
Neste artigo, você aprenderá:
- O que são os pipelines de IA da Vertex.
- Por que você pode integrar a API SERP da Bright Data a eles para verificação de fatos (e muitos outros casos de uso).
- Como criar um pipeline de verificação de fatos no Vertex IA usando a API SERP da Bright Data para recuperar o contexto atualizado da pesquisa na Web.
Vamos nos aprofundar!
O que são os pipelines do Vertex IA?
O Vertex IA Pipelines é um serviço gerenciado no Google Cloud que automatiza, orquestra e reproduz fluxos de trabalho de aprendizado de máquina de ponta a ponta.
Esse serviço permite dividir processos complexos de ML – como processamento de dados, treinamento e implantação – em uma série de componentes modulares que podem ser rastreados, versionados e executados em um ambiente sem servidor.
Em resumo, o Vertex IA Pipelines simplifica o ciclo de vida dos MLOps, facilitando a criação de sistemas de ML repetíveis e dimensionáveis.
Criação de um pipeline de verificação de fatos no Vertex IA: por que e como
Os LLMs são certamente poderosos, mas seu conhecimento é estático. Portanto, um LLM treinado em 2024 não tem conhecimento dos movimentos do mercado de ações de ontem, dos resultados esportivos de ontem à noite etc. Isso leva a respostas “obsoletas” ou “alucinadas”.
Para resolver esse problema, você pode criar um sistema que “fundamenta” um LLM com dados atualizados da Internet. Antes de o LLM gerar uma resposta, ele recebe informações externas para garantir que seu resultado seja baseado em fatos atuais. É disso que se trata o RAG(Retrieval-Augmented Generation)!
Agora, o Gemini fornece uma ferramenta de base para conectar os modelos Gemini à Pesquisa Google. No entanto, essa ferramenta não está pronta para produção, tem problemas de escalabilidade e não oferece controle total sobre a origem dos dados de base. Veja essa ferramenta em ação em nosso agente de otimização de conteúdo GEO/SEO.
Uma alternativa mais profissional e flexível é a API SERP da Bright Data. Essa API permite que você execute programaticamente consultas de pesquisa em mecanismos de pesquisa e recupere o conteúdo completo da SERP. Em outros termos, ela lhe oferece uma fonte confiável de conteúdo novo e verificável que pode ser integrado aos seus fluxos de trabalho de LLM. Descubra tudo o que ele tem a oferecer explorando sua documentação.
Por exemplo, é possível integrar a API SERP ao Vertex IA Pipelines como parte de um pipeline de verificação de fatos. Isso consistirá em três etapas:
- Extrair consultas: Um LLM lê o texto de entrada e identifica as principais alegações de fato, convertendo-as em consultas pesquisáveis no Google.
- Obter contexto de pesquisa na Web: Esse componente pega essas consultas e chama a API SERP da Bright Data para buscar resultados de pesquisa em tempo real.
- Verificação de fatos: Uma etapa final do LLM pega o texto original e o contexto de pesquisa recuperado e gera um relatório de verificação de fatos.
Observação: esse é apenas um dos muitos casos de uso possíveis para a API SERP em um pipeline de dados/ML.
Como integrar a API SERP da Bright Data para pesquisa na Web em um pipeline de IA da Vertex
Nesta seção, você será orientado em cada etapa necessária para implementar um pipeline de verificação de fatos no Vertex IA Pipelines. Isso dependerá da API SERP da Bright Data, que será usada para buscar o contexto factual da pesquisa na Web.
Lembre-se de que a verificação de fatos é apenas um dos muitos casos de uso (como descoberta de notícias, resumo de conteúdo, análise de tendências ou assistência à pesquisa) em que é possível utilizar a API SERP em um nó de pipeline do Vertex IA. Portanto, você pode adaptar facilmente essa implementação a muitos outros cenários.
Para esclarecer isso, siga as etapas abaixo!
Pré-requisitos
Para acompanhar esta seção do tutorial, verifique se você tem:
- Uma conta do Google Cloud Console.
- Uma conta da Bright Data com uma chave de API ativa (de preferência com permissões de administrador).
Siga o guia oficial da Bright Data para saber como recuperar sua chave de API. Guarde-a em um local seguro, pois você precisará dela em breve.
Etapa 1: criar e configurar um novo projeto do Google Cloud
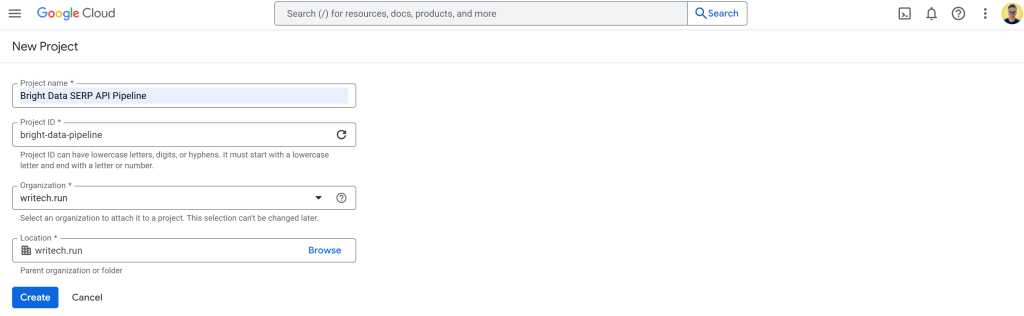
Faça login no Console do Google Cloud e crie um novo projeto. Além disso, verifique se o faturamento está ativado (também não há problema em usar uma avaliação gratuita).
Neste exemplo, chame o projeto do Google Cloud de “Bright Data API SERP Pipeline” e defina o ID do projeto como bright-data-pipeline:
Depois que o projeto for criado, selecione-o para começar a trabalhar nele. Agora você deve ver uma exibição como esta:
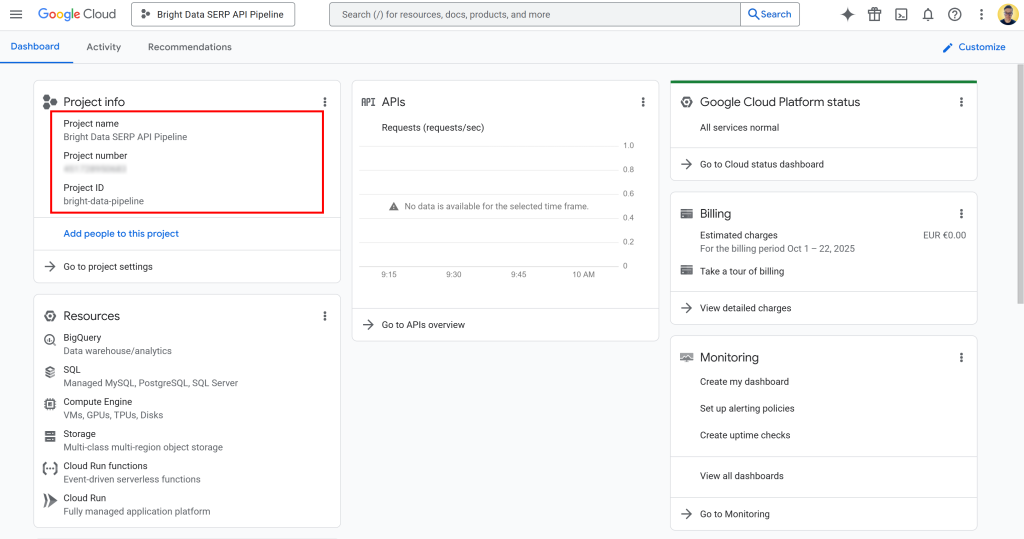
Nessa página, você pode encontrar o nome do projeto, o número do projeto e o ID do projeto. Você precisará do número e do ID do projeto mais adiante no tutorial, portanto, anote-os e guarde-os em um local seguro.
Agora que seu projeto do Google Cloud está pronto, a próxima etapa é ativar as APIs necessárias. Na barra de pesquisa, digite “APIs & Services”, acesse a página e clique no botão “Enable APIs and services” (Ativar APIs e serviços):

Procure e ative as seguintes APIs:
Essas duas APIs são necessárias para usar e desenvolver com o Vertex IA no Vertex IA Workbench.
Observação: o pipeline também depende de várias outras APIs, que geralmente são ativadas por padrão. Em caso de problemas, verifique se elas também estão ativadas:
- “API do gerenciador de recursos de nuvem”
- “API de armazenamento em nuvem”
- “API de uso do serviço”
- “API do mecanismo de computação”
- “API Gemini para Google Cloud”
- “API de registro em nuvem”
Se alguma delas estiver desativada, ative-a manualmente antes de continuar.
Pronto! Agora você tem um projeto do Google Cloud.
Etapa 2: configurar o bucket de armazenamento na nuvem
Para executar o Vertex IA Pipelines, você precisa de um bucket do Cloud Storage. Isso ocorre porque o Vertex IA precisa armazenar artefatos de pipeline, como dados intermediários, arquivos de modelo, registros e metadados gerados durante a execução do pipeline. Em outras palavras, o bucket configurado atua como o espaço de trabalho em que os componentes do pipeline leem e gravam dados.
Para criar um bucket, pesquise por “Cloud Storage” no Console do Google Cloud. Abra o primeiro resultado, selecione “Buckets” no menu à esquerda e pressione o botão “Create” (Criar):
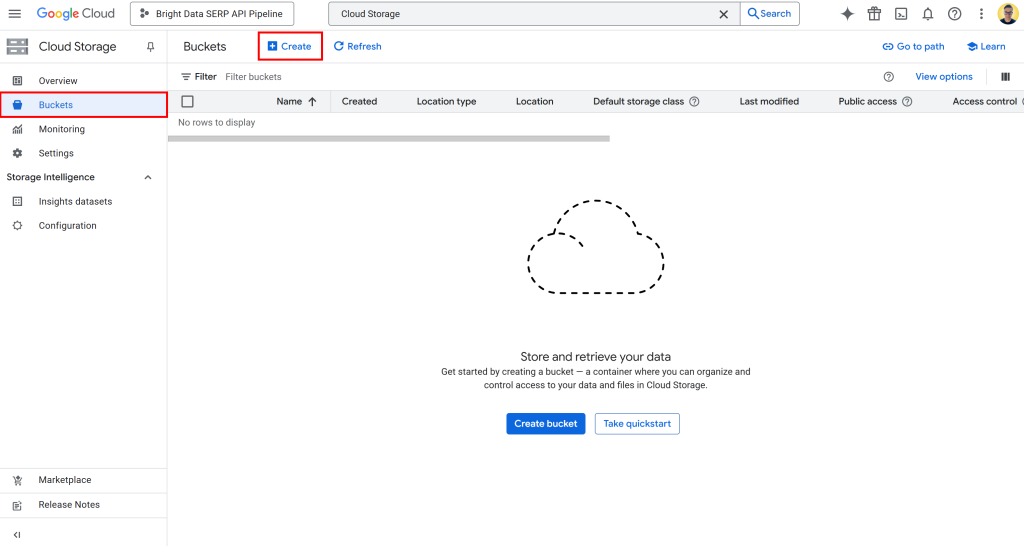
No formulário de criação do bucket:
- Dê a ele um nome globalmente exclusivo, como
bright-data-pipeline-artifacts. - Escolha um tipo de local e uma região. Para simplificar, recomendamos selecionar a opção “us (várias regiões nos Estados Unidos)”.
Depois de criado, anote o nome do bucket, pois você precisará dele mais tarde na configuração do pipeline. Agora você deve ver algo parecido com isto:
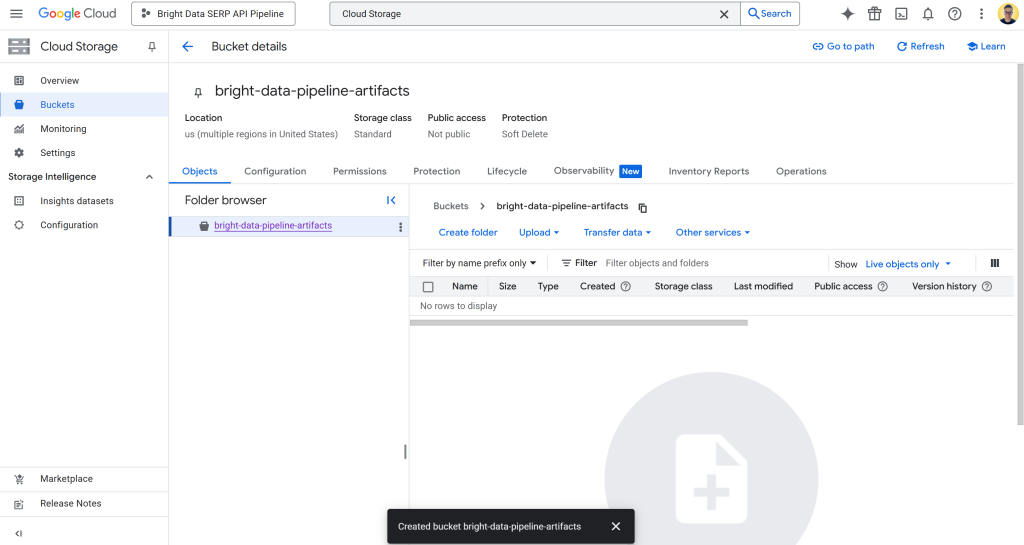
Nesse caso, o nome do bucket é:
bright-data-pipeline-artifacts Enquanto o URI do bucket é:
gs://bright-data-pipeline-artifactsComo você escolheu a multirregião “us”, pode acessar esse bucket por meio de qualquer região us-* compatível. Isso inclui us-central1, us-east1, …, us-west1…, etc. Recomendamos definir us-central1.
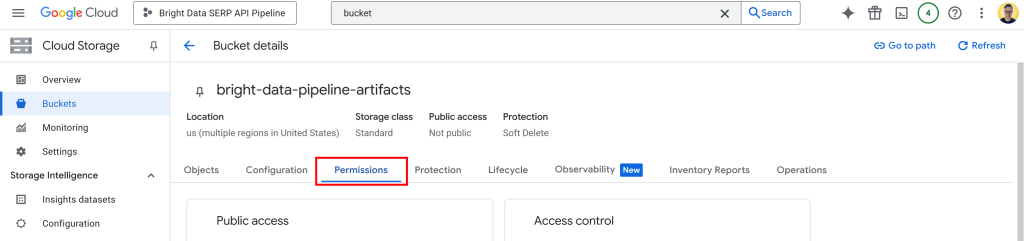
Agora, você precisa dar permissão ao Vertex IA para ler e gravar dados em seu bucket. Para fazer isso, clique no nome do bucket para abrir sua página de detalhes e, em seguida, vá para a guia “Permissions” (Permissões):
Clique no botão “Grant access” (Conceder acesso) e adicione uma nova regra de permissão da seguinte forma:
- Principal:
<YOUR_GC_PROJECT_NUMBER>[email protected] - Função:
Administrador de armazenamento
(Importante: Para ambientes de produção, atribua somente as funções mínimas necessárias. O uso do acesso completo “Storage Admin” é apenas para simplificar essa configuração).
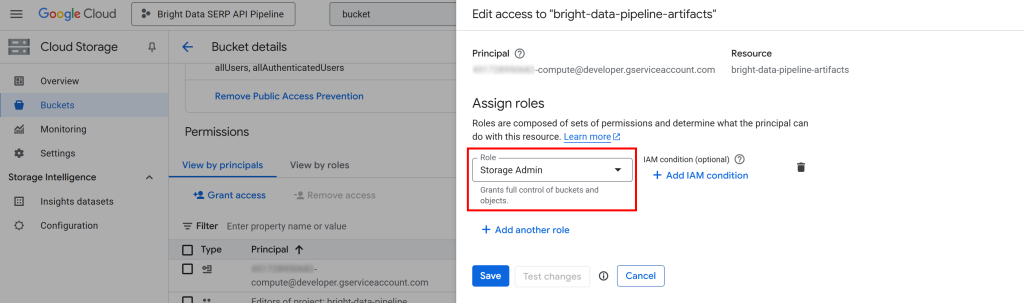
Clique em “Save” (Salvar) para confirmar a nova função, que concede ao serviço do Compute Engine do seu projeto a capacidade de acessar e gerenciar objetos no seu bucket do Cloud Storage.
Sem essa permissão, seu pipeline do Vertex IA não conseguiria ler ou gravar dados durante a execução, o que levaria a erros 403 Forbidden, como o abaixo:
google.api_core.exceptions.Forbidden: 403 GET https://storage.googleapis.com/storage/v1/b/bright-data-pipeline-artifacts?fields=name&prettyPrint=false: <YOUR_GC_PROJECT_NUMBER>[email protected] não tem storage.buckets.get acesso ao bucket do Google Cloud Storage. Permissão 'storage.buckets.get' negada no recurso (ou ele pode não existir).Incrível! O bucket do Google Cloud Storage foi configurado.
Etapa 3: configurar as permissões do IAM
Assim como no caso do bucket do Cloud Storage, você também precisa conceder à conta de serviço do Compute Engine do seu projeto as permissões IAM adequadas.
Essas permissões permitem que a Vertex IA crie e gerencie trabalhos de pipeline em seu nome. Sem elas, o pipeline não terá autoridade para iniciar ou controlar sua execução dentro do seu projeto do Google Cloud.
Para configurá-las, pesquise “IAM & Admin” no Console do Google Cloud e abra a página.
Clique no botão “Conceder acesso” e, em seguida, adicione as duas funções a seguir à sua conta de serviço padrão do Compute Engine (ou seja, <YOUR_GC_PROJECT_NUMBER>[email protected]):
- “Usuário da conta de serviço”
- “Usuário do Vertex IA”
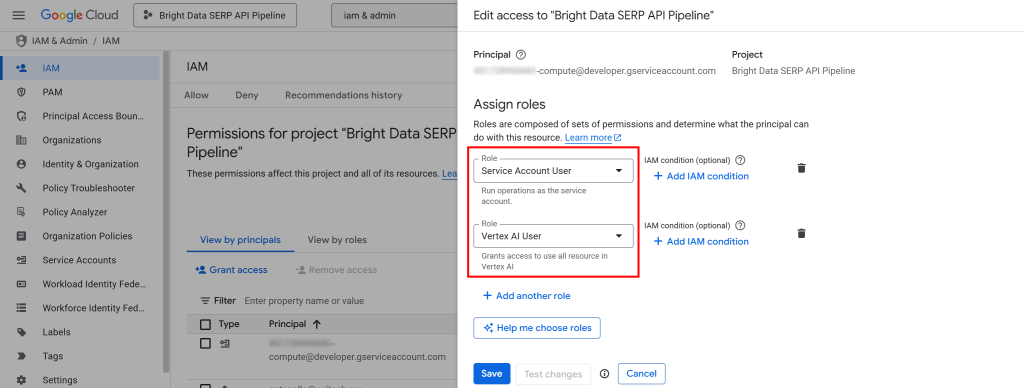
Depois de atribuir as funções, pressione o botão “Save” (Salvar). Dessa forma, seu pipeline do Vertex IA poderá usar os recursos de computação do seu projeto e executar cargas de trabalho gerenciadas.
Em resumo, isso informa ao Google Cloud que seus pipelines do Vertex IA estão autorizados a agir em nome da conta de serviço de computação do seu projeto. Sem essas permissões, você encontrará erros 403 Forbidden, como o abaixo, ao tentar iniciar um trabalho de pipeline:
403 POST https://us-central1-aiplatform.googleapis.com/v1/projects/bright-data-pipeline/locations/us-central1/pipelineJobs?pipelineJobId=XXXXXXXXXXXXXXXXXXXXXXX&%24alt=json%3Benum-encoding%3Dint: Permission 'aiplatform.pipelineJobs.create' denied on resource '//aiplatform.googleapis.com/projects/bright-data-pipeline/locations/us-central1' (or it may not exist). [{'@type': 'type.googleapis.com/google.rpc.ErrorInfo', 'reason': 'IAM_PERMISSION_DENIED', 'domain': 'aiplatform.googleapis.com', 'metadata': {'resource': 'projects/bright-data-pipeline/locations/us-central1', 'permission': 'aiplatform.pipelineJobs.create'}}]Tudo pronto! O IAM agora está configurado e pronto para a execução do pipeline do Vertex IA.
Etapa 4: começar a usar o Vertex IA Workbench
Para simplificar o desenvolvimento, você criará nosso pipeline do Vertex IA diretamente na nuvem, sem necessidade de configuração local.
Especificamente, você usará o Vertex IA Workbench, um ambiente de desenvolvimento baseado em JupyterLab totalmente gerenciado na plataforma Vertex IA do Google Cloud. Ele foi desenvolvido para dar suporte a fluxos de trabalho completos de ciência de dados, desde a prototipagem até a implantação do modelo.
Observação: antes de prosseguir, certifique-se de que a “API de notebooks” esteja ativada, pois essa API é necessária para o funcionamento do Vertex IA Workbench.
Para acessar o Vertex IA Workbench, pesquise por “Vertex IA Workbench” no Google Cloud Console e abra a página. Em seguida, na guia “Instâncias”, clique em “Criar nova” para iniciar uma nova instância:
Observação: embora o Vertex IA Workbench ofereça suporte ao Jupyter 4 para novas instâncias, todos os ambientes atualmente usam o JupyterLab 3 por padrão. Essa versão já vem com as bibliotecas e os drivers mais recentes da GPU NVIDIA e da Intel pré-instalados. Portanto, para este tutorial, você deve optar pelo JupyterLab 3.
No formulário de criação de instância, deixe todos os valores de configuração padrão, incluindo o tipo de máquina padrão (que deve ser n1-standard-4). Essa máquina é mais do que suficiente para este guia.
Clique em “Create” e lembre-se de que levará alguns minutos para que a instância seja provisionada e iniciada. Quando ela estiver pronta, você verá uma nova entrada na tabela “Instances” (Instâncias) com um link chamado “Open JupyterLab” (Abrir JupyterLab). Clique nele:
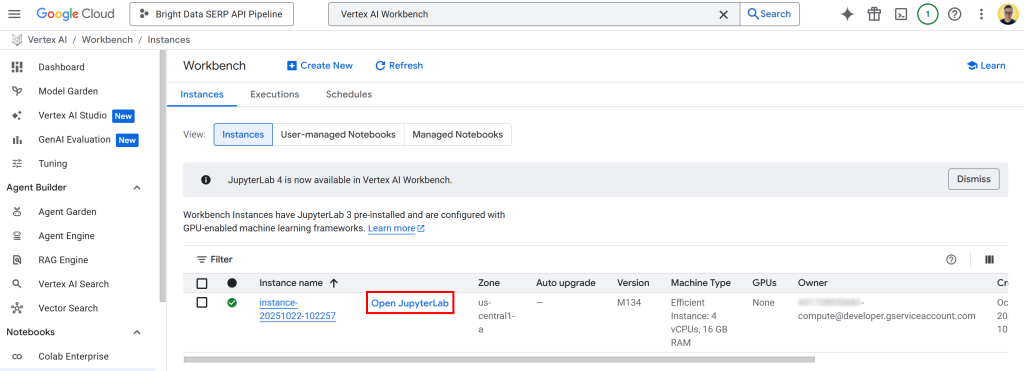
Você será redirecionado para seu ambiente do JupyterLab baseado na nuvem, totalmente hospedado no Google Cloud:
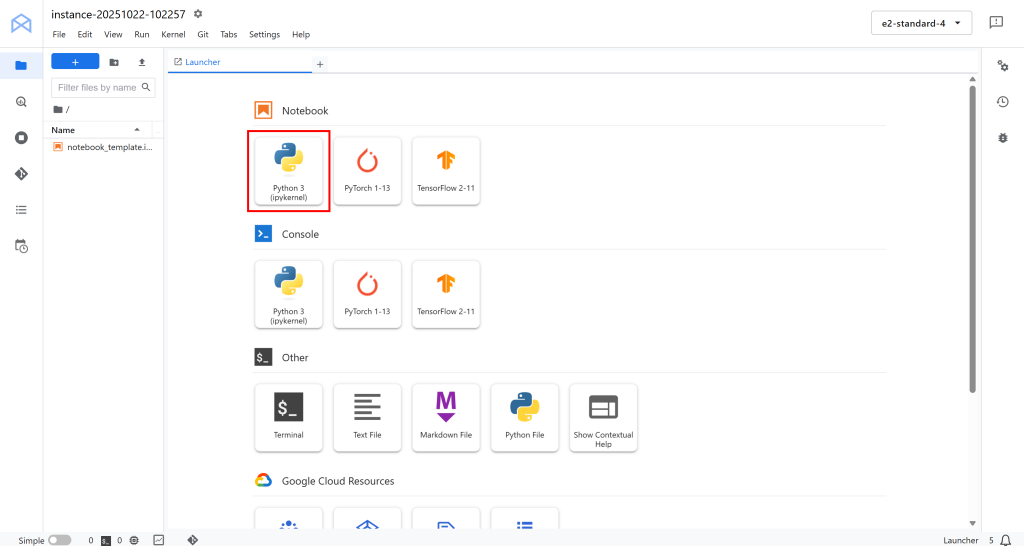
Aqui, clique em “Python 3 (ipykernel)” em “Notebook” para criar um novo notebook. Esse notebook servirá como seu ambiente de desenvolvimento para escrever e testar o pipeline de IA da Vertex integrado à Bright Data:
Fantástico! Você está pronto para começar a codificar e criar a lógica do pipeline de dados para IA do Vertex.
Etapa 5: instalar e inicializar as bibliotecas Python necessárias
Em seu notebook, comece adicionando e executando a seguinte célula para instalar todas as bibliotecas Python necessárias para este projeto:
!pip install kfp google-cloud-aiplatform google-genai brightdata-sdk --quiet --upgradeIsso pode levar alguns minutos, portanto, seja paciente enquanto o ambiente configura tudo.
Veja o que cada biblioteca faz e por que ela é necessária:
kfp: Este é o SDK do Kubeflow Pipelines, que permite definir, compilar e executar pipelines de aprendizado de máquina de forma programática em Python. Ele vem com decoradores e classes para criar componentes de pipeline.Google-cloud-aiplatform: O Vertex IA SDK para Python. Ele fornece o que você precisa para interagir diretamente com os serviços Vertex IA do Google Cloud, incluindo modelos de treinamento, implantação de pontos de extremidade e execução de pipelines.google-genai: O SDK de IA generativa do Google, que permite usar e orquestrar o Gemini e outros modelos generativos (também no Vertex IA). Isso é útil, pois o pipeline inclui tarefas LLM.(Lembre-se: o Vertex IA SDK está obsoleto).brightdata-sdk: O SDK da Bright Data, usado para conectar e buscar dados em tempo real por meio da API SERP da Bright Data ou de outras fontes de dados da Web diretamente de seu pipeline.
Depois que todas as bibliotecas estiverem instaladas, importe-as e inicialize o Vertex IA SDK com o seguinte código em uma célula dedicada:
import kfp
from kfp.dsl import component, pipeline, Input, Output, Artifact
from kfp import compiler
from google.cloud import aiplatform
from typing import List
# Substitua pelos segredos de seu projeto
PROJECT_ID = "<YOUR_GC_PROJECT_ID>"
REGION = "<SUA_REGIÃO>" # (por exemplo, "us-central1")
BUCKET_URI = "<YOUR_BUCKET_URI>" # (por exemplo, "gs://bright-data-pipeline-artifacts")
# Inicializar o Vertex IA SDK
aiplatform.init(project=PROJECT_ID, location=REGION, staging_bucket=BUCKET_URI)A função aiplatform.init() configura seu ambiente Python para se comunicar com o Vertex IA. Ela define o projeto, a região e o bucket de preparação para que todas as operações subsequentes do Vertex IA, como a criação de pipelines, o treinamento de trabalhos ou a implantação de modelos, usem automaticamente o contexto correto.
Em resumo, essa única linha de código conecta a sessão do notebook ao projeto do Google Cloud e informa ao Vertex IA onde armazenar artefatos de pipeline e dados temporários. Muito bem!
Etapa nº 6: definir o componente de extração de consulta
Lembre-se de que um pipeline do Vertex IA é criado a partir de componentes, sendo que um componente é apenas uma função Python que executa uma tarefa específica. Conforme explicado anteriormente, esse pipeline terá três componentes.
Vamos começar com o primeiro, o componente extract_queries!
O componente extract_queries:
- Recebe o texto a ser verificado como entrada.
- Usa um modelo Gemini (por meio da biblioteca
google-genai) para gerar uma lista de consultas de pesquisa que podem ser feitas no Google e que ajudariam a verificar as alegações de fato nesse texto. - Retorna essa lista como uma matriz Python
(List[str])
Implemente-o da seguinte forma:
@component(
base_image="python:3.10",
packages_to_install=["google-genai"],
)
def extract_queries(
input_text: str,
project: str,
location: str,
) -> List[str]:
from google import genai
from google.genai.types import GenerateContentConfig, HttpOptions
from typing import List
importar json
# Inicializar o SDK do Google Gen IA com a integração do Vertex
cliente = genai.Client(
vertexai=True,
project=project,
location=location,
http_options=HttpOptions(api_version="v1")
)
# O esquema de saída, que é uma matriz de cadeias de caracteres
response_schema = {
"type": "ARRAY",
"items": {
"type": "STRING"
}
}
# O prompt do extrator de consultas
prompt = f"""
Você é um verificador de fatos profissional. Seu trabalho é ler o texto a seguir e extrair
uma lista de consultas de pesquisa específicas, que podem ser pesquisadas no Google, que seriam necessárias
para verificar as principais alegações de fato.
Retorne *apenas* uma lista Python de strings, e nada mais.
Exemplo:
Entrada: "A Torre Eiffel, construída em 1889 por Gustave Eiffel, tem 300 metros de altura."
Saída: ["when was the eiffel tower built", "who built the eiffel tower", "how tall is the eiffel tower"]
Aqui está o texto para verificação de fatos:
---
"{input_text}"
---
"""
response = client.models.generate_content(
model="gemini-2.5-flash",
contents=prompt,
config=GenerateContentConfig(
# Forçar o modelo a retornar uma matriz JSON de cadeias de caracteres
response_mime_type="application/json",
response_schema=response_schema,
),
)
# O 'response.text' conterá de forma confiável uma cadeia de caracteres JSON em conformidade com o esquema (por exemplo, '["query_1", ..., "query_n"]')
lista_de_consulta: List[str] = json.loads(response.text.strip())
return query_listLembre-se de que os componentes do KFP devem ser autônomos. Isso significa que todas as importações devem ser declaradas dentro da função do componente, e não globalmente.
Observe que os parâmetros vertexai=True, project=project e location=location em genai.Client() são necessários para conectar o cliente google-genai ao seu ambiente Vertex IA. Eles garantem que o modelo configurado seja executado na mesma região e no mesmo projeto que seu pipeline.
Quanto à escolha do modelo, você deve usar o Gemini 2.5 Flash aqui porque ele é leve e rápido. De qualquer forma, você pode definir outro modelo Gemini para obter maior precisão, se necessário.
Um componente já está pronto, faltam mais dois!
Etapa 7: criar o componente API SERP SERP-Powered Web Search Context Retriever
Agora que você gerou uma lista de consultas que podem ser consultadas pelo Google, é hora de pesquisar o contexto na Web. Para isso, use a API SERP da Bright Data, que lhe permite extrair programaticamente os resultados de pesquisa (Google, por padrão) de forma estruturada e escalonável.
A maneira mais fácil de acessar a API SERP a partir do Python é por meio do SDK oficial e de código aberto da Bright Data. Essa biblioteca lhe fornece métodos simples para chamar os produtos da Bright Data, incluindo a API SERP. Saiba mais sobre ela na documentação.
Em particular, o componente fetch_web_search_context:
- Aceita uma lista de consultas de pesquisa geradas na etapa anterior.
- Usa o Bright Data SDK para chamar a API SERP em paralelo para cada consulta.
- Recupera os resultados da pesquisa (por padrão, do Google).
- Salva todos os resultados como um artefato JSON, um arquivo que pode ser usado por outros componentes do pipeline.
Crie esse componente em uma célula de notebook dedicada como esta:
@component(
base_image="python:3.10",
packages_to_install=["brightdata-sdk"],
)
def fetch_web_search_context(
queries: List[str],
api_key: str,
output_file: Output[Artifact],
):
"""
Recebe uma lista de consultas, pesquisa cada uma delas usando o Bright Data SDK,
e grava todos os resultados como um artefato de arquivo JSON.
"""
da brightdata import bdclient
importar json
# Inicializar o cliente do SDK da Bright Data
cliente = bdclient(api_token=api_key)
# Chamar a API SERP nas consultas de entrada
resultados = client.search(
queries,
data_format="markdown"
)
# Gravar os resultados em um arquivo de artefato
with open(output_file.path, "w") as f:
json.dump(results, f)Observe que a API SERP foi configurada para retornar o conteúdo no formato Markdown, que é ideal para ingestão em LLMs.
Além disso, como a saída desse componente pode ser muito grande, é melhor armazená-la como um artefato. Os artefatos são armazenados em seu bucket do Google Cloud Storage e permitem que os componentes em um pipeline do Vertex IA passem dados entre si de forma eficiente, sem sobrecarregar a memória ou exceder os limites de transferência de dados.
Aqui vamos nós! Graças ao poder dos recursos de pesquisa na Web da Bright Data, agora você tem o contexto de pesquisa apoiado pelo Google pronto para ser usado como entrada para o próximo componente, em que um LLM realizará a verificação de fatos.
Etapa 8: implementar o componente de verificação de fatos
Semelhante ao componente de extração de consulta, esta etapa também envolve chamar um LLM. No entanto, em vez de gerar consultas, esse componente usa os resultados de pesquisa na Web coletados na etapa anterior como evidência contextual para verificar os fatos do texto de entrada original.
Essencialmente, ele executa um fluxo de trabalho no estilo RAG baseado em SERP, em que o conteúdo recuperado da Web orienta o processo de verificação do modelo.
Em uma nova célula do notebook, defina o componente fact_check_with_web_search_context da seguinte forma:
@component(
base_image="python:3.10",
packages_to_install=["google-genai"],
)
def fact_check_with_web_search_context(
input_text: str,
web_search_context_file: Input[Artifact],
project: str,
location: str,
) -> str:
importar json
do google import genai
# Carregar o contexto de pesquisa na Web do artefato
with open(web_search_context_file.path, "r") as f:
web_search_context = json.load(f)
cliente = genai.Client(
vertexai=True,
project=project,
location=location
)
prompt = f"""
Você é um verificador de fatos IA. Compare o texto original com o contexto de pesquisa JSON
e produza um relatório de verificação de fatos em Markdown.
[Texto original]
"{input_text}"
[Contexto de pesquisa na Web]
"{json.dumps(web_search_context)}"
"""
response = client.models.generate_content(
model="gemini-2.5-pro",
contents=prompt
)
return response.textEssa tarefa é mais complexa e requer raciocínio sobre várias fontes de evidência. Portanto, é melhor usar um modelo mais capaz, como o Gemini 2.5 Pro.
Excelente! Agora você definiu todos os três componentes que compõem o pipeline do Vertex IA.
Etapa nº 9: Definir e compilar o pipeline
Conecte todos os três componentes em um único pipeline do Kubeflow. Cada componente será executado sequencialmente, com a saída de uma etapa que se torna a entrada da próxima.
É assim que se define o pipeline:
@pipeline(
name="bright-data-fact-checker-pipeline",
description="Obtém o contexto SERP para verificar os fatos em um documento de texto."
)
def fact_check_pipeline(
input_text: str,
bright_data_api_key: str,
projeto: str = PROJECT_ID,
location: str = REGION,
):
# Etapa 1: extrair consultas do Google do texto de entrada para verificação
step1 = extract_queries(
input_text=input_text,
project=project,
location=location
)
# Etapa 2: buscar resultados de SERP da Bright Data sobre as consultas de pesquisa
step2 = fetch_web_search_context(
queries=step1.output,
bright_data_api_key=bright_data_api_key
)
# Etapa 3: realizar a verificação de fatos usando o contexto de pesquisa na Web recuperado anteriormente
step3 = fact_check_with_web_search_context(
input_text=input_text,
web_search_context_file=step2.outputs["output_file"],
project=project,
location=location
) Em essência, essa função une os três componentes que você criou anteriormente. Ela começa gerando consultas de verificação de fatos, depois recupera os resultados da pesquisa para cada consulta usando a API SERP da Bright Data e, por fim, executa um modelo Gemini para verificar as alegações com base nas evidências coletadas.
Em seguida, é necessário compilar o pipeline em uma especificação JSON que a Vertex IA possa executar:
compiler.Compiler().compile(
pipeline_func=fact_check_pipeline,
package_path="fact_check_pipeline.json"
)Esse comando converte sua definição de pipeline Python em um arquivo de especificação de pipeline JSON chamado fact_check_pipeline.json.
Esse arquivo JSON é um projeto no qual o Vertex IA Pipelines confia para entender como orquestrar o fluxo de trabalho. Ele descreve cada componente, suas entradas e saídas, dependências, imagens de contêineres e ordem de execução.
Ao executar esse arquivo JSON no Vertex IA, o Google Cloud provisiona automaticamente a infraestrutura, executa cada componente na ordem correta e lida com a passagem de dados entre as etapas. Pipeline completo!
Etapa 10: executar o pipeline
Suponha que você queira testar o pipeline do Vertex IA em uma declaração claramente falsa como esta:
“Paris é a capital da Alemanha, que usa o iene como moeda.”
Adicione a seguinte célula ao seu notebook Jupyter. Essa adição define a lógica para iniciar o pipeline:
TEXT_TO_CHECK = """
Paris é a capital da Alemanha, que usa o iene como moeda.
"""
# Substitua por sua chave da API da Bright Data
BRIGHT_DATA_API_KEY = "<SUA_CHAVE_DE_API_DE_DADOS_BRIGHT>"
print("Iniciando o trabalho do pipeline...")
# Definir o trabalho do pipeline
job = aiplatform.PipelineJob(
display_name="fact-check-pipeline-run",
template_path="fact_check_pipeline.json",
pipeline_root=BUCKET_URI,
parameter_values={
"input_text": TEXT_TO_CHECK,
"bright_data_api_key": BRIGHT_DATA_API_KEY
}
)
# Executar o trabalho
job.run()
print("nTrabalho enviado! Você pode ver seu progresso na UI do Vertex IA.")Esse código cria um novo trabalho do Vertex IA Pipeline, especificando o JSON do pipeline que você compilou anteriormente(fact_check_pipeline.json), seu bucket de armazenamento como a raiz do pipeline e os parâmetros necessários para essa execução específica (ou seja, o texto de entrada a ser verificado e sua chave da API Bright Data).
Depois de executar essa célula, o Vertex IA orquestrará automaticamente todo o seu pipeline na nuvem.
Observação de segurança: este exemplo codifica a chave da API da Bright Data diretamente no notebook para simplificar, mas isso não é seguro para ambientes de produção. Em uma implementação no mundo real, você deve armazenar e recuperar credenciais confidenciais, como chaves de API, usando o Google Cloud Secret Manager para evitar exposição acidental (por exemplo, em registros).
Para executar seu pipeline, selecione todas as células e pressione o botão “▶” em seu notebook Jupyter. Você obterá essa saída na última célula:
Isso significa que o pipeline de verificação de fatos do Vertex IA está sendo executado com êxito. Uau!
Etapa 11: Monitorar a execução do pipeline
Para verificar o status do trabalho do pipeline, acesse a página Vertex IA Pipelines no Google Cloud Console do seu projeto:
https://console.cloud.google.com/vertex-ai/pipelines?project={PROJECT_ID}Portanto, neste caso, o URL é:
https://console.cloud.google.com/vertex-ai/pipelines?project=bright-data-pipelineCole o URL no navegador e você verá uma página como esta:
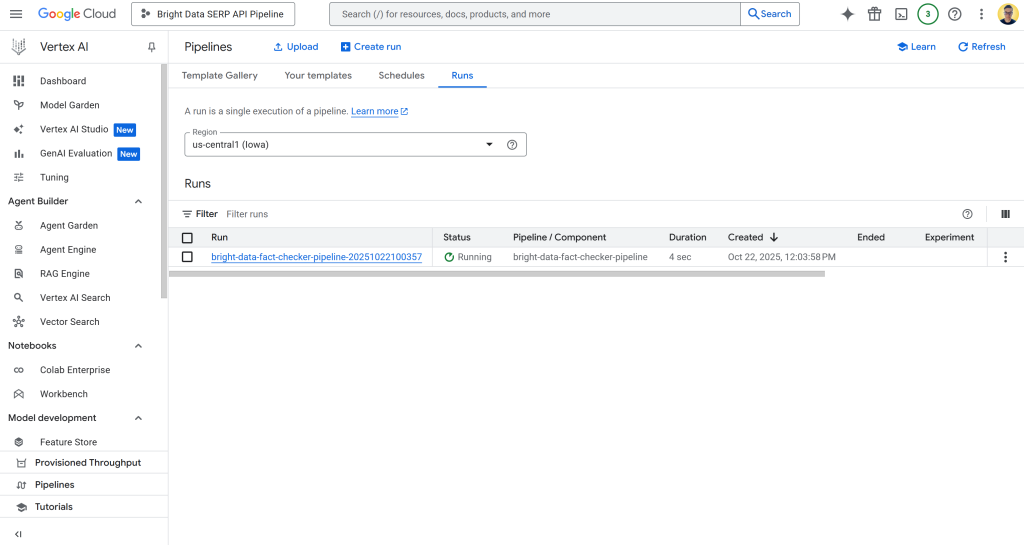
Clique na primeira entrada da tabela “Runs” para abrir a página de execução do trabalho do pipeline:
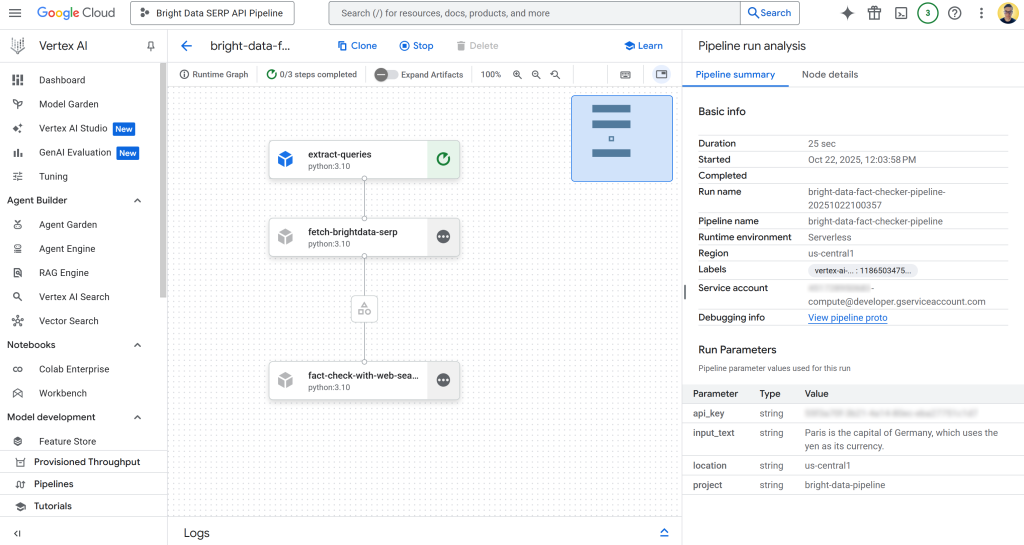
Aqui, você pode ver visualmente os componentes que compõem o pipeline. Também é possível verificar o status de cada nó, visualizar logs detalhados e observar o fluxo de dados do início ao fim do pipeline à medida que ele é executado.
Etapa 12: explorar a saída
Quando a execução do pipeline estiver concluída, cada nó mostrará uma marca de verificação indicando a conclusão bem-sucedida:
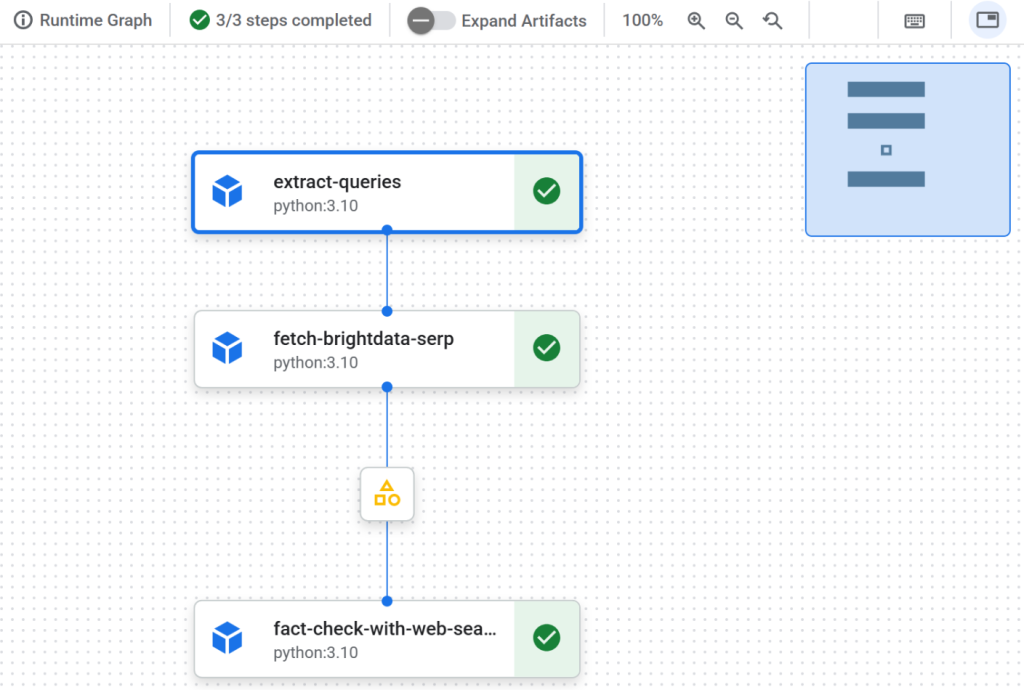
Clique no primeiro nó para inspecionar as consultas extraídas do texto de entrada que podem ser usadas pelo Google. Neste exemplo, as consultas geradas foram:
"qual é a capital da Alemanha""qual é a moeda usada pela Alemanha"
Essas consultas são perfeitamente adequadas para verificar as afirmações factuais na declaração de entrada:
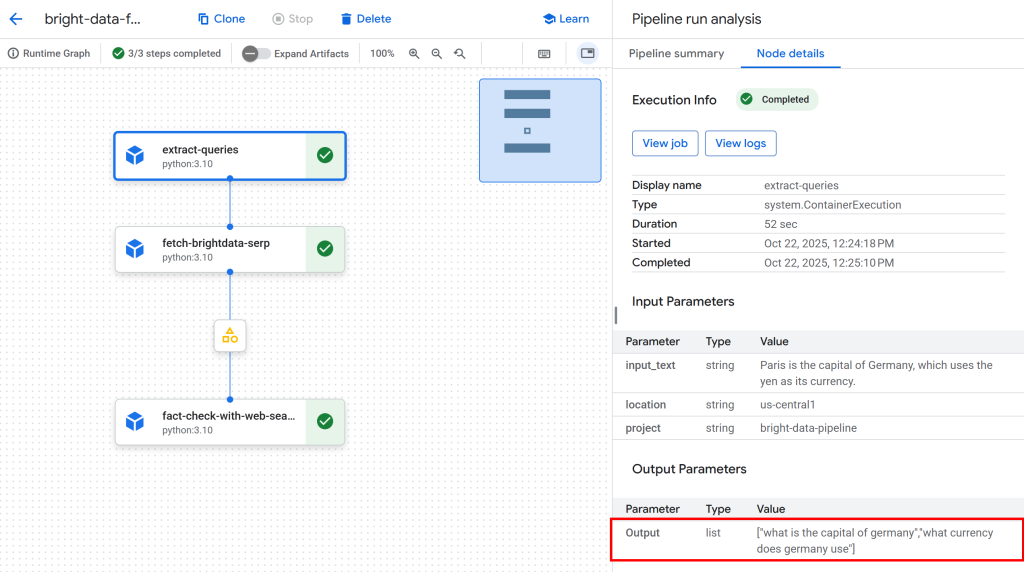
Em seguida, clique no nó do artefato entre o segundo e o terceiro nó. Você receberá um link para o arquivo JSON armazenado no seu bucket configurado do Google Cloud Storage (nesse caso, bright-data-pipeline-artifacts).
Você também pode acessar a página desejada diretamente navegando até o bucket no Console do Cloud:
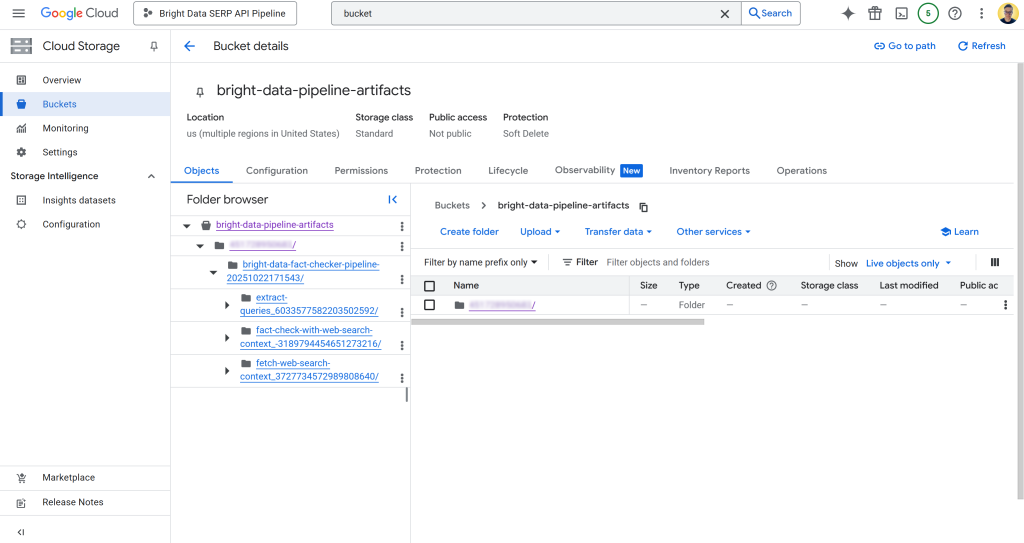
Dentro do bucket, você verá uma pasta para cada componente. Em detalhes, a pasta do componente fetch_web_search_context contém um arquivo JSON com o contexto de pesquisa na Web recuperado por meio da API SERP, armazenado como uma matriz de strings formatadas em Markdown:
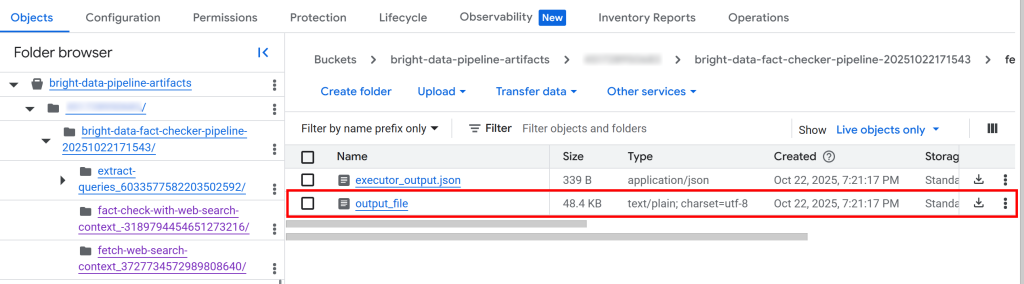
Se você baixar e abrir o arquivo, verá algo parecido com isto:
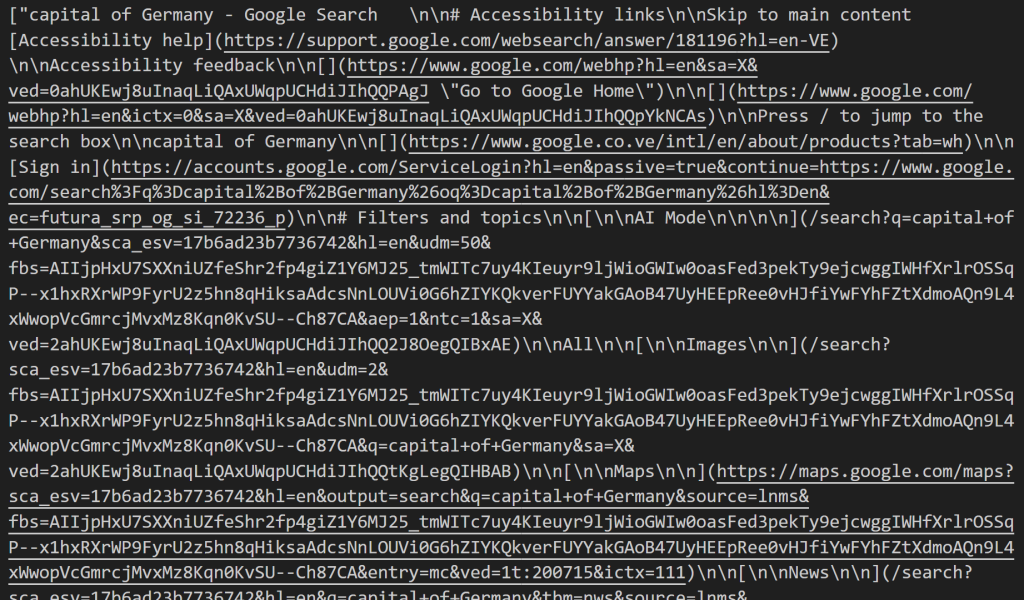
Esse conteúdo é a representação Markdown das SERPs recuperadas para cada consulta de pesquisa identificada.
De volta à UI do pipeline do Vertex IA, clique no nó de saída para inspecionar os resultados gerais:
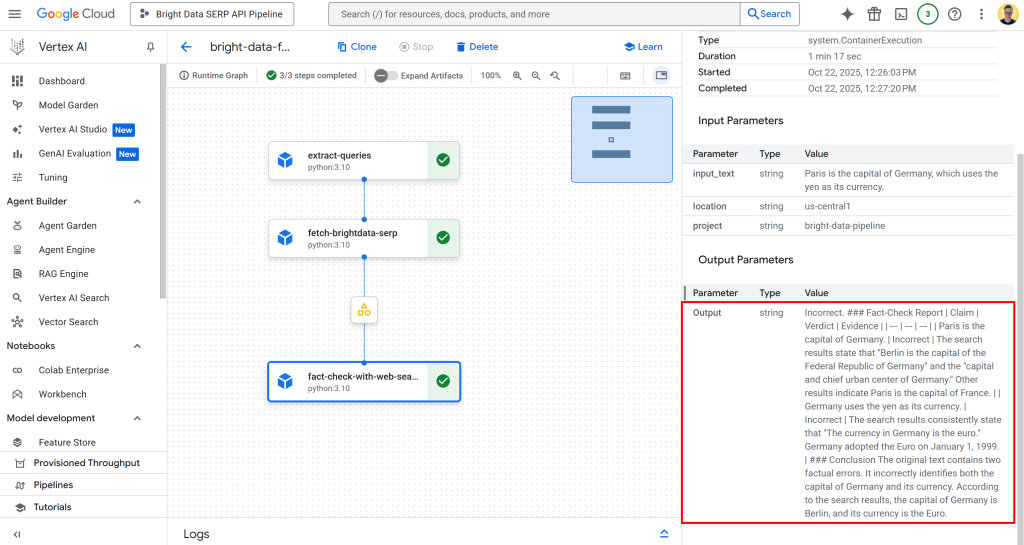
Como você pode ver, a saída é um relatório detalhado de verificação de fatos em Markdown. A mesma saída também é salva no arquivo executor_output.json na pasta bucket para a execução do pipeline. Baixe-o e abra-o em um IDE como o Visual Studio Code para inspecioná-lo:
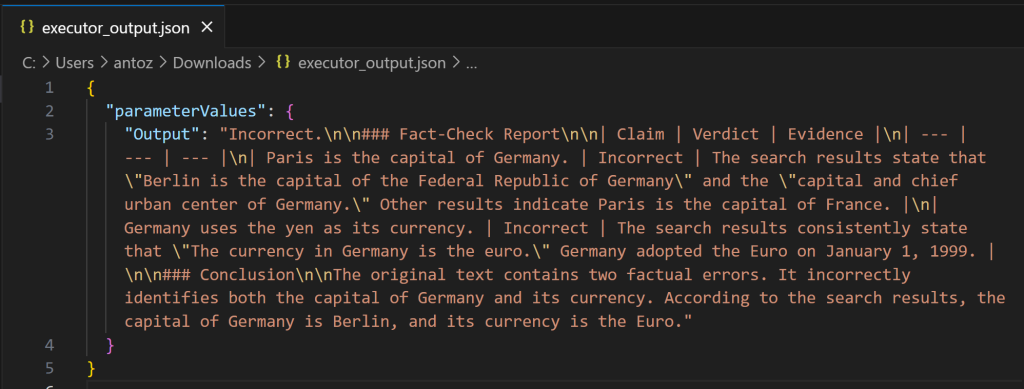
Copie a string Markdown em um arquivo .md (por exemplo, report.md) para visualizá-la com mais clareza:
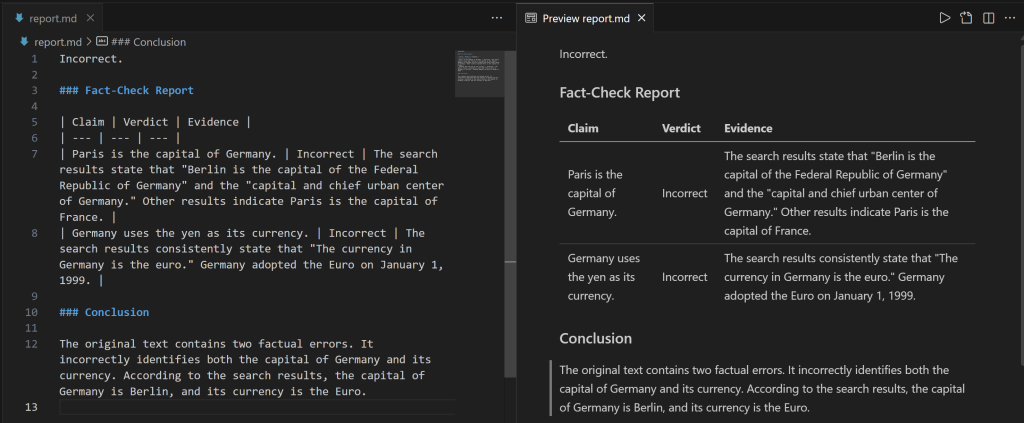
O relatório fornece informações detalhadas sobre quais partes da declaração de entrada estavam incorretas e quais são os fatos verificados.
E pronto! Isso demonstra o poder da integração da pesquisa na Web da Bright Data para recuperar informações contextuais em um pipeline Vertex IA baseado em RAG.
Próximas etapas
Não se esqueça de que este foi apenas um exemplo simples para demonstrar a viabilidade de usar a recuperação de dados de pesquisa na Web da Bright Data em um pipeline da Vertex IA. Em cenários do mundo real, esses componentes provavelmente fariam parte de um pipeline muito mais longo e complexo.
Os dados de entrada poderiam vir de várias fontes, como documentos comerciais, relatórios internos, bancos de dados, arquivos e muito mais. Além disso, o fluxo de trabalho poderia incluir muitas outras etapas e não necessariamente terminaria apenas com um relatório de verificação de fatos.
Conclusão
Nesta postagem do blog, você aprendeu como aproveitar a API SERP da Bright Data para recuperar o contexto de pesquisa na Web em um pipeline de IA da Vertex. O fluxo de trabalho de IA apresentado aqui é ideal para quem deseja criar um pipeline de verificação de fatos programático e confiável para garantir que seus dados sejam precisos.
Para criar fluxos de trabalho de IA avançados semelhantes, explore toda a gama de soluções para recuperar, validar e transformar dados ao vivo da Web usando a infraestrutura de IA da Bright Data.
Crie uma conta gratuita na Bright Data hoje mesmo e comece a experimentar nossas ferramentas de dados da Web prontas para IA!




