

Neste guia, você verá:
- O que o NVIDIA NeMo Framework oferece, especialmente para a criação de agentes de IA usando o NVIDIA NeMo Agent Toolkit.
- Como integrar o Bright Data a um agente de IA NAT usando ferramentas personalizadas via LangChain.
- Como conectar um fluxo de trabalho do NVIDIA NeMo Agent Toolkit ao Bright Data Web MCP.
Vamos começar!
Uma introdução ao NVIDIA NeMo Framework
A estrutura NVIDIA NeMo é uma plataforma de desenvolvimento de IA abrangente e nativa da nuvem, projetada para criar, personalizar e implantar modelos de IA generativos, incluindo LLMs e modelos multimodais.
Ela oferece ferramentas completas para todo o ciclo de vida da IA — desde o treinamento e o ajuste fino até a avaliação e a implantação. O NeMo também aproveita o treinamento distribuído em grande escala e inclui componentes para tarefas como curadoria de dados, avaliação de modelos e implementação de barreiras de segurança.
É suportada por uma biblioteca Python de código aberto com mais de 16 mil estrelas no GitHub e imagens Docker dedicadas.
NVIDIA NeMo Agent Toolkit
Parte da estrutura NVIDIA NeMo, o NVIDIA NeMo Agent Toolkit (abreviado em “NAT”) é uma estrutura de código aberto para construir, otimizar e gerenciar sistemas complexos de agentes de IA.
Ele ajuda a conectar diversos agentes e ferramentas em fluxos de trabalho unificados com observabilidade profunda, criação de perfis e análise de custos, atuando como um “condutor” para operações com vários agentes e ajudando a dimensionar aplicativos de IA.
O NAT enfatiza a composibilidade, tratando agentes e ferramentas como chamadas de função modulares. Ele também oferece recursos para identificar gargalos, automatizar avaliações e gerenciar sistemas de IA agênicos de nível empresarial.
Para obter mais informações, consulte:
Conectando LLMs e dados ao vivo com as ferramentas Bright Data
O NVIDIA NeMo Agent Toolkit oferece a flexibilidade, personalização, observabilidade e escalabilidade necessárias para criar e gerenciar projetos de IA de nível empresarial. Ele dá às organizações a capacidade de orquestrar fluxos de trabalho complexos de IA, conectar vários agentes e monitorar o desempenho e os custos.
No entanto, mesmo as aplicações NAT mais sofisticadas enfrentam as limitações inerentes aos LLMs. Estas incluem conhecimentos desatualizados devido a dados de treinamento estáticos e falta de acesso a informações da web em tempo real.
A solução é integrar seu fluxo de trabalho do NVIDIA NeMo Agent Toolkit a um provedor de dados da web para IA, como a Bright Data.
A Bright Data oferece ferramentas para Scraping de dados, pesquisa, automação de navegador e muito mais. Essas soluções capacitam seu sistema de IA a recuperar dados acionáveis em tempo real e liberar todo o seu potencial para aplicações empresariais!
Como conectar o Bright Data a um NVIDIA NeMo IA Agent
Uma maneira de aproveitar os recursos do Bright Data em um NVIDIA NeMo IA Agent é criando ferramentas personalizadas por meio do NeMo Agent Toolkit.
Essas ferramentas se conectarão aos produtos Bright Data por meio de funções personalizadas com tecnologia LangChain (ou qualquer outra integração compatível com bibliotecas de construção de agentes de IA).
Siga as instruções abaixo!
Pré-requisitos
Para acompanhar este tutorial, você precisa de:
- Python 3.11, 3.12 ou 3.13 instalado localmente.
- Uma conta Bright Data configurada para integração com as ferramentas oficiais LangChain.
- Uma conta NVIDIA NIM com uma chave API configurada.
Não se preocupe em configurar as contas Bright Data e NVIDIA NIM agora, pois você será orientado sobre isso em capítulos dedicados.
Observação: em caso de problemas durante a instalação ou ao executar o kit de ferramentas, certifique-se de estar em uma das plataformas compatíveis.
Etapa 1: Recupere sua chave API NVIDIA NIM
A maioria dos fluxos de trabalho do NVIDIA NeMo Agent requer uma variável de ambiente NVIDIA_API_KEY. Isso é necessário para autenticar a conexão com os LLMs NVIDIA NIM por trás do fluxo de trabalho.
Para recuperar sua chave API, comece criando uma conta NVIDIA NIM (se ainda não tiver uma). Faça login e clique na imagem da sua conta no canto superior direito. Selecione a opção “Chaves API”:
Você será direcionado para a página Chaves de API. Clique no botão “Gerar chave de API” para criar uma nova chave:
Dê um nome à sua chave API e clique em “Gerar chave”:
Uma janela modal exibirá sua chave API. Clique no botão “Copiar chave API” e armazene a chave em um local seguro, pois você precisará dela em breve.
Parabéns! Você está pronto para instalar o NVIDIA NeMo Agent Toolkit e começar a usar.
Etapa 2: Configure um projeto NVIDIA NeMo
Para instalar a versão estável mais recente do NeMo Agent Toolkit, execute:
pip install nvidia-natO NeMo Agent Toolkit tem muitas dependências opcionais que podem ser instaladas junto com o pacote principal. Essas dependências opcionais são agrupadas por estrutura.
Depois de instalado, você deve ter acesso ao comando nat. Verifique se ele funciona executando:
nat --versionVocê deverá ver uma saída semelhante a:
nat, versão 1.3.1Em seguida, crie uma pasta raiz para seu aplicativo NVIDIA NeMo. Por exemplo, chame-a de “bright_data_nvidia_nemo”:
mkdir bright_data_nvidia_nemoDentro dessa pasta, crie um fluxo de trabalho do NeMo Agent chamado “web_data_workflow” usando:
nat workflow create --workflow-dir bright_data_nvidia_nemo web_data_workflow Observação: se você encontrar o erro “Um privilégio necessário não é mantido pelo cliente”, execute o comando como administrador.
Se for bem-sucedido, você deverá ver logs como:
Instalando fluxo de trabalho 'web_data_workflow'...
Fluxo de trabalho 'web_data_workflow' instalado com sucesso.
Fluxo de trabalho 'web_data_workflow' criado com sucesso em <seu_caminho>Sua pasta de projeto bright_data_nvidia_nemo/web_data_workflow agora conterá a seguinte estrutura:
bright_data_nvidia_nemo/web_data_workflow/
├── configs -> src/web_data_workflow/configs
├── data -> src/text_file_ingest/data
├── pyproject.toml
└── src/
├── web_data_workflow.egg-info/
└── web_data_workflow/
├── __init__.py
├── configs/
│ └── config.yml
├── dados/
├── __init__.py
├── register.py
└── web_data_workflow.pyCada arquivo e pasta representa o seguinte:
configs/→src/web_data_workflow/configs: Link simbólico para facilitar o acesso à configuração do fluxo de trabalho.data/→src/text_file_ingest/data: Link simbólico para armazenar dados de amostra ou arquivos de entrada.pyproject.toml: Arquivo de metadados e dependências do projeto.src/: Diretório do código-fonte.web_data_workflow.egg-info/: Pasta de metadados criada pelas ferramentas de empacotamento Python.web_data_workflow/: Módulo principal do fluxo de trabalho.__init__.py: Inicializa o módulo.configs/config.yml: Arquivo de configuração do fluxo de trabalho onde você define o comportamento de tempo de execução (configuração LLM, definições de função/ferramenta, tipo e configurações do agente, orquestração do fluxo de trabalho, etc.).
data/: Diretório para armazenar dados específicos do fluxo de trabalho, entradas de amostra ou arquivos de teste.register.py: Módulo de registro para conectar suas funções personalizadas ao NAT.web_data_workflow.py: Arquivo de amostra que define ferramentas personalizadas.
Abra o projeto em seu IDE Python favorito e dedique algum tempo para se familiarizar com os arquivos gerados.
Você verá que a definição do fluxo de trabalho está localizada no arquivo abaixo:
bright_data_nvidia_nemo/web_data_workflow/web_data_workflow/configs/config.ymlAbra-o e você verá a seguinte configuração YAML:
funções:
current_datetime:
_type: current_datetime
web_data_workflow:
_type: web_data_workflow
prefixo: "Olá:"
llms:
nim_llm:
_type: nim
nome_do_modelo: meta/llama-3.1-70b-instruct
temperatura: 0.0
workflow:
_type: react_agent
llm_name: nim_llm
tool_names: [current_datetime, web_data_workflow]Isso define um fluxo de trabalho do agente ReAct alimentado pelo modelo meta/llama-3.1-70b-instruct da NVIDIA NIM, com acesso a:
- A ferramenta integrada
current_datetime. - A ferramenta personalizada
web_data_workflow.
Em particular, a ferramenta web_data_workflow em si é definida em:
bright_data_nvidia_nemo/web_data_workflow/web_data_workflow/web_data_workflow.pyEssa ferramenta de amostra recebe uma entrada de texto e a retorna prefixada com uma string predefinida (por exemplo, “Olá:”).
Ótimo! Agora você tem um fluxo de trabalho pronto com o NAT.
Etapa 3: Teste o fluxo de trabalho atual
Antes de personalizar o fluxo de trabalho gerado, é uma boa ideia dedicar algum tempo para se familiarizar com ele e entender como funciona. Isso facilitará a adaptação do fluxo de trabalho para integração com o Bright Data.
Comece navegando até a pasta do fluxo de trabalho em seu terminal:
cd ./bright_data_nvidia_nemo/web_data_workflowAntes de executar o fluxo de trabalho, você deve definir a variável de ambiente NVIDIA_API_KEY. No Linux/macOS, execute:
export NVIDIA_API_KEY="<SUA_CHAVE_API_NVIDIA>"Da mesma forma, no Windows PowerShell, execute:
$Env:NVIDIA_API_KEY="<SUA_CHAVE_API_NVIDIA>"Substitua o espaço reservado <SUA_CHAVE_API_NVIDIA> pela chave API NVIDIA NIM que você recuperou anteriormente.
Agora, teste o fluxo de trabalho com o comando nat run da seguinte maneira:
nat run --config_file configs/config.yml --input "Olá! Como vai?"Isso carrega o arquivo config.yml (por meio do link simbólico configs/ ) e envia o prompt “Olá! Como vai?”.
Você deverá ver uma saída como esta: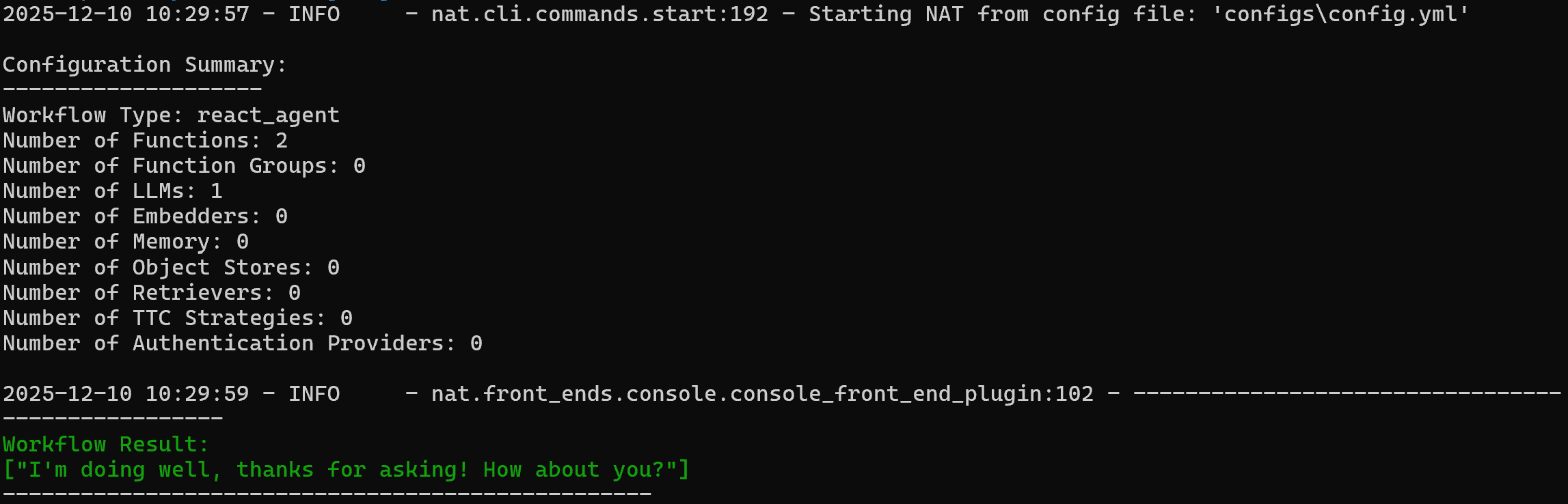
Observe que o agente respondeu com:
Estou bem, obrigado por perguntar! E você?Para verificar se a ferramenta web_data_workflow personalizada funciona, tente um prompt como:
nat run --config_file configs/config.yml --input “Use a ferramenta web_data_workflow em 'World!'”Como a ferramenta web_data_workflow está configurada com o prefixo “Olá:”, o resultado esperado é:
Resultado do fluxo de trabalho:
['Olá: Mundo!']Observe como o resultado corresponde ao comportamento esperado: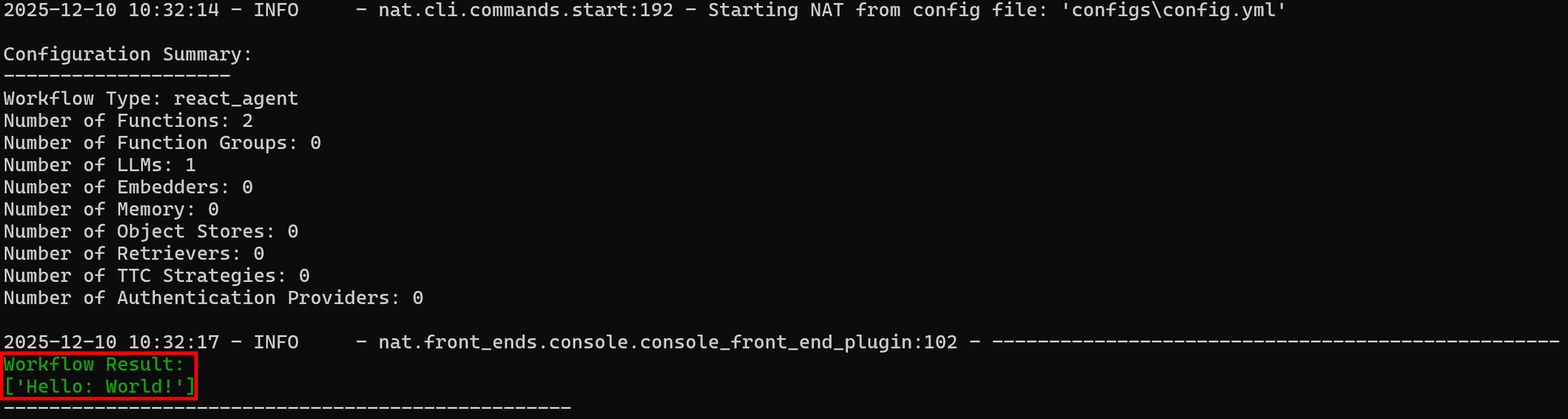
Incrível! Seu fluxo de trabalho NAT está funcionando perfeitamente. Agora você está pronto para integrá-lo ao Bright Data.
Etapa 4: Instale as ferramentas LangChain Bright Data
Um dos aspectos peculiares do NVIDIA NeMo Agent Toolkit é que ele funciona com outras bibliotecas de IA, incluindo LangChain, LlamaIndex, CrewAI, Agno, Microsoft Semantic Kernel, Google ADK e muitas outras.
Para simplificar a integração com o Bright Data, em vez de reinventar a roda, usaremos as ferramentas oficiais do Bright Data para LangChain.
Para obter mais orientações sobre essas ferramentas, consulte a documentação oficial ou estas postagens do blog:
Prepare-se para usar o LangChain no NVIDIA NeMo Agent Toolkit instalando as seguintes bibliotecas:
pip install "nvidia-nat[langchain]" langchain-brightdataOs pacotes necessários são:
"nvidia-nat[langchain]": um subpacote para integrar o LangChain (ou LangGraph) ao NeMo Agent Toolkit.langchain-brightdata: fornece integrações LangChain para o conjunto de ferramentas de coleta de dados da web da Bright Data. Ele permite que agentes de IA coletem resultados de mecanismos de pesquisa, acessem sites com restrições geográficas ou protegidos contra bots e extraiam dados estruturados de plataformas populares como Amazon, LinkedIn e muitas outras.
Para evitar problemas durante a implantação, certifique-se de que o arquivo pyproject.toml do seu projeto inclua:
dependencies = [
"nvidia-nat[langchain]~=1.3",
"langchain-brightdata~=0.1.3",
]Observação: ajuste as versões desses pacotes conforme necessário para o seu projeto.
Ótimo! Agora, seu fluxo de trabalho do NVIDIA NeMo Agent pode se integrar às ferramentas LangChain para conexões simplificadas com o Bright Data.
Etapa 5: Prepare a integração com o Bright Data
As ferramentas LangChain Bright Data funcionam conectando-se aos serviços Bright Data configurados em sua conta. As duas ferramentas apresentadas neste artigo são:
BrightDataSERP: busca resultados de mecanismos de pesquisa para localizar páginas da web regulatórias relevantes. Ela se conecta à API SERP da Bright Data.BrightDataUnblocker: acessa qualquer site público, mesmo que seja restrito geograficamente ou protegido por medidas anti-bot. Isso ajuda o agente a extrair conteúdo de páginas da web individuais e aprender com elas. Ele se conecta à API Web Unblocker da Bright Data.
Para utilizar essas ferramentas, você precisa de uma conta Bright Data com uma zona API SERP e uma zona Web Unblocker API configuradas. Vamos configurá-las!
Se você ainda não tem uma conta Bright Data, crie uma nova. Caso contrário, faça login e acesse seu painel. Em seguida, navegue até a página “Proxies & Scraping” e verifique a tabela “My Zones”: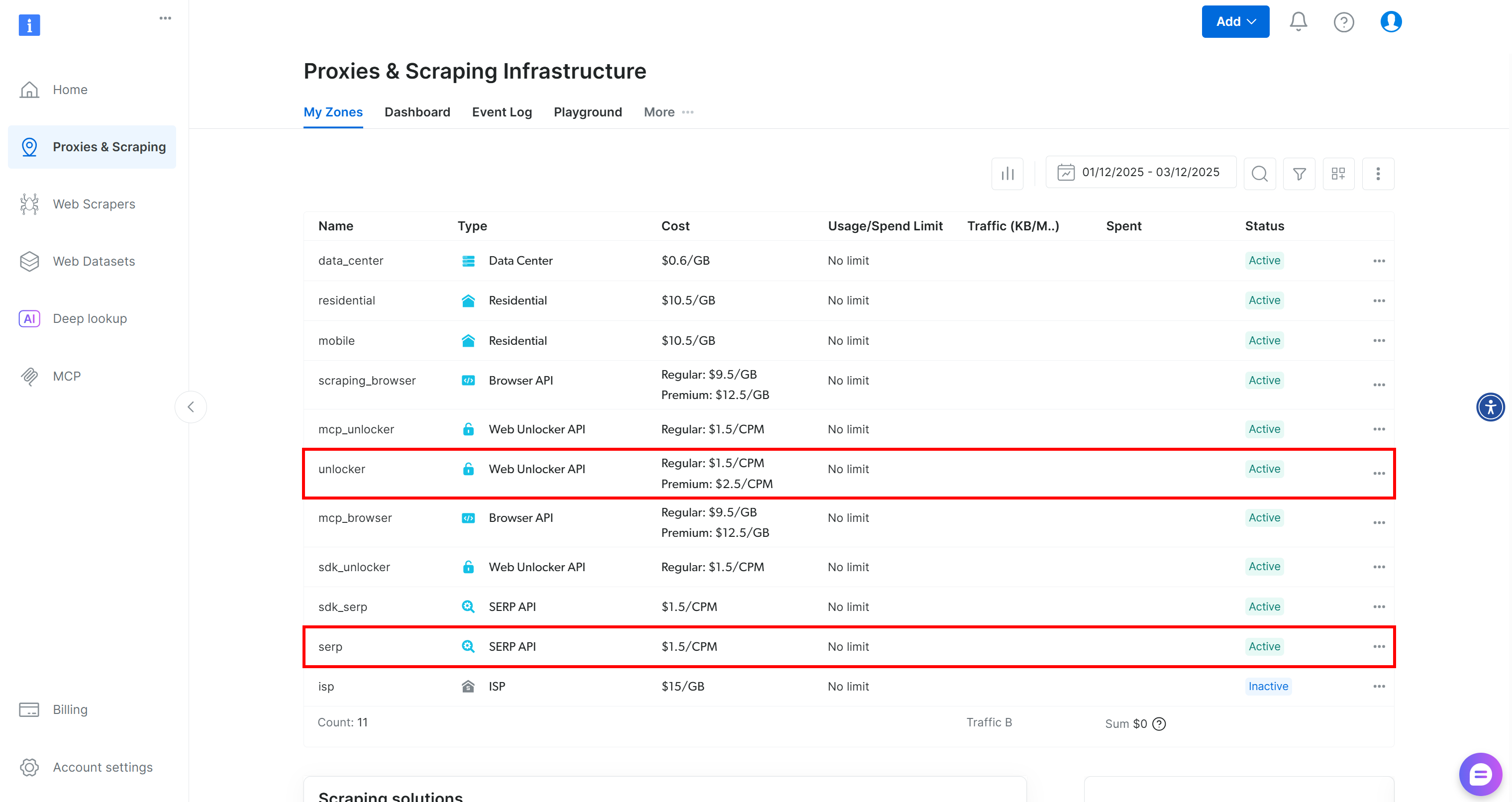
Se a tabela já contiver uma zona da API Web Unlocker chamada unlocker e uma zona da API SERP chamada serp, você está pronto. Isso porque:
- A ferramenta
BrightDataSERPLangChain se conecta automaticamente a uma zona API SERP chamadaserp. - A ferramenta
BrightDataUnblockerLangChain se conecta automaticamente a uma zona Web Unblocker API chamadaweb_unlocker.
Se essas duas zonas estiverem faltando, você terá que criá-las. Role para baixo nos cartões “Unblocker API” e “API SERP” e clique nos botões “Create zone” (Criar zona). Siga o assistente para adicionar as duas zonas com os nomes necessários: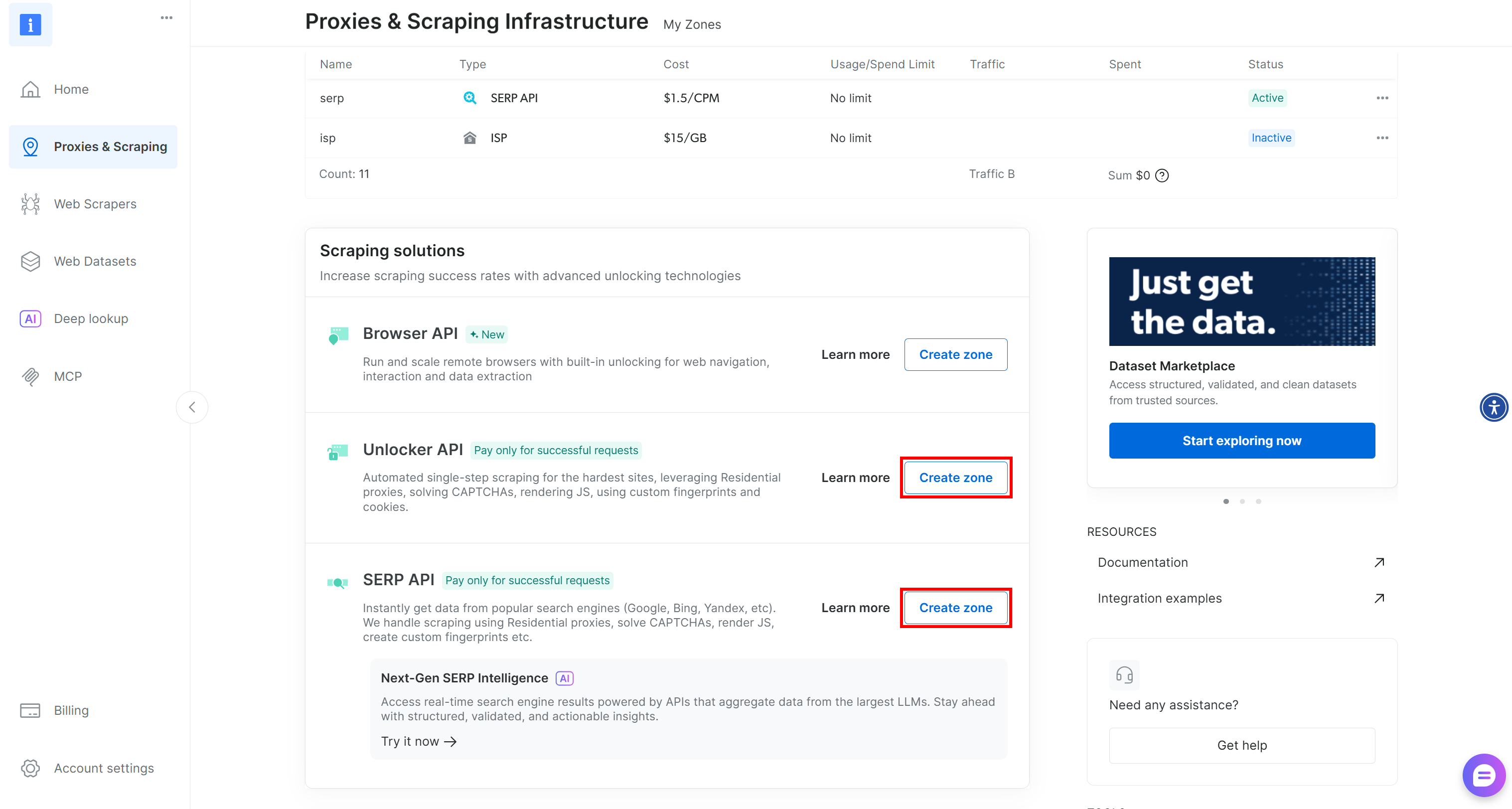
Para obter orientações passo a passo, consulte estas páginas de documentação:
Por fim, você precisa informar às ferramentas LangChain Bright Data como autenticar sua conta. Gere sua chave API Bright Data e armazene-a como uma variável de ambiente:
export BRIGHT_DATA_API_KEY="<SUA_CHAVE_BRIGHT_DATA_API>"Ou, no PowerShell:
$Env:BRIGHT_DATA_API_KEY="<SUA_CHAVE_API_BRIGHT_DATA>"Ótimo! Agora você tem todos os pré-requisitos para conectar seu agente NVIDIA NeMo ao Bright Data por meio das ferramentas LangChain.
Etapa 6: definir as ferramentas personalizadas da Bright Data
Agora você tem todos os blocos de construção para criar novas ferramentas no fluxo de trabalho do NVIDIA NeMo Agent Toolkit. Essas ferramentas permitirão que o agente interaja com a API SERP e a API Web Unblocker da Bright Data, permitindo que ele pesquise na web e extraia dados de qualquer página pública.
Comece adicionando um arquivo bright_data.py à pasta src/ do seu projeto: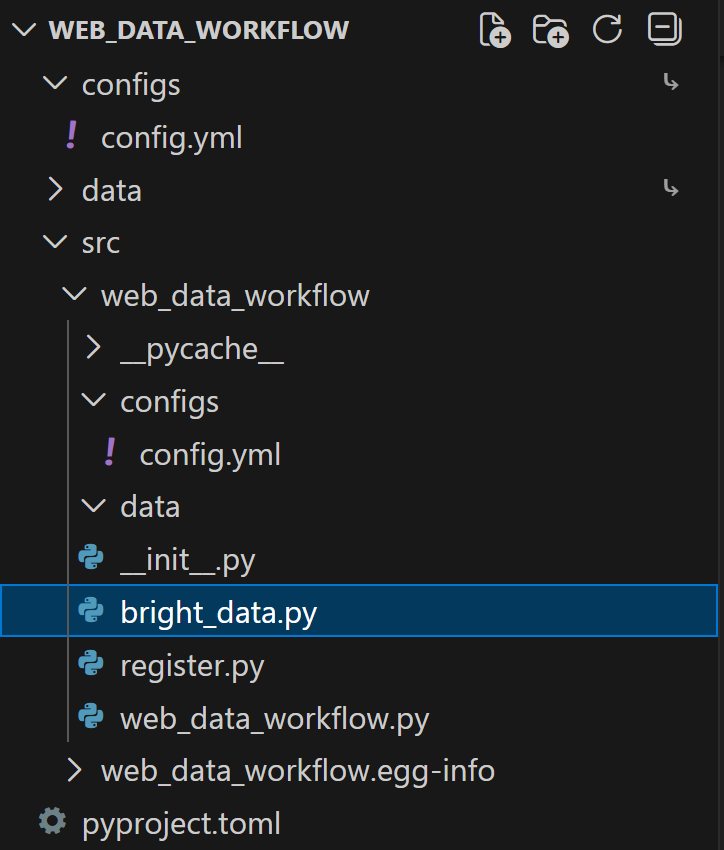
Defina uma ferramenta personalizada para interagir com a API SERP da seguinte maneira:
# bright_data_nvidia_nemo/web_data_workflow/src/web_data_workflow/bright_data.py
from pydantic import Field
from typing import Optional
from nat.builder.builder import Builder
from nat.builder.function_info import FunctionInfo
from nat.cli.register_workflow import register_function
from nat.data_models.function import FunctionBaseConfig
import json
class BrightDataSERPAPIToolConfig(FunctionBaseConfig, name="bright_data_serp_api"):
"""
Configuração para a ferramenta Bright Data API SERP.
Requer BRIGHT_DATA_API_KEY.
"""
api_key: str = Field(
default="",
description="Sua chave API Bright Data usada para solicitações SERP."
)
# Parâmetros SERP padrão (substituições opcionais)
search_engine: str = Field(
default="google",
description="Mecanismo de pesquisa para consulta (padrão: google)."
)
country: str = Field(
default="us",
description="Código de país de duas letras para resultados localizados (padrão: us)."
)
language: str = Field(
default="en",
description="Código de idioma de duas letras (padrão: en)."
)
search_type: Opcional[str] = Campo(
padrão=Nenhum,
descrição="Tipo de pesquisa: Nenhum, 'shop', 'isch', 'nws', 'jobs'."
)
device_type: Opcional[str] = Campo(
padrão=Nenhum,
descrição="Tipo de dispositivo: Nenhum, 'mobile', 'ios', 'android'."
)
parse_results: Opcional[bool] = Campo(
padrão=Nenhum,
descrição="Se deve retornar JSON estruturado em vez de HTML bruto."
)
@register_function(config_type=BrightDataSERPAPIToolConfig)
async def bright_data_serp_api_function(tool_config: BrightDataSERPAPIToolConfig, builder: Builder):
import os
from langchain_brightdata import BrightDataSERP
# Definir chave API se estiver faltando
if not os.environ.get("BRIGHT_DATA_API_KEY"):
if tool_config.api_key:
os.environ["BRIGHT_DATA_API_KEY"] = tool_config.api_key
async def _bright_data_serp_api(
query: str,
search_engine: Optional[str] = None,
country: Optional[str] = None,
language: Optional[str] = None,
search_type: Optional[str] = None,
device_type: Optional[str] = None,
parse_results: Opcional[bool] = Nenhum,
) -> str:
"""
Executa uma consulta de pesquisa em tempo real usando a API SERP da Bright Data.
Argumentos:
query (str): O texto da consulta de pesquisa.
search_engine (str, opcional): Mecanismo de pesquisa a ser usado (padrão: google).
country (str, opcional): Código do país para resultados localizados.
language (str, opcional): Código do idioma para resultados localizados.
search_type (str, opcional): Tipo de pesquisa (por exemplo, None, 'isch', 'shop', 'nws').
device_type (str, opcional): Tipo de dispositivo (por exemplo, None, 'mobile', 'ios').
parse_results (bool, opcional): Se deve retornar JSON estruturado.
Retorna:
str: Resultados da pesquisa formatados em JSON.
"""
serp_client = BrightDataSERP(
bright_data_api_key=os.environ["BRIGHT_DATA_API_KEY"]
)
payload = {
"query": query,
"search_engine": search_engine ou tool_config.search_engine,
"country": country ou tool_config.country,
"language": language ou tool_config.language,
"search_type": search_type ou tool_config.search_type,
"device_type": device_type ou tool_config.device_type,
"parse_results": (
parse_results
se parse_results não for None
caso contrário, tool_config.parse_results
),
}
# Remova os parâmetros explicitamente definidos como None
payload = {k: v para k, v em payload.items() se v não for None}
resultados = serp_client.invoke(payload)
retornar json.dumps(resultados)
yield FunctionInfo.from_fn(
_bright_data_serp_api,
descrição=_bright_data_serp_api.__doc__,
)
Este trecho define uma ferramenta NVIDIA NeMo Agent personalizada chamada bright_data_serp_api. Primeiro, você precisa definir uma classe BrightDataSERPAPIToolConfig, que especifica os argumentos necessários e os parâmetros configuráveis suportados pela API SERP para Google (por exemplo, a chave da API, mecanismo de pesquisa, país, idioma, tipo de dispositivo, tipo de pesquisa, se os resultados devem ser analisados em JSON, etc.).
Em seguida, uma função personalizada bright_data_serp_api_function() é registrada como uma função de fluxo de trabalho NeMo. A função verifica se a chave da API Bright Data está definida no ambiente e, em seguida, define uma função assíncrona _bright_data_serp_api().
A função _bright_data_serp_api() constrói uma solicitação de pesquisa usando o cliente BrightDataSERP da LangChain, invoca-a e retorna os resultados no formato JSON. Por fim, ela expõe a função à estrutura do NeMo Agent por meio do FunctionInfo, que contém todos os metadados necessários para que o agente chame a função.
Observação: retornar resultados como JSON fornece uma saída de string padronizada. Esse é um truque útil, considerando que as respostas da API SERP podem variar (JSON analisado, HTML bruto etc.) dependendo dos argumentos configurados.
Da mesma forma, você pode definir uma ferramenta bright_data_web_unlocker_api no mesmo arquivo com:
class BrightDataWebUnlockerAPIToolConfig(FunctionBaseConfig, name="bright_data_web_unlocker_api"):
"""
Configuração para a ferramenta Bright Data Web Unlocker.
Permite acessar páginas com restrição geográfica ou protegidas contra bots usando o
Bright Data Web Unlocker.
Requer BRIGHT_DATA_API_KEY.
"""
api_key: str = Field(
default="",
description="Chave API Bright Data para o Web Unlocker."
)
country: str = Field(
default="us",
description="Código de país de duas letras simulado para a solicitação (padrão: us)."
)
data_format: str = Field(
default="html",
description="Formato do conteúdo de saída: 'html', 'markdown' ou 'screenshot'."
)
zone: str = Field(
default="unblocker",
description='Zona Bright Data a ser usada (padrão: "unblocker").'
)
@register_function(config_type=BrightDataWebUnlockerAPIToolConfig)
async def bright_data_web_unlocker_api_function(tool_config: BrightDataWebUnlockerAPIToolConfig, builder: Builder):
import os
import json
from typing import Optional
from langchain_brightdata import BrightDataUnlocker
# Defina a variável de ambiente, se necessário
if not os.environ.get("BRIGHT_DATA_API_KEY") and tool_config.api_key:
os.environ["BRIGHT_DATA_API_KEY"] = tool_config.api_key
async def _bright_data_web_unlocker_api(
url: str,
country: Optional[str] = None,
data_format: Optional[str] = None,
) -> str:
"""
Acesse uma URL com restrição geográfica ou protegida contra bots usando o Bright Data Web Unlocker.
Argumentos:
url (str): URL de destino a ser buscada.
country (str, opcional): Substitua o país simulado.
data_format (str, opcional): Formato do conteúdo de saída ('html', 'markdown', 'screenshot').
Retorna:
str: O conteúdo buscado do site de destino.
"""
unlocker = BrightDataUnlocker()
result = unlocker.invoke({
"url": url,
"country": country ou tool_config.country,
"data_format": data_format ou tool_config.data_format,
"zone": tool_config.zone,
})
return json.dumps(result)
yield FunctionInfo.from_fn(
_bright_data_web_unlocker_api,
description=_bright_data_web_unlocker_api.__doc__,
)
Ajuste os valores padrão dos argumentos para ambas as ferramentas com base nas suas necessidades.
Lembre-se de que BrightDataSERP e BrightDataUnlocker tentam ler a chave API da variável de ambiente BRIGHT_DATA_API_KEY (que você configurou anteriormente, portanto, está tudo pronto).
Em seguida, importe essas duas ferramentas adicionando a seguinte linha ao register.py:
# bright_data_nvidia_nemo/web_data_workflow/src/web_data_workflow/register.py
# ...
from .bright_data import bright_data_serp_api_function, bright_data_web_unlocker_api_functionAs duas ferramentas não estão disponíveis para uso no arquivo config.yml. O motivo é que o arquivo pyproject.toml gerado automaticamente contém:
[project.entry-points.'nat.components']
web_data_workflow = "web_data_workflow.register"Isso diz ao comando nat: “Ao carregar o fluxo de trabalho web_data_workflow, procure componentes no módulo web_data_workflow.register ”.
Observação: da mesma forma, você pode criar uma ferramenta para BrightDataWebScraperAPI para integrar com as APIs de Scraping de dados da Bright Data. Isso equipa o agente com a capacidade de recuperar feeds de dados estruturados de sites populares como Amazon, Instagram, LinkedIn, Yahoo Finance e muitos outros.
Pronto! Resta apenas atualizar o arquivo config.yml de acordo para permitir que o agente se conecte a essas duas novas ferramentas.
Etapa 7: Configure as ferramentas Bright Data
Em config.yml, importe as ferramentas Bright Data e passe-as para o agente com:
# bright_data_nvidia_nemo/web_data_workflow/src/web_data_workflow/configs/config.yml
funções:
# Defina e personalize as ferramentas personalizadas da Bright Data
bright_data_serp_api:
_type: bright_data_serp_api
bright_data_web_unlocker_api:
_type: bright_data_web_unlocker_api
data_format: markdown
llms:
nim_llm:
_type: nim
model_name: meta/llama-3.1-70b-instruct # Substitua por um modelo de IA pronto para uso empresarial
temperature: 0.0
workflow:
_type: react_agent
llm_name: nim_llm
tool_names: [bright_data_serp_api, bright_data_web_unlocker_api] # Configure as ferramentas Bright Data
Para usar as ferramentas definidas anteriormente:
- Adicione-as na seção
de funçõesdo arquivoconfig.yml. Observe que você pode personalizá-las por meio dos argumentos expostos por suas classesFunctionBaseConfig. Por exemplo, a ferramentabright_data_web_unlocker_apifoi configurada para retornar dados no formato Markdown, que é umformato excelentepara agentes de IA processarem. - Liste as ferramentas dentro do campo
tool_namesno blocode fluxo de trabalhopara que o agente possa chamá-las.
Fantástico! Seu React Agent, com tecnologia meta/llama-3.1-70b-instruct, agora tem acesso às duas ferramentas personalizadas baseadas em LangChain:
bright_data_serp_apibright_data_web_unlocker_api
Observação: neste exemplo, o LLM está configurado como um modelo NVIDIA NIM. Considere mudar para um modelo mais voltado para empresas, dependendo das suas necessidades de implantação.
Etapa 8: teste o fluxo de trabalho do NVIDIA Nemo Agent Toolkit
Para verificar se o fluxo de trabalho do NVIDIA NeMo Agent Toolkit agora pode interagir com as ferramentas Bright Data, você precisa de uma tarefa que acione a pesquisa na web e a extração de dados da web.
Por exemplo, imagine que sua empresa deseja monitorar os novos produtos e preços dos concorrentes para apoiar a inteligência de negócios. Se o seu concorrente for a Nike, você poderia escrever um prompt como:
Pesquise na web para descobrir os tênis Nike mais recentes. A partir dos resultados da pesquisa recuperados, selecione até três das páginas da web mais relevantes, dando prioridade às páginas oficiais do site da Nike. Acesse essas páginas e recupere seu conteúdo no formato Markdown. Para o modelo de tênis descoberto, forneça o nome, o status de lançamento, o preço, as informações principais e um link para a página oficial da Nike (se disponível).Certifique-se de que as variáveis de ambiente NVIDIA_API_KEY e BRIGHT_DATA_API_KEY estejam definidas e, em seguida, execute seu agente com:
nat run --config_file configs/config.yml --input "Pesquise na web para descobrir os últimos modelos de tênis da Nike. A partir dos resultados da pesquisa, selecione até três das páginas mais relevantes, dando prioridade às páginas oficiais do site da Nike. Acesse essas páginas e recupere seu conteúdo no formato Markdown. Para os modelos de tênis encontrados, forneça o nome, status de lançamento, preço, informações importantes e um link para a página oficial da Nike (se disponível).”A saída inicial será algo como: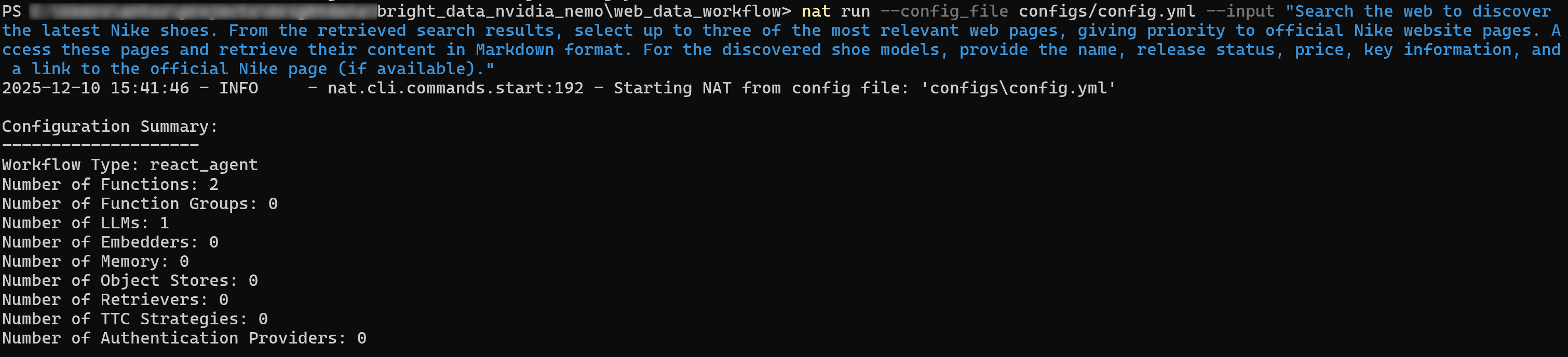
Se você ativar o modo verboso (defina verbose: true no bloco de fluxo de trabalho ), verá o agente executando as seguintes etapas:
- Chamar a API SERP com consultas como “últimos sapatos Nike” e “novos sapatos Nike”.
- Selecione as páginas mais relevantes, priorizando a página oficial“Novos tênis”da Nike.
- Usar a ferramenta Web Unlocker API para acessar a página selecionada e extrair seu conteúdo no formato Markdown.
- Processar os dados extraídos e produzir uma lista estruturada de resultados:
[Air Jordan 11 Retro “Gamma” - Tênis masculino](https://www.nike.com/t/air-jordan-11-retro-gamma-mens-shoes-DYkD1oXL/CT8012-047)
Status de lançamento: Em breve
Cores: 1
Preço: US$ 235
[Air Jordan 11 Retro “Gamma” - Calçados infantis](https://www.nike.com/t/air-jordan-11-retro-gamma-big-kids-shoes-LJyljnZt/378038-047)
Status do lançamento: Em breve
Cores: 1
Preço: US$ 190
# Omitido por brevidade...Esses resultados correspondem exatamente ao que você encontraria na página “Novos sapatos” da Nike: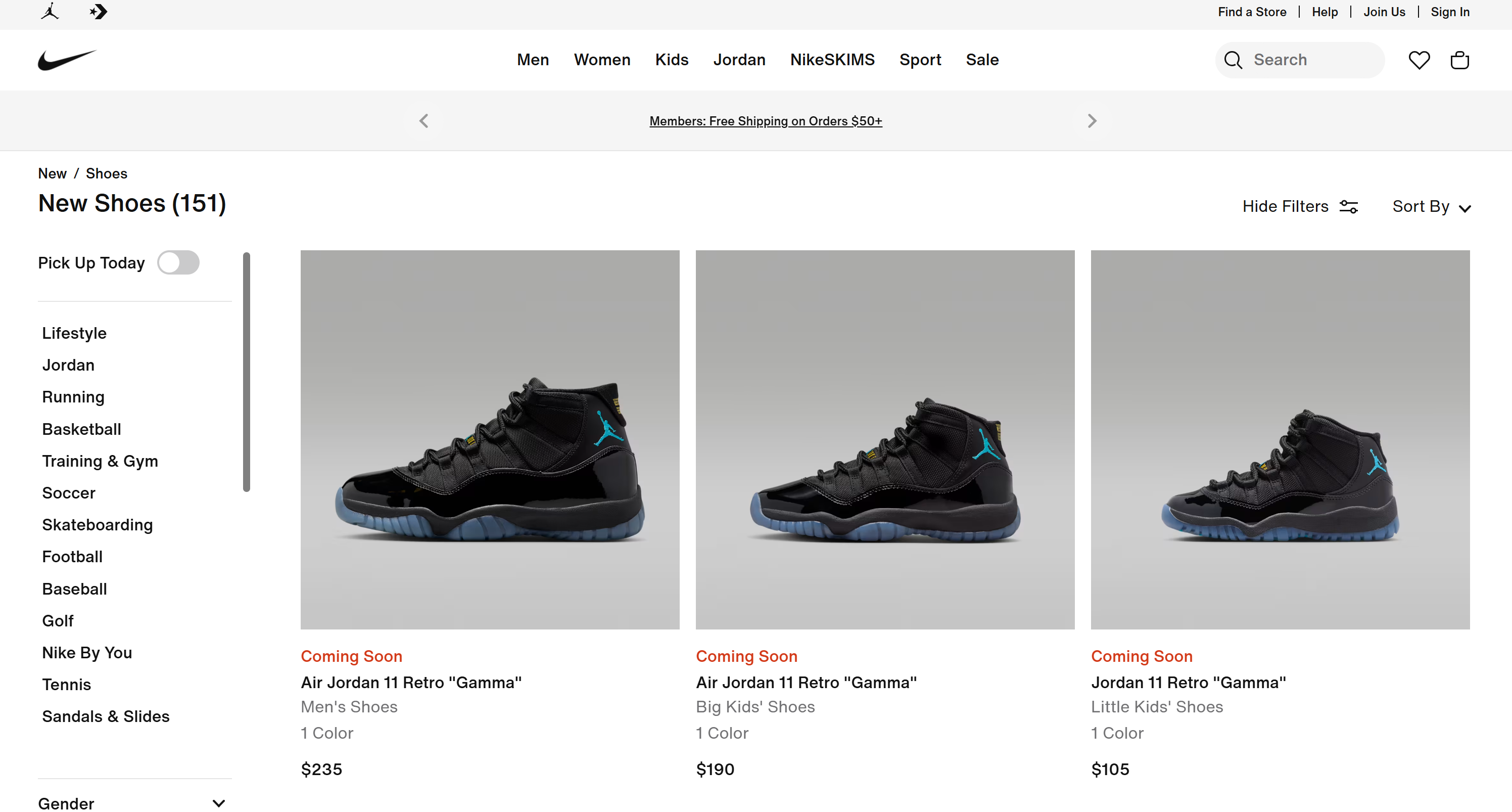
Missão cumprida! O agente de IA pesquisou autonomamente na web, selecionou as páginas certas, as extraiu e obteve insights estruturados sobre os produtos. Nada disso seria possível sem a integração das ferramentas Bright Data ao seu fluxo de trabalho NAT!
Lembre-se de que a inteligência de negócios agênica é apenas um dos muitos casos de uso possibilitados pelas soluções da Bright Data quando combinadas com o NVIDIA NeMo Agent Toolkit. Tente ajustar a configuração da ferramenta, integrar ferramentas adicionais ou alterar o prompt de entrada para explorar mais cenários!
Conecte o NVIDIA NeMo Agent Toolkit com a Bright Data via Web MCP
Outra maneira de integrar o NVIDIA NeMo Agent Toolkit aos produtos Bright Data é conectando-o ao Web MCP. Para obter mais detalhes, consulte a documentação oficial.
O Web MCP fornece acesso a mais de 60 ferramentas criadas com base na plataforma de automação da web e coleta de dados da Bright Data. Mesmo na versão gratuita, você já pode ter acesso a duas ferramentas poderosas:
| Ferramenta | Descrição |
|---|---|
search_engine |
Busque resultados do Google, Bing ou Yandex no formato JSON ou Markdown. |
scrape_as_markdown |
Extraia qualquer página da web para Markdown limpo, contornando medidas anti-bot. |
Mas o Web MCP realmente se destaca com o modo Pro. Esse nível premium não é gratuito, mas desbloqueia a extração de dados estruturados para as principais plataformas, como Amazon, Zillow, LinkedIn, YouTube, TikTok, Google Maps e muito mais, além de ferramentas adicionais para ações automatizadas do navegador.
Observação: para configuração do projeto e pré-requisitos, consulte o capítulo anterior.
Agora, vamos ver como usar o Web MCP da Bright Data dentro do NVIDIA NeMo Agent Toolkit!
Etapa 1: instale o pacote NVIDIA NAT MCP
Como mencionado anteriormente, o NVIDIA NeMo Agent Toolkit é modular. O pacote principal fornece a base, e recursos adicionais são adicionados por meio de extensões opcionais.
Para suporte ao MCP, o pacote necessário é o nvidia-nat[mcp]. Instale-o com:
pip install nvidia-nat[mcp]Seu agente do NVIDIA NeMo Agent Toolkit agora pode se conectar a servidores MCP. Em particular, para garantir desempenho e confiabilidade de nível empresarial, você se conectará ao Web MCP da Bright Data usando comunicação HTTP remota streamável através do servidor remoto gerenciado.
Etapa 2: Configure a conexão remota Web MCP
Em seu config.yml, configure a conexão com o servidor Web MCP remoto da Bright Data usando o protocolo HTTP Streamable:
# bright_data_nvidia_nemo/web_data_workflow/src/web_data_workflow/configs/config.yml
function_groups:
bright_data_web_mcp:
_type: mcp_client
server:
transport: streamable-http
url: "https://mcp.brightdata.com/mcp?token=<SUA_CHAVE_API_BRIGHT_DATA>&pro=1" tool_call_timeout: 600
auth_flow_timeout: 300
reconnect_enabled: true
reconnect_max_attempts: 3
llms:
nim_llm:
_type: nim
model_name: meta/llama-3.1-70b-instruct # Substitua por um modelo de IA pronto para uso corporativo
temperature: 0.0
workflow:
_type: react_agent
llm_name: nim_llm
tool_names: [bright_data_web_mcp]
Desta vez, em vez de definir ferramentas no bloco de funções, você usa function_groups. Isso configura a conexão Web MCP e recupera todo o conjunto de ferramentas MCP do servidor remoto. O grupo é então passado para o agente através do campo tool_names, assim como as ferramentas individuais.
A URL do Web MCP inclui o parâmetro de consulta &pro=1. Isso habilita o modo Pro, que é opcional, mas altamente recomendado para uso corporativo, pois desbloqueia o conjunto completo de ferramentas de extração de dados estruturados, não apenas as básicas.
Etapa 3: verifique a conexão Web MCP
Execute o NVIDIA NeMo Agent com um novo prompt. Nos logs iniciais, você deverá ver o agente carregando todas as ferramentas expostas pelo Web MCP: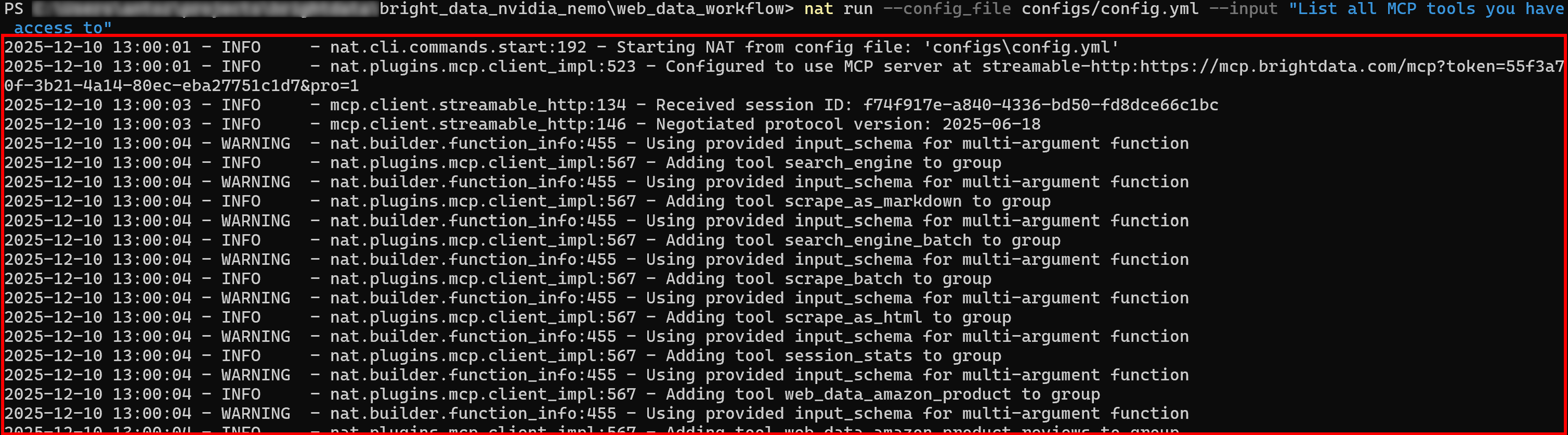
Se o modo Pro estiver ativado, todas as mais de 60 ferramentas serão carregadas inicialmente.
Em seguida, os registros de resumo da configuração mostrarão um único grupo de funções, como esperado: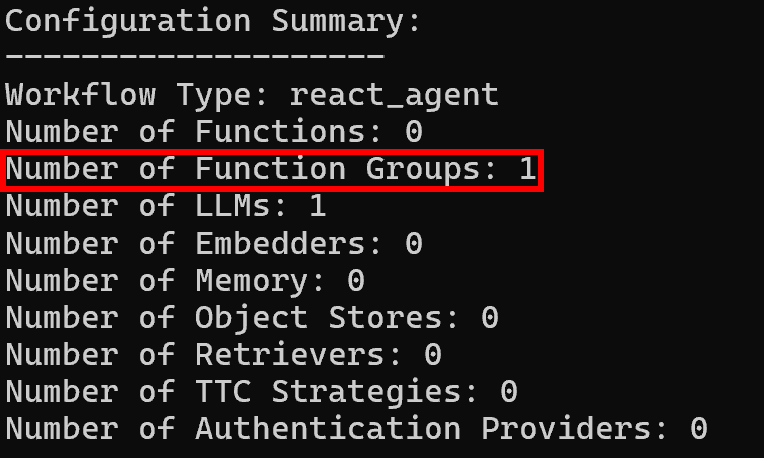
Et voilà! Seu fluxo de trabalho do NVIDIA NeMo Agent Toolkit agora tem acesso total a todos os recursos fornecidos pelo Bright Data Web MCP.
Conclusão
Nesta postagem do blog, você aprendeu como integrar o Bright Data ao NVIDIA NeMo Agent Toolkit, seja por meio de ferramentas personalizadas com tecnologia LangChain ou via Web MCP.
Essas configurações abrem as portas para pesquisas na web em tempo real, extração de dados estruturados, acesso a feeds da web ao vivo e interações automatizadas na web dentro dos fluxos de trabalho NAT. Ele aproveita o conjunto completo de serviços Bright Data para IA, liberando todo o potencial de seus agentes de IA!
Inscreva-se hoje mesmo na Bright Data e comece a integrar nossas ferramentas de dados da web prontas para IA!




