Neste guia, você aprenderá o seguinte:
- O que é a Dify e por que usá-la.
- O motivo pelo qual você deve integrá-lo a um plug-in de raspagem completo.
- Benefícios da integração da Dify com o plug-in de raspagem de dados da Bright Data.
- Um tutorial passo a passo para criar um fluxo de trabalho de raspagem da Dify.
Vamos mergulhar de cabeça!
Dify: O poder do desenvolvimento de IA com pouco código
A Dify é uma plataforma de desenvolvimento de aplicativos LLM de código aberto. Ela funciona como uma solução LLM-ops que simplifica a criação de aplicativos alimentados por IA.
Mais especificamente, ele ajuda os desenvolvedores a criar e lançar aplicativos de IA agêntica prontos para uso, fornecendo:
- Criador de fluxo de trabalho visual: Projete processos de IA em várias etapas usando uma interface de arrastar e soltar. Você pode encadear diferentes modelos, ferramentas e lógicas sem ficar atolado em códigos padronizados.
- Agnosticismo de modelos: Integre-se a uma ampla variedade de LLMs, desde modelos proprietários, como a série GPT da OpenAI, até várias alternativas de código aberto. Isso lhe dá a flexibilidade de escolher o melhor para o seu caso de uso.
- Backend-as-a-service (BaaS): Lidar com as complexidades de hospedagem, dimensionamento e gerenciamento da infraestrutura de backend. Isso permite que você se concentre em aproveitar os recursos de IA em vez de gerenciar a infraestrutura subjacente.
- Extensibilidade: Amplie facilmente a funcionalidade por meio de plugins e ferramentas personalizadas de fornecedores terceirizados. Isso torna a Dify adaptável a uma ampla gama de casos de uso.
A necessidade de um plug-in de raspagem dedicado na Dify
A raspagem da Web em larga escala apresenta muitos desafios. Os sites usam medidas anti-bot que podem bloquear facilmente tentativas simples de recuperação de dados. Como resultado, a criação e a manutenção de um sistema para superar esses obstáculos são complexas e consomem muitos recursos.
É exatamente nesse ponto que o plug-in Bright Data Dify entra em ação. O plug-in lida com todas as complexidades subjacentes, desde a rotação de proxy e o gerenciamento de IP até a solução de CAPTCHAs e a análise de dados. Em outras palavras, ele garante que seu agente Dify receba dados da Web consistentes e de alta qualidade.
Em detalhes, o plug-in Bright Data fornece essas ferramentas:
- Feeds de dados estruturados: Para obter dados estruturados e organizados de mais de 50 plataformas, como páginas de produtos de comércio eletrônico ou listagens de imóveis.
- Extrair como markdown: Ele remove anúncios, barras de navegação e outros elementos não essenciais, fornecendo uma versão limpa e formatada em markdown do texto.
- Ferramenta de mecanismo de pesquisa: Realize consultas diretamente em mecanismos de pesquisa como Google, Bing, Yandex e muitos outros. Você pode usá-la para monitorar as classificações de pesquisa de palavras-chave específicas, descobrir conteúdo de concorrentes ou em fluxos de trabalho SERP RAG.
Benefícios da integração da Dify com o plug-in Bright Data
Quando você conecta os recursos de orquestração de IA da Dify com os de raspagem da Bright Data, você desbloqueia essa funcionalidade:
- Acesso a dados em tempo real: Em vez de depender de dados desatualizados, seu agente de IA pode consultar a Web em tempo real para obter informações atualizadas. Isso garante que seus aplicativos de IA operem com os dados mais atuais disponíveis.
- Automatize pesquisas e análises complexas: Ao alimentar dados diretamente em um LLM dentro de um fluxo de trabalho da Dify, você pode automatizar tarefas que, de outra forma, exigiriam horas de trabalho manual. Por exemplo, você pode criar um fluxo de trabalho RAG para monitorar uma lista de produtos da concorrência em um site de comércio eletrônico.
- Simplificar a complexidade técnica: A raspagem da Web não é fácil, pois os sites empregam técnicas sofisticadas de bloqueio contra raspagem. O plug-in Bright Data evita os bloqueios para você. Tudo isso, enquanto a Dify fornece a interface simples para aproveitar esse poder.
- Versatilidade para diversos casos de uso: O plug-in o equipa com várias ferramentas, incluindo a obtenção de dados estruturados, a raspagem de qualquer página para limpar a marcação e a realização de consultas a mecanismos de pesquisa. Isso torna a integração Dify + Bright Data adaptável a vários casos de uso.
Integração da Dify com a Bright Data para resumo de produtos: Tutorial passo a passo
É hora de seguir um tutorial passo a passo para saber como usar a integração entre a Dify e a Bright Data.
O objetivo do fluxo de trabalho que você criará é fornecer um produto da Amazon como entrada e receber seu resumo. O produto que você usará é da Amazon e é um Apple AirTag:
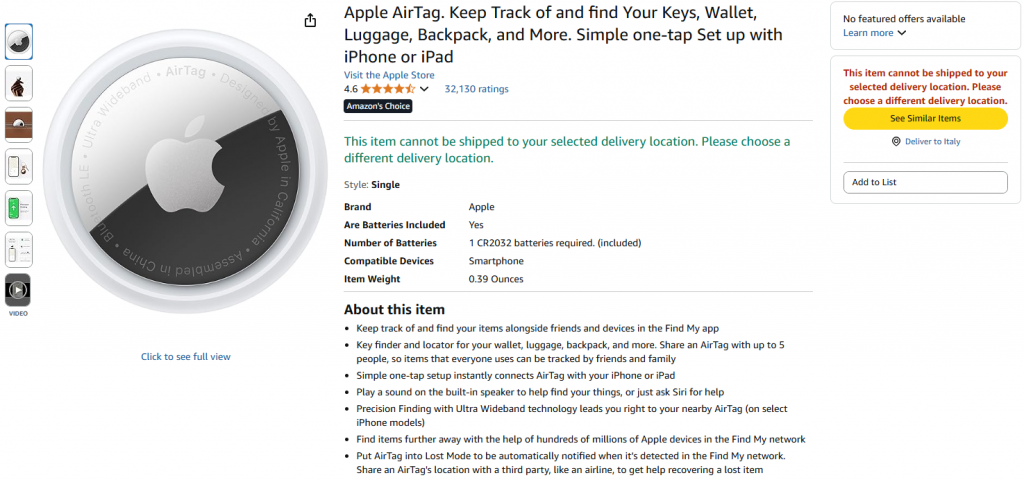
Para atingir o objetivo de raspagem de IA, você criará um fluxo de trabalho de quatro estágios conectando diferentes nós. Cada nó tem um trabalho específico:
- Um nó “Start” para definir a variável de entrada, que é o URL da página do produto Amazon.
- Um nó “Structured Data Feeds” (Feeds de dados estruturados) pegará esse URL e extrairá seu conteúdo, extraindo todos os dados estruturados da página da Amazon.
- Um nó “LLM” para processar os dados extraídos. Você o instruirá com um prompt específico para gerar o resumo do produto.
- Um nó “End” para apresentar o texto resumido gerado pelo LLM.
Todo esse processo de raspagem de IA em quatro etapas é totalmente visual. Você conectará esses nós em um fluxo simples e não precisará escrever uma única linha de código.
Siga as instruções para criar seu fluxo de trabalho de IA de raspagem da Web sem código com a Bright Data na Dify!
Requisitos
Para reproduzir este tutorial sobre como integrar a Dify com a Bright Data, você precisa:
- Uma conta Dify (uma conta gratuita é suficiente).
- Uma chave de API da Bright Data.
Se você ainda não os tiver, use os links acima e siga as instruções para configurar tudo.
Pré-requisitos
Para usar o nó do LLM, primeiro você precisa configurar a integração do LLM na Dify. Para isso, clique na imagem de seu perfil e selecione a opção “Settings” (Configurações):

Você será redirecionado para a página que permite selecionar um modelo (a guia “Model Provider”). Por exemplo, você pode instalar o plug-in do provedor OpenAI:
Muito bem! Agora você está pronto para iniciar seu fluxo de trabalho de raspagem da Web da Dify.
Etapa 1: Faça o download do plug-in Bright Data e integre-o
Faça download do pacote mais recente do plug-in Bright Data no repositório oficial da Dify. Em seguida, pressione “PLUGINS” e selecione a opção “Install from Local Package File” (Instalar do arquivo de pacote local):
Selecione o arquivo local que você baixou anteriormente e clique no botão “Install” (Instalar):

Muito bom! O pacote de integração da Bright Data agora está carregado e instalado na Dify.
Etapa 2: criar um novo aplicativo Dify
Na página inicial do espaço de trabalho da Dify, crie um novo aplicativo do zero selecionando “Create from Blank” (Criar do zero), conforme mostrado abaixo:
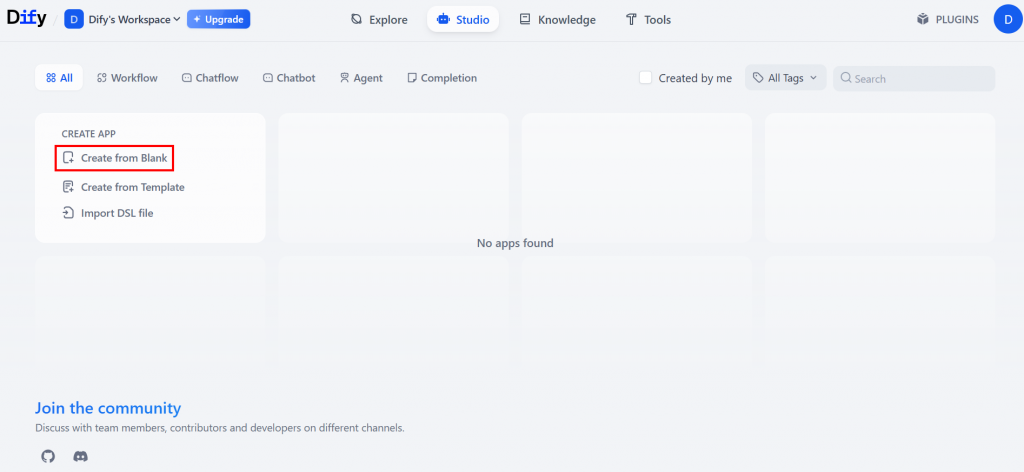
Em seguida, escolha o tipo “Workflow” (Fluxo de trabalho) e clique em “Create” (Criar):
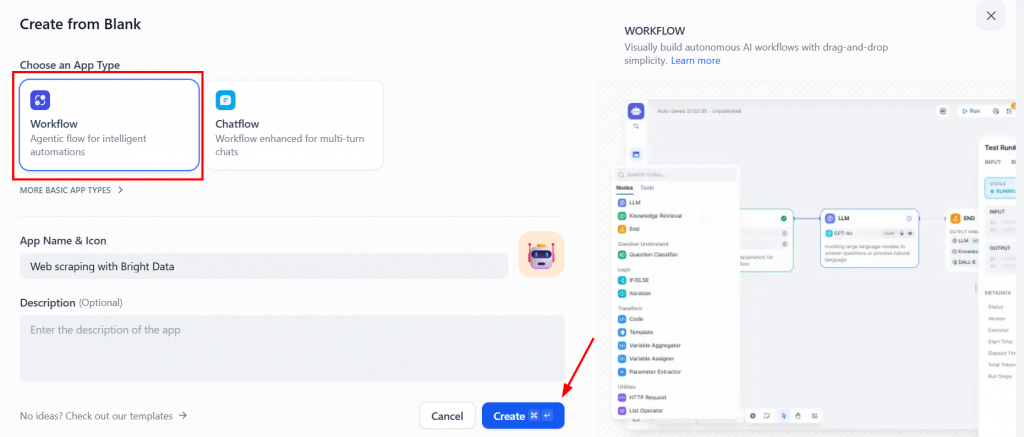
Veja abaixo como será o novo fluxo de trabalho em branco:
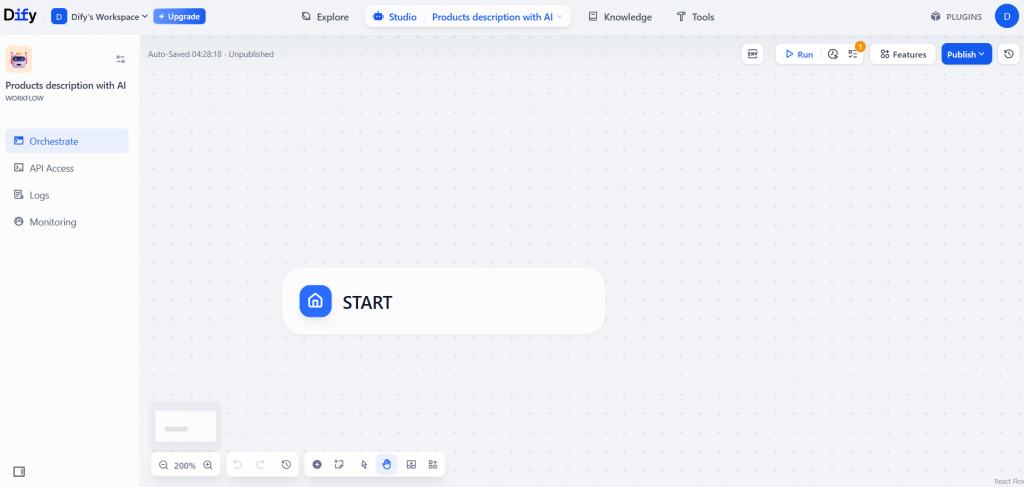
Excelente! Você acabou de criar um novo fluxo de trabalho da Dify. É hora de adicionar os nós necessários para a raspagem da Web.
Etapa 3: Configurar nós para raspagem da Web
Agora, você pode adicionar os nós ao seu fluxo de trabalho e definir os parâmetros necessários para o fluxo de trabalho de raspagem da Web da Dify por meio do Bright Data.
Comece clicando no nó “Start” (Início) e, em seguida, em “INPUT FIELD” (Campo de entrada):
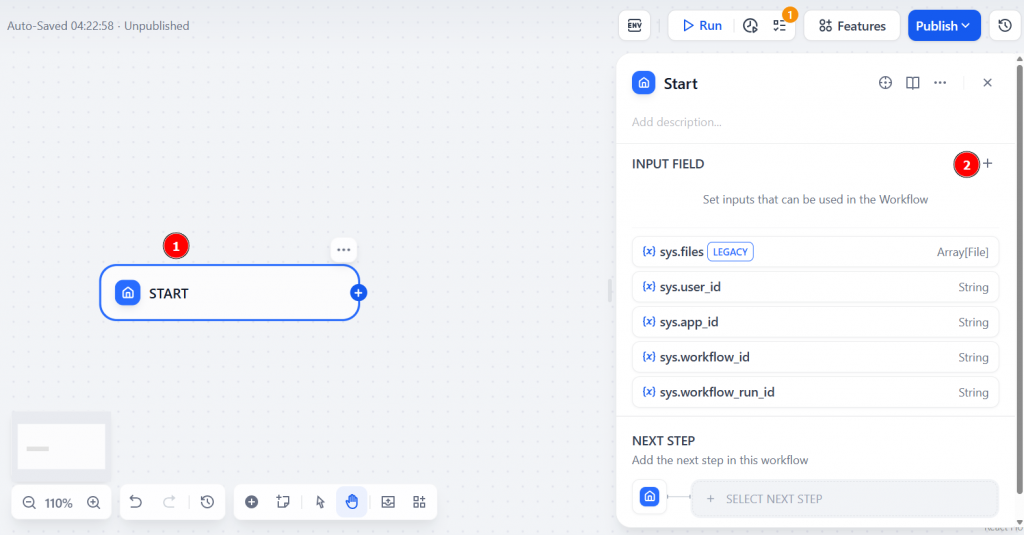
Selecione “Paragraph” (Parágrafo) como um tipo e dê um nome ao campo “Variable Name” (Nome da variável). Por exemplo, product_url. Altere o valor de “Max length” para que seja pelo menos 200. Isso representa o URL da página de destino a ser extraída. Você precisará passar a ele uma entrada para iniciar o fluxo de trabalho.
Confirme clicando no botão “Save” (Salvar):

Perfeito! O nó “Start” está configurado corretamente.
Continue clicando em “+” no nó “Start” (Início). Selecione “Tools” (Ferramentas) > “Bright Data Web Scraper” (Raspador da Web de Dados Brilhantes) > “Structured Data Feeds” (Feeds de Dados Estruturados):

O nó da Bright Data atua como a ponte que conecta seu fluxo de trabalho da Dify à [infraestrutura de IA da Bright Data](
/ai). Ele dá ao seu agente de raspagem de IA a capacidade de raspar as informações necessárias da Web.
Ao selecionar a ferramenta “Structured Data Feeds” (Feeds de dados estruturados), você transformará uma página de produto da Amazon confusa em uma saída JSON estruturada com campos de dados previsíveis.
Agora, clique em “Authorize” (Autorizar) para inserir seu token da API da Bright Data:
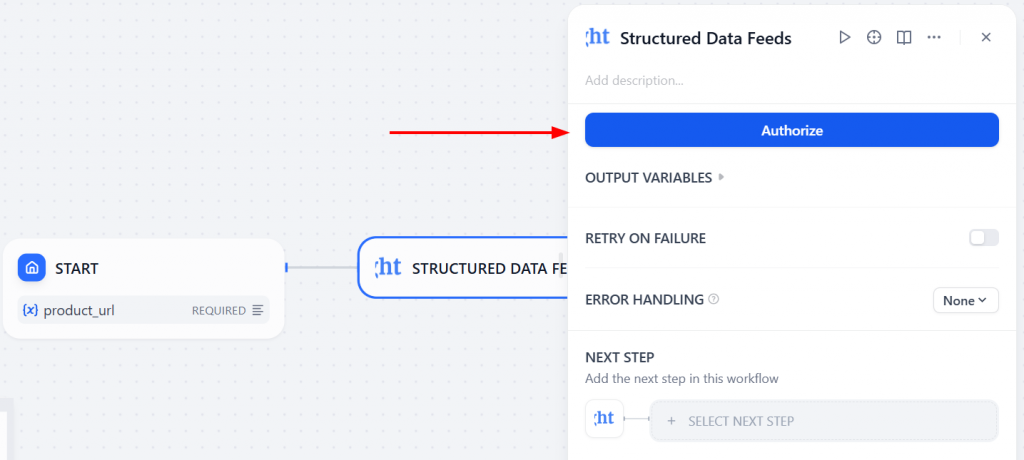
Selecione product_url como a variável de entrada. Dessa forma, o nó “Start” passará o valor real da URL do produto como entrada do nó Bright Data.
Para fazer isso, digite “/” no campo “Target URL” (URL de destino) e será exibida uma lista de variáveis disponíveis. Além disso, adicione uma descrição no campo “Data Request Description” (Descrição da solicitação de dados):

Muito bem! O nó Bright Data está configurado. Você pode passar para o próximo nó.
Clique no “+” e adicione um nó LLM:
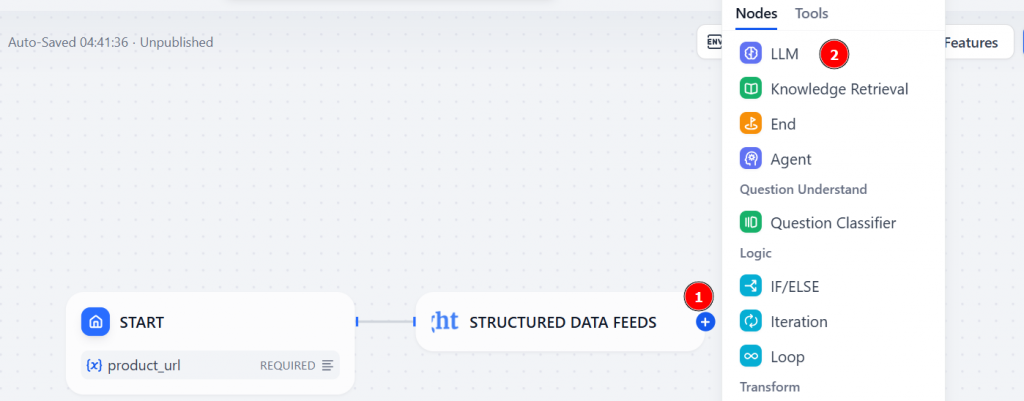
Na seção “MODEL” (Modelo), selecione “Configure model” (Configurar modelo) e selecione um modelo LLM na lista:
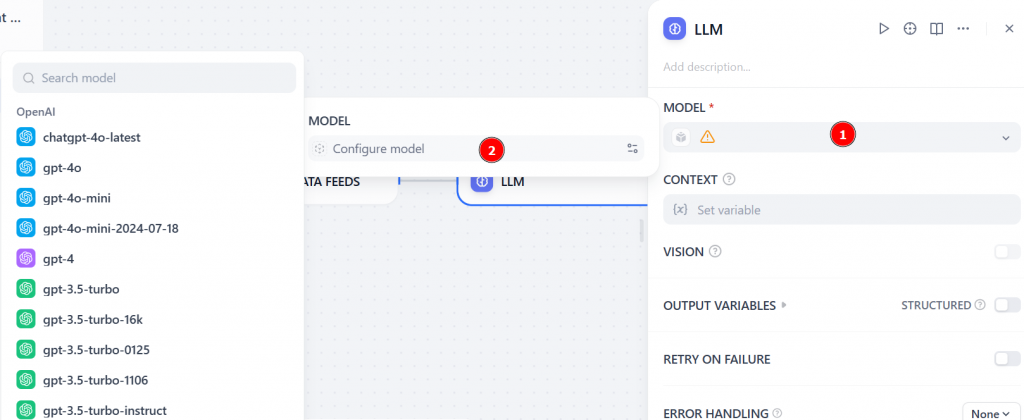
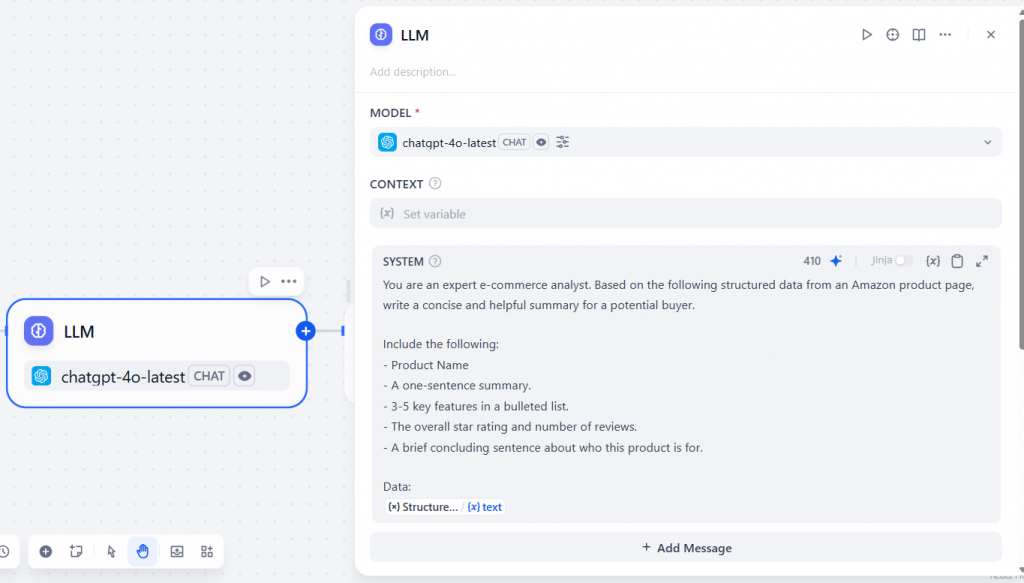
Na seção “SYSTEM”, adicione um prompt, como, por exemplo:
You are an expert e-commerce analyst. Based on the following structured data from an Amazon product page, write a concise and helpful summary for a potential buyer.
Include the following:
- Product name.
- A one-sentence summary.
- 3-5 key features in a bulleted list.
- The overall star rating and number of reviews.
- A brief concluding sentence about who this product is for.
Data:
{{Structure_Data_Feeds.text}}Esse prompt diz ao LLM para agir como um analista de comércio eletrônico com o objetivo de criar um resumo do produto extraído. Ele também solicita a inclusão de detalhes específicos, como o nome do produto e alguns recursos principais. Observe que ele inclui o resultado do texto do nó do plug-in Bright Data no final.
Esta é a aparência da seção preenchida:
Na seção “Data” (Dados) do prompt, adicione o texto como a variável de entrada. Isso permitirá que o LLM use o conteúdo que o nó Bright Data recuperou do URL de destino. Se você clicar em “/”, obterá a lista de variáveis disponíveis que podem ser selecionadas.
Muito bem! Agora você pode adicionar o último nó ao fluxo de trabalho.
A saída do fluxo de trabalho pode ser obtida com a adição de um nó “End”:

A variável de saída deve ser uma cadeia de caracteres proveniente do nó LLM. Para isso, clique na seção “OUTPUT VARIABLE” (Variável de saída) e selecione “text” (texto) em “LLM”:
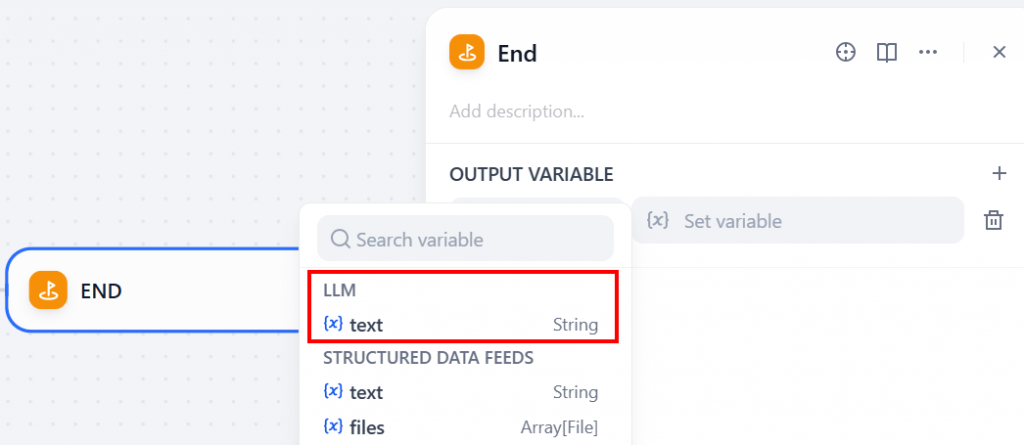
Incrível! Seu fluxo de trabalho está configurado corretamente. Agora você está pronto para executá-lo.
Etapa 4: Executar o fluxo de trabalho
Abaixo está o fluxo de trabalho de raspagem da Web no Dify por meio do plug-in Bright Data:
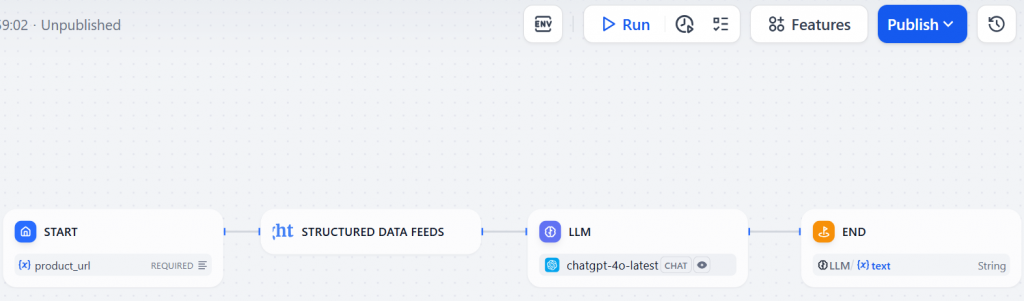
Como você pode ver, ele consiste em apenas quatro nós – exatamente como previsto na introdução deste capítulo. Além disso, você não precisou escrever uma única linha de código para atingir o objetivo!
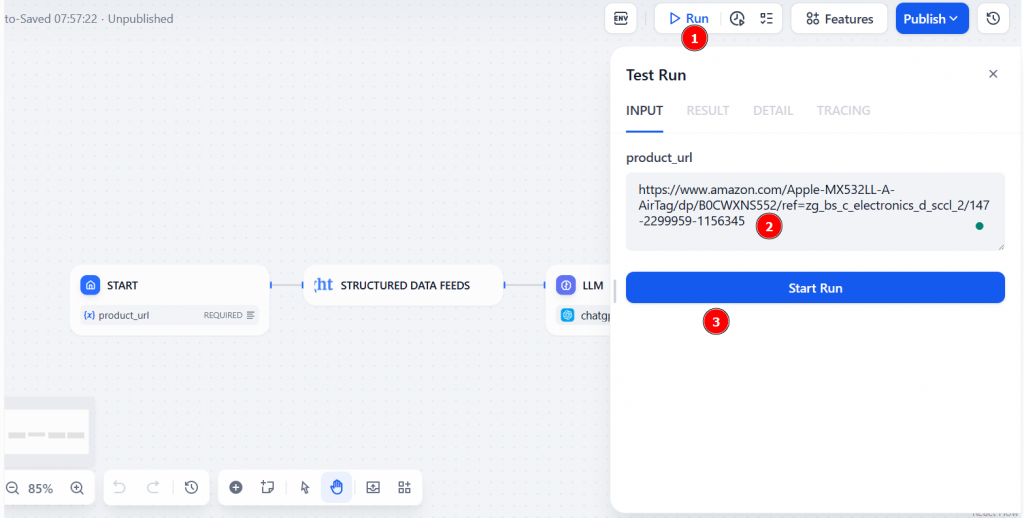
Para executar o fluxo de trabalho, clique em “Run” (Executar). Nesse ponto, você precisa adicionar o URL do produto da Amazon no campo “product_url”. Em seguida, clique em “Start Run” (Iniciar execução) para iniciar o fluxo de trabalho de raspagem da Web da Dify:
O resultado estará disponível na guia “Result” (Resultado):
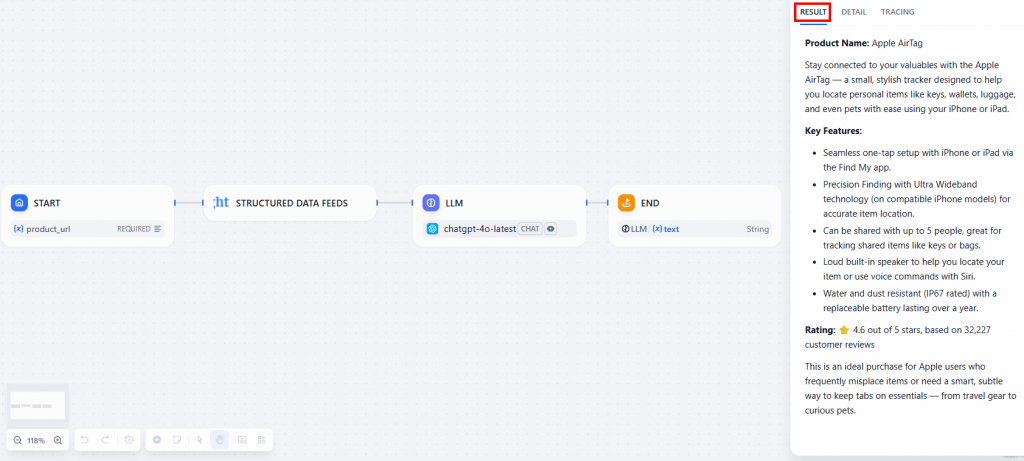
Abaixo está o resultado como texto:
**Product Name:** Apple AirTag
Stay connected to your valuables with the Apple AirTag — a small, stylish tracker designed to help you locate personal items like keys, wallets, luggage, and even pets with ease using your iPhone or iPad.
**Key Features:**
- Seamless one-tap setup with iPhone or iPad via the Find My app.
- Precision Finding with Ultra Wideband technology (on compatible iPhone models) for accurate item location.
- Can be shared with up to 5 people, great for tracking shared items like keys or bags.
- Loud built-in speaker to help you locate your item or use voice commands with Siri.
- Water and dust resistant (IP67 rated) with a replaceable battery lasting over a year.
**Rating:** ⭐ 4.6 out of 5 stars, based on 32,227 customer reviews
This is an ideal purchase for Apple users who frequently misplace items or need a smart, subtle way to keep tabs on essentials — from travel gear to curious pets.Conforme solicitado, o LLM informou o que você pediu no prompt:
- Um resumo de uma frase sobre o produto.
- 5 recursos principais.
- A classificação.
- Uma frase conclusiva, informando a quem esse produto se destina.
Se você já tentou fazer scraping de grandes sites de comércio eletrônico, como a Amazon, sabe como é difícil:
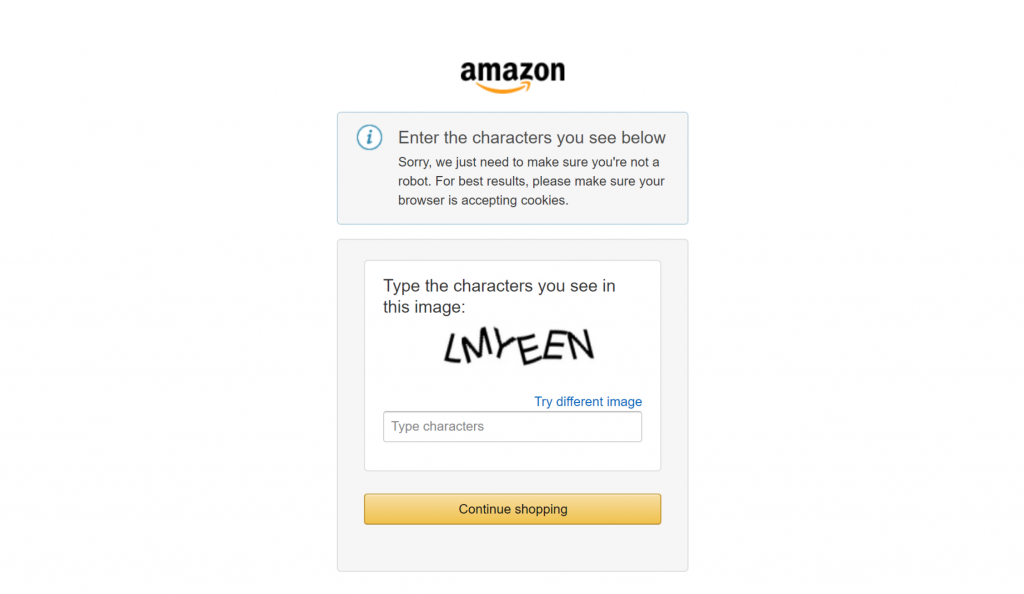
É nesse ponto que a integração da Bright Data faz toda a diferença. Ela lidou com todas as complexas medidas antirrastreamento nos bastidores, garantindo que o processo de recuperação de dados funcionasse conforme o esperado.
E pronto! Você concluiu com êxito seu primeiro projeto de integração da Dify com a Bright Data.
Conclusão
Neste artigo, você aprendeu a usar o Dify para criar um fluxo de trabalho de raspagem de IA sem código. Isso não teria sido possível sem o plug-in Bright Data Dify. Como mostrado aqui, esse plug-in expõe várias ferramentas avançadas para raspagem da Web em fluxos de trabalho de IA.
Agora, um dos principais desafios na criação de um fluxo de trabalho de raspagem confiável para seus agentes de IA é ter acesso a dados da Web de alta qualidade. Isso requer ferramentas para recuperar, validar e transformar o conteúdo da Web, que é exatamente o que a infraestrutura de IA da Bright Data foi criada para oferecer.
Crie uma conta gratuita na Bright Data e comece a fazer experiências com nossas ferramentas de dados prontas para IA hoje mesmo!