
Se você estiver desenvolvendo um aplicativo de geração aumentada por recuperação (RAG), precisará de dados atualizados sobre o seu tema – não um PDF estático de um tutorial. Mas extrair artigos reais significa barreiras anti-bot e solicitações bloqueadas. Mesmo com os dados, você ainda precisa fragmentar, incorporar, indexar e conectar a recuperação.
Este tutorial faz tudo isso. A Bright Data encontra e extrai artigos sobre qualquer tema, o Weaviate os armazena e pesquisa, e você obtém respostas com citações em um único script Python.
TL;DR
Transforme qualquer tópico em uma base de conhecimento pesquisável e capaz de responder perguntas – alimentada por dados da web em tempo real, em vez de dados de treinamento desatualizados.
- A API SERP da Bright Data encontra URLs de artigos reais para o seu tópico; o Web Unlocker os extrai (mesmo de sites protegidos contra bots).
- O Weaviate vetoriza automaticamente trechos via Cohere, os indexa com pesquisa híbrida e gera respostas citadas em uma única chamada de API
- Execute
o python3 pipeline.py, insira um tópico e obtenha respostas RAG citadas em poucos minutos. - Código-fonte completo no GitHub – clone e execute
Obtenha suas chaves de API e experimente com seu próprio tópico.
Veja como fica o resultado final:

Execute o pipeline em 3 a 5 minutos
Se você já tem chaves de API, execute o pipeline agora:
# 1. Clone o repositório (requer Python 3.10+)
git clone https://github.com/triposat/weaviate-bright-data-rag.git
cd weaviate-bright-data-rag
# 2. Instale as dependências
pip3 install -r requirements.txt
# 3. Crie seu arquivo .env
cp .env.example .env
# Edite o .env e preencha suas chaves de API (veja “Obtenha suas chaves de API” abaixo)
# 4. Execute-o
python3 pipeline.pyO pipeline solicita um tópico e detecta automaticamente suas zonas do Bright Data. Ele localiza e extrai artigos reais. Ele os fragmenta e armazena no Weaviate (vetorizados automaticamente via Cohere), executa consultas de demonstração e entra no modo interativo para suas próprias perguntas.
Obtenha suas chaves de API (grátis para começar)
Você precisa de 3 chaves de API – 1 de cada serviço. O Cohere e o Weaviate não exigem cartão de crédito; o Bright Data oferece crédito de avaliação gratuita no momento da inscrição.
1. Chave de API da Bright Data
Crie uma chave de API e 2 zonas:
- Cadastre-se em brightdata.com
- Vá para Configurações da conta → Usuários e chaves de API
- Crie uma nova chave API → copie-a → cole-a como o valor
BRIGHT_DATA_API_TOKENno seu arquivo.env
O pipeline também precisa de 2 zonas: API SERP e Web Unlocker. Verifique se você já as possui em Proxies e Scraping → Minhas Zonas. Se não as encontrar, crie-as:
- Vá para Proxy e Scraping → selecione Minhas Zonas
- Selecione Adicionar → escolha o tipo de zona API SERP → nomeie-a como quiser (por exemplo,
serp) → salve - Selecione Adicionar novamente → escolha o tipo de zona Unlocker API → nomeie-a como quiser (por exemplo,
unlocker) → salve
Você não precisa copiar nomes de zonas ou senhas. O pipeline usa sua chave de API para detectá-los automaticamente.
2. Chave de API do Cohere (gratuita)
O Cohere lida tanto com a incorporação quanto com a geração neste pipeline:
- Acesse dashboard.cohere.com
- Cadastre-se com Google, GitHub ou e-mail – não é necessário cartão de crédito
- Sua chave de API de avaliação é exibida no painel – copie-a
- O plano de avaliação tem limite de uso, mas é generoso (a execução automatizada usa menos de 20 chamadas; cada pergunta interativa adiciona mais 2)
3. Credenciais do Weaviate Cloud (gratuito)
Crie um cluster sandbox gratuito para armazenar e consultar seus vetores:
- Acesse console.weaviate.cloud
- Cadastre-se com o Google ou o GitHub
- Selecione Criar cluster → escolha Sandbox (Gratuito) → escolha uma região → crie
- Aguarde cerca de 30 segundos e, em seguida, selecione seu cluster → guia Detalhes
- Copie o Endpoint REST (a URL do seu cluster) e a Chave API
Observação: os clusters Sandbox expiram após 14 dias. Se o seu cluster expirar, crie um novo e atualize a URL e a chave no seu arquivo .env. Execute novamente o pipeline.py para reimportar seus dados.
Depois de obter todas as 3 chaves, volte à seção “Execute o pipeline em 3–5 minutos” e siga as etapas de clonagem/instalação.
Como o pipeline RAG funciona de ponta a ponta
O pipeline tem quatro etapas: coleta de dados, processamento, armazenamento de vetores e geração:
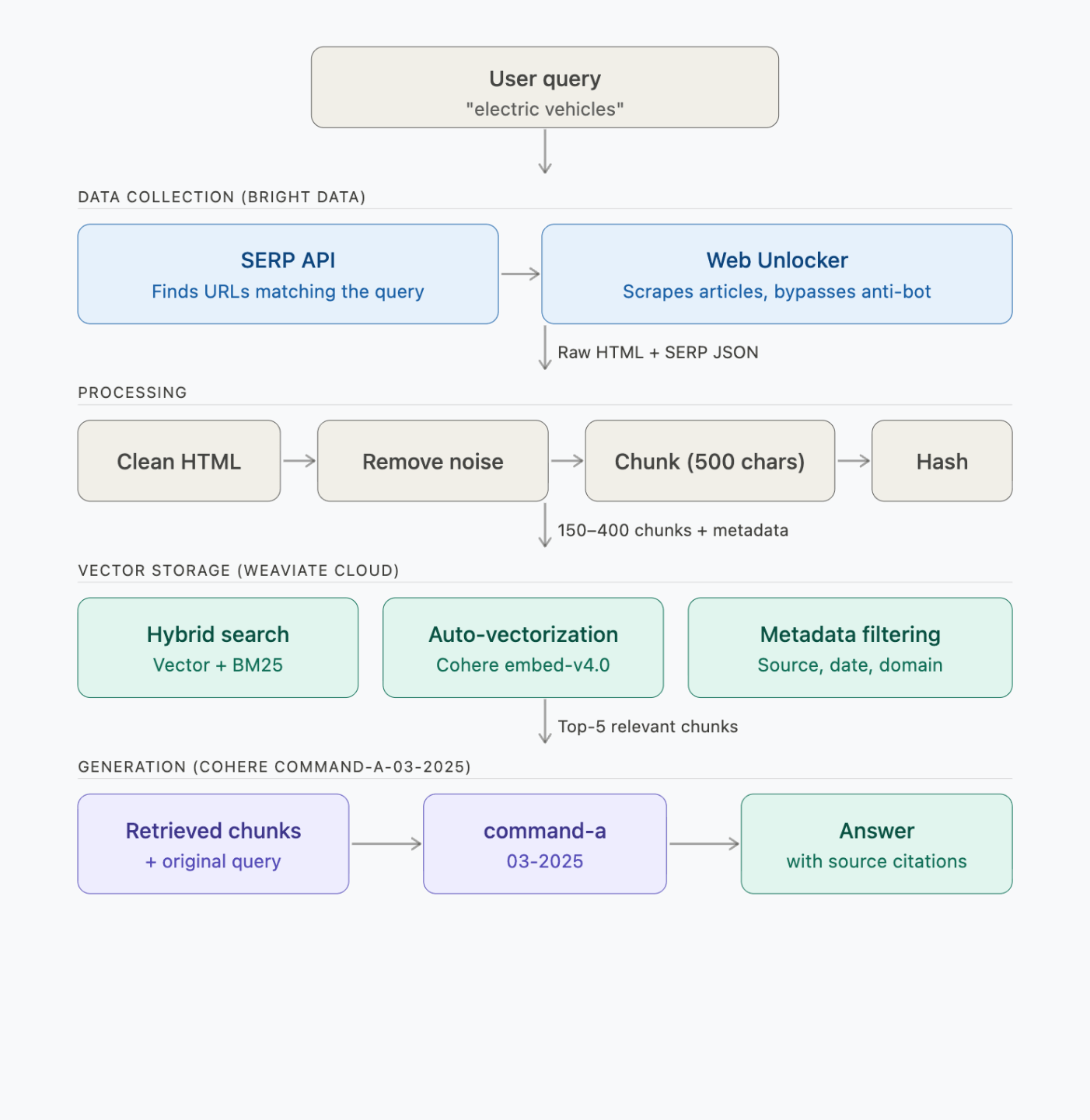
Cada etapa faz estas chamadas de API:
| Etapa | O que é executado | Tempo | Chamadas de API |
|---|---|---|---|
| 1. Encontrar + extrair | Bright Data SERP + Web Unlocker | ~2–3 min | 2 SERP + 6 solicitações de extração |
| 2. Processar + fragmentar | Local (BeautifulSoup + chunker) | <1 seg | 0 |
| 3. Incorporar + armazenar | Weaviate → Cohere embed-v4.0 | ~30–60 seg | ~150–400 incorporações (em lote) |
| 4. Consulta (3 demonstrações) | Weaviate → Cohere command-a-03-2025 | ~5 seg/consulta | 1 pesquisa + 1 geração por consulta |
O que a Bright Data faz no pipeline
A Bright Data é uma plataforma de dados da web. Neste pipeline, ela desempenha duas funções:
| Produto | O que ela faz neste pipeline |
|---|---|
| API SERP | Você insere um tópico, a API SERP pesquisa no Google e retorna URLs reais de artigos – sem necessidade de URLs codificadas |
| Web Unlocker | Extrai 6 artigos por tópico, incluindo sites com proteção anti-bot – de 200 mil a 1,8 milhão de caracteres cada |
Este pipeline usa a API SERP e o Web Unlocker. Para outras abordagens de coleta de dados, consulte a lista completa de produtos da Bright Data.
Por que usar a Bright Data para RAG
Aqui estão alguns pontos importantes ao coletar dados para RAG:
- Rastreamento confiável. O Web Unlocker lida com tentativas de recarga, rotação de IP e impressão digital do navegador automaticamente, para que o pipeline não pare em páginas anti-bot no meio da execução.
- Saída pronta para LLM. A API Crawl retorna Markdown limpo em vez de HTML bruto, eliminando o pré-processamento para pipelines de incorporação (este tutorial usa o Web Unlocker + BeautifulSoup, mas a API Crawl é uma opção mais rápida se você não precisar de HTML bruto).
- Escalabilidade. Este tutorial faz o scraping de 6 artigos. Em produção, você pode precisar de 6.000. A infraestrutura de IA da Bright Data suporta scraping simultâneo nessa escala sem alterações de código de sua parte.
- Conformidade. A Bright Data está em conformidade com GDPR e a CCPA e exige verificação de identidade antes de conceder acesso total à rede.
O que o Weaviate faz no pipeline
O Weaviate é um banco de dados vetorial de código aberto. Ele realiza a recuperação e a geração em uma única chamada de API, para que você não precise chamar o LLM separadamente.
Aqui, o Weaviate armazena os trechos extraídos e os vetoriza por meio do Cohere. Quando você faz uma consulta, ele executa uma pesquisa híbrida e gera uma resposta por meio de sua API de pesquisa generativa.
| Recurso | Como funciona neste pipeline |
|---|---|
| Pesquisa híbrida | Combina vetores semânticos (70%) com correspondência de palavras-chave BM25 (30%) por meio do parâmetro alfa ajustável |
| Pesquisa generativa integrada | Recupera os 5 principais trechos e gera respostas citadas em uma única chamada generate.hybrid() |
| Vetorização automática | O Weaviate chama a API de incorporação do Cohere automaticamente durante a importação – você não precisa escrever nenhum código de incorporação |
| Filtragem de metadados | Armazena URL de origem, domínio, carimbo de data/hora da extração e tipo de conteúdo junto com cada trecho |
Weaviate em escala
O Weaviate também possui recursos que este pipeline não utiliza, mas que são importantes em escala:
- Licenciado sob a BSD de 3 cláusulas – você pode hospedar por conta própria ou criar um fork, se necessário
- Várias opções de implantação – Weaviate Cloud (sandbox gratuita), Nuvem Dedicada, Kubernetes auto-hospedado
- Multilocação – mais de 50.000 locatários por nó para aplicativos SaaS
- Quantização rotacional – compressão vetorial de 4x com 98–99% de recall
Construa o pipeline RAG passo a passo
Cada etapa abaixo mostra a lógica central do pipeline.py. O código-fonte completo está no GitHub.
Configuração do projeto e importações
Comece importando as dependências e carregando as credenciais do seu arquivo .env:
import os
import sys
import time
import hashlib
import requests
import urllib3
from urllib.parse import quote
from datetime import datetime, timezone
from dotenv import load_dotenv
from bs4 import BeautifulSoup
import weaviate
from weaviate.classes.init import Auth
from weaviate.classes.config import Configure, Property, DataType
urllib3.disable_warnings()
load_dotenv()
# Carregar credenciais do .env
COHERE_API_KEY = os.getenv("COHERE_API_KEY")
WEAVIATE_URL = os.getenv("WEAVIATE_URL")
WEAVIATE_API_KEY = os.getenv("WEAVIATE_API_KEY")
BD_API_TOKEN = os.getenv("BRIGHT_DATA_API_TOKEN")
COLLECTION_NAME = "WebResearch"
def clean_url(url):
"""Corrigir artefatos nbsp em URLs (devido a problemas de codificação em alguns sites)."""
cleaned = url.replace("nbsp", "-")
while "--" in cleaned:
cleaned = cleaned.replace("--", "-")
return cleaned
def clean_generated_text(text):
"""Limpa o texto gerado por LLM para exibição no terminal."""
text = text.replace("**", "")
text = text.replace("nbsp", "-")
while "--" in text:
text = text.replace("--", "-")
return textAntes de fazer qualquer coisa, o pipeline verifica se todas as credenciais necessárias estão definidas no seu arquivo .env:
def validate_env():
"""Verifica se todas as variáveis de ambiente necessárias estão definidas."""
missing = []
if not BD_API_TOKEN:
missing.append("BRIGHT_DATA_API_TOKEN")
if not COHERE_API_KEY:
missing.append("COHERE_API_KEY")
if not WEAVIATE_URL:
missing.append("WEAVIATE_URL")
if not WEAVIATE_API_KEY:
missing.append("WEAVIATE_API_KEY")
if missing:
print("ERRO: Variáveis de ambiente ausentes no arquivo .env:")
for var in missing:
print(f" - {var}")
# ... imprime exemplo de formato .env ...
print("nConsulte a publicação no blog para saber como obter cada chave (tudo gratuito para começar).")
sys.exit(1)Você não precisa configurar nomes de zona ou senhas – o pipeline os descobre automaticamente a partir da sua chave de API:
def discover_bright_data_credentials():
"""
Descobre automaticamente as credenciais de Proxy da Bright Data a partir da chave de API.
Funciona para qualquer conta da Bright Data. Não são necessários valores codificados.
"""
headers = {"Authorization": f"Bearer {BD_API_TOKEN}"}
# 1. Obter zonas ativas
zones = requests.get(
"https://api.brightdata.com/zone/get_active_zones", headers=headers
).json()
# Selecionar a primeira zona de cada tipo (se houver várias, defina o nome explicitamente)
zone_names = {}
for z in zones:
if z["type"] not in zone_names:
zone_names[z["type"]] = z["name"]
# "unblocker" é o nome da API do produto Web Unlocker
unlocker_zone = zone_names.get("unblocker")
serp_zone = zone_names.get("serp")
# 2. Obter senhas da zona
unlocker_pwd = requests.get(
f"https://api.brightdata.com/zone/passwords?zone={unlocker_zone}",
headers=headers,
).json()["passwords"][0]
serp_pwd = requests.get(
f"https://api.brightdata.com/zone/passwords?zone={serp_zone}",
headers=headers,
).json()["passwords"][0]
# 3. Obter o ID do cliente (o endpoint de custo retorna {customer_id: cost_data})
cost = requests.get(
f"https://api.brightdata.com/zone/cost?zone={unlocker_zone}",
headers=headers,
).json()
customer_id = list(cost.keys())[0]
return customer_id, unlocker_zone, unlocker_pwd, serp_zone, serp_pwdClone o repositório, adicione sua chave de API e o pipeline cuida do resto.
Passo 1: Encontre e extraia artigos com o Bright Data
O pipeline usa a API SERP para encontrar URLs de artigos sobre o seu tópico e, em seguida, extrai cada um deles por meio do Web Unlocker:
def get_bd_proxy(customer_id, zone, password):
"""Crie a URL do Proxy do Bright Data."""
proxy = f"http://brd-customer-{customer_id}-zone-{zone}:{password}@brd.superproxy.io:33335"
return {"http": Proxy, "https": Proxy}
def search_serp(query, customer_id, zone, password, num=10):
"""Pesquise no Google via API SERP da Bright Data e retorne resultados orgânicos."""
proxies = get_bd_proxy(customer_id, zone, password)
# brd_json=1 instrui a Bright Data a retornar JSON estruturado em vez de HTML bruto
search_url = f"https://www.google.com/search?q={quote(query)}&brd_json=1&num={num}"
try:
# verify=False ignora a verificação SSL para o Proxy BD.
# Para produção, instale o certificado CA da Bright Data em vez disso:
# https://docs.brightdata.com/general/account/ssl-certificate
response = requests.get(search_url, proxies=proxies, timeout=30, verify=False)
if response.status_code == 200:
data = response.json()
return [
{
"title": item.get("title", ""),
"url": item.get("link", ""),
"description": item.get("description", ""),
}
for item in data.get("organic", [])
]
exceto Exception como e:
print(f"Erro SERP: {str(e)[:60]}", end=" ", flush=True)
return []search_serp() envia a consulta através do Proxy SERP da Bright Data e retorna JSON estruturado (títulos, URLs, descrições). O parâmetro brd_json=1 instrui a Bright Data a analisar o HTML do Google e convertê-lo em JSON limpo para você.
Em seguida, find_articles_for_topic() executa duas consultas SERP por tópico e filtra os resultados, enquanto scrape_url() busca cada artigo através do Web Unlocker:
def find_articles_for_topic(topic, customer_id, serp_zone, serp_pwd):
"""Use a API SERP da Bright Data para encontrar URLs de artigos reais sobre um tópico."""
search_queries = [
f"{topic} últimas notícias e tendências",
f"{topic} guia de análise aprofundada",
]
# Ignora domínios que retornam conteúdo que não seja de artigos (vídeos, feeds, mídias sociais)
skip_domains = {
"youtube.com", "twitter.com", "x.com", "facebook.com", "instagram.com",
"reddit.com", "linkedin.com", "wikipedia.org", "amazon.com", "tiktok.com",
}
skip_extensions = (".pdf", ".doc", ".ppt", ".xls", ".zip", ".mp4", ".mp3")
all_urls = []
seen_domains = set()
serp_docs = []
para query em search_queries:
results = search_serp(query, customer_id, serp_zone, serp_pwd, num=10)
se results:
# Salvar títulos + descrições da SERP como um documento para que o LLM possa
# consultar resumos de artigos mesmo que a extração completa falhe
serp_text = f"Resultados da pesquisa do Google para: {query}nn"
for r in results:
serp_text += f"Título: {r['title']}nURL: {r['url']}n"
serp_text += f"Resumo: {r['description']}nn"
serp_docs.append({
"url": f"https://google.com/search?q={quote(query)}",
"html": serp_text,
"scraped_at": datetime.now(timezone.utc).isoformat(),
"is_serp": True,
})
# Extrair URLs de artigos (1 por domínio para diversidade)
for r in results:
url = r.get("url", "")
if not url:
continue
domain = url.split("/")[2] if "://" in url else ""
base_domain = ".".join(domain.split(".")[-2:])
if base_domain in skip_domains:
continue
if any(url.lower().endswith(ext) for ext in skip_extensions):
continue
if base_domain in seen_domains:
continue # Um artigo por domínio para diversidade
seen_domains.add(base_domain)
all_urls.append(url)
return all_urls[:6], serp_docs # 6 principais URLs
def scrape_url(url, customer_id, zone, password, retries=2):
"""Rastreia uma URL usando o Bright Data Web Unlocker com repetição automática."""
proxies = get_bd_proxy(customer_id, zona, password)
# Não são necessários cabeçalhos personalizados: o Web Unlocker gerencia User-Agent,
# cookies e impressões digitais automaticamente.
for attempt in range(retries + 1):
try:
# verify=False ignora a verificação SSL para o Proxy BD.
# Para produção, instale o certificado CA da Bright Data:
# https://docs.brightdata.com/general/account/ssl-certificate
response = requests.get(
url, proxies=proxies, timeout=60, verify=False
)
if response.status_code == 200:
return {
"url": url,
"html": response.text,
"scraped_at": datetime.now(timezone.utc).isoformat(),
}
else:
print(f"HTTP {response.status_code}", end=" → ", flush=True)
except Exception as e:
print(f"Erro: {str(e)[:60]}", end=" → ", flush=True)
if attempt < retries:
time.sleep(2)
return Nonecollect_data() combina ambas as etapas – o SERP encontra as URLs, o Web Unlocker as extrai:
def collect_data(topic, customer_id, unlocker_zone, unlocker_pwd, serp_zone, serp_pwd):
"""Encontre artigos sobre o tópico via SERP e, em seguida, extraia-os com o Web Unlocker."""
documents = []
# 1. Use a API SERP para encontrar URLs de artigos
urls_to_scrape, serp_docs = find_articles_for_topic(
topic, customer_id, serp_zone, serp_pwd
)
if not urls_to_scrape:
return []
# 2. Extraia os artigos encontrados com o Web Unlocker
for i, url in enumerate(urls_to_scrape):
domain = url.split("/")[2] if "://" in url else url
print(f" ({i+1}/{len(urls_to_scrape)}) {domain}... ", end="", flush=True)
result = scrape_url(url, customer_id, unlocker_zone, unlocker_pwd)
if result:
documents.append(result)
print(f"OK ({len(result['html']):,} caracteres)")
else:
print("FALHA (ignorando)")
# 3. Adicionar resultados da SERP como documentos adicionais
documents.extend(serp_docs)
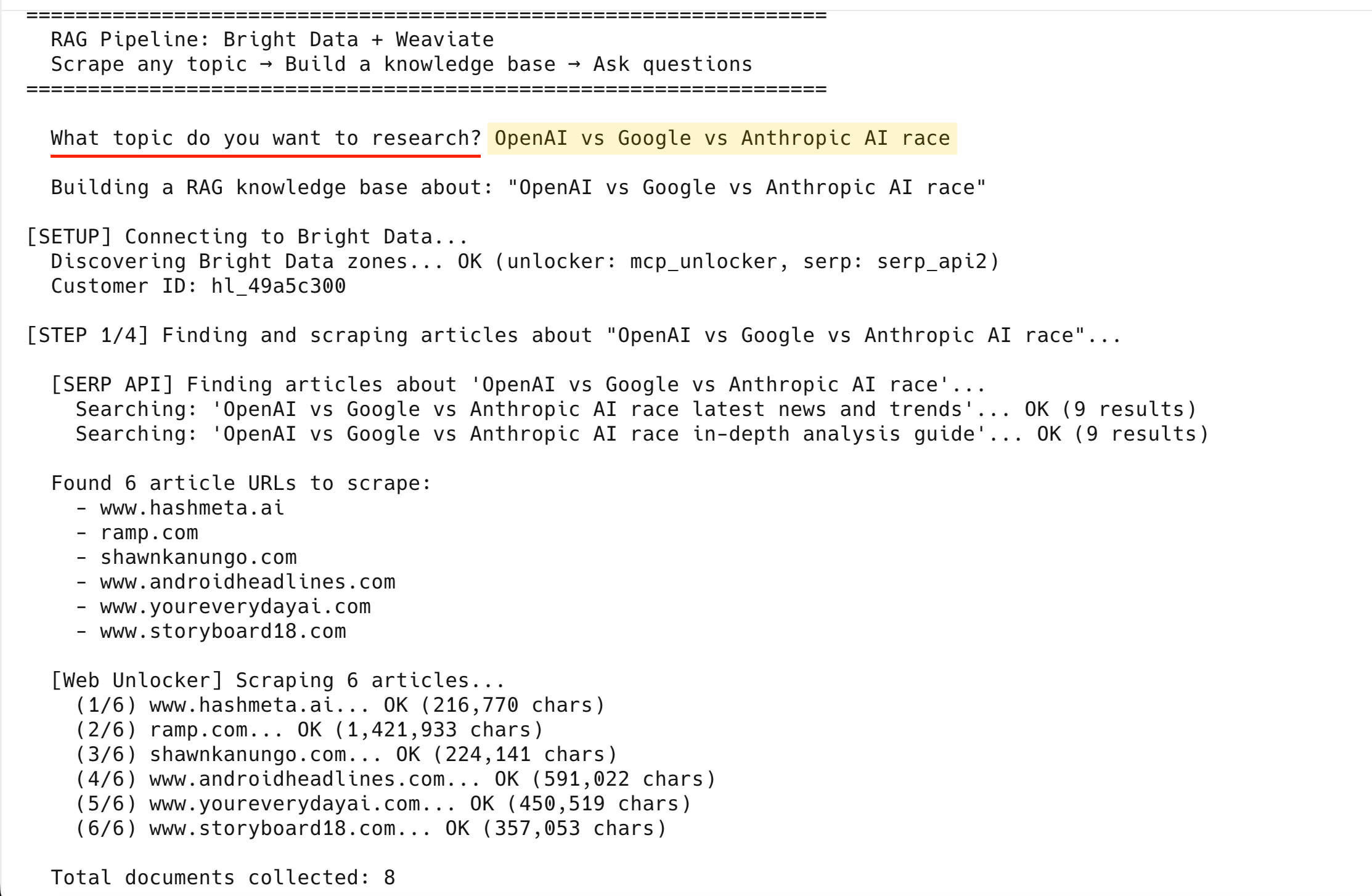
return documentsA execução com “OpenAI vs Google vs Anthropic IA race” produz esta saída:
[API SERP] Encontrando artigos sobre 'OpenAI vs Google vs Anthropic IA race'...
Pesquisando: 'OpenAI vs Google vs Anthropic IA race últimas notícias e tendências'... OK (9 resultados)
Pesquisando: 'OpenAI vs Google vs Anthropic IA race guia de análise aprofundada'... OK (9 resultados)
Encontrados 6 URLs de artigos para extrair:
- www.hashmeta.ia
- ramp.com
- shawnkanungo.com
- www.androidheadlines.com
- www.youreverydayai.com
- www.storyboard18.com
[Web Unlocker] Scraping de dados para 6 artigos...
(1/6) www.hashmeta.ai... OK (216.770 caracteres)
(2/6) ramp.com... OK (1.421.933 caracteres)
(3/6) shawnkanungo.com... OK (224.141 caracteres)
(4/6) www.androidheadlines.com... OK (591.022 caracteres)
(5/6) www.youreverydayai.com... OK (450.519 caracteres)
(6/6) www.storyboard18.com... OK (357.053 caracteres)
Total de documentos coletados: 8Todos os 6 foram coletados com sucesso – as 2 páginas de resultados da SERP elevam o total para 8 documentos.
Se o Web Unlocker falhar em uma URL após 3 tentativas, o pipeline a ignora e continua com os artigos restantes.
Neste ponto, você tem 8 documentos brutos (6 artigos + 2 páginas de resultados SERP). Agora, limpe-os e divida-os em blocos para incorporação.
Etapa 2: Limpe e divida os dados
O HTML bruto contém cerca de 90% de ruído. A etapa de processamento o transforma em texto limpo e o divide em blocos de 500 caracteres (cerca de 125 tokens) que se separam nos limites das frases, sempre que possível.
O tamanho dos blocos controla uma escolha fundamental do RAG: blocos menores (200–500 caracteres) proporcionam recuperação precisa por fato, enquanto blocos maiores (1000–2000 caracteres) fornecem ao LLM mais contexto circundante, ao custo de resultados de pesquisa mais ruidosos. O padrão de 500 caracteres funciona bem para perguntas factuais (“Qual é a taxa de vitórias da Anthropic contra a OpenAI no setor empresarial?”). Aumente o chunk_size para 1500–2000 para consultas que precisam de um contexto mais amplo, como resumos ou comparações.
A sobreposição de 50 caracteres evita a perda de informações nas fronteiras – sem ela, uma frase que abrange 2 blocos é dividida e nenhum dos blocos contém o pensamento completo.
def clean_html(html, is_serp=False):
"""Limpa o HTML para obter texto limpo, removendo navegação, anúncios e conteúdo padrão."""
if is_serp:
return html # Os resultados da SERP já são texto limpo
soup = BeautifulSoup(html, "html.parser")
# Remover elementos indesejados
for tag in soup(["nav", "footer", "header", "script", "style",
"aside", "iframe", "noscript", "svg", "form", "button"]):
tag.decompose()
# Remover contêineres comuns de anúncios/cookies/pop-ups
for selector in [".ad", ".ads", ".cookie", ".popup", ".modal", ".sidebar",
"#cookie-banner", "#ad-container", "[role='banner']",
"[role='navigation']", "[role='complementary']"]:
for el in soup.select(selector):
el.decompose()
text = soup.get_text(separator="n", strip=True)
linhas = [linha.strip() for linha in text.splitlines() if linha.strip()]
return "n".join(linhas)
def chunk_text(text, chunk_size=500, chunk_overlap=50):
"""Divide o texto em blocos sobrepostos, separando-os nos limites das frases.
A sobreposição garante que as frases nos limites dos blocos não sejam perdidas entre os blocos."""
if len(text) <= chunk_size:
return [text]
chunks = []
start = 0
while start < len(text):
end = start + chunk_size
# Tenta quebrar no limite de uma frase
if end < len(text):
for sep in [". ", ".n", "nn", "n", " "]:
last_sep = text[max(start, end - 100):end].rfind(sep)
if last_sep != -1:
end = max(start, end - 100) + last_sep + len(sep)
break
chunk = text[start:end].strip()
if chunk and len(chunk) > 50:
chunks.append(chunk)
start = end - chunk_overlap
return chunks
def process_documents(documents):
"""Limpa, divide em blocos e adiciona metadados a todos os documentos."""
all_chunks = []
for doc in documents:
is_serp = doc.get("is_serp", False)
clean_text = clean_html(doc["html"], is_serp=is_serp)
if len(clean_text) < 100:
continue
chunks = chunk_text(clean_text)
domain = doc["url"].split("/")[2] if "://" in doc["url"] else "unknown"
para i, chunk em enumerate(chunks):
all_chunks.append({
"text": chunk,
"source_url": doc["url"],
"source_domain": domain,
"scraped_at": doc["scraped_at"],
"chunk_index": i,
"total_chunks": len(chunks),
"content_hash": hashlib.md5(chunk.encode()).hexdigest(),
"content_type": "serp_result" se is_serp senão "article",
})
return all_chunksApós o processamento, 8 documentos se transformam em cerca de 150–400 trechos de texto limpos (dependendo do comprimento do artigo), cada um com metadados (URL de origem, domínio, carimbo de data/hora, hash do conteúdo).
Etapa 3: Incorporar e armazenar no Weaviate
Conecte-se ao Weaviate Cloud, crie uma coleção com vetorização Cohere e importe todos os fragmentos em lote.
def connect_weaviate():
"""Conecte-se ao Weaviate Cloud com tempos de espera estendidos."""
client = weaviate.connect_to_weaviate_cloud(
cluster_url=WEAVIATE_URL,
auth_credentials=Auth.api_key(WEAVIATE_API_KEY),
headers={"X-Cohere-Api-Key": COHERE_API_KEY},
additional_config=weaviate.classes.init.AdditionalConfig(
timeout=weaviate.classes.init.Timeout(init=30, query=60, insert=120),
),
skip_init_checks=True, # Evita o tempo de espera do gRPC em sandboxes inativas
)
if not client.is_ready():
print(" ERRO: O cluster do Weaviate não está pronto.")
print(" Verifique seu WEAVIATE_URL e WEAVIATE_API_KEY em .env")
print(" Certifique-se de que seu cluster de sandbox esteja em execução em console.weaviate.cloud")
sys.exit(1)
return client
def setup_collection(client):
"""Cria a coleção com pesquisa híbrida + configuração generativa."""
# Exclui qualquer coleção existente com este nome – executar novamente com um
# novo tópico substitui a base de conhecimento anterior, não a complementa.
if client.collections.exists(COLLECTION_NAME):
client.collections.delete(COLLECTION_NAME)
print(f" Coleção '{COLLECTION_NAME}' existente excluída")
client.collections.create(
name=COLLECTION_NAME,
description="Artigos da Web coletados via Bright Data para RAG",
# Cohere embed-v4.0: vetoriza automaticamente o texto no momento da importação
vector_config=Configure.Vectors.text2vec_cohere(
model="embed-v4.0",
),
# Cohere command-a-03-2025: gera respostas RAG no momento da consulta
generative_config=Configure.Generative.cohere(
model="command-a-03-2025",
),
properties=[
Property(name="text", data_type=DataType.TEXT,
description="O conteúdo de texto do fragmento"),
Property(name="source_url", data_type=DataType.TEXT,
skip_vectorization=True),
Property(name="source_domain", data_type=DataType.TEXT,
skip_vectorization=True),
Property(name="scraped_at", data_type=DataType.TEXT,
skip_vectorization=True),
Propriedade(nome="chunk_index", tipo_de_dados=DataType.INT,
ignorar_vectorização=True),
Propriedade(nome="total_chunks", tipo_de_dados=DataType.INT,
ignorar_vectorização=True),
Propriedade(nome="content_hash", tipo_de_dados=DataType.TEXT,
ignorar_vectorização=True),
Property(name="content_type", data_type=DataType.TEXT,
skip_vectorization=True),
],
)
print(f" Criação da coleção '{COLLECTION_NAME}'")Algumas observações importantes:
skip_vectorization=Truenos campos de metadados – apenas o campode textoé incorporado, economizando chamadas de API e produzindo vetores mais limposcontent_hasharmazenado por bloco – use-o para pular a reincorporação de conteúdo inalterado ao adicionar lógica de raspagem incremental (o pipeline atual reimporta dados novos a cada execução)
Comportamento de reexecução: o pipeline exclui e recria a coleção a cada execução. Executar com “IA race” e depois “quantum computing” substitui os dados da IA race. Para manter vários tópicos, altere
COLLECTION_NAMEpara um nome exclusivo por tópico (por exemplo,WebResearch_ai_race,WebResearch_quantum).
Mais informações sobre a preparação de conjuntos de dados vetoriais prontos para IA no guia da Bright Data.
A função store_chunks() insere em lote todos os blocos na coleção:
def store_chunks(client, chunks):
"""Importa em lote os chunks para o Weaviate (vetorizados automaticamente via Cohere)."""
collection = client.collections.use(COLLECTION_NAME)
with collection.batch.fixed_size(batch_size=50) as batch:
for chunk in chunks:
batch.add_object(properties=chunk)
failed = len(collection.batch.failed_objects) if collection.batch.failed_objects else 0
if failed > 0:
print(f" Primeiro erro: {collection.batch.failed_objects[0].message[:120]}")
return failedbatch.fixed_size(50) divide as importações em lotes para aumentar a taxa de transferência, em vez de inserções individuais. Na execução de teste, todos os blocos foram importados sem falhas. O Weaviate chama o Cohere para incorporar cada bloco no momento da importação.
Etapa 4: Consulta com pesquisa e geração híbridas
Com todos os blocos incorporados e indexados, consulte-os usando a função rag_query(). Ela chama generate.hybrid() para realizar a recuperação e a geração em uma única solicitação:
def rag_query(client, question, alpha=0.7, limit=5):
"""Executa uma consulta RAG usando a pesquisa híbrida do Weaviate + IA generativa."""
collection = client.collections.use(COLLECTION_NAME)
response = collection.generate.hybrid(
query=question,
alpha=alpha, # 0.7 = 70% semântica, 30% palavra-chave
limit=limit,
grouped_task=f"""Com base nos documentos recuperados abaixo, responda a esta pergunta:
"{question}"
Instruções:
- Forneça uma resposta clara e abrangente
- Cite a URL da fonte para cada afirmação principal
- Se a informação parecer desatualizada ou contraditória, indique isso
- Mantenha a resposta concisa, mas informativa (2 a 4 parágrafos)""",
)
print(f"n P: {question}")
print(f" {'─' * 60}")
if response.generated:
print(f" R: {clean_generated_text(response.generated)}")
else:
print(" R: (Nenhuma resposta gerada — verifique sua chave da API SERP)")
# Separe as fontes dos artigos dos trechos do resumo da SERP
article_sources = []
serp_sources = []
seen_urls = set()
for obj in response.objects:
url = obj.properties.get("source_url", "unknown")
if url in seen_urls:
continue
seen_urls.add(url)
content_type = obj.properties.get("content_type", "")
domain = obj.properties.get("source_domain", "")
if content_type == "serp_result":
serp_sources.append((domain, url))
else:
article_sources.append((domain, clean_url(url)))
print(f"n Fontes ({len(response.objects)} trechos recuperados):")
for domain, url in article_sources:
print(f" - [{domain}] {url}")
if not article_sources and serp_sources:
print(" (Com base nos resumos da SERP — nenhum trecho de artigo correspondente)")
return responseA pesquisa vetorial pura pode deixar de encontrar termos exatos como “GPT-5” ou “Claude Code”. A pesquisa por palavra-chave pura deixa de encontrar conteúdo semanticamente relacionado. A combinação alpha=0.7 oferece ambos. O algoritmo BlockMax WAND da Weaviate mantém o componente de palavras-chave BM25 rápido em escala.
Com limit=5, a consulta recupera os 5 principais trechos — contexto suficiente para uma resposta detalhada sem sobrecarregar o LLM com ruído. Aumente para 10 para perguntas amplas que abrangem vários subtópicos; diminua para 3 para pesquisas factuais precisas. O parâmetro grouped_task envia todos os trechos recuperados para o Cohere em um único prompt, para que ele possa escrever uma resposta única. A alternativa, single_prompt, gera uma resposta por trecho – útil para resumos por documento, mas não para respostas entre fontes.
Consulte o resumo da Bright Data sobre APIs de pesquisa semântica para mais opções.
Junte todas as 4 etapas
A função main() executa o pipeline completo. Você escolhe um tópico e ela cuida do resto:
def main():
print("=" * 65)
print(" Pipeline RAG: Bright Data + Weaviate")
print(" Rastreie qualquer tópico → Construa uma base de conhecimento → Faça perguntas")
print("=" * 65)
# ── Validar ambiente ──
validate_env()
# ── Solicitar um tópico ao usuário ──
print()
try:
topic = input(" Qual tópico você deseja pesquisar? ").strip()
except (EOFError, KeyboardInterrupt):
print("n Adeus!")
return
if not topic:
print(" Nenhum tópico inserido. Saindo.")
return
print(f'n Criando uma base de conhecimento RAG sobre: "{topic}"')
# ── Descobrir credenciais da Bright Data automaticamente ──
print("n[CONFIGURAÇÃO] Conectando-se à Bright Data...")
cust_id, unlocker_zone, unlocker_pwd, serp_zone, serp_pwd = (
discover_bright_data_credentials()
)
# ── Etapa 1: Encontrar e extrair artigos sobre o tópico ──
print(f'n[ETAPA 1/4] Encontrando e extraindo artigos sobre "{topic}"...')
documents = collect_data(
topic, cust_id, unlocker_zone, unlocker_pwd, serp_zone, serp_pwd
)
print(f"n Total de documentos coletados: {len(documents)}")
if not documents:
print(" ERRO: Nenhum documento coletado. Tente um tópico diferente.")
return
# ── Etapa 2: Processar e dividir em blocos ──
print("n[ETAPA 2/4] Processando e dividindo documentos em blocos...")
chunks = process_documents(documents)
print(f" Criados {len(chunks)} fragmentos a partir de {len(documents)} documentos")
if not chunks:
print(" ERRO: Nenhum fragmento criado. Os documentos podem ser muito curtos.")
return
# ── Etapa 3: Armazenar no Weaviate ──
print("n[PASSO 3/4] Armazenando no Weaviate (incorporação + indexação)...")
print(" Conectando ao Weaviate Cloud...", end=" ", flush=True)
client = connect_weaviate()
print("OK")
print(" Configurando a coleção...")
setup_collection(client)
print(f" Importando {len(chunks)} blocos (vetorização automática via Cohere)...")
failed = store_chunks(client, chunks)
print(f" Importado: {len(chunks) - failed} sucesso, {failed} falha")
# Verificar contagem
collection = client.collections.use(COLLECTION_NAME)
count = collection.aggregate.over_all(total_count=True).total_count
print(f" Total de objetos no Weaviate: {count}")
# ── Etapa 4: Consultas de demonstração + Modo interativo ──
print(f'n[ETAPA 4/4] Consultas RAG sobre "{topic}"...')
print("=" * 65)
demo_queries = [
f"Quais são os últimos desenvolvimentos e tendências em {topic}?",
f"Quais são os maiores desafios e riscos em {topic}?",
f"Quais são as perspectivas futuras para {topic}?",
]
for question in demo_queries:
rag_query(client, question)
print()
# ── Resumo ──
print("=" * 65)
print(" Pipeline concluído!")
print(f' Tópico: "{topic}"')
print(f" - Coletou {len(documents)} fontes via Bright Data")
print(f" - Armazenados {count} blocos no Weaviate")
print(f" - Executadas {len(demo_queries)} consultas RAG de demonstração")
print("=" * 65)
# ── Modo interativo ──
print(f'n Sua base de conhecimento sobre "{topic}" está pronta!')
print(" Pergunte o que quiser. Digite 'quit' para sair.n")
while True:
try:
user_question = input(" Sua pergunta: ").strip()
except (EOFError, KeyboardInterrupt):
print("n Adeus!")
break
if not user_question:
continue
if user_question.lower() in ("quit", "exit", "q"):
print(" Adeus!")
break
rag_query(client, user_question)
print()
client.close()
if __name__ == "__main__":
main()Execute:
python3 pipeline.pyRespostas do RAG da execução de teste da corrida de IA
O pipeline foi executado com o tópico “OpenAI vs Google vs Anthropic: a corrida pela IA”. Estas são respostas RAG de exemplo de uma execução de teste – seus resultados refletirão os artigos que estiverem disponíveis no momento da execução.
Consulta 1: “Quais são os últimos desenvolvimentos e tendências na corrida entre OpenAI, Google e Anthropic IA?”
A corrida de IA entre OpenAI, Google e Anthropic continua a evoluir rapidamente, com cada empresa aproveitando seus pontos fortes exclusivos. A OpenAI mantém a liderança em receita e adoção pelo consumidor, beneficiando-se de sua vantagem de pioneirismo. A Anthropic está diminuindo a diferença na adoção corporativa, com ferramentas especializadas como o Claude Code e uma taxa de sucesso de 70% em confrontos diretos entre empresas que adquirem serviços de IA. O Google traz recursos computacionais incomparáveis e integração perfeita em todo o seu ecossistema.
Fontes: shawnkanungo[.]com, hashmeta[.]ia, ramp[.]com
Pergunta 2: “Quais são os maiores desafios e riscos na corrida entre OpenAI, Google e Anthropic IA?”
A OpenAI enfrenta o desafio de manter seu ritmo de inovação enquanto preserva sua independência, especialmente porque depende de parcerias para obter recursos computacionais. O Google luta contra a inércia burocrática e corre o risco de canibalizar seu principal negócio de publicidade em buscas, à medida que a IA conversacional reduz os cliques em anúncios. A Anthropic, posicionada como priorizando a segurança, deve transformar seu foco na interpretabilidade em participação de mercado em um mercado impulsionado por capacidades.
Fontes: hashmeta[.]ia, shawnkanungo[.]com
Pergunta 3: “Quais são as perspectivas futuras para a corrida entre OpenAI, Google e Anthropic IA?”
A OpenAI lidera em receita e adoção pelos consumidores, com seu roteiro incluindo o GPT-5 e investimentos na redução dos custos de inferência. O sucesso futuro da Anthropic depende da emergência de requisitos regulatórios para explicabilidade — seus investimentos iniciais em segurança e interpretabilidade poderiam proporcionar uma vantagem significativa. O Google continua sendo um forte concorrente, particularmente na adaptação de ferramentas como o Gemini para casos de uso específicos e na integração da IA em fluxos de trabalho cotidianos.
Fontes: hashmeta[.]ia, shawnkanungo[.]com
Cada resposta é baseada em artigos coletados durante a mesma execução do pipeline. Cada citação aponta para uma fonte coletada na Etapa 1 — você pode verificar qualquer afirmação abrindo a URL. Se você perguntar sobre algo que os artigos coletados não abordam, o modelo informará isso ou dará uma resposta menos detalhada.
Após as consultas de demonstração, o pipeline entra no modo interativo, onde você pode fazer suas próprias perguntas:

Indo para produção
Se você precisar disso em produção, vai precisar de multilocação, conformidade e controles de custo. (Para ter uma visão mais ampla, veja como o RAG se encaixa em uma pilha de tecnologia de agente de IA em produção.)
Multilocação para isolamento de dados
Se você estiver desenvolvendo o RAG para vários clientes, a multilocação do Weaviate oferece a cada locatário um shard dedicado com índices vetoriais isolados:
from weaviate.classes.config import Configure
from weaviate.classes.tenants import Tenant
# Habilitar multilocação na coleção
collection = client.collections.create(
name="WebContent",
multi_tenancy_config=Configure.multi_tenancy(enabled=True),
# ... vetorizador + configuração generativa
)
# Cada cliente recebe seu próprio locatário isolado
collection.tenants.create([
Tenant(name="customer_a"),
Tenant(name="customer_b"),
Tenant(name="customer_c"),
])
# Coletar e armazenar dados por locatário
tenant_collection = collection.with_tenant("customer_a")
with tenant_collection.batch.dynamic() as batch:
for chunk in customer_a_chunks:
batch.add_object(properties=chunk)Um único nó suporta mais de 50.000 locatários ativos – um cluster de 20 nós lida com um milhão.
Otimização de custos
Quatro técnicas reduzem o custo à medida que seus dados crescem:
- Quantização rotacional Weaviate – compressão vetorial de 4x com 98–99% de recall.
- Hashing de conteúdo – o campo
content_hashpermite atualizações incrementais que ignoram a reincorporação de chunks inalterados (veja a Etapa 3 acima) skip_vectorization=Truenos campos de metadados – incorpore apenas o que é relevante.- Bright Data Dataset Marketplace – use Conjuntos de dados pré-coletados em vez de fazer scraping para domínios comuns.
Isso é importante quando você vai além de um protótipo para um único usuário.
Erros comuns e como corrigi-los
Se você encontrar um problema, verifique primeiro esta tabela:
| Problema | Causa | Solução |
|---|---|---|
Weaviate gRPC DEADLINE_EXCEEDED |
O cluster da sandbox ficou inativo durante a coleta | Execute novamente o pipeline.py – o script se reconecta automaticamente. Se o problema persistir, verifique seu cluster no console do Weaviate |
Limite de taxa da API Cohere (429) |
O plano de avaliação tem limite de taxa | Aguarde um minuto e tente novamente, ou verifique o uso no painel da Cohere. A execução automatizada usa menos de 20 chamadas; cada pergunta interativa adiciona mais 2 |
Nenhuma zona do Web Unlocker encontrada |
Sua conta Bright Data não possui uma zona do Web Unlocker | Vá para Bright Data → Proxies e Scraping → Minhas Zonas → crie uma zona do Web Unlocker |
Nenhuma zona API SERP encontrada |
Sua conta Bright Data não possui uma zona SERP | Vá para Bright Data → Proxies e Scraping → Minhas Zonas → crie uma zona API SERP |
HTTP 403 em todas as URLs |
As tentativas do Web Unlocker se esgotaram | Tente um tópico diferente – alguns sites de nicho usam bloqueio anti-bot rigoroso. Veja como contornar CAPTCHAs para opções avançadas |
Cluster Weaviate não está pronto |
Sandbox expirada (limite de 14 dias) | Crie uma nova sandbox no console do Weaviate e atualize o arquivo .env |
| Modelo Cohere indisponível | command-a-03-2025 ou embed-v4.0 descontinuados |
Verifique os modelos disponíveis em docs.cohere.com/docs/models e atualize o parâmetro model= em setup_collection() |
ModuleNotFoundError: Nenhum módulo chamado 'weaviate' |
Dependências não instaladas | Execute pip3 install -r requirements.txt a partir do diretório do projeto |
Se o seu erro não estiver listado, verifique a saída completa – o pipeline registra cada etapa com detalhes.
Casos de uso
A mesma arquitetura funciona para qualquer tópico. Algumas ideias:
- Inteligência competitiva – tópico: “estratégia de preços do concorrente X”. O pipeline coleta dados de sites de concorrentes, páginas de preços e relatórios de analistas. Em seguida, pergunte: “Como os preços corporativos do concorrente X se comparam aos nossos?”
- Pesquisa de mercado – tópico: “tendências de fintech no Sudeste Asiático”. Colete notícias regionais e publicações do setor, permitindo que você pergunte coisas como “Quais são as principais tendências emergentes de fintech no Sudeste Asiático?”
- Comércio eletrônico – tópico: “mercado de moda sustentável”. Rastreia relatórios de mercado e pesquisas de mercado. “Quais marcas de moda sustentável estão ganhando participação de mercado?”
- Pesquisa técnica – tópico: “melhores práticas de segurança do Kubernetes”. Colete dados de blogs técnicos e alertas de segurança para que você possa perguntar sobre CVEs específicos ou configurações incorretas.
O que desenvolver a seguir
Este é um protótipo funcional com restrições conhecidas:
- Substitui a coleção completa a cada execução (sem atualizações incrementais) – use
content_hashpara adicionar comparações - Processa apenas texto; tabelas, imagens e PDFs nas páginas coletadas são descartados
- Encontra conteúdo por meio da pesquisa do Google – para URLs específicas, passe-as diretamente para
scrape_url() - É executado como uma CLI para um único usuário
A partir daqui, você pode:
- Agendamento – execute o pipeline em uma tarefa cron para manter sua base de conhecimento atualizada
- Multilocação – forneça a cada cliente seu próprio fragmento isolado (consulte a seção “Entrando em produção” acima)
- Diferentes fontes de dados – use a API Bright Data Web Scraper para dados estruturados da Amazon ou do LinkedIn, ou a API Crawl para Markdown de sites completos
- Front-end – encapsule
rag_query()em um endpoint Flask ou FastAPI e conecte uma interface de chat - RAG agentivo – construir um sistema RAG agentivo que decida por conta própria quando e o que coletar
- LangChain – porte o pipeline para o LangChain com a Bright Data para orquestração de cadeias e memória integradas
Perguntas frequentes
Quais tópicos funcionam com este pipeline?
Qualquer tópico que tenha artigos na web aberta. O pipeline usa a API SERP da Bright Data para pesquisar seu tópico no Google e, em seguida, extrai os principais resultados. Tópicos de nicho com menos páginas indexadas retornam menos artigos, mas o pipeline ainda funciona – ele simplesmente usa o que encontrar.
Quanto custa para executar?
Todos os três serviços oferecem maneiras gratuitas de começar. O plano de avaliação da Cohere é gratuito e não requer cartão de crédito. A Weaviate Cloud oferece um cluster sandbox gratuito, e a Bright Data oferece uma avaliação gratuita para a API SERP e o Web Unlocker.
Posso usar um modelo de embedding ou LLM diferente?
Sim. Altere o parâmetro do modelo em setup_collection() tanto para as incorporações quanto para a geração. O Weaviate oferece suporte aos vetorizadores Cohere, OpenAI, Google e Hugging Face prontos para uso. Para trocar, substitua text2vec_cohere por text2vec_openai, atualize o cabeçalho da chave da API em connect_weaviate() e execute o pipeline novamente.
Como mantenho a base de conhecimento atualizada?
Execute pipeline.py novamente com o mesmo tópico. O pipeline exclui a coleção antiga e cria uma nova com os dados recém-extraídos. Para uso em produção, adicione uma verificação de content_hash para pular a reincorporação de blocos que não foram alterados. Programe o pipeline em uma tarefa cron para atualizar os dados automaticamente em qualquer intervalo.
E se eu já tiver URLs para coletar?
Pule a etapa de descoberta da SERP. Em collect_data(), substitua a chamada find_articles_for_topic() pela sua própria lista de URLs e passe cada URL para scrape_url(). O restante do pipeline (divisão em blocos, incorporação, consulta) funciona da mesma maneira.
Como faço para coletar mais de 6 artigos?
Altere a fatia [:6] no final de find_articles_for_topic() para um número maior (por exemplo, [:12]). Você também pode adicionar mais consultas de pesquisa à lista search_queries para obter uma gama mais ampla de resultados. Mais artigos significam mais tempo de scraping e mais fragmentos, mas o restante do pipeline lida com isso automaticamente.





