

Ao fazer scraping de dados na web, você frequentemente encontrará paginação, onde o conteúdo está espalhado por várias páginas. Lidar com essa paginação pode ser desafiador, pois diferentes sites usam diferentes técnicas de paginação.
Neste artigo, explicarei as técnicas comuns de paginação e mostrarei como lidar com elas com um exemplo prático de código.
O que é paginação?
Sites como plataformas de comércio eletrônico, sites de empregos e mídias sociais usam paginação para gerenciar grandes quantidades de dados. Exibir tudo em uma única página aumentaria significativamente o tempo de carregamento e consumiria muita memória. A paginação divide o conteúdo em várias páginas e oferece opções de navegação como “Próximo”, números de página ou carregamento automático à medida que você rola a página. Isso torna a navegação mais rápida e organizada.
Tipos de paginação
A complexidade da paginação pode variar, desde a simples paginação numerada até técnicas mais avançadas, como rolagem infinita ou carregamento dinâmico de conteúdo. Na minha experiência, encontrei três tipos principais de paginação, que acredito serem os mais comumente usados em sites:
- Paginação numerada: os usuários navegam por páginas discretas usando links numerados.
- Paginação com clique para carregar: os usuários clicam em um botão (por exemplo, “Carregar mais”) para carregar conteúdo adicional.
- Rolagem infinita: o conteúdo é carregado automaticamente à medida que os usuários rolam a página para baixo.
Vamos nos aprofundar em cada um deles com mais detalhes!
Paginação numerada
Esta é a técnica de paginação mais comum, frequentemente chamada de “Paginação Próxima e Anterior”, “Paginação com setas” ou “Paginação baseada em URL”. Apesar dos diferentes nomes, a ideia central é a mesma: as páginas são vinculadas usando links numerados. Você pode navegar alterando o número da página na URL. Para saber quando parar a paginação, você pode verificar se o botão “Próximo” está desativado ou se não há novos dados disponíveis.
Geralmente, fica assim:

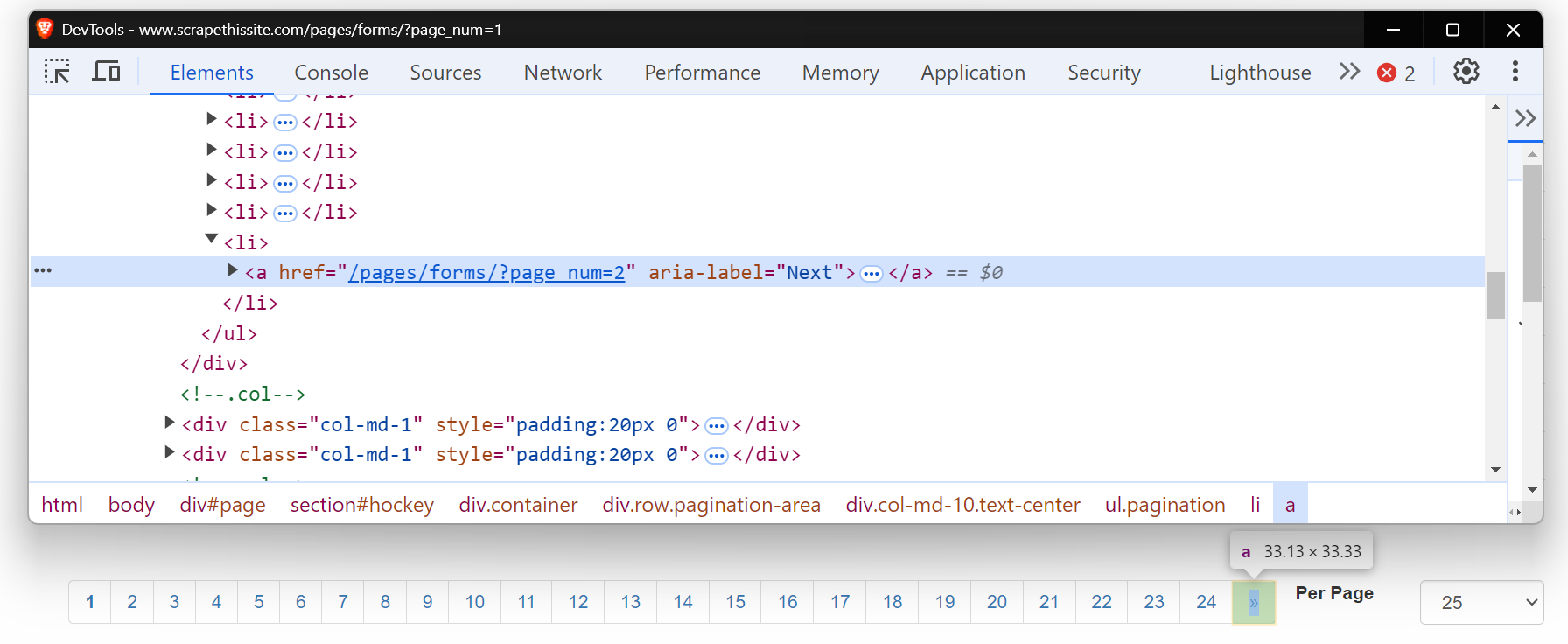
Vamos dar um exemplo! Vamos navegar por todas as páginas do site Scrapethesite. A barra de paginação deste site tem um total de 24 páginas.

Você notará que, ao clicar no botão “>>”, a URL muda da seguinte forma:
- 1ª página: https://www.scrapethissite.com/pages/forms/
- 2ª página: https://www.scrapethissite.com/pages/forms/?page_num=2
- 3ª página: https://www.scrapethissite.com/pages/forms/?page_num=3
Agora, observe o HTML desse botão “Próximo”. É uma tag âncora (<a>) com um atributo href que direciona para a próxima página. O atributo aria-label mostra que o botão “Próximo” ainda está ativo.
Quando não houver mais páginas, o atributo aria-label desaparecerá, indicando o fim da paginação.
Vamos começar escrevendo um Scraper básico para navegar por essas páginas. Primeiro, configure seu ambiente instalando os pacotes necessários. Para um guia detalhado sobre Scraping de dados com Python, você pode conferir a postagem detalhada do blog aqui.
pip install requests beautifulsoup4 lxmlAqui está o código para paginar cada página:
import requests
from bs4 import BeautifulSoup
base_url = "https://www.scrapethissite.com/pages/forms/?page_num="
# Comece com a página 1
page_num = 1
while True:
url = f"{base_url}{page_num}"
response = requests.get(url)
soup = BeautifulSoup(response.content, "lxml")
print(f"Atualmente na página: {page_num}")
# Verifique se o botão “Próximo” existe
botão_próximo = soup.find("a", {"aria-label": "Próximo"})
if botão_próximo:
# Vá para a próxima página
numero_da_página += 1
else:
# Não há mais páginas, saia do loop
imprimir("Chegou à última página.")
breakEste código navega pelas páginas verificando se o botão “Próximo” (com aria-label="Próximo") existe. Se o botão estiver presente, ele incrementa o page_num e faz uma nova solicitação com a URL atualizada. O loop continua até que o botão “Próximo” não seja mais encontrado, indicando a última página.
Execute o código e você verá que navegamos com sucesso por todas as páginas.

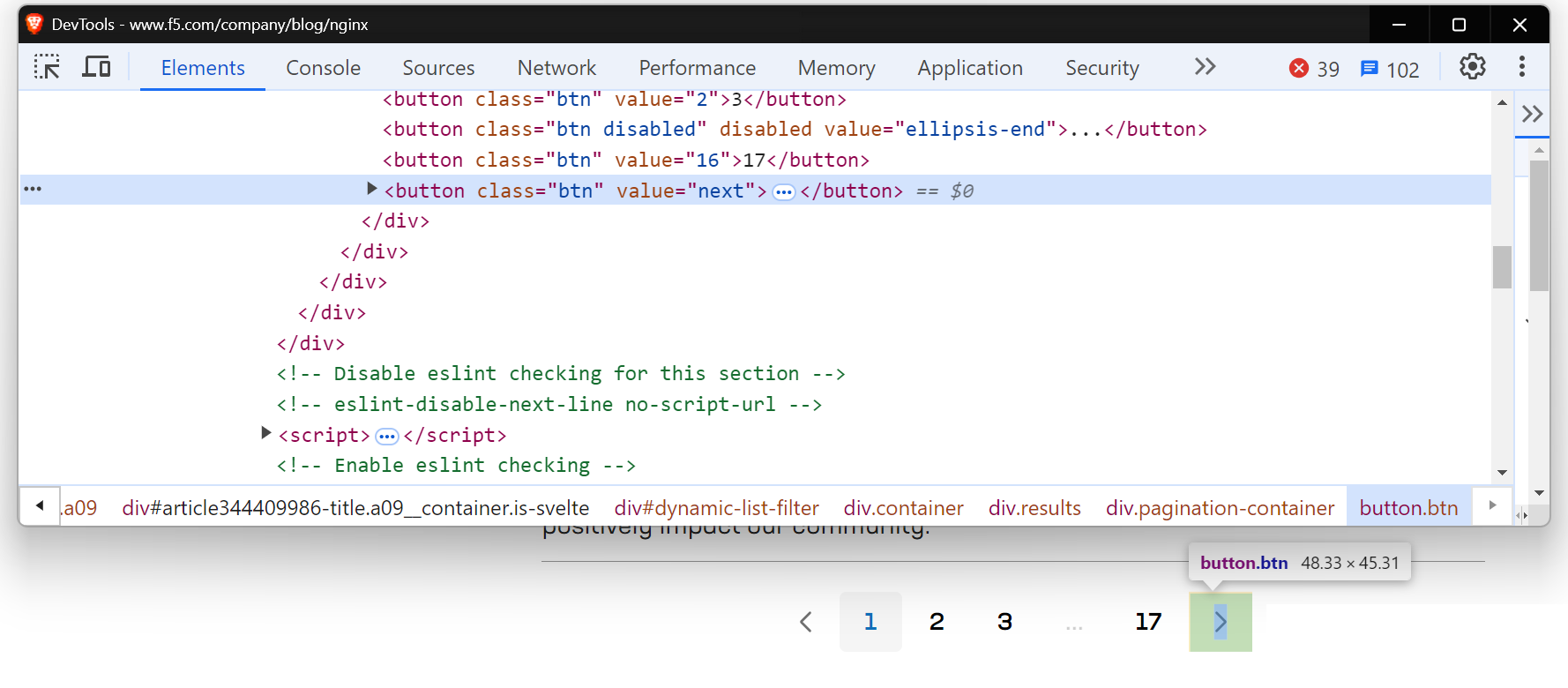
Alguns sites têm um botão “Próximo” que não altera a URL, mas ainda carrega novo conteúdo na mesma página. Nesses casos, os métodos tradicionais de Scraping de dados podem não funcionar bem. Ferramentas como Selenium ou Playwright são mais adequadas, pois podem interagir com a página e simular ações como clicar em botões para recuperar o conteúdo carregado dinamicamente. Para saber mais sobre como usar o Selenium para essas tarefas, você pode ler um guia detalhado aqui.
Você encontrará uma situação semelhante ao tentar fazer scraping da página do blog NGINX.
Vamos usar o Playwright para lidar com conteúdo carregado dinamicamente. Se você é novo no Playwright, confira este guia útil de introdução.
Agora, antes de escrever o código, execute o seguinte comando para configurar o Playwright em sua máquina:
pip install playwright
playwright installAqui está o código:
import asyncio
from playwright.async_api import async_playwright
# Defina uma função assíncrona
async def scrape_nginx_blog():
async with async_playwright() as p:
# Inicie uma instância do navegador Chromium no modo headless
browser = await p.chromium.launch(headless=True)
page = await browser.new_page()
# Navegue até a página do blog NGINX
await page.goto("https://www.f5.com/company/blog/nginx")
page_num = 1
enquanto True:
imprimir(f"Atualmente na página {page_num}")
# Localizar o botão 'Próximo' usando um localizador de botão com o valor "próximo"
next_button = page.locator('button[value="next"]')
# Verifique se o botão “Próximo” está habilitado
if await next_button.is_enabled():
await next_button.click() # Clique no botão “Próximo” para ir para a próxima página
await page.wait_for_timeout(
2000
) # Aguarde 2 segundos para permitir que o novo conteúdo seja carregado
page_num += 1
else:
print("Não há mais páginas. Raspagem concluída.")
break # Saia do loop se não houver mais páginas disponíveis
await browser.close() # Feche o navegador
# Execute a função de raspagem assíncrona
asyncio.run(scrape_nginx_blog())O código usa o Playwright assíncrono para navegar por todas as páginas. Ele entra em um loop que verifica o botão “Próximo”. Se o botão estiver habilitado, ele clica para ir para a próxima página e aguarda o carregamento do conteúdo. Esse processo se repete até que não haja mais páginas disponíveis. Por fim, o navegador é fechado assim que a coleta de dados é concluída.
Execute o código e você verá que navegamos com sucesso por todas as páginas.
Paginação com clique para carregar
Em muitos sites, você provavelmente já viu botões como “Carregar mais”, “Mostrar mais” ou “Ver mais”. Esses são exemplos de paginação clicável, comumente usada em sites modernos. Esses botões carregam conteúdo dinamicamente por meio de JavaScript. O principal desafio aqui é simular a interação do usuário — automatizar o processo de clicar no botão para carregar mais conteúdo.
Vamos usar a seção do blog da Bright Data como exemplo. Ao visitar e rolar a página para baixo, você verá um botão “Ver mais” que carrega as postagens do blog quando clicado.
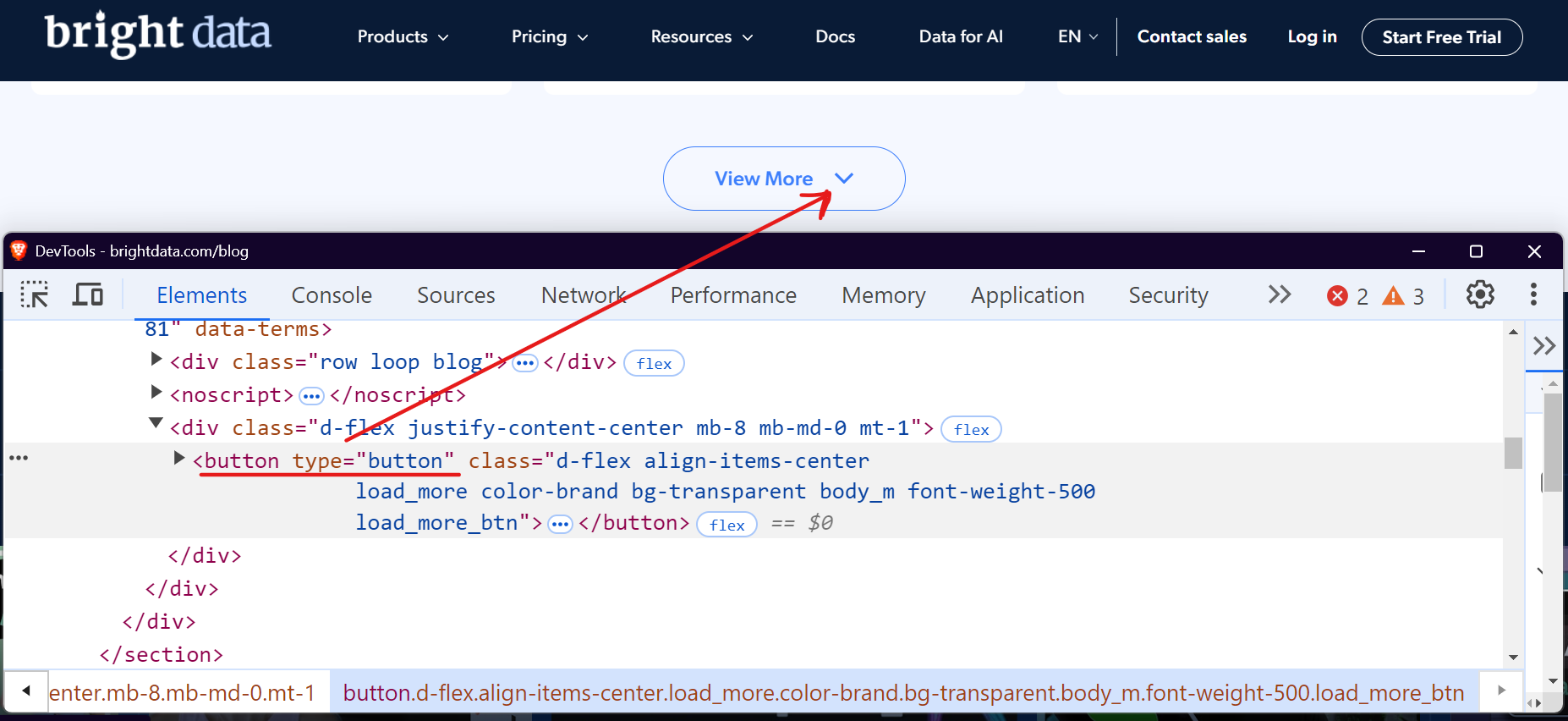
Você pode usar ferramentas como Selenium ou Playwright para automatizar esse processo clicando repetidamente no botão “Carregar mais” até que não haja mais conteúdo disponível. Vamos ver como podemos lidar com isso facilmente com o Playwright.
import asyncio
from playwright.async_api import async_playwright
async def scrape_brightdata_blog():
async with async_playwright() as p:
# Inicie um navegador sem interface gráfica
browser = await p.chromium.launch(headless=True)
page = await browser.new_page()
# Navegue até o blog da Bright Data
await page.goto("https://brightdata.com/blog")
page_num = 1
while True:
print(f"Atualmente na página {page_num}")
# Localize o botão "Ver mais"
view_more_button = page.locator("button.load_more_btn")
# Verifique se o botão está visível e ativado
if (
await view_more_button.count() > 0
and await view_more_button.is_visible()
):
await view_more_button.click()
await page.wait_for_timeout(2000)
page_num += 1
else:
imprimir("Não há mais páginas para carregar. Raspagem concluída.")
break
# Fechar o navegador
await browser.close()
# Executar a função de raspagem
asyncio.run(scrape_brightdata_blog())O código localiza o botão “Ver mais” usando o seletor CSS button.load_more_btn. Em seguida, ele verifica se o botão existe e está visível usando count() > 0 e is_visible(). Se o botão estiver visível, ele interage com ele usando o método click() e aguarda 2 segundos para permitir que o novo conteúdo seja carregado. Esse processo se repete em um loop até que o botão não esteja mais visível.
Execute o código e você verá que navegamos com sucesso por todas as páginas.

Raspamos com sucesso todas as 52 páginas da seção do blog da Bright Data. Isso mostra que o site tem um total de 52 páginas, o que só descobrimos após o processo de raspagem. No entanto, é possível saber o número total de páginas antes da raspagem.
Para fazer isso, abra as Ferramentas do desenvolvedor, navegue até a guia “Rede” e filtre as solicitações selecionando “Fetch/XHR”. Em seguida, clique no botão “Ver mais” novamente e você notará que uma solicitação AJAX é acionada.
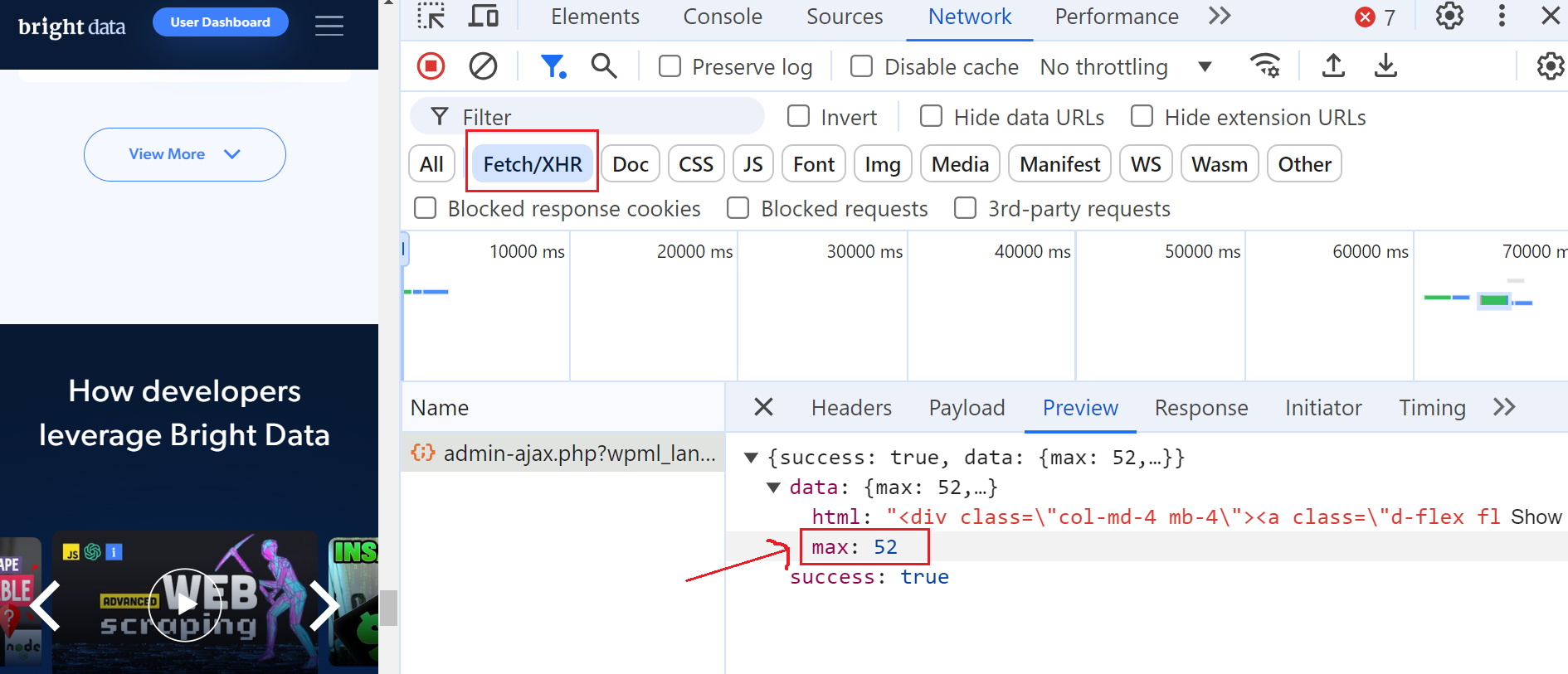
Clique nessa solicitação e navegue até a seção “Visualizar”, onde você verá que o número máximo de páginas é 52. Em seguida, vá até a seção “Carga útil” e você verá que há 6 postagens de blog por página e que estamos atualmente na página 3.
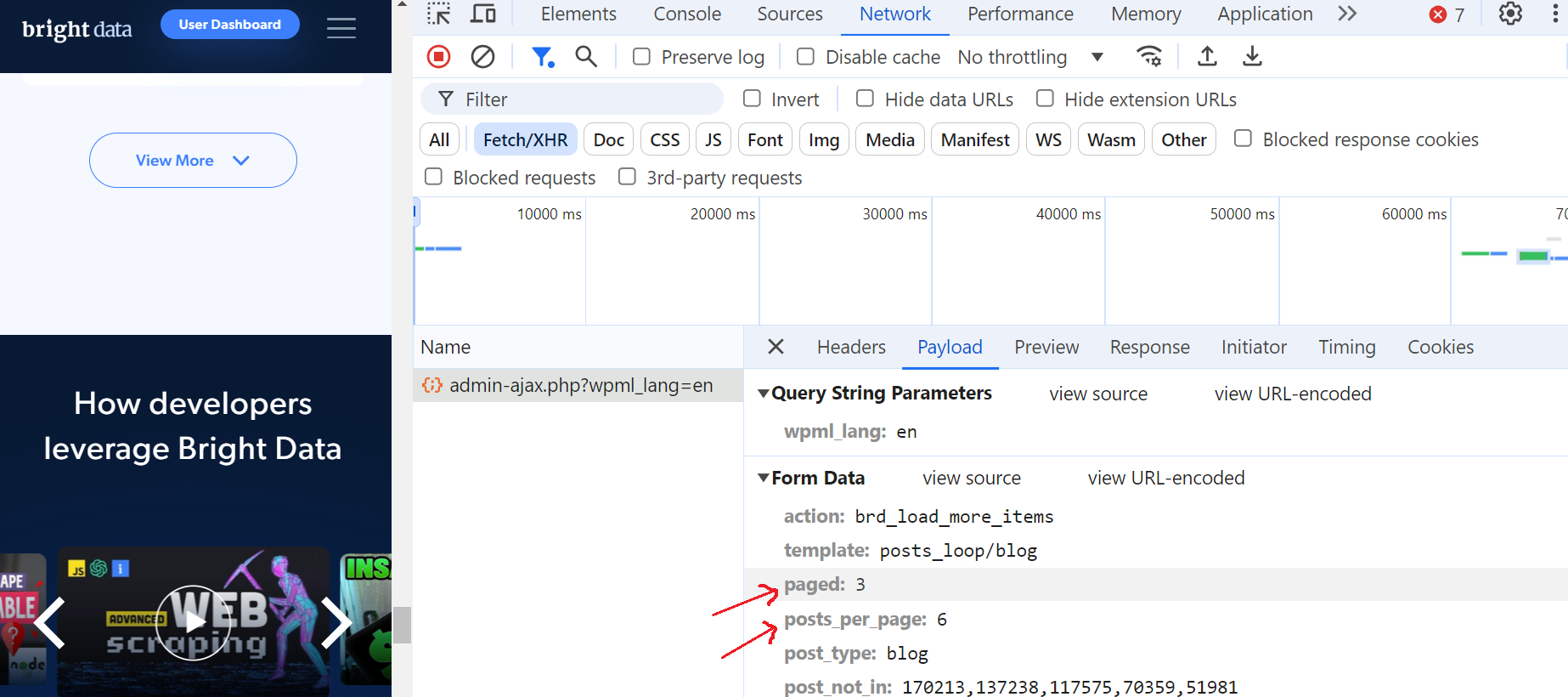
Isso é fantástico!
Paginação com rolagem infinita
Em vez dos botões “anterior/próximo”, muitos sites agora usam rolagem infinita, o que melhora a experiência do usuário, eliminando a necessidade de clicar em várias páginas. Essa técnica carrega automaticamente novos conteúdos à medida que o usuário rola a página para baixo. No entanto, ela apresenta desafios únicos para os Scrapers, pois requer o monitoramento das alterações no DOM e o tratamento de solicitações AJAX.
Vamos dar um exemplo da vida real. Ao visitar o site da Nike, você notará que os tênis são carregados automaticamente à medida que você rola a página para baixo. A cada rolagem, um ícone de carregamento aparece brevemente e, em um piscar de olhos, mais tênis são exibidos, conforme mostrado na imagem abaixo:
Ao clicar na solicitação (d9a5bc), você pode encontrar todos os dados da página atual na guia “Resposta”.
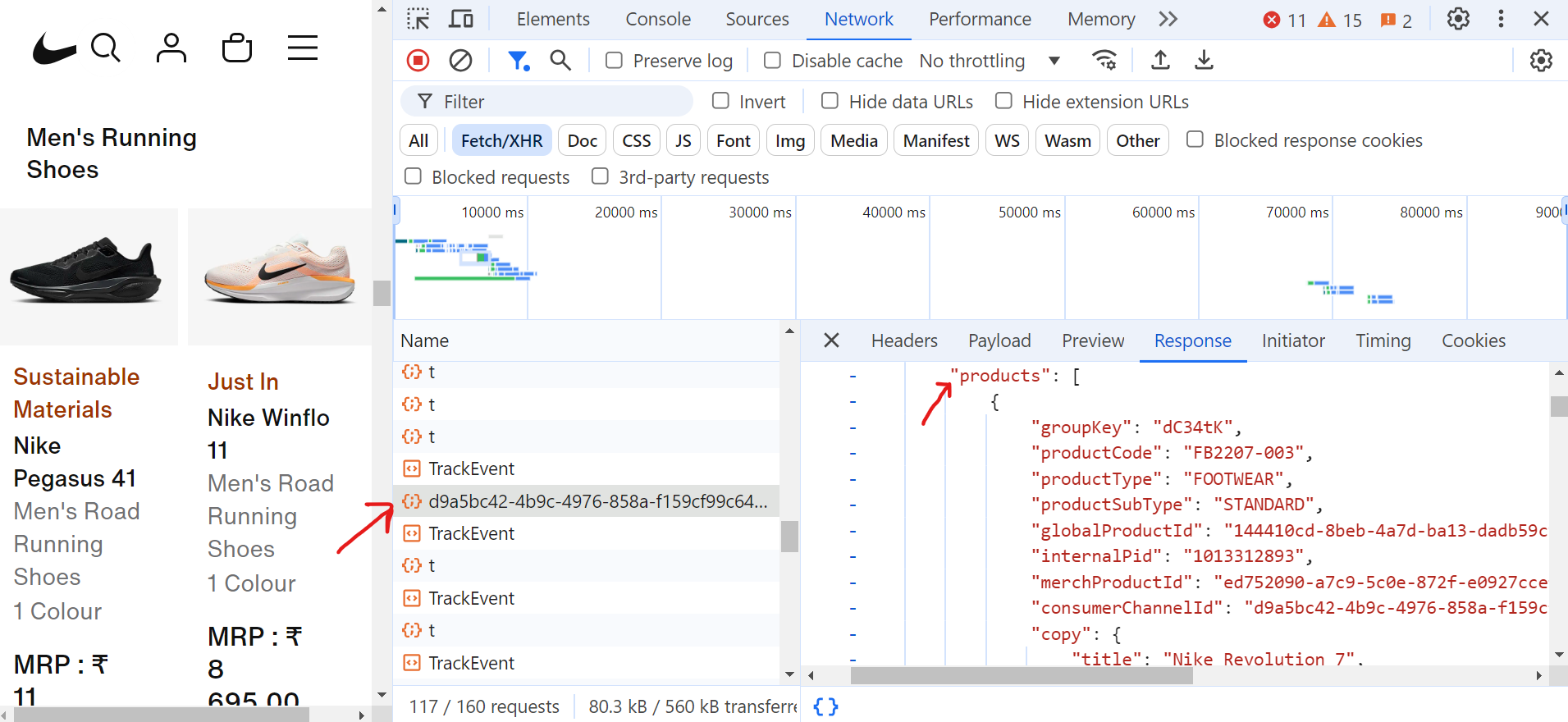
Agora, para lidar com a paginação, você precisa continuar rolando a página até chegar ao final. Conforme você rola, o navegador fará muitas solicitações, mas apenas algumas dessas solicitações Fetch/XHR conterão os dados reais de que você precisa.
Aqui está o código que lida com a paginação e extrai os títulos dos sapatos:
import asyncio
from urllib.parse import parse_qs, urlparse
from playwright.async_api import async_playwright
async def scroll_to_bottom(page) -> None:
"""Role até o final da página até que não haja mais conteúdo carregado."""
last_height = await page.evaluate("document.body.scrollHeight")
scroll_count = 0
while True:
# Role para baixo
await page.evaluate("window.scrollTo(0, document.body.scrollHeight);")
await asyncio.sleep(2) # Aguarde o carregamento de novo conteúdo
scroll_count += 1
print(f"Iteração de rolagem: {scroll_count}")
# Verificar se a altura de rolagem mudou
new_height = await page.evaluate("document.body.scrollHeight")
if new_height == last_height:
print("Chegou ao final da página.")
break # Sair se nenhum novo conteúdo for carregado
last_height = new_height
async def extrair_dados_do_produto(resposta, produtos_extraídos) -> None:
"""Extrair dados do produto da resposta."""
url_analisada = urlparse(resposta.url)
parâmetros_da_consulta = parse_qs(url_analisada.query)
if "queryType" in query_params and query_params["queryType"][0] == "PRODUCTS":
data = await response.json()
for grouping in data.get("productGroupings", []):
for product in grouping.get("products", []):
title = product.get("copy", {}).get("title")
extracted_products.append({"title": title})
async def scrape_shoes(target_url: str) -> None:
async with async_playwright() as playwright:
browser = aguardar playwright.chromium.launch(headless=True)
página = aguardar browser.new_page()
produtos extraídos = []
# Configurar ouvinte para respostas de dados do produto
página.on(
"response",
lambda response: extrair_dados_do_produto(
response, produtos extraídos),
)
# Navegue até a página e role até o final
imprimir("Navegando até a página...")
aguardar página.goto(target_url, wait_until="domcontentloaded")
aguardar asyncio.sleep(2)
aguardar scroll_to_bottom(página)
# Salvar títulos de produtos em um arquivo de texto
with open("product_titles.txt", "w") as title_file:
for product in extracted_products:
title_file.write(product["title"] + "n")
print(f"Raspagem concluída!")
await browser.close()
if __name__ == "__main__":
asyncio.run(
scrape_shoes(
"https://www.nike.com/in/w/mens-running-shoes-37v7jznik1zy7ok")
)No código, a função scroll_to_bottom rola continuamente até o final da página para carregar mais conteúdo. Ela começa registrando a altura atual da rolagem e, em seguida, rola repetidamente para baixo. Após cada rolagem, ela verifica se a nova altura da rolagem difere da última altura registrada. Se a altura permanecer inalterada, ela conclui que não há mais conteúdo sendo carregado e sai do loop. Essa abordagem garante que todos os produtos disponíveis sejam totalmente carregados antes que o processo de raspagem continue.
Veja o que acontece quando você executa o código:

Após a execução bem-sucedida do código, um novo arquivo de texto será criado contendo todos os títulos dos tênis Nike.
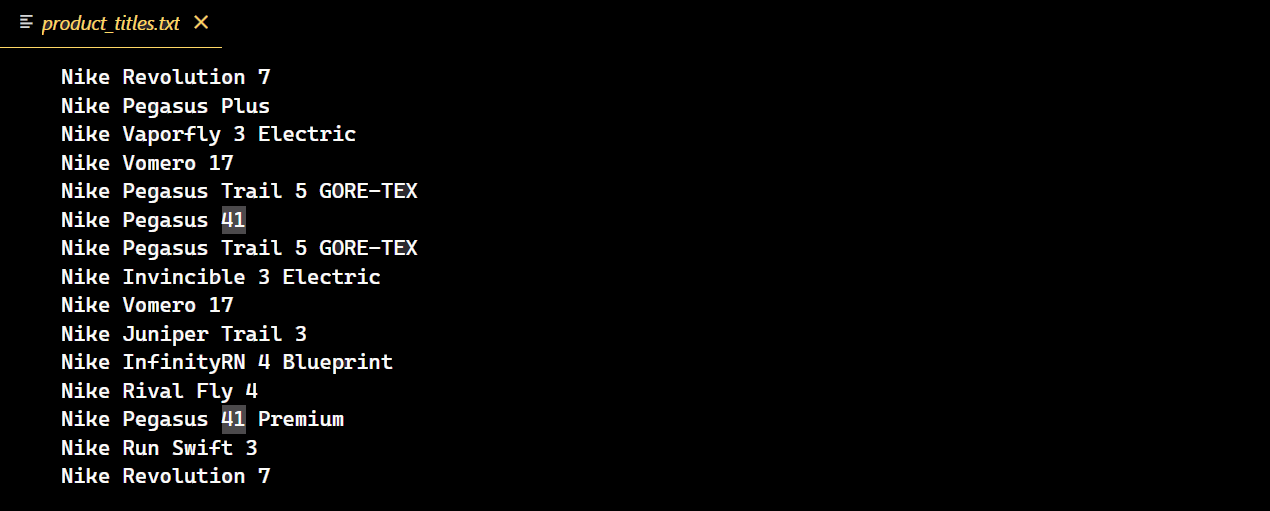
Desafios na paginação
O risco de ser bloqueado aumenta ao lidar com conteúdo paginado, e alguns sites podem bloqueá-lo após apenas uma página. Por exemplo, se você tentar fazer scraping de dados no Glassdoor, poderá encontrar vários desafios de Scraping de dados, um dos quais é o desafio CAPTCHA da Cloudflare, como eu experimentei.
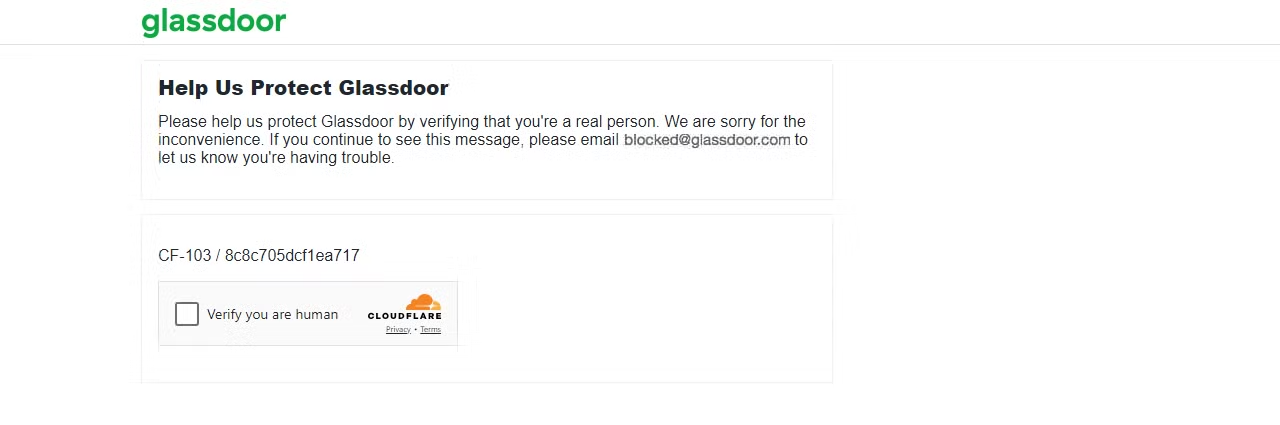
Vamos fazer uma solicitação à página do Glassdoor e ver o que acontece.
import requests
url = "https://www.glassdoor.com/"
response = requests.get(url)
print(f"Código de status: {response.status_code}")O resultado é um código de status 403.
Isso mostra que o Glassdoor detectou sua solicitação como proveniente de um bot ou Scraper, resultando em um desafio CAPTCHA. Se você continuar enviando várias solicitações, seu IP poderá ser bloqueado imediatamente.
Para contornar esses bloqueios e extrair efetivamente os dados de que você precisa, você pode usar proxies no Python Requests para evitar banimentos de IP ou imitar um navegador real, alternando o User Agent. No entanto, é importante observar que nenhum desses métodos pode garantir a prevenção da detecção avançada de bots.
Então, qual é a solução definitiva? Vamos mergulhar nisso a seguir!
Incorpore as soluções da Bright Data
A Bright Data é uma excelente solução para contornar medidas sofisticadas de combate a bots. Ela se integra perfeitamente ao seu projeto usando apenas algumas linhas de código e oferece uma variedade de soluções para qualquer mecanismo avançado de combate a bots.
Uma de suas soluções é a API de Scraper, que simplifica a extração de dados de qualquer site, lidando automaticamente com a rotação de IP e a Resolução de CAPTCHA. Isso permite que você se concentre na análise de dados, em vez de nas complexidades da recuperação de dados.
Por exemplo, no nosso caso, encontramos desafios ao tentar contornar o CAPTCHA no Glassdoor. Para lidar com isso, você pode usar a API Scraper do Glassdoor da Bright Data, que foi projetada especificamente para contornar esses obstáculos e extrair dados perfeitamente do site.
Para começar a usar a API do Scraper do Glassdoor, siga estas etapas:
Primeiro, crie uma conta. Acesse o site da Bright Data, clique em “Teste grátis” e siga as instruções de inscrição. Depois de fazer login, você será redirecionado para o seu painel, onde receberá alguns créditos gratuitos.
Agora, vá para a seção API do Web Scraper e selecione Glassdoor na categoria de dados B2B. Você encontrará várias opções de coleta de dados, como coletar empresas por URL ou coletar listas de empregos por URL.
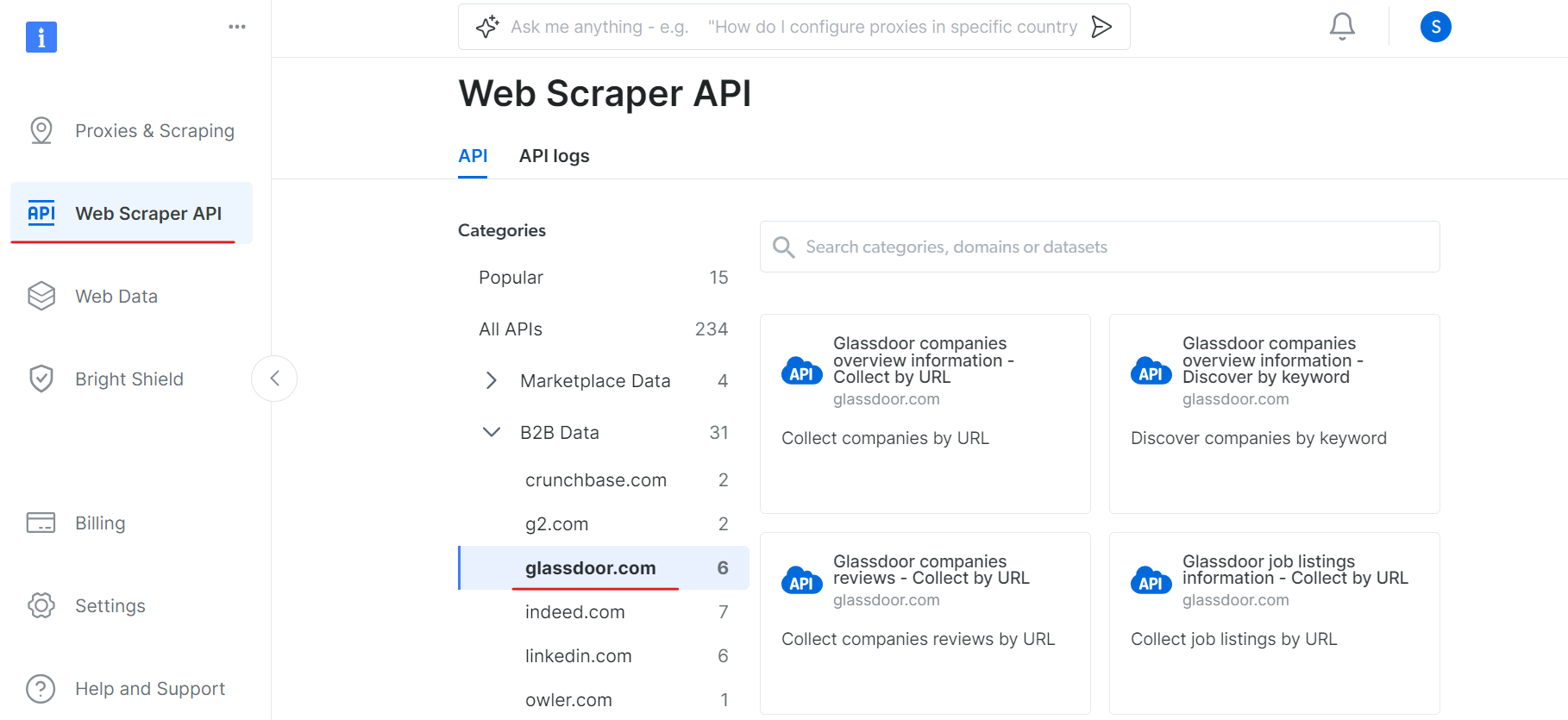
Em “Informações gerais sobre as empresas do Glassdoor”, obtenha seu token de API e copie o ID do seu conjunto de dados (por exemplo, gd_l7j0bx501ockwldaqf).
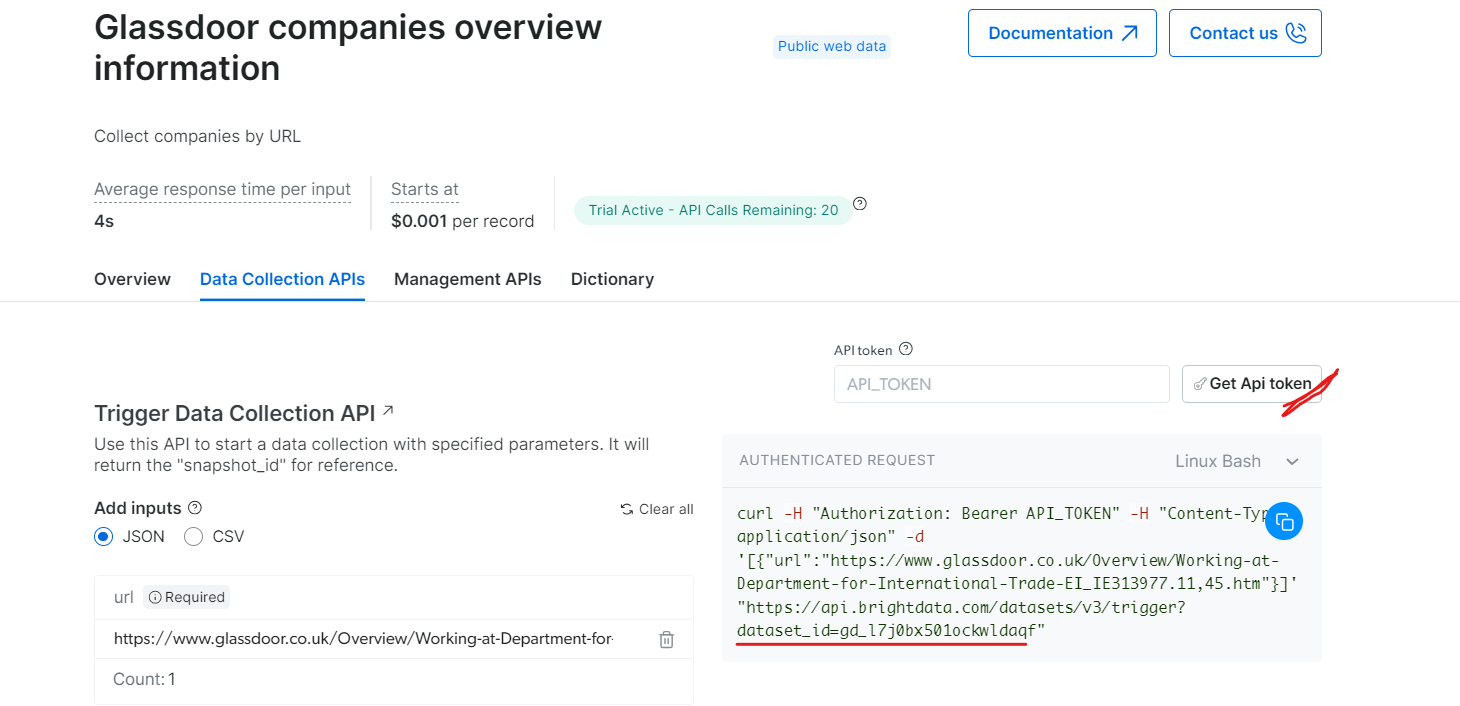
Agora, aqui está um trecho de código simples que mostra como extrair dados da empresa fornecendo a URL, o token da API e o ID do Conjunto de dados.
import requests
import json
def trigger_dataset(api_token, dataset_id, company_url):
"""
Aciona um conjunto de dados usando a API BrightData.
Args:
api_token (str): O token da API para autenticação.
dataset_id (str): O ID do conjunto de dados a ser acionado.
company_url (str): A URL da página da empresa a ser analisada.
Retorna:
dict: A resposta JSON da API.
"""
headers = {
"Authorization": f"Bearer {api_token}",
"Content-Type": "application/json",
}
payload = json.dumps([{"url": company_url}])
response = requests.post(
"https://api.brightdata.com/conjuntos_de_dados/v3/trigger",
headers=headers,
params={"dataset_id": dataset_id},
data=payload,
)
return response.json()
api_token = "API_Token"
dataset_id = "DATASET_ID"
company_url = "https://www.glassdoor.com/"
response_data = trigger_dataset(api_token, dataset_id, company_url)
print(response_data)Ao executar o código, você receberá um ID de instantâneo, conforme mostrado abaixo:

Use o ID do instantâneo para recuperar os dados reais da empresa. Execute o seguinte comando no seu terminal. Para Windows, use:
curl.exe -H "Authorization: Bearer API_TOKEN"
"https://api.brightdata.com/conjuntos_de_dados/v3/snapshot/s_m0v14wn11w6tcxfih8?format=json"Para Linux:
curl -H "Authorization: Bearer API_TOKEN"
"https://api.brightdata.com/conjuntos-de-dados/v3/snapshot/s_m0v14wn11w6tcxfih8?format=json"Após executar o comando, você obterá os dados desejados.
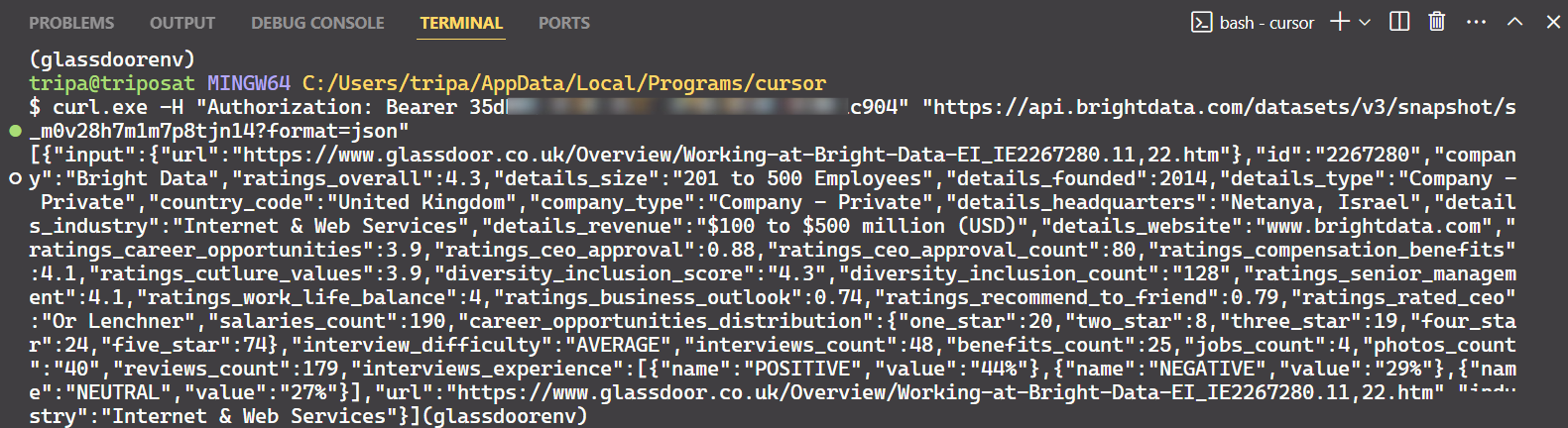
É só isso!
Da mesma forma, você pode extrair vários tipos de dados do Glassdoor modificando o código. Expliquei um método, mas existem outras cinco maneiras de fazer isso. Portanto, recomendo explorar essas opções para coletar os dados que você deseja. Cada método é adaptado a necessidades específicas de dados e ajuda você a obter exatamente os dados de que precisa.
Conclusão
Este artigo discutiu vários métodos de paginação comumente usados em sites modernos, como paginação numerada, botões “carregar mais” e rolagem infinita. Ele também forneceu exemplos de código para implementar efetivamente essas técnicas de paginação. No entanto, embora lidar com a paginação fosse uma parte do Scraping de dados da web, superar a detecção anti-bot apresentava um desafio significativo.
Evitar detecções anti-bot avançadas pode ser bastante complexo e muitas vezes produz graus variados de sucesso. As ferramentas da Bright Data oferecem uma solução simplificada e econômica, incluindo Web Unlocker, Navegador de scraping e Web Scraper APIs para todas as suas necessidades de Scraping de dados. Com apenas algumas linhas de código, você pode alcançar uma taxa de sucesso mais alta sem o incômodo de gerenciar medidas anti-bot complexas.
Não tem interesse em se envolver no processo de scraping? Confira nosso Marketplace de Conjuntos de Dados!
Inscreva-se hoje para um teste gratuito.





