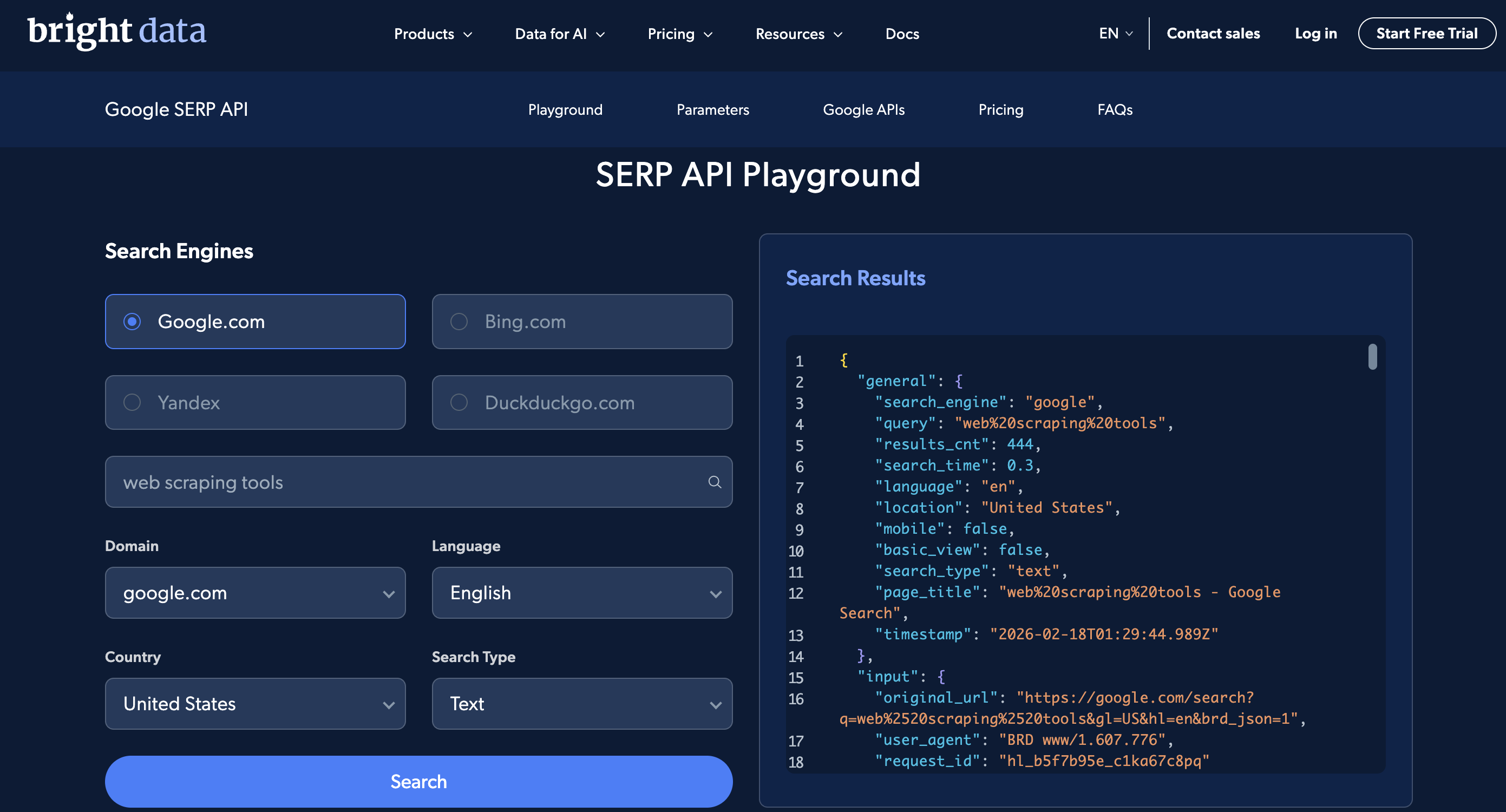
A interface do usuário do Playground: escolha um mecanismo de pesquisa, país e idioma, insira uma consulta e veja a resposta JSON parsed à direita.
Crie uma conta para executar os exemplos acima (novas contas recebem crédito gratuito para testes).
Casos de uso do mundo real
Essas combinações de parâmetros aparecem repetidamente em fluxos de trabalho de scraping de produção.
Rastreamento de classificação de SEO
Acompanhe as classificações de palavras-chave em diferentes locais combinando q, gl, hl, pws=0, udm=14 e start:
# Verifique a classificação de “ferramentas de Scraping de dados” nos EUA, Reino Unido e Alemanha
curl --proxy brd.superproxy.io:33335
--proxy-user brd-customer-<CUSTOMER_ID>-zone-<ZONE_NAME>:<PASSWORD> -k
"https://www.google.com/search?q=tools de Scraping de dados&gl=us&hl=en&pws=0&udm=14&brd_json=1"
# Em seguida, repita com gl=gb e gl=de
# Use start=10, start=20 para verificar as posições além da página 1Veja como criar um rastreador de classificação SEO com v0 e API SERP para obter um guia completo.
Monitoramento de anúncios da concorrência
Os posicionamentos dos anúncios dos seus concorrentes mudam diariamente. Combine termos de marca com tbs=qdr:d para encontrar alterações recentes:
https://www.google.com/search?q=competitor+brand+name&gl=us&hl=en&tbs=qdr:d&brd_json=1A resposta JSON separa top_ads, bottom_ads e popular_products (anúncios de listagem de produtos) dos resultados orgânicos.
Comparação de preços e inteligência de comércio eletrônico
Para comparar preços entre mercados, altere o valor gl mantendo tbm=shop:
https://www.google.com/search?q=sony+wh-1000xm5&tbm=shop&gl=us&brd_json=1
https://www.google.com/search?q=sony+wh-1000xm5&tbm=shop&gl=gb&brd_json=1
https://www.google.com/search?q=sony+wh-1000xm5&tbm=shop&gl=de&brd_json=1Monitoramento de notícias e análise de sentimentos
https://www.google.com/search?q=openai&tbm=nws&tbs=qdr:h&filter=0&brd_json=1. Use tbm=nws para notícias, tbs=qdr:h para a última hora, filter=0 para impedir que o Google agrupe artigos semelhantes. Execute isso em uma tarefa cron para monitoramento de cobertura por hora.
Pesquisa com IA e aplicações RAG
Aplicações LLM em dados de pesquisa ao vivo usando a API SERP como camada de recuperação. A integração LangChain (Método 4 acima), o servidor MCP e as chamadas diretas da API funcionam. Veja como construir um chatbot RAG com a API SERP para um exemplo prático.
SEO local e monitoramento de vários locais
As classificações locais podem diferir significativamente entre as cidades. Use uule com gl e pws=0 para comparar:
# Verifique as classificações para "encanador perto de mim" em 3 cidades
curl --proxy brd.superproxy.io:33335
--proxy-user brd-customer-<CUSTOMER_ID>-zona-<ZONA_NAME>:<PASSWORD> -k
“https://www.google.com/search?q=plumber+near+me&uule=Chicago,Illinois,United+States&gl=us&pws=0&brd_json=1”
# Repita com uule=Miami,Florida,United+States e uule=Seattle,Washington,United+StatesCompare os resultados do snack_pack (pacote local de 3) e orgânicos entre os locais para identificar onde suas listagens precisam ser melhoradas.
Pesquisa acadêmica e de mercado
https://www.google.com/search?q=site:arxiv.org+large+language+models&lr=lang_en&tbs=cdr:1,cd_min:01/01/2025,cd_max:12/31/2025&brd_json=1Combine site: com filtros lr e intervalo de datas tbs para criar Conjuntos de dados de pesquisa focados. Substitua arxiv.org por scholar.google.com, pubmed.ncbi.nlm.nih.gov ou qualquer outro domínio.
Conclusão
O que realmente importa de tudo o que foi mencionado acima:
- Use
gl+hl+pws=0+udm=14para um rastreamento de classificação consistente e não personalizado em todos os mercados numestá obsoleto. Usestartpara paginação ou o endpoint Top 100 da Bright Data para resultados em massaudm=14remove as visões gerais de IA e retorna resultados orgânicos clássicos.udmestendetbmcom modos adicionaistbslida com filtragem de tempo, classificação por data (sbd:1) e pesquisa literal (li:1)- Caracteres especiais precisam de codificação de URL. O ponto-e-vírgula em
ibp=htl%3Bjobsé o erro de codificação mais comum, junto com consultas não latinas
O Google continua mudando esses parâmetros. Eles removeram num sem aviso prévio e podem fazer o mesmo com start ou descontinuar tbm em favor de udm. Se você estiver fazendo scraping em um volume significativo, a API SERP da Bright Data lida com renderização, rotação e Parsing. Experimente com os exemplos acima.
Próximos passos
Leitura recomendada, com base no seu caso de uso:
Se você deseja começar a fazer scraping no Google agora:
- Como fazer scraping dos resultados de pesquisa do Google com Python: tutorial completo em Python com código funcional
- Como fazer scraping da visão geral do Google AI: extraia resumos gerados por IA
- Como fazer scraping do Google AI Mode: faça scraping da pesquisa conversacional com IA do Google
Se você estiver criando aplicativos de IA:
- Crie um chatbot RAG com a API SERP: baseie as respostas LLM em dados de pesquisa ao vivo
- Crie um rastreador de classificação de SEO com v0 e API SERP: passo a passo
- Agente GEO & SEO IA: otimize o conteúdo para mecanismos de pesquisa alimentados por IA
- CrewAI com API SERP: fluxos de trabalho de IA com vários agentes
Se você estiver avaliando provedores de API SERP:
- As melhores APIs SERP e de pesquisa na web de 2026: comparação lado a lado dos principais provedores
- Scraping gerenciado x baseado em API: comparação entre serviços gerenciados e abordagens baseadas em API
Outras fontes de dados do Google:
- Como coletar dados do Google Trends
- Melhores provedores de dados de hotéis: comparação de serviços de coleta de dados de hotéis
- Melhores provedores de dados de voos: comparação entre serviços de coleta de dados de voos
Referências externas:
- Aprimorar pesquisas no Google: guia oficial do Google para aprimorar consultas de pesquisa
Referências:
- Bright Data Google Search API (GitHub)
- API SERP da Bright Data (GitHub)
- Documentação da API SERP da Bright Data
Perguntas frequentes
O que são parâmetros de pesquisa do Google?
Os parâmetros de pesquisa do Google são pares de chave-valor anexados à URL https://www.google.com/search? que controlam como os resultados da pesquisa são gerados e exibidos. Por exemplo, q=pizza define a consulta de pesquisa, gl=us direciona para os Estados Unidos e hl=en define o idioma da interface para inglês. Eles são separados por & e seguem o ? na URL.
Qual é a diferença entre gl e hl na pesquisa do Google?
O parâmetro gl controla a geolocalização (o país de onde a pesquisa parece ter origem), afetando os resultados exibidos. O parâmetro hl controla o idioma do host (o idioma da interface do Google). Por exemplo, gl=de&hl=en fornece resultados relevantes para a Alemanha, mas com a interface exibida em inglês.
O parâmetro num do Google está obsoleto?
Não está apenas obsoleto. Ele não funciona de forma alguma. O Google o desativou silenciosamente entre 12 e 14 de setembro de 2025. Passar num=100 não faz nada, e o Google retorna 10 resultados independentemente do que aconteça. Use start para paginação ou o endpoint Top 100 da API Web Scraper da Bright Data para obter as posições 1 a 100 em uma única solicitação.
O que é o parâmetro udm do Google?
udm provavelmente significa User Display Mode (Modo de Exibição do Usuário, com base na engenharia reversa da comunidade; o Google não confirmou a sigla). Você usará principalmente udm=14, que remove as visões gerais de IA e retorna resultados orgânicos clássicos. Outros valores incluem udm=2 (imagens), udm=39 (vídeos curtos) e udm=50 (modo IA). udm estende tbm com modos adicionais, e ambos ainda funcionam. Todos os valores estão listados na seção udm.
Qual é a diferença entre tbm e udm?
tbm é o parâmetro mais antigo, udm é a extensão mais recente. Eles se sobrepõem para imagens, notícias e compras (tbm=isch ≈ udm=2), mas udm também inclui recursos que tbm não suporta: Modo IA (udm=50), fóruns (udm=18), vídeos curtos (udm=39). Ambos funcionam hoje. Crie um novo código com base no udm e mantenha o tbm como alternativa.
Como faço para paginar os resultados do Google agora que o num está obsoleto?
Use o parâmetro start. start=0 (ou omitido) fornece os resultados 1–10, start=10 fornece os resultados 11–20 e assim por diante. Cada página retorna 10 resultados. Para as posições 1–100 em uma única solicitação, use o endpoint Top 100 da Bright Data com os parâmetros start_page e end_page.
Como filtrar os resultados do Google por data?
Use o parâmetro tbs. tbs=qdr:h = última hora, tbs=qdr:d = último dia, tbs=qdr:w = última semana, tbs=qdr:m = último mês, tbs=qdr:y = último ano. Para um intervalo de datas personalizado: tbs=cdr:1,cd_min:MM/DD/AAAA,cd_max:MM/DD/AAAA. Adicione tbs=sbd:1 para classificar por data em vez de relevância.
Como posso extrair resultados de pesquisa do Google sem ser bloqueado?
Manter um Scraper do Google em escala requer a atualização de analisadores HTML sempre que o Google altera sua marcação, a resolução de CAPTCHA, a rotação de IPs e a renderização de JavaScript para cada solicitação desde janeiro de 2025. Uma API SERP gerenciada lida com essa infraestrutura. Você envia uma URL, recebe um JSON estruturado de volta e não precisa manter o analisador.





