

Neste guia, você aprenderá:
- O que é o Protocolo de Contexto do Modelo (MCP) e por que ele é importante para os agentes de IA
- Como configurar o servidor MCP da Bright Data com o Augment Code
- Como usar a pesquisa na web, a extração de markdown e as ferramentas API SERP
- Como navegar em sites dinâmicos usando o Navegador de scraping
- Como combinar codificação de IA com dados da web em tempo real para fluxos de trabalho práticos
Antes de mergulhar na configuração, é útil entender as duas tecnologias que você conectará.
O que é o Protocolo de Contexto do Modelo (MCP)?
O MCP é uma maneira padronizada para modelos de IA se conectarem a ferramentas externas e fontes de dados. Pense no MCP como a porta USB-C para LLMs. Assim como o USB-C permite conectar qualquer periférico a qualquer dispositivo com um único padrão, o MCP permite que modelos de IA se conectem a qualquer fonte de dados ou ferramenta por meio de um protocolo unificado.
Antes do MCP, conectar um LLM a ferramentas externas significava criar integrações personalizadas para cada combinação. Quer que seu agente com tecnologia Claude pesquise na web? Crie uma integração. Mudar para GPT? Recrie-a. Adicionar uma nova fonte de dados? Mais código personalizado.
O MCP elimina essa complexidade. Ele define uma maneira padrão para os modelos de IA descobrirem, invocarem e receberem resultados de ferramentas externas. Crie um servidor MCP uma vez e qualquer cliente compatível com MCP poderá usá-lo.
Para um aprofundamento técnico, consulte nosso guia sobre servidores MCP para Scraping de dados.
Agora que você entende como o MCP padroniza as conexões de ferramentas, vamos dar uma olhada no assistente de codificação de IA que você aprimorará com o acesso à web.
O que é o Augment Code?
O Augment Code é um assistente de codificação de IA projetado para bases de código grandes e complexas. Ao contrário das ferramentas que se concentram no preenchimento automático linha por linha, o Augment Code indexa todo o seu projeto e entende as dependências entre arquivos.
O principal diferencial é o que eles chamam de Context Engine. Em vez de apenas oferecer uma grande janela de contexto (mais de 200 mil tokens), ele indexa ativamente sua base de código e mantém o conhecimento da arquitetura do seu projeto. Peça para refatorar uma função e ele identificará quais outros arquivos importam essa função e precisam de atualizações.
Principais recursos
- Indexação completa da base de código. O Augment indexa todo o seu projeto, incluindo dependências em vários repositórios. As perguntas extraem o contexto relevante de qualquer lugar da sua base de código.
- Modo agente. Além do chat e do preenchimento automático, o Augment pode executar tarefas de várias etapas de forma autônoma. Você pode pedir para ele adicionar tratamento de erros a todas as chamadas de API, e ele aplica isso à sua base de código, arquivo por arquivo.
- Flexibilidade IDE. Funciona com VS Code, todos os IDEs JetBrains (IntelliJ, PyCharm, WebStorm), Vim/Neovim e oferece uma ferramenta CLI chamada Auggie para fluxos de trabalho de terminal.
- Certificações de segurança. Certificado SOC 2 Tipo II e em conformidade com ISO/IEC 42001.
O Augment Code se destaca na compreensão da sua base de código, mas tem uma limitação significativa: ele não consegue ver o que está acontecendo na web ao vivo. É aí que entra o Bright Data.
Por que combinar o Bright Data MCP com o Augment Code?

A janela de contexto e os recursos de agente do Augment Code o tornam eficaz em tarefas complexas e com várias etapas. Mas ele não pode acessar a web ao vivo por conta própria. Ele não pode verificar se um endpoint de API mudou na semana passada, verificar as versões atuais da biblioteca ou coletar Inteligência competitiva.
O servidor MCP da Bright Data preenche essa lacuna. O servidor MCP oferece mais de 60 ferramentas para acesso à web. De acordo com a documentação da Bright Data, isso inclui acesso a mais de 150 milhões de IPs residencialis em 195 países.
Ao conectá-los, você obtém:
| Categoria | O que faz | Exemplos de ferramentas |
|---|---|---|
| Pesquisa na web | Consultar mecanismos de pesquisa programaticamente | search_engine, search_engine_batch |
| Extração de páginas | Extrair conteúdo de qualquer URL | scrape_as_markdown, scrape_as_html |
| Automação do navegador | Navegar, clicar, digitar, rolar | scraping_browser_navigate, scraping_browser_click_ref |
| Extração estruturada | Obtenha JSON limpo de mais de 60 plataformas | web_data_amazon_product, web_data_linkedin_profile |
As ferramentas do Navegador de scraping merecem atenção. Ao contrário das simples solicitações de busca, essas ferramentas controlam um navegador real que lida com renderização JavaScript, fluxos de login, rolagem infinita e navegação em várias etapas. Isso é importante para sistemas agênicos que precisam interagir com aplicativos web modernos.
Quando testei essa configuração pela primeira vez, pedi à Augment para verificar se a API OpenAI tinha alguma alteração recente em sua limitação de taxa. Em cerca de oito segundos, ela extraiu a documentação atual, comparou-a com o que eu tinha armazenado em cache localmente e sinalizou que os limites de token por minuto haviam mudado para o endpoint GPT-4 Turbo. Essa única consulta me poupou de implantar um código que teria atingido os limites de taxa em produção.
Com os benefícios claros, vamos percorrer o processo de configuração real.
Conectando o Bright Data ao código Augment
Pré-requisitos
Antes de começar, certifique-se de ter:
- Node.js 18+ instalado
- Extensão Augment Code instalada no VS Code (ou seu IDE preferido)
- Uma conta Bright Data (configuração descrita abaixo)
Não se preocupe se ainda não tiver um token da API Bright Data. Vamos orientá-lo na criação de um na próxima seção.
Etapa 1: crie sua conta Bright Data e obtenha um token API
Para começar, você precisará de uma conta Bright Data e um token API para autenticação no servidor MCP, o que leva cerca de dois minutos.
- Acesse brightdata.com e clique em “Teste grátis” para criar sua conta.
- Depois de fazer login no painel, navegue até Configurações (o ícone de engrenagem) na barra lateral esquerda e clique em Tokens API.
- Clique em “Criar token” e dê a ele um nome descritivo, como “Augment Code MCP”.
- Copie seu novo token e armazene-o com segurança. Você precisará dele para a próxima etapa.
Etapa 2: Configure o Bright Data MCP no Augment Code
Este tutorial usa a extensão Augment Code para Visual Studio Code.
O Augment oferece três métodos para adicionar servidores MCP: Easy MCP (configuração com um clique), GUI do Painel de configurações e importação JSON. Usaremos a importação JSON, pois ela oferece controle total sobre as opções de configuração.
- Abra o VS Code e clique no ícone do Augment Code na barra de atividades (barra lateral esquerda).
- No painel Augment, clique no ícone de engrenagem (Configurações) no canto superior direito. Isso abre a página de configurações do Augment em uma nova guia.
- Clique na seção Servidores MCP.
- Clique em “Importar de JSON”.
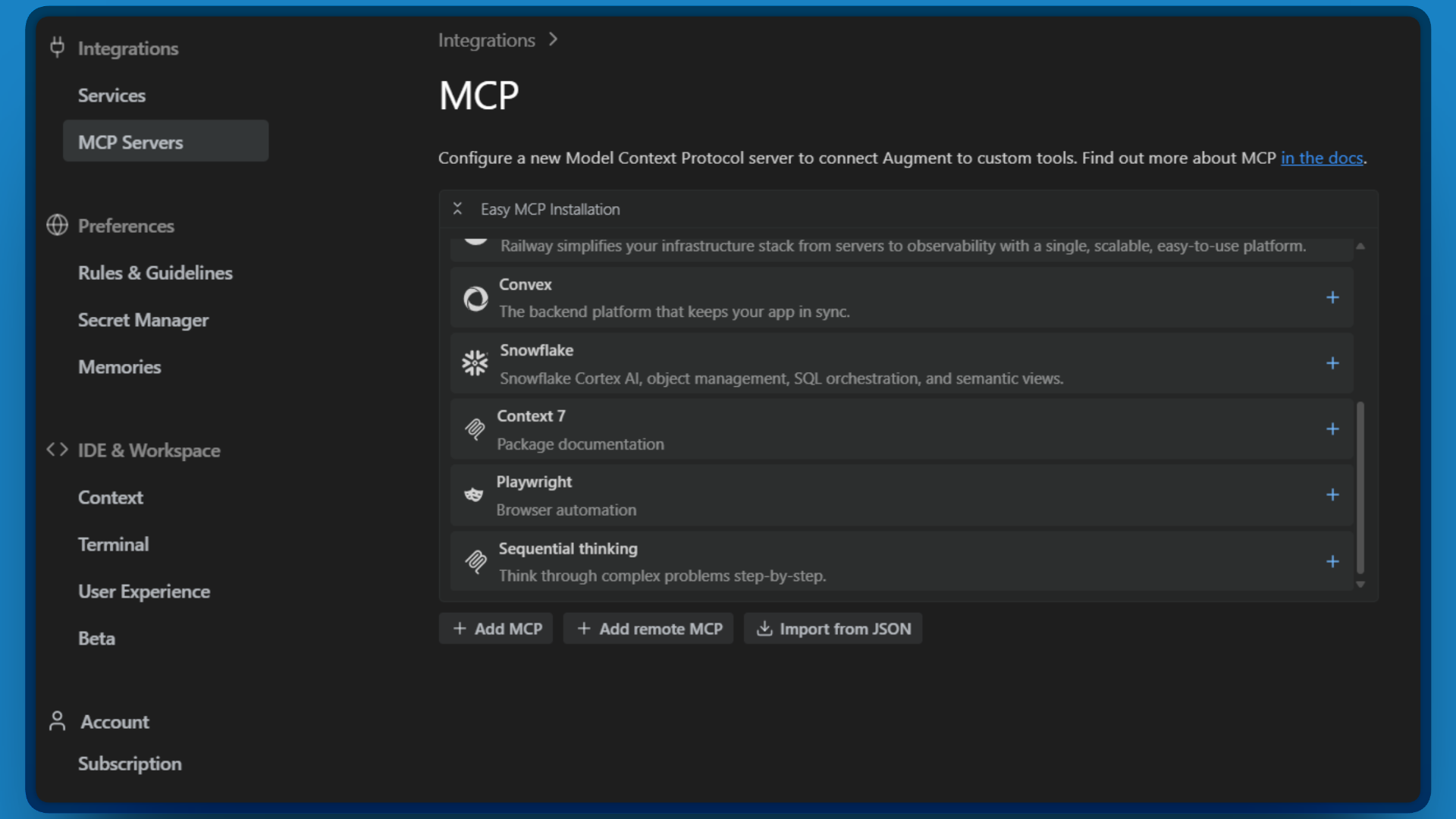
Agora é hora de colar sua configuração. Copie o JSON abaixo, substituindo<YOUR_API_TOKEN>pelo token Bright Data que você criou na Etapa 1:
{
"mcpServers": {
"Bright Data": {
"command": "npx",
"args": ["@brightdata/mcp"],
"env": {
"API_TOKEN": ""
}
}
}
}Reinicie o VS Code para garantir que o servidor MCP seja inicializado corretamente e, então, seu Augment terá acesso total à Infraestrutura de scraping de dados da Bright Data.
Alternativa: configuração do servidor remoto
Se você preferir não executar nada localmente, pode se conectar diretamente ao servidor hospedado da Bright Data usando SSE (Server-Sent Events):
{
"mcpServers": {
"Bright Data": {
"url": "https://mcp.brightdata.com/sse?token=&pro=1",
"type": "sse"
}
}
}Essa abordagem remota não requer nenhuma configuração local. O servidor MCP é executado inteiramente na infraestrutura da Bright Data, o que pode ser útil se você estiver trabalhando em uma máquina na qual não é possível instalar pacotes npm ou se preferir minimizar as dependências locais.
Etapa 3: Verifique a conexão
Para verificar a conexão, vamos confirmar se tudo está funcionando antes de mergulhar nos recursos avançados.
- Abra o painel Augment Code no VS Code clicando no ícone Augment na barra de atividades.
- Inicie um novo chat e digite uma solicitação simples que exija acesso à web, como:
“Pesquise na web por ‘novos recursos do Python 3.13’ e resuma os principais resultados”.
- Observe como o Augment Code invoca a ferramenta
search_enginee retorna os resultados da pesquisa atual.
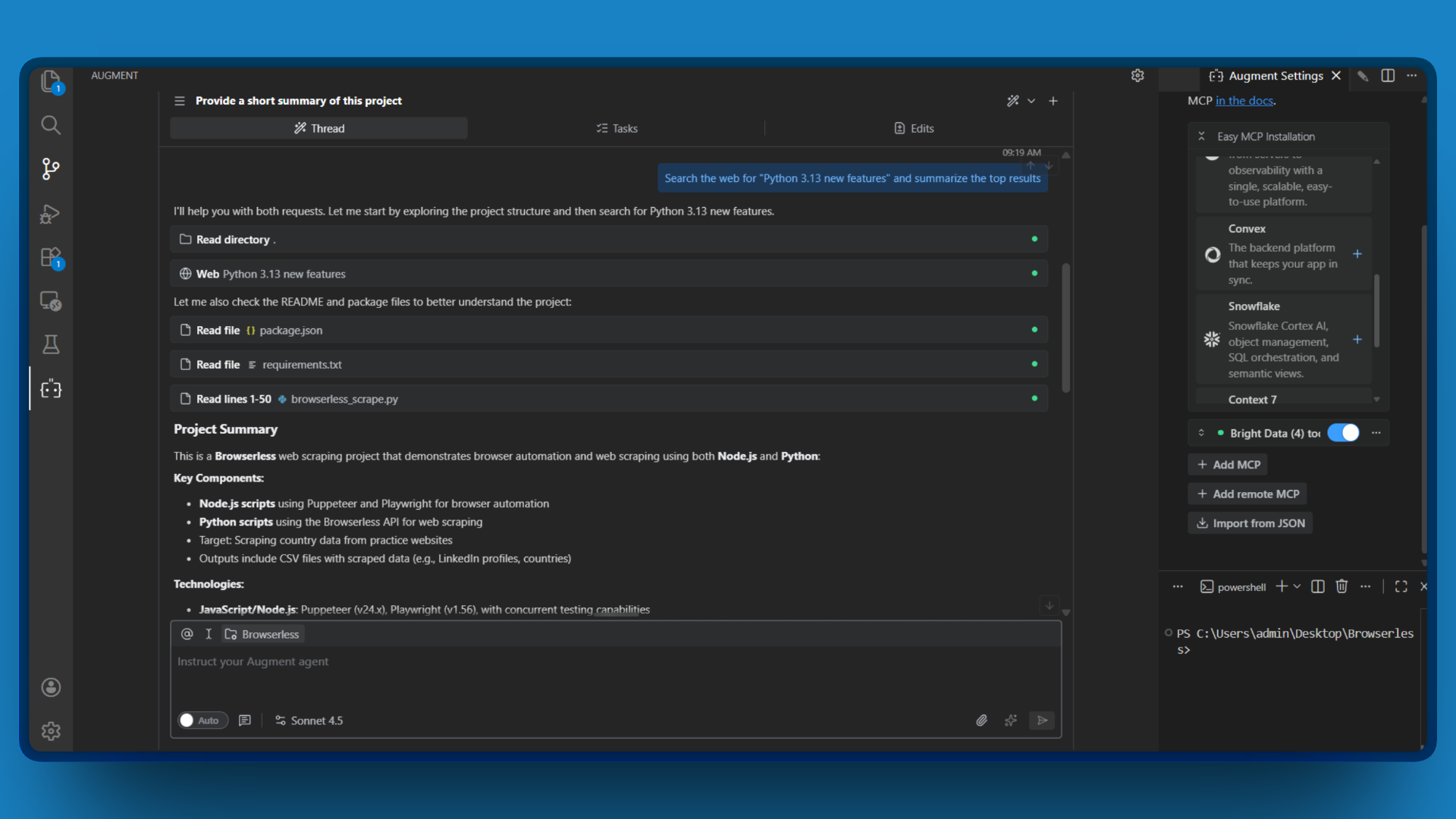
Se você vir os resultados da pesquisa extraídos da web ao vivo, parabéns! Sua conexão Bright Data MCP está funcionando.
Quando você solicita ao Augment Code para pesquisar na web, o fluxo é o seguinte:
- O Augment Code analisa sua solicitação e determina que precisa de dados da web
- O MCP Client (integrado ao Augment) consulta o Bright Data MCP Server para obter as ferramentas disponíveis
- O servidor MCP retorna a lista de ferramentas, incluindo search_engine
- O Augment Code invoca o search_engine com sua consulta
- A Bright Data executa a pesquisa usando sua API SERP, lidando automaticamente com medidas de segmentação geográfica e antibots
- Os resultados são enviados de volta através do MCP para o Augment Code, que os formata para você
Todo esse processo ocorre em segundos. Você nunca sai do seu IDE.
Com a conexão verificada, você está pronto para explorar o que essas ferramentas podem realmente fazer.
Usando as ferramentas clássicas do Bright Data MCP
Agora que a conexão está estabelecida, vamos explorar as ferramentas básicas que funcionam tanto no Modo Rápido (gratuito) quanto no Modo Pro.
Pesquisa na Web com search_engine
A ferramenta search_engine consulta o Google, Bing ou Yandex e retorna resultados estruturados. É perfeita para:
- Pesquisar a documentação atual da API quando você precisa dos endpoints mais recentes
- Encontrar tutoriais recentes ou respostas do Stack Overflow para bibliotecas desconhecidas
- Verificar as versões atuais dos pacotes antes de adicionar dependências
- Coletar inteligência competitiva sobre produtos ou serviços semelhantes
Por exemplo, se você instruir o Augment a:
Pesquisar as últimas alterações significativas do Next.js 15 e listá-las
O Augment Code invoca o search_engine, processa os resultados e fornece um resumo das alterações significativas com as fontes. Não é necessário alternar entre guias.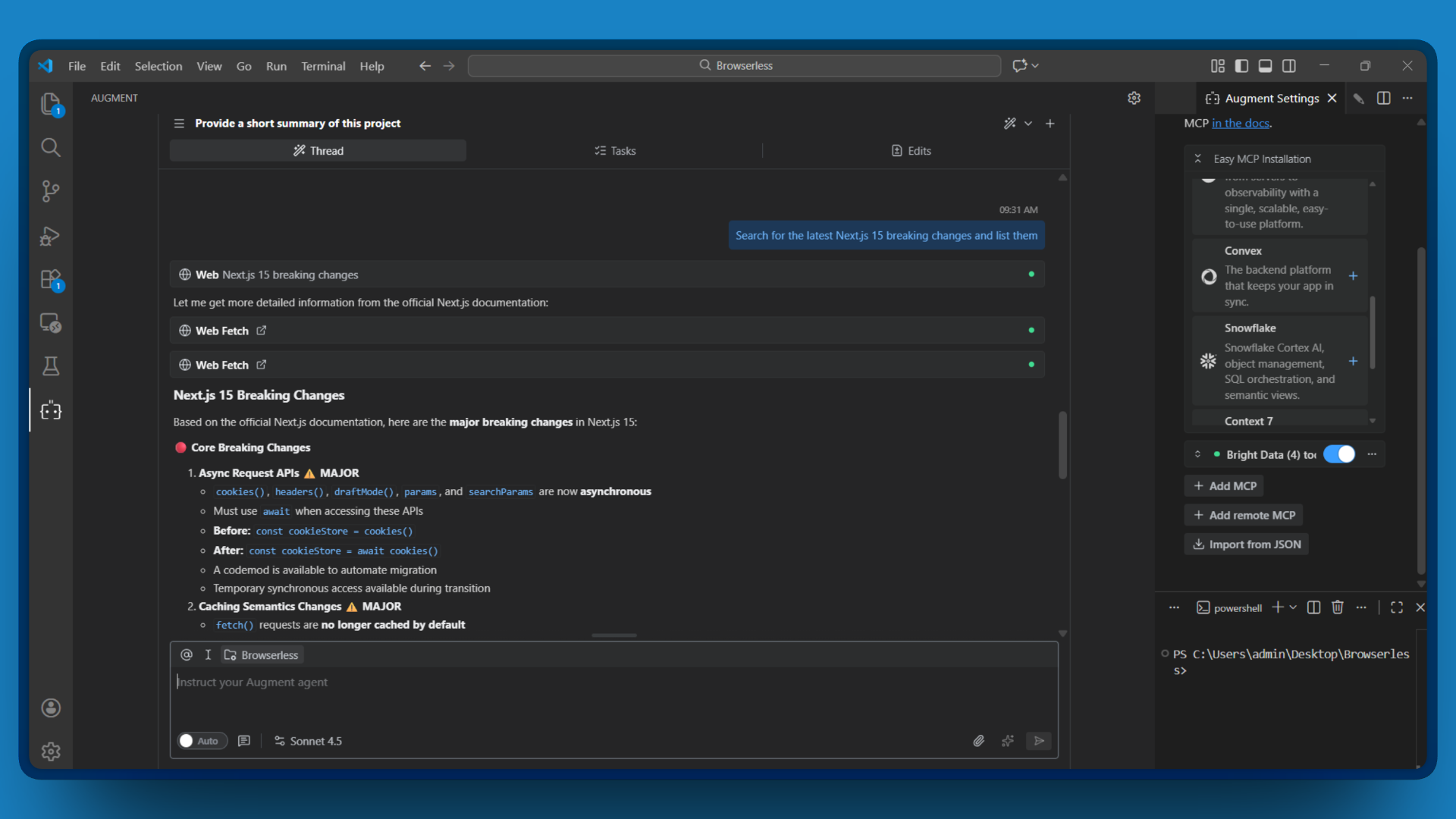
Para pesquisas em lote (até 10 consultas de uma vez), o Modo Pro desbloqueia o search_engine_batch.
Raspagem de página com scrape_as_markdown
Quando você precisa do conteúdo completo de uma página específica, o scrape_as_markdown o busca e converte o HTML em Markdown limpo. Essa ferramenta usa a tecnologia Web Unlocker para contornar CAPTCHAs e medidas anti-bot automaticamente.
Exemplo de prompt:
Extraia a documentação da API Stripe em https://stripe.com/docs/api e explique seus métodos de autenticação
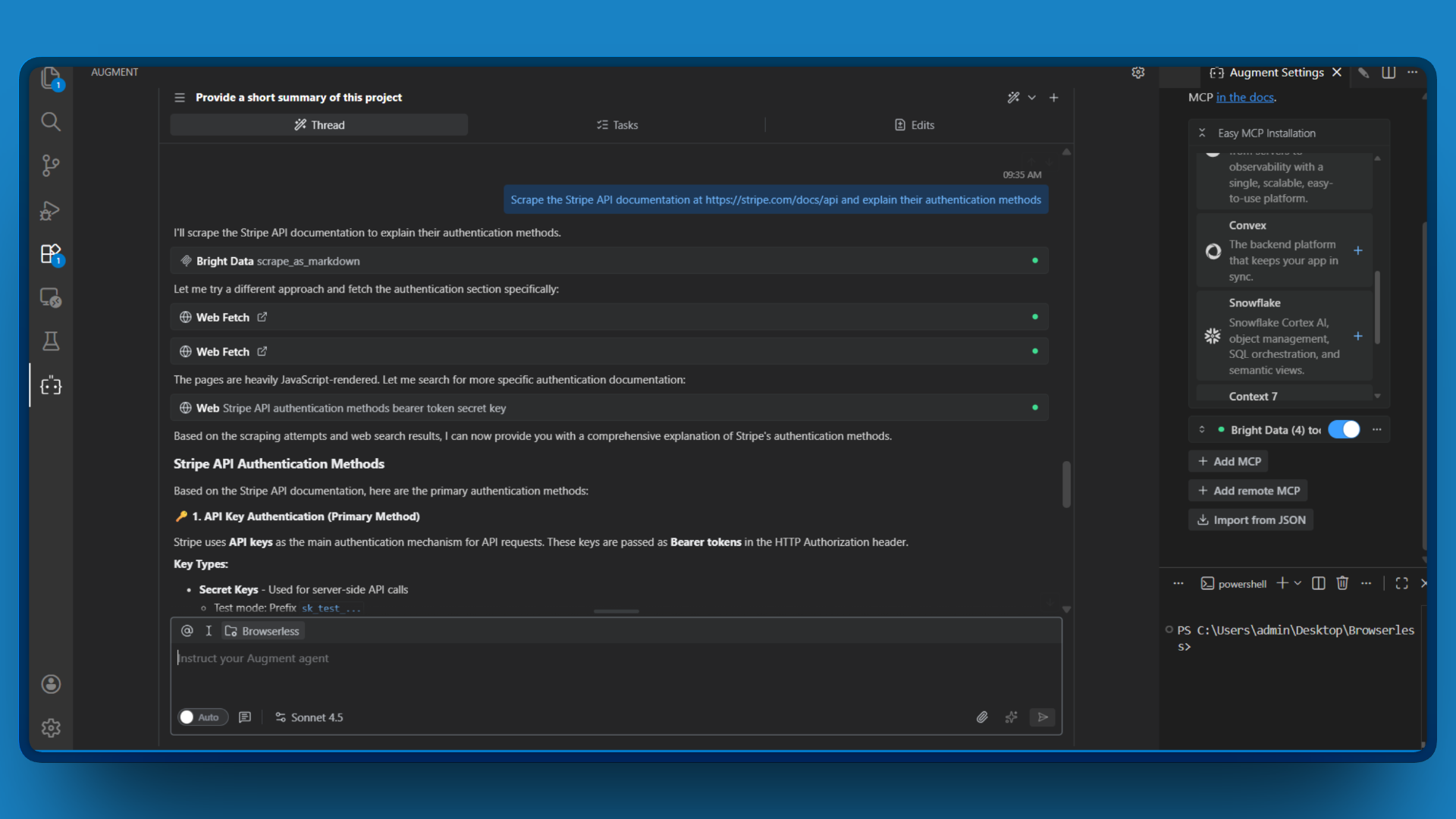
A ferramenta retorna o conteúdo da página como Markdown, que o Augment Code analisa e resume. Você obtém as informações necessárias sem precisar ler manualmente uma documentação densa.
Dados estruturados com APIs de dados da Web
Para plataformas populares, o Parsing manual do HTML não é necessário. O Modo Pro inclui extratores pré-construídos que retornam JSON limpo e estruturado.
Exemplo de prompt:
Obtenha os detalhes do produto para esta listagem da Amazon: https://www.amazon.com/dp/B0CHX3QBCH
A ferramenta web_data_amazon_product retorna dados estruturados, incluindo título, preço, avaliações, comentários e especificações. Não é necessário código de Parsing.
Os extratores disponíveis cobrem mais de 60 plataformas, incluindo:
- Comércio eletrônico: Amazon, Walmart, eBay, Etsy, Best Buy, Google Shopping
- Redes sociais: LinkedIn, Instagram, Facebook, TikTok, X/Twitter, YouTube, Reddit
- Negócios: Crunchbase, ZoomInfo, Zillow, Google Maps
- Finanças: Yahoo Finance, Reuters
Veja a lista completa na documentação das ferramentas MCP.
Com várias ferramentas disponíveis, saber qual delas usar em diferentes situações ajudará você a trabalhar com mais eficiência.
Escolhendo a ferramenta certa
Ferramentas diferentes são adequadas para situações diferentes. Use esta tabela para escolher a ferramenta certa:
| Situação | Ferramenta recomendada | Por quê |
|---|---|---|
| Pesquisa rápida de fatos | search_engine |
Rápido, retorna resultados estruturados, baixo custo |
| Precisa do conteúdo completo da página | scrape_as_markdown |
Lida com medidas anti-bot, retorna texto limpo |
| A página requer JavaScript | scraping_browser_navigate |
Renderiza JS, aguarda conteúdo dinâmico |
| Login ou fluxo em várias etapas | Ferramentas do Navegador de scraping | Pode clicar, digitar, lidar com autenticação |
| Amazon, LinkedIn, etc. | APIsweb_data_* |
Retorna JSON estruturado, sem necessidade de Parsing |
| Várias pesquisas ao mesmo tempo | search_engine_batch |
Até 10 consultas, mais eficiente |
Regra geral: comece com a ferramenta mais simples que possa funcionar. Passe para a automação do navegador apenas quando os métodos mais simples falharem.
Mesmo com a ferramenta certa selecionada, você pode ocasionalmente encontrar problemas. Veja como diagnosticar e corrigir os problemas mais comuns.
Solução de problemas comuns
Encontrando problemas? Veja aqui as soluções para os problemas mais comuns:
Erro “Ferramenta não encontrada”
Se o Augment Code não conseguir encontrar as ferramentas da Bright Data, comece verificando se o seu token de API está correto e não expirou. Em seguida, verifique se a configuração do MCP foi salva corretamente e tente reiniciar o Augment Code completamente, em vez de apenas recarregá-lo. Se o problema persistir, verifique os logs do Augment em busca de erros de conexão.
Respostas lentas
A automação do navegador naturalmente leva mais tempo do que a simples extração, portanto, se as respostas parecerem lentas, há algumas coisas a serem lembradas. A renderização do JavaScript leva tempo porque o Navegador de scraping precisa renderizar totalmente as páginas antes de interagir com elas. Páginas complexas com muitos elementos interativos exigem instantâneos maiores, o que também aumenta o tempo de processamento.
Para páginas mais simples que não exigem interação, considere usar scrape_as_markdown como uma alternativa mais rápida.
Limitação de taxa
Se você atingir os limites de taxa, comece verificando seu uso no painel do Bright Data. Você também pode ajustar a variável de ambiente RATE_LIMIT em sua configuração para gerenciar melhor a frequência das solicitações. Para projetos exigentes que requerem limites mais altos, considere atualizar seu plano.
Além das questões técnicas, conectar agentes de IA à web introduz considerações de segurança que vale a pena ter em mente.
Práticas recomendadas de segurança
Ao conectar agentes de IA à web, a segurança é importante. Tenha em mente estes princípios:
- Trate o conteúdo extraído como não confiável. Nunca execute código de páginas extraídas nem passe conteúdo bruto para eval().
- Use extração estruturada quando disponível. As ferramentas web_data_* retornam JSON validado, reduzindo os riscos de injeção em comparação com o Parsing de HTML bruto.
- Armazene tokens de API com segurança. Use variáveis de ambiente, não valores codificados em sua base de código.
- Revise as ações do agente. Monitore o que seu agente está fazendo, especialmente em ambientes de produção.
Com essas práticas em vigor, você está pronto para começar a construir.
Conclusão
O servidor MCP da Bright Data transforma o Augment Code de um assistente focado em código em um agente com reconhecimento da web capaz de coletar informações em tempo real. Com mais de 60 ferramentas para pesquisa, scraping, automação de navegador e extração estruturada (apoiadas por mais de 150 milhões de IPs residencialis e taxas de sucesso de 99,95%), seu assistente de codificação de IA agora pode:
- Pesquisar documentação atual e APIs ativas
- Coletar inteligência competitiva automaticamente
- Automatizar fluxos de trabalho complexos de coleta de dados
- Navegar em sites dinâmicos com interações em várias etapas
As ferramentas do Navegador de scraping são particularmente poderosas para sistemas agenticos. Usando instantâneos ARIA e referências de elementos estáveis, seu agente lida com fluxos de login, formulários com várias etapas e conteúdo dinâmico que dificultariam abordagens de scraping mais simples.
Pronto para dar ao seu assistente de codificação de IA acesso à web em tempo real?
Para técnicas mais avançadas, confira nossos guias sobre como criar agentes de IA com o LlamaIndex e integrar o MCP com o CrewAI.





