

Neste guia, você verá:
- O que é o AG2 e como ele oferece suporte ao desenvolvimento de sistemas de agente único e multiagente, bem como os benefícios de estendê-lo com a Bright Data.
- Os pré-requisitos para começar a usar essa integração.
- Como potencializar uma arquitetura multiagente AG2 com o Bright Data por meio de ferramentas personalizadas.
- Como conectar o AG2 ao Web MCP da Bright Data.
Vamos começar!
Uma introdução ao AG2 (anteriormente AutoGen)
O AG2 é uma estrutura AgentOS de código aberto para a criação de agentes de IA e sistemas multiagentes capazes de colaborar de forma autônoma para resolver tarefas complexas. Ele permite criar fluxos de trabalho de agente único, orquestrar vários agentes especializados e integrar ferramentas externas em pipelines modulares prontos para produção.
O AG2, anteriormente AutoGen, é uma evolução da biblioteca Microfost AutoGen. Ele preserva a arquitetura original e a compatibilidade com versões anteriores, ao mesmo tempo em que permite fluxos de trabalho multiagentes, integração de ferramentas e IA com intervenção humana. Escrito em Python, ele tem mais de 4 mil estrelas no GitHub.
(Se você estiver procurando orientações sobre como integrar o Bright Data ao AutoGen, consulte a postagem dedicada no blog.)
O AG2 oferece a flexibilidade e os padrões de orquestração avançados necessários para levar projetos de IA agênica da experimentação à produção.
Alguns de seus principais recursos incluem padrões de conversação multiagente, suporte humano no loop, integração de ferramentas e gerenciamento estruturado de fluxo de trabalho. Seu objetivo final é ajudá-lo a construir sistemas sofisticados de IA com o mínimo de sobrecarga.
Apesar dessas capacidades maravilhosas, os agentes AG2 ainda enfrentam limitações centrais do LLM: conhecimento estático dos dados de treinamento e nenhum acesso nativo às informações da web ao vivo!
A integração do AG2 com um provedor de dados da web como a Bright Data resolve todas essas questões. Conectar os agentes AG2 às APIs da Bright Data para Scraping de dados, pesquisa e automação do navegador permite dados da web estruturados em tempo real, aumentando sua inteligência, autonomia e utilidade prática.
Pré-requisitos
Para acompanhar este guia, você precisa de:
- Python 3.10 ou superior instalado em sua máquina local.
- Uma conta Bright Data com a API Web Unlocker, API SERP e uma chave API configurada. (Este tutorial irá guiá-lo por todas as configurações necessárias.)
- Uma chave API OpenAI (ou uma chave API de qualquer outro LLM compatível com AG2).
Também é útil ter alguma familiaridade com os produtos e serviços da Bright Data, bem como um conhecimento básico de como funciona o sistema de ferramentas AG2.
Como integrar a Bright Data em um fluxo de trabalho multiagente AG2
Nesta seção passo a passo, você criará um fluxo de trabalho AG2 multiagente com base nos serviços da Bright Data. Em particular, um agente dedicado à recuperação de dados da web acessará o Web Unlocker e a API SERP da Bright Data por meio de funções personalizadas da ferramenta AG2.
Esse sistema multiagente identificará os principais influenciadores em plataformas como o Twitch no setor alimentício para apoiar a promoção de um novo tipo de hambúrguer. Este exemplo demonstra como o AG2 pode automatizar a coleta de dados, produzir relatórios comerciais estruturados e permitir a tomada de decisões informadas, tudo sem esforço manual.
Veja como implementá-lo!
Etapa 1: crie um projeto AG2
Abra um terminal e crie uma nova pasta para o seu projeto AG2. Por exemplo, nomeie-a ag2-bright-data-agent:
mkdir ag2-bright-data-agentag2-bright-data-agent/ conterá o código Python para implementar e orquestrar agentes AG2 que se integram às funções do Bright Data.
Em seguida, vá para o diretório do projeto e crie um ambiente virtual dentro dele:
cd ag2-bright-data-agent
python -m venv .venvAdicione um novo arquivo chamado agent.py à raiz do projeto. A estrutura do seu projeto agora deve ficar assim:
ag2-bright-data-agent/
├── .venv/
└── agent.py # <----O arquivo agent.py conterá a definição do agente AG2 e a lógica de orquestração.
Abra a pasta do projeto em seu IDE Python preferido, como o Visual Studio Code com a extensão Python ou o PyCharm Community Edition.
Agora, ative o ambiente virtual que você acabou de criar. No Linux ou macOS, execute:
source .venv/bin/activateDe forma equivalente, no Windows, execute:
.venv/Scripts/activateCom o ambiente virtual ativado, instale as dependências PyPI necessárias:
pip install ag2[openai] requests python-dotenvEste aplicativo depende das seguintes bibliotecas:
ag2[openai]: Para construir e orquestrar fluxos de trabalho de IA multiagente alimentados por modelos OpenAI.requests: Para fazer solicitações HTTP aos serviços da Bright Data por meio de ferramentas personalizadas.python-dotenv: para carregar segredos necessários a partir de variáveis de ambiente definidas em um arquivo.env
Parabéns! Agora você tem um ambiente Python pronto para uso para desenvolvimento de IA multiagente com AG2.
Etapa 2: Configurar a integração LLM
Os agentes AG2 que você criará nas próximas etapas precisam de um cérebro, que é fornecido por um LLM. Cada agente pode usar sua própria configuração LLM, mas, para simplificar, conectaremos todos os agentes ao mesmo modelo OpenAI.
O AG2 inclui um mecanismo integrado para carregar as configurações do LLM a partir de um arquivo de configuração dedicado. Para fazer isso, adicione o seguinte código ao agent.py:
from autogen import LLMConfig
# Carregar a configuração LLM do arquivo de lista de configuração OpenAI
llm_config = LLMConfig.from_json(path="OAI_CONFIG_LIST")Este código carrega a configuração LLM de um arquivo chamado OAI_CONFIG_LIST.json. Crie este arquivo no diretório raiz do seu projeto:
ag2-bright-data-agent/
├── .venv/
├── OAI_CONFIG_LIST.json # <----
└── agent.pyAgora, preencha OAI_CONFIG_LIST.json com o seguinte conteúdo:
[
{
"model": "gpt-5-mini",
"api_key": "<SUA_CHAVE_API_OPENAI>"
}
]Substitua o espaço reservado <SUA_CHAVE_API_OPENAI> pela sua chave API OpenAI real. Essa configuração alimenta seus agentes AG2 usando o modelo GPT-5 Mini, mas você pode trocar por qualquer outro modelo OpenAI compatível, se necessário.
A variável llm_config será passada para seus agentes e para o orquestrador de bate-papo em grupo. Isso permite que eles raciocinem, se comuniquem e executem tarefas usando o LLM configurado. Incrível!
Etapa 3: gerenciar a leitura de variáveis de ambiente
Seus agentes AG2 agora podem se conectar ao OpenAI, mas também precisam acessar outro serviço de terceiros: Bright Data. Assim como o OpenAI, o Bright Data autentica solicitações usando uma chave API externa.
Para evitar riscos de segurança, você nunca deve codificar chaves API diretamente em seu código. Em vez disso, a melhor prática é carregá-las a partir de variáveis de ambiente. É exatamente por isso que você instalou o python-dotenv anteriormente.
Primeiro, importe python-dotenv em agent.py. Use-o para carregar variáveis de ambiente de um arquivo .env usando a função load_dotenv():
from dotenv import load_dotenv
import os
# Carregue as variáveis de ambiente do arquivo .env
load_dotenv()Em seguida, adicione um arquivo .env ao diretório raiz do seu projeto, que deve conter:
ag2-bright-data-agent/
├── .venv/
├── OAI_CONFIG_LIST.json
├── .env # <----
└── agent.pyDepois de adicionar seus valores secretos ao arquivo .env, você poderá acessá-los no código usando os.getenv():
ENV_VALUE = os.getenv("ENV_NAME")Ótimo! Seu script pode carregar com segurança segredos de integração de terceiros a partir de variáveis de ambiente.
Etapa 4: Configurar os serviços da Bright Data
Conforme previsto na introdução, o agente de dados da web se conectará à API SERP e à API Web Unlocker da Bright Data para lidar com pesquisas na web e recuperação de conteúdo de páginas da web. Juntos, esses serviços dão ao agente a capacidade de buscar dados da web em tempo real em uma camada de recuperação de dados no estilo RAG.
Para interagir com esses dois serviços, você terá que definir duas ferramentas AG2 personalizadas mais tarde. Antes de fazer isso, você deve configurar tudo em sua conta Bright Data.
Comece criando uma conta Bright Data, se ainda não tiver uma. Caso contrário, faça login e acesse seu painel. A partir daí, navegue até a página “Proxies & Scraping” e revise a tabela “My Zones” que lista os serviços configurados em seu perfil: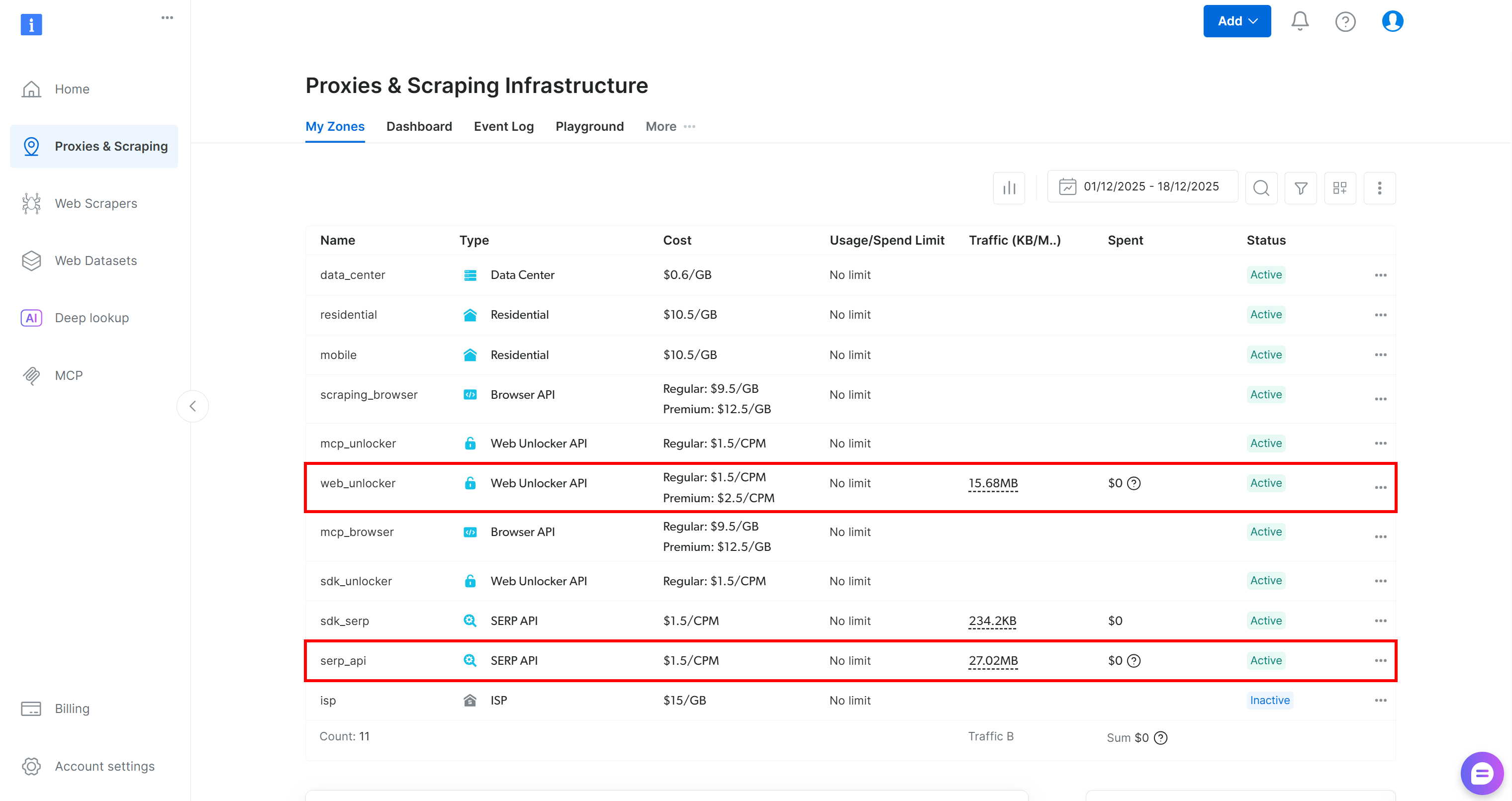
Se, como acima, a tabela já incluir uma zona Web Unlocker API (neste caso, chamada web_unlocker) e uma zona API SERP (neste caso, chamada serp_api), então você está pronto. Essas duas zonas serão usadas por suas ferramentas AG2 personalizadas para chamar os serviços Bright Data necessários.
Se uma ou ambas as zonas estiverem faltando, role para baixo até os cartões “Unblocker API” e “API SERP” e clique em “Criar zona” para cada um. Siga o assistente de configuração para criar ambas as zonas: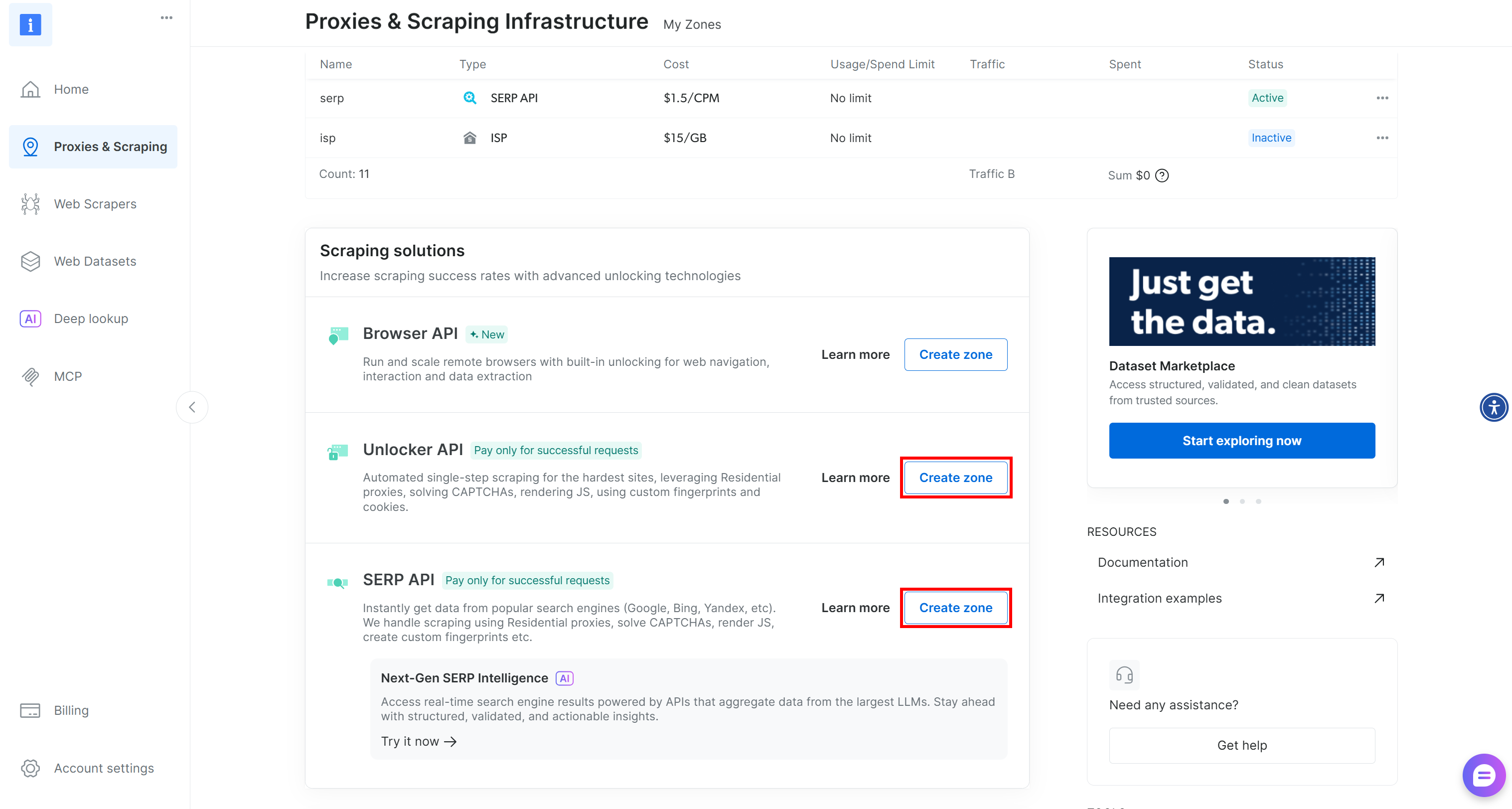
Para obter instruções detalhadas passo a passo, consulte a documentação oficial:
Importante: a partir de agora, vamos assumir que suas zonas são chamadas de serp_api e web_unlocker, respectivamente.
Quando suas zonas estiverem prontas, gere sua chave API da Bright Data. Armazene-a como uma variável de ambiente em .env:
BRIGHT_DATA_API_KEY="<SUA_CHAVE_API_BRIGHT_DATA>"Em seguida, carregue-a em agent.py, conforme mostrado abaixo:
BRIGHT_DATA_API_KEY = os.getenv("BRIGHT_DATA_API_KEY")Perfeito! Você tem todos os elementos necessários para conectar seus agentes AG2 aos serviços API SERP e Web Unlocker da Bright Data por meio de ferramentas personalizadas.
Etapa 5: Defina as ferramentas da Bright Data para seus agentes AG2
No AG2, as ferramentas fornecem recursos especializados que os agentes podem invocar para realizar ações e tomar decisões. Por trás dos bastidores, as ferramentas são simplesmente funções Python personalizadas que o AG2 expõe aos agentes de maneira estruturada.
Nesta etapa, você implementará duas funções de ferramenta em agent.py:
serp_api_tool(): Conecta-se à API SERP da Bright Data para realizar pesquisas no Google.web_unlocker_api_tool(): Conecta-se à API Bright Data Web Unlocker para recuperar o conteúdo da página da web, contornando todos os sistemas anti-bot.
Ambas as ferramentas usam o cliente HTTP Python Requests para fazer solicitações POST autenticadas à Bright Data com base nos documentos:
- Envie sua primeira solicitação com a API SERP da Bright Data
- Envie sua primeira solicitação com a API Web Unlocker da Bright Data
Para definir as duas funções da ferramenta, adicione o seguinte código ao agent.py:
from typing import Annotated
import requests
import urllib.parse
def serp_api_tool(
query: Annotated[str, "A consulta de pesquisa do Google"],)
-> str:
payload = {
"zone": "serp_api", # Substitua pelo nome da sua zona API SERP da Bright Data
"url": f"https://www.google.com/search?q={urllib.parse.quote_plus(query)}&brd_json=1",
"format": "raw",
}
headers = {
"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}",
"Content-Type": "application/json",
}
response = requests.post(
"https://api.brightdata.com/request",
json=payload,
headers=headers,
)
response.raise_for_status()
return response.text
def web_unlocker_api_tool(
url_to_fetch: Anotado[str, "URL da página de destino a ser buscada"],
data_format: Anotado[
str | Nenhum,
"Formato da página de saída (por exemplo, 'markdown' ou omitir para HTML bruto)"
] = "markdown",)
-> str:
payload = {
"zone": "web_unlocker", # Substitua pelo nome da sua zona Bright Data Web Unlocker
"url": url_to_fetch,
"format": "raw",
"data_format": data_format,
}
headers = {
"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}",
"Content-Type": "application/json",
}
response = requests.post(
"https://api.brightdata.com/request",
json=payload,
headers=headers
)
response.raise_for_status()
return response.textAs duas ferramentas autenticam as solicitações usando sua chave API da Bright Data e enviam solicitações POST para o endpoint da API da Bright Data:
serp_api_tool()consulta o Google e recupera os resultados da pesquisa em formato JSON estruturado, ativando o parâmetrobrd_json=1.web_unlocker_api_tool()busca qualquer página da web e retorna seu conteúdo em Markdown (ou HTML bruto, se desejado).
Importante: tanto JSON quanto Markdown são formatos excelentes para ingestão de LLM em agentes de IA.
Observe que ambas as funções usam Python typing junto com Annotated para descrever seus argumentos. Os tipos são necessários para transformar essas funções em ferramentas AG2 adequadas, enquanto as descrições de anotação ajudam o LLM a entender como preencher cada argumento ao invocar as ferramentas de dentro de um agente.
Ótimo! Seu aplicativo AG2 agora inclui duas ferramentas Bright Data, prontas para serem configuradas e utilizadas por seus agentes de IA.
Etapa 6: Implemente os agentes AG2
Agora que suas ferramentas estão instaladas, é hora de construir a estrutura do agente de IA descrita na introdução. Essa configuração consiste em três agentes complementares:
user_proxy: atua como a camada de execução, executando chamadas de ferramentas com segurança e orquestrando o fluxo de trabalho sem intervenção humana. É uma instância doUserProxyAgent, um agente AG2 especial que funciona como um Proxy para o usuário, executando código e fornecendo feedback a outros agentes conforme necessário.web_data_agent: responsável pela descoberta e recuperação de dados da web. Este agente pesquisa a web usando a API SERP da Bright Data e recupera o conteúdo da página por meio da API Web Unlocker. Como umConversableAgent, ele pode se comunicar com outros agentes e humanos, processar informações, seguir instruções definidas em sua mensagem de sistema e muito mais.reporting_agent: analisa os dados coletados e os transforma em um relatório Markdown estruturado e pronto para uso comercial para os tomadores de decisão.
Juntos, esses agentes formam um pipeline multiagente totalmente autônomo, projetado para a identificação de streamers do Twitch e a promoção de um produto direcionado.
Em agent.py, especifique todos os três agentes com o seguinte código:
from autogen import (
UserProxyAgent,
ConversableAgent,)
# Executa chamadas de ferramentas e orquestra o fluxo de trabalho sem intervenção humana
user_proxy = UserProxyAgent(
name="user_proxy",
code_execution_config=False,
human_input_mode="NEVER",
llm_config=llm_config,
)
# Responsável por pesquisar e recuperar dados da web
web_data_agent = ConversableAgent(
name="web_data_agent",
code_execution_config=False,
llm_config=llm_config,
system_message=(
"""
Você é um agente de recuperação de dados da web.
Você pesquisa na web usando a ferramenta Bright Data API SERP
e recupera o conteúdo da página usando a ferramenta Web Unlocker API.
"""
),
)
# Analisa os dados coletados e produz um relatório estruturado
reporting_agent = ConversableAgent(
name="reporting_agent",
code_execution_config=False,
system_message=(
"""
Você é um analista de marketing.
Você produz relatórios Markdown estruturados e prontos para uso comercial
destinados a tomadores de decisão.
"""
),
llm_config=llm_config,
# Encerra automaticamente a conversa assim que a palavra "relatório" aparece
is_termination_msg=lambda msg: "relatório" em (msg.get("conteúdo", "") ou "").lower()
)No código acima, observe que:
- Os agentes AG2 podem executar códigos contidos em mensagens (por exemplo, blocos de código) e passar os resultados para o próximo agente. Nesta configuração, a execução de código é desativada via
code_execution_config=Falsepor motivos de segurança. - Todos os agentes são alimentados pelo
llm_configcarregado na Etapa 2. - O
reporting_agentinclui uma funçãois_termination_msgpara encerrar automaticamente o fluxo de trabalho assim que a mensagem contiver a palavra “report”, sinalizando que a saída final foi produzida.
Em seguida, você registrará as ferramentas Bright Data com o web_data_agent para habilitar a recuperação da web!
Etapa 7: Registre as ferramentas AG2 Bright Data
Registre as funções Bright Data como ferramentas e atribua-as ao web_data_agent por meio do register_function(). O agente user_proxy atuará como executor dessas ferramentas, conforme exigido pela arquitetura do AG2:
from autogen import register_function
# Registrar a ferramenta de pesquisa SERP para o agente de dados da web
register_function(
serp_api_tool,
caller=web_data_agent,
executor=user_proxy,
description="Use a API SERP da Bright Data para realizar uma pesquisa no Google e retornar resultados brutos."
)
# Registrar a ferramenta Web Unlocker para buscar páginas protegidas
register_function(
web_unlocker_api_tool,
caller=web_data_agent,
executor=user_proxy,
description="Buscar uma página da web usando a API Web Unlocker da Bright Data, contornando proteções anti-bot comuns.",
)Observe que cada função inclui uma descrição concisa para ajudar o LLM a entender sua finalidade e saber quando chamá-la.
Com essas ferramentas registradas, o web_data_agent agora pode planejar pesquisas na web e acesso a páginas da web, enquanto o user_proxy lida com a execução.
Seu pipeline multiagente AG2 agora é totalmente capaz de descobrir e extrair dados de forma autônoma usando as APIs da Bright Data. Missão cumprida!
Etapa 8: Apresente a lógica de orquestração multiagente AG2
O AG2 oferece suporte a várias maneiras de orquestrar e gerenciar vários agentes. Neste exemplo, você verá o padrão GroupChat.
O núcleo de um chat em grupo AG2 é que todos os agentes contribuem para um único tópico de conversa, compartilhando o mesmo contexto. Essa abordagem é ideal para tarefas que exigem colaboração entre vários agentes, como em nosso pipeline.
Em seguida, um GroupChatManager lida com a coordenação dos agentes dentro do chat em grupo. Ele oferece suporte a diferentes estratégias para selecionar o próximo agente a agir. Aqui, você configurará a estratégia automática padrão, que aproveita o LLM do gerente para decidir qual agente deve falar em seguida.
Combine tudo para a orquestração de múltiplos agentes conforme abaixo:
from autogen import (
GroupChat,
GroupChatManager,)
# Defina o chat em grupo com vários agentes
groupchat = GroupChat(
agents=[user_proxy, web_data_agent, reporting_agent],
speaker_selection_method="auto",
messages=[],
max_round=20
)
# Gerente responsável pela coordenação das interações dos agentes
manager = GroupChatManager(
name="group_manager",
groupchat=groupchat,
llm_config=llm_config
)Observação: o fluxo de trabalho será encerrado quando o reporting_agent produzir uma mensagem que acione sua lógica is_termination_msg ou após 20 rodadas de interações entre os agentes (devido ao argumento max_round ), o que ocorrer primeiro.
Pronto! As definições dos agentes e a lógica de orquestração estão completas. A etapa final é iniciar o fluxo de trabalho e exportar os resultados.
Etapa 9: Inicie o fluxo de trabalho Agentic e exporte o resultado
Descreva a tarefa de pesquisa de influenciadores de streamers do Twitch em detalhes e passe-a como uma mensagem para o agente user_proxy para execução:
prompt_message = """
Cenário:
---------
Uma marca de alimentos e bebidas deseja promover um novo tipo de hambúrguer.
Objetivo:
- Pesquisar a página da categoria Alimentos e Bebidas no TwitchMetrics
- Buscar o conteúdo da página da categoria TwitchMetrics recuperada do SERP e selecionar os 5 principais streamers
- Visitar a página de perfil do TwitchMetrics de cada streamer e recuperar informações relevantes
- Produzir um relatório Markdown estruturado incluindo:
- Nome do canal
- Alcance estimado
- Foco do conteúdo
- Adequação do público
- Viabilidade do alcance da marca
"""
# Iniciar o fluxo de trabalho multiagente
user_proxy.initiate_chat(recipient=manager, message=prompt_message)Quando o fluxo de trabalho terminar, salve a saída (ou seja, o relatório Markdown) no disco com:
com open("report.md", "w", encoding="utf-8") as f:
f.write(user_proxy.last_message()["content"])Incrível! Seu fluxo de trabalho multiagente AG2 + Bright Data agora está totalmente operacional e pronto para coletar, analisar e relatar dados de influenciadores do Twitch.
Etapa 10: Junte tudo
O código final no seu arquivo agent.py será:
from autogen import (
LLMConfig,
UserProxyAgent,
ConversableAgent,
register_function,
GroupChat,
GroupChatManager,)
from dotenv import load_dotenv
import os
from typing import Annotated
import requests
import urllib.parse
# Carregue a configuração LLM do arquivo de lista de configuração OpenAI
llm_config = LLMConfig.from_json(path="OAI_CONFIG_LIST")
# Carregue as variáveis de ambiente do arquivo .env
load_dotenv()
# Recupere a chave API Bright Data das variáveis de ambiente
BRIGHT_DATA_API_KEY = os.getenv("BRIGHT_DATA_API_KEY")
# Definir as funções para implementar as ferramentas Bright Data
def serp_api_tool(
query: Annotated[str, "A consulta de pesquisa do Google"],)
-> str:
payload = {
"zone": "serp_api", # Substitua pelo nome da sua zona API SERP Bright Data
"url": f"https://www.google.com/search?q={urllib.parse.quote_plus(query)}&brd_json=1",
"format": "raw",
}
headers = {
"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}",
"Content-Type": "application/json",
}
response = requests.post(
"https://api.brightdata.com/request",
json=payload,
headers=headers,
)
response.raise_for_status()
return response.text
def web_unlocker_api_tool(
url_to_fetch: Anotado[str, "URL da página de destino a ser buscada"],
data_format: Anotado[
str | Nenhum,
"Formato da página de saída (por exemplo, 'markdown' ou omitir para HTML bruto)"
] = "markdown",)
-> str:
payload = {
"zone": "web_unlocker", # Substitua pelo nome da sua zona Bright Data Web Unlocker
"url": url_to_fetch,
"format": "raw",
"data_format": data_format,
}
headers = {
"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}",
"Content-Type": "application/json",
}
response = requests.post(
"https://api.brightdata.com/request",
json=payload,
headers=headers
)
response.raise_for_status()
return response.text
# Executa chamadas de ferramentas e orquestra o fluxo de trabalho sem intervenção humana
user_proxy = UserProxyAgent(
name="user_proxy",
code_execution_config=False,
human_input_mode="NEVER",
llm_config=llm_config,
)
# Responsável por pesquisar e recuperar dados da web
agente_de_dados_da_web = ConversableAgent(
nome="agente_de_dados_da_web",
configuração_de_execução_de_código=False,
configuração_llm=configuração_llm,
mensagem_do_sistema=(
"""
Você é um agente de recuperação de dados da web.
Você pesquisa na web usando a ferramenta Bright Data API SERP
e recupera o conteúdo da página usando a ferramenta Web Unlocker API.
"""
),
)
# Analisa os dados coletados e produz um relatório estruturado
reporting_agent = ConversableAgent(
name="reporting_agent",
code_execution_config=False,
system_message=(
"""
Você é um analista de marketing.
Você produz relatórios Markdown estruturados e prontos para uso comercial
destinados a tomadores de decisão.
"""
),
llm_config=llm_config,
# Encerra automaticamente a conversa assim que a palavra "relatório" aparece
is_termination_msg=lambda msg: "relatório" em (msg.get("content", "") ou "").lower()
)
# Registrar uma ferramenta de pesquisa SERP para o agente de dados da web
register_function(
serp_api_tool,
caller=web_data_agent,
executor=user_proxy,
description="Use a API SERP da Bright Data para realizar uma pesquisa no Google e retornar resultados brutos."
)
# Registrar a ferramenta Web Unlocker para buscar páginas protegidas
register_function(
web_unlocker_api_tool,
caller=web_data_agent,
executor=user_proxy,
description="Busque uma página da web usando a API Web Unlocker da Bright Data, contornando as proteções anti-bot comuns.",
)
# Definir o chat em grupo com vários agentes
groupchat = GroupChat(
agents=[user_proxy, web_data_agent, reporting_agent],
speaker_selection_method="auto",
messages=[],
max_round=20
)
# Gerente responsável por coordenar as interações dos agentes
gerente = GroupChatManager(
nome="gerente_do_grupo",
chat_em_grupo=chat_em_grupo,
llm_config=llm_config)
mensagem_de_prompt = """
Cenário:
---------
Uma marca de alimentos e bebidas deseja promover um novo tipo de hambúrguer.
Objetivo:
- Pesquisar a página da categoria Alimentos e Bebidas no TwitchMetrics
- Buscar o conteúdo da página da categoria TwitchMetrics recuperado do SERP e selecionar os 5 principais streamers
- Visitar a página de perfil do TwitchMetrics de cada streamer e recuperar informações relevantes
- Produzir um relatório Markdown estruturado incluindo:
- Nome do canal
- Alcance estimado
- Foco do conteúdo
- Adequação do público
- Viabilidade do alcance da marca
"""
# Iniciar o fluxo de trabalho multiagente
user_proxy.initiate_chat(recipient=manager, message=prompt_message)
# Persista o relatório final em um arquivo Markdown
com open("report.md", "w", encoding="utf-8") como f:
f.write(user_proxy.last_message()["content"])Graças à poderosa API AG2, com apenas cerca de 170 linhas de código, você criou um fluxo de trabalho multiagente complexo, pronto para uso corporativo e alimentado pela Bright Data!
Etapa 11: Teste o sistema multiagente
No seu terminal, verifique se o seu aplicativo de agente AG2 funciona com:
python agent.pyA saída esperada será semelhante a esta: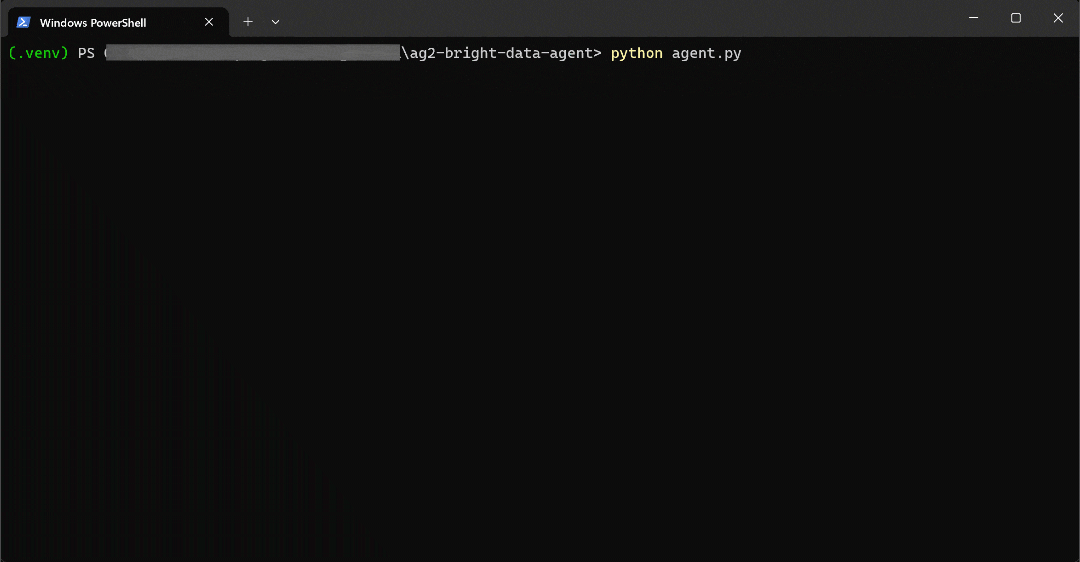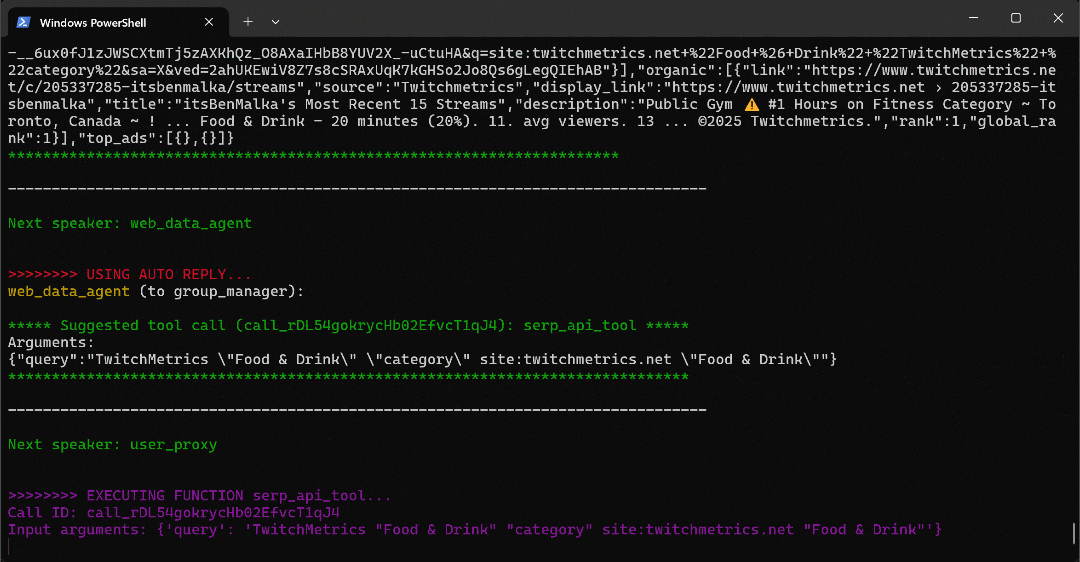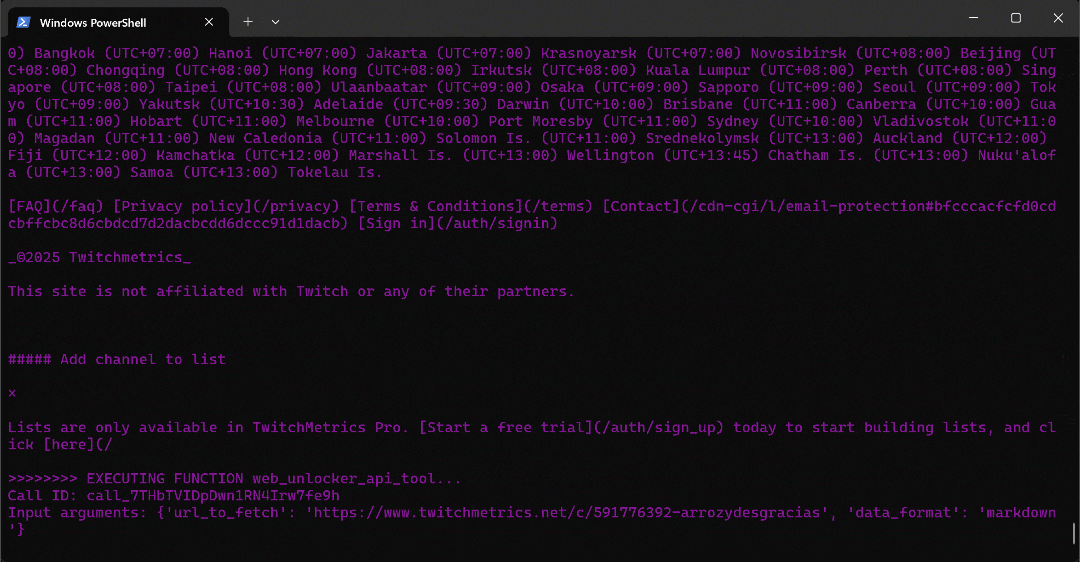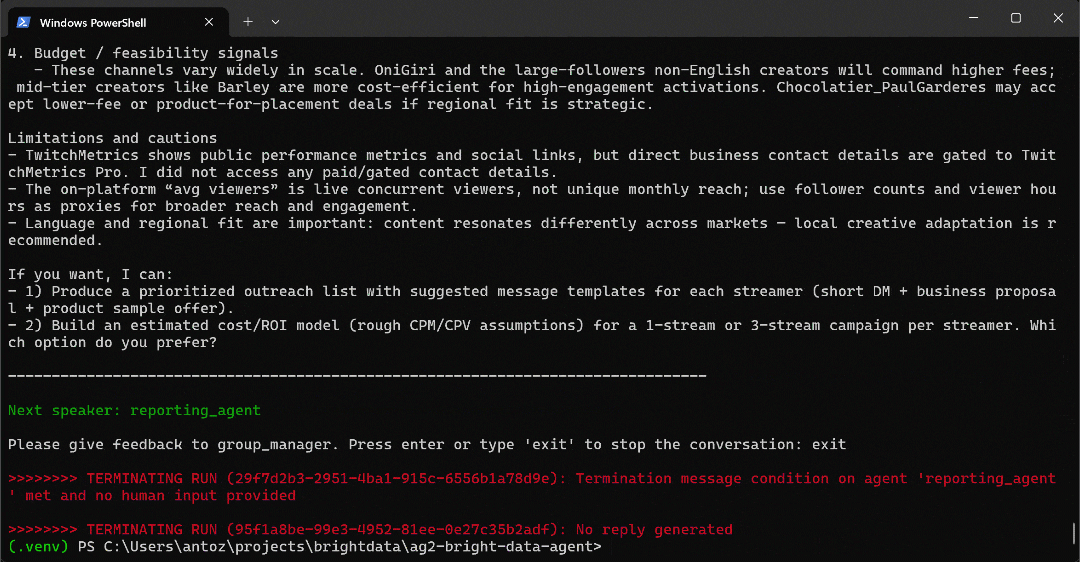
Em detalhes, observe como o fluxo de trabalho multiagente prossegue passo a passo:
- O
web_data_agentdetermina que precisa chamar oserp_api_toolpara localizar a página da categoria “Alimentos e bebidas” do TwitchMetrics. - Por meio do agente
user_proxy, a ferramenta executa várias consultas de pesquisa. - Depois que a página da categoria TwitchMetrics correta é identificada, ela chama o
web_unlocker_api_toolpara extrair o conteúdo no formato Markdown. - A partir da saída do Markdown, ele extrai as URLs dos 5 principais perfis de influenciadores do TwitchMetrics na categoria “Alimentos e Bebidas”.
- A ferramenta
web_unlocker_api_toolé chamada novamente para recuperar o conteúdo da página de cada perfil em Markdown. - Todos os dados coletados são passados para o
reporting_agent, que os analisa e produz o relatório final.
Esse relatório final é salvo em disco como report.md, conforme especificado no código:
Visualize-o no VS Code usando a visualização Markdown para ver como o relatório é detalhado e rico em informações: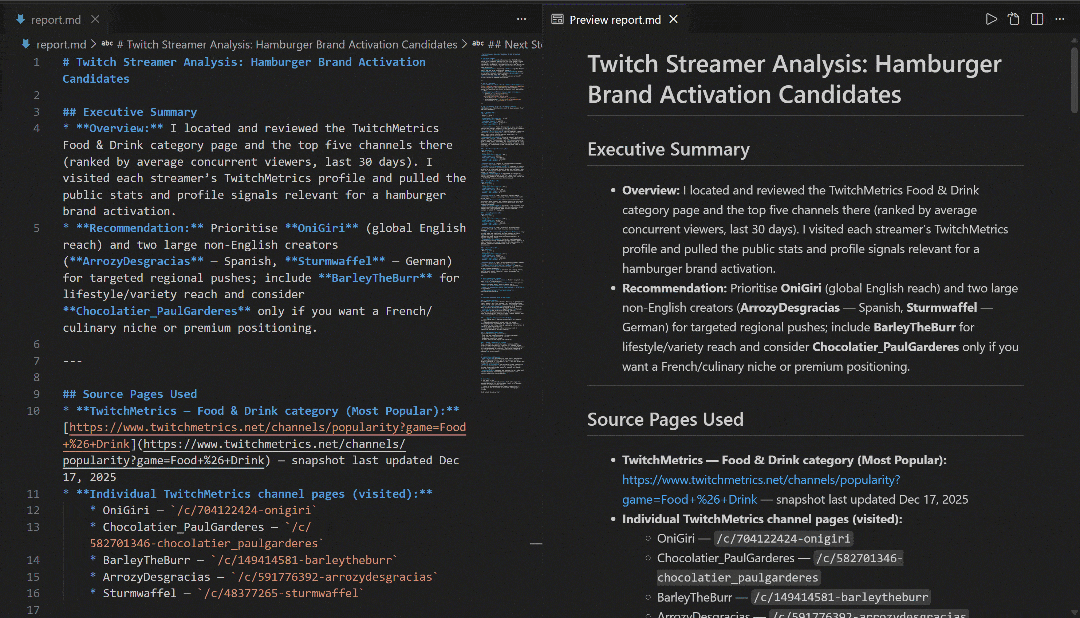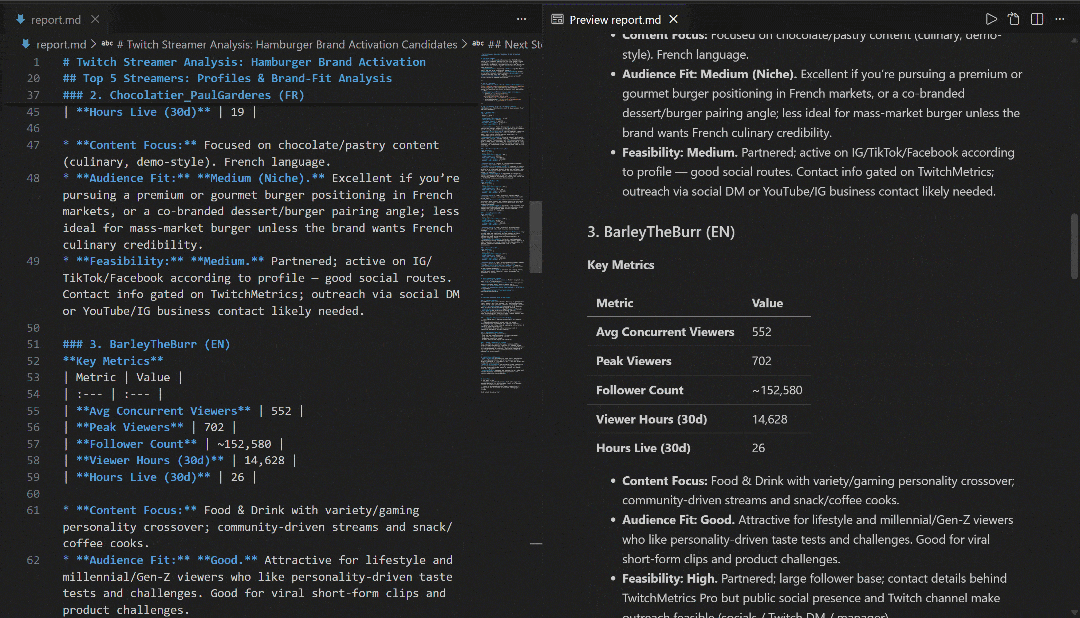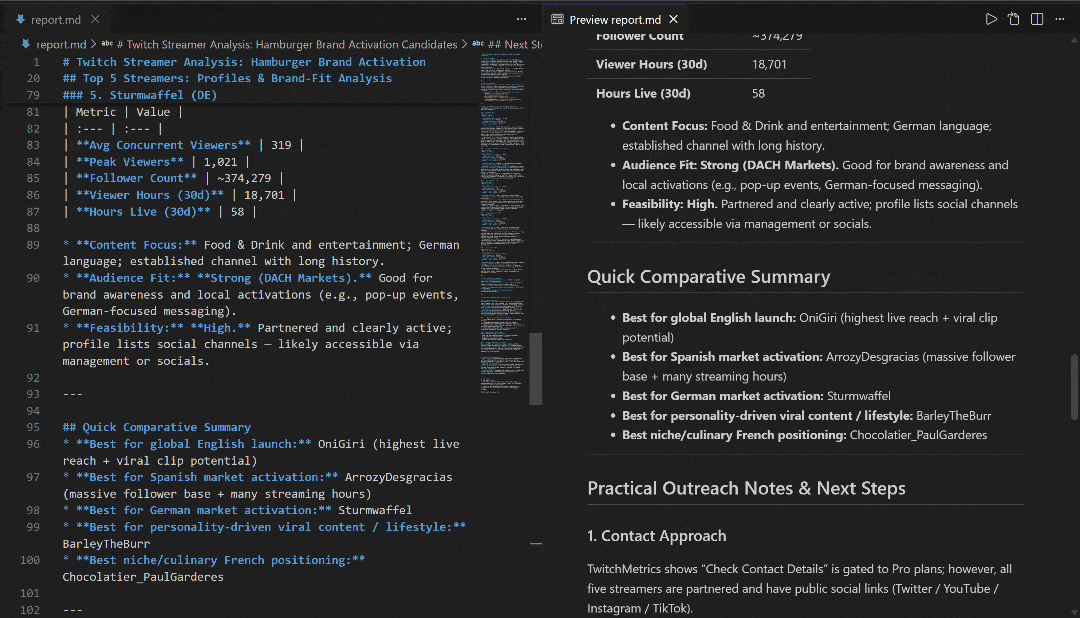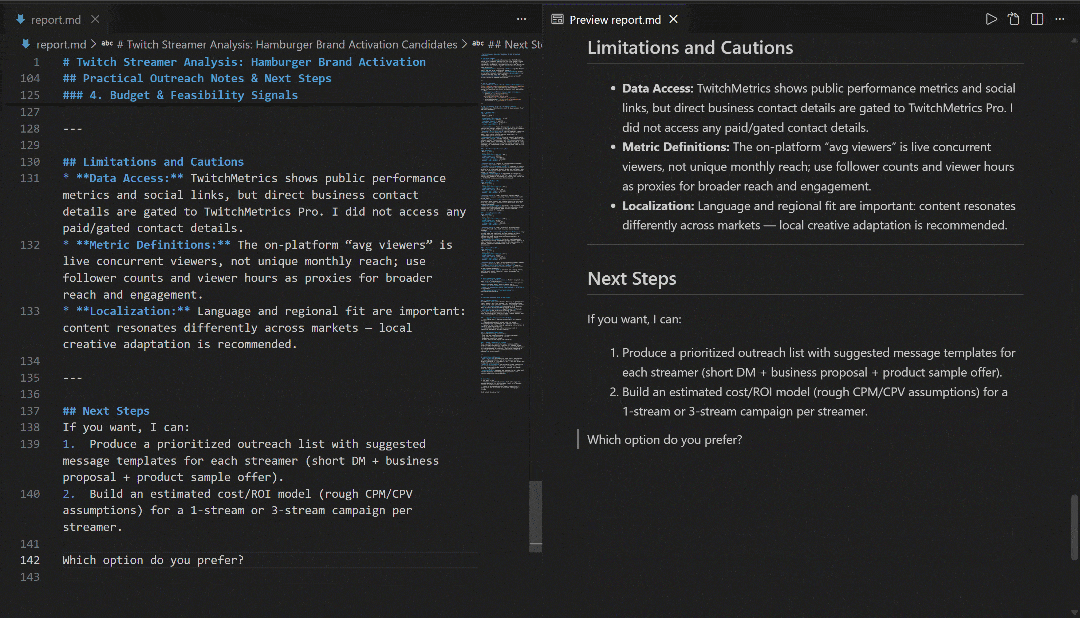
Se você está se perguntando de onde vêm os dados de origem, verifique a página da categoria de transmissão Food & Drink Twitch no TwitchMetrics: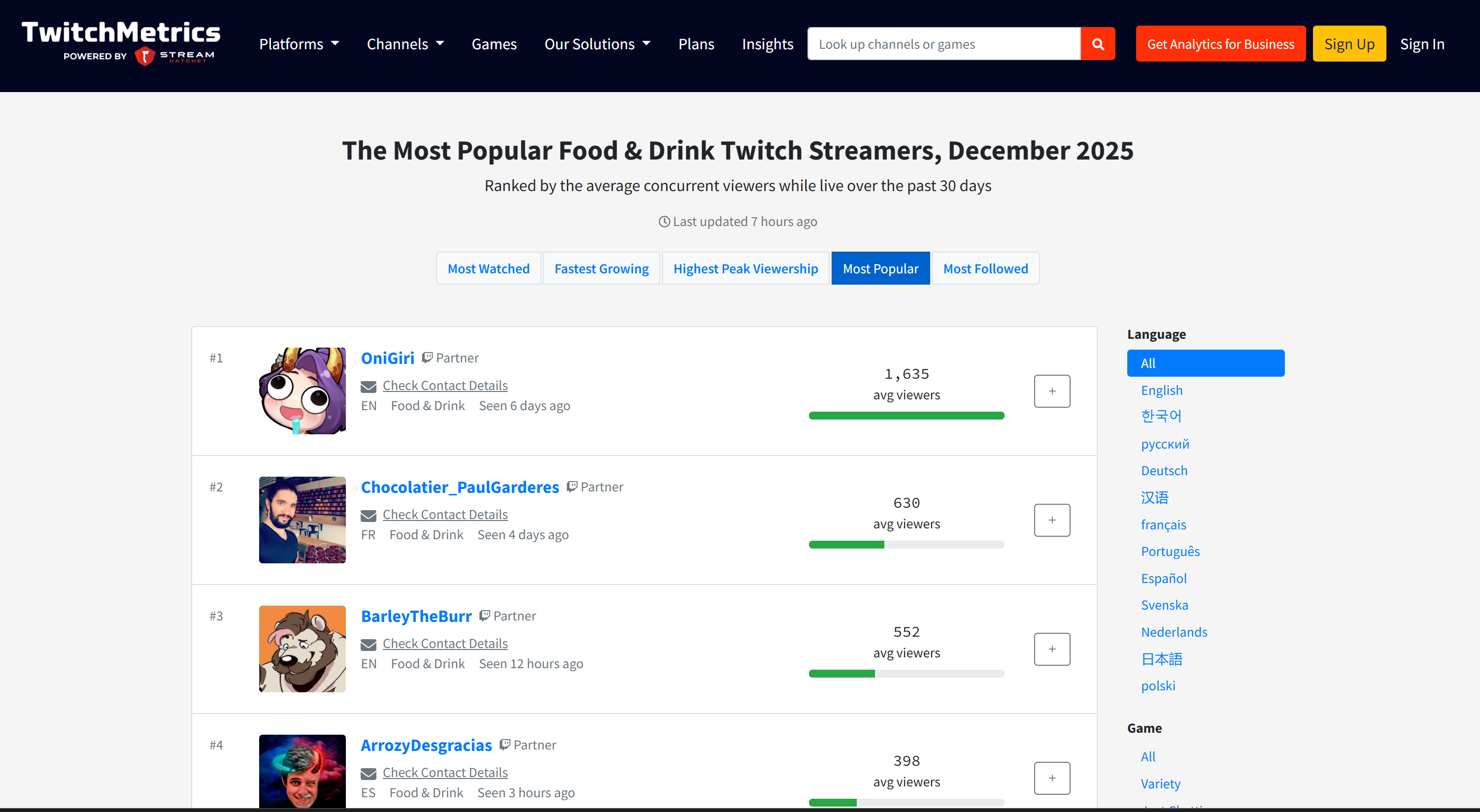
Observe que as informações do streamer do Twitch no relatório correspondem às páginas de perfil dedicadas do TwitchMetrics para cada um dos 5 principais perfis: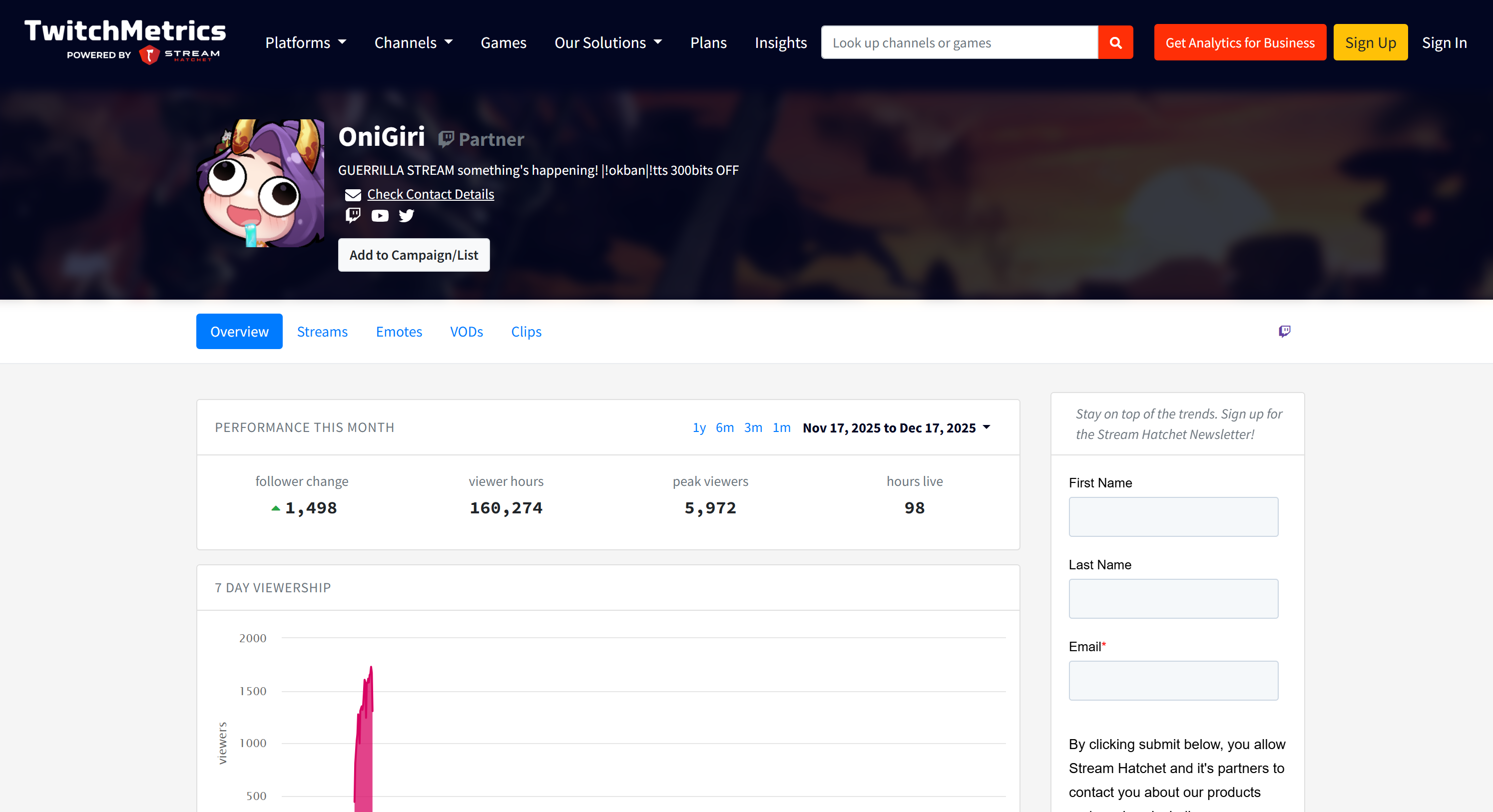
Todas essas informações foram recuperadas automaticamente pelo sistema multiagente, demonstrando o poder do AG2 e sua integração com o Bright Data.
Agora, fique à vontade para experimentar diferentes prompts de entrada. Graças ao Bright Data, seu fluxo de trabalho multiagente AG2 pode lidar com uma variedade de tarefas do mundo real.
Et voilà! Você acabou de testemunhar os recursos de um fluxo de trabalho AG2 aprimorado com o Bright Data
Conectando o AG2 ao Bright Data Web MCP: um guia passo a passo
Outra maneira de integrar o Bright Data ao AG2 é através do servidor Bright Data Web MCP.
O Web MCP dá acesso a mais de 60 ferramentas criadas com base na plataforma de automação web e coleta de dados da Bright Data. Mesmo na versão gratuita, ele oferece duas ferramentas poderosas:
| Ferramenta | Descrição |
|---|---|
search_engine |
Busque resultados do Google, Bing ou Yandex no formato JSON ou Markdown. |
scrape_as_markdown |
Extraia qualquer página da web para Markdown limpo, contornando medidas anti-bot. |
O modo Pro do Web MCP leva a funcionalidade ainda mais longe. Esta opção premium desbloqueia a extração de dados estruturados para as principais plataformas, como Amazon, LinkedIn, Instagram, Reddit, YouTube, TikTok, Google Maps e muito mais. Também adiciona ferramentas para automação avançada do navegador.
Observação: para configurar o projeto, consulte a Etapa 1 do capítulo anterior.
A seguir, vamos ver como usar o Web MCP da Bright Data no AG2!
Pré-requisitos
Para seguir esta seção do tutorial, você precisa ter o Node.js instalado localmente, pois ele é necessário para executar o Web MCP em sua máquina.
Você também deve instalar o pacote MCP para AG2 com:
pip install ag2[mcp]Isso permite que o AG2 atue como um cliente MCP.
Etapa 1: Comece a usar o Web MCP da Bright Data
Antes de conectar o AG2 ao Web MCP da Bright Data, certifique-se de que sua máquina local possa executar o servidor MCP. Isso é importante porque você verá como se conectar ao servidor Web MCP localmente.
Observação: o Web MCP também está disponível como um servidor remoto via Streamable HTTP, que é mais adequado para casos de uso de nível empresarial graças à sua escalabilidade ilimitada.
Primeiro, certifique-se de ter uma conta Bright Data. Se você já tiver, basta fazer login. Para uma configuração rápida, siga as instruções na seção“MCP”do seu painel:
Para obter orientações adicionais, consulte as etapas abaixo.
Comece gerando sua chave API Bright Data. Armazene-a em um local seguro, pois você a utilizará em breve para autenticar sua instância Web MCP local.
Em seguida, instale o Web MCP globalmente em sua máquina usando o pacote @brightdata/mcp:
npm install -g @brightdata/mcpInicie o servidor MCP executando:
API_TOKEN="<SUA_API_BRIGHT_DATA>" npx -y @brightdata/mcpOu, de forma equivalente, no PowerShell:
$Env:API_TOKEN="<YOUR_BRIGHT_DATA_API>"; npx -y @brightdata/mcpSubstitua <YOUR_BRIGHT_DATA_API> pelo seu token da API Bright Data. Esses comandos definem a variável de ambiente API_TOKEN necessária e iniciam o servidor Web MCP localmente.
Se for bem-sucedido, você deverá ver uma saída semelhante a esta:
Por padrão, o Web MCP cria duas zonas na sua conta Bright Data na primeira inicialização:
mcp_unlocker: uma zona para o Web Unlocker.mcp_browser: uma zona para a API do navegador.
Essas zonas alimentam as mais de 60 ferramentas disponíveis no Web MCP.
Você pode verificar se as zonas foram criadas acessando “Proxies e Infraestrutura de scraping” no painel do Bright Data: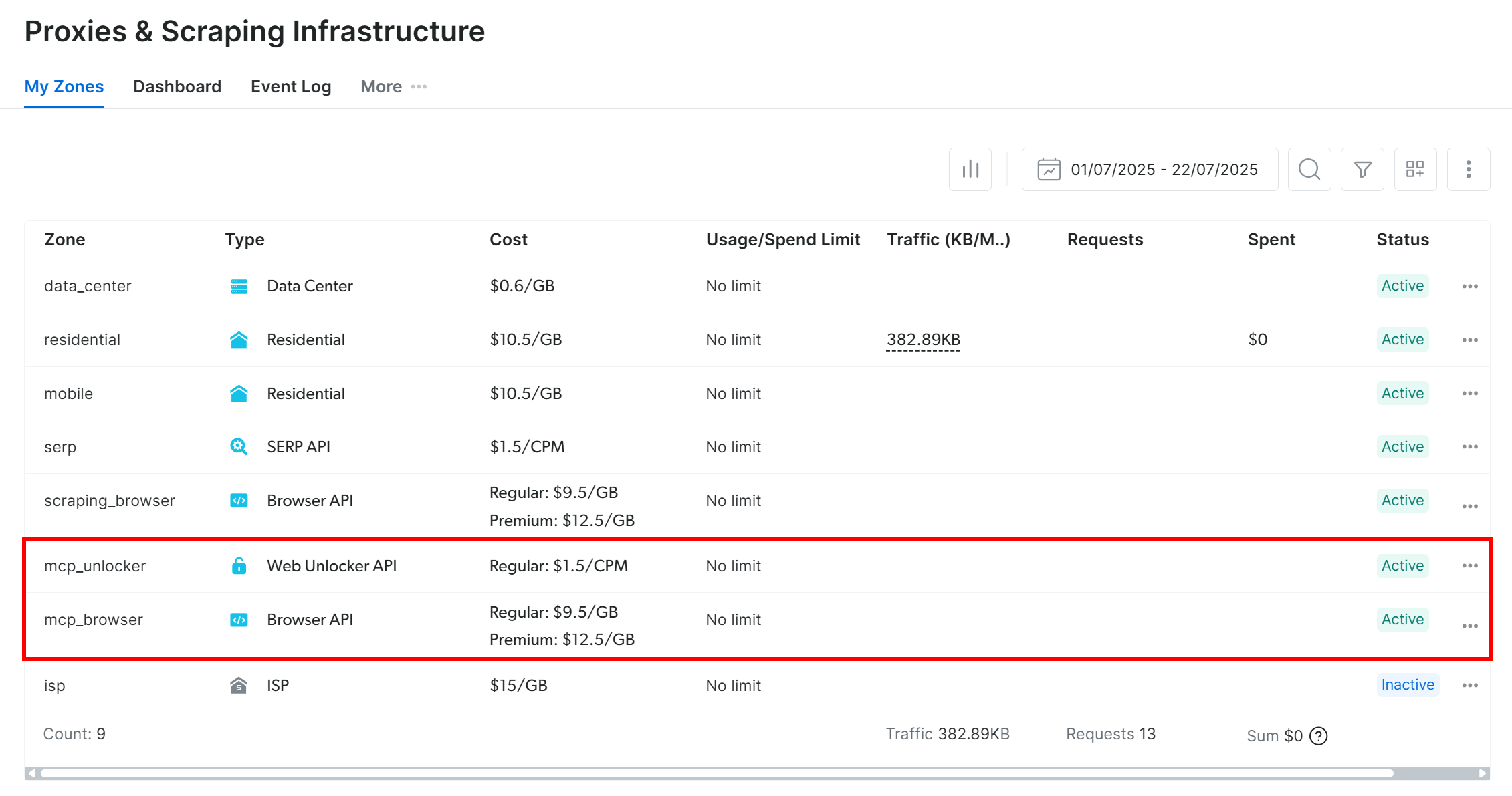
No nível gratuito do Web MCP, apenas as ferramentas search_engine e scrape_as_markdown (e suas versões em lote) estão disponíveis.
Para desbloquear todas as ferramentas, habilite o modo Pro definindo a variável de ambiente PRO_MODE="true":
API_TOKEN="<YOUR_BRIGHT_DATA_API>" PRO_MODE="true" npx -y @brightdata/mcpOu, no Windows:
$Env:API_TOKEN="<SUA_API_BRIGHT_DATA>"; $Env:PRO_MODE="true"; npx -y @brightdata/mcpO modo Pro desbloqueia todas as mais de 60 ferramentas, mas não está incluído no plano gratuito e pode acarretar custos adicionais.
Pronto! Você verificou que o servidor Web MCP é executado localmente. Interrompa o processo MCP por enquanto, pois a próxima etapa é configurar o AG2 para iniciar o servidor localmente e conectar-se a ele.
Etapa 2: integração do Web MCP no AG2
Use o cliente AG2 MCP para se conectar a uma instância local do Web MCP via STDIO e recuperar as ferramentas disponíveis:
from mcp import ClientSession, StdioServerParameters
from mcp.client.stdio import stdio_client
from autogen.mcp import create_toolkit
# Instruções para se conectar a uma instância local do Web MCP
server_params = StdioServerParameters(
command="npx",
args=["-y", "@brightdata/mcp"],
env={
"API_TOKEN": BRIGHT_DATA_API_KEY,
"PRO_MODE": "true" # Opcional
},)
async com stdio_client(server_params) como (read, write), ClientSession(read, write) como sessão:
# Crie uma sessão de conexão MCP e recupere as ferramentas
await session.initialize()
web_mcp_toolkit = await create_toolkit(session, use_mcp_resources=False)O objeto StdioServerParameters reflete o comando npx que você executou anteriormente, incluindo variáveis de ambiente para credenciais e configurações:
API_TOKEN: Obrigatório. Defina como sua chave API da Bright Data.PRO_MODE: Opcional. Remova se quiser permanecer no nível gratuito (search_engineescrape_as_markdowne suas versões em lote apenas).
A sessão é usada para se conectar ao Web MCP e criar um kit de ferramentas AG2 MCP usando create_toolkit.
Observação: conforme destacado em uma questão dedicada no GitHub, a opção use_mcp_resources=False é necessária para evitar o erro mcp.shared.exceptions.McpError: Método não encontrado.
Depois de criado, o objeto web_mcp_toolkit contém todas as ferramentas Web MCP. Verifique isso com:
for tool in web_mcp_toolkit.tools:
print(tool.name)
print(tool.description)
print("---n")A saída será: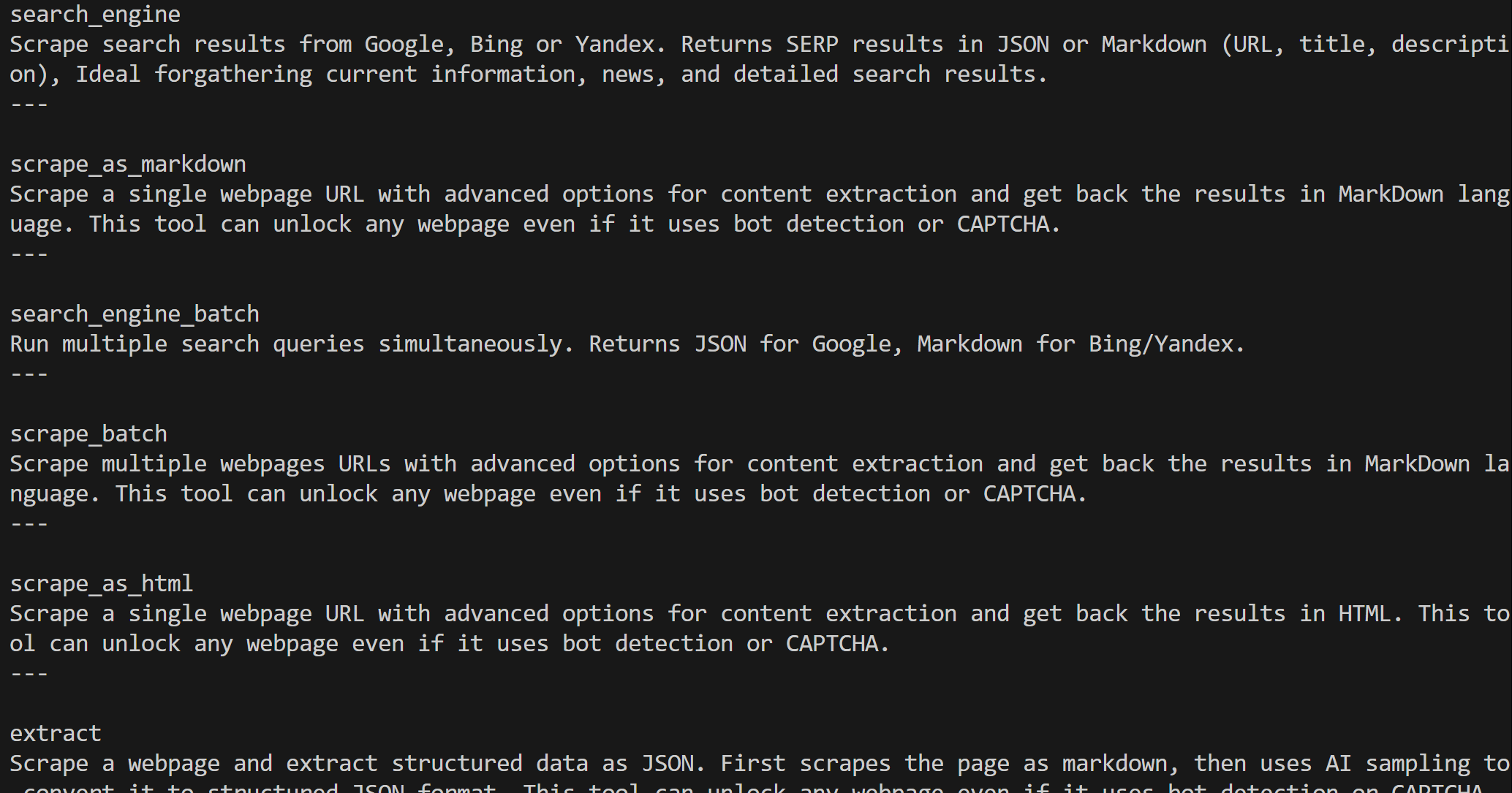
Dependendo do nível configurado, você terá todas as mais de 60 ferramentas Web MCP (modo Pro) ou apenas as ferramentas do nível gratuito.
Excelente! Sua conexão Web MCP agora está totalmente funcional no AG2.
Etapa 3: conecte as ferramentas Web MCP a um agente
A maneira mais simples de testar a integração do Web MCP no AG2 é por meio de um AssistantAgent, uma subclasse do ConversableAgent projetada para resolver tarefas rapidamente usando o LLM. Primeiro, defina o agente e registre o kit de ferramentas Web MCP com ele:
from autogen import AssistantAgent
# Defina um agente capaz de pesquisar e recuperar dados da web
assistant_agent = AssistantAgent(
name="assistant",
code_execution_config=False,
llm_config=llm_config,
system_message="""
Você tem acesso a todas as ferramentas expostas pelo Web MCP, incluindo:
- Pesquisa na web
- Scraping de dados e busca de páginas
- Feeds de dados da Web
- Simulação de usuário baseada em navegador
Use essas ferramentas quando necessário.
""")
# Registre as ferramentas Web MCP com o agente
web_mcp_toolkit.register_for_llm(assistant_agent)Depois de registrado, você pode iniciar o agente usando a função a_run() e especificar diretamente as ferramentas a serem usadas. Por exemplo, veja como testar o agente em uma tarefa de Scraping de dados da Amazon:
prompt = """
Recupere dados do seguinte produto da Amazon e produza um resumo rápido com as principais informações:
"""
# Execute o agente estendido Web MCP de forma assíncrona
result = await assistant_agent.a_run(
message=prompt,
tools=web_mcp_toolkit.tools,
user_input=False,)
await result.process()Importante: lembre-se de que esta é apenas uma demonstração para mostrar a integração. Graças a todas as ferramentas Web MCP, o agente pode lidar com tarefas muito mais complexas e com várias etapas em diferentes plataformas da web e fontes de dados.
Etapa 4: Código final + execução
Abaixo está o código final para sua integração AG2 + Bright Data Web MCP:
import asyncio
from autogen import (
LLMConfig,
AssistantAgent,)
from dotenv import load_dotenv
import os
from mcp import ClientSession, StdioServerParameters
from mcp.client.stdio import stdio_client
from autogen.mcp import create_toolkit
# Carregar variáveis de ambiente do arquivo .env
load_dotenv()
# Recuperar a chave da API Bright Data das variáveis de ambiente
BRIGHT_DATA_API_KEY = os.getenv("BRIGHT_DATA_API_KEY")
# Defina o kit de ferramentas MCP contendo todas as ferramentas Web MCP
async def launch_mcp_agent():
# Carregue a configuração LLM do arquivo de lista de configuração OpenAI
llm_config = LLMConfig.from_json(path="OAI_CONFIG_LIST")
# Instruções para se conectar a uma instância Web MCP local
server_params = StdioServerParameters(
command="npx",
args=["-y", "@brightdata/mcp"],
env={
"API_TOKEN": BRIGHT_DATA_API_KEY,
"PRO_MODE": "true" # Opcional
},
)
async com stdio_client(server_params) como (read, write), ClientSession(read, write) como sessão:
# Crie uma sessão de conexão MCP e recupere as ferramentas
await session.initialize()
web_mcp_toolkit = await create_toolkit(session, use_mcp_resources=False)
# Defina um agente capaz de pesquisar e recuperar dados da web
assistant_agent = AssistantAgent(
name="assistant",
code_execution_config=False,
llm_config=llm_config,
system_message="""
Você tem acesso a todas as ferramentas expostas pelo Web MCP, incluindo:
- Pesquisa na web
- Scraping de dados e busca de páginas
- Feeds de dados da Web
- Simulação de usuário baseada em navegador
Use essas ferramentas quando necessário.
""")
# Registrar as ferramentas Web MCP com o agente
web_mcp_toolkit.register_for_llm(assistant_agent)
# O prompt a ser passado para o agente
prompt = """
Recupere os dados do seguinte produto da Amazon e produza um resumo rápido com as principais informações:
"""
# Execute o agente Web MCP-extended de forma assíncrona
resultado = aguardar assistente_agente.a_run(
mensagem=prompt,
ferramentas=web_mcp_toolkit.tools,
entrada_do_usuário=False,
)
aguardar resultado.processar()
asyncio.run(iniciar_agente_mcp())Execute-o e o resultado será: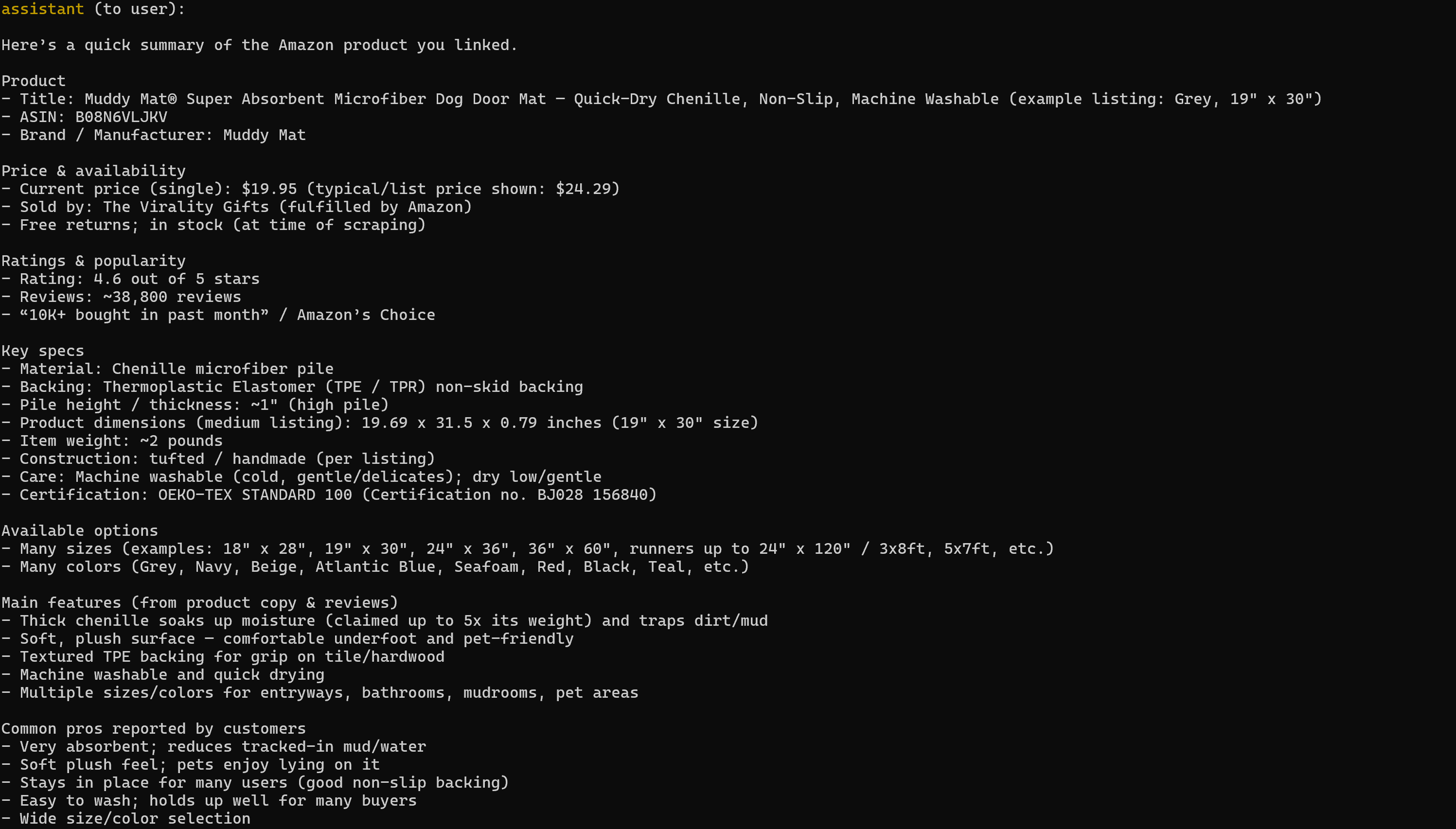
Observe que o relatório gerado inclui todos os dados relevantes da página do produto Amazon de destino:
Se você já tentou extrair dados de produtos da Amazon em Python, sabe que não é brincadeira. A Amazon emprega o notoriamente difícil CAPTCHA da Amazon, bem como outras medidas anti-bot. Além disso, as páginas de produtos estão em constante mudança e têm estruturas variadas.
O Web MCP da Bright Data cuida de tudo isso para você. Na versão gratuita, ele chama a ferramenta scrape_as_markdown nos bastidores para recuperar a estrutura da página em Markdown limpo via Web Unlocker. No modo Pro, ele aproveita o produto web_data_amazon_product, que chama o Amazon Scraper da Bright Data para coletar dados de produtos totalmente estruturados.
É isso! Agora você sabe como estender o AG2 com o Bright Data Web MCP.
Conclusão
Neste tutorial, você aprendeu como integrar o Bright Data ao AG2, seja por meio de funções personalizadas ou via Web MCP.
Essa integração permite que os agentes AG2 realizem pesquisas na web, extraiam dados estruturados, acessem feeds da web ao vivo e automatizem interações na web. Tudo isso é alimentado pelo conjunto de serviços da Bright Data para IA
Crie uma conta Bright Data gratuitamente e comece a explorar nossas ferramentas de dados da web prontas para IA hoje mesmo!




