

Neste guia, você aprenderá:
- Por que a Dify é uma plataforma avançada para a criação de agentes de IA.
- Por que os recursos de pesquisa na Web são indispensáveis para os agentes de IA.
- Como criar um agente de IA na Dify que possa pesquisar na Web.
Vamos mergulhar de cabeça!
Desbloqueio do desenvolvimento de automação do fluxo de trabalho agêntico com a Dify
A Dify é uma plataforma inovadora, com pouco ou nenhum código, projetada para simplificar a criação de aplicativos LLM. Você pode usá-la na nuvem ou na versão de código aberto, e ela oferece suporte a fluxos de trabalho agênticos.
Ele fornece um editor visual intuitivo, permitindo que você crie e gerencie facilmente a lógica complexa de IA com a funcionalidade de arrastar e soltar. A Dify trabalha com uma ampla variedade de LLMs, desde os proprietários até os de código aberto, oferecendo a você a flexibilidade de escolher o melhor modelo para o seu projeto.
Funcionando como um BaaS(Backend-as-a-Service), ele lida com a infraestrutura de IA para você. Além disso, ele vem com suporte para extensões e plugins para melhorar ainda mais seus recursos. Isso abre a porta para funcionalidades expandidas em seus aplicativos de IA por meio de integrações de terceiros.
Por que os agentes de IA devem ser capazes de pesquisar na Web
A capacidade dos agentes de IA de pesquisar na Web é uma necessidade fundamental para obter respostas inteligentes e atualizadas. As primeiras iterações de LLMs, como o ChatGPT e o Gemini, muitas vezes tinham dificuldades para fornecer informações atuais ou de nicho. Isso ocorre porque eles eram limitados pela natureza estática dos dados de treinamento.
Um salto importante em sua precisão ocorreu exatamente quando eles foram equipados com a capacidade de pesquisar na Web.

Esse recurso permite que o LLM obtenha informações sob demanda, com o objetivo final de expandir sua base de conhecimento para reduzir as alucinações.
Ao mesmo tempo, os recursos integrados de pesquisa na Web para LLMs geralmente são exclusivos de modelos pagos. Além disso, simplesmente “pesquisar na Web” não é suficiente. O motivo é que o grande volume e a natureza não verificada dos dados da Internet ainda podem levar a imprecisões ou resultados irrelevantes.
O verdadeiro poder está em ter acesso a dados SERP(Search Engine Results Page, página de resultados do mecanismo de busca) confiáveis e verificados diretamente de mecanismos de busca confiáveis, como Google, Bing, DuckDuckGo e similares. Esses dados são moldados por algoritmos de classificação sofisticados que incluem verificações de qualidade rigorosas.
Como resultado, os dados SERP garantem uma base muito mais confiável para que os agentes de IA sintetizem informações e gerem respostas bem informadas. Veja por que um caso de uso comum em IA é a criação de um chatbot baseado em RAG que aproveita os dados SERP.
Para fornecer um fluxo de trabalho de agente de IA da Dify com dados SERP, você pode usar o plug-in Bright Data Dify. Entre as ferramentas que ele oferece está uma chamada “Search Engine“. Ele fornece resultados de pesquisa em tempo real do Google, Bing, Yandex e outros mecanismos de pesquisa importantes, conectando-se à API SERP da Bright Data.
Graças a essa integração, seus agentes de IA sem código podem explorar a vastidão da Web e se beneficiar da credibilidade de mecanismos de pesquisa confiáveis.
Criando um agente de IA que pode pesquisar na Web em Dify: Tutorial passo a passo
Nesta seção guiada, você criará um fluxo de trabalho de agente de IA que:
- Aceita uma frase-chave como entrada.
- Usa a ferramenta “Search Engine” (Mecanismo de pesquisa) do plug-in Bright Data para pesquisar no Google usando essa frase-chave.
- Processa os resultados da pesquisa com um LLM.
Todo esse processo é totalmente visual, sem necessidade de codificação. Você conectará cada nó por meio de uma interface simples de arrastar e soltar para dar vida ao seu agente de IA.
Vamos agora criar seu fluxo de trabalho de IA de pesquisa na Web sem código e com a tecnologia Bright Data na Dify!
Pré-requisitos
Para seguir este tutorial sobre a criação de um agente de IA de pesquisa na Web na Dify, você precisará do seguinte:
- Uma conta Dify (um plano gratuito é suficiente).
- Uma chave de API da Bright Data.
Se você ainda não os tiver, use os links acima e siga as instruções de configuração.
Observação: para uso em produção, você também precisará de uma chave de API de um provedor de LLM (como OpenAI, Anthropic ou Gemini).
Etapa 1: Configurar uma integração LLM na Dify
Para usar um LLM na Dify, primeiro você precisa configurar a integração do LLM. Comece clicando em sua imagem de perfil e selecionando “Settings” (Configurações):

Em seguida, navegue até a página “Model Provider” (Provedor de modelo). Aqui, por exemplo, você pode instalar o plug-in do provedor OpenAI:
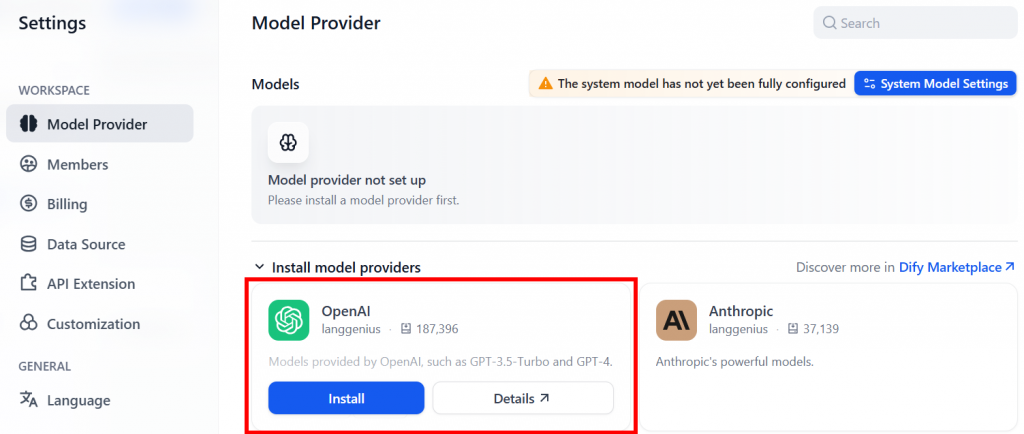
Por padrão, você recebe 200 créditos de mensagens gratuitas. Para remover essa limitação, depois de instalar o plug-in, defina suas configurações do OpenAI adicionando sua chave de API do OpenAI:
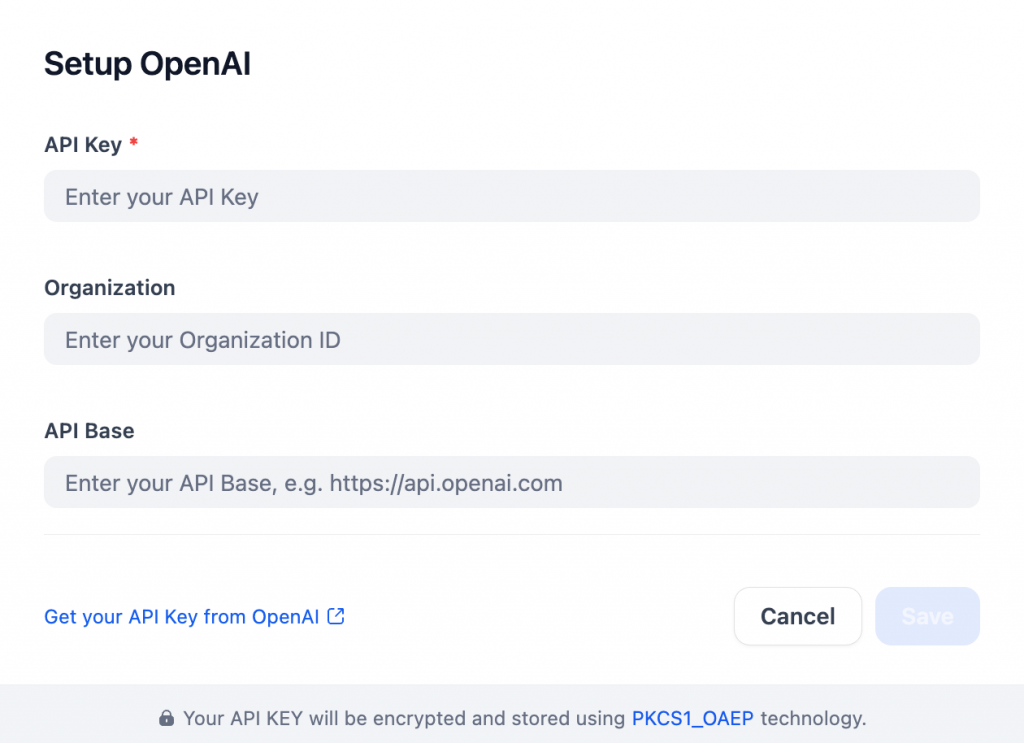
Como alternativa, para obter uma integração LLM permanente e gratuita, considere usar o provedor Gemini LLM. Alguns modelos Gemini, como o Flash 2.0, são de uso gratuito, mesmo por meio de APIs.
Ótimo! Agora você está pronto para começar a criar seu fluxo de trabalho de IA da Dify com recursos de pesquisa na Web.
Etapa 2: Instalar o plug-in Bright Data
Visite a página de versões no repositório do GitHub para o plug-in do Bright Data e faça download do arquivo chamado brightdata_plugin.difypkg.
Para instalá-lo na Dify, clique em “PLUGINS” para abrir o mercado de plug-ins e selecione “Install from Local Package File” (Instalar do arquivo de pacote local):
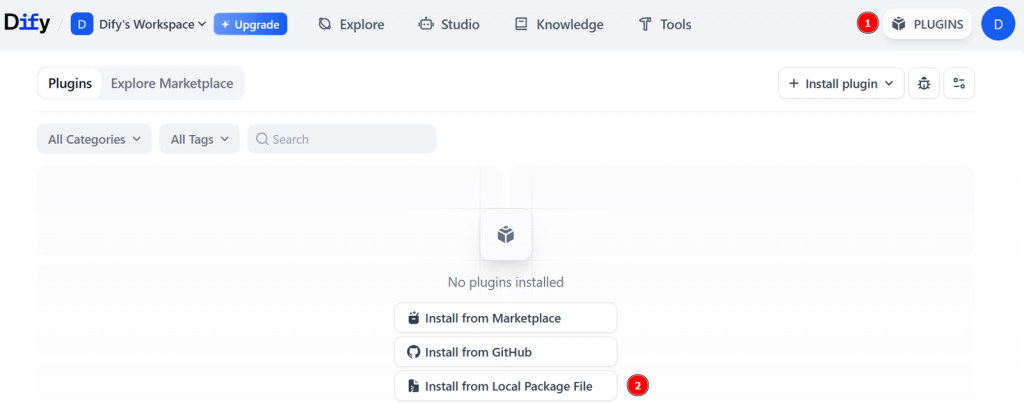
Escolha o arquivo local .difypkg que você baixou anteriormente e clique no botão “Install” (Instalar):

É isso aí! O plug-in Bright Data agora está instalado com sucesso na Dify.
Etapa nº 3: Crie seu novo aplicativo Dify
Agora que tudo está configurado, você está pronto para começar a criar seu agente de IA. Na página inicial do espaço de trabalho da Dify, crie um novo aplicativo selecionando “Create from Blank” (Criar do zero), conforme mostrado abaixo:

Em seguida, escolha “Workflow” (Fluxo de trabalho) como tipo de aplicativo, dê um nome ao seu aplicativo de IA e clique em “Create” (Criar):

Isso gerará uma tela de fluxo de trabalho nova e em branco:
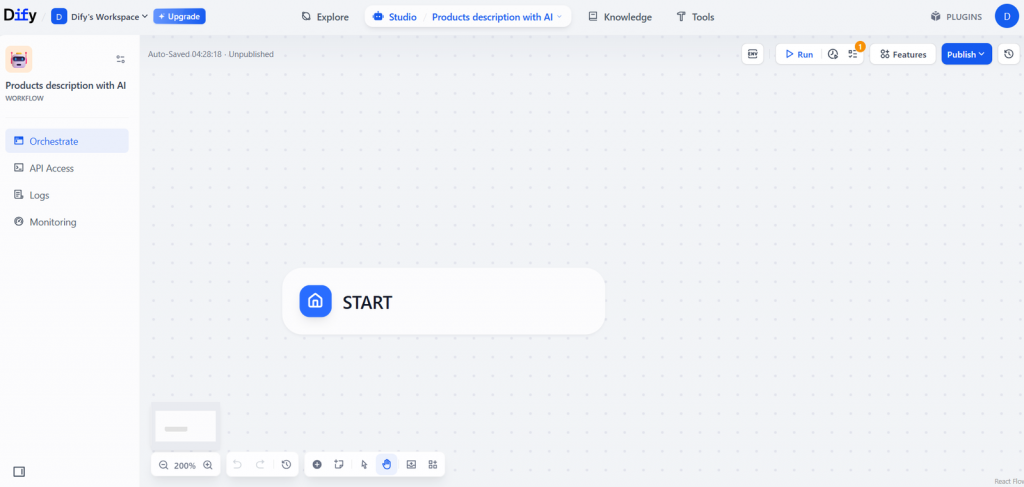
Antes de começar a criar seu agente de IA sem código, reserve um momento para descrever o que o agente deve fazer e de quais nós você precisará. Para este tutorial, você pode atingir o objetivo por meio de um fluxo de trabalho simples de quatro etapas com os seguintes nós:
- Um nó “Start” para definir a variável de entrada (a frase-chave).
- Um nó de “Mecanismo de pesquisa” para pesquisar na Web usando essa frase-chave.
- Um nó “LLM” para analisar os resultados da pesquisa e extrair insights úteis usando um prompt personalizado.
- Um nó “End” para exibir o relatório final gerado pela IA.
Fantástico! É hora de implementar seu fluxo de trabalho de IA de pesquisa na Web na Dify.
Etapa 4: Configure o nó “Start” (Início)
Comece clicando no nó “Start” (Início) e, em seguida, selecione “INPUT FIELD” (Campo de entrada):
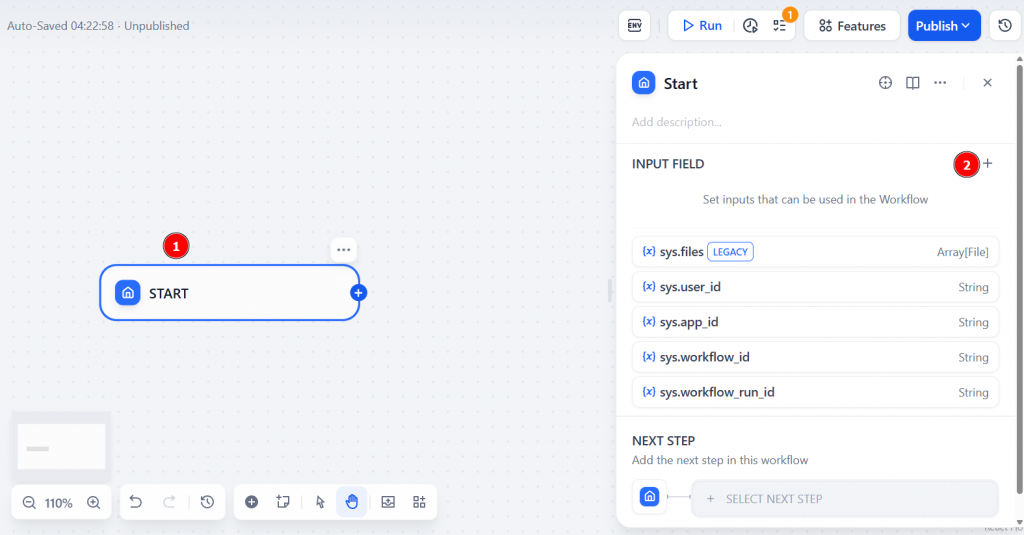
Defina o “Field Type” (Tipo de campo) como “Short Text” (Texto curto), pois você digitará uma consulta de texto curto como entrada. Nomeie o campo de entrada como search_topic. Isso representa a frase-chave que o agente de IA usará para realizar a pesquisa na Web.
Clique em “Save” (Salvar) para confirmar:

Muito bem! O nó “Start” agora está configurado corretamente.
Etapa 5: Integrar o nó “Mecanismo de pesquisa
Continue clicando no ícone “+” do nó “Iniciar”. Em seguida, vá para “Ferramentas” > “Bright Data Web Scraper” > “Mecanismo de pesquisa”:
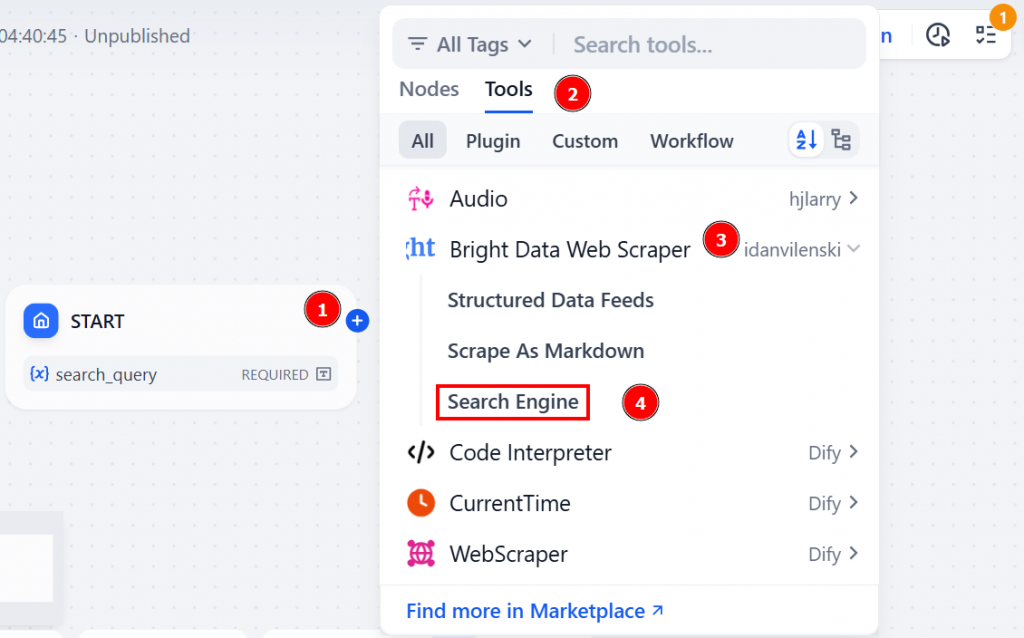
Esse nó de plug-in da Bright Data serve como ponte entre o fluxo de trabalho da Dify e a infraestrutura de IA da Bright Data. Especificamente, a ferramenta “Search Engine” permite que seu agente de IA recupere resultados de pesquisa em tempo real diretamente da Web.
Agora, clique em “Authorize” (Autorizar) e insira seu token da API da Bright Data:
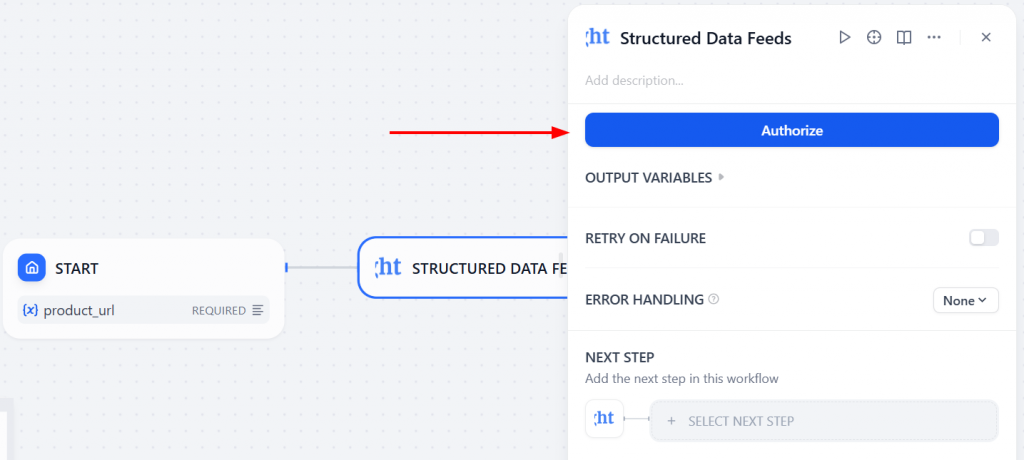
Uma vez autorizado, o plug-in Bright Data será conectado à sua conta.
Agora, passe a variável de entrada que você configurou anteriormente. No campo “Search Query”, digite “/” para exibir as variáveis disponíveis e selecione search_topic. O nó “Search Engine” executará uma pesquisa ao vivo na Web com base na entrada do usuário:

Por fim, no menu suspenso “SEARCH ENGINE” (mecanismo de pesquisa), escolha o mecanismo de pesquisa que deseja usar (neste tutorial, usaremos o Google):
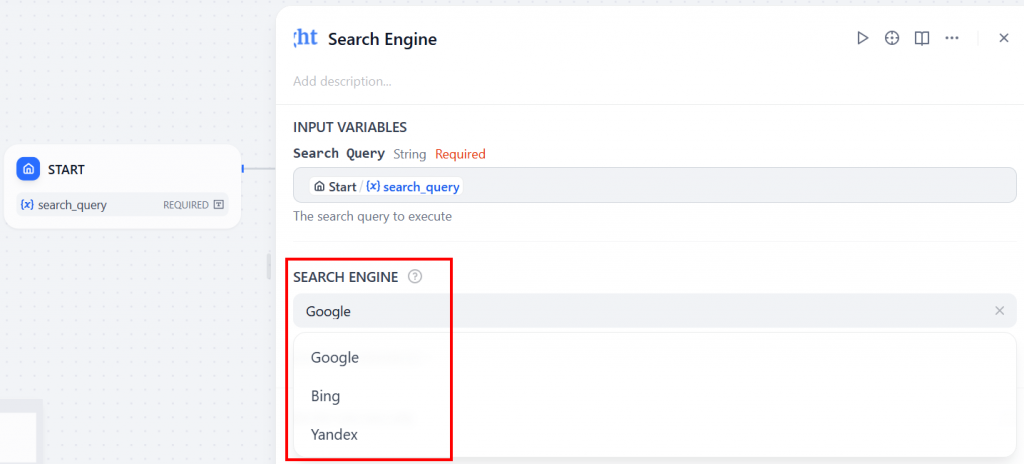
Excelente! O nó “Mecanismo de pesquisa” da Bright Data já está instalado.
Etapa nº 6: adicionar o nó “LLM”
No nó “Search Engine” (Mecanismo de pesquisa), clique no ícone “+” e selecione o nó “LLM”:

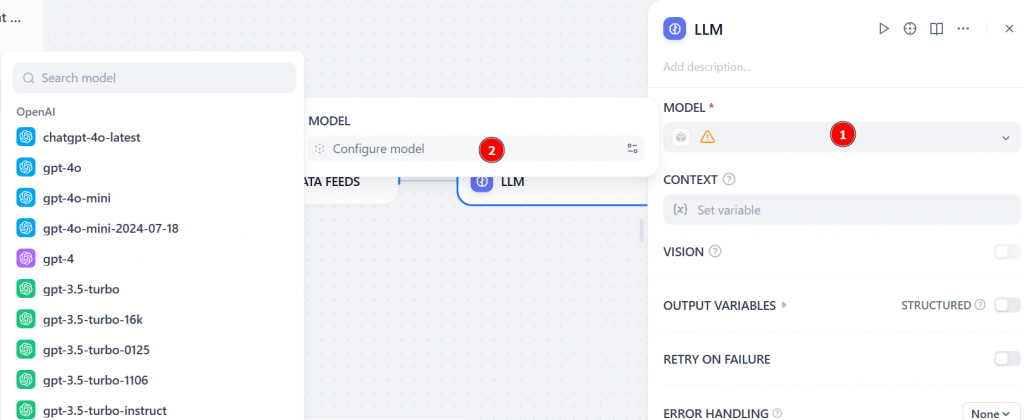
Na seção “MODEL” (Modelo), clique em “Configure model” (Configurar modelo) e escolha um LLM na lista (por exemplo, gpt-4):
Na seção “SYSTEM”, digite um prompt como o seguinte:
You are an expert SEO analyst. You have been given data containing the results from a Google search.
Based on this information, please report on the following:
- Common Talking Points: What are the most common themes and keywords you see repeated in the search result titles and descriptions?
- Dominant Content Types: Based on the titles, what kind of articles seem to be ranking? (e.g., "What is...", "Top 10...", "Beginner's Guide...", "Vs...").
Also, report the URLs.
Search Results Data:
{{Search_engine.text}}Esse prompt instrui o LLM a:
- Analise os resultados da pesquisa retornados pelo nó “Search Engine” (Mecanismo de pesquisa).
- Extraia temas recorrentes, formatos de conteúdo populares e URLs associados – atuando como um analista de SEO.
Observação: a variável {{Search_engine.text}} passa a saída de texto do nó “Search Engine” diretamente para o prompt do LLM. Em outras palavras, o LLM tem acesso aos dados de pesquisa na Web em tempo real retornados pelo nó “Search Engine”.
Veja a seguir como será a configuração do nó “LLM”:
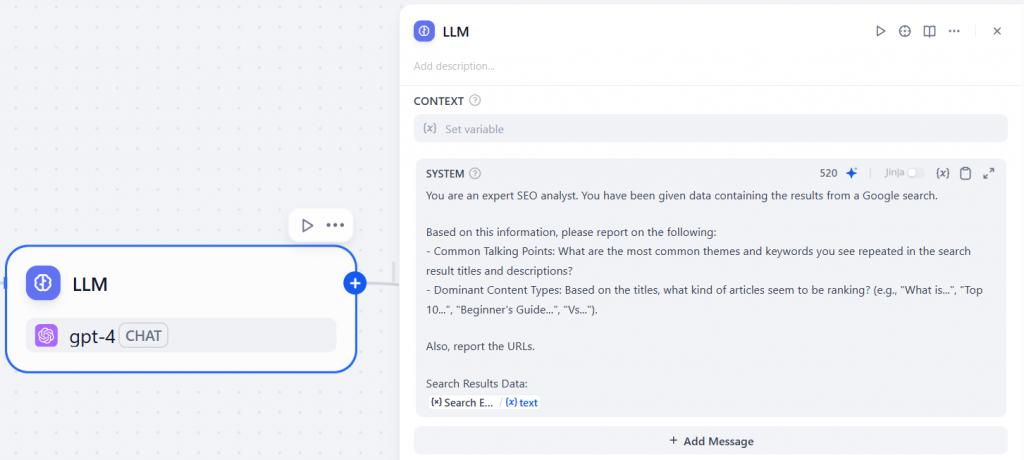
Fantástico! Só falta adicionar o último nó ao fluxo de trabalho.
Etapa nº 7: finalize o fluxo de trabalho de IA com um nó “final”
Complete seu fluxo de trabalho adicionando um nó “End”:

Esse nó retornará a saída final gerada pelo LLM. Para configurar esse comportamento, clique na seção “OUTPUT VARIABLE” (Variável de saída) e selecione a variável de texto do nó do LLM:
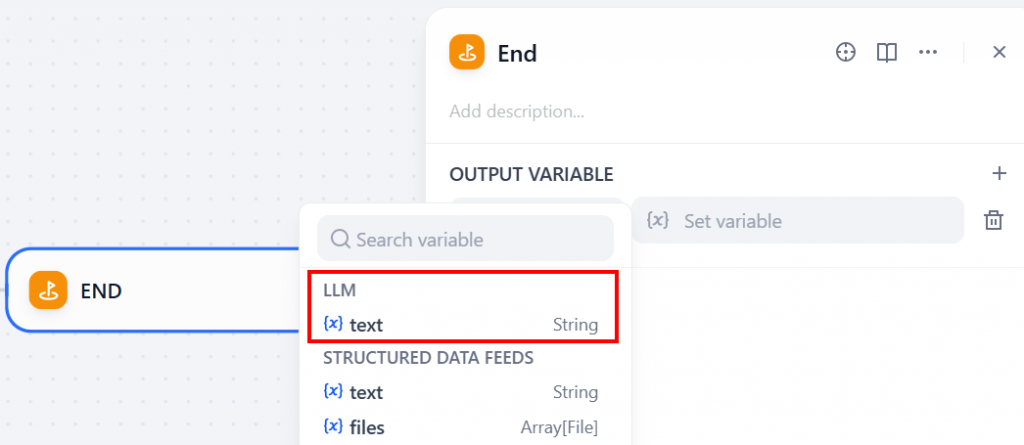
Essa configuração garante que a resposta final do seu LLM (com base nos resultados do mecanismo de pesquisa em tempo real) seja retornada como a saída de todo o fluxo de trabalho.
Etapa 8: Executar o fluxo de trabalho de pesquisa na Web com IA
Este é o seu fluxo de trabalho final de IA de pesquisa na Web na Dify, alimentado pela ferramenta “Search Engine” da Bright Data:
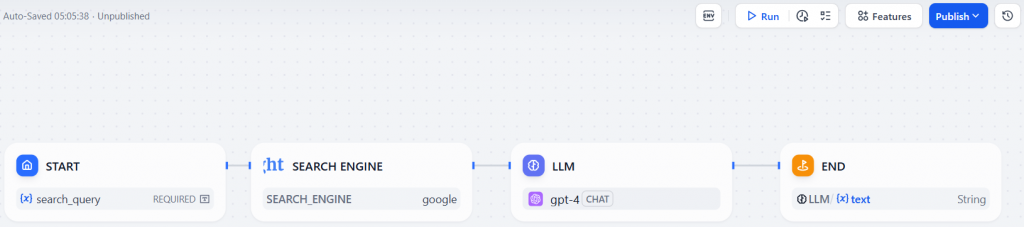
Para executar o fluxo de trabalho, clique no botão “Run” (Executar). No campo de entrada para search_topic, digite o tópico que deseja pesquisar (por exemplo,“novos protocolos de IA“). Em seguida, pressione “Start Run” (Iniciar execução) para iniciar o agente:
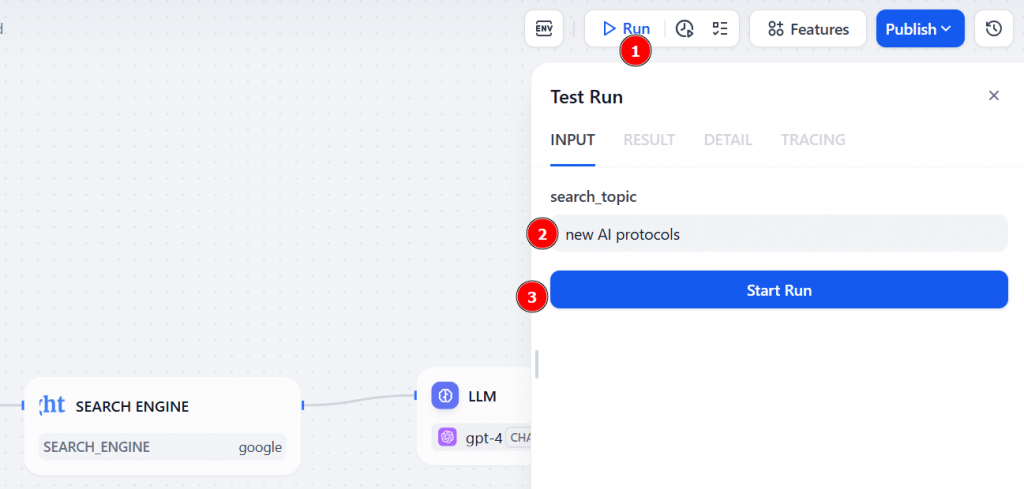
O fluxo de trabalho será iniciado agora. O nó Bright Data realizará uma pesquisa ao vivo no Google e o nó LLM receberá os resultados e gerará o resumo conforme as instruções.
O resultado final aparecerá na guia “Result” (Resultado). Ele pode ter a seguinte aparência:

Abaixo está o resultado como texto:
Common Talking Points: The most frequently mentioned themes and keywords in the search results are "AI protocols", "Model Context Protocol (MCP)", "Agent2Agent (A2A) protocol", "Agent Communication Protocol (ACP)", "AI integration", "AI agent communications", "non-deterministic behavior", "secure, two-way connections", "data sources", and "AI-powered tools". These terms suggest a focus on new methodologies and standards in AI technology, particularly in terms of communication and integration.
Dominant Content Types: The search results seem to include a mix of explanatory articles, guides, and news updates. There are multiple "What is..." type articles, explaining terms like MCP, A2A, and ACP. "A developer's guide to AI protocols..." and "What Every AI Engineer Should Know About A2A, MCP &..." are examples of guide-type articles, while titles like "Introducing the Model Context Protocol Anthropic" and "AI Will Be Governed by Protocols No One Has Agreed on yet" suggest news updates or announcements.
URLs:
1. https://www.anthropic.com/news/model-context-protocol
2. https://www.infoworld.com/article/4007686/a-developers-guide-to-ai-protocols-mcp-a2a-and-acp.html
3. https://www.businessinsider.com/ai-protocol-rules-future-2025-6
4. https://www.cio.com/article/3991302/ai-protocols-set-standards-for-scalable-results.html
5. https://www.forbes.com/sites/craigsmith/2025/04/07/how-a-simple-protocol-is-changing-everything-about-ai/
6. https://hackernoon.com/mcp-a2a-agp-acp-making-sense-of-the-new-ai-protocols
7. https://www.youtube.com/watch?v=rmphqjsc4Po
8. https://www.youtube.com/watch?v=CQywdSdi5iA
9. https://www.youtube.com/watch?v=TQXG4r0U2PQ
10. https://techstrong.ai/aiops/model-context-protocol-the-new-standard-for-ai-interoperability/
11. https://developers.googleblog.com/en/a2a-a-new-era-of-agent-interoperability/
12. https://www.axios.com/2025/04/17/model-context-protocol-anthropic-open-sourceConforme instruído, o modelo LLM informou os resultados conforme solicitado:
- Identificou pontos de discussão comuns, como “Protocolo de contexto de modelo (MCP)” e “Protocolo de agente para agente (A2A)”.
- Destaque para os tipos de conteúdo dominantes, incluindo guias do desenvolvedor e artigos informativos.
- Listou URLs relevantes para leitura adicional.
E pronto! Você criou com sucesso um agente de IA que pode pesquisar informações em tempo real na Web e fornecer insights personalizados.
Conclusão
Neste artigo, você aprendeu a usar o Dify para criar um fluxo de trabalho de IA sem código capaz de pesquisar na Web. Essa funcionalidade é possível graças ao plug-in Bright Data Dify, que fornece uma ferramenta “Search Engine” que recupera dados SERP em tempo real dos principais mecanismos de pesquisa.
Embora esse seja apenas um exemplo, muitos outros casos de uso são possíveis. Independentemente de suas metas específicas de fluxo de trabalho de IA, os agentes eficazes precisam ter acesso a ferramentas para recuperar, validar e transformar dados da Web. É exatamente isso que a infraestrutura de IA da Bright Data oferece.
Crie uma conta gratuita na Bright Data e comece a fazer experiências com nossas ferramentas de dados prontas para IA hoje mesmo!





