
Nesta postagem do blog, você verá:
- O que é o social listening e por que ele é valioso.
- Por que a IA agênica é a melhor abordagem para realizá-la.
- Os principais obstáculos ao uso da IA para monitoramento de mídias sociais, especialmente por meio de agentes.
- Como superá-los com ferramentas dedicadas de scraping de mídias sociais, prontas para uso com agentes.
- Um guia passo a passo para criar um fluxo de trabalho de escuta social baseado em agentes no LangChain, com o apoio das ferramentas de scraping de redes sociais da Bright Data.
- O que você precisa para transformar este exemplo em um fluxo de trabalho baseado em agentes pronto para produção.
- Exemplos de fluxos de trabalho agenticos reais para monitoramento de redes sociais.
Vamos começar!
Monitoramento de redes sociais: o que é, como funciona e exemplos
O monitoramento de redes sociais é o processo de monitorar e analisar conversas digitais para entender o que as pessoas estão dizendo sobre uma marca, produto, anúncio, setor ou tópico específico.
Vai além do simples rastreamento de menções. O monitoramento de redes sociais ajuda a descobrir tendências, medir o sentimento e entender como o público externo realmente se sente. Seu objetivo final é gerar insights que orientem o marketing, as decisões sobre produtos e o suporte ao cliente.
Em um nível geral, o monitoramento de redes sociais geralmente segue um processo de duas etapas:
- Monitoramento: Rastrear plataformas de mídia social em busca de menções, comentários e conversas relacionadas a um tópico-alvo (por exemplo, concorrentes, sua marca, palavras-chave relevantes etc.).
- Análise: Interpretar esses dados para entender o que está acontecendo, identificar padrões e tomar medidas para melhorar os resultados ou obter insights mais profundos.
Por exemplo, uma empresa poderia estudar discussões não filtradas no Reddit em comunidades de nicho para descobrir pontos fracos ou solicitações de recursos. Da mesma forma, uma marca pode analisar comentários e hashtags no Instagram para avaliar o engajamento e a percepção da marca.
Por que um fluxo de trabalho de IA agênico é ideal para o social listening
Os fluxos de trabalho tradicionais de escuta social são geralmente estáticos, construídos sobre uma série de componentes que alimentam dados da entrada à saída em um pipeline fixo.
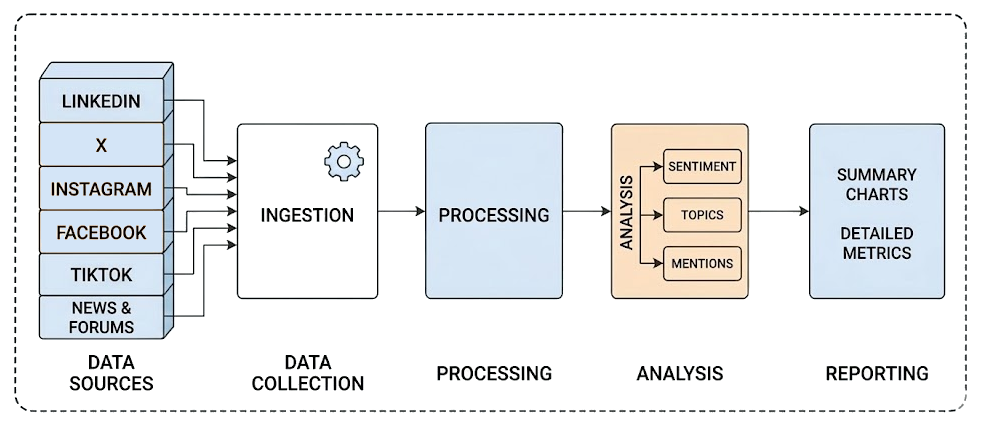
Essa abordagem funciona bem para muitos processos de análise de dados, mas enfrenta dificuldades com dados de mídias sociais. A razão é que interpretar o contexto e se adaptar continuamente a novas conversas é extremamente desafiador. É aqui que a IA, especialmente por meio de fluxos de trabalho agenticos, se torna uma excelente opção!
Um fluxo de trabalho de monitoramento de redes sociais baseado em agentes transforma esse fluxo de dados passivo em um mecanismo de inteligência ativo. Afinal, ao contrário de pipelines estáticos, os agentes de IA podem se comportar de forma autônoma.
Por exemplo, se um agente detectar um pico incomum de sentimento no Reddit, ele pode investigar proativamente tópicos relacionados no X ou no Threads para encontrar a causa raiz. Além disso, ele pode realizar uma pesquisa mais aprofundada no próprio Reddit (ou, potencialmente, até mesmo no Google) para entender o que está acontecendo.
Em particular, as principais vantagens de um fluxo de trabalho de escuta social baseado em agentes são:
- Análise profunda de sentimentos: além de simplesmente atribuir rótulos “positivo/neutro/negativo”, a IA compreende o sarcasmo e o contexto cultural. Isso proporciona uma visão de alta fidelidade dos dados de entrada, particularmente em termos de sentimento e engajamento.
- Pesquisa autônoma: os agentes podem buscar proativamente tendências emergentes ou aprofundar-se em conversas em andamento sem a necessidade de intervenção manual constante.
- Integração entre plataformas: fluxos de trabalho baseados em agentes podem monitorar várias redes simultaneamente, agregando insights em uma única visão acionável.
Ao passar de pipelines fixos para o raciocínio agênico, você pode começar a ouvir verdadeiramente as mídias sociais. Essa mudança leva a um sistema dinâmico que evolui tão rapidamente quanto a própria conversa, sem exigir alterações nos elementos do pipeline.
Desafios na escuta de mídias sociais com IA
Não há dúvida de que a IA tornou a escuta social significativamente mais fácil, especialmente quando se trata de entender o “porquê”. Modelos avançados de IA/ML podem analisar sentimentos, prever possíveis tendências e até mesmo interpretar nuances. No entanto, um grande desafio permanece: como coletar dados de mídias sociais de forma confiável e em escala?
A ideia principal é conectar seu fluxo de trabalho de agente diretamente às APIs das plataformas sociais (se disponíveis). No entanto, as APIs oficiais podem ser caras, sujeitas a limites de taxa e podem incluir restrições sobre como você pode processar os dados recuperados. Além disso, as respostas das APIs podem mudar com o tempo ou ser incompletas. Por esses motivos, as APIs muitas vezes não são uma opção prática, e muitas equipes recorrem ao Scraping de dados.
Ainda assim, o scraping de mídias sociais é inerentemente difícil por várias razões:
- Complexidade e mudanças da plataforma: os sites de redes sociais evoluem constantemente, com padrões interativos e de navegação complexos e altamente dinâmicos. Isso transforma o Parsing de dados em uma tarefa difícil.
- Medidas anti-bot: CAPTCHAs, verificações de autenticidade humana e limites de taxa exigem estratégias sofisticadas para rotação de IP, gerenciamento de impressões digitais e muito mais.
- Fragmentação de dados: os dados estão espalhados por várias plataformas (X, Instagram, Threads, TikTok, Reddit, LinkedIn, YouTube, Facebook etc.), dificultando a criação de um conjunto de dados unificado de redes sociais.
Mesmo quando você tem acesso a ferramentas confiáveis de scraping de redes sociais, dois obstáculos adicionais permanecem:
- Compatibilidade da ferramenta: a ferramenta de scraping deve ser compatível com a biblioteca de IA ou o fluxo de trabalho agênico que você planeja usar.
- Usabilidade dos dados: os dados coletados devem ser estruturados, limpos e entregues em um formato que a IA possa compreender facilmente. Atrasos, formatação inconsistente ou campos de dados ausentes podem reduzir a eficácia dos fluxos de trabalho agenticos e aumentar o risco de alucinações. Descubra os melhores formatos de dados para IA agentica.
Assim, embora a IA transforme o monitoramento de redes sociais, o verdadeiro gargalo está na aquisição de dados.
Ferramentas preparadas para IA para uma escuta social agentiva fundamentada e escalável
Você sabe que permitir que agentes de IA acessem dados confiáveis de mídias sociais é o principal obstáculo nos fluxos de trabalho de escuta social agentica. Como resultado, a solução é clara: os agentes precisam de acesso a ferramentas confiáveis e prontas para uso corporativo para a coleta de dados de mídias sociais.
Quando acionadas de forma autônoma por agentes de IA, essas ferramentas extraem dados otimizados para IA de plataformas de mídia social selecionadas. Os dados retornados formam a base para que a IA analise, raciocine e infira insights. O desafio é encontrar boas ferramentas, pois sem elas você enfrentará os problemas típicos de confiabilidade e escalabilidade associados ao Scraping de dados.
Assim, as ferramentas de scraping de mídias sociais prontas para uso por agentes devem:
- Ser altamente robustas, com altas taxas de sucesso e tempo de inatividade mínimo.
- Suportar solicitações simultâneas para lidar com grandes volumes de dados.
- Retornar conteúdo em formatos ideais para ingestão de LLM, como JSON ou Markdown.
- Integrar-se perfeitamente com a biblioteca de agentes de IA de sua escolha — seja LangChain, LlamaIndex, CrawlAI, Agno, Dify ou frameworks semelhantes.
- Lidar com medidas anti-bot, incluindo limites de taxa, rotação de IP, CAPTCHAs e outras proteções.
- Oferecer suporte a várias plataformas de mídia social.
É exatamente isso que a Bright Data oferece por meio de seu serviço Social Media Scraper. Vamos explorar isso com mais detalhes!
Ferramentas de scraping de redes sociais preparadas para IA da Bright Data
A Bright Data é a plataforma líder em coleta de dados da web, ocupando também o primeiro lugar entre os principais provedores de dados de redes sociais. Entre suas soluções de scraping preparadas para IA, o Social Media Scraper se destaca por fluxos de trabalho baseados em agentes:
- Alcança 99,99% de confiabilidade e 99,95% de taxas de sucesso, garantindo fluxo contínuo de dados para agentes de IA com tempo de inatividade mínimo.
- Projetado para escalabilidade, suportando alta simultaneidade graças a uma rede de Proxies com 150 milhões de IPs em 195 países.
- Permite o scraping em massa de até 5.000 páginas de redes sociais simultaneamente, permitindo que os agentes lidem com uma grande quantidade de dados.
- Retorna formatos estruturados e prontos para LLM, como JSON e Markdown, otimizados para rápida ingestão, raciocínio e processamento de IA a jusante.
- Oferece integrações oficiais com mais de 70 frameworks e soluções de IA, além de APIs nativas para implementações personalizadas.
- Lida automaticamente com desafios de anti-bot e anti-scraping para você.
- Oferece suporte às principais plataformas, como Facebook, Instagram, LinkedIn, TikTok, X, Pinterest, Quora, YouTube, Threads, Reddit, Vimeo e muito mais.
- O modelo de pagamento por sucesso garante eficiência de custos, tornando a coleta de dados em grande escala impulsionada pela IA previsível e econômica.
Observação: esta solução também está disponível nativamente por meio do servidor Web MCP da Bright Data, permitindo uma integração simplificada em fluxos de trabalho de agentes.
Como criar um agente de monitoramento de redes sociais com o suporte da Bright Data
Nesta seção guiada, você verá como começar com um agente de monitoramento de redes sociais simples. Ele será criado no LangChain e conectado ao Gemini, mas qualquer outra estrutura de agente de IA e provedor de LLM funcionará.
Observação: Se você deseja instruções práticas sobre como usar as soluções da Bright Data para criar um aplicativo baseado em IA para monitoramento de redes sociais, consulte o webinar“Criação de um aplicativo de monitoramento de redes sociais baseado em IA”.
Siga as etapas abaixo!
Pré-requisitos
Para seguir este tutorial, certifique-se de ter:
- Python 3.10 instalado localmente.
- Uma conta da Bright Data com uma chave de API pronta.
- Uma chave API Gemini (ou uma chave API de qualquer outro provedor de LLM compatível com o LangChain).
- Um conhecimento básico de como os agentes do LangChain funcionam.
Consulte o guia oficial para configurar sua chave API da Bright Data. Guarde-a em local seguro, pois você precisará dela para conectar seu agente LangChain à Bright Data usando as ferramentas oficiais LangChain–Bright Data.
Para obter mais informações sobre a integração do Bright Data com o LangChain, consulte as postagens do blog abaixo:
- Usando o LangChain e o Bright Data para pesquisa na Web
- Scraping de dados com LangChain e Bright Data
Passo 1: Configure seu projeto LangChain
Crie um novo projeto Python para seu agente de monitoramento de redes sociais:
mkdir agentic-social-listening
cd agentic-social-listeningNa pasta do projeto, crie um ambiente virtual e ative-o:
python -m venv .venv
source .venv/bin/activate # ou no Windows: .venvScriptsactivateAdicione um arquivo agent.py, que conterá a lógica do seu agente de monitoramento de redes sociais. A estrutura do seu projeto deve ficar assim:
agentic-social-listening/
├── .venv/
└── agent.pyNo ambiente virtual ativado, instale as bibliotecas necessárias:
pip install langchain langchain-google-genai langchain-brightdataSão elas:
langchain: Simplifica a criação de agentes de IA.langchain-google-genai: Conecta seu agente ao Gemini por meio da integraçãoChatGoogleGenerativeAI.langchain-brightdata: Conecta seu agente LangChain às soluções de scraping da Bright Data por meio da integração oficial, conforme explicado na documentação.
Ótimo! Carregue a pasta do projeto em seu IDE Python favorito e prepare-se para desenvolver um fluxo de trabalho de monitoramento de redes sociais com agentes.
Passo 2: Defina o fluxo de trabalho do agente
Suponha que você queira criar um agente de monitoramento de redes sociais que acompanhe o sentimento e as menções em duas postagens (uma no Instagram e outra no TikTok) para o mesmo anúncio. Embora as postagens sejam diferentes, o anúncio subjacente é idêntico.
Este é um exemplo interessante porque mostra como um agente pode rastrear o engajamento em várias plataformas para uma única campanha, identificar sentimentos sobrepostos e específicos de cada plataforma e detectar menções ao produto ou solicitações promocionais.
Aqui, usaremos um anúncio da Nike. É assim que ele aparece no Instagram: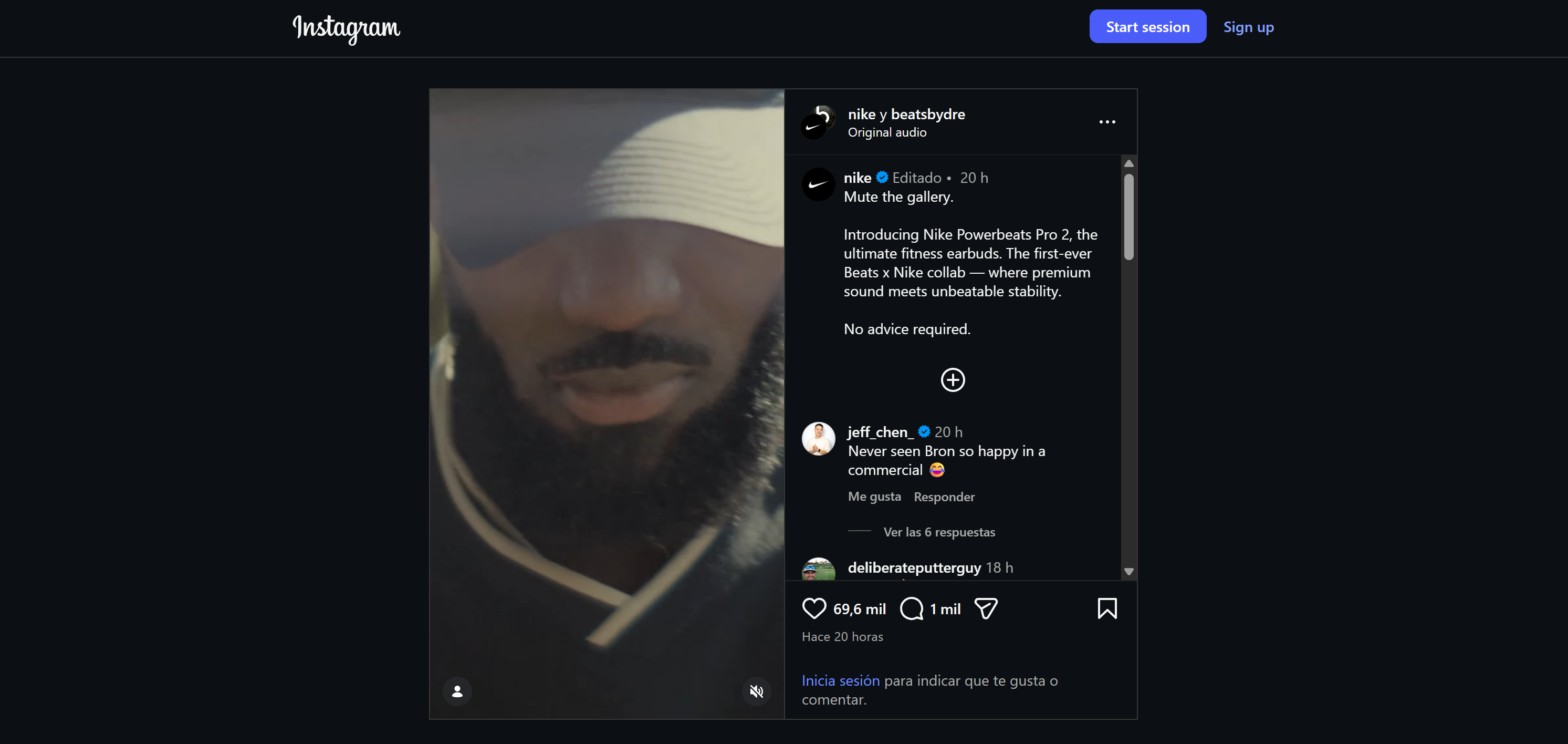
E é assim que aparece no TikTok: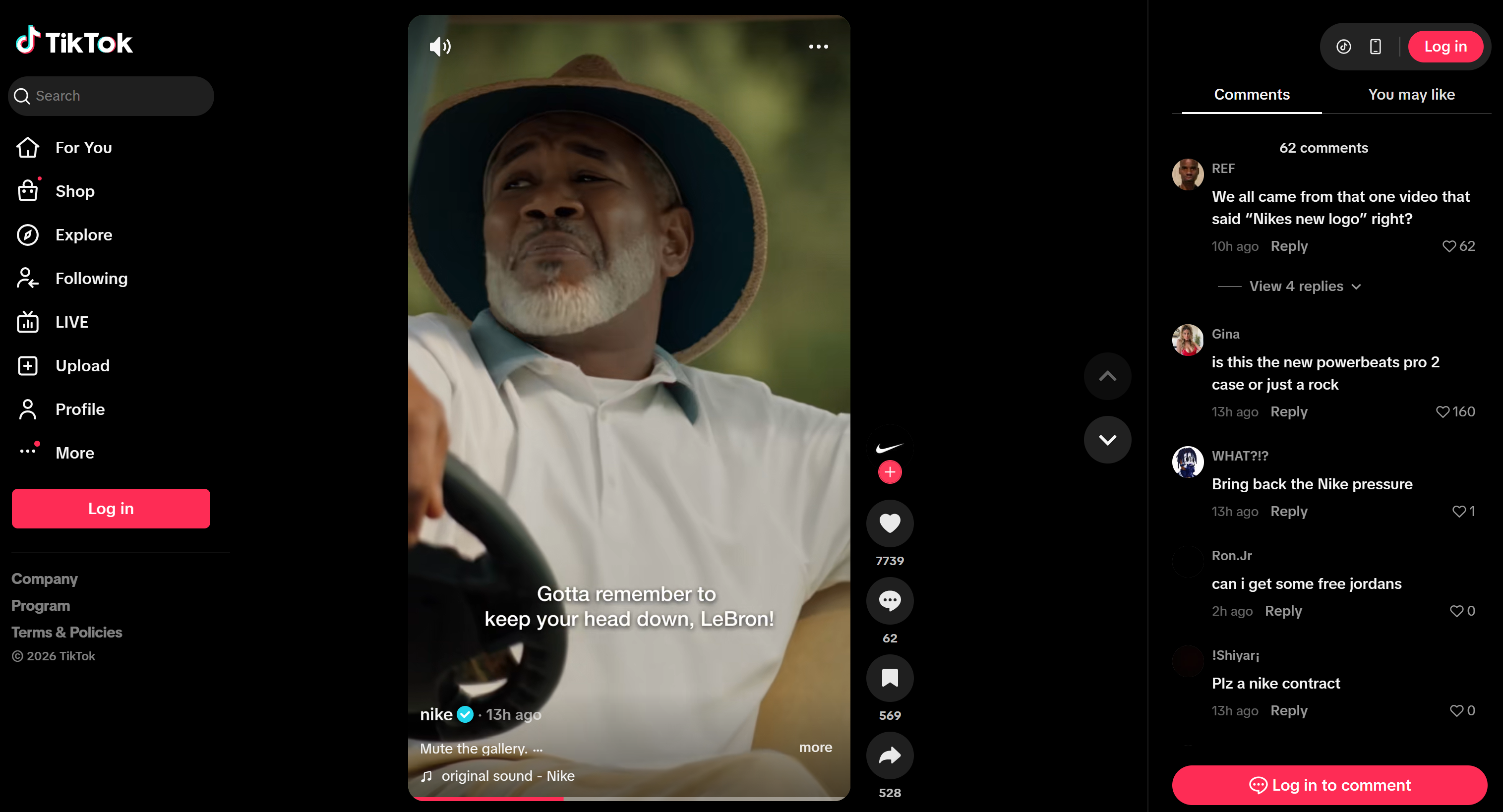
A ideia é permitir que o agente de IA use a API Social Media Scraper da Bright Data para buscar comentários de ambas as postagens. Em seguida, ele analisará e processará esses dados por meio de seu cérebro LLM alimentado pelo Gemini. Isso completa um fluxo de trabalho básico de monitoramento de redes sociais por agente.
Observação: este é apenas um exemplo, presumindo que você já tenha as postagens sociais de destino. Em um cenário pronto para produção, as ferramentas da Bright Data podem ser usadas para pesquisar na web, rastrear contas inteiras de mídia social e lidar com escuta social multiplataforma em escala.
Tudo certo! Hora de desenvolver o agente.
Etapa 3: Implementar o agente
Para construir o agente de escuta social apresentado anteriormente, adicione as seguintes linhas de código ao arquivo agent.py:
# pip install langchain langchain-google-genai langchain-brightdata
from langchain_brightdata import BrightDataWebScraperAPI
from langchain_google_genai import ChatGoogleGenerativeAI
from langchain.agents import create_agent
# Substitua pelas suas chaves de API reais
GOOGLE_API_KEY = "<SUA_CHAVE_DE_API_DO_GOOGLE>"
BRIGHT_DATA_API_KEY = "<SUA_CHAVE_API_BRIGHT_DATA>"
# Inicialize o mecanismo LLM
llm = ChatGoogleGenerativeAI(
model="gemini-3-flash-preview",
google_api_key=GOOGLE_API_KEY
)
# Inicializar a ferramenta API do Bright Data Web Scraper
web_scraper_api_tool = BrightDataWebScraperAPI(
bright_data_api_key=BRIGHT_DATA_API_KEY
)
# Criar um agente ReAct com acesso às APIs de Scraping de dados do Bright Data
agent = create_agent(llm, [web_scraper_api_tool])
# Defina uma consulta simples de monitoramento de redes sociais
prompt = """
Você é um especialista em monitoramento de redes sociais.
Alvos:
- Instagram Reel: "https://www.instagram.com/nike/reel/DV_PTxKDueO/"
- Vídeo do TikTok: "https://www.tiktok.com/@nike/video/7618336096694406414"
Tarefa:
1. Use a API Social Media Scraper da Bright Data para coletar todos os comentários das publicações de destino.
2. Gere um relatório em Markdown resumindo o engajamento e o sentimento.
3. Destaque os comentários que mencionem outros produtos da Nike, promoções ou solicitações interessantes dos usuários para análise posterior.
"""
# Transmita a saída passo a passo do agente
for step in agent.stream(
{
"messages": prompt
},
stream_mode="values",
):
step["messages"][-1].pretty_print()É isso que o código faz:
- Lê as credenciais de acesso às APIs do Gemini e da Bright Data (em produção, leia-as dos arquivos de configuração).
- Cria um mecanismo de IA com tecnologia Gemini para processar e analisar dados de mídias sociais.
- Conecta o agente às APIs de scraping da Bright Data (incluindo a API Social Media Scraper) por meio da ferramenta
BrightDataWebScraperAPIdo LangChain. - Usa a função
create_agent()para definir um agente ReAct capaz de chamar as ferramentas de scraping da Bright Data dinamicamente. - Instrui o agente sobre os alvos (publicações no Instagram e no TikTok) e as tarefas (coleta de comentários, análise de sentimentos, geração de relatórios e sinalização de menções importantes).
- Inicia o agente e transmite o resultado para o terminal.
Missão concluída! Você implementou um fluxo de trabalho simples com agente para monitoramento de redes sociais.
Etapa 4: Teste o agente
Execute o agente com:
python agent.pyVocê verá o agente executando a ferramenta bright_data_web_scraper (como esperado):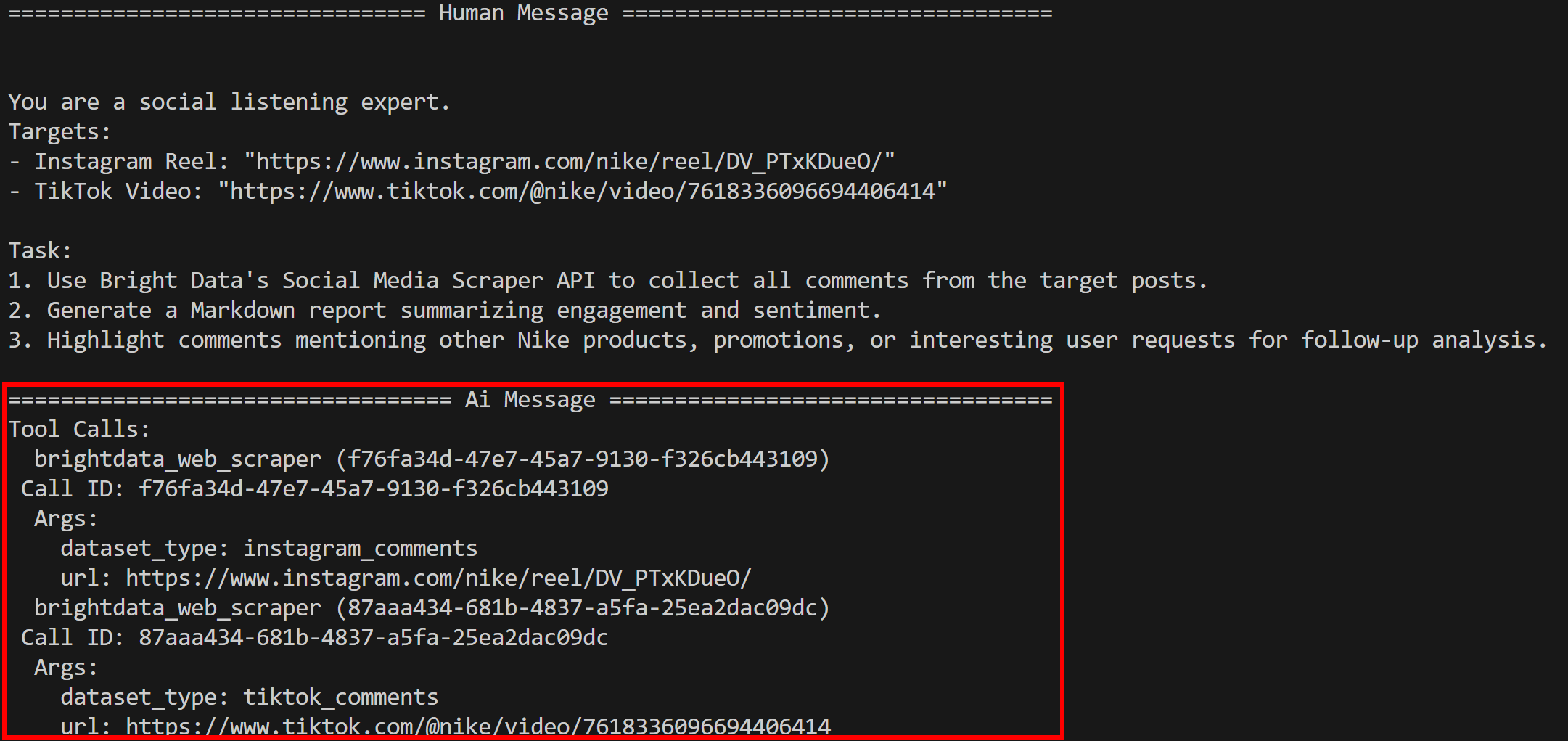
Especificamente, ele chama as ferramentas subjacentes instagram_comments e tiktok_comments. Nos bastidores, essas ferramentas dependem do Bright Data Instagram Comments Scraper e do TikTok Comments Scraper.
Os resultados da ferramenta são retornados em dados estruturados em JSON, contendo todos os comentários coletados das duas postagens: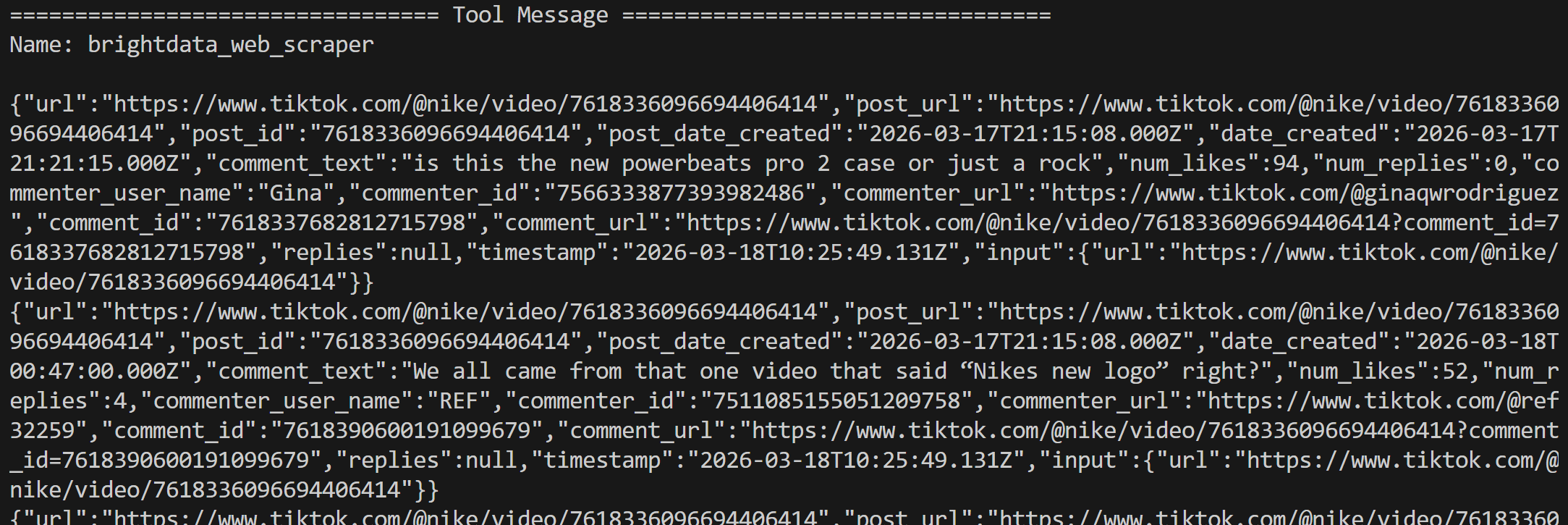
Em seguida, o agente processa os comentários para monitoramento de redes sociais conforme instruído e gera um relatório em Markdown: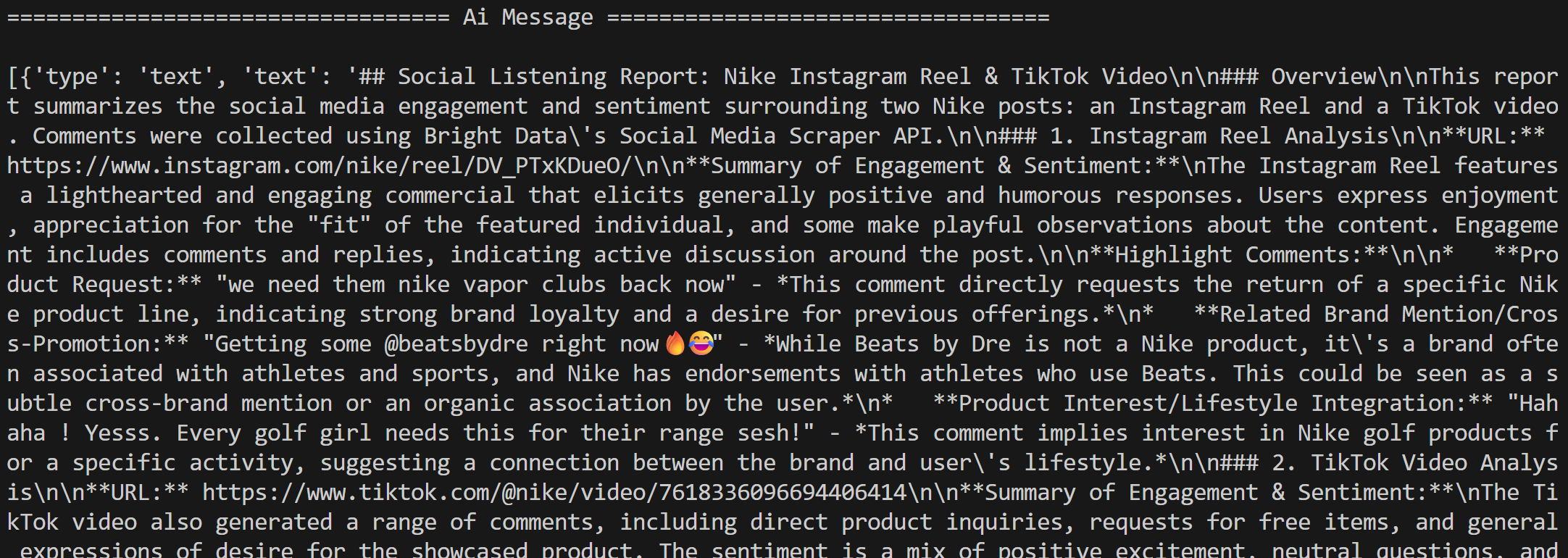
Quando visualizado em um renderizador Markdown, o relatório aparece assim: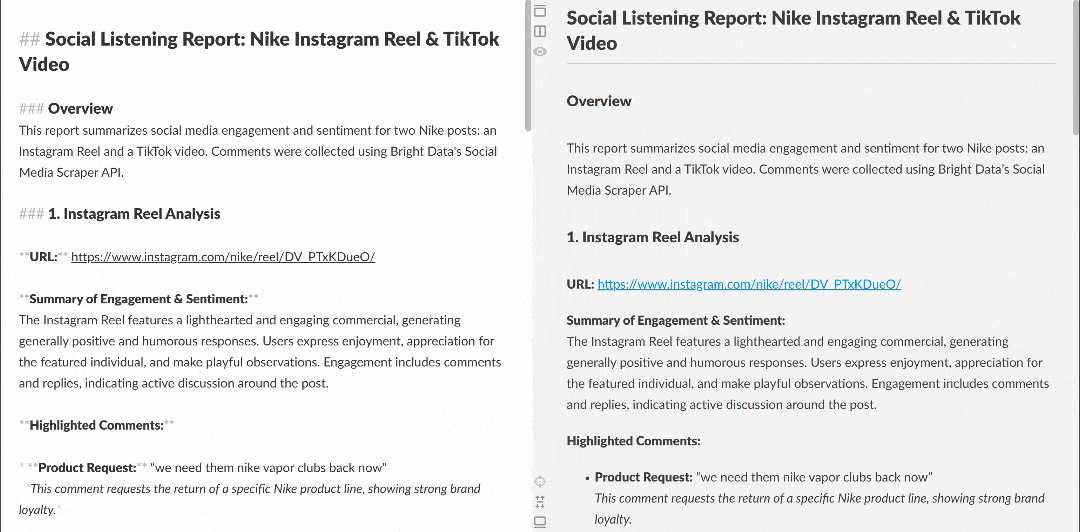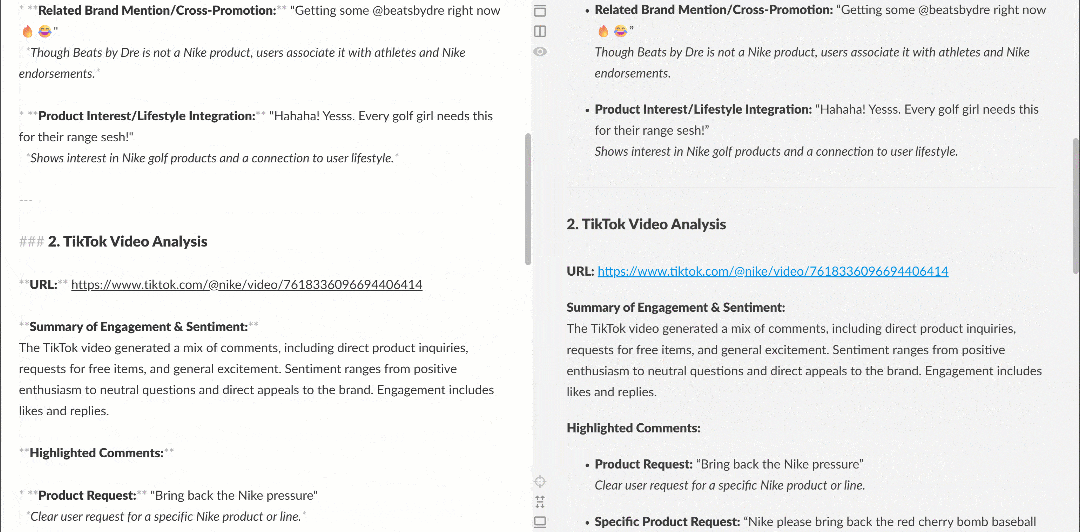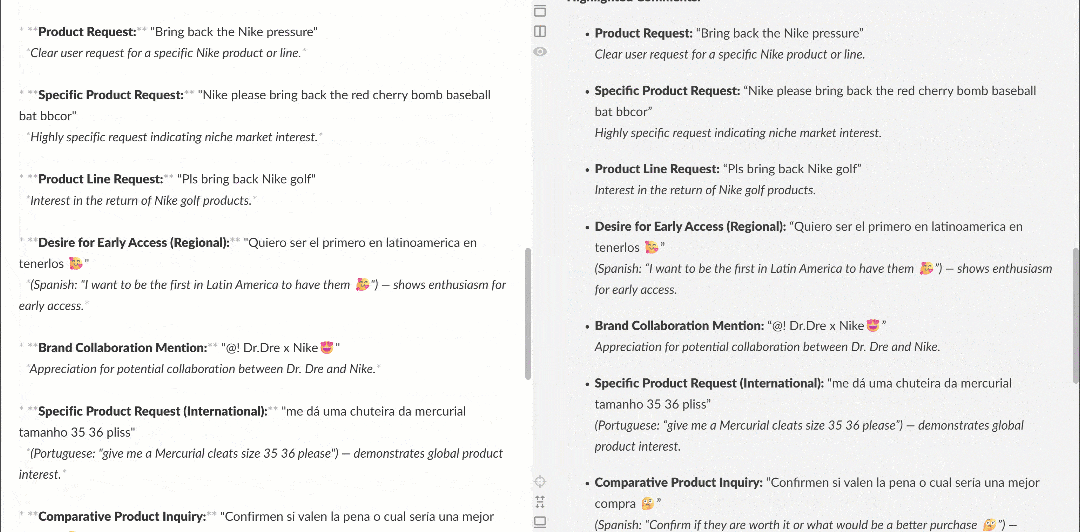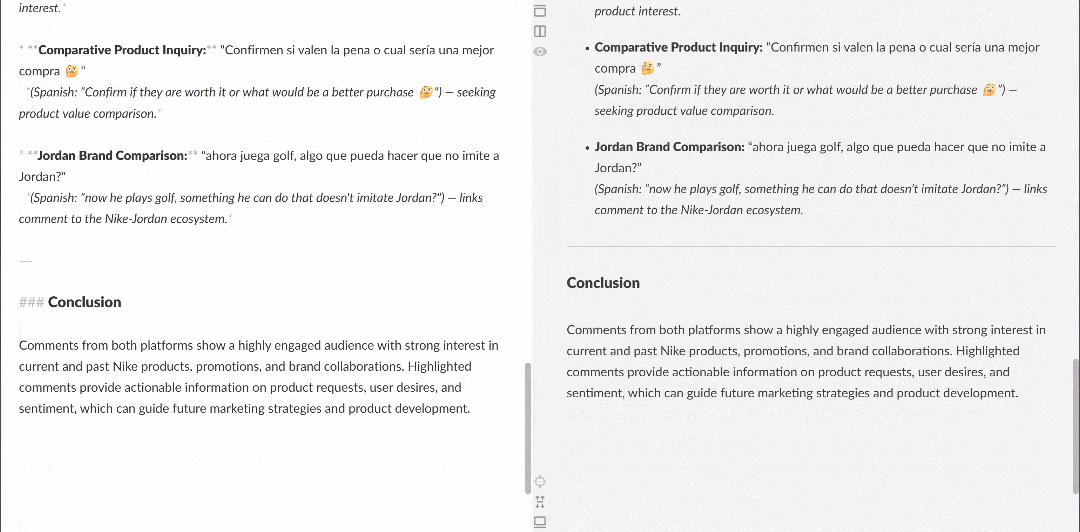
Observe como ele contém insights interessantes, como vários usuários pedindo à Nike para trazer de volta a Nike Golf ou se concentrar mais em produtos de golfe. Esses são detalhes que um fluxo de trabalho básico de análise de sentimento poderia ter deixado passar.
Além disso, se ocorrer um erro ou se o agente determinar que os dados recuperados são insuficientes para atingir a meta, ele buscará automaticamente comentários adicionais ou repetirá as chamadas para as ferramentas da Bright Data. Isso torna o agente totalmente autônomo.
Et voilà! Você acabou de aprender a criar um fluxo de trabalho de monitoramento de mídias sociais com agente, alimentado pela Bright Data, no LangChain.
Fluxos de trabalho com agentes prontos para produção para monitoramento de redes sociais
O capítulo anterior mostrou como criar um agente simples de monitoramento de redes sociais. No entanto, um fluxo de trabalho baseado em agente pronto para produção é muito mais complexo. Vamos explorar como projetá-lo e as etapas para implementá-lo!
Arquitetura
Em fluxos de trabalho de monitoramento de redes sociais baseados em agentes, contar com vários agentes de IA especializados tende a produzir melhores resultados do que usar um único agente monolítico. Cada agente deve se concentrar em uma responsabilidade distinta, e uma possível configuração de agentes é:
- Agente de recuperação de dados: coleta postagens, comentários, perfis ou métricas de engajamento de várias plataformas de mídia social por meio de ferramentas como o Social Media Scraper da Bright Data.
- Agente de análise: processa os dados coletados para extrair tendências, sentimentos e outros insights acionáveis, transformando conteúdo social bruto em inteligência significativa.
- Agente de relatórios/saída: formata os dados analisados em painéis, resumos ou arquivos (JSON, CSV) para fácil consumo por humanos ou outros sistemas de IA.
- Agente de coordenação: supervisiona o fluxo de trabalho, garantindo transferências tranquilas, avaliando a qualidade dos resultados e iterando processos automaticamente quando são necessárias melhorias ou coleta adicional de dados.
Roteiro
Considerando os quatro agentes, implemente um fluxo de trabalho baseado em agentes para monitoramento de redes sociais da seguinte forma:
- Escolha a pilha de agentes de IA: selecione com base nos tipos de agentes necessários, integrações de ferramentas e facilidade de orquestração do fluxo de trabalho.
- Adicione os agentes: crie quatro agentes provisórios dentro da estrutura de agentes de IA escolhida.
- Integre ferramentas de scraping de mídias sociais: conceda ao agente de recuperação de dados acesso ao Social Media Scraper da Bright Data ou a scrapers de mídias sociais específicos.
- Configure as tarefas de recuperação de dados: instrua o agente de recuperação de dados a buscar os dados de mídia social necessários.
- Analise os dados coletados: instrua o agente de análise a processar texto, sentimento, tendências e métricas de engajamento.
- Gere relatórios estruturados: instrua o agente de relatórios a produzir o resultado desejado com base nos dados analisados.
- Coordenar e iterar: Implemente o agente de coordenação para monitorar resultados, acionar ciclos repetidos, etc.
- Projete o ciclo de agentes: conecte os quatro agentes (Recuperação de dados → Análise → Relatórios → Coordenação).
- Automatizar o agendamento do fluxo de trabalho: Configure execuções recorrentes para monitoramento contínuo das redes sociais.
Exemplos de fluxos de trabalho de monitoramento de redes sociais com agentes
Considerando o roteiro de agentes de IA apresentado anteriormente, você pode criar vários fluxos de trabalho de monitoramento de mídias sociais baseados em agentes. Aqui estão alguns exemplos!
Monitoramento do sentimento em relação à marca
Os agentes de IA rastreiam continuamente menções à sua marca nas plataformas sociais. Utilizando o Social Media Scraper da Bright Data, os agentes coletam publicações, comentários e reações, analisam o sentimento, detectam tendências emergentes e sinalizam picos negativos, permitindo uma gestão proativa da reputação.
Análise da concorrência
Os agentes de IA monitoram hashtags, palavras-chave e discussões nos comentários do TikTok, X, Reddit e YouTube. A IA então detecta estratégias de conteúdo, desempenho de campanhas e padrões de engajamento do público, ajudando você a ajustar sua própria estratégia em tempo real.
Descoberta e previsão de tendências
Agentes de IA monitoram hashtags, palavras-chave e discussões no TikTok, X e Reddit. As APIs de Scraper da Bright Data fornecem dados estruturados e prontos para LLM para que os agentes detectem tendências em ascensão, prevejam a popularidade e orientem decisões de marketing ou de produto.
Detecção e resposta a crises
Os agentes ficam atentos a picos repentinos de sentimento negativo ou publicações virais em várias redes. Com o Social Media Scraper da Bright Data, a IA pode alertar as equipes imediatamente, redigir respostas contextuais ou acionar fluxos de trabalho automatizados de escalonamento.
Análise de feedback de campanhas
Agentes de IA coletam reações dos usuários, comentários e métricas de postagens do Facebook, Instagram, YouTube ou outras plataformas. Graças aos Scrapers da Bright Data, os agentes recuperam os dados necessários para acompanhar o sucesso da campanha e otimizar estratégias de comunicação.
Conclusão
Neste artigo, você aprendeu o que é o monitoramento de mídias sociais, o que ele envolve e por que os fluxos de trabalho automatizados são a melhor maneira de implementá-lo. Você também obteve uma compreensão clara dos desafios envolvidos e de como superá-los usando ferramentas de scraping de mídias sociais preparadas para IA.
A Bright Data oferece suporte ao monitoramento de redes sociais por meio de um Social Media Scraper dedicado, de nível empresarial e fácil de integrar. Isso permite que você crie fluxos de trabalho baseados em agentes escaláveis para o monitoramento de redes sociais (e outros casos de uso de marketing de mídia social) sem perder confiabilidade ou desempenho.
Crie hoje mesmo uma conta gratuita na Bright Data e explore nossas soluções de coleta de dados da web preparadas para IA!
Perguntas frequentes
Qual é a diferença entre escuta social e monitoramento social?
O monitoramento de redes sociais rastreia “o que” aconteceu, coletando notificações, curtidas e métricas. Já o social listening analisa o “porquê”, observando o sentimento e as tendências por trás dessas conversas para orientar a estratégia de longo prazo.
Qual é a diferença entre análise de sentimento e monitoramento de redes sociais?
A análise de sentimento avalia emoções ou opiniões em textos, como positivo, negativo ou neutro. O social listening é mais abrangente: ele monitora conversas em várias plataformas para acompanhar tendências, percepção da marca e feedback dos clientes, frequentemente utilizando a análise de sentimento como uma de suas ferramentas.
Um agente de IA pode ser usado para escuta social?
Sim, agentes de IA podem ser usados para o social listening. Na verdade, eles são ideais para a tarefa devido à sua capacidade de se adaptar a cenários mutáveis ou inesperados, o que é típico do cenário em constante evolução das mídias sociais.
Quais ferramentas uma IA precisa para acessar o social listening?
Agentes de IA para escuta social requerem ferramentas para coletar dados de mídias sociais. Ao se integrarem a scrapers como o Social Media Scraper da Bright Data, os agentes podem monitorar múltiplas plataformas em escala, fornecendo inteligência acionável em tempo real.
Em quais plataformas de mídia social faz sentido aplicar o monitoramento de redes sociais?
As plataformas de mídia social mais relevantes para a coleta de dados para o social listening por agentes são X, Reddit, Threads, Facebook, Instagram, LinkedIn, TikTok, Quora, Pinterest, YouTube e Vimeo.




