

Um guia passo a passo para criar um pipeline de scraping sem servidor no Google Cloud usando Cloud Run, Firestore, BigQuery, Workflows e Cloud Scheduler.
Neste artigo, você aprenderá:
- Por que uma arquitetura sem servidor funciona bem para pipelines de Scraping de dados.
- Como configurar a infraestrutura necessária do Google Cloud do zero.
- Como implantar um serviço de scraping privado e um serviço de API público no Cloud Run.
- Como orquestrar execuções de scraping com o Cloud Workflows e automatizá-las com o Cloud Scheduler.
- Como armazenar e consultar dados coletados usando o Firestore e o BigQuery.
- Como verificar se todo o seu pipeline está funcionando de ponta a ponta.
Vamos começar!
Por que criar um pipeline de scraping sem servidor?
A maioria dos tutoriais de scraping se limita ao script. Você obtém um pouco de HTML, talvez analise alguns campos, e pronto. Mas quando se trata de executar scrapers em produção, você precisa de respostas para perguntas mais difíceis: para onde vão os dados? Como executá-los em uma programação? Como consultar os resultados posteriormente? Como manter os custos baixos quando o Scraper não está em execução?
É aí que entra o serverless. O Google Cloud Run só cobra quando seus serviços estão processando solicitações. Não há servidores para gerenciar, nem computação ociosa gastando dinheiro durante a noite. Combine isso com o Firestore para rastreamento de tarefas, o BigQuery para análises e o Cloud Workflows para orquestração, e você terá uma arquitetura de pipeline de dados que escala para zero quando ociosa e é ativada sob demanda.
Ao final deste guia, você terá:
- Um
serviço de scraperprivado no Cloud Run que faz a extração real. - Um
serviço de APIpúblico no Cloud Run que expõe seus dados. - Coleções do Firestore que rastreiam o status e os resultados das tarefas.
- Uma tabela do BigQuery que você pode consultar para análises.
- Um Cloud Workflow que coordena toda a execução da extração.
- Uma tarefa do Cloud Scheduler que a aciona em um cron.
Entendendo a arquitetura
Antes de começarmos a executar comandos, é útil ver como todas as peças se conectam. Passamos um bom tempo descobrindo a arquitetura certa quando criamos isso pela primeira vez, então vamos explicar tudo para você.
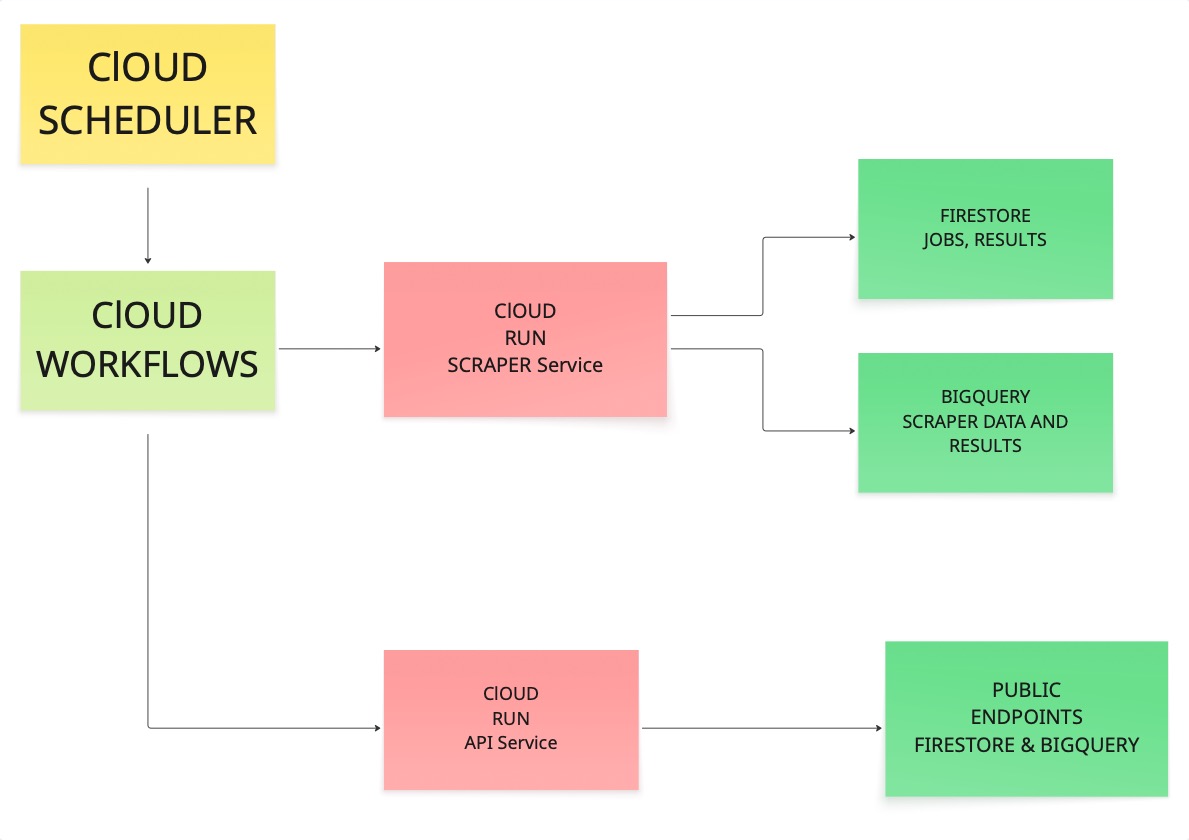
O agendador aciona um fluxo de trabalho. O fluxo de trabalho chama o Scraper. O Scraper visita URLs, extrai conteúdo e grava os resultados no Firestore e no BigQuery. Em seguida, o serviço de API lê esses armazenamentos e expõe os dados por meio de pontos de extremidade públicos.
Se cada elo dessa cadeia funcionar, você terá algo em que pode confiar na produção.
Pré-requisitos
Antes de começar, certifique-se de ter o seguinte:
- Uma conta do Google.
- Um projeto GCP com faturamento habilitado (os custos serão mínimos, mas o faturamento deve estar ativo).
- Node.js 18 ou superior.
- A CLI
gcloudinstalada em seu computador.
Execute uma verificação rápida:
node --version
npm --version
gcloud --versionSe todos os três exibirem os números da versão, você está pronto para continuar.
Configurando seu projeto do Google Cloud
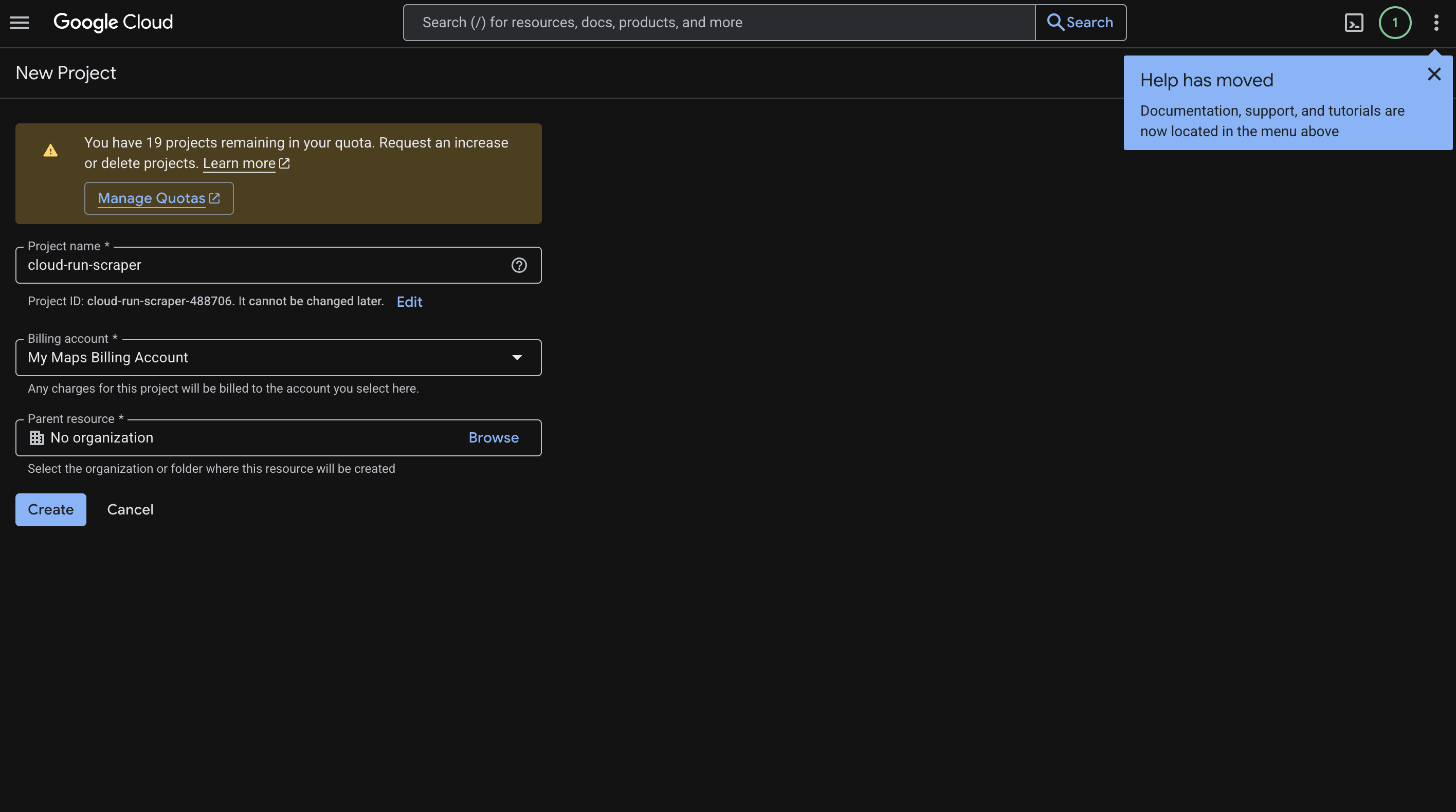
Acesse o Cloud Console e crie um novo projeto. Chamamos o nosso de cloud-run-scraper, mas você pode nomeá-lo como achar melhor para o seu caso de uso.
Veja o que fazer:
- Digite o nome do seu projeto.
- Clique em Criar.
- Copie o ID do projeto gerado (algo como
cloud-run-scraper-123456). Você precisará dele ao longo do guia. - Acesse Faturamento e vincule uma conta de faturamento ao projeto.
Esta é a aparência da tela:
Configurando seu shell
Recomendamos definir algumas variáveis de ambiente antecipadamente para que você não precise copiar e colar IDs de projeto em todos os lugares. Isso mantém seus comandos organizados e reutilizáveis:
export PROJECT_ID="YOUR_PROJECT_ID"
export REGION="us-central1"
export REPO_NAME="cloud-run-scraper-repo"
export BQ_DATASET="scraper_data"
export BQ_TABLE="scraped_results"Em seguida, direcione o gcloud para o seu projeto:
gcloud config set project "$PROJECT_ID"
gcloud config set run/region "$REGION"E autentique (isso abrirá seu navegador):
gcloud auth login
gcloud auth application-default loginHabilitando as APIs necessárias
Uma coisa que confunde as pessoas com o Google Cloud é que nada funciona até que você ative explicitamente as APIs necessárias. Pense nisso como acionar disjuntores. Execute isso uma vez e pronto:
gcloud services enable
run.googleapis.com
cloudbuild.googleapis.com
workflows.googleapis.com
artifactregistry.googleapis.com
cloudscheduler.googleapis.com
bigquery.googleapis.com
firestore.googleapis.com
secretmanager.googleapis.comVocê pode verificar se todos estão habilitados com:
gcloud services list --enabled | rg "run.googleapis.com|cloudbuild.googleapis.com|workflows.googleapis.com|artifactregistry.googleapis.com|cloudscheduler.googleapis.com|bigquery.googleapis.com|firestore.googleapis.com"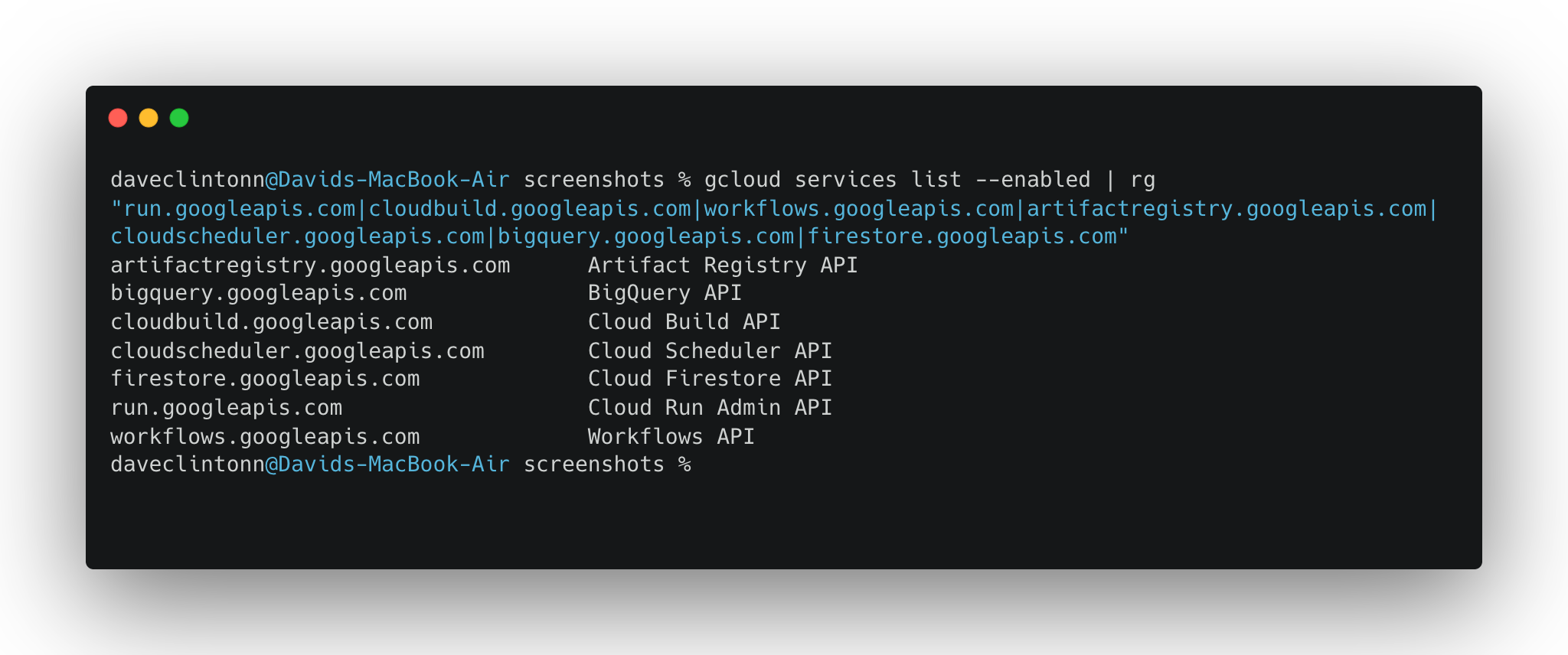
Configurando o Firestore
Precisamos do Firestore no modo nativo para armazenar dados de rastreamento de tarefas e coletar resultados:
gcloud firestore databases create --location="$REGION" --type=firestore-nativeSe você já tiver o Firestore configurado neste projeto, pode pular esta etapa. Será exibida uma mensagem de erro informando que o banco de dados já existe.
Criando o Artifact Registry
O Registro de artefatos é onde suas imagens do Docker ficarão armazenadas. Pense nele como um registro de contêineres privado no GCP:
gcloud artifacts repositories create "$REPO_NAME"
--repository-format=docker
--location="$REGION"
--description="Imagens Docker para cloud-run-Scraper"Em seguida, informe ao Docker como autenticar com ele:
gcloud auth configure-docker "$REGION-docker.pkg.dev"Configurando o BigQuery
Agora, vamos criar o conjunto de dados e a tabela do BigQuery onde os dados coletados serão armazenados. É isso que torna todo o pipeline útil: um fluxo de pipeline ETL bem estruturado permite executar consultas SQL em todos os seus dados coletados para revelar tendências, filtrar por fonte ou criar painéis.
Crie o conjunto de dados:
bq --location="$REGION" mk -d "$PROJECT_ID:$BQ_DATASET"Em seguida, crie a tabela com o esquema usado pelo Scraper:
bq mk --table
"$PROJECT_ID:$BQ_DATASET.$BQ_TABLE"
url:STRING,title:STRING,content:STRING,scraped_at:TIMESTAMP,job_id:STRING,source:STRING,metadata:STRINGVerifique rapidamente se funcionou:
bq show "$PROJECT_ID:$BQ_DATASET.$BQ_TABLE"Obtenha as permissões IAM corretas
Esta parte não é a mais empolgante, mas é fundamental. Seus serviços Cloud Run precisam de permissão para se comunicar com o Firestore, o BigQuery e entre si. Sem essas ligações IAM, você receberá erros 403 misteriosos, sem nenhuma explicação clara.
Primeiro, pegue sua conta de serviço de computação:
PROJECT_NUMBER=$(gcloud projects describe "$PROJECT_ID" --format="value(projectNumber)")
COMPUTE_SA="${PROJECT_NUMBER}[email protected]"
echo "$COMPUTE_SA"Em seguida, conceda as funções necessárias:
gcloud projects add-iam-policy-binding "$PROJECT_ID"
--member="serviceAccount:${COMPUTE_SA}"
--role="roles/datastore.user"
gcloud projects add-iam-policy-binding "$PROJECT_ID"
--member="serviceAccount:${COMPUTE_SA}"
--role="roles/bigquery.dataEditor"
gcloud projects add-iam-policy-binding "$PROJECT_ID"
--member="serviceAccount:${COMPUTE_SA}"
--role="roles/bigquery.jobUser"
gcloud projects add-iam-policy-binding "$PROJECT_ID"
--member="serviceAccount:${COMPUTE_SA}"
--role="roles/run.invoker"
gcloud projects add-iam-policy-binding "$PROJECT_ID"
--member="serviceAccount:${COMPUTE_SA}"
--role="roles/workflows.invoker"São cinco vinculações de função. Cada uma permite que a conta de serviço execute uma ação específica: ler/gravar no Firestore, inserir no BigQuery, invocar serviços do Cloud Run e acionar fluxos de trabalho.
Instalando dependências
Na raiz do repositório, instale as dependências para ambos os serviços:
npm --prefix scraper-service install
npm --prefix api-service installImplantando o serviço Scraper
Este é o carro-chefe de todo o pipeline. É o serviço que visita URLs, extrai conteúdo e grava os resultados no Firestore e no BigQuery. Se você deseja lidar com cenários anti-bot mais complexos em seu Scraper, vale a pena explorar ferramentas como o Navegador de scraping da Bright Data para automação de navegador baseada em nuvem em escala.
Estamos implantando-o como um serviço privado. Observe o sinalizador --no-allow-unauthenticated. Somente solicitações autenticadas, como as do nosso fluxo de trabalho, podem chamá-lo:
gcloud run deploy scraper-service
--source ./scraper-service
--region "$REGION"
--memory 2Gi
--cpu 2
--timeout 300
--no-allow-unauthenticated
--set-env-vars NODE_ENV=productionObtenha a URL assim que ela for implantada:
SCRAPER_URL=$(gcloud run services describe scraper-service --region "$REGION" --format='value(status.url)')
echo "$SCRAPER_URL"Salve essa URL. Você precisará dela para a configuração do fluxo de trabalho.
Implantando o serviço de API
O serviço API é o lado público do pipeline. Ele lê do Firestore e do BigQuery e expõe pontos de extremidade para que você ou seu front-end possam acessar os dados coletados:
gcloud run deploy api-service
--source ./api-service
--region "$REGION"
--memory 512Mi
--cpu 1
--timeout 60
--allow-unauthenticated
--set-env-vars NODE_ENV=productionObtenha a URL:
API_URL=$(gcloud run services describe api-service --region "$REGION" --format='value(status.url)')
echo "$API_URL"Testando seus serviços implantados
Agora vem a parte divertida: acessar seus serviços ativos e garantir que tudo funcione. Lembre-se de que desafios comuns de Scraping de dados, como bloqueio de IP e limitação de taxa, podem afetar seu Scraper mesmo em uma configuração sem servidor, por isso vale a pena ter uma estratégia para isso desde o início.
Experimente o seguinte com seu serviço de API:
curl -s "$API_URL/"
curl -s "$API_URL/jobs?limit=10"
curl -s "$API_URL/analytics/summary"Para o Scraper, você precisa passar um token de autenticação, pois é um serviço privado:
curl -s -X POST
-H "Authorization: Bearer $(gcloud auth print-identity-token)"
-H "Content-Type: application/json"
-d '{"url":"http://books.toscrape.com"}'
"$SCRAPER_URL/scrape"Você também pode passar seletores CSS personalizados se quiser direcionar elementos específicos em uma página:
curl -s -X POST
-H "Authorization: Bearer $(gcloud auth print-identity-token)"
-H "Content-Type: application/json"
-d '{"url":"http://books.toscrape.com","selectors":{"title":"h1, h2","content":"p, article"}}'
"$SCRAPER_URL/scrape"Configurando o fluxo de trabalho
O fluxo de trabalho é o que vincula o Scraper a uma programação. É um arquivo YAML que instrui o Cloud Workflows a chamar o Scraper para cada URL da lista.
Abra workflows/scrape-pipeline.yaml e defina o scraper_url como a URL que você obteve na etapa de implantação do Scraper.
Em seguida, implante-o:
gcloud workflows deploy scrape-pipeline
--location "$REGION"
--source workflows/scrape-pipeline.yaml
--service-account "$COMPUTE_SA"Criando a tarefa do agendador
É aqui que o pipeline se torna totalmente automático. Estamos configurando uma tarefa cron que executa o fluxo de trabalho todos os dias às 6h UTC:
gcloud scheduler jobs create http scrape-pipeline-daily
--location "$REGION"
--schedule "0 6 * * *"
--uri "https://workflowexecutions.googleapis.com/v1/projects/${PROJECT_ID}/locations/${REGION}/workflows/scrape-pipeline/executions"
--http-method POST
--oauth-service-account-email "$COMPUTE_SA"
--oauth-token-scope "https://www.googleapis.com/auth/cloud-platform"
--message-body '{"argument":"{"urls":["http://books.toscrape.com","http://quotes.toscrape.com"]}"}'Se a tarefa já existir e você quiser apenas atualizá-la:
gcloud scheduler jobs update http scrape-pipeline-daily
--location "$REGION"
--schedule "0 6 * * *"
--uri "https://workflowexecutions.googleapis.com/v1/projects/${PROJECT_ID}/locations/${REGION}/workflows/scrape-pipeline/executions"
--http-method POST
--oauth-service-account-email "$COMPUTE_SA"
--oauth-token-scope "https://www.googleapis.com/auth/cloud-platform"
--message-body '{"argument":"{"urls":["http://books.toscrape.com","http://quotes.toscrape.com"]}"}'Executando seu primeiro teste completo
Não espere pelo agendador. Acione o fluxo de trabalho manualmente e observe toda a execução do pipeline:
gcloud workflows run scrape-pipeline
--location "$REGION"
--data '{"urls":["http://books.toscrape.com","http://quotes.toscrape.com"]}'Você pode monitorar a execução com:
gcloud workflows executions list scrape-pipeline --location "$REGION"Aguarde um ou dois minutos. Quando a execução mostrar SUCCEEDED, seus dados devem estar fluindo para o Firestore e o BigQuery.
Verificando os dados
Agora, vamos confirmar se os dados realmente chegaram onde deveriam.
Verifique o BigQuery para contar as linhas:
bq query --use_legacy_sql=false "SELECT COUNT(*) AS total_rows FROM `${PROJECT_ID}.${BQ_DATASET}.${BQ_TABLE}`"Veja os resultados mais recentes coletados:
bq query --use_legacy_sql=false "SELECT source, url, scraped_at, job_id FROM `${PROJECT_ID}.${BQ_DATASET}.${BQ_TABLE}` ORDER BY scraped_at DESC LIMIT 10"Verifique o Firestore no console. Você deverá ver duas coleções: jobs e results.
Em seguida, acesse a API para confirmar se ela consegue ler tudo:
curl -s "$API_URL/jobs?limit=1"Pegue um jobId da resposta e aprofunde-se:
curl -s "$API_URL/jobs/YOUR_JOB_ID"
curl -s "$API_URL/results/YOUR_JOB_ID"Se tudo isso retornar dados, seu pipeline está funcionando de ponta a ponta.
CI/CD com Cloud Build
O repositório inclui um arquivo cloudbuild.yaml que lida com a construção e a implantação de ambos os serviços de uma só vez. Quando você quiser enviar alterações, basta executar:
gcloud builds submit --config cloudbuild.yaml .Esse único comando irá construir ambas as imagens Docker, enviá-las para o Artifact Registry e implantar ambos os serviços Cloud Run. Se você deseja expandir além de um único pipeline, confira esta visão geral das principais ferramentas de Scraping de dados para ver como diferentes soluções podem complementar uma configuração baseada em nuvem como esta.
Lista de verificação final
Antes de considerar o trabalho concluído, execute estas etapas de verificação:
gcloud run services list --region us-central1deve mostrar os dois serviços.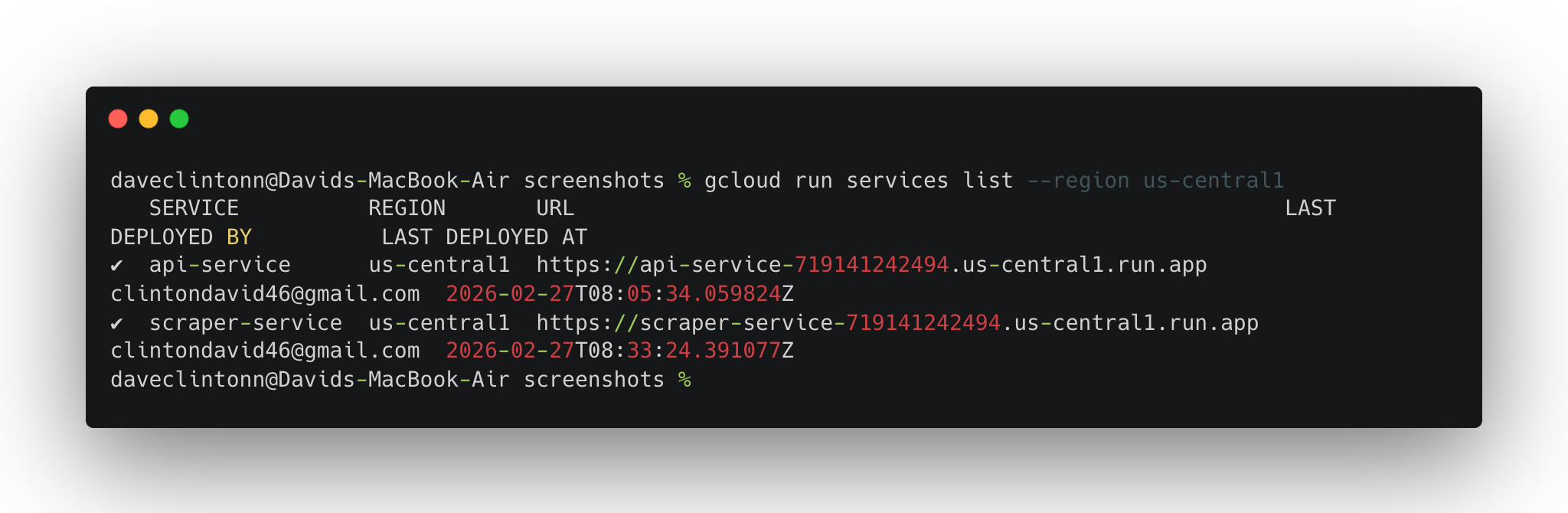
gcloud workflows describe scrape-pipeline --location us-central1deve retornar os detalhes do fluxo de trabalho.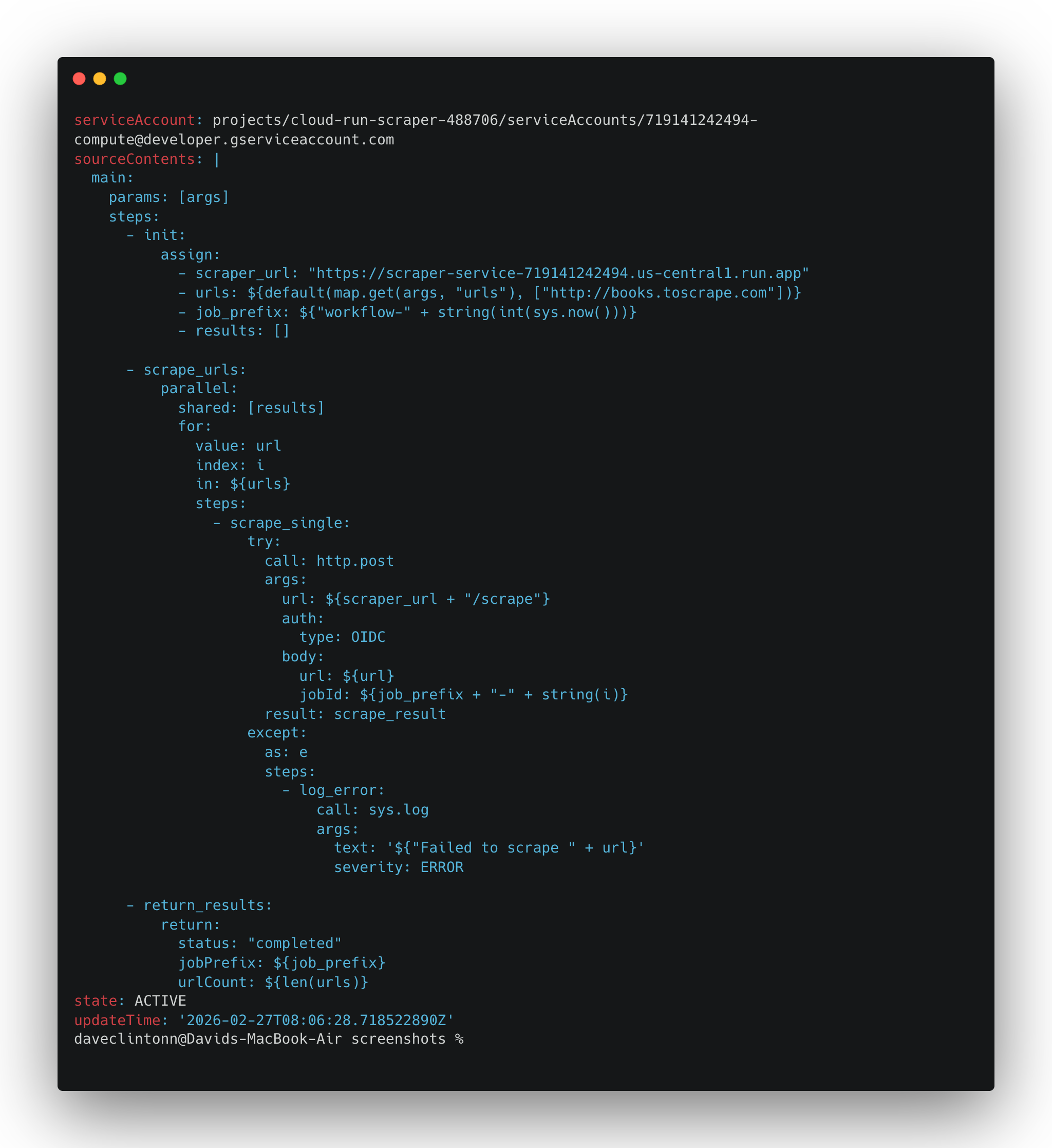
gcloud scheduler jobs list --location us-central1deve mostrar a tarefa do agendador.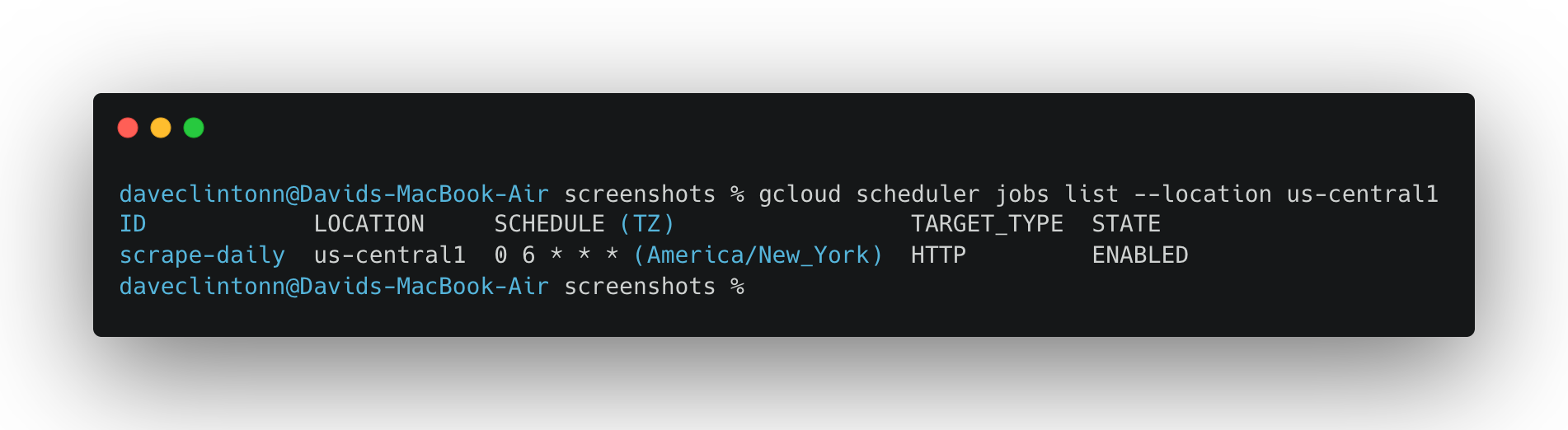
- O Firestore deve ter coleções
de tarefaseresultados. - A tabela do BigQuery deve ter linhas.
- O endpoint da API
/jobsdeve retornar registros reais.
Se todas as seis verificações forem concluídas, você não está mais executando uma demonstração. Você tem um pipeline real que faz scraping dentro do prazo, armazena dados em dois locais e os disponibiliza por meio de uma API pública.
Conclusão
Neste guia, mostramos como construir um pipeline completo de Scraping de dados na web sem servidor no Google Cloud. Abordamos a configuração da infraestrutura, a implantação de dois serviços Cloud Run, a orquestração de execuções de scraping com o Cloud Workflows e a automação de tudo com o Cloud Scheduler.
Se você preferir uma abordagem gerenciada em vez de manter sua própria infraestrutura, pode explorar os Conjuntos de dados pré-coletados da Bright Data ou o Scraper Studio para transformar qualquer site em um pipeline de dados pronto para uso. Você também pode ler nosso guia sobre scraping sem servidor com Scrapy e AWS para ver como uma arquitetura semelhante se parece em um provedor de nuvem diferente. Clone o projeto, troque por seus próprios URLs de destino e você terá um pipeline de scraping em funcionamento.






