

Python é, de longe, a linguagem dominante no Scraping de dados em todo o mundo. Nem sempre foi assim. No final da década de 1990 e início da década de 2000, o Scraping de dados era feito quase inteiramente em Perl e PHP.
Hoje, vamos colocar o Python frente a frente com um dos titãs do desenvolvimento web do passado, o PHP. Vamos examinar algumas diferenças entre cada linguagem e ver qual delas oferece a melhor experiência de Scraping de dados.
Pré-requisitos
Se você decidir acompanhar, precisará ter o Python e o PHP instalados. Clique em cada um dos respectivos links de download e siga as instruções para o seu sistema operacional específico.
- Python
- PHP
Você pode verificar a instalação de cada uma com os seguintes comandos.
Python
python --version
Você deverá ver um resultado semelhante a este.
Python 3.10.12
PHP
php --version
Aqui está o resultado.
PHP 8.3.14 (cli) (compilado em: 25 de novembro de 2024, 18:07:16) (NTS)
Copyright (c) The PHP Group
Zend Engine v4.3.14, Copyright (c) Zend Technologies
com Zend OPcache v8.3.14, Copyright (c), por Zend Technologies
Um conhecimento básico de ambas as linguagens seria útil, mas não é um requisito. Na verdade, eu nunca tinha escrito nada em PHP até agora!
Comparação entre Python e PHP para Scraping de dados
Antes de criarmos nosso projeto, precisamos examinar cada uma dessas linguagens com um pouco mais de detalhes.
- Sintaxe: Python tem uma sintaxe mais legível e amplamente adotada, especialmente na comunidade de dados.
- Biblioteca padrão: ambas as linguagens oferecem bibliotecas padrão ricas.
- Frameworks de scraping: o Python tem uma seleção muito maior de frameworks de scraping.
- Desempenho: o PHP tende a oferecer velocidades mais rápidas, pois foi criado para rodar na web.
- Manutenção: o Python tende a ser mais fácil de manter devido à sua sintaxe clara e ao forte apoio da comunidade.
| Recurso | Python | PHP |
|---|---|---|
| Facilidade de uso | Acessível para iniciantes e fácil de aprender | Mais difícil para desenvolvedores iniciantes |
| Biblioteca padrão | Rica e repleta de recursos | Rica e repleta de recursos |
| Ferramentas de scraping | Muitas ferramentas de scraping de terceiros | Ecossistema muito menor |
| Suporte de dados | Construído com o processamento de dados em mente | Bibliotecas e ferramentas básicas disponíveis |
| Comunidade | Grandes comunidades e suporte | Comunidades menores com suporte limitado |
| Manutenção | Fácil de manter, uso generalizado | Difícil, programadores são difíceis de encontrar |
O que rastrear?
Como se trata apenas de uma demonstração e queremos um site que permaneça consistente para benchmarking, vamos usar quotes.toscrape.com. Este site oferece conteúdo consistente e não bloqueia Scrapers. É perfeito para casos de teste.
Na imagem abaixo, você pode ver um dos itens de citação na página. É um div com a classe quote. Precisamos encontrar todos esses itens primeiro.
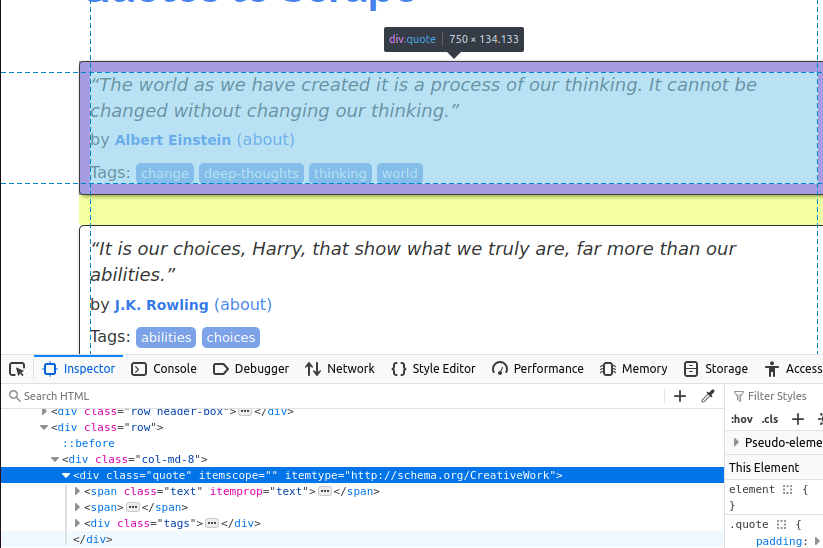
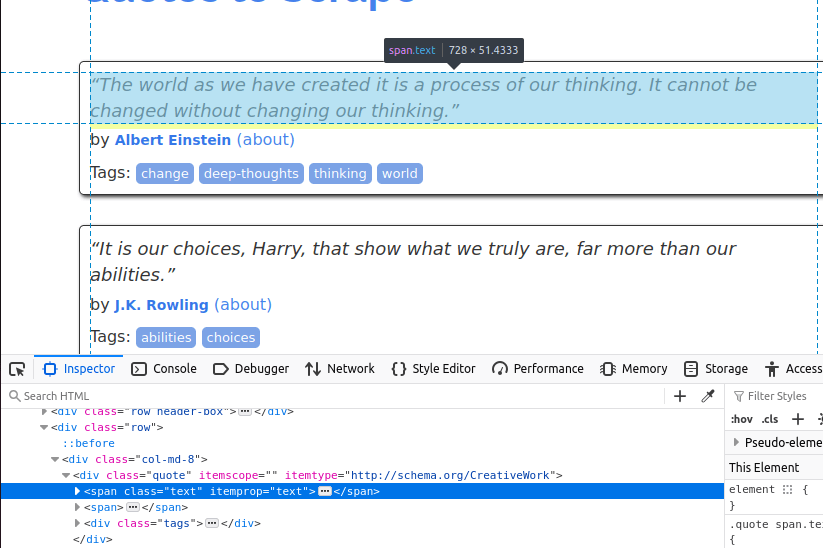
Depois de encontrar todos os cartões de citação na página, precisamos extrair itens individuais de cada um.
O texto vem incorporado em um elemento span com a classe text.
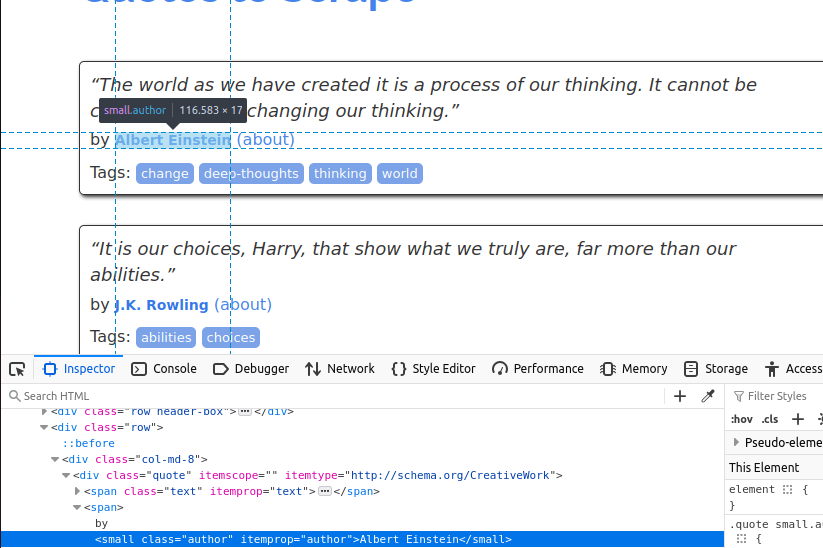
Agora, precisamos obter o autor. Ele vem dentro de um pequeno item com a classe author.
Por fim, extrairemos as tags. Elas estão dentro de elementos com a classe tag.

Agora que sabemos quais dados queremos, estamos prontos para começar.
Introdução
Agora é hora de configurar tudo. Precisaremos de algumas dependências com Python e PHP.
Python
Para Python, precisamos instalar Requests e BeautifulSoup.
Podemos instalar ambos com o pip.
pip install requests
pip install beautifulsoup4
PHP
Aparentemente, todas essas dependências deveriam vir pré-instaladas com o PHP. No entanto, quando fui usá-las, elas não estavam.
sudo apt install php-curl
sudo apt install php-xml
Com nossas dependências instaladas, estamos prontos para começar a programar.
Raspando os dados
Comecei escrevendo o seguinte Scraper em Python. O código abaixo faz uma série de solicitações ao quotes.toscrape.com. Ele extrai o texto, o nome e o autor de cada citação. Depois de obter todas as citações, nós as gravamos em um arquivo JSON. Fique à vontade para copiar/colar em seu próprio arquivo Python.
Python
import requests
from bs4 import BeautifulSoup
import json
page_number = 1
output_json = []
while page_number <= 5:
response = requests.get(f"https://quotes.toscrape.com/page/{page_number}")
soup = BeautifulSoup(response.text, "html.parser")
divs = soup.select("div[class='quote']")
for div in divs:
tags = []
quote_text = div.select_one("span[class='text']").text
author = div.select_one("small[class='author']").text
tag_holders = div.select("a[class='tag']")
para tag_holder em tag_holders:
tags.append(tag_holder.text)
quote_dict = {
"author": author,
"quote": quote_text.strip(),
"tags": tags
}
output_json.append(quote_dict)
page_number+=1
com open("quotes.json", "w") como arquivo:
json.dump(output_json, arquivo, indent=4)
imprimir("Raspagem concluída. Citações salvas em quotes.json.")
- Primeiro, definimos variáveis para
page_numbereoutput_json. Enquanto page_number <= 5diz ao Scraper para continuar seu trabalho até que tenhamos raspado 5 páginas.response = requests.get(f"https://quotes.toscrape.com/page/{page_number}")envia uma solicitação para a página em que estamos.- Encontramos todos os nossos elementos
divalvo comdivs = soup.select("div[class='quote']"). - Iteramos pelos
divse extraímos seus dados:quote_text:div.select_one("span[class='text']").textauthor:div.select_one("small[class='author']").texttags: Encontramos todos os elementostag_holdere, em seguida, extraímos seu texto individualmente.
- Quando terminamos tudo isso, salvamos a matriz
output_jsonem um arquivo eimprimimosuma mensagem no terminal.
Aqui estão algumas capturas de tela de algumas de nossas execuções. Fizemos mais execuções do que isso, mas, para sermos concisos, usaremos uma amostra de 3 execuções aqui.
A execução 1 levou 11,642 segundos.

A execução 2 levou 11,413.

A execução 3 levou 10,258.

Nosso tempo médio de execução com Python é de 11,104 segundos.
PHP
Depois de escrever o código Python, pedi ao ChatGPT para reescrevê-lo em PHP. Inicialmente, o código não funcionou, mas após alguns pequenos ajustes, ficou utilizável.
<?php
$pageNumber = 1;
$outputJson = [];
while ($pageNumber <= 5) {
$url = "https://quotes.toscrape.com/page/$pageNumber";
$ch = curl_init($url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, true);
$response = curl_exec($ch);
curl_close($ch);
if ($response === false) {
echo "Erro ao buscar a página $pageNumbern";
break;
}
$dom = new DOMDocument();
@$dom->loadHTML($response);
$xpath = new DOMXPath($dom);
$quoteDivs = $xpath->query("//div[@class='quote']");
foreach ($quoteDivs as $div) {
$quoteText = $xpath->query(".//span[@class='text']", $div)->item(0)->textContent ?? "";
$author = $xpath->query(".//small[@class='author']", $div)->item(0)->textContent ?? "";
$tagElements = $xpath->query(".//a[@class='tag']", $div);
$tags = [];
foreach ($tagElements as $tagElement) {
$tags[] = $tagElement->textContent;
}
$outputJson[] = [
"author" => trim($author),
"quote" => trim($quoteText),
"tags" => $tags
];
}
$pageNumber++;
}
$jsonData = json_encode($outputJson, JSON_PRETTY_PRINT | JSON_UNESCAPED_UNICODE);
file_put_contents("quotes.json", $jsonData);
echo "Raspagem concluída. Citações salvas em quotes.json.n";
- Semelhante ao código Python, começamos com as variáveis
pageNumbereoutputJson. - Usamos um loop
whilepara manter o tempo de execução da extração real:while ($pageNumber <= 5). $ch = curl_init($url);configura nossa solicitação HTTP. Usamoscurl_setopt()para seguir redirecionamentos.$response = curl_exec($ch);executa a solicitação HTTP.$dom = new DOMDocument();configura um novo objetoDOMpara usarmos. Isso é semelhante ao que fizemos anteriormente comBeautifulSoup().- Obtemos nossos
divsusando seu Xpath em vez de seu seletor CSS:$quoteDivs = $xpath->query("//div[@class='quote']"); $quoteText = $xpath->query(".//span[@class='text']", $div)->item(0)->textContent ?? "";gera o texto de cada citação.$author = $xpath->query(".//small[@class='author']", $div)->item(0)->textContent ?? "";nos fornece o autor.- Obtemos nossas
tagsencontrando novamente todos os elementos de tag e iterando-os com um loop para extrair seu texto. - Finalmente, quando tudo estiver pronto, salvamos nossa saída em um arquivo json e imprimimos uma mensagem na tela.
Aqui estão os resultados da nossa execução usando PHP.
A execução 1 levou 11,351 segundos.

A execução 2 levou 9,846.

A execução 3 levou 9,795 segundos.

Nossa média com PHP foi de 10,33 segundos.
Com mais testes, o PHP continuou a produzir resultados mais rápidos… Às vezes, em apenas 7 segundos!
Considere usar a Bright Data
Se as seções acima fizeram sentido para você, escreva Scrapers! Quando você extrai dados para viver, coisas como as que você vê acima são o tipo de código que você escreverá o tempo todo!
Oferecemos uma variedade de produtos que podem tornar seus scrapers mais robustos.O Navegador de scrapingoferece um navegador remoto com integração de Proxy e renderização JavaScript integradas. Se você deseja apenas proxies e Resolução de CAPTCHA sem um navegador, useo Web Unlocker.
Os Scrapers não são para todos.
Se você só quer obter seus dados e seguir com o seu dia, dê uma olhada em nossos Conjuntos de dados.Nós fazemos a extração para que você não precise fazer isso.Dê uma olhada em nossosConjuntos de dados prontos para uso. Nossos Conjuntos de dados mais populares são LinkedIn, Amazon, Crunchbase, Zillow e Glassdoor. Você pode visualizar dados de amostra gratuitamente e baixar relatórios em formato CSV ou JSON.
Conclusão
Com uma velocidade média de 11,104 segundos em Python e 10,33 segundos em PHP, nosso scraper PHP foi consistentemente mais rápido que o scraper Python. Parte disso pode ser relacionada à latência do servidor, mas em testes adicionais, o PHP continuou a superar o Python em quase todas as execuções.
Embora definitivamente supere o Python na categoria de velocidade, isso não é exatamente verdade para a sintaxe. Atualmente, poucos desenvolvedores se sentem à vontade com a sintaxe usada em linguagens como PHP ou Perl. Elas são linguagens de script do passado. Além disso, sua equipe pode não se sentir à vontade com PHP. É preciso um tipo especial de programador para escrever esse tipo de código o tempo todo e manter os aplicativos legados funcionando.
Leve suas operações de scraping para o próximo nível com a Bright Data. Inscreva-se agora e comece seu teste grátis!





