

O Google AI Mode representa uma mudança fundamental na forma como os resultados de pesquisa são apresentados, oferecendo respostas conversacionais com tecnologia de IA que sintetizam informações de várias fontes. Para as empresas que monitoram sua presença digital, equipes de inteligência competitiva e profissionais de SEO, esse novo formato de pesquisa cria oportunidades e desafios para a extração de dados.
Este guia abrangente aborda o que é o Modo AI do Google, por que a extração desses dados oferece valor comercial estratégico, os desafios técnicos que você enfrentará e as abordagens manuais e automatizadas para extrair essas informações de forma eficiente e em escala.
O que é o Modo IA do Google?
O Google AI Mode é a mais nova experiência de pesquisa do Google que fornece respostas sintetizadas e conversacionais na parte superior dos resultados, permitindo que os usuários façam perguntas de acompanhamento naturalmente. Cada resposta inclui links de origem em destaque, facilitando o acesso ao conteúdo subjacente.
Por trás disso, o AI Mode aproveita o Gemini juntamente com os sistemas de pesquisa do Google, usando uma abordagem de “query fan-out”. Essa técnica divide as perguntas em subtópicos e executa várias pesquisas relacionadas em paralelo, trazendo à tona um material mais relevante do que as consultas únicas tradicionais podem oferecer.
Aqui está um exemplo do Google AI Mode respondendo a uma consulta de pesquisa com fontes citadas (lado direito), nas quais os usuários podem clicar para obter mais detalhes:
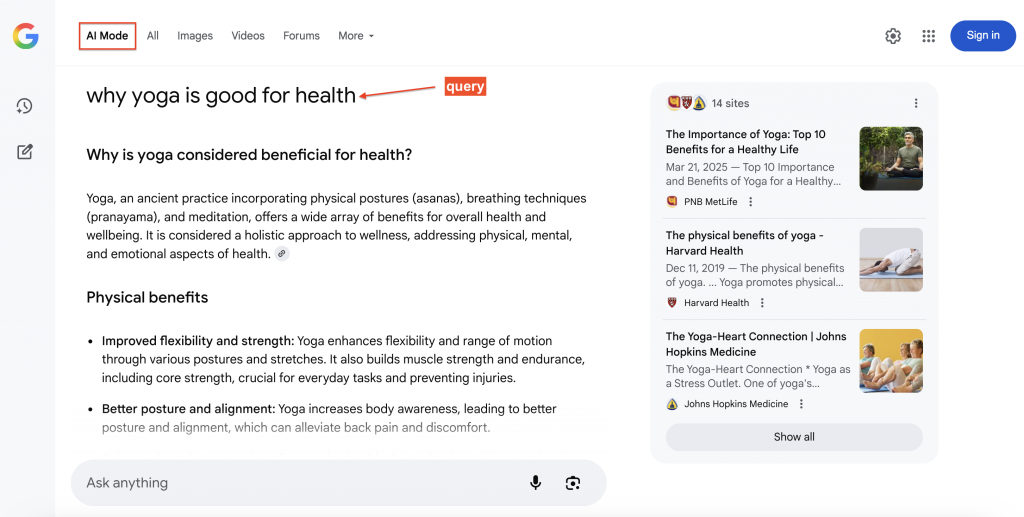
Por que extrair dados do Google AI Mode?
Os dados do Google AI Mode fornecem insights mensuráveis que afetam significativamente o SEO, o desenvolvimento de produtos e a pesquisa competitiva.
- Rastreamento do compartilhamento de citações. Monitore quais domínios o Google AI referencia para suas consultas-alvo, incluindo a ordem de classificação e a frequência ao longo do tempo. Isso indica a autoridade do tópico e ajuda a medir se as melhorias no conteúdo levam a uma maior inclusão de respostas de IA.
- Inteligência competitiva. Capture quais marcas, produtos ou locais aparecem nas consultas de recomendação e comparação. Isso revela o posicionamento do mercado, a dinâmica da concorrência e os atributos que as respostas de IA enfatizam.
- Análise de lacunas de conteúdo. Compare os principais fatos nas respostas do Modo IA com o conteúdo existente para identificar oportunidades de criação de conteúdo estruturado, como perguntas frequentes, guias ou tabelas de dados que geram citações.
- Monitoramento da marca. Analise as respostas geradas pela IA sobre sua marca ou setor para identificar informações desatualizadas e atualizar seu conteúdo adequadamente.
- Pesquisa e desenvolvimento. Armazene as respostas do Modo IA com metadados (registros de data e hora, locais, entidades) para alimentar os sistemas internos de IA, dar suporte às equipes de pesquisa e aprimorar os aplicativos RAG.
Método 1 – raspagem manual com automação do navegador
A raspagem do modo AI do Google requer uma automação sofisticada do navegador devido à natureza dinâmica e com muito JavaScript do conteúdo gerado por AI. As estruturas de automação do navegador, como Playwright, Selenium ou Puppeteer, usam mecanismos reais do navegador para executar JavaScript, aguardar o carregamento do conteúdo e replicar a experiência de navegação humana, o que é importante para capturar respostas de IA geradas dinamicamente.
Veja como o Modo IA do Google aparece nos resultados de pesquisa:
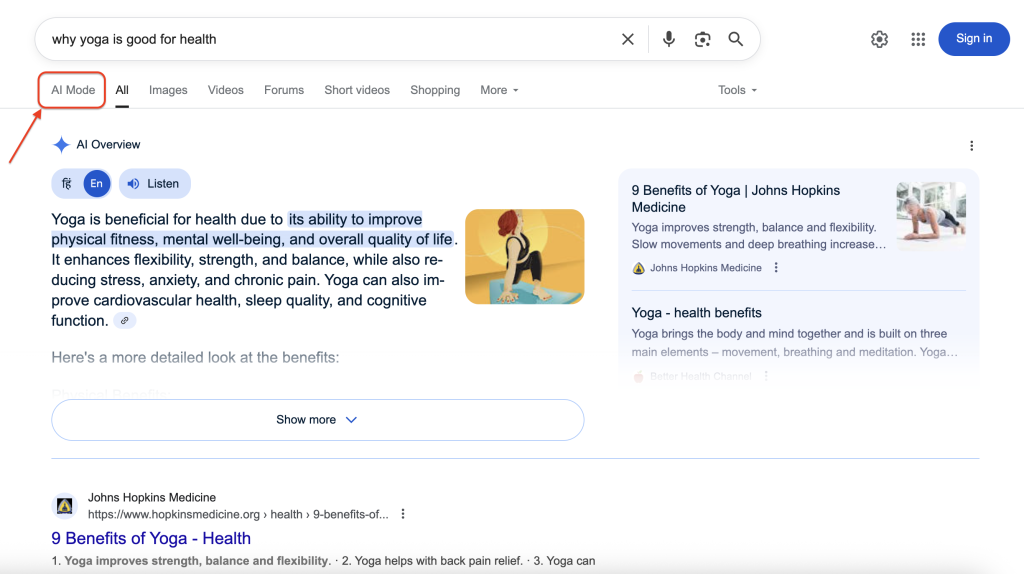
Clicar no Modo de IA revela a interface de conversação completa com respostas detalhadas e citações de fontes. Nosso objetivo é acessar e extrair programaticamente essas informações ricas e estruturadas.
Etapa 1 – Configuração do ambiente e pré-requisitos
Instale a versão mais recente do Python e, em seguida, instale as dependências necessárias. Para este tutorial, instale o Playwright executando estes comandos em seu terminal:
pip install playwright
playwright installEsse comando instala o Playwright e baixa os binários de navegador necessários (executáveis de navegador necessários para automação).
Etapa 2 – importação de dependências e configuração
Importe as bibliotecas essenciais para a tarefa de raspagem:
importar asyncio
importar urllib.parse
from playwright.async_api import async_playwrightDetalhamento da biblioteca:
- asyncio – permite a programação assíncrona para melhorar o desempenho e as operações simultâneas.
- urllib.parse – lida com a codificação de URL para garantir que as consultas sejam formatadas corretamente para solicitações da Web.
- playwright – fornece recursos de automação do navegador para interagir com o Google como um usuário humano.
Etapa 3 – arquitetura e parâmetros da função
Defina a função de raspagem principal com parâmetros e valores de retorno claros:
async def scrape_google_ai_mode(query: str, output_path: str = "ai_response.txt") -> bool:Parâmetros da função:
- query – termo de pesquisa a ser enviado ao Google AI Mode.
- output_path – destino do arquivo para salvar a resposta (o padrão é “ai_response.txt”).
- Retorna um valor booleano que indica o sucesso(True) ou a falha(False) da extração de conteúdo.
Etapa 4 – construção do URL e ativação do modo AI
Construa o URL de pesquisa que aciona a interface do Modo IA do Google:
url = f "https://www.google.com/search?q={urllib.parse.quote_plus(query)}&udm=50"Principais componentes:
- urllib.parse.quote_plus(query) – codifica com segurança a consulta de pesquisa, convertendo espaços em ‘+’ e escapando caracteres especiais.
- udm=50 – parâmetro crítico que ativa a interface do Modo AI do Google.
Etapa 5 – Configuração do navegador e antidetecção
Inicie uma instância do navegador configurada para evitar a detecção e, ao mesmo tempo, manter um comportamento realista:
async with async_playwright() as pw:
browser = await pw.chromium.launch(
headless=False, args=["--disable-blink-features=AutomationControlled"]
)
page = await browser.new_page(
user_agent="Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) "
"AppleWebKit/537.36 (KHTML, como Gecko) "
"Chrome/120.0.0.0 Safari/537.36"
)Detalhes da configuração:
- headless=False – exibe a janela do navegador para depuração (definido como True para ambientes de produção).
- -disable-blink-features=AutomationControlled – remove os indicadores de detecção de automação.
- Agente do usuário – imita um navegador Chrome legítimo no macOS para reduzir a probabilidade de detecção de bots.
Essas medidas antidetecção ajudam o scraper a parecer um usuário normal navegando no Google em vez de um script automatizado.
Etapa 6 – navegação e carregamento de conteúdo dinâmico
Navegue até o URL construído e aguarde o carregamento completo do conteúdo dinâmico:
aguarde page.goto(url, wait_until="networkidle")
await page.wait_for_timeout(2000)Explicação da estratégia de carregamento:
- wait_until=”networkidle ” – aguarda até que a atividade da rede pare, indicando que a página foi totalmente carregada.
- wait_for_timeout – buffer adicional para geração de conteúdo de IA.
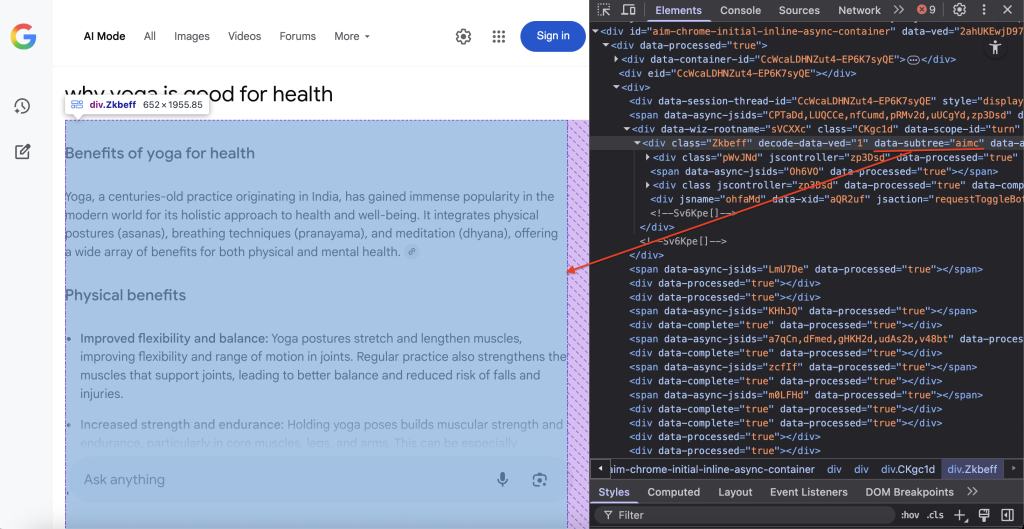
Etapa 7 – localização do conteúdo e extração do DOM
Localize o contêiner DOM específico que abriga o conteúdo do Modo AI do Google:
container = await page.query_selector('div[data-subtree="aimc"]')O seletor CSS div[data-subtree=”aimc”] tem como alvo o AIMC (AI Mode Container) do Google.
Etapa 8 – Extração e armazenamento de dados
Extraia o conteúdo do texto e salve-o no arquivo especificado:
if container:
text = (await container.inner_text()).strip()
se text:
with open(output_path, "w", encoding="utf-8") as f:
f.write(text)
print(f "Resposta de IA salva para '{output_path}' ({len(text):,} caracteres)")
await browser.close()
return True
else:
print("O contêiner do modo AI foi encontrado, mas não contém conteúdo.")
else:
print("Nenhum conteúdo do Modo AI foi detectado na página.")
await browser.close()
return FalseFluxo do processo:
- Verificar se o contêiner AI existe na página usando a consulta DOM.
- Extrair conteúdo de texto simples sem marcação HTML usando inner_text().
- Salvar o conteúdo no arquivo especificado com codificação UTF-8.
- Fechar adequadamente os recursos do navegador para evitar vazamentos de memória.
Etapa 9 – executar a função de raspagem
Execute a operação completa de raspagem chamando a função com a consulta desejada:
if __name__ == "__main__":
asyncio.run(scrape_google_ai_mode("why yoga is good for health"))Código completo
Aqui está o código completo que combina todas as etapas:
importar asyncio
importar urllib.parse
from playwright.async_api import async_playwright
async def scrape_google_ai_mode(
query: str, output_path: str = "ai_response.txt"
) -> bool:
url = f "https://www.google.com/search?q={urllib.parse.quote_plus(query)}&udm=50"
async with async_playwright() as pw:
browser = await pw.chromium.launch(
headless=False, args=["--disable-blink-features=AutomationControlled"]
)
page = await browser.new_page(
user_agent="Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) "
"AppleWebKit/537.36 (KHTML, como Gecko) "
"Chrome/139.0.0.0 Safari/537.36"
)
await page.goto(url, wait_until="networkidle")
await page.wait_for_timeout(1000)
container = await page.query_selector('div[data-subtree="aimc"]')
if container:
text = (await container.inner_text()).strip()
if text:
with open(output_path, "w", encoding="utf-8") as f:
f.write(text)
print(
f "Resposta de IA salva para '{output_path}' ({len(text):,} caracteres)"
)
await browser.close()
return True
else:
print("O contêiner do modo AI foi encontrado, mas está vazio.")
else:
print("Nenhum conteúdo do Modo AI foi encontrado.")
await browser.close()
return False
se __name__ == "__main__":
asyncio.run(scrape_google_ai_mode("why yoga is good for health"))Quando executado com êxito, esse script cria um arquivo de texto que contém a resposta de IA extraída:

Excelente trabalho! Você conseguiu extrair o conteúdo do Google AI Mode.
Desafios e limitações da raspagem manual
A raspagem manual traz desafios operacionais significativos que se tornam mais pronunciados em escala.
- Detecção anti-bot e verificação CAPTCHA. O Google implementa mecanismos de detecção sofisticados que identificam padrões de tráfego automatizados. Após um número limitado de solicitações, o sistema aciona a verificação CAPTCHA, bloqueando efetivamente a coleta de dados adicionais.
- Complexidade da infraestrutura e da manutenção. Operações bem-sucedidas em larga escala exigem várias técnicas para evitar o bloqueio, como redes de proxy residenciais de alta qualidade, rotação de agentes de usuário, evasão de impressões digitais do navegador e estratégias sofisticadas de distribuição de solicitações. Isso gera uma sobrecarga técnica substancial e custos de manutenção contínuos.
- Mudanças dinâmicas de conteúdo e layout. O Google atualiza frequentemente sua estrutura de interface, o que pode quebrar os analisadores existentes da noite para o dia, exigindo atenção imediata e atualizações de código para manter a funcionalidade.
- Complexidade da análise. As respostas do Modo IA contêm estruturas aninhadas, citações dinâmicas e formatação variável que exigem uma lógica de análise sofisticada. Manter a precisão em diferentes tipos de resposta exige testes extensivos e tratamento de erros.
- Limitações de escalabilidade. As abordagens manuais têm dificuldades com o processamento em massa, o gerenciamento de solicitações simultâneas e o desempenho consistente em regiões geográficas e verticais de pesquisa.
Essas limitações destacam por que muitas organizações preferem soluções especializadas que lidam com a complexidade de forma profissional. Isso nos leva a explorar a API do Google AI Mode Scraper da Bright Data, criada especificamente para esse fim.
Método 2 – API do raspador do modo de IA do Google
A API do raspador do modo de IA do Google da Bright Data fornece uma solução pronta para produção que elimina a complexidade de manter a infraestrutura de raspagem e, ao mesmo tempo, oferece confiabilidade e desempenho de nível empresarial. A API extrai pontos de dados abrangentes, incluindo HTML da resposta, texto da resposta, links anexados, citações e 12 campos adicionais.
Principais recursos
- Gerenciamento automatizado de antibot e proxy. A API aproveita a extensa rede de proxy residencial da Bright Data com mais de 150 milhões de endereços IP, combinada com técnicas avançadas de evasão de antibot. Essa infraestrutura elimina os encontros de CAPTCHA e as preocupações com o bloqueio de IP.
- Saída de dados estruturados. A API fornece dados formatados de forma consistente em vários formatos de exportação, incluindo JSON, NDJSON e CSV, para opções de integração flexíveis.
- Escalabilidade de nível empresarial. Criada para operações de alto volume, a API processa milhares de consultas de forma eficiente com escalonamento de custos previsível por meio do nosso modelo de preços de pagamento por resultado bem-sucedido.
- Personalização geográfica. A especificação de países-alvo para resultados específicos do local permite que você entenda como as respostas de IA variam entre diferentes mercados e dados demográficos dos usuários.
- Operação sem manutenção. Nossa equipe monitora e adapta continuamente o scraper às alterações do Google. Quando o Google modifica as interfaces do Modo AI ou implementa novas medidas antibot, as atualizações são implantadas automaticamente sem exigir nenhuma ação da sua equipe de desenvolvimento.
O resultado? Extração abrangente de dados do Google AI Mode com confiabilidade empresarial e sem sobrecarga de infraestrutura.
Primeiros passos com a API do Google AI Mode Scraper
O processo de implementação envolve a configuração da conta e a geração de chave de API para novos usuários da Bright Data, seguido pela escolha do método de integração de sua preferência. Crie sua conta gratuita da Bright Data e gere seu token de autenticação da API em quatro etapas simples.
Depois disso, navegue até a Biblioteca de raspadores da Web da Bright Data e pesquise por “google” para localizar as opções de raspador disponíveis. Clique em “google.com”.
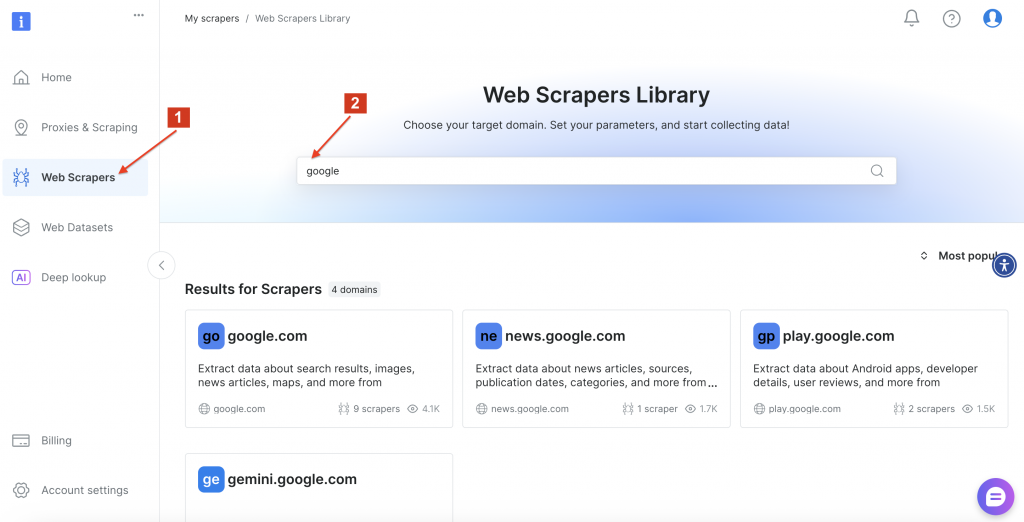
Em seguida, selecione a opção “Google AI Mode Search” na interface.
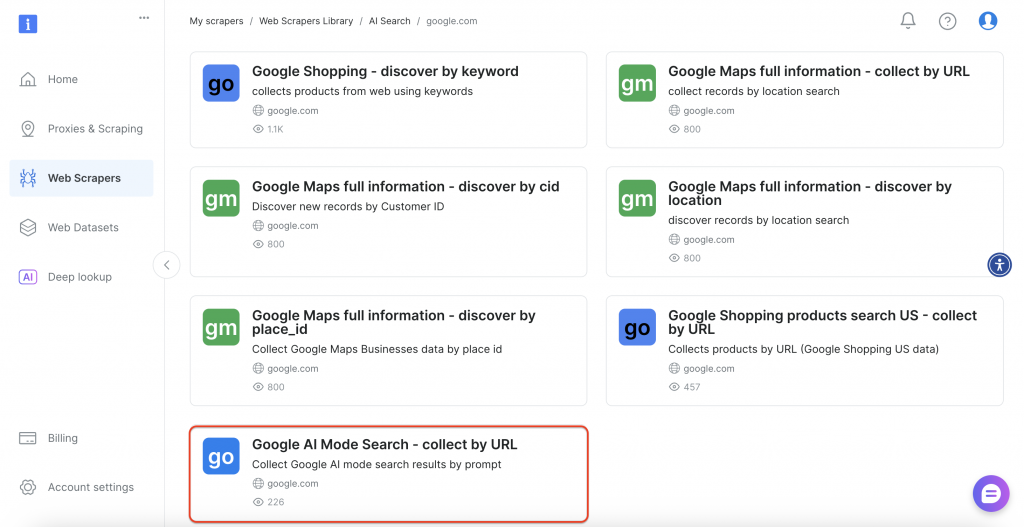
O raspador oferece métodos de implementação sem código e baseados em API para acomodar diferentes requisitos técnicos e recursos de equipe.
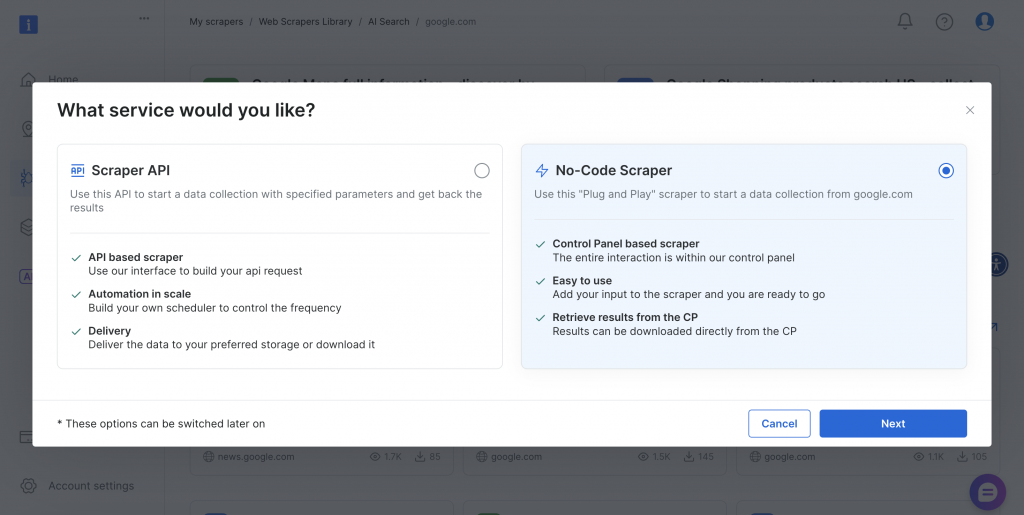
Vamos explorar as duas abordagens.
Raspagem interativa (raspador sem código)
A interface baseada na Web oferece uma abordagem fácil de usar para aqueles que preferem não trabalhar com código. Você pode inserir consultas de pesquisa diretamente no painel ou carregar arquivos CSV contendo várias consultas para processamento em lote. A plataforma lida com tudo automaticamente e fornece os resultados como arquivos para download.
Parâmetros obrigatórios:
- URL – padrão definido como https://google.com/aimode (isso permanece constante).
- Prompt – sua consulta de pesquisa ou pergunta para a análise de IA do Google.
- País – localização geográfica para resultados específicos da região (opcional).
Configuração adicional:
- Configurações de entrega – selecione o formato de saída e o método de entrega de sua preferência.
- Esquema personalizado – escolha os campos de dados a serem incluídos em sua exportação.
- Processamento em lote – processe várias consultas simultaneamente por meio de upload de CSV.
Vamos realizar uma pesquisa simples usando o prompt “how meditation helps mental health” (como a meditação ajuda na saúde mental) com “India” (Índia) como o país de destino. Clique no botão “Start collecting” (Iniciar coleta) para iniciar o processo.
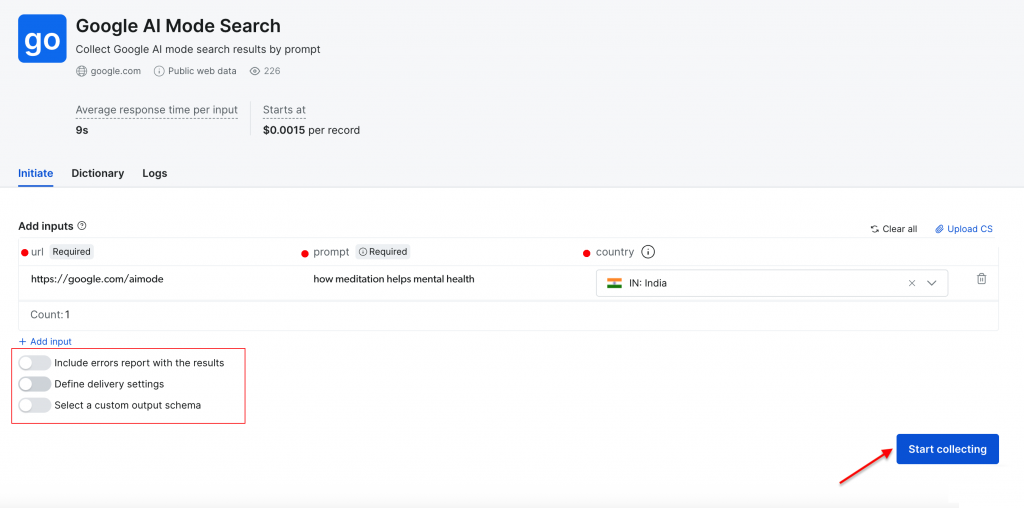
O painel de controle fornece acompanhamento do progresso em tempo real(Ready, Running) e, após a conclusão, você pode fazer o download dos resultados no formato de sua preferência.
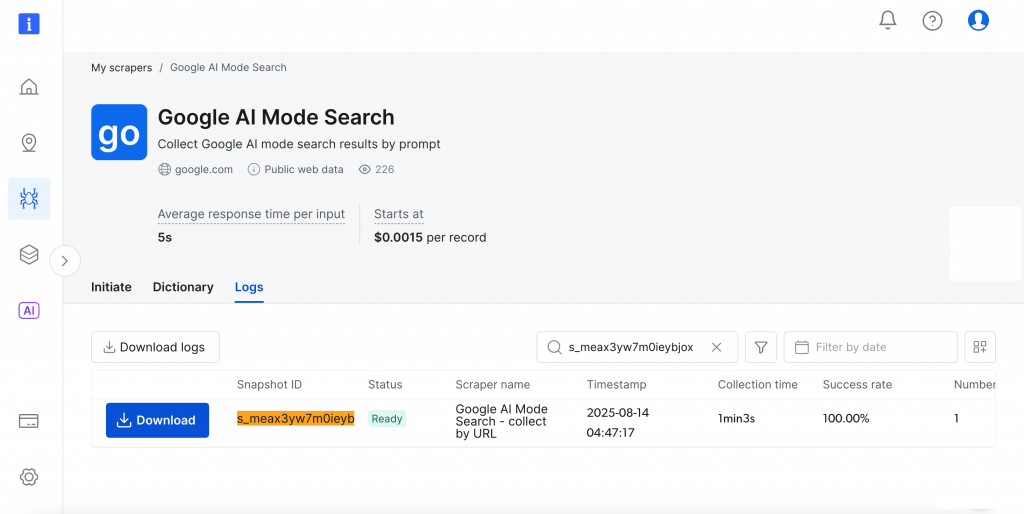
Muito legal, não é?
Raspagem baseada em API (API Scraper)
A abordagem programática oferece maior flexibilidade e recursos de automação por meio de endpoints de API RESTful. O abrangente construtor de solicitações de API e a interface de gerenciamento fornecem controle total sobre suas operações de raspagem:
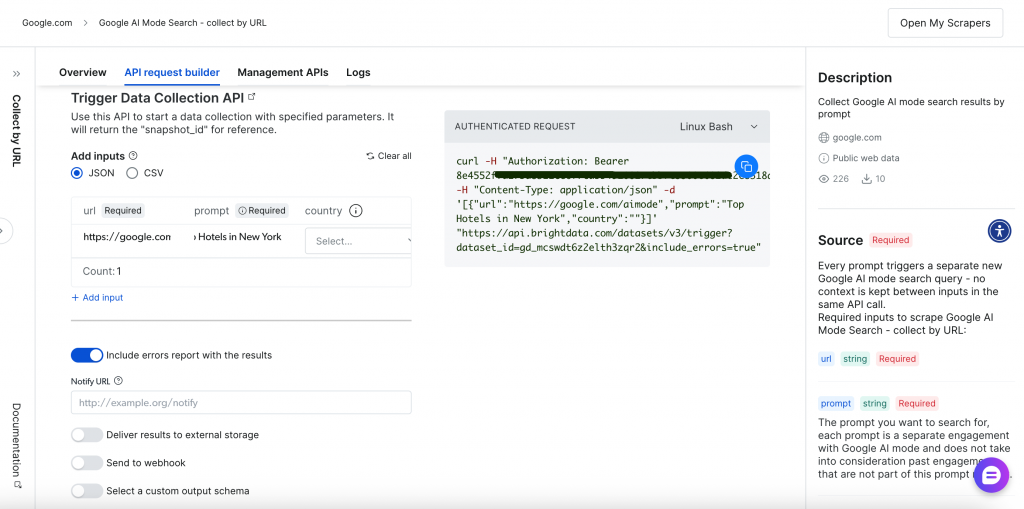
Vamos examinar o processo de raspagem baseado em API.
Etapa 1 – acionar a coleta de dados
Primeiro, acione a coleta de dados usando um destes métodos:
Execução de consulta única:
curl -H "Authorization: Bearer <YOUR_API_TOKEN>"
-H "Content-Type: application/json"
-d '[
{
"url": "https://google.com/aimode",
"prompt": "dicas de saúde para usuários de computador",
"country" (país): "US"
}
]'
"https://api.brightdata.com/datasets/v3/trigger?dataset_id=gd_mcswdt6z2elth3zqr2&include_errors=true"Processamento em lote com upload de CSV:
curl -H "Authorization: Bearer <YOUR_API_TOKEN>"
-F 'data=@/path/to/your/queries.csv'
"https://api.brightdata.com/datasets/v3/trigger?dataset_id=gd_mcswdt6z2elth3zqr2&include_errors=true"Componentes da solicitação:
- Autenticação – token de portador no cabeçalho para acesso seguro.
- ID do conjunto de dados – identificador específico para o raspador do Google AI Mode.
- Formato de entrada – matriz JSON ou arquivo CSV contendo parâmetros de consulta.
- Tratamento de erros – inclua o parâmetro de erros para obter feedback abrangente.
Você também pode selecionar seu método de entrega via webhook para tratamento automatizado de resultados.
Etapa 2 – Monitore o progresso do trabalho
Use o ID do Snapshot retornado para acompanhar o progresso da coleta:
curl -H "Authorization: Bearer <YOUR_API_TOKEN>"
"https://api.brightdata.com/datasets/v3/progress/<snapshot_id>"A resposta indica “running” (em execução) durante a coleta de dados e “ready” (pronto) quando os resultados estiverem disponíveis para download.
Etapa 3 – download dos resultados
Faça o download do conteúdo do snapshot ou entregue-o ao armazenamento especificado. Recupere os resultados concluídos em seu formato preferido:
curl -H "Authorization: Bearer <YOUR_API_TOKEN>"
"https://api.brightdata.com/datasets/v3/snapshot/<snapshot_id>?format=json"A API retorna dados estruturados abrangentes para cada consulta:
{
"url": "https://www.google.co.in/search?q=health+tips+for+computer+users&hl=en&udm=50&aep=11&...",
"prompt": "dicas de saúde para usuários de computador",
"answer_html": "<html>... resposta HTML completa...</html>",
"answer_text": "Dicas de saúde para usuários de computadornnPassar longos períodos na frente de um computador pode levar a vários problemas de saúde, incluindo cansaço visual, dor musculoesquelética e redução da atividade física...",
"links_attached": [
{
"url": "https://www.aao.org/eye-health/tips-prevention/computer-usage",
"text": nulo,
"position" (posição): 1
},
{
"url": "https://uhs.princeton.edu/health-resources/ergonomics-computer-use",
"text": nulo,
"position" (posição): 2
}
],
"citations": [
{
"url": "https://www.ramsayhealth.co.uk/blog/lifestyle/five-healthy-tips-for-working-at-a-computer",
"title": nulo,
"description" (descrição): "Ramsay Health Care",
"icon": "https://...icon-url...",
"domain" (domínio): "https://www.ramsayhealth.co.uk",
"cited": false
},
{
"url": "https://my.clevelandclinic.org/health/diseases/24802-computer-vision-syndrome",
"title": nulo,
"description" (descrição): "Cleveland Clinic",
"icon": "https://...icon-url...",
"domain": "https://my.clevelandclinic.org",
"cited": false
}
],
"country" (país): "IN",
"answer_text_markdown": "Dicas de saúde para usuários de computador...",
"timestamp": "2026-08-07T05:02:56.887Z",
"input": {
"url": "https://google.com/aimode",
"prompt": "dicas de saúde para usuários de computador",
"country" (país): "IN"
}
}Tão simples e eficaz!
Esse fluxo de trabalho direto da API se integra perfeitamente a qualquer aplicativo ou projeto. O construtor de solicitações de API da Bright Data também fornece exemplos de código em várias linguagens de programação para facilitar a implementação.
Conclusão
Exploramos duas abordagens: uma solução do tipo “faça você mesmo” usando Python e Playwright, e a API pronta para uso do Google AI Mode Scraper da Bright Data.
No cenário de pesquisa em rápida evolução, em que os algoritmos e as interfaces mudam com frequência, ter uma infraestrutura de raspagem robusta e bem mantida é inestimável. A API elimina a necessidade de atualizar constantemente a lógica de análise ou de gerenciar as restrições de IP, permitindo que você se concentre totalmente na análise dos ricos insights gerados pela IA dos resultados de pesquisa do Google e na extração do valor máximo dos dados.
Faça o seguinte
- Expanda sua coleta de dados do Google. Como você já está trabalhando com o Modo de IA do Google, considere explorar outras fontes de dados do Google. Também temos um guia abrangente sobre a extração de visões gerais de IA do Google para uma cobertura mais ampla. Você pode acessar recursos especializados do Google News, Maps, Search, Trends, Reviews, Hotels, Videos e Flights.
- Teste sem riscos. Todos os principais produtos incluem opções de avaliação gratuita, além de igualarmos os primeiros depósitos em até US$ 500. Isso lhe dá espaço para experimentar a funcionalidade expandida antes de assumir compromissos.
- Dimensione com soluções integradas. À medida que suas necessidades aumentam, considere o servidor Web MCP, que conecta aplicativos de IA diretamente a dados da Web sem desenvolvimento personalizado para cada site. Comece agora com um plano gratuito de 5.000 solicitações mensais!
- Infraestrutura empresarial quando estiver pronta. Muitas equipes começam com projetos individuais como o seu e, posteriormente, precisam de uma infraestrutura robusta para operações maiores. A plataforma completa fornece a infraestrutura subjacente quando você estiver pronto para expandir.
Não tem certeza sobre o próximo passo? Fale com a nossa equipe – nós o mapearemos para você.






