
Neste guia, você descobrirá:
- O que é Langflow e por que ele se tornou tão popular.
- As limitações do uso de LLMs padrão em aplicativos Langflow e como superá-las com dados externos.
- Como criar um aplicativo de IA Langflow integrado ao Bright Data para acesso a dados da Web.
Vamos mergulhar de cabeça!
O que é Langflow?
O Langflow é uma ferramenta de código aberto criada em Python e JavaScript para criar e implantar agentes e fluxos de trabalho com tecnologia de IA. Com mais de 92 mil estrelas no GitHub, é uma das bibliotecas mais populares e amplamente adotadas para o desenvolvimento de agentes de IA.
O Langflow opera como uma plataforma de desenvolvimento visual de baixo código. Ele permite que você crie aplicativos complexos de IA simplesmente conectando componentes pré-construídos por meio de uma interface de arrastar e soltar. Essa abordagem elimina a necessidade de codificação extensiva. Ainda assim, ele oferece suporte à integração de código personalizado para máxima flexibilidade.
O Langflow expõe uma ampla gama de recursos de IA, incluindo agentes, LLMs, armazenamentos de vetores e integração com qualquer API, modelo ou banco de dados.
Por que os aplicativos de IA precisam de acesso aos dados
Em comparação com outras estruturas, o Langflow se destaca como uma plataforma visual de baixo código para a criação de aplicativos de IA. Mas, assim como qualquer outro sistema alimentado por LLM, os aplicativos baseados no Langflow são tão inteligentes quanto os dados aos quais têm acesso.
Os LLMs são treinados com base em conjuntos de dados estáticos e não têm conhecimento integrado de eventos em tempo real ou de dados comerciais privados. Isso os torna desconectados do mundo atual, a menos que você os conecte a fontes de dados novas e relevantes. E a Web é a fonte de informações mais abrangente disponível.
Para superar essas limitações dos LLMs, o Langflow permite que você se conecte a pipelines de dados da Web flexíveis. Esse padrão é fundamental em casos de uso importantes, como:
- Fluxos de trabalho RAG, em que os dados recuperados aprimoram o resultado do LLM.
- Pipelines de dados, onde os dados são extraídos e limpos antes da análise.
- Agentes de IA, que precisam de conhecimento externo para realizar tarefas como responder a consultas, resumir documentos ou executar pesquisas na Web.
Agora, a recuperação de dados públicos precisos da Web não é trivial. Você precisa de uma infraestrutura que possa:
- Conecte-se a praticamente qualquer site (mesmo aqueles protegidos por tecnologias antirrastreamento).
- Extraia os dados necessários de forma confiável.
- Devolva-o em um formato estruturado e pronto para IA.
É exatamente isso que a Bright Data oferece. Ao combinar o Langflow com as ferramentas da Bright Data, seu aplicativo de IA ganha recursos poderosos, incluindo:
- Raspagem da Web em tempo real, contornando as defesas anti-bot.
- Extração de dados estruturados de plataformas de primeira linha, como Amazon, LinkedIn, Zillow e outras.
- Acesso a resultados de mecanismos de pesquisa para dados SERP em tempo real e baseados em consultas.
- Captura visual de dados por meio de capturas de tela automatizadas de página inteira.
Você pode se conectar à Bright Data diretamente por meio de um componente Langflow personalizado. Isso significa que você não precisa criar ou manter uma lógica de back-end complexa. Basta conectar o componente ao seu fluxo e você estará pronto para começar!
Criação de um aplicativo de IA em Langflow com acesso a dados da Web graças à Bright Data
Neste tutorial passo a passo, você usará o Langflow para criar um agente de IA capaz de recuperar dados da Web em tempo real, integrando-o ao Bright Data.
Lembre-se de que a configuração do agente de IA apresentada aqui é apenas um exemplo simples do que você pode criar graças a essa integração. Há inúmeros outros aplicativos de IA que você pode criar usando a integração Bright Data × Langflow. Para se inspirar, explore nossa lista de possíveis casos de uso.
Siga o guia abaixo para criar um agente de IA com tecnologia Bright Data no Langflow!
Pré-requisitos
Para seguir este tutorial, verifique se você atende aos seguintes requisitos:
- Pelo menos uma CPU dual-core e 2 GB de RAM (recomendado: CPU multi-core e pelo menos 4 GB de RAM).
- Python versão 3.10 a 3.12 no Windows, ou 3.10 a 3.13 no macOS/Linux, instalado localmente.
uvinstalado localmente.- Uma chave de API da Bright Data.
- Uma chave de API para se conectar a um dos LLMs compatíveis (aqui, usaremos o Gemini, que é gratuito para uso via API).
Não se preocupe se não tiver uma chave de API da Bright Data, pois você será orientado no processo de configuração durante o tutorial.
Para instalar o uv, execute o seguinte comando:
pip install uvSe você for usuário do Windows, também precisará do Microsoft Visual C++ 14.0 ou superior. Faça o download e siga o guia de suporte para concluir a instalação.
Etapa 1: Configurar o Langflow
Primeiro, crie uma pasta para seu projeto Langflow e navegue até ela:
mkdir langflow-agent
cd langflow-agentA pasta langflow-agent servirá como diretório do projeto Langflow.
Dentro da pasta do projeto, crie um ambiente virtual Python usando uv:
uv venv venvEm seguida, no macOS/Linux, ative-o com:
source venv/bin/activateDe forma equivalente, no Windows, execute:
venvScriptsactivateCom seu ambiente virtual ativado, instale o Langflow em seu ambiente de projeto:
uv pip install langflowIsso levará algum tempo, portanto, seja paciente.
Após a conclusão da instalação, verifique se a configuração funciona executando o aplicativo com este comando:
uv run langflow runAguarde até que o LangFlow inicialize o servidor local. Quando estiver pronto, ele deverá estar disponível nesta página em seu navegador:
http://localhost:7860Abra-o e, se tudo tiver ocorrido como esperado e esta for a primeira vez que você usa o Langflow, você verá esta interface:
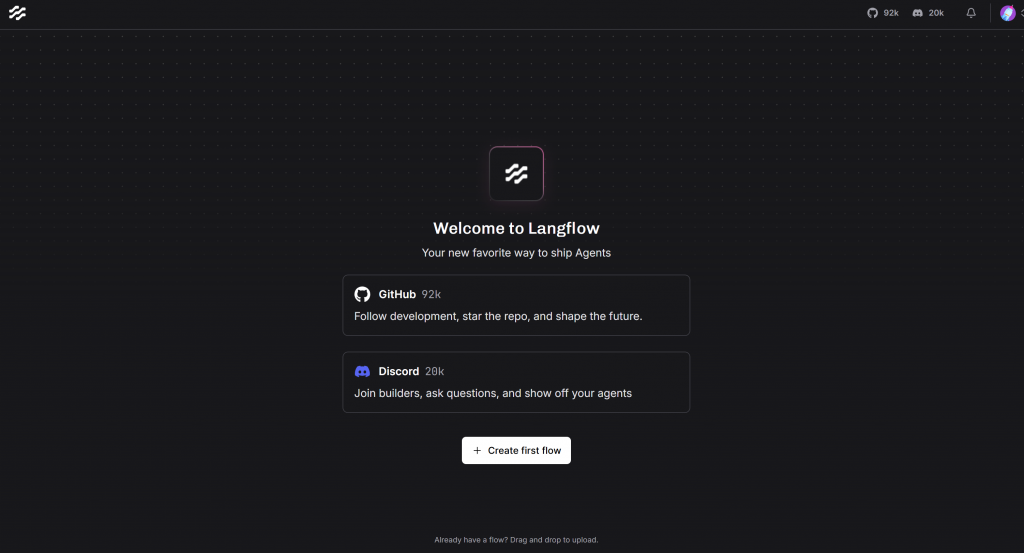
Se você encontrar algum erro, consulte o guia de instalação oficial.
Incrível! Sua configuração do LangFlow já está funcionando.
Etapa 2: Configurar o Bright Data
Para dar ao seu aplicativo de IA a capacidade de recuperar dados da Web, você precisa conectá-lo à infraestrutura de IA da Bright Data.
A Bright Data oferece muitas soluções de coleta de dados, mas, neste tutorial, vamos nos concentrar nelas:
- Web Unlocker: Uma API de raspagem avançada que ignora as proteções de bots e retorna qualquer página da Web em formato HTML ou Markdown.
Observação: A integração com outras ferramentas da Bright Data, como as APIs do Web Scraper, também é possível, mas este guia se concentra no Web Unlocker de uso geral.
Para usar o Web Unlocker em seu aplicativo Langflow, primeiro você precisa:
- Configure uma zona do Web Unlocker em sua conta da Bright Data.
- Gere seu token da API da Bright Data para autenticar as solicitações.
Siga as instruções abaixo para fazer as duas coisas! Como referência, considere também explorar a documentação oficial.
Primeiro, se você ainda não tiver uma conta da Bright Data, inscreva-se gratuitamente. Se já tiver, faça login e abra seu painel de controle. Clique no botão “Proxies & Scraping”:
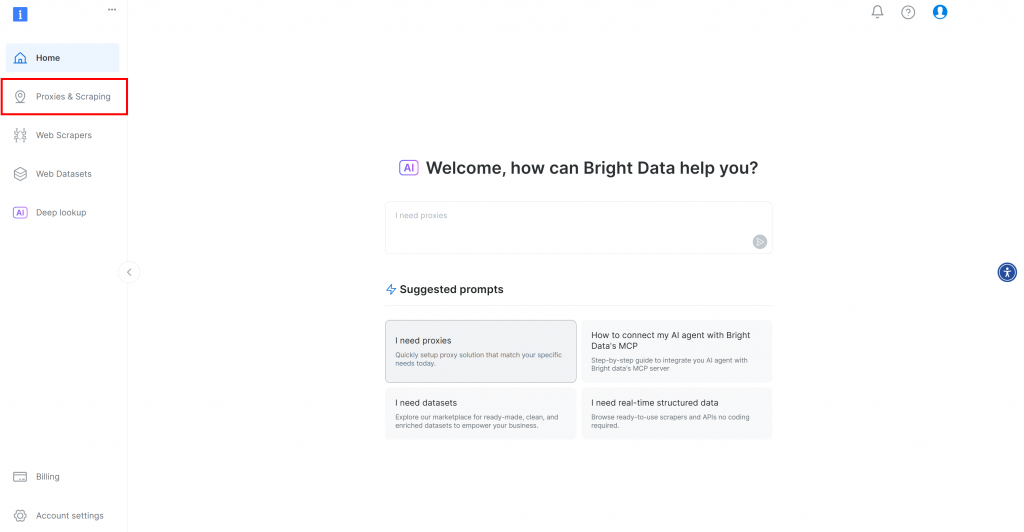
Você será redirecionado para a página “Proxies & Scraping Infrastructure”:

Se já tiver uma zona do Web Unlocker, você a verá listada nesta página. Neste exemplo, a zona já existe e é chamada de "unblocker" (lembre-se desse nome, pois você precisará dele mais tarde).
Se você ainda não tiver a zona necessária, role para baixo até o cartão “Web Unlocker API” e clique em “Create zone” (Criar zona):
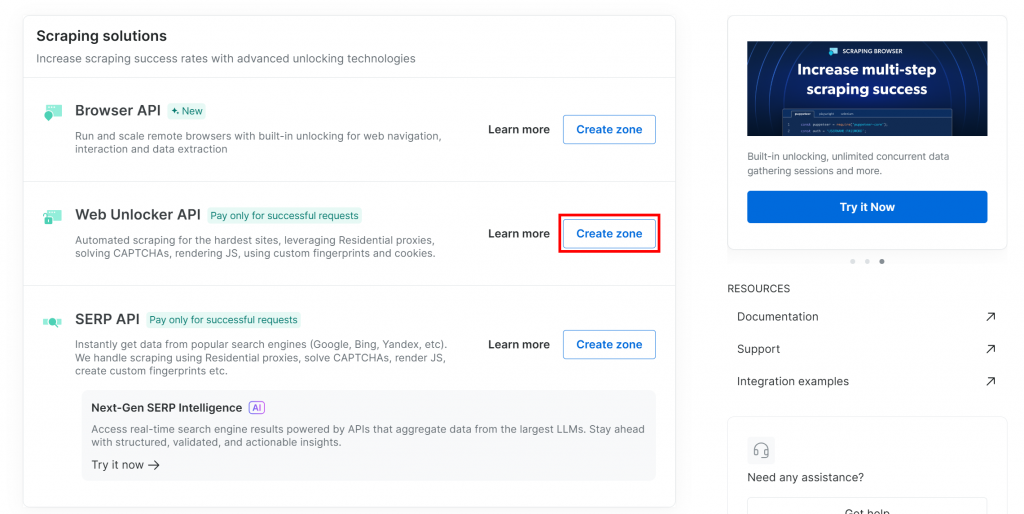
Dê um nome à sua zona (como “unlocker”), ative os recursos avançados para obter o melhor desempenho e pressione o botão “Add” (Adicionar):
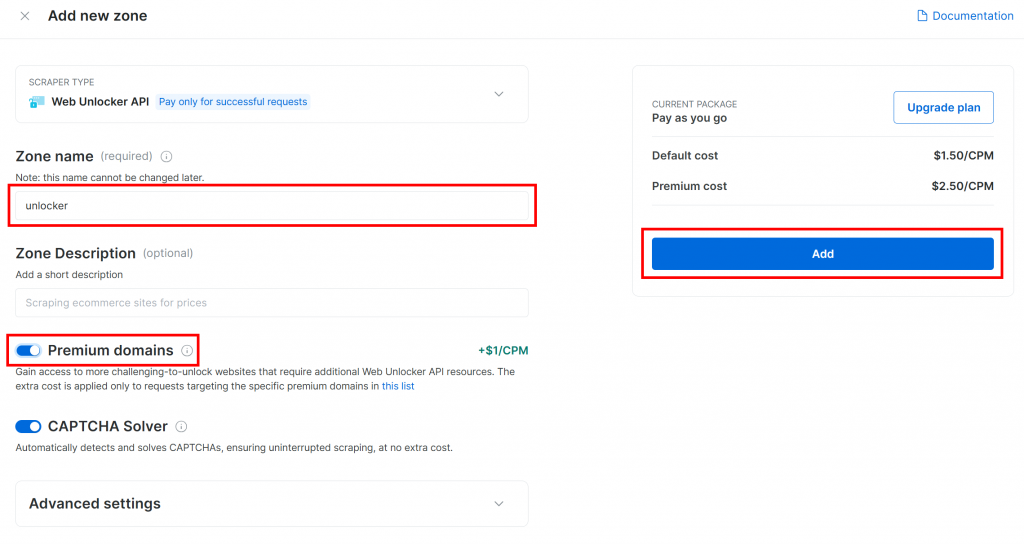
Depois de criada, você chegará à página de detalhes da zona. Verifique se o botão de alternância está definido como “Active” (Ativo), o que confirma que o produto está pronto para ser usado:
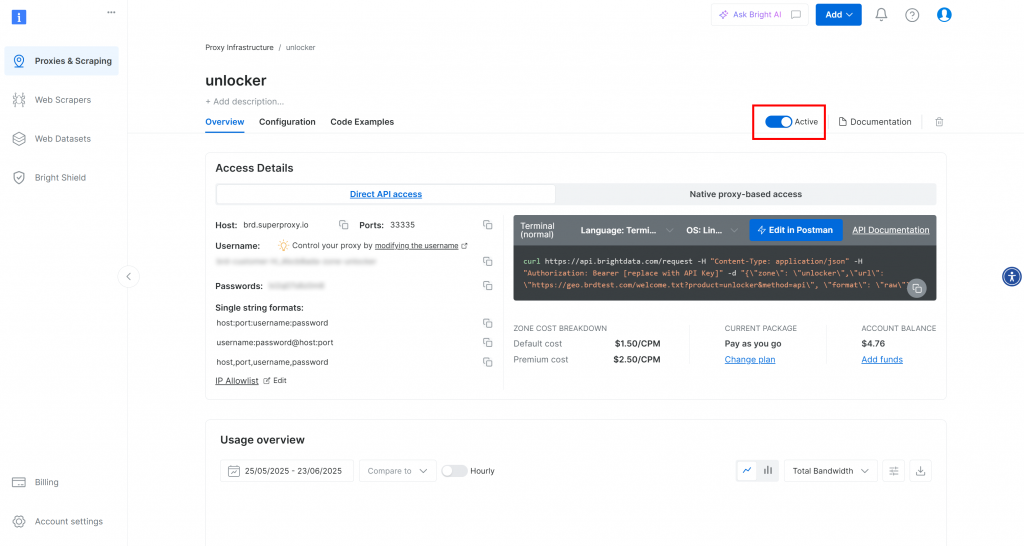
Agora, siga a documentação oficial da Bright Data para gerar sua chave de API. Depois de obtê-la, guarde-a em um local seguro, pois você precisará dela em breve.
Perfeito! Você está pronto para integrar o Bright Data ao Langflow usando um componente personalizado.
Etapa nº 3: inicializar um novo fluxo em branco
Antes de continuar, você deve criar um novo fluxo do Langflow. Volte para o servidor local do Langflow e clique no botão “Criar primeiro fluxo”:

O seguinte modal será exibido. Pressione o botão “Blank Flow” no canto inferior direito:
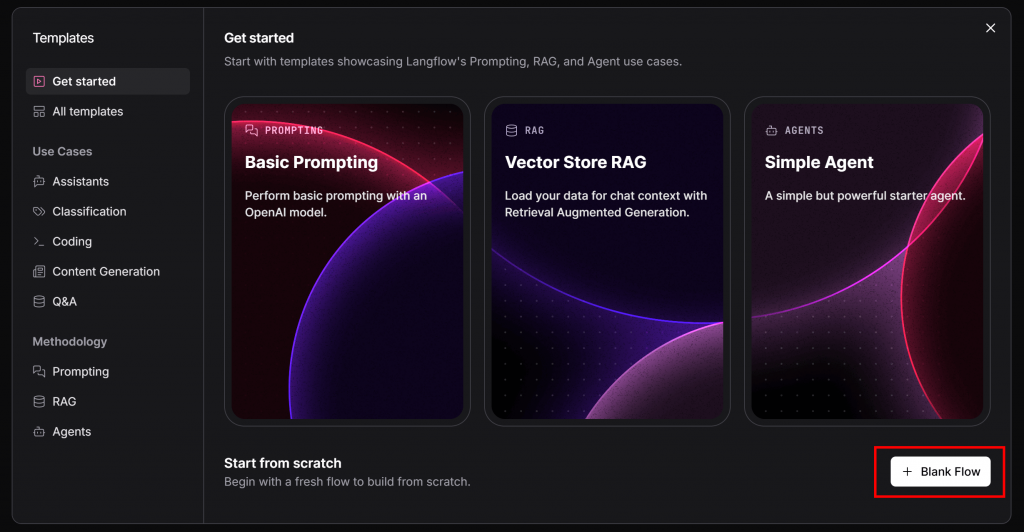
Dê um nome ao seu fluxo, como “Langflow x Bright Data AI App”. Depois de criado, você verá uma tela em branco como esta:
A tela acima é onde você pode adicionar e conectar componentes para definir seu aplicativo de IA. Muito bem!
Etapa 4: Definir um componente de dados Bright personalizado
A maneira mais fácil de integrar o Langflow à Bright Data é criando um componente personalizado. Isso permitirá que seu agente de IA colete dados da Web usando a API Web Unlocker da Bright Data.
No Langflow, os componentes personalizados são classes Python definidas por:
- Entradas: Os dados ou parâmetros que seu componente requer.
- Saídas: Os dados que seu componente retorna aos nós downstream.
- Lógica: O processamento interno para converter entradas em saídas.
Especificamente, seu componente personalizado Langflow x Bright Data deve
- Aceite sua chave de API da Bright Data e o nome da zona do Web Unlocker como entradas (para autenticação).
- Receba o URL de destino da página da Web que você deseja extrair.
- Execute uma solicitação à API do Web Unlocker, configurada para retornar a página no formato Markdown (que é ideal para consumo de IA).
- Retorna o conteúdo recuperado como saída.
Você pode implementar todos os itens acima com o seguinte componente Python personalizado:
from langflow.custom import Component
from langflow.io import SecretStrInput, StrInput, Output
from langflow.schema import Data
import httpx
# A Langflow custom component must extend Component
class BrightDataComponent(Component):
# The component name shown in the Langflow UI
display_name = "Bright Data"
# The description in the component details
description = "Retrieve data from the web in Markdown format using Bright Data"
icon = "sparkles" # UI icon identifier
name = "BrightData" # Internal name used by Langflow
# --- INPUTS ---
# Define the inputs required by the component
inputs = [
SecretStrInput(
name="api_key",
display_name="Bright Data API Key",
required=True,
info="Your Bright Data API key from the dashboard"
),
StrInput(
name="zone",
display_name="Web Unlocker Zone Name",
info="The name of the Web Unlocker zone to connect to (e.g., 'web_unlocker')",
required=True
),
StrInput(
name="url",
display_name="Target URL",
info="The URL to transform into Markdown data",
tool_mode=True
),
]
# --- OUTPUT ---
# Define the output returned by the component
outputs = [
Output(
name="web_data",
display_name="Web Data Result",
method="get_web_data" # The name of the method used to generate the output
)
]
# --- LOGIC ---
# This method retrieves web data from Bright Data and returns it
def get_web_data(self) -> Data:
try:
# Bright Data Web Unlocker API endpoint
url = "https://api.brightdata.com/request"
# Request headers including API key for authentication
headers = {
"Authorization": f"Bearer {self.api_key}",
"Content-Type": "application/json"
}
# Payload specifying the zone, URL, and output format
payload = {
"zone": self.zone,
"url": self.url,
"format": "raw",
"data_format": "markdown"
}
# Send the POST request with a 180-second timeout
with httpx.Client(timeout=180.0) as client:
response = client.post(url, json=payload, headers=headers)
# Raise an error if HTTP status code is not 2xx
response.raise_for_status()
# Extract contains the Markdown-formatted web data
markdown_data = response.text
return Data(data={"data": markdown_data})
# Handle timeout errors
except httpx.TimeoutException:
error_msg = "The Web Unlocker request timed out"
return Data(data={"error": error_msg, "data": None})
# Handle other HTTP errors (e.g., 4xx, 5xx)
except httpx.HTTPStatusError as e:
error_msg = f"Request failed with status {e.response.status_code}: {e.response.text}"
return Data(data={"error": error_msg, "data": None})O BrightDataComponent aceita as seguintes entradas:
- Sua chave de API da Bright Data.
- Seu nome de zona do Web Unlocker.
- O URL da página que você deseja extrair.
Em seguida, ele usa o cliente HTTPX Python para enviar uma solicitação à API do Web Unlocker, configurada para retornar a resposta no formato Markdown. A representação Markdown da página retornada pela API torna-se a saída do componente.
Observação: usamos o HTTPX porque é a biblioteca de cliente HTTP padrão disponível no Langflow. Para saber mais sobre ela, leia nosso guia sobre como usar o HTTPX para raspagem da Web.
Fantástico! Veja como adicionar esse componente ao seu fluxo e permitir que o agente de IA consuma sua saída.
Etapa 5: Adicionar o componente de dados Bright personalizado
Para registrar o componente que você definiu anteriormente, clique no botão “New Custom Component” (Novo componente personalizado) no canto inferior esquerdo. Um novo componente personalizado genérico “Hello, World” aparecerá em sua tela. Passe o mouse sobre ele e clique na seção “Code” (Código) para personalizar sua lógica:
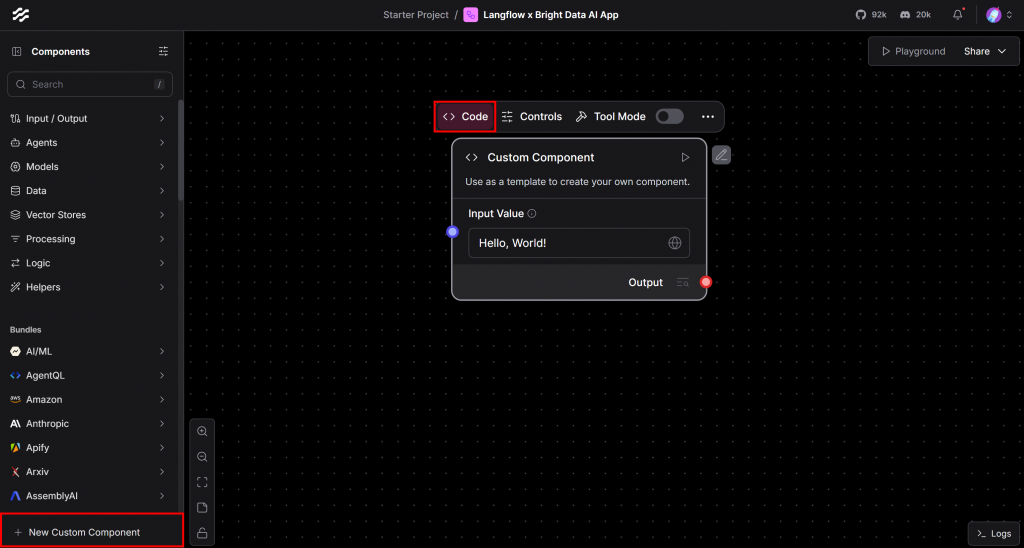
No editor de código exibido, cole o código-fonte completo de sua classe BrightDataComponent:
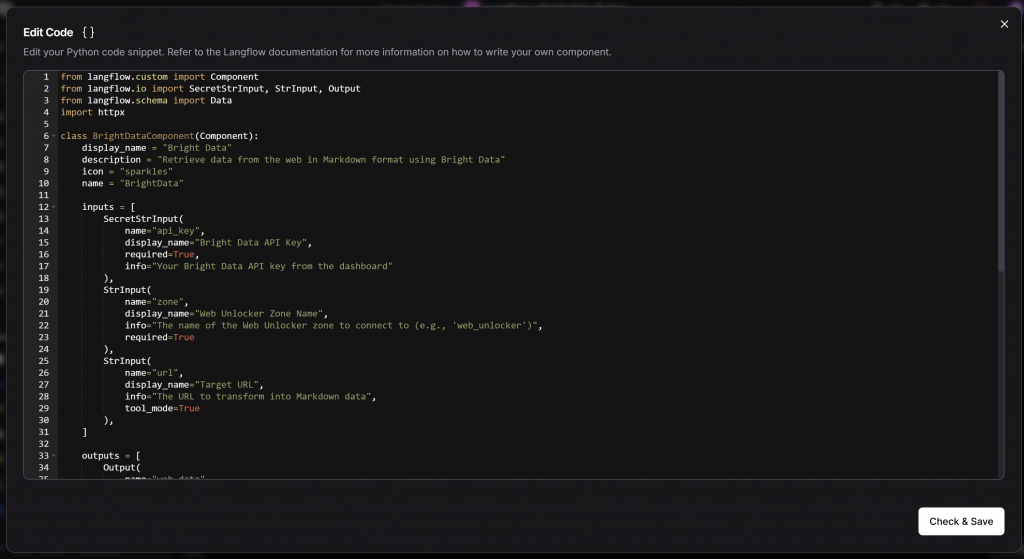
Pressione o botão “Check & Save” (Verificar e salvar). Agora você deve ver o “Componente personalizado” genérico substituído pelo seu componente Bright Data:
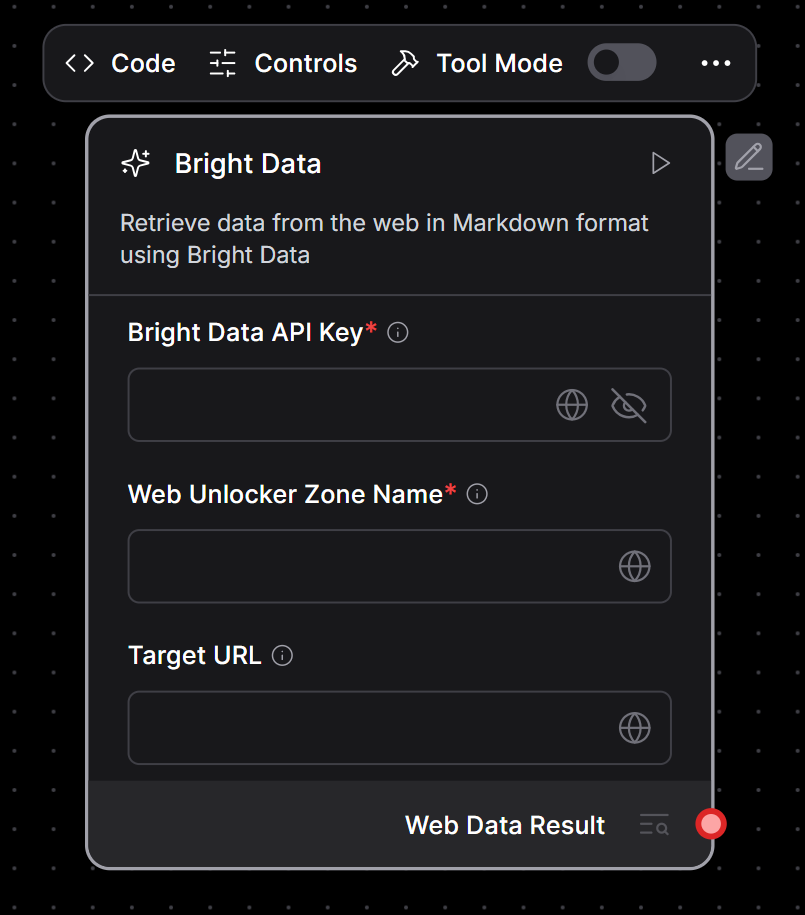
Como você pode ver, o componente personalizado de espaço reservado foi atualizado com seu componente personalizado para integração com o Bright Data.
Observação: não é necessário recriar o componente Bright Data manualmente em cada fluxo.
Basta armazenar o componente personalizado em um arquivo Python e carregá-lo automaticamente usando o método descrito na documentação do Langflow.
Maravilhoso! Seu fluxo de IA agora pode se integrar à Bright Data para recuperar dados da Web.
Etapa 6: conectar o agente de IA aos dados brilhantes
Você pode usar o componente Bright Data diretamente no seu aplicativo Langflow ou transformá-lo em uma ferramenta com a qual os agentes de IA podem interagir. Ao transformá-lo em uma ferramenta, você está dando ao agente a capacidade de buscar conteúdo ao vivo de qualquer página da Web em formato Markdown amigável à IA. Em outras palavras, você está permitindo que sua IA acesse e recupere informações em tempo real de qualquer site.
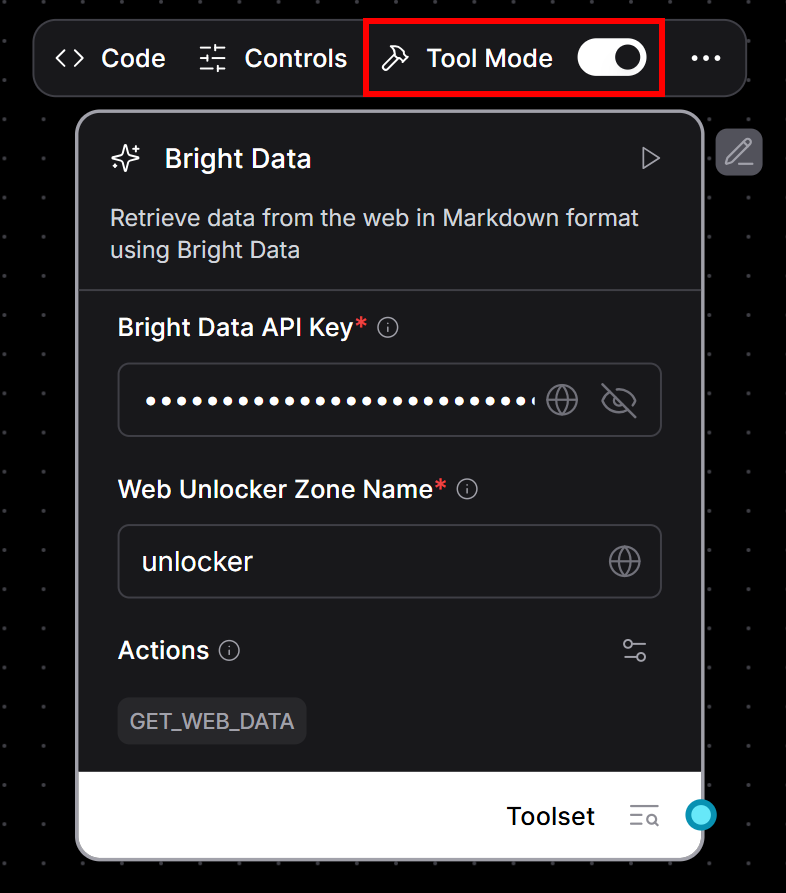
Para tornar o Bright Component uma ferramenta:
- Passe o mouse sobre o componente Bright Data.
- Ative o interruptor “Tool Mode” (Modo ferramenta) para habilitá-lo.
- Preencha os campos obrigatórios:
- Sua chave de API da Bright Data.
- Seu nome de zona do Web Unlocker (por exemplo,
"unlocker").
Isso é o que você deve ver agora:
Agora que seu componente Bright Data está pronto como uma ferramenta, conecte-o a um agente de IA:
- Na barra lateral esquerda, localize o componente “Agents > Agent”.
- Arraste-o para a tela.
- Configure o agente para usar seu LLM preferido (neste exemplo, usaremos o Gemini, selecionando um modelo gratuito como
gemini-2.5-flashe colando sua chave de API do Gemini). - Conecte a saída do componente Bright Data à entrada “Tools” do componente Agent:
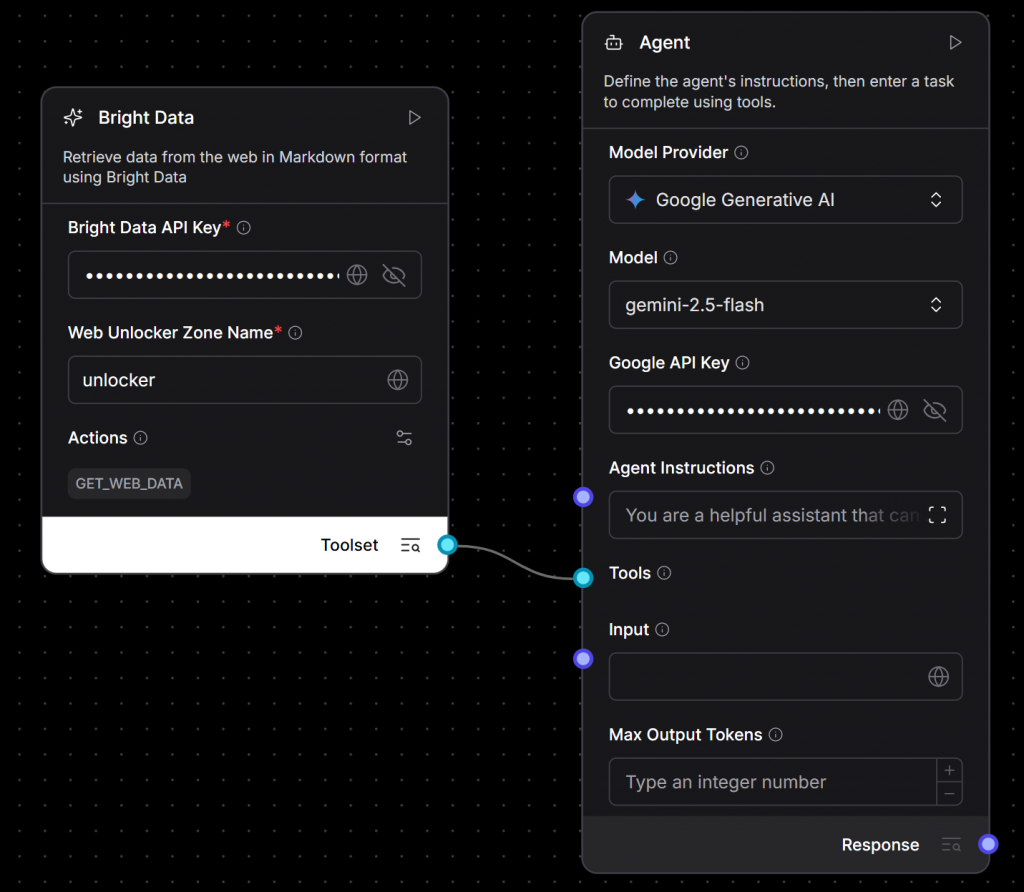
Aqui vamos nós! O núcleo do seu aplicativo de IA agora está totalmente conectado. Você acabou de criar um agente com tecnologia Gemini que pode recuperar dinamicamente o conteúdo da Web ao vivo usando a infraestrutura de raspagem da Bright Data.
Etapa nº 7: Concluir o fluxo
Para que seu fluxo de IA seja totalmente funcional, ele precisa de um componente de entrada e um de saída. Portanto, vá em frente e conecte um componente de entrada do Chat ao seu agente de IA e um componente de saída do Chat para receber sua resposta.
Depois disso, seu fluxo deve ser parecido com o seguinte:
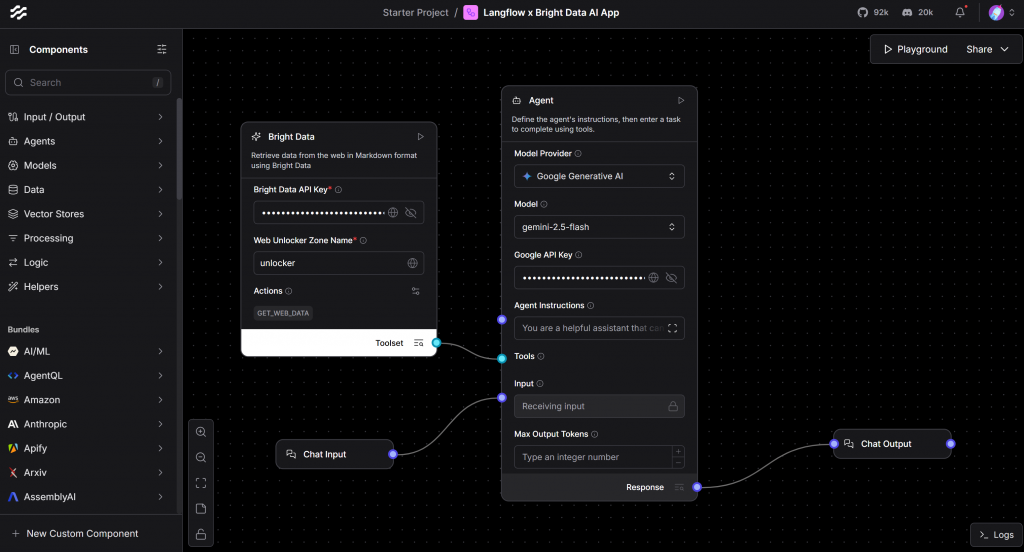
A configuração acima oferece uma interface semelhante a um bate-papo para interagir com seu agente de IA.
É isso aí! Seu aplicativo Langflow × Bright Data AI agora está completo e pronto para ser usado.
Etapa nº 8: Teste o aplicativo de IA
Para iniciar seu aplicativo de IA, clique no botão “Playground” no canto superior direito da interface do Langflow:

É isso que você deve ver:
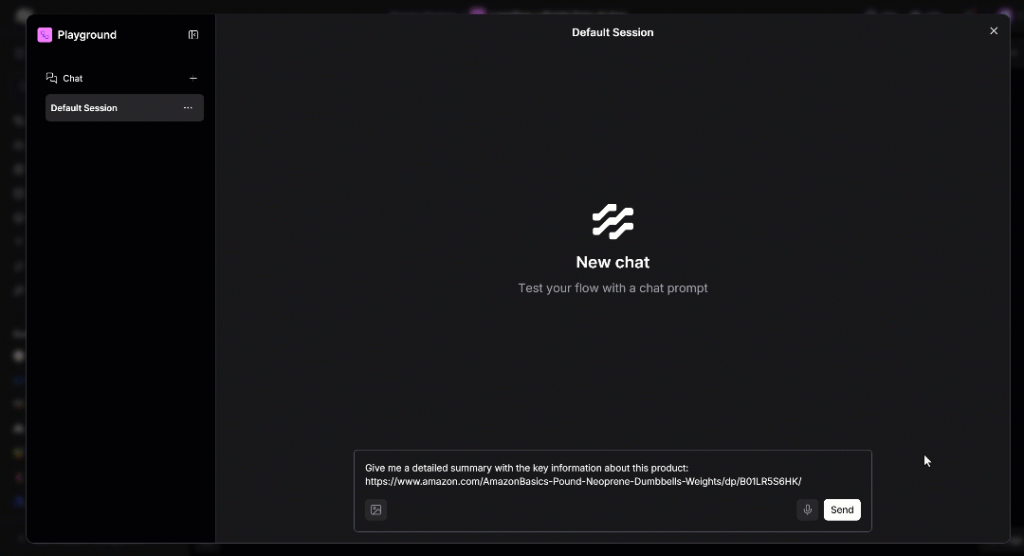
O que você obtém é uma experiência no estilo do ChatGPT, mas com a ajuda de seu próprio agente de IA. Para verificar se tudo funciona, tente digitar um prompt como:
Give me a detailed summary with the key information about this product:
https://www.amazon.com/AmazonBasics-Pound-Neoprene-Dumbbells-Weights/dp/B01LR5S6HK/Veja abaixo o que acontecerá nos bastidores:
- O prompt vai da Entrada de bate-papo para o componente AI Agent.
- O agente usa o LLM configurado (Gemini, neste caso) e aciona a ferramenta necessária proveniente do componente Bright Data.
- O agente recebe o conteúdo da Web extraído, processa-o e passa a resposta final para o Chat Output (que corresponde à resposta que você verá no chat).
O prompt acima é um ótimo teste, pois o Gemini sozinho não consegue extrair sites como o da Amazon devido às suas proteções antibot. O Web Unlocker da Bright Data resolve isso ignorando o CAPTCHA da Amazon, extraindo dados da página e fornecendo-os em formato Markdown pronto para IA.
Execute o prompt e isso é o que você deverá ver:
Para confirmar que o agente usou o Bright Data, expanda a lista suspensa “Accessing web_get_data”:
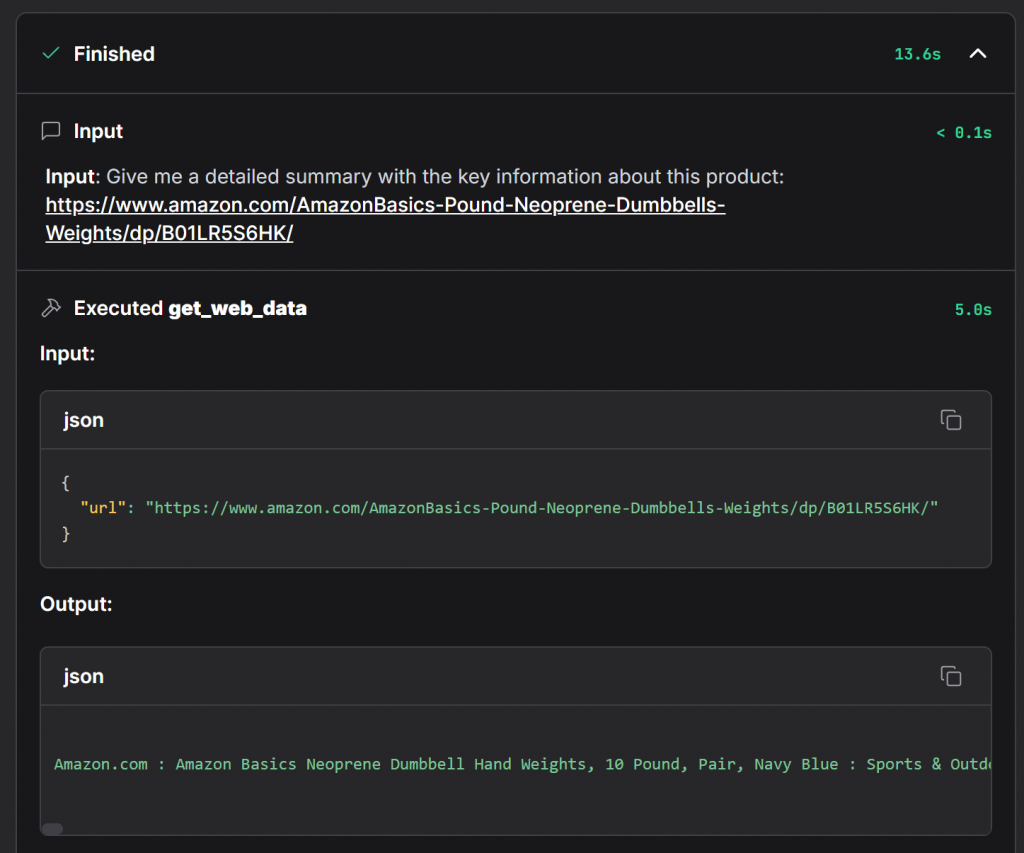
Isso mostra os detalhes completos da chamada da função get_web_data, que é o método principal em seu componente Bright Data. Lá, você pode verificar se os dados foram recuperados com êxito da página do produto da Amazon.
Aqui está uma captura de tela parcial do resultado real produzido pelo agente de IA:

Todas as informações contidas neste resumo gerado por IA são reais e não alucinadas, como você pode verificar visitando a página original da Amazon:
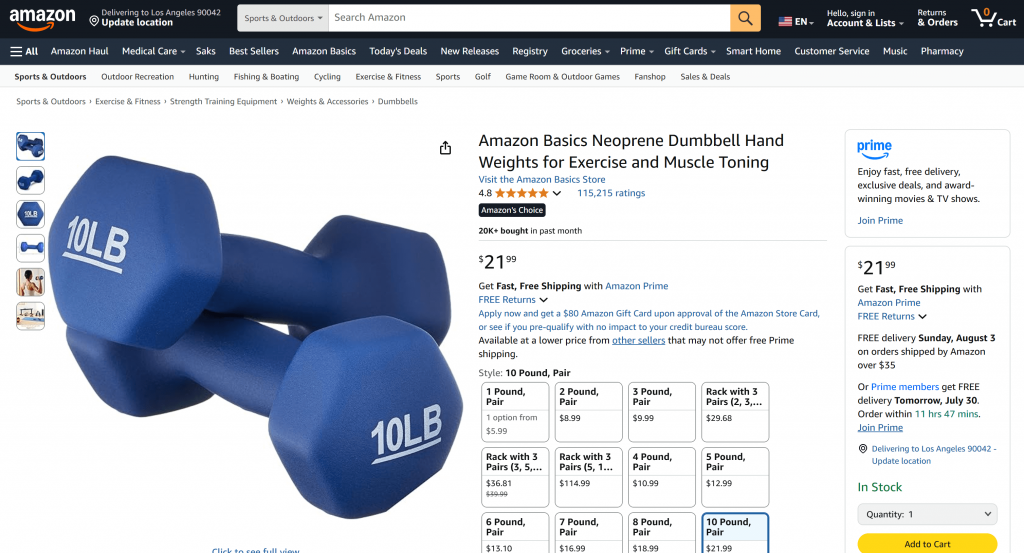
E pronto! Você acabou de criar e testar um aplicativo de IA com acesso a dados da Web usando Langflow e Bright Data.
Próximas etapas
Agora que sua integração está pronta e funcionando, veja as próximas etapas que você pode realizar:
- Implante seu agente usando um dos métodos oficialmente suportados, seja na nuvem ou em seu próprio servidor.
- Amplie a integração conectando outros produtos da Bright Data, como as APIs do Web Scraper ou as APIs SERP. Para fazer isso, basta modificar a lógica em seu
BrightDataComponentpara chamar diferentes APIs da Bright Data , conforme descrito na documentação oficial. - Recombine seus componentes para criar casos de uso mais avançados, incluindo pipelines RAG, fluxos de trabalho de dados, fluxos de automação de IA e muito mais.
- Conecte seu agente de IA ao servidor MCP da Bright Data para integrá-lo a mais de 50 ferramentas prontas para uso.
Conclusão
Neste artigo, você aprendeu a usar o Langflow para criar um agente de IA com acesso a dados da Web. Isso foi possível por meio de uma integração personalizada com as ferramentas da Bright Data. Essa configuração dá ao seu LLM a capacidade de recuperar e processar dados de praticamente qualquer site em tempo real.
Lembre-se de que o que apresentamos aqui foi apenas um exemplo básico. Se o seu objetivo for criar agentes mais avançados, você precisará de ferramentas para buscar, validar e transformar dados da Web em tempo real em informações otimizadas para o consumo de IA. Isso é especificamente o que você pode encontrar na infraestrutura de IA da Bright Data.
Crie uma conta gratuita na Bright Data e comece a fazer experiências com nossas ferramentas de recuperação de dados prontas para IA!




