

Neste tutorial, você aprenderá:
- Como uma abordagem baseada no fan-out da consulta e na comparação da Visão geral da IA do Google pode ser usada para aprimorar o GEO e o SEO.
- Como criar esse fluxo de trabalho em um alto nível usando seis agentes de IA.
- Como implementar esse fluxo de trabalho de otimização de conteúdo de IA com o CrewAI, integrado ao Gemini e ao Bright Data.
- Algumas ideias e conselhos para aprimorar ainda mais o fluxo de trabalho.
Vamos mergulhar de cabeça!
TL;DR
Deseja ir direto para os arquivos de projeto prontos para uso? Confira o projeto no GitHub.
Explicando o Fan-Out da consulta e a comparação da visão geral da IA para melhorar o GEO e o SEO
Todos sabemos que SEO(Search Engine Optimization) é a arte de melhorar a visibilidade de um site nos resultados de pesquisa orgânica. Mas o mundo agora está fazendo a transição para o GEO(Generative Engine Optimization).
Se você não conhece o GEO, trata-se de uma estratégia de marketing digital que se concentra em tornar o conteúdo mais visível nos mecanismos de pesquisa com tecnologia de IA, como Google AI Overviews, ChatGPT e outros.
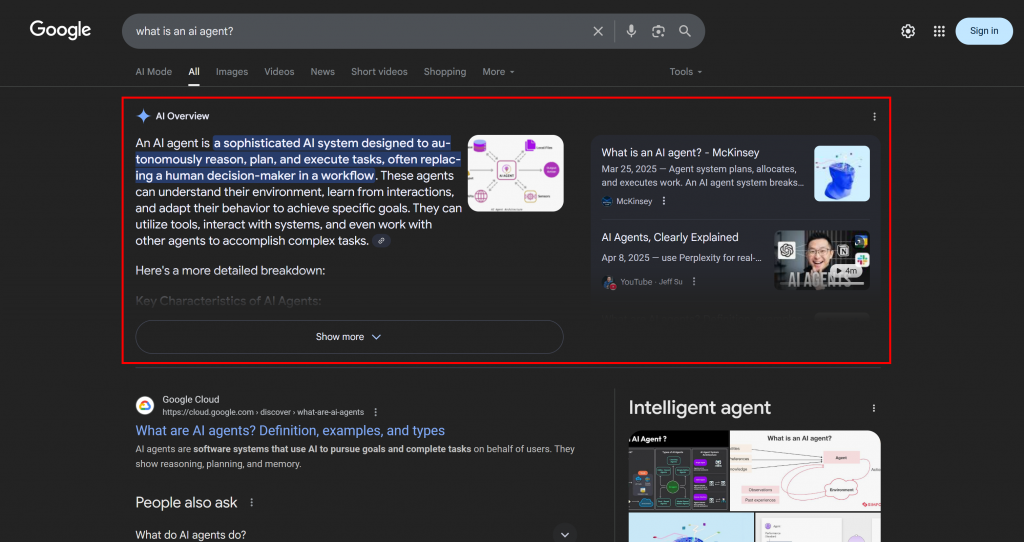
Como os LLMs são essencialmente caixas-pretas, não há uma maneira direta de “otimizar” uma página da Web para GEO (assim como o SEO era antes de as ferramentas de pesquisa de volume de palavras-chave estarem disponíveis).
O que você pode fazer é seguir uma abordagem empírica: observar os resumos gerados por IA no mundo real e consultar os fãs de suas palavras-chave alvo. Considerando um termo de pesquisa específico, se determinados tópicos continuarem aparecendo nos resultados da IA, você deverá otimizar o conteúdo da sua página em torno desses tópicos.
No contexto da pesquisa com IA do Google, um fan-out de consulta é uma técnica que transforma uma única consulta do usuário em uma rede de subconsultas relacionadas. Em vez de simplesmente fazer a correspondência entre a consulta original e a melhor resposta, o Google AI Mode vai além, gerando e pesquisando várias perguntas relacionadas de uma só vez.
Como você pode ver no exemplo abaixo, o Google AI Mode geralmente retorna cerca de 10 links relacionados com resumos curtos para ajudá-lo a explorar o tópico com mais profundidade:
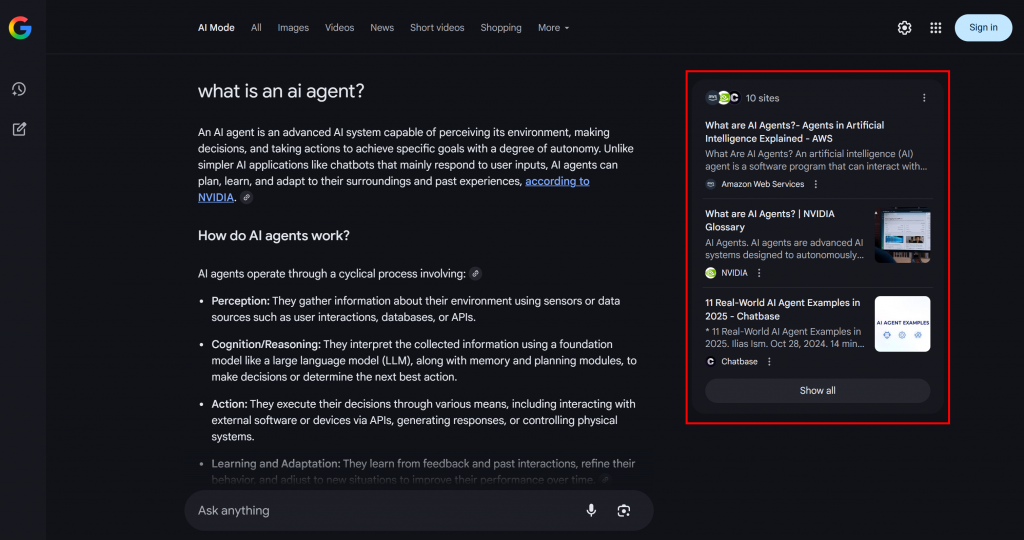
Isso é o que é um fan-out de consulta do Google, que pode ser definido em termos mais simples como uma coleção de subconsultas relacionadas geradas a partir de uma única pesquisa de IA.
Se determinados tópicos continuarem a se repetir nos fan-outs de consulta e nas visões gerais de IA, faz sentido estruturar uma página de conteúdo em torno deles. Como efeito colateral positivo, essa abordagem também pode melhorar o SEO tradicional, já que mecanismos como o Google provavelmente impulsionarão as páginas nas SERPs que já apresentam bom desempenho em seus resultados de pesquisa com IA.
Agora que você já entendeu os conceitos básicos, aprofunde-se nas especificações técnicas dessa abordagem de GEO!
Como criar um sistema de otimização GEO multiagente
Como você pode imaginar, implementar um agente de IA para dar suporte ao seu fluxo de trabalho de otimização de conteúdo GEO não é simples. Uma abordagem eficaz é contar com um sistema multiagente baseado em seis agentes especializados:
- Title Scraper: Extrai o título ou o cabeçalho principal de uma página da Web, com base em seu URL.
- Pesquisador de consultas do Google: Utiliza o título extraído para chamar a ferramenta de pesquisa do Google disponível no Gemini e gerar um fan-out de consulta.
- Extrator de consulta principal do Google: Analisa o fan-out da consulta para identificar e extrair a principal consulta de pesquisa semelhante à do Google.
- Recuperador de visão geral de IA do Google: Usa a consulta principal para realizar uma pesquisa SERP do Google e recupera a seção Visão geral da IA a partir dela.
- Sumarizador de fan-out de consulta: Condensa o conteúdo do fan-out da consulta (que normalmente é bastante longo) em um resumo Markdown otimizado, destacando os principais tópicos.
- Otimizador de conteúdo de IA: Compara o resumo de fan-out da consulta com a Visão geral de IA do Google para identificar padrões e tópicos recorrentes. Ele gera um documento Markdown de saída contendo insights acionáveis para a otimização do conteúdo GEO.
Agora, alguns dos agentes descritos acima são bastante genéricos e podem ser implementados com a maioria dos LLMs (por exemplo, o Google Main Query Extractor, o Query Fan-Out Summarizer e o AI Content Optimizer). Entretanto, outros agentes exigem recursos mais especializados e acesso a modelos ou ferramentas específicos.
Por exemplo, o Google Main Query Extractor precisa acessar a ferramenta google_search, que só está disponível nos modelos Gemini. Da mesma forma, o agente Title Scraper precisa acessar o conteúdo da página da Web para extrair o título. Essa tarefa pode ser desafiadora, pois muitos sites têm medidas anti-AI em vigor. Para evitar problemas, você pode integrar o Title Scraper com o Web Unlocker. Essa API de raspagem da Bright Data recupera o conteúdo em HTML bruto ou no formato Markdown otimizado para IA, ignorando todos os bloqueios para você.
Da mesma forma, o Google AI Overview Retriever requer uma ferramenta como a API SERP da Bright Data para executar a consulta de pesquisa e extrair a visão geral da IA em tempo real.
Em outras palavras, graças à infraestrutura de IA da Gemini e da Bright Data, você pode implementar esse caso de uso de GEO/SEO. O que você precisa agora é de um sistema de criação de agentes de IA para orquestrar esses agentes, conforme descrito neste gráfico resumido:
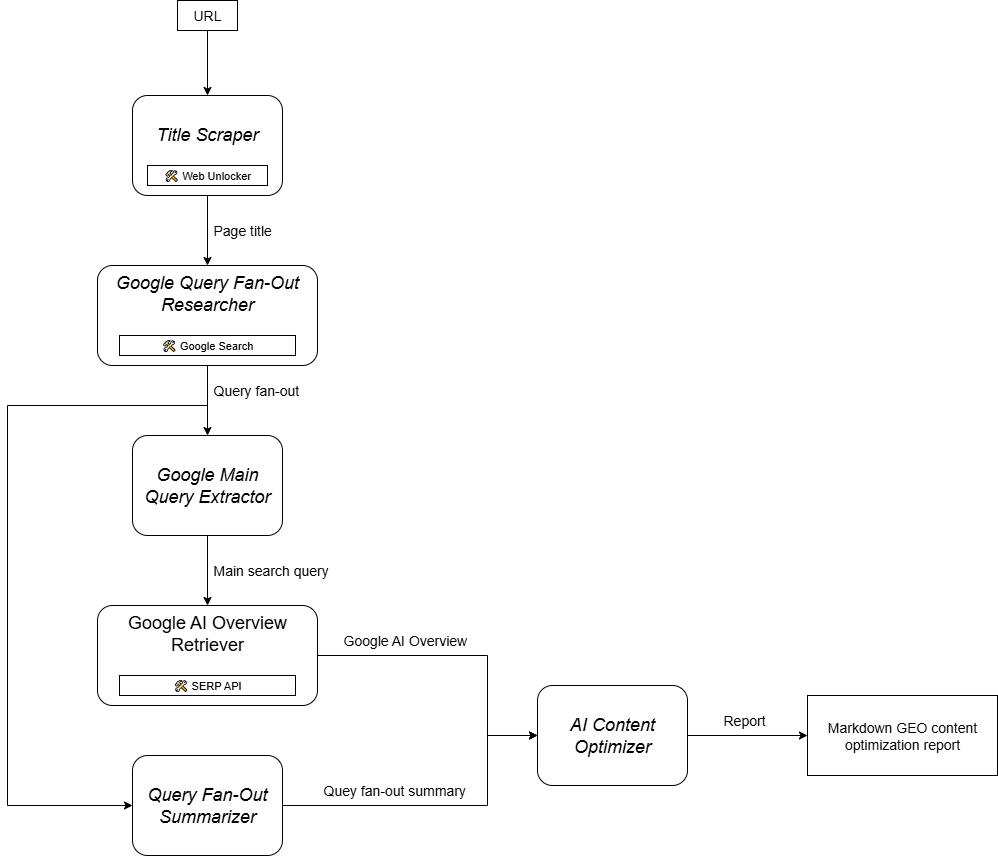
Como o CrewAI foi projetado especificamente para orquestrar sistemas multiagentes, ele é a estrutura ideal para criar e gerenciar esse fluxo de trabalho.
Implementação de um sistema de otimização de conteúdo GEO multiagente na CrewAI usando dados da Gemini e da Bright
Siga as etapas abaixo para saber como criar um sistema multiagente que forneça um fluxo de trabalho repetível para otimizar páginas da Web para mecanismos de pesquisa com IA. Ao analisar sistematicamente os fan-outs de consultas e as visões gerais de IA, essa abordagem ajuda você a descobrir tópicos de alta prioridade e a estruturar o conteúdo para obter classificações mais altas orientadas por IA.
O código abaixo foi escrito em Python usando o CrewAI, com integração do Bright Data e do Gemini para fornecer aos agentes as ferramentas e os recursos necessários.
Pré-requisitos
Para acompanhar este tutorial, certifique-se de que você tenha:
- Python 3.10+ instalado localmente.
- Uma chave de API Gemini (não são necessários créditos).
- Uma conta da Bright Data.
Não se preocupe se você não tiver uma conta da Bright Data. Você será orientado durante o processo de configuração de uma conta.
Além disso, é muito importante entender um pouco o funcionamento da CrewAI. Antes de começar, recomendamos que você leia os documentos oficiais.
Etapa 1: Configure seu aplicativo CrewAI
O CrewAI requer o uv para instalação. Você pode instalá-lo globalmente com o seguinte comando:
pip install uvComo alternativa, siga o guia de instalação oficial do seu sistema operacional.
Em seguida, instale o CrewAI globalmente em seu sistema:
uv tool install crewai Agora, crie um novo projeto CrewAI chamado ai_content_optimization_agent:
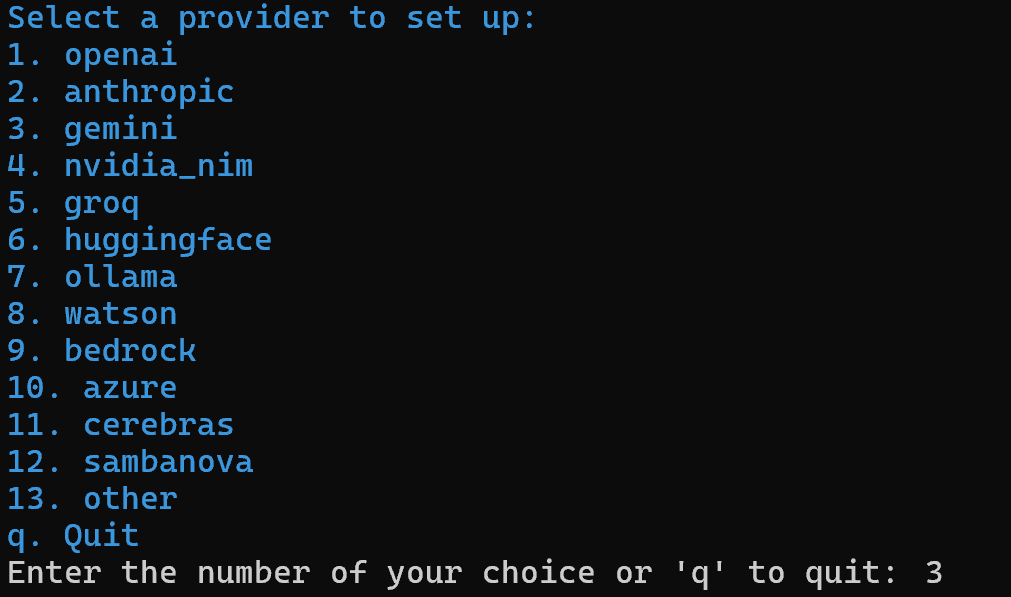
crewai create crew ai_content_optimization_agentVocê será solicitado a selecionar um provedor de IA. Como o fluxo de trabalho atual opera no Gemini, escolha a opção 3:
Em seguida, selecione um modelo Gemini:
Você pode escolher qualquer um dos modelos disponíveis, pois ele será substituído mais adiante neste artigo. Portanto, isso não é importante.
Continue colando sua chave de API do Gemini:

Após essa etapa, seu projeto na estrutura da pasta ai_content_optimization_agent/ terá a seguinte aparência:
ai_content_optimization_agent/
├── .gitignore
├── knowledge/
├── pyproject.toml
├── README.md
├── .env
└── src/
└── ai_content_optimization_agent/
├── __init__.py
├── main.py
├── crew.py
├── tools/
│ ├── custom_tool.py
│ └── __init__.py
└── config/
├── agents.yaml
└── tasks.yamlCarregue o projeto em seu IDE Python favorito e familiarize-se com ele. Explore os arquivos atuais e observe que .env já contém o modelo Gemini selecionado e sua chave de API Gemini:
MODEL=<SELECTED_GEMINI_MODEL>
GEMINI_API_KEY=<YOUR_GEMINI_API_KEY>Se você não estiver familiarizado com os arquivos do CrewAI ou tiver problemas, consulte o guia de instalação oficial.
Navegue até a pasta do projeto em seu terminal:
cd ai_content_optimization_agentEm seguida, inicialize um ambiente virtual Python dentro dele:
python -m venv .venv Observação: o ambiente virtual deve ter o nome .venv. Caso contrário, o comando crewai run para iniciar o fluxo de trabalho do CrewAI falhará.
No Linux e no macOS, ative o ambiente virtual com:
source .venv/bin/activateComo alternativa, no Windows, execute:
.venvScriptsactivatePronto! Agora você tem um projeto CrewAI em branco.
Etapa 2: Integrar o Gemini
Como mencionado anteriormente, por padrão, o CrewAI adiciona o modelo Gemini selecionado ao arquivo .env. Para configurar o modelo mais recente, substitua a variável de ambiente MODEL no arquivo .env da seguinte forma:
MODEL=gemini/gemini-2.5-flashDessa forma, seus agentes de IA orquestrados com o CrewAI poderão se conectar ao gemini-2.5-flash. No momento em que este texto foi escrito, esse é o modelo mais recente do Gemini Flash. Além disso, ele tem limites de taxa muito generosos quando interrogado via API (como nesta integração da CrewAI).
Em crew.py, carregue o nome MODEL do ambiente usando:
MODEL = os.getenv("MODEL")Essa variável será usada posteriormente para definir o LLM nos agentes.
Não se esqueça de importar os da biblioteca padrão do Python:
import osLegal! A configuração do Gemini acabou.
Etapa 3: Instalar e configurar as ferramentas de dados brilhantes do CrewAI
Extrair o título de uma página da Web por meio de IA não é simples. A maioria dos LLMs não consegue acessar diretamente o conteúdo da página da Web. E mesmo quando eles têm ferramentas integradas para fazer isso, muitas vezes elas falham devido a medidas avançadas contra raspagem, como impressão digital do navegador e CAPTCHAs. Os mesmos desafios se aplicam à raspagem de SERP ao vivo, pois o Google impede ativamente a raspagem automatizada.
É aqui que o Bright Data se torna fundamental. Felizmente, ele tem suporte oficial por meio das ferramentas de dados brilhantes da CrewAI.
Para começar, inscreva-se em uma conta da Bright Data (ou faça login se já tiver uma). Em seguida, acesse o painel de controle do seu perfil e siga as instruções oficiais para configurar uma zona do Web Unlocker:

Certifique-se de que a zona esteja definida como “Ativa”:
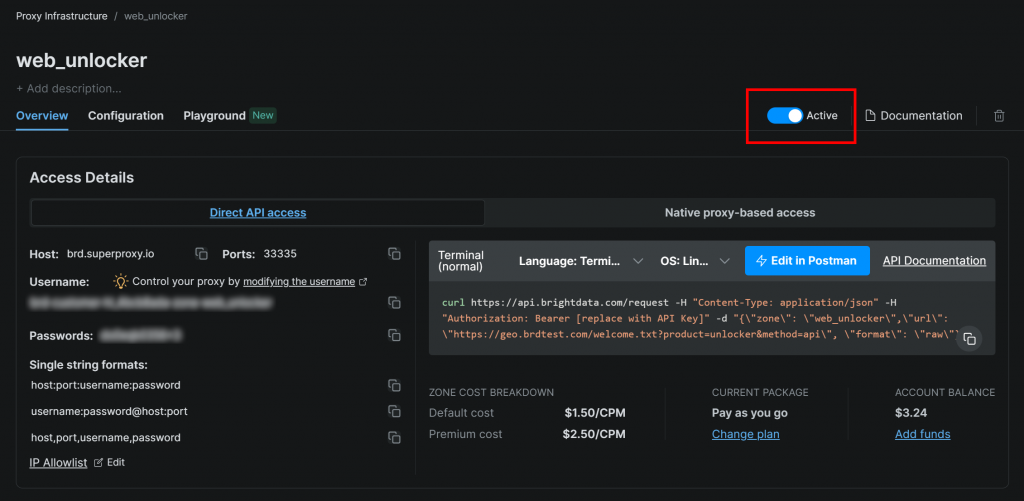
Nesse caso, o nome da zona do Web Unlocker é "web_unlocker", mas você pode dar o nome que quiser. Tenha esse nome em mente, pois você precisará dele em breve.
Depois de concluir a configuração, siga o guia oficial para gerar sua chave de API da Bright Data. Guarde-a com segurança, pois você precisará dela em breve.
Agora, em seu ambiente virtual ativado, instale os requisitos da ferramenta CrewAI Bright Data:
pip install crewai[tools] aiohttp requestsPara que a integração funcione, adicione suas credenciais da Bright Data ao arquivo .env por meio dos dois envs a seguir:
BRIGHT_DATA_API_KEY="<BRIGHT_DATA_API_KEY>"
BRIGHT_DATA_ZONE="<YOUR_BRIGHT_DATA_ZONE>"Substitua o e por sua chave real da API da Bright Data e pelo nome da zona do Web Unlocker, respectivamente.
Em seguida, em crew.py, importe as ferramentas do Bright Data:
from crewai_tools import BrightDataWebUnlockerTool, BrightDataSearchToolInicialize-os conforme abaixo:
web_unlocker_tool = BrightDataWebUnlockerTool()
serp_search_tool = BrightDataSearchTool()Agora você pode fornecer recursos de desbloqueio da Web e de recuperação de SERP aos seus agentes simplesmente passando essas ferramentas para eles. Fantástico!
Etapa 4: Criar o agente de raspagem de títulos
Agora você tem tudo pronto para criar seu primeiro agente. Comece com o agente Title Scraper, que é responsável por extrair o título de uma página da Web.
Para obter o título da página, há duas maneiras principais:
- Recupera o conteúdo do texto do elemento HTML
<h1>. - Se o
<h1>estiver faltando, peça à IA para inferir o título da página com base no restante do conteúdo da página.
Não se esqueça de que isso requer a integração da ferramenta Web Unlocker. Em crew.py, defina o agente e a tarefa CrewAI da seguinte forma:
@agent
def title_scraper_agent(self) -> Agent:
return Agent(
config=self.agents_config["title_scraper_agent"],
tools=[web_unlocker_tool], # <--- Web Unlocker tool integration
verbose=True,
llm=MODEL,
)
@task
def scrape_title_task(self) -> Task:
return Task(
config=self.tasks_config["scrape_title_task"],
agent=self.title_scraper_agent(),
max_retries=3,
)Como essa tarefa envolve a chamada de uma ferramenta de terceiros, faz sentido ativar a lógica de repetição (até 3 vezes) por meio da opção max_retries. Isso evita que todo o fluxo de trabalho falhe devido a problemas temporários de rede ou erros de ferramenta. A mesma lógica deve ser aplicada a todas as outras tarefas que dependem de serviços de terceiros (por meio de ferramentas) ou envolvem operações complexas de IA que podem falhar devido a erros de processamento do LLM.
Em seguida, em seu arquivo de configuração agents.yaml, defina o agente Title Scraper da seguinte forma:
title_scraper_agent:
role: "Title Scraper"
goal: "Extract the main H1 heading or title from a given web page URL."
backstory: "You are an expert scraper with a specialization in identifying and extracting the main heading (H1) or title of a webpage."Em seguida, em tasks.yaml, descreva sua tarefa principal da seguinte forma:
scrape_title_task:
description: |
1. Visit the URL: '{url}'.
2. Scrape the page's full content using the Bright Data Web Unlocker tool (using the Markdown data format).
3. Locate and extract only the text within the `<h1>` tag. If no `<h1>` tag is present, infer a title from the page content.
4. Output the extracted text as a plain string.
expected_output: "The plain string containing the extracted text from the specified URL."Observe como essa tarefa lê o URL de uma entrada da CrewAI graças à sintaxe {url}. Você verá como preencher esse argumento de entrada em uma das próximas etapas.
Excelente! O agente Title Scraper está concluído. Agora você aplicará uma lógica semelhante para definir todos os agentes restantes.
Etapa 5: Implementar o agente pesquisador Fan-Out do Google Query
O CrewAI não oferece uma maneira integrada de acessar a ferramenta de pesquisa do Google disponível nos modelos Gemini. Em vez disso, você precisa definir uma integração personalizada do Gemini LLM , conforme mostrado no repositório oficial de integração do Gemini CrewAI.
Essencialmente, você deve criar uma classe que estenda a classe CrewAI LLM. Isso se conectará ao Gemini e habilitará a ferramenta google_search. Você pode colocar essa classe em um arquivo chamado gemini_google_search_llm.py dentro de uma subpasta llms/ personalizada (ou pode colocar a classe diretamente na parte superior do crew.py).
Defina sua classe de integração personalizada do Gemini LLM da seguinte forma:
# src/ai_content_optimization_agent/llms/gemini_google_search_llm.py
from crewai import LLM
import os
from typing import Any, Optional
# Define a custom Gemini LLM integration with Google Search grounding
class GeminiWithGoogleSearch(LLM):
"""
A Gemini-specific LLM that has the "google_search" tool enabled.
"""
def __init__(self, model: str | None = None, **kwargs):
if not model:
# Use a default Gemini model.
model = os.getenv("MODEL")
super().__init__(model, **kwargs)
def call(
self,
messages: str | list[dict[str, str]],
tools: list[dict] | None = None,
callbacks: list[Any] | None = None,
available_functions: dict[str, Any] | None = None,
from_task: Optional[Any] = None,
from_agent: Optional[Any] = None,
) -> str | Any:
if not tools:
tools = []
# LiteLLM will throw a warning if it sees `google_search`,
# so you must use camel case here
tools.insert(0, {"googleSearch": {}})
return super().call(
messages=messages,
tools=tools,
callbacks=callbacks,
available_functions=available_functions,
from_task=from_task,
from_agent=from_agent,
)Isso permite que você acesse a ferramenta Google Search no seu modelo Gemini configurado.
Observação: a ferramenta Google Search inclui algumas cotas na camada gratuita da API, portanto, você pode usá-la em seu aplicativo sem precisar de um plano premium.
Em seguida, em crew.py, importe a classe GeminiWithGoogleSearch:
from .llms.gemini_google_search_llm import GeminiWithGoogleSearchUse-a para especificar o agente Query Fan-Out Researcher da seguinte forma:
@agent
def query_fanout_researcher_agent(self) -> Agent:
return Agent(
config=self.agents_config["query_fanout_researcher_agent"],
verbose=True,
llm=GeminiWithGoogleSearch(MODEL), # <--- Gemini integration with the Google Search tool
)
@task
def google_search_task(self) -> Task:
return Task(
config=self.tasks_config["google_search_task"],
context=[self.scrape_title_task()],
agent=self.query_fanout_researcher_agent(),
max_retries=3,
markdown=True,
output_file="output/query_fanout.md",
)Observe que o LLM usado na classe Agent é uma instância da classe personalizada GeminiWithGoogleSearch. Como a tarefa de geração de fan-out de consulta produz uma saída valiosa para depuração e análise posterior, você deve exportá-la para um arquivo de saída personalizado. Nesse caso, a saída produzida será armazenada no arquivo output/query_fanout.md.
Além disso, observe como o contexto da tarefa principal do agente é exatamente a saída da tarefa principal do agente anterior no fluxo de trabalho. Dessa forma, o agente atual terá acesso ao resultado produzido pelo agente Title Scraper. Em particular, ele utilizará isso como entrada ao executar a recuperação de fan-out por meio da ferramenta Google Search.
Em seguida, em agents.yaml, adicione:
query_fanout_researcher_agent:
role: "Google Query Fan-Out Researcher"
goal: "Given a title, perform a comprehensive web search to get the query fan-out."
backstory: "You are an AI research assistant, powered by the Google Search tool from Gemini."E em tasks.yaml:
google_search_task:
description: |
1. Use the title from the previous task as your search query.
2. Perform a web search using the Google Search tool.
3. Return the results from the Google Search tool.
expected_output: "The output from the Google Search tool in Markdown format."Se você estiver se perguntando como é o fan-out de uma consulta, veja abaixo um pequeno trecho de um resultado real da ferramenta google_search:
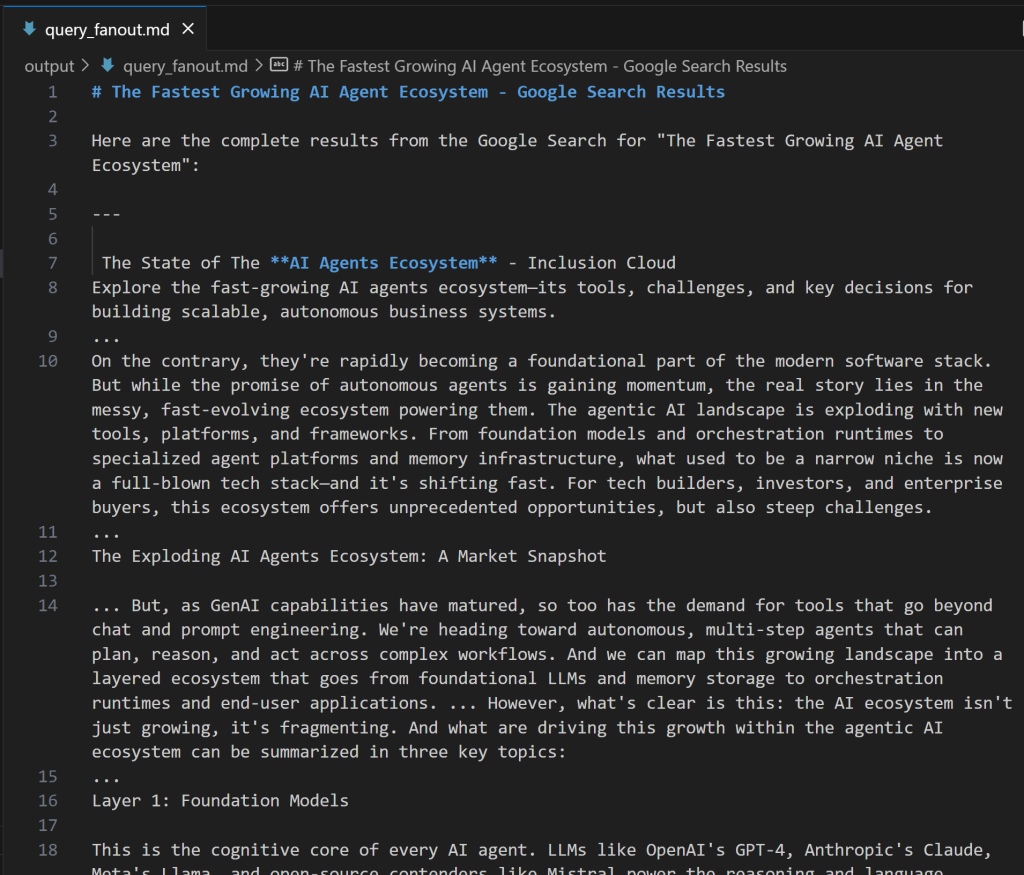
Perfeito! O agente do Google Query Fan-Out Researcher está pronto.
Etapa nº 6: Definir os agentes restantes
Assim como antes, prossiga definindo os agentes restantes no crew.py:
@agent
def main_query_extractor_agent(self) -> Agent:
return Agent(
config=self.agents_config["main_query_extractor_agent"],
verbose=True,
llm=MODEL,
)
@task
def main_query_extraction_task(self) -> Task:
return Task(
config=self.tasks_config["main_query_extraction_task"],
context=[self.google_search_task()],
agent=self.main_query_extractor_agent(),
)
@agent
def ai_overview_retriever_agent(self) -> Agent:
return Agent(
config=self.agents_config["ai_overview_retriever_agent"],
tools=[serp_search_tool], # <--- SERP API tool integration
verbose=True,
llm=MODEL,
)
@task
def ai_overview_extraction_task(self) -> Task:
return Task(
config=self.tasks_config["ai_overview_extraction_task"],
context=[self.main_query_extraction_task()],
agent=self.ai_overview_retriever_agent(),
max_retries=3,
markdown=True,
output_file="output/ai_overview.md",
)
@agent
def query_fanout_summarizer_agent(self) -> Agent:
return Agent(
config=self.agents_config["query_fanout_summarizer_agent"],
verbose=True,
llm=MODEL,
)
@task
def query_fanout_summarization_task(self) -> Task:
return Task(
config=self.tasks_config["query_fanout_summarization_task"],
context=[self.google_search_task()],
agent=self.query_fanout_summarizer_agent(),
markdown=True,
output_file="output/query_fanout_summary.md",
)
@agent
def ai_content_optimizer_agent(self) -> Agent:
return Agent(
config=self.agents_config["ai_content_optimizer_agent"],
verbose=True,
llm=MODEL,
)
@task
def compare_ai_overview_task(self) -> Task:
return Task(
config=self.tasks_config["compare_ai_overview_task"],
context=[self.query_fanout_summarization_task(), self.ai_overview_extraction_task()],
agent=self.ai_content_optimizer_agent(),
max_retries=3,
markdown=True,
output_file="output/report.md",
)Respectivamente, o código acima especifica:
- O agente Google Main Query Extractor e sua principal tarefa.
- O agente Google AI Overview Retriever e sua principal tarefa.
- O agente Query Fan-Out Summarizer e sua principal tarefa.
- O agente AI Content Optimizer e sua principal tarefa.
Complete as definições do agente adicionando estas linhas ao arquivo agents.yaml:
main_query_extractor_agent:
role: "Google Main Query Extractor"
goal: "Extract the main Google-like search query from a provided query fan-out."
backstory: "You are an AI assistant specialized in parsing query fan-outs and identifying the main, concise search query suitable for Google searches."
ai_overview_retriever_agent:
role: "Google AI Overview Retriever"
goal: "Given a query fan-out, extract the main search query and use it to perform a SERP search on Google to retrieve the AI Overview section."
backstory: "You are an AI SERP search assistant with the ability to retrieve SERPs from Google."
query_fanout_summarizer_agent:
role: "Query Fan-Out Summarizer"
goal: "Generate a concise and structured summary from the provided query fan-out."
backstory: "You are an AI summarization expert focused on condensing query fan-outs into clear, actionable summaries in Markdown format."
ai_content_optimizer_agent:
role: "AI Content Optimizer"
goal: "Compare a summary generated from a query fan-out with the Google AI Overview, identify patterns and similarities, and generate a list of action items based on common topics."
backstory: "You are an AI assistant that analyzes content summaries and AI overviews to find recurring themes, patterns, and actionable insights to optimize content strategies."E estas linhas no tasks.yaml:
main_query_extraction_task:
description: |
1. From the provided query fan-out, extract the main search query.
2. Transform the search query into a concise, Google-like keyphrase that users would type into Google.
expected_output: "A short, clear, Google-style search query."
ai_overview_extraction_task:
description: |
1. Use the search query from the previous task to perform a SERP search on Google via the Bright Data SERP Search tool by setting the `brd_ai_overview` argument to 2.
2. Retrieve and return an aggregated Markdown version of the AI Overview section from the search results.
3. After all attempts, if none of the responses contain a Google AI Overview, generate one based on the results from the SERP API, and include a note indicating it was generated.
expected_output: "The AI Overview section Markdown format (either retrieved from the SERP API or generated if unavailable)."
query_fanout_summarization_task:
description: |
1. Generate a summary from the query fan-out received as input.
expected_output: "A Markdown summary containing the main information from the query fan-out."
compare_ai_overview_task:
description: |
1. Compare the previously generated summary with the Google AI Overview provided as input.
2. Identify patterns and similarities (such as sub-topics or recurring themes), as well as differences between the two sources.
3. Generate a list of action items based on the comparison, focusing on topics that appear in both the Google AI Overview and the initial summary.
4. Produce a summary table to compare the patterns, similarities, and differences, containing these columns: Aspect, Query Fan-Out Summary, Google AI Overview, Similarities/Patterns, Differences.
expected_output: |
A comparison report in Markdown that highlights patterns, similarities, and a list of action items derived from the query fan-out.
The document must with a summary table presenting the main similarities and differences, and then all remaining content.Veja como a tarefa ai_overview_extraction_task inclui especificações técnicas para recuperar a visão geral da IA na resposta da API SERP. Saiba mais na documentação oficial.
Maravilhoso! Todos os seus agentes de IA no fluxo de trabalho de otimização de conteúdo GEO já foram criados. Em seguida, é hora de adicionar uma equipe para orquestrá-los.
Etapa nº 7: Agregar todos os agentes em uma equipe
Dentro do crew.py, defina uma nova função Crew para executar os agentes sequencialmente:
@crew
def crew(self) -> Crew:
return Crew(
agents=self.agents,
tasks=self.tasks,
process=Process.sequential,
verbose=True,
)Incrível! A classe AiContentOptimizationAgent no arquivo crew.py está completa. Você só precisa executar seu método crew() no arquivo main.py para iniciar o fluxo de trabalho.
Etapa 8: Definir o fluxo de execução
Substituir o arquivo main.py para:
- Leia o URL de entrada do terminal usando a função
input()do Python. - Use o URL fornecido para criar a entrada de agente necessária.
- Inicialize uma instância do
AiContentOptimizationAgente chame seu métodocrew(), passando um objeto de entrada com o campo{url}necessário preenchido. - Execute o fluxo de trabalho de IA.
Implemente toda a lógica acima no main.py da seguinte forma:
#!/usr/bin/env python
import warnings
from ai_content_optimization_agent.crew import AiContentOptimizationAgent
warnings.filterwarnings("ignore", category=SyntaxWarning, module="pysbd")
def run():
# Read URL from the terminal
url = input("Please enter the URL to process: ").strip()
if not url:
raise ValueError("No URL provided. Exiting.")
# Build the required agent input
inputs = {
"url": url,
}
try:
print(f"Analyzing '${url}' for AI content optimization...")
# Run the multi-agent workflow
AiContentOptimizationAgent().crew().kickoff(inputs=inputs)
except Exception as e:
raise Exception(f"An error occurred while running the crew: {e}")Etapa nº 9: teste seu agente
Em seu ambiente virtual ativado, antes de iniciar o agente, instale as dependências necessárias com:
crewai installEm seguida, inicie seu sistema de otimização GEO multiagente:
crewai runVocê será solicitado a inserir o URL de entrada:

Neste exemplo, usaremos uma página do próprio site da CrewAI como entrada:
https://www.crewai.com/ecosystem
Esta página apresenta os principais atores do ecossistema de agentes de IA.
Execute o agente nessa página e você verá um resultado como este:
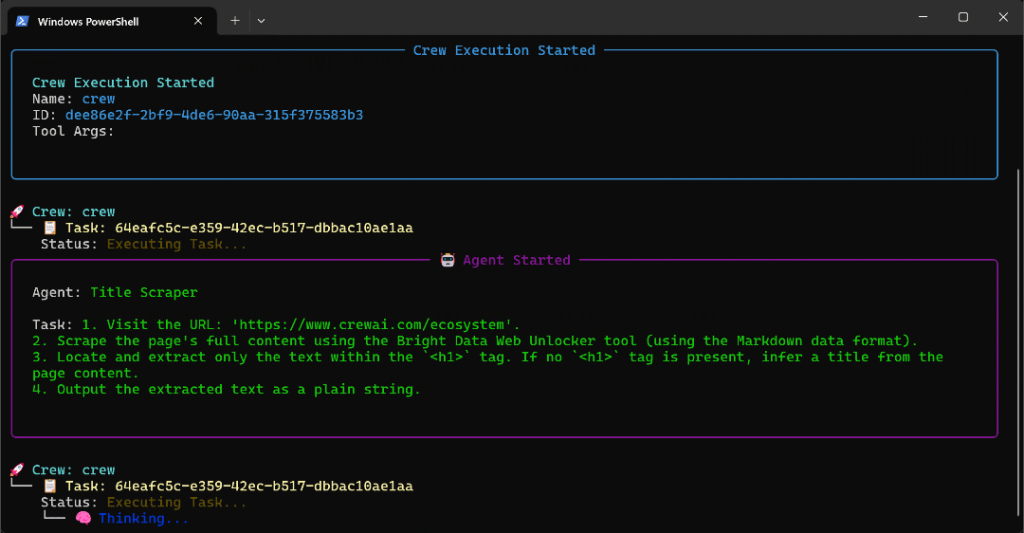
O GIF acima foi acelerado, mas isso é o que acontece passo a passo:
- O agente Title Scraper coleta o título da página por meio da ferramenta Bright Data Web Unlocker. O resultado é
"O ecossistema de agentes de IA de crescimento mais rápido"(exatamente como mostrado na captura de tela da página). - O Google Query Fan-Out Researcher gera a saída do fan-out da consulta a partir da ferramenta
google_search. Isso produz o arquivoquery_fanout.mdna pastaoutput/. - O Google Main Query Extractor identifica a principal consulta de pesquisa semelhante à do Google a partir do fan-out da consulta. O resultado é
"crescimento do ecossistema de agentes de IA". - O Google AI Overview Retriever obtém a visão geral da IA para a consulta de pesquisa por meio da API SERP da Bright Data. A saída é armazenada em
ai_overview.md. - O agente Query Fan-Out Summarizer condensa o conteúdo do fan-out da consulta em um resumo Markdown detalhado em
query_fanout_summary.md. - O AI Content Optimizer compara o resumo de fan-out da consulta com a Visão geral do Google AI para gerar o arquivo final
do relatório.md.
No final da execução, a pasta output/ deve conter os quatro arquivos a seguir:
Abra o report.md no modo de visualização no Visual Studio Code e role por ele:

Como você pode ver, ele contém um relatório detalhado de Markdown para ajudá-lo a otimizar o conteúdo da página de entrada fornecida para GEO (e SEO)!
Agora, use esse agente nos URLs das páginas da Web que você deseja melhorar para classificação de IA e você aprimorará seu posicionamento de GEO e SEO.
E pronto! Missão cumprida.
Próximas etapas
O agente de otimização de conteúdo de IA criado acima já é bastante avançado, mas sempre pode ser aprimorado. Uma ideia é adicionar outro agente no início do fluxo de trabalho que recebe um mapa do site como entrada (opcionalmente, usando um regex para filtrar URLs, por exemplo, para selecionar somente publicações de blog). Esse agente poderia então passar os URLs para o fluxo de trabalho existente, possivelmente em paralelo, permitindo que você analise várias páginas para otimização de conteúdo de IA ao mesmo tempo.
Em geral, lembre-se de que você pode experimentar as instruções em agents.yaml e tasks.yaml para adaptar o comportamento de cada um dos seis agentes ao seu caso de uso específico. Não são necessárias habilidades técnicas avançadas para fazer esses ajustes!
Conclusão
Neste artigo, você aprendeu como aproveitar os recursos de integração de IA da Bright Data para criar um fluxo de trabalho multiagente complexo para otimização de GEO/SEO no CrewAI.
O fluxo de trabalho de IA apresentado aqui é ideal para quem está procurando uma maneira programática de melhorar o conteúdo da página da Web para os mecanismos de pesquisa tradicionais e para as pesquisas baseadas em IA.
Para criar fluxos de trabalho avançados semelhantes, explore toda a gama de soluções para recuperação, validação e transformação de dados da Web em tempo real na infraestrutura de IA da Bright Data.
Crie uma conta gratuita na Bright Data hoje mesmo e comece a fazer experiências com nossas ferramentas da Web prontas para IA!




