

O Exa é um mecanismo de busca semântico. O Bright Data é uma infraestrutura de dados da web. São produtos fundamentalmente diferentes, e a escolha de qual usar depende inteiramente do que seu agente de IA realmente precisa fazer.
Esta comparação analisa ambos os produtos em todas as dimensões que importam para equipes de IA em produção: custo, limites de taxa, cobertura, acesso e dados históricos. Sem avaliações vagas, apenas números e fatos.
TL;DR – Bright Data vs. Exa em resumo
- O Exa é um mecanismo de busca semântico; a Bright Data é uma infraestrutura de dados da web.
- A API SERP da Bright Data custa US$ 1,50 por 1 mil solicitações; a Exa cobra US$ 7 por 1 mil.
- O limite de taxa padrão
de pesquisado Exa é de 10 QPS. A Bright Data não tem limite de solicitações simultâneas. - O Bright Data Web Unlocker pode rastrear páginas protegidas contra bots. O Exa não pode.
- A Bright Data possui mais de 50 PB de dados históricos da web. O Exa opera apenas em tempo real.
- O recurso “Find Similar” do Exa é exclusivo, sem equivalente direto no Bright Data.
- Use a Exa para descoberta semântica. Use a Bright Data para extração de ground-truth em escala.
Bright Data x Exa: Comparação direta
| Dimensão | Bright Data | Exa |
|---|---|---|
| Categoria do produto | Infraestrutura de dados da Web (rede de Proxy + scraping + Conjuntos de dados) | API de mecanismo de busca semântica |
| Abordagem de pesquisa | Scraping de mecanismos de busca reais (Google, Bing, Yandex, etc.) via API SERP + descoberta em tempo real via API Discover | Índice neural baseado em embeddings personalizados (índice próprio) |
| Resultados por consulta | Até 1.000 (API Discover) | Até 100 (padrão); até 1.000 na versão Enterprise |
| Conteúdo da página completa | Sim, extração em tempo real via Web Unlocker, retornada como Markdown | Sim, via endpoint /contents (US$ 1 por 1.000 páginas extras) |
| Anti-bot e contorno de CAPTCHA | Sim, integrado ao Web Unlocker; mais de 150 milhões de IPs de Proxy | Não, não é possível rastrear atrás de barreiras de login ou proteção anti-bot |
| Dados históricos | Sim, mais de 50 PB de arquivo da Web; Conjuntos de dados pré-construídos | Não, apenas índice em tempo real |
| Limites de taxa | Sem limite para solicitações simultâneas (API SERP) | Padrão de 10 QPS em /search; personalizado na versão Enterprise |
| Preços (PAYG) | A partir de US$ 1,50 por 1.000 solicitações (API SERP) | US$ 7 por 1.000 solicitações (busca padrão, 1 a 10 resultados) |
| Mecanismos de busca compatíveis | Google, Bing, DuckDuckGo, Yandex, Baidu, Naver, Yahoo | Índice neural proprietário da Exa |
| Conformidade | GDPR, CCPA, SOC 2, SOC 3, ISO 27701 | SOC 2 Tipo II, opção ZDR |
| Integração com MCP | Sim, Bright Data MCP Server (gratuito, 5.000 solicitações gratuitas/mês) | Sim, Exa MCP Server |
| Integrações de frameworks | LangChain, LlamaIndex, CrewAI, Agno, Dify, n8n, Zapier, mais de 70 | LangChain, LlamaIndex, CrewAI, Vercel IA SDK, mais de 20 |
| Nível gratuito | Sim, avaliação gratuita | Sim, 1.000 solicitações/mês |
| SLA empresarial | Sim, SLA de 99,9%, Gerente de conta dedicado | Sim, SLA personalizado, integração individual |
O que é o Exa?
O Exa é um mecanismo de busca desenvolvido especificamente para aplicações de IA. Em vez de usar a indexação tradicional por palavras-chave, o Exa criou seu próprio índice neural, um modelo de embeddings em grande escala treinado na web. Quando você faz uma consulta no Exa, ele realiza uma busca vetorial semântica nesse índice e retorna resultados classificados por relevância conceitual, e não por sobreposição de palavras-chave.
Essa escolha arquitetônica é o principal diferencial do Exa. Ele responde a perguntas como “encontre artigos semelhantes a este URL do arXiv” ou “empresas que fazem o que a Nvidia faz com semicondutores” de maneiras que um Scraper de SERP baseado em palavras-chave não consegue. Em março de 2026, o índice da Exa incluía mais de 1 bilhão de perfis de pessoas e 70 milhões de entradas de empresas, além de oferecer modos de pesquisa dedicados para notícias, código e relatórios financeiros. Se você estiver avaliando alternativas à Exa, as principais alternativas à Exa para pesquisa na web com IA apresentam uma comparação detalhada de ferramentas concorrentes, incluindo Bright Data, Tavily e Firecrawl.
O que a Exa faz bem
Pesquisa semântica “Encontrar semelhantes”. Nenhuma outra API de pesquisa oferece “encontre páginas conceitualmente semelhantes a este URL”. É uma lacuna de capacidade genuína que a Bright Data não preenche.
Recuperação de baixa latência. O Exa Instant oferece respostas em menos de 200 ms. A pesquisa padrão leva de 100 a 1.200 ms. Para interfaces de chat interativas e agentes em tempo real, essa velocidade é uma vantagem real.
Experiência do desenvolvedor. SDKs em Python e TypeScript, integrações nativas com LangChain, LlamaIndex e CrewAI, suporte a MCP Server e generosas 1.000 solicitações gratuitas por mês. Passar do zero para uma integração de agente funcional leva apenas alguns minutos.
Índices de domínios especializados. O índice de pessoas da Exa (mais de 1 bilhão de perfis, mais de 50 milhões de atualizações semanais) e o índice de empresas (mais de 70 milhões de empresas) foram criados especificamente para agentes de recrutamento, pipelines de inteligência de vendas e fluxos de trabalho de enriquecimento de dados corporativos.
Alta precisão em benchmarks. Na recuperação multi-hop do WebWalker, a Exa obteve 81% contra 71% da Tavily em uma avaliação de empresas da Fortune 100 (janeiro de 2025). No benchmark de 100 consultas da AIMultiple em 8 APIs, a Exa ficou em 3º lugar com uma pontuação de agente de 14,39.
Limitações centrais do Exa em escala
O limite de taxa do Exa restringe as cargas de trabalho de produção. O limite padrão de /search é de 10 QPS (600 solicitações por minuto). Confirmado diretamente nos documentos oficiais de limites de taxa do Exa. Para pipelines com múltiplos agentes executando milhares de tarefas de pesquisa em paralelo, esse teto obriga as equipes a criarem lógica de repetição de tentativas e enfileiramento de solicitações desde o primeiro dia. Clientes corporativos podem negociar limites mais altos, mas isso requer uma conversa de vendas separada.
O Exa não consegue penetrar na proteção anti-bot. O Exa rastreia a web aberta de acordo com sua própria programação. Ele não consegue acessar páginas protegidas por Cloudflare, barreiras de login, sistemas CAPTCHA ou detecção de bots com uso intensivo de JavaScript. Para Inteligência competitiva, Monitoramento de preços ou qualquer caso de uso em que as páginas mais valiosas também sejam as mais protegidas, essa é uma limitação significativa.
Sem camada de dados históricos. O Exa opera apenas em tempo real. Não há produto de arquivo, nem Conjuntos de dados históricos, nem maneira de comparar os resultados de hoje com os do último trimestre. Para detecção de anomalias, análise de tendências ou resultados de agentes baseados em linhas de base, essa é uma lacuna estrutural.
O índice do Exa não é o Google. O Exa retorna resultados de seu próprio índice neural proprietário, não do Google, Bing ou Yandex. Para qualquer caso de uso que exija saber exatamente o que um usuário real vê no Google neste momento (monitoramento de SEO, inteligência de anúncios, rastreamento de classificação, Proteção de marca), o índice do Exa é a fonte de dados errada.
A estrutura de preços não se adapta bem a grandes volumes. Com 1 milhão de solicitações por mês, a pesquisa padrão da Exa custa mais de US$ 7.000. Com conteúdo de página inteira, esse valor sobe para mais de US$ 8.000. A Exa atualizou seus preços em março de 2026, aumentando a pesquisa padrão de US$ 5/1 mil para US$ 7/1 mil e introduzindo um plano Agentic a US$ 12/1 mil.
O que é a Bright Data?
A Bright Data é uma infraestrutura de dados da web. Ela não possui um índice de pesquisa próprio, mas acessa a web real em tempo real e em grande escala, por meio de um conjunto de produtos projetados para diferentes padrões de aquisição de dados.
A API SERP coleta resultados reais do Google, Bing, Yandex, Baidu, DuckDuckGo, Yahoo e Naver em tempo real, de qualquer um dos 195 países, com segmentação geográfica por cidade. Ela retorna o que um usuário real naquele local veria, neste exato momento, e não o que qualquer índice acredita que ele deveria ver.
A API Discover foi criada especificamente para cargas de trabalho de agentes que precisam de evidências mais amplas e profundas da web ativa, em vez de uma lista superficial de links classificados por SEO. Ela encontra URLs ativos com até 1.000 resultados por solicitação, classificados de acordo com a intenção específica do agente, em vez da posição de SEO, com conteúdo Markdown limpo opcional para fundamentação e verificação RAG. Ao contrário dos mecanismos de busca ou índices em cache, cada solicitação do Discover é executada no momento da consulta na web em tempo real, tornando-o particularmente adequado para Inteligência competitiva, monitoramento de riscos e fluxos de trabalho de due diligence.
O Web Unlocker busca qualquer página da web, incluindo aquelas protegidas por Cloudflare, CAPTCHAs, barreiras de login ou renderização em JavaScript, e retorna conteúdo Markdown limpo. Ele encaminha as solicitações por uma rede de mais de 150 milhões de IPs residencialis em 195 países, lidando automaticamente com a contornagem de detecção.
A camada de Conjuntos de dados fornece dados estruturados pré-construídos em mais de 100 domínios. A API Web Archive fornece mais de 50 PB de dados históricos da web que remontam a anos atrás, tornando-a a solução perfeita para contextualização histórica.
Como a Bright Data aborda os dados da web para IA
A arquitetura da Bright Data é construída em torno de uma premissa central: a verdade fundamental é a web real em tempo real, não qualquer aproximação de um índice. Para equipes de IA corporativas que desenvolvem sistemas de produção, isso é importante quando:
- Seu agente precisa buscar a página de preços de um concorrente, e essa página bloqueia Scrapers
- Seu agente precisa saber o que o Google realmente exibe para uma palavra-chave, e não o que um índice neural estima
- Seu agente precisa executar 10.000 consultas em paralelo sem atingir o limite de taxa
- Seu agente precisa entender se os resultados de hoje são anômalos em comparação com os de seis meses atrás
A Bright Data conta com a confiança de mais de 20.000 clientes, incluindo empresas da Fortune 500, e é citada no Relatório de Panorama Competitivo da Gartner para Soluções de Coleta de Dados da Web. Possui certificações GDPR, CCPA, SOC 2, SOC 3 e ISO 27701.
Os principais produtos: API SERP, Discover API, Web Unlocker, Conjuntos de dados
| Produto | O que faz | Preço |
|---|---|---|
| API SERP | Rastreamento em tempo real de 7 mecanismos de busca, 195 países, saída estruturada em JSON/Markdown | A partir de US$ 1,50/1 mil resultados (PAYG); a partir de US$ 1,00/1 mil a partir de 2 milhões/mês |
| API Discover | Descoberta de URLs em tempo real com até 1.000 resultados por solicitação, classificados por intenção, conteúdo Markdown opcional | Gratuito (beta) |
| Web Unlocker | Busca qualquer página protegida por anti-bot, retorna Markdown limpo | A partir de US$ 1 por 1.000 solicitações |
| Conjuntos de datos | Dados estruturados pré-criados de mais de 100 domínios | A partir de US$ 250 por 100 mil registros |
| API de arquivo da web | Mais de 50 PB de dados históricos da web | A partir de US$ 0,20/1 mil páginas HTML |
| Servidor MCP | Conecte agentes de IA diretamente ao conjunto completo de produtos da Bright Data | Gratuito, 5.000 solicitações/mês |
Comparação de preços: Bright Data x Exa
Preços da Exa (março de 2026)
| Produto | Preço |
|---|---|
| Pesquisa padrão (1 a 10 resultados) | US$ 7 / 1.000 solicitações |
| Resultados adicionais além de 10 | +$1 / 1.000 resultados |
| Pesquisa Agente / Profunda | $12 / 1.000 solicitações |
| Pesquisa Profunda com Raciocínio | $15 / 1.000 solicitações |
| Conteúdo (texto de página inteira) | $1 / 1.000 páginas |
| API de respostas | $5 / 1.000 respostas |
| Nível gratuito | 1.000 solicitações/mês |
| Empresarial | Personalizado |
Nuance importante: os preços da Exa são cumulativos. Se o seu agente precisar de 10 resultados mais o conteúdo da página completa, você paga pela pesquisa (US$ 7) mais o conteúdo (US$ 1) por 1.000 solicitações. O custo efetivo mínimo para agentes que precisam do texto completo embutido é de US$ 8/1.000.
Preços da Bright Data
| Produto | Preço |
|---|---|
| API SERP (PAYG) | US$ 1,50 / 1.000 resultados |
| API SERP (380 mil resultados/mês) | $1,30 / 1.000 resultados |
| API SERP (900 mil resultados/mês) | $1,10 / 1.000 resultados |
| API SERP (2 milhões de resultados/mês) | $1,00 / 1.000 resultados |
| Web Unlocker | A partir de US$ 1 / 1.000 solicitações |
| Conjuntos de datos | A partir de US$ 250 / 100 mil registros |
| Arquivo da Web | A partir de US$ 0,20 / 1.000 páginas HTML |
| API Discover | Gratuito (beta) |
| Servidor MCP | Gratuito (5.000 solicitações/mês) |
Custo em escala: os números são gritantes
| Volume | Exa (somente pesquisa padrão) | Exa (busca + conteúdo) | API SERP da Bright Data |
|---|---|---|---|
| 10.000 solicitações | $70 | $80 | $15 |
| 100.000 solicitações | $700 | $800 | $130–150 |
| 1.000.000 de solicitações | Mais de US$ 7.000 | Mais de US$ 8.000 | $1.000–1.500 |
Com 1 milhão de solicitações por mês, a Bright Data é de 5 a 7 vezes mais barata que a Exa apenas em termos de pesquisa. Para uma comparação completa de provedores de API SERP e pesquisa na web em grande escala, consulte as melhores APIs SERP e de pesquisa na web de 2026. Para agentes que precisam do conteúdo da página inteira, a diferença aumenta ainda mais: a Exa acrescenta US$ 1 por 1.000; o Bright Data Web Unlocker começa em US$ 1 por 1.000 com tudo incluído.
A Bright Data não tem limite de solicitações simultâneas
Essa não é uma diferença sutil. O limite de taxa padrão de /search da Exa é de 10 QPS, 10 consultas por segundo, 600 por minuto. Isso é confirmado na documentação oficial de limites de taxa da Exa.
A API SERP da Bright Data não tem limite para solicitações simultâneas. De acordo com suas próprias perguntas frequentes: “Não há limite para o número de solicitações simultâneas. A API SERP foi desenvolvida para escalar.”
Para cargas de trabalho com um único agente e uma consulta por vez, isso não importa. Para pipelines de IA em produção executando dezenas ou centenas de tarefas de pesquisa paralelas, sistemas de Inteligência competitiva, estruturas de pesquisa com múltiplos agentes e pilhas de monitoramento em tempo real, a diferença é fundamental. Com a Exa, você está projetando em torno de um limite máximo desde o primeiro dia.
A Bright Data consegue acessar páginas que o Exa não consegue
O Exa rastreia a web aberta. Ele não consegue acessar:
- Páginas protegidas pelo Cloudflare
- Sites com barreiras de login ou requisitos de autenticação
- Páginas com aplicação de CAPTCHA
- Sites com uso intenso de JavaScript que não fornecem conteúdo para solicitações HTTP brutas
- Conteúdo com restrições geográficas que exija endereços IP locais
Isso não é uma crítica, simplesmente está fora do escopo do produto da Exa.
O Web Unlocker da Bright Data foi desenvolvido especificamente para resolver esse problema. Ele encaminha solicitações por mais de 150 milhões de IPs residencialis, lida com a identificação de navegadores, gerencia a Resolução de CAPTCHA e retorna o conteúdo completo da página renderizada como Markdown limpo. Para equipes que precisam entender todo o escopo do que envolve o contorno de sistemas anti-bot, o guia para contornar o Cloudflare para Scraping de dados aborda as técnicas relevantes em profundidade. Para inteligência competitiva de preços, onde os dados mais valiosos geralmente estão nas páginas mais protegidas, essa é a capacidade essencial.
Aqui está um exemplo básico de como um agente de produção usaria a API SERP da Bright Data em comparação com o Exa para a mesma tarefa:
# API SERP da Bright Data - resultados reais do Google, sem limite de taxa
import requests
response = requests.get(
"https://api.brightdata.com/serp/req",
headers={"Authorization": "Bearer YOUR_API_KEY"},
params={
"q": "competitor pricing enterprise 2026",
"gl": "us",
"num": 10,
"data_format": "markdown" # Saída pronta para LLM
}
)
results = response.json()
# Exa - pesquisa semântica, limite de 10 QPS
from exa_py import Exa
exa = Exa(api_key="SUA_CHAVE_EXA")
results = exa.search_and_contents(
"preços da concorrência para empresas em 2026",
num_results=10,
text=True
)
# $7/1k (pesquisa) + $1/1k (conteúdo) = $8/1k custo efetivoO resultado funcional é semelhante para consultas básicas. As diferenças surgem quando você precisa executar isso em paralelo para 1.000 concorrentes ou quando a página de destino bloqueia os rastreadores do Exa. Veja este exemplo:
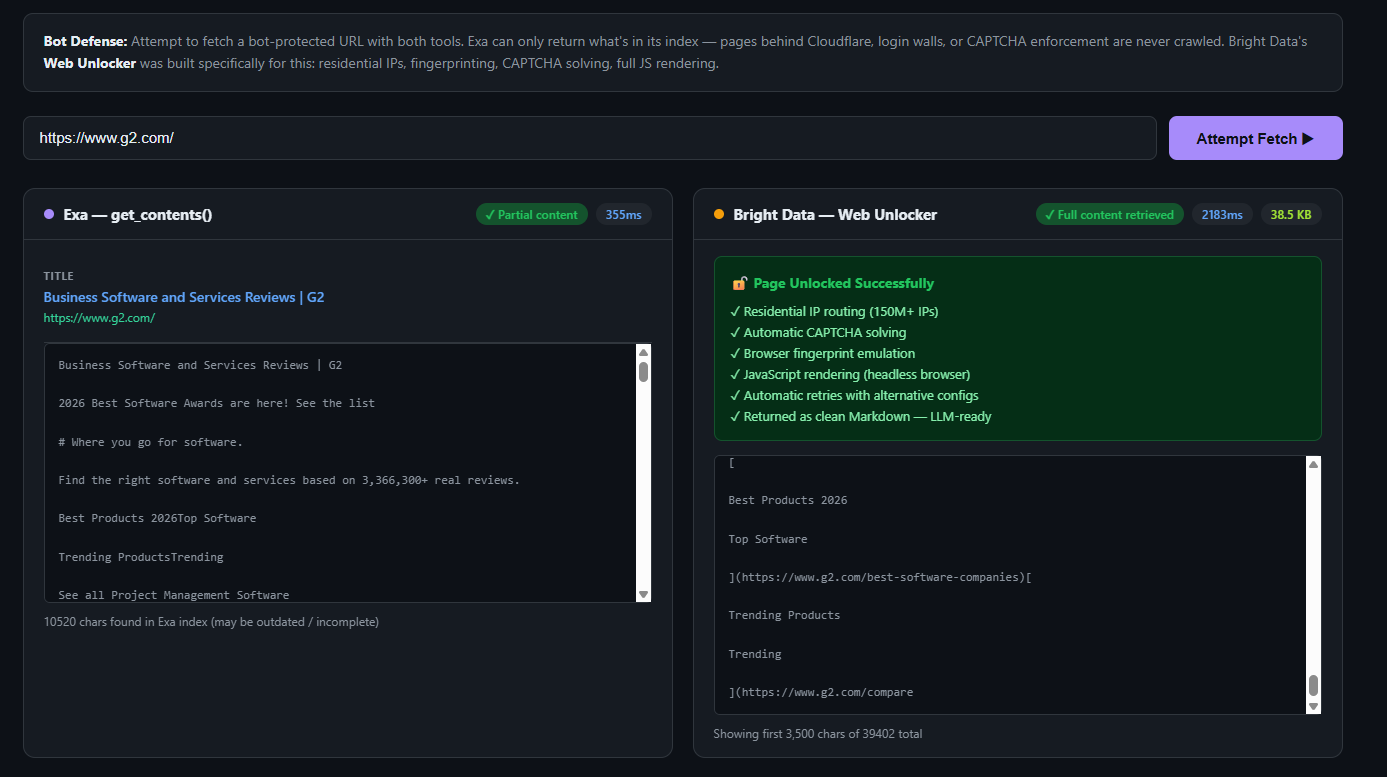
Se você quiser experimentar por conta própria, confira esta demonstração no GitHub.
O Exa não possui camada de dados históricos
Agentes de IA que detectam mudanças de preços, alterações de políticas ou movimentos de mercado precisam de uma linha de base para trabalhar. Não é possível rotular algo como uma anomalia sem saber como é o normal.
O Exa opera apenas em tempo real. Não há produto de arquivo, Conjuntos de dados históricos nem capacidade de séries temporais.
A API Web Archive da Bright Data contém mais de 50 PB de dados históricos da web, crescendo diariamente. Conjuntos de dados estruturados pré-construídos abrangem mais de 100 domínios e fornecem bases de referência históricas para comércio eletrônico, mídias sociais, mercado imobiliário e muito mais. Para trabalhos de inteligência longitudinal, monitorando como a página de preços de um concorrente mudou ao longo de 12 meses, acompanhando registros regulatórios ao longo do tempo, detectando mudanças na opinião pública, a Bright Data possui a infraestrutura e o Exa não.
Guia de decisão de casos de uso
| Caso de uso | Melhor escolha | Motivo |
|---|---|---|
| Prototipagem RAG / hackathon | Exa | Rápido, plano gratuito, LangChain nativo, configuração mínima |
| Pesquisa de similaridade semântica (“encontrar páginas como esta URL”) | Exa | O endpoint “Find Similar” não tem equivalente na Bright Data |
| Enriquecimento de pessoas/empresas (agentes de recrutamento, inteligência de vendas) | Exa | Mais de 1 bilhão de perfis indexados, índice estruturado de empresas |
| Inteligência competitiva de preços (conteúdo de páginas em tempo real) | Bright Data | Web Unlocker contorna o anti-bot; o Exa não consegue acessar páginas protegidas |
| Agente de produção com mais de 1.000 consultas simultâneas | Bright Data | Sem limite máximo de taxa; API SERP desenvolvida para cargas de trabalho paralelas |
| Dados reais do SERP do Google (SEO, monitoramento de anúncios, acompanhamento de classificação) | Bright Data | A API SERP extrai dados reais do Google; a Exa usa seu próprio índice |
| Linha de base histórica / detecção de anomalias | Bright Data | Arquivo da Web com mais de 50 PB, Conjuntos de dados, capacidade de séries temporais |
| Páginas atrás do Cloudflare / barreiras de login | Bright Data | Web Unlocker; o Exa não consegue acessar conteúdo protegido |
| Pesquisa em múltiplos mecanismos (Google + Bing + Yandex) | Bright Data | A API SERP abrange 7 principais mecanismos de busca em 195 países |
| Experiência de usuário (UX) de chat interativo de baixa latência | Exa | O Exa Instant oferece respostas em menos de 200 ms |
| Custo competitivo para grandes volumes (mais de 100 mil consultas/mês) | Bright Data | US$ 1–1,50/1 mil vs. US$ 7–15/1 mil do Exa |
Quando escolher o Exa
O Exa é a ferramenta certa se:
- Você estiver desenvolvendo um protótipo ou realizando pesquisas em fase inicial. As 1.000 solicitações mensais gratuitas, o suporte nativo ao LangChain/LlamaIndex e a integração simples do SDK tornam a Exa a maneira mais fácil de adicionar pesquisa na web a um agente de IA.
- Seu principal caso de uso for a similaridade semântica. “Encontre páginas como este URL” é uma funcionalidade exclusiva da Exa. Se esse for seu principal padrão de pesquisa, escolha a Exa.
- Você precisa de dados estruturados sobre pessoas ou empresas. O índice de mais de 1 bilhão de perfis e o índice de mais de 70 milhões de empresas do Exa foram genuinamente criados para agentes de inteligência de vendas e recrutamento.
- A latência é a principal restrição. Menos de 200 ms via Exa Instant supera qualquer solução de scraping em tempo real para aplicativos interativos.
- Seu volume de consultas está entre 50.000 e 100.000 solicitações por mês e você não precisa de dados reais do Google nem de acesso a páginas protegidas.
Quando escolher a Bright Data
A Bright Data é a ferramenta certa se:
- Você estiver operando em escala de produção. Solicitações simultâneas ilimitadas e um SLA de 99,9% de tempo de atividade significam que não há necessidade de soluções alternativas de engenharia para limites de taxa.
- Você precisa de resultados reais do Google. A API SERP faz scraping do Google real (e do Bing, Yandex, Baidu, Yahoo, Naver, DuckDuckGo) em tempo real, em qualquer país, mostrando o que usuários reais veem, não o que um índice neural estima.
- Seu agente precisa acessar páginas protegidas. O Web Unlocker lida com Cloudflare, barreiras CAPTCHA, páginas de login e renderização de JavaScript. O Exa não consegue.
- Você precisa de dados históricos. A API do Web Archive fornece mais de 50 PB de dados históricos para estabelecer uma base de referência e realizar análises longitudinais.
- O custo em escala é um fator importante. Com mais de 100.000 solicitações por mês, a Bright Data é de 5 a 7 vezes mais barata que a Exa.
- Você está construindo sistemas de nível empresarial. Mais de 20.000 clientes, adoção pela Fortune 500, reconhecimento da Gartner e mais de 70 integrações com frameworks de IA significam que a Bright Data se encaixa nas pilhas de dados empresariais existentes.
Conclusão: duas ferramentas diferentes para duas tarefas diferentes
A Exa e a Bright Data não estão competindo pelo mesmo trabalho.
A Exa é excelente no que foi projetada para fazer: pesquisa neural semântica, integração rápida de desenvolvedores e índices especializados para pessoas e empresas. Se você precisa encontrar páginas conceitualmente semelhantes, explorar uma vizinhança semântica ou pesquisar 1 bilhão de perfis do LinkedIn, a arquitetura da Exa é adequada para essas tarefas.
A Bright Data foi criada para um conjunto diferente de problemas: acessar a verdade fundamental da web ativa em escala de produção, incluindo as partes da web que bloqueiam os rastreadores. A API SERP fornece resultados reais do Google a US$ 1,50/1 mil, sem limite de solicitações simultâneas. O Web Unlocker alcança páginas que os rastreadores da Exa não conseguem acessar. O Web Archive fornece a linha de base histórica que as APIs apenas ativas não podem oferecer.
Aqui está o quadro de decisão:
- Se o seu agente precisa encontrar páginas semanticamente semelhantes, pesquisar mais de 1 bilhão de perfis ou retornar respostas em menos de 200 ms, a Exa foi projetada para isso.
- Se o seu agente precisa de escala de produção, dados reais do Google, acesso anti-bot, bases de referência históricas ou eficiência de custo acima de 100.000 consultas/mês, a Bright Data é a infraestrutura certa.
Muitas equipes de IA em produção usam ambas: o Exa para descoberta semântica nos estágios iniciais de um pipeline e o Bright Data para verificação em tempo real, extração de páginas completas e inteligência de SERP em escala. Elas não são mutuamente exclusivas. Elas apenas têm limites diferentes e, em escala empresarial, o limite do Exa se torna evidente rapidamente. Para equipes que avaliam toda a gama dos principais servidores MCP para fluxos de trabalho de IA, o Servidor MCP da Bright Data é consistentemente classificado como a opção líder para fundamentar agentes em dados da web em tempo real.
Perguntas frequentes
Qual é a diferença entre a Bright Data e a Exa?
O Exa é uma API de mecanismo de busca semântica que retorna resultados a partir de seu próprio índice neural. A Bright Data é uma infraestrutura de dados da web que rastreia mecanismos de busca reais, extrai páginas protegidas por sistemas anti-bot e fornece Conjuntos de dados históricos. Eles resolvem problemas diferentes em escalas diferentes.
A Bright Data é mais barata que a Exa?
Sim. A API SERP da Bright Data custa a partir de US$ 1,50 por 1.000 solicitações, com pagamento conforme o uso. A pesquisa padrão da Exa custa US$ 7 por 1.000 solicitações. Com 1 milhão de solicitações por mês, a Bright Data é cerca de 5 a 7 vezes mais barata.
A Exa consegue rastrear sites protegidos pelo Cloudflare?
Não. A Exa não consegue rastrear páginas protegidas pelo Cloudflare, barreiras de login ou sistemas CAPTCHA. O Web Unlocker da Bright Data foi desenvolvido especificamente para contornar a proteção anti-bot, utilizando uma rede de mais de 150 milhões de IPs residencialis.
O Exa tem um limite de taxa?
Sim. O limite de taxa padrão de pesquisa do Exa é de 10 QPS (600 solicitações por minuto). Clientes corporativos podem negociar limites mais altos. A API SERP da Bright Data não tem limite de solicitações simultâneas.
Qual é a melhor alternativa ao Exa para agentes de IA corporativos?
A Bright Data é a principal alternativa empresarial ao Exa. Ela oferece solicitações simultâneas ilimitadas, scraping em tempo real do Google/Bing/Yandex, contorno de proteção anti-bot via Web Unlocker, arquivos de dados históricos e suporte para fluxos de trabalho de agentes de IA baseados em MCP, tudo com preços baseados em pagamento por sucesso.
A Exa possui dados históricos?
Não. O Exa opera apenas em tempo real, sem produtos de arquivo ou Conjuntos de dados. A API Web Archive da Bright Data contém mais de 50 PB de dados históricos da web, crescendo diariamente.




