

Neste guia, você verá o seguinte:
- O que são sites com muito JavaScript.
- Desafios e métodos para extraí-los por meio da renderização do navegador.
- Como funciona a interceptação de chamadas AJAX e suas limitações.
- A solução moderna para raspagem de sites com muito JavaScript.
Vamos mergulhar de cabeça!
O que é um site com muito JavaScript?
No âmbito da raspagem da Web, um site é “pesado em JavaScript” quando os dados a serem coletados não estão no documento HTML inicial retornado pelo servidor. Em vez disso, o conteúdo real é obtido dinamicamente e renderizado por JavaScript no navegador do usuário.
A forma como um site usa o JavaScript afeta diretamente a maneira como você precisa proceder para extrair os dados. Normalmente, os sites baseados em JavaScript seguem estes três padrões principais:
- Aplicativos de página única (SPAs): Um SPA é uma página da Web que depende do JavaScript para atualizar seções específicas com novo conteúdo do servidor. Em outras palavras, todo o aplicativo da Web é apenas uma única página da Web que não é recarregada para cada interação do usuário.
- Interações orientadas pelo usuário: O conteúdo aparece somente depois que o usuário executa ações específicas. Exemplos são os botões “carregar mais” e a paginação dinâmica.
- Dados assíncronos: Muitos sites carregam um layout de página básico primeiro para aumentar a velocidade e, em seguida, fazem chamadas em segundo plano usando AJAX para buscar dados. Esse mecanismo é comum para atualizações ao vivo, como a atualização dos preços das ações sem recarregar a página.
Raspagem de sites com muito JavaScript por meio da renderização completa do navegador
As ferramentas de automação do navegador permitem que você escreva scripts que iniciam e controlam os navegadores da Web. Isso permite que eles executem o JavaScript necessário para renderizar totalmente uma página. Em seguida, você pode usar a seleção de elementos HTML e as APIs de extração de dados que essas ferramentas fornecem para extrair os dados necessários.
Essa é a abordagem fundamental para a extração de sites com muito JavaScript, e a apresentaremos nas seções a seguir:
- Como funcionam as ferramentas de automação.
- O que são os modos “headless” e “headful”.
- Desafios e soluções com essa abordagem.
- As ferramentas de automação de navegador mais usadas.
Como funcionam as ferramentas de automação
As ferramentas de automação do navegador operam usando um protocolo (por exemplo, CDP ou BiDi) para enviar comandos diretamente a um navegador. Em termos mais simples, elas expõem uma API completa para emitir comandos como “navegar para este URL”, “localizar este elemento” e “clicar neste botão”.
O navegador executa esses comandos na página, executando qualquer JavaScript necessário para as interações descritas em seu script de raspagem. A ferramenta de automação do navegador também pode acessar o DOM(Document Object Model) renderizado. É aí que você pode encontrar os dados a serem extraídos.
Navegadores sem cabeça versus navegadores “com cabeça”
Quando você automatiza um navegador, precisa decidir como ele deve ser executado. Normalmente, você escolhe entre dois modos:
- Cheio de cabeça: O navegador é iniciado com sua interface gráfica completa, exatamente como quando um usuário humano o abre. Você pode ver a janela do navegador na tela e observar como o script clica, digita e navega em tempo real. Isso é útil para confirmar visualmente que o script funciona conforme o esperado. Também pode fazer com que sua automação se pareça mais com a atividade real do usuário para os sistemas antibot. Por outro lado, a execução de um navegador com uma GUI consome muitos recursos (todos nós sabemos como os navegadores consomem muita memória), o que torna a raspagem da Web mais lenta.
- Sem cabeça: O navegador é executado em segundo plano sem uma interface visível. Ele usa menos recursos do sistema e é muito mais rápido. Esse é o padrão para scrapers de produção, especialmente ao executar centenas de instâncias paralelas em um servidor. No lado negativo, se não for configurado com cuidado, um navegador sem GUI pode parecer suspeito. Descubra os melhores navegadores sem interface gráfica do mercado.
Desafios e soluções com a renderização do navegador
Automatizar um navegador é apenas a primeira etapa ao lidar com sites com muito JavaScript. Ao extrair esses sites, você inevitavelmente enfrentará duas categorias principais de desafios, incluindo:
- Navegação complexa: Os scripts de raspagem devem ser mais do que meros seguidores de comandos. Você precisa programá-los para lidar com toda a jornada do usuário. Isso significa escrever código para raspar fluxos de navegação complexos, como aguardar o carregamento de novos conteúdos e lidar com a rolagem infinita. A extração de sites com muito JavaScript inclui a manipulação de formulários de várias páginas, menus suspensos e muito mais.
- Evasão de sistemas antibot: Quando não aplicada adequadamente, a automação do navegador é uma bandeira vermelha que os sistemas antibot podem detectar. Para ter sucesso em um cenário de raspagem com ferramentas de automação de navegador, seu raspador deve, de alguma forma, parecer humano, enfrentando desafios como:
- Impressão digital do navegador: Os anti-bots analisam centenas de pontos de dados do navegador do cliente para criar uma assinatura exclusiva. Isso inclui sua string User-Agent, resolução de tela, fontes instaladas, recursos de renderização WebGL e muito mais. Claramente, uma configuração de automação padrão é facilmente identificável. Definir um User-Agent sem cabeça é uma ótima dica. Você também pode precisar de ferramentas especializadas, como o undetected-chromedriver, que modifica várias opções do navegador para que ele se pareça com o navegador de um usuário comum.
- Análise comportamental: Os anti-bots também observam como o scraper interage com a página. Um script que clica em um botão 5 milissegundos após o carregamento de uma página obviamente não é humano. Se o comportamento for sinalizado como robótico, o sistema de defesa poderá bani-lo.
- CAPTCHAs: Os CAPTCHAs costumam ser o maior obstáculo para os métodos de raspagem baseados na automação do navegador. Isso ocorre porque os scripts de automação padrão não conseguem resolvê-los de forma autônoma. Para superar isso, é necessário integrar serviços de resolução de CAPTCHA.
Para obter mais orientações, consulte nosso guia sobre raspagem de sites dinâmicos.
Principais estruturas de automação do navegador
As três estruturas dominantes para automação de navegadores são:
- Playwright: é uma estrutura moderna da Microsoft. Foi projetada desde o início para lidar com as complexidades dos sites modernos. Isso o torna uma das principais opções para novos projetos de raspagem. Está disponível em JavaScript, Python, C# e Java, com suporte a linguagens adicionais fornecido pela comunidade. Isso torna a raspagem da Web com o Playwright uma boa opção para a maioria dos desenvolvedores.
- Selenium: é o titã de código aberto da automação da Web. Seus maiores pontos fortes estão em sua versatilidade. Em particular, ele é compatível com quase todas as linguagens de programação e navegadores, e tem um ecossistema amplo e maduro. É por isso que o Selenium é amplamente usado como uma ferramenta de automação de navegador para raspagem.
- Puppeteer: É uma biblioteca desenvolvida pelo Google que fornece controle granular sobre os navegadores baseados no Chrome e no Chromium por meio do CDP(Chrome DevTools Protocol). Agora, ela também oferece suporte ao Firefox. Com essa biblioteca, você pode se apresentar como um usuário comum simulando o comportamento do usuário em um navegador controlado. Isso faz com que o Puppeteer seja amplamente usado para raspagem da Web.
Veja como essas soluções (e outras) se comparam em nosso repositório sobre as melhores ferramentas de automação de navegador.
Método alternativo: Replicação de chamadas AJAX
Em vez de arcar com o custo de renderizar uma página da Web visual inteira no navegador, você pode adotar uma abordagem de detetive. Em vez disso, você pode identificar as chamadas diretas de API que o front-end do site faz para o back-end e replicá-las você mesmo.
Essas chamadas de API geralmente retornam os dados brutos que o site renderiza posteriormente na página, para que você possa direcioná-los diretamente. Essa técnica se baseia na imitação de chamadas AJAX e é comumente conhecida como raspagem de API da Web.
Vamos ver como isso funciona!
Como funciona a abordagem de replicação de chamadas AJAX
A replicação AJAX é uma técnica prática de raspagem. A ideia central é ignorar a renderização da página inteira imitando as solicitações de rede (geralmente chamadas AJAX) que o aplicativo da Web faz para buscar dados de seu back-end.
Em um nível elevado, isso envolve duas etapas principais:
- Bisbilhotar: Abra as Ferramentas do desenvolvedor do seu navegador (normalmente a guia “Rede” com o filtro “Fetch/XHR” ativado) e interaja com o site. Observe quais chamadas de API são feitas em segundo plano quando novos dados são carregados. Por exemplo, durante a rolagem infinita ou ao clicar nos botões “Carregar mais”.
- Repetição: Depois de identificar a solicitação de API correta, anote o URL, o método HTTP (GET, POST, etc.), os cabeçalhos e a carga útil (se houver). Em seguida, replique essa solicitação em seu script de raspagem usando um cliente HTTP como Requests in Python.
Esses pontos de extremidade da API geralmente retornam dados em um formato estruturado, na maioria das vezes JSON. Essa é uma grande vantagem, pois você pode acessar os dados JSON sem o incômodo extra de analisar o HTML.
Por exemplo, dê uma olhada na chamada de API feita por um site que usa rolagem infinita para carregar mais dados:
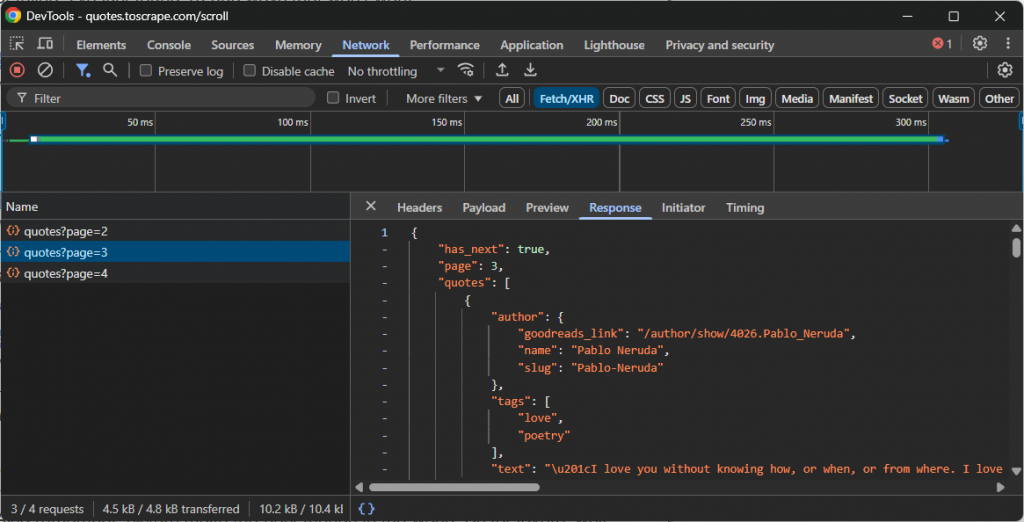
Nesse caso, você pode escrever um script de raspagem simples que reproduza a chamada de API de rolagem infinita acima e, em seguida, acesse os dados.
Principais desafios ao interceptar chamadas AJAX
Quando funciona, essa abordagem é rápida, eficaz e simples. Ainda assim, ela apresenta alguns desafios:
- Cargas ofuscadas: A API pode exigir cargas criptografadas ou não retornar JSON limpo e legível. Pode ser uma cadeia de caracteres criptografada que uma função JavaScript específica sabe como decodificar. Essa é uma medida antirrastreamento que requer engenharia reversa.
- Endpoints e cabeçalhos dinâmicos: Os pontos de extremidade da API e como chamá-los (por exemplo, definir os cabeçalhos adequados, adicionar a carga útil correta e assim por diante) mudam com o tempo. O principal desafio dessa solução é que qualquer evolução na API interromperá o raspador. Isso exige a manutenção do código para restaurar a funcionalidade, o que é um problema comum na maioria das abordagens de raspagem da Web (mas não em todas, como veremos a seguir).
- Impressão digital de TLS: Os anti-bots mais avançados analisam o “handshake TLS”, que é a assinatura digital do programa. Eles podem distinguir facilmente entre uma solicitação do Chrome e uma de um script Python padrão. Para contornar isso, você precisa de ferramentas especializadas que possam personificar a assinatura TLS de um navegador.
Uma abordagem moderna para a raspagem de sites com muito JavaScript: Agentes de raspagem de navegador com tecnologia de IA
Os métodos descritos até agora ainda enfrentam grandes desafios. Uma solução mais moderna para a raspagem de sites com muito JavaScript exige uma mudança de paradigma. A ideia é passar da escrita de comandos imperativos para a definição de objetivos declarativos usando agentes de navegador orientados por IA.
Um navegador agente é um navegador integrado a um LLM que entende o conteúdo, o contexto e o layout visual da página. Isso muda fundamentalmente a forma como abordamos a raspagem da Web, especialmente para sites com muito JavaScript.
Esses sites normalmente exigem interações complexas do usuário para carregar os dados desejados. Tradicionalmente, você teria que injetar lógica para replicar essas interações em seus scripts. Essa abordagem é inerentemente frágil e exige muita manutenção. O problema é que toda vez que o fluxo do usuário é alterado, é necessário atualizar manualmente a lógica de automação.
Graças aos agentes de navegador com tecnologia de IA, você pode evitar tudo isso. Um simples prompt descritivo pode gerar uma automação eficaz que se adapta mesmo quando a interface do usuário ou o fluxo do site muda. Essa flexibilidade é uma grande vantagem e abre as portas para muitas outras possibilidades de automação, e é por isso que a IA agêntica está ganhando força rapidamente.
Agora, por mais avançada que seja sua biblioteca de agentes de navegador de IA, sua lógica de raspagem ainda depende de navegadores comuns. Isso significa que você continua vulnerável a problemas como impressão digital do navegador e CAPTCHAs. O dimensionamento dessas soluções também se torna difícil devido a limites de taxa e proibições de IP.
A verdadeira solução é uma plataforma de raspagem baseada em nuvem e pronta para IA que se integra a qualquer biblioteca agêntica e é projetada para evitar bloqueios. É exatamente isso que o Navegador de agentes da Bright Data oferece.
O Agent Browser permite que você execute fluxos de trabalho orientados por IA em navegadores remotos que nunca são bloqueados. Ele é infinitamente dimensionável, suporta os modos headless e headful e é alimentado pela rede proxy mais confiável do mundo.
Conclusão
Neste artigo, você aprendeu o que são sites com muito JavaScript, além de desafios e soluções comuns para extrair dados deles. Cada implementação descrita tem suas limitações, mas a que mais se destaca é o uso de um navegador agente.
Conforme discutido, o Navegador de agentes da Bright Data permite que você resolva todos os problemas comuns de raspagem enquanto se integra às bibliotecas de IA agêntica mais populares.
Se você usa agentes avançados de raspagem de IA, precisa de ferramentas confiáveis para recuperar, validar e transformar o conteúdo da Web. Para obter todos esses recursos e muito mais, explore a infraestrutura de IA da Bright Data.
Crie uma conta na Bright Data e experimente todos os nossos produtos e serviços para o desenvolvimento de agentes de IA!





