

As avaliações de clientes espalhadas por várias plataformas criam desafios de análise para as empresas. O monitoramento manual das avaliações consome muito tempo e, muitas vezes, deixa de lado insights essenciais. Este guia mostra como criar um agente de IA que coleta, analisa e categoriza automaticamente as avaliações de diferentes fontes.
Você aprenderá:
- Como criar um sistema de inteligência de avaliação usando o CrewAI e o Web MCP da Bright Data
- Como realizar uma análise de sentimento baseada em aspectos no feedback do cliente
- Como categorizar as avaliações por tópico e gerar insights acionáveis
Confira o projeto final no GitHub!
O que é o CrewAI?
O CrewAI é uma estrutura de código aberto para a criação de equipes colaborativas de agentes de IA. Você define as funções, as metas e as ferramentas dos agentes para executar fluxos de trabalho complexos. Cada agente lida com tarefas específicas enquanto trabalha em conjunto para atingir um objetivo comum.
O CrewAI consiste em:
- Agente: Um trabalhador acionado pelo LLM com responsabilidades e ferramentas definidas
- Tarefa: Um trabalho específico com requisitos de saída claros
- Ferramenta: Funções que os agentes usam para trabalhos especializados, como extração de dados.
- Equipe: Um conjunto de agentes trabalhando juntos
O que é MCP?
O MCP (Model Context Protocol) é um padrão JSON-RPC 2.0 que conecta agentes de IA a ferramentas externas e fontes de dados por meio de uma interface unificada.
O servidor Web MCP da Bright Data oferece acesso direto a recursos de raspagem da Web com proteção antibot por meio de mais de 150 milhões de IPs residenciais rotativos, renderização de JavaScript para conteúdo dinâmico, saída JSON limpa de dados raspados e mais de 50 ferramentas prontas para diferentes plataformas.
O que estamos construindo: Agente de inteligência de revisão de várias fontes
Criaremos um sistema CrewAI que extrai automaticamente avaliações de empresas específicas de várias plataformas, como G2, Capterra, Trustpilot e TrustRadius, e recupera a classificação de cada uma delas, além das principais avaliações, realiza análise de sentimento baseada em aspectos, categoriza o feedback em tópicos (suporte, preço, facilidade de uso), pontua o sentimento de cada categoria e gera insights de negócios acionáveis.
Pré-requisitos
Configure seu ambiente de desenvolvimento com:
- Python 3.11 ou superior
- Node.js e npm para o servidor Web MCP
- Conta da Bright Data – Inscreva-se e crie um token de API (créditos de avaliação gratuitos estão disponíveis).
- Chave de API do Nebius – Crie uma chave no Nebius AI Studio (clique em + Get API Key). Você pode usá-la gratuitamente. Não é necessário um perfil de faturamento.
- Ambiente virtual Python – Mantém as dependências isoladas; consulte a documentação do
venv.
Configuração do ambiente
Crie o diretório do seu projeto e instale as dependências:
python -m venv venv
# macOS/Linux: source venv/bin/activate
# Windows: venv\Scripts\activate
pip install "crewai-tools[mcp]" crewai mcp python-dotenv pandas textblob
Crie um novo arquivo chamado review_intelligence.py e adicione as seguintes importações:
from crewai import Agent, Task, Crew, Process
from crewai_tools import MCPServerAdapter
de mcp import StdioServerParameters
de crewai.llm import LLM
importar os
import json
import pandas as pd
from datetime import datetime
from dotenv import load_dotenv
from textblob import TextBlob
load_dotenv()
Configuração do Bright Data Web MCP
Crie um arquivo .env com suas credenciais:
BRIGHT_DATA_API_TOKEN="seu_api_token_aqui"
WEB_UNLOCKER_ZONE="sua_web_unlocker_zone"
BROWSER_ZONE="seu_navegador_zona"
NEBIUS_API_KEY="sua_nebius_api_key"
Você precisa:
- Token de API: Gerar um novo token de API no painel de controle da Bright Data
- Zona do Web Unlocker: Criar uma nova zona do Web Unlocker para sites de imóveis
- Zona de API do navegador: Crie uma nova zona de API do navegador para sites de imóveis com muito JavaScript
- Chave da API do Nebius: Já criada em Pré-requisitos
Configure o servidor LLM e Web MCP em review_intelligence.py:
llm = LLM(
model="nebius/Qwen/Qwen3-235B-A22B",
api_key=os.getenv("NEBIUS_API_KEY")
)
server_params = StdioServerParameters(
comando="npx",
args=["@brightdata/mcp"],
env={
"API_TOKEN": os.getenv("BRIGHT_DATA_API_TOKEN"),
"WEB_UNLOCKER_ZONE": os.getenv("WEB_UNLOCKER_ZONE"),
"BROWSER_ZONE": os.getenv("BROWSER_ZONE"),
},
)
Definição de agentes e tarefas
Defina agentes especializados para diferentes aspectos da análise de avaliações. O agente raspador de avaliações extrai avaliações de clientes de várias plataformas e retorna dados JSON limpos e estruturados com texto de avaliação, classificações, datas e origem da plataforma. Esse agente tem conhecimento especializado em raspagem da Web, com uma compreensão profunda das estruturas da plataforma de avaliação e a capacidade de contornar medidas antibot.
def build_review_scraper_agent(mcp_tools):
return Agent(
role="Coletor de dados de avaliação",
goal=(
"Extrair avaliações de clientes de várias plataformas e retornar dados JSON limpos e estruturados"
"dados JSON estruturados com texto da avaliação, classificações, datas e fonte da plataforma".
),
backstory=(
"Especialista em raspagem da Web com profundo conhecimento das estruturas de plataformas de avaliação. "
"Hábil em contornar medidas anti-bot e extrair conjuntos de dados completos de avaliações "
"da Amazon, Yelp, Google Reviews e outras plataformas."
),
tools=mcp_tools,
llm=llm,
max_iter=3,
verbose=True,
)
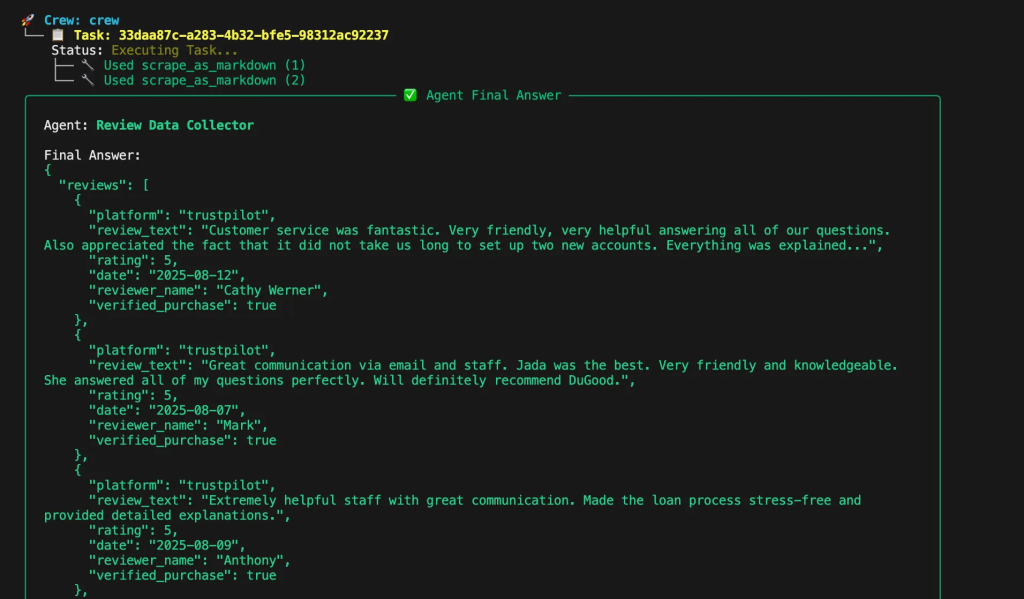
O agente analisador de sentimentos analisa o sentimento das avaliações em três aspectos principais: Qualidade do suporte, satisfação com o preço e facilidade de uso. Ele fornece pontuações numéricas e raciocínio detalhado para cada categoria. Esse agente é especializado em processamento de linguagem natural e análise de sentimentos de clientes, com experiência na identificação de indicadores emocionais e padrões de feedback específicos de aspectos.
def build_sentiment_analyzer_agent():
return Agent(
role="Especialista em análise de sentimentos",
goal=(
"Analisar o sentimento das avaliações em três aspectos principais: Qualidade do suporte, "
"Satisfação com o preço e facilidade de uso. Forneça pontuações numéricas e "
" "e uma justificativa detalhada para cada categoria."
),
backstory=(
"Cientista de dados especializado em processamento de linguagem natural e "
"análise de sentimento do cliente. Especialista em identificar indicadores emocionais, pistas de contexto "
"e padrões de feedback específicos de aspectos em avaliações de clientes."
),
llm=llm,
max_iter=2,
verbose=True,
)
O agente gerador de insights transforma os resultados da análise de sentimentos em insights de negócios acionáveis. Ele identifica tendências, destaca problemas críticos e fornece recomendações específicas para aprimoramento. Esse agente traz experiência em análise estratégica com habilidades em otimização da experiência do cliente e tradução de dados de feedback em ações comerciais concretas.
def build_insights_generator_agent():
return Agent(
role="Analista de inteligência comercial",
goal=(
"Transformar os resultados da análise de sentimentos em insights de negócios acionáveis. "
"Identificar tendências, destacar problemas críticos e fornecer recomendações específicas "
"recomendações específicas para aprimoramento."
),
backstory=(
"Analista estratégico com experiência em otimização da experiência do cliente. "
"Hábil em traduzir dados de feedback do cliente em negócios concretos"
"ações concretas e estruturas de prioridade."
),
llm=llm,
max_iter=2,
verbose=True,
)
Montagem e execução da equipe
Crie tarefas para cada estágio do pipeline de análise. A tarefa de raspagem coleta avaliações de páginas de produtos especificadas e gera um JSON estruturado com informações da plataforma, texto da avaliação, classificações, datas e status de verificação.
def build_scraping_task(agent, product_urls):
return Task(
description=f "Extrair avaliações destas páginas de produtos: {product_urls}",
expected_output="""{
"reviews": [
{
"platform": "amazon",
"review_text": "Ótimo produto, envio rápido...",
"rating": 5,
"date": "2024-01-15",
"nome_do_avaliador": "John D.",
"verified_purchase": true
}
],
"total_reviews": 150,
"platforms_scraped": ["amazon", "yelp"]
}""",
agent=agent,
)
A tarefa de análise de sentimentos processa as avaliações para analisar os aspectos de Suporte, Preço e Facilidade de uso. Ela retorna pontuações numéricas, classificações de sentimentos, temas principais e contagens de avaliações para cada categoria.
def build_sentiment_analysis_task(agent):
return Task(
description="Analisar o sentimento em relação aos aspectos de suporte, preço e facilidade de uso",
expected_output="""{
"aspect_analysis": {
"support_quality": {
"score": 4.2,
"sentimento": "positivo",
"key_themes": ["responsivo", "útil", "experiente"],
"review_count": 45
},
"pricing_satisfaction": {
"score": 3.1,
"sentimento": "misto",
"key_themes": ["caro", "valor", "competitivo"],
"review_count": 67
},
"ease_of_use": {
"score": 4.7,
"Sentiment": "muito positivo",
"key_themes": ["intuitive", "simple", "user-friendly"],
"review_count": 89
}
}
}""",
agent=agent,
)
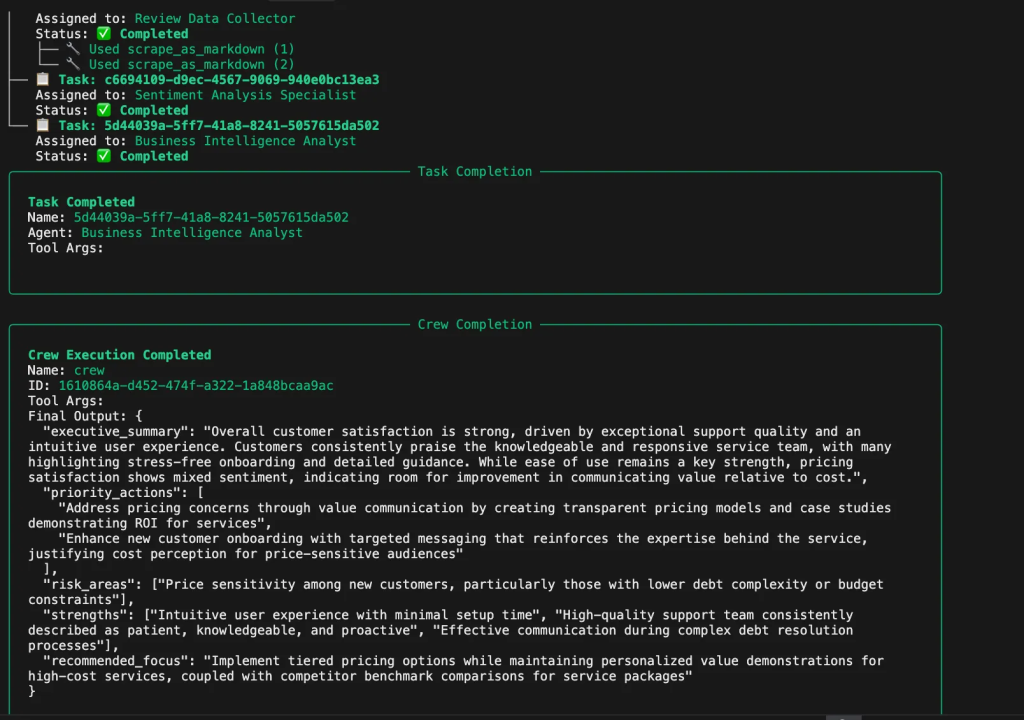
A tarefa de insights gera inteligência comercial acionável a partir dos resultados da análise de sentimentos. Ela fornece resumos executivos, ações prioritárias, áreas de risco, identificação de pontos fortes e recomendações estratégicas.
def build_insights_task(agent):
return Task(
description="Gerar insights de negócios acionáveis a partir da análise de sentimentos",
expected_output="""{
"executive_summary": "A satisfação geral do cliente é forte...",
"priority_actions": [
"Abordar as preocupações com preços por meio da comunicação de valores",
"Manter excelentes padrões de facilidade de uso"
],
"risk_areas": ["Sensibilidade ao preço entre novos clientes"],
"strengths": ["Experiência intuitiva do usuário", "Equipe de suporte de qualidade"],
"recommended_focus": "Pricing strategy optimization" (Otimização da estratégia de preços)
}""",
agent=agent,
)
Análise de sentimento baseada em aspecto
Adicione funções de análise de sentimento que identifiquem aspectos específicos mencionados nas avaliações e calcule as pontuações de sentimento para cada área de interesse.
def analyze_aspect_sentiment(reviews, aspect_keywords):
"""Analisar o sentimento de aspectos específicos mencionados nas avaliações."""
aspect_reviews = []
for review in reviews:
text = review.get('review_text', '').lower()
if any(keyword in text for keyword in aspect_keywords):
blob = TextBlob(review['review_text'])
sentiment_score = blob.sentiment.polarity
aspect_reviews.append({
'text': review['review_text'],
'sentiment_score': sentiment_score,
'rating': review.get('rating', 0),
'platform': review.get('platform', '')
})
return aspect_reviews
Categorização de avaliações em tópicos (suporte, preço, facilidade de uso)
A função de categorização organiza as avaliações em tópicos de Suporte, Preço e Facilidade de Uso com base na correspondência de palavras-chave. As palavras-chave de suporte incluem termos relacionados ao atendimento e à assistência ao cliente. As palavras-chave de preço abrangem menções de custo, valor e acessibilidade.
def categorize_by_aspects(reviews):
"""Categorize as avaliações em tópicos de suporte, preço e facilidade de uso."""
support_keywords = ['support', 'help', 'service', 'customer', 'response', 'assistance']
pricing_keywords = ['preço', 'custo', 'caro', 'barato', 'valor', 'dinheiro', 'acessível']
usability_keywords = ['easy', 'difficult', 'intuitive', 'complicated', 'user-friendly', 'interface']
categorized = {
'support': analyze_aspect_sentiment(reviews, support_keywords),
'pricing': analyze_aspect_sentiment(reviews, pricing_keywords),
'ease_of_use': analyze_aspect_sentiment(reviews, usability_keywords)
}
return categorized
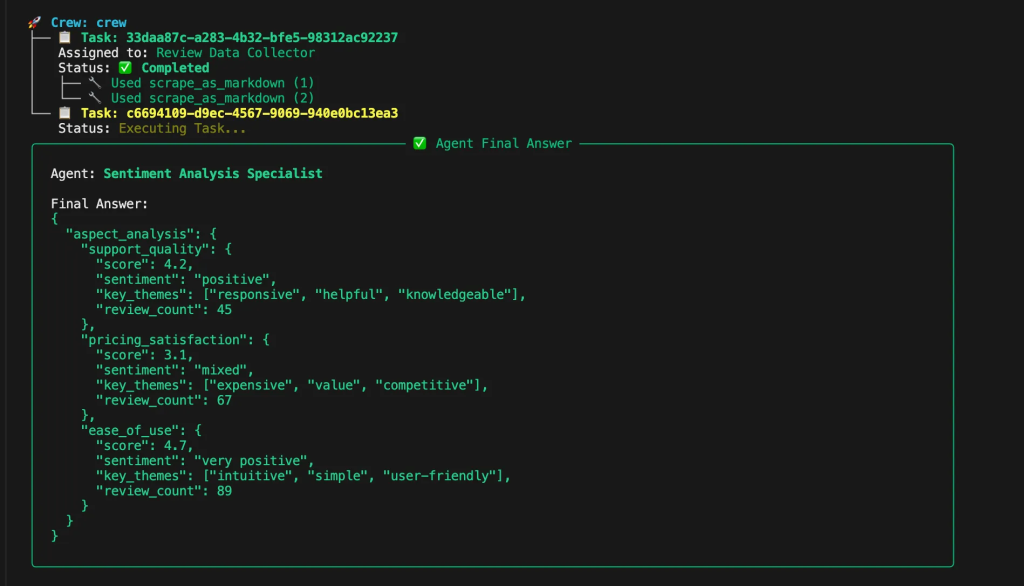
Pontuação de sentimento para cada tópico
Implemente a lógica de pontuação que converte a análise de sentimento em classificações numéricas e categorias significativas.
def calculate_aspect_scores(categorized_reviews):
"""Calcular pontuações numéricas para cada categoria de aspecto."""
scores = {}
para aspecto, avaliações em categorized_reviews.items():
if not reviews:
scores[aspect] = {'score': 0, 'count': 0, 'sentiment': 'neutral'}
continue
# Calcular a pontuação média do sentimento
sentiment_scores = [r['sentiment_score'] for r in reviews]
avg_sentiment = sum(sentiment_scores) / len(sentiment_scores)
# Converter para a escala de 1 a 5
normalized_score = ((avg_sentiment + 1) / 2) * 5
# Determinar a categoria do sentimento
se avg_sentiment > 0,3:
sentiment_category = 'positive'
elif avg_sentiment < -0,3:
sentiment_category = 'negative'
senão:
sentiment_category = 'neutral'
pontuações[aspecto] = {
'score': round(normalized_score, 1),
'count': len(reviews),
'sentiment': sentiment_category,
'raw_sentiment': round(avg_sentiment, 2)
}
return scores
Geração do relatório final de insights
Conclua a execução do fluxo de trabalho orquestrando todos os agentes e tarefas em sequência. A função principal cria agentes especializados para raspagem, análise de sentimentos e geração de insights. Ela reúne esses agentes em uma equipe com processamento sequencial de tarefas.
def analyze_reviews(product_urls):
"""Função principal para orquestrar o fluxo de trabalho de inteligência de análise."""
with MCPServerAdapter(server_params) as mcp_tools:
# Criar agentes
scraper_agent = build_review_scraper_agent(mcp_tools)
sentiment_agent = build_sentiment_analyzer_agent()
insights_agent = build_insights_generator_agent()
# Criar tarefas
scraping_task = build_scraping_task(scraper_agent, product_urls)
sentiment_task = build_sentiment_analysis_task(sentiment_agent)
insights_task = build_insights_task(insights_agent)
# Montagem da equipe
equipe = Equipe(
agentes=[agente_de_raspagem, agente_de_sentimento, agente_de_insights],
tasks=[scraping_task, sentiment_task, insights_task],
process=Process.sequential,
verbose=True
)
return crew.kickoff()
se __name__ == "__main__":
product_urls = [
"<https://www.amazon.com/product-example-1>",
"<https://www.yelp.com/biz/business-example>"
]
try:
result = analyse_reviews(product_urls)
print("Análise de inteligência de revisão concluída!")
print(json.dumps(result, indent=2))
except Exception as e:
print(f "A análise falhou: {str(e)}")
Executar a análise:
python review_intelligence.py
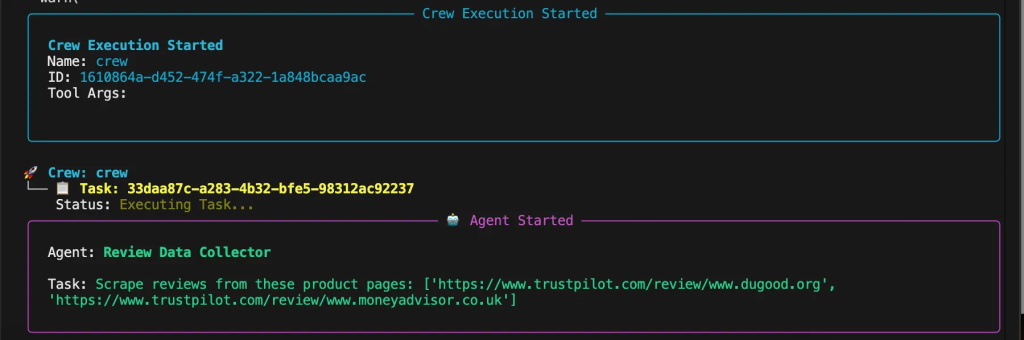
Você verá o processo de pensamento do agente no console à medida que cada agente planeja e executa suas tarefas. O sistema mostrará como ele é:
- Extraindo dados de avaliação abrangentes de várias plataformas
- Analisando as lacunas da concorrência e o posicionamento no mercado
- Processando padrões de sentimento e avaliações de pontuação de qualidade
- Identificando menções de recursos e inteligência de preços
- Fornecendo recomendações estratégicas e alertas de risco
Conclusão
Ao automatizar a inteligência de avaliação com a CrewAI e a poderosa plataforma de dados da Web da Bright Data, você pode obter insights mais profundos sobre os clientes, simplificar sua análise competitiva e tomar decisões comerciais mais inteligentes. Com os produtos da Bright Data e as soluções de raspagem da Web anti-bot líderes do setor, você está equipado para dimensionar a coleta de avaliações e a análise de sentimentos para qualquer setor. Para obter as estratégias e atualizações mais recentes, explore o blog da Bright Data ou saiba mais em nossos guias detalhados de raspagem da Web para começar a maximizar o valor do feedback de seus clientes hoje mesmo.





