

O Crawl4AI e o Firecrawl são dois dos maiores produtos de IA do setor de coleta de dados. Neste guia, examinaremos o uso básico e as estatísticas de ambos os produtos.
Quando terminar de ler, você poderá responder às seguintes perguntas.
- O que é o Crawl4AI?
- O que é o Firecrawl?
- Onde cada um deles se destaca?
- Onde eles falham?
- Por que a Bright Data é uma ótima alternativa a ambos?
Entender como essas novas ferramentas se comparam ajuda a destacar as soluções abrangentes e dimensionáveis da Bright Data. Quer você precise de recursos gerais de raspagem ou de um conjunto completo de coleta de dados, a Bright Data oferece tecnologia comprovada.
Visão geral e objetivo
Antes de nos aprofundarmos nos detalhes, vamos dar uma olhada mais de perto no que cada um desses produtos é e para quem eles são comercializados. Como eles foram criados para finalidades diferentes, esta não é uma comparação de maçãs com maçãs. É mais uma comparação do tipo “caixa de ferramentas x canivete suíço”.
Crawl4AI

O Crawl4AI é uma biblioteca Python de código aberto que facilita e torna mais acessível a raspagem da Web com tecnologia de IA. Ela é voltada mais para desenvolvedores focados em expandir seus pipelines de extração. Ela é totalmente de código aberto. O código está disponível gratuitamente em sua página do GitHub. O Crawl4AI se alinha mais com as ferramentas de raspagem tradicionais da Bright Data.
Firecrawl
O Firecrawl é um dos líderes empresariais em raspagem da Web com tecnologia de IA. Eles oferecem uma estrutura independente de idioma e muitas opções de integração. A Firecrawl atrai a maior parte de seu interesse de pessoas que tradicionalmente não estariam na coleta de dados ou necessariamente no desenvolvimento. Com o Firecrawl, a raspagem se torna acessível a pessoas que nem sempre têm habilidades de codificação.
Recursos exclusivos
Crawl4AI
O Crawl4AI se destaca por ser totalmente de código aberto e usar licenciamento permissivo. Dê uma olhada nos recursos que tornam o Crawl4AI uma opção muito atraente para os desenvolvedores. Essa ferramenta oferece opções configuráveis e confiança por meio da transparência no código.
- Código aberto: Qualquer pessoa pode examinar o código. Os bugs são frequentemente detectados e corrigidos rapidamente pela comunidade. A base de código transparente significa que não há surpresas, se você souber ler código.
- Extração com LLM e sem LLM: Com o Crawl4AI, você tem a opção de usar um modelo local pequeno para extração ou pode se conectar a um modelo externo, como o Deepseek.
- Licenciamento permissivo: A licença por trás do Crawl4AI é muito flexível e permissiva. Isso atrai o interesse tanto de amadores quanto de desenvolvedores corporativos.
- Biblioteca Python: O Crawl4AI não é um serviço de assinatura. É uma biblioteca Python. Você pode conectá-la a outras coisas e, se quiser, pode criar seu próprio scraper proprietário usando o Crawl4AI como backend.
Firecrawl
O Firecrawl é uma das ferramentas empresariais mais populares para raspagem da Web. Eles oferecem uma estrutura independente de linguagem – você pode usar Python, JavaScript ou o site da GUI para realizar a extração. Eles oferecem uma variedade de planos adaptados tanto para amadores quanto para clientes corporativos.
- Empresarial: O Firecrawl é um produto empresarial. Eles oferecem uma opção de código aberto. Entretanto, sua principal linha de produtos é voltada para pessoas que desejam uma coleta de dados escalonável hoje.
- Não depende do idioma: O Firecrawl oferece suporte à GUI por meio de seu aplicativo da Web. Eles também oferecem suporte a SDK para Python e JavaScript. Também há SDKs orientados pela comunidade em Go e Rust. Com o Firecrawl, você não está limitado ao Python. Você não está nem mesmo limitado a um ambiente de programação.
- Processamento de linguagem natural (NLP): O Firecrawl é voltado para o desenvolvimento e a coleta de dados por meio de linguagem natural. Você diz ao modelo o que fazer. Em seguida, o modelo executa a tarefa de coleta.
Facilidade de uso
Crawl4AI
Começar a usar o Crawl4AI é relativamente simples. Você pode instalá-lo via pip e chamá-lo em seu ambiente Python. Os snippets abaixo mostram como instalá-lo e verificar sua instalação.
Instale o Crawl4AI com o comando abaixo.
pip install crawl4aiExecute a configuração para instalar os navegadores e as ferramentas.
crawl4ai-setupUse o comando doctor para verificar sua instalação e identificar quaisquer problemas.
crawl4ai-doctorO código abaixo é muito simples. Ele vem diretamente da documentação do Crawl4AI aqui. Cole-o em qualquer arquivo Python e execute-o com python nome-do-arquivo.py. Na prática, o Crawl4AI funciona melhor como um comando shell. A execução direta a partir do VSCode ou de outros IDEs tende a causar problemas de asyncio.
import asyncio
from crawl4ai import AsyncWebCrawler, BrowserConfig, CrawlerRunConfig
async def main():
async with AsyncWebCrawler() as crawler:
result = await crawler.arun(
url="https://www.example.com",
)
print(result.markdown[:300]) # Show the first 300 characters of extracted text
if __name__ == "__main__":
asyncio.run(main())Firecrawl
Ao começar a usar o Firecrawl, basta navegar até o playground deles e inserir o URL de destino. Essa interface é muito amigável para quem não é desenvolvedor.
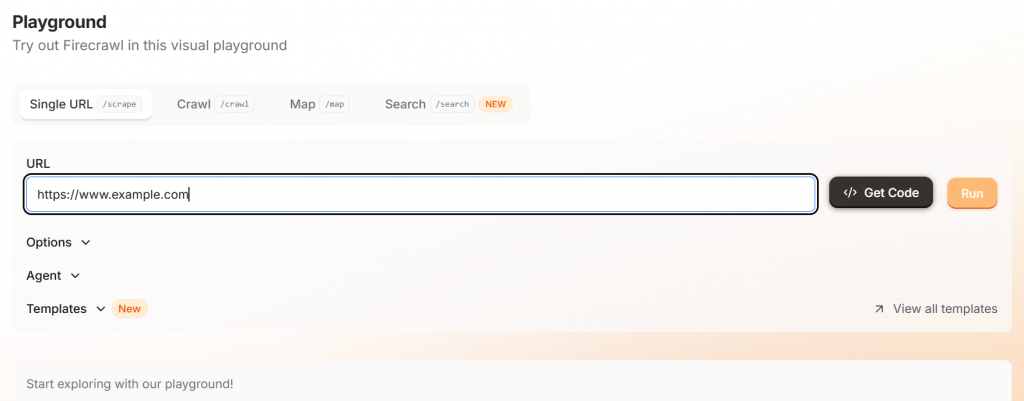
Se você clicar no botão “Run” (Executar), verá um exemplo de saída com sua opção de markdown ou JSON.
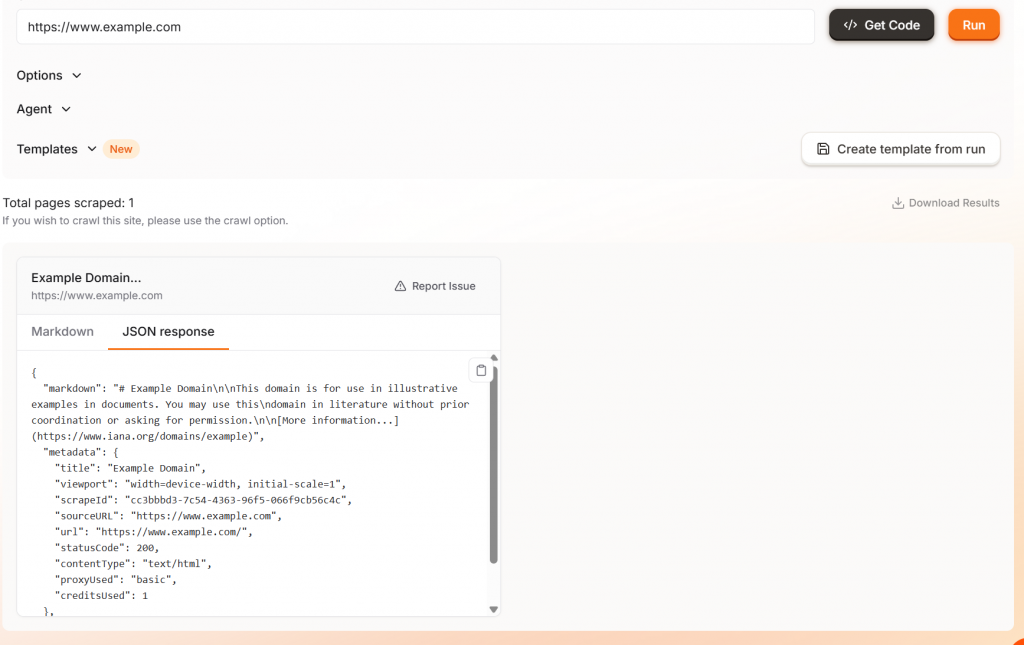
Desempenho e escalabilidade
Crawl4AI
O snippet abaixo vem do código de exemplo que você viu anteriormente. Em suma, foram necessários pouco menos de dois segundos para raspar o domínio de exemplo. Sem um LLM, o Crawl4AI é excepcionalmente rápido. Ele rivaliza com a coleta manual de dados com o Requests e o BeautifulSoup em termos de desempenho.

No entanto, a raspagem de markdown e o HTML bruto são os mais limpos possíveis. O Crawl4AI lista o suporte para extração de JSON sem um LLM, mas o suporte é limitado e cheio de erros. Para extrair estruturas de dados completas, você precisa adicionar um suporte LLM ao seu código. Esse é o custo oculto do Crawl4AI: você precisa hospedar ou pagar por um LLM externo para concluir trabalhos reais de análise.
No código abaixo, usamos um modelo OpenAI para analisar a página do Books to Scrape. Se você decidir executá-lo por conta própria, certifique-se de substituir a chave da API pela sua própria.
import asyncio
import json
from pydantic import BaseModel
from crawl4ai import AsyncWebCrawler, BrowserConfig, CrawlerRunConfig, CacheMode, LLMConfig
from crawl4ai.extraction_strategy import LLMExtractionStrategy
openai_api_key = "your-openai-api-key"
class Product(BaseModel):
name: str
price: str
async def main():
#tell the llm what to scrape and set config
llm_strategy = LLMExtractionStrategy(
llm_config = LLMConfig(provider="openai/gpt-4o-mini", api_token=openai_api_key),
schema=Product.model_json_schema(),
extraction_type="schema",
instruction="Extract all product objects with 'name' and 'price' from the content.",
chunk_token_threshold=1000,
overlap_rate=0.0,
apply_chunking=True,
input_format="markdown",
extra_args={"temperature": 0.0, "max_tokens": 800}
)
#build the crawler config
crawl_config = CrawlerRunConfig(
extraction_strategy=llm_strategy,
cache_mode=CacheMode.BYPASS
)
#create a browser config if needed
browser_cfg = BrowserConfig(headless=True)
async with AsyncWebCrawler(config=browser_cfg) as crawler:
#crawl a single page
result = await crawler.arun(
url="https://books.toscrape.com",
config=crawl_config
)
if result.success:
#assume the extracted content is json
data = json.loads(result.extracted_content)
print("Extracted items:", data)
#show usage stats
llm_strategy.show_usage()
else:
print("Error:", result.error_message)
if __name__ == "__main__":
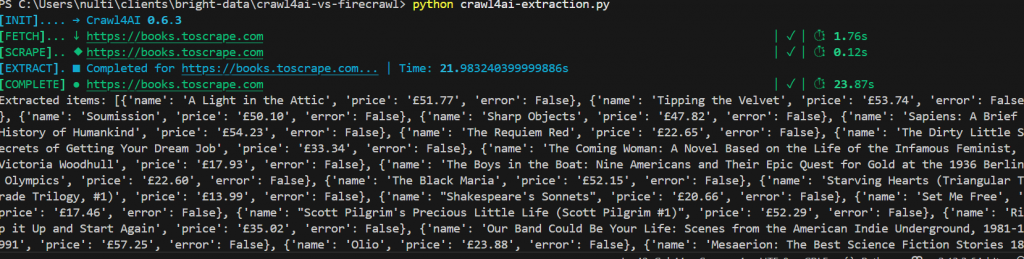
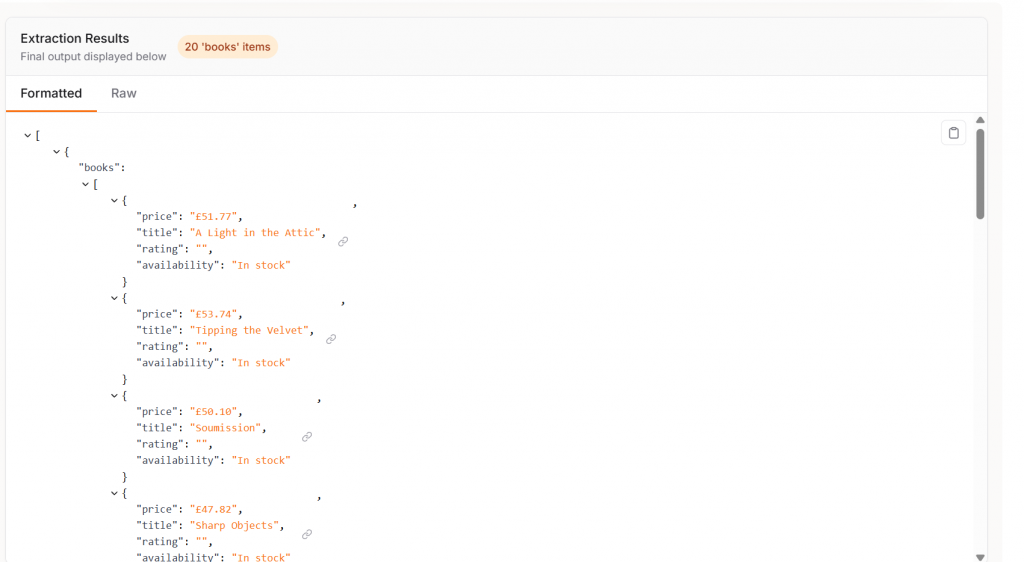
asyncio.run(main())Aqui está o nosso resultado. No total, demorou pouco menos de 25 segundos. Você também pode ver cada livro listado junto com seu preço em um objeto JSON estruturado de forma limpa.
Firecrawl
O Firecrawl simplesmente permite que você insira um URL e ele raspa a página. Ao usar a versão padrão do Firecrawl, ele gera sua página como markdown bruto despejado em um objeto JSON.
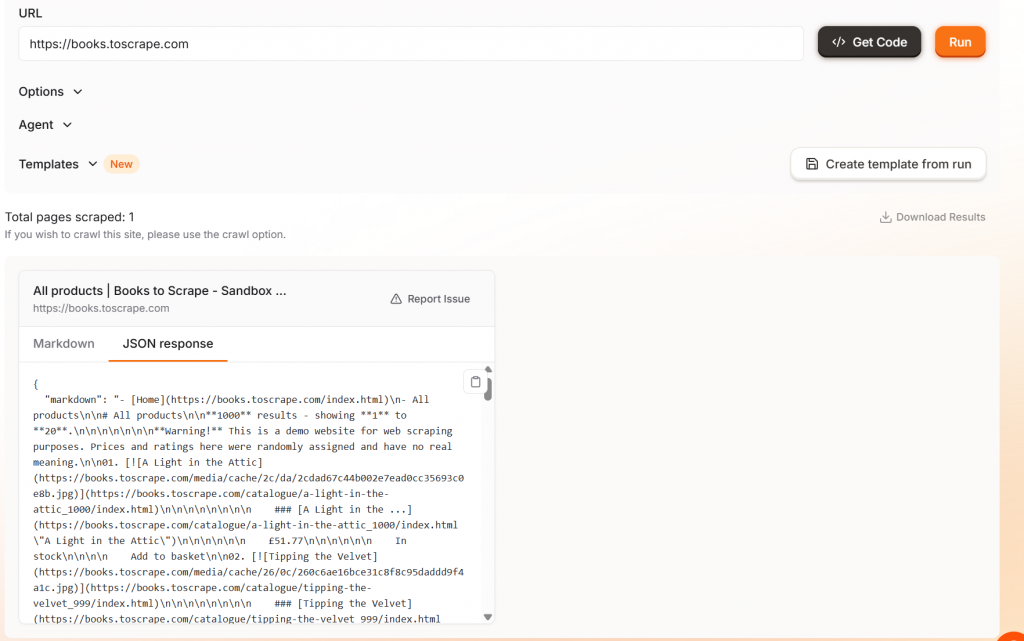
O Firecrawl tem um recurso interessante quando você executa seu código. À medida que seu scraper é executado, você pode observar o navegador enquanto ele renderiza a página.
Qualidade e precisão dos dados
Crawl4AI
Quando conectado ao GPT-4o, o Crawl4AI funcionou com 100% de precisão. Para verificar nossa contagem de itens, adicionamos a seguinte linha ao nosso código.
print("Total products scraped:", len(data))Como você pode ver no resultado abaixo, o Crawl4AI e o GPT-4o encontraram todos os 20 itens na página.

Quando combinado com um LLM, o Crawl4AI se torna uma ferramenta surpreendentemente avançada com precisão notável.
Firecrawl
Na verdade, o Firecrawl oferece dois produtos diferentes quando se trata de raspagem. Você pode usar o velho e simples Firecrawl para opções de raspagem simples e sujas. O Firecrawl Extract permite que você extraia objetos JSON estruturados.
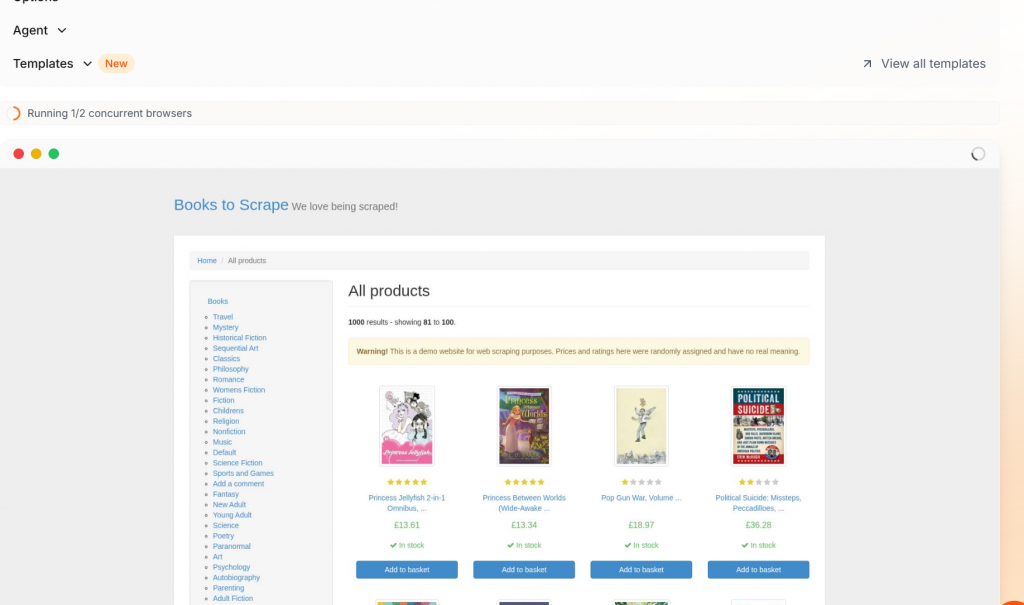
Firecrawl regular
Este é o resultado do Books To Scrape usando o Firecrawl normal. Como você pode ver, é ruim, muito ruim. O Firecrawl converteu a página em markdown. Em seguida, ele dividiu a marcação bruta em campos aparentemente aleatórios de JSON. Esses dados precisam ser limpos ainda mais usando código manualmente ou passados para um LLM.
{
"markdown": "All products \| Books to Scrape - Sandboxnn[Books to Scrape](index.html) We love being scraped!nn- [Home](index.html)n- All productsnn- [Books](catalogue/category/books_1/index.html) - [Travel](catalogue/category/books/travel_2/index.html)n - [Mystery](catalogue/category/books/mystery_3/index.html)n - [Historical Fiction](catalogue/category/books/historical-fiction_4/index.html)n - [Sequential Art](catalogue/category/books/sequential-art_5/index.html)n - [Classics](catalogue/category/books/classics_6/index.html)n - [Philosophy](catalogue/category/books/philosophy_7/index.html)n - [Romance](catalogue/category/books/romance_8/index.html)n - [Womens Fiction](catalogue/category/books/womens-fiction_9/index.html)n - [Fiction](catalogue/category/books/fiction_10/index.html)n - [Childrens](catalogue/category/books/childrens_11/index.html)n - [Religion](catalogue/category/books/religion_12/index.html)n - [Nonfiction](catalogue/category/books/nonfiction_13/index.html)n - [Music](catalogue/category/books/music_14/index.html)n - [Default](catalogue/category/books/default_15/index.html)n - [Science Fiction](catalogue/category/books/science-fiction_16/index.html)n - [Sports and Games](catalogue/category/books/sports-and-games_17/index.html)n - [Add a comment](catalogue/category/books/add-a-comment_18/index.html)n - [Fantasy](catalogue/category/books/fantasy_19/index.html)n - [New Adult](catalogue/category/books/new-adult_20/index.html)n - [Young Adult](catalogue/category/books/young-adult_21/index.html)n - [Science](catalogue/category/books/science_22/index.html)n - [Poetry](catalogue/category/books/poetry_23/index.html)n - [Paranormal](catalogue/category/books/paranormal_24/index.html)n - [Art](catalogue/category/books/art_25/index.html)n - [Psychology](catalogue/category/books/psychology_26/index.html)n - [Autobiography](catalogue/category/books/autobiography_27/index.html)n - [Parenting](catalogue/category/books/parenting_28/index.html)n - [Adult Fiction](catalogue/category/books/adult-fiction_29/index.html)n - [Humor](catalogue/category/books/humor_30/index.html)n - [Horror](catalogue/category/books/horror_31/index.html)n - [History](catalogue/category/books/history_32/index.html)n - [Food and Drink](catalogue/category/books/food-and-drink_33/index.html)n - [Christian Fiction](catalogue/category/books/christian-fiction_34/index.html)n - [Business](catalogue/category/books/business_35/index.html)n - [Biography](catalogue/category/books/biography_36/index.html)n - [Thriller](catalogue/category/books/thriller_37/index.html)n - [Contemporary](catalogue/category/books/contemporary_38/index.html)n - [Spirituality](catalogue/category/books/spirituality_39/index.html)n - [Academic](catalogue/category/books/academic_40/index.html)n - [Self Help](catalogue/category/books/self-help_41/index.html)n - [Historical](catalogue/category/books/historical_42/index.html)n - [Christian](catalogue/category/books/christian_43/index.html)n - [Suspense](catalogue/category/books/suspense_44/index.html)n - [Short Stories](catalogue/category/books/short-stories_45/index.html)n - [Novels](catalogue/category/books/novels_46/index.html)n - [Health](catalogue/category/books/health_47/index.html)n - [Politics](catalogue/category/books/politics_48/index.html)n - [Cultural](catalogue/category/books/cultural_49/index.html)n - [Erotica](catalogue/category/books/erotica_50/index.html)n - [Crime](catalogue/category/books/crime_51/index.html)nn# All productsnn**1000** results - showing **1** to **20**.nnnnnnn**Warning!** This is a demo website for web scraping purposes. Prices and ratings here were randomly assigned and have no real meaning.nn01. [](catalogue/a-light-in-the-attic_1000/index.html)nnnnnnnn ### [A Light in the ...](catalogue/a-light-in-the-attic_1000/index.html "A Light in the Attic")nnnnnn £51.77nnnnnn In stocknnnn Add to basketnn02. [](catalogue/tipping-the-velvet_999/index.html)nnnnnnnn ### [Tipping the Velvet](catalogue/tipping-the-velvet_999/index.html "Tipping the Velvet")nnnnnn £53.74nnnnnn In stocknnnn Add to basketnn03. [](catalogue/soumission_998/index.html)nnnnnnnn ### [Soumission](catalogue/soumission_998/index.html "Soumission")nnnnnn £50.10nnnnnn In stocknnnn Add to basketnn04. [](catalogue/sharp-objects_997/index.html)nnnnnnnn ### [Sharp Objects](catalogue/sharp-objects_997/index.html "Sharp Objects")nnnnnn £47.82nnnnnn In stocknnnn Add to basketnn05. [](catalogue/sapiens-a-brief-history-of-humankind_996/index.html)nnnnnnnn ### [Sapiens: A Brief History ...](catalogue/sapiens-a-brief-history-of-humankind_996/index.html "Sapiens: A Brief History of Humankind")nnnnnn £54.23nnnnnn In stocknnnn Add to basketnn06. [](catalogue/the-requiem-red_995/index.html)nnnnnnnn ### [The Requiem Red](catalogue/the-requiem-red_995/index.html "The Requiem Red")nnnnnn £22.65nnnnnn In stocknnnn Add to basketnn07. [](catalogue/the-dirty-little-secrets-of-getting-your-dream-job_994/index.html)nnnnnnnn ### [The Dirty Little Secrets ...](catalogue/the-dirty-little-secrets-of-getting-your-dream-job_994/index.html "The Dirty Little Secrets of Getting Your Dream Job")nnnnnn £33.34nnnnnn In stocknnnn Add to basketnn08. [](catalogue/the-coming-woman-a-novel-based-on-the-life-of-the-infamous-feminist-victoria-woodhull_993/index.html)nnnnnnnn ### [The Coming Woman: A ...](catalogue/the-coming-woman-a-novel-based-on-the-life-of-the-infamous-feminist-victoria-woodhull_993/index.html "The Coming Woman: A Novel Based on the Life of the Infamous Feminist, Victoria Woodhull")nnnnnn £17.93nnnnnn In stocknnnn Add to basketnn09. [](catalogue/the-boys-in-the-boat-nine-americans-and-their-epic-quest-for-gold-at-the-1936-berlin-olympics_992/index.html)nnnnnnnn ### [The Boys in the ...](catalogue/the-boys-in-the-boat-nine-americans-and-their-epic-quest-for-gold-at-the-1936-berlin-olympics_992/index.html "The Boys in the Boat: Nine Americans and Their Epic Quest for Gold at the 1936 Berlin Olympics")nnnnnn £22.60nnnnnn In stocknnnn Add to basketnn10. [](catalogue/the-black-maria_991/index.html)nnnnnnnn ### [The Black Maria](catalogue/the-black-maria_991/index.html "The Black Maria")nnnnnn £52.15nnnnnn In stocknnnn Add to basketnn11. [](catalogue/starving-hearts-triangular-trade-trilogy-1_990/index.html)nnnnnnnn ### [Starving Hearts (Triangular Trade ...](catalogue/starving-hearts-triangular-trade-trilogy-1_990/index.html "Starving Hearts (Triangular Trade Trilogy, \#1)")nnnnnn £13.99nnnnnn In stocknnnn Add to basketnn12. [](catalogue/shakespeares-sonnets_989/index.html)nnnnnnnn ### [Shakespeare's Sonnets](catalogue/shakespeares-sonnets_989/index.html "Shakespeare's Sonnets")nnnnnn £20.66nnnnnn In stocknnnn Add to basketnn13. [](catalogue/set-me-free_988/index.html)nnnnnnnn ### [Set Me Free](catalogue/set-me-free_988/index.html "Set Me Free")nnnnnn £17.46nnnnnn In stocknnnn Add to basketnn14. [](catalogue/scott-pilgrims-precious-little-life-scott-pilgrim-1_987/index.html)nnnnnnnn ### [Scott Pilgrim's Precious Little ...](catalogue/scott-pilgrims-precious-little-life-scott-pilgrim-1_987/index.html "Scott Pilgrim's Precious Little Life (Scott Pilgrim \#1)")nnnnnn £52.29nnnnnn In stocknnnn Add to basketnn15. [](catalogue/rip-it-up-and-start-again_986/index.html)nnnnnnnn ### [Rip it Up and ...](catalogue/rip-it-up-and-start-again_986/index.html "Rip it Up and Start Again")nnnnnn £35.02nnnnnn In stocknnnn Add to basketnn16. [](catalogue/our-band-could-be-your-life-scenes-from-the-american-indie-underground-1981-1991_985/index.html)nnnnnnnn ### [Our Band Could Be ...](catalogue/our-band-could-be-your-life-scenes-from-the-american-indie-underground-1981-1991_985/index.html "Our Band Could Be Your Life: Scenes from the American Indie Underground, 1981-1991")nnnnnn £57.25nnnnnn In stocknnnn Add to basketnn17. [](catalogue/olio_984/index.html)nnnnnnnn ### [Olio](catalogue/olio_984/index.html "Olio")nnnnnn £23.88nnnnnn In stocknnnn Add to basketnn18. [](catalogue/mesaerion-the-best-science-fiction-stories-1800-1849_983/index.html)nnnnnnnn ### [Mesaerion: The Best Science ...](catalogue/mesaerion-the-best-science-fiction-stories-1800-1849_983/index.html "Mesaerion: The Best Science Fiction Stories 1800-1849")nnnnnn £37.59nnnnnn In stocknnnn Add to basketnn19. [](catalogue/libertarianism-for-beginners_982/index.html)nnnnnnnn ### [Libertarianism for Beginners](catalogue/libertarianism-for-beginners_982/index.html "Libertarianism for Beginners")nnnnnn £51.33nnnnnn In stocknnnn Add to basketnn20. [](catalogue/its-only-the-himalayas_981/index.html)nnnnnnnn ### [It's Only the Himalayas](catalogue/its-only-the-himalayas_981/index.html "It's Only the Himalayas")nnnnnn £45.17nnnnnn In stocknnnn Add to basketnnn-nPage 1 of 50nnn- [next](catalogue/page-2.html)",
"metadata": {
"language": "en-us",
"description": "",
"created": "24th Jun 2016 09:29",
"viewport": "width=device-width",
"title": "n All products | Books to Scrape - Sandboxn",
"robots": "NOARCHIVE,NOCACHE",
"favicon": "https://books.toscrape.com/static/oscar/favicon.ico",
"scrapeId": "aa3667ec-647b-42ab-adb2-9c35e042896d",
"sourceURL": "https://books.toscrape.com",
"url": "https://books.toscrape.com/",
"statusCode": 200,
"contentType": "text/html",
"proxyUsed": "basic",
"creditsUsed": 80
},
"scrape_id": "aa3667ec-647b-42ab-adb2-9c35e042896d"
}O Firecrawl normal obtém a página, mas não faz muito mais do que isso. Você obtém uma página de markdown fatiada em um grande objeto JSON. Você pode buscar a página, mas é necessário muito trabalho para transformar sua página da Web em dados utilizáveis.
Extrato do Firecrawl
O Extract é o próximo nível. Com o Extract, você obtém suporte total para raspagem por meio de NLP. Informe ao modelo quais dados devem ser obtidos e ele os extrairá da página. Como você pode ver na imagem abaixo, recebemos até mesmo um esquema recomendado contendo os campos de título, preço e disponibilidade. Se estiver satisfeito com seu esquema, clique no botão “Run” (Executar).
Observe que seu site vem anexado com /* – isso diz ao Extract para rastrear automaticamente o site inteiro. Para economizar créditos, remova o /*.
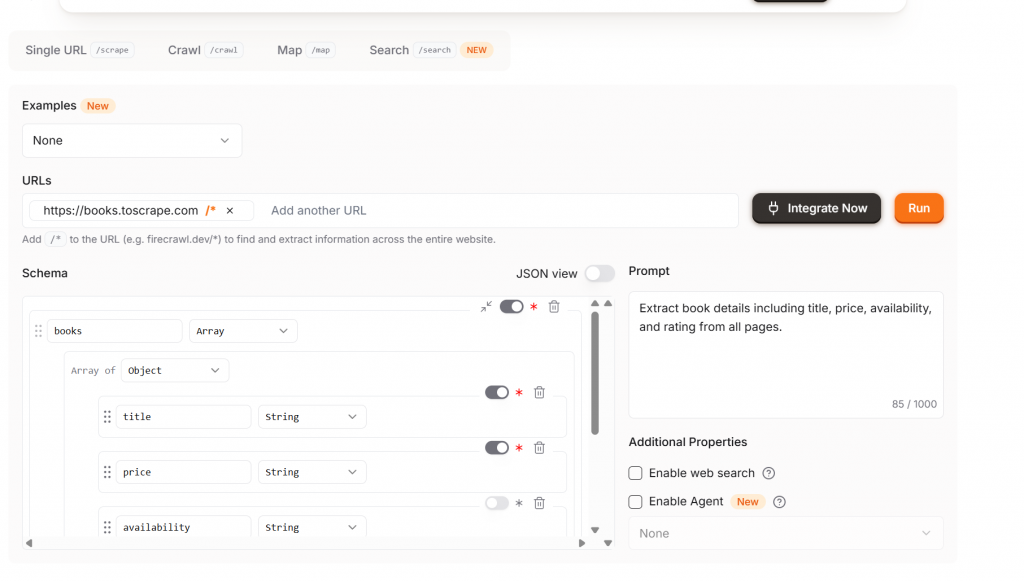
Se você quiser um rastreamento de uma única página, certifique-se de alterar Extract da configuração padrão. A imagem abaixo mostra nossa configuração para rastrear uma única página. O operador /* é muito fácil de ser ignorado, economize seu dinheiro e use-o somente quando necessário.
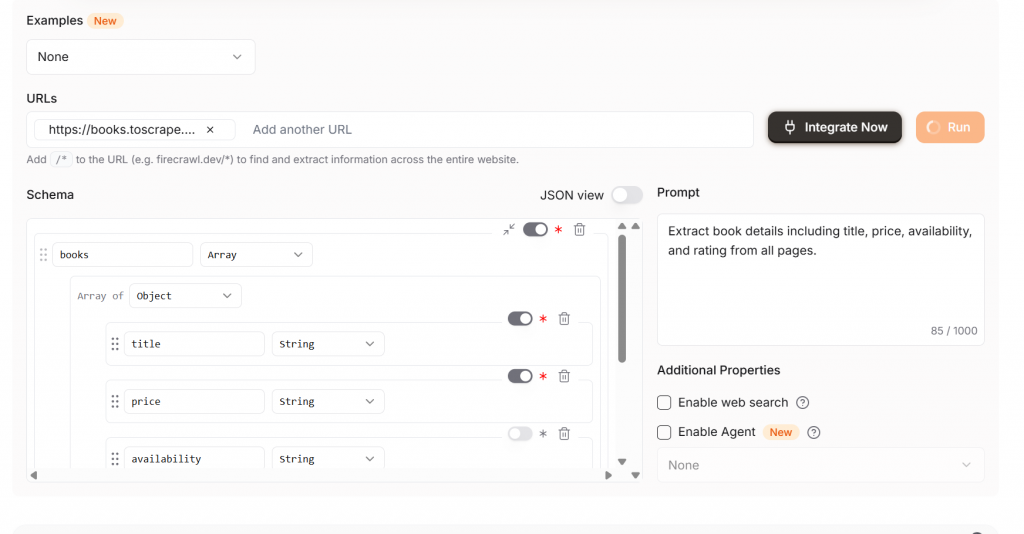
Com o Firecrawl Extract, nossa saída vem limpa e pronta para ser usada imediatamente. Como você pode ver, obtemos objetos JSON estruturados com as seguintes características.
títulopreçoclassificaçãodisponibilidade
Segurança e conformidade
Crawl4AI
O Crawl4AI não vem com garantias de conformidade incorporadas ao software. Ele oferece algumas configurações que podem ajudá-lo a manter a conformidade com itens como o arquivo robots.txt.
Ao usar a Crawl4AI, você é responsável por sua própria conformidade com leis como GDPR e CCPA. O Crawl4AI oferece quase nenhuma ajuda com a conformidade legal e de segurança. Isso significa que, ao executar um projeto em escala, você provavelmente precisará contratar ajuda adicional para garantir que esteja seguindo as práticas adequadas.
Firecrawl
De acordo com a documentação, o Firecrawl fornece suas informações ao Google para processamento. Eles declaram explicitamente em seus termos que seguem o GDPR e a CCPA, mas que você mesmo deve respeitar essas políticas. Qualquer violação desses atos é de sua responsabilidade e que eles não são responsáveis pelo uso indevido de suas ferramentas.
O Firecrawl oferece mais proteção de responsabilidade do que o Crawl4AI. No entanto, isso ainda não é muito. Seus produtos não vêm com grades de proteção. Espera-se que você siga as regras e, se não o fizer, será responsável por qualquer uso indevido. Para obter mais informações, dê uma olhada nos Termos de Serviço completos do Firecrawl.
Preços e licenciamento
Crawl4AI
O Crawl4AI é de uso gratuito para qualquer pessoa. Usamos o termo “gratuito” aqui de forma bastante vaga. Como você deve ter percebido ao acompanhar o processo, qualquer trabalho real de extração requer a integração com o LLM. Você pode hospedar o LLM por conta própria ou conectar-se a um serviço como a API do OpenAI. Ao usar o Crawl4AI, você ainda precisa pagar por serviços externos ou custos de infraestrutura se hospedar por conta própria. Esses custos aumentam. O Crawl4AI não reduzirá seu custo operacional a zero.
O Crawl4AI é distribuído sob a licença Apache. Você tem permissão para modificar, distribuir e até mesmo vender comercialmente os derivados do Crawl4AI. Se você tiver ajuda de conformidade, a licença permissiva do Crawl4AI o torna uma opção muito atraente para desenvolvedores e equipes de dados.
Firecrawl
Firecrawl regular
O Vanilla Firecrawl vem em uma variedade de níveis de preços. Você pode experimentar o plano gratuito. Seus planos pagos variam de US$ 16/mês para 3.000 páginas até US$ 333/mês para 500.000 páginas.

Extrato do Firecrawl
Ao usar o Extract, os planos pagos variam de US$ 89/mês para 18.000.000 de tokens por ano até US$ 719/mês para 192.000.000 de tokens de API por ano.

Licenciamento do Firecrawl
A Firecrawl usa licenças diferentes para uma variedade de seus produtos. Você pode ver todas as suas diferentes licenças aqui. Observe que o Firecrawl é um produto de nível empresarial e que você não poderá reempacotar o código dele como se fosse seu. Até mesmo seu código-fonte aberto é distribuído sob a licença AGPL-3.0. Assim como outros contratos de software GNU, essa licença é altamente restritiva quando se trata de uso corporativo.
Comunidade e suporte
Crawl4AI
Como um projeto de código aberto, o Crawl4AI oferece o suporte limitado que pode com os recursos que possui. Não há help desk ou SLA. No entanto, você pode entrar em contato com os desenvolvedores pelo canal Discord. Os tempos de espera podem variar. Não espere que uma equipe dedicada rastreie problemas e resolva suas necessidades em tempo hábil.
Firecrawl
No painel de controle, o Firecrawl oferece opções de suporte, como documentação, páginas de perguntas frequentes e atualizações de status. Você pode entrar em contato com a equipe de suporte por meio do botão “Contact Support”, embora a prioridade varie de acordo com o nível do plano. Você também pode participar do canal Discord para obter suporte da comunidade.

Casos de uso no mundo real
Crawl4AI
O Crawl4AI tem uma variedade de casos de uso no mundo real para desenvolvedores modernos. Você só está limitado pelo que pode criar.
- Suporte de back-end: Se você decidir criar seus próprios produtos de dados, poderá integrar o Crawl4AI a um LLM próprio e vender seus produtos.
- Agentes de IA: Como fizemos anteriormente neste artigo, você pode conectar LLMs externos diretamente ao Crawl4AI para operações de extração avançadas com saída de estrutura de dados personalizada – CSV, JSON, XML – qualquer formato que seu LLM tenha visto é um formato viável.
- Projetos de hobby e startups: Ferramentas de código aberto, como o Crawl4AI, oferecem acessibilidade rápida para experimentos, provas de conceitos e protótipos de pipeline.
Firecrawl
O Firecrawl foi criado para equipes que precisam de raspagem de alto volume com muito pouco desenvolvimento interno. Se você quiser passar de uma ideia a um produto tangível sem muito trabalho, o Firecrawl pode ajudar com isso.
- Rastreamento em nível de produção: O Firecrawl foi criado para rastreamento em escala. Suas ferramentas rastreiam até mesmo sites completos por padrão.
- Monitoramento de conteúdo: Execute rastreamentos de rotina nos concorrentes para monitorar seus preços e conteúdo.
- Dados limpos e prontos: Com o Extract, você pode passar seus dados diretamente para a equipe de dados com pouca ou nenhuma limpeza necessária.
Prós e contras
| Crawl4AI | Firecrawl | |
|---|---|---|
| Prós | – Código-fonte totalmente aberto e transparente. – Licença Apache permissiva – crie, modifique, revenda. – Flexível: Opções com LLM ou sem LLM. – Biblioteca Python plug-and-play para pipelines personalizados. |
– Muito simples para quem não é desenvolvedor: GUI, playground, prompt de NLP. – Funciona em várias linguagens (Python, JS, Go, Rust). – Rápida implementação para raspagem única ou rotineira. – Preços empresariais e níveis de suporte disponíveis. |
| Contras | – Requer um LLM separado para extração estruturada real – adiciona custos ocultos. – Suporte limitado à conformidade integrada – o usuário deve gerenciar o GDPR/CCPA. – Particularidades de assíncrono – o shell funciona melhor, os IDEs podem quebrá-lo. |
– A saída básica geralmente é confusa sem o Extract – a marcação bruta exige mais trabalho. – Não há barreiras reais para conformidade – o usuário ainda é responsável. – Núcleo de código fechado, restrições da AGPL limitam as compilações personalizadas. – Os custos de uso podem aumentar rapidamente com a escala ou com o rastreamento de curingas. |
Por que você deve considerar a Bright Data
Tanto o Crawl4AI quanto o Firecrawl têm desvantagens. O Crawl4AI vem com necessidades de desenvolvedor e custos ocultos de LLM. Com o Firecrawl, você fica preso a níveis de uso e ao ecossistema do Firecrawl.
A Bright Data oferece uma variedade de produtos que podem ajudar a preencher os mesmos nichos de ambas as ferramentas mencionadas anteriormente.
Principais ferramentas de dados brilhantes
- APIs de raspador: execute raspadores pré-construídos com dados limpos e prontos para uso, sempre que você quiser.
- API do Web Unlocker: Ignore bloqueios de sites e resolva CAPTCHAs, faça scraping como markdown e até mesmo controle sua geolocalização.
- API do navegador: Controle um navegador remoto com proxies integrados e solução de CAPTCHA a partir do seu ambiente de programação.
- Conjuntos de dados: Acesse uma vasta biblioteca de conjuntos de dados históricos de mais de 100 domínios que datam de anos atrás.
Nosso servidor MCP lhe dá acesso a todos os melhores produtos da Bright Data em um pacote amigável para LLM. Conecte-o ao seu LLM, escreva seus prompts e deixe que o sistema faça seu trabalho.
Opções de integração de dados brilhantes
Oferecemos até mesmo integração com algumas das melhores ferramentas dos setores de IA e desenvolvimento atualmente. Estamos adicionando novas integrações o tempo todo. Consulte nossos documentos para obter a lista mais atualizada.
Conclusão
Na Bright Data, não resolvemos apenas um problema de raspagem – oferecemos um ecossistema completo para sua pilha de IA. Desde a coleta de dados em tempo real até a utilização de arquivos históricos para treinamento, garantimos que você gaste seu tempo com insights, não com infraestrutura.
Comece seu teste gratuito hoje mesmo e veja a diferença.





