

A maioria das equipes de dados não falha porque não consegue coletar dados. Elas falham porque os dados brutos chegam bagunçados, duplicados e inconsistentes, e não há uma forma disciplinada de transformá-los em algo em que analistas e modelos possam confiar. A arquitetura medallion é o padrão que a maioria das plataformas de dados modernas usa para resolver exatamente esse problema, movendo os dados por três camadas progressivamente mais limpas: bronze, prata e ouro.
Este guia explica o padrão da forma como um engenheiro de dados precisa entendê-lo: como cada camada se comporta, como os dados se movem fisicamente entre elas e onde os dados web obtidos externamente entram como entrada bruta de bronze.
Neste artigo:
- O que é a arquitetura medallion e por que o Databricks a popularizou
- O que cada camada — bronze, prata e ouro — faz e quem as consome
- Como os dados se movem pelas camadas com formatos de tabela, transações ACID e captura de dados de alteração
- Onde dados externos e dados web entram no padrão como fonte bronze
- Melhores práticas, armadilhas comuns e os casos de uso em que o padrão se destaca
O que é a arquitetura medallion?
A arquitetura medallion é um padrão de design para organizar dados dentro de um lakehouse, de modo que sua estrutura e qualidade melhorem a cada estágio, à medida que fluem do bronze para a prata e depois para o ouro. O nome toma emprestada a metáfora das medalhas: os dados entram como bronze bruto de baixo valor e são refinados em prata mais valiosa, depois em ouro. Você também verá o nome arquitetura multi-hop, pois cada registro passa por vários saltos antes de estar pronto para consumo.
O padrão foi popularizado pelo Databricks junto com seu paradigma lakehouse e o formato de tabela Delta Lake, que teve seu código aberto em 2019. Um lakehouse combina o baixo custo de armazenamento de um data lake com os recursos de confiabilidade de um data warehouse, como transações ACID e aplicação de esquema. A arquitetura medallion é o princípio organizador que dá a esse lakehouse um fluxo claro de confiança. Hoje é uma convenção multiplataforma: a mesma linguagem de bronze, prata e ouro aparece na documentação do Databricks, do Microsoft Fabric e do Snowflake.
A ideia central é simples. Em vez de limpar os dados em uma etapa opaca, você mantém uma cópia bruta permanente e os refina em estágios, onde cada estágio tem um contrato claro. Essa separação é o que torna o padrão tão duradouro, e é a base para tudo o que se segue.
Por que equipes de dados o adotam
A arquitetura medallion merece seu lugar porque resolve vários problemas ao mesmo tempo.
Qualidade de dados incremental e inspecionável. A qualidade é aprimorada em estágios, em vez de em uma única transformação difícil de rastrear. Cada salto tem uma função definida, então quando algo parece errado você sabe qual camada inspecionar.
Reprocessamento a partir dos dados brutos. Como a camada bronze é um arquivo histórico permanente, você pode reconstruir as tabelas prata e ouro a qualquer momento sem voltar ao sistema de origem. Se uma transformação tiver um bug ou a lógica de negócios mudar, você reproduz a partir do bronze em vez de coletar novamente dados que podem não estar mais disponíveis.
Linhagem e auditabilidade. O bronze preserva o payload original, fornecendo um registro forense. Equipes de conformidade e auditoria podem rastrear qualquer número em um dashboard até o registro bruto exato de onde ele veio.
Separação de responsabilidades entre consumidores. Camadas diferentes servem a públicos diferentes. Engenheiros de dados e equipes de operações trabalham no bronze e na prata. Analistas e cientistas de dados trabalham na prata. Analistas de negócios, executivos e aplicações consomem o ouro.
Atendimento a múltiplos consumidores. Uma única entidade prata limpa pode alimentar muitas tabelas ouro, para que finanças, operações e marketing possam construir suas próprias visões prontas para consumo a partir da mesma fonte confiável.
Esse também é o motivo pelo qual o padrão se encaixa naturalmente com a mentalidade ELT. Você carrega os dados brutos primeiro e depois os transforma dentro da plataforma, em vez de transformar tudo antes de eles chegarem. Se quiser uma revisão sobre o fluxo de ingestão mais amplo, o guia sobre pipelines ETL e a visão geral de arquitetura de pipeline de dados se encaixam perfeitamente no modelo medallion.
As três camadas em detalhes
O fluxo é linear em conceito: os dados brutos chegam no bronze, são refinados para a prata e moldados para consumo no ouro.
flowchart LR
S["External and web sources"] --> B["Bronze: raw, as-is, append-only"]
B --> SI["Silver: cleaned, conformed, deduplicated"]
SI --> G["Gold: aggregated, business-level"]
G --> C["BI, dashboards, ML, applications"]Os dados são progressivamente refinados à medida que passam do bronze para a prata e depois para o ouro.
Camada bronze: bruta e imutável
O bronze é a zona de pouso para tudo o que chega de sistemas de origem externos. Suas tabelas espelham a forma da fonte como está, com algumas colunas extras de metadados registrando detalhes como o timestamp de carregamento e o processo que gravou a linha. As prioridades aqui são a velocidade de captura, um arquivo histórico durável da fonte, linhagem limpa e a opção de reprocessar posteriormente sem nunca reler o sistema de origem.
O bronze tem algumas propriedades definidoras. Ele contém o estado bruto dos dados em seu formato original. É incrementado de forma acumulativa e cresce ao longo do tempo. Serve como a única fonte de verdade, preservando a fidelidade dos dados exatamente como chegaram. Destina-se ao processamento downstream em vez de acesso direto por analistas.
Um detalhe importante de implementação: no bronze geralmente não se aplicam tipos. O Databricks recomenda armazenar a maioria dos campos como string, VARIANT ou binário para se proteger contra mudanças inesperadas de esquema upstream. Na prática, o bronze é schema-on-read. Você captura primeiro e interpreta depois, o que é exatamente o que você quer quando o esquema da fonte está fora do seu controle. As fontes bronze podem ser qualquer combinação de entradas em streaming e em lote, incluindo armazenamento de objetos na nuvem como Amazon S3, Google Cloud Storage e Azure Data Lake Storage, barramentos de mensagens como Kafka e Kinesis, e sistemas federados.
Camada prata: limpa e conformada
A prata é onde os registros bronze são correspondidos, mesclados, conformados e limpos — o suficiente para dar ao negócio uma visão coerente única de suas entidades, conceitos e transações principais. Pense em registros mestre de clientes, transações deduplicadas e tabelas de referência cruzada. Ao reconciliar dados de muitas fontes em uma forma consistente, a prata se torna a camada que alimenta análises de autoatendimento, relatórios ad-hoc, análises avançadas e aprendizado de máquina.
As operações que tipicamente acontecem aqui são concretas: aplicação de esquema, tratamento de valores nulos e ausentes, deduplicação, resolução de registros fora de ordem e com atraso, verificações de qualidade de dados, evolução de esquema, conversão de tipos e joins. É também aqui que você começa a modelagem de dados real, frequentemente usando estruturas mais normalizadas e com bom desempenho de escrita. Rastrear métricas de qualidade de dados nessa etapa é o que separa uma camada prata confiável de uma simples cópia do bronze.
Uma boa prática firme: não escreva na prata diretamente da ingestão. Se você pular o bronze e escrever diretamente na prata, introduz falhas por mudanças de esquema e registros de origem corrompidos, e perde a capacidade de reproduzir. A prata deve sempre incluir pelo menos uma representação validada e não agregada de cada registro, para que análises detalhadas ainda sejam possíveis sem descer ao bronze bruto.
Camada ouro: pronta para o negócio
O ouro contém dados prontos para consumo e específicos para projetos. Os modelos aqui são mais desnormalizados e otimizados para leituras rápidas com menos joins, e é aqui que as transformações finais e as regras de negócio chegam. É o lar do trabalho da camada de apresentação: análises de clientes e estoque, segmentação, relatórios de vendas e similares. Na prática, você frequentemente encontrará esquemas estrela no estilo Kimball ou data marts no estilo Inmon nessa camada.
O ouro representa visões altamente refinadas que impulsionam dashboards, aprendizado de máquina e aplicações. Os dados frequentemente são fortemente agregados e filtrados para períodos de tempo ou regiões específicos. Como um único domínio de negócios raramente se encaixa em uma forma, muitas equipes constroem múltiplas tabelas ouro — por exemplo, visões separadas para finanças, operações e RH — todas derivadas da mesma base prata.
A tabela abaixo resume como as três camadas diferem.
| Camada | Estado dos dados | Operações típicas | Consumidores principais |
|---|---|---|---|
| Bronze | Bruto, como está, somente acréscimo | Ingestão, captura de metadados, preservação do histórico | Engenheiros de dados, equipes de auditoria e conformidade |
| Prata | Limpo, conformado, deduplicado | Validação, deduplicação, aplicação de esquema, joins | Engenheiros de dados, analistas, cientistas de dados |
| Ouro | Agregado, nível de negócios | Agregações finais, regras de negócio, esquemas estrela | Desenvolvedores de BI, executivos, aplicações, ML |
Como os dados se movem pelas camadas
A arquitetura medallion é um padrão lógico, mas repousa sobre um conjunto específico de mecânicas físicas. O quadro completo é assim: muitas fontes alimentam o bronze, os dados se refinam pela prata e pelo ouro dentro do lakehouse, e muitos consumidores leem a partir do ouro.
flowchart LR
subgraph SRC["Sources"]
WEB["Web data via Bright Data"]
DB["Databases and apps"]
MB["Message buses: Kafka, Kinesis"]
end
subgraph LH["Lakehouse: Delta, Iceberg, or Hudi on Parquet"]
BRONZE["Bronze: raw, append-only"] --> SILVER["Silver: cleaned, conformed"] --> GOLD["Gold: business aggregates"]
end
subgraph CON["Consumers"]
BI["BI and dashboards"]
ML["ML and AI"]
APP["Applications"]
end
WEB --> BRONZE
DB --> BRONZE
MB --> BRONZE
GOLD --> BI
GOLD --> ML
GOLD --> APPUma pilha medallion de referência: muitas fontes chegam no bronze, refinam-se pela prata e pelo ouro e servem a muitos consumidores.
Formatos de tabela e arquivo. As camadas geralmente são construídas sobre um formato de tabela aberto em cima de arquivos Parquet em armazenamento de objetos na nuvem. O Delta Lake é o formato nativo no Databricks e no Microsoft Fabric: internamente armazena dados como Parquet, mas adiciona um log de transações e estatísticas que fornecem confiabilidade e desempenho além do Parquet simples. O Apache Iceberg é uma alternativa igualmente capaz quando a interoperabilidade com múltiplos motores é importante, e o Apache Hudi é uma boa opção para ingestão com muitos upserts e captura de dados de alteração. Os três oferecem as garantias ACID das quais o padrão depende.
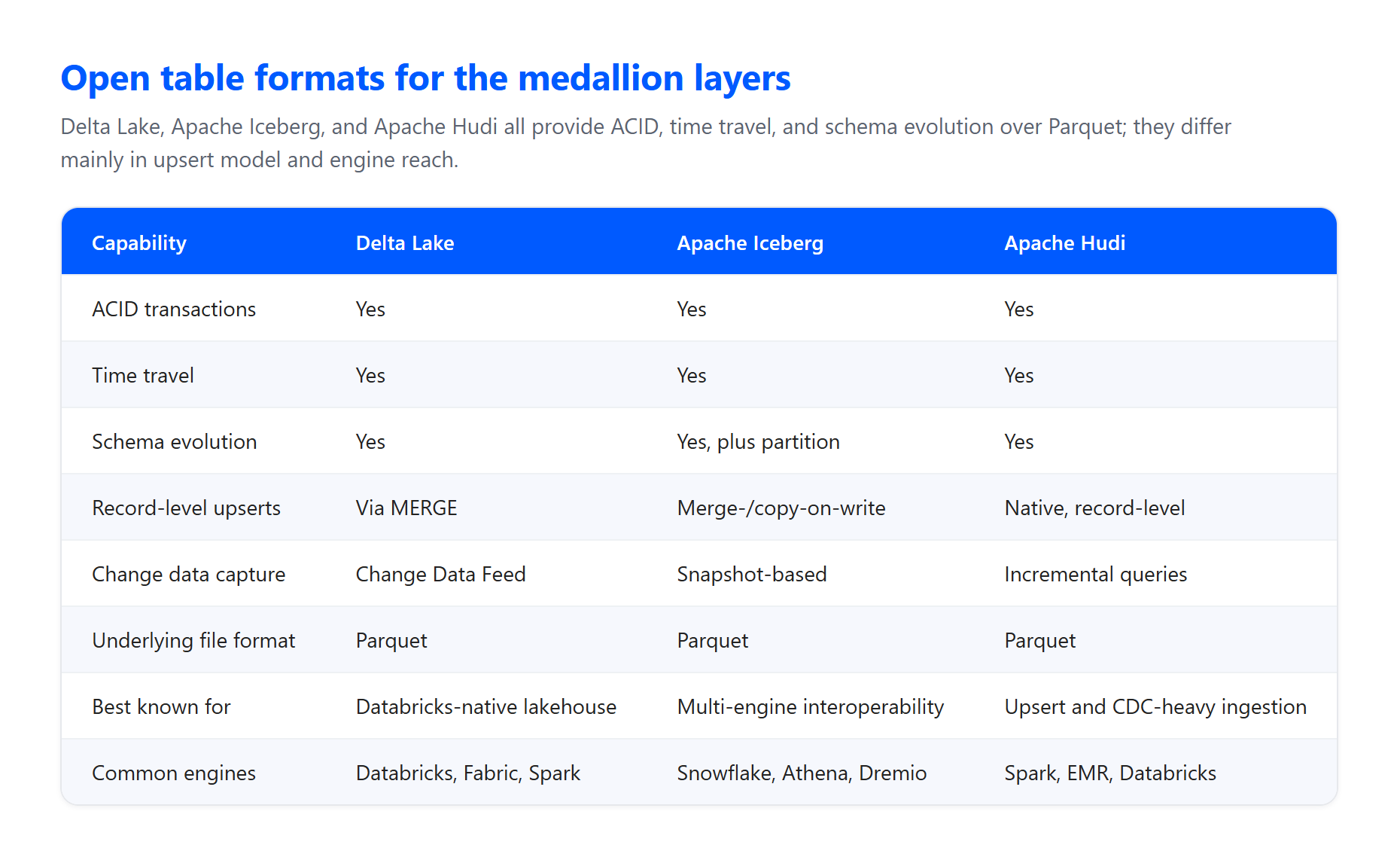
Transações ACID. A arquitetura garante atomicidade, consistência, isolamento e durabilidade à medida que os dados passam por validações e transformações. Isso é o que impede que um job com falha deixe uma tabela parcialmente gravada e corrompida, o que importa enormemente quando muitos pipelines leem e escrevem simultaneamente.
Cargas incrementais e captura de dados de alteração. Raramente se reprocessa tudo em cada execução. O Change Data Feed do Delta Lake permite que as camadas downstream consumam apenas o que mudou. Por exemplo, você pode habilitar o feed em uma tabela prata e usá-lo para atualizar incrementalmente as agregações ouro sem uma atualização completa a cada execução. A ingestão incremental no bronze é uma troca entre custo e latência: o streaming contínuo tem a menor latência e o maior custo, as cargas incrementais disparadas custam menos mas adicionam latência, e as cargas em lote completo têm a maior latência.
Idempotência. A ingestão bronze deve ser idempotente, para que a reexecução de uma carga não crie duplicatas nem perca dados. O design somente de acréscimo mais a deduplicação na prata é o que torna a reprodução segura possível.
Orquestração, lote e streaming. Ferramentas como o Apache Spark lidam com as transformações de bronze para prata e de prata para ouro, tanto em modos de lote quanto de streaming estruturado. Frameworks declarativos como Spark Declarative Pipelines, visões de lake materializadas do Microsoft Fabric e tarefas do Snowflake reduzem o código repetitivo de mover dados entre camadas. Orquestradores como o Apache Airflow coordenam as execuções. Um exemplo prático desse padrão de orquestração, usando Airflow para agendamento e Spark para transformação, é mostrado neste guia de pipeline com Airflow e Spark, e uma variante em streaming neste guia de Spark Structured Streaming.
Vale notar que o vocabulário medallion não é universal. O popular framework de transformação dbt estrutura projetos em camadas de staging, intermediate e marts. As preocupações mapeiam estreitamente para bronze, prata e ouro, mas os nomes são distintos, então não assuma que os dois vocabulários são intercambiáveis ao ler documentação.
Onde os dados web entram: a camada bronze
Aqui está a parte que a maioria dos diagramas de arquitetura ignora: de onde os dados externos realmente vêm e como eles chegam ao bronze em um estado utilizável?
A camada bronze é definida como a zona de pouso para todos os sistemas de origem externos, e o Databricks lista explicitamente armazenamento de objetos na nuvem como S3, GCS e ADLS entre as fontes bronze válidas. Essa é a junção onde os dados web coletados externamente se encaixam. Preços de concorrentes, catálogos de produtos, registros públicos de empresas, resultados de pesquisa e dados de avaliações são todos insumos brutos que pertencem ao bronze em sua forma original, com suas peculiaridades e inconsistências preservadas para a camada prata resolver.
É exatamente aqui que a Bright Data opera. A Bright Data é uma plataforma de dados web que coleta dados públicos da web em escala e os entrega como arquivos estruturados brutos, o que a torna uma fonte natural para a camada bronze. O alinhamento é direto: os destinos para os quais a Bright Data entrega são os mesmos armazenamentos de objetos na nuvem que as plataformas lakehouse tratam como entradas bronze.
flowchart LR
W["Public web: sites, SERPs, marketplaces"] --> BD["Bright Data ingestion: Web Scraper API, Datasets, Data Firehose"]
BD -->|"JSON, NDJSON, CSV, Parquet"| L["Cloud storage: S3, GCS, Azure, or Snowflake"]
L --> BR["Bronze layer: raw, preserved as source of truth"]
BR --> SV["Silver: clean and conform"]
SV --> GD["Gold: serve analytics and ML"]Dados web externos entregues pela Bright Data chegam ao armazenamento na nuvem como camada bronze e fluem pela prata e pelo ouro.
Existem várias maneiras de alimentar o bronze, dependendo se você precisa de um fluxo em lote, sob demanda ou contínuo de dados:
- A Web Scraper API transforma qualquer site em um endpoint de dados estruturados com mais de 437 scrapers pré-construídos, retornando dados como JSON, NDJSON ou CSV. É o gatilho sob demanda para registros bronze frescos.
- Os conjuntos de dados prontos para uso fornecem dados pré-coletados de centenas de domínios populares, disponíveis para download imediato ou atualizados em um cronograma. Este é o caminho em lote para o bronze.
- O Data Firehose entrega um fluxo contínuo e em tempo real de registros web diretamente para o Amazon S3, um webhook ou um stream, adequado para um padrão de ingestão bronze em streaming.
- A API SERP fornece resultados estruturados de mecanismos de busca, uma entrada bronze comum para pipelines de inteligência competitiva e monitoramento de mecanismos generativos.
- O Navegador de scraping lida com sites pesados em JavaScript, fornecendo dados de página renderizados que a coleta estática perderia.
- Para feeds especializados, a Company Data API e os conjuntos de dados para IA e LLM curados entregam dados verticais prontos para inserir em um pipeline, enquanto a Web Archive API fornece snapshots históricos para tabelas bronze de séries temporais.
A história de entrega é o que torna isso limpo. Os conjuntos de dados da Bright Data exportam como JSON, NDJSON, CSV, XLSX e, importante, Parquet — o formato colunar que as tabelas lakehouse usam nativamente. Os destinos de entrega incluem Amazon S3, Google Cloud Storage, Microsoft Azure Blob Storage, Snowflake, Google Cloud Pub/Sub, SFTP, webhook e download direto via API. Na prática, isso significa que um conjunto de dados agendado pode chegar ao seu bucket bronze no S3 como Parquet em uma cadência recorrente, sem nenhum código de cola para escrever. O Scraper Studio sem código estende isso ainda mais, permitindo que você construa um scraper visualmente e carregue a saída diretamente no S3, GCS, Azure, BigQuery ou Snowflake.
Dois princípios mantêm isso fiel ao padrão medallion. Primeiro, preserve o payload bruto. Deposite a saída do provedor no bronze exatamente como entregue, incluindo campos que você ainda não usa, para que você mantenha o registro forense completo. Segundo, normalize na prata, não no bronze. Formatos de data, moeda, mapeamento de campos e deduplicação entre fontes pertencem ao salto prata, independentemente de como o provedor externo estruturou seus dados. Se você está decidindo entre os caminhos em lote e sob demanda, a comparação entre conjuntos de dados versus APIs de scraping de dados é um bom ponto de partida, assim como o guia sobre dados estruturados versus não estruturados.
A confiabilidade importa aqui mais do que em qualquer lugar, porque uma fonte bronze que falha silenciosamente contamina todas as camadas acima dela. A Bright Data reporta uma taxa média de sucesso de 98,44% em um benchmark independente de onze provedores, apoiada por uma rede de proxies residenciais de 400M+ IPs obtidos eticamente e uma meta de disponibilidade de 99,99%. Para equipes com requisitos de governança, a Bright Data mantém conformidade com GDPR, CCPA, SOC 2 Tipo II e ISO 27001 e coleta apenas dados publicamente disponíveis, que é exatamente o tipo de proveniência que uma trilha de auditoria na camada bronze pretende capturar.
Um exemplo prático: do scrape bruto à tabela ouro
A teoria é mais fácil de confiar quando você pode executá-la. Abaixo está um pipeline medallion mínimo em uma pequena amostra real de dados de produtos web: doze listagens coletadas de resultados de pesquisa ao vivo da Amazon nos EUA e no Reino Unido em três categorias. O código é deliberadamente simples, para que o padrão — não as ferramentas — seja o que se destaca.
Bronze. Deposite as linhas exatamente como coletadas. Os preços ainda são strings, as moedas são mistas e nada é limpo ou descartado.
import pandas as pd
# Bronze: raw scraped rows, landed as-is with ingestion metadata
bronze = pd.DataFrame(scraped_rows)
bronze["_ingested_at"] = "2026-06-23T00:00:00Z"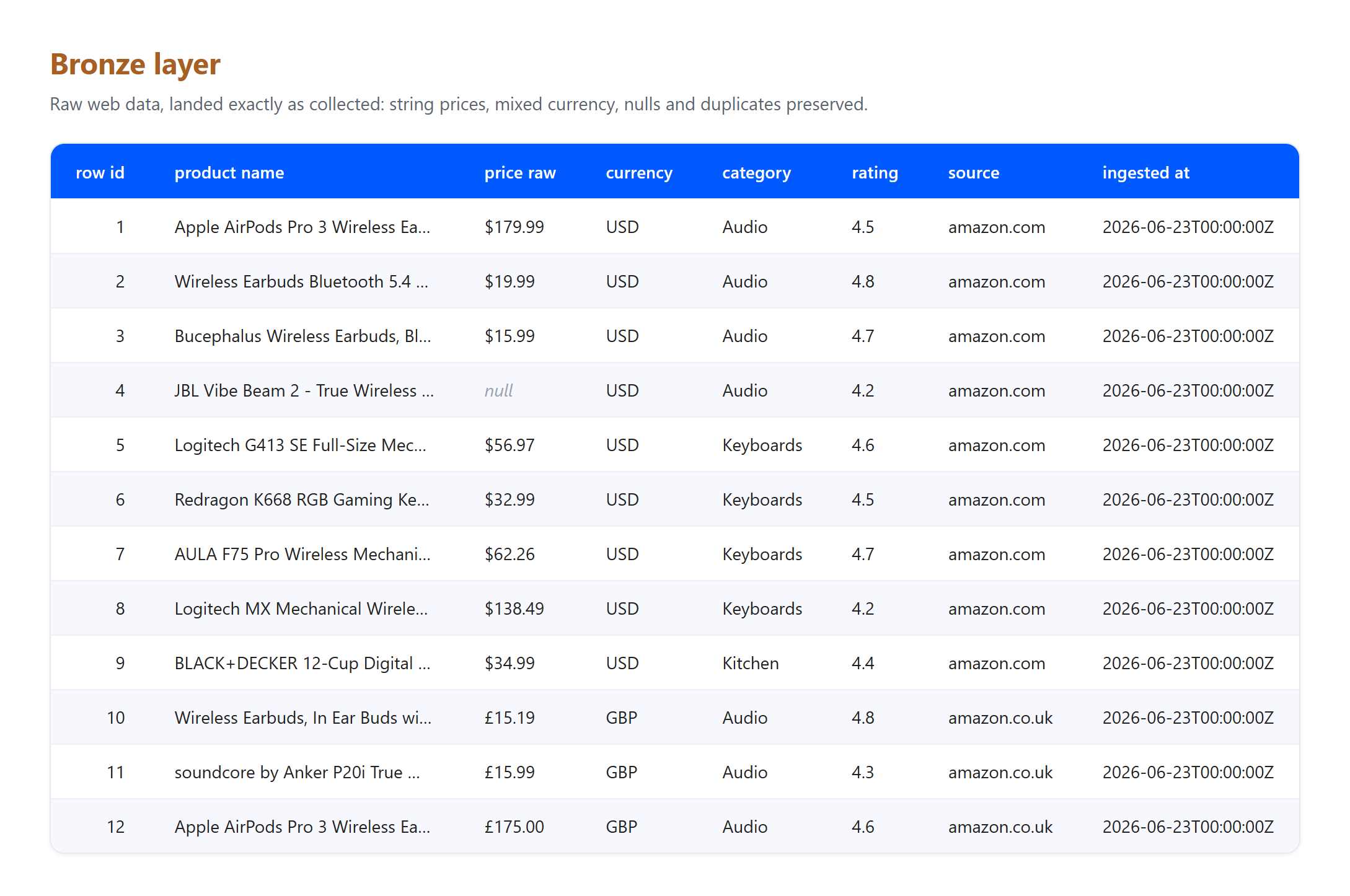
Prata. Analise os preços como números, normalize tudo para USD, decodifique entidades HTML nos títulos, descarte linhas sem preço utilizável e deduplique o mesmo produto capturado mais de uma vez.
import html, re
def to_usd(price_raw, gbp_rate=1.27): # 1.27 is an illustrative fixed rate
if not price_raw:
return None # no price, the row cannot be trusted
is_gbp = "£" in price_raw
value = float(re.sub(r"[^0-9.]", "", price_raw.replace(",", "")))
return round(value * gbp_rate, 2) if is_gbp else round(value, 2)
silver = bronze.copy()
silver["price_usd"] = silver["price_raw"].map(to_usd)
silver["rating"] = silver["rating"].astype(float) # text rating to number
silver["product_name"] = silver["product_name"].map(html.unescape) # & becomes &
silver = silver[silver["price_usd"].notna()] # drop unpriced rows
silver = silver.sort_values("price_usd").drop_duplicates("product_name") # dedup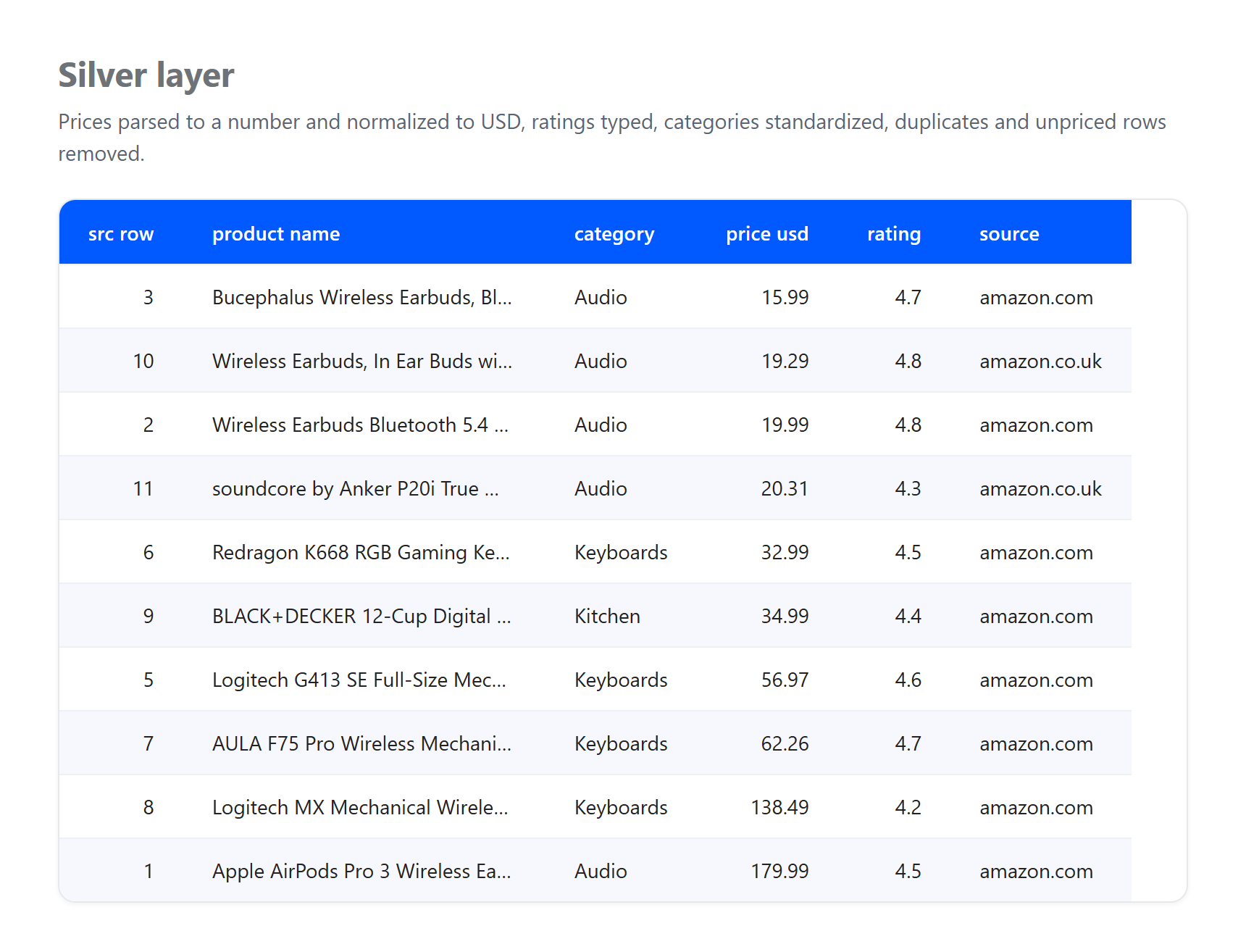
Ouro. Agregue os registros limpos na visão de negócios que um dashboard ou modelo realmente consulta.
gold = (
silver.groupby("category")
.agg(
products=("product_name", "count"),
avg_price_usd=("price_usd", "mean"),
min_price_usd=("price_usd", "min"),
max_price_usd=("price_usd", "max"),
avg_rating=("rating", "mean"),
)
.round(2)
.reset_index()
)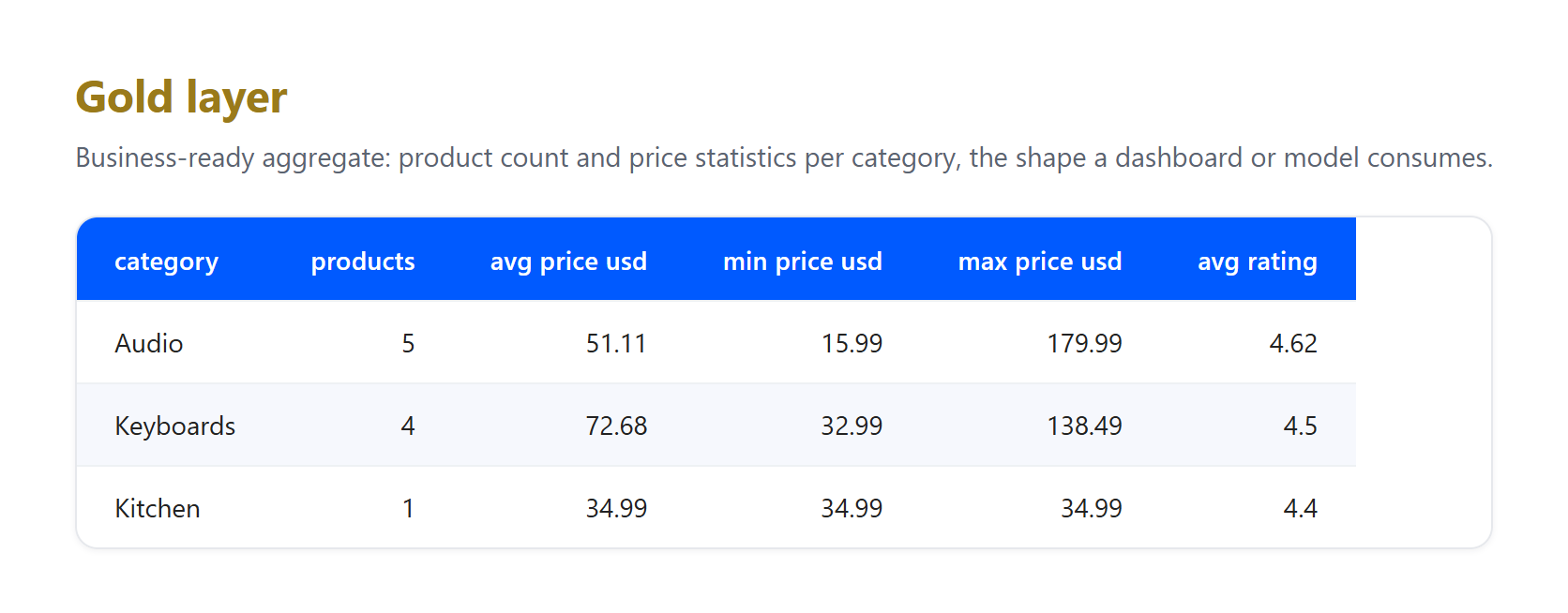
Observe o que as camadas absorveram, porque é exatamente o que um pipeline real precisa enfrentar. Esta é uma pequena amostra real coletada em 23 de junho de 2026, e a taxa de GBP para USD é uma taxa fixa ilustrativa, não uma conversão ao vivo. Três artefatos genuínos chegaram ao bronze e foram resolvidos na prata: uma listagem chegou sem preço e foi descartada, o mesmo produto Apple AirPods Pro 3 foi capturado tanto nas páginas dos EUA quanto do Reino Unido e foi deduplicado para um único registro, e títulos com entidades HTML brutas como & foram decodificados em texto simples. Nenhuma dessas limpezas pertence ao bronze, cuja única função é preservar o que chegou. Essa separação de responsabilidades é o ponto central do padrão.
O ecossistema de ferramentas do lakehouse
O padrão medallion é implementado em um conjunto familiar de ferramentas. Nenhuma delas é intercambiável com as outras, mas uma arquitetura funcional geralmente combina várias.
- Databricks é a plataforma lakehouse comercial que cunhou tanto o paradigma lakehouse quanto a arquitetura medallion, com suporte nativo ao Delta Lake e ferramentas de pipeline declarativo.
- Delta Lake é o formato de tabela de código aberto que adiciona transações ACID, aplicação de esquema, viagem no tempo e captura de dados de alteração sobre o Parquet.
- Apache Spark é o motor de computação distribuída que executa as transformações de bronze para prata e de prata para ouro em lote ou streaming.
- Apache Iceberg é um formato de tabela aberto preferido quando múltiplos motores precisam ler as mesmas tabelas.
- Apache Hudi é um formato de tabela aberto com forte suporte a upsert em nível de registro e extração incremental, comum em camadas bronze com muitas alterações.
- Snowflake suporta o padrão nativamente, incluindo tabelas Iceberg gerenciadas para a camada ouro.
- dbt é o framework de transformação baseado em SQL que muitas equipes usam para construir as camadas prata e ouro.
- Microsoft Fabric implementa a arquitetura medallion nativamente no OneLake, padronizando no Delta Lake.
Se sua plataforma é Snowflake ou Google Cloud, os guias de integração para Bright Data com Snowflake Cortex e o fluxo de trabalho Vertex AI mais API SERP mostram a transferência bronze em contexto.
Melhores práticas
Algumas convenções separam uma implementação limpa de uma frágil.
- Não escreva na prata a partir da ingestão. Sempre deposite os dados brutos no bronze primeiro, para que mudanças de esquema e registros corrompidos não possam quebrar suas tabelas refinadas.
- Mantenha o bronze com tipagem fraca. Armazene a maioria dos campos como string, VARIANT ou binário para que a deriva de esquema upstream não perca dados.
- Leia o bronze como stream sempre que possível. Para fontes somente de acréscimo, leituras em streaming mantêm a latência baixa; reserve leituras em lote para conjuntos de dados pequenos.
- Sempre mantenha um registro não agregado na prata. A agregação pertence ao ouro, para que a prata permaneça reutilizável por muitos consumidores.
- Não force o ouro a ser em tempo real. O ouro é otimizado para agregações frequentemente consultadas e atualizadas em lote. Adaptá-lo para cargas de trabalho de baixa latência tende a criar pipelines frágeis e caros.
- Nomeie as tabelas por camada. Um namespace como catalog.bronze.table, catalog.silver.table, catalog.gold.table comunica o nível de confiança de qualquer tabela de relance.
Armadilhas comuns e críticas
O padrão é robusto, mas é mal utilizado com frequência suficiente para que os modos de falha estejam bem documentados.
Pular o bronze. É tentador quando os dados externos já parecem limpos, mas pular o bronze remove a trilha de auditoria e a capacidade de reprocessar. A semântica da sua camada prata muda silenciosamente quando não há registro bruto por trás dela.
Tratar a prata como ouro. Quando equipes constroem KPIs de negócios e agregações pesadas diretamente na prata, diferentes equipes definem métricas de forma diferente e não há uma versão única e autorizada. Mantenha as agregações no ouro.
Ler o bronze bruto como se fossem dados de produção. O bronze não é verificado e frequentemente é bagunçado. Apontar um dashboard para ele leva a contagens duplicadas e resultados inconsistentes. O bronze é um registro histórico, não uma fonte de verdade para análises.
Entrelaçamento entre camadas. Quando os pipelines vazam responsabilidades entre camadas — por exemplo, ingerindo eventos brutos diretamente no ouro — uma única mudança de esquema pode se propagar por toda a pilha.
Há também uma crítica legítima de aplicar o padrão rigidamente. Como uma análise colocou, aplicar uma estrutura rígida de três camadas a todas as fontes leva a ineficiências quando certos conjuntos de dados não precisam de limpeza extensiva, e o encadeamento sequencial adiciona latência que casos de uso em tempo real podem não tolerar. A comunidade de praticantes respondeu propondo camadas extras em alguns designs, como uma zona de pouso pré-bronze ou uma camada platina acima do ouro para servir operações e aprendizado de máquina.
A forma saudável de ler tudo isso é que a arquitetura medallion é um framework flexível, não um mandato. O próprio Databricks afirma que seguir a arquitetura medallion é uma prática recomendada, mas não um requisito, e o projeto Delta Lake a descreve como um framework opcional e flexível. Use o número de camadas e a nomenclatura que se adequem aos seus padrões de consulta e aos seus consumidores.
Casos de uso comuns
O padrão se destaca mais claramente onde as entradas brutas são bagunçadas e muitos consumidores precisam de saídas confiáveis.
- Monitoramento de preços e inteligência de e-commerce. Dados de produtos e preços coletados de muitos varejistas chegam ao bronze como estão, são normalizados e deduplicados na prata e alimentam dashboards de rastreamento de preços e sortimento no ouro.
- Dados para IA e dados de treinamento de aprendizado de máquina. Texto em escala web e dados estruturados chegam brutos no bronze, são limpos e deduplicados na prata e moldados em features prontas para modelos no ouro. Os passos práticos são abordados neste guia de scraping de dados para aprendizado de máquina, e a estratégia mais ampla no artigo sobre o flywheel de dados para IA.
- Pesquisa de mercado e dados alternativos. Sinais externos de muitas fontes são conformados na prata em uma única visão de pesquisa e depois agregados em indicadores ouro.
- Monitoramento de busca e SERP. Um fluxo contínuo de resultados de pesquisa flui para o bronze, é estruturado na prata e se consolida em métricas de visibilidade e share of voice no ouro.
- Enriquecimento firmográfico e de clientes. Feeds de dados de empresas enriquecem registros internos na camada prata, produzindo tabelas ouro para vendas e marketing.
Para o encanamento de engenharia por trás desses casos, os guias sobre AWS Glue ETL, AWS Step Functions, pipelines Kubeflow, o pipeline Mage AI e conectar dados web ao vivo ao Tableau mostram cada um um caminho real de bronze ao serviço. Os fundamentos da etapa de extração em si são abordados neste guia sobre extração de dados.
Conclusão
A arquitetura medallion perdura porque oferece às equipes uma linguagem compartilhada para transformar dados brutos em dados confiáveis, um salto disciplinado de cada vez. O bronze preserva a verdade, a prata a torna consistente e o ouro a torna útil. O padrão só funciona tão bem quanto os dados brutos que o alimentam, razão pela qual uma fonte bronze confiável e bem estruturada não é um detalhe, mas uma fundação.
Para dados externos e web, essa fundação é onde a Bright Data se encaixa: coleta de nível de produção entregue como JSON, CSV ou Parquet diretamente no armazenamento na nuvem que seu lakehouse já trata como bronze. Pronto para alimentar sua camada bronze com dados web confiáveis? Teste grátis e veja como rapidamente os dados web brutos podem fluir para o seu pipeline.
Perguntas frequentes
P: O que é a arquitetura medallion em termos simples?
É uma forma de organizar dados em um lakehouse para que fiquem mais limpos e úteis à medida que passam por três camadas. Os dados brutos chegam na camada bronze, são limpos e padronizados na camada prata e agregados em tabelas prontas para o negócio na camada ouro. Cada camada tem uma função clara, o que facilita o gerenciamento e a auditoria da qualidade dos dados.
P: Qual é a diferença entre as camadas bronze, prata e ouro?
O bronze contém dados brutos exatamente como chegaram, somente de acréscimo e não transformados, como fonte permanente de verdade. A prata contém dados limpos e conformados, com deduplicação, aplicação de esquema e joins aplicados para que os dados sejam confiáveis e consistentes. O ouro contém dados agregados de nível de negócios modelados para relatórios específicos, dashboards, aprendizado de máquina e aplicações.
P: A arquitetura medallion é a mesma coisa que ETL?
Não, mas estão relacionadas. ETL descreve extrair, transformar e carregar dados. A arquitetura medallion é um padrão de camadas que organiza onde essas transformações acontecem. Em um lakehouse geralmente segue um estilo ELT, onde os dados brutos são carregados no bronze primeiro e transformados em estágios para prata e ouro dentro da plataforma.
P: Sempre preciso das três camadas?
Não. O Databricks descreve a arquitetura medallion como uma prática recomendada, não um requisito. Alguns conjuntos de dados que chegam limpos podem não precisar de uma etapa prata extensiva, e alguns casos de uso em tempo real contornam deliberadamente partes do fluxo. O número de camadas e a nomenclatura devem se adequar aos seus padrões de consulta e consumidores. A principal ressalva é que pular o bronze remove sua trilha de auditoria bruta e sua capacidade de reprocessar.
P: Qual formato de arquivo devo usar para tabelas medallion?
A maioria das implementações usa um formato de tabela aberto como Delta Lake, Apache Iceberg ou Apache Hudi, todos construídos sobre arquivos Parquet em armazenamento de objetos na nuvem. Esses formatos adicionam transações ACID, aplicação de esquema e viagem no tempo, dos quais o padrão depende. O Delta Lake é o formato nativo no Databricks e no Microsoft Fabric, enquanto o Iceberg é comum quando múltiplos motores leem as mesmas tabelas.
P: Como dados externos ou web se encaixam em uma arquitetura medallion?
Dados externos e web são uma entrada da camada bronze. Você deposita os dados coletados brutos — por exemplo, dados de produtos, preços, pesquisa ou empresas — em sua forma original no bronze e depois os normaliza e deduplica na prata. Como as plataformas lakehouse tratam armazenamento de objetos na nuvem como S3, GCS e Azure como fontes bronze válidas, um provedor como a Bright Data pode entregar dados web como JSON, CSV ou Parquet diretamente nesses armazenamentos, onde se tornam a camada bronze.
P: A arquitetura medallion está vinculada ao Databricks?
O Databricks popularizou o termo junto com o paradigma lakehouse e o Delta Lake, mas o padrão não é exclusivo dele. A mesma linguagem de bronze, prata e ouro é usada na documentação do Microsoft Fabric e do Snowflake, e os formatos de tabela abertos subjacentes funcionam em muitos motores. O padrão é uma convenção geral, não o produto de um único fornecedor.





