Neste guia, você aprenderá:
- O que é um scraper do LinkedIn
- Uma comparação entre o Scraping de dados do LinkedIn e a recuperação de dados por meio de suas APIs
- Como contornar a barreira de login do LinkedIn
- Como criar um script de scraping do LinkedIn em Python
- Como obter dados do LinkedIn com uma solução mais simples e eficaz
Vamos começar!
O que é um Scraper do LinkedIn?
Um scraper do LinkedIn é uma ferramenta que extrai automaticamente dados das páginas do LinkedIn. Ele normalmente tem como alvo páginas populares, como perfis, listas de empregos, páginas de empresas e artigos.
O Scraper coleta informações importantes dessas páginas e as apresenta em formatos úteis, como CSV ou JSON. Esses dados são valiosos para geração de leads, busca de emprego, análise de concorrentes e identificação de tendências de mercado, entre outros casos de uso.
Scraping de dados do LinkedIn x API do LinkedIn
O LinkedIn fornece uma API oficial que permite que os desenvolvedores se integrem à plataforma e recuperem alguns dados. Então, por que você deveria considerar o Scraping de dados do LinkedIn? A resposta é simples e envolve quatro pontos principais:
- A API retorna apenas um subconjunto de dados definido pelo LinkedIn, que pode ser muito menor do que os dados disponíveis por meio do Scraping de dados.
- As APIs podem mudar com o tempo, limitando o controle que você tem sobre os dados aos quais pode acessar.
- A API do LinkedIn é focada principalmente em integrações de marketing e vendas, especialmente para usuários da versão gratuita.
- A API do LinkedIn pode custar dezenas de dólares por mês, mas ainda tem limitações rígidas sobre os dados e o número de perfis dos quais você pode recuperar dados.
A comparação entre as duas abordagens para obter dados do LinkedIn leva à seguinte tabela resumida:
| Aspecto | API do LinkedIn | Scraping de dados para LinkedIn |
|---|---|---|
| Disponibilidade de dados | Limitada a um subconjunto de dados definido pelo LinkedIn | Acesso a todos os dados disponíveis publicamente no site |
| Controle sobre os dados | O LinkedIn controla os dados fornecidos | Controle total sobre os dados que você recupera |
| Foco | Principalmente para integrações de marketing e vendas | Pode segmentar qualquer página do LinkedIn |
| Custo | Pode custar dezenas de dólares por mês | Sem custo direto (exceto pela infraestrutura) |
| Limitações | Número limitado de perfis e dados por mês | Sem limitações rígidas |
Para obter mais informações, leia nosso guia sobre Scraping de dados vs API.
Que dados extrair do LinkedIn
Aqui está uma lista parcial dos tipos de dados que você pode extrair do LinkedIn:
- Perfil: detalhes pessoais, experiência profissional, formação acadêmica, conexões, etc.
- Empresas: informações sobre a empresa, listas de funcionários, vagas de emprego, etc.
- Anúncios de vagas: descrições de cargos, candidaturas, critérios, etc.
- Cargos: cargo, empresa, localização, salário, etc.
- Artigos: publicações, artigos escritos por usuários, etc.
- LinkedIn Learning: cursos, certificações, percursos de aprendizagem, etc.
Como evitar a barreira de login do LinkedIn
Se você tentar visitar a página de empregos do LinkedIn diretamente após uma pesquisa no Google no modo de navegação anônima (ou enquanto estiver desconectado), é isso que você verá:
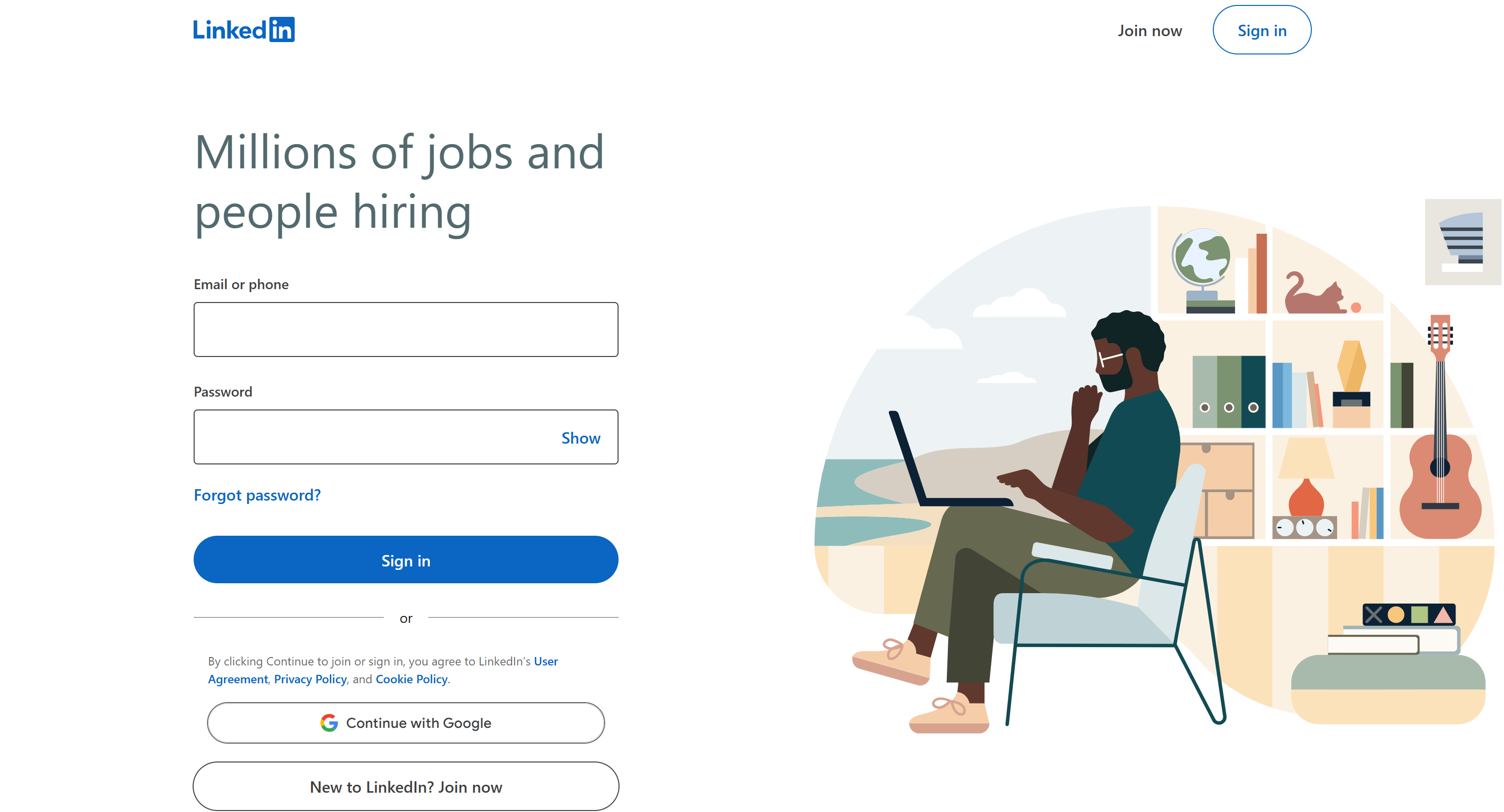
A página acima pode levar você a acreditar que a busca por vagas no LinkedIn só é possível após o login. Como extrair dados por trás de uma barreira de login pode levar a problemas legais, pois pode violar os termos de serviço do LinkedIn, é melhor evitar isso.
Felizmente, existe uma solução simples para acessar a página de empregos sem ser bloqueado. Tudo o que você precisa fazer é visitar a página inicial do LinkedIn e clicar na guia “Empregos”:
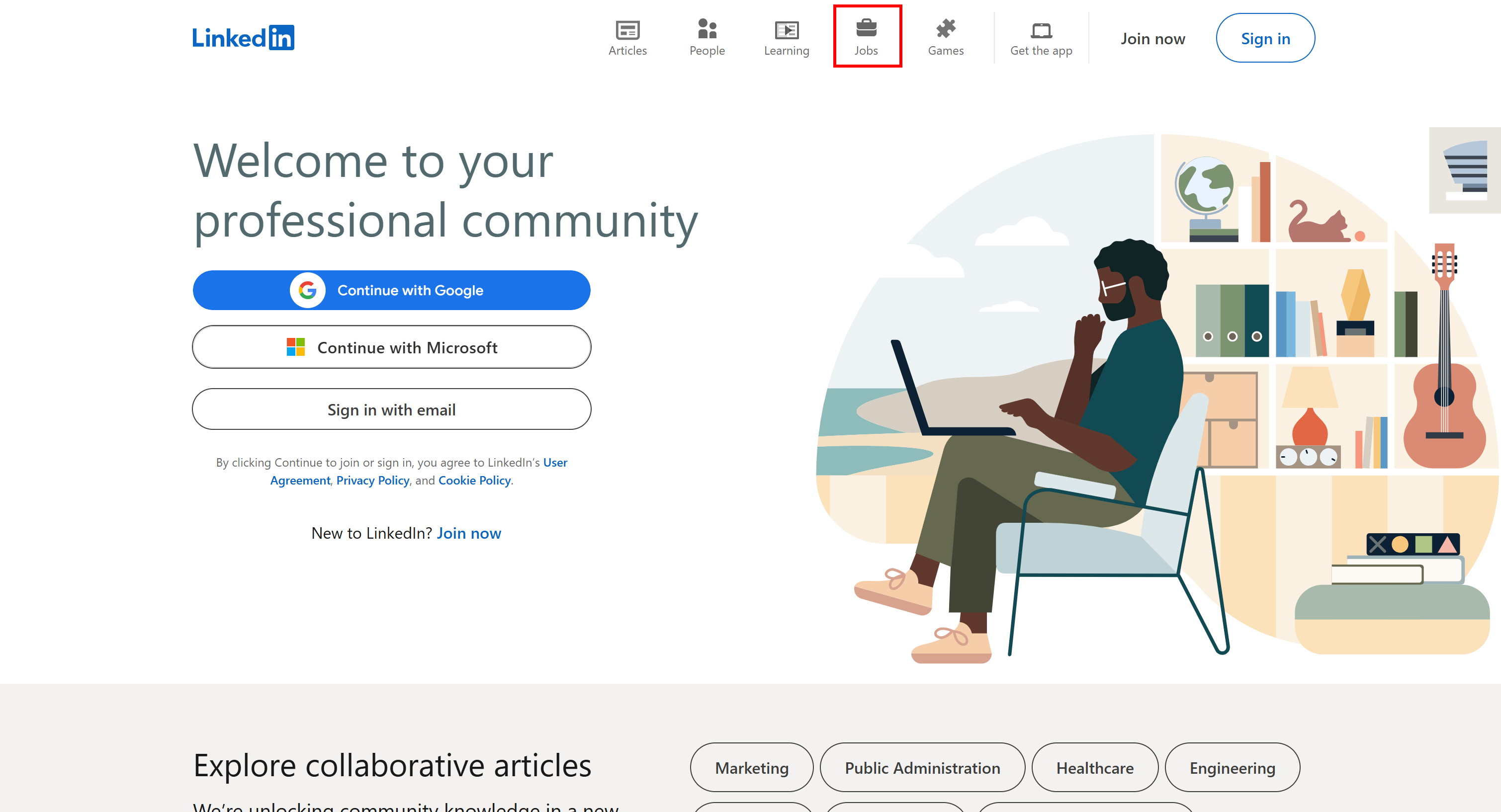
Desta vez, você terá acesso à página de busca de empregos:
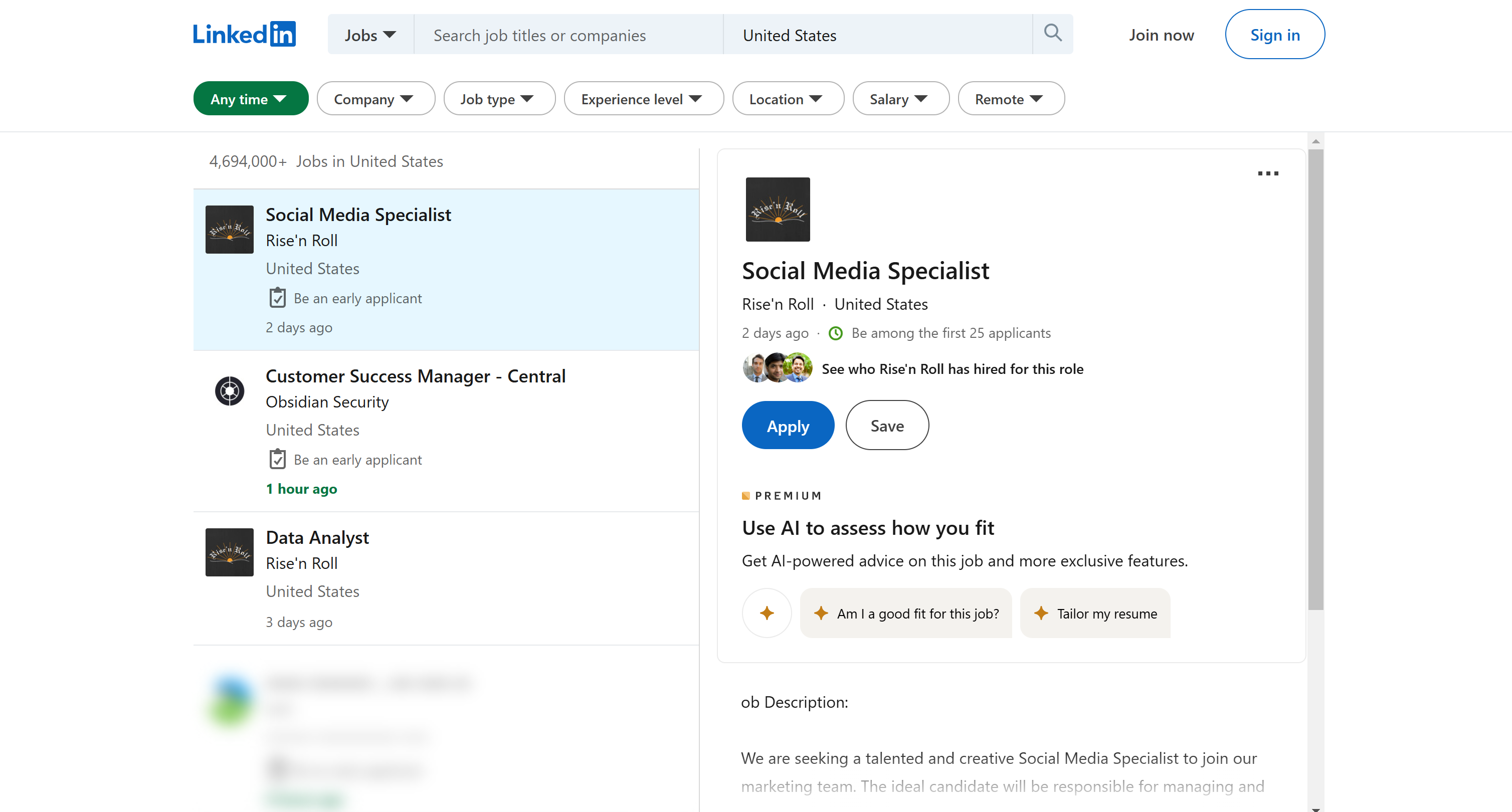
Como você pode ver na barra de URL do seu navegador, desta vez, a URL contém parâmetros de consulta especiais:
https://www.linkedin.com/jobs/search?trk=guest_homepage-basic_guest_nav_menu_jobs&position=1&pageNum=0
Em particular, o argumento trk=guest_homepage-basic_guest_nav_menu_jobs parece ser o fator-chave que impede o LinkedIn de impor uma barreira de login.
No entanto, isso não significa que você possa acessar todos os dados do LinkedIn. Algumas seções ainda exigem que você esteja conectado. No entanto, como veremos a seguir, essa não é uma limitação significativa para o Scraping de dados do LinkedIn.
Crie um script de Scraping de dados do LinkedIn: guia passo a passo
Nesta seção do tutorial, você aprenderá como extrair dados de anúncios de vagas para engenheiros de software em Nova York do LinkedIn:
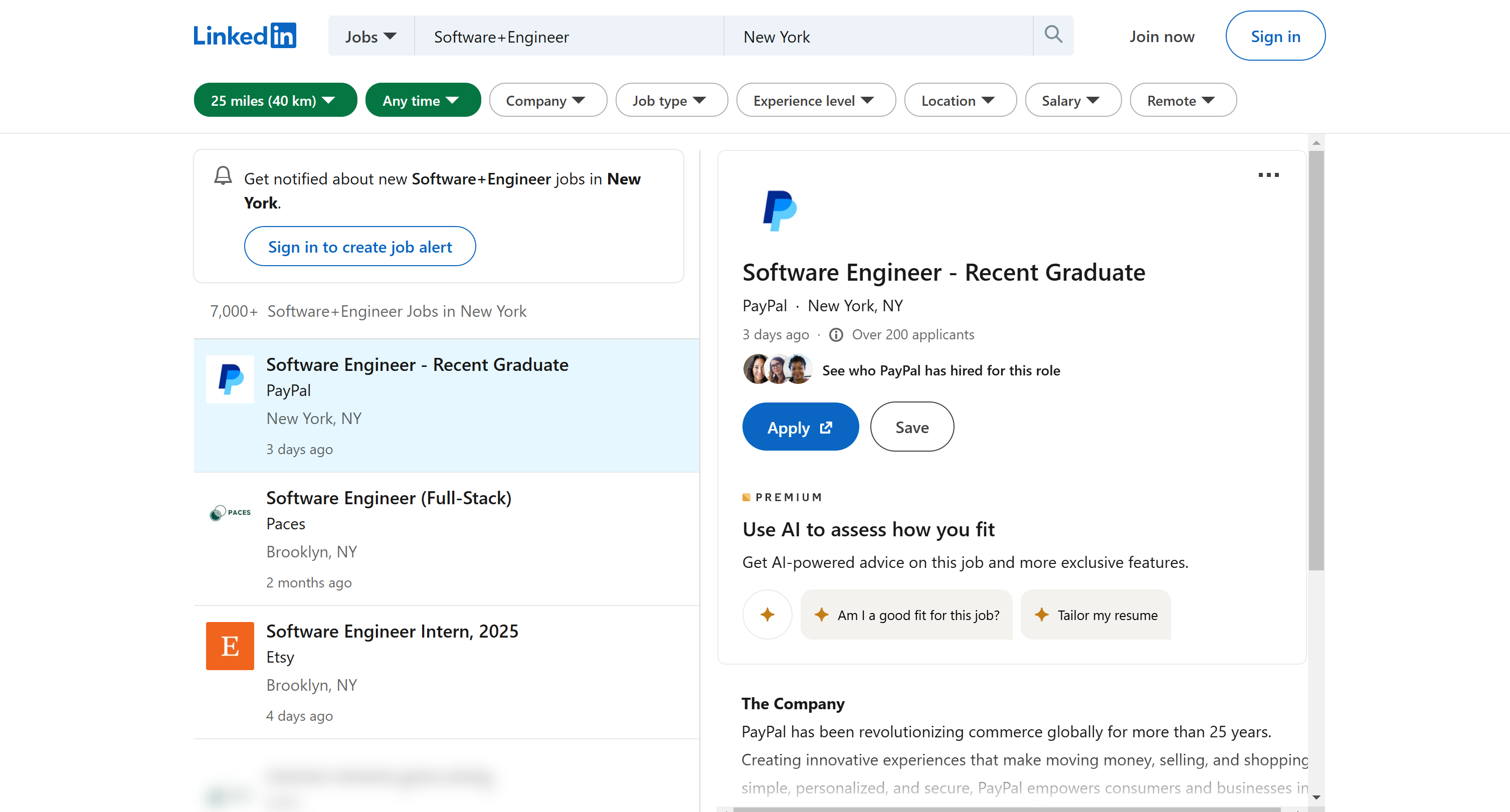
Começaremos pela página de resultados da pesquisa, recuperaremos automaticamente as URLs das listas de vagas e, em seguida, extrairemos os dados de suas páginas de detalhes. O Scraper do LinkedIn será escrito em Python, uma das melhores linguagens de programação para Scraping de dados.
Vamos realizar o scraping de dados do LinkedIn com Python!
Etapa 1: Configuração do projeto
Antes de começar, certifique-se de que o Python 3 esteja instalado em seu computador. Caso contrário, baixe-o e siga o assistente de instalação.
Agora, use o comando abaixo para criar uma pasta para o seu projeto de scraping:
mkdir linkedin-scraper
linkedin-scraper representa a pasta do projeto do seu Scraper Python do LinkedIn.
Entre nela e inicialize um ambiente virtual dentro dela:
cd linkedin-Scraper
python -m venv venv
Carregue a pasta do projeto em seu IDE Python favorito. O Visual Studio Code com a extensão Python ou o PyCharm Community Edition são opções adequadas.
Crie um arquivo scraper.py na pasta do projeto, que deve conter esta estrutura de arquivos:
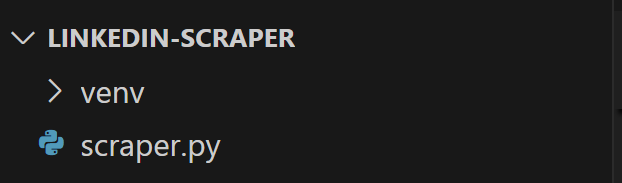
No momento, o scraper.py é um script Python em branco, mas em breve conterá a lógica de scraping desejada.
No terminal do IDE, ative o ambiente virtual. No Linux ou macOS, execute este comando:
./env/bin/activate
De forma equivalente, no Windows, execute:
env/Scripts/activate
Ótimo! Agora você tem um ambiente Python para Scraping de dados.
Etapa 2: Seleção e instalação das bibliotecas de scraping
Antes de mergulhar na programação, você deve analisar o site de destino para determinar as ferramentas de scraping adequadas para o trabalho.
Comece abrindo a página de pesquisa de empregos do LinkedIn no modo de navegação anônima, conforme explicado anteriormente. O uso do modo de navegação anônima garante que você esteja desconectado e que nenhum dado em cache interfira no processo de scraping.
É isso que você deve ver:
O LinkedIn exibe vários pop-ups no navegador. Eles podem ser irritantes ao usar ferramentas de automação de navegador, como Selenium ou Playwright.
Felizmente, se você inspecionar o código-fonte HTML da página retornada pelo servidor, verá que ele já contém a maioria dos dados da página:
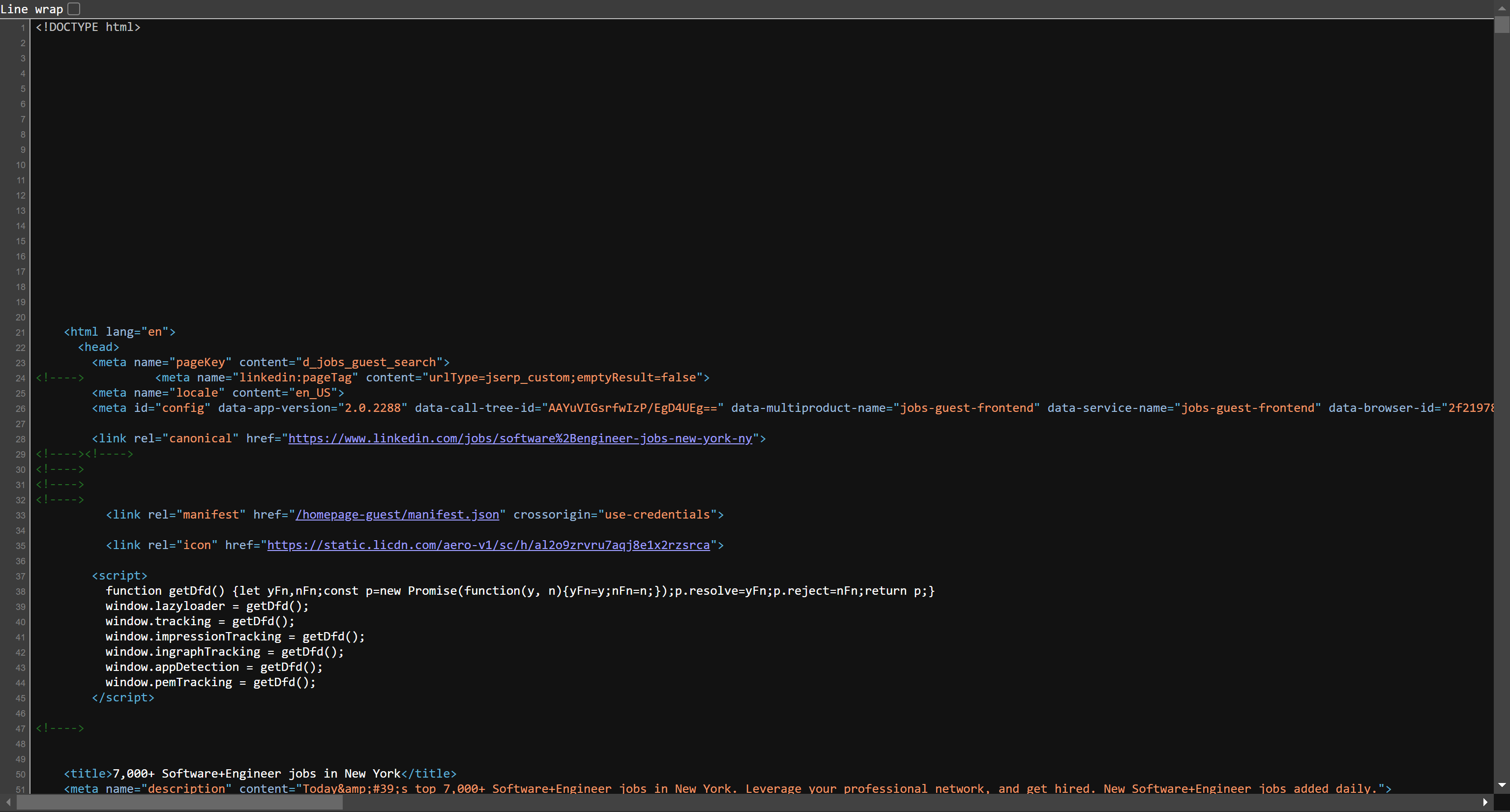
Da mesma forma, se você verificar a guia “Rede” no DevTools, perceberá que a página não depende de chamadas de API dinâmicas significativas:
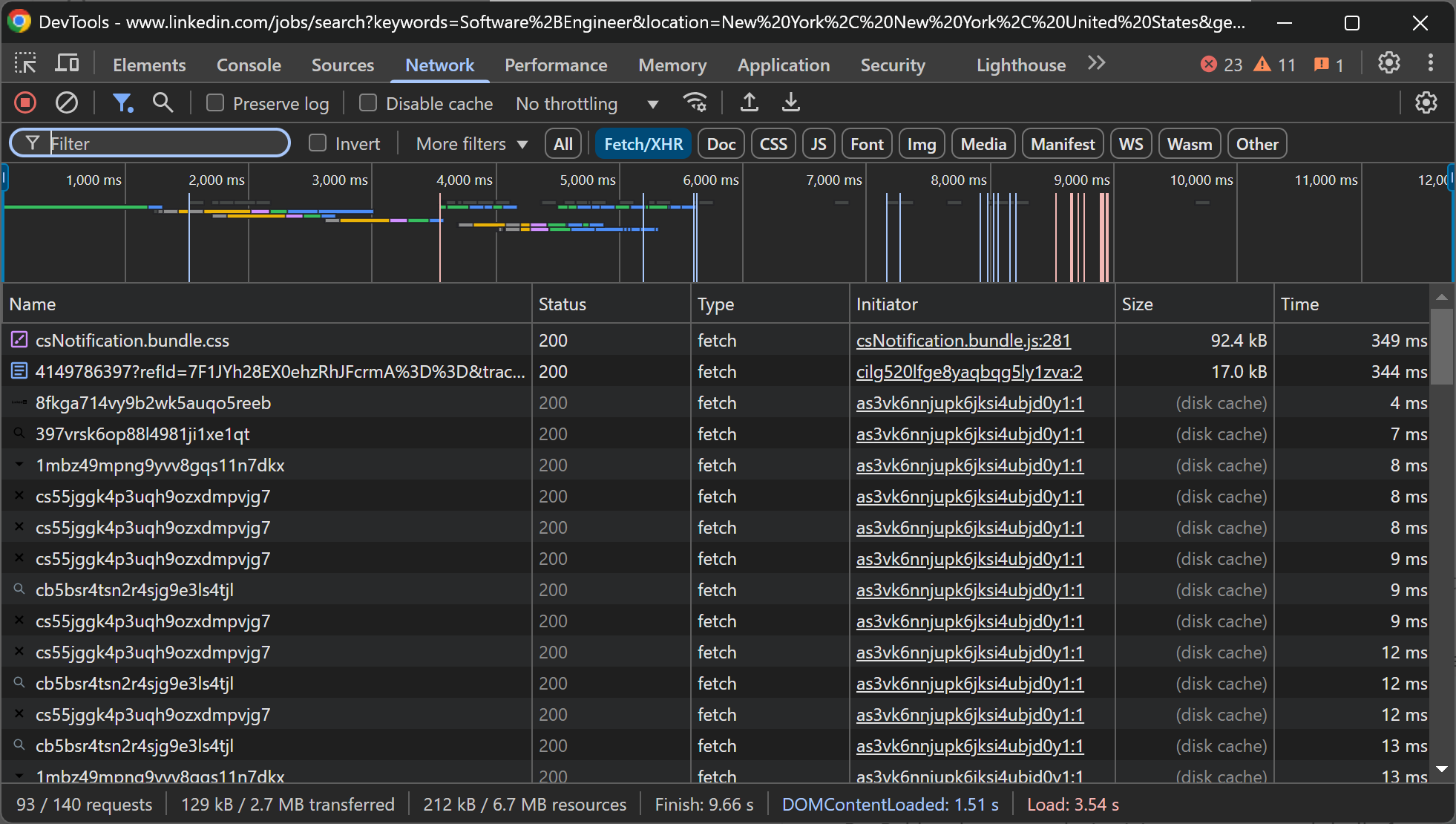
Em outras palavras, a maior parte do conteúdo das páginas de vagas do LinkedIn é estática. Isso significa que você não precisa de uma ferramenta de automação de navegador para extrair dados do LinkedIn. Uma combinação de um cliente HTTP e um analisador HTML será suficiente para recuperar os dados das vagas.
Portanto, usaremos duas bibliotecas Python para extrair vagas do LinkedIn:
- Requests: uma biblioteca HTTP simples para enviar solicitações GET e recuperar o conteúdo de páginas da web.
- Beautiful Soup: um poderoso analisador HTML que facilita a extração de dados de páginas da web.
Em um ambiente virtual ativado, instale ambas as bibliotecas com:
pip install requests beautifulsoup4
Em seguida, importe-as no Scraper.py com:
from bs4 import BeautifulSoup
import requests
Ótimo! Agora você tem tudo o que precisa para começar a fazer scraping no LinkedIn.
Etapa 3: estruturar o script de scraping
Conforme explicado na introdução desta seção, o Scraper do LinkedIn realizará duas tarefas principais:
- Recuperar URLs de páginas de vagas da página de pesquisa de vagas do LinkedIn
- Extrair detalhes de cada página de emprego específica
Para manter o script bem organizado, estruture seu arquivo scraper.py com duas funções:
def retrieve_job_urls(job_search_url):
pass
# A ser implementado...
def scrape_job(job_url):
pass
# A ser implementado...
# Chamadas de função e lógica de exportação de dados...
Abaixo está o que as duas funções fazem:
retrieve_job_urls(job_search_url): Aceita a URL da página de pesquisa de vagas e retorna uma lista de URLs de páginas de vagas.scrape_job(job_url): Aceita uma URL da página de vagas e extrai detalhes da vaga, como título, empresa, localização e descrição.
Em seguida, no final do script, chame essas funções e implemente a lógica de exportação de dados para armazenar os dados de vagas extraídos. É hora de implementar essa lógica!
Etapa 4: conecte-se à página de busca de vagas
Na função retrieve_job_urls(), use a biblioteca requests para buscar a página de destino usando a URL passada como argumento:
response = requests.get(job_url)
Nos bastidores, isso executa uma solicitação HTTP GET para a página de destino e recupera o documento HTML retornado pelo servidor.
Para acessar o conteúdo HTML da resposta, use o atributo .text:
html = response.text
Excelente! Agora você está pronto para realizar o Parsing do HTML e começar a extrair URLs de vagas.
Etapa 5: recuperar URLs de vagas
Para realizar o Parsing do HTML recuperado anteriormente, passe-o para o construtor Beautiful Soup:
soup = BeautifulSoup(html, "html.parser")
O segundo argumento especifica o analisador HTML a ser usado. html.parser é o analisador padrão incluído na biblioteca padrão do Python.
Em seguida, inspecione os elementos do cartão de vaga na página de busca de vagas do LinkedIn. Clique com o botão direito do mouse em um deles e selecione “Inspect” nas DevTools do seu navegador:
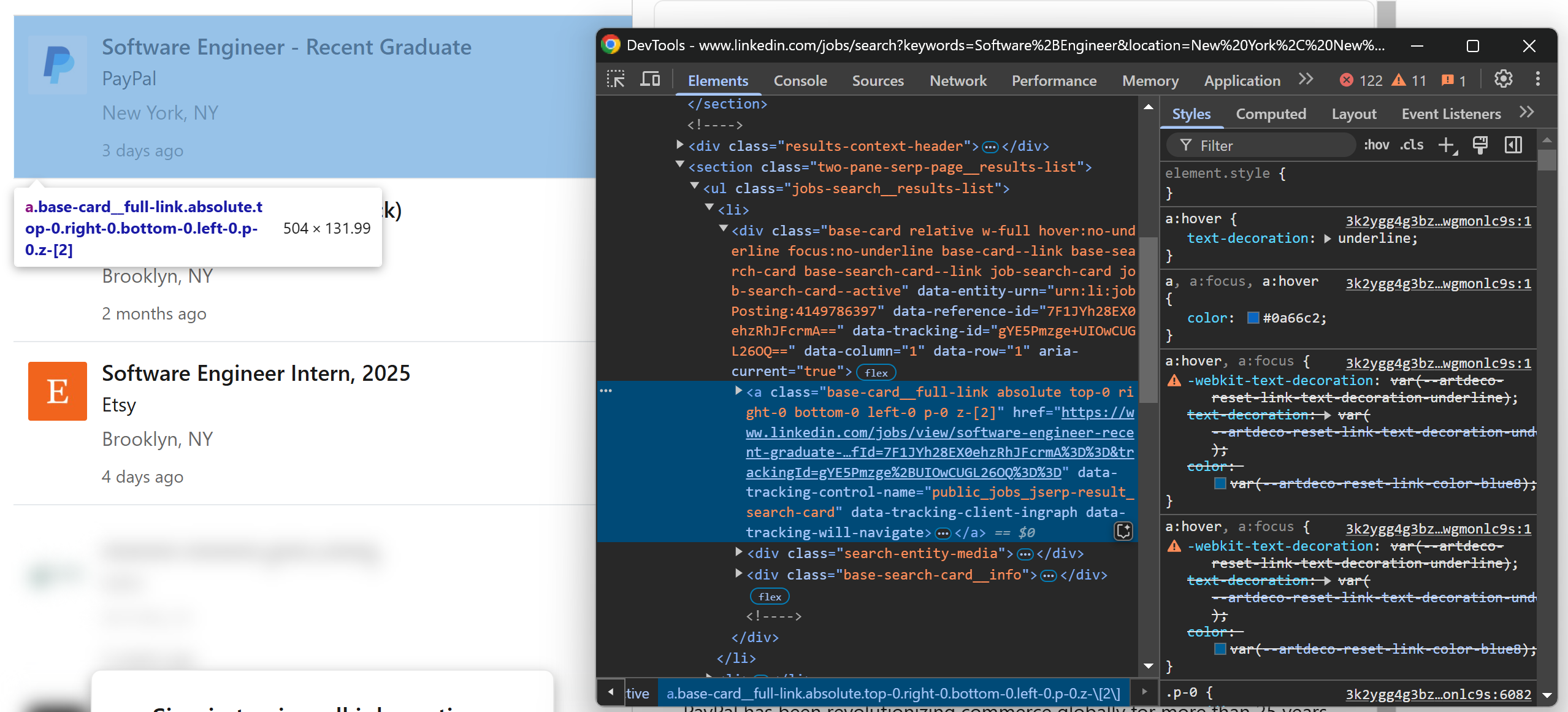
Como você pode ver no código HTML do cartão de emprego, os URLs de vagas podem ser extraídos usando o seguinte seletor CSS:
[data-tracking-control-name="public_jobs_jserp-result_search-card"]
Observação: usar atributos data-* para seleção de nós no Scraping de dados é ideal, pois eles são frequentemente usados para testes ou rastreamento interno. Isso os torna menos propensos a mudar com o tempo.
Agora, se você der uma olhada na página, verá que alguns cartões de emprego podem aparecer borrados atrás de um elemento de convite para login:
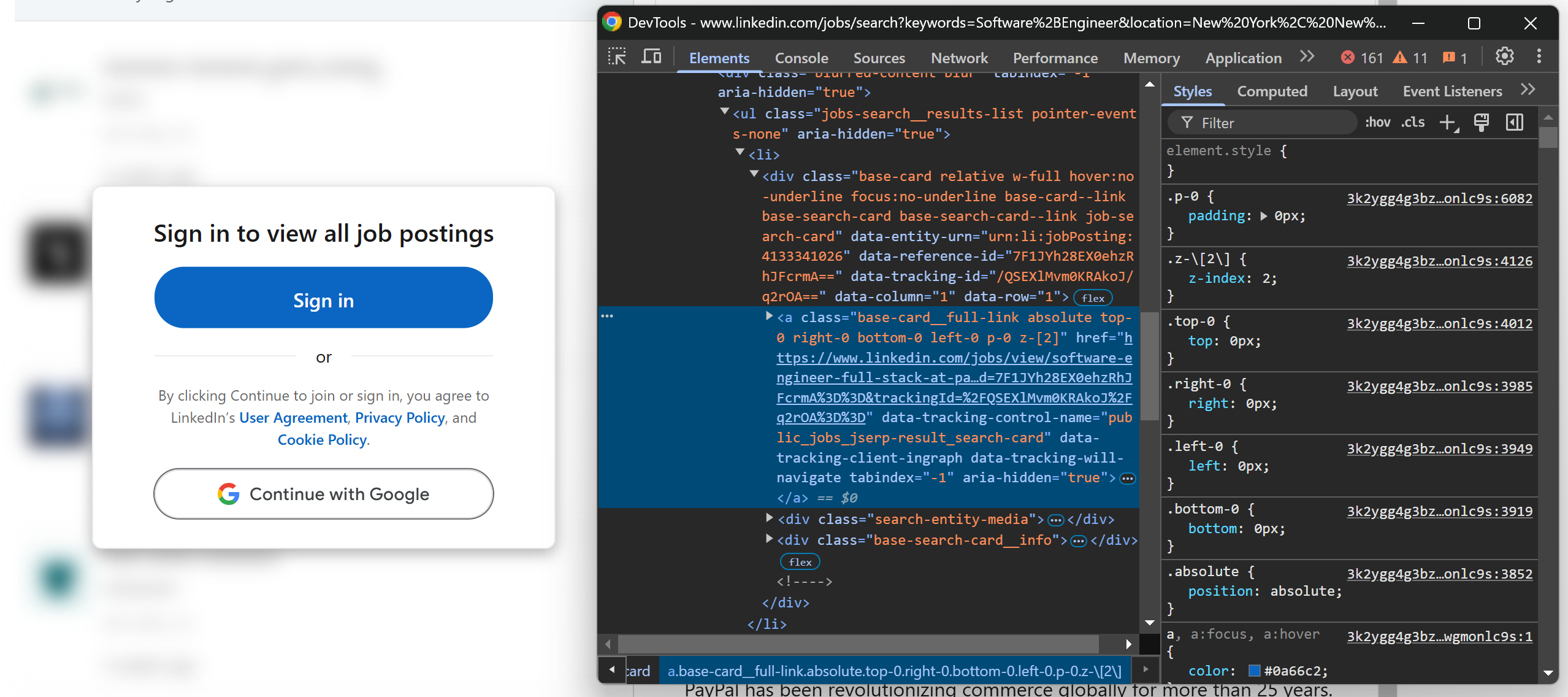
Não se preocupe, pois isso é apenas um efeito de front-end. O HTML subjacente ainda contém as URLs da página de vagas, então você pode obter essas URLs sem fazer login.
Aqui está a lógica para extrair URLs de anúncios de vagas da página de empregos do LinkedIn:
job_urls = []
job_url_elements = soup.select("[data-tracking-control-name="public_jobs_jserp-result_search-card"]")
for job_url_element in job_url_elements:
job_url = job_url_element["href"]
job_urls.append(job_url)
select() retorna todos os elementos que correspondem ao seletor CSS fornecido, que contêm links de vagas. Em seguida, o script:
- Itera por esses elementos
- Acessa o atributo HTML
href(a URL da página do emprego) - Anexa-o à lista
job_urls
Se você não estiver familiarizado com a lógica acima, leia nosso guia sobre Scraping de dados com Beautiful Soup.
No final desta etapa, sua função retrieve_job_urls() ficará assim:
def retrieve_job_urls(job_search_url):
# Faça uma solicitação HTTP GET para obter o HTML da página
response = requests.get(job_search_url)
# Acesse o HTML e analise-o
html = response.text
soup = BeautifulSoup(html, "html.parser")
# Onde armazenar os dados coletados
job_urls = []
# Lógica de coleta
job_url_elements = soup.select("[data-tracking-control-name="public_jobs_jserp-result_search-card"]")
para job_url_element em job_url_elements:
# Extrair a URL da página de emprego e anexá-la à lista
job_url = job_url_element["href"]
job_urls.append(job_url)
retornar job_urls
Você pode chamar esta função na página de destino conforme abaixo:
public_job_search_url = "https://www.linkedin.com/jobs/search?keywords=Software%2BEngineer&location=New%20York%2C%20New%20York%2C%20United%20States&geoId=102571732&trk=public_jobs_jobs-search-bar_search-submit&position=1&pageNum=0"
job_urls = retrieve_job_urls(public_job_search_url)
Bom trabalho! Você concluiu a primeira tarefa do seu Scraper do LinkedIn.
Etapa 6: Inicialize a tarefa de scraping de dados de vagas
Agora, concentre-se na função scrape_job(). Assim como antes, use a biblioteca requests para buscar o HTML da página de empregos a partir da URL fornecida e analise-o com o Beautiful Soup:
response = requests.get(job_url)
html = response.text
soup = BeautifulSoup(html, "html.parser")
Como a extração de dados de vagas do LinkedIn envolve a extração de várias informações, vamos dividi-la em duas etapas para simplificar o processo.
Etapa 7: Recuperação de dados de vagas — Parte 1
Antes de começar a extrair dados do LinkedIn, você precisa inspecionar uma página de detalhes de uma vaga de emprego para entender quais dados ela contém e como recuperá-los.
Para fazer isso, abra uma página de vagas de emprego no modo de navegação anônima e use o DevTools para inspecionar a página. Concentre-se na seção superior da página de anúncios de vagas:
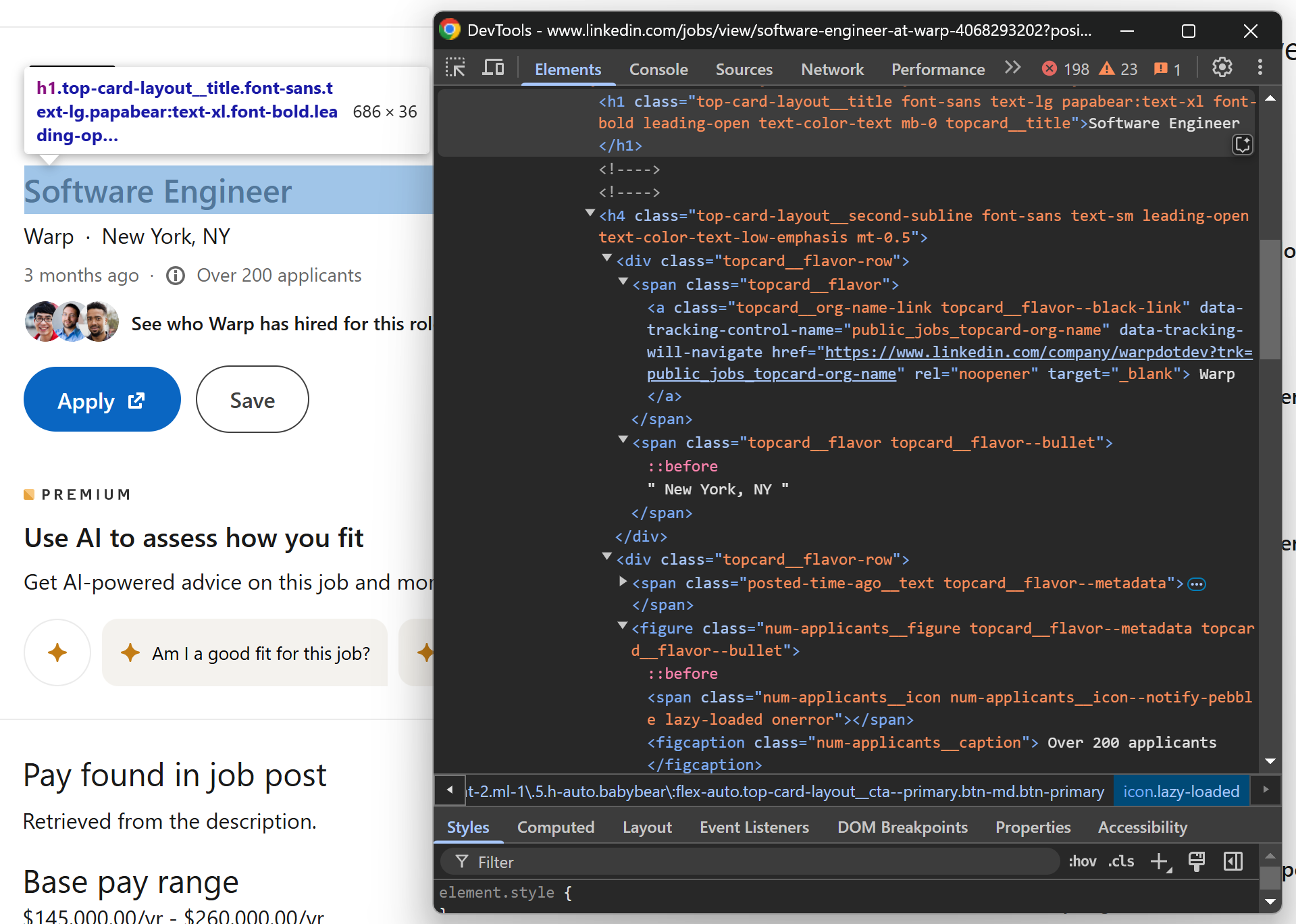
Observe que você pode extrair os seguintes dados:
- O título da vaga de emprego da tag
<h1> - A empresa que oferece a vaga a partir do elemento
[data-tracking-control-name="public_jobs_topcard-org-name"] - As informações de localização de
.topcard__flavor--bullet - O número de candidatos do nó
.num-applicants__caption
Na função scrape_job(), após o Parsing do HTML, use a seguinte lógica para extrair esses campos:
title_element = soup.select_one("h1")
title = title_element.get_text().strip()
company_element = soup.select_one("[data-tracking-control-name="public_jobs_topcard-org-name"]")
company_name = company_element.get_text().strip()
company_url = company_element["href"]
elemento_localização = soup.select_one(".topcard__flavor--bullet")
localização = elemento_localização.get_text().strip()
elemento_candidatos = soup.select_one(".num-applicants__caption")
candidatos = elemento_candidatos.get_text().strip()
A função strip() é necessária para remover quaisquer espaços à esquerda ou à direita do texto extraído.
Em seguida, concentre-se na seção de salários da página.
Você pode recuperar essas informações por meio do seletor CSS .salary. Como nem todas as vagas têm essa seção, você precisa de uma lógica extra para verificar se o elemento HTML está presente na página:
elemento_salário = soup.select_one(".salary")
se elemento_salário não for None:
salário = elemento_salário.get_text().strip()
caso contrário:
salário = None
Quando .salary não estiver na página, select_one() retornará None, e a variável salary será definida como None.
Ótimo! Você acabou de extrair parte dos dados de uma página de vagas de emprego do LinkedIn.
Etapa 8: Recuperação de dados de vagas — Parte 2
Agora, concentre-se na seção inferior da página de vagas do LinkedIn, começando pela descrição da vaga:
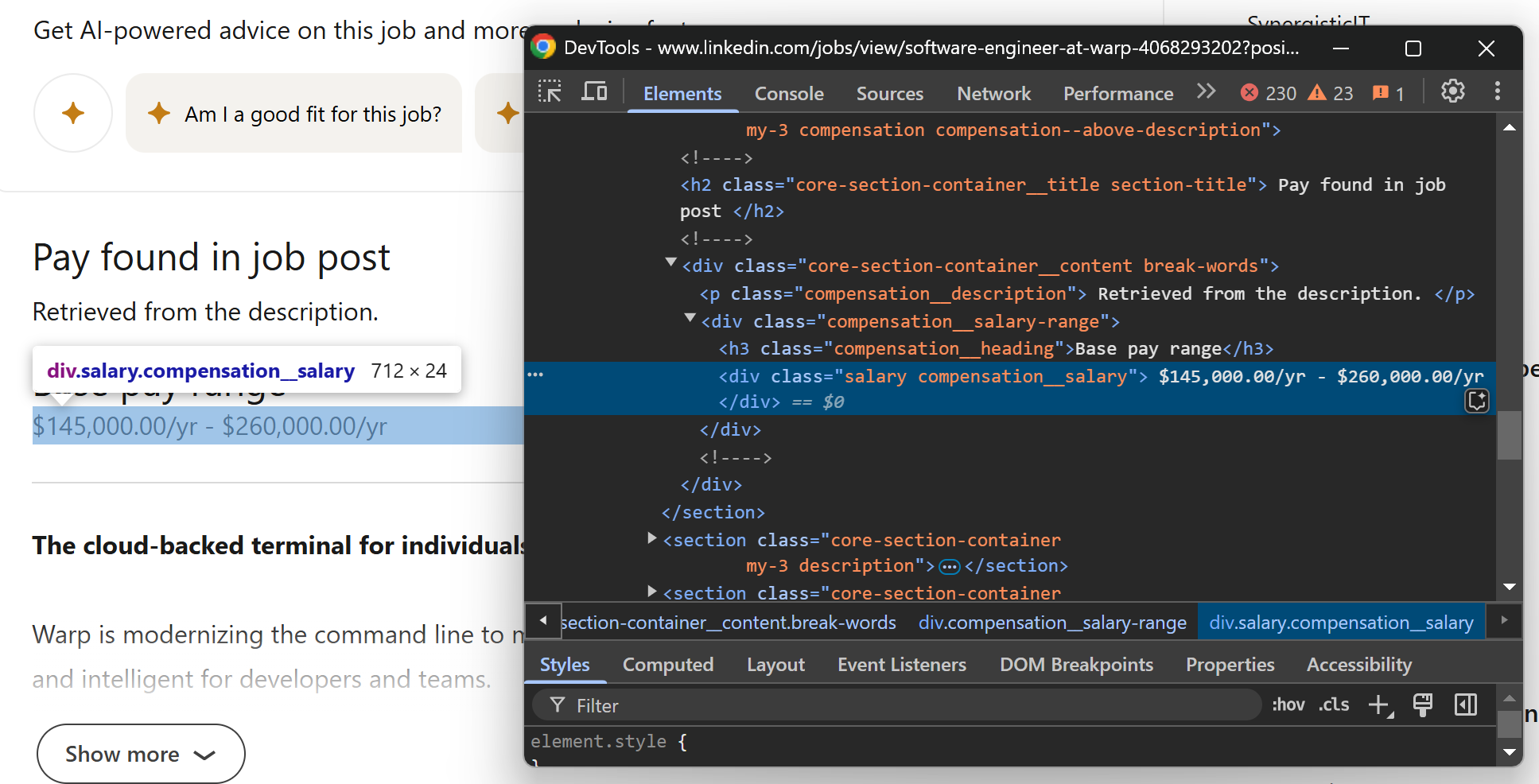
Você pode acessar o texto da descrição do cargo a partir do elemento .description__text .show-more-less-html usando este código:
description_element = soup.select_one(".description__text .show-more-less-html")
description = description_element.get_text().strip()
Por fim, a parte mais desafiadora do Scraping de dados do LinkedIn é lidar com a seção de critérios:
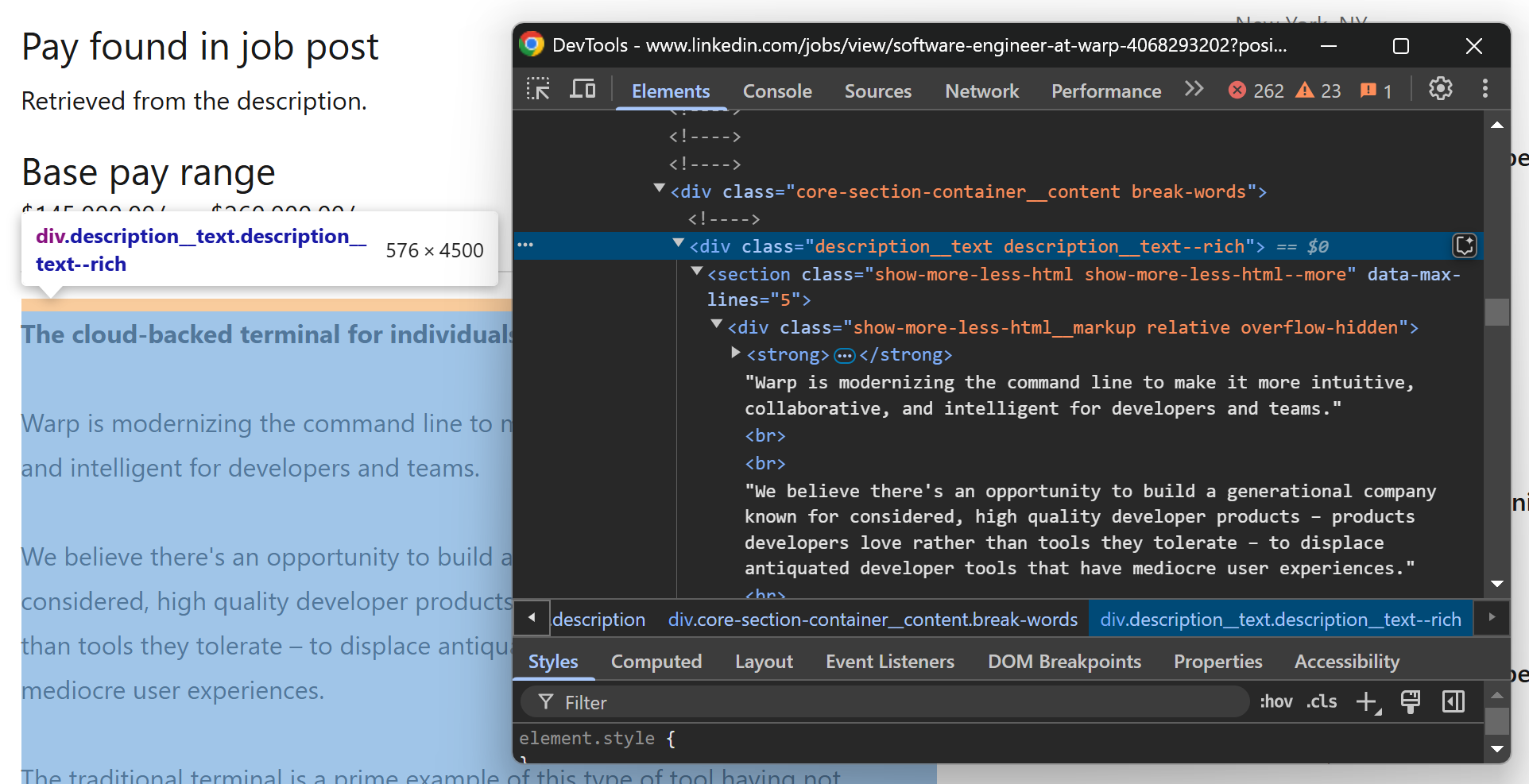
Nesse caso, você não pode prever exatamente quais dados estarão presentes na página. Portanto, você precisa tratar cada entrada como um par <nome, valor>. Para extrair os dados dos critérios:
- Selecione o elemento
<ul>usando o seletor CSS.description__job-criteria-list li - Itere sobre os elementos selecionados e, para cada um deles:
- Extraia o nome do item de
.description__job-criteria-subheader - Extraia o valor do item de
.description__job-criteria-text - Anexe os dados extraídos como um dicionário a uma matriz
- Extraia o nome do item de
Implemente a lógica de extração do LinkedIn para a seção de critérios com estas linhas de código:
criteria = []
criteria_elements = soup.select(".description__job-criteria-list li")
for criteria_element in criteria_elements:
name_element = criteria_element.select_one(".description__job-criteria-subheader")
name = name_element.get_text().strip()
value_element = criteria_element.select_one(".description__job-criteria-text")
value = value_element.get_text().strip()
criteria.append({
"name": name,
"value": value
})
Perfeito! Você acabou de extrair com sucesso os dados da vaga. O próximo passo é coletar todos os dados extraídos do LinkedIn em um objeto e retorná-los.
Etapa 9: coletar os dados extraídos
Use os dados coletados nas duas etapas anteriores para preencher um objeto de vaga e retorná-lo da função:
job = {
"url": job_url,
"title": title,
"company": {
"name": company_name,
"url": company_url
},
"location": location,
"applications": applicants,
"salary": salary,
"description": description,
"criteria": criteria
}
return job
Após concluir as três etapas anteriores, scrape_job() deve ficar assim:
def scrape_job(job_url):
# Envie uma solicitação HTTP GET para buscar o HTML da página
response = requests.get(job_url)
# Acesse o texto HTML da resposta e analise-o
html = response.text
soup = BeautifulSoup(html, "html.parser")
# Lógica de raspagem
title_element = soup.select_one("h1")
title = title_element.get_text().strip()
company_element = soup.select_one("[data-tracking-control-name="public_jobs_topcard-org-name"]")
company_name = company_element.get_text().strip()
company_url = company_element["href"]
location_element = soup.select_one(".topcard__flavor--bullet")
location = location_element.get_text().strip()
applicants_element = soup.select_one(".num-applicants__caption")
applicants = applicants_element.get_text().strip()
elemento_salário = soup.select_one(".salary")
se elemento_salário não for None:
salário = elemento_salário.get_text().strip()
caso contrário:
salário = None
elemento_descrição = soup.select_one(".description__text .show-more-less-html")
descrição = descrição_element.get_text().strip()
critérios = []
elementos_critérios = soup.select(".descrição__critérios-de-trabalho-lista li")
para elemento_critério em elementos_critérios:
elemento_nome = elemento_critério.select_one(".descrição__critérios-de-trabalho-subcabeçalho")
nome = nome_element.get_text().strip()
valor_element = critérios_element.select_one(".description__job-criteria-text")
valor = valor_element.get_text().strip()
critérios.append({
"nome": nome,
"valor": valor
})
# Colete os dados extraídos e retorne-os
job = {
"url": job_url,
"title": title,
"company": {
"name": company_name,
"url": company_url
},
"location": localização,
"applications": candidatos,
"salary": salário,
"description": descrição,
"criteria": critérios
}
retornar job
Para coletar os dados do emprego, chame esta função iterando sobre as URLs de emprego retornadas por retrieve_job_urls(). Em seguida, acrescente os dados coletados a uma matriz de empregos:
empregos = []
para url_do_emprego em url_dos_empregos:
emprego = extrair_emprego(url_do_emprego)
empregos.acrescentar(emprego)
Fantástico! A lógica de extração de dados do LinkedIn está concluída.
Etapa 10: Exportar para JSON
Os dados de vagas extraídos do LinkedIn agora estão armazenados em uma matriz de objetos. Como esses objetos não são planos, faz sentido exportar esses dados em um formato estruturado como JSON.
O Python permite exportar dados para JSON sem a necessidade de dependências extras. Para fazer isso, você pode usar a seguinte lógica:
file_name = "jobs.json"
with open(file_name, "w", encoding="utf-8") as file:
json.dump(jobs, file, indent=4, ensure_ascii=False)
A função open() cria o arquivo de saída jobs.json, que é preenchido com json.dump(). O indent=4 garante que o JSON seja formatado para facilitar a leitura, e ensure_ascii=False garante que os caracteres não ASCII sejam codificados corretamente.
Para que o código funcione, não se esqueça de importar json da Biblioteca Padrão do Python:
import json
Etapa 11: Finalize a lógica de scraping
Agora, o script de scraping do LinkedIn está basicamente completo. Ainda assim, há algumas melhorias que você pode fazer:
- Limite o número de trabalhos raspados
- Adicione alguns registros para monitorar o progresso do script
O primeiro ponto é importante porque:
- Você não quer sobrecarregar o servidor de destino com muitas solicitações do seu Scraper do LinkedIn
- Você não sabe quantos trabalhos existem em uma única página
Portanto, faz sentido limitar o número de trabalhos coletados da seguinte forma:
scraping_limit = 10
jobs_to_scrape = job_urls[:scraping_limit]
jobs = []
for job_url in jobs_to_scrape:
# ...
Isso limitará as páginas coletadas a até 10.
Em seguida, adicione algumas instruções print() para monitorar o que o script está fazendo enquanto está em execução:
public_job_search_url = "https://www.linkedin.com/jobs/search?keywords=Software%2BEngineer&location=New%20York%2C%20New%20York%2C%20United%20States&geoId=102571732&trk=public_jobs_jobs-search-bar_search-submit&position=1&pageNum=0"
print("Iniciando a recuperação de vagas a partir da URL de pesquisa do LinkedIn...")
job_urls = retrieve_job_urls(public_job_search_url)
print(f"Recuperadas {len(job_urls)} URLs de vagasn")
scraping_limit = 10
jobs_to_scrape = job_urls[:scraping_limit]
print(f"Raspando {len(jobs_to_scrape)} vagas...n")
jobs = []
para job_url em jobs_to_scrape:
imprimir(f"Iniciando extração de dados em "{job_url}"")
job = scrape_job(job_url)
jobs.append(job)
imprimir(f"Vaga extraída")
imprimir(f"nExportando {len(jobs)} vagas extraídas para JSON")
nome_do_arquivo = "jobs.json"
com open(nome_do_arquivo, "w", encoding="utf-8") como arquivo:
json.dump(empregos, arquivo, indent=4, ensure_ascii=False)
imprimir(f"Empregos salvos com sucesso em "{nome_do_arquivo}"n")
A lógica de registro ajudará você a acompanhar o progresso do Scraper, o que é essencial, considerando que ele passa por várias etapas.
Etapa 12: Junte tudo
Este é o código final do seu script de scraper do LinkedIn:
from bs4 import BeautifulSoup
import requests
import json
def retrieve_job_urls(job_search_url):
# Faça uma solicitação HTTP GET para obter o HTML da página
response = requests.get(job_search_url)
# Acesse o HTML e analise-o
html = response.text
soup = BeautifulSoup(html, "html.parser")
# Onde armazenar os dados coletados
job_urls = []
# Lógica de coleta
job_url_elements = soup.select("[data-tracking-control-name="public_jobs_jserp-result_search-card"]")
for job_url_element in job_url_elements:
# Extrair a URL da página de emprego e anexá-la à lista
job_url = job_url_element["href"]
job_urls.append(job_url)
return job_urls
def scrape_job(job_url):
# Enviar uma solicitação HTTP GET para buscar o HTML da página
response = requests.get(job_url)
# Acesse o texto HTML da resposta e analise-o
html = response.text
soup = BeautifulSoup(html, "html.parser")
# Lógica de scraping
title_element = soup.select_one("h1")
title = title_element.get_text().strip()
elemento_empresa = soup.select_one("[data-tracking-control-name="public_jobs_topcard-org-name"]")
nome_empresa = elemento_empresa.get_text().strip()
url_empresa = elemento_empresa["href"]
elemento_localização = soup.select_one(".topcard__flavor--bullet")
localização = elemento_localização.get_text().strip()
elemento_candidatos = soup.select_one(".num-candidatos__caption")
candidatos = elemento_candidatos.get_text().strip()
elemento_salário = soup.select_one(".salário")
if salary_element is not None:
salary = salary_element.get_text().strip()
else:
salary = None
description_element = soup.select_one(".description__text .show-more-less-html")
description = description_element.get_text().strip()
criteria = []
critérios_elementos = soup.select(".description__job-criteria-list li")
para critérios_elementos em critérios_elementos:
nome_elemento = critérios_elementos.select_one(".description__job-criteria-subheader")
nome = nome_elemento.get_text().strip()
elemento_valor = elemento_critério.select_one(".description__job-criteria-text")
valor = elemento_valor.get_text().strip()
critérios.append({
"nome": nome,
"valor": valor
})
# Colete os dados extraídos e retorne-os
job = {
"url": job_url,
"title": title,
"company": {
"name": company_name,
"url": company_url
},
"location": localização,
"applications": candidatos,
"salary": salário,
"description": descrição,
"criteria": critérios
}
retornar job
# A URL pública da página de pesquisa de empregos do LinkedIn
public_job_search_url = "https://www.linkedin.com/jobs/search?keywords=Software%2BEngineer&location=New%20York%2C%20New%20York%2C%20United%20States&geoId=102571732&trk=public_jobs_jobs-search-bar_search-submit&position=1&pageNum=0"
imprimir("Iniciando a recuperação de vagas a partir da URL de pesquisa do LinkedIn...")
# Recuperando as URLs individuais para cada vaga na página
job_urls = retrieve_job_urls(public_job_search_url)
imprimir(f"URLs de vagas {len(job_urls)} recuperadasn")
# Rastrear apenas até 10 vagas da página
limite_de_rastreamento = 10
vagas_para_rastrear = job_urls[:limite_de_rastreamento]
imprimir(f"Rastreando {len(vagas_para_rastrear)} vagas...n")
# Extrair dados de cada página de vaga
jobs = []
para job_url em jobs_to_scrape:
imprimir(f"Iniciando extração de dados em "{job_url}"")
job = scrape_job(job_url)
jobs.append(job)
imprimir(f"Vaga extraída")
# Exportar os dados extraídos para CSV
print(f"nExportando {len(jobs)} empregos extraídos para JSON")
nome_do_arquivo = "jobs.json"
com open(nome_do_arquivo, "w", encoding="utf-8") como arquivo:
json.dump(jobs, arquivo, indent=4, ensure_ascii=False)
imprimir(f"Empregos salvos com sucesso em "{nome_do_arquivo}"n")
Inicie com o seguinte comando:
python Scraper.py
O scraper do LinkedIn deve registrar as seguintes informações:
Iniciando a recuperação de empregos a partir da URL de pesquisa do LinkedIn...
Recuperadas 60 URLs de empregos
Raspando 10 empregos...
Iniciando a extração de dados em "https://www.linkedin.com/jobs/view/software-engineer-recent-graduate-at-paypal-4149786397?position=1&pageNum=0&refId=nz9sNo7HULREru1eS2L9nA%3D%3D&trackingId=uswFC6EjKkfCPcv0ykaojw%3D%3D"
Vaga extraída
# omitido por brevidade...
Iniciando extração de dados em "https://www.linkedin.com/jobs/view/software-engineer-full-stack-at-paces-4090771382?position=2&pageNum=0&refId=UKcPcvFZMOsZrn0WhZYqtg%3D%3D&trackingId=p6UUa6cgbpYS1gDkRlHV2g%3D%3D"
Vaga extraída
Exportando 10 vagas extraídas para JSON
Vagas salvas com sucesso em "jobs.json"
Das 60 páginas de vagas encontradas, o script extraiu apenas 10 vagas. Portanto, o arquivo de saída jobs.json gerado pelo script conterá exatamente 10 vagas:
[
{
"url": "https://www.linkedin.com/jobs/view/software-engineer-recent-graduate-at-paypal-4149786397?position=1&pageNum=0&refId=UKcPcvFZMOsZrn0WhZYqtg%3D%3D&trackingId=UzOyWl8Jipb1TFAGlLJxqw%3D%3D",
"title": "Engenheiro de Software - Recém-formado",
"company": {
"name": "PayPal",
"url": "https://www.linkedin.com/company/paypal?trk=public_jobs_topcard-org-name"
},
"localização": "Nova Iorque, NY",
"candidaturas": "Mais de 200 candidatos",
"salário": nulo,
"descrição": "Omitido por brevidade...",
"critérios": [
{
"nome": "Nível de antiguidade",
"valor": "Não aplicável"
},
{
"nome": "Tipo de emprego",
"valor": "Tempo integral"
},
{
"nome": "Função do cargo",
"valor": "Engenharia"
},
{
"nome": "Setores",
"valor": "Desenvolvimento de software, serviços financeiros e tecnologia, informação e Internet"
}
]
},
// outras 8 posições...
{
"url": "https://www.linkedin.com/jobs/view/software-engineer-full-stack-at-paces-4090771382?position=2&pageNum=0&refId=UKcPcvFZMOsZrn0WhZYqtg%3D%3D&trackingId=p6UUa6cgbpYS1gDkRlHV2g%3D%3D",
"title": "Engenheiro de Software (Full-Stack)",
"company": {
"name": "Paces",
"url": "https://www.linkedin.com/company/pacesai?trk=public_jobs_topcard-org-name"
},
"localização": "Brooklyn, NY",
"candidaturas": "Mais de 200 candidatos",
"salário": "$150.000,00/ano - $200.000,00/ano",
"descrição": "Omitida por motivos de brevidade...",
"critérios": [
{
"nome": "Nível de antiguidade",
"valor": "Nível inicial"
},
{
"nome": "Tipo de emprego",
"valor": "Tempo integral"
},
{
"nome": "Função",
"valor": "Engenharia e Tecnologia da Informação"
},
{
"nome": "Setores",
"valor": "Desenvolvimento de Software"
}
]
},
]
Et voilà! O Scraping de dados do LinkedIn em Python não é tão difícil assim.
Otimize a extração de dados do LinkedIn
O script que criamos pode fazer com que a extração de dados do LinkedIn pareça uma tarefa simples, mas não é o caso. A barreira de login e as técnicas de ofuscação de dados podem rapidamente se tornar desafios, especialmente à medida que você amplia sua operação de extração.
Além disso, o LinkedIn possui mecanismos de limitação de taxa para bloquear scripts automatizados que fazem muitas solicitações. Uma solução comum é alternar seu endereço IP em Python, mas isso requer um esforço adicional.
Além disso, lembre-se de que o LinkedIn está em constante evolução, portanto, os esforços e custos de manutenção do seu Scraper não são insignificantes. O LinkedIn possui um tesouro de dados em vários formatos, desde anúncios de emprego até artigos. Para recuperar todas essas informações, você precisaria criar diferentes Scrapers e gerenciá-los todos.
Esqueça o incômodo com a API do Scraper do LinkedIn da Bright Data. Essa ferramenta dedicada pode coletar todos os dados do LinkedIn de que você precisa e entregá-los por meio de integrações sem código ou por meio de endpoints simples que você pode chamar com qualquer cliente HTTP.
Use-a para coletar perfis, publicações, empresas, vagas de emprego e muito mais do LinkedIn em segundos, sem precisar gerenciar toda uma arquitetura de coleta.
Conclusão
Neste tutorial passo a passo, você aprendeu o que é um Scraper do LinkedIn e os tipos de dados que ele pode recuperar. Você também criou um script Python para coletar anúncios de vagas de emprego do LinkedIn.
O desafio é que o LinkedIn usa bloqueios de IP e barreiras de login para bloquear scripts automatizados. Evite esses problemas com nosso Scraper do LinkedIn.
Se o Scraping de dados não é para você, mas ainda assim está interessado nos dados, confira nossos Conjuntos de dados do LinkedIn prontos para uso!
Crie uma conta gratuita na Bright Data hoje mesmo para experimentar nossas APIs de Scraper ou explorar nossos Conjuntos de dados.