
Nesta postagem do blog, você verá:
- O que é o Ctush e por que ele é um aplicativo CLI tão amado para assistência de codificação de IA.
- Como ampliá-lo com a interação com a Web e a extração de dados o torna muito mais eficaz.
- Como conectar a CLI do Crush com o servidor MCP da Bright Data Web para criar um agente de codificação de IA aprimorado.
Vamos nos aprofundar!
O que é o Crush?
O Crush é um agente de codificação de IA de código aberto para seu terminal. Em particular, o Crush CLI é um aplicativo CLI baseado em Go que traz assistência de IA diretamente para o ambiente do terminal. Ele oferece uma TUI(Terminal User Interface, interface de usuário de terminal) para interagir com vários LLMs para ajudar na codificação, depuração e outras tarefas de desenvolvimento.
Especificamente, é isso que torna o Crush especial:
- Multiplataforma: Funciona em todos os principais terminais do macOS, Linux, Windows (PowerShell e WSL), FreeBSD, OpenBSD e NetBSD.
- Suporte a vários modelos: Escolha entre uma ampla variedade de LLMs, integre seu próprio LLM por meio de APIs compatíveis com OpenAI ou Anthropic ou conecte-se a modelos locais.
- Experiência baseada em sessões: Mantenha várias sessões de trabalho e contextos por projeto.
- Altamente flexível: Possibilidade de alternar entre LLMs no meio da sessão, preservando o contexto.
- Pronto para LSP: O Crush é compatível com LSP(Language Server Protocols) para obter contexto e inteligência adicionais, assim como um IDE moderno.
- Extensível: Oferece suporte à integração por meio de funcionalidades de terceiros via MCPs(HTTP, stdio e SSE).
O projeto já alcançou mais de 10 mil estrelas no GitHub e é mantido ativamente por uma vibrante comunidade de desenvolvedores, com mais de 35 colaboradores.
Superando a lacuna de conhecimento dos LLMs na CLI do Crush com o Web MCP
Um desafio comum a todos os LLMs é ter um limite de conhecimento. O LLM que você configura na CLI do Crush não é diferente. Como esses modelos são treinados em um conjunto de dados fixo, seu conhecimento é um instantâneo estático do passado. Isso significa que eles não conhecem eventos ou desenvolvimentos recentes.
Essa é uma desvantagem importante no mundo acelerado da tecnologia. Sem uma base de conhecimento atualizada, um LLM pode sugerir bibliotecas obsoletas, práticas de programação desatualizadas ou simplesmente desconhecer novos recursos e ferramentas.
Agora, e se o seu assistente de codificação Crush AI pudesse fazer mais do que apenas recuperar informações antigas? Imagine que ele fosse capaz de pesquisar na Web a documentação, os artigos e os guias mais recentes e, em seguida, usar esses dados em tempo real para fornecer uma assistência melhor e mais precisa.
Você pode conseguir isso conectando o Crush a uma solução que ofereça aos LLMs o poder de acesso à Web e recuperação de dados. É exatamente isso que você obtém com o servidor Web MCP da Bright Data. Esse servidor de código aberto(agora com um nível gratuito!) equipa você com mais de 60 ferramentas prontas para IA para interação na Web e coleta de dados.
Integração do Web MCP da Bright Data
Abaixo estão duas das principais ferramentas que você pode encontrar nesse servidor MCP:
search_engine: Conecta-se à API SERP para realizar pesquisas no Google, Bing ou Yandex e retornar os dados da página de resultados do mecanismo de pesquisa no formato HTML ou Markdown.scrape_as_markdown: Utiliza o Web Unlocker para extrair o conteúdo de uma única página da Web. Ele oferece suporte a opções avançadas de extração, ignorando sistemas de detecção de bots e resolvendo CAPTCHAs para você.
Além dessas, há mais de 55 ferramentas especializadas para interagir com páginas da Web (como scraping_browser_click) e coletar feeds de dados estruturados de vários domínios, incluindo Amazon, LinkedIn e TikTok. Por exemplo, a ferramenta web_data_amazon_product pode extrair informações detalhadas e estruturadas de produtos diretamente da Amazon usando um URL de produto.
Com essas ferramentas, aqui estão algumas maneiras de aproveitar o Bright Data Web MCP com o Crush:
- Recupere informações atualizadas para seus projetos, como preços de ações do Yahoo Finance ou detalhes de produtos de sites de comércio eletrônico. Armazene esses dados em arquivos locais para análise, teste, simulação e muito mais.
- Permita que a IA busque a documentação mais recente de uma biblioteca ou estrutura que você esteja usando, certificando-se de que o código sugerido esteja atualizado e não obsoleto.
- Colete links com reconhecimento de contexto e integre esses recursos em arquivos Markdown, documentação ou outros resultados, tudo isso sem sair do editor de código.
Prepare-se para ver como o Web MCP pode aprimorar seu agente Crush CLI!
Como conectar o Crush ao Web MCP da Bright Data
Neste tutorial guiado, você aprenderá como instalar e configurar o Crush localmente e integrá-lo ao Web MCP da Bright Data. O resultado será um agente de codificação de IA aprimorado capaz de:
- Extrair uma página de produto da Amazon em tempo real.
- Armazenar os dados em um arquivo JSON local.
- Criar um script Node.js para carregar e processar esses dados.
Siga as instruções abaixo!
Pré-requisitos
Antes de começar, verifique se você tem o seguinte:
- Node.js instalado localmente (recomenda-se a versão LTS mais recente).
- Uma chave de API de um dos provedores de LLM compatíveis (neste guia, usaremos o Google Gemini).
- Uma conta da Bright Data com uma chave de API pronta (não se preocupe, você será orientado a criar uma se ainda não a tiver).
Além disso, o conhecimento prévio é opcional, mas útil:
- Uma compreensão geral de como o MCP funciona.
- Alguma familiaridade com o servidor Bright Data Web MCP e suas ferramentas.
- Conhecimento do funcionamento dos agentes de codificação da CLI e de como eles podem interagir com o sistema de arquivos.
Etapa 1: instalar e configurar o Crush
Instale a CLI do Crush globalmente em seu sistema por meio do pacote npm @charmland/crush:
npm install -g @charmland/crushSe você não quiser instalar a CLI via npm, descubra as outras opções de instalação.
Agora você pode iniciar o Crush com:
crushO que você verá é a tela de seleção de LLM abaixo:
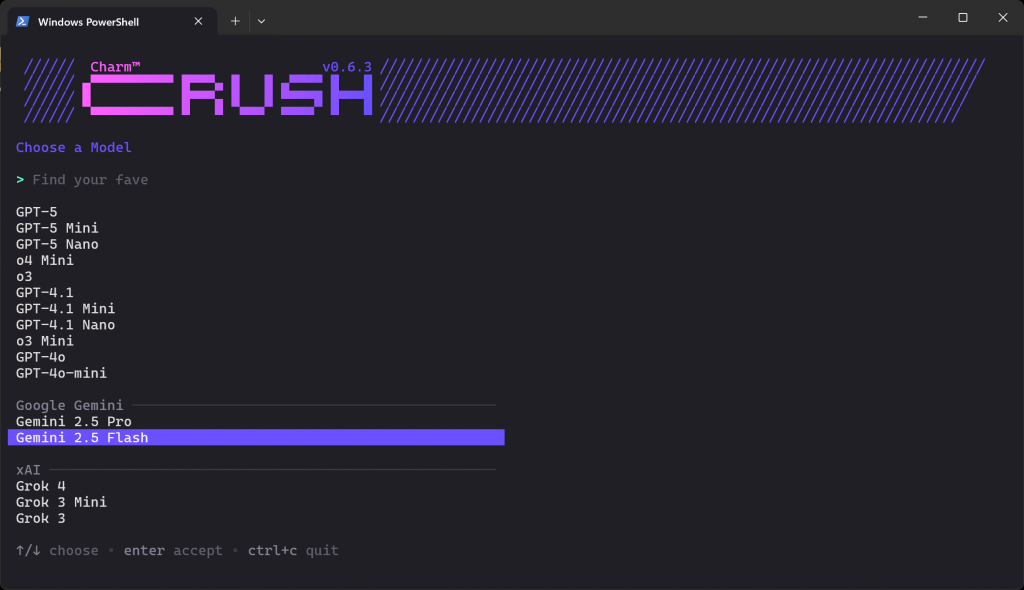
Há dezenas de provedores e centenas de modelos para escolher. Use as teclas de seta para navegar até encontrar o modelo desejado no provedor em que você tem uma chave de API. Neste exemplo, selecionaremos “Gemini 2.5 Flash” (que é essencialmente gratuito para uso via API).
Em seguida, você será solicitado a inserir sua chave de API. Cole-a e pressione Enter:
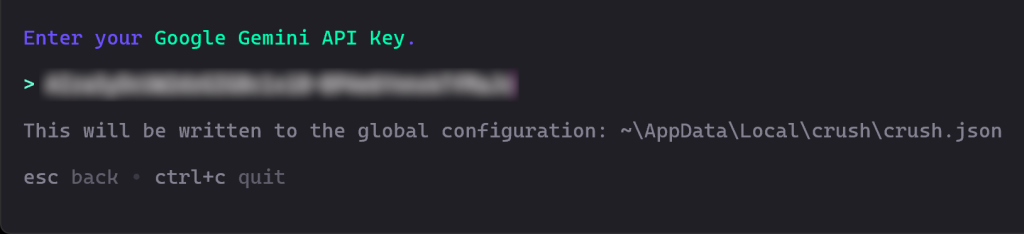
Nesse caso, cole sua chave de API do Google Gemini, que pode ser obtida gratuitamente no Google Studio AI.
Em seguida, o Crush validará sua chave de API para confirmar que ela funciona.
Quando a validação for concluída, você verá algo parecido com isto:
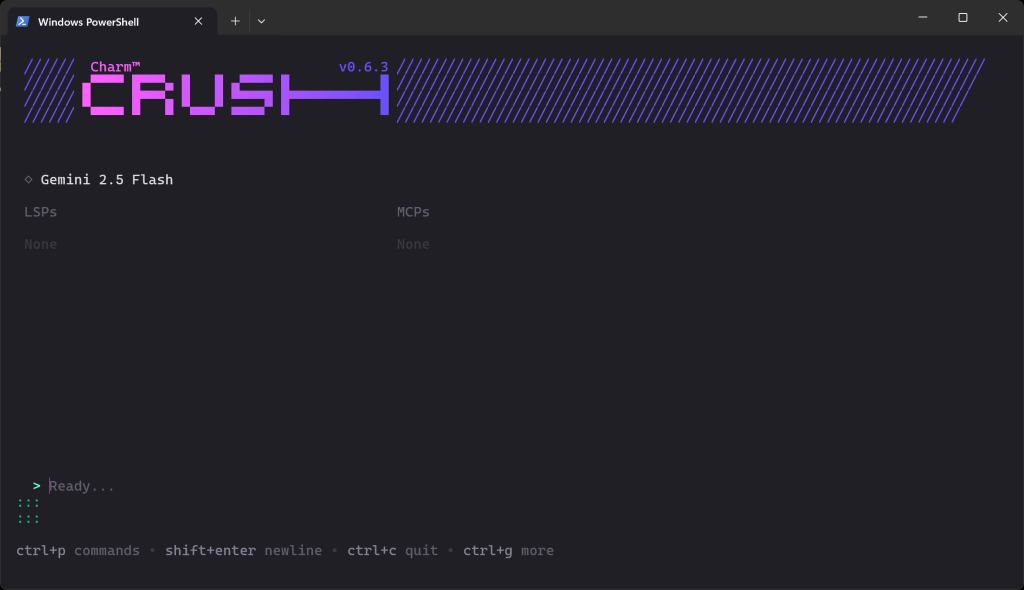
Na seção “Ready…” (Pronto…), agora você pode digitar o seu prompt.
Observação: se você iniciar a CLI do Crush novamente, não será solicitado a configurar uma conexão LLM pela segunda vez. Isso ocorre porque sua chave LLM configurada é salva automaticamente na configuração global $HOME/.config/crush/crush.json (ou, no Windows, %USERPROFILE%AppDataLocalcrushcrush.json)
Abra o arquivo de configuração global crush.json no Visual Studio Code (ou em seu IDE favorito) para inspecioná-lo:
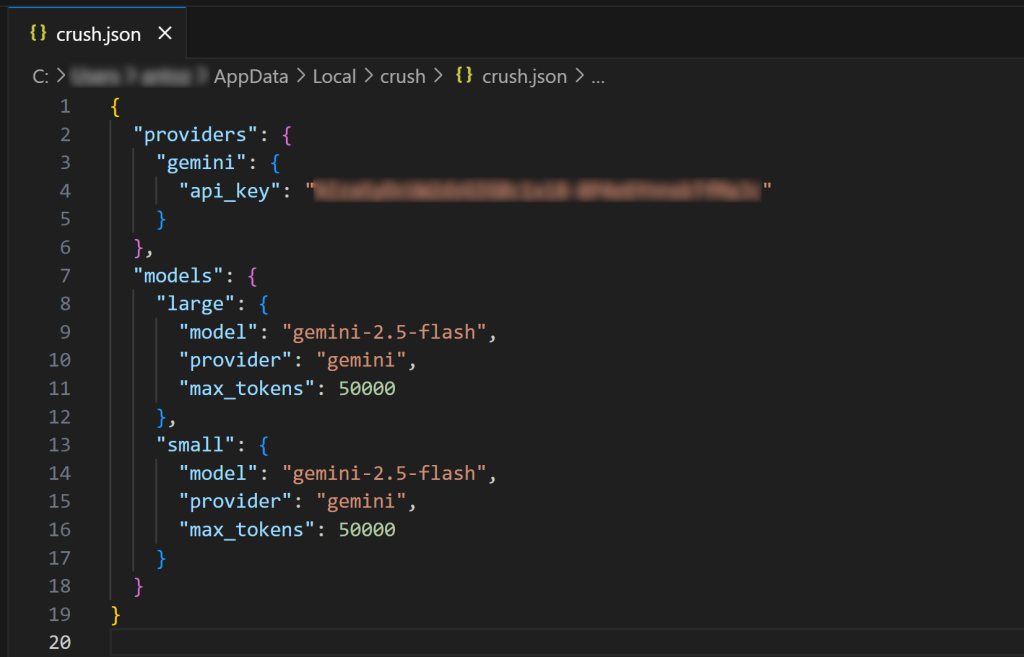
Como você pode ver, o arquivo crush.json contém sua chave de API juntamente com a configuração do modelo escolhido. Ele foi preenchido pela CLI do Crush quando você selecionou um LLM. Você também pode editar esse arquivo para configurar outros modelos de IA(até mesmo modelos locais).
Da mesma forma, você pode criar arquivos crush.json ou .crush.json locais dentro do diretório do projeto para substituir a configuração global. Para obter mais detalhes, consulte a documentação oficial.
Incrível! A CLI do Crush agora está instalada e funcionando em seu sistema.
Etapa 2: testar o Web MCP da Bright Data
Se você ainda não tiver uma, crie uma conta da Bright Data. Caso contrário, basta fazer login na sua conta existente.
Em seguida, siga as instruções oficiais para gerar sua chave de API da Bright Data. Guarde-a em um local seguro, pois você precisará dela em breve. Para simplificar, vamos supor que você esteja usando uma chave de API com permissões de administrador.
Instale o Web MCP globalmente usando o pacote @brightdata/mcp com:
npm install -g @brightdata/mcpEm seguida, verifique se o servidor funciona com este comando Bash:
API_TOKEN="<YOUR_BRIGHT_DATA_API>" npx -y @brightdata/mcpOu, de forma equivalente, no Windows PowerShell:
$Env:API_TOKEN="<YOUR_BRIGHT_DATA_API>"; npx -y @brightdata/mcpSubstitua o espaço reservado <YOUR_BRIGHT_DATA_API> pelo token real da API da Bright Data que você gerou anteriormente. Os comandos acima definem a variável de ambiente API_TOKEN necessária e acionam o servidor MCP por meio do pacote npm @brightdata/mcp.
Se tudo funcionar corretamente, você verá registros como este:

Na primeira inicialização, o servidor MCP cria automaticamente duas zonas em sua conta da Bright Data:
mcp_unlocker: Uma zona para o Web Unlocker.mcp_browser: Uma zona para a API do navegador.
Essas zonas são necessárias para usar toda a gama de ferramentas do servidor MCP.
Para confirmar que elas foram criadas, faça login no painel da Bright Data e vá para a página “Proxies & Scraping Infrastructure“. Você deverá ver as duas zonas listadas:
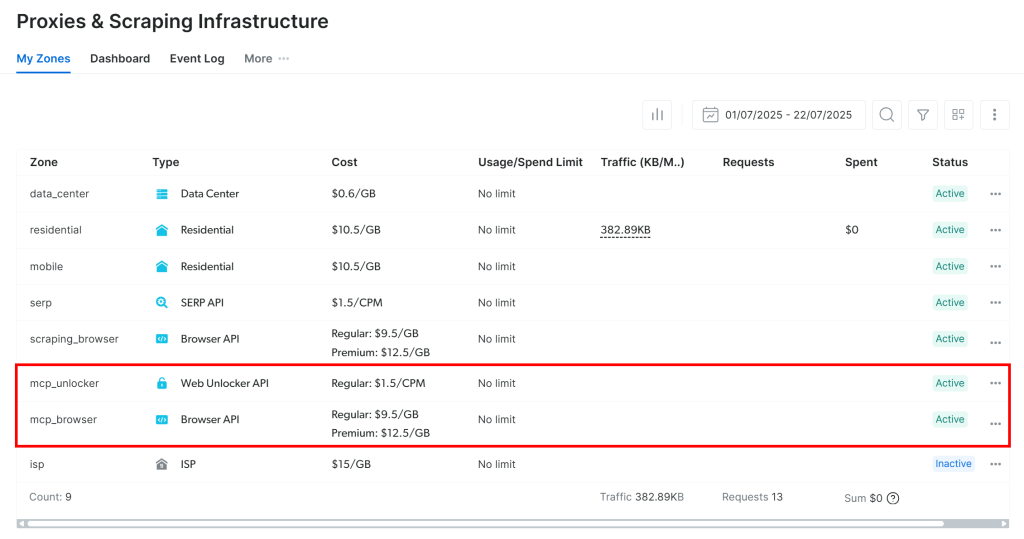
Observação: se o seu token de API não tiver permissões de administrador, essas zonas talvez não sejam criadas para você. Nesse caso, você pode configurá-las manualmente e especificar seus nomes usando variáveis de ambiente, conforme ilustrado nos documentos oficiais.
Lembre-se: por padrão, o servidor MCP expõe apenas as ferramentas search_engine e scrape_as_markdown.
Para desbloquear ferramentas avançadas para automação do navegador e feeds de dados estruturados, você precisa ativar o modo Pro. Para isso, defina a variável de ambiente PRO_MODE=true antes de iniciar o servidor MCP:
API_TOKEN="<YOUR_BRIGHT_DATA_API>" PRO_MODE="true" npx -y @brightdata/mcpOu, no Windows:
$Env:API_TOKEN="<YOUR_BRIGHT_DATA_API>"; $Env:PRO_MODE="true"; npx -y @brightdata/mcpImportante: com o modo Pro, você terá acesso a todas as mais de 60 ferramentas. No entanto, as ferramentas extras no modo Pro não estão incluídas no nível gratuito, e você terá que pagar taxas.
Saiba mais sobre o servidor Web MCP da Bright Data na documentação oficial.
Perfeito! Você verificou que o servidor Web MCP está sendo executado corretamente em sua máquina. Pare o servidor, pois a próxima etapa será configurar o Crush para iniciá-lo e conectar-se a ele na inicialização.
Etapa nº 3: configurar o Web MCP no Crush
O Crush oferece suporte à integração do MCP por meio da entrada mcp no arquivo de configuração local ou global crush.json.
Neste exemplo, vamos supor que você queira configurar o Web MCP da Bright Data globalmente no ambiente CLI do Crush. Portanto, abra o arquivo de configuração global:
- No Linux/macOS:
$HOME/.config/crush/crush.json. - No Windows:
%USERPROFILE%AppDataLocalcrushcrush.json.
Certifique-se de que ele contenha o seguinte:
"mcp": {
"brightData": {
"type": "stdio",
"command" (comando): "npx",
"args": [
"-y",
"@brightdata/mcp"
],
"env": {
"API_TOKEN": "<SUA CHAVE_API_DATA_BRIGHT_DATA>",
"PRO_MODE": "true"
}
}
}Nessa configuração:
- A entrada
mcpinforma ao Crush como iniciar servidores MCP externos. - A entrada
brightDatadefine o comando e as variáveis de ambiente necessárias para executar o Web MCP. (Lembre-se: A definição dePRO_MODEé opcional, mas recomendada. Além disso, substitua<YOUR_BRIGHT_DATA_API_KEY>pela sua chave de API do Bright Data).
Em outras palavras, essa configuração adiciona um servidor MCP personalizado chamado brightData. O Crush usa as variáveis de ambiente que você definiu no arquivo e inicia o servidor por meio do comando npx especificado (que corresponde ao comando mostrado na etapa anterior). Em termos mais simples, o Crush agora pode iniciar um processo Web MCP local e se conectar a ele na inicialização.
Excelente! É hora de testar a integração do MCP na CLI do Crush.
Etapa 4: verificar a conexão do MCP
Feche todas as instâncias do Crush em execução e inicie-o novamente:
crush Se a conexão com o MCP funcionar conforme o esperado, você verá a entrada brightData listada na seção “MCPs”:
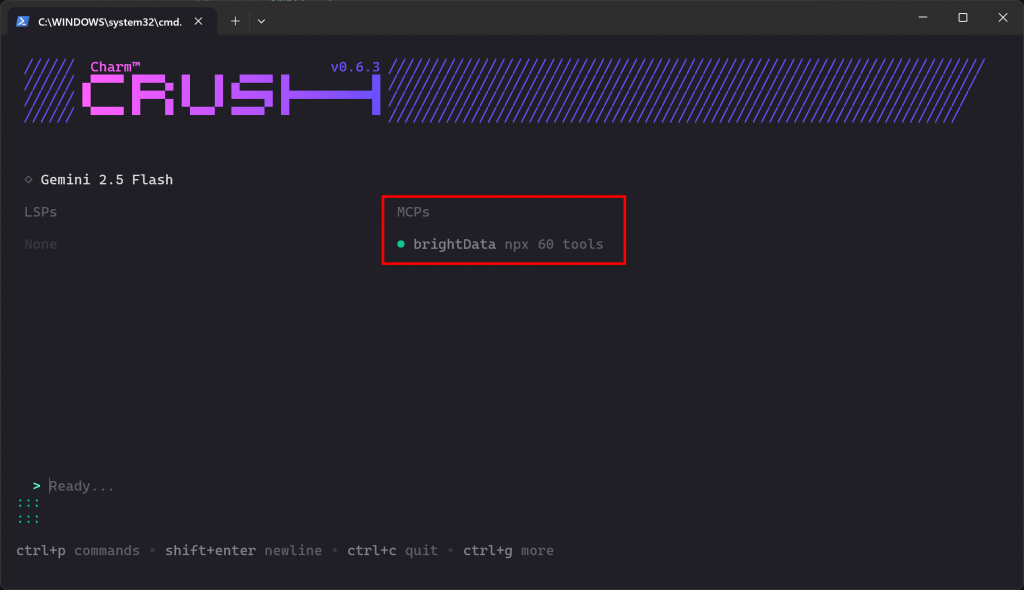
A CLI indica que 60 ferramentas estão disponíveis. Isso ocorre porque o configuramos para ser executado no modo Pro. Caso contrário, você só teria acesso a 2 ferramentas(scrape_as_markdown e search_engine). Muito bem!
Etapa 5: executar uma tarefa no Crush
Para verificar os novos recursos na configuração da CLI do Crush, tente executar um prompt como este:
Extraia dados de "https://www.amazon.com/Microfiber-Cleaning-Cloth-Performance-Washes/dp/B08BRJHJF9/", salve-os em um arquivo local "product.json" e defina um script Node.js "script.js" para carregar o arquivo e imprimir seu conteúdo no terminal.Esse é um ótimo caso de teste porque solicita a recuperação de dados de produtos novos, o que deve ser feito usando as ferramentas expostas pelo Web MCP da Bright Data. Além disso, ele demonstra um fluxo de trabalho realista que você pode usar ao simular ou configurar um projeto de análise de dados.
Cole o prompt no Crush e pressione Enter para executá-lo. Você deverá ver algo parecido com isto:
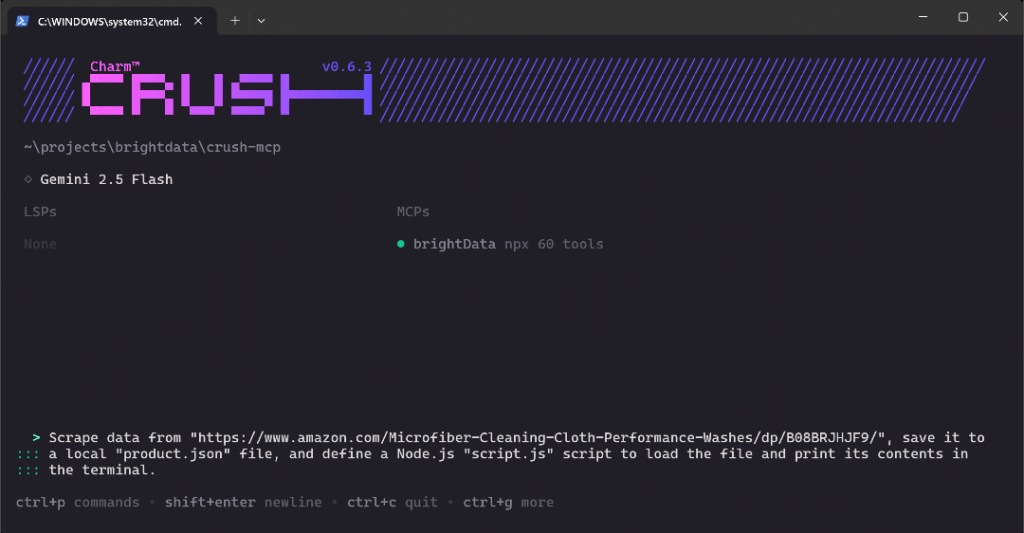
O GIF acima foi acelerado, mas o que acontece é o seguinte, passo a passo:
- O Crush identifica a ferramenta
web_data_amazon_product(referenciada comomcp_brightData_web_data_amazon_productpela CLI) como a correta para a tarefa e solicita sua permissão para executá-la. - Depois de aprovada, a tarefa de raspagem é executada por meio da integração do MCP.
- Os dados de produto JSON resultantes são exibidos no terminal.
- O Crush pergunta se pode salvar esses dados em um arquivo local chamado
product.json. - Após a aprovação, o arquivo é criado e preenchido com os dados extraídos.
- Em seguida, a CLI do Crush gera a lógica JavaScript para o
script.js, que carrega e imprime o conteúdo do JSON. - Depois que você aprovar, o arquivo
script.jsserá criado. - Você será solicitado a dar permissão para executar o script Node.js.
- Depois de conceder a permissão,
o script.jsé executado e os dados do produto são impressos no terminal.
Observe que a CLI solicitou a execução do script Node.js produzido, mesmo que você não o tenha solicitado explicitamente. Esse comportamento foi intencional, pois facilita o teste (e, portanto, a correção em caso de erros) e agrega valor ao fluxo de trabalho.
No final, seu diretório de trabalho deverá conter estes dois arquivos:
├── prodcut.json
└── script.jsAbra o product.json no VS Code e você verá:
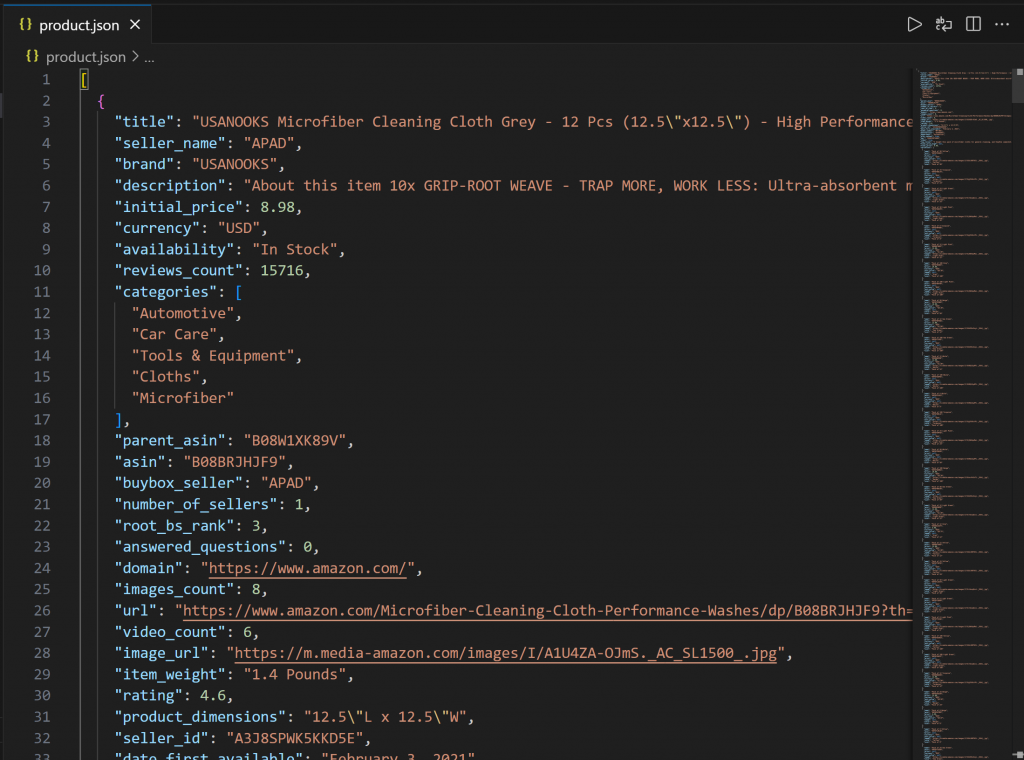
Esse arquivo contém dados reais de produtos extraídos da Amazon por meio do Web MCP da Bright Data.
Agora, abra script.js:
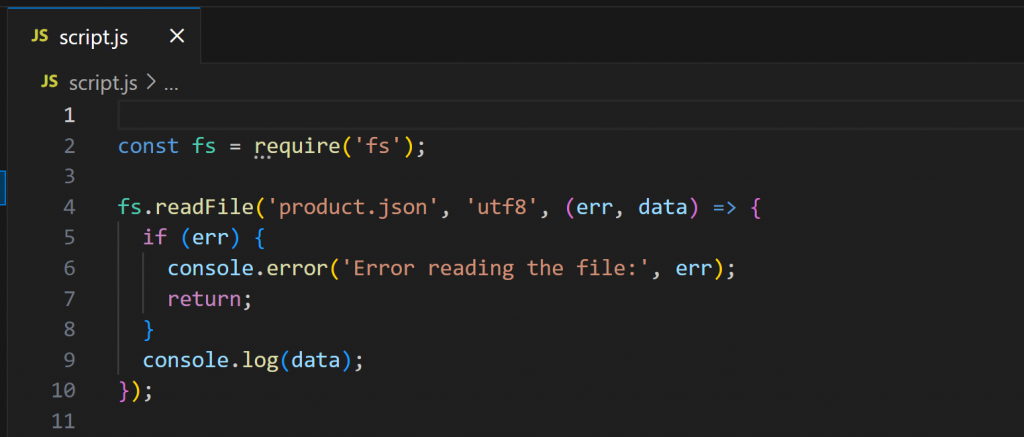
Esse script usa o Node.js para carregar e exibir o conteúdo do product.json. Execute-o com:
node script.jsO resultado deve ser:
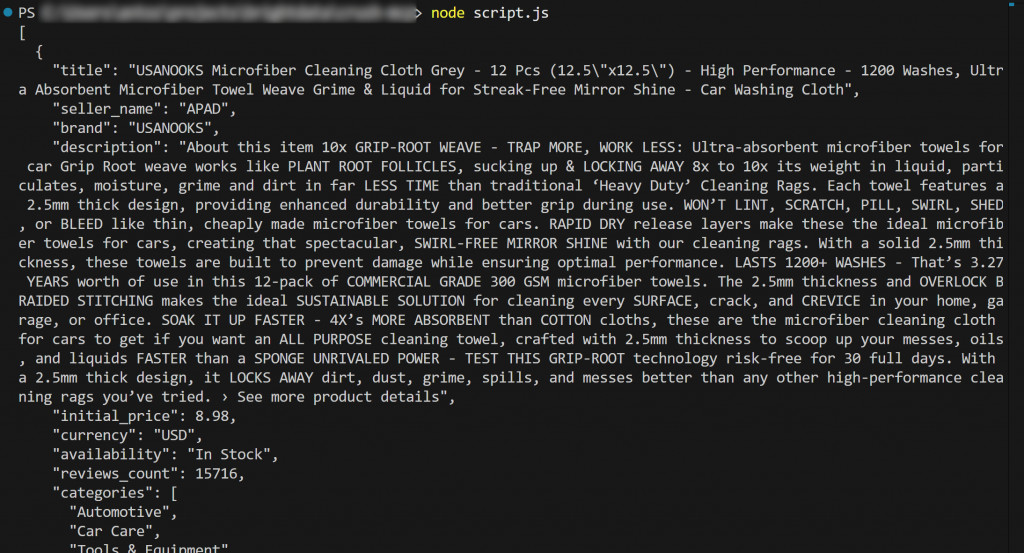
Et voilà! O fluxo de trabalho foi bem-sucedido.
Em detalhes, o conteúdo carregado do product.json e impresso no terminal corresponde aos dados reais que você pode encontrar na página original do produto da Amazon.
Importante: product.json contém dados raspados genuínos – não conteúdo alucinado ou inventado produzido pela IA. É fundamental ressaltar isso, pois raspar a Amazon é notoriamente difícil devido às suas proteções antibot avançadas (por exemplo, por causa do Amazon CAPTCHA). Portanto, um LLM comum sozinho não conseguiria atingir esse objetivo!
Esse exemplo mostra o verdadeiro poder de combinar o Crush com o servidor MCP da Bright Data. Agora, experimente novos prompts e explore fluxos de trabalho de dados mais avançados e orientados por LLM diretamente na CLI!
Conclusão
Neste tutorial, você viu como conectar o Crush com o Web MCP da Bright Data(que agora oferece um nível gratuito!). O resultado é um poderoso agente de codificação CLI capaz de acessar e interagir com a Web. Essa integração é possível graças ao suporte incorporado do Crush CLI para servidores MCP.
A tarefa de exemplo neste guia foi intencionalmente simples. No entanto, não se esqueça de que, com essa integração, você pode lidar com casos de uso muito mais complexos. Afinal, as ferramentas do Bright Data Web MCP oferecem suporte a uma ampla variedade de cenários agênticos.
Para criar agentes mais avançados, explore toda a gama de serviços disponíveis na infraestrutura de IA da Bright Data.
Inscreva-se em uma conta gratuita da Bright Data e comece a fazer experiências com ferramentas da Web prontas para IA hoje mesmo!





