

Ao longo deste guia, usaremos o LlamaIndex para extrair dados com suas ferramentas Bright Data. Ao terminar este tutorial, você poderá fazer tudo o que segue.
- Extrair dados do site como markdown
- Faça capturas de tela de páginas da Web
- Realize pesquisas no Google de dentro do seu aplicativo
- Acione coleções sob demanda usando feeds de dados e a API Web Scraper da Bright Data
Introdução: O que é o LlamaIndex?
Antes da era da IA, a coleta de dados era um processo frágil e de alta manutenção. Uma única alteração no layout do site poderia interromper todo o seu pipeline. Nos tempos modernos, esse não é o caso – desde que você esteja usando as ferramentas certas.
O LlamaIndex conecta modelos de linguagem a ferramentas e fontes de dados externas. Ele vem pré-embalado com modelos mínimos criados para funcionar minimamente com esses conjuntos de ferramentas. Em nosso caso específico, o LlamaIndex pode se integrar ao servidor MCP da Bright Data.
Nas próximas seções, examinaremos os recursos do conjunto de ferramentas Bright Data da LlamaIndex. Certifique-se de que você tenha o Python instalado.
Pré-requisitos
Nossos requisitos aqui são surpreendentemente leves. Para operações simples de raspagem, não precisamos nem mesmo de um LLM. Você precisa do LlamaIndex e de uma chave de API da Bright Data – é só isso!
LlamaIndex
O LlamaIndex oferece um conjunto completo de ferramentas que você pode instalar com o seguinte comando. Se estiver procurando apenas fazer scraping da Web, isso não é estritamente necessário.
pip install llama-indexVocê pode instalar o Bright Data Tools com o seguinte comando via pip.
pip install llama-index-tools-brightdataDados brilhantes
Primeiro, você precisa de uma conta na Bright Data. Você pode usar este link para se inscrever para uma avaliação gratuita do Unlocker. Depois de obter uma conta, salve sua chave de API.
Você pode encontrar sua chave de API no painel de “proxies” da Bright Data ou nas configurações do usuário.

Raspagem com o LlamaIndex
BrightDataToolSpec: Sua ponte para o MCP da Bright Data
O LlamaIndex nos dá acesso à classe BrightDataToolSpec. O snippet abaixo configura o acesso a todas as ferramentas. Lembre-se de substituir a chave de API pela sua própria e o nome da zona por uma de suas zonas pessoais.
from llama_index.tools.brightdata import BrightDataToolSpec
brightdata = BrightDataToolSpec(
api_key="your-api-key",
zone="your-zone-name")Raspar como Markdown
O snippet abaixo configura você para extrair qualquer página e retornar seu conteúdo como markdown. O método scrape_as_markdown() faz tudo isso para nós.
from llama_index.tools.brightdata import BrightDataToolSpec
brightdata = BrightDataToolSpec(
api_key="your-api-key",
zone="your-zone-name")
result = brightdata.scrape_as_markdown(url="https://www.amazon.com")
print(result.text)Aqui estão alguns exemplos de saída do comando. Como você pode ver, estamos conseguindo extrair dados da Amazon e convertê-los em markdown.

## Skip to
* [ Main content](#skippedLink)
---
## Keyboard shortcuts
* Search
alt + /
* Cart
shift + alt + C
* Home
shift + alt + H
* Orders
shift + alt + O
* Show/Hide shortcuts
shift + alt + Z
To move between items, use your keyboard's up or down arrows.
[ .us ](/ref=nav%5Flogo)
Delivering to Bothell 98011 Update location
All
Select the department you want to search in All Departments Alexa Skills All The Best Pets Amazon Autos Amazon Devices Amazon Fresh Amazon Global Store Amazon Haul Amazon One Medical Amazon Pharmacy Amazon Resale Appliances Apps & Games Arts, Crafts & Sewing Audible Books & Originals Automotive Parts & Accessories Baby Beauty & Personal Care Books CDs & Vinyl Cell Phones & Accessories Clothing, Shoes & Jewelry Women's Clothing, Shoes & Jewelry Men's Clothing, Shoes & Jewelry Girl's Clothing, Shoes & Jewelry Boy's Clothing, Shoes & Jewelry Baby Clothing, Shoes & Jewelry Collectibles & Fine Art Computers Credit and Payment Cards Digital Music Electronics Garden & Outdoor Gift Cards Grocery & Gourmet Food Handmade Health, Household & Baby Care Home & Business Services Home & Kitchen Industrial & Scientific Just for Prime Kindle Store Luggage & Travel Gear Luxury Stores Magazine Subscriptions Metropolitan Market Movies & TV Musical Instruments Office Products Pet Supplies Premium Beauty Prime Video Same-Day Store Smart Home Software Sports & Outdoors Subscribe & Save Subscription Boxes Tools & Home Improvement Toys & Games Under $10 Video Games Whole Foods Market
Search Amazon
[ EN ](/customer-preferences/edit?ie=UTF8&preferencesReturnUrl=%2F&ref%5F=topnav%5Flang)
[ Hello, sign in Account & Lists ](https://www.amazon.com/ap/signin?openid.pape.max%5Fauth%5Fage=0&openid.return%5Fto=https%3A%2F%2Fwww.amazon.com%2F%3F%5Fencoding%3DUTF8%26ref%5F%3Dnav%5Fya%5Fsignin&openid.identity=http%3A%2F%2Fspecs.openid.net%2Fauth%2F2.0%2Fidentifier%5Fselect&openid.assoc%5Fhandle=usflex&openid.mode=checkid%5Fsetup&openid.claimed%5Fid=http%3A%2F%2Fspecs.openid.net%2Fauth%2F2.0%2Fidentifier%5Fselect&openid.ns=http%3A%2F%2Fspecs.openid.net%2Fauth%2F2.0)
[ Returns & Orders ](/gp/css/order-history?ref%5F=nav%5Forders%5Ffirst) [ 0 Cart ](/gp/cart/view.html?ref%5F=nav%5Fcart)
[ All ](/gp/site-directory?ref%5F=nav%5Fem%5Fjs%5Fdisabled)
* [Amazon Haul](/haul/store?ref%5F=nav%5Fcs%5Fhul%5Fdisb)
* [Medical Care ](https://health.amazon.com/prime?ref%5F=nav%5Fcs%5Fall%5Fhealth%5Fingress%5Fonem%5Fh)
* [Saks](/luxurystores/saks?ref%5F=nav%5Fcs%5Fsaks%5Fdisc)
* [Best Sellers](/gp/bestsellers/?ref%5F=nav%5Fcs%5Fbestsellers)
* [Amazon Basics](/Amazon%5FBasics?channel=discovbar&field-lbr%5Fbrands%5Fbrowse-bin=AmazonBasics&ref%5F=nav%5Fcs%5Famazonbasics)
* [New Releases](/gp/new-releases/?ref%5F=nav%5Fcs%5Fnewreleases)
* [Registry](/gp/browse.html?node=16115931011&ref%5F=nav%5Fcs%5Fregistry)
* [Groceries ](/fmc/learn-more?ref%5F=nav%5Fcs%5Fgroceries)
* [Today's Deals](/deals?ref%5F=nav%5Fcs%5Fgb)
* [Gift Cards ](/gift-cards/b/?ie=UTF8&node=2238192011&ref%5F=nav%5Fcs%5Fgc)
* [Smart Home](/Smart-Home/b/?ie=UTF8&node=6563140011&ref%5F=nav%5Fcs%5Fsmart%5Fhome)
* [Music](/music/player?ref%5F=nav%5Fcs%5Fmusic)
* [Prime ](/prime?ref%5F=nav%5Fcs%5Fprimelink%5Fnonmember)
* [Customer Service](/gp/help/customer/display.html?nodeId=508510&ref%5F=nav%5Fcs%5Ffs%5Fhub%5Fnavbar%5Fc)
* [Books](/books-used-books-textbooks/b/?ie=UTF8&node=283155&ref%5F=nav%5Fcs%5Fbooks)
* [Pharmacy](https://pharmacy.amazon.com/?nodl=0&ref%5F=nav%5Fcs%5Fpharmacy)
* [Luxury Stores](/luxurystores?ref%5F=nav%5Fcs%5Fluxury)
* [Amazon Home](/home-garden-kitchen-furniture-bedding/b/?ie=UTF8&node=1055398&ref%5F=nav%5Fcs%5Fhome)
* [Fashion](/amazon-fashion/b/?ie=UTF8&node=7141123011&ref%5F=nav%5Fcs%5Ffashion)
* [Toys & Games](/toys/b/?ie=UTF8&node=165793011&ref%5F=nav%5Fcs%5Ftoys)
* [Beauty & Personal Care](/Beauty-Makeup-Skin-Hair-Products/b/?ie=UTF8&node=3760911&ref%5F=nav%5Fcs%5Fbeauty)
* [Sell](/b/?%5Fencoding=UTF8&ld=AZUSSOA-sell&node=12766669011&ref%5F=nav%5Fcs%5Fsell)
* [Gift Shop](/gcx/Gifts-for-Everyone/gfhz/?ref%5F=nav%5Fcs%5Fgiftfinder)
* [Automotive](/automotive-auto-truck-replacements-parts/b/?ie=UTF8&node=15684181&ref%5F=nav%5Fcs%5Fautomotive)
* [Home Improvement](/Tools-and-Home-Improvement/b/?ie=UTF8&node=228013&ref%5F=nav%5Fcs%5Fhi)
* [Computers](/computer-pc-hardware-accessories-add-ons/b/?ie=UTF8&node=541966&ref%5F=nav%5Fcs%5Fpc)
* [Sports & Outdoors](/sports-outdoors/b/?ie=UTF8&node=3375251&ref%5F=nav%5Fcs%5Fsports)
[Prime Day is July 8-11](/primeday/?%5Fencoding=UTF8&ref%5F=nav%5Fswm%5FUS%5FPD25%5FLU%5FGW%5FSWM%5FAnnounce&pf%5Frd%5Fp=72020f4f-d636-4d60-9e39-399532eba237&pf%5Frd%5Fs=nav-sitewide-msg-text&pf%5Frd%5Ft=4201&pf%5Frd%5Fi=navbar-4201&pf%5Frd%5Fm=ATVPDKIKX0DER&pf%5Frd%5Fr=JA1EM1AGN54HEE871RFM) Como fazer capturas de tela
As capturas de tela são outra excelente ferramenta para a coleta de dados na Web. A maioria dos LLMs modernos pode visualizar e interpretar imagens. No trecho abaixo, tiramos uma captura de tela da página com o método get_screenshot().
from llama_index.tools.brightdata import BrightDataToolSpec
brightdata = BrightDataToolSpec(
api_key="your-api-key",
zone="your-zone-name")
result = brightdata.get_screenshot(url="https://example.com", output_path="my-screenshot.png")A captura abaixo veio do BrightDataToolSpec. Esse pode ser o método mais fácil de captura de tela disponível em todo o Python.
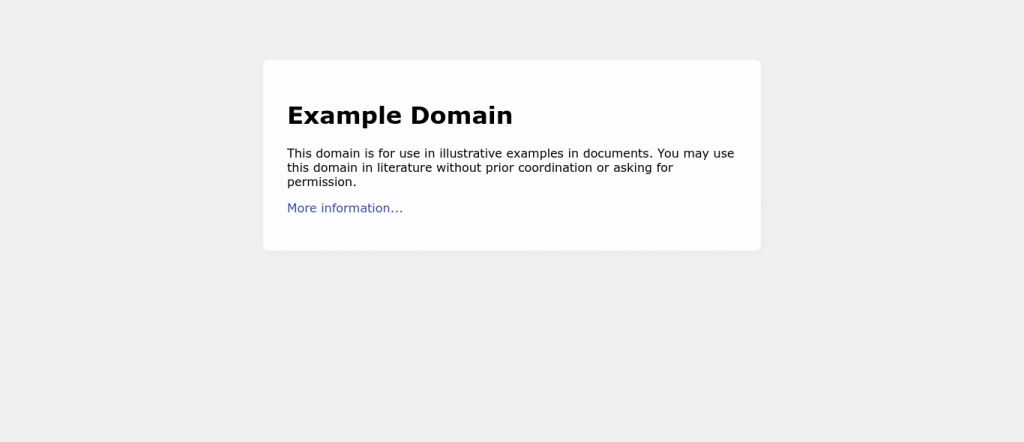
Mecanismo de busca
Assim como as ferramentas anteriores, chamamos o mecanismo de busca usando um método simples search_engine(). Por padrão, ele usa o Google, mas você pode usar qualquer mecanismo de busca que desejar. Você pode saber mais sobre nossos parâmetros de consulta SERP aqui.
Os seguintes mecanismos de pesquisa estão disponíveis.
- Bing
- Yandex
- DuckDuckGo
from llama_index.tools.brightdata import BrightDataToolSpec
brightdata = BrightDataToolSpec(
api_key="your-api-key",
zone="mcp_unlocker")
result = brightdata.search_engine(
query="Top News Articles"
)
with open("output.json", "w") as file:
json.dump(json.loads(result.json()), file, indent=4)Observe como estamos chamando json.loads() antes de despejar os dados em um arquivo JSON. Mesmo ao usar .json(), o LlamaIndex gera seu JSON como uma string. Se você quiser lidar com ele como um dict, json.loads() o converte em um objeto JSON tradicional.
Aqui está uma pequena parte do arquivo JSON que nosso scraper grava.
{
"id_": "34bcf1ea-998a-48ce-beb2-0d6feff950e1",
"embedding": null,
"metadata": {
"query": "Top News Articles",
"engine": "google",
"url": "https://www.google.com/search?q=Top%20News%20Articles&num=10"
},
"excluded_embed_metadata_keys": [],
"excluded_llm_metadata_keys": [],
"relationships": {},
"metadata_template": "{key}: {value}",
"metadata_separator": "\n",
"text_resource": {
"embeddings": null,
"text": "# Accessibility Links\n\nSkip to main content[Accessibility help](https://support.google.com/websearch/answer/181196?hl=en)\n\nAccessibility feedback\n\n[](https://www.google.com/webhp?hl=en&ictx=0&sa=X&ved=0ahUKEwizmMaNvoCOAxUmmYkEHa58MagQpYkNCAo)\n\nPress / to jump to the search box\n\nTop News Articles\n\n[Sign in](https://accounts.google.com/ServiceLogin?hl=en&passive=true&continue=https://www.google.com/search%3Fq%3DTop%2BNews%2BArticles%26num%3D10%26oq%3DTop%2BNews%2BArticles%26uule%3Dw%2BCAIQICINVW5pdGVkIFN0YXRlcw%26hl%3Den%26sourceid%3Dchrome%26ie%3DUTF-8&ec=GAZAAQ)\n\n# Filters and Topics\n\n[AI Mode](/search?q=Top+News+Articles&sca%5Fesv=62890ff6c1b2e448&hl=en&udm=50&API do Web Scraper
A API de raspagem permite que você crie feeds de dados que acionam coleções sob demanda. No código abaixo, usamos web_data_feed() para acionar uma coleção da API do Scraper.
from llama_index.tools.brightdata import BrightDataToolSpec
brightdata = BrightDataToolSpec(
api_key="your-api-key",
zone="mcp_unlocker")
result = brightdata.web_data_feed(
source_type="linkedin_person_profile",
url="https://www.linkedin.com/in/williamhgates/",
timeout=600,
polling_interval=30)
print(result)Após alguns instantes, vá para a página de registros. Você verá todas as suas coleções registradas e prontas para download com o clique de um botão.

Conclusão
Agora, você elevou o nível de sua coleta de dados da Web e reduziu drasticamente sua carga de trabalho. Com o LlamaIndex, o Bright Data e apenas algumas linhas de Python, você pode extrair quase todos os dados que quiser da Web.
Seja extraindo markdown, capturando telas, executando pesquisas no Google ou acionando trabalhos completos de raspagem, o LlamaIndex e o Bright Data lhe dão o poder de coletar seus dados valiosos.
Pronto para ir para o próximo nível? Conecte essa combinação de ferramentas avançadas a um pipeline de dados em tempo real ou crie um agente de IA.
Inscreva-se para uma avaliação gratuita agora e aumente o nível de sua coleta de dados hoje mesmo!





