

Neste guia, você aprenderá:
- Por que o GPT Vision é uma ótima opção para tarefas de extração de dados que vão além das técnicas tradicionais de análise.
- Como realizar a raspagem visual da Web usando o GPT Vision em Python.
- A principal limitação dessa abordagem e como contorná-la.
Vamos mergulhar de cabeça!
Por que usar o GPT Vision para raspagem de dados?
O GPT Vision é um modelo de IA multimodal que compreende texto e imagens. Esses recursos estão disponíveis nos modelos OpenAI mais recentes. Ao passar uma imagem para o GPT Vision, você pode realizar a extração de dados visuais, ideal para cenários em que a análise de dados tradicional não funciona.
A análise regular de dados envolve escrever regras personalizadas para recuperar dados de documentos (por exemplo, seletores CSS ou expressões XPath para obter dados de páginas HTML). Agora, o problema é que as informações podem ser visualmente incorporadas em imagens, banners ou elementos complexos da interface do usuário que não podem ser acessados com técnicas de análise padrão.
O GPT Vision ajuda você a extrair dados dessas fontes de difícil acesso. Os dois casos de uso mais comuns são:
- Raspagem visual da Web: Extraia conteúdo da Web diretamente de capturas de tela de páginas, sem se preocupar com alterações ou elementos visuais na página.
- Extração de documentos com base em imagens: Recupere dados estruturados de capturas de tela ou digitalizações de arquivos locais, como currículos, faturas, menus e recibos.
Para uma abordagem não visual, consulte nosso guia sobre raspagem da Web com o ChatGPT.
Como extrair dados de capturas de tela com a visão GPT em Python
Nesta seção passo a passo, você aprenderá a criar um script de raspagem da Web do GPT Vision. Em detalhes, o scraper automatizará essas tarefas:
- Use o Playwright para se conectar à página da Web de destino.
- Faça uma captura de tela da seção específica da qual deseja extrair dados.
- Passe a captura de tela para o GPT Vision e solicite que ele extraia dados estruturados.
- Exporte os dados extraídos para um arquivo JSON.
O alvo é uma página de produto específica de “Books to Scrape”:
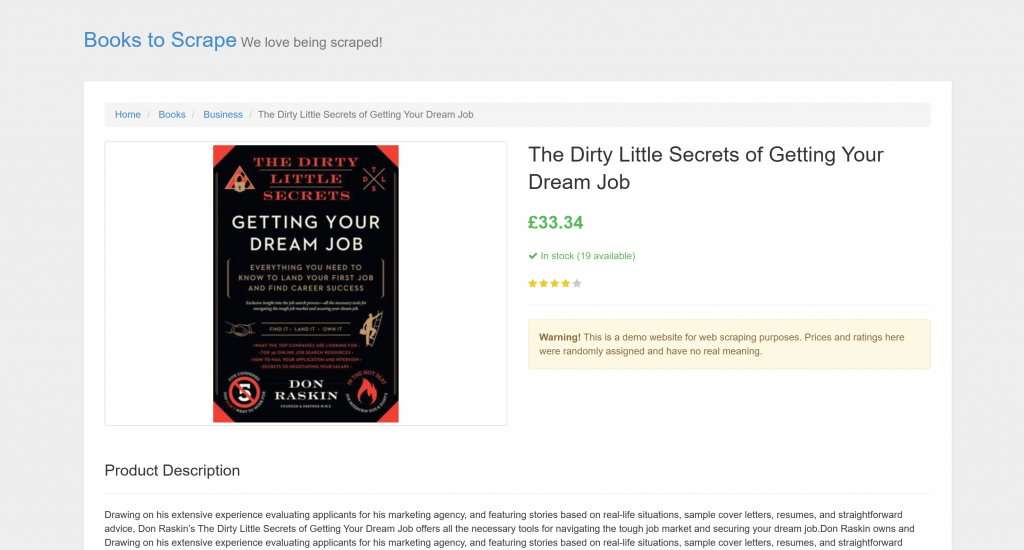
Essa página é perfeita para testes porque aceita explicitamente bots de raspagem automatizados. Além disso, ela inclui elementos visuais, como o widget de classificação por estrelas, que são difíceis de lidar com os métodos de análise convencionais.
Observação: o snippet de exemplo será escrito em Python para simplificar e porque o OpenAI Python SDK é amplamente adotado. No entanto, você pode obter os mesmos resultados usando o SDK OpenAI JavaScript ou qualquer outra linguagem compatível.
Siga as etapas abaixo para saber como extrair dados da Web usando o GPT Vision!
Pré-requisitos
Antes de começar, verifique se você tem:
- Python 3.8 ou superior instalado em seu computador.
- Uma chave de API da OpenAI para acessar a API do GPT Vision.
Para recuperar sua chave de API da OpenAI, siga o guia oficial.
Os conhecimentos básicos a seguir também o ajudarão a tirar o máximo proveito deste artigo:
- Conhecimento básico de automação de navegador, especialmente com o uso do Playwright.
- Familiaridade com o funcionamento do GPT Vision.
Observação: uma ferramenta de automação de navegador, como o Playwright, é necessária para essa abordagem. O motivo é que você precisa renderizar a página de destino em um navegador. Em seguida, depois que a página for carregada, você poderá fazer uma captura de tela da seção específica na qual está interessado. Isso pode ser feito usando a API Screenshots do Playwright.
Etapa 1: Crie seu projeto Python
Execute o seguinte comando em seu terminal para criar uma nova pasta para seu projeto de raspagem:
mkdir gpt-vision-scrapergpt-vision-scraper/ servirá como a pasta principal do projeto para a criação de seu coletor de dados da Web usando o GPT Vision.
Navegue até a pasta e crie um ambiente virtual Python dentro dela:
cd gpt-vision-scraper
python -m venv venvAbra a pasta do projeto em seu IDE Python preferido. O Visual Studio Code com a extensão Python ou o PyCharm Community Edition são suficientes.
Dentro da pasta do projeto, crie um arquivo scraper.py:
gpt-vision-scraper
├─── venv/
└─── scraper.py # <------------Neste momento, o scraper.py é apenas um arquivo vazio. Em breve, ele conterá a lógica para raspagem visual da Web do LLM por meio do GPT Vision.
Em seguida, ative o ambiente virtual em seu terminal. No Linux ou macOS, inicie:
source venv/bin/activateDe forma equivalente, no Windows, execute:
venv/Scripts/activateMuito bom! Seu ambiente Python agora está pronto para a extração visual com o GPT Vision.
Observação: Nas etapas a seguir, você verá como instalar as dependências necessárias. Se preferir instalá-las todas de uma vez, execute este comando:
pip install playwright openaiEntão:
python -m playwright installÓtimo! Seu ambiente Python agora está pronto.
Etapa 2: conectar-se ao site de destino
Primeiro, você precisa instruir o Playwright a visitar o site de destino usando um navegador controlado. Em seu ambiente virtual ativado, instale o Playwright com:
pip install playwright Em seguida, conclua a instalação fazendo o download dos binários do navegador necessários:
python -m playwright installEm seguida, importe o Playwright em seu script e use a função goto() para navegar até a página de destino:
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
# Launch a new Playwright instance
browser = p.chromium.launch()
page = browser.new_page()
# Visit the target page
url = "https://books.toscrape.com/catalogue/the-dirty-little-secrets-of-getting-your-dream-job_994/index.html"
page.goto(url)
# Screenshotting logic...
# Close the browser and release its resources
browser.close()Se você não estiver familiarizado com essa API, leia nosso artigo sobre raspagem da Web com o Playwright.
Muito bom! Agora você tem um script do Playwright que se conecta com sucesso à página de destino. É hora de tirar uma captura de tela dele.
Etapa nº 3: Faça uma captura de tela da página
Antes de escrever a lógica para fazer uma captura de tela, lembre-se de que a OpenAI cobra com base no uso de tokens. Em outras palavras, quanto maior for a captura de tela de entrada, maior será o gasto.
Para manter os custos baixos, é melhor limitar a captura de tela apenas aos elementos HTML que contêm os dados nos quais você está interessado. Isso é possível, pois o Playwright suporta capturas de tela baseadas em nós. Ter uma captura de tela reduzida também ajudará o GPT Vision a se concentrar no conteúdo relevante, o que reduz o risco de alucinações.
Comece abrindo a página de destino em seu navegador e familiarizando-se com sua estrutura. Em seguida, clique com o botão direito do mouse no conteúdo e selecione “Inspect” (Inspecionar) para abrir o DevTools do navegador:
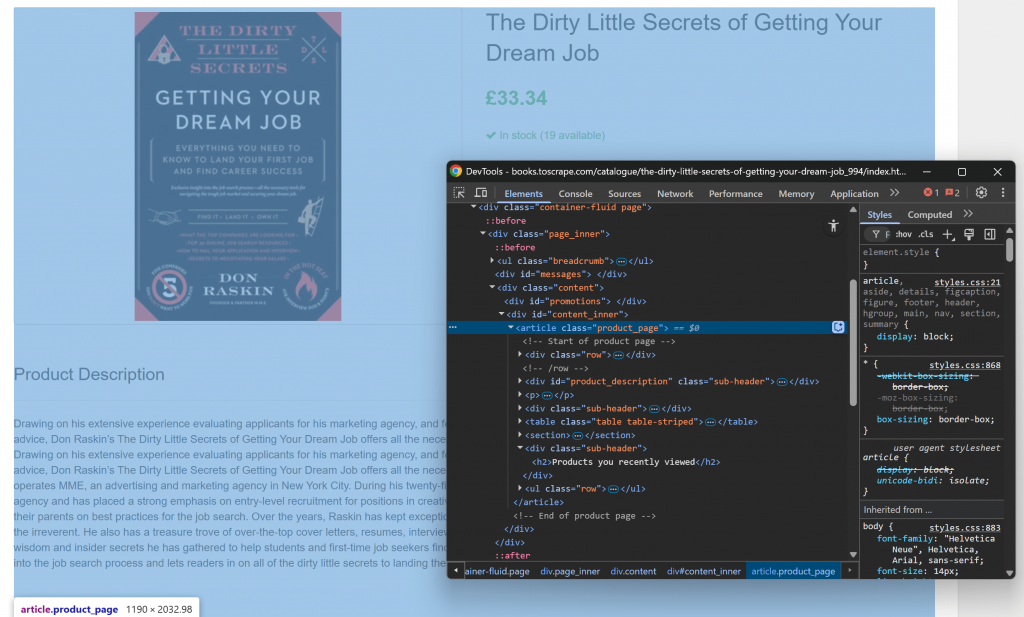
Você perceberá que a maior parte do conteúdo relevante está contida no elemento HTML .product_page.
Como esse elemento pode ser carregado dinamicamente ou revelado com JavaScript, você deve esperar por ele antes de capturar:
product_page_element = page.locator(".product_page")
product_page_element.wait_for()Por padrão, wait_for() aguardará até 30 segundos para que o elemento apareça no DOM. Essa microetapa é fundamental, pois você não quer fazer uma captura de tela de uma seção vazia ou invisível.
Agora, utilize o método screenshot() no localizador selecionado para tirar uma captura de tela apenas desse elemento:
product_page_element.screenshot(path=SCREENSHOT_PATH)Aqui, SCREENSHOT_PATH é uma variável que contém o nome do arquivo de saída, como, por exemplo:
SCREENSHOT_PATH = "product_page.png"Armazenar essas informações em uma variável é uma boa ideia, pois você precisará delas novamente em breve.
Se você iniciar o script, ele gerará um arquivo chamado product_page.png contendo:
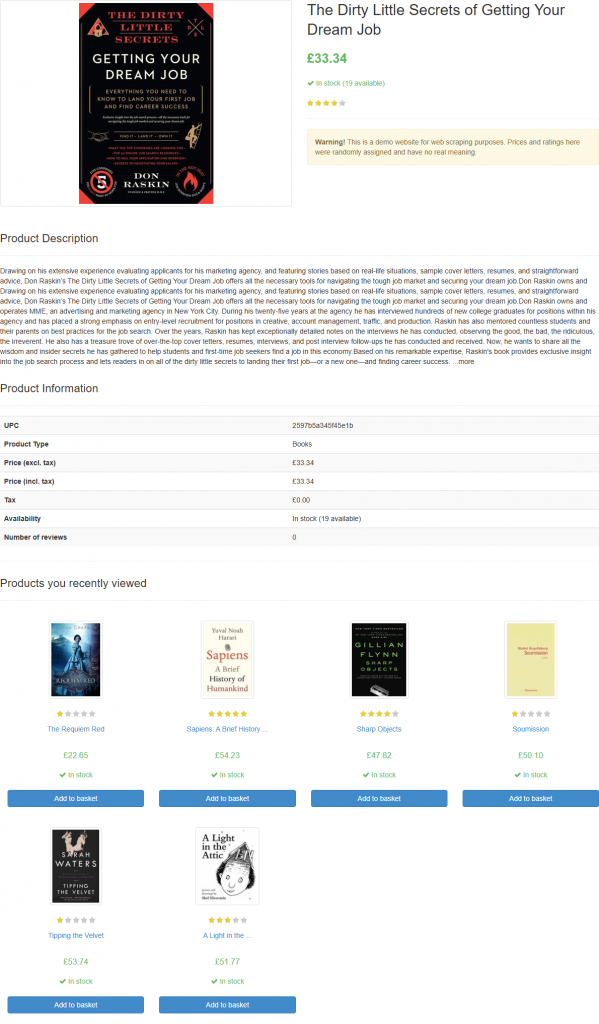
Observação: Salvar a captura de tela em um arquivo é a melhor prática, pois você pode querer analisá-la novamente mais tarde usando técnicas ou modelos diferentes.
Fantástico! A parte da captura de tela acabou.
Etapa 4: Configurar o OpenAI em Python
Para empregar o GPT Vision para raspagem da Web, você pode usar o OpenAI Python SDK. Com seu ambiente virtual ativado, instale o pacote openai:
pip install openaiEm seguida, importe o cliente OpenAI em scraper.py:
from openai import OpenAIContinue inicializando uma instância do cliente OpenAI:
client = OpenAI()Isso permite que você se conecte mais facilmente à API OpenAI, inclusive às APIs Vision. Por padrão, o construtor OpenAI() procura sua chave de API na variável de ambiente OPENAI_API_KEY. Definir esse ambiente é a maneira recomendada de configurar a autenticação com segurança.
Para fins de desenvolvimento ou teste, como alternativa, você pode adicionar a chave diretamente no código:
OPENAI_API_KEY = "<YOUR_OPENAI_API_KEY>"
client = OpenAI(api_key=OPENAI_API_KEY)Substitua o por sua chave de API OpenAI real.
Maravilhoso! Sua configuração do OpenAI está concluída e você está pronto para usar o GPT Vision para raspagem da Web.
Etapa 5: Enviar a solicitação de raspagem do GPT Vision
O GPT Vision aceita imagens de entrada em vários formatos, incluindo URLs de imagens públicas. Como você está trabalhando com um arquivo local, deve enviar a imagem para o servidor OpenAI convertendo-a em uma cadeia de caracteres codificada em Base64.
Para converter seu arquivo de captura de tela em Base64, escreva o seguinte código:
with open(SCREENSHOT_PATH, "rb") as image_file:
base64_image = base64.b64encode(image_file.read()).decode("utf-8") Isso exige essa importação da biblioteca padrão do Python:
import base64Agora, passe a imagem codificada para o GPT Vision para fazer a raspagem visual da Web:
response = client.responses.create(
model="gpt-4.1-mini",
input=[
{
"role": "user",
"content": [
{
"type": "input_text",
"text": """
Extract structured data (e.g., title, description, rating in the format "x/5", etc.) from the following product page.
Ignore the "Products you recently viewed" section.
Return the data in JSON format using lowercase snake_case attribute names.
"""
},
{
"type": "input_image",
"image_url": f"data:image/png;base64,{base64_image}"
}
]
}
],
text={"format": {"type": "json_object"}} # Enable JSON Mode to get output data in JSON format
)Observação: o exemplo acima define o modelo gpt-4.1, mas você pode usar qualquer modelo da OpenAI que ofereça suporte a recursos visuais.
Observe como o GPT Vision está diretamente integrado à API de respostas. Isso significa que você não precisa configurar nada de especial. Basta incluir sua imagem Base64 usando "type": "input_image", e você está pronto para começar.
O prompt de raspagem usado acima é:
Extract structured data (e.g., title, description, rating in the format "x/5", etc.) from the following product page.
Ignore the "Products you recently viewed" section.
Return the data in JSON format using lowercase snake_case attribute names.Talvez você não conheça a estrutura exata da página de destino, portanto, deve manter o prompt bastante genérico (mas ainda focado no objetivo). Aqui, instruímos explicitamente o modelo a ignorar as seções nas quais não estamos interessados. Além disso, pedimos para retornar um objeto JSON com nomes de chaves limpos e bem estruturados.
Observe que a solicitação da API do OpenAI Responses está configurada para funcionar no modo JSON. É assim que você pode garantir que o modelo produzirá uma saída no formato JSON. Para que esse recurso funcione, seu prompt deve incluir uma instrução para retornar dados em JSON, como:
Return the data in JSON format using lowercase snake_case attribute names.Caso contrário, a solicitação falhará com:
openai.BadRequestError: Error code: 400 - {
'error': {
'message': "Response input messages must contain the word 'json' in some form to use 'text.format' of type 'json_object'.",
'type': 'invalid_request_error',
'param': 'input',
'code': None
}
}Quando a solicitação for concluída com êxito, você poderá acessar os dados estruturados analisados usando:
json_product_data = response.output_textOpcionalmente, para analisar a string resultante e convertê-la em um dicionário Python:
import json
product_data = json.loads(json_product_data)Lógica de análise de dados do GPT Vision concluída! Resta apenas exportar os dados extraídos para um arquivo JSON local.
Etapa nº 6: Exportar os dados extraídos
Escreva a string JSON de saída produzida pela chamada da API do GPT Vision com:
with open("product.json", "w", encoding="utf-8") as f:
f.write(json_product_data)Isso criará um arquivo product.json que armazenará os dados extraídos visualmente.
Muito bem! Seu coletor de dados da Web com a tecnologia GPT Vision está pronto.
Etapa nº 7: Juntar tudo
Abaixo está o código final do scraper.py:
from playwright.sync_api import sync_playwright
from openai import OpenAI
import base64
# Where to store the page screenshot
SCREENSHOT_PATH = "product_page.png"
with sync_playwright() as p:
# Launch a new Playwright instance
browser = p.chromium.launch()
page = browser.new_page()
# Visit the target page
url = "https://books.toscrape.com/catalogue/the-dirty-little-secrets-of-getting-your-dream-job_994/index.html"
page.goto(url)
# Wait for the product page element to be on the DOM
product_page_element = page.locator(".product_page")
product_page_element.wait_for()
# Take a full screenshot of the element
product_page_element.screenshot(path=SCREENSHOT_PATH)
# Close the browser and release its resources
browser.close()
# Initialize the OpenAI client
OPENAI_API_KEY = "<YOUR_OPENAI_API_KEY>" # Replace with your OpenAI API key
client = OpenAI(api_key=OPENAI_API_KEY)
# Read the screenshot from the filesystem
with open(SCREENSHOT_PATH, "rb") as image_file:
base64_image = base64.b64encode(image_file.read()).decode("utf-8")
# Perform the data extraction request via GPT Vision
response = client.responses.create(
model="gpt-4.1-mini",
input=[
{
"role": "user",
"content": [
{
"type": "input_text",
"text": """
Extract structured data (e.g., title, description, rating in the format "x/5", etc.) from the following product page.
Ignore the "Products you recently viewed" section.
Return the data in JSON format using lowercase snake_case attribute names.
"""
},
{
"type": "input_image",
"image_url": f"data:image/png;base64,{base64_image}"
}
]
}
],
text={"format": {"type": "json_object"}} # Enable JSON Mode to get output data in JSON format
)
# Extract the output data and export it to a JSON file
json_product_data = response.output_text
with open("product.json", "w", encoding="utf-8") as f:
f.write(json_product_data)Uau! Em menos de 65 linhas de código, você acabou de realizar a raspagem visual da Web com o GPT Vision.
Execute o scraper do GPT Vision com:
python scraper.pyO script demorará um pouco e, em seguida, gravará um arquivo product.json na pasta do seu projeto. Abra-o e você verá:
{
"title": "The Dirty Little Secrets of Getting Your Dream Job",
"price_gbp": "£33.34",
"availability": "In stock (19 available)",
"rating": "4/5",
"description": "Drawing on his extensive experience evaluating applicants for his marketing agency, and featuring stories based on real-life situations, sample cover letters, resumes, and straightforward advice, Don Raskin’s The Dirty Little Secrets of Getting Your Dream Job offers all the necessary tools for navigating the tough job market and securing your dream job... [omitted for brevity]",
"product_information": {
"upc": "2597b5a345f45e1b",
"product_type": "Books",
"price_excl_tax": "£33.34",
"price_incl_tax": "£33.34",
"tax": "£0.00",
"availability": "In stock (19 available)"
}
}Observe como ele extraiu com êxito todas as informações do produto na página, inclusive a classificação da avaliação do elemento puramente visual:
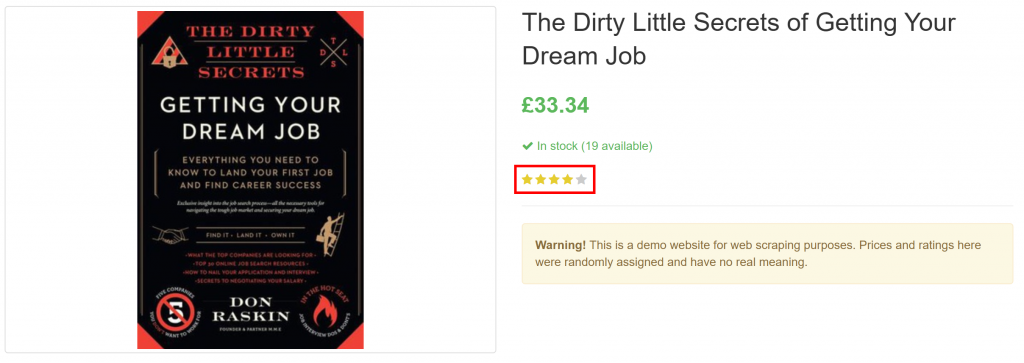
E pronto! O GPT Vision foi capaz de transformar uma captura de tela em um arquivo JSON bem estruturado.
Próximas etapas
Para aprimorar seu scraper do GPT Vision, considere os seguintes ajustes:
- Torná-lo reutilizável: Refatore o script para aceitar o URL de destino, o seletor CSS do elemento a ser aguardado e o prompt do LLM da CLI. Dessa forma, você pode extrair diferentes páginas sem modificar o código.
- Proteja sua chave de API: em vez de codificar sua chave de API OpenAI, armazene-a em um arquivo
.enve carregue-a usando o pacotepython-dotenv. Como alternativa, defina-a como uma variável de ambiente global denominadaOPENAI_API_KEY. Ambos os métodos ajudam a proteger suas credenciais e a manter sua base de código segura.
Superando a maior limitação do Visual Web Scraping
O principal desafio dessa abordagem de raspagem da Web está na etapa de captura de tela. Embora tenha funcionado perfeitamente em um site sandbox como o “Books to Scrape”, os sites do mundo real apresentam uma realidade diferente.
Muitos sites modernos implementam medidas antirrastreamento que podem bloquear seu script antes que você possa acessar a página. Mesmo que seu scraper acesse a página com sucesso, você ainda poderá receber um erro ou um desafio de verificação humana. Por exemplo, isso acontece quando se usa o vanilla Playwright em sites como o G2.com:

Esses problemas podem ser causados por impressão digital do navegador, reputação de IP, limitação de taxa, desafios CAPTCHA ou outros.
A maneira mais robusta de contornar esses bloqueios é confiar em uma API de desbloqueio da Web dedicada!
O Web Unlocker da Bright Data é um endpoint de raspagem avançado que conta com o apoio de uma rede proxy de mais de 150 milhões de IPs. Em particular, ele oferece falsificação de impressões digitais, renderização de JavaScript, recursos de resolução de CAPTCHA e muitos outros recursos. Ele suporta até mesmo captura de tela, o que significa que você pode ignorar totalmente a lógica manual de captura de tela do Playwright.
Digamos que você queira extrair a classificação média por estrelas da página do vendedor G2 da Bright Data:
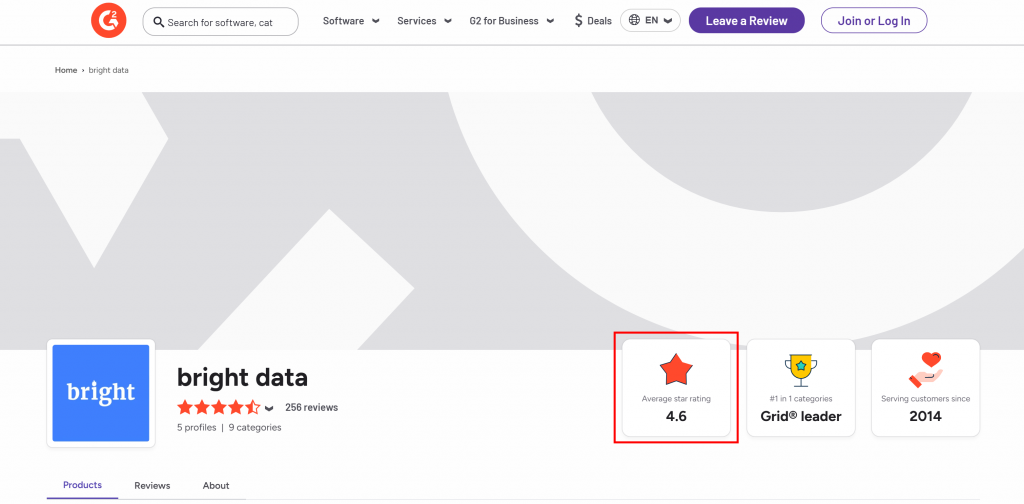
Para começar, configure o Web Unlocker conforme explicado nos documentos e recupere sua chave de API da Bright Data. Use o GPT Vision junto com o Web Unlocker da seguinte forma:
# pip install requests
import requests
from openai import OpenAI
import base64
BRIGHT_DATA_API_KEY = "<YOUR_BRIGHT_DATA_API_KEY>" # Replace with your Bright Data API key
# Get a screenshot of the target page using Bright Data Web Unlocker
url = "https://api.brightdata.com/request"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}"
}
payload = {
"zone": "web_unlocker", # Replace with your Web Unlocker zone name
"url": "https://www.g2.com/sellers/bright-data", # Your target page
"format": "raw",
"data_format": "screenshot" # Enable the screenshotting mode
}
response = requests.post(url, headers=headers, json=payload)
# Where to store the scraped screenshot
SCREENSHOT_PATH = "screenshot.png"
# Save the screenshot to a file (e.g., for further analysis in the future)
with open(SCREENSHOT_PATH, "wb") as f:
f.write(response.content)
# Initialize the OpenAI client
OPENAI_API_KEY = "<YOUR_OPENAI_API_KEY>" # Replace with your OpenAI API key
client = OpenAI(api_key=OPENAI_API_KEY)
# Read the screenshot file and convert its contents to Base64
with open(SCREENSHOT_PATH, "rb") as image_file:
base64_image = base64.b64encode(image_file.read()).decode("utf-8")
# Perform the scraping request using GPT Vision
response = client.responses.create(
model="gpt-4.1-mini",
input=[
{
"role": "user",
"content": [
{
"type": "input_text",
"text": """
Return the average star rating from the following image.
"""
},
{
"type": "input_image",
"image_url": f"data:image/png;base64,{base64_image}"
}
]
}
],
)
print(response.output_text)Execute o script acima e ele produzirá um resultado como:
The average star rating from the image is 4.6.Essa é a informação correta, pois você pode confirmar isso visualmente no arquivo screenshot.png gerado e retornado pelo Web Unlocker:
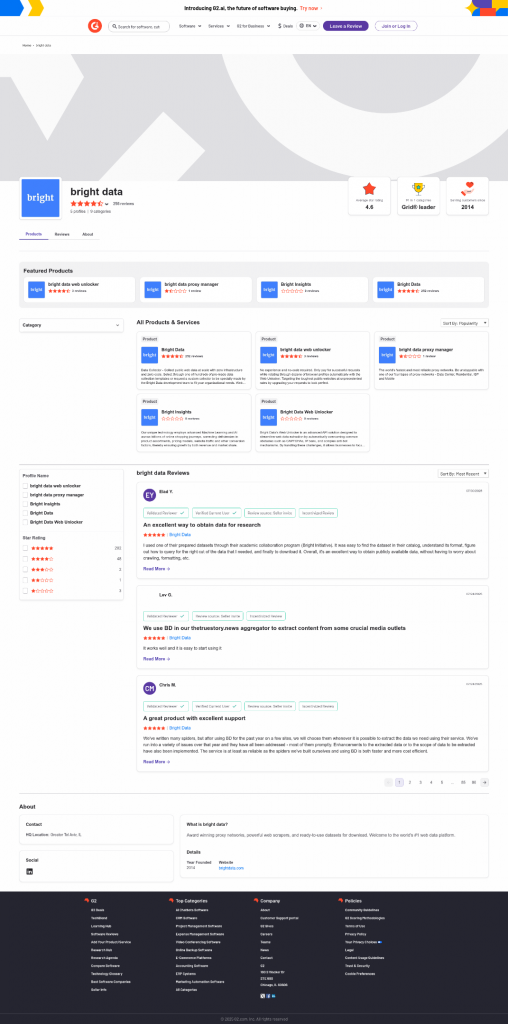
Observe que você pode usar o Web Unlocker para recuperar o HTML totalmente desbloqueado da página ou até mesmo obter seu conteúdo em um formato Markdown otimizado para IA.
E assim, sem mais bloqueios, sem mais dores de cabeça. Agora você tem um raspador da Web de nível de produção, alimentado pelo GPT Vision, que funciona até mesmo em sites protegidos.
Veja o OpenAI SDK e o Web Unlocker trabalhando juntos em um cenário de raspagem mais complexo.
Conclusão
Neste tutorial, você aprendeu a combinar o GPT Vision com os recursos de captura de tela do Playwright para criar um raspador da Web com tecnologia de IA. O maior desafio (ou seja, ser bloqueado ao fazer capturas de tela) foi resolvido com a API Bright Data Web Unlocker.
Conforme discutido, a combinação do GPT Vision com a funcionalidade de captura de tela fornecida pela API do Web Unlocker permite extrair visualmente os dados de qualquer site. Tudo isso, sem escrever código de análise personalizado. Esse é apenas um dos muitos cenários cobertos pelos produtos e serviços de IA da Bright Data.
Crie uma conta da Bright Data gratuitamente e experimente nossas soluções de dados!




