

Este tutorial abordará:
- Porquê extrair dados de comércio eletrónico da web?
- Bibliotecas e ferramentas de raspagem do eBay
- Raspagem de produtos do eBay com Beautiful Soup
Porquê extrair dados de comércio eletrónico da web?
A raspagem de dados do comércio eletrónico permite-lhe obter informações úteis para diferentes cenários e atividades. Estes incluem:
- Monitorização de preços: Ao acompanhar os sítios web de comércio eletrónico, as empresas podem monitorizar os preços dos produtos em tempo real. Isto ajuda-o a identificar as flutuações de preços, a detetar tendências e a ajustar a sua estratégia de preços em conformidade. Se é um consumidor, isto o ajudará a encontrar as melhores ofertas e a poupar dinheiro.
- Análise da concorrência: Ao coletar informações sobre as ofertas de produtos, preços, descontos e promoções dos seus concorrentes, pode tomar decisões baseadas em dados sobre as suas próprias estratégias de preços, variedade de produtos e campanhas de marketing.
- Estudos de mercado: Os dados do comércio eletrónico fornecem informações valiosas sobre as tendências do mercado, as preferências dos consumidores e os padrões de procura. Pode utilizar essas informações como fonte de um processo de análise de dados para estudar tendências emergentes e compreender o comportamento dos clientes.
- Análise do sentimento: Ao raspar as opiniões dos clientes dos sítios de comércio eletrónico, pode obter informações sobre a satisfação dos clientes, a retroalimentação sobre os produtos e as áreas a melhorar.
No que diz respeito à raspagem de dados do comércio eletrónico, o eBay é uma das escolhas mais populares por, pelo menos, três boas razões:
- Dispõe de uma vasta gama de produtos.
- Baseia-se num sistema de leilão e licitação que lhe permite obter muito mais dados do que a Amazon e plataformas semelhantes.
- Tem vários preços para os mesmos produtos (Leilão + Comprar agora!)
Ao extrair dados do eBay, pode aceder a uma grande quantidade de informação para apoiar a sua estratégia de monitorização, comparação ou análise de preços.
Bibliotecas e ferramentas de raspagem do eBay
Python é considerada uma das melhores linguagens para raspagem graças à sua facilidade de utilização, sintaxe simples e vasto ecossistema de bibliotecas. Será, portanto, a linguagem de programação escolhida para a raspagem de eBay. Explore o nosso guia detalhado sobre como fazer raspagem da web com Python.
Agora é necessário escolher as bibliotecas de raspagem corretas de entre as muitas disponíveis. Para tomar a decisão certa, explore o eBay no navegador. Ao inspecionar as chamadas AJAX feitas pela página, verificará que a maior parte dos dados do sítio está incorporada no documento HTML devolvido pelo servidor.
Isto significa que um simples cliente HTTP para replicar o pedido ao servidor e um analisador HTML serão suficientes. Por este motivo, recomendamos:
- Requests: A biblioteca de cliente HTTP mais popular para Python. Simplifica o processo de envio de pedidos HTTP e o tratamento das respetivas respostas, facilitando a obtenção de conteúdos de páginas a partir de servidores web.
- Beautiful Soup: Uma biblioteca de Python de análise de HTML e XML com todos os recursos. É sobretudo utilizada para a raspagem da web, uma vez que fornece métodos poderosos para explorar o DOM e extrair dados dos seus elementos.
Graças a Requests e a Beautiful Soup, poderá fazer raspagem do sítio-alvo com Python. Vamos ver como!
Raspagem de produtos do eBay com Beautiful Soup
Siga este tutorial passo-a-passo e aprenda a construir um script de Python para raspagem da web do eBay.
Passo 1: Começar
Para implementar a raspagem de preços, é necessário cumprir estes pré-requisitos:
- Python 3+ instalado no seu computador: Descarregue o instalador, inicie-o e siga o assistente de instalação.
- Um IDE de Python à sua escolha: O Visual Studio Code com a extensão de Python ou o PyCharm Community Edition são duas ótimas escolhas.
Em seguida, inicialize um projeto Python com um ambiente virtual chamado ebay-scraper, executando os comandos abaixo:
mkdir ebay-scrapernncd ebay-scrapernnpython -m venv env
Entre na pasta do projeto e adicione um ficheiro scraper.py que contenha o seguinte trecho:
print('Hello, World!')
Este é um trecho de exemplo que apenas imprime “Hello, World!”, mas que em breve conterá a lógica para raspar o eBay.
Verifique se funciona, executando-o com:
python scraper.py
No terminal, deve ver:
Hello, World!
Ótimo, agora tem um projeto Python!
Passo 2: Instalar as bibliotecas de raspagem
Está na altura de adicionar as bibliotecas necessárias para efetuar a raspagem da web às dependências do seu projeto. Execute o comando abaixo na pasta do projeto para instalar os pacotes Beautiful Soup e Requests:
pip install beautifulsoup4 requests
Importe as bibliotecas em scraper.py e prepare-se para as utilizar para extrair dados do eBay:
import requestsnnfrom bs4 import BeautifulSoupnn# scraping logic...
Certifique-se de que o seu IDE de Python não reporta erros, e está pronto para implementar a monitorização de preços com raspagem!
Passo 3: Descarregar a página web de destino
Se é um usuário do eBay, deve ter reparado que o URL da página do produto segue o formato abaixo:
https://www.ebay.com/itm/u003cITM_IDu003e
Como pode ver, é um URL dinâmico que se altera com base no ID do elemento.
Por exemplo, este é o URL de um produto do eBay:
https://www.ebay.com/itm/225605642071?epid=26057553242u0026hash=item348724e757:g:~ykAAOSw201kD1unu0026amdata=enc%3AAQAIAAAA4OMICjL%2BH6HBrWqJLiCPpCurGf8qKkO7CuQwOkJClqK%2BT2B5ioN3Z9pwm4r7tGSGG%2FI31uN6k0IJr0SEMEkSYRrz1de9XKIfQhatgKQJzIU6B9GnR6ZYbzcU8AGyKT6iUTEkJWkOicfCYI5N0qWL8gYV2RGT4zr6cCkJQnmuYIjhzFonqwFVdYKYukhWNWVrlcv5g%2BI9kitSz8k%2F8eqAz7IzcdGE44xsEaSU2yz%2BJxneYq0PHoJoVt%2FBujuSnmnO1AXqjGamS3tgNcK5Tqu36QhHRB0tiwUfAMrzLCOe9zTa%7Ctkp%3ABFBMmNDJgZJi
Aqui, 225605642071 é o identificador único do artigo. Note-se que os parâmetros de consulta não são necessários para visitar a página. Pode removê-los e o eBay continuará a carregar corretamente a página do produto.
Em vez de codificar a página de destino no seu script, pode fazê-lo ler o ID do elemento a partir de um argumento da linha de comando. Desta forma, pode extrair dados de qualquer página de produto.
Para isso, atualize o scraper.py da seguinte forma:
import requestsnnfrom bs4 import BeautifulSoupnnimport sysnn# if there are no CLI parametersnnif len(sys.argv) u003c= 1:nn print('Item ID argument missing!')nn sys.exit(2)nn# read the item ID from a CLI argumentnnitem_id = sys.argv[1]nn# build the URL of the target product pagennurl = f'https://www.ebay.com/itm/{item_id}'nn# scraping logic...nnAssume you want to scrape the product 225605642071. You can launch your scraper with:nnpython scraper.py 225605642071
Graças a sys, é possível aceder aos argumentos da linha de comandos. O primeiro elemento de sys.argv é o nome do seu script, scraper.py. Para obter o ID do artigo, é necessário direcionar o elemento com o índice 1.
Se esquecer o ID do artigo na ILC, a aplicação falhará com o erro abaixo:
Item ID argument missing!
Caso contrário, lerá o parâmetro da ILC e o utilizará numa f-string para gerar o URL de destino do produto a ser raspado. Neste caso, o URL conterá:
nhttps://www.ebay.com/itm/225605642071
Agora, pode utilizar requests para descarregar a página web com a seguinte linha de código:
page = requests.get(url)
Nos bastidores, request.get() executa um pedido HTTP GET para o URL passado como parâmetro. page armazenará a resposta produzida pelo servidor de eBay, incluindo o conteúdo HTML da página de destino.
Fantástico! Vamos aprender como obter dados a partir disso.
Passo 4: Analisar o documento HTML
page.text contém o documento HTML devolvido pelo servidor. Passa-o para o construtor BeautifulSoup() para o analisar:
soup = BeautifulSoup(page.text, 'html.parser')
O segundo parâmetro especifica o analisador utilizado por Beautiful Soup. Se você não está familiarizado com ele, html.parser é o nome do analisador HTML incorporado no Python.
A variável soup agora armazena uma estrutura de árvore que expõe alguns métodos úteis para selecionar elementos do DOM. Os mais populares são:
- find(): Retorna o primeiro elemento HTML que corresponde à condição do seletor passada como parâmetro.
- find_all(): Devolve uma lista de elementos HTML que correspondem à estratégia do seletor de entrada.
- select_one(): Retorna os elementos HTML que correspondem ao seletor CSS de entrada.
- select(): Devolve uma lista de elementos HTML que correspondem ao seletor CSS passado como parâmetro.
Utilize-os para selecionar elementos HTML por etiqueta, ID, classes CSS e muito mais. Depois, pode extrair dados dos seus atributos e conteúdo de texto. Veja como!
Passo 5: Inspecionar a página do produto
Se pretende estruturar uma estratégia de raspagem de dados eficaz, deve primeiro familiarizar-se com a estrutura das páginas web alvo. Abra o seu navegador e visite alguns produtos do eBay.
Começará por notar que, consoante a categoria do produto, a página contém informações diferentes. Nos produtos eletrónicos, terá acesso a especificações técnicas.

Quando visita produtos de vestuário, vê os tamanhos e as cores disponíveis.

Estas inconsistências na estrutura das páginas web tornam a raspagem um pouco difícil. No entanto, alguns campos de informação encontram-se em cada página, como os preços dos produtos e dos portes de envio.
Familiarize-se também com as ferramentas de desenvolvimento do seu navegador. Clique com o botão direito do rato num elemento HTML que contenha dados interessantes e selecione “Inspecionar”. Isto abrirá a janela abaixo:
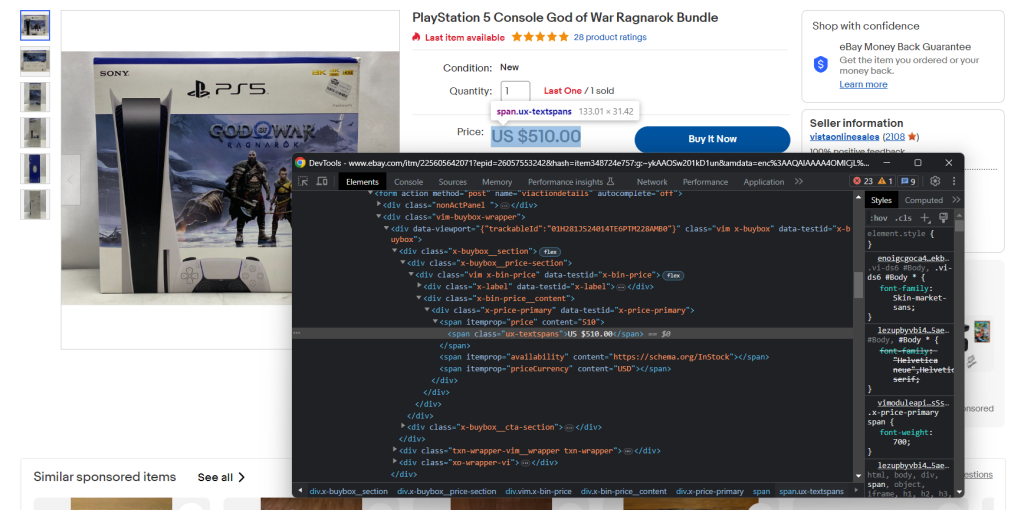
Aqui, pode explorar a estrutura do DOM da página e compreender como definir estratégias de seleção eficazes.
Passe algum tempo a inspecionar as páginas dos produtos com as ferramentas de desenvolvimento.
Passo 6: Extrair os dados relativos aos preços
Em primeiro lugar, é necessária uma estrutura de dados para armazenar os dados a raspar. Inicialize um dicionário de Python com:
item = {}
Como deve ter reparado na etapa anterior, os dados relativos aos preços encontram-se nesta secção:

Inspecione o elemento HTML de preço:
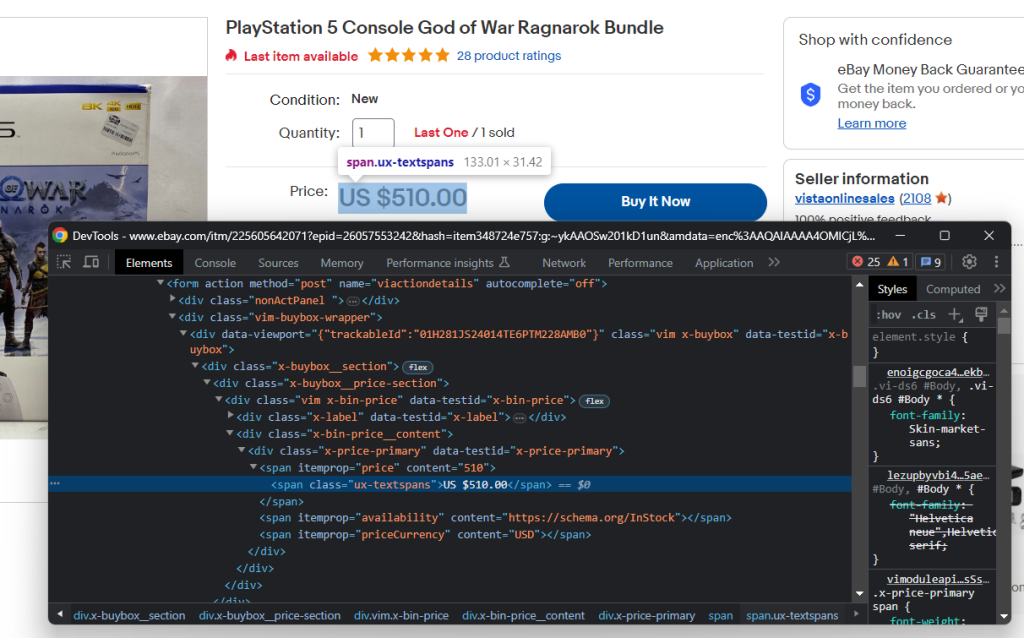
Pode obter o preço do produto com o seletor CSS abaixo:
.x-price-primary span[itemprop=u0022priceu0022]nnAnd the currency with:nn.x-price-primary span[itemprop=u0022priceCurrencyu0022]nnApply those selectors in Beautiful Soup and retrieve the desired data with:nnprice_html_element = soup.select_one('.x-price-primary span[itemprop=u0022priceu0022]')nnprice = price_html_element['content']nncurrency_html_element = soup.select_one('.x-price-primary span[itemprop=u0022priceCurrencyu0022]')nncurrency = currency_html_element['content']
Este trecho seleciona os elementos HTML de preço e moeda e, em seguida, coleta a cadeia contida no seu atributo de conteúdo.
Não se esqueça de que o preço acima indicado é apenas uma parte do preço total que terá de pagar para obter o artigo que pretende. Esse valor inclui também os custos de envio.
Inspecione o elemento de envio:
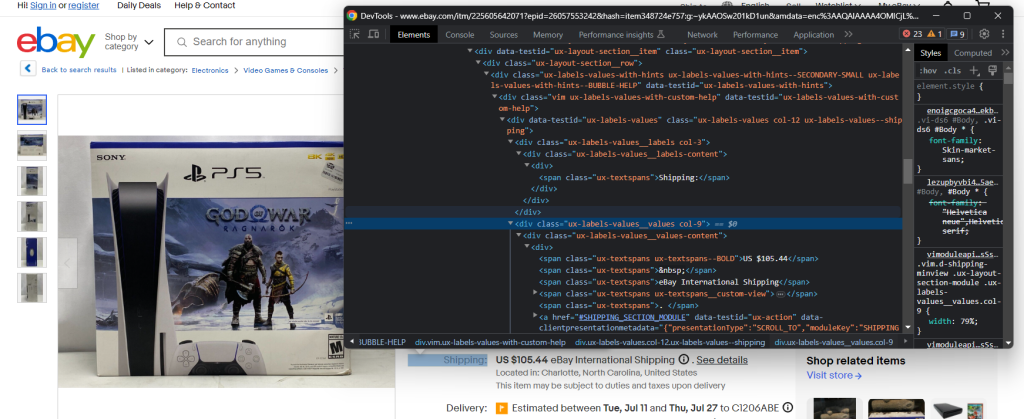
Desta vez, a extração dos dados pretendidos é um pouco mais complicada, uma vez que não existe um seletor CSS fácil para obter o elemento. O que pode fazer é iterar sobre cada .ux-labels-values__labels div. Quando o elemento atual contém a cadeia “Shipping:”, pode aceder ao irmão seguinte no DOM e extrair o preço de .ux-textspans–BOLD:
Your Code Here...
O elemento preço de envio contém os dados desejados no seguinte formato:
US $105.44
Para extrair o preço, pode utilizar um regex com o método re.findall(). Não se esqueça de acrescentar a seguinte linha na secção de importação do seu script:
import re nnAdd the collected data to the item dictionary:nnitem['price'] = pricennitem['shipping_price'] = shipping_pricennitem['currency'] = currencynnPrint it with:nnprint(item)nnAnd you will get:nn{'price': '499.99', 'shipping_price': '72.58', 'currency': 'USD'}
Isto é suficiente para implementar um processo de rastreio de preços em Python. No entanto, existem muitas outras informações úteis na página de produto do eBay. Por isso, vale a pena aprender a extraí-las!
Passo 7: Recuperar os detalhes do artigo
Se der uma vista de olhos ao separador “Acerca deste artigo”, verá que contém muitos dados interessantes:
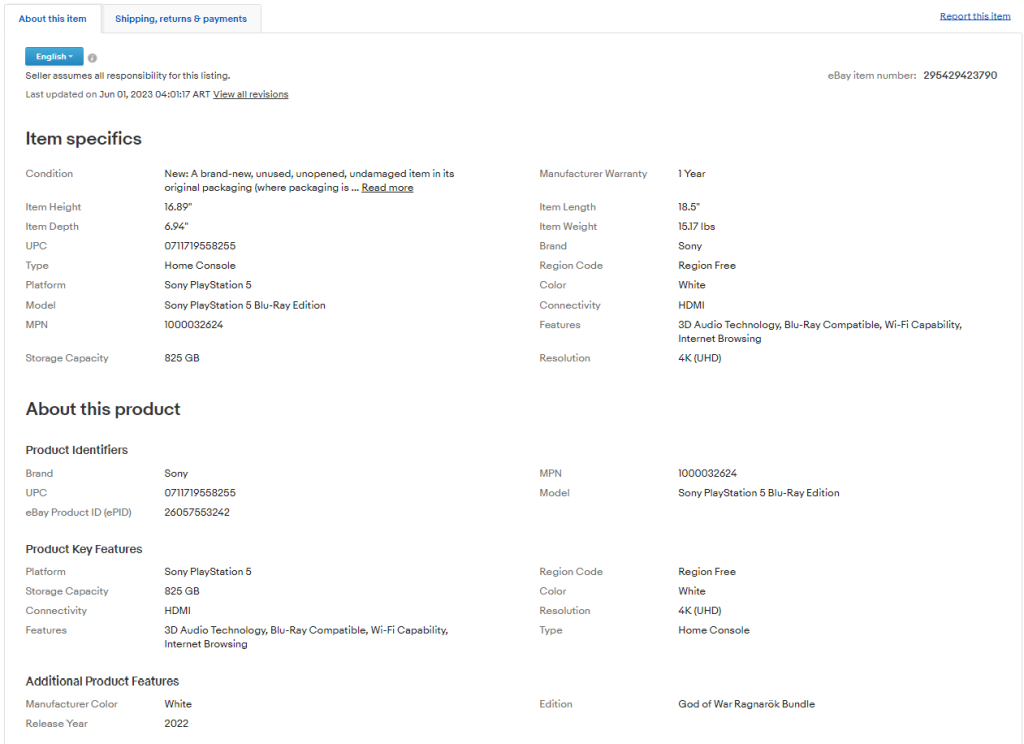
As secções e os campos nelas contidos mudam de produto para produto, pelo que é necessário encontrar uma forma de os raspar a todos com uma abordagem inteligente.
Em pormenor, as secções mais importantes são “Especificidades do artigo” e “Acerca deste artigo”. Estes dois estão presentes na maioria dos produtos. Inspecione uma das dois e repare que pode selecioná-las com:
.section-title
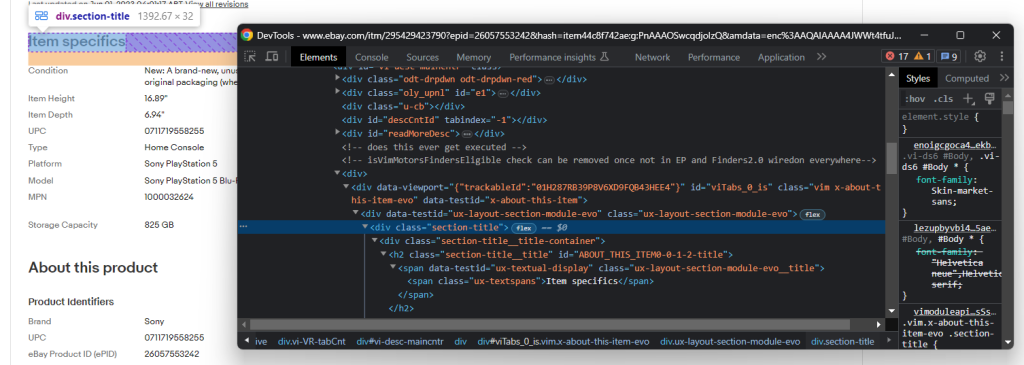
Dada uma secção, explore a sua estrutura do DOM:
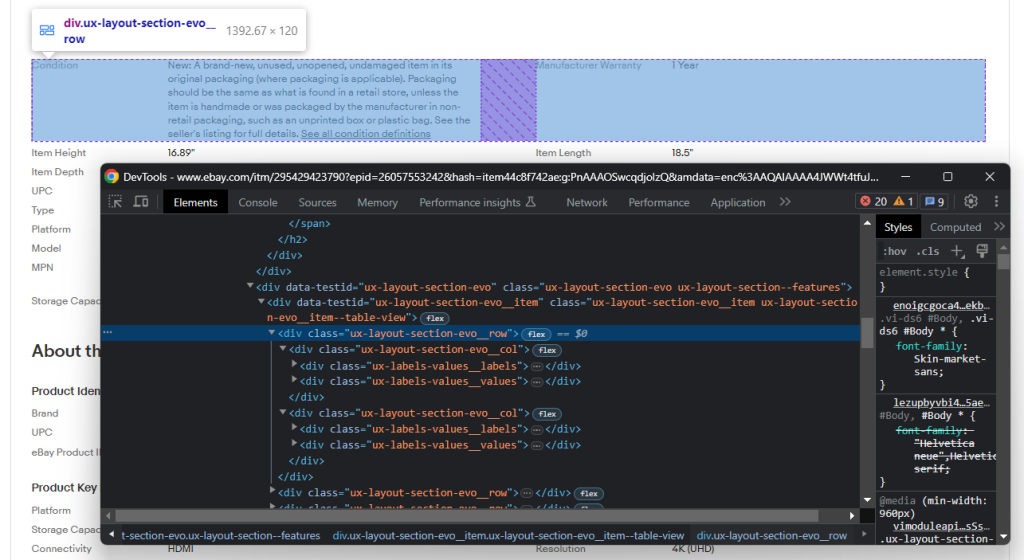
Note-se que é composto por várias linhas, cada uma com alguns elementos .ux-layout-section-evo__col. Estes contêm dois elementos:
- .ux-labels-values__labels: O nome do atributo.
- .ux-labels-values__values: O valor do atributo.
Agora está pronto para raspar todas as informações da secção de detalhes de forma programática com:
section_title_elements = soup.select('.section-title')nnfor section_title_element in section_title_elements:nn if 'Item specifics' in section_title_element.text or 'About this product' in section_title_element.text:nn # get the parent element containing the entire sectionnn section_element = section_title_element.parentnn for section_col in section_element.select('.ux-layout-section-evo__col'):nn print(section_col.text)nn col_label = section_col.select_one('.ux-labels-values__labels')nn col_value = section_col.select_one('.ux-labels-values__values')nn # if both elements are presentnn if col_label is not None and col_value is not None:nn item[col_label.text] = col_value.text
Este código percorre cada elemento de campo de detalhe HTML e adiciona o par chave-valor associado a cada atributo de produto ao dicionário de elementos.
No final do ciclo for, o elemento conterá:
{'price': '499.99', 'shipping_price': '72.58', 'currency': 'USD', 'Condition': u0022New: A brand-new, unused, unopened, undamaged item in its original packaging (where packaging is applicable). Packaging should be the same as what is found in a retail store, unless the item is handmade or was packaged by the manufacturer in non-retail packaging, such as an unprinted box or plastic bag. See the seller's listing for full details. See all condition definitionsopens in a new window or tab u0022, 'Manufacturer Warranty': '1 Year', 'Item Height': '16.89u0022', 'Item Length': '18.5u0022', 'Item Depth': '6.94u0022', 'Item Weight': '15.17 lbs', 'UPC': '0711719558255', 'Brand': 'Sony', 'Type': 'Home Console', 'Region Code': 'Region Free', 'Platform': 'Sony PlayStation 5', 'Color': 'White', 'Model': 'Sony PlayStation 5 Blu-Ray Edition', 'Connectivity': 'HDMI', 'MPN': '1000032624', 'Features': '3D Audio Technology, Blu-Ray Compatible, Wi-Fi Capability, Internet Browsing', 'Storage Capacity': '825 GB', 'Resolution': '4K (UHD)', 'eBay Product ID (ePID)': '26057553242', 'Manufacturer Color': 'White', 'Edition': 'God of War Ragnarök Bundle', 'Release Year': '2022'}
Maravilhoso! Acabou de atingir o seu objetivo de recuperação de dados!
Passo 8: Exportar dados raspados para JSON
Neste momento, os dados raspados são armazenados num dicionário de Python. Para o tornar mais facilmente partilhável e legível, pode exportá-lo para JSON com:
import jsonnn# scraping logic...nnwith open('product_info.json', 'w') as file:nn json.dump(item, file)
Primeiro, é necessário inicializar um ficheiro product_info.json com open(). Em seguida, pode escrever a representação JSON do dicionário de elementos no ficheiro de saída com json.dump(). Confira nosso artigo para saber mais sobre como analisar e serializar dados para JSON em Python.
O pacote json vem da biblioteca padrão de Python, pelo que nem sequer é necessário instalar uma dependência extra para atingir o objetivo.
Ótimo! Começou com dados em bruto contidos numa página web e agora tem dados JSON semiestruturados. Chegou a altura de dar uma vista de olhos a todo o raspador do eBay.
Passo 9: Juntar tudo
Aqui está o script scraper.py completo:
Your Code Here...
Em menos de 70 linhas de código, pode construir um raspador da web para monitorizar dados de produtos do eBay.
Como exemplo, lance-o contra o elemento identificado pelo ID 225605642071 com:
python scraper.py 225605642071
No final do processo de raspagem, o ficheiro product_info.json abaixo aparecerá na pasta raiz do seu projeto:
{nn u0022priceu0022: u0022499.99u0022,nn u0022shipping_priceu0022: u002272.58u0022,nn u0022currencyu0022: u0022USDu0022,nn u0022Conditionu0022: u0022New: A brand-new, unused, unopened, undamaged item in its original packaging (where packaging is applicable). Packaging should be the same as what is found in a retail store, unless the item is handmade or was packaged by the manufacturer in non-retail packaging, such as an unprinted box or plastic bag. See the seller's listing for full detailsu0022,nn u0022Manufacturer Warrantyu0022: u00221 Yearu0022,nn u0022Item Heightu0022: u002216.89"u0022,nn u0022Item Lengthu0022: u002218.5"u0022,nn u0022Item Depthu0022: u00226.94"u0022,nn u0022Item Weightu0022: u002215.17 lbsu0022,nn u0022UPCu0022: u00220711719558255u0022,nn u0022Brandu0022: u0022Sonyu0022,nn u0022Typeu0022: u0022Home Consoleu0022,nn u0022Region Codeu0022: u0022Region Freeu0022,nn u0022Platformu0022: u0022Sony PlayStation 5u0022,nn u0022Coloru0022: u0022Whiteu0022,nn u0022Modelu0022: u0022Sony PlayStation 5 Blu-Ray Editionu0022,nn u0022Connectivityu0022: u0022HDMIu0022,nn u0022MPNu0022: u00221000032624u0022,nn u0022Featuresu0022: u00223D Audio Technology, Blu-Ray Compatible, Wi-Fi Capability, Internet Browsingu0022,nn u0022Storage Capacityu0022: u0022825 GBu0022,nn u0022Resolutionu0022: u00224K (UHD)u0022,nn u0022eBay Product ID (ePID)u0022: u002226057553242u0022,nn u0022Manufacturer Coloru0022: u0022Whiteu0022,nn u0022Editionu0022: u0022God of War Ragnarok Bundleu0022,nn u0022Release Yearu0022: u00222022u0022nn}
Parabéns! Acabou de aprender a fazer raspagem do eBay em Python!
Conclusão
Neste guia, descobriu porque é que o eBay é um dos melhores alvos de raspagem para seguir os preços dos produtos e como o conseguir. Em pormenor, viu como construir um raspador em Python que pode recuperar dados de artigos num tutorial passo-a-passo. Como mostrado aqui, não é complexo e requer apenas algumas linhas de código.
Ao mesmo tempo, percebeu como a estrutura das páginas do Ebay é inconsistente. O raspador aqui construído pode, portanto, funcionar para um produto mas não para outro. Além disso, a IU do eBay muda frequentemente, o que obriga a uma manutenção contínua do script. Felizmente, pode evitar isto com o nosso raspador do eBay!
Se quiser alargar o seu processo de raspagem e extrair preços de outras plataformas de comércio eletrónico, tenha em conta que muitas delas dependem fortemente do JavaScript. Quando se trata de sítios deste tipo, uma abordagem tradicional baseada num analisador HTML não funciona. Em vez disso, precisa de uma ferramenta que possa processar JavaScript e que seja capaz de lidar automaticamente com impressões digitais, CAPTCHAs e tentativas automáticas por você. É exatamente este o objetivo da nossa nova solução: o Navegador de Raspagem!
Não quer lidar com a raspagem da web do eBay, mas está interessado nos dados dos artigos? Adquira um conjunto de dados do eBay.


