

Neste guia, você aprenderá:
- O que é o SDK do OpenAI Agents
- Por que integrá-lo a um serviço de desbloqueio da Web é fundamental para maximizar sua eficácia
- Como criar um agente Python usando o SDK do OpenAI Agents e uma API do Web Unlocker em um tutorial detalhado passo a passo
Vamos mergulhar de cabeça!
O que é o SDK do OpenAI Agents?
O OpenAI Agents SDK é uma biblioteca Python de código aberto da OpenAI. Ela foi projetada para criar aplicativos de IA baseados em agentes de forma simples, leve e pronta para produção. Essa biblioteca é uma evolução refinada do projeto experimental anterior da OpenAI chamado Swarm.
O OpenAI Agents SDK se concentra em fornecer apenas alguns primitivos principais com abstração mínima:
- Agentes: LLMs emparelhados com instruções e ferramentas específicas para executar tarefas
- Transferências: Para permitir que os agentes deleguem tarefas a outros agentes quando necessário
- Barreiras de proteção: Para validar as entradas do agente para garantir que elas atendam aos formatos ou condições esperados
Esses blocos de construção, combinados com a flexibilidade do Python, facilitam a definição de interações complexas entre agentes e ferramentas.
O SDK também inclui rastreamento integrado, para que você possa visualizar, depurar e avaliar os fluxos de trabalho dos agentes. Ele ainda oferece suporte a modelos de ajuste fino para seus casos de uso específicos.
As maiores limitações dessa abordagem para a criação de agentes de IA
A maioria dos agentes de IA tem como objetivo automatizar operações em páginas da Web, seja recuperando conteúdo ou interagindo com elementos em uma página. Em outras palavras, eles precisam navegar na Web de forma programática.
Além dos possíveis mal-entendidos do próprio modelo de IA, o maior desafio que esses agentes enfrentam é lidar com as medidas de proteção dos sites. O motivo é que muitos sites implementam tecnologias anti-bot e anti-raspagem que podem bloquear ou enganar os agentes de IA. Isso é especialmente verdadeiro atualmente, pois os CAPTCHAs anti-AI e os sistemas avançados de detecção de bots estão se tornando cada vez mais comuns.
Então, esse é o fim do caminho para os agentes da Web com IA? Absolutamente não!
Para superar essas barreiras, você precisa aprimorar a capacidade do seu agente de navegar na Web, integrando-o a uma solução como a API Web Unlocker da Bright Data. Essa ferramenta funciona com qualquer cliente ou solução HTTP que se conecte à Internet (inclusive agentes de IA), atuando como um gateway de desbloqueio da Web. Ela fornece HTML limpo e desbloqueado de qualquer página da Web. Não há mais CAPTCHAs, proibições de IP ou conteúdo bloqueado.
Veja por que a combinação do SDK do OpenAI Agents com a API do Web Unlocker é a melhor estratégia para a criação de agentes de IA avançados e com experiência na Web!
Como integrar o SDK de agentes a uma API do Web Unlocker
Nesta seção guiada, você aprenderá a integrar o SDK do OpenAI Agents com a API do Web Unlocker da Bright Data para criar um agente de IA capaz de:
- Resumir o texto de qualquer página da Web
- Recuperação de dados estruturados de produtos em sites de comércio eletrônico
- Coleta de informações importantes de artigos de notícias
Para isso, o agente instruirá o OpenAI Agents SDK a usar a API do Web Unlocker como um mecanismo para buscar o conteúdo de qualquer página da Web. Depois que o conteúdo for recuperado, o agente aplicará a lógica de IA para extrair e formatar os dados conforme necessário para cada uma das tarefas acima.
Isenção de responsabilidade: os três casos de uso acima são apenas exemplos. A abordagem mostrada aqui pode ser estendida a muitos outros cenários, personalizando o comportamento do agente.
Siga as etapas abaixo para criar um agente de raspagem de IA em Python usando o SDK do OpenAI Agents e a API do Web Unlocker da Bright Data para obter alto desempenho!
Pré-requisitos
Antes de mergulhar neste tutorial, verifique se você tem o seguinte:
- Python 3 ou superior instalado localmente
- Uma conta ativa da Bright Data
- Uma conta ativa do OpenAI
- Um entendimento básico de como funcionam as solicitações HTTP
- Algum conhecimento sobre o funcionamento dos modelos Pydantic
- Uma ideia geral de como os agentes de IA funcionam
Não se preocupe se tudo ainda não estiver configurado. Você será orientado sobre a configuração nas próximas seções.
Etapa 1: Configuração do projeto
Antes de começarmos, verifique se o Python 3 está instalado em seu sistema. Caso contrário, baixe o Python e siga as instruções de instalação do seu sistema operacional.
Abra seu terminal e crie uma nova pasta para seu projeto de agente de raspagem:
mkdir openai-sdk-agentA pasta openai-sdk-agent conterá todo o código do seu agente baseado em Python e alimentado pelo SDK do Agents.
Navegue até a pasta do projeto e configure um ambiente virtual:
cd openai-sdk-agent
python -m venv venvCarregue a pasta do projeto em seu IDE Python favorito. O Visual Studio Code com a extensão Python ou o PyCharm Community Edition são ótimas opções.
Dentro da pasta openai-sdk-agent, crie um novo arquivo Python chamado agent.py. Sua estrutura de pastas agora deve ter a seguinte aparência:

Atualmente, o scraper.py é um script Python em branco, mas em breve conterá a lógica desejada do agente de IA.
No terminal do IDE, ative o ambiente virtual. No Linux ou macOS, execute este comando:
./env/bin/activateDe forma equivalente, no Windows, execute:
env/Scripts/activateEstá tudo pronto! Agora você tem um ambiente Python para criar um agente de IA avançado usando o SDK do OpenAI Agents e um desbloqueador da Web.
Etapa 2: Instale as dependências do projeto e comece a trabalhar
Este projeto usa as seguintes bibliotecas Python:
openai-agents: O OpenAI Agents SDK, usado para criar agentes de IA em Python.solicitações: Para conectar-se à API do Web Unlocker da Bright Data e buscar o conteúdo HTML de uma página da Web na qual o agente de IA operará. Saiba mais em nosso guia sobre como dominar a biblioteca Python Requests.pydantic: Definir modelos de saída estruturados, permitindo que o agente retorne dados em um formato claro e validado.markdownify: Para converter conteúdo HTML bruto em Markdown limpo. (Em breve explicaremos por que isso é útil).python-dotenv: para carregar variáveis de ambiente de um arquivo.env. É nesse arquivo que armazenaremos os segredos do OpenAI e do Bright Data.
Em um ambiente virtual ativado, instale todos eles com:
pip install requests pydantic openai-agents openai-agents markdownify python-dotenvAgora, inicialize o scraper.py com as seguintes importações e código padrão assíncrono:
import asyncio
from agents import Agent, RunResult, Runner, function_tool
import requests
from pydantic import BaseModel
from markdownify import markdownify as md
from dotenv import load_dotenv
# AI agent logic...
async def run():
# Call the async AI agent logic...
if __name__ == "__main__":
asyncio.run(run())Maravilhoso! Hora de carregar as variáveis de ambiente.
Etapa 3: Configurar a leitura das variáveis de ambiente
Adicione um arquivo .env na pasta do seu projeto:

Esse arquivo conterá suas variáveis de ambiente, como chaves de API e tokens secretos. Para carregar as variáveis de ambiente do arquivo .env, use load_dotenv() do pacote dotenv:
load_dotenv()Agora, você pode ler variáveis de ambiente específicas usando os.getenv() desta forma:
os.getenv("ENV_NAME")Não se esqueça de importar os da biblioteca padrão do Python:
import osÓtimo! As variáveis de ambiente estão prontas para serem lidas.
Etapa 4: Configurar o SDK do OpenAI Agents
Você precisa de uma chave de API da OpenAI válida para utilizar o SDK do OpenAI Agents. Se você ainda não gerou uma, siga o guia oficial da OpenAI para criar sua chave de API.
Depois de obtê-la, adicione a chave ao seu arquivo .env da seguinte forma:
OPENAI_API_KEY="<YOUR_OPENAI_KEY>"Certifique-se de substituir o pelo espaço reservado com sua chave real.
Não é necessária nenhuma configuração adicional, pois o SDK do openai-agents foi projetado para ler automaticamente a chave de API do env OPENAI_API_KEY.
Etapa 5: Configurar a API do Web Unlocker
Se ainda não o fez, crie uma conta na Bright Data. Caso contrário, basta fazer o login.
Em seguida, leia a documentação oficial do Web Unlocker da Bright Data para recuperar seu token de API. Como alternativa, siga as etapas abaixo.
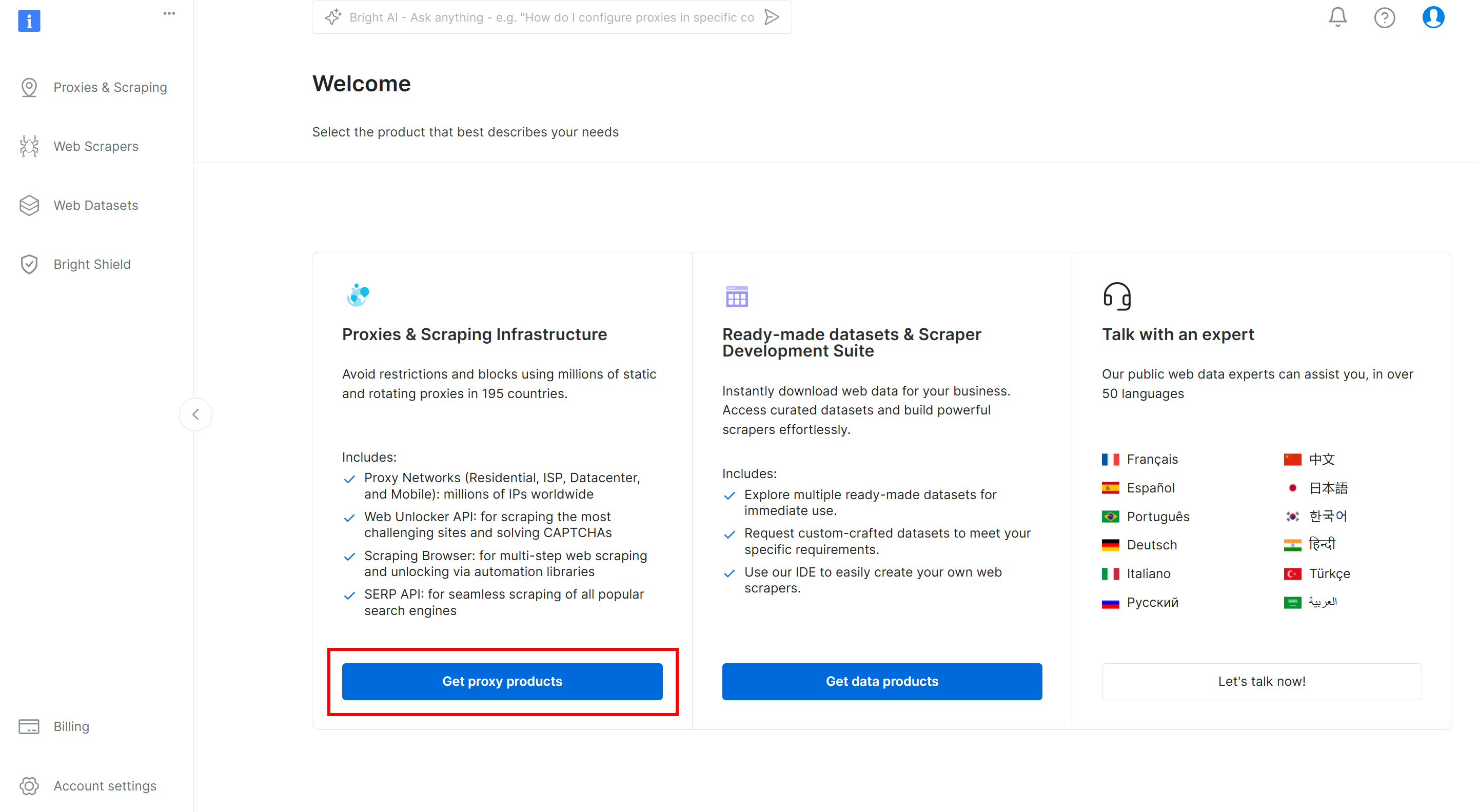
Na página “User Dashboard” (Painel do usuário) da Bright Data, pressione a opção “Get proxy products” (Obter produtos proxy):
Na tabela de produtos, localize a linha denominada “unblocker” e clique nela:
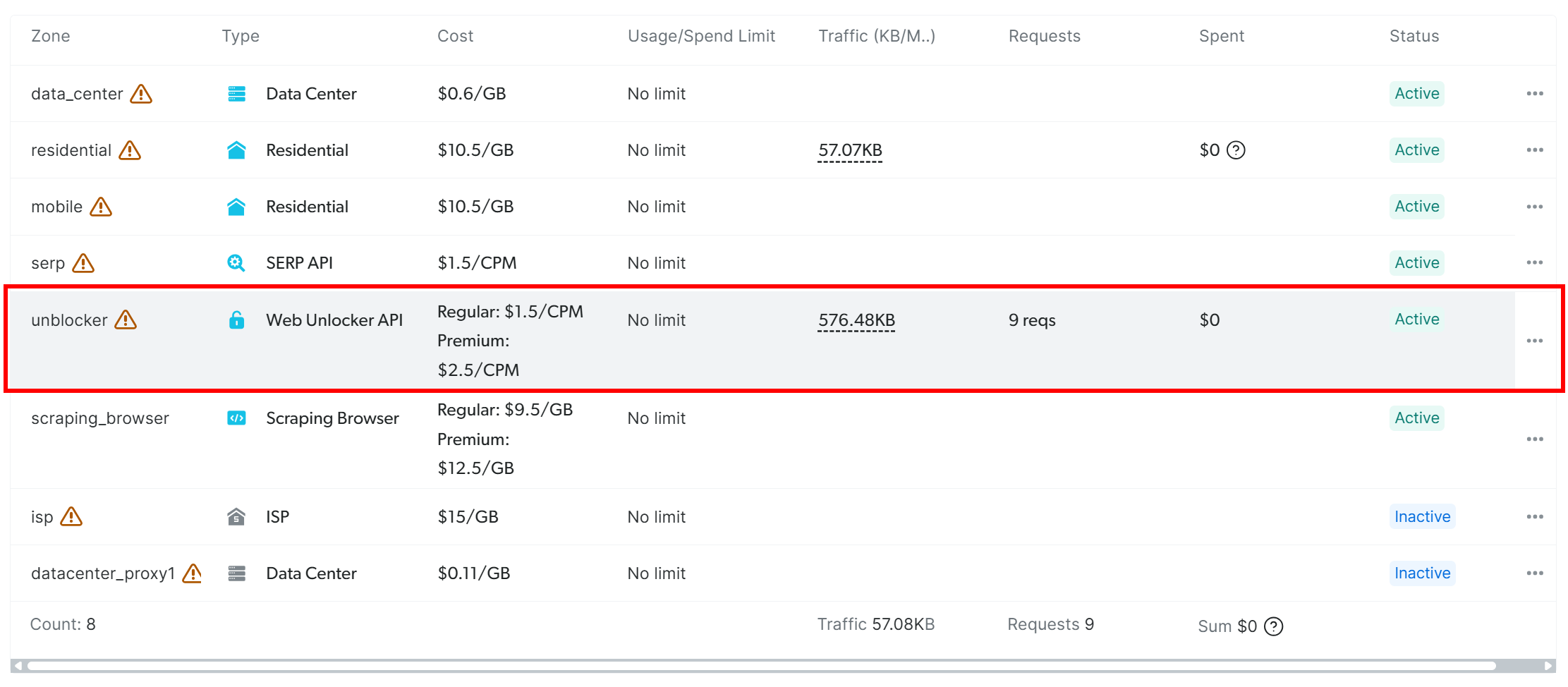
⚠️Note: Você terá que criar uma nova zona de API do Web Unblocker primeiro, caso ainda não tenha feito isso. Consulte a documentação de configuração do Web Unblocker para começar.
Na página “unlocker”, copie seu token de API usando o ícone da área de transferência:

Além disso, verifique se o botão de alternância no canto superior direito está ativado, o que indica que o produto Web Unlocker está ativo.
Na guia “Configuration” (Configuração), verifique se essas opções estão ativadas para otimizar a eficácia:

No arquivo .env, adicione a seguinte variável de ambiente:
BRIGHT_DATA_WEB_UNLOCKER_API_TOKEN="<YOUR_BRIGHT_DATA_WEB_UNLOCKER_API_TOKEN>"Substitua o espaço reservado pelo seu token de API real.
Perfeito! Agora você pode usar o SDK da OpenAI e a API do Web Unlocker da Bright Data em seu projeto.
Etapa 6: Criar a função de extração de conteúdo da página da Web
Crie uma função get_page_content() que:
- Lê a variável de ambiente
BRIGHT_DATA_WEB_UNLOCKER_API_TOKEN - Usa
solicitaçõespara enviar uma solicitação à API do Web Unlocker da Bright Data usando o URL fornecido - Recupera o HTML bruto retornado pela API
- Converte o HTML em Markdown e o retorna
É assim que você pode implementar a lógica acima:
@function_tool
def get_page_content(url: str) -> str:
"""
Retrieves the HTML content of a given web page using Bright Data's Web Unlocker API,
bypassing anti-bot protections. The response is converted from raw HTML to Markdown
for easier and cheaper processing.
Args:
url (str): The URL of the web page to scrape.
Returns:
str: The Markdown-formatted content of the requested page.
"""
# Read the Bright Data's Web Unlocker API token from the envs
BRIGHT_DATA_WEB_UNLOCKER_API_TOKEN = os.getenv("BRIGHT_DATA_WEB_UNLOCKER_API_TOKEN")
# Configure the Web Unlocker API call
api_url = "https://api.brightdata.com/request"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {BRIGHT_DATA_WEB_UNLOCKER_API_TOKEN}"
}
data = {
"zone": "unblocker",
"url": url,
"format": "raw"
}
# Make the call to Web Uncloker to retrieve the unblocked HTML of the target page
response = requests.post(api_url, headers=headers, data=json.dumps(data))
# Extract the raw HTML response
html = response.text
# Convert the HTML to markdown and return it
markdown_text = md(html)
return markdown_textObservação 1: A função deve ser anotada com @function_tool. Esse decorador especial informa ao OpenAI Agents SDK que essa função pode ser usada como uma ferramenta por um agente para executar ações específicas. Nesse caso, a função atua como o “mecanismo” que o agente pode utilizar para recuperar o conteúdo da página da Web em que irá operar.
Observação 2: A função get_page_content() deve declarar explicitamente os tipos de entrada.
Se você os omitir, receberá um erro como: Erro ao obter resposta: Código de erro: 400 - {'error': {'message': "Esquema inválido para a função 'get_page_content': Em context=('properties', 'url'), o esquema deve ter uma chave 'type'.``"
Agora, você deve estar se perguntando: por que converter HTML bruto em Markdown? A resposta é simples: eficiência de desempenho e custo-benefício!
O HTML é altamente detalhado e geralmente inclui elementos desnecessários, como scripts, estilos e metadados. Esse é um conteúdo de que os agentes de IA normalmente não precisam. Se o seu agente precisa apenas do essencial, como texto, links e imagens, o Markdown oferece uma representação muito mais limpa e compacta.
Em detalhes, a transformação de HTML para Markdown pode reduzir o tamanho da entrada em até 99%, economizando ambos:
- Tokens, que reduzem o custo ao usar modelos OpenAI
- Tempo de processamento, pois os modelos trabalham mais rapidamente com entradas menores
Para obter mais informações, leia o artigo “Por que os novos agentes de IA estão escolhendo Markdown em vez de HTML?“
Etapa nº 7: Definir os modelos de dados
Para funcionar corretamente, os agentes do OpenAI SDK precisam de modelos Pydantic para definir a estrutura esperada de seus dados de saída. Agora, lembre-se de que o agente que estamos construindo pode retornar uma das três saídas possíveis:
- Um resumo da página
- Informações sobre o produto
- Informações sobre artigos de notícias
Portanto, vamos definir três modelos Pydantic correspondentes:
class Summary(BaseModel):
summary: str
class Product(BaseModel):
name: str
price: Optional[float] = None
currency: Optional[str] = None
ratings: Optional[int] = None
rating_score: Optional[float] = None
class News(BaseModel):
title: str
subtitle: Optional[str] = None
authors: Optional[List[str]] = None
text: str
publication_date: Optional[str] = NoneObservação: o uso de Optional torna seu agente mais robusto e de uso geral. Nem todas as páginas incluirão todos os dados definidos no esquema, portanto, essa flexibilidade ajuda a evitar erros quando faltam campos.
Não se esqueça de importar Optional e List da digitação:
from typing import Optional, ListFantástico! Agora você está pronto para criar a lógica do seu agente.
Etapa 8: inicializar a lógica do agente
Use a classe Agent do SDK openai-agents para definir os três agentes especializados:
summarization_agent = Agent(
name="Text Summarization Agent",
instructions="You are a content summarization agent that summarizes the input text.",
tools=[get_page_content],
output_type=Summary,
)
product_info_agent = Agent(
name="Product Information Agent",
instructions="You are a product parsing agent that extracts product details from text.",
tools=[get_page_content],
output_type=Product,
)
news_info_agent = Agent(
name="News Information Agent",
instructions="You are a news parsing agent that extracts relevant news details from text.",
tools=[get_page_content],
output_type=News,
)Cada agente:
- Inclui uma cadeia de instruções clara que descreve o que ele deve fazer. Isso é o que o OpenAI Agents SDK usará para orientar o comportamento do agente.
- Emprega
get_page_content()como uma ferramenta para recuperar os dados de entrada (ou seja, o conteúdo da página da Web). - Retorna sua saída em um dos modelos Pydantic
(Summary,ProductouNews) definidos anteriormente.
Para encaminhar automaticamente as solicitações do usuário para o agente especializado correto, defina um agente de nível superior:
routing_agent = Agent(
name="Routing Agent",
instructions=(
"You are a high-level decision-making agent. Based on the user's request, "
"hand off the task to the appropriate agent."
),
handoffs=[summarization_agent, product_info_agent, news_info_agent],
) Esse é o agente que você interrogará em sua função run() para conduzir a lógica do agente de IA.
Etapa nº 9: implementar o loop de execução
Na função run(), adicione o seguinte loop para iniciar a lógica do agente de IA:
# Keep iterating until the use type "exit"
while True:
# Read the user's request
request = input("Your request -> ")
# Stops the execution if the user types "exit"
if request.lower() in ["exit"]:
print("Exiting the agent...")
break
# Read the page URL to operate on
url = input("Page URL -> ")
# Routing the user's request to the right agent
output = await Runner.run(routing_agent, input=f"{request} {url}")
# Conver the agent's output to a JSON string
json_output = json.dumps(output.final_output.model_dump(), indent=4)
print(f"Output -> n{json_output}nn")Esse loop escuta continuamente a entrada do usuário e processa cada solicitação, encaminhando-a para o agente correto (resumo, produto ou notícias). Ele combina a consulta do usuário com o URL de destino, executa a lógica e, em seguida, imprime o resultado estruturado no formato JSON usando json. Importe-o com:
import jsonIncrível! Sua integração do OpenAI Agents SDK com a API do Web Unlocker da Bright Data está concluída.
Etapa nº 10: Juntar tudo
Seu arquivo scraper.py agora deve conter:
import asyncio
from agents import Agent, RunResult, Runner, function_tool
import requests
from pydantic import BaseModel
from markdownify import markdownify as md
from dotenv import load_dotenv
import os
from typing import Optional, List
import json
# Load the environment variables from the .env file
load_dotenv()
# Define the Pydantic output models for your AI agent
class Summary(BaseModel):
summary: str
class Product(BaseModel):
name: str
price: Optional[float] = None
currency: Optional[str] = None
ratings: Optional[int] = None
rating_score: Optional[float] = None
class News(BaseModel):
title: str
subtitle: Optional[str] = None
authors: Optional[List[str]] = None
text: str
publication_date: Optional[str] = None
@function_tool
def get_page_content(url: str) -> str:
"""
Retrieves the HTML content of a given web page using Bright Data's Web Unlocker API,
bypassing anti-bot protections. The response is converted from raw HTML to Markdown
for easier and cheaper processing.
Args:
url (str): The URL of the web page to scrape.
Returns:
str: The Markdown-formatted content of the requested page.
"""
# Read the Bright Data's Web Unlocker API token from the envs
BRIGHT_DATA_WEB_UNLOCKER_API_TOKEN = os.getenv("BRIGHT_DATA_WEB_UNLOCKER_API_TOKEN")
# Configure the Web Unlocker API call
api_url = "https://api.brightdata.com/request"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {BRIGHT_DATA_WEB_UNLOCKER_API_TOKEN}"
}
data = {
"zone": "unblocker",
"url": url,
"format": "raw"
}
# Make the call to Web Uncloker to retrieve the unblocked HTML of the target page
response = requests.post(api_url, headers=headers, data=json.dumps(data))
# Extract the raw HTML response
html = response.text
# Convert the HTML to markdown and return it
markdown_text = md(html)
return markdown_text
# Define the individual OpenAI agents
summarization_agent = Agent(
name="Text Summarization Agent",
instructions="You are a content summarization agent that summarizes the input text.",
tools=[get_page_content],
output_type=Summary,
)
product_info_agent = Agent(
name="Product Information Agent",
instructions="You are a product parsing agent that extracts product details from text.",
tools=[get_page_content],
output_type=Product,
)
news_info_agent = Agent(
name="News Information Agent",
instructions="You are a news parsing agent that extracts relevant news details from text.",
tools=[get_page_content],
output_type=News,
)
# Define a high-level routing agent that delegates tasks to the appropriate specialized agent
routing_agent = Agent(
name="Routing Agent",
instructions=(
"You are a high-level decision-making agent. Based on the user's request, "
"hand off the task to the appropriate agent."
),
handoffs=[summarization_agent, product_info_agent, news_info_agent],
)
async def run():
# Keep iterating until the use type "exit"
while True:
# Read the user's request
request = input("Your request -> ")
# Stops the execution if the user types "exit"
if request.lower() in ["exit"]:
print("Exiting the agent...")
break
# Read the page URL to operate on
url = input("Page URL -> ")
# Routing the user's request to the right agent
output = await Runner.run(routing_agent, input=f"{request} {url}")
# Conver the agent's output to a JSON string
json_output = json.dumps(output.final_output.model_dump(), indent=4)
print(f"Output -> n{json_output}nn")
if __name__ == "__main__":
asyncio.run(run())E pronto! Em pouco mais de 100 linhas de Python, você criou um agente de IA que pode:
- Resumir o conteúdo de qualquer página da Web
- Extraia informações sobre produtos de qualquer site de comércio eletrônico
- Extraia detalhes de notícias de qualquer artigo on-line
É hora de vê-lo em ação!
Etapa 11: testar o agente de IA
Para iniciar seu agente de IA, execute:
python agent.pyAgora, suponha que você queira resumir o conteúdo do hub de serviços de IA da Bright Data. Basta inserir uma solicitação como esta:

Abaixo está o resultado em formato JSON que você obterá:

Desta vez, suponha que você queira recuperar os dados do produto de uma página de produto da Amazon, como a listagem do PS5:

Normalmente, o CAPTCHA da Amazon e os sistemas anti-bot bloqueariam sua solicitação. Graças à API do Web Unlocker, seu agente de IA pode acessar e analisar a página sem ser bloqueado:
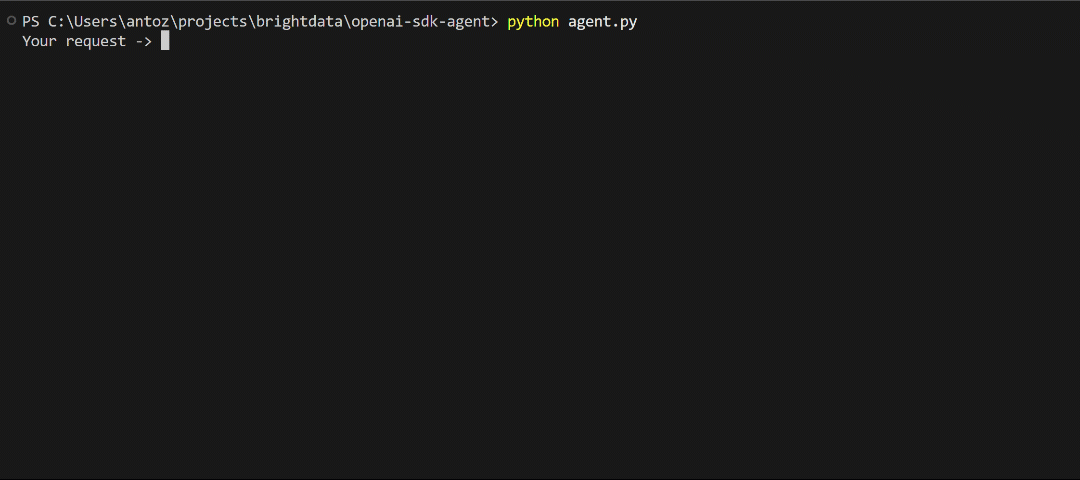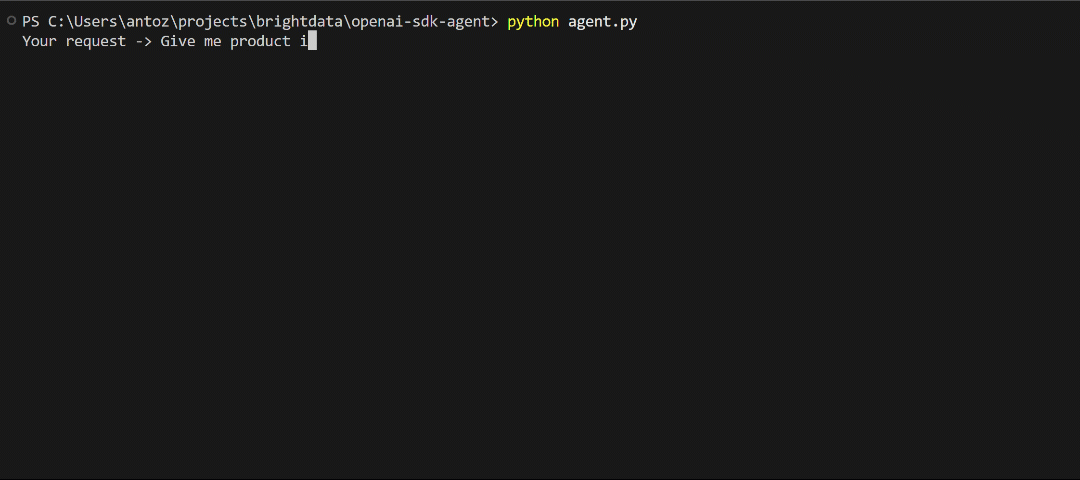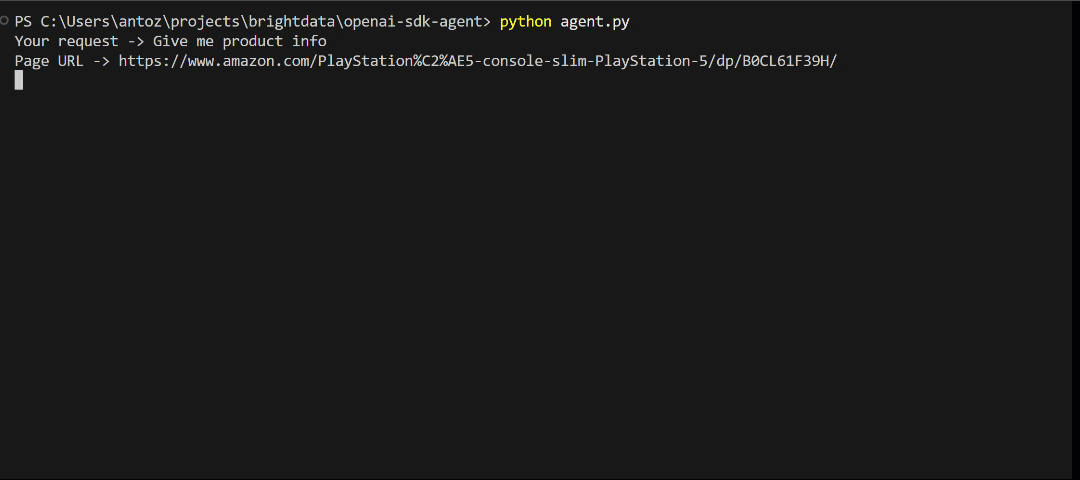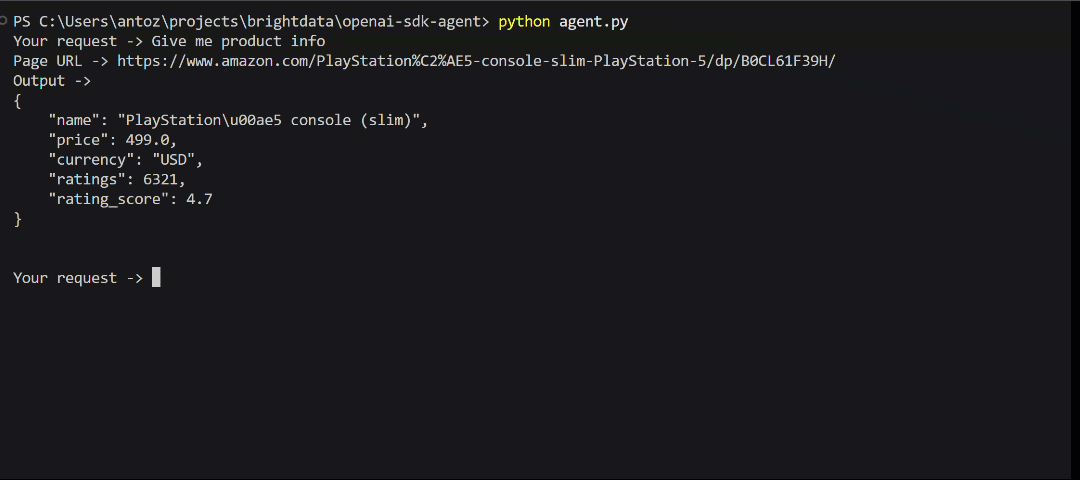
O resultado será:
{
"name": "PlayStationu00ae5 console (slim)",
"price": 499.0,
"currency": "USD",
"ratings": 6321,
"rating_score": 4.7
}Esses são os dados exatos do produto na página da Amazon!
Por fim, considere que você deseja obter informações de notícias estruturadas de um artigo do Yahoo News:
Atinja sua meta com os seguintes dados:
Your request -> Give me news info
Page URL -> https://www.yahoo.com/news/pope-francis-dies-88-080859417.htmlO resultado será:
{
"title": "Pope Francis Dies at 88",
"subtitle": null,
"authors": [
"Nick Vivarelli",
"Wilson Chapman"
],
"text": "Pope Francis, the 266th Catholic Church leader who tried to position the church to be more inclusive, died on Easter Monday, Vatican officials confirmed. He was 88. (omitted for brevity...)",
"publication_date": "Mon, April 21, 2026 at 8:08 AM UTC"
}Mais uma vez, o agente de IA fornece dados precisos e, graças ao Web Unlocker, não há bloqueios do site de notícias!
Conclusão
Nesta publicação do blog, você aprendeu a usar o OpenAI Agents SDK em combinação com uma API de desbloqueio da Web para criar um agente da Web altamente eficaz em Python.
Conforme demonstrado, a combinação do OpenAI SDK com a API Web Unlocker da Bright Data ajuda a criar agentes de IA que podem operar de forma confiável em praticamente qualquer página da Web. Esse é apenas um exemplo de como os produtos e serviços da Bright Data podem dar suporte a integrações poderosas de IA.
Explore nossas soluções para o desenvolvimento de agentes de IA:
- Agentes autônomos de IA: Pesquise, acesse e interaja com qualquer site em tempo real usando um conjunto avançado de APIs.
- Aplicativos de IA verticais: crie pipelines de dados confiáveis e personalizados para extrair dados da Web de fontes específicas do setor.
- Modelos básicos: Acesse conjuntos de dados compatíveis e em escala da Web para potencializar o pré-treinamento, a avaliação e o ajuste fino.
- IA multimodal: aproveite o maior repositório do mundo de imagens, vídeos e áudio otimizados para IA.
- Provedores de dados: Conecte-se com provedores confiáveis para obter conjuntos de dados de alta qualidade e prontos para IA em escala.
- Pacotes de dados: Obtenha conjuntos de dados selecionados e prontos para uso – estruturados, enriquecidos e anotados.
Para obter mais informações, explore nossa linha completa de produtos de IA.
Crie uma conta na Bright Data e experimente todos os nossos produtos e serviços para o desenvolvimento de agentes de IA!




