

Neste tutorial prático, você aprenderá como extrair dados do Glassdoor usando o Playwright Python. Você também aprenderá sobre as técnicas anti-extração empregadas pelo Glassdoor e como a Bright Data pode ajudar. Você também aprenderá sobre a solução da Bright Data que torna a extração do Glassdoor muito mais rápida.
Pule a extração, obtenha os dados
Quer pular o processo de extração e acessar os dados diretamente? Considere dar uma olhada em nosso conjunto de dados do Glassdoor.
O conjunto de dados do Glassdoor oferece uma visão geral completa da empresa, com avaliações e perguntas frequentes que fornecem informações sobre empregos e empresas. Você pode usar nosso conjunto de dados do Glassdoor para encontrar tendências de mercado e informações comerciais sobre empresas e como os funcionários atuais e antigos as percebem e avaliam. Com base em suas necessidades, você tem a opção de comprar o conjunto de dados completo ou um subconjunto personalizado.
O conjunto de dados está disponível em formatos como JSON, NDJSON, JSON Lines, CSV ou Parquet e também pode ser compactado em arquivos .gz, se desejar.
É legal fazer scraping do Glassdoor?
Sim, é legal extrair dados do Glassdoor, mas isso deve ser feito de forma ética e em conformidade com os termos de serviço, o arquivo robots.txt e as políticas de privacidade do Glassdoor. Um dos maiores mitos é que extrair dados públicos, como avaliações de empresas e listas de vagas de emprego, não é legal. No entanto, isso não é verdade. Isso deve ser feito dentro dos limites legais e éticos.
Como extrair dados do Glassdoor
O Glassdoor usa JavaScript para renderizar seu conteúdo, o que pode tornar a extração mais complexa. Para lidar com isso, você precisa de uma ferramenta que possa executar JavaScript e interagir com a página da web como um navegador. Algumas opções populares são Playwright, Puppeteer e Selenium. Para este tutorial, usaremos o Playwright Python.
Vamos começar a construir o scraper do Glassdoor do zero! Seja você novo no Playwright ou já familiarizado com ele, este tutorial está aqui para ajudá-lo a construir um scraper da web usando o Playwright Python.
Configurando o ambiente de trabalho
Antes de começar, certifique-se de que você tenha o seguinte configurado em sua máquina:
- site oficial
- Visual Studio Code
Em seguida, abra um terminal e crie uma nova pasta para o seu projeto Python, depois navegue até ela:
mkdir glassdoor-scraper
cd glassdoor-scraper
Crie e ative um ambiente virtual:
python -m venv glassdoorenv
glassdoorenvScriptsactivate
Instale o Playwright:
pip install playwright
Em seguida, instale os binários do navegador:
playwright install
Essa instalação pode demorar um pouco, então, por favor, seja paciente.
Veja como é o processo completo de configuração:
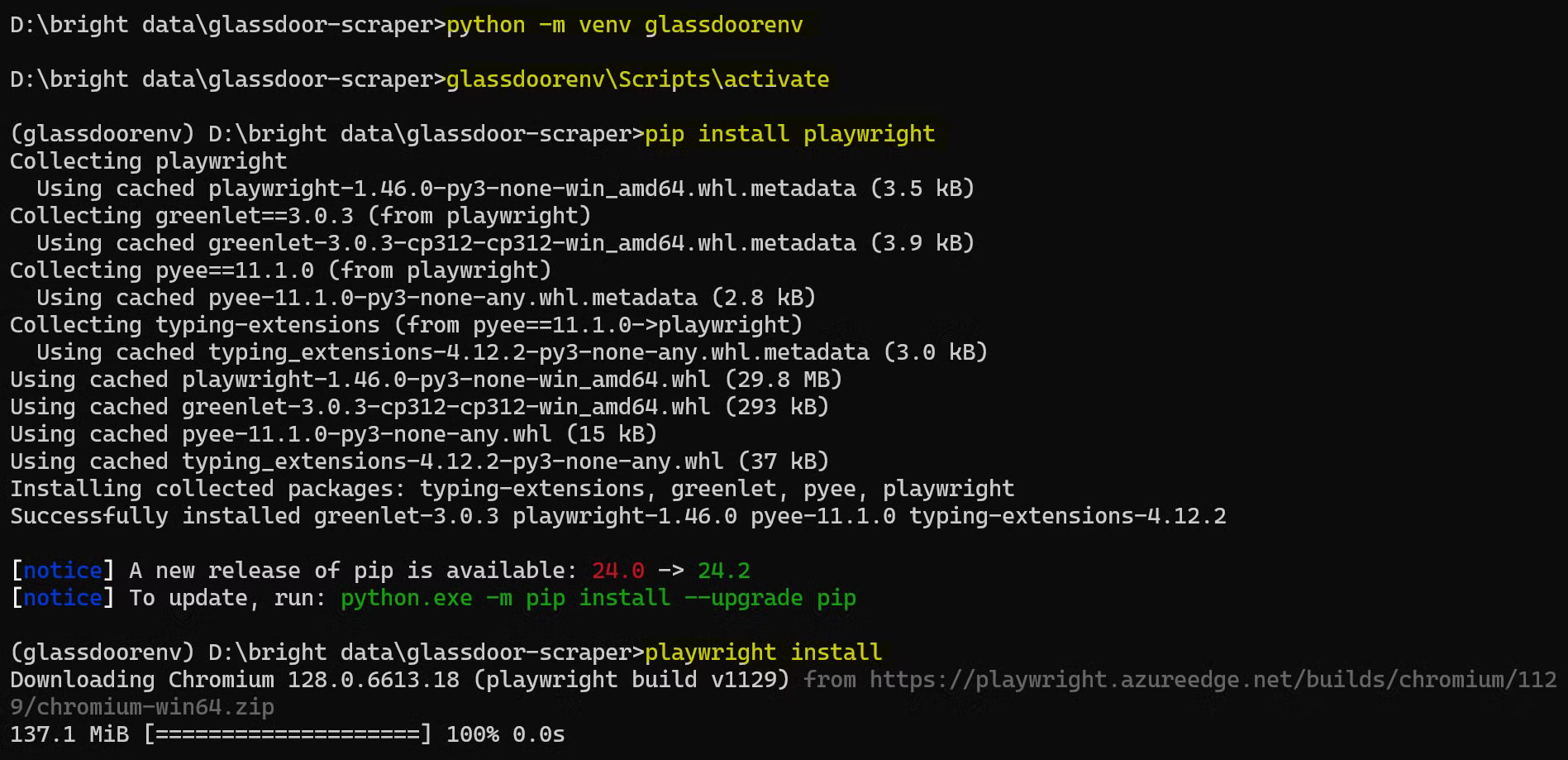
Agora você está pronto para começar a escrever seu código de scraper do Glassdoor!
Entendendo a estrutura do site Glassdoor
Antes de começar a fazer scraping no Glassdoor, é importante entender sua estrutura. Para este tutorial, vamos nos concentrar em fazer scraping de empresas em um local específico que tenham funções específicas.
Por exemplo, se você deseja encontrar empresas na cidade de Nova York com funções de aprendizado de máquina e uma classificação geral superior a 3,5, será necessário aplicar os filtros apropriados à sua pesquisa.
Dê uma olhada na página de empresas do Glassdoor:
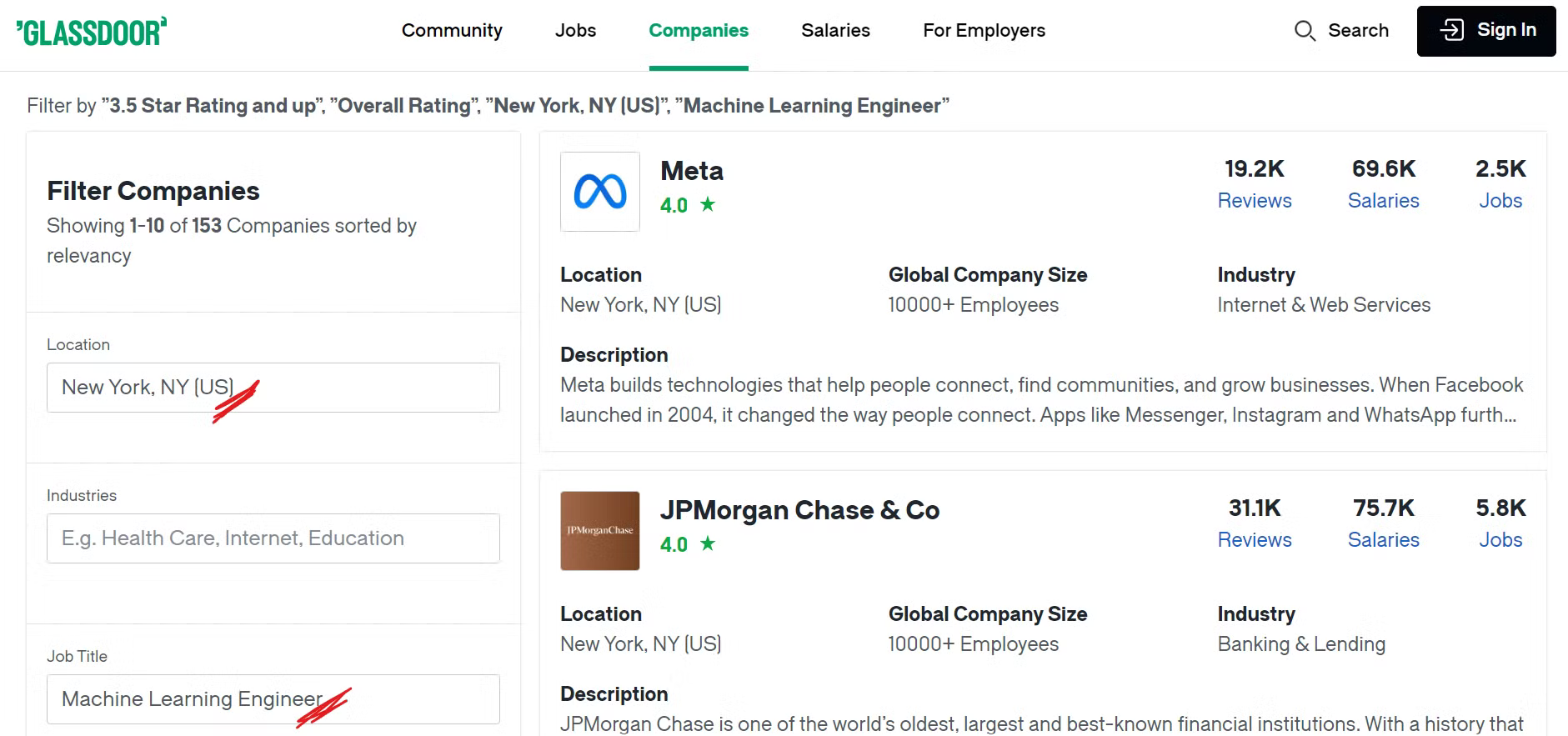
Agora, você pode ver várias empresas listadas aplicando os filtros desejados e talvez esteja se perguntando quais dados específicos iremos coletar. Vamos ver a seguir!
Identificando pontos de dados importantes
Para coletar os dados do Glassdoor de maneira eficaz, você precisa identificar o conteúdo que deseja coletar.
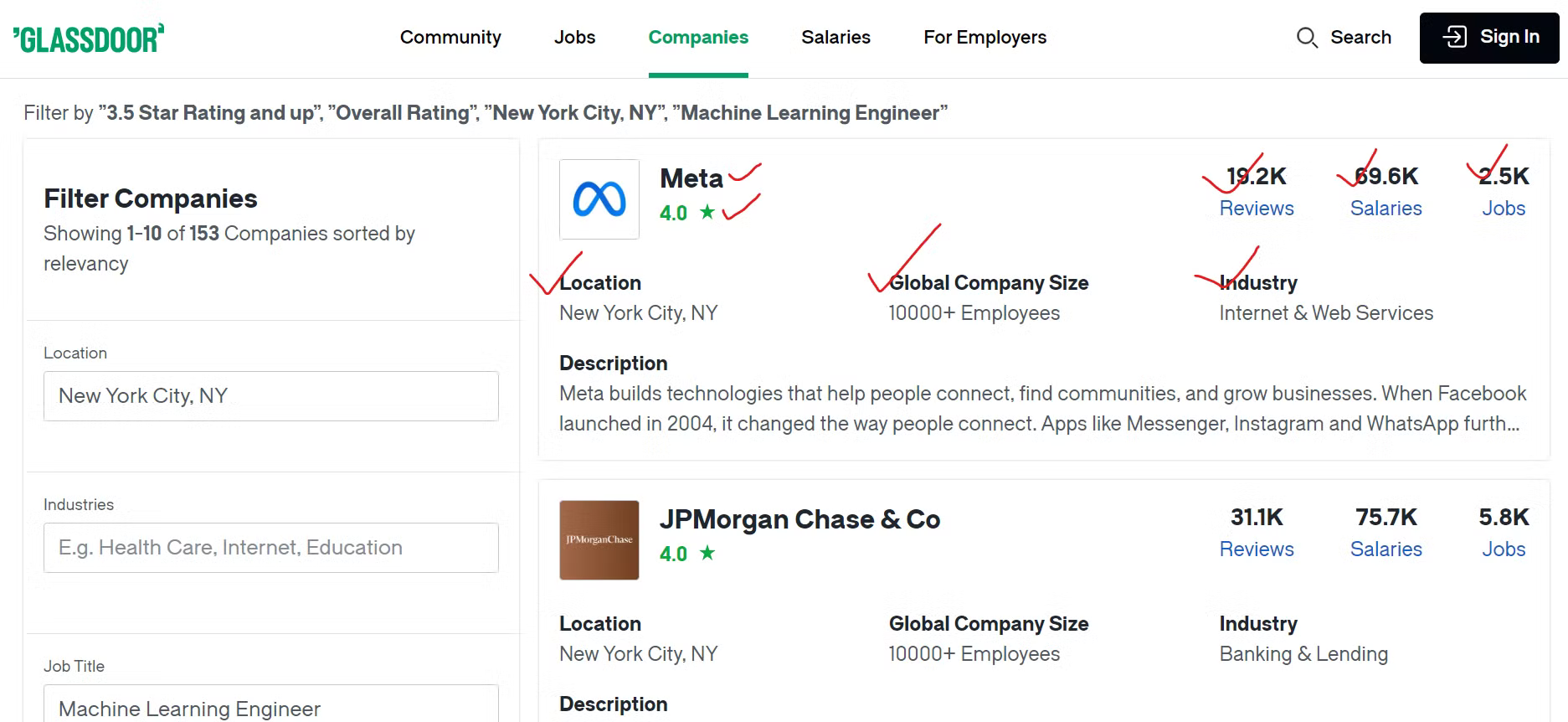
Extrairemos vários detalhes sobre cada empresa, como o nome da empresa, um link para suas listas de vagas e o número total de vagas disponíveis. Além disso, coletaremos o número de avaliações de funcionários, a contagem de salários informados e o setor em que a empresa atua. Também extrairemos a localização geográfica da empresa e o número total de funcionários em todo o mundo.
Criando o Glassdoor Scraper
Agora que você identificou os dados que deseja coletar, é hora de criar o scraper usando o Playwright Python.
Comece inspecionando o site do Glassdoor para localizar os elementos do nome da empresa e das avaliações, conforme mostrado na imagem abaixo:
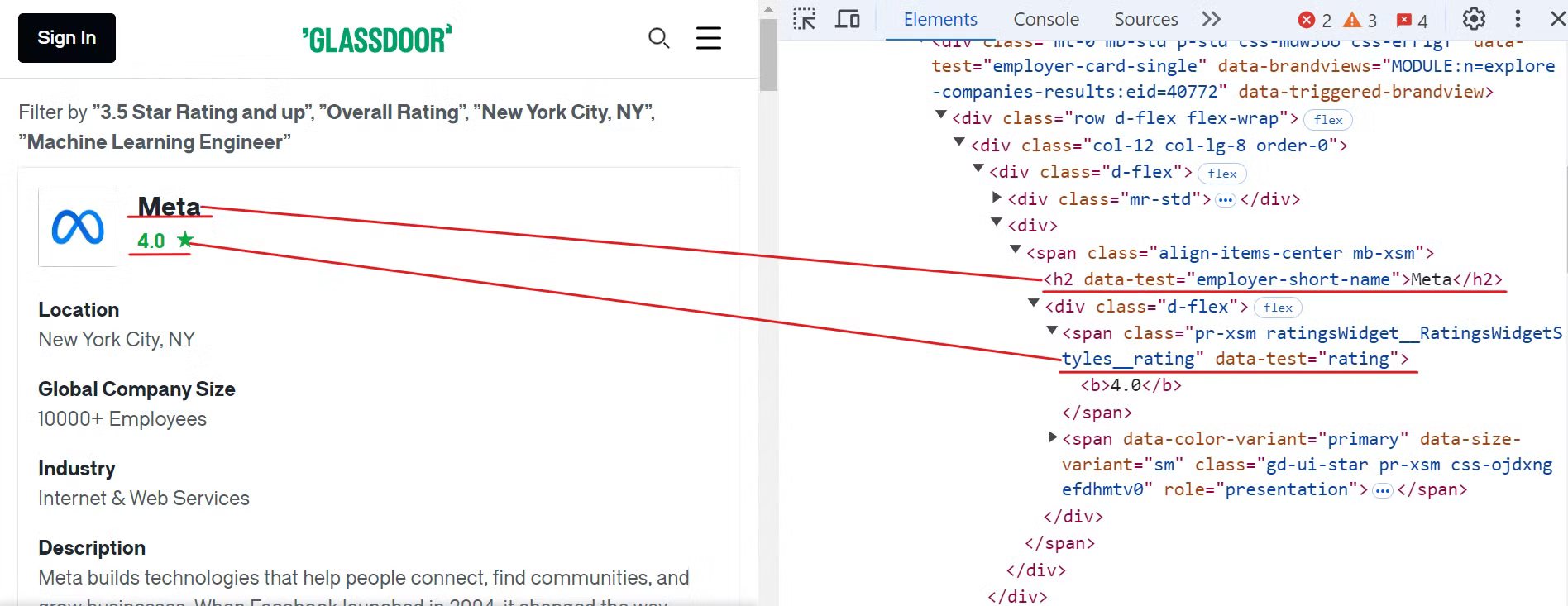
Para extrair esses dados, você pode usar os seguintes seletores CSS:
[data-test="employer-short-name"]
[data-test="rating"]
Da mesma forma, você pode extrair outros dados relevantes usando seletores CSS simples, conforme mostrado na imagem abaixo:
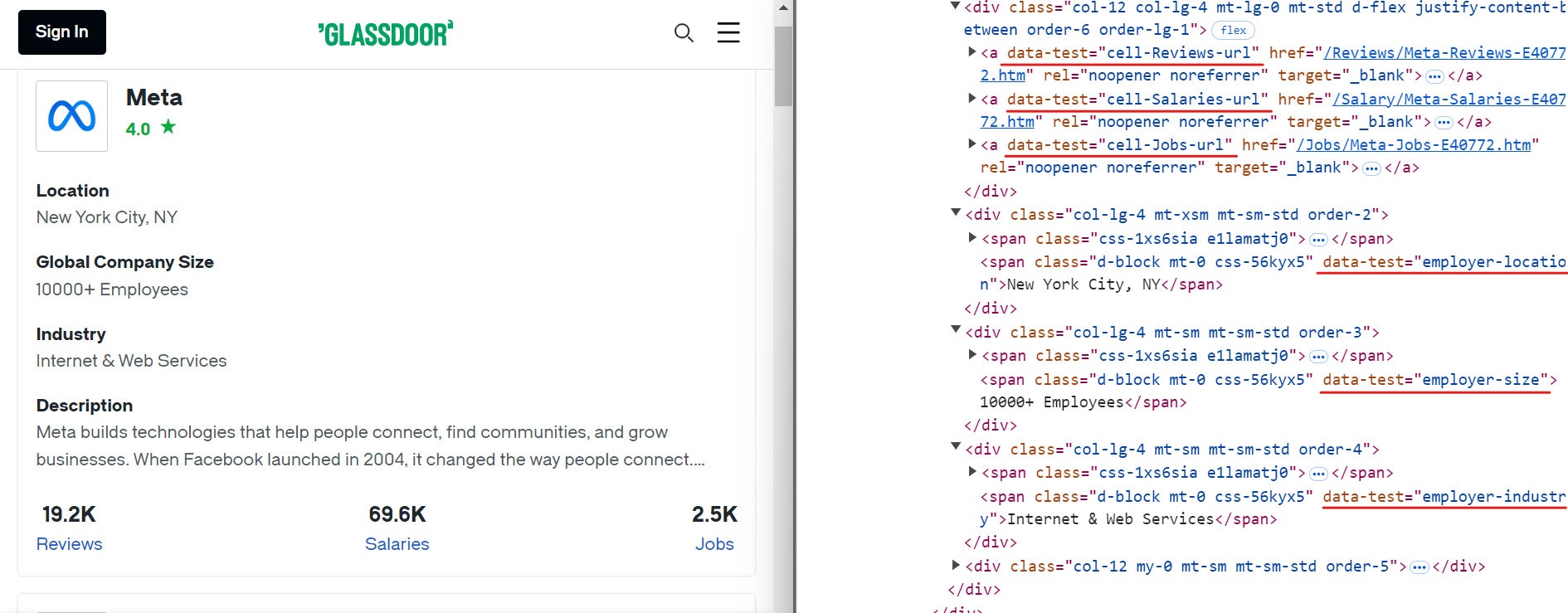
Aqui estão os seletores CSS que você pode usar para extrair dados adicionais:
[data-test="employer-location"] /* Localização geográfica da empresa */
[data-test="employer-size"] /* Número de funcionários em todo o mundo */
[data-test="employer-industry"] /* Setor em que a empresa atua */
[data-test="cell-Jobs-url"] /* Link para as listas de vagas da empresa */
[data-test="cell-Jobs"] h3 /* Número total de vagas de emprego */
[data-test="cell-Reviews"] h3 /* Número de avaliações de funcionários */
[data-test="cell-Salaries"] h3 /* Contagem de salários relatados */
Em seguida, crie um novo arquivo chamado glassdoor.py e adicione o seguinte código:
import asyncio
from urllib.parse import urlencode, urlparse
from playwright.async_api import async_playwright, Playwright
async def scrape_data(playwright: Playwright):
# Inicie uma instância do navegador Chromium
browser = await playwright.chromium.launch(headless=False)
page = await browser.new_page()
# Defina a URL base e os parâmetros de consulta para a pesquisa no Glassdoor
base_url = "https://www.glassdoor.com/Explore/browse-companies.htm?"
query_params = {
"overall_rating_low": "3.5",
"locId": "1132348",
"locType": "C",
"locName": "Nova York, NY (EUA)",
"occ": "Engenheiro de Aprendizado de Máquina",
"filterType": "RATING_OVERALL",
}
# Construa a URL completa com parâmetros de consulta e navegue até ela
url = f"{base_url}{urlencode(query_params)}"
await page.goto(url)
# Inicialize um contador para os registros extraídos
record_count = 0
# Localize todos os cartões da empresa na página e itere por eles para extrair dados
company_cards = await page.locator('[data-test="employer-card-single"]').all()
para cartão em cartões_da_empresa:
tente:
# Extraia dados relevantes de cada cartão da empresa
nome_da_empresa = aguarde cartão.localizador('[data-test="employer-short-name"]').conteúdo_texto(tempo_limite=2000) ou "N/A"
classificação = aguardar cartão.localizador('[data-test="classificação"]').conteúdo_texto(tempo_limite=2000) ou "N/A"
localização = aguardar cartão.localizador('[data-test="localização_empregador"]').conteúdo_texto(tempo_limite=2000) ou "N/A"
global_company_size = aguardar card.locator('[data-test="employer-size"]').text_content(timeout=2000) ou "N/A"
industry = aguardar card.locator('[data-test="employer-industry"]').text_content(timeout=2000) ou "N/A"
# Construir a URL para listas de empregos
jobs_url_path = aguardar card.locator('[data-test="cell-Jobs-url"]').get_attribute("href", tempo limite=2000) ou "N/A"
parsed_url = urlparse(base_url)
jobs_url_path = f"{parsed_url.scheme}://{parsed_url.netloc}{jobs_url_path}"
# Extrair dados adicionais sobre vagas, avaliações e salários
jobs_count = aguardar card.locator('[data-test="cell-Jobs"] h3').text_content(timeout=2000) ou "N/A"
reviews_count = aguardar card.locator('[data-test="cell-Reviews"] h3').text_content(timeout=2000) ou "N/A"
salaries_count = aguardar card.locator('[data-test="cell-Salaries"] h3').text_content(timeout=2000) ou "N/A"
# Imprimir os dados extraídos
print({
"Empresa": nome_da_empresa,
"Classificação": classificação,
"URL dos empregos": jobs_url_path,
"Jobs Count": jobs_count,
"Reviews Count": reviews_count,
"Salaries Count": salaries_count,
"Industry": industry,
"Location": location,
"Global Company Size": global_company_size,
})
record_count += 1
except Exception as e:
print(f"Erro ao extrair dados da empresa: {e}")
print(f"Total de registros extraídos: {record_count}")
# Fechar o navegador
await browser.close()
# Ponto de entrada para o script
async def main():
async with async_playwright() as playwright:
await scrape_data(playwright)
if __name__ == "__main__":
asyncio.run(main())
Este código configura um script Playwright para extrair dados da empresa aplicando filtros específicos. Por exemplo, ele aplica filtros como localização (Nova York, NY), classificação (3,5+) e cargo (engenheiro de aprendizado de máquina).
Em seguida, ele inicia uma instância do navegador Chromium, navega até a URL do Glassdoor que inclui esses filtros e extrai os dados de cada cartão da empresa na página. Depois de coletar os dados, ele imprime as informações extraídas no console.
E aqui está o resultado:

Bom trabalho!
Ainda há um problema. Atualmente, o código extrai apenas 10 registros, enquanto há aproximadamente 150 registros disponíveis na página. Isso mostra que o script captura apenas os dados da primeira página. Para extrair mais registros, precisamos implementar o tratamento de paginação, que será abordado na próxima seção.
Tratamento da paginação
Cada página do Glassdoor exibe dados de aproximadamente 10 empresas. Para extrair todos os registros disponíveis, você precisa lidar com a paginação navegando por cada página até chegar ao fim. Para lidar com a paginação, você deve localizar o botão “Próximo”, verificar se ele está habilitado e clicar nele para prosseguir para a próxima página. Repita esse processo até que não haja mais páginas disponíveis.
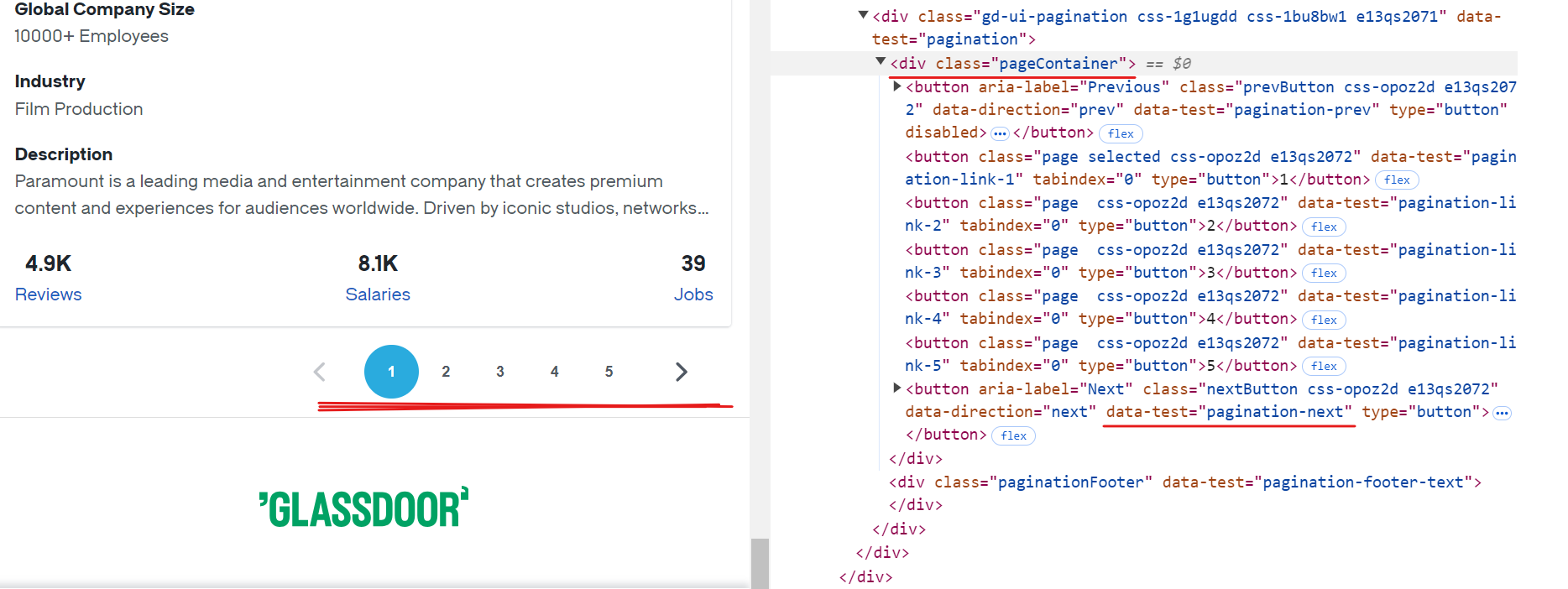
O seletor CSS para o botão “Próximo” é [data-test="pagination-next"], que está presente dentro de uma tag <div> com a classe pageContainer, conforme mostrado na imagem acima.
Aqui está um trecho de código que mostra como lidar com a paginação:
while True:
# Certifique-se de que o contêiner de paginação esteja visível antes de continuar
await page.wait_for_selector(".pageContainer", timeout=3000)
# Identifique o botão “Próximo” na página
next_button = page.locator('[data-test="pagination-next"]')
# Determine se o botão “próximo” está desativado, não mostrando mais páginas
is_disabled = await next_button.get_attribute("disabled") is not None
if is_disabled:
break # Pare se não houver mais páginas para navegar
# Navegue para a próxima página
await next_button.click()
await asyncio.sleep(3) # Aguarde até que a página carregue completamente
Aqui está o código modificado:
import asyncio
from urllib.parse import urlencode, urlparse
from playwright.async_api import async_playwright, Playwright
async def scrape_data(playwright: Playwright):
# Inicie uma instância do navegador Chromium
browser = await playwright.chromium.launch(headless=False)
page = await browser.new_page()
# Defina a URL base e os parâmetros de consulta para a pesquisa no Glassdoor
base_url = "https://www.glassdoor.com/Explore/browse-companies.htm?"
query_params = {
"overall_rating_low": "3.5",
"locId": "1132348",
"locType": "C",
"locName": "Nova York, NY (EUA)",
"occ": "Engenheiro de Aprendizado de Máquina",
"filterType": "RATING_OVERALL",
}
# Construa a URL completa com parâmetros de consulta e navegue até ela
url = f"{base_url}{urlencode(query_params)}"
await page.goto(url)
# Inicializar um contador para os registros extraídos
record_count = 0
while True:
# Localizar todos os cartões da empresa na página e iterar por eles para extrair dados
company_cards = await page.locator('[data-test="employer-card-single"]').all()
for card in company_cards:
try:
# Extrair dados relevantes de cada cartão da empresa
company_name = aguardar cartão.localizador('[data-test="employer-short-name"]').conteúdo_texto(tempo_limite=2000) ou "N/A"
classificação = aguardar cartão.localizador('[data-test="classificação"]').conteúdo_texto(tempo_limite=2000) ou "N/A"
localização = aguardar cartão.localizador('[data-test="localização_empregador"]').conteúdo_texto(tempo_limite=2000) ou "N/A"
tamanho_global_da_empresa = aguardar cartão.localizador('[data-test="tamanho-do-empregador"]').conteúdo_textual(tempo_limite=2000) ou "N/A"
setor = aguardar cartão.localizador('[data-test="setor-do-empregador"]').conteúdo_textual(tempo_limite=2000) ou "N/A"
# Construir a URL para listas de empregos
jobs_url_path = aguardar card.locator('[data-test="cell-Jobs-url"]').get_attribute("href", tempo limite=2000) ou "N/A"
parsed_url = urlparse(base_url)
jobs_url_path = f"{parsed_url.scheme}://{parsed_url.netloc}{jobs_url_path}"
# Extrair dados adicionais sobre vagas, avaliações e salários
jobs_count = aguardar card.locator('[data-test="cell-Jobs"] h3').text_content(timeout=2000) ou "N/A"
reviews_count = aguardar card.locator('[data-test="cell-Reviews"] h3').text_content(timeout=2000) ou "N/A"
salaries_count = await card.locator('[data-test="cell-Salaries"] h3').text_content(timeout=2000) ou "N/A"
# Imprimir os dados extraídos
print({
"Company": company_name,
"Rating": rating,
"Jobs URL": jobs_url_path,
"Jobs Count": jobs_count,
"Reviews Count": reviews_count,
"Salaries Count": salaries_count,
"Industry": industry,
"Location": location,
"Global Company Size": global_company_size,
})
record_count += 1
exceto Exception como e:
imprimir(f"Erro ao extrair dados da empresa: {e}")
tentar:
# Certifique-se de que o contêiner de paginação esteja visível antes de continuar
aguardar página.wait_for_selector(".pageContainer", tempo limite=3000)
# Identifique o botão "próximo" na página
botão_próximo = página.localizador('[data-test="pagination-next"]')
# Determine se o botão "próximo" está desativado, não mostrando mais páginas
está_desativado = aguardar botão_próximo.obter_atributo("desativado") não é None
se está_desativado:
interromper # Interrompa se não houver mais páginas para navegar
# Navegue para a próxima página
await next_button.click()
await asyncio.sleep(3) # Aguarde até que a página carregue completamente
except Exception as e:
print(f"Erro ao navegar para a próxima página: {e}")
break # Saia do loop em caso de erro de navegação
print(f"Total de registros extraídos: {record_count}")
# Fechar o navegador
await browser.close()
# Ponto de entrada para o script
async def main():
async with async_playwright() as playwright:
await scrape_data(playwright)
if __name__ == "__main__":
asyncio.run(main())
O resultado é:

Ótimo! Agora você pode extrair dados de todas as páginas disponíveis, não apenas da primeira.
Salvar dados em CSV
Agora que você extraiu os dados, vamos salvá-los em um arquivo CSV para processamento posterior. Para fazer isso, você pode usar o módulo csv do Python. Abaixo está o código atualizado que salva os dados extraídos em um arquivo CSV:
import asyncio
import csv
from urllib.parse import urlencode, urlparse
from playwright.async_api import async_playwright, Playwright
async def scrape_data(playwright: Playwright):
# Inicie uma instância do navegador Chromium
browser = await playwright.chromium.launch(headless=False)
page = await browser.new_page()
# Defina a URL base e os parâmetros de consulta para a pesquisa no Glassdoor
base_url = "https://www.glassdoor.com/Explore/browse-companies.htm?"
query_params = {
"overall_rating_low": "3.5",
"locId": "1132348",
"locType": "C",
"locName": "Nova York, NY (EUA)",
"occ": "Engenheiro de Aprendizado de Máquina",
"filterType": "RATING_OVERALL",
}
# Construa a URL completa com parâmetros de consulta e navegue até ela
url = f"{base_url}{urlencode(query_params)}"
await page.goto(url)
# Abra o arquivo CSV para gravar os dados extraídos
with open("glassdoor_data.csv", mode="w", newline="", encoding="utf-8") as file:
writer = csv.writer(file)
writer.writerow([
"Empresa", "URL das vagas", "Contagem de vagas", "Contagem de avaliações", "Contagem de salários",
"Setor", "Localização", "Tamanho global da empresa", "Classificação"
])
# Inicializar um contador para os registros extraídos
record_count = 0
while True:
# Localizar todos os cartões da empresa na página e iterá-los para extrair dados
company_cards = await page.locator('[data-test="employer-card-single"]').all()
for card in company_cards:
try:
# Extrair dados relevantes de cada cartão da empresa
company_name = await card.locator('[data-test="employer-short-name"]').text_content(timeout=2000) or "N/A"
classificação = aguardar cartão.localizador('[data-test="classificação"]').conteúdo_texto(tempo_limite=2000) ou "N/A"
localização = aguardar cartão.localizador('[data-test="localização_empregador"]').conteúdo_texto(tempo_limite=2000) ou "N/A"
tamanho_global_da_empresa = aguardar card.locator('[data-test="tamanho-da-empresa"]').text_content(timeout=2000) ou "N/A"
setor = aguardar card.locator('[data-test="setor-da-empresa"]').text_content(timeout=2000) ou "N/A"
# Construir a URL para listas de empregos
jobs_url_path = aguardar card.locator('[data-test="cell-Jobs-url"]').get_attribute("href", timeout=2000) ou "N/A"
parsed_url = urlparse(base_url)
jobs_url_path = f"{parsed_url.scheme}://{parsed_url.netloc}{jobs_url_path}"
# Extrair dados adicionais sobre vagas, avaliações e salários
jobs_count = await card.locator('[data-test="cell-Jobs"] h3').text_content(timeout=2000) or "N/A"
reviews_count = await card.locator('[data-test="cell-Reviews"] h3').text_content(timeout=2000) or "N/A"
salaries_count = await card.locator('[data-test="cell-Salaries"] h3').text_content(timeout=2000) or "N/A"
# Grave os dados extraídos no arquivo CSV
writer.writerow([
company_name, jobs_url_path, jobs_count, reviews_count, salaries_count,
industry, location, global_company_size, rating
])
record_count += 1
except Exception as e:
print(f"Erro ao extrair dados da empresa: {e}")
tente:
# Certifique-se de que o contêiner de paginação esteja visível antes de continuar
aguarde page.wait_for_selector(".pageContainer", timeout=3000)
# Identifique o botão "próximo" na página
botão_próximo = page.locator('[data-test="pagination-next"]')
# Determine se o botão “próximo” está desativado, não mostrando mais páginas
is_disabled = await next_button.get_attribute("disabled") is not None
if is_disabled:
break # Pare se não houver mais páginas para navegar
# Navegue para a próxima página
await next_button.click()
await asyncio.sleep(3) # Aguarde até que a página carregue completamente
except Exception as e:
print(f"Erro ao navegar para a próxima página: {e}")
break # Saia do loop em caso de erro de navegação
print(f"Total de registros extraídos: {record_count}")
# Fechar o navegador
await browser.close()
# Ponto de entrada para o script
async def main():
async with async_playwright() as playwright:
await scrape_data(playwright)
if __name__ == "__main__":
asyncio.run(main())
Este código agora salva os dados extraídos em um arquivo CSV chamado glassdoor_data.csv.
O resultado é:
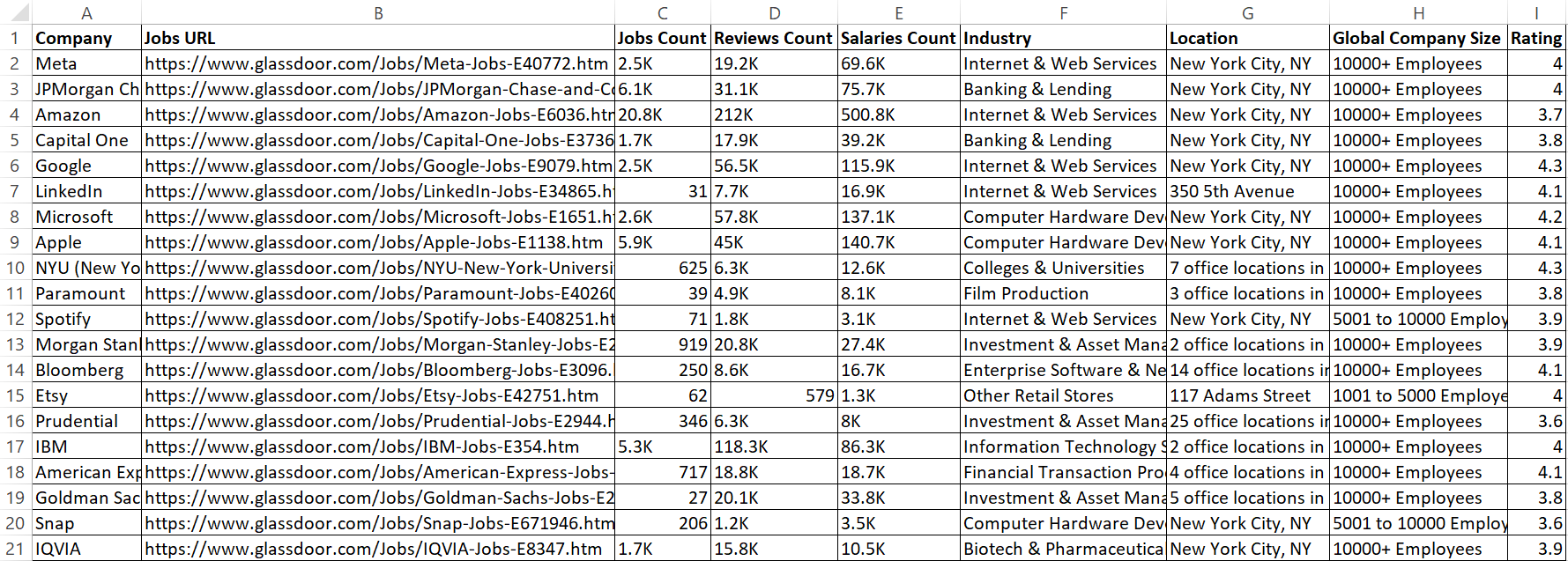
Ótimo! Agora, os dados parecem mais organizados e fáceis de ler.
Técnicas anti-scraping empregadas pela Glassdoor
A Glassdoor monitora o número de solicitações provenientes de um endereço IP dentro de um determinado período. Se as solicitações excederem um limite definido, a Glassdoor pode bloquear temporária ou permanentemente o endereço IP. Além disso, se for detectada uma atividade incomum, a Glassdoor pode apresentar um desafio CAPTCHA, como eu experimentei.
O método discutido acima é adequado para scraping de algumas centenas de empresas. No entanto, se você precisar fazer scraping de milhares, há um risco maior de que os mecanismos anti-bot da Glassdoor sinalizem seu script de scraping automatizado, como aconteceu comigo ao fazer scraping de volumes maiores de dados.
Extrair dados do Glassdoor pode ser difícil devido aos seus mecanismos anti-extração. Contornar esses mecanismos anti-bot pode ser frustrante e consumir muitos recursos. No entanto, existem estratégias para ajudar seu scraper a imitar o comportamento humano e reduzir a probabilidade de ser bloqueado. Algumas técnicas comuns incluem Proxy rotativo, definir cabeçalhos de solicitação reais, randomizar taxas de solicitação e muito mais. Embora essas técnicas possam melhorar suas chances de sucesso na extração, elas não garantem 100% de sucesso.
Portanto, a melhor abordagem para extrair dados do Glassdoor, apesar de suas medidas anti-bot, é usar uma API do Glassdoor Scraper 🚀
Uma alternativa melhor: API do Glassdoor Scraper
A Bright Data oferece um conjunto de dados do Glassdoor que vem pré-coletado e estruturado para análise, conforme discutido anteriormente no blog. Se você não deseja adquirir um conjunto de dados e está procurando uma solução mais eficiente, considere usar a API Glassdoor Scraper da Bright Data.
Esse poderoso API foi projetado para coletar dados do Glassdoor de maneira integrada, lidando com conteúdo dinâmico e contornando medidas anti-bot com facilidade. Com essa ferramenta, você pode economizar tempo, garantir a precisão dos dados e se concentrar em extrair insights acionáveis a partir dos dados.
Para começar a usar a API Glassdoor Scraper, siga estas etapas:
Primeiro, crie uma conta. Acesse o site da Bright Data, clique em “Teste grátis” e siga as instruções de inscrição. Depois de fazer login, você será redirecionado para o seu painel, onde receberá alguns créditos gratuitos.
Agora, vá para a seção API Web Scraper e selecione Glassdoor na categoria de dados B2B. Você encontrará várias opções de coleta de dados, como coletar empresas por URL ou coletar listas de empregos por URL.
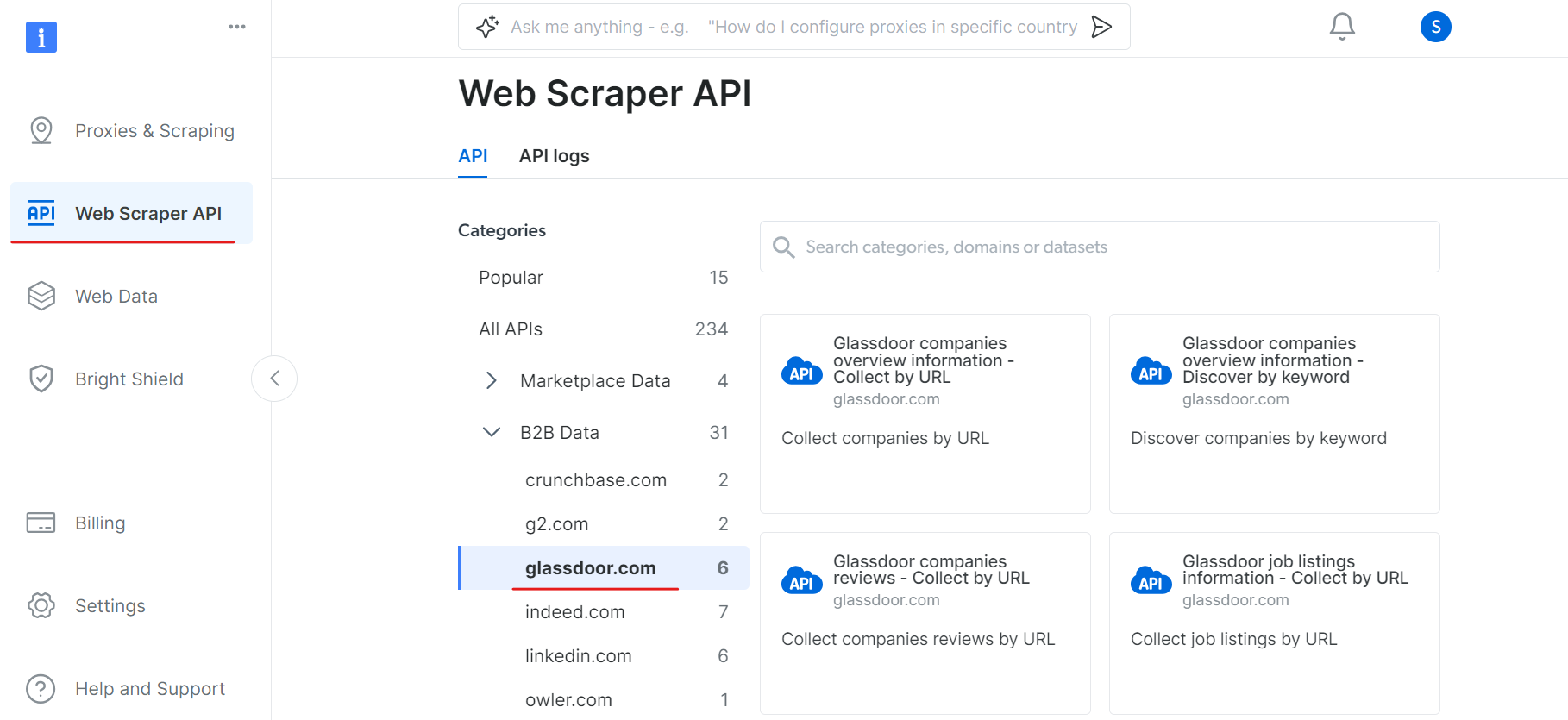
Em “Informações gerais sobre as empresas do Glassdoor”, obtenha seu token de API e copie o ID do seu conjunto de dados (por exemplo, gd_l7j0bx501ockwldaqf).
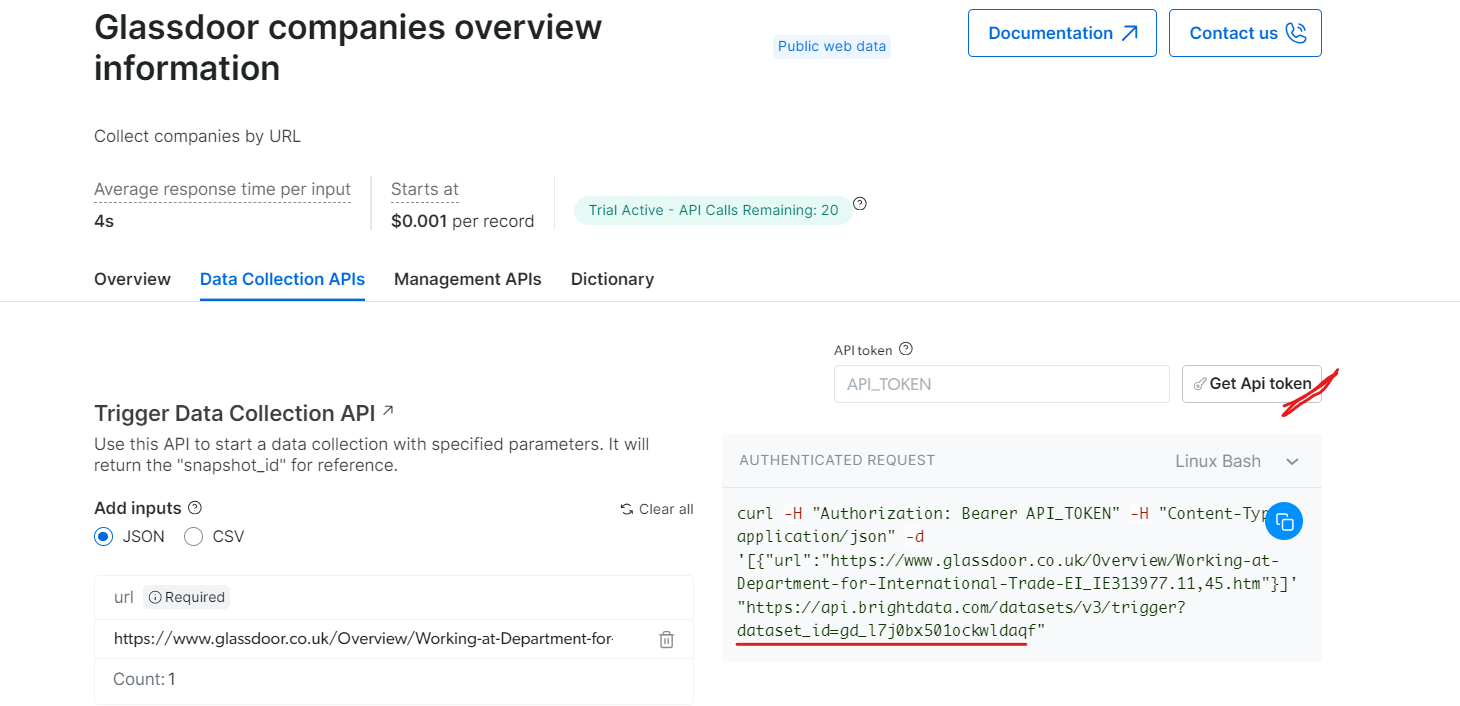
Agora, aqui está um trecho de código simples que mostra como extrair dados da empresa fornecendo a URL, o token da API e o ID do conjunto de dados.
import requests
import json
def trigger_dataset(api_token, dataset_id, company_url):
"""
Aciona um conjunto de dados usando a API BrightData.
Args:
api_token (str): O token da API para autenticação.
dataset_id (str): O ID do conjunto de dados a ser acionado.
company_url (str): A URL da página da empresa a ser analisada.
Retorna:
dict: A resposta JSON da API.
"""
headers = {
"Authorization": f"Bearer {api_token}",
"Content-Type": "application/json",
}
payload = json.dumps([{"url": company_url}])
response = requests.post(
"https://api.brightdata.com/conjuntos_de_datos/v3/trigger",
headers=headers,
params={"dataset_id": dataset_id},
data=payload,
)
return response.json()
api_token = "API_Token"
dataset_id = "DATASET_ID"
company_url = "COMPANY_PAGE_URL"
response_data = trigger_dataset(api_token, dataset_id, company_url)
print(response_data)
Ao executar o código, você receberá um ID de instantâneo, conforme mostrado abaixo:

Use o ID do instantâneo para recuperar os dados reais da empresa. Execute o seguinte comando no seu terminal. Para Windows, use:
curl.exe -H "Authorization: Bearer API_TOKEN"
"https://api.brightdata.com/conjuntos_de_datos/v3/snapshot/s_m0v14wn11w6tcxfih8?format=json"
Para Linux:
curl -H "Authorization: Bearer API_TOKEN"
"https://api.brightdata.com/conjuntos_de_datos/v3/snapshot/s_m0v14wn11w6tcxfih8?format=json"
Após executar o comando, você obterá os dados desejados.
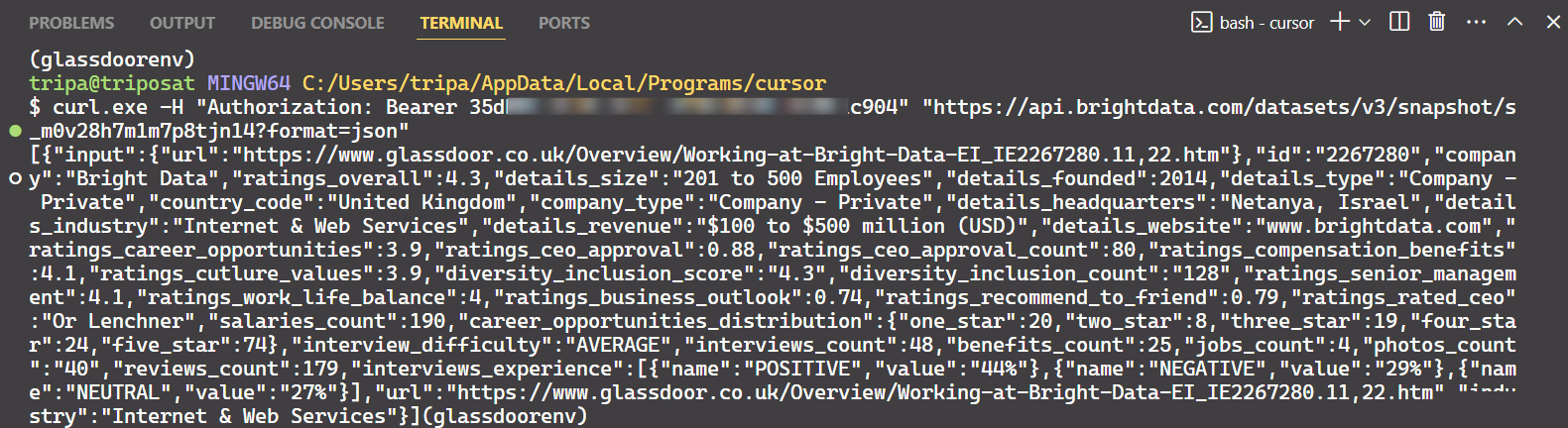
É só isso!
Da mesma forma, você pode extrair vários tipos de dados do Glassdoor modificando o código. Expliquei um método, mas existem outras cinco maneiras de fazer isso. Portanto, recomendo explorar essas opções para coletar os dados que você deseja. Cada método é adaptado a necessidades específicas de dados e ajuda você a obter exatamente os dados de que precisa.
Conclusão
Neste tutorial, você aprendeu como extrair dados do Glassdoor usando o Playwright Python. Você também aprendeu sobre as técnicas anti-extração empregadas pelo Glassdoor e como contorná-las. Para resolver essas questões, foi introduzida a API Bright Data Glassdoor Scraper, que ajuda você a superar as medidas anti-extração do Glassdoor e extrair os dados de que precisa sem problemas.
Você também pode experimentar o Navegador de scraping, um navegador de última geração que pode ser integrado a qualquer outra ferramenta de automação de navegador. O Navegador de scraping pode contornar facilmente as tecnologias anti-bot, evitando a identificação do navegador. Ele conta com recursos como rotação de agente do usuário, rotação de IP e resolução de CAPTCHA.
Inscreva-se agora e experimente os produtos da Bright Data gratuitamente.






