

Neste artigo, você aprenderá:
- Se os dados sintéticos são verdadeiramente o futuro do treinamento de IA e ML.
- O que são dados reais da web, seus principais tipos e como coletá-los em escala.
- O que são dados sintéticos, como podem ser categorizados e como são gerados com sucesso.
- O impacto dos dados sintéticos vs reais em termos de custo, privacidade, robustez e qualidade de distribuição.
- Como a escolha dos dados afeta o pipeline de treinamento de IA e o desempenho do modelo.
- Por que uma abordagem híbrida combinando ambos os tipos de dados é frequentemente a estratégia mais eficaz.
- Os prós e contras de cada abordagem.
Vamos começar.
Os Dados Sintéticos São o Futuro da IA/ML, ou os Dados da Web Ainda Importam?
As leis de escalonamento de IA mostram que o desempenho tende a melhorar à medida que os modelos são treinados com mais parâmetros, mais computação e, fundamentalmente, mais dados. Em outras palavras, modelos maiores exigem conjuntos de dados exponencialmente maiores para sustentar os ganhos de desempenho.
Historicamente, os dados reais da web serviram como base do treinamento moderno de IA, mas dados de alta qualidade da web são finitos. É famosa a declaração de Elon Musk de que as empresas de IA ficaram sem dados de treinamento e “esgotaram” a soma do conhecimento humano disponível para o treinamento de modelos.
Além disso, os dados da web estão cada vez mais duplicados e são caros de coletar, limpar e verificar legalmente. Isso também destaca a importância de selecionar provedores de conjuntos de dados da web que entreguem conjuntos de dados otimizados para IA, regularmente atualizados e em conformidade com as normas de privacidade.
Essas pressões estão acelerando o interesse em fontes de dados alternativas, especialmente em dados sintéticos. De acordo com o Gartner, até 2030, os dados sintéticos devem superar os dados do mundo real no treinamento de modelos de IA. A empresa atribui essa mudança a requisitos de privacidade mais rigorosos, escassez de dados do mundo real e organizações que buscam alternativas de menor custo para reduzir riscos legais e de conformidade.
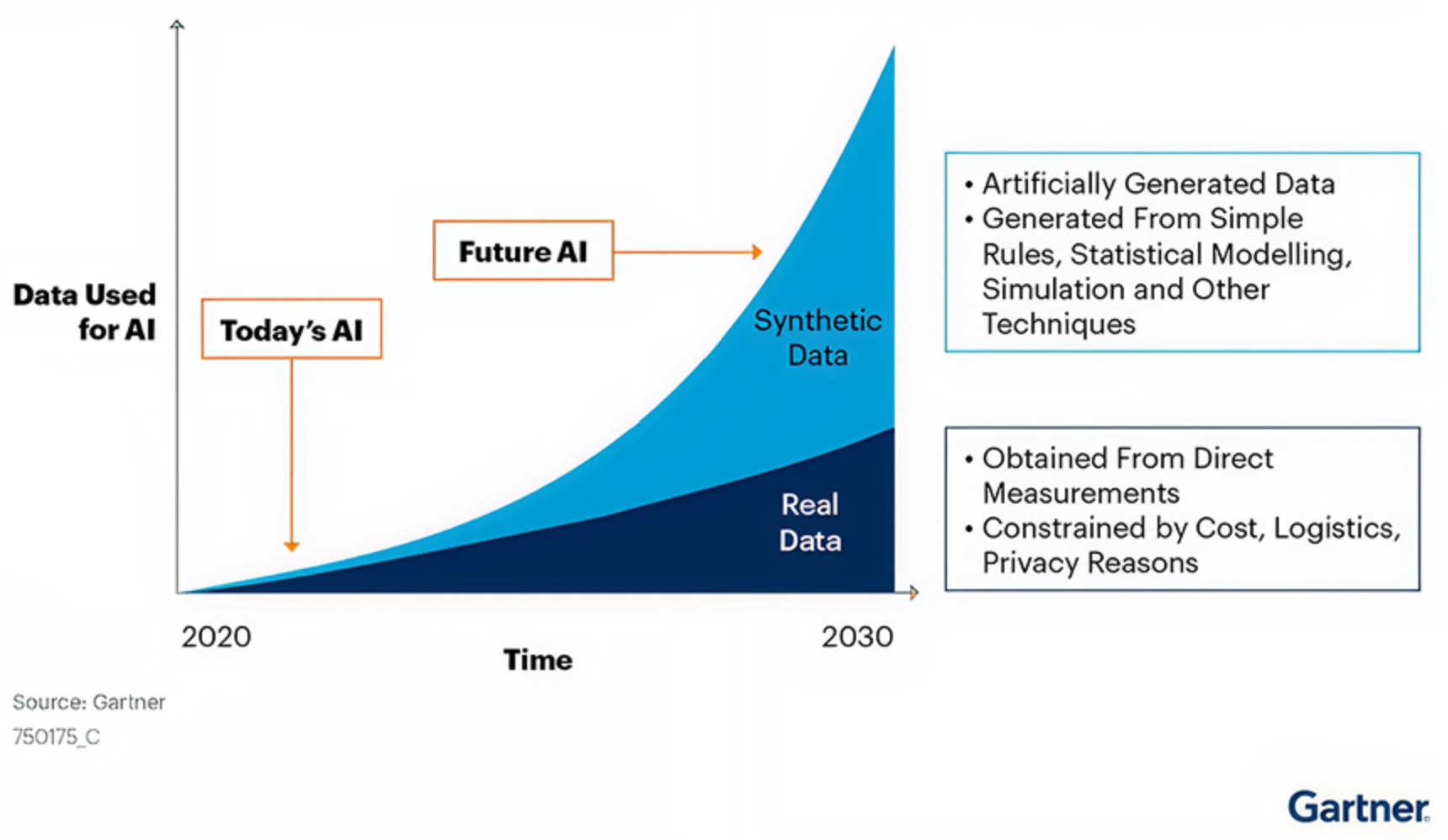
Ao mesmo tempo, essa previsão deve ser vista como uma estimativa, e não como uma inevitabilidade. A internet continua gerando enormes volumes de conteúdo, com aproximadamente 402 milhões de terabytes de dados da web criados todos os dias!
Para colocar em perspectiva, o GPT-3 foi treinado em aproximadamente 45 terabytes de texto bruto antes da filtragem. Essa comparação sugere que os dados em escala web gerados por humanos continuam sendo vastos e altamente relevantes para o treinamento de IA.
Como resultado, é improvável que o futuro do treinamento de IA dependa exclusivamente de dados sintéticos. Em vez disso, muitos especialistas em aprendizado de máquina esperam uma abordagem híbrida, um tema que examinaremos mais adiante neste artigo.
Dados Sintéticos vs Dados Reais da Web: Comparando os Dois Paradigmas de Dados
Nos capítulos a seguir, você aprenderá o que são dados sintéticos e dados reais da web, o que cada um oferece e como se comparam em múltiplos aspectos do treinamento de modelos de IA. Começaremos com os dados reais da web, por serem mais naturais de compreender, e depois passaremos aos dados sintéticos.
Para uma comparação de alto nível imediata, confira a tabela de dados sintéticos vs dados reais da web abaixo:
| Dados Reais da Web | Dados Sintéticos | |
|---|---|---|
| Definição | Dados coletados de fontes reais da web | Dados gerados artificialmente que imitam distribuições do mundo real usando modelos ou regras |
| Exemplos | Páginas web, fóruns, artigos de notícias, páginas de produtos, PDFs, etc. | Textos gerados por LLM, imagens de GAN, ambientes simulados de robótica, conjuntos de dados baseados em regras, etc. |
| Objetivo principal | Capturar a complexidade do mundo real e o comportamento natural | Aumentar escala, cobertura e controlabilidade |
| Tipos de dados | Não estruturados (texto, imagens), semiestruturados (JSON, XML) | Estruturados, semiestruturados, não estruturados (texto, imagem, áudio, vídeo) |
| Como são obtidos | Principalmente Scraping de dados | Geração por LLM, GANs, VAEs, sistemas baseados em regras, motores de simulação |
| Risco de privacidade | Maior (PII, conformidade necessária) | Baixo (sem dados reais de usuários se gerado corretamente) |
| Qualidade dos dados | Ruidosos, inconsistentes, mas autênticos | Limpos, estruturados, mas podem conter artefatos ou alucinações |
| Distribuição | Distribuição natural do mundo real | Controlada, mas pode introduzir viés sintético ou desvio |
| Robustez | Forte generalização para entradas do mundo real | Forte para cenários específicos, generalização mais fraca |
| Cobertura de cauda longa | Naturalmente presente, mas esparsa | Pode ser gerada explicitamente e sobreamostrada |
| Risco de viés | Reflete o viés do mundo real | Pode amplificar ou introduzir novos vieses |
| Papel típico no pipeline | Pré-treinamento, ajuste fino, avaliação | Pré-treinamento, aumento, geração de casos extremos |
| Riscos | Escassez de dados, restrições de conformidade, ruído | Lacuna sintético-real, colapso do modelo, padrões alucinados |
Agora é hora de mergulhar nos dois paradigmas de dados centrais que moldam o treinamento moderno de IA!
Explorando o Mundo dos Dados Reais da Web
Aqui, abordaremos tudo o que você precisa saber sobre dados reais da web para treinamento de modelos de IA.
O Que São Dados da Web?
Dados da web são informações coletadas de páginas web e outras fontes públicas da web, principalmente por meio de Scraping de dados. Incluem conteúdo não estruturado, como texto, imagens, código, metadados e documentos (por exemplo, PDFs), além de dados semiestruturados como JSON e XML.
Tipos de Dados da Web
Existem muitas categorias possíveis de dados da web. Ainda assim, em alto nível, especialmente no contexto de IA, é útil distinguir entre dois tipos principais:
- Dados históricos da web: Normalmente coletados por meio de pipelines de Scraping de dados, depois limpos, enriquecidos, deduplicados e agregados em conjuntos de dados estruturados em formatos como CSV, JSON e Parquet. Esses conjuntos de dados são usados para pré-treinamento e ajuste fino de modelos.
- Dados ao vivo da web: Recuperados em tempo real de páginas web por meio de scraping ou APIs. Refletem as informações mais atualizadas disponíveis na internet. Isso os torna particularmente úteis para fundamentar respostas de IA e para sistemas RAG, onde a atualidade e a precisão factual são fundamentais.
Juntas, essas duas formas de dados da web desempenham papéis complementares nos sistemas modernos de IA.
Como Obter Dados da Web
Para obter dados da web para treinamento de IA/ML, você precisa de um pipeline escalável de Scraping de dados. Construir isso internamente requer expertise técnica significativa.
Envolve lidar com uma ampla gama de desafios anti-scraping, como bloqueio de IP, Resolução de CAPTCHA e limitadores de taxa. Além disso, requer fortes capacidades de engenharia de dados para limpeza, deduplicação e normalização. Como resultado, as empresas preferem depender de plataformas dedicadas de dados da web, como a Bright Data.
A Bright Data oferece um ecossistema completo para coleta e entrega de dados da web. O que a destaca é sua rede de Proxies residenciais com mais de 400 milhões de IPs em 195 países, que suporta coleta de dados da web altamente escalável e concorrente. Essa infraestrutura de nível empresarial também está em conformidade com GDPR e CCPA, além de outros padrões de privacidade e segurança.
A oferta da Bright Data para dados da web inclui:
- Marketplace de dados da web: Uma coleção de mais de 350 conjuntos de dados prontos para uso cobrindo mais de 250 domínios (incluindo Reddit, Amazon, LinkedIn, Yahoo Finance e muitos outros). Esses conjuntos de dados abrangem mais de 17 petabytes de dados da web e são otimizados para treinamento de ML e aplicações de IA. São entregues em múltiplos formatos, como JSON, CSV e Parquet, via entrega em nuvem e outros métodos de distribuição.
- Produtos de Scraping de dados: Um conjunto de soluções baseadas em API para extração de dados ao vivo da web:
– API Web Unlocker: Contorna bloqueios e CAPTCHAs para garantir acesso a dados em qualquer página web.
– API SERP: Entrega resultados estruturados e em tempo real de mecanismos de busca como Google, Bing, Yandex e outros.
– API Discover: Retorna um conjunto classificado e ao vivo de URLs da web pública, pronto para processamento downstream.
– API Crawl: Realiza rastreamento escalável de sites e extração estruturada de dados.
– APIs Scraper: Cobrem mais de 120 sites para extração direta de dados estruturados de domínios populares.
A Bright Data também oferece serviços gerenciados para aquisição de dados completa. Eles permitem que as organizações se concentrem no desenvolvimento de modelos em vez de na engenharia de dados.
Entrando no Universo dos Dados Sintéticos
Neste capítulo, você explorará o uso de dados sintéticos para treinamento de modelos de IA/ML.
O Que São Dados Sintéticos?
Dados sintéticos são informações geradas artificialmente que replicam os padrões estatísticos e as características dos dados do mundo real. Em vez de serem coletados de eventos reais, são produzidos artificialmente.
Tipos de Dados Sintéticos
Os dados sintéticos podem ser categorizados:
- Por composição e nível de privacidade:
– Totalmente sintéticos: Gerados inteiramente do zero usando modelos de aprendizado de máquina treinados em dados reais. Por não conterem Pontos de dados originais, oferecem o mais alto nível de proteção de privacidade.
– Parcialmente sintéticos: Tomam um conjunto de dados real existente e substituem apenas os atributos sensíveis (como nomes, endereços ou números de Seguro Social) por valores artificiais. Isso preserva tendências específicas dos dados enquanto anonimiza as informações pessoais identificáveis.
– Híbridos: Combinam registros reais e anonimizados com registros gerados artificialmente. Isso é comumente usado para “sobreamostrar” ou enriquecer conjuntos de dados criando artificialmente eventos raros (por exemplo, adicionando registros sintéticos de fraude a um conjunto de dados bancários).
- Por estrutura de dados:
– Dados estruturados: Dados altamente organizados e quantitativos apresentados em formatos tabulares.
– Dados não estruturados: Formatos de dados qualitativos ou com muita mídia. Incluem texto sintético, imagens, vídeo e áudio gerados artificialmente.
Como Produzir Dados Sintéticos
Em alto nível, os dados sintéticos podem ser gerados usando três abordagens predominantes:
- Totalmente gerados por IA: Criados usando modelos como GANs (Redes Adversariais Generativas), VAEs (Autoencoders Variacionais) ou LLMs. Esses sistemas aprendem a distribuição subjacente de conjuntos de dados reais e, em seguida, geram amostras completamente novas que se assemelham aos dados originais sem copiá-los diretamente.
- Geração baseada em regras: Onde os dados são produzidos usando regras predefinidas escritas por humanos, restrições ou lógica de negócios. Isso garante consistência estrita, correção estrutural e comportamento controlado, tornando-o útil para sistemas que requerem saídas previsíveis.
- Dados simulados ou fictícios: Gerados por meio de simulações físicas ou comportamentais. É comumente usado em ambientes como direção autônoma ou robótica, onde gêmeos digitais e motores de física criam cenários realistas de “e se”.
Impacto dos Dados Sintéticos vs Dados Reais da Web no Treinamento de Modelos de IA/ML
Vamos agora comparar vários aspectos para entender as consequências de usar dados sintéticos vs dados reais da web para treinamento de IA.
Distribuição de Dados e Realismo
Os dados da web se aproximam estreitamente de uma distribuição de dados natural. Capturam a complexidade inerente da linguagem e do comportamento humano como aparecem no mundo real. Isso traz benefícios importantes, incluindo correlações naturais entre características, casos extremos autênticos, estilos linguísticos diversos e ruído realista, como erros humanos, ambiguidade e inconsistências.
No entanto, os dados reais da web também são inerentemente desorganizados. Frequentemente são desequilibrados, duplicados, difíceis de curar em escala e podem conter conteúdo de baixa qualidade ou spam que requer filtragem extensiva.
Em contraste, os dados sintéticos representam uma distribuição controlada. São intencionalmente projetados e gerados, permitindo que os profissionais moldem as propriedades do conjunto de dados de forma precisa. Isso permite distribuições de classes equilibradas, cobertura direcionada de cenários específicos, geração de eventos raros e aprendizado curricular estruturado.
Ao mesmo tempo, os dados sintéticos introduzem riscos importantes, incluindo desvio de distribuição, artefatos irrealistas, colapso de modo e super-regularização quando o gerador é muito restrito.
Importante: Um conceito central de aprendizado de máquina nesse sentido é a lacuna sintético-real, semelhante ao problema de simulação-para-real em robótica. Modelos treinados intensamente em dados sintéticos podem ter desempenho inferior em entradas realistas porque a distribuição gerada não corresponde totalmente à realidade.
Cobertura de Cauda Longa
Os dados reais da web naturalmente incluem uma ampla gama de conhecimentos. Isso inclui fatos obscuros, eventos raros e casos extremos inesperados que surgem organicamente da atividade humana. No entanto, esses exemplos de cauda longa são inerentemente esparsos. Por definição, eventos raros aparecem com pouca frequência, o que dificulta que os modelos aprendam padrões robustos a partir deles durante o treinamento.
Por outro lado, você pode usar dados sintéticos para gerar explicitamente cenários raros ou sub-representados. Dessa forma, você pode direcionar lacunas específicas em um conjunto de dados e melhorar a cobertura onde os dados reais são insuficientes. Exemplos incluem bugs raros de codificação e idiomas de baixo recurso.
Uma grande vantagem de usar dados sintéticos para cobertura de cauda longa é a capacidade de sobreamostrar eventos raros. Isso pode ajudar a reduzir o desequilíbrio de classes e melhorar o desempenho do modelo em casos infrequentes, mas importantes. Ainda assim, se cenários raros forem artificialmente super-representados, as prioridades aprendidas pelo modelo podem se tornar distorcidas.
Por exemplo, se casos de exploits de cibersegurança forem muito sobreamostrados em dados sintéticos, o modelo pode começar a superestimar sua probabilidade em ambientes do mundo real. Como resultado, uma calibração cuidadosa é fundamental para garantir que a geração sintética de cauda longa melhore a cobertura sem introduzir distribuições irrealistas.
Considerações de Custo e Privacidade
Como mencionado anteriormente, as empresas raramente constroem sua própria infraestrutura de Scraping de dados e conjuntos de dados. Em vez disso, dependem de provedores de dados terceirizados, como a Bright Data, que abstraem o rastreamento, o desbloqueio, a limpeza e a entrega. Isso muda fundamentalmente tanto a estrutura de custos quanto as trocas de privacidade na aquisição de dados.
Abaixo está uma visão geral simplificada do modelo de preços da Bright Data para coleta de dados da web:
| Preço | Planos personalizados para empresas | Conformidade com GDPR | Conformidade com CCPA | Conformidade com regulamentos da SEC | |
|---|---|---|---|---|---|
| Conjuntos de dados | De $0,001 a $0,0025 por registro | ✔️ | ✔️ | ✔️ | ✔️ |
| APIs de Scraping de dados | $1-$1,5/1K resultados | ✔️ | ✔️ | ✔️ | ✔️ |
A Bright Data também oferece serviços de anotação de dados, ajudando as organizações a reduzir ainda mais a dependência de engenharia de dados interna. Importante ressaltar que seus dados estão alinhados com frameworks de privacidade, o que ajuda a reduzir riscos legais e regulatórios.
Sem esses provedores de dados da web, você teria que lidar internamente com o desenvolvimento de infraestrutura, manutenção contínua e a complexa governança de PII, material protegido por direitos autorais e dados comportamentais sensíveis.
Com dados sintéticos, os principais custos vêm da computação de inferência e do acesso a modelos professores ou APIs. Do ponto de vista da privacidade, os dados gerados artificialmente oferecem uma vantagem inerente. Por serem gerados e não coletados de indivíduos reais, os dados sintéticos eliminam naturalmente a exposição a informações pessoais identificáveis.
Agora, a escolha certa entre dados sintéticos e dados reais da web depende dos requisitos de qualidade, escala, restrições de privacidade e o caso de uso alvo. Dependendo desses fatores, qualquer abordagem pode ser mais ou menos econômica do que a outra.
Fatores de Qualidade dos Dados
Os dados da web geralmente fornecem supervisão fraca. Os modelos aprendem a partir de sinais que ocorrem naturalmente, como previsão do próximo token, metadados e conteúdo gerado por humanos. O problema é que os dados reais são ruidosos e podem conter desinformação, contradições, spam, opiniões tendenciosas e formatação inconsistente.
Ao contrário, os dados sintéticos oferecem maior controle sobre a qualidade e a supervisão. Podem fornecer rótulos perfeitamente formatados, saídas estruturadas, raciocínio passo a passo e exemplos verificados automaticamente. Por exemplo, conjuntos de dados sintéticos podem incluir respostas matematicamente verificadas ou trechos de código validados por testes unitários. Isso melhora a consistência e facilita o treinamento direcionado.
O principal risco com dados sintéticos é que sua qualidade é fundamentalmente limitada pela qualidade do modelo gerador, algoritmo ou abordagem subjacente. Alucinações geradas ou erros factuais podem se propagar para o conjunto de dados final, fazendo com que os modelos aprendam padrões incorretos com confiança. Da mesma forma, vieses ocultos presentes nos sistemas de geração também podem ser herdados por modelos downstream. Por outro lado, os dados sintéticos suportam um ajuste de alinhamento e segurança mais forte.
Generalização e Robustez
Uma das questões mais importantes no aprendizado de máquina é o quão bem um modelo generaliza para entradas não vistas. Em outros termos, qual fonte de dados leva a uma melhor robustez sob desvio de distribuição: dados reais da web ou dados sintéticos?
Os dados da web tendem a alcançar forte robustez, pois refletem o comportamento humano, a linguagem e o ruído que ocorrem naturalmente. Isso melhora o desempenho em entradas fora da distribuição e aprimora a transferência de domínio, especialmente quando os modelos são implantados em ambientes imprevisíveis.
Em vez disso, os dados sintéticos são mais adequados para otimização direcionada. Permitem criar com precisão exemplos de treinamento para habilidades específicas, casos extremos ou cenários raros.
Considerações Principais ao Treinar IA com Dados Sintéticos ou Reais da Web
Agora que você conhece as diferenças entre dados sintéticos e dados da web, está pronto para ver as implicações práticas do uso de cada abordagem no treinamento de modelos de IA.
Pipelines de Treinamento de Dados
Ao depender de dados da web, o pipeline normalmente segue estas etapas:
- Rastreamento: Coletar dados brutos de sites usando sistemas de scraping em larga escala ou bots personalizados de Scraping de dados em múltiplos domínios.
- Deduplicação: Remover conteúdo duplicado ou quase duplicado para reduzir a redundância e melhorar a diversidade e a eficiência do conjunto de dados.
- Detecção de idioma: Identificar o idioma de cada amostra e filtrar ou segmentar o conjunto de dados com base nos requisitos de idioma alvo.
- Pontuação de qualidade: Avaliar e classificar o conteúdo usando heurísticas ou modelos para filtrar informações de baixa qualidade ou irrelevantes.
- Filtragem de toxicidade: Detectar e remover conteúdo prejudicial, inseguro ou inadequado para garantir a segurança do treinamento e a conformidade.
- Remoção de PII e descontaminação: Remover informações pessoais identificáveis e eliminar a contaminação de fontes sensíveis ou indesejadas.
Quando se trata de pipelines de dados sintéticos, as etapas são mais focadas na geração:
- Geração de prompts: Projetar prompts ou modelos que definam a estrutura, a tarefa ou o cenário para a criação de dados sintéticos.
- Amostragem do modelo: Gerar saídas candidatas usando modelos generativos, como LLMs, GANs ou outros sistemas.
- Verificação: Validar saídas usando verificações automatizadas, regras ou ferramentas externas para garantir correção e consistência.
- Filtragem: Remover amostras de baixa qualidade, inconsistentes ou alucinadas que não atendam aos padrões predefinidos.
- Pontuação de recompensa: Atribuir pontuações de qualidade ou preferência para classificar e selecionar os melhores exemplos sintéticos.
- Refinamento iterativo: Melhorar a qualidade dos dados por meio de ciclos repetidos de geração, filtragem e reamostragem para aprimorar a robustez.
Como você pode notar, os pipelines de dados reais da web se concentram na limpeza de entradas ruidosas do mundo real. Já os pipelines sintéticos tratam mais do controle e da validação das saídas geradas. Por fim, após a produção do conjunto de dados de treinamento, você pode prosseguir com o treinamento do modelo de IA.
Comparação de Desempenho
A questão final é se os dados sintéticos podem superar os dados reais da web.
Um recente artigo sobre IA para Engenharia de Requisitos (AI4RE) sugere que conjuntos de dados gerados por LLM podem ser uma alternativa forte quando os dados reais são escassos ou difíceis de acessar. Resultados empíricos mostram que modelos treinados exclusivamente em dados sintéticos podem superar aqueles treinados apenas em conjuntos de dados criados por humanos. Em detalhes, foram observadas melhorias de até +37% em precisão e +30% em recall em comparação com baselines de dados reais apenas.
Dito isso, esta não é uma conclusão binária ou absoluta. As evidências não sugerem que os dados sintéticos devam substituir completamente os dados reais, mas sim que o melhor desempenho é frequentemente alcançado por meio de uma abordagem híbrida. Saiba mais sobre isso!
Dados Sintéticos + Dados Reais da Web: Por Que uma Abordagem Híbrida Funciona Melhor
O debate entre dados sintéticos e dados reais da web não é mais sobre escolher um ou outro, mas sobre como combiná-los.
Evidências recentes mostram que configurações híbridas combinando dados sintéticos e reais alcançam ganhos de até +85% em precisão e uma duplicação do recall em comparação com o uso apenas de dados reais da web.
Ao mesmo tempo, múltiplos estudos e relatórios do setor destacam que misturar ingenuamente amostras sintéticas e reais pode, na verdade, degradar o desempenho devido a incompatibilidade de distribuição, redundância ou amplificação de viés. Isso deixa claro que os ganhos de desempenho dependem de um design cuidadoso do conjunto de dados, e não de simples acumulação de dados.
Uma questão aberta fundamental é a proporção ideal entre dados sintéticos e reais. Não há uma resposta universal. Alguns profissionais adotam uma divisão 80/20 no estilo Pareto (principalmente dados reais com aumento sintético), enquanto outros preferem misturas mais equilibradas, como 60/40, dependendo da complexidade da tarefa, do risco do domínio e da disponibilidade de dados.
Da mesma forma, a posição dos dados sintéticos no pipeline importa. A prática do setor orienta uma estratégia em estágios: pré-treinamento com predominância sintética para cobertura, seguido de ajuste fino com dados reais para fundamentação e avaliação.
Em última análise, os pipelines híbridos funcionam melhor porque combinam pontos fortes complementares. Os dados sintéticos fornecem escala e cobertura de casos extremos, enquanto os dados reais da web garantem fidelidade, realismo e avaliação confiável em ambientes de produção.
Dados Reais da Web vs Dados Sintéticos: Prós e Contras
Como seção de resumo, veja as vantagens e desvantagens dos dois paradigmas de dados.
Dados Reais da Web
👍 Prós:
- Captura padrões e ruídos autênticos do mundo real
- Forte referência para avaliação e validação
- Reduz o risco de viés sintético ou artefatos
👎 Contras:
- Caro e demorado para coletar e rotular
- Pode ser limitado por restrições de privacidade e regulatórias
- Pode ser desequilibrado ou incompleto
Dados Sintéticos
👍 Prós:
- Altamente escalável e rápido de gerar
- Pode simular eventos raros e casos extremos
- Suporta pipelines de treinamento com preservação de privacidade
👎 Contras:
- Risco de lacuna de domínio vs dados do mundo real
- Requer validação cuidadosa e controle de qualidade
- Pode carecer de diversidade em comparação com dados reais, levando ao overfitting em artefatos sintéticos
Dados Reais da Web + Dados Sintéticos
👍 Prós:
- Combina escala (sintético) com realismo (dados reais)
- Frequentemente alcança o melhor desempenho na prática
- Maior robustez em casos extremos e casos normais
👎 Contras:
- Requer balanceamento cuidadoso e ajuste de proporções
- Risco de degradação de desempenho se misturado inadequadamente
- Design e manutenção de pipeline mais complexos
Conclusão
Neste artigo sobre dados sintéticos vs dados reais da web, você aprendeu o impacto de usar dados do mundo real ou gerados artificialmente para treinamento de modelos de IA/ML. Como sempre acontece nessas situações, não há um único vencedor. A abordagem certa depende do seu orçamento específico, habilidades técnicas e metas de desempenho.
Independentemente da configuração, os dados da web ainda desempenham um papel central no treinamento de modelos de IA, seja para pré-treinamento ou ajuste fino final. Sua ampla cobertura e fundamentação no mundo real os tornam essenciais. No entanto, algumas empresas preferem optar por abordagens mais voltadas para dados sintéticos. O principal motivo é a complexidade de construir e manter pipelines de recuperação de dados da web internamente.
É aqui que a Bright Data pode ajudar. Com infraestrutura de nível empresarial, altamente escalável e em conformidade, ela oferece:
- Conjuntos de dados da web: Mais de 350 conjuntos de dados prontos com bilhões de registros, já coletados, curados e otimizados para casos de uso de treinamento de IA.
- Produtos de Scraping de dados: Soluções baseadas em API para acessar dados frescos da web de muitos sites em escala.
Além disso, a Bright Data oferece serviços de anotação de dados. Fornece soluções de rotulagem escaláveis, precisas e personalizáveis para casos de uso de PLN, visão computacional e reconhecimento de fala.
Descubra todas as soluções Bright Data para IA!
Crie uma conta Bright Data gratuitamente e explore nossas soluções de dados da web!






