

Neste artigo, você aprenderá:
- O que é validação de dados, quando usá-la, as verificações que ela envolve e quais bibliotecas você deve usar para implementá-la.
- Como realizar a validação de dados com um exemplo real em Python.
- O que é verificação de dados, como funciona, exemplos de verificações e melhores abordagens.
- Como implementar a verificação de dados usando um agente de IA dedicado.
- Uma tabela resumida comparando validação de dados e verificação de dados.
Vamos começar!
Validação de dados: tudo o que você precisa saber
Comece esta jornada de validação de dados versus verificação de dados explorando a primeira abordagem: validação de dados.
O que é validação de dados e por que ela é importante?
A validação de dados é o processo de verificar a precisão, a qualidade e a integridade dos dados. Normalmente, ela é realizada antes que os dados sejam armazenados, usados ou processados. Seu objetivo final é garantir um nível consistente de qualidade e confiança.
Em particular, essa técnica verifica se os dados seguem regras e padrões definidos. Ela impede que informações incorretas ou incompletas entrem em um sistema, aplicativo, fluxo de trabalho ou continuem passando por um pipeline de dados.
A validação de dados é fundamental para manter a alta qualidade dos dados. A validação de dados também desempenha um papel importante no cumprimento de requisitos de conformidade, como GDPR e CCPA, bem como no seguimento das melhores práticas de segurança.
Ao aplicar a validação de dados, você pode detectar erros e problemas em seus dados antecipadamente. Isso ajuda a identificar problemas no ciclo de vida dos dados antes que eles se agravem, evitando erros dispendiosos e complicações graves.
Exemplos de verificações de validação de dados
As verificações de validação de dados que você pode aplicar são inúmeras e dependem de suas necessidades específicas, do tipo de campos de dados e de cenários específicos. Algumas das verificações mais importantes incluem:
- Verificação do tipo de dados: confirma se os dados inseridos em um campo são do tipo correto (por exemplo, garantindo que um campo
de idadeaceite apenas números). - Verificação de formato: verifica se os dados estão em conformidade com um padrão específico, como um formato de número de telefone como
(XXX) XXX-XXXX, um formato de data comoAAAA-MM-DDou um formato de e-mail como[email protected]. - Verificação de intervalo: garante que um valor numérico esteja dentro de um intervalo mínimo e máximo predefinido (por exemplo, um campo
de pontuaçãodeve estar entre0e100). - Verificação de presença: confirma que um campo obrigatório não foi deixado em branco ou nulo, garantindo que nenhuma informação crítica esteja faltando.
- Verificação de código: valida se uma entrada foi selecionada a partir de uma lista predefinida de valores aceitáveis (por exemplo, um código de país da lista ISO 3166).
- Verificação de consistência: verifica se os dados em vários campos dentro da mesma entrada ou em entradas diferentes são lógicos e consistentes (por exemplo, uma data de pedido deve ser anterior à data de entrega).
- Verificação de exclusividade: evita entradas duplicadas em campos que exigem valores exclusivos, como um ID de funcionário ou endereço de e-mail.
Quando realizar
Como regra geral, a validação de dados deve ser realizada continuamente ao longo do ciclo de vida dos dados. Ao mesmo tempo, quanto mais cedo ela ocorrer, mais eficazmente evitará a propagação de erros. Isso é conhecido como abordagem “shift-left” para a qualidade dos dados.
Portanto, o momento mais proativo e eficiente para validar os dados é no momento da entrada. Detectar erros nesse momento garante que dados incorretos nunca entrem em seus sistemas, economizando tempo e recursos na limpeza posterior. Isso se aplica a dados inseridos por usuários (por exemplo, por meio de formulários ou uploads de arquivos), dados recuperados por meio de Scraping de dados ou dados de repositórios públicos ou abertos nos quais você não confia totalmente.
Para dados enviados pelo usuário, como por meio de uma API em um sistema back-end, a validação em tempo real pode fornecer feedback imediato (por exemplo, sinalizando um endereço de e-mail formatado incorretamente ou um número de telefone incompleto diretamente na resposta da API com erros400 Bad Request).
No entanto, nem sempre é possível validar os dados imediatamente. Por exemplo, em pipelines ETL ou ELT, a validação geralmente é aplicada em estágios específicos:
- Após a extração: para verificar se os dados extraídos de um sistema de origem não foram corrompidos ou perdidos durante o trânsito.
- Após a transformação: para verificar se a saída de cada etapa de transformação (por exemplo, agregações) atende às regras e padrões esperados.
Mesmo após o armazenamento dos dados, você deve verificá-los periodicamente. Isso porque os dados não são estáticos, pois podem ser atualizados, enriquecidos ou reutilizados. Portanto, há a necessidade de validação contínua.
Como validar dados
O processo de validação de dados envolve as seguintes etapas:
- Definir requisitos: estabelecer regras de validação claras com base nas necessidades comerciais, padrões regulatórios e expectativas (por exemplo, definir um esquema com regras para seus dados).
- Coletar dados: reúna dados de várias fontes, como Scraping de dados, APIs ou bancos de dados.
- Aplicar a validação: implemente as regras definidas para verificar a precisão, consistência e integridade dos dados.
- Lidar com erros: registre, coloque em quarentena ou corrija registros inválidos de acordo com as políticas da organização. Forneça feedback claro aos usuários quando eles inserirem dados incorretos.
- Carregar dados: depois que os dados forem validados e limpos, carregue-os no sistema de destino, como um data warehouse.
Observação: você verá como aplicar essas etapas no próximo capítulo por meio de um exemplo guiado em Python.
Bibliotecas para validação de dados
Abaixo está uma tabela com algumas das melhores bibliotecas de código aberto para validação de dados:
| Biblioteca | Linguagem de programação | Estrelas no GitHub | Descrição |
|---|---|---|---|
| Pydantic | Python | 25,3 mil | Validação de dados usando dicas de tipo Python |
| Marshmallow | Python | 7,2 mil | Uma biblioteca leve para converter objetos complexos de e para tipos de dados Python simples |
| Cerberus | Python | 3,2 mil | Biblioteca leve e extensível para validação de dados em Python |
| jsonschema | Python | 4,8 mil | Uma implementação da especificação JSON Schema para Python |
| Validator.js | JavaScript | 23,6 mil | Uma biblioteca de validadores e sanitizadores de strings. |
| Joi | JavaScript | 21,2 mil | A biblioteca de validação de dados mais poderosa para JS |
| Sim | JavaScript | 23,6 mil | Validação de esquema de objetos extremamente simples |
| Ajv | JavaScript | 14,4 mil | O validador de esquema JSON mais rápido. Compatível com JSON Schema draft-04/06/07/2019-09/2020-12 e JSON Type Definition (RFC8927) |
| FluentValidation | C# (.NET) | 9,5 mil | Uma biblioteca de validação .NET popular para criar regras de validação fortemente tipadas |
| validator | Go | 19,1 mil | Go Validação de estruturas e campos, incluindo campos cruzados, estruturas cruzadas, mapas, fatias e matrizes |
Como aplicar a validação de dados em Python: exemplo passo a passo
Neste tutorial guiado, você aprenderá como aplicar a validação de dados aos dados de entrada em JSON usando Pydantic. Este tutorial abordará os principais aspectos da criação de um processo para validar dados.
Descrição do cenário
Suponha que você esteja recuperando dados de um site de comércio eletrônico. Em particular, concentre-se nesta página da web do produto:
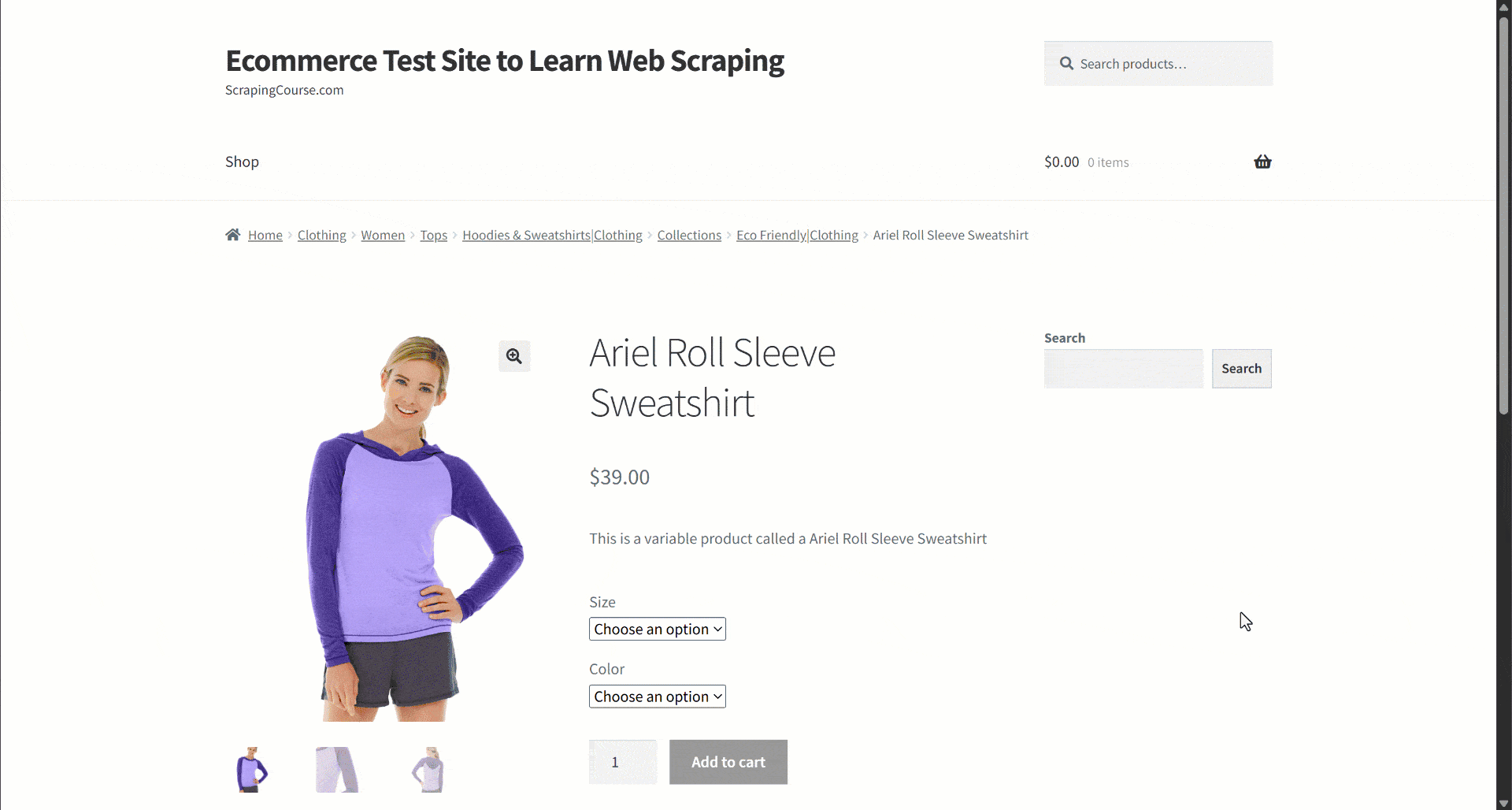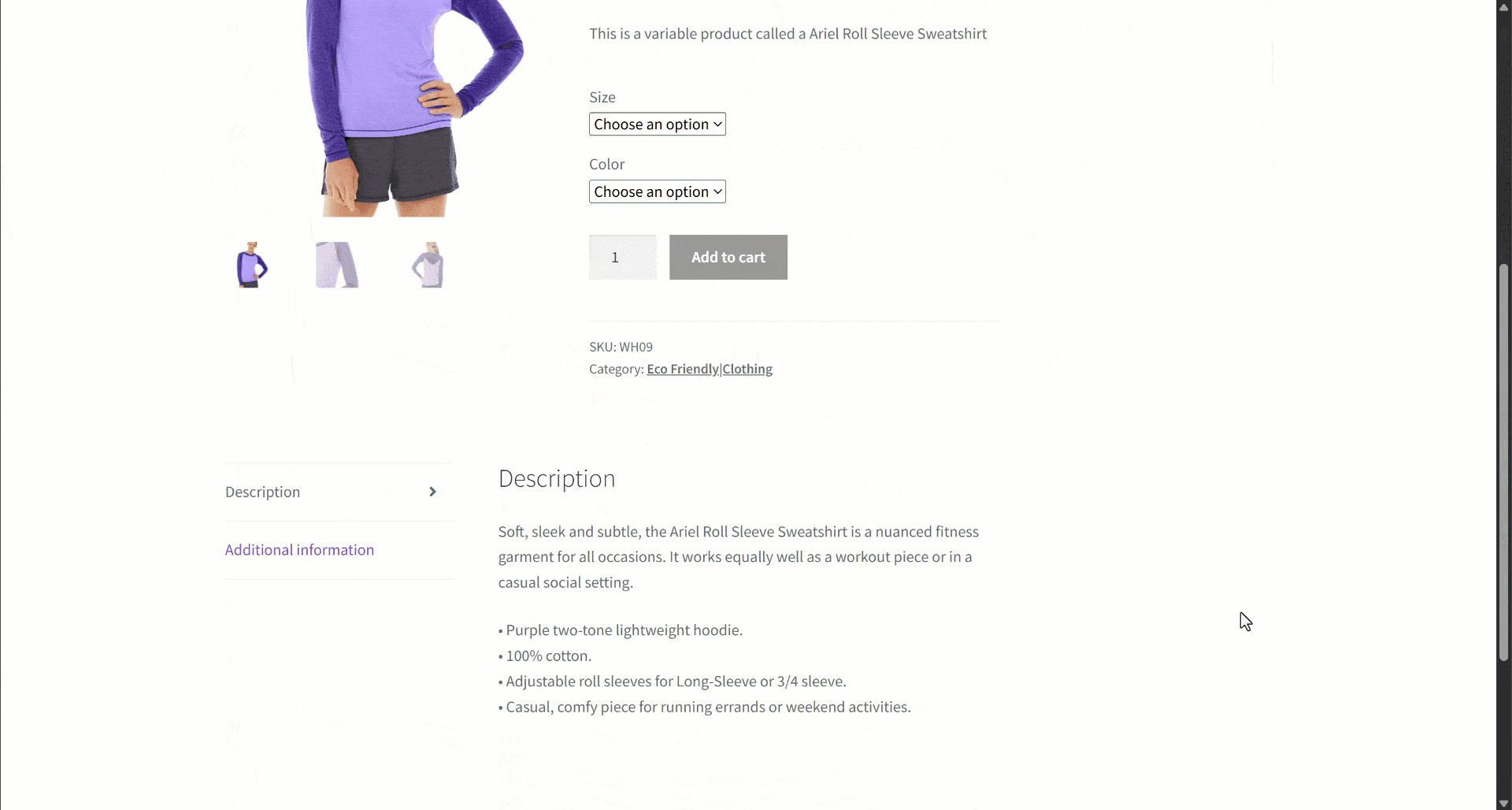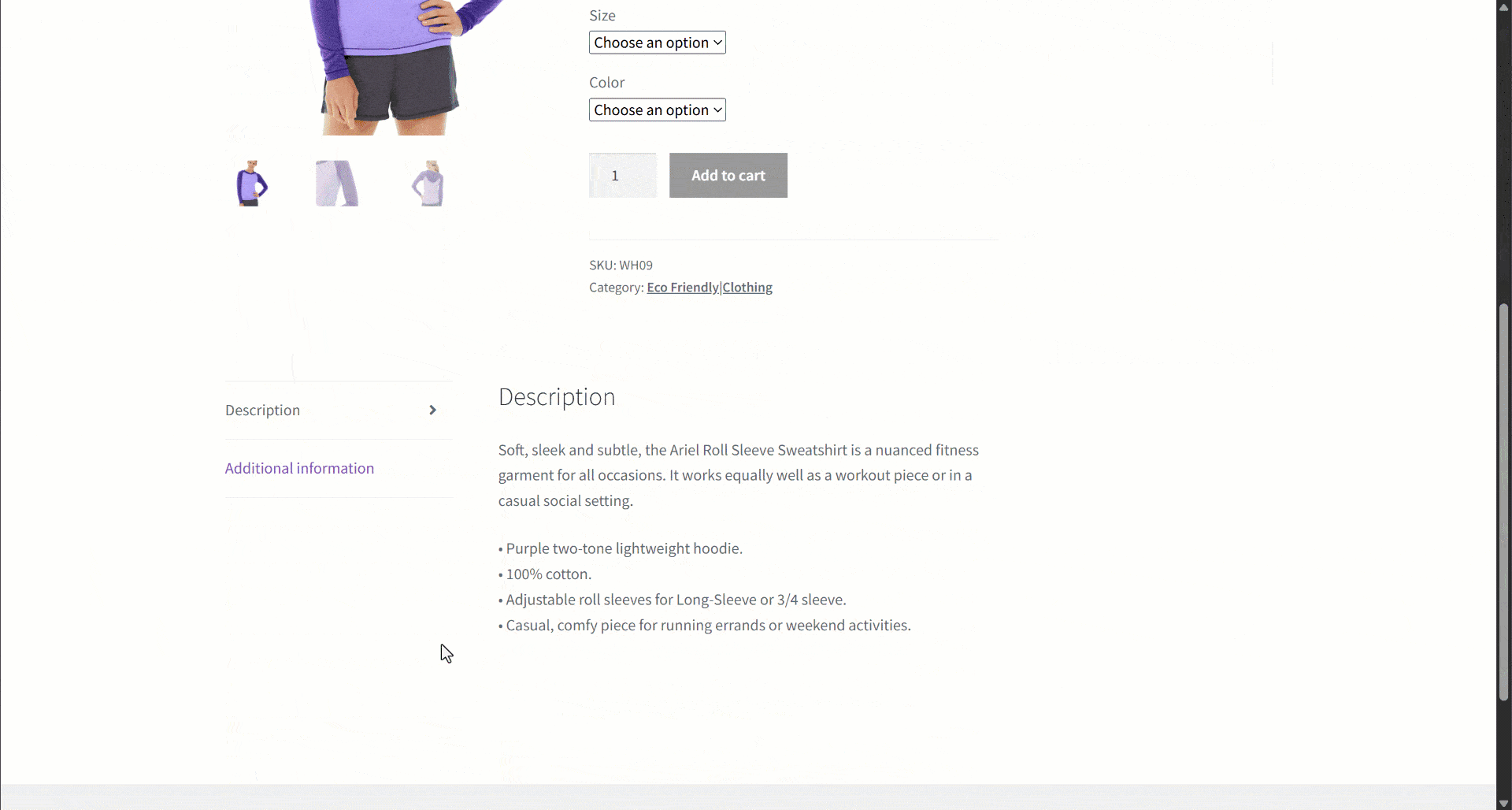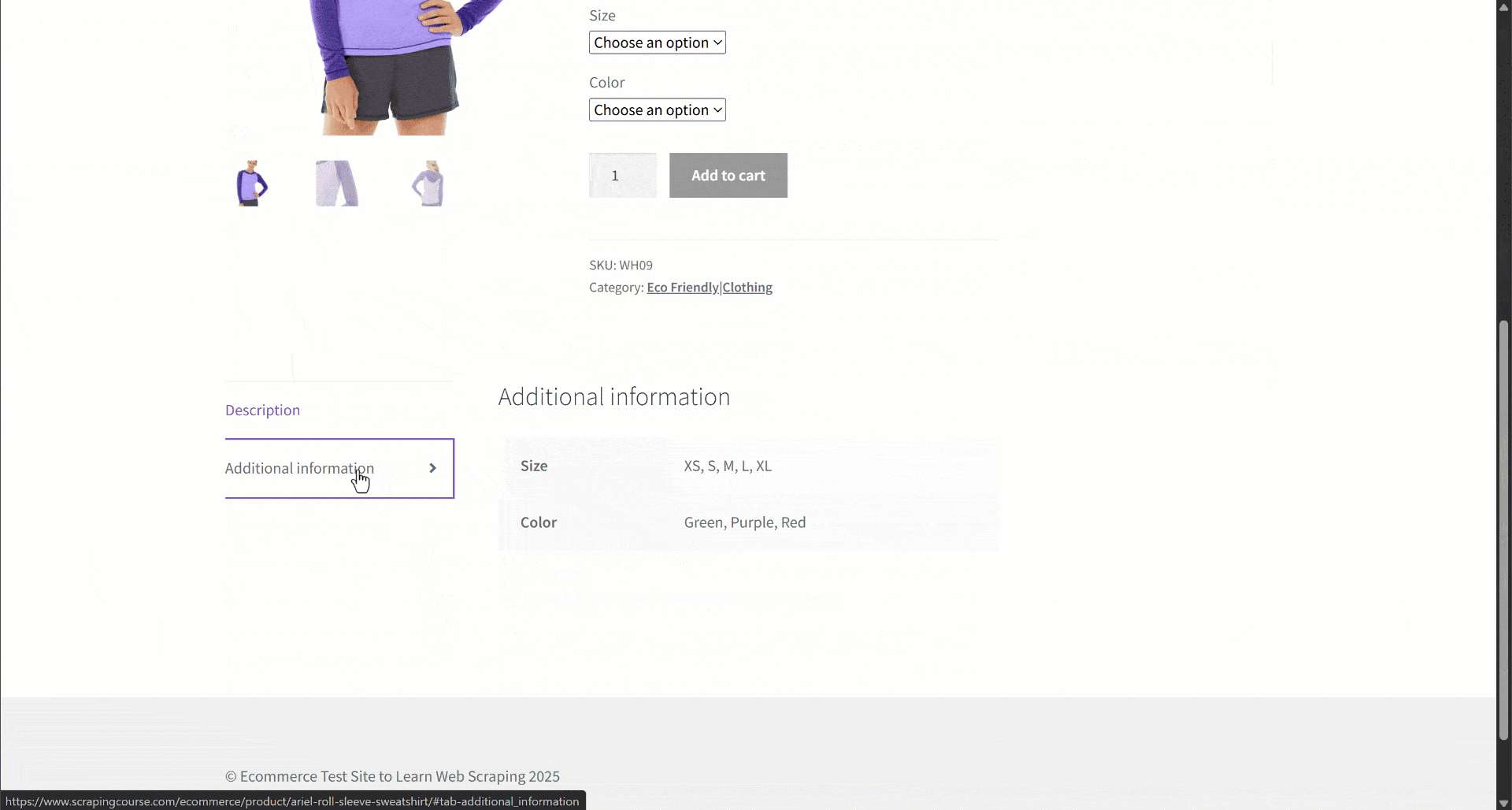
Durante a extração de dados, você fornece o conteúdo da página a um LLM para simplificar o Parsing dos dados. Agora, os LLMs podem ser imprecisos e podem produzir dados inventados, não confiáveis ou incompletos. É por isso que aplicar a validação de dados é tão importante.
Para simplificar, vamos supor que você já tenha um projeto Python com um ambiente de desenvolvimento configurado.
Etapa 1: definir o esquema e as regras de destino
Comece inspecionando a página de destino e observe que a página do produto contém os seguintes campos:
- URL do produto: a URL da página do produto.
- Nome do produto: uma string contendo o nome do produto.
- Imagens: uma lista de URLs de imagens.
- Preço: o preço como um número flutuante.
- Moeda: um único caractere que representa a moeda.
- SKU: Uma string contendo o ID do produto.
- Categoria: Uma matriz contendo uma ou mais categorias.
- Descrição: Um campo de texto com a descrição do produto.
- Descrição longa: Um campo de texto contendo a descrição completa do produto com todos os detalhes.
- Informações adicionais: Um objeto contendo:
- Opções de tamanho: uma matriz de strings com os tamanhos disponíveis.
- Opções de cor: Uma matriz de strings com as cores disponíveis.
Em seguida, represente isso em um modelo Pydantic, conforme mostrado abaixo:
# pip install pip install pydantic
from typing import List, Optional, Annotated
from pydantic import BaseModel, ConfigDict, HttpUrl, PositiveFloat, StringConstraints, model_validator
class AdditionalInformation(BaseModel):
size_options: Optional[List[str]] = None # nulo
color_options: Optional[List[str]] = None # nulo
class Product(BaseModel):
model_config = ConfigDict(strict=True, extra="forbid")
product_url: HttpUrl # obrigatório, deve ser um URL válido
product_name: str # obrigatório
imagens: Opcional[Lista[HttpUrl]] = Nenhum # lista de URLs válidos, nulo
preço: Opcional[PositiveFloat] = Nenhum # nulo, deve ser >= 0
moeda: Opcional[Anotado[str, StringConstraints(min_length=1, max_length=1)]] = Nenhum # nulo, caractere único
sku: str # obrigatório
category: Opcional[Lista[str]] = Nenhum # nulo
description: Opcional[str] = Nenhum # nulo
long_description: Opcional[str] = Nenhum # nulo
additional_information: Opcional[InformaçãoAdicional] = Nenhum # nulo
@model_validator(mode="after")
# Regra de validação personalizada para garantir que o preço esteja sempre associado a uma moeda
def check_currency_if_price(cls, values):
price = values.price
currency = values.currency
if price is not None and not currency:
raise ValueError("currency must be provided if price is set")
return valuesObserve que o modelo Product não apenas define os campos e seus tipos (por exemplo, str, HttpUrl, etc.), mas também inclui restrições de validação (por exemplo, a moeda deve ser um único caractere). Além disso, ele inclui regras de validação rígidas para garantir que o preço esteja sempre associado a uma moeda, e quaisquer campos extras que não correspondam diretamente ao modelo são proibidos.
Etapa 2: coletar os dados
Suponha que você recupere dados por meio do Scraping de dados com IA, conforme mostrado em um dos tutoriais abaixo:
- Scraping de dados com ChatGPT: tutorial passo a passo
- Scraping de dados com Gemini: tutorial completo
- Scraping de dados usando Perplexity: guia passo a passo
- Scraping de dados com Claude: Parsing alimentado por IA em Python
Você obterá um arquivo product.json contendo os dados coletados. Aqui, vamos supor que o LLM o preencheu assim:
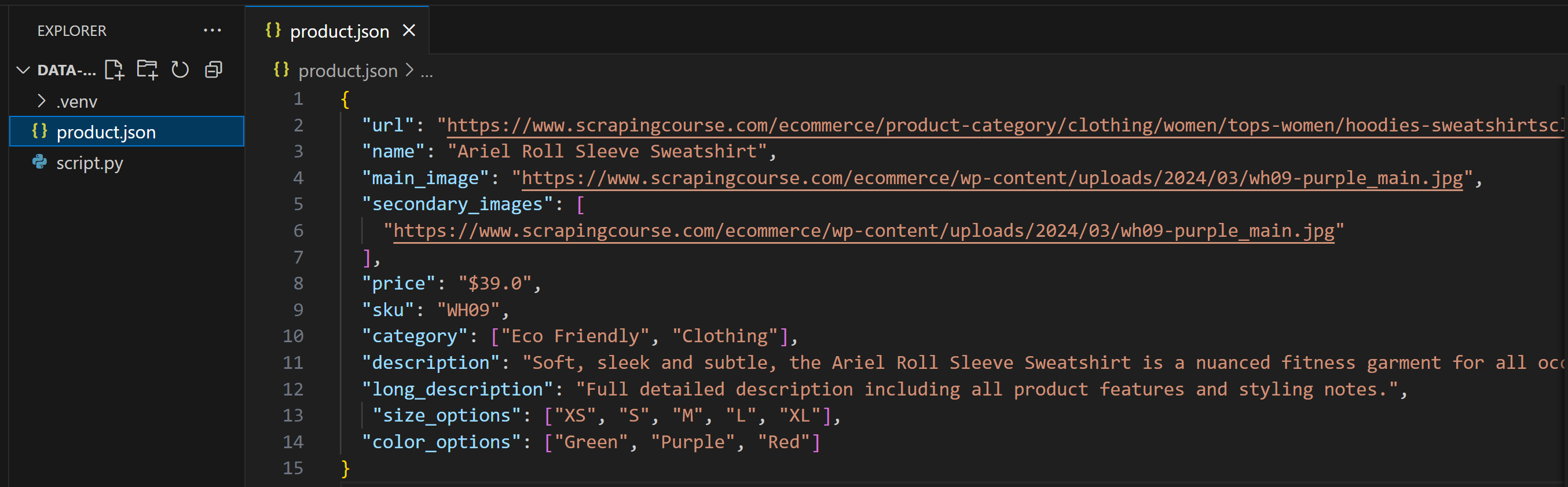
Como você pode ver, essa saída não corresponde exatamente ao modelo Pydantic. Isso é comum se você não especificar explicitamente uma estrutura de saída em seu prompt ou se a IA estiver configurada com uma temperatura muito alta.
Etapa 3: aplique as regras de validação
Carregue os dados do arquivo product.json:
import json
input_data_file_name = "product.json"
with open(input_data_file_name, "r", encoding="utf-8") as f:
product_data = json.load(f)Em seguida, valide-os com o Pydantic da seguinte maneira:
tente:
# Valide os dados através do modelo Pydantic
produto = Product(**product_data)
imprimir("Validação bem-sucedida!")
exceto ValidationError como e:
imprimir("Falha na validação:")
imprimir(e)Execute seu script e você obterá uma saída de erro como esta:
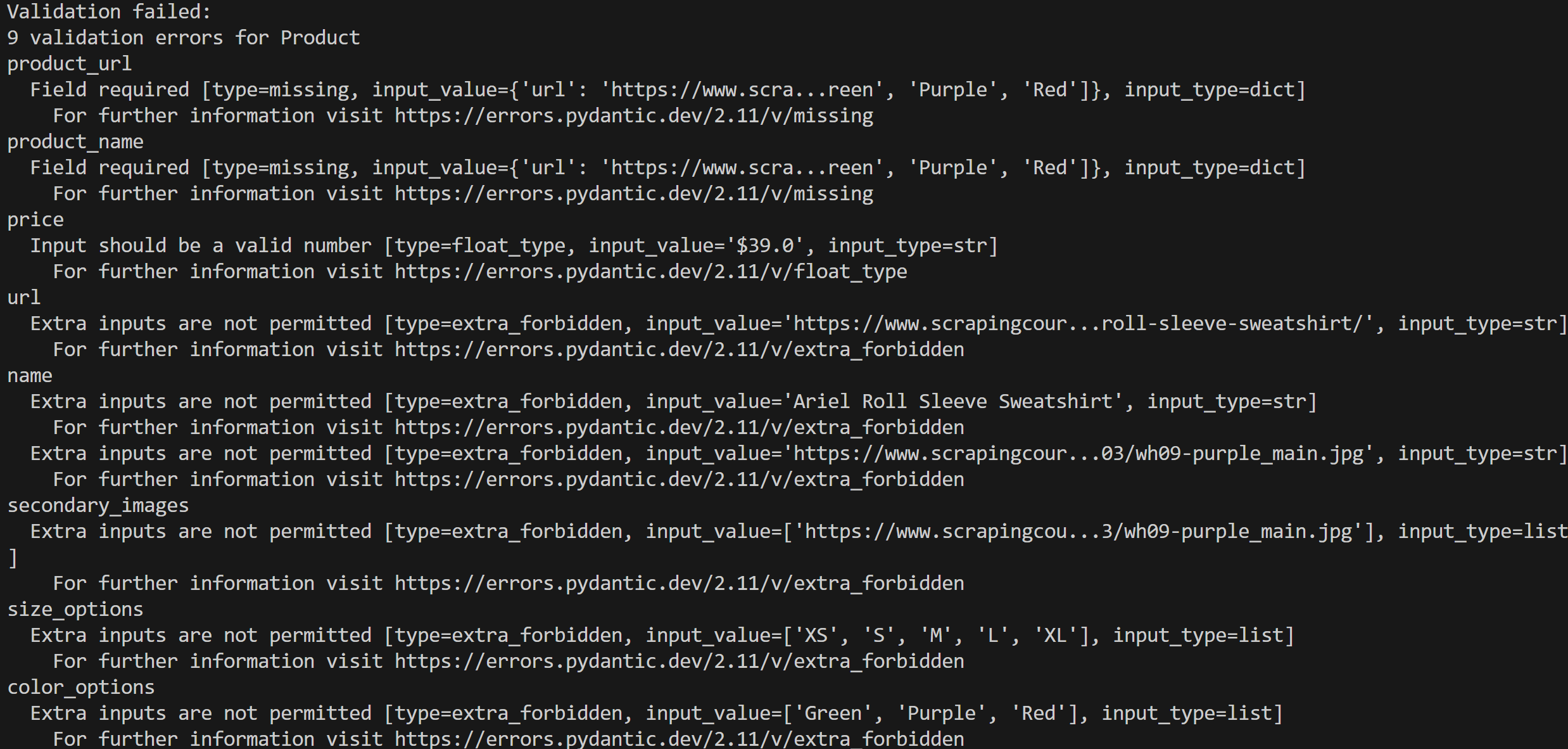
Nesse caso, foram detectados 9 erros de validação porque os dados de entrada não estão em conformidade com o modelo Product.
Etapa 4: Corrigir os erros
Não existe um processo universal para corrigir automaticamente os dados de forma que eles sejam aprovados na etapa de validação. Cada pipeline ou fluxo de trabalho de dados é diferente, e talvez seja necessário intervir em diferentes aspectos dele.
Nesse caso, a solução é tão simples quanto especificar claramente o formato de saída esperado no prompt do LLM, um recurso compatível com a maioria dos LLMs, como o OpenAI.
Dica: você pode ver esse recurso em ação em nosso guia sobre Scraping de dados visual com GPT Vision.
Caso contrário, se o recurso de saída estruturada não estiver disponível, você sempre pode pedir ao LLM para corresponder ao modelo Pydantic esperado no prompt, despejando-o como uma string JSON:
prompt = f"""
Extraia os dados do conteúdo da página fornecida e retorne-os com a seguinte estrutura:
{Product.model_json_schema()}
CONTEÚDO:
<conteúdo da página>
"""Em ambos os casos, a saída do LLM deve corresponder ao formato esperado.
Após fazer essa alteração, product.json conterá:
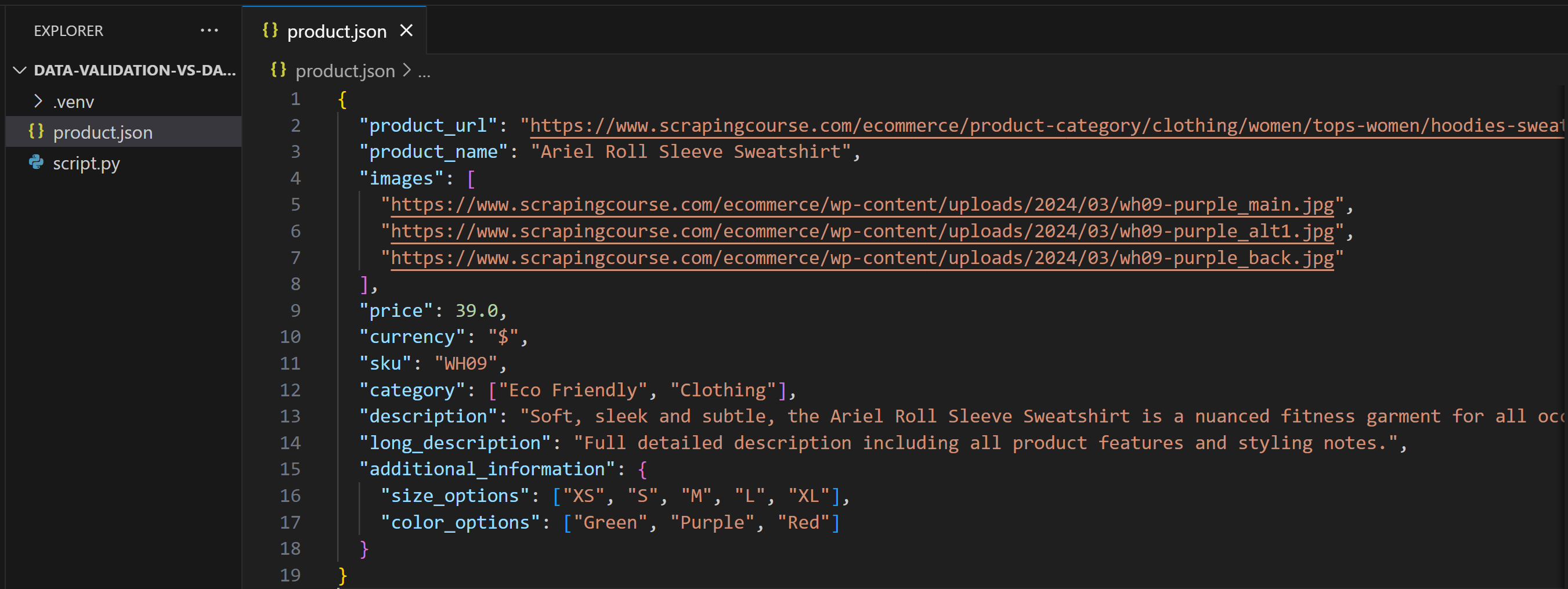
Desta vez, quando você executar o script, ele produzirá:

Ótimo! A validação dos dados foi aprovada. Depois que os dados forem validados, você poderá prosseguir com o processamento, armazená-los em um banco de dados ou realizar outras operações.
Verificação de dados: o essencial explicado
Vamos continuar este guia de validação de dados x verificação de dados com foco na segunda técnica: verificação de dados.
O que é verificação de dados e por que ela é importante?
A verificação de dados é o processo de verificar se os dados são precisos e refletem fatos do mundo real. Isso é feito comparando as informações com fontes confiáveis.
Ao contrário da validação de dados, que apenas verifica se os dados atendem a regras predefinidas (por exemplo, se um endereço de e-mail está formatado corretamente), a verificação confirma que os dados são verdadeiros e correspondem à realidade (por exemplo, que o e-mail realmente existe e pertence à pessoa pretendida).
A verificação de dados é fundamental para garantir a qualidade dos dados, especialmente quando se trata do significado das informações. Afinal, mesmo dados bem estruturados e aparentemente limpos podem conter informações erradas. Confiar em dados imprecisos pode resultar em erros dispendiosos, tomadas de decisão equivocadas, experiências ruins para os clientes e ineficiências operacionais.
Exemplos de verificações de dados
A verificação de dados pode ser complicada, e a abordagem correta depende muito dos dados de entrada e do domínio em que você está operando. Ainda assim, alguns métodos comuns de verificação incluem:
- Verificação automatizada: uso de software especializado, serviços de terceiros ou sistemas de IA agênciosa para cruzar dados com fontes confiáveis.
- Revisão: revisar manualmente documentos, dados ou campos de dados para garantir que contenham informações precisas. Isso pode ser feito manualmente por humanos usando seu conhecimento sobre um tópico ou automaticamente por IA.
- Entrada dupla: dois sistemas separados (ou agentes de IA autônomos) inserem dados sobre o mesmo tópico de forma independente. Os registros são então comparados e quaisquer discrepâncias são sinalizadas para revisão ou correção.
- Verificação dos dados de origem: comparar os dados armazenados em um banco de dados com os documentos de origem originais (por exemplo, registros médicos de pacientes) para confirmar se eles correspondem.
Quando fazer isso
A verificação de dados deve ser feita sempre que você não confiar totalmente na fonte dos dados. Um exemplo comum é quando se usa IA para gerar ou enriquecer dados, o que pode produzir informações plausíveis, mas imprecisas.
Outro cenário em que a verificação de dados é importante é quando os dados foram transferidos ou armazenados, como durante migrações ou consolidações. Após essas tarefas, você precisa garantir que os dados resultantes permaneçam precisos. A verificação de dados também é relevante como parte da manutenção contínua da qualidade dos dados.
Lembre-se de que a verificação de dados geralmente segue a validação de dados. Se a estrutura dos dados não corresponder ao formato esperado, a verificação não faz sentido, pois os dados podem não ser totalmente utilizáveis. Somente depois que os dados passam pela validação é que faz sentido prosseguir com a verificação.
Verificar os dados é certamente mais complexo do que validá-los, pois não é possível obter resultados determinísticos (como demonstrado anteriormente com um script Python simples). Isso ocorre porque é muito difícil determinar com certeza absoluta se as informações são verdadeiras.
Principais abordagens para a verificação de dados
Ao lidar com conteúdo enviado pelo usuário, a melhor maneira de verificá-lo é por meio da verificação humana. Exemplos incluem:
- Verificação de e-mail: depois que um usuário insere um endereço de e-mail durante o registro, um e-mail automático com um link ou código de confirmação é enviado para garantir que o endereço seja válido e acessível.
- Verificação do número de telefone: uma senha de uso único (OTP) é enviada por mensagem de texto ou ligação telefônica para confirmar que o número é válido, ativo e pertence ao usuário.
Da mesma forma, você pode solicitar que os usuários enviem documentos ou contas para verificação de identidade ou endereço. Esses documentos podem ser processados com sistemas OCR para verificar se os dados inseridos pelo usuário correspondem às informações nos documentos enviados. Embora essa abordagem ainda possa ser vulnerável a fraudes, ela é muito útil para aumentar a confiabilidade dos dados.
O verdadeiro desafio surge ao recuperar dados públicos da web, a maior e mais desestruturada fonte de informações. Nesse caso, é difícil determinar se as informações estão corretas. A abordagem geral é priorizar fontes confiáveis (por exemplo, documentação, declarações oficiais) e, dado algum conteúdo de entrada, rastrear sua origem, verificá-lo online em relação a fontes confiáveis e comparar os resultados.
Fazer isso manualmente é extremamente demorado, e é por isso que muitas dessas tarefas agora são automatizadas usando agentes de IA equipados com ferramentas para pesquisa e Scraping de dados da web.
Como verificar dados: exemplo em Python
Nesta seção, você encontrará um exemplo passo a passo de como construir um agente de IA para verificação de dados. O agente irá:
- Pegar um texto de amostra como entrada.
- Passar as informações para um LLM estendido com ferramentas de pesquisa e Scraping de dados na web.
- Pedir à IA para identificar os principais tópicos no texto de origem e pesquisar no Google por páginas relevantes e confiáveis para verificar a precisão.
- Raspear as informações dessas páginas e compará-las com o texto de origem.
- Retornará um relatório indicando se os dados estão precisos e, caso contrário, sugerirá como corrigi-los.
Esse tipo de fluxo de trabalho não seria possível sem uma infraestrutura pronta para IA que ofereça suporte à recuperação de dados da web, pesquisa, interação e muito mais, como a fornecida pela infraestrutura de IA da Bright Data.
Para uma integração mais fácil, usaremos o Bright Data Web MCP, que oferece mais de 60 ferramentas. Especificamente, seu nível gratuito inclui estas duas ferramentas:
search_engine: Recupera resultados de pesquisa do Google, Bing ou Yandex em JSON ou Markdown.scrape_as_markdown: extraia qualquer página da web em formato Markdown limpo, contornando a detecção de bots e CAPTCHA.
Essas duas ferramentas são suficientes para alimentar o agente de verificação de dados e atingir o objetivo!
Descrição do cenário
Suponha que você tenha alguns dados de entrada em um arquivo summary.txt que deseja verificar se estão corretos. Por exemplo, este contém um breve resumo do Super Bowl LIX:

Você criará um agente de verificação de dados usando o LangChain integrado ao Web MCP. Para acompanhar, você precisará de:
- Python instalado localmente.
- Um projeto LangChain configurado.
- Uma chave API Bright Data para autenticar sua conexão com o Web MCP.
- Uma chave API OpenAI.
Antes de começar, consulte nosso tutorial sobre como usar o adaptador LangChain MCP para integração com o Web MCP da Bright Data. Se você preferir usar outras estruturas ou ferramentas, confira estes guias:
- Criando agentes de Scraping de dados com CrewAI e o Model Context Protocol (MCP) da Bright Data
- Criação de um chatbot CLI com LlamaIndex e MCP da Bright Data
- Integração do Claude Code com o Web MCP da Bright Data
- Como criar um chatbot RAG com GPT-4o usando dados SERP
Criar um agente de IA para verificação de dados
Veja como você pode criar o agente de verificação de dados usando LangChain e Web MCP da Bright Data:
# pip install langchain["openai"] langchain-mcp-adapters langgraph
import asyncio
import os
os.environ["OPENAI_API_KEY"] = "<YOUR_OPENAI_API_KEY>" # Substitua pela sua chave API OpenAI
from langchain_openai import ChatOpenAI
from mcp import ClientSession, StdioServerParameters
from mcp.client.stdio import stdio_client
from langchain_mcp_adapters.tools import load_mcp_tools
from langgraph.prebuilt import create_react_agent
async def main():
# Carregue os dados de entrada para verificar
input_file_name = "summary.txt"
with open(input_file_name, "r", encoding="utf-8") as f:
summary_data_to_verify = f.read()
# Inicializar o mecanismo LLM
llm = ChatOpenAI(
model="gpt-5-nano",
)
# Configuração para conectar-se a uma instância local do servidor Bright Data Web MCP
server_params = StdioServerParameters(
command="npx",
args=["-y", "@brightdata/mcp"],
env={
"API_TOKEN": "<YOUR_BRIGHT_DATA_API_KEY>", # Substitua pela sua chave API Bright Data
}
)
# Conecte-se ao servidor MCP
async with stdio_client(server_params) as (read, write):
async with ClientSession(read, write) as session:
# Inicialize a sessão do cliente MCP
await session.initialize()
# Obtenha as ferramentas MCP
tools = await load_mcp_tools(session)
# Crie o agente ReAct
agente = create_react_agent(llm, ferramentas)
# Descrição da tarefa do agente
prompt_de_entrada = f"""
Dado o conteúdo de entrada abaixo, execute as seguintes etapas:
1. Identifique o tópico principal como uma consulta de pesquisa semelhante ao Google e use-o para realizar uma pesquisa na web para reunir informações sobre ele.
2. A partir dos resultados da pesquisa, selecione as duas ou três fontes mais confiáveis (por exemplo, sites de notícias confiáveis, revistas, publicações oficiais).
3. Extraia o conteúdo das páginas selecionadas.
4. Compare as informações extraídas com o conteúdo de entrada para determinar se são precisas.
5. Se não forem precisas, produza um relatório listando todos os erros encontrados no conteúdo de entrada, juntamente com as informações corrigidas e links para as fontes de apoio.
Conteúdo de entrada:
{summary_data_to_verify}
"""
# Transmita a resposta do agente
async for step in agent.astream({"messages": [input_prompt]}, stream_mode="values"):
step["messages"][-1].pretty_print()
if __name__ == "__main__":
asyncio.run(main())Concentre-se no prompt em si, pois é a parte mais importante do script acima.
Executar o agente
Inicie seu agente e você verá que ele identifica corretamente o tópico principal como “Super Bowl LIX”. Em seguida, ele executará uma pesquisa no Google usando a ferramentasearch_engine do Web MCP:

A partir da SERP resultante, ele identifica os artigos da ESPN e da CBS Sports como as fontes primárias e os extrai usando a ferramenta scrape_as_markdown:
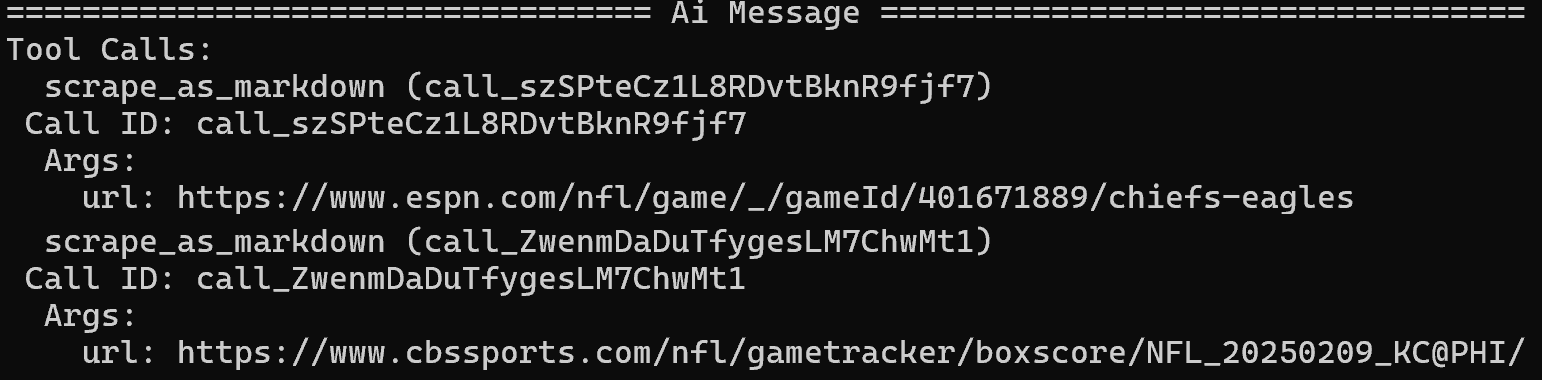
Depois de extrair o conteúdo das três fontes de notícias, ele produz o seguinte relatório Markdown:
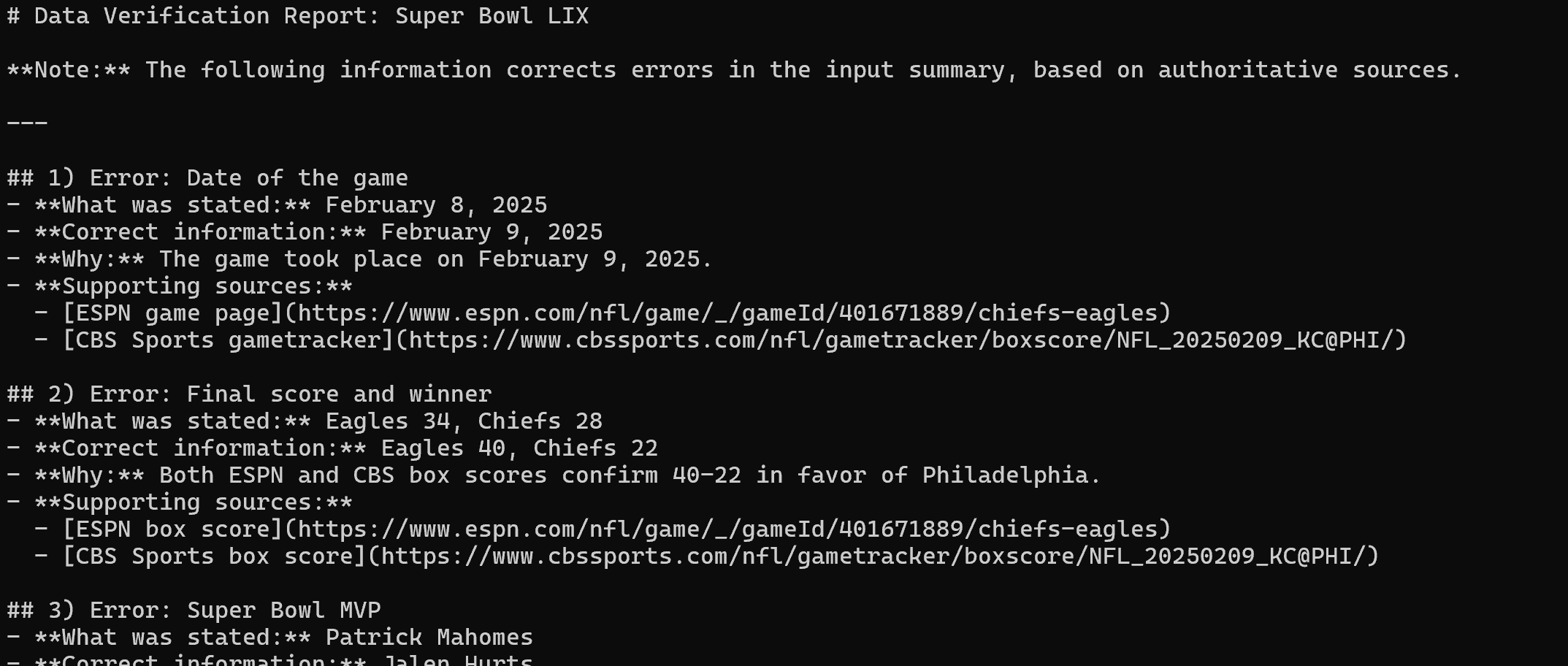
Renderize-o no Visual Studio Code e você verá o relatório final.
Como você pode ver, graças aos recursos de pesquisa na web e Scraping de dados do Web MCP, o agente LangChain conseguiu identificar todos os erros no texto original incorreto. Missão cumprida!
Validação de dados x verificação de dados: tabela resumida
Compare as duas técnicas na tabela resumida de validação de dados vs. verificação de dados abaixo:
| Aspecto | Validação de dados | Verificação de dados |
|---|---|---|
| Definição | Verifica a precisão, qualidade e integridade dos dados em relação a regras e padrões predefinidos antes do uso ou armazenamento. | Confirma que os dados refletem com precisão os fatos do mundo real, comparando-os com fontes confiáveis. |
| Objetivo | Garante que os dados estejam em conformidade com os formatos, tipos, intervalos e regras esperados; impede que dados inválidos entrem nos sistemas. | Garante que os dados sejam verdadeiros, precisos e confiáveis para a tomada de decisões. |
| Momento | Realizado no momento da entrada, após a extração, após a transformação ou periodicamente. | Executado após a validação ou sempre que a confiabilidade da fonte de dados for incerta; normalmente após a coleta ou transferência de dados. |
| Complexidade | Relativamente simples; verificações determinísticas com base em regras definidas. | Mais complexo; pode envolver incerteza, fontes externas e revisão manual; resultados não determinísticos possíveis. |
| Exemplo | o preço deve ser ≥ 0 |
Verifique se o preço corresponde ao listado oficialmente na loja |
Comentário final
Como você aprendeu nesta postagem do blog sobre validação de dados versus verificação de dados, a validação e a verificação de dados abordam duas tarefas diferentes, mas complementares. Em particular, ambas contribuem para alcançar alta qualidade de dados. Outro ponto semelhante é que ignorar qualquer uma delas pode causar problemas significativos em processos baseados em dados, que dão suporte à maioria das operações comerciais.
É por isso que é realmente indispensável escolher um provedor de dados confiável e seguro que ofereça várias soluções para garantir a validação adequada dos dados e forneça as ferramentas para construir um sistema eficaz de verificação de dados.
A Bright Data é um excelente exemplo. Ela oferece uma ampla gama de produtos, incluindo Conjuntos de dados validados e prontos para uso e uma seleção abrangente de soluções de Scraping de dados preparadas para IA para coletar informações precisas da web, apoiando os fluxos de trabalho de validação e verificação.
Cadastre-se hoje mesmo para obter uma conta gratuita na Bright Data e explore nossos serviços de dados!




