

Neste guia, você aprenderá:
- O que é o LlamaIndex e por que ele é tão amplamente utilizado.
- O que o torna único para o desenvolvimento de agentes de IA, especialmente seu suporte integrado para integrações de dados.
- Como usar o LlamaIndex para criar um agente de IA com recursos de recuperação de dados de sites gerais e mecanismos de pesquisa específicos.
Vamos mergulhar de cabeça!
O que é o LlamaIndex?
O LlamaIndex é uma estrutura de dados Python de código aberto para a criação de aplicativos baseados em LLM.
Ele ajuda você a criar fluxos de trabalho e agentes de IA prontos para a produção, capazes de encontrar e recuperar informações relevantes, sintetizar insights, gerar relatórios detalhados, realizar ações automatizadas e muito mais.
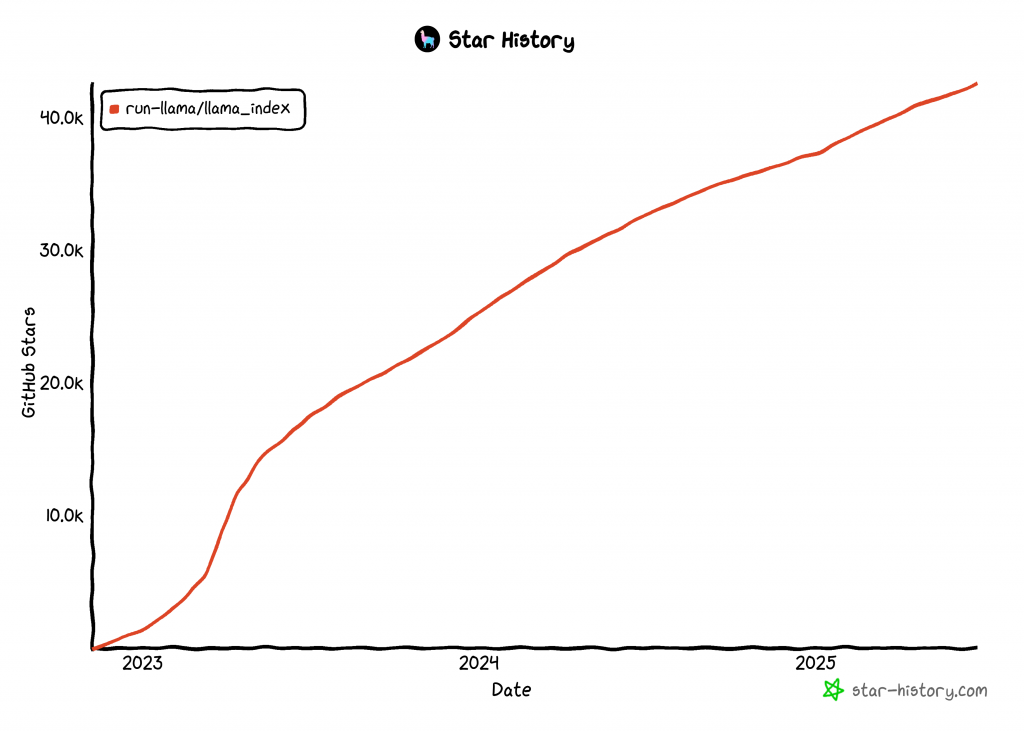
A LlamaIndex é uma das bibliotecas de crescimento mais rápido para a criação de agentes de IA, com mais de 42 mil estrelas no GitHub:
Integrar dados em seu agente de IA LlamaIndex
Em comparação com outras tecnologias de criação de agentes de IA, o LlamaIndex se concentra em dados. É por isso que o repositório GitHub do projeto define o LlamaIndex como uma “estrutura de dados”.
Especificamente, o LlamaIndex aborda uma das maiores limitações dos LLMs. Trata-se da falta de conhecimento sobre eventos atuais ou em tempo real. Essa limitação ocorre porque os LLMs são treinados em conjuntos de dados estáticos e não têm acesso integrado a informações atualizadas.
Para resolver esse problema, o LlamaIndex oferece suporte a ferramentas que:
- Forneça conectores de dados para ingerir dados de APIs, PDFs, documentos do Word, bancos de dados SQL, páginas da Web e muito mais.
- Estruture seus dados usando índices, gráficos e outros formatos otimizados para o consumo do LLM.
- Habilite a recuperação avançada para que você possa inserir um prompt do LLM e receber uma resposta com conhecimento ampliado, fundamentada em um contexto relevante.
- Suporte à integração perfeita com estruturas externas, como LangChain, Flask, Docker e ChatGPT.
Em outros termos, criar com o LlamaIndex normalmente significa combinar a biblioteca principal com um conjunto de plug-ins/integrações adaptados ao seu caso de uso. Por exemplo, explore um cenário de raspagem da Web do LlamaIndex.
Atualmente, a Web é a maior e mais abrangente fonte de dados do planeta. Portanto, o ideal é que um agente de IA tenha acesso a eles para fundamentar suas respostas e executar tarefas com mais eficiência. É aqui que as ferramentas de dados brilhantes da LlamaIndex entram em ação!
Com as ferramentas da Bright Data, seu agente de IA LlamaIndex ganha:
- Funcionalidade de raspagem da Web em tempo real de qualquer página da Web.
- Dados estruturados de produtos e plataformas de sites como Amazon, LinkedIn, Zillow, Facebook e muitos outros.
- A capacidade de recuperar resultados de mecanismos de pesquisa para qualquer consulta de pesquisa.
- Captura visual de dados por meio de capturas de tela de página inteira, útil para resumo ou análise visual.
Veja como essa integração funciona no próximo capítulo!
Crie um agente do LlamaIndex que possa fazer a busca na Web usando ferramentas de dados brilhantes
Nesta seção passo a passo, você aprenderá a usar o LlamaIndex para criar um agente de IA Python que se conecta às ferramentas da Bright Data.
Essa integração dará ao seu agente recursos avançados de acesso a dados da Web. Em detalhes, o agente de IA ganhará a capacidade de extrair conteúdo de qualquer página da Web, buscar resultados de mecanismos de pesquisa em tempo real e muito mais. Para obter mais informações, consulte nossa documentação oficial.
Siga as etapas abaixo para criar seu agente de IA com base em dados da Bright Data usando o LlamaIndex!
Pré-requisitos
Para seguir este tutorial, você precisará do seguinte:
- Python 3.9 ou superior instalado em seu computador (recomenda-se a versão mais recente).
- Uma chave API da Bright Data para integração com o
BrightDataToolSpec. - Uma chave de API de um provedor de LLM compatível (neste guia, usaremos o Gemini, que é gratuito para uso via API. Sinta-se à vontade para usar qualquer provedor suportado pelo LlamaIndex).
Não se preocupe se você ainda não tiver uma chave de API da Gemini ou da Bright Data. Nas próximas etapas, explicaremos como criar ambas.
Etapa 1: Crie seu projeto Python
Comece abrindo um terminal e criando uma nova pasta para seu projeto de agente de IA LlamaIndex:
mkdir llamaindex-bright-data-agentllamaindex-bright-data-agent/ conterá o código para o seu agente de IA com recursos de recuperação de dados da Web com a tecnologia Bright Data.
Em seguida, vá para o diretório do projeto e crie um ambiente virtual dentro dele:
cd llamaindex-bright-data-agent
python -m venv venvAgora, abra a pasta do projeto em seu IDE Python favorito. Recomendamos o Visual Studio Code (com a extensão Python) ou o PyCharm Community Edition.
Crie um novo arquivo chamado agent.py na raiz da pasta. A estrutura de seu projeto agora deve ser semelhante a esta:
llamaindex-bright-data-agent/
├── venv/
└── agent.pyEm seu terminal, ative o ambiente virtual. No Linux ou macOS, execute este comando:
source venv/bin/activateDe forma equivalente, no Windows, execute:
venv/Scripts/activateNas próximas etapas, vamos orientá-lo na instalação dos pacotes necessários. Ainda assim, se você preferir instalar todos eles agora, execute:
pip install python-dotenv llama-index-tools-brightdata llama-index-llms-gemini llama-indexObservação: estamos instalando o llama-index-llms-gemini porque este tutorial usa o Gemini como provedor de LLM. Se estiver planejando usar um provedor diferente, certifique-se de instalar a integração correspondente do LlamaIndex para ele.
Está tudo pronto! Agora você tem um ambiente de desenvolvimento Python pronto para criar um agente de IA usando as ferramentas LlamaIndex e Bright Data.
Etapa 2: Configurar a leitura das variáveis de ambiente
Seu agente LlamaIndex se conectará a serviços externos como Gemini e Bright Data por meio de chaves de API. Por motivos de segurança, nunca codifique chaves de API diretamente no seu código Python. Em vez disso, use variáveis de ambiente para mantê-las privadas.
Para facilitar o trabalho com variáveis de ambiente, instale a biblioteca python-dotenv. Em seu ambiente virtual ativado, execute:
pip install python-dotenvEm seguida, abra o arquivo agent.py e adicione as seguintes linhas na parte superior para carregar variáveis de um arquivo .env:
from dotenv import load_dotenv
load_dotenv()A função load_dotenv() procura um arquivo .env no diretório raiz do projeto e carrega automaticamente seus valores no ambiente.
Agora, crie um arquivo .env junto com o arquivo agent.py, da seguinte forma:
llamaindex-bright-data-agent/
├── venv/
├── .env # <-------------
└── agent.pyPerfeito! Agora você configurou uma maneira segura de gerenciar credenciais de API confidenciais para serviços de terceiros. Tim para continuar a configuração inicial, preenchendo o arquivo .env com os envs necessários.
Etapa 3: comece a usar a Bright Data
No momento em que este texto foi escrito, o BrightDataToolSpec expõe as seguintes ferramentas no LlamaIndex:
scrape_as_markdown: Extrai o conteúdo bruto de qualquer página da Web e o retorna no formato Markdown.get_screenshot: Captura uma captura de tela de página inteira de uma página da Web e a salva localmente.search_engine: Executa uma consulta de pesquisa em mecanismos de pesquisa como Google, Bing, Yandex e outros. Ele retorna o SERP inteiro ou uma versão estruturada em JSON desses dados.web_data_feed: Recupera dados JSON estruturados de plataformas conhecidas.
As três primeiras ferramentas – scrape_as_markdown, get_screenshot e search_engine - usam a API Web Unlocker da Bright Data. Essa solução abre as portas para a extração e captura de tela da Web de qualquer site, mesmo aqueles com proteção antibot rigorosa. Além disso, ela é compatível com o acesso a dados da Web SERP de todos os principais mecanismos de pesquisa.
Em contrapartida, o web_data_feed utiliza a API Web Scraper da Bright Data. Esse endpoint retorna dados pré-estruturados de uma lista predefinida de plataformas compatíveis, como Amazon, Instagram, LinkedIn, ZoomInfo e outras.
Para integrar essas ferramentas, você precisará:
- Ative a solução Web Unlocker em seu painel de controle da Bright Data.
- Recupere seu token da API da Bright Data, que concede acesso à API do Web Unlocker e do Web Scraper.
Siga as etapas abaixo para concluir a configuração!
Primeiro, se você ainda não tiver uma conta da Bright Data, vá em frente e [crie uma](). Se já tiver uma conta, faça login e abra o painel de controle. Clique no botão “Get proxy products” (Obter produtos proxy):
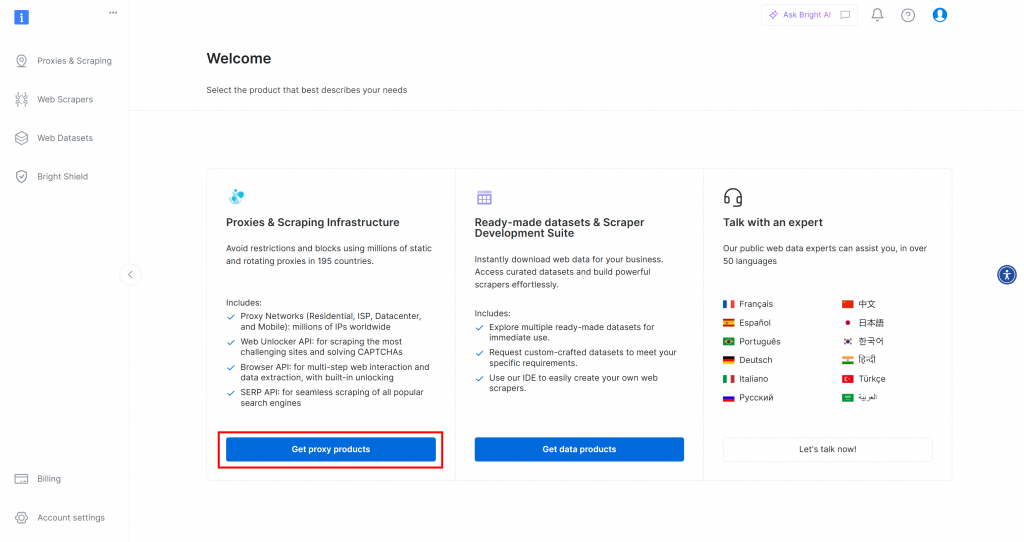
Você será redirecionado para a página “Proxies & Scraping Infrastructure”:
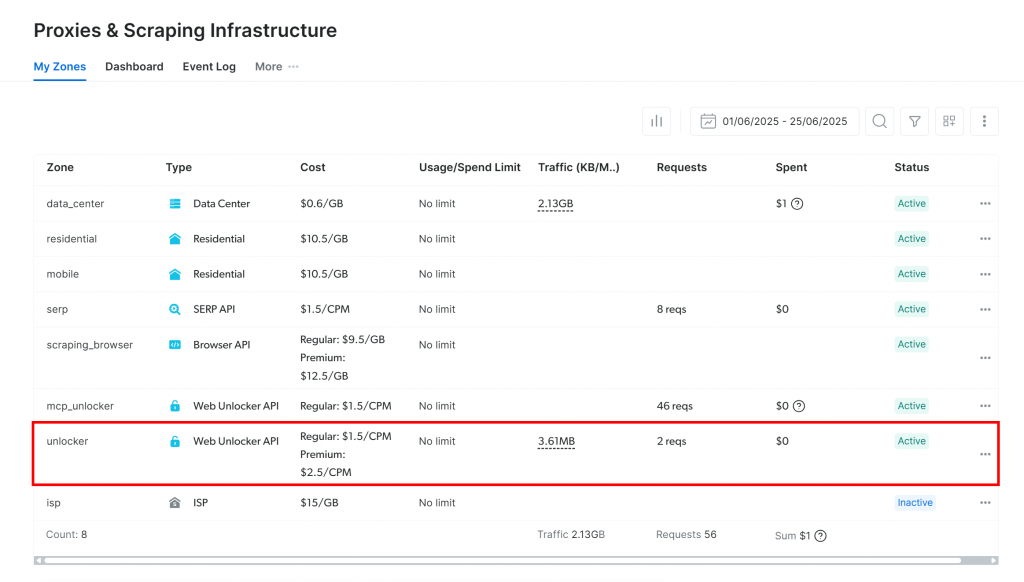
Se você já estiver vendo uma zona ativa da API do Web Unlocker (como acima), você está pronto para começar. O nome da zona(unlocker, neste caso) é importante, pois você precisará dele mais tarde em seu código.
Se ainda não tiver uma, role para baixo até a seção “Web Unlocker API” e clique em “Create zone” (Criar zona):
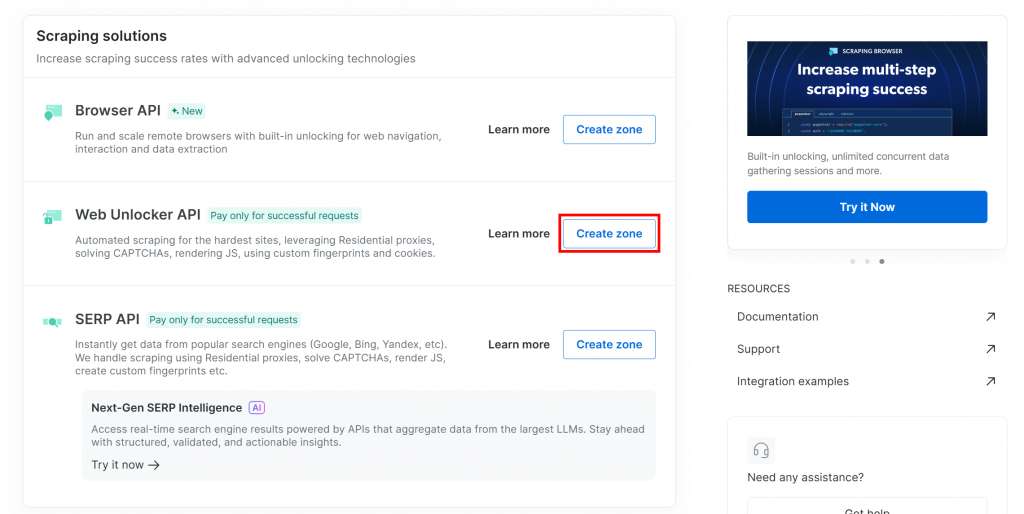
Dê um nome à sua nova zona, como unlocker, ative os recursos avançados para obter melhor desempenho e clique em “Add” (Adicionar):
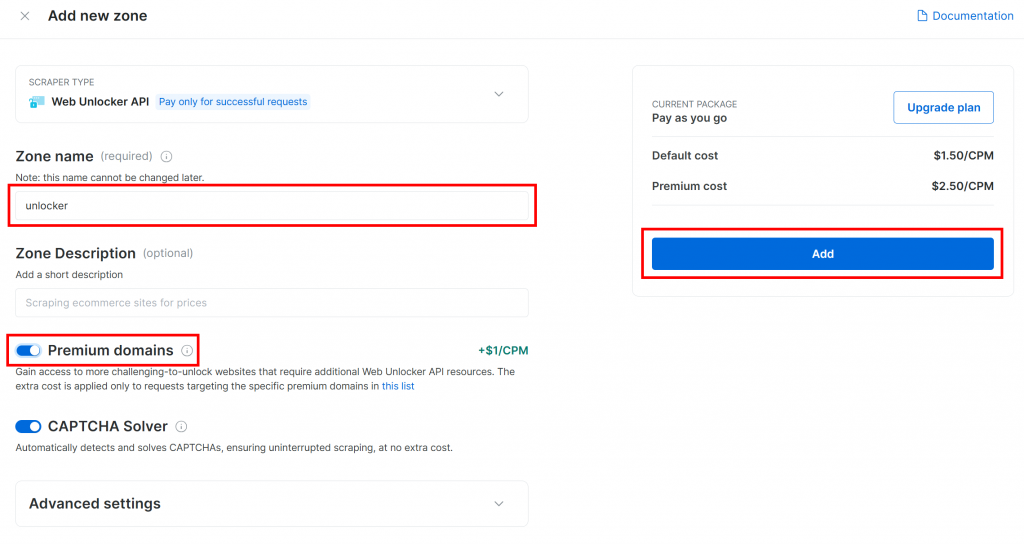
Depois que a zona for criada, você será redirecionado para a página de configuração da zona:
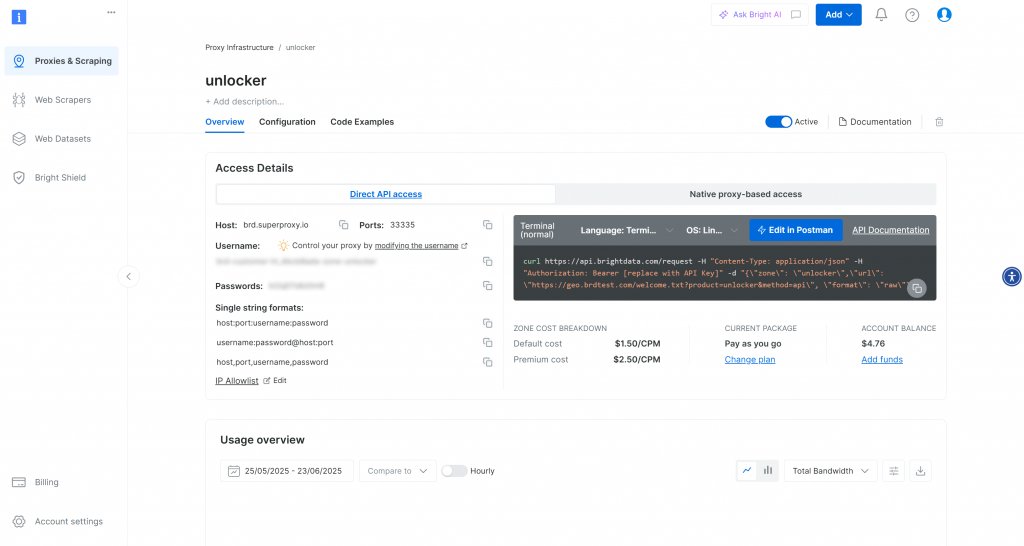
Certifique-se de que o botão de ativação esteja definido como “Active” (Ativo). Isso confirma que a zona está configurada corretamente e pronta para uso.
Em seguida, siga o guia oficial da Bright Data para gerar sua chave de API. Depois de obtê-la, armazene-a com segurança em seu arquivo .env da seguinte forma:
BRIGHT_DATA_API_KEY="<YOUR_BRIGHT_DATA_API_KEY>"Substitua o pelo valor real da chave da API.
Incrível! É hora de integrar as ferramentas da Bright Data em seu script de agente do LlamaIndex.
Etapa 4: Instalar e configurar as ferramentas de dados brilhantes do LlamaIndex
Em agent.py, comece carregando sua chave da API da Bright Data no ambiente:
BRIGHT_DATA_API_KEY = os.getenv("BRIGHT_DATA_API_KEY")Não se esqueça de importar os da biblioteca padrão do Python:
import osCom seu ambiente virtual ativado, instale o pacote de ferramentas LlamaIndex Bright Data:
pip install llama-index-tools-brightdataEm seu arquivo agent.py, importe a classe BrightDataToolSpec:
from llama_index.tools.brightdata import BrightDataToolSpecEm seguida, crie uma instância do BrightDataToolSpec usando sua chave de API e o nome da zona:
brightdata_tool_spec = BrightDataToolSpec(
api_key=BRIGHT_DATA_API_KEY,
zone="<BRIGHT_DATA_WEB_UNLOCKER_API_ZONE_NAME>", # Replace with the actual value
verbose=True, # Useful while developing
)Substitua o pelo nome da zona da API do Web Unlocker que você configurou anteriormente. Nesse caso, é unlocker:
brightdata_tool_spec = BrightDataToolSpec(
api_key=BRIGHT_DATA_API_KEY,
zone="unlocker",
verbose=True,
)Observe que a opção verbose foi definida como True. Isso é útil durante o desenvolvimento, pois imprime informações úteis sobre o que está acontecendo quando o agente LlamaIndex faz solicitações por meio do Bright Data.
Em seguida, converta a especificação da ferramenta em uma lista de ferramentas utilizáveis em seu agente:
brightdata_tools = brightdata_tool_spec.to_tool_list()Fantástico! As ferramentas da Bright Data agora estão integradas e prontas para alimentar seu agente LlamaIndex. A próxima etapa é conectar seu LLM.
Etapa nº 5: Preparar o modelo LLM
Para usar o Gemini (o provedor de LLM escolhido), comece instalando o pacote de integração necessário:
pip install llama-index-llms-google-genaiEm seguida, importe a classe GoogleGenAI do pacote instalado:
from llama_index.llms.google_genai import GoogleGenAIAgora, inicialize o Gemini LLM da seguinte forma:
llm = GoogleGenAI(
model="models/gemini-2.5-flash",
)Neste exemplo, estamos usando o modelo gemini-2.5-flash. Você pode trocá-lo por qualquer outro modelo Gemini compatível, conforme necessário.
Nos bastidores, o GoogleGenAI procura automaticamente uma variável de ambiente chamada GEMINI_API_KEY. Para defini-la, abra seu arquivo .env e adicione a seguinte linha:
GEMINI_API_KEY="<YOUR_GEMINI_API_KEY>"Substitua o pelo espaço reservado com sua chave de API Gemini real. Se você não tiver uma, obtenha-a gratuitamente seguindo o guia oficial.
Observação: Se você preferir usar um provedor de LLM diferente, o LlamaIndex oferece suporte a várias opções. Basta consultar a documentação oficial do LlamaIndex para obter instruções de configuração.
Bom trabalho! Agora você tem todos os componentes principais conectados para criar um agente LlamaIndex com recursos de recuperação de dados da Web.
Etapa nº 6: Criar o agente LlamaIndex
Primeiro, instale o pacote principal do LlamaIndex:
pip install llama-indexEm seguida, em seu arquivo agent.py, importe a classe FunctionCallingAgent:
from llama_index.core.agent import FunctionCallingAgentFunctionCallingAgent é um tipo especial de agente de IA do LlamaIndex que pode interagir com ferramentas externas, como as ferramentas do Bright Data que você configurou anteriormente.
Inicialize o agente com suas ferramentas LLM e Bright Data desta forma:
agent = FunctionCallingAgent.from_tools(
tools=brightdata_tools,
llm=llm,
verbose=True, # Useful while developing
)Isso configura um agente de IA que processa as entradas do usuário usando o LLM e pode chamar as ferramentas do Bright Data para recuperar informações conforme necessário. O sinalizador verbose=True é útil durante o desenvolvimento porque mostra quais ferramentas o agente está usando para cada solicitação.
Muito bem! A integração do LlamaIndex + Bright Data está concluída. A próxima etapa é criar o REPL para uso interativo.
Etapa nº 7: implementar o REPL
REPL significa “Read-Eval-Print Loop” e é um padrão de programação interativa em que você pode inserir comandos, fazer com que sejam avaliados e ver os resultados imediatamente. Nesse contexto, você:
- Digite um comando ou tarefa.
- Deixe o agente de IA avaliar e lidar com isso.
- Veja a resposta.
Esse loop continua indefinidamente, até que você digite "exit".
Ao lidar com agentes de IA, o REPL tende a ser mais prático do que enviar prompts isolados. O motivo é que ele permite que o agente do LlamaIndex mantenha o contexto da sessão, melhorando suas respostas ao aprender com as interações anteriores.
Agora, implemente a lógica do REPL no agent.py conforme abaixo:
# Implement the REPL interaction loop
print("Gemini-powered Agent with Bright Data tools for web data retrieval. Type 'exit' to quit.n")
while True:
# Read the user request for the AI agent from the CLI
request = input("Request -> ")
# Terminate the execution if the user type "exit"
if request.strip().lower() == "exit":
print("nAgent terminated")
break
try:
# Execute the request
response = agent.chat(request)
print(f"nResponse ->:n{response}n")
except Exception as e:
print(f"nError: {str(e)}n")Este REPL:
- Lê a entrada do usuário a partir da linha de comando com
input(). - Avalia-o usando o agente LlamaIndex com tecnologia Gemini e Bright Data com
agent.chat(). - Imprime a resposta de volta ao console.
Fantástico! O agente de IA LlamaIndex está pronto.
Etapa 8: Junte tudo e execute o agente
Isso é o que seu arquivo agent.py deve conter agora:
from dotenv import load_dotenv
import os
from llama_index.tools.brightdata import BrightDataToolSpec
from llama_index.llms.google_genai import GoogleGenAI
from llama_index.core.agent import FunctionCallingAgent
# Load environment variables from the .env file
load_dotenv()
# Read the Bright Data API key from the envs
BRIGHT_DATA_API_KEY = os.getenv("BRIGHT_DATA_API_KEY")
# Set up the Bright Data Tools
brightdata_tool_spec = BrightDataToolSpec(
api_key=BRIGHT_DATA_API_KEY,
zone="unlocker",
verbose=True, # Useful while developing
)
brightdata_tools = brightdata_tool_spec.to_tool_list()
# Configure the connection to Gemini
llm = GoogleGenAI(
model="models/gemini-2.5-flash",
)
# Create the LlamaIndex agent powered by Gemini and connected to Bright Data tools
agent = FunctionCallingAgent.from_tools(
tools=brightdata_tools,
llm=llm,
verbose=True, # Useful while developing
)
# Implement the REPL interaction loop
print("Gemini-powered Agent with Bright Data tools for web data retrieval. Type 'exit' to quit.n")
while True:
# Read the user request for the AI agent from the CLI
request = input("Request -> ")
# Terminate the execution if the user type "exit"
if request.strip().lower() == "exit":
print("nAgent terminated")
break
try:
# Execute the request
response = agent.chat(request)
print(f"nResponse ->:n{response}n")
except Exception as e:
print(f"nError: {str(e)}n")Execute o script do agente usando o seguinte comando:
python agent.pyQuando o script for iniciado, você verá algo parecido com isto:

Digite o prompt a seguir no terminal:
Generate a report summarizing the most important information about the product "Death Stranding 2" using data from its Amazon page: "https://www.amazon.com/Death-Stranding-2-Beach-PlayStation-5/dp/B0F19GPDW3/"O resultado será:
Isso foi muito rápido, então vamos detalhar o que aconteceu:
- O agente identifica que a tarefa requer dados de produtos da Amazon, portanto, ele chama a ferramenta
web_data_feedcom essa entrada:{"source_type": "amazon_product", "url": "https://www.amazon.com/Death-Stranding-2-Beach-PlayStation-5/dp/B0F19GPDW3/"} - Essa ferramenta consulta de forma assíncrona a API Amazon Web Scraper da Bright Data para obter dados estruturados de produtos.
- Quando a resposta JSON é retornada, o agente a alimenta no Gemini LLM.
- O Gemini processa os novos dados e gera um resumo claro e preciso.
Em outras palavras, diante do prompt, o agente seleciona de forma inteligente a melhor ferramenta. Nesse caso, é a web_data_feed. Ela recupera dados de produtos em tempo real da página da Amazon em questão com uma abordagem assíncrona. Em seguida, o LLM usa esses dados para gerar um resumo significativo.
Nesse caso, o agente de IA retornou:
Here's a summary report for "Death Stranding 2: On The Beach - PS5" based on its Amazon product page:
**Product Report: Death Stranding 2: On The Beach - PS5**
* **Title:** Death Stranding 2: On The Beach - PS5
* **Brand/Manufacturer:** Sony Interactive Entertainment
* **Price:** $69.99 USD
* **Release Date:** June 26, 2026
* **Availability:** Available for pre-order.
**Description:**
"Death Stranding 2: On The Beach" is an upcoming PlayStation 5 title from legendary game creator Hideo Kojima. Players will embark on a new journey with Sam and his companions to save humanity from extinction, traversing a world filled with otherworldly enemies and obstacles. The game explores the question of human connection and promises to once again change the world through its unique narrative and gameplay.
**Key Features:**
* **Pre-order Bonus:** Includes Quokka Hologram, Battle Skeleton Silver (LV1,LV2,LV3), Boost Skeleton Silver (LV1,LV2,LV3), and Bokka Silver (LV1,LV2,LV3).
* **Open World:** Features large, varied open-world environments with unique challenges.
* **Gameplay Choices:** Offers multiple approaches to combat and stealth, allowing players to choose between aggressive tactics, sneaking, or avoiding danger.
* **New Story:** Continues the narrative from the original Death Stranding, following Sam on a fresh journey with unexpected twists.
* **Player Interaction:** Player actions can influence how other players interact with the game's world.
**Category & Ranking:**
* **Categories:** Video Games, PlayStation 5, Games
* **Best Sellers Rank:** #10 in Video Games, #1 in PlayStation 5 Games
**Sales Performance:**
* **Bought in past month:** 7,000 unitsObserve como o agente de IA não seria capaz de alcançar esse resultado sem as ferramentas de dados brilhantes. Isso se deve ao fato de que:
- O produto escolhido da Amazon é um produto novo e os LLMs não são treinados com dados tão recentes.
- Os LLMs podem não ser capazes de extrair ou acessar páginas da Web em tempo real por conta própria.
- A extração de produtos da Amazon é notoriamente difícil devido aos rigorosos sistemas anti-bot, como o famoso CAPTCHA da Amazon.
Importante: se você tentar outros prompts, verá que o agente seleciona e usa automaticamente as ferramentas configuradas apropriadas para recuperar os dados necessários para gerar respostas fundamentadas.
E pronto! Agora, você tem um agente de IA do LlamaIndex com recursos de acesso a dados da Web de alto nível, com a tecnologia da integração com a Bright Data.
Conclusão
Neste artigo, você aprendeu a usar o LlamaIndex para criar um agente de IA com acesso em tempo real a dados da Web, graças às ferramentas do Bright Data.
Essa integração dá ao seu agente a capacidade de recuperar conteúdo público da Web em formato Markdown, formatos JSON estruturados e até mesmo como capturas de tela. Isso é válido tanto para sites quanto para mecanismos de pesquisa.
Lembre-se de que a integração vista aqui foi apenas um exemplo básico. Se o seu objetivo é criar agentes mais avançados, você precisará de ferramentas confiáveis para recuperar, validar e transformar dados da Web em tempo real. É exatamente para isso que a infraestrutura de IA da Bright Data foi criada.
Crie uma conta gratuita na Bright Data e comece a explorar nossas ferramentas de dados prontas para IA hoje mesmo!





