

Este sistema encontra novos leads usando inteligência da web em tempo real, detecta automaticamente sinais de compra e gera divulgação personalizada com base em eventos comerciais reais. Vá direto para a ação no GitHub.
Você aprenderá:
- Como construir sistemas multiagentes usando o CrewAI para tarefas especializadas de prospecção
- Como aproveitar o Bright Data MCP para inteligência em tempo real sobre empresas e contatos
- Como detectar eventos desencadeadores, como contratações, financiamentos e mudanças na liderança, automaticamente
- Como gerar abordagens personalizadas com base em inteligência de negócios em tempo real
- Como criar um pipeline automatizado, desde a descoberta de clientes potenciais até a integração com o CRM
Vamos começar!
O desafio do desenvolvimento de vendas moderno
O desenvolvimento de vendas tradicional depende de pesquisas manuais, que incluem: alternar entre perfis do LinkedIn, sites de empresas e artigos de notícias para identificar clientes potenciais. Essa abordagem é demorada, propensa a erros e muitas vezes leva a listas de contatos desatualizadas e comunicação mal direcionada.
A integração do CrewAI com o Bright Data automatiza todo o fluxo de trabalho de prospecção, reduzindo horas de trabalho manual a apenas alguns minutos.
O que estamos construindo: sistema inteligente de desenvolvimento de vendas
Você criará um sistema de IA com vários agentes que encontra empresas que correspondem ao seu perfil de cliente ideal. Ele rastreará eventos que indicam intenção de compra, reunirá informações verificadas sobre tomadores de decisão e criará mensagens personalizadas usando inteligência de negócios real. O sistema se conecta diretamente ao seu CRM para manter um pipeline qualificado.
Pré-requisitos
Configure seu ambiente de desenvolvimento com estes requisitos:
- Instalaçãodo Python 3.11
- Conta Bright Data com acesso MCP
- Chave API OpenAI para geração de IA
- Credenciais do HubSpot CRM para integração do pipeline
Configuração do ambiente
Crie o diretório do seu projeto e instale as dependências. Comece configurando um ambiente virtual limpo para evitar conflitos com outros projetos Python.
python -m venv ai_bdr_env
source ai_bdr_env/bin/activate # Windows: ai_bdr_envScriptsactivate
pip install crewai "crewai-tools[mcp]" openai pandas python-dotenv streamlit requestsCrie a configuração do ambiente:
BRIGHT_DATA_API_TOKEN="your_bright_data_api_token"
OPENAI_API_KEY="your_openai_api_key"
HUBSPOT_API_KEY="your_hubspot_api_key"Construindo o sistema IA BDR
Agora vamos começar a construir os agentes de IA para o nosso sistema AI BDR.
Etapa 1: Configuração do Bright Data MCP
Crie a base para a Infraestrutura de scraping de dados que coleta dados em tempo real de várias fontes. O cliente MCP lida com toda a comunicação com a rede de scraping da Bright Data.
Crie um arquivo mcp_client.py no diretório raiz do seu projeto e adicione o seguinte código:
from crewai import Agent, Task
from crewai.tools import BaseTool
from typing import Any
from pydantic import BaseModel, Field
from .utils import validate_companies_input, safe_mcp_call, deduplicate_by_key, extract_domain_from_url
class CompanyDiscoveryInput(BaseModel):
industry: str = Field(description="Setor-alvo para descoberta de empresas")
size_range: str = Field(description="Faixa de tamanho da empresa (startup, pequena, média, grande)")
location: str = Field(default="", description="Localização geográfica ou região")
class CompanyDiscoveryTool(BaseTool):
nome: str = "discover_companies"
descrição: str = "Encontre empresas que correspondam aos critérios ICP usando Scraping de dados"
args_schema: tipo[BaseModel] = CompanyDiscoveryInput
mcp: Qualquer = Nenhum
def __init__(self, mcp_client):
super().__init__()
self.mcp = mcp_client
def _run(self, industry: str, size_range: str, location: str = "") -> list:
companies = []
search_terms = [
f"{industry} companies {size_range}",
f"{industry} startups {location}",
f"{industry} technology companies"
]
para termo em termos_de_busca:
resultados = self._search_companies(termo)
para empresa em resultados:
enriquecido = self._enrich_company_data(empresa)
se self._matches_icp(enriquecido, setor, faixa_de_tamanho):
empresas.append(enriquecido)
retorne deduplicate_by_key(companhias, lambda c: c.get('domain') ou c['name'].lower())
def _search_companies(self, termo):
"""Pesquise empresas usando pesquisa real na web através da Bright Data."""
tente:
companhias = []
search_queries = [
f"{term} directory",
f"{term} list",
f"{term} news"
]
for query in search_queries:
try:
results = self._perform_company_search(query)
companies.extend(results)
if len(companies) >= 10:
break
excepto Exception como e:
imprimir(f"Erro na consulta de pesquisa '{query}': {str(e)}")
continuar
retornar self._filter_unique_companies(companies)
exceto Exception como e:
imprimir(f"Erro ao pesquisar empresas para '{term}': {str(e)}")
retornar []
def _enrich_company_data(self, company):
linkedin_data = safe_mcp_call(self.mcp, 'scrape_company_linkedin', company['name'])
website_data = safe_mcp_call(self.mcp, 'scrape_company_website', company.get('domain', ''))
employee_count = linkedin_data.get('employee_count') or 150
return {
**company,
'linkedin_intelligence': linkedin_data,
'website_intelligence': website_data,
'employee_count': employee_count,
'icp_score': 0
}
def _matches_icp(self, empresa, setor, intervalo_tamanho):
pontuação = 0
se setor.lower() em empresa.get('setor', '').lower():
pontuação += 30
se self._check_size_range(empresa.get('employee_count', 0), intervalo_tamanho):
pontuação += 25
if company.get('name') and company.get('domain'):
score += 20
company['icp_score'] = score
return score >= 20
def _check_size_range(self, count, size_range):
intervalos = {'startup': (1, 50), 'pequena': (51, 200), 'média': (201, 1000)}
tamanho_mínimo, tamanho_máximo = intervalos.get(intervalo_tamanho, (0, 999999))
retornar tamanho_mínimo <= contagem <= tamanho_máximo
def _perform_company_search(self, query):
"""Realizar pesquisa de empresas usando Bright Data MCP."""
search_result = safe_mcp_call(self.mcp, 'search_company_news', query)
if search_result and search_result.get('results'):
return self._extract_companies_from_mcp_results(search_result['results'], query)
else:
print(f"Nenhum resultado MCP para: {query}")
return []
def _filter_unique_companies(self, companies):
"""Filtrar empresas duplicadas."""
seen_names = set()
unique_companies = []
for company in companies:
name_key = company.get('name', '').lower()
if name_key and name_key not in seen_names:
seen_names.add(name_key)
unique_companies.append(company)
return unique_companies
def _extract_companies_from_mcp_results(self, mcp_results, original_query):
"""Extrair informações da empresa dos resultados da pesquisa MCP."""
companies = []
para resultado em mcp_results[:10]:
tente:
título = resultado.get('title', '')
url = resultado.get('url', '')
trecho = resultado.get('snippet', '')
nome_da_empresa = self._extract_company_name_from_result(título, url)
if nome_da_empresa and len(nome_da_empresa) > 2:
domínio = self._extract_domain_from_url(url)
setor = self._extract_industry_from_query(original_query)
empresas.append({
'nome': nome_da_empresa,
'domínio': domínio,
'setor': setor
})
exceto Exception como e:
imprimir(f"Erro ao extrair empresa do resultado MCP: {str(e)}")
continuar
retornar empresas
def _extrair_nome_da_empresa_do_resultado(self, título, url):
"""Extrair nome da empresa do título ou URL do resultado da pesquisa."""
importar re
if title:
title_clean = re.sub(r'[|-—–].*$', '', title).strip()
title_clean = re.sub(r's+(Inc|Corp|LLC|Ltd|Solutions|Systems|Technologies|Software|Platform|Company)$', '', title_clean, flags=re.IGNORECASE)
if len(title_clean) > 2 and len(title_clean) < 50:
return title_clean
if url:
domain_parts = url.split('/')[2].split('.')
if len(domain_parts) > 1:
return domain_parts[0].title()
return None
def _extract_domain_from_url(self, url):
"""Extrair domínio da URL."""
return extract_domain_from_url(url)
def _extract_industry_from_query(self, query):
"""Extrair setor da consulta de pesquisa."""
query_lower = query.lower()
mapeamentos_setoriais = {
'saas': 'SaaS',
'fintech': 'FinTech',
'ecommerce': 'E-commerce',
'healthcare': 'Healthcare',
'ai': 'IA/ML',
'machine learning': 'IA/ML',
'artificial intelligence': 'IA/ML'
}
para palavra-chave, setor em mapeamentos_setoriais.itens():
se palavra-chave em consulta_minúscula:
retornar setor
retornar 'Tecnologia'
def create_company_discovery_agent(mcp_client):
return Agent(
role='Especialista em descoberta de empresas',
goal='Encontrar clientes potenciais de alta qualidade que correspondam aos critérios ICP',
backstory='Especialista em identificar clientes potenciais usando inteligência web em tempo real.',
tools=[CompanyDiscoveryTool(mcp_client)],
verbose=True
)Este cliente MCP gerencia todas as tarefas de Scraping de dados usando a infraestrutura de IA da Bright Data. Ele oferece acesso confiável a páginas de empresas no LinkedIn, sites corporativos, bancos de dados de financiamento e fontes de notícias. O cliente cuida do pool de conexões e lida automaticamente com proteções anti-bot.
Etapa 2: Agente de descoberta de empresas
Transforme seus critérios de perfil de cliente ideal em um sistema de descoberta inteligente que encontra empresas que atendem aos seus requisitos específicos. O agente pesquisa várias fontes e aprimora os dados da empresa com inteligência de negócios.
Primeiro, crie uma pasta agents na raiz do seu projeto. Em seguida, crie um arquivo agents/company_discovery.py e adicione o seguinte código:
from crewai import Agent, Task
from crewai.tools import BaseTool
from typing import Any
from pydantic import BaseModel, Field
from .utils import validate_companies_input, safe_mcp_call, deduplicate_by_key, extract_domain_from_url
class CompanyDiscoveryInput(BaseModel):
industry: str = Field(description="Setor-alvo para descoberta de empresas")
size_range: str = Field(description="Faixa de tamanho da empresa (startup, pequena, média, grande)"
location: str = Field(default="", description="Localização geográfica ou região")
class CompanyDiscoveryTool(BaseTool):
nome: str = "discover_companies"
descrição: str = "Encontre empresas que correspondam aos critérios ICP usando Scraping de dados"
args_schema: tipo[BaseModel] = CompanyDiscoveryInput
mcp: Qualquer = Nenhum
def __init__(self, mcp_client):
super().__init__()
self.mcp = mcp_client
def _run(self, industry: str, size_range: str, location: str = "") -> list:
companies = []
search_terms = [
f"{industry} companies {size_range}",
f"{industry} startups {location}",
f"{industry} technology companies"
]
para termo em termos_de_busca:
resultados = self._search_companies(termo)
para empresa em resultados:
enriquecido = self._enrich_company_data(empresa)
se self._matches_icp(enriquecido, setor, faixa_de_tamanho):
empresas.append(enriquecido)
retorne deduplicate_by_key(companhias, lambda c: c.get('domain') ou c['name'].lower())
def _search_companies(self, termo):
"""Pesquise empresas usando pesquisa real na web através da Bright Data."""
tente:
companhias = []
search_queries = [
f"{term} directory",
f"{term} list",
f"{term} news"
]
for query in search_queries:
try:
results = self._perform_company_search(query)
companies.extend(results)
if len(companies) >= 10:
break
excepto Exception como e:
imprimir(f"Erro na consulta de pesquisa '{query}': {str(e)}")
continuar
retornar self._filter_unique_companies(companies)
exceto Exception como e:
imprimir(f"Erro ao pesquisar empresas para '{term}': {str(e)}")
retornar []
def _enrich_company_data(self, company):
linkedin_data = safe_mcp_call(self.mcp, 'scrape_company_linkedin', company['name'])
website_data = safe_mcp_call(self.mcp, 'scrape_company_website', company.get('domain', ''))
employee_count = linkedin_data.get('employee_count') or 150
return {
**company,
'linkedin_intelligence': linkedin_data,
'website_intelligence': website_data,
'employee_count': employee_count,
'icp_score': 0
}
def _matches_icp(self, empresa, setor, intervalo_tamanho):
pontuação = 0
if setor.lower() in empresa.get('setor', '').lower():
pontuação += 30
if self._check_size_range(empresa.get('employee_count', 0), intervalo_tamanho):
pontuação += 25
if company.get('name') and company.get('domain'):
score += 20
company['icp_score'] = score
return score >= 20
def _check_size_range(self, count, size_range):
intervalos = {'startup': (1, 50), 'pequena': (51, 200), 'média': (201, 1000)}
tamanho_mínimo, tamanho_máximo = intervalos.get(intervalo_tamanho, (0, 999999))
retornar tamanho_mínimo <= contagem <= tamanho_máximo
def create_company_discovery_agent(mcp_client):
return Agent(
role='Especialista em descoberta de empresas',
goal='Encontrar clientes potenciais de alta qualidade que correspondam aos critérios ICP',
backstory='Especialista em identificar clientes potenciais usando inteligência da web em tempo real.',
tools=[CompanyDiscoveryTool(mcp_client)],
verbose=True
)O agente de descoberta pesquisa várias fontes de dados para encontrar empresas que se encaixam no seu perfil de cliente ideal. Ele adiciona informações comerciais do LinkedIn e de sites corporativos para cada empresa. Em seguida, ele filtra os resultados com base nos critérios de pontuação que você pode definir. O processo de deduplicação mantém as listas de clientes potenciais limpas, evitando entradas duplicadas.
Etapa 3: Agente de detecção de gatilhos
Monitore eventos comerciais que mostram intenção de compra e o melhor momento para contato. O agente analisa padrões de contratação, anúncios de financiamento, mudanças na liderança e sinais de expansão para priorizar os clientes potenciais.
Crie um arquivo agents/trigger_detection.py e adicione o seguinte código:
from crewai import Agent, Task
from crewai.tools import BaseTool
from datetime import datetime, timedelta
from typing import Any, List
from pydantic import BaseModel, Field
from .utils import validate_companies_input, safe_mcp_call
class TriggerDetectionInput(BaseModel):
companies: List[dict] = Field(description="Lista de empresas a serem analisadas para eventos de gatilho")
class TriggerDetectionTool(BaseTool):
name: str = "detect_triggers"
description: str = "Encontre sinais de contratação, notícias de financiamento, mudanças na liderança"
args_schema: type[BaseModel] = TriggerDetectionInput
mcp: Qualquer = Nenhum
def __init__(self, mcp_client):
super().__init__()
self.mcp = mcp_client
def _run(self, empresas) -> lista:
empresas = validate_companies_input(empresas)
se não empresas:
retornar []
para empresa em empresas:
gatilhos = []
sinais_de_contratação = self._detect_hiring_triggers(empresa)
gatilhos.extend(sinais_de_contratação)
sinais_de_financiamento = self._detect_funding_triggers(empresa)
gatilhos.extend(sinais_de_financiamento)
sinais_de_liderança = self._detect_leadership_triggers(empresa)
gatilhos.extend(sinais_de_liderança)
sinais_de_expansão = self._detect_expansion_triggers(empresa)
gatilhos.extend(sinais_de_expansão)
empresa['trigger_events'] = triggers
empresa['trigger_score'] = self._calculate_trigger_score(triggers)
return sorted(empresas, key=lambda x: x.get('trigger_score', 0), reverse=True)
def _detect_hiring_triggers(self, company):
"""Detecta gatilhos de contratação usando dados do LinkedIn."""
linkedin_data = safe_mcp_call(self.mcp, 'scrape_company_linkedin', company['name'])
triggers = []
if linkedin_data:
hiring_posts = linkedin_data.get('hiring_posts', [])
recent_activity = linkedin_data.get('recent_activity', [])
if hiring_posts:
triggers.append({
'type': 'hiring_spike',
'severity': 'high',
'description': f"Contratação ativa detectada na {company['name']} - {len(hiring_posts)} vagas em aberto",
'date_detected': datetime.now().isoformat(),
'source': 'linkedin_api'
})
if recent_activity:
triggers.append({
'type': 'company_activity',
'severity': 'medium',
'description': f"Aumento da atividade no LinkedIn na {company['name']}",
'date_detected': datetime.now().isoformat(),
'source': 'linkedin_api'
})
return triggers
def _detect_funding_triggers(self, company):
"""Detectar gatilhos de financiamento usando pesquisa de notícias."""
funding_data = safe_mcp_call(self.mcp, 'search_funding_news', company['name'])
triggers = []
if funding_data and funding_data.get('results'):
gatilhos.append({
'tipo': 'rodada_de_financiamento',
'gravidade': 'alta',
'descrição': f"Atividade recente de financiamento detectada em {empresa['nome']}",
'data_detectada': datetime.now().isoformat(),
'fonte': 'pesquisa_de_notícias'
})
retornar gatilhos
def _detect_leadership_triggers(self, company):
"""Detectar mudanças na liderança usando a pesquisa de notícias."""
return self._detect_keyword_triggers(
company, 'leadership_change', 'medium',
['ceo', 'cto', 'vp', 'hired', 'joins', 'appointed'],
f"Mudanças na liderança detectadas na {company['name']}"
)
def _detect_expansion_triggers(self, company):
"""Detectar expansão dos negócios usando pesquisa de notícias."""
return self._detect_keyword_triggers(
company, 'expansion', 'medium',
['expansion', 'new office', 'opening', 'market'],
f"Expansão dos negócios detectada na {company['name']}"
)
def _detect_keyword_triggers(self, company, trigger_type, severity, keywords, description):
"""Método genérico para detectar gatilhos com base em palavras-chave nas notícias."""
news_data = safe_mcp_call(self.mcp, 'search_company_news', company['name'])
triggers = []
if news_data and news_data.get('results'):
for result in news_data['results']:
if any(keyword in str(result).lower() for keyword in keywords):
gatilhos.append({
'tipo': tipo_gatilho,
'gravidade': gravidade,
'descrição': descrição,
'data_detectada': datetime.now().isoformat(),
'fonte': 'pesquisa_notícias'
})
break
retornar gatilhos
def _calculate_trigger_score(self, triggers):
severity_weights = {'high': 15, 'medium': 10, 'low': 5}
return sum(severity_weights.get(t.get('severity', 'low'), 5) for t in triggers)
def create_trigger_detection_agent(mcp_client):
return Agent(
role='Analista de Eventos Desencadeadores',
goal='Identificar sinais de compra e o momento ideal para contato',
backstory='Especialista em detectar eventos comerciais que indicam disposição para comprar.',
tools=[TriggerDetectionTool(mcp_client)],
verbose=True
)O sistema de detecção de gatilhos monitora vários sinais comerciais que mostram a intenção de compra e os melhores momentos para contato. Ele analisa padrões de contratação a partir de anúncios de emprego no LinkedIn, acompanha anúncios de financiamento em fontes de notícias, observa mudanças na liderança e identifica atividades de expansão. Cada gatilho recebe uma pontuação de gravidade que ajuda a priorizar os clientes potenciais com base na urgência e no tamanho da oportunidade.
Etapa 4: Agente de pesquisa de contatos
Encontre e verifique as informações de contato dos tomadores de decisão, considerando as pontuações de confiança de várias fontes de dados. O agente prioriza os contatos com base em sua função e na qualidade dos dados.
Crie um arquivo agents/contact_research.py e adicione o seguinte código:
from crewai import Agent, Task
from crewai.tools import BaseTool
from typing import Any, List
from pydantic import BaseModel, Field
import re
from .utils import validate_companies_input, safe_mcp_call, validate_email, deduplicate_by_key
class ContactResearchInput(BaseModel):
companies: List[dict] = Field(description="Lista de empresas para pesquisar contatos")
target_roles: List[str] = Field(description="Lista de funções-alvo para encontrar contatos")
class ContactResearchTool(BaseTool):
name: str = "research_contacts"
descrição: str = "Encontre e verifique informações de contato de tomadores de decisão usando MCP"
args_schema: tipo[BaseModel] = ContactResearchInput
mcp: Qualquer = Nenhum
def __init__(self, mcp_client):
super().__init__()
self.mcp = mcp_client
def _run(self, companies, target_roles) -> list:
companies = validate_companies_input(companies)
if not companies:
return []
if not isinstance(target_roles, list):
target_roles = [target_roles] if target_roles else []
for company in companies:
contacts = []
para role em target_roles:
role_contacts = self._search_contacts_by_role(company, role)
para contact em role_contacts:
enriched = self._enrich_contact_data(contact, company)
se self._validate_contact(enriched):
contacts.append(enriched)
empresa['contatos'] = self._deduplicate_contacts(contatos)
empresa['pontuação_de_contato'] = self._calculate_contact_quality(contatos)
retornar empresas
def _search_contacts_by_role(self, empresa, função):
"""Pesquisar contatos por função usando MCP."""
contatos = []
search_query = f"{company['name']} {role} LinkedIn contact"
search_result = safe_mcp_call(self.mcp, 'search_company_news', search_query)
if search_result and search_result.get('results'):
contacts.extend(self._extract_contacts_from_mcp_results(search_result['results'], role))
if not contacts:
contact_query = f"{company['name']} {role} email contact"
contact_result = safe_mcp_call(self.mcp, 'search_company_news', contact_query)
if contact_result and contact_result.get('results'):
contacts.extend(self._extract_contacts_from_mcp_results(contact_result['results'], role))
return contacts[:3]
def _extract_contacts_from_mcp_results(self, results, role):
"""Extrair informações de contato dos resultados da pesquisa MCP."""
contacts = []
for result in results:
try:
title = result.get('title', '')
snippet = result.get('snippet', '')
url = result.get('url', '')
names = self._extract_names_from_text(title + ' ' + snippet)
para name_parts em names:
se len(name_parts) >= 2:
first_name, last_name = name_parts[0], ' '.join(name_parts[1:])
contactos.append({
'primeiro_nome': primeiro_nome,
'sobrenome': sobrenome,
'título': função,
'linkedin_url': url se 'linkedin' em url, caso contrário '',
'fontes_de_dados': 1,
'fonte': 'mcp_search'
})
if len(contacts) >= 2:
break
except Exception as e:
print(f"Erro ao extrair contato do resultado: {str(e)}")
continue
return contacts
def _extract_names_from_text(self, text):
"""Extraia nomes prováveis do texto."""
import re
padrões_de_nome = [
r'b([A-Z][a-z]+)s+([A-Z][a-z]+)b',
r'b([A-Z][a-z]+)s+([A-Z].?s*[A-Z][a-z]+)b',
r'b([A-Z][a-z]+)s+([A-Z][a-z]+)s+([A-Z][a-z]+)b'
]
names = []
para pattern em name_patterns:
matches = re.findall(pattern, text)
para match em matches:
se isinstance(match, tuple):
names.append(list(match))
retornar names[:3]
def _enrich_contact_data(self, contact, company):
if not contact.get('email'):
contact['email'] = self._generate_email(
contact['first_name'],
contact['last_name'],
company.get('domain', '')
)
contact['email_valid'] = validate_email(contact.get('email', ''))
contact['confidence_score'] = self._calculate_confidence(contact)
return contact
def _generate_email(self, first, last, domain):
if not all([first, last, domain]):
return ""
return f"{first.lower()}.{last.lower()}@{domain}"
def _calculate_confidence(self, contact):
score = 0
if contact.get('linkedin_url'): score += 30
if contact.get('email_valid'): score += 25
se contato.obter('fontes_de_dados', 0) > 1: pontuação += 20
se todos(contato.obter(f) para f em ['nome', 'sobrenome', 'título']): pontuação += 25
retornar pontuação
def _validate_contact(self, contato):
obrigatório = ['nome', 'sobrenome', 'título']
retorne (todos(contato.get(f) para f em obrigatório) e
contato.get('confidence_score', 0) >= 50)
def _deduplicate_contacts(self, contatos):
unique = deduplicate_by_key(
contacts,
lambda c: c.get('email', '') or f"{c.get('first_name', '')}_{c.get('last_name', '')}"
)
return sorted(unique, key=lambda x: x.get('confidence_score', 0), reverse=True)
def _calculate_contact_quality(self, contacts):
if not contacts:
return 0
avg_confidence = sum(c.get('confidence_score', 0) for c in contacts) / len(contacts)
high_quality = sum(1 for c in contacts if c.get('confidence_score', 0) >= 75)
retornar min(confiança_média + (alta_qualidade * 5), 100)
def criar_agente_de_pesquisa_de_contatos(cliente_mcp):
retornar Agente(
função='Especialista em Inteligência de Contatos',
objetivo='Encontrar informações de contato precisas para tomadores de decisão usando MCP',
histórico='Especialista em encontrar e verificar informações de contato usando ferramentas avançadas de pesquisa MCP.',
ferramentas=[FerramentaDePesquisaDeContatos(cliente_mcp)],
verboso=True
)O sistema de pesquisa de contatos identifica tomadores de decisão pesquisando funções no LinkedIn e nos sites das empresas. Ele gera endereços de e-mail usando padrões corporativos típicos e verifica as informações de contato por meio de vários métodos de verificação. O sistema atribui pontuações de confiança com base na qualidade das fontes de dados. O processo de deduplicação mantém as listas de contatos limpas, priorizando-as por confiança de verificação.
Etapa 5: Geração inteligente de mensagens
Transforme a inteligência de negócios em mensagens personalizadas que mencionam eventos desencadeadores específicos e mostram pesquisas. O gerador cria vários formatos de mensagem para diferentes canais.
Crie um arquivo agents/message_generation.py e adicione o seguinte código:
from crewai import Agent, Task
from crewai.tools import BaseTool
from typing import Any, List
from pydantic import BaseModel, Field
import openai
import os
class MessageGenerationInput(BaseModel):
companies: List[dict] = Field(description="Lista de empresas com contatos para gerar mensagens")
message_type: str = Field(default="cold_email", description="Tipo de mensagem a ser gerada (cold_email, linkedin_message, follow_up)")
class MessageGenerationTool(BaseTool):
name: str = "generate_messages"
description: str = "Criar contato personalizado com base em inteligência empresarial"
args_schema: type[BaseModel] = MessageGenerationInput
client: Any = None
def __init__(self):
super().__init__()
self.client = openai.OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
def _run(self, companies, message_type="cold_email") -> list:
# Certifique-se de que companies é uma lista
if not isinstance(companies, list):
print(f"Aviso: esperava uma lista de empresas, mas obtive {type(companies)}")
return []
if not companies:
print("Nenhuma empresa fornecida para geração de mensagens")
retornar []
para empresa em empresas:
se não for instância de (empresa, dicionário):
imprimir(f"Aviso: esperava um dicionário de empresas, mas obtive {type(empresa)}")
continuar
para contato em empresa.obter('contatos', []):
se não for instância de (contato, dicionário):
continuar
mensagem = self._generate_personalized_message(contato, empresa, tipo_mensagem)
contato['mensagem_gerada'] = mensagem
contato['pontuação_qualidade_mensagem'] = self._calculate_message_quality(mensagem, empresa)
retornar empresas
def _generate_personalized_message(self, contato, empresa, tipo_mensagem):
context = self._build_message_context(contact, company)
if message_type == "cold_email":
return self._generate_cold_email(context)
elif message_type == "linkedin_message":
return self._generate_linkedin_message(context)
else:
retornar self._generate_cold_email(contexto)
def _build_message_context(self, contato, empresa):
gatilhos = empresa.get('trigger_events', [])
gatilho_primário = gatilhos[0] se gatilhos else None
retornar {
'nome_do_contato': contato.get('first_name', ''),
'contact_title': contact.get('title', ''),
'company_name': company.get('name', ''),
'industry': company.get('industry', ''),
'primary_trigger': primary_trigger,
'trigger_count': len(triggers)
}
def _generate_cold_email(self, context):
trigger_text = ""
if context['primary_trigger']:
trigger_text = f"Percebi que {context['company_name']} {context['primary_trigger']['description'].lower()}."
prompt = f"""Escreva um e-mail frio personalizado:
Contato: {context['contact_name']}, {context['contact_title']} na {context['company_name']}
Setor: {context['industry']}
Contexto: {trigger_text}
Requisitos:
- Linha de assunto que faça referência ao evento desencadeador
- Saudação pessoal com o primeiro nome
- Abertura que demonstre pesquisa
- Breve proposta de valor
- Chamada à ação clara
- Máximo de 120 palavras
Formato:
ASSUNTO: [linha de assunto]
CORPO: [corpo do e-mail]"""
response = self.client.chat.completions.create(
model="gpt-4",
messages=[{"role": "user", "content": prompt}],
temperature=0.7,
max_tokens=300
)
return self._parse_email_response(response.choices[0].message.content)
def _generate_linkedin_message(self, context):
prompt = f"""Escreva uma solicitação de conexão no LinkedIn (máximo de 300 caracteres):
Contato: {context['contact_name']} na {context['company_name']}
Contexto: {context.get('primary_trigger', {}).get('description', '')}
Seja profissional, faça referência à atividade da empresa, sem argumentos de venda diretos."""
response = self.client.chat.completions.create(
model="gpt-4",
messages=[{"role": "user", "content": prompt}],
temperature=0.7,
max_tokens=100
)
retorno {
'assunto': 'Solicitação de conexão no LinkedIn',
'corpo': resposta.choices[0].message.content.strip()
}
def _parse_email_response(self, resposta):
linhas = resposta.strip().split('n')
assunto = ""
linhas_do_corpo = []
para linha em linhas:
se linha.começa com('ASSUNTO:'):
assunto = linha.substitui('ASSUNTO:', '').remove()
ou se linha.começa com('CORPO:'):
linhas_corpo.acrescenta(linha.substitui('CORPO:', '').remove())
ou se linhas_corpo:
linhas_do_corpo.append(linha)
retornar {
'assunto': assunto,
'corpo': 'n'.join(linhas_do_corpo).strip()
}
def _calcular_qualidade_da_mensagem(self, mensagem, empresa):
pontuação = 0
corpo = mensagem.get('corpo', '').lower()
if company.get('name', '').lower() in message.get('subject', '').lower():
score += 25
if company.get('trigger_events') and any(t.get('type', '') in body for t in company['trigger_events']):
score += 30
if len(corpo.split()) <= 120:
pontuação += 20
if qualquer(palavra em corpo para palavra em ['ligar', 'reunião', 'discutir', 'conectar']):
pontuação += 25
retornar pontuação
def criar_agente_geração_mensagem():
retornar Agente(
função='Especialista em Personalização',
objetivo='Criar uma abordagem personalizada atraente que obtenha respostas',
histórico='Especialista em elaborar mensagens que demonstram pesquisa e agregam valor.',
ferramentas=[FerramentaGeraçãoMensagem()],
verboso=True
)O sistema de geração de mensagens transforma a inteligência empresarial em mensagens personalizadas. Ele faz referência a eventos desencadeadores específicos e mostra pesquisas detalhadas. Ele cria linhas de assunto que se encaixam no contexto, saudações personalizadas e propostas de valor que correspondem à situação de cada cliente potencial. O sistema gera vários formatos de mensagem que funcionam bem para diferentes canais. Ele mantém a qualidade da personalização consistente.
Etapa 6: Pontuação de leads e gerenciador de pipeline
Pontue os clientes potenciais usando vários fatores de inteligência e, em seguida, exporte automaticamente os leads qualificados para o seu sistema de CRM. O gerenciador prioriza os leads com base na adequação, no momento e na qualidade dos dados.
Crie um arquivo agents/pipeline_manager.py e adicione o seguinte código:
from crewai import Agent, Task
from crewai.tools import BaseTool
from datetime import datetime
from typing import List
from pydantic import BaseModel, Field
import requests
import os
from .utils import validate_companies_input
class LeadScoringInput(BaseModel):
companies: List[dict] = Field(description="Lista de empresas a pontuar")
class LeadScoringTool(BaseTool):
name: str = "score_leads"
description: str = "Pontuação de leads com base em vários fatores de inteligência"
args_schema: type[BaseModel] = LeadScoringInput
def _run(self, companies) -> list:
companies = validate_companies_input(companies)
if not companies:
return []
for company in companies:
score_breakdown = self._calculate_lead_score(company)
company['lead_score'] = score_breakdown['total_score']
company['score_breakdown'] = score_breakdown
company['lead_grade'] = self._assign_grade(score_breakdown['total_score'])
return sorted(companies, key=lambda x: x.get('lead_score', 0), reverse=True)
def _calculate_lead_score(self, company):
breakdown = {
'icp_score': min(company.get('icp_score', 0) * 0.3, 25),
'trigger_score': min(company.get('trigger_score', 0) * 2, 30),
'contact_score': min(company.get('contact_score', 0) * 0.2, 20),
'timing_score': self._assess_timing(company),
'company_health': self._assess_health(empresa)
}
breakdown['total_score'] = soma(breakdown.values())
retornar breakdown
def _assess_timing(self, empresa):
gatilhos = empresa.get('trigger_events', [])
se não houver gatilhos:
retornar 0
recent_triggers = soma(1 para t em triggers se 'alto' em t.get('gravidade', ''))
retornar min(recent_triggers * 8, 15)
def _assess_health(self, company):
pontuação = 0
se company.get('trigger_events'):
pontuação += 5
if company.get('employee_count', 0) > 50:
score += 5
return score
def _assign_grade(self, score):
if score >= 80: return 'A'
elif score >= 65: return 'B'
elif score >= 50: return 'C'
else: return 'D'
class CRMIntegrationInput(BaseModel):
companies: List[dict] = Field(description="Lista de empresas a exportar para o CRM")
min_grade: str = Field(default="B", description="Nota mínima do lead a exportar (A, B, C, D)")
classe CRMIntegrationTool(BaseTool):
nome: str = "crm_integration"
descrição: str = "Exportar leads qualificados para o HubSpot CRM"
args_schema: tipo[BaseModel] = CRMIntegrationInput
def _run(self, empresas, nota_mínima='B') -> dict:
empresas = validate_companies_input(companhias)
if not companhias:
return {"message": "Nenhuma empresa fornecida para exportação para o CRM", "success": 0, "errors": 0}
qualificados = [c for c in companhias if isinstance(c, dict) and c.get('lead_grade', 'D') in ['A', 'B']]
if not os.getenv("HUBSPOT_API_KEY"):
return {"error": "Chave API HubSpot não configurada", "success": 0, "errors": 0}
results = {"success": 0, "errors": 0, "details": []}
para empresa em qualificada:
para contato em empresa.get('contacts', []):
se não for instância(contato, dict):
continue
resultado = self._create_hubspot_contact(contato, empresa)
se resultado.get('success'):
resultados['success'] += 1
senão:
resultados['errors'] += 1
resultados['detalhes'].append(resultado)
retornar resultados
def _create_hubspot_contact(self, contato, empresa):
api_key = os.getenv("HUBSPOT_API_KEY")
se não houver api_key:
retornar {"sucesso": False, "erro": "Chave API HubSpot não configurada"}
url = "https://api.hubapi.com/crm/v3/objects/contacts"
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
trigger_summary = "; ".join([
f"{t.get('type', '')}: {t.get('description', '')}"
for t in company.get('trigger_events', [])
])
email = contact.get('email', '').strip()
if not email:
return {"success": False, "error": "É necessário um e-mail de contato", "contact": contact.get('first_name', 'Desconhecido')}
propriedades = {
"email": email,
"primeiro nome": contato.get('primeiro nome', ''),
"sobrenome": contato.get('sobrenome', ''),
"cargo": contato.get('cargo', ''),
"company": company.get('name', ''),
"website": f"https://{company.get('domain', '')}" se company.get('domain') else "",
"hs_lead_status": "NEW",
"lifecyclestage": "lead"
}
if company.get('lead_score'):
properties["lead_score"] = str(company.get('lead_score', 0))
if company.get('lead_grade'):
properties["lead_grade"] = company.get('lead_grade', 'D')
if trigger_summary:
propriedades["trigger_events"] = trigger_summary[:1000]
se contact.get('confidence_score'):
propriedades["contact_confidence"] = str(contact.get('confidence_score', 0))
propriedades["ai_discovery_date"] = datetime.now().isoformat()
tente:
resposta = solicitações.post(url, json={"propriedades": propriedades}, cabeçalhos=cabeçalhos, tempo limite=30)
se resposta.status_code == 201:
retornar {
"sucesso": Verdadeiro,
"contato": contato.obter('primeiro_nome', ''),
"empresa": empresa.obter('nome', ''),
"hubspot_id": resposta.json().obter('id')
}
elif resposta.código_status == 409:
contato_existente = response.json()
retorne {
"sucesso": True,
"contato": contact.get('primeiro_nome', ''),
"empresa": company.get('nome', ''),
"hubspot_id": existing_contact.get('id'),
"nota": "Contato já existe"
}
else:
error_detail = response.text if response.text else f"HTTP {response.status_code}"
return {
"success": False,
"contact": contact.get('first_name', ''),
"company": company.get('name', ''),
"error": f"API Error: {error_detail}"
}
except requests.exceptions.RequestException as e:
return {
"success": False,
"contact": contact.get('first_name', ''),
"company": company.get('name', ''),
"error": f"Erro de rede: {str(e)}"
}
exceto Exception como e:
retorne {
"sucesso": False,
"contato": contato.get('primeiro_nome', ''),
"empresa": empresa.get('nome', ''),
"erro": f"Erro inesperado: {str(e)}"
}
def create_pipeline_manager_agent():
return Agent(
role='Gerente de Pipeline',
goal='Pontuar leads e gerenciar a integração de CRM para clientes potenciais qualificados',
backstory='Especialista em avaliar a qualidade de clientes potenciais e gerenciar o pipeline de vendas.',
tools=[LeadScoringTool(), CRMIntegrationTool()],
verbose=True
)O sistema de pontuação de leads avalia os clientes potenciais em várias áreas, incluindo o quanto eles se encaixam no perfil do cliente ideal, a urgência dos eventos desencadeadores, a qualidade dos dados de contato e fatores de tempo. Ele fornece análises detalhadas de pontuação que permitem a priorização baseada em dados e atribui automaticamente notas em letras para uma qualificação rápida. A ferramenta de integração de CRM exporta leads qualificados diretamente para o HubSpot, garantindo que todos os dados de inteligência estejam formatados corretamente para que a equipe de vendas possa fazer o acompanhamento.
Etapa 6.1: Utilitários compartilhados
Antes de criar o aplicativo principal, crie um arquivo agents/utils.py com funções utilitárias compartilhadas usadas em todos os agentes:
"""
Funções utilitárias compartilhadas para todos os módulos de agente.
"""
from typing import List, Dict, Any
import re
def validate_companies_input(companies: Any) -> List[Dict]:
"""Valida e normaliza a entrada de empresas em todos os agentes."""
if isinstance(companies, dict) and 'companies' in companies:
companies = companies['companies']
if not isinstance(companies, list):
print(f"Aviso: esperava uma lista de empresas, mas recebi {type(companies)}")
return []
if not companies:
print("Nenhuma empresa fornecida")
return []
valid_companies = []
for company in companies:
if isinstance(company, dict):
valid_companies.append(company)
else:
print(f"Aviso: Esperava um dicionário de empresas, mas recebi {type(company)}")
retornar empresas_válidas
def chamada_mcp_segura(cliente_mcp, nome_método: str, *args, **kwargs) -> Dict:
"""Chame métodos MCP com segurança e tratamento de erros consistente."""
tente:
método = getattr(mcp_client, nome_do_método)
resultado = método(*args, **kwargs)
retorne resultado se resultado e não resultado.get('error') else {}
exceto Exception como e:
imprima(f"Erro ao chamar MCP {nome_do_método}: {str(e)}")
retorne {}
def validate_email(email: str) -> bool:
"""Valida o formato do e-mail."""
pattern = r'^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+.[a-zA-Z]{2,}$'
return bool(re.match(pattern, email))
def deduplicate_by_key(items: Lista[Dict], função_chave) -> Lista[Dict]:
"""Remover duplicatas da lista de dicionários usando uma função chave."""
seen = conjunto()
itens_únicos = []
para item em itens:
chave = função_chave(item)
se chave e chave não estiverem em visto:
visto.adicionar(chave)
itens_únicos.acrescentar(item)
retornar itens_únicos
def extrair_domínio_de_url(url: str) -> str:
"""Extrair domínio de URL com análise de fallback."""
if not url:
return ""
try:
from urllib.parse import urlparse
parsed = urlparse(url)
return parsed.netloc
except:
if '//' in url:
return url.split('//')[1].split('/')[0]
return ""Você também precisará criar um arquivo agents/__init__.py vazio para tornar a pasta agents um pacote Python.
Etapa 7: Orquestração do sistema
Crie o aplicativo Streamlit principal que coordena todos os agentes em um fluxo de trabalho inteligente. A interface fornece feedback em tempo real e permite que os usuários personalizem parâmetros para diferentes cenários de prospecção.
Crie um arquivo ai_bdr_system.py no diretório raiz do seu projeto e adicione o seguinte código:
import streamlit as st
import os
from dotenv import load_dotenv
from crewai import Crew, Process, Task
import pandas as pd
from datetime import datetime
import json
from mcp_client import Bright DataMCP
from agents.company_discovery import create_company_discovery_agent
from agents.trigger_detection import create_trigger_detection_agent
from agents.contact_research import create_contact_research_agent
from agents.message_generation import create_message_generation_agent
from agents.pipeline_manager import create_pipeline_manager_agent
load_dotenv()
st.set_page_config(
page_title="Sistema IA BDR/SDR",
page_icon="🤖",
layout="wide")
st.title("🤖 Sistema IA BDR/SDR Agent")
st.markdown("**Prospecção em tempo real com inteligência multiagente e personalização baseada em gatilhos**")
if 'workflow_results' not in st.session_state:
st.session_state.workflow_results = None
with st.sidebar:
try:
st.image("bright-data-logo.png", width=200)
st.markdown("---")
except:
st.markdown("**🌐 Desenvolvido pela Bright Data**")
st.markdown("---")
st.header("⚙️ Configuração")
st.subheader("Perfil do cliente ideal")
industry = st.selectbox("Setor", ["SaaS", "FinTech", "Comércio eletrônico", "Saúde", "IA/ML"])
size_range = st.selectbox("Tamanho da empresa", ["startup", "pequena", "média", "grande"])
location = st.text_input("Localização (opcional)", placeholder="São Francisco, Nova York, etc.")
max_companies = st.slider("Número máximo de empresas", 5, 50, 20)
st.subheader("Tomadores de decisão alvo")
all_roles = ["CEO", "CTO", "VP de Engenharia", "Chefe de Produto", "VP de Vendas", "CMO", "CFO"]
target_roles = st.multiselect("Funções", all_roles, default=["CEO", "CTO", "VP de Engenharia"])
st.subheader("Configuração de divulgação")
message_types = st.multiselect(
"Tipos de mensagem",
["cold_email", "linkedin_message", "follow_up"],
default=["cold_email"]
)
with st.expander("Inteligência avançada"):
enable_competitive = st.checkbox("Inteligência competitiva", value=True)
enable_validation = st.checkbox("Validação de múltiplas fontes", value=True)
min_lead_grade = st.selectbox("Classificação mínima de exportação de CRM", ["A", "B", "C"], index=1)
st.divider()
st.subheader("🔗 Status da API")
apis = [
("Bright Data", "BRIGHT_DATA_API_TOKEN", "🌐"),
("OpenAI", "OPENAI_API_KEY", "🧠"),
("HubSpot CRM", "HUBSPOT_API_KEY", "📊")
]
para nome, env_var, ícone em apis:
if os.getenv(env_var):
st.success(f"{icon} {name} Conectado")
else:
if name == "HubSpot CRM":
st.warning(f"⚠️ {name} Necessário para exportação de CRM")
elif name == "Bright Data":
st.error(f"❌ {name} Ausente")
if st.button("🔧 Ajuda de configuração", key="bright_data_help"):
st.info("""
**Configuração do Bright Data necessária:**
1. Obtenha as credenciais no painel do Bright Data
2. Atualize o arquivo .env com:
```
BRIGHT_DATA_API_TOKEN=sua_senha
WEB_UNLOCKER_ZONA=lum-customer-username-zona-zonename
```
3. Consulte BRIGHT_DATA_SETUP.md para obter um guia detalhado
**Erro atual**: 407 Autenticação inválida = credenciais incorretas
""")
else:
st.error(f"❌ {name} Ausente")
col1, col2 = st.columns([3, 1])
with col1:
st.subheader("🚀 Fluxo de trabalho de prospecção de IA")
if st.button("Iniciar prospecção multiagente", type="primary", use_container_width=True):
chaves_necessárias = ["BRIGHT_DATA_API_TOKEN", "OPENAI_API_KEY"]
chaves_ausentes = [chave para chave em chaves_necessárias se não for os.getenv(chave)]
if missing_keys:
st.error(f"Chaves API necessárias ausentes: {', '.join(missing_keys)}")
st.stop()
progress_bar = st.progress(0)
status_text = st.empty()
try:
mcp_client = Bright DataMCP()
discovery_agent = create_company_discovery_agent(mcp_client)
trigger_agent = create_trigger_detection_agent(mcp_client)
contact_agent = create_contact_research_agent(mcp_client)
message_agent = create_message_generation_agent()
pipeline_agent = create_pipeline_manager_agent()
status_text.text("🔍 Descobrindo empresas que correspondem ao ICP...")
progress_bar.progress(15)
discovery_task = Task(
description=f"Encontre {max_companies} empresas em {industry} (tamanho {size_range}) em {location}",
expected_output="Lista de empresas com pontuações ICP e inteligência",
agent=discovery_agent
)
equipe_descoberta = Equipe(
agentes=[agente_descoberta],
tarefas=[tarefa_descoberta],
processo=Processo.sequencial
)
empresas = agente_descoberta.ferramentas[0]._executar(setor, faixa_tamanho, localização)
st.sucesso(f"✅ Descobertas {len(empresas)} empresas")
status_text.text("🎯 Analisando eventos desencadeadores e sinais de compra...")
progress_bar.progress(30)
trigger_task = Task(
descrição="Detectar picos de contratação, rodadas de financiamento, mudanças na liderança e sinais de expansão",
resultado esperado="Empresas com eventos desencadeadores e pontuações",
agente=trigger_agent
)
trigger_crew = Crew(
agents=[trigger_agent],
tasks=[trigger_task],
process=Process.sequential
)
companies_with_triggers = trigger_agent.tools[0]._run(companies)
total_triggers = sum(len(c.get('trigger_events', [])) for c in companies_with_triggers)
st.success(f"✅ Detectados {total_triggers} eventos desencadeadores")
progress_bar.progress(45)
status_text.text("👥 Localizando contatos de tomadores de decisão...")
contact_task = Task(
description=f"Encontrar contatos verificados para funções: {', '.join(target_roles)}",
expected_output="Empresas com informações de contato dos tomadores de decisão",
agent=contact_agent
)
contact_crew = Crew(
agents=[contact_agent],
tasks=[contact_task],
process=Process.sequential
)
companies_with_contacts = contact_agent.tools[0]._run(companies_with_triggers, target_roles)
total_contacts = sum(len(c.get('contacts', [])) for c in companies_with_contacts)
st.success(f"✅ Encontrados {total_contacts} contatos verificados")
progress_bar.progress(60)
status_text.text("✍️ Gerando mensagens personalizadas de divulgação...")
message_task = Task(
description=f"Gerar {', '.join(message_types)} para cada contato usando inteligência de gatilho",
expected_output="Empresas com mensagens personalizadas",
agent=message_agent
)
message_crew = Crew(
agents=[message_agent],
tasks=[message_task],
process=Process.sequential
)
companies_with_messages = message_agent.tools[0]._run(companies_with_contacts, message_types[0])
total_messages = sum(len(c.get('contacts', [])) for c in companies_with_messages)
st.success(f"✅ Geradas {total_messages} mensagens personalizadas")
progress_bar.progress(75)
status_text.text("📊 Pontuando leads e atualizando o CRM...")
pipeline_task = Task(
description=f"Pontuar leads e exportar nota {min_lead_grade}+ para o HubSpot CRM",
expected_output="Leads pontuados com resultados de integração do CRM",
agent=pipeline_agent
)
pipeline_crew = Crew(
agents=[pipeline_agent],
tasks=[pipeline_task],
process=Process.sequential
)
final_companies = pipeline_agent.tools[0]._run(companies_with_messages)
qualified_leads = [c for c in final_companies if c.get('lead_grade', 'D') in ['A', 'B']]
crm_results = {"success": 0, "errors": 0}
if os.getenv("HUBSPOT_API_KEY"):
crm_results = pipeline_agent.tools[1]._run(final_companies, min_lead_grade)
progress_bar.progress(100)
status_text.text("✅ Fluxo de trabalho concluído com sucesso!")
st.session_state.workflow_results = {
'companies': final_companies,
'total_companies': len(final_companies),
'total_triggers': total_triggers,
'total_contacts': total_contacts,
'qualified_leads': len(qualified_leads),
'crm_results': crm_results,
'timestamp': datetime.now()
}
except Exception as e:
st.error(f"❌ Falha no fluxo de trabalho: {str(e)}")
st.write("Verifique as configurações da API e tente novamente.")
if st.session_state.workflow_results:
results = st.session_state.workflow_results
st.markdown("---")
st.subheader("📊 Resultados do fluxo de trabalho")
col1, col2, col3, col4 = st.columns(4)
com col1:
st.metric("Empresas analisadas", results['total_companies'])
com col2:
st.metric("Eventos acionados", results['total_triggers'])
com col3:
st.metric("Contatos encontrados", resultados['total_contacts'])
com col4:
st.metric("Leads qualificados", resultados['qualified_leads'])
se resultados['crm_results']['success'] > 0 ou resultados['crm_results']['errors'] > 0:
st.subheader("🔄 Integração com o HubSpot CRM")
col1, col2 = st.columns(2)
com col1:
st.metric("Exportado para o CRM", resultados['crm_results']['success'], delta="contacts")
com col2:
if results['crm_results']['errors'] > 0:
st.metric("Erros de exportação", results['crm_results']['errors'], delta_color="inverse")
st.subheader("🏢 Inteligência empresarial")
para empresa em resultados['empresas'][:10]:
com st.expander(f"📋 {empresa.obter('nome', 'Desconhecido')} - Nota {empresa.obter('nota_liderança', 'D')} (Pontuação: {empresa.obter('pontuação_liderança', 0):.0f})"):
col1, col2 = st.columns(2)
com col1:
st.write(f"**Setor:** {company.get('industry', 'Desconhecido')}")
st.write(f"**Domínio:** {company.get('domain', 'Desconhecido')}")
st.write(f"**Pontuação ICP:** {company.get('icp_score', 0)}")
gatilhos = empresa.obter('eventos_gatilho', [])
se gatilhos:
st.escrever("**🎯 Eventos Gatilho:**")
para gatilho em gatilhos:
severity_emoji = {"high": "🔥", "medium": "⚡", "low": "💡"}.get(trigger.get('severity', 'low'), '💡')
st.write(f"{severity_emoji} {trigger.get('description', 'Desconhecido trigger')}")
com col2:
contacts = company.get('contacts', [])
se contacts:
st.write("**👥 Tomadores de decisão:**")
para contact em contacts:
confiança = contato.obter('confiança_pontuação', 0)
confiança_cor = "🟢" se confiança >= 75 else "🟡" se confiança >= 50 else "🔴"
st.write(f"{confiança_cor} **{contato.obter('primeiro_nome', '')} {contato.obter('sobrenome', '')}**")
st.write(f" {contact.get('title', 'Título desconhecido')}")
st.write(f" 📧 {contact.get('email', 'Sem e-mail')}")
st.write(f" Confiança: {confidence}%")
message = contact.get('generated_message', {})
if message.get('subject'):
st.write(f" **Assunto:** {message['subject']}")
if message.get('body'):
preview = message['body'][:100] + "..." if len(message['body']) > 100 else message['body']
st.write(f" **Pré-visualização:** {preview}")
st.write("---")
st.subheader("📥 Exportar e ações")
col1, col2, col3 = st.columns(3)
with col1:
export_data = []
for company in results['companies']:
para contato em empresa.obter('contatos', []):
export_data.append({
'Empresa': empresa.obter('nome', ''),
'Setor': empresa.obter('setor', ''),
'Nível de lead': empresa.obter('nível_de_lead', ''),
'Pontuação de lead': empresa.obter('pontuação_de_lead', 0),
'Contagem de Gatilhos': len(company.get('trigger_events', [])),
'Nome do Contato': f"{contact.get('first_name', '')} {contact.get('last_name', '')}",
'Cargo': contact.get('title', ''),
'E-mail': contact.get('email', ''),
'Confiança': contact.get('confidence_score', 0),
'Assunto': contact.get('generated_message', {}).get('subject', ''),
'Mensagem': contact.get('generated_message', {}).get('body', '')
})
if export_data:
df = pd.DataFrame(export_data)
csv = df.to_csv(index=False)
st.download_button(
label="📄 Baixar relatório completo (CSV)",
data=csv,
file_name=f"ai_bdr_prospects_{datetime.now().strftime('%Y%m%d_%H%M')}.csv",
mime="text/csv",
use_container_width=True
)
com col2:
se st.button("🔄 Sincronizar com o HubSpot CRM", use_container_width=True):
se não os.getenv("HUBSPOT_API_KEY"):
st.warning("Chave API HubSpot necessária para exportação CRM")
caso contrário:
com st.spinner("Sincronizando com o HubSpot..."):
pipeline_agent = create_pipeline_manager_agent()
new_crm_results = pipeline_agent.tools[1]._run(results['companies'], min_lead_grade)
st.session_state.workflow_results['crm_results'] = new_crm_results
st.rerun()
com col3:
se st.button("🗑️ Limpar resultados", use_container_width=True):
st.session_state.workflow_results = None
st.rerun()
se __name__ == "__main__":
passO sistema de orquestração Streamlit coordena todos os agentes em um fluxo de trabalho eficiente, com acompanhamento do progresso em tempo real e configurações personalizáveis. Ele oferece exibições claras dos resultados com métricas, informações detalhadas da empresa e opções de exportação. A interface facilita o gerenciamento de operações complexas com vários agentes por meio de um painel intuitivo que as equipes de vendas podem usar sem habilidades técnicas.
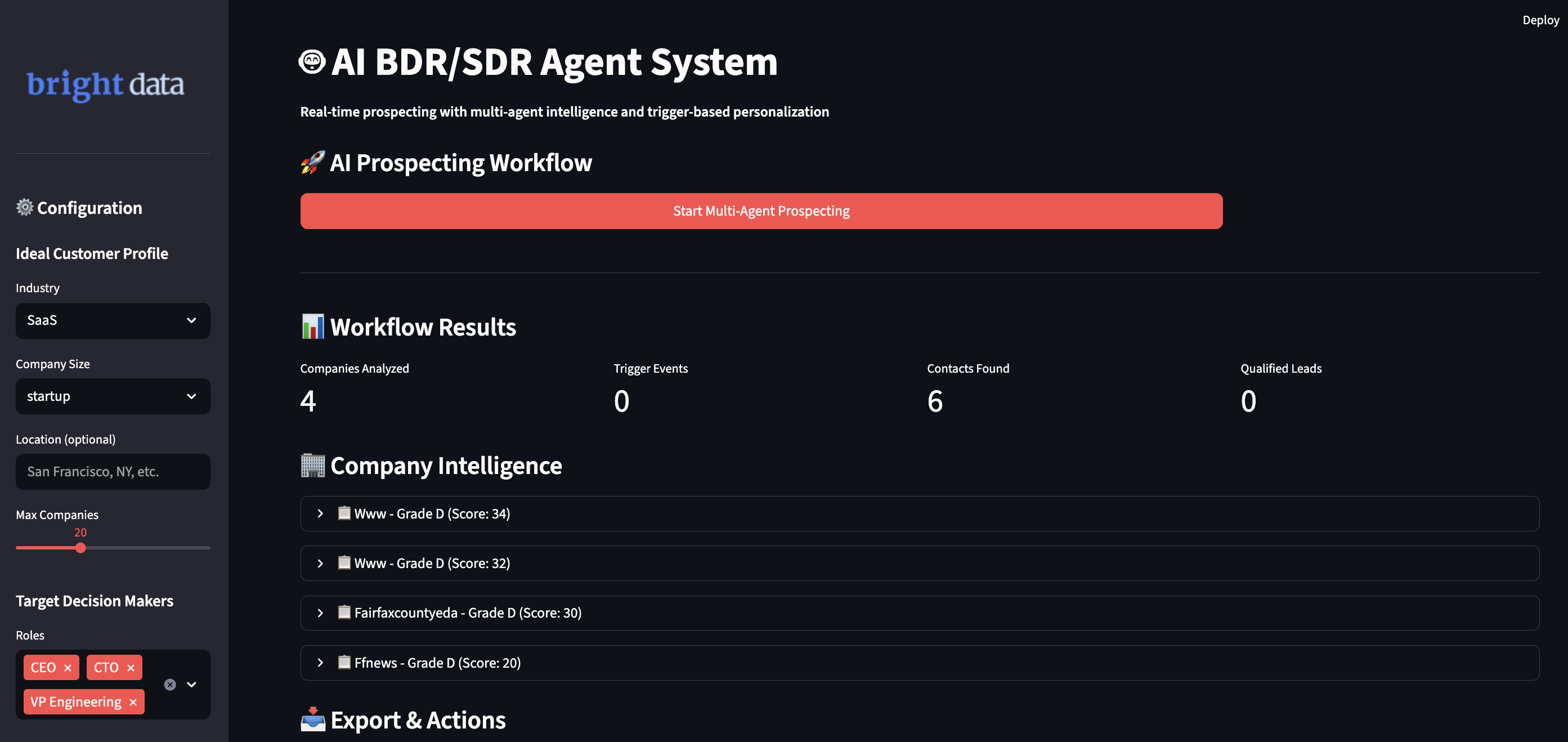
Executando seu sistema IA BDR
Execute o aplicativo para iniciar fluxos de trabalho de prospecção inteligente. Abra seu terminal e vá para o diretório do seu projeto.
streamlit run ai_bdr_system.py
Você verá o fluxo de trabalho inteligente do sistema à medida que ele lida com suas necessidades:
- Ele encontra empresas que correspondem ao seu perfil de cliente ideal usando verificações de dados em tempo real.
- Ele rastreia eventos desencadeadores de várias fontes para encontrar o melhor momento.
- Ele pesquisa contatos de tomadores de decisão usando várias fontes e pontuações de confiabilidade.
- Ele cria mensagens personalizadas que mencionam insights comerciais específicos.
- Ele pontua leads automaticamente e adiciona clientes potenciais qualificados ao seu pipeline de CRM.
Considerações finais
Este sistema de IA BDR mostra como a automação pode otimizar a prospecção e a qualificação de leads. Para aprimorar ainda mais seu pipeline de vendas, considere os produtos da Bright Data, como nosso conjunto de dados do LinkedIn para obter dados precisos de contatos e empresas, bem como outros Conjuntos de Dados e ferramentas de automação criados para equipes de BDR e vendas.
Explore mais soluções na documentação da Bright Data.
Crie uma conta gratuita na Bright Data para começar a construir seus fluxos de trabalho BDR automatizados.





