

De assistentes de pesquisa autônomos a agentes que gerenciam fluxos de trabalho inteiros, os agentes de IA estão rapidamente se tornando mais do que apenas uma tendência; eles estão moldando o futuro do trabalho, do desenvolvimento e da tomada de decisões. Mas por trás de cada agente capaz há uma pilha de tecnologia cuidadosamente construída, um sistema em camadas de ferramentas que permite que esses agentes raciocinem, ajam e se adaptem.
O que está impulsionando a próxima geração de automação
Para os desenvolvedores, é essencial compreender essa pilha. Não se trata apenas de quais ferramentas estão em alta, mas de como elas funcionam juntas, onde está o valor real e quais elementos fundamentais devem estar presentes para que os agentes tenham um desempenho confiável.
Na Bright Data, trabalhamos com equipes de IA em todos os setores, e uma coisa é clara: todo agente começa com dados. Neste artigo, vamos percorrer as camadas centrais da pilha de tecnologia do agente de IA, começando pela mais crítica: coleta e integração de dados.
Coleta e integração de dados
O primeiro passo para construir agentes mais inteligentes
Antes que um agente de IA possa raciocinar, planejar ou agir, ele precisa entender o mundo em que opera. Esse entendimento começa com dados do mundo real, em tempo real e, muitas vezes, não estruturados. Seja para treinar um modelo, alimentar um sistema de geração aumentada por recuperação (RAG) ou permitir que um agente responda às mudanças do mercado em tempo real, os dados são o combustível.
É aí que entra a Bright Data.
Fornecemos a infraestrutura que permite que as equipes de IA acessem a web pública em escala, com precisão e em conformidade. Nossas ferramentas são projetadas para tornar a coleta de dados não apenas possível, mas também perfeita.
O papel da Bright Data na pilha
- API de pesquisa – Exibe conteúdo relevante da web em tempo real, ideal para pesquisa aprimorada por RAG e LLM.
- API Unlocker – Contorna proteções anti-bot para garantir acesso confiável a fontes de dados públicas.
- API Web Scraper – Extraia dados estruturados de mais de 120.000 sites, prontos para uso imediato.
- Custom Scraper – Soluções personalizadas para nichos verticais e necessidades específicas de agentes.
- Dataset Marketplace – Conjuntos de dados pré-coletados para prototipagem rápida ou ajuste fino de modelos.
- Anotações de IA – Serviços com intervenção humana para rotular e refinar dados de treinamento.
“Se os agentes de IA são o cérebro, a Bright Data é os olhos.”
Caso de uso: Agente de inteligência de comércio eletrônico
Uma empresa de varejo cria um agente de IA para monitorar os preços e a disponibilidade de produtos dos concorrentes. Usando a API Web Scraper e a API Unlocker da Bright Data, o agente coleta dados em tempo real dos sites dos concorrentes e os alimenta em um mecanismo de preços que ajusta as ofertas dinamicamente.
Agente de IA Full Techstack
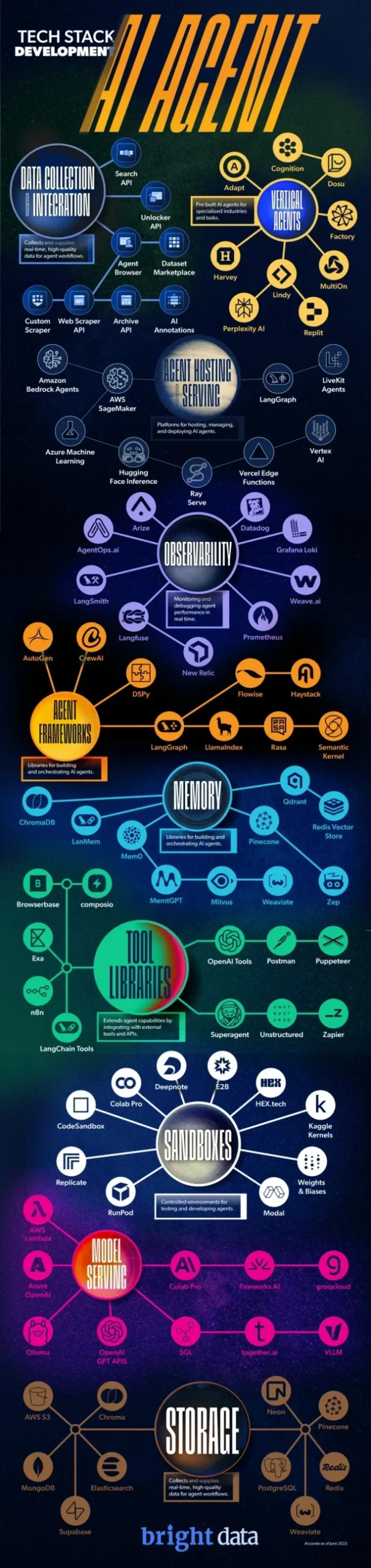
Serviços de hospedagem de agentes
Onde os agentes de IA ganham vida
Depois que um agente tem acesso aos dados, ele precisa de um lugar para operar um ambiente digital onde possa raciocinar, tomar decisões e agir. Esse é o papel dos serviços de hospedagem de agentes: eles fornecem a infraestrutura que transforma modelos estáticos em sistemas dinâmicos e autônomos.
Essas plataformas gerenciam tudo, desde a orquestração até a execução, e garantem que os agentes possam ser dimensionados, interagir com APIs e operar continuamente.
O que os desenvolvedores estão usando
- LangGraph – Um tempo de execução baseado em gráficos para a criação de fluxos de trabalho de agentes com estado e várias etapas.
- Hugging Face Inference Endpoints – Hospeda e serve modelos e agentes, com ferramentas como Transformers Agents para interações em tempo real.
- AWS (Bedrock, Lambda, SageMaker) – Oferece infraestrutura flexível e escalável para implantar e gerenciar agentes em escala.
As plataformas de hospedagem são os sistemas operacionais do mundo dos agentes, mas mesmo o agente mais bem hospedado é tão bom quanto os dados em que se baseia.
Observabilidade
Tornando os agentes de IA transparentes, rastreáveis e confiáveis
À medida que os agentes se tornam mais autônomos, a necessidade de entender o que eles estão fazendo e por quê se torna essencial. As ferramentas de observabilidade ajudam os desenvolvedores a monitorar o desempenho, rastrear decisões e depurar problemas em tempo real.
O que os desenvolvedores estão usando
- LangSmith (LangChain) – Rastreia, depura e avalia fluxos de trabalho alimentados por LLM.
- Weights & Biases – Rastreia o desempenho do modelo, experimentos e comportamento do agente ao longo do tempo.
- WhyLabs – Monitora desvios de dados e anomalias de modelos em ambientes de produção.
A observabilidade transforma os agentes de caixas pretas em caixas de vidro, dando aos desenvolvedores a visibilidade de que precisam para construir confiança e iterar com segurança.
Estruturas de agentes
Os planos para construir agentes mais inteligentes e capazes
As estruturas definem como os agentes são estruturados, como raciocinam, interagem com ferramentas e colaboram com outros agentes. À medida que a complexidade dos agentes aumenta, as estruturas estão evoluindo para oferecer suporte a sistemas multiagentes, decomposição de tarefas e planejamento dinâmico.
O que os desenvolvedores estão usando
- Crew IA – Permite que equipes de agentes colaborem, cada um com funções e responsabilidades definidas.
- LangGraph – Suporta lógica de ramificação e fluxos de trabalho com estado para comportamentos complexos de agentes.
- DSPy – Uma estrutura declarativa para otimizar e ajustar pipelines LLM.
As estruturas fornecem aos agentes sua estrutura e lógica, mas dependem de dados precisos e em tempo real para funcionar de maneira eficaz.
Memória
Como os agentes se lembram, aprendem e permanecem cientes do contexto
Os sistemas de memória permitem que os agentes retenham o contexto, lembrem-se de interações passadas e construam um entendimento de longo prazo. Normalmente alimentada por bancos de dados vetoriais, a memória é essencial para personalização, continuidade e raciocínio complexo.
O que os desenvolvedores estão usando
- ChromaDB – Leve e ideal para desenvolvimento local-first.
- Qdrant – Pesquisa vetorial escalável e pronta para produção com filtragem híbrida.
- Weaviate – Modular e compatível com ML, frequentemente usado em implantações de nível empresarial.
A memória permite que os agentes aprendam e se adaptem, mas sua utilidade depende dos dados que ela armazena, reforçando a necessidade de entradas de alta qualidade desde o início.
Bibliotecas de ferramentas
Como os agentes agem no mundo real
As bibliotecas de ferramentas dão aos agentes a capacidade de interagir com APIs de sistemas externos, bancos de dados, mecanismos de pesquisa e muito mais. É isso que transforma modelos de linguagem em agentes acionáveis.
O que os desenvolvedores estão usando
- LangChain – Um ecossistema robusto para encadear LLMs com ferramentas, memória e fluxos de trabalho.
- OpenAI Functions – Permite que os agentes chamem ferramentas externas diretamente de dentro dos modelos GPT.
- Exa – Permite a pesquisa na web em tempo real, frequentemente usada em agentes de pesquisa e sistemas RAG.
As bibliotecas de ferramentas são o que tornam os agentes úteis, mas sua eficácia depende da qualidade dos dados com os quais eles interagem.
Sandboxes
Onde os agentes executam códigos e testam ideias com segurança
Os agentes precisam cada vez mais escrever e executar código, seja para análise de dados, simulações ou tomada de decisões dinâmicas. As sandboxes fornecem ambientes seguros e isolados para fazer exatamente isso.
O que os desenvolvedores estão usando
- OpenAI Code Interpreter – Executa Python com segurança dentro do GPT-4 para tarefas com grande volume de dados.
- Replit – Um ambiente de codificação baseado em nuvem com integração de IA.
- Modal – Infraestrutura sem servidor que funciona como uma camada segura de execução de código.
As sandboxes permitem que os agentes raciocinem sobre os problemas e gerem resultados acionáveis, mas, novamente, a qualidade desses resultados depende da qualidade das entradas.
Serviço de modelo
O segundo cérebro: onde as decisões são tomadas
Se os dados são o primeiro cérebro do agente de IA, o que os agentes sabem, então o modelo de serviço é a segunda maneira como eles pensam.
É aqui que os LLMs são hospedados e acessados, fornecendo o raciocínio e a geração de linguagem que alimentam todas as decisões do agente. O desempenho, a latência e a precisão dessa camada afetam diretamente a eficácia do agente.
O que os desenvolvedores estão usando
- OpenAI (GPT-4, GPT-4o) – Padrão da indústria para raciocínio de uso geral e recursos multimodais.
- Anthropic (Claude) – Conhecido por janelas de contexto longas e design focado no alinhamento.
- Mistral – Modelos de peso aberto que oferecem alto desempenho a um custo menor.
- Groq – Inferência de latência ultrabaixa para respostas em tempo real do agente.
- AWS ( SageMaker, Bedrock) – Infraestrutura escalável para atender modelos proprietários e abertos.
A execução de modelos é onde o insight se transforma em ação, mas mesmo os melhores modelos precisam de dados de alta qualidade e em tempo real para raciocinar de forma eficaz.
Armazenamento
Onde os agentes mantêm seu histórico, conhecimento e estado
Os sistemas de armazenamento oferecem suporte à persistência de longo prazo, registrando interações, salvando resultados e mantendo o estado entre as sessões. Eles são essenciais para a reprodutibilidade, conformidade e melhoria contínua.
O que os desenvolvedores estão usando
- Amazon S3 – A melhor opção para armazenamento de objetos escalável.
- Google Cloud Storage (GCS) – Seguro e integrado às ferramentas de IA do Google.
- Bancos de dados vetoriais (por exemplo, Qdrant, Weaviate) – Armazenam incorporações e contexto semântico para recuperação.
O armazenamento garante que os agentes possam aprender com o passado e se expandir ao longo do tempo, mas o valor do que é armazenado começa com a qualidade do que é coletado.
Seus agentes são tão inteligentes quanto seus dados
Os agentes de IA são tão capazes quanto as informações nas quais se baseiam. Eles podem raciocinar, planejar e agir, mas somente se tiverem acesso aos dados certos no momento certo. Sem isso, mesmo a pilha de tecnologia mais sofisticada se torna um ciclo fechado: poderoso, mas desconectado do mundo real.
É por isso que os dados não são apenas uma parte da pilha, eles são a base. E, no ecossistema de IA atual, a fonte de dados mais valiosa é a web pública.
Na Bright Data, tornamos esses dados acessíveis.
Nossas ferramentas impulsionam a primeira e mais crítica etapa do fluxo de trabalho do agente de IA: coleta e integração de dados. Conectamos os agentes à web pública em tempo real, fornecendo os dados estruturados, confiáveis e escaláveis de que eles precisam para entender o mundo, tomar decisões informadas e realizar ações significativas.
Todas as camadas da pilha tecnológica — estruturas de agentes, sistemas de memória, bibliotecas de ferramentas, modelos de serviço — dependem dessa base. Porque sem informações precisas e atualizadas, os agentes não podem se adaptar, personalizar ou executar.
De certa forma, seus agentes têm dois cérebros:
- Os dados; o que eles sabem.
- O modelo; como eles pensam.
Antes que seus agentes possam agir, eles precisam entender.
Antes de compreenderem, eles precisam ver.
A Bright Data é a forma como eles veem o mundo.
Próximo passo
Explore como a Bright Data pode impulsionar sua pilha de agentes de IA: https://brightdata.com/ai/products-for-ai





