
Neste tutorial, você verá:
- O que é o opencode, quais recursos ele oferece e por que não deve ser confundido com o Crush.
- Como ampliá-lo com interação com a Web e recursos de extração de dados pode torná-lo ainda mais útil.
- Como conectar o opencode ao servidor MCP da Bright Data na CLI para criar um agente de codificação de IA avançado.
Vamos nos aprofundar!
O que é o opencode?
O opencode é um agente de codificação de IA de código aberto criado para o terminal. Em particular, ele funciona como:
- Uma TUI(Terminal User Interface) em sua CLI.
- Uma integração de IDE no Visual Studio Code, Cursor, etc.
- Uma extensão do GitHub.
Mais detalhadamente, o opencode permite que você:
- Configurar uma interface de terminal responsiva e com tema.
- Carregar o LSP(Language Server Protocols) correto para seu LLM.
- Executar vários agentes em paralelo no mesmo projeto.
- Compartilhar links para qualquer sessão para referência ou depuração.
- Faça login no Anthropic para usar sua conta Claude Pro ou Max, além de integrar-se a outros mais de 75 provedores de LLM via Models.dev (incluindo modelos locais).
Como você pode ver, a CLI é agnóstica em relação ao LLM. Ela foi desenvolvida principalmente em Go e TypeScript e já acumulou mais de 20 mil estrelas no GitHub, o que comprova sua popularidade na comunidade.
Observação: essa tecnologia não deve ser confundida com o Crush, um projeto diferente cujo nome original era “opencode”. Saiba mais sobre a disputa de nomes no X. Se você estiver procurando o Crush, consulte nosso guia sobre a integração do Crush com o Web MCP da Bright Data.
Por que é importante integrar o Web MCP da Bright Data na TUI do opencode
Não importa qual LLM você acabe configurando no opencode, todos eles compartilham a mesma limitação: o conhecimento deles é estático. Os dados em que foram treinados representam um instantâneo no tempo, que rapidamente se torna desatualizado. Isso é especialmente verdadeiro em campos de rápida evolução, como o desenvolvimento de software.
Agora, imagine dar ao seu assistente de CLI do opencode a capacidade de:
- Obter novos tutoriais e documentação.
- Consultar guias ao vivo enquanto escreve código.
- Navegar em sites dinâmicos com a mesma facilidade com que navega em seus arquivos locais.
Esses são exatamente os recursos que você desbloqueia ao conectá-lo ao Web MCP da Bright Data.
O Web MCP da Bright Data fornece acesso a mais de 60 ferramentas prontas para IA, projetadas para interação com a Web em tempo real e coleta de dados, todas alimentadas pela infraestrutura de IA da Bright Data.
As duas ferramentas mais usadas(mesmo disponíveis no nível gratuito) no Web MCP da Bright Data são:
| Ferramenta | Descrição da ferramenta |
|---|---|
scrape_as_markdown |
Extrai o conteúdo de uma única página da Web com opções avançadas de extração, retornando os dados resultantes em Markdown. Pode ignorar a detecção de bots e CAPTCHA. |
search_engine |
Extraia resultados de pesquisa do Google, Bing ou Yandex. Retorna dados SERP em formato JSON ou Markdown. |
Além dessas duas, há mais de 55 ferramentas especializadas para interagir com páginas da Web (por exemplo, scraping_browser_click) e coletar dados estruturados de vários domínios, como LinkedIn, Amazon, Yahoo Finance, TikTok e outros. ool recupera informações de perfil estruturadas de uma página pública do LinkedIn quando recebe o URL de um profissional.
É hora de verificar como o Web MCP funciona dentro do opencode!
Como conectar o opencode ao Web MCP da Bright Data
Saiba como instalar e configurar o opencode localmente e integrá-lo ao servidor Web MCP da Bright Data. O resultado será um agente de codificação estendido com acesso a mais de 60 ferramentas da Web. Esse agente CLI será usado em uma tarefa de exemplo para:
- Extrair uma página de produto do LinkedIn em tempo real para coletar dados de perfil do mundo real.
- Armazenar os dados localmente em um arquivo JSON.
- Criar um script Node.js para carregar e processar os dados.
Siga as etapas abaixo!
Observação: esta seção do tutorial se concentra no uso do opencode por meio da CLI. No entanto, você pode usar uma configuração semelhante para integrá-lo diretamente ao seu IDE, conforme mencionado na documentação.
Pré-requisitos
Antes de começar, verifique se você tem o seguinte:
- Um ambiente macOS ou Linux (os usuários do Windows devem usar a WSL).
- Uma assinatura do Claude Pro ou Max ou uma conta do Anthropic com alguns fundos e uma chave de API (neste tutorial, usaremos uma chave de API do Anthropic, mas você pode configurar qualquer outro LLM compatível).
- Node.js instalado localmente (recomendamos a versão mais recente do LTS).
- Uma conta da Bright Data com uma chave de API pronta.
Não se preocupe com a configuração do Bright Data por enquanto, pois você será orientado nas etapas a seguir.
A seguir, apresentamos alguns conhecimentos básicos opcionais, mas úteis:
- Uma compreensão geral de como o MCP funciona.
- Alguma familiaridade com o Web MCP da Bright Data e suas ferramentas.
Etapa 1: Instalar o opencode
Instale o opencode em seu sistema baseado em Unix usando o seguinte comando:
curl -fsSL https://opencode.ai/install | bashIsso fará o download do instalador de https://opencode.ai/install e o executará para configurar o opencode em seu computador. Explore as outras opções de instalação possíveis.
Verifique se o opencode está funcionando com:
opencodeSe você encontrar um erro do tipo “missing executable” (executável ausente) ou “unrecognized command” (comando não reconhecido), reinicie o computador e tente novamente.
Se tudo funcionar como esperado, você verá algo parecido com isto:

Ótimo! Agora o opencode está pronto para ser usado.
Etapa 2: configurar o LLM
O opencode pode se conectar a muitos LLMs, mas os modelos recomendados são da Anthropic. Certifique-se de que você tenha uma assinatura Claude Max ou Pro, ou uma conta Anthropic com alguns fundos e uma chave de API.
As etapas a seguir mostrarão como conectar o opencode à sua conta Anthropic via chave de API, mas qualquer outra integração de LLM compatível também funcionará.
Feche a janela do opencode com o comando /exit e, em seguida, inicie a autenticação com um provedor LLM usando:
opencode auth login Você será solicitado a selecionar um provedor de modelo de IA:

Escolha “Anthropic” pressionando Enter e, em seguida, selecione a opção “Manually enter API key”:

Cole sua chave de API do Anthropic e pressione Enter:

A configuração do LLM está concluída. Reinicie o opencode, inicie o comando /models e você poderá selecionar um modelo Anthropic. Por exemplo, escolha “Claude Opus 4.1”:
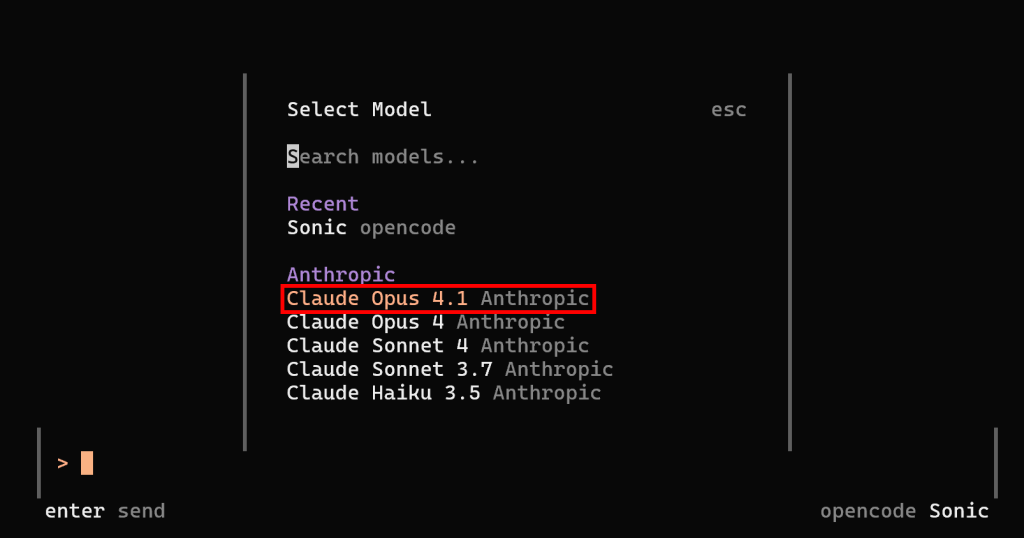
Pressione Enter e você verá:

Observe como o opencode agora opera usando o modelo Anthropic Claude Opus 4.1 configurado. Muito bem!
Etapa 3: inicializar seu projeto opencode
Vá para o diretório de seu projeto usando o comando cd e inicie o opencode lá:
cd <caminho_para_sua_pasta_de_projeto>
opencodeExecute o comando /init para inicializar um projeto do opencode. A saída deve ser semelhante a esta:

Especificamente, o comando /init criará um arquivo AGENTS.md. Semelhante ao CLAUDE.md ou às regras do Cursor, ele fornece instruções personalizadas para o opencode. Essas instruções são incluídas no contexto do LLM para personalizar seu comportamento para seu projeto específico.
Abra o arquivo AGENTS.md em seu IDE (por exemplo, Visual Studio Code) e você verá:

Personalize-o de acordo com suas necessidades para instruir o agente de codificação de IA sobre como operar no diretório do seu projeto.
Dica: o arquivo AGENTS.md deve ser confirmado no repositório Git da pasta do projeto.
Etapa 4: testar o Web MCP da Bright Data
Antes de tentar integrar seu agente opencode com o servidor Web MCP da Bright Data, é importante entender como esse servidor funciona e se sua máquina pode executá-lo.
Se ainda não o fez, comece criando uma conta da Bright Data. Caso contrário, se já tiver uma, basta fazer o login. Para uma configuração rápida, dê uma olhada na página “MCP” da sua conta:

Caso contrário, siga as instruções abaixo.
Agora, gere sua chave de API da Bright Data. Certifique-se de armazená-la em um local seguro, pois você precisará dela em breve. Aqui, assumiremos que você está usando uma chave de API com permissões de administrador, pois isso facilita a integração.
No terminal, instale o Web MCP globalmente por meio do pacote @brightdata/mcp:
npm install -g @brightdata/mcpVerifique se o servidor MCP local funciona com este comando Bash:
API_TOKEN="<YOUR_BRIGHT_DATA_API>" npx -y @brightdata/mcpSubstitua o espaço reservado <YOUR_BRIGHT_DATA_API> pelo token real da API da Bright Data. O comando define a variável de ambiente API_TOKEN necessária e, em seguida, aciona o Web MCP por meio do pacote @brightdata/mcp.
Em caso de sucesso, você deverá ver registros semelhantes a este:

Na primeira inicialização, o pacote configura automaticamente duas zonas padrão em sua conta da Bright Data:
mcp_unlocker: Uma zona para o Web Unlocker.mcp_browser: Uma zona para a API do navegador.
Essas duas zonas são exigidas pelo Web MCP para alimentar todas as ferramentas que ele expõe.
Para confirmar que as duas zonas acima foram criadas, faça login na sua conta da Bright Data. No painel, navegue até a página“Proxies & Scraping Infrastructure“. Lá, você deverá ver as duas zonas na tabela:

Observação: se o seu token de API não tiver permissões de administrador, essas zonas talvez não sejam criadas automaticamente. Nesse caso, você pode configurá-las manualmente no painel e especificar seus nomes por meio de variáveis de ambiente, conforme explicado na página do pacote no GitHub.
Por padrão, o servidor MCP expõe apenas as ferramentas search_engine e scrape_as_markdown(que podem ser usadas gratuitamente!).
Para desbloquear recursos avançados, como automação do navegador e recuperação de feed de dados estruturados, você deve ativar o modo Pro. Para fazer isso, defina a variável de ambiente PRO_MODE=true antes de iniciar o servidor MCP:
API_TOKEN="<YOUR_BRIGHT_DATA_API>" PRO_MODE="true" npx -y @brightdata/mcpImportante: Quando o modo Pro estiver ativado, você terá acesso a todas as mais de 60 ferramentas. Por outro lado, o modo Pro não está incluído no nível gratuito e incorrerá em cobranças adicionais.
Perfeito! Você acabou de verificar que o servidor Web MCP funciona em sua máquina. Interrompa o processo do servidor, pois agora você configurará o opencode para iniciá-lo e se conectar a ele.
Etapa 5: integrar o Web MCP ao opencode
O opencode suporta a integração do MCP por meio da entradamcp no arquivo de configuração. Lembre-se de que há duas abordagens de configuração compatíveis:
- Globalmente: Por meio do arquivo em
~/.config/opencode/opencode.json. A configuração global é útil para configurações como temas, provedores ou vinculações de teclas. - Por projeto: Por meio de um arquivo
opencode.jsonlocal no diretório do seu projeto.
Suponha que você queira configurar a integração do MCP localmente. Comece adicionando um arquivo opencode.json em seu diretório de trabalho.
Em seguida, abra o arquivo e verifique se ele contém as seguintes linhas:
{
"$schema": "https://opencode.ai/config.json",
"mcp": {
"brightData": {
"type" (tipo): "local",
"enabled": true,
"command": [
"npx",
"-y",
"@brightdata/mcp"
],
"environment" (ambiente): {
"API_TOKEN": "<SUA CHAVE_API_DATA_BRIGHT_DATA>",
"PRO_MODE": "true"
}
}
}
}Substitua <YOUR_BRIGHT_DATA_API_KEY> pela chave da API da Bright Data que você gerou e testou anteriormente.
Nessa configuração:
- O objeto
mcpinforma ao opencode como iniciar servidores MCP externos. - A entrada
brightDataespecifica o comando(npx) e as variáveis de ambiente necessárias para iniciar o Web MCP.(PRO_MODEé opcional, mas sua ativação desbloqueia o conjunto completo de ferramentas disponíveis).
Em outras palavras, a configuração opencode.json acima instrui a CLI a executar o mesmo comando npx com as variáveis de ambiente definidas anteriormente. Isso dá ao opencode a capacidade de iniciar e se conectar ao servidor Bright Data Web MCP.
Até o momento em que este texto foi escrito, não havia nenhum comando dedicado para verificar as conexões do servidor MCP ou as ferramentas disponíveis. Portanto, vamos direto para o teste!
Etapa 6: executar uma tarefa no opencode
Para verificar os recursos da Web do seu agente de codificação opencode aprimorado, inicie um prompt como o seguinte:
Extraia "https://it.linkedin.com/in/antonello-zanini" e armazene os dados resultantes em um arquivo local "profile.json". Em seguida, configure um script Node.js básico que leia o arquivo JSON e retorne seu conteúdoIsso representa um caso de uso do mundo real, pois coleta dados reais e os utiliza em um script Node.js.
Inicie o opencode, digite o prompt e pressione Enter para executá-lo. Você verá um comportamento semelhante a este:

O GIF foi acelerado, mas isso é o que acontece passo a passo:
- O modelo Claude Opus define um plano.
- A primeira etapa do plano é recuperar os dados do LinkedIn. Para fazer isso, o LLM seleciona a ferramenta MCP apropriada
(web_data_linkedin_person_profile, referenciada comoBrightdata_web_data_linkedin_person_profilena CLI) com os argumentos corretos extraídos do prompt(https://it.linkedin.com/in/antonello-zanini). - O LLM coleta os dados de destino por meio da ferramenta de raspagem do LinkedIn e atualiza o plano.
- Os dados são armazenados em um arquivo
profile.jsonlocal. - Um script Node.js (chamado
readProfile.js) é criado para ler os dados doprofile.jsone imprimi-los. - Você verá um resumo das etapas executadas, com instruções para executar o script Node.js produzido.
Neste exemplo, a saída final produzida pela tarefa tem a seguinte aparência:

No final da interação, seu diretório de trabalho deve conter estes arquivos:
├── AGENTS.md
├── opencode.json
├─── profile.json # <-- criado pela CLI
readProfile.js # <-- criado pela CLIMaravilhoso! Vamos agora verificar se os arquivos gerados contêm os dados e a lógica pretendidos.
Etapa 7: explorar e testar a saída
Abra o diretório do projeto no Visual Studio Code e comece inspecionando o arquivo profile.json:

Importante: Os dados em profile.json são dados reais do LinkedIn coletados pelo Bright Data LinkedIn Scraper por meio da ferramenta MCP dedicada web_data_linkedin_person_profile. Não se trata de conteúdo alucinado ou inventado gerado pelo modelo Claude!
Os dados do LinkedIn foram recuperados com êxito, como você pode verificar ao inspecionar a página de perfil público do LinkedIn mencionada no prompt:

Observação: a raspagem do LinkedIn é notoriamente desafiadora devido às suas sofisticadas proteções anti-bot. Um LLM comum não pode executar essa tarefa de forma confiável, o que demonstra como seu agente de codificação se tornou poderoso graças à integração do Bright Data Web MCP.
Em seguida, dê uma olhada no arquivo readProfile.js:
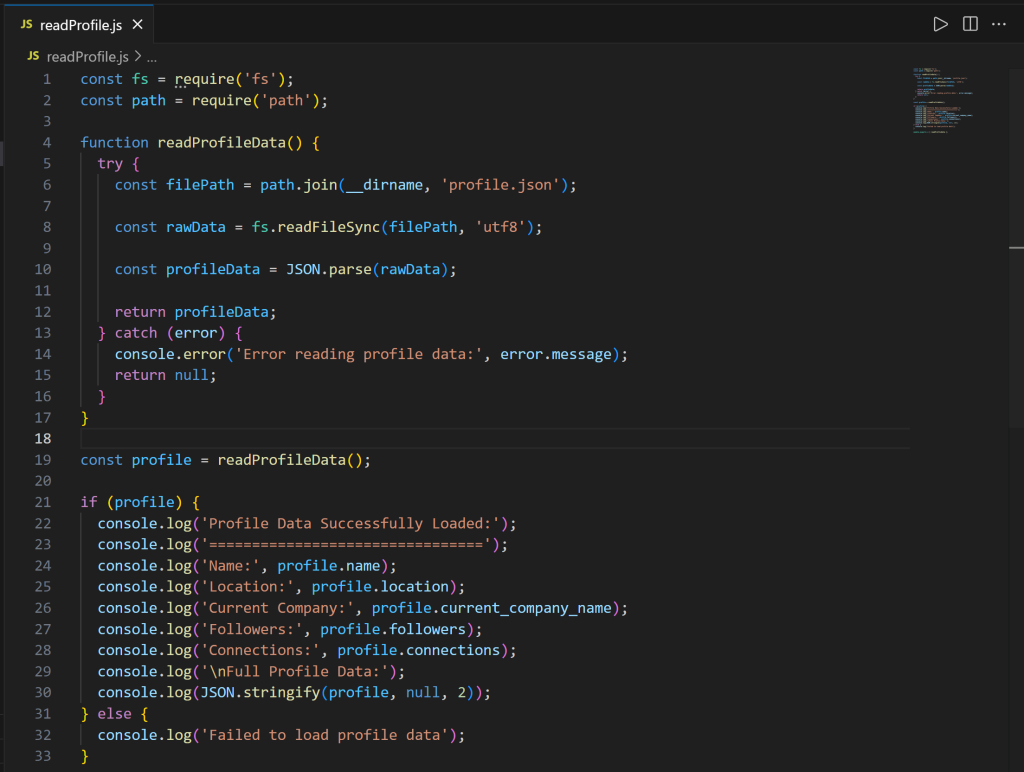
Observe que o código define uma função readProfileData() para ler os dados do perfil do LinkedIn em profile.json. Essa função é então chamada para imprimir os dados do perfil com todos os detalhes.
Teste o script com:
node readProfile.jsA saída deve ser:

Veja como o script produzido imprime os dados raspados do LinkedIn conforme planejado.
Missão concluída! Experimente diferentes prompts e teste fluxos de trabalho de dados avançados orientados por LLM diretamente na CLI.
Conclusão
Neste artigo, você viu como conectar o opencode ao Web MCP da Bright Data(que agora oferece um nível gratuito!). O resultado é um agente de codificação de IA rico em ferramentas capaz de extrair dados da Web e interagir com eles.
Para criar agentes de IA mais complexos, explore toda a gama de serviços e produtos disponíveis na infraestrutura de IA da Bright Data. Essas soluções oferecem suporte a uma ampla variedade de cenários agênticos, incluindo várias integrações de CLI.
Inscreva-se gratuitamente na Bright Data e comece a fazer experiências com nossas ferramentas da Web prontas para IA!




