

Fazer com que um pipeline de dados de produtos da Amazon funcione no seu laptop é uma coisa. Mantê-lo funcionando em produção, com Proxies, CAPTCHAs, alterações de layout e bloqueios de IP, é outra. Mesmo que você resolva a questão da extração em si, ainda precisará de agendamento, novas tentativas, tratamento de erros e uma maneira de realmente ver o que coletou.
Vamos construir tudo isso aqui. Usaremos a API de Scraping de dados da Bright Data e o Mage IA para conectar um pipeline que coleta produtos e avaliações da Amazon, executa a análise de sentimento Gemini e envia tudo para o PostgreSQL e um painel Streamlit. O pipeline completo é executado com o Docker e uma única chave API (além de uma chave Gemini opcional para análise de IA).
TL;DR: inteligência de produtos da Amazon sem construir Infraestrutura de scraping.
- O que você ganha: um pipeline que descobre produtos por palavra-chave, analisa avaliações com a IA Gemini e exibe um painel Streamlit ao vivo.
- Quanto custa: pagamento conforme o uso, cobrado por registro (página de preços), 5 a 8 minutos do início ao fim
- Como funciona: a Bright Data lida com Proxies, CAPTCHAs e Parsing; a Mage IA lida com agendamento, novas tentativas e ramificação
- Como começar:
docker compose up– todo o código no repositório GitHub
O que estamos construindo: um pipeline de integração Bright Data + IA
A API de Scraping de dados da Bright Data lida com a camada de scraping. Você envia uma palavra-chave ou uma URL de produto e recebe um JSON estruturado (títulos, preços, avaliações, comentários, informações do vendedor), já analisado. Sem infraestrutura de Proxy para gerenciar, sem HTML para analisar. Quando a Amazon altera seu site, a Bright Data normalmente atualiza seus analisadores. Seu código permanece o mesmo.
Se você nunca usou o Mage IA antes, ele é uma ferramenta de pipeline de dados gratuita e de código aberto, semelhante ao Airflow, mas sem o boilerplate. Você escreve Python em um editor no estilo notebook, onde cada bloco é uma unidade reutilizável com seu próprio teste e visualização de saída. O que importa aqui: o Mage IA suporta pipelines ramificados, basicamente um DAG (gráfico acíclico direcionado) com caminhos paralelos. Ele também possui lógica de repetição integrada por bloco e variáveis de pipeline que você pode alterar a partir da interface do usuário, sem necessidade de edições de código.
O pipeline tem 6 blocos em dois ramos paralelos:
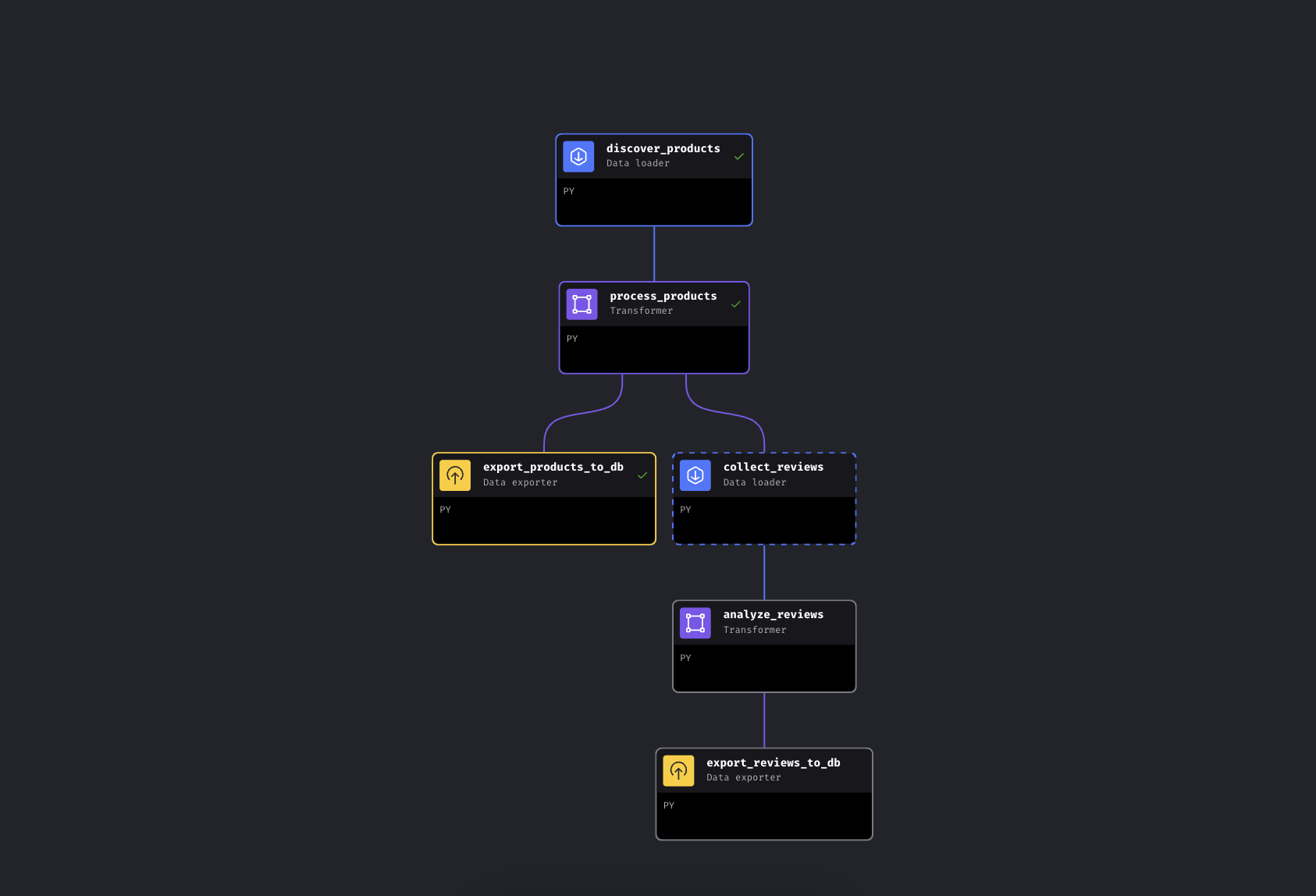
O pipeline ramificado na IA Mage. O ramo esquerdo exporta produtos imediatamente, o ramo direito coleta e analisa avaliações
O pipeline descobre produtos por palavra-chave via Bright Data, os enriquece com faixas de preço e classificações e, em seguida, se ramifica. Um caminho exporta produtos para o PostgreSQL imediatamente, enquanto o outro coleta avaliações dos principais produtos, as executa no Gemini para análise de sentimento e também as exporta.
Estamos usando o Mage IA aqui porque o pipeline se ramifica (é um DAG, não um script linear – se a coleta de avaliações falhar, os dados do seu produto já estarão seguros), mas as chamadas da API Bright Data são apenas solicitações HTTP. Elas funcionam da mesma maneira no Airflow, Prefect, Dagster ou em um script Python simples.
Início rápido
Clone o repositório, adicione suas chaves de API e execute-o. Tudo é executado no Docker, então você não precisa ter o Python instalado localmente.
Pré-requisitos
Você precisará de:
- Docker e Docker Compose (obtenha o Docker)
- Uma conta Bright Data com token de API
- Uma chave API do Google Gemini (nível gratuito disponível com limites; consulte a seção Gemini abaixo)
- Conhecimento básico de Python e Docker. Não é necessária experiência em scraping; esse é o objetivo
Etapa 1: clonar e configurar
Clone o repositório e crie seu arquivo de configuração:
git clone https://github.com/triposat/mage-brightdata-demo.git
cd mage-brightdata-demo
cp .env.example .envAgora adicione suas chaves API ao .env:
BRIGHT_DATA_API_TOKEN=sua_chave_api_aqui
GEMINI_API_KEY=sua_chave_api_gemini_aquiObtenha seu token da API Bright Data: inscreva-se no [Bright Data] (avaliação gratuita, sem necessidade de cartão de crédito) e, em seguida, acesse Configurações da conta e crie uma chave de API. O pipeline usa dois Scrapers da API de Scraping de dados (um para descoberta de produtos e outro para avaliações), cobrados por registro, com Pagamento por uso. Consulte a página de preços para saber as taxas atuais.
Obtenha sua chave API Gemini: acesse o Google AI Studio, faça login e clique em Criar chave API. Nível gratuito, sem necessidade de cartão de crédito. O pipeline também funciona sem ela; ele recorre à avaliação baseada em sentimentos.
Etapa 2: inicie os serviços
docker compose up -dSe você quiser verificar se suas chaves foram carregadas:
docker compose exec mage python -c "import os; t=os.getenv('BRIGHT_DATA_API_TOKEN',''); assert t and t!='your_api_token_here', 'Token not set'; print('OK')"Isso inicia três contêineres:
| Serviço | URL | Finalidade |
|---|---|---|
| Mage IA | http://localhost:6789 |
Editor e programador de pipeline |
| Painel Streamlit | http://localhost:8501 |
Visualização de dados em tempo real + chat |
| PostgreSQL | localhost:5432 |
Armazenamento de dados |
A primeira execução baixa imagens e instala dependências, levando cerca de 3 a 5 minutos, dependendo da sua conexão. Reiniciar com docker compose stop/start leva alguns segundos; docker compose down/up reinstala pacotes pip e leva cerca de um minuto.
Todos os três serviços em execução
Etapa 3: execute o pipeline
Abra http://localhost:6789, vá para Pipelines, clique em amazon_product_intelligence, clique em Triggers na barra lateral esquerda e clique em Run@once.
O painel do IA Mage
O pipeline leva cerca de 5 a 8 minutos do início ao fim. A maior parte desse tempo é dedicada às APIs da Bright Data coletando dados da Amazon; o enriquecimento e as exportações do banco de dados levam segundos, e a análise do Gemini depende do tamanho do lote e dos limites de taxa. Quando todos os 6 blocos ficarem verdes, abra http://localhost:8501 para ver o painel.
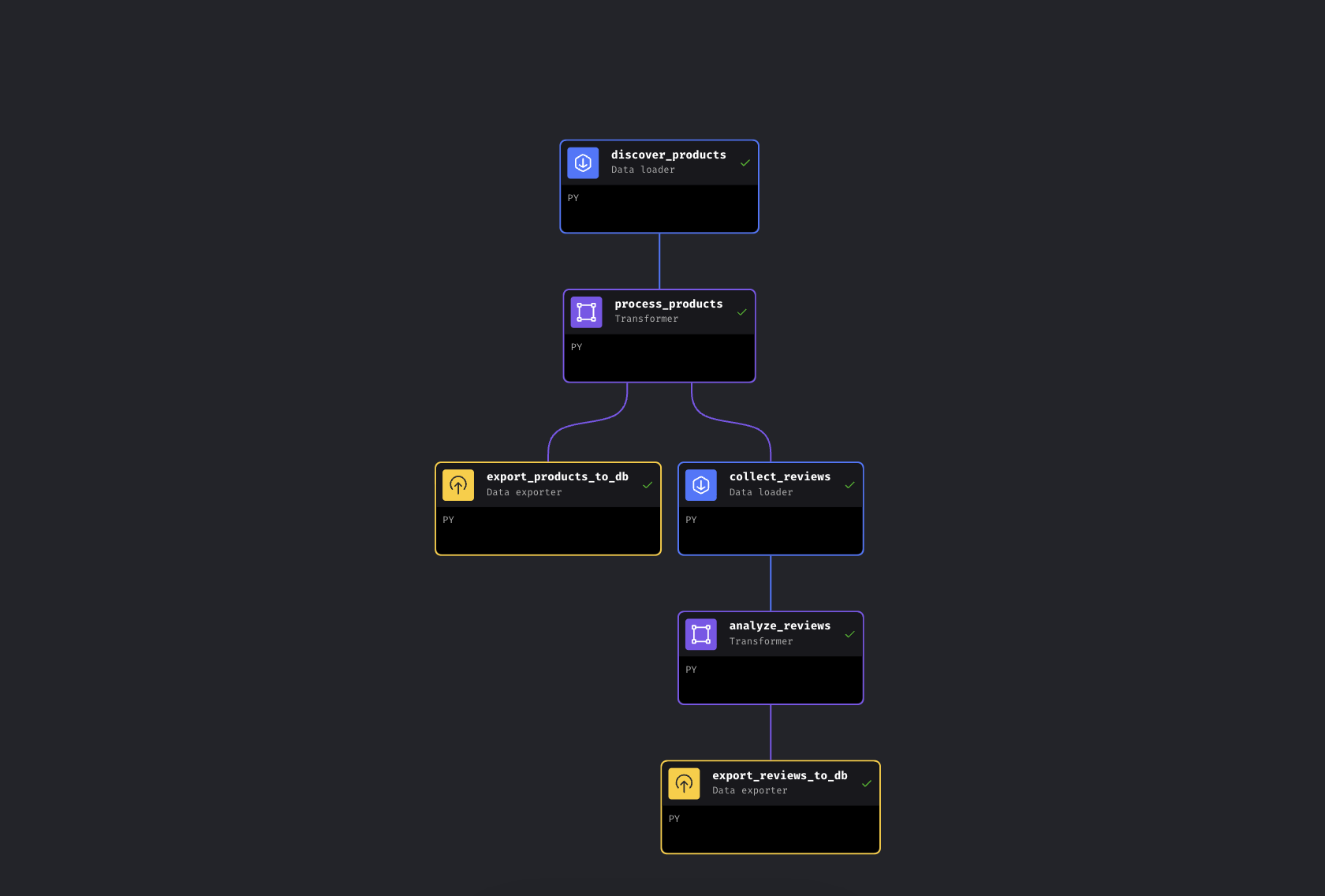
Todos os 6 blocos verdes. Pipeline concluído
Como funciona o pipeline de dados do Mage IA
Vamos examinar o código. Vamos nos concentrar nas integrações da Bright Data e na análise do Gemini.
Conectando a API de Scraping de dados da Bright Data ao Mage IA
Enviamos palavras-chave para a API de produtos da Amazon e recebemos dados estruturados. A Bright Data chama isso de Scraper de “descoberta” – ele encontra produtos por palavra-chave ou categoria. O bloco de avaliações usa posteriormente um Scraper de avaliações separado, que recebe URLs de produtos como entrada. A API usa um padrão assíncrono: acione a coleta, obtenha um ID de instantâneo e faça a pesquisa até que os resultados estejam prontos.
DATASET_ID = "gd_l7q7dkf244hwjntr0" # Amazon Products (verifique o repositório para obter os IDs atuais)
API_BASE = "https://api.brightdata.com/conjuntos-de-dados/v3"
# Acione a coleta (usa /scrape – muda automaticamente para assíncrono se >1 min; para produção, considere /trigger)
response = requests.post(
f"{API_BASE}/scrape",
headers={"Authorization": f"Bearer {api_token}",
"Content-Type": "application/json"},
params={"dataset_id": DATASET_ID,
"type": "discover_new",
"discover_by": "keyword",
"limit_per_input": kwargs.get('limit_per_keyword', 5)},
json={"input": [{"keyword": kw} for kw in keywords]})
snapshot_id = response.json()["snapshot_id"]
# Pesquise até que os resultados estejam prontos
data = requests.get(
f"{API_BASE}/snapshot/{snapshot_id}",
headers={"Authorization": f"Bearer {api_token}"},
params={"format": "json"}
).json()Aqui está o que a Bright Data responde:
{
"title": "Suporte de alumínio para laptop BESIGN LS03",
"asin": "B07YFY5MM8", // ID exclusiva do produto da Amazon
"url": "https://www.amazon.com/dp/B07YFY5MM8",
"initial_price": 19.99,
"final_price": 16.99,
"currency": "USD",
"rating": 4.8,
"reviews_count": 22776,
"seller_name": "BESIGN",
"categories": ["Produtos de escritório", "Material escolar e de escritório"],
"image_url": "https://m.media-amazon.com/images/I/..."
}O kwargs.get('limit_per_keyword', 5) extrai as variáveis do pipeline do IA, para que você possa ajustá-lo a partir da interface do usuário.
Adicionando uma segunda chamada de API: coleta de avaliações da Amazon
O coletor de avaliações pega os produtos processados do bloco upstream e os classifica por número de avaliações. Ele seleciona os N primeiros e insere suas URLs da Amazon em uma segunda API da Bright Data:
REVIEWS_DATASET_ID = "gd_le8e811kzy4ggddlq" # Avaliações da Amazon
# Principais produtos do upstream (passados automaticamente pelo Mage AI)
top_products = data.sort_values('reviews_count', ascending=False).head(top_n)
product_urls = top_products['url'].dropna().tolist()
# Insira URLs na API de avaliações (mesmo padrão /scrape)
response = requests.post(
f"{API_BASE}/scrape",
headers={"Authorization": f"Bearer {api_token}",
"Content-Type": "application/json"},
params={"dataset_id": REVIEWS_DATASET_ID},
json={"input": [{"url": url} for url in product_urls]})
# Mesmo padrão de pesquisa assíncrona que os produtos...Ambos os blocos API têm configuração de repetição no metadata.yaml da demonstração: se uma chamada falhar, o pipeline repete três vezes com um atraso de 30 segundos. Cada bloco nesta demonstração também tem uma função @test que é executada após a execução. Se falhar, os blocos a jusante não são executados, para que os dados incorretos não acabem na sua base de dados.
Adicionando análise de IA: bloco de pipeline de sentimento Gemini
Em vez da correspondência de palavras-chave (que sinalizaria “não é barato, ótima qualidade!” como negativo por causa da palavra “barato”), usamos o Gemini para entender o contexto. O bloco processa avaliações em lotes com uma rotação de três modelos para permanecer dentro dos limites da camada gratuita:
GEMINI_MODELS = ["gemini-2.5-flash-lite", "gemini-2.5-flash", "gemini-2.5-pro"] # verifique o repositório para modelos atuais
prompt = f"""Analise essas avaliações. Para CADA uma, retorne JSON com:
- "sentiment": "Positivo", "Neutro" ou "Negativo"
- "issues": problemas específicos do produto mencionados
- "themes": 1-3 tags de tópicos
- "summary": resumo de uma frase
Retorne APENAS JSON.nn{reviews_text}"""
para modelo em modelos:
tente:
resposta = cliente.modelos.gerar_conteúdo(modelo=modelo, conteúdo=prompt)
retorne json.loads(resposta.texto.strip())
exceto Exceção como e:
se '429' em str(e):
continue # Taxa limitada -- gire para o próximo modeloA rotação começa com flash-lite (o mais barato e rápido), recorre ao flash e, em seguida, ao pro. Se os três forem esgotados, a avaliação recebe uma classificação baseada no sentimento. As cotas do nível gratuito mudam periodicamente, mas a rotação dos três modelos lida com a maioria dos limites de taxa automaticamente. O Gemini retorna sentimento, problemas específicos (como “oscilações em superfícies irregulares” ou “dobradiça se solta com o tempo”) e 1 a 3 tags temáticas por avaliação. Cada avaliação também vem com um resumo de uma frase.
Os blocos restantes (um transformador para níveis de preço e cálculos de desconto e dois exportadores de banco de dados com lógica upsert) são diretos. Eles estão no repositório GitHub, caso você queira se aprofundar.
Saída do pipeline: resultados e painel Streamlit
Veja o que o pipeline produziu em uma execução com as palavras-chave padrão: “suporte para laptop” e “fones de ouvido sem fio”. Seus resultados variam dependendo das listagens atuais da Amazon.
Nesta execução: 10 produtos descobertos, 20 avaliações analisadas pelo Gemini. As avaliações dos fones de ouvido revelaram reclamações que não aparecem na média de 4,3 estrelas – temas como “qualidade do som”, “duração da bateria” e “conectividade” com problemas específicos associados.
O que o pipeline adiciona aos seus dados brutos:
| Campo | Exemplo | Adicionado por |
|---|---|---|
best_price |
$16,99 | Transformador (calculado) |
discount_percent |
15,0 | Transformador (calculado) |
faixa_de_preço |
Orçamento (<$25) | Transformador (enriquecido) |
categoria_de_classificação |
Excelente (4,5-5) | Transformador (enriquecido) |
sentimento |
Negativo | Gemini IA |
problemas |
[“O Bluetooth perde a conexão com frequência”] | Gemini IA |
temas |
[“conectividade”, “duração da bateria”] | Gemini IA |
ai_summary |
“A bateria dura apenas 2 horas, apesar da promessa de 8 horas” | Gemini IA |
Veja como isso funciona na prática – todos os 10 produtos com campos enriquecidos visíveis:
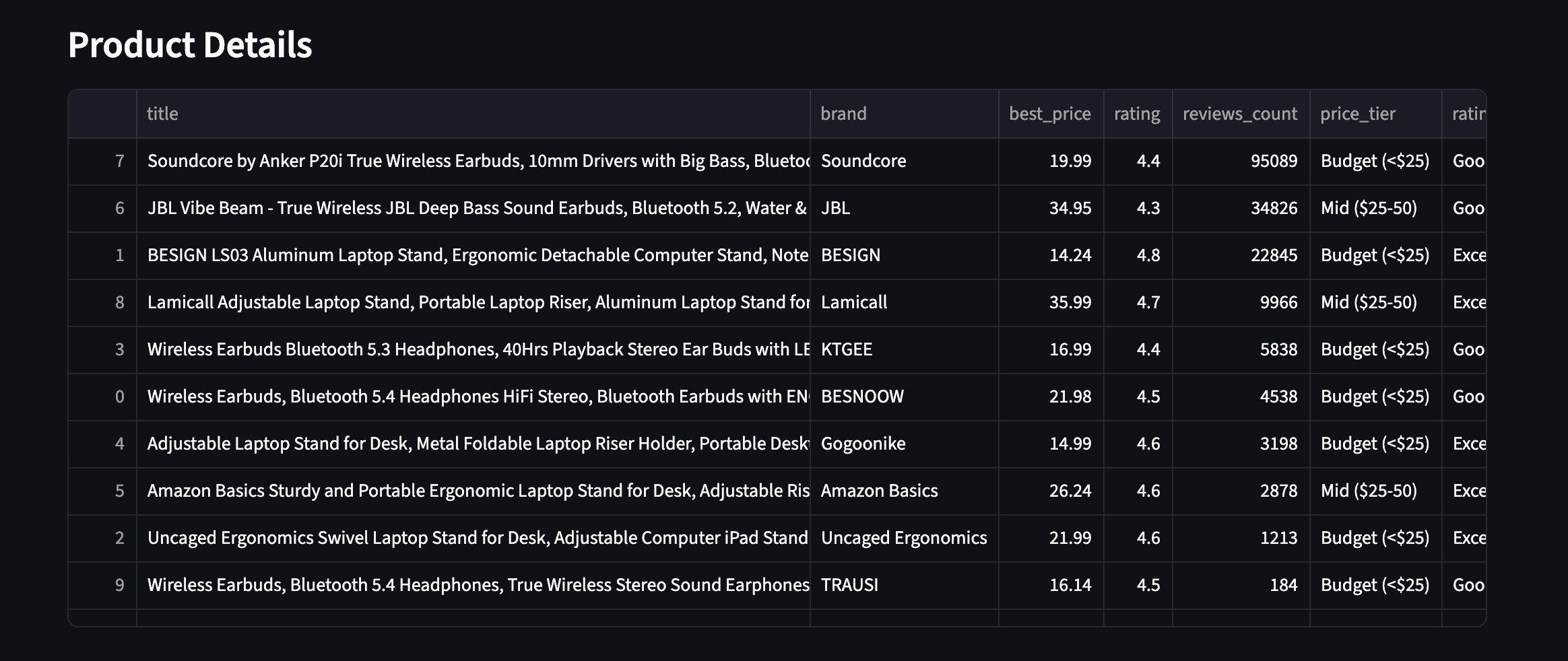
Todos os 10 produtos com campos enriquecidos. Faixas de preço, classificações e contagem de avaliações de duas categorias diferentes de produtos
O painel
Abra http://localhost:8501 para acessar o painel Streamlit. Clique em Atualizar dados na barra lateral para obter os resultados mais recentes do PostgreSQL.
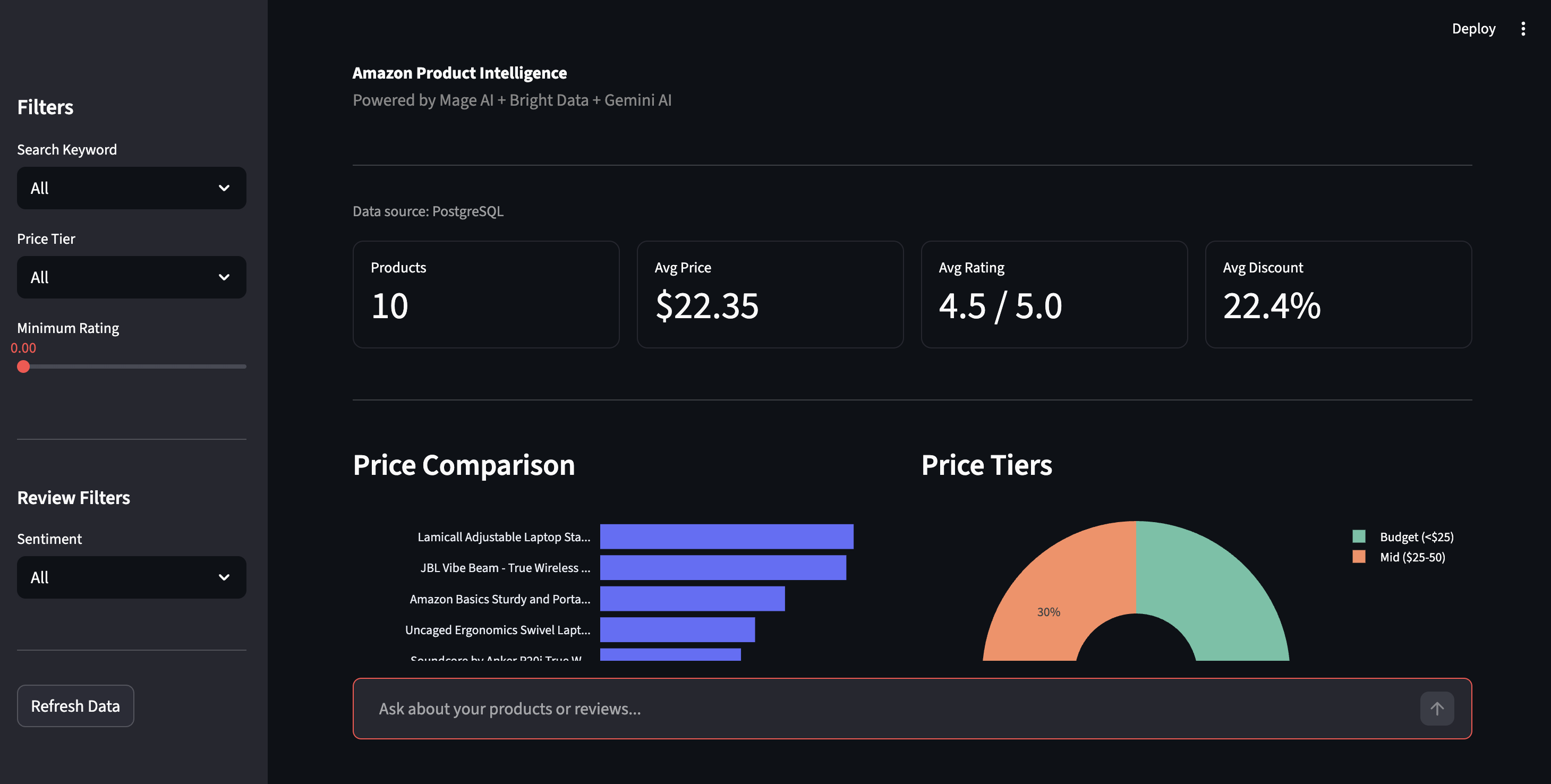
Painel de inteligência de produtos — comparação de preços, faixas de preço e controles de filtragem
A barra lateral permite filtrar por faixa de preço, classificação ou sentimento. A visualização do sentimento mostra a divisão Positiva/Negativa em todas as avaliações, com as questões específicas que o Gemini destacou: “Bluetooth perde a conexão”, “dobradiça se solta com o tempo”, o tipo de detalhe que as classificações por estrelas ocultam.

Discriminação de sentimentos e problemas do produto detectados pela IA. Reclamações reais extraídas pelo Gemini, não correspondência de palavras-chave
O painel também possui um recurso chamado “Converse com seus dados ”. Faça perguntas em inglês simples e a Gemini responderá usando seus dados reais coletados como contexto. Aqui está um exemplo de uma execução separada com mais produtos:
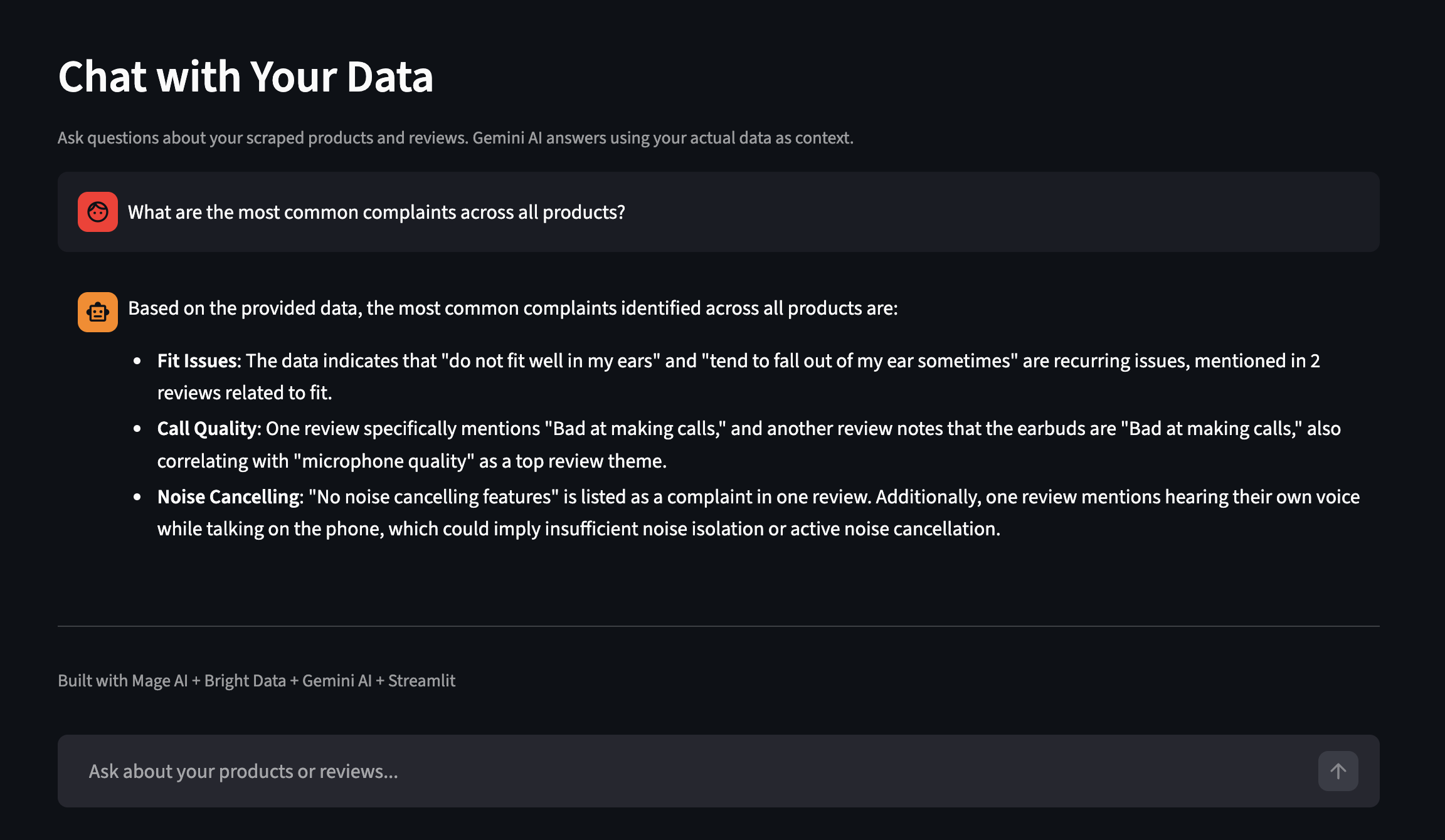
Faça perguntas sobre seus dados coletados em linguagem simples
Dimensionando o pipeline
A demonstração é executada com duas palavras-chave e 10 produtos.
Variáveis do pipeline
Todas configuráveis a partir da interface do usuário do IA ou metadata.yaml:
| Variável | O que controla | Padrão |
|---|---|---|
palavras-chave |
Termos de pesquisa da Amazon | ["suporte para laptop", "fones de ouvido sem fio"] |
limite_por_palavra-chave |
Produtos por palavra-chave da Bright Data | 5 |
top_n_products |
Quantos produtos mais vendidos recebem avaliações coletadas | 2 |
avaliações_por_produto |
Número máximo de avaliações por produto | 10 |
sort_by |
Como classificar os produtos para seleção de avaliações | contagem_de_avaliações |
Altere as palavras-chave para ["capa de celular", "hub USB-C"] e você terá um conjunto de dados totalmente diferente. Sem alterações no código.
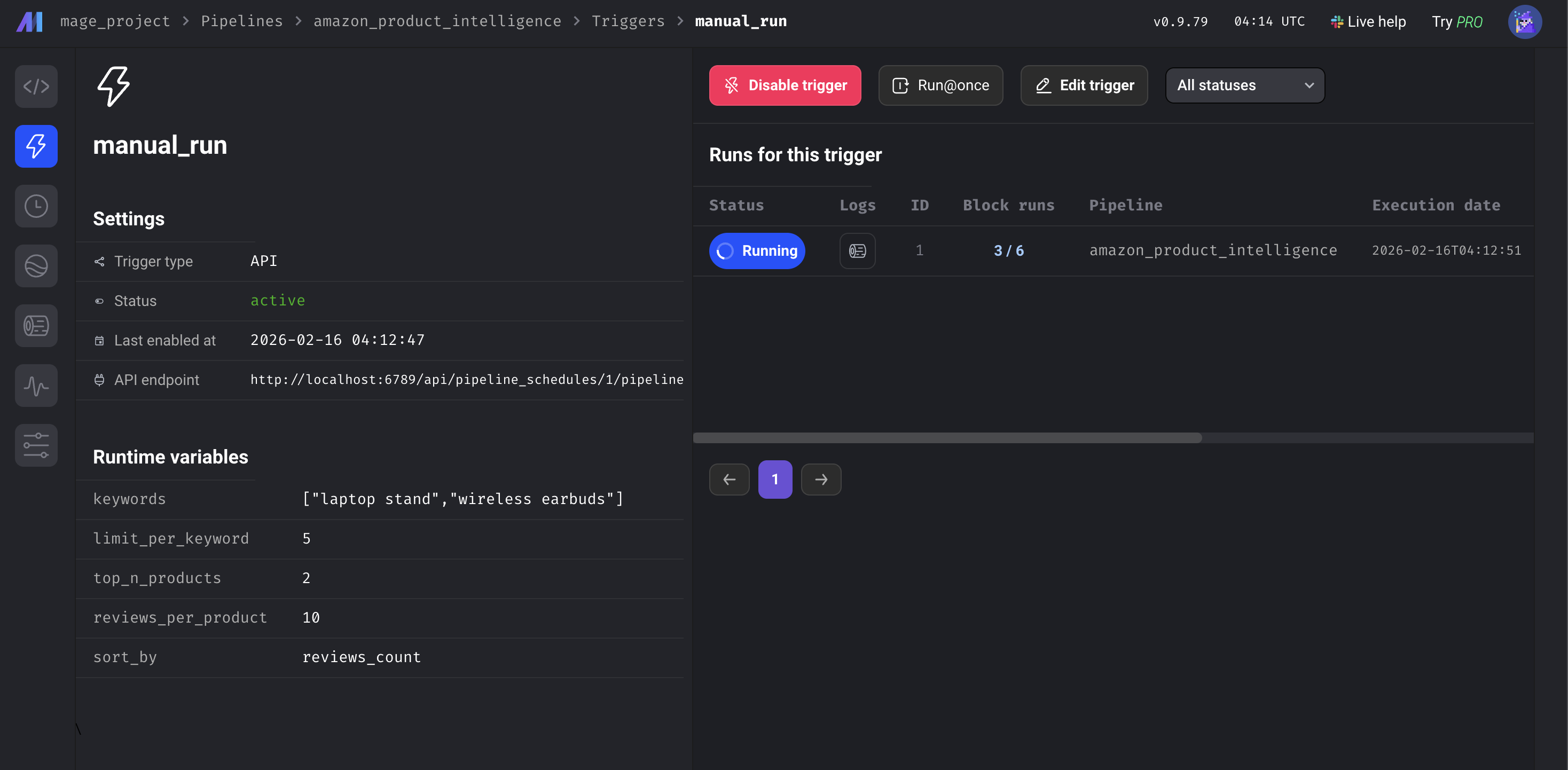
Variáveis de pipeline na interface do usuário do Mage IA
Agendamento
Para executar isso em uma programação, vá para Triggers na barra lateral do Mage IA, clique em + New trigger, selecione Schedule e escolha uma frequência (uma vez, de hora em hora, diariamente, semanalmente, mensalmente ou cron personalizado).
Cada execução faz upserts por ASIN – ela substitui os dados dos mesmos produtos, preservando os resultados de outras palavras-chave. Um backup CSV com carimbo de data/hora também é salvo para comparação histórica.
Depois de ter algumas execuções de dados, você pode consultar o PostgreSQL diretamente para revelar reclamações que as classificações por estrelas não mostram:
-- Encontre produtos com alto sentimento negativo
SELECT asin, product_name,
AVG(CASE WHEN sentiment = 'Negative' THEN 1 ELSE 0 END) as negative_rate
FROM amazon_reviews
GROUP BY asin, product_name
HAVING AVG(CASE WHEN sentiment = 'Negative' THEN 1 ELSE 0 END) > 0.2;Para monitorar seus próprios produtos em vez de pesquisar palavras-chave, remova os parâmetros type, discover_by e limit_per_input e passe as URLs dos seus produtos diretamente como [{"url": "https://www.amazon.com/dp/YOUR_ASIN"}].
Se você precisa de painéis e alertas sem precisar criá-los, o Bright Insights faz isso sem configuração extra para dados de varejo.
Ampliação. Esta demonstração é executada no Docker em uma única máquina, mas o Mage IA oferece suporte a um executor Kubernetes para produção, e as APIs da Bright Data lidam com a simultaneidade em sua extremidade (com limites de taxa para solicitações em lote). A ampliação consiste em adicionar capacidade ao Mage IA, não em alterar seu código de coleta de dados.
Integração de outros scrapers da Bright Data
O mesmo padrão de pipeline funciona com qualquer um dos Scrapers prontos da Bright Data para mais de 100 sites. Por exemplo, consulte os repositórios Google Maps Scraper, LinkedIn Scraper e Crunchbase Scraper. Para mudar da Amazon para outra plataforma, troque o DATASET_ID nos blocos do carregador de dados e ajuste os parâmetros de entrada para corresponder ao esquema do novo Scraper.
Para encontrar o ID e os campos de entrada corretos, navegue pela Biblioteca de Scrapers em seu painel ou chame o endpoint /datasets/list – o Construtor de Solicitações de API no painel mostra exatamente o que cada Scraper espera. A análise Gemini e a estrutura do pipeline são mantidas como estão; os blocos de enriquecimento e exportação podem precisar de ajustes nos nomes das colunas se os campos de resposta do novo Scraper forem diferentes dos da Amazon.
Solução de problemas
Se algo der errado durante a configuração ou execução, aqui estão as soluções mais comuns:
- A porta 6789 ou 8501 já está em uso. Outro serviço está ocupando a porta. Interrompa esse serviço ou edite
o docker-compose.ymlpara remapear as portas (por exemplo, altere6789:6789para6790:6789). - A API da Bright Data retorna 401 Não autorizado. Seu token de API está ausente ou malformado. Vá para Configurações da conta, copie o token completo e certifique-se de que não haja espaços à direita no seu arquivo
.env. O token é uma longa sequência hexadecimal (64 caracteres). Se o que você copiou for curto ou tiver traços como um UUID, você pode ter copiado o campo errado. - O Gemini retorna 429 (limite de taxa) em todos os modelos. O nível gratuito tem limites por minuto que mudam periodicamente. O pipeline lida com isso alternando entre três modelos, mas se todos os três forem esgotados, as avaliações voltam para o sentimento baseado em classificação. Para evitar isso: reduza
reviews_per_productnas variáveis do pipeline, adicione umtime.sleep(60)entre os lotes no bloco Gemini ou habilite o faturamento em seu projeto Google IA para cotas mais altas. Verifique a página de limites de taxa do Google para saber as cotas atuais. - Um bloco do pipeline aparece em vermelho (falha). Acesse a página Logs do seu pipeline (acessível na barra lateral esquerda) para ver o erro. Você pode filtrar por nome do bloco e nível de log. Causas comuns: token de API expirado, tempo limite de rede na API Bright Data (aumente
max_wait_secondsno bloco) ou uma resposta Gemini que não é JSON válida (a função@testdo bloco detecta isso). - O Docker Compose é lento ou falha no Apple Silicon. A imagem Mage IA é multi-arquitetura e funciona no ARM, mas a extração inicial pode demorar mais. Se a compilação falhar com um erro de memória, aumente a alocação de memória do Docker Desktop para pelo menos 4 GB em Configurações → Recursos.
Próximos passos
Você tem um pipeline funcional que coleta dados de produtos da Amazon, executa análises de avaliações com IA e armazena tudo no PostgreSQL – sem proxies, sem analisadores, sem tarefas cron que você tem medo de tocar.
Se você seguiu as instruções, personalize-o. Troque a lista de palavras-chave em metadata.yaml por uma categoria de produto diferente – sem necessidade de alterações no código. Para uma personalização mais profunda, direcione-o para ASINs específicos ou mude para um Scraper Bright Data totalmente diferente.
É novo aqui? [Comece com um teste grátis do Bright Data]() (sem necessidade de cartão de crédito), clone o repositório de demonstração e execute o docker compose up.
Perguntas frequentes
Perguntas comuns sobre esta configuração:
Como faço para extrair dados de produtos da Amazon com Python?
Você pode criar seu próprio Scraper com requests e BeautifulSoup (que deixa de funcionar quando a Amazon altera os layouts) ou usar o Scraper da Amazon da Bright Data, que retorna JSON estruturado a partir de uma única chamada de API. Para um exemplo independente em Python, consulte o repositório Amazon Scraper. Para um aprofundamento, consulte o guia completo de scraping da Amazon da Bright Data
Quanto custa extrair dados da Amazon com a Bright Data?
A API de Scraping de dados usa preços pré-pagos, cobrados por cada 1.000 registros coletados. O nível gratuito do Gemini cobre a análise de IA. Novas contas têm direito a um teste gratuito. Consulte a página de preços para ver as taxas atuais.
Posso fazer scraping do Walmart, eBay ou outros sites de comércio eletrônico com este pipeline?
Troque o DATASET_ID nos blocos do carregador de dados e ajuste os parâmetros de entrada para corresponder ao novo esquema do Scraper. A análise do Gemini e a estrutura do pipeline são mantidas; os blocos de enriquecimento e exportação podem precisar de ajustes nos nomes das colunas.
O que acontece quando a Amazon altera o layout da página?
Nada do seu lado. A Bright Data mantém os analisadores, portanto, quando a Amazon atualiza seu HTML, suas chamadas de API e formato de resposta normalmente permanecem os mesmos.
Preciso do Gemini ou posso usar um LLM diferente?
O pipeline funciona sem o Gemini; ele recorre à avaliação baseada em sentimentos. Para trocar por um LLM diferente (OpenAI, Claude, Llama), modifique a função analyze_reviews no bloco Gemini. O formato do prompt permanece o mesmo; basta alterar a chamada da API.





