Graças às suas extensas bibliotecas e ferramentas, o PHP é uma ótima linguagem para criar web scrapers. Projetado especificamente para desenvolvimento web, o PHP lida com tarefas de web scraping com facilidade e confiabilidade.
Existem muitos métodos diferentes para extrair dados de sites usando PHP, e você explorará alguns métodos distintos neste artigo. Especificamente, você aprenderá a extrair dados de sites usando curl, file_get_contents, Symfony BrowserKit e o componente Symfony Panther. Além disso, você aprenderá sobre alguns desafios comuns que pode enfrentar durante o web scraping e como evitá-los.
Nesta seção, você aprenderá alguns métodos de web scraping comumente usados em sites básicos e complexos/dinâmicos.
Observe: embora abordemos vários métodos neste tutorial, essa não é uma lista completa.
Pré-requisitos
Para acompanhar este tutorial, você precisa da versão mais recente do PHP e do Composer, um gerenciador de dependências para PHP. Este artigo foi testado usando PHP 8.1.18 e Composer 2.5.5.
Depois que o PHP e o Composer estiverem configurados, crie um diretório chamado php-web-scraping e cd nele:
mkdir php-web-scraping
cd $_
Você trabalhará nesse diretório durante o resto do tutorial.
curl
A curl é uma biblioteca de baixo nível quase ubíqua e uma ferramenta CLI escrita em C. Ela pode ser usada para buscar o conteúdo de uma página web usando HTTP ou HTTPS. Em quase todas as plataformas, o PHP vem com suporte à curl ativado por padrão.
Nesta seção, você extrairá dados de uma página web bem básica que lista os países por população com base nas estimativas das Nações Unidas. Você extrairá os links no menu junto com os textos dos links.
Para começar, crie um arquivo chamado curl.php e inicialize a curl nesse arquivo com a função curl_init :
<?php
$ch = curl_init();
Em seguida, defina as opções para buscar a página web. Isso inclui definir o URL e o método HTTP (GET, POST etc.) usando a função curl_setopt:
Nesse código, você define o URL de destino como a página web e o método como GET. O CURLOPT_RETURNTRANSFER diz à curl para retornar a resposta HTML.
Quando a curl estiver pronta, você poderá fazer a solicitação usando curl_exec:
$response = curl_exec($ch);
Obter os dados HTML é apenas a primeira etapa no web scraping. Para extrair dados da resposta HTML, você precisa usar várias técnicas. O método mais simples é usar expressões regulares para uma extração muito básica de HTML. No entanto, observe que você não pode analisar HTML arbitrário com regex, mas para uma análise muito simples, regex é suficiente.
Por exemplo, extraia as tags <a> , que têm atributos href e title e contêm um <span;>:
Em seguida, libere os recursos usando a função curl_close :
curl_close($ch);
Execute o código com o seguinte:
php curl.php
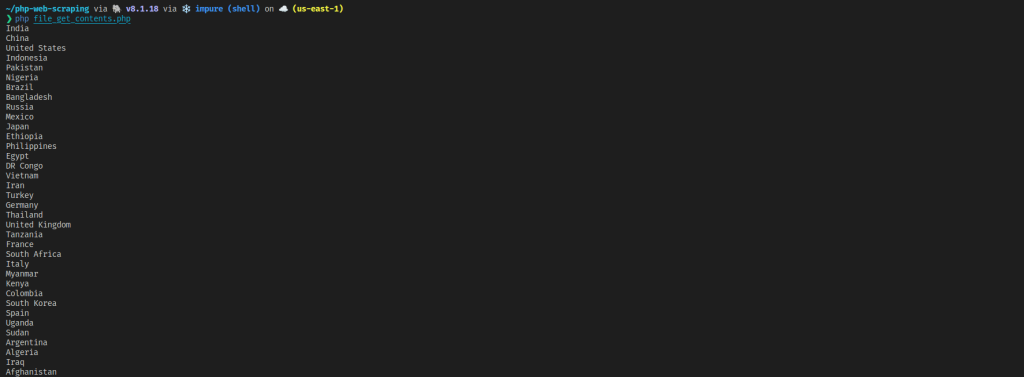
Você verá que ele extrai corretamente os links:
A curl oferece um controle de muito baixo nível sobre como uma página web é buscada em HTTP/HTTPS. Você pode ajustar as diferentes propriedades de conexão e até mesmo adicionar outras medidas, como servidores proxy (falaremos mais sobre isso depois), agentes de usuário e tempo limite.
Além disso, a curl vem instalada por padrão na maioria dos sistemas operacionais, o que a torna uma ótima opção para escrever um web scraper multiplataforma.
No entanto, como você viu, a curl não é suficiente por si só e você precisa de um analisador HTML para coletar dados adequadamente. A curl também não consegue executar JavaScript em uma página web, o que significa que você não pode extrair dados de páginas web dinâmicas e aplicativos de página única (SPAs) com a curl.
file_get_contents
A função file_get_contents é usada principalmente para ler o conteúdo de um arquivo. No entanto, ao passar um URL HTTP, você pode buscar dados HTML de uma página web. Isso significa que file_get_contents pode substituir o uso da curl no código anterior.
Nesta seção, você extrairá dados da mesma página de antes, mas desta vez, o scraper será mais avançado e você poderá extrair os nomes de todos os países da tabela.
Crie um arquivo chamado file_get-contents.php e comece passando um URL para file_get_contents:
A variável $html agora contém o código HTML da página web.
Semelhante ao exemplo anterior, buscar os dados HTML é apenas a primeira etapa. Para deixar as coisas mais interessantes, use libxml para selecionar elementos usando os seletores XPath . Para fazer isso, primeiro você precisa inicializar um DOMDocument e carregar o HTML nele:
$doc = new DOMDocument;
libxml_use_internal_errors(true);
$doc->loadHTML($html);
libxml_clear_errors();
Aqui, você seleciona os países na seguinte ordem: o primeiro elemento tbody , um elemento tr dentro do elemento tbody, o primeiro td no elemento tr e um a com um atributo title dentro do elemento td .
O código a seguir inicializa uma classe DOMXPath e usa evaluate para selecionar o elemento usando o seletor XPath:
$xpath = new DOMXpath($doc);
$countries = $xpath->evaluate('(//tbody)[1]/tr/td[1]//a[@title=true()]');
Só resta fazer o loop pelos elementos e imprimir o texto:
foreach($countries as $country) {
echo $country->textContent . "n";
}
Execute o código com o seguinte:
php file_get_contents.php
Como você pode ver, file_get_contents é mais simples de usar do que curl e geralmente é usado para buscar rapidamente o código HTML de uma página web. No entanto, ele tem as mesmas desvantagens da curl: você precisa de um parser de HTML adicional e não pode extrair dados de páginas web dinâmicas e SPAs. Além disso, você perde os controles finos fornecidos pela curl. No entanto, sua simplicidade o torna uma boa opção para extrair dados de sites estáticos básicos.
Symfony BrowserKit
Symfony BrowserKit é um componente do framework Symfony que simula o comportamento de um navegador real. Isso significa que você pode interagir com a página web como em um navegador real, por exemplo, clicando em botões/links, enviando formulários e voltando e avançando no histórico.
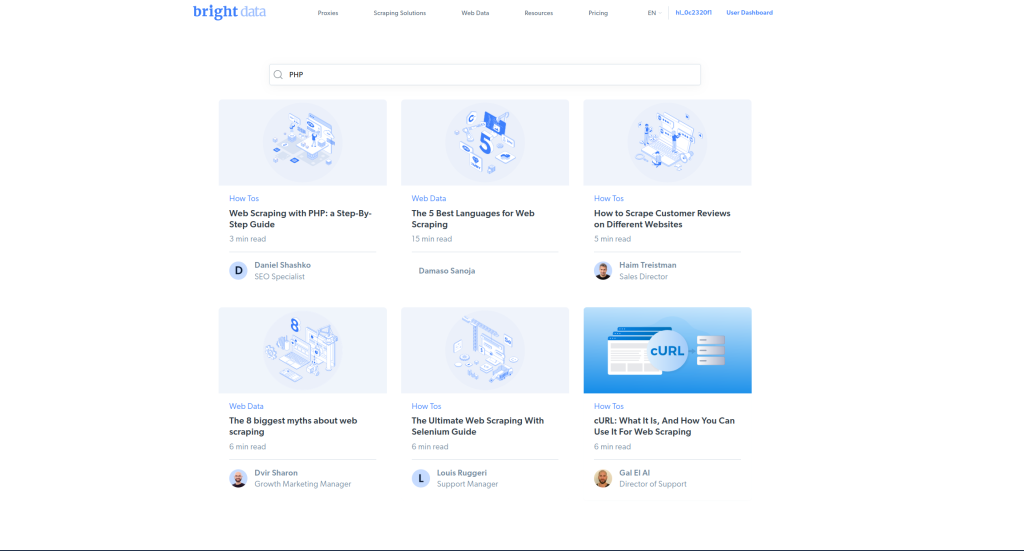
Nesta seção, você visitará o blog da Bright Data, inserirá PHP na caixa de pesquisa e enviará o formulário de pesquisa. Em seguida, você extrairá os nomes dos artigos do resultado:
Para usar o Symfony BrowserKit, você deve instalar o componente BrowserKit com o Composer:
composer require symfony/browser-kit
Você também precisa instalar o componente HttpClient para fazer solicitações HTTP pela internet:
composer require symfony/http-client
O BrowserKit suporta a seleção de elementos usando seletores XPath por padrão. Neste exemplo, você usa seletores CSS. Para isso, você também precisa instalar o componente CssSelector :
composer require symfony/css-selector
Crie um arquivo chamado symfony-browserkit.php. Nesse arquivo, inicialize HttpBrowser:
<?php
require "vendor/autoload.php";
use SymfonyComponentBrowserKitHttpBrowser;
$client = new HttpBrowser();
Use a função request para fazer uma solicitação GET :
Para selecionar o formulário em que o botão de pesquisa está, você precisa selecionar o botão em si e usar a função form para obter o formulário anexo. O botão pode ser selecionado com a função filter passando seu ID. Depois que o formulário for selecionado, você poderá enviá-lo usando a função submit da classe Httpbrowser .
Ao passar um hash dos valores das entradas, a função submit pode preencher o formulário antes de ser enviado. No código a seguir, a entrada com o nome q recebeu o valor PHP, que é o mesmo que digitar PHP na caixa de pesquisa:
Embora o Symfony BrowserKit seja um avanço em relação aos dois métodos anteriores em termos de interação com páginas web, ele ainda é limitado porque não pode executar JavaScript. Isso significa que você não pode extrair dados de sites dinâmicos e SPAs usando o BrowserKit.
Symfony Panther
Symfony Panther é outro componente Symfony que envolve o componente BrowserKit. No entanto, o Symfony Panther oferece uma grande vantagem: em vez de simular um navegador, ele executa o código em um navegador real usando o protocolo WebDriver para controlar remotamente um navegador real. Isso significa que você pode extrair dados de qualquer site, incluindo sites dinâmicos e SPAs.
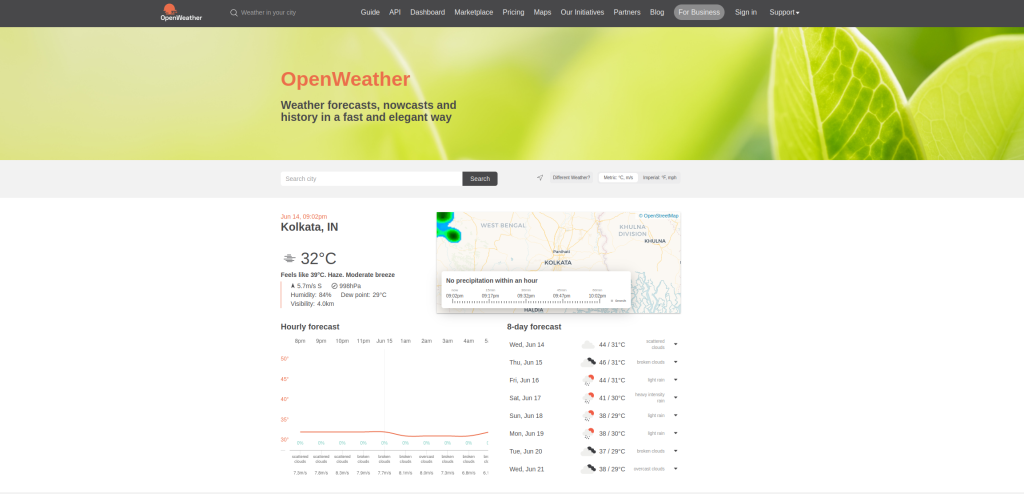
Nesta seção, você carregará a página inicial do OpenWeather, digitará o nome da sua cidade na caixa de pesquisa, realizará a pesquisa e extrairá o clima atual da sua cidade:
Para começar, instale o Symfony Panther com o Composer:
composer require symfony/panther
Você também precisa instalar o dbrekelmans/browser-driver-installer, que consegue detectar automaticamente o navegador instalado em seu sistema e instalar o driver correto para ele. Certifique-se de ter um navegador baseado no Firefox ou no Chromium instalado em seu sistema:
composer require dbrekelmans/bdi
Para instalar o driver apropriado no diretório de drivers , execute a ferramenta bdi :
vendor/bin/bdi detect drivers
Crie um arquivo chamado symfony-panther.php e comece inicializando um cliente Panther:
<?php
require 'vendor/autoload.php';
use SymfonyComponentPantherClient;
$client = Client::createFirefoxClient();
Observe: dependendo do seu navegador, talvez seja necessário usar createChromeClient ou createSeleniumClient em vez de createFirefoxClient.
Como o Panther usa o Symfony BrowserKit nos bastidores, os códigos a seguir são muito semelhantes ao código na seção Symfony BrowserKit.
Você começa carregando a página web usando a função request . Quando a página carrega, ela é inicialmente coberta por uma div com a classe owm-loader , que mostra a barra de progresso do carregamento. Você precisa esperar que essa div desapareça antes de começar a interagir com a página. Isso pode ser feito usando a função waitForStaleness , que pega um seletor CSS e aguarda ele ser removido do DOM.
Depois que a barra de carregamento for removida, você precisará aceitar os cookies para que o banner de cookies seja fechado. Para isso, a função selectButton é útil, pois ela pode pesquisar um botão pelo texto. Depois de identificar o botão, a função click executa um clique nele:
Observe: dependendo da rapidez com que a página carrega, a barra de carregamento pode desaparecer antes que a função waitForStaleness seja executada. Isso gera uma exceção. É por isso que essa linha foi encapsulada em um bloco try-catch.
Agora é hora de digitar Kolkata na barra de pesquisa. Selecione a barra de pesquisa com a função filter e use a função sendKeys para inserir informações na barra de pesquisa. Em seguida, clique no botão Pesquisar :
Depois que o botão é selecionado, uma caixa de sugestão de preenchimento automático aparece. Você pode usar a função waitForVisibility para esperar até que a lista fique visível e depois clicar no primeiro item usando a combinação de filter e click como antes:
Aqui, você está esperando que o elemento com o seletor .orange-text+h2 contenha Kolkata. Isso indica que os resultados foram carregados.
Execute o código com o seguinte:
php symfony-panther.php
Seu resultado ficará assim:
Desafios e possíveis soluções para a extração de dados da web
Embora o PHP facilite a criação de web scrapers, navegar em projetos de extração de dados na vida real pode ser complexo. Inúmeras situações podem surgir, apresentando desafios que precisam ser resolvidos. Esses desafios podem resultar de fatores como a estrutura dos dados (por exemplo, paginação) ou medidas antibot tomadas pelos proprietários do site (por exemplo, armadilhas honeypot).
Nesta seção, você aprenderá sobre alguns desafios comuns e como combatê-los.
Navegando por sites paginados
Ao extrair dados de praticamente qualquer site na vida real, é provável que você se depare com uma situação em que os dados não sejam carregados de uma só vez. Ou seja, os dados são paginados. Pode haver dois tipos de paginação:
Todas as páginas estão localizadas em URLs separados. O número da página é passado por meio de um parâmetro de consulta ou de um caminho. Por exemplo, exemplo.com?pagina=3 ou exemplo.com/pagina/3.
As novas páginas são carregadas usando JavaScript quando o botão Próximo é selecionado.
No primeiro cenário, você pode carregar as páginas em um loop e extrair seus dados como páginas web separadas. Por exemplo, usando file_get_contents, o código a seguir extrai as primeiras dez páginas de um site de exemplo:
for($page = 1; $page <= 10; $page++) {
$html = file_get_contents('https://example.com/page/{$page}');
// DO the scraping
}
No segundo cenário, você precisa usar uma solução que possa executar JavaScript, como o Symfony Panther. Neste exemplo, você precisa clicar no botão apropriado que carrega a próxima página. Não se esqueça de esperar um pouco até que a nova página seja carregada:
for($page = 1; $page <= 10; $page++>) {
// Do the scraping
// Load the next page
$crawler->selectButton("Next")->click();
$client->waitForElementToContain(".current-page", $page+1)
}
Observe: você deve substituir a lógica de espera apropriada que faça sentido para o site específico do qual você está extraindo.
Proxies rotativos
Um servidor proxy atua como intermediário entre seu computador e o servidor web de destino. Isso impede que o servidor web veja seu endereço IP, preservando assim seu anonimato.
No entanto, você não deve confiar em um único servidor proxy, pois ele pode ser banido. Em vez disso, você precisa usar vários servidores proxy e alternar entre eles. O código a seguir fornece uma solução muito básica em que um conjunto de proxies é usado e um deles é escolhido aleatoriamente:
CAPTCHAs são usados por muitos sites para garantir que o usuário é humano e não um bot. Infelizmente, isso significa que seu web scraper pode ser capturado.
CAPTCHAs podem ser muito primitivos, como uma simples caixa de seleção perguntando: “Você é humano?” Ou eles podem usar um algoritmo mais avançado, como o reCAPTCHA ou o hCaptcha do Google. Você provavelmente pode se safar com CAPTCHAs primitivos usando a manipulação básica de páginas web (por exemplo, marcando uma caixa de seleção), mas para combater CAPTCHAs avançados, você precisa de uma ferramenta dedicada como o 2Captcha. O 2Captcha usa humanos para resolver CAPTCHAs. Você só precisa passar os detalhes necessários para a API do 2Captcha e ela retornará o CAPTCHA resolvido.
Para começar a usar o 2Captcha, você precisa criar uma conta e obter uma chave de API.
Instale o 2Captcha com o Composer:
composer require 2captcha/2captcha
Em seu código, crie uma instância de TwoCaptcha:
$solver = new TwoCaptchaTwoCaptcha('YOUR_API_KEY');
As armadilhas honeypot são uma medida antibot que imita um serviço ou rede para atrair scrapers e crawlers para desviá-los do alvo real. Embora os honeypots sejam úteis para a prevenção contra ataques de bots, eles podem ser problemáticos para a extração de dados da web. Você não quer que seu scraper fique preso em um honeypot.
Existem todos os tipos de medidas que você pode tomar para evitar ser atraído para uma armadilha honeypot. Por exemplo, os links do honeypot geralmente ficam ocultos para que um usuário real não os veja, mas um bot pode detectá-los. Para evitar a armadilha, você pode tentar evitar clicar em links ocultos (links com propriedades CSS display: none ou visibility: none).
Outra opção é fazer a rotação dos proxies para que, se um dos endereços IP do servidor proxy for capturado no honeypot e banido, você ainda possa se conectar por meio de outros proxies.
Conclusão
Graças à biblioteca e aos frameworks superiores do PHP, criar um web scraper é fácil. Neste artigo, você aprendeu como fazer o seguinte:
Extrair dados de um site estático usando curl e regex
Extrair dados de um site estático usando file_get_contents e libxml
Extrair dados de um site estático usando o Symfony BrowserKit e enviar formulários
Extrair dados de um site dinâmico complexo usando o Symfony Panther
Infelizmente, ao fazer a extração de dados usando esses métodos, você aprendeu que o scraping com PHP traz complexidades adicionais. Por exemplo, talvez seja necessário organizar vários proxies e construir cuidadosamente seu scraper para evitar honeypots.
E é aqui que entra a Bright Data…
Sobre os proxies da Bright Data:
Proxies residenciais: com mais de 72 milhões de IPs reais de 195 países, os proxies residenciais da Bright Data permitem que você acesse o conteúdo de qualquer site, independentemente da localização, evitando CAPTCHAs e o banimento de IPs.
Proxies de ISPs: com mais de 700.000 IPs de ISPs, usufrua de IPS estáticos reais de qualquer cidade do mundo, atribuídos por ISPs e alugados à Bright Data para seu uso exclusivo, pelo tempo que você precisar.
Proxies de datacenters: com mais de 770.000 IPs de datacenters, a rede de proxies de datacenters da Bright Data é constituída por vários tipos de IPs no mundo todo, em um pool de IPs compartilhado ou para compra individual.
Proxies móveis: com mais de 7 milhões de IPs móveis, a avançada rede de IPs móveis da Bright Data oferece a maior e mais rápida rede mundial de IPs reais em 3G/4G/5G.
Junte-se à maior rede de proxies do mundo e faça uma avaliação gratuita.