

Treinar um modelo de IA envolve ensiná-lo a reconhecer padrões em dados para tomar decisões. O fine-tuning (ajuste fino) é uma estratégia que adapta modelos treinados em grandes conjuntos de dados, como o GPT-4 da OpenAI, para conjuntos de dados menores e específicos para determinada tarefa, continuando o processo de treinamento.
Nas seções a seguir, exploraremos mais profundamente o processo de treinar um modelo de IA customizado usando o fine-tuning da OpenAI, guiando você por cada etapa do processo.
Entendendo IA e treinamento de modelos
Inteligência Artificial (IA) envolve desenvolver sistemas capazes de tarefas que normalmente exigem inteligência humana, como aprendizado, resolução de problemas e tomada de decisões. No cerne de um modelo de IA está um conjunto de algoritmos que fazem previsões com base em dados de entrada. O aprendizado de máquina (ML), um subconjunto da IA, permite que as máquinas aprendam a partir de dados e melhorem o desempenho de forma autônoma.
Os modelos de IA aprendem de forma semelhante a uma criança que distingue gatos de cachorros, observando características, fazendo suposições, corrigindo erros e tentando novamente. Esse processo, conhecido como treinamento de modelo, envolve processar dados de entrada, analisar e processar padrões e usar esse conhecimento para fazer previsões. O desempenho do modelo é avaliado comparando sua saída com o resultado esperado, e são feitos ajustes para melhorar esse desempenho. Com treinamento suficiente, o conjunto de algoritmos do modelo representará um preditor matemático preciso para uma determinada situação, capaz de lidar com diferentes variações dos dados de entrada.
Treinar um modelo do zero envolve ensinar um modelo a aprender padrões nos dados sem qualquer conhecimento prévio. Isso requer uma grande quantidade de dados e recursos computacionais, e o modelo pode não ter um bom desempenho com uma quantidade limitada de dados.
O fine-tuning, por outro lado, começa com um modelo pré-treinado que já aprendeu padrões gerais a partir de um conjunto de dados grande. Em seguida, esse modelo é treinado adicionalmente em um conjunto de dados menor e específico, permitindo que ele aplique o conhecimento previamente aprendido à nova tarefa, muitas vezes resultando em melhor desempenho com menos dados e recursos computacionais. O fine-tuning é particularmente útil quando o conjunto de dados específico da tarefa é relativamente pequeno.
Preparação para Fine-Tuning
Embora o fine-tuning de um modelo existente com treinamento adicional em um conjunto de dados selecionado possa parecer uma opção mais atraente do que construir e treinar um modelo de IA do zero, o sucesso do processo de fine-tuning depende de vários fatores-chave.
Escolhendo o modelo certo
Ao selecionar um modelo base para fine-tuning, considere o seguinte:
Alinhamento de Tarefa: É importante definir claramente o escopo do seu problema e a funcionalidade esperada do modelo. Escolha modelos que se destaquem em tarefas semelhantes às suas, pois a dissimilaridade entre a tarefa-fonte e a tarefa-alvo durante o processo de fine-tuning pode levar a uma redução de desempenho. Por exemplo, para tarefas de geração de texto, o GPT-3 pode ser adequado, enquanto para tarefas de classificação de texto, BERT ou RoBERTa podem ser melhores.
Tamanho e Complexidade do Modelo: Equilibre desempenho e eficiência conforme necessário, pois, embora modelos maiores capturem melhor padrões complexos, eles exigem mais recursos.
Métricas de Avaliação: Escolha métricas de avaliação relevantes para sua tarefa. Por exemplo, a acurácia pode ser importante para classificação, enquanto BLEU ou ROUGE podem ser úteis para tarefas de geração de linguagem.
Comunidade e Recursos: Dê preferência a modelos com uma grande comunidade de suporte e recursos abundantes para resolução de problemas e implementação. Priorize modelos com orientações claras de fine-tuning para sua tarefa e procure fontes confiáveis para checkpoints de modelos pré-treinados.
Coleta e preparação de dados
Quando se faz fine-tuning, a qualidade e a diversidade dos seus dados podem impactar significativamente o desempenho do modelo. Aqui estão algumas considerações importantes:
Tipos de Dados Necessários: O tipo de dado depende da sua tarefa específica e dos dados nos quais o modelo foi pré-treinado. Para tarefas de PLN, normalmente você precisa de dados de texto de fontes como livros, artigos, postagens em redes sociais ou transcrições de fala. Use métodos como raspagem de dados da web, pesquisas ou APIs de plataformas de mídia social para coletar dados. Por exemplo, a raspagem de dados da web com IA pode ser particularmente útil quando é necessário um grande volume de dados diversos e atualizados.
Limpeza e Anotação de Dados: A limpeza de dados envolve remover dados irrelevantes, lidar com dados ausentes ou inconsistentes e normalizar. A anotação envolve rotular os dados para que o modelo possa aprender a partir deles. O uso de ferramentas automatizadas, como a Bright data, pode agilizar esses processos e melhorar a eficiência.
Incorporação de um conjunto de dados diversificado e representativo: Durante o fine-tuning do modelo, usar um conjunto de dados diversificado e representativo garante que o modelo aprenda a partir de várias perspectivas, resultando em previsões mais generalizadas e confiáveis. Por exemplo, se você estiver fazendo fine-tuning em um modelo de análise de sentimento para resenhas de filmes, seu conjunto de dados deve incluir resenhas de uma ampla variedade de filmes, gêneros e sentimentos, refletindo a distribuição de classes do mundo real.
Configurando o ambiente de treinamento
Garanta que você tenha o hardware e o software necessários para o modelo de IA e o framework escolhidos. Por exemplo, Large Language Models (LLMs) geralmente exigem grande poder computacional, normalmente fornecido por GPUs.
Frameworks como TensorFlow ou PyTorch são comumente usados para o treinamento de modelos de IA. Instalar as bibliotecas e ferramentas relevantes, juntamente com quaisquer dependências adicionais, é essencial para uma integração perfeita no fluxo de trabalho de treinamento. Por exemplo, ferramentas como a API da OpenAI podem ser necessárias para fazer fine-tuning em modelos específicos desenvolvidos pela OpenAI.
O Processo de Fine-Tuning
Tendo entendido o básico de fine-tuning, vejamos uma aplicação em processamento de linguagem natural (PLN).
Utilizarei a API da OpenAI para fazer fine-tuning de um modelo pré-treinado. Atualmente, o fine-tuning é possível para modelos como gpt-3.5-turbo-0125 (recomendado), gpt-3.5-turbo-1106, gpt-3.5-turbo-0613, babbage-002, davinci-002 e o experimental gpt-4-0613. O fine-tuning do GPT-4 está em fase experimental, e usuários elegíveis podem solicitar acesso na interface de fine-tuning.
1. Preparação do conjunto de dados
De acordo com um estudo, descobriu-se que o GPT-3.5 carece de raciocínio analítico. Portanto, vamos tentar fazer fine-tuning no modelo gpt-3.5-turbo para melhorar seu raciocínio analítico, usando um conjunto de dados de questões de raciocínio analítico do Law School Admission Test (AR-LSAT), lançado em 2022. O conjunto de dados disponível publicamente pode ser encontrado aqui.
A qualidade de um modelo fine-tuned depende diretamente dos dados utilizados no processo. Cada exemplo no conjunto de dados deve ser uma conversa formatada de acordo com a API Chat Completions da OpenAI, contendo uma lista de mensagens onde cada mensagem tem um papel (role), conteúdo (content) e, opcionalmente, um nome (name). Esses exemplos devem ser armazenados como um arquivo no formato JSONL.
O formato de conversa exigido para fazer fine-tuning em gpt-3.5-turbo é o seguinte:
{"messages": [{"role": "system", "content": ""}, {"role": "user", "content": ""}, {"role": "assistant", "content": ""}]}
Nesse formato, “messages” é uma lista de mensagens que formam uma conversa entre três "roles": system, user e assistant. O “content” do papel “system” deve especificar o comportamento do sistema que foi ajustado (fine-tuned).
Abaixo está um exemplo formatado retirado do conjunto de dados AR-LSAT, que usaremos neste guia:

Aqui estão as principais considerações ao criar o conjunto de dados:
- página de preços da OpenAI
- notebook de contagem de tokens
- script Python
2. Gerando a chave de API e instalando a biblioteca OpenAI
Para fazer fine-tuning em um modelo da OpenAI, é obrigatório ter uma conta de desenvolvedor da OpenAI com crédito suficiente.
Para gerar a chave de API e instalar a biblioteca OpenAI, siga estas etapas:
1. Inscreva-se no site oficial da OpenAI.
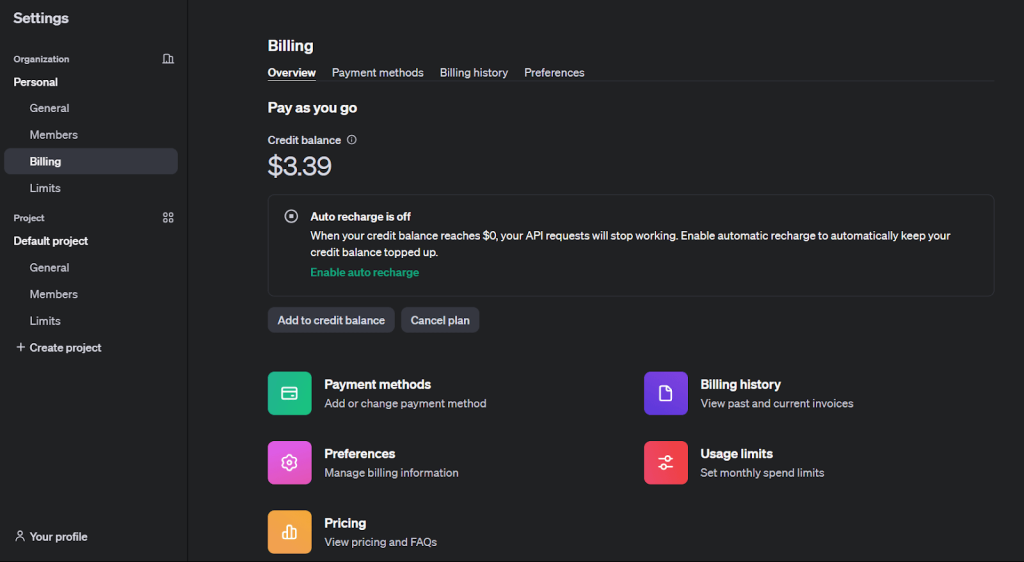
2. Para habilitar o fine-tuning, adicione crédito em sua conta na aba ‘Billing’ em ‘Settings’.
3. Clique no ícone de perfil de usuário no canto superior esquerdo e selecione “API Keys” para acessar a página de criação de chaves.
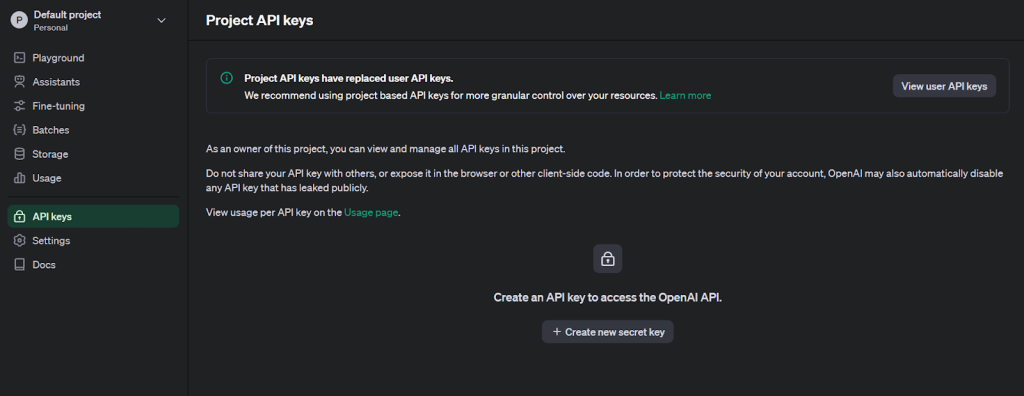
4. Gere uma nova chave secreta fornecendo um nome.

5. Instale a biblioteca Python OpenAI para fine-tuning.
pip install openai
6. Use a biblioteca os para definir o token como uma variável de ambiente e estabelecer comunicação com a API.
import os
from openai import OpenAI
# Defina a variável de ambiente OPENAI_API_KEY
os.environ['OPENAI_API_KEY'] = 'A chave gerada na etapa 4'
client = OpenAI(api_key=os.environ['OPENAI_API_KEY'])
3. Fazendo upload dos arquivos de treinamento e validação
Depois de validar seus dados, faça o upload dos arquivos usando a Files API para trabalhos de fine-tuning.
training_file_id = client.files.create(
file=open(training_file_name, "rb"),
purpose="fine-tune"
)
validation_file_id = client.files.create(
file=open(validation_file_name, "rb"),
purpose="fine-tune"
)
print(f"Training File ID: {training_file_id}")
print(f"Validation File ID: {validation_file_id}")
Os identificadores exclusivos para os dados de treinamento e validação serão exibidos após a execução bem-sucedida.

4. Criando um trabalho de fine-tuning
Depois de enviar os arquivos, você pode criar um trabalho de fine-tuning pela interface ou de forma programática.
Aqui está como iniciar um trabalho de fine-tuning usando o SDK da OpenAI:
response = client.fine_tuning.jobs.create(
training_file=training_file_id.id,
validation_file=validation_file_id.id,
model="gpt-3.5-turbo",
hyperparameters={
"n_epochs": 10,
"batch_size": 3,
"learning_rate_multiplier": 0.3
}
)
job_id = response.id
status = response.status
print(f'Fine-tunning model with jobID: {job_id}.')
print(f"Training Response: {response}")
print(f"Training Status: {status}")
model: o nome do modelo a ser ajustado (fine-tuned) (gpt-3.5-turbo,babbage-002,davinci-002ou um modelo fine-tuned existente).training_fileevalidation_file: os IDs de arquivo retornados quando os arquivos foram enviados.n_epochs,batch_sizeelearning_rate_multiplier: hiperparâmetros que podem ser personalizados.
Para definir mais parâmetros de fine-tuning, consulte a especificação da API de fine-tuning.
O código acima gera as seguintes informações para o jobID (ftjob-0EVPunnseZ6Xnd0oGcnWBZA7):

Um trabalho de fine-tuning pode levar tempo para ser concluído. Ele pode ficar na fila atrás de outros trabalhos, e a duração do treinamento pode variar de minutos a horas, dependendo do modelo e do tamanho do conjunto de dados.
Quando o treinamento for concluído, um e-mail de confirmação será enviado ao usuário que iniciou o trabalho de fine-tuning.
Você pode acompanhar o status do seu trabalho de fine-tuning na interface de fine-tuning:
5. Analisando o modelo fine-tuned
A OpenAI calcula as seguintes métricas durante o treinamento:
- Training loss
- Training token accuracy
- Validation loss
- Validation token accuracy
A validation loss e a validation token accuracy são calculadas de duas formas: em um pequeno lote de dados a cada etapa e no conjunto de validação completo ao final de cada época. A validation loss e validation token accuracy completas são as métricas mais precisas para acompanhar o desempenho do seu modelo e servem como uma verificação de consistência para garantir um treinamento estável (loss deve diminuir, token accuracy deve aumentar).
Enquanto um trabalho de fine-tuning está ativo, você pode visualizar essas métricas por meio de
1. Interface:

2. API:
import os
from openai import OpenAI
client = OpenAI(api_key=os.environ['OPENAI_API_KEY'],)
jobid = 'jobid que você deseja monitorar'
print(f"Streaming events for the fine-tuning job: {jobid}")
# signal.signal(signal.SIGINT, signal_handler)
events = client.fine_tuning.jobs.list_events(fine_tuning_job_id=jobid)
try:
for event in events:
print(f'{event.data}')
except Exception:
print("Stream interrupted (client disconnected).")
O código acima exibirá os eventos de streaming para o trabalho de fine-tuning, incluindo o número da etapa, training loss, validation loss, total de etapas e mean token accuracy para treinamento e validação:
Streaming events for the fine-tuning job: ftjob-0EVPunnseZ6Xnd0oGcnWBZA7
{'step': 67, 'train_loss': 0.30375099182128906, 'valid_loss': 0.49169286092122394, 'total_steps': 67, 'train_mean_token_accuracy': 0.8333333134651184, 'valid_mean_token_accuracy': 0.8888888888888888}
6. Ajustando parâmetros e o conjunto de dados para melhorar o desempenho
Se os resultados de um trabalho de fine-tuning não forem tão bons quanto esperado, considere as seguintes formas de melhorar o desempenho:
1. Ajustar o conjunto de dados de treinamento:
- Para refinar seu conjunto de dados de treinamento, considere adicionar exemplos que abordem as fraquezas do modelo e garanta que a distribuição de respostas nos seus dados corresponda à distribuição esperada.
- Também é importante verificar se há problemas nos dados que o modelo está reproduzindo e garantir que seus exemplos contenham todas as informações necessárias para a resposta.
- Mantenha consistência nos dados criados por várias pessoas e padronize o formato de todos os exemplos de treinamento para corresponder ao esperado na inferência.
- Em geral, dados de alta qualidade são mais eficazes do que uma grande quantidade de dados de baixa qualidade.
2. Ajustar os hiperparâmetros:
- A OpenAI permite que você especifique três hiperparâmetros; épocas, learning rate multiplier e batch size.
- Comece com valores padrão gerados pelas funções internas com base no tamanho do conjunto de dados e, se necessário, ajuste-os.
- Se o modelo não seguir os dados de treinamento como esperado, aumente o número de épocas.
- Se o modelo ficar menos diverso do que o esperado, diminua o número de épocas em 1 ou 2.
- Se o modelo não parecer estar convergindo, aumente o learning rate multiplier.
7. Usando um modelo de checkpoint
Atualmente, a OpenAI fornece acesso aos checkpoints das últimas três épocas de um trabalho de fine-tuning. Esses checkpoints são modelos completos que podem ser usados para inferência e para futuros ajustes (fine-tuning).
Para acessar esses checkpoints, aguarde o término de um trabalho com sucesso e, então, consulte o endpoint de checkpoints com o ID do seu trabalho de fine-tuning. Cada objeto de checkpoint terá o campo fine_tuned_model_checkpoint preenchido com o nome do checkpoint do modelo. Você também pode obter o nome do modelo de checkpoint por meio da interface de fine-tuning.
Você pode validar os resultados do modelo de checkpoint executando consultas com um prompt e o nome do modelo usando a função openai.chat.completions.create():
completion = client.chat.completions.create(
model="ft:gpt-3.5-turbo-0125:personal::9PWZuZo5",
messages=[
{"role": "system", "content": "Instructions: You will be presented with a passage and a question about that passage. There are four options to be chosen from, you need to choose the only correct option to answer that question. If the first option is right, you generate the answer 'A', if the second option is right, you generate the answer 'B', if the third option is right, you generate the answer 'C', if the fourth option is right, you generate the answer 'D', if the fifth option is right, you generate the answer 'E'. Read the question and options thoroughly and select the correct answer from the four answer labels. Read the passage thoroughly to ensure you know what the passage entails"},
{"role": "user", "content": "Passage: For the school paper, five studentsu2014Jiang, Kramer, Lopez, Megregian, and O'Neillu2014each review one or more of exactly three plays: Sunset, Tamerlane, and Undulation, but do not review any other plays. The following conditions must apply: Kramer and Lopez each review fewer of the plays than Megregian. Neither Lopez nor Megregian reviews any play Jiang reviews. Kramer and O'Neill both review Tamerlane. Exactly two of the students review exactly the same play or plays as each other.Question: Which one of the following could be an accurate and complete list of the students who review only Sunset?nA. LopeznB. O'NeillnC. Jiang, LopeznD. Kramer, O'NeillnE. Lopez, MegregiannAnswer:"}
]
)
print(completion.choices[0].message)
O resultado recuperado a partir do dicionário de resposta é:

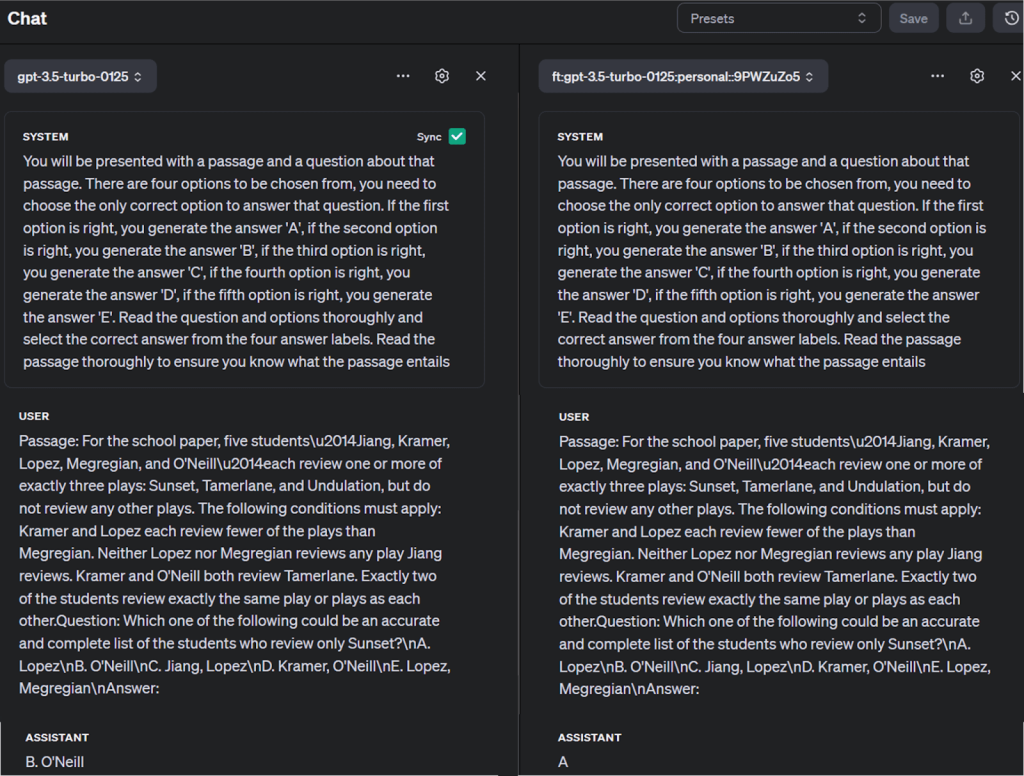
Você também pode comparar o modelo fine-tuned com outros modelos no Playground da OpenAI, como mostrado abaixo:
Dicas e Boas Práticas
Para um fine-tuning bem-sucedido, considere estas dicas:
Qualidade dos dados: Garanta que seus dados específicos da tarefa sejam limpos, diversos e representativos para evitar overfitting, em que o modelo tem bom desempenho nos dados de treinamento, mas desempenho ruim em dados não vistos.
Seleção de hiperparâmetros: Escolha hiperparâmetros apropriados para evitar convergência lenta ou desempenho insatisfatório. Isso pode ser complexo e demorado, mas é crucial para um treinamento eficaz.
Gerenciamento de recursos: Esteja ciente de que fazer fine-tuning em modelos grandes requer muitos recursos computacionais e tempo.
Evitando Armadilhas
Overfitting e underfitting: Equilibre a complexidade do seu modelo e a quantidade de treinamento para evitar overfitting (alta variância) e underfitting (alto viés).
Esquecimento catastrófico: Durante o fine-tuning, o modelo pode “esquecer” o conhecimento geral aprendido anteriormente. Avalie regularmente o desempenho do modelo em uma variedade de tarefas para mitigar esse problema.
Sensibilidade a mudanças de domínio: Se o seu conjunto de dados de fine-tuning diferir significativamente do conjunto de dados de pré-treinamento, você pode enfrentar problemas de mudança de domínio. Use técnicas de adaptação de domínio para contornar essa lacuna.
Salvando e Reutilizando Modelos
Após o treinamento, salve o estado do seu modelo para reutilizá-lo posteriormente. Isso inclui os parâmetros do modelo e qualquer estado do otimizador que foi utilizado. Assim, você poderá retomar o treinamento do mesmo estado futuramente.
Considerações Éticas
Amplificação de vieses: Modelos pré-treinados podem herdar vieses, que podem se amplificar durante o fine-tuning. Procure sempre optar por modelos pré-treinados que tenham sido testados quanto a vieses e equidade, se sua aplicação exigir previsões imparciais.
Saídas indesejadas: Modelos fine-tuned podem gerar respostas plausíveis, mas incorretas. Implemente mecanismos robustos de pós-processamento e validação para lidar com isso.
Deslocamento do modelo (model drift): O desempenho de um modelo pode se deteriorar ao longo do tempo devido a mudanças no ambiente ou na distribuição de dados. Monitore o desempenho do seu modelo regularmente e refaça o fine-tuning conforme necessário.
Técnicas Avançadas e Aprendizado Adicional
Técnicas avançadas em fine-tuning de LLMs incluem Low Ranking Adaptation (LoRA) e Quantized LoRA (QLoRA), que reduzem custos computacionais e financeiros, mantendo o desempenho. Parameter Efficient Fine Tuning (PEFT) adapta os modelos de forma eficiente com parâmetros mínimos treináveis. DeepSpeed e ZeRO otimizam o uso de memória para treinamento em larga escala. Essas técnicas abordam desafios como overfitting, esquecimento catastrófico e sensibilidade à mudança de domínio, aprimorando a eficiência e a eficácia do fine-tuning de LLMs.
Além do fine-tuning, existem outras técnicas avançadas de treinamento, como aprendizado por transferência (transfer learning) e aprendizado por reforço (reinforcement learning). Aprendizado por transferência envolve aplicar conhecimento adquirido em um problema a outro problema relacionado, enquanto aprendizado por reforço é um tipo de aprendizado de máquina em que um agente aprende a tomar decisões ao realizar ações em um ambiente para maximizar uma recompensa.
Para aqueles interessados em se aprofundar no treinamento de modelos de IA, os recursos abaixo podem ser úteis:
- Attention is all you need, de Ashish Vaswani et al.
- O livro “Deep Learning” de Ian Goodfellow, Yoshua Bengio e Aaron Courville
- O livro “Speech and Language Processing” de Daniel Jurafsky e James H. Martin
- Diferentes formas de treinar LLMs
- Mastering LLM Techniques: Training
- Curso de NLP da Hugging Face
Conclusão
Treinar um modelo de IA é um processo que exige uma quantidade significativa de dados de alta qualidade. Embora definir o problema, selecionar um modelo e refiná-lo por meio de iterações sejam etapas essenciais, o verdadeiro diferencial está na qualidade e volume de dados utilizados. Em vez de criar e manter raspadores de dados da web, você pode simplificar a coleta de dados usando conjuntos de dados pré-construídos ou personalizados disponíveis na plataforma da Bright Data.
Com o Dataset Marketplace, você pode acessar conjuntos de dados validados e prontos de sites populares ou gerar conjuntos de dados personalizados para atender às suas necessidades específicas usando a plataforma automatizada. Dessa forma, você pode se concentrar em treinar seus modelos de forma eficiente, com dados precisos e em conformidade, permitindo resultados mais rápidos e confiáveis em diversos setores.
Explore as soluções de conjunto de dados da Bright Data e integre-as facilmente ao seu fluxo de trabalho para coleta de dados.
Cadastre-se agora e comece seu teste gratuito da infraestrutura de scraping da Bright Data, incluindo amostras gratuitas de conjuntos de dados.





