

Neste guia, você aprenderá:
- O que é a Gestão de Riscos de Terceiros (TPRM) e por que razão a triagem manual falha
- Como criar um agente de IA autônomo que investiga fornecedores em busca de mídia adversa
- Como integrar a API SERP e o Web Unlocker da Bright Data para uma coleta de dados confiável e atualizada
- Como usar o OpenHands SDK para geração de scripts de agentes e o OpenAI para análise de riscos
- Como aprimorar o agente com a API do navegador para cenários complexos, como registros judiciais
Vamos começar!
O problema com a triagem manual de fornecedores
As equipes de conformidade empresarial enfrentam uma tarefa impossível: monitorar centenas de fornecedores terceirizados em busca de sinais de risco em toda a web. As abordagens tradicionais envolvem:
- Pesquisas manuais no Google para cada nome de fornecedor combinadas com palavras-chave como “processo judicial”, “falência” ou “fraude”
- Encontrar paywalls e CAPTCHAs ao tentar acessar artigos de notícias e registros judiciais
- Documentação inconsistente, sem um processo padronizado para registrar as descobertas
- Ausência de monitoramento contínuo, a triagem de fornecedores ocorre uma vez durante a integração e nunca mais
Essa abordagem falha por três motivos críticos:
- Escala: um único analista pode investigar minuciosamente talvez 5 a 10 fornecedores por dia
- Acesso: fontes protegidas, como registros judiciais e sites de notícias premium, bloqueiam o acesso automatizado
- Continuidade: as avaliações pontuais não detectam os riscos que surgem após a integração
A solução: um agente TPRM autônomo
Um agente TPRM automatiza todo o fluxo de trabalho de investigação de fornecedores usando três camadas especializadas:
- Descoberta (API SERP): o agente pesquisa no Google por sinais de alerta, como processos judiciais, ações regulatórias e dificuldades financeiras
- Acesso (Web Unlocker): quando resultados relevantes estão protegidos por paywalls ou CAPTCHAs, o agente contorna essas barreiras para extrair o conteúdo completo
- Ação (OpenAI + OpenHands SDK): o agente analisa o conteúdo quanto à gravidade do risco usando o OpenAI e, em seguida, usa o OpenHands SDK para gerar scripts de monitoramento Python que verificam diariamente se há novas notícias adversas na mídia
Esse sistema transforma horas de pesquisa manual em minutos de análise automatizada.
Pré-requisitos
Antes de começar, certifique-se de ter:
- Python 3.12 ou superior (necessário para o OpenHands SDK)
- Uma conta Bright Data com acesso à API (versão de avaliação gratuita disponível)
- Uma chave API OpenAI para análise de risco
- Uma conta OpenHands Cloud ou sua própria chave API LLM para geração de scripts de agentes
- Conhecimento básico de Python e APIs REST
Arquitetura do projeto
O agente TPRM segue um pipeline de três etapas:
┌─────────────────┐ ┌─────────────────┐ ┌─────────────────┐
│ DESCOBERTA │────▶│ ACESSO │────▶│ AÇÃO │
│ (API SERP) │ │ (Web Unlocker) │ │ (OpenAI + SDK) │
└─────────────────┘ └─────────────────┘ └─────────────────┘
│ │ │
Pesquisar no Google Contornar paywalls Analisar riscos
para sinais de alerta e CAPTCHAs Gerar scriptsCrie a seguinte estrutura de projeto:
tprm-agent/
├── src/
│ ├── __init__.py
│ ├── config.py # Configuração
│ ├── discovery.py # Integração da API SERP
│ ├── access.py # Integração do Web Unlocker
│ ├── actions.py # OpenAI + OpenHands SDK
│ ├── agent.py # Orquestração principal
│ └── browser.py # API do navegador (aprimoramento)
├── api/
│ └── main.py # Pontos de extremidade FastAPI
├── scripts/
│ └── generated/ # Scripts de monitoramento gerados automaticamente
├── .env
├── requirements.txt
└── README.md
Configuração do ambiente
Crie um ambiente virtual e instale as dependências necessárias:
python -m venv venv
source venv/bin/activate # Windows: venvScriptsactivate
pip install requests fastapi uvicorn python-dotenv pydantic openai beautifulsoup4 playwright openhands-sdk openhands-tools
Crie um arquivo .env para armazenar suas credenciais de API:
# Token da API Bright Data (para API SERP)
BRIGHT_DATA_API_TOKEN=seu_token_api
# Zona SERP Bright Data
BRIGHT_DATA_SERP_ZONE=nome_da_sua_zona_serp
# Credenciais do Bright Data Web Unlocker
BRIGHT_DATA_CUSTOMER_ID=seu_id_de_cliente
BRIGHT_DATA_UNLOCKER_ZONE=nome_da_sua_zona_unlocker
BRIGHT_DATA_UNLOCKER_PASSWORD=senha_da_sua_zona
# OpenAI (para análise de risco)
OPENAI_API_KEY=sua_chave_openai_api
# OpenHands (para geração de scripts agenticos)
# Use OpenHands Cloud: openhands/claude-sonnet-4-5-20260929
# Ou traga o seu próprio: anthropic/claude-sonnet-4-5-20260929
LLM_API_KEY=sua_chave_llm_api
LLM_MODEL=openhands/claude-sonnet-4-5-20260929Configuração do Bright Data
Etapa 1: crie sua conta Bright Data
Inscreva-se na Bright Data e acesse o painel.
Etapa 2: Configure a zona API SERP
- Vá para Proxies e Infraestrutura de scraping
- Clique em Adicionar e selecione API SERP
- Dê um nome à sua zona (por exemplo,
tprm_serp) - Copie o nome da sua zona e anote o seu token API em Configurações > Tokens API
A API SERP retorna resultados de pesquisa estruturados do Google sem ser bloqueada. Adicione brd_json=1 à sua URL de pesquisa para obter uma saída JSON analisada.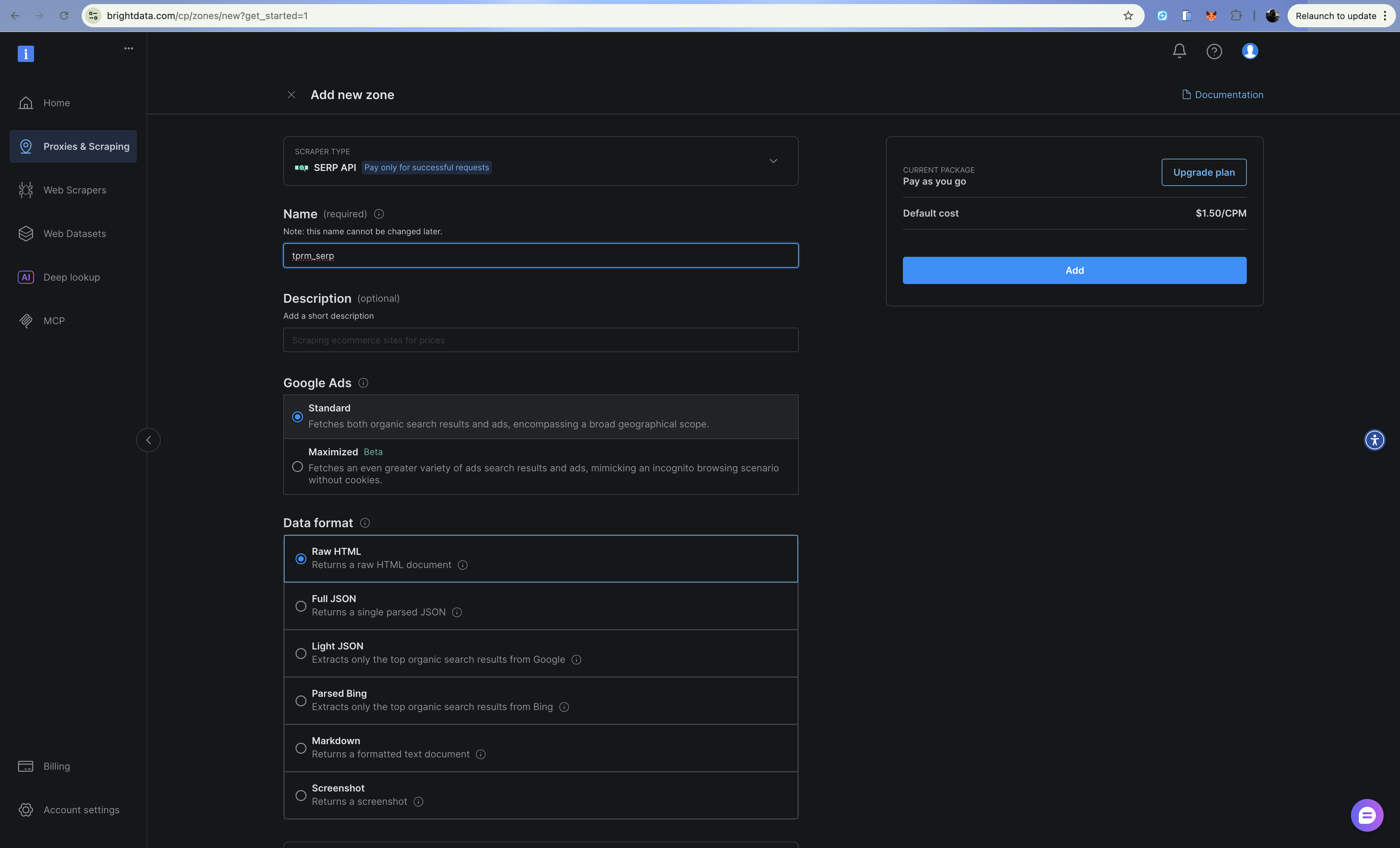
Etapa 3: Configure a zona do Web Unlocker
- Clique em Adicionar e selecione Web Unlocker
- Dê um nome à sua zona (por exemplo,
tprm_unlocker) - Copie as credenciais da sua zona (formato do nome de usuário:
brd-customer-CUSTOMER_ID-zone-ZONE_NAME)
O Web Unlocker lida com CAPTCHAs, impressões digitais e rotação de IP automaticamente por meio de um endpoint Proxy.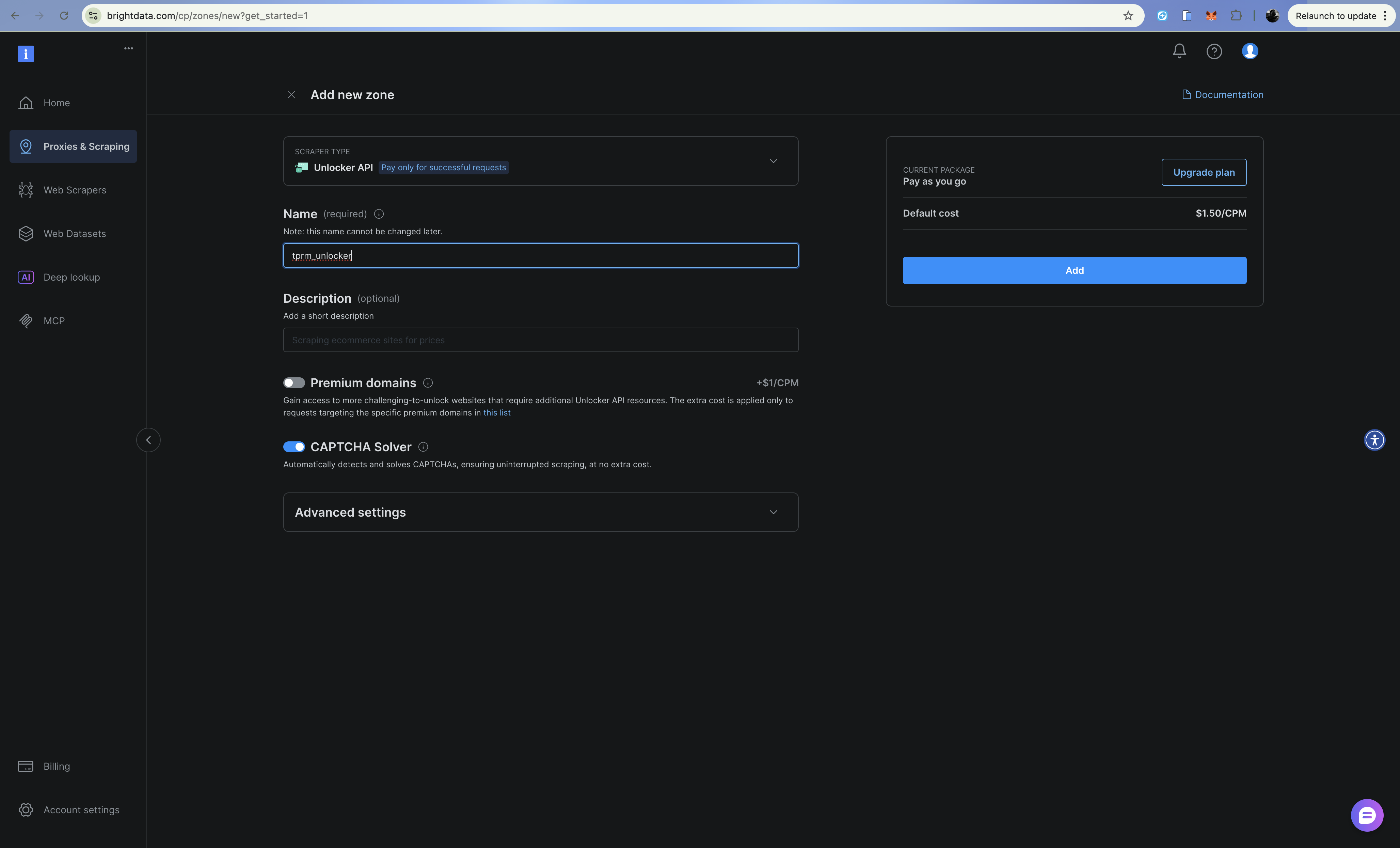
Criando a camada de descoberta (API SERP)
A camada de descoberta pesquisa no Google por mídia adversa sobre fornecedores usando a API SERP. Crie src/discovery.py:
import requests
from typing import Optional
from dataclasses import dataclass
from urllib.parse import quote_plus
from config import settings
@dataclass
class SearchResult:
title: str
url: str
snippet: str
source: str
class DiscoveryClient:
"""Pesquise mídia adversa usando a API SERP da Bright Data (API direta)."""
RISK_CATEGORIES = {
"litigation": ["processo judicial", "litígio", "processado", "processo judicial", "ação judicial"],
"financial": ["falência", "insolvência", "dívida", "problemas financeiros", "incumprimento"],
"fraud": ["fraude", "golpe", "investigação", "acusação", "escândalo"],
"regulatory": ["violação", "multa", "penalidade", "sanções", "conformidade"],
“operacional”: ["recall", "questão de segurança", "cadeia de suprimentos", "interrupção"],
}
def __init__(self):
self.api_url = "https://api.brightdata.com/request"
self.headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {settings.BRIGHT_DATA_API_TOKEN}",
}
def _build_queries(self, vendor_name: str, categories: Optional[list] = None) -> list[str]:
"""Crie consultas de pesquisa para cada categoria de risco."""
categorias = categorias ou lista(self.RISK_CATEGORIES.keys())
consultas = []
para categoria em categorias:
palavras-chave = self.RISK_CATEGORIES.get(categoria, [])
palavra-chave_str = " OR ".join(palavras-chave)
query = f'"{vendor_name}" ({keyword_str})'
queries.append(query)
return queries
def search(self, query: str) -> list[SearchResult]:
"""Executa uma única consulta de pesquisa usando a API SERP da Bright Data."""
tente:
# Crie uma URL de pesquisa do Google com brd_json=1 para JSON analisado
encoded_query = quote_plus(query)
google_url = f"https://www.google.com/search?q={encoded_query}&hl=en&gl=us&brd_json=1"
payload = {
"zone": settings.BRIGHT_DATA_SERP_ZONE,
"url": google_url,
"format": "raw",
}
response = requests.post(
self.api_url,
headers=self.headers,
json=payload,
timeout=30,
)
response.raise_for_status()
data = response.json()
results = []
organic = data.get("organic", [])
para item em orgânico:
resultados.append(
SearchResult(
title=item.get("title", ""),
url=item.get("link", ""),
snippet=item.get("description", ""),
source=item.get("displayed_link", ""),
)
)
retornar resultados
exceto Exceção como e:
imprimir(f"Erro de pesquisa: {e}")
retornar []
def discover_adverse_media(
self,
nome_fornecedor: str,
categorias: Optional[list] = None,
) -> dict[str, list[SearchResult]]:
"""Pesquisar mídia adversa em todas as categorias de risco."""
consultas = self._build_queries(nome_fornecedor, categorias)
nomes_de_categorias = categorias ou lista(self.RISK_CATEGORIES.keys())
resultados_categorizados = {}
para categoria, consulta em zip(nomes_de_categorias, consultas):
imprimir(f" Pesquisando: {categoria}...")
resultados = self.search(consulta)
resultados_categorizados[categoria] = resultados
retornar resultados_categorizados
def filtrar_resultados_relevantes(
self, resultados: dict[str, list[SearchResult]], nome_do_fornecedor: str
) -> dict[str, list[SearchResult]]:
"""Filtrar resultados irrelevantes."""
filtrados = {}
fornecedor_minúsculo = nome_do_fornecedor.lower()
para categoria, itens em resultados.itens():
relevante = []
para item em itens:
se (
fornecedor_minúsculo em item.título.minúsculo
ou fornecedor_minúsculo em item.trecho.minúsculo
):
relevante.append(item)
filtrado[categoria] = relevante
retornar filtrado
A API SERP retorna JSON estruturado com resultados orgânicos, facilitando o Parsing de títulos, URLs e trechos para cada resultado de pesquisa.
Criando a camada de acesso (Web Unlocker)
Quando a camada de descoberta encontra URLs relevantes, a camada de acesso recupera o conteúdo completo usando a API Web Unlocker. Crie src/access.py:
import requests
from bs4 import BeautifulSoup
from dataclasses import dataclass
from typing import Optional
from config import settings
@dataclass
class ExtractedContent:
url: str
title: str
text: str
publish_date: Optional[str]
author: Optional[str]
success: bool
error: Optional[str] = None
class AccessClient:
"""Acesse conteúdo protegido usando o Bright Data Web Unlocker (baseado em API)."""
def __init__(self):
self.api_url = "https://api.brightdata.com/request"
self.headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {settings.BRIGHT_DATA_API_TOKEN}",
}
def fetch_url(self, url: str) -> ExtractedContent:
"""Busca e extrai conteúdo de uma URL usando a API Web Unlocker."""
tente:
payload = {
"zone": settings.BRIGHT_DATA_UNLOCKER_ZONE,
"url": url,
"format": "raw",
}
response = requests.post(
self.api_url,
headers=self.headers,
json=payload,
timeout=60,
)
response.raise_for_status()
# A API Web Unlocker retorna o HTML diretamente
html_content = response.text
content = self._extract_content(html_content, url)
return content
except requests.Timeout:
return ExtractedContent(
url=url,
title="",
text="",
publish_date=None,
author=None,
success=False,
error="Request timed out",
)
exceto Exception como e:
retorne ExtractedContent(
url=url,
title="",
text="",
publish_date=None,
author=None,
success=False,
error=str(e),)
def _extract_content(self, html: str, url: str) -> ExtractedContent:
"""Extrair conteúdo do artigo do HTML."""
soup = BeautifulSoup(html, "html.parser")
# Remover elementos indesejados
for element in soup(["script", "style", "nav", "footer", "header", "aside"]):
element.decompose()
# Extrair título
title = ""
if soup.title:
title = soup.title.string or ""
elif soup.find("h1"):
title = soup.find("h1").get_text(strip=True)
# Extrair conteúdo principal
artigo = soup.find("article") ou soup.find("main") ou soup.find("body")
texto = artigo.get_text(separator="n", strip=True) se artigo else ""
# Limitar comprimento do texto
texto = texto[:10000] se len(texto) > 10000 else texto
# Tentar extrair a data de publicação
publish_date = None
date_meta = soup.find("meta", {"property": "article:published_time"})
if date_meta:
publish_date = date_meta.get("content")
# Tentar extrair autor
autor = Nenhum
autor_meta = soup.find("meta", {"name": "author"})
se autor_meta:
autor = autor_meta.get("content")
retornar ExtractedContent(
url=url,
title=title,
text=text,
publish_date=publish_date,
author=author,
success=True,
)
def fetch_multiple(self, urls: list[str]) -> list[ExtractedContent]:
"""Buscar várias URLs sequencialmente."""
resultados = []
para url em URLs:
imprimir(f" Buscando: {url[:60]}...")
conteúdo = self.fetch_url(url)
se não conteúdo.sucesso:
imprimir(f" Erro: {conteúdo.erro}")
resultados.append(conteúdo)
retornar resultados
O Web Unlocker lida automaticamente com CAPTCHAs, impressões digitais do navegador e rotação de IP. Ele simplesmente encaminha suas solicitações através do Proxy e cuida do resto.
Construindo a camada de ação (OpenAI + OpenHands SDK)
A camada de ação usa o OpenAI para analisar a gravidade do risco e o OpenHands SDK para gerar scripts de monitoramento que usam a API Bright Data Web Unlocker. O OpenHands SDK fornece recursos de agente: o agente pode raciocinar, editar arquivos e executar comandos para criar scripts prontos para produção.
Crie src/actions.py:
import os
import json
from datetime import datetime, UTC
from dataclasses import dataclass, asdict
from openai import OpenAI
from pydantic import SecretStr
from openhands.sdk import LLM, Agent, Conversation, Tool
from openhands.tools.terminal import TerminalTool
from openhands.tools.file_editor import FileEditorTool
from config import settings
@dataclass
class RiskAssessment:
vendor_name: str
category: str
severity: str
summary: str
key_findings: list[str]
sources: list[str]
recommended_actions: list[str]
assessed_at: str
@dataclass
classe MonitoringScript:
nome_do_fornecedor: str
caminho_do_script: str
urls_monitoradas: lista[str]
frequência_de_verificação: str
criado_em: str
classe ActionsClient:
"""Analise riscos usando OpenAI e gere scripts de monitoramento usando OpenHands SDK."""
def __init__(self):
# OpenAI para análise de riscos
self.openai_client = OpenAI(api_key=settings.OPENAI_API_KEY)
# OpenHands para geração de scripts agênicos
self.llm = LLM(
model=settings.LLM_MODEL,
api_key=SecretStr(settings.LLM_API_KEY),
)
self.workspace = os.path.join(os.getcwd(), "scripts", "generated")
os.makedirs(self.workspace, exist_ok=True)
def analyze_risk(
self,
vendor_name: str,
category: str,
content: list[dict],
) -> RiskAssessment:
"""Analisar o conteúdo extraído quanto à gravidade do risco usando OpenAI."""
content_summary = "nn".join(
[f"Fonte: {c['url']}nTítulo: {c['title']}nConteúdo: {c['text'][:2000]}" for c in content]
)
prompt = f"""Analise o seguinte conteúdo sobre "{vendor_name}" para avaliação de risco de terceiros.
Categoria: {category}
Conteúdo:
{content_summary}
Forneça uma resposta JSON com:
{{
"severity": "baixa|média|alta|crítica",
"summary": "resumo de 2 a 3 frases das conclusões",
"key_findings": ["conclusão 1", "conclusão 2", ...],
"recommended_actions": ["ação 1", "ação 2", ...]
}}
Considere:
- A gravidade deve ser baseada no impacto potencial nos negócios
- Crítico = ação imediata necessária (fraude ativa, pedido de falência)
- Alto = risco significativo que requer investigação
- Médio = preocupação notável que vale a pena monitorar
- Baixo = problema menor ou questão histórica
"""
response = self.openai_client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": prompt}],
response_format={"type": "json_object"},
)
response_text = response.choices[0].message.content
tente:
resultado = json.loads(response_text)
exceto (json.JSONDecodeError, ValueError):
resultado = {
"gravidade": "média",
"resumo": "Não foi possível analisar a avaliação de risco",
"principais conclusões": [],
"ações recomendadas": ["Revisão manual necessária"],
}
retornar RiskAssessment(
nome_fornecedor=nome_fornecedor,
categoria=categoria,
gravidade=resultado.obter("gravidade", "média"),
resumo=resultado.obter("resumo", ""),
principais_conclusões=resultado.obter("principais_conclusões", []),
sources=[c["url"] for c in content],
recommended_actions=result.get("recommended_actions", []),
assessed_at=datetime.now(UTC).isoformat(),
)
def gerar_script_de_monitoramento(
self,
nome_do_fornecedor: str,
urls: lista[str],
palavras-chave_de_verificação: lista[str],
) -> ScriptDeMonitoramento:
"""Gere um script de monitoramento Python usando o agente OpenHands SDK."""
script_name = f"monitor_{vendor_name.lower().replace(' ', '_')}.py"
script_path = os.path.join(self.workspace, script_name)
prompt = f"""Crie um script de monitoramento Python em {script_path} que:
1. Verifique diariamente se há novos conteúdos nessas URLs: {urls[:5]}
2. Procure por estas palavras-chave: {check_keywords}
3. Envie um alerta (imprima no console) se for encontrado novo conteúdo relevante
4. Registre todas as verificações em um arquivo JSON chamado 'monitoring_log.json'
O script DEVE usar a API Bright Data Web Unlocker para contornar paywalls e CAPTCHAs:
- Ponto final da API: https://api.brightdata.com/request
- Use a variável de ambiente BRIGHT_DATA_API_TOKEN para o token Bearer
- Use a variável de ambiente BRIGHT_DATA_UNLOCKER_ZONE para o nome da zona
- Faça solicitações POST com carga JSON: {{"zone": "zone_name", "url": "target_url", "format": "raw"}}
- Adicione o cabeçalho: "Authorization": "Bearer <token>"
- Adicione o cabeçalho: "Content-Type": "application/json"
O script deve:
- Carregar as credenciais da Bright Data a partir das variáveis de ambiente usando python-dotenv
- Usar a API Bright Data Web Unlocker para todas as solicitações HTTP (NÃO solicitações simples.get)
- Tratar erros com elegância usando try/except
- Incluir uma função main() que possa ser executada diretamente
- Suportar agendamento via cron
- Armazenar hashes de conteúdo para detectar alterações
Escreva o script completo em {script_path}.
"""
# Criar agente OpenHands com ferramentas de terminal e editor de arquivos
agent = Agent(
llm=self.llm,
tools=[
Tool(name=TerminalTool.name),
Tool(name=FileEditorTool.name),
],
)
# Execute o agente para gerar o script
conversation = Conversation(agent=agent, workspace=self.workspace)
conversation.send_message(prompt)
conversation.run()
return MonitoringScript(
vendor_name=vendor_name,
script_path=script_path,
urls_monitored=urls[:5],
check_frequency="daily",
created_at=datetime.now(UTC).isoformat(),
)
def export_assessment(self, assessment: RiskAssessment, output_path: str) -> None:
"""Exportar avaliação de risco para arquivo JSON."""
with open(output_path, "w") as f:
json.dump(asdict(assessment), f, indent=2)A principal vantagem de usar o OpenHands SDK em vez da simples geração de código baseada em prompts é que o agente pode iterar seu trabalho, testando o script, corrigindo erros e refinando até que funcione corretamente.
Orquestração do agente
Agora vamos conectar tudo. Crie src/agent.py:
from dataclasses import dataclass
from datetime import datetime, UTC
from typing import Optional
from discovery import DiscoveryClient, SearchResult
from access import AccessClient, ExtractedContent
from actions import ActionsClient, RiskAssessment, MonitoringScript
@dataclass
class InvestigationResult:
vendor_name: str
started_at: str
completed_at: str
total_sources_found: int
total_sources_accessed: int
risk_assessments: list[RiskAssessment]
monitoring_scripts: list[MonitoringScript]
errors: list[str]
classe TPRMAgent:
"""Agente autônomo para investigações de gerenciamento de riscos de terceiros."""
def __init__(self):
self.discovery = DiscoveryClient()
self.access = AccessClient()
self.actions = ActionsClient()
def investigar(
self,
nome_do_fornecedor: str,
categorias: Optional[list[str]] = None,
gerar_monitores: bool = True,
) -> ResultadoDaInvestigação:
"""Executar uma investigação completa do fornecedor."""
iniciado_em = datetime.now(UTC).isoformat()
erros = []
risk_assessments = []
monitoring_scripts = []
# Fase 1: Descoberta (API SERP)
print(f"[Descoberta] Pesquisando mídia adversa sobre {vendor_name}...")
tente:
resultados_brutos = self.discovery.discover_adverse_media(nome_do_fornecedor, categorias)
resultados_filtrados = self.discovery.filter_relevant_results(resultados_brutos, nome_do_fornecedor)
exceto Exception como e:
erros.append(f"Falha na descoberta: {str(e)}")
retornar ResultadoDaInvestigação(
nome_do_fornecedor=nome_do_fornecedor,
iniciado_em=iniciado_em,
concluído_em=datetime.now(UTC).isoformat(),
total_fontes_encontradas=0,
total_fontes_acessadas=0,
avaliações_de_risco=[],
scripts_de_monitoramento=[],
erros=erros,
)
total_fontes = soma(len(resultados) para resultados em resultados_filtrados.valores())
imprimir(f"[Descoberta] Encontradas {total_fontes} fontes relevantes")
# Etapa 2: Acesso (Web Unlocker)
imprimir(f"[Acesso] Extraindo conteúdo das fontes...")
all_urls = []
url_to_category = {}
para categoria, resultados em filtered_results.items():
para resultado em resultados:
all_urls.append(result.url)
url_to_category[result.url] = categoria
tente:
extracted_content = self.access.fetch_multiple(all_urls)
successful_extractions = [c para c em extracted_content se c.success]
exceto Exception como e:
error_msg = f"Falha no acesso: {str(e)}"
imprimir(f"[Acesso] {error_msg}")
errors.append(error_msg)
successful_extractions = []
print(f"[Acesso] Fontes {len(successful_extractions)} extraídas com sucesso")
# Etapa 3: Ação - Analisar riscos (OpenAI)
print(f"[Ação] Analisando riscos...")
category_content = {}
for content in successful_extractions:
categoria = url_para_categoria.get(conteúdo.url, "desconhecido")
se categoria não estiver em conteúdo_da_categoria:
conteúdo_da_categoria[categoria] = []
conteúdo_da_categoria[categoria].append({
"url": conteúdo.url,
"título": conteúdo.título,
"texto": conteúdo.texto,
})
para categoria, lista_de_conteúdos em categoria_conteúdo.itens():
se não houver lista_de_conteúdos:
continue
tente:
avaliação = self.ações.analisar_risco(nome_do_fornecedor, categoria, lista_de_conteúdos)
risk_assessments.append(avaliação)
exceto Exception como e:
errors.append(f"Falha na análise de risco para {categoria}: {str(e)}")
# Etapa 3: Ação - Gerar scripts de monitoramento
se generate_monitors e successful_extractions:
print(f"[Ação] Gerando scripts de monitoramento...")
tente:
urls_para_monitorar = [c.url para c em extrações_bem-sucedidas[:10]]
palavras-chave = [nome_do_fornecedor, "processo judicial", "falência", "fraude"]
script = self.ações.gerar_script_de_monitoramento(
nome_do_fornecedor, urls_para_monitorar, palavras-chave
)
scripts_de_monitoramento.append(script)
exceto Exception como e:
erros.append(f"Falha na geração do script: {str(e)}")
concluído_em = datetime.now(UTC).isoformat()
imprimir(f"[Concluído] Investigação concluída")
return InvestigationResult(
vendor_name=vendor_name,
started_at=started_at,
completed_at=completed_at,
total_sources_found=total_sources,
total_sources_accessed=len(successful_extractions),
risk_assessments=risk_assessments,
monitoring_scripts=monitoring_scripts,
errors=errors,
)
def main():
"""Exemplo de uso."""
agente = TPRMAgent()
resultado = agente.investigar("Acme Corp")
imprimir(f"n{'='*50}")
imprimir(f"Investigação concluída: {resultado.nome_do_fornecedor}")
imprimir(f"Fontes encontradas: {result.total_sources_found}")
imprimir(f"Fontes acessadas: {result.total_sources_accessed}")
imprimir(f"Avaliações de risco: {len(result.risk_assessments)}")
imprimir(f"Scripts de monitoramento: {len(result.monitoring_scripts)}")
para avaliação em result.risk_assessments:
print(f"n[{assessment.category.upper()}] Gravidade: {assessment.severity}")
print(f"Resumo: {assessment.summary}")
if __name__ == "__main__":
main()
O agente coordena as três camadas, lidando com erros de maneira elegante e produzindo um resultado de investigação abrangente.
Configuração
Crie src/config.py para configurar todos os segredos e chaves necessários para que o aplicativo seja executado com sucesso:
import os
from dotenv import load_dotenv
load_dotenv()
class Settings:
# API SERP
BRIGHT_DATA_API_TOKEN: str = os.getenv("BRIGHT_DATA_API_TOKEN", "")
BRIGHT_DATA_SERP_ZONE: str = os.getenv("BRIGHT_DATA_SERP_ZONE", "")
# Web Unlocker
BRIGHT_DATA_CUSTOMER_ID: str = os.getenv("BRIGHT_DATA_CUSTOMER_ID", "")
BRIGHT_DATA_UNLOCKER_ZONE: str = os.getenv("BRIGHT_DATA_UNLOCKER_ZONE", "")
BRIGHT_DATA_UNLOCKER_PASSWORD: str = os.getenv("BRIGHT_DATA_UNLOCKER_PASSWORD", "")
# OpenAI (para análise de risco)
OPENAI_API_KEY: str = os.getenv("OPENAI_API_KEY", "")
# OpenHands (para geração de scripts agenticos)
LLM_API_KEY: str = os.getenv("LLM_API_KEY", "")
LLM_MODEL: str = os.getenv("LLM_MODEL", "openhands/claude-sonnet-4-5-20260929")
settings = Settings()Construindo a camada API
Usando FastAPI, você criará api/main.py para expor o agente por meio de pontos finais REST:
from fastapi import FastAPI, HTTPException, BackgroundTasks
from pydantic import BaseModel
from typing import Optional
import uuid
import sys
sys.path.insert(0, 'src')
from agent import TPRMAgent, InvestigationResult
app = FastAPI(
title="TPRM Agent API",
description="Agente autônomo de gerenciamento de riscos de terceiros",
version="1.0.0",)
investigations: dict[str, InvestigationResult] = {}
agent = TPRMAgent()
class InvestigationRequest(BaseModel):
vendor_name: str
categories: Optional[list[str]] = None
generate_monitors: bool = True
classe InvestigationResponse(BaseModel):
investigation_id: str
status: str
message: str
@app.post("/investigate", response_model=InvestigationResponse)
def start_investigation(
request: InvestigationRequest,
background_tasks: BackgroundTasks,
):
"""Iniciar uma nova investigação de fornecedor."""
investigation_id = str(uuid.uuid4())
def run_investigation():
result = agent.investigate(
vendor_name=request.vendor_name,
categories=request.categories,
generate_monitors=request.generate_monitors,
)
investigations[investigation_id] = result
tarefas_em_segundo_plano.adicionar_tarefa(executar_investigação)
retornar RespostaDeInvestigação(
id_investigação=id_investigação,
status="iniciada",
mensagem=f"Investigação iniciada para {nome_fornecedor}",
)
@app.get("/investigate/{investigation_id}")
def get_investigation(investigation_id: str):
"""Obter resultados da investigação."""
if investigation_id not in investigations:
raise HTTPException(status_code=404, detail="Investigação não encontrada ou ainda em andamento")
return investigations[investigation_id]
@app.get("/reports/{vendor_name}")
def get_reports(vendor_name: str):
"""Obter todos os relatórios de um fornecedor."""
vendor_reports = [
result
for result in investigations.values()
if result.vendor_name.lower() == vendor_name.lower()
]
if not relatórios_fornecedor:
raise HTTPException(status_code=404, detail="Nenhum relatório encontrado para este fornecedor")
return relatórios_fornecedor
@app.get("/health")
def verificação_de_integridade():
"""Ponto final de verificação de integridade."""
return {"status": "integridade"}Execute a API localmente:
python -m uvicorn API.main:app --reloadAcesse http://localhost:8000/docs para explorar a documentação interativa da API.
Aprimorando com a API do navegador (Navegador de scraping)
Para cenários complexos, como registros judiciais que exigem o envio de formulários ou sites com muito JavaScript, você pode aprimorar o agente com a API do navegador da Bright Data (Navegador de scraping). Você pode configurá-la de maneira semelhante à API Web Unlocker e à API SERP.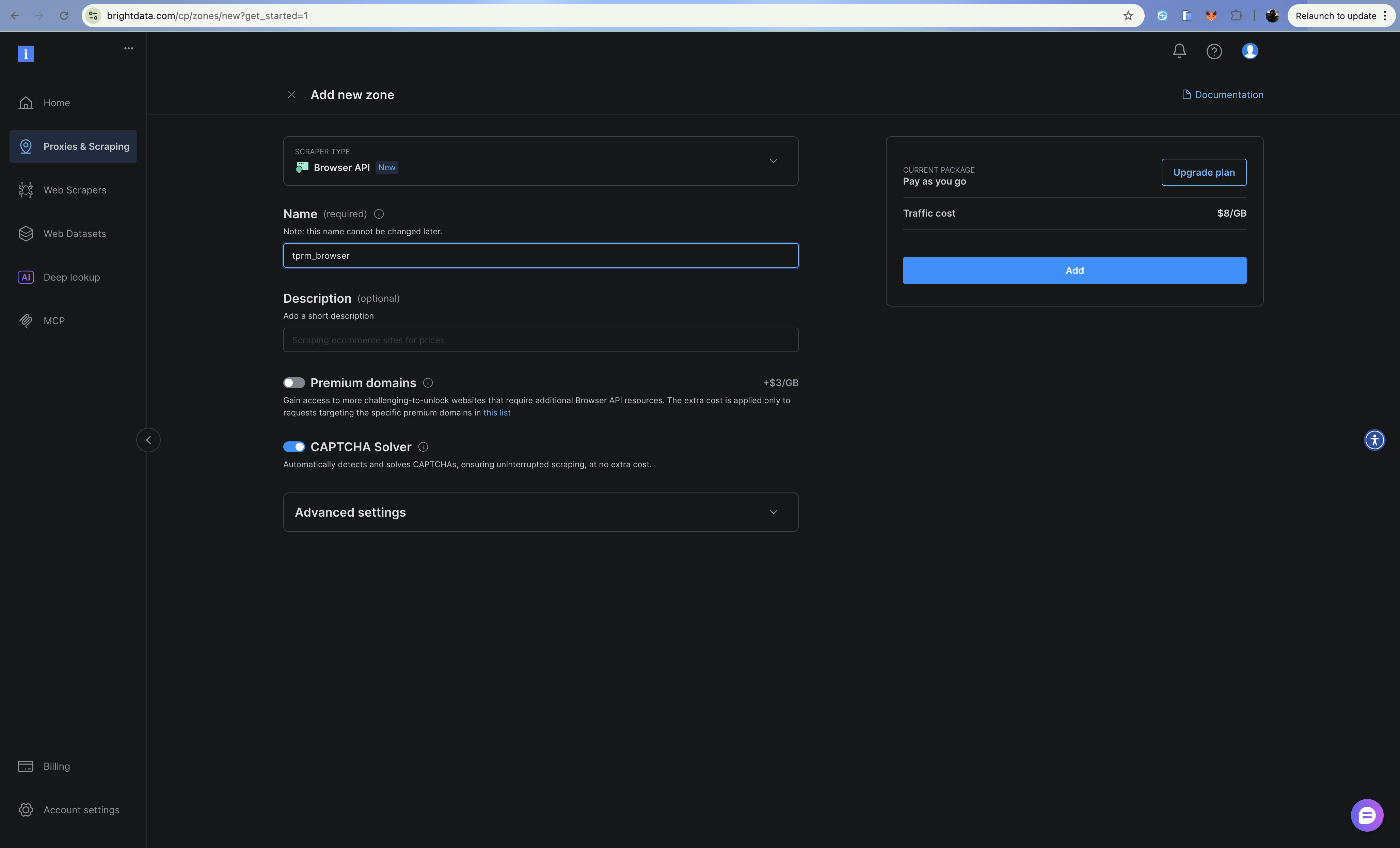
A API do navegador fornece um navegador hospedado na nuvem que você controla via Playwright através do Chrome DevTools Protocol (CDP). Isso é útil para:
- Pesquisas em registros judiciais que exigem o envio de formulários e navegação
- Sites comuso intenso de JavaScript e carregamento dinâmico de conteúdo
- Fluxos de autenticação em várias etapas
- Captura de capturas de tela para documentação de conformidade
Configuração
Adicione credenciais da API do navegador ao seu .env:
# API do navegador
BRIGHT_DATA_BROWSER_USER: str = os.getenv("BRIGHT_DATA_BROWSER_USER", "")
BRIGHT_DATA_BROWSER_PASSWORD: str = os.getenv("BRIGHT_DATA_BROWSER_PASSWORD", "")Implementação do cliente do navegador
Crie src/browser.py:
import asyncio
from playwright.async_api import async_playwright
from dataclasses import dataclass
from typing import Optional
from config import settings
@dataclass
class BrowserContent:
url: str
title: str
text: str
screenshot_path: Optional[str]
sucesso: bool
erro: Opcional[str] = Nenhum
classe Cliente do Navegador:
"""Acesse conteúdo dinâmico usando a API do Navegador Bright Data (Navegador de scraping).
Use isso para:
- Sites com muito JavaScript que exigem renderização completa
- Formulários com várias etapas (por exemplo, pesquisas em registros judiciais)
- Sites que exigem cliques, rolagem ou interação
- Captura de capturas de tela para documentação de conformidade
"""
def __init__(self):
# Criar endpoint WebSocket para conexão CDP
auth = f"{settings.BRIGHT_DATA_BROWSER_USER}:{settings.BRIGHT_DATA_BROWSER_PASSWORD}"
self.endpoint_url = f"wss://{auth}@brd.superproxy.io:9222"
async def fetch_dynamic_page(
self,
url: str,
wait_for_selector: Optional[str] = None,
take_screenshot: bool = False,
screenshot_path: Optional[str] = None,
) -> BrowserContent:
"""Busca conteúdo de uma página dinâmica usando a API do navegador."""
async com async_playwright() como playwright:
tente:
imprimir(f"Conectando ao Navegador de scraping da Bright Data...")
navegador = aguardar playwright.chromium.connect_over_cdp(self.endpoint_url)
tente:
página = aguardar navegador.new_page()
imprimir(f"Navegando para {url}...")
esperar página.goto(url, tempo limite=120000)
esperar seletor específico, se fornecido
se esperar_seletor:
esperar página.esperar_seletor(esperar_seletor, tempo limite=30000)
# Obter conteúdo da página
title = await page.title()
# Extrair texto
text = await page.evaluate("() => document.body.innerText")
# Tirar captura de tela, se solicitado
if take_screenshot and screenshot_path:
await page.screenshot(path=screenshot_path, full_page=True)
retornar BrowserContent(
url=url,
title=title,
text=text[:10000],
screenshot_path=screenshot_path se take_screenshot, caso contrário None,
success=True,
)
finalmente:
await browser.close()
exceto Exception como e:
retorne BrowserContent(
url=url,
title="",
text="",
screenshot_path=None,
success=False,
error=str(e),
)
async def preencher_e_enviar_formulário(
self,
url: str,
form_data: dict[str, str],
seletor_enviar: str,
seletor_resultado: str,
) -> BrowserContent:
"""Preencha um formulário e obtenha resultados - útil para registros judiciais."""
async com async_playwright() como playwright:
tente:
navegador = aguarde playwright.chromium.connect_over_cdp(self.endpoint_url)
tente:
página = aguarde navegador.new_page()
aguarde página.goto(url, timeout=120000)
# Preencha os campos do formulário
para seletor, valor em form_data.items():
await page.fill(seletor, valor)
# Envie o formulário
await page.click(submit_selector)
# Aguarde os resultados
await page.wait_for_selector(result_selector, timeout=30000)
title = aguardar página.title()
text = aguardar página.evaluate("() => document.body.innerText")
retornar BrowserContent(
url=url,
title=title,
text=text[:10000],
screenshot_path=None,
success=True,
)
finalmente:
await browser.close()
exceto Exception como e:
retorne BrowserContent(
url=url,
title="",
text="",
screenshot_path=None,
success=False,
error=str(e),
)
async def scroll_and_collect(
self,
url: str,
scroll_count: int = 5,
wait_between_scrolls: float = 1.0,
) -> BrowserContent:
"""Lidar com páginas de rolagem infinita."""
async com async_playwright() como playwright:
tente:
navegador = aguarde playwright.chromium.connect_over_cdp(self.endpoint_url)
tente:
página = aguarde navegador.new_page()
aguarde página.goto(url, timeout=120000)
# Role para baixo várias vezes
para i no intervalo (scroll_count):
await page.evaluate("window.scrollTo(0, document.body.scrollHeight)")
await asyncio.sleep(wait_between_scrolls)
title = aguardar página.title()
text = aguardar página.evaluate("() => document.body.innerText")
retornar BrowserContent(
url=url,
title=title,
text=text[:10000],
screenshot_path=None,
success=True,
)
finalmente:
aguardar browser.close()
exceto Exception como e:
retornar BrowserContent(
url=url,
title="",
text="",
screenshot_path=None,
success=False,
error=str(e),)
# Exemplo de uso para pesquisa no registro do tribunal
async def example_court_search():
client = BrowserClient()
# Exemplo: Pesquisar um registro judicial
result = await client.fill_and_submit_form(
url="https://example-court-registry.gov/search",
form_data={
"#party-name": "Acme Corp",
"#case-type": "civil",
},
submit_selector="#search-button",
result_selector=".search-results",
)
if result.success:
print(f"Registros judiciais encontrados: {result.text[:500]}")
else:
print(f"Erro: {result.error}")
if __name__ == "__main__":
asyncio.run(example_court_search())Quando usar a API do navegador vs Web Unlocker
| Cenário | Uso |
|---|---|
| Solicitações HTTP simples | Web Unlocker |
| Páginas HTML estáticas | Web Unlocker |
| CAPTCHAs ao carregar | Web Unlocker |
| Conteúdo renderizado em JavaScript | API do navegador |
| Envios de formulários | API do navegador |
| Navegação em várias etapas | API do navegador |
| Capturas de tela necessárias | API do navegador |
Implantação com Railway
Seu agente TPRM pode ser implantado em produção usando Railway ou Render, que suportam aplicativos Python com tamanhos de dependência maiores.
O Railway é a opção mais fácil para implantar aplicativos Python com dependências pesadas, como o OpenHands SDK. Você deve se inscrever e criar uma conta para que isso funcione.
Etapa 1: Instale o Railway CLI globalmente
npm i -g @railway/cliEtapa 2: Adicione um arquivo Procfile.
Na pasta raiz do seu aplicativo, crie um novo arquivo Procfile e adicione o conteúdo abaixo. Isso servirá como configuração ou comando de inicialização para a implantação
web: uvicorn API.main:app --host 0.0.0.0 --port $PORTPasso 3: Faça login e inicialize o Railway no diretório do projeto
railway login
railway initPasso 4: Implante
railway up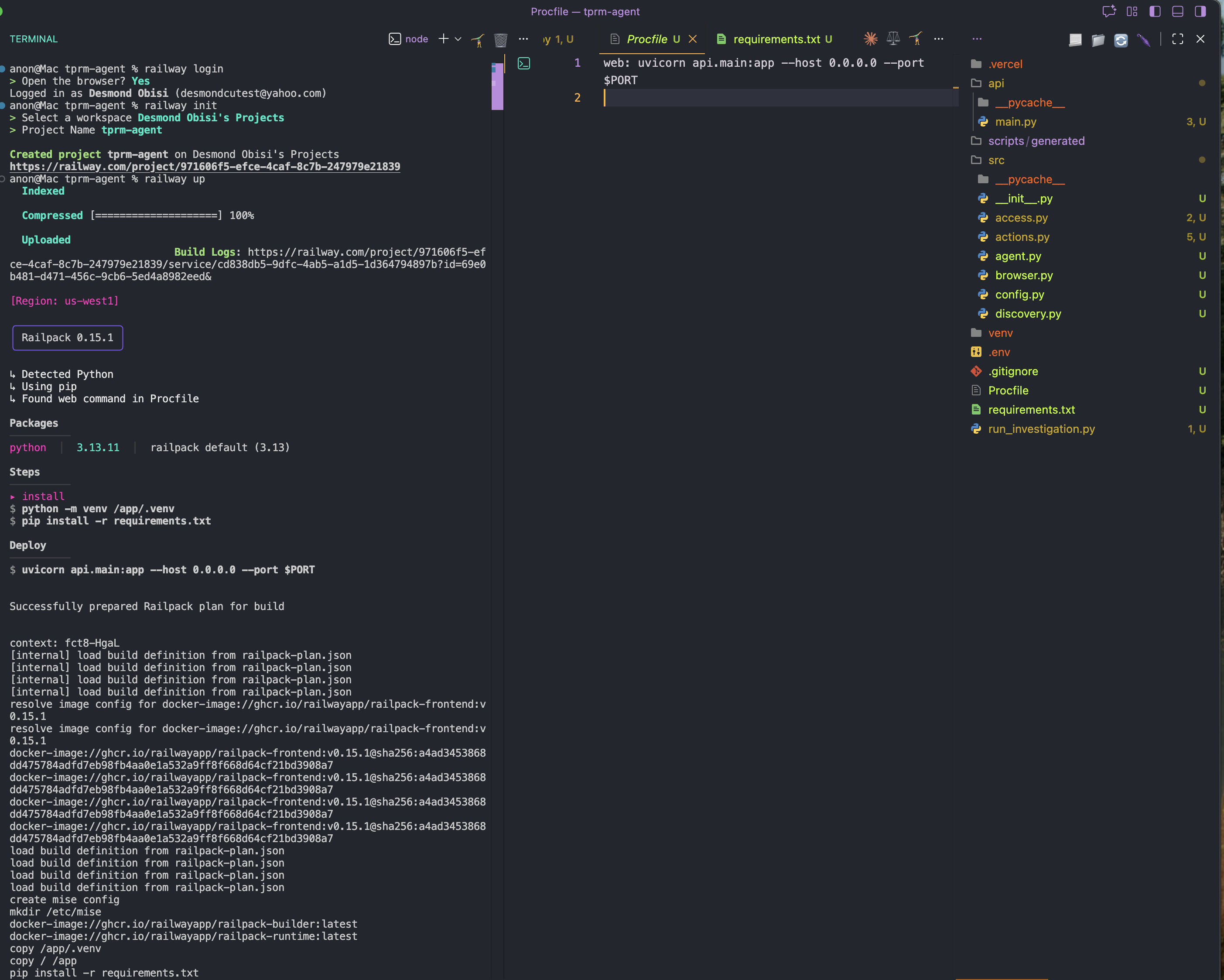
Etapa 5: Adicionar variáveis de ambiente
Acesse o painel do seu projeto Railway → Configurações → Variáveis compartilhadas e adicione estas variáveis e seus valores, conforme mostrado abaixo:
BRIGHT_DATA_API_TOKEN
BRIGHT_DATA_SERP_ZONE
BRIGHT_DATA_UNLOCKER_ZONE
OPENAI_API_KEY
LLM_API_KEY
LLM_MODEL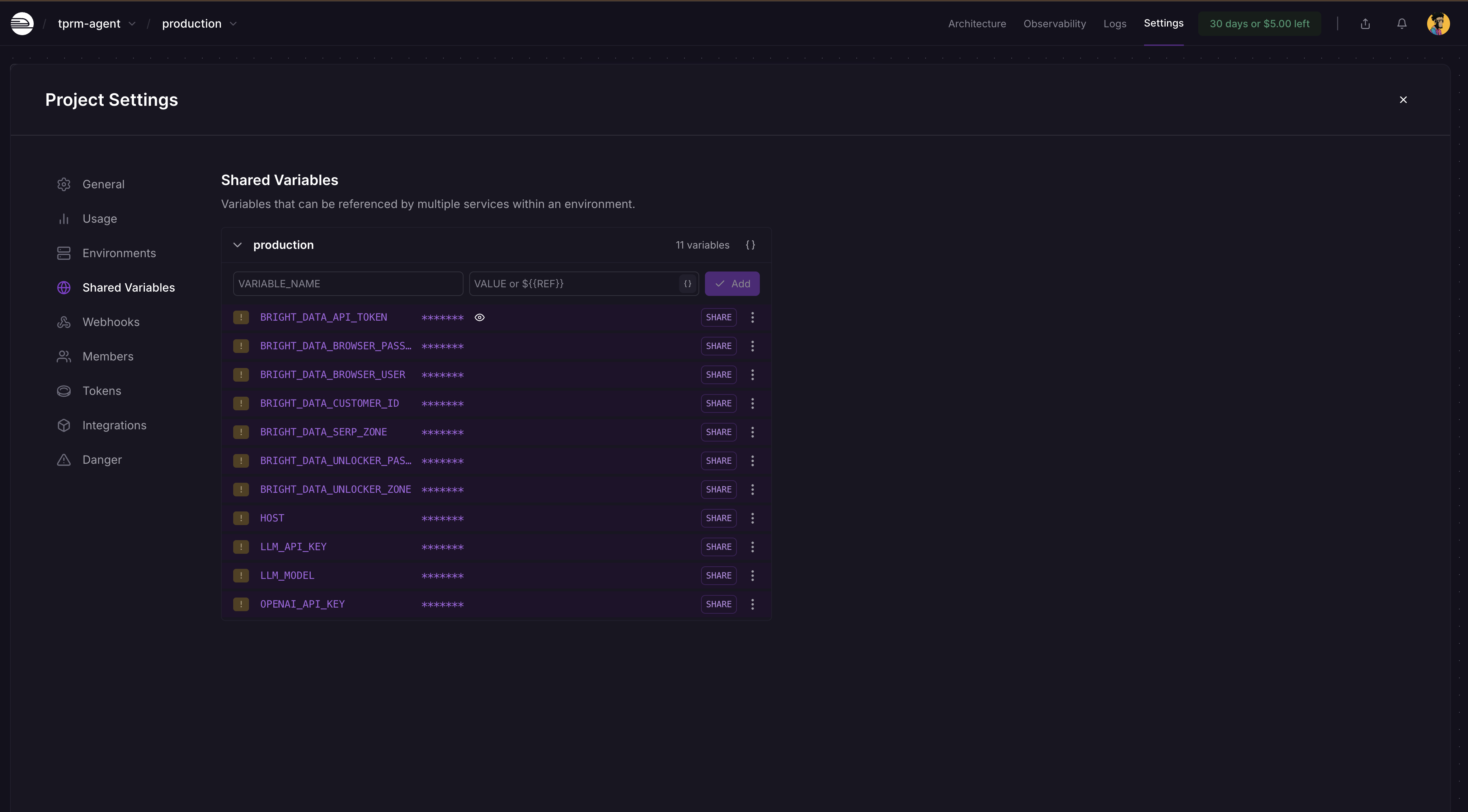
O Railway detectará automaticamente as alterações e solicitará que você implante novamente no painel. Clique em Implantar e seu aplicativo será atualizado com os segredos.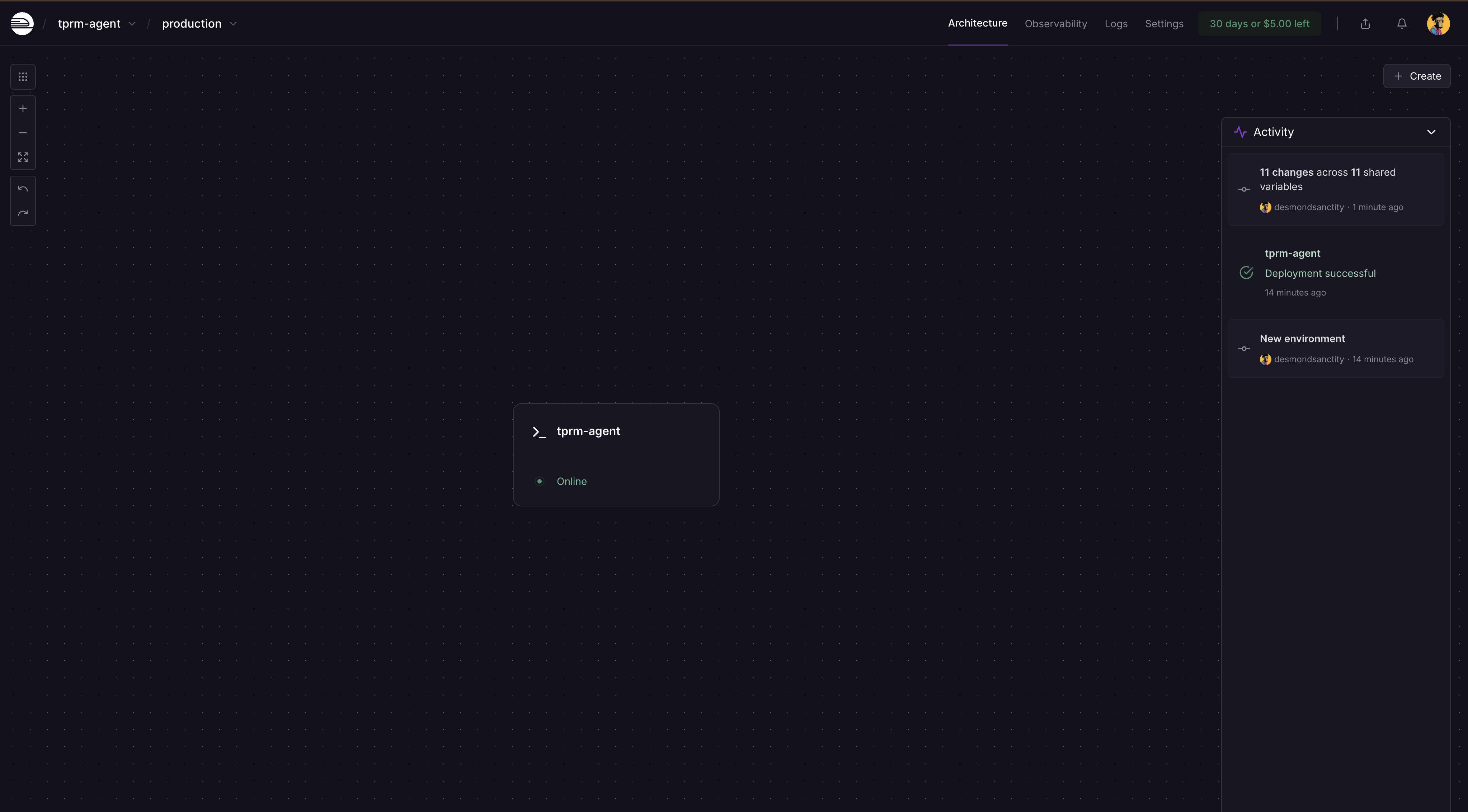
Após a reimplantação, clique no cartão de serviço e selecione Configurações. Você verá onde gerar um domínio, pois o serviço ainda não está disponível publicamente. Clique em Gerar domínio para obter sua URL pública.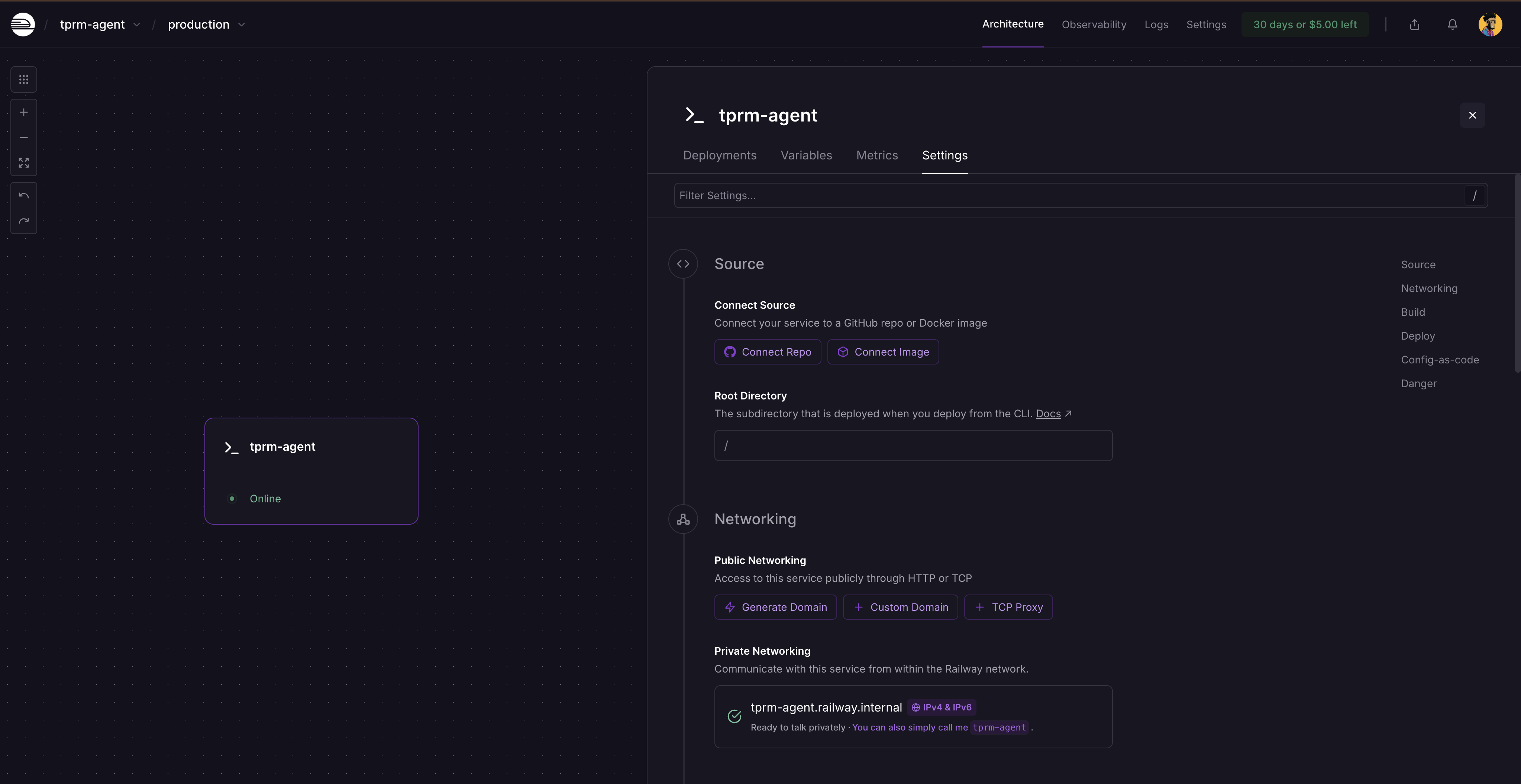
Executando uma investigação completa
Executando localmente com curl
Inicie o servidor FastAPI:
# Ative seu ambiente virtual
source venv/bin/activate # No Windows: venvScriptsactivate
# Execute o servidor
python -m uvicorn api.main:app --reloadAcesse http://localhost:8000/docs para explorar a documentação interativa da API.
Fazendo solicitações de API
- Inicie uma investigação:
curl -X POST "http://localhost:8000/investigate"
-H "Content-Type: application/json"
-d '{
"vendor_name": "Acme Corp",
"categories": ["litigation", "fraud"],
"generate_monitors": true
}'- Isso retorna um ID de investigação:
{
"investigation_id": "f6af2e0f-991a-4cb7-949e-2f316e677b5c",
"status": "iniciada",
"message": "Investigação iniciada para Acme Corp"
}- Verifique o status da investigação:
curl http://localhost:8000/investigate/f6af2e0f-991a-4cb7-949e-2f316e677b5cExecutando o agente como um script
Crie um arquivo chamado run_investigation.py na raiz do seu projeto:
import sys
sys.path.insert(0, 'src')
from agent import TPRMAgent
def investigate_vendor():
"""Executar uma investigação completa do fornecedor."""
agent = TPRMAgent()
# Executar investigação
result = agent.investigate(
vendor_name="Acme Corp",
categories=["litigation", "financial", "fraud"],
generate_monitors=True,
)
# Imprimir resumo
print(f"n{'='*60}")
imprimir(f"Investigação concluída: {result.vendor_name}")
imprimir(f"{'='*60}")
imprimir(f"Fontes encontradas: {result.total_sources_found}")
imprimir(f"Fontes acessadas: {result.total_sources_accessed}")
imprimir(f"Avaliações de risco: {len(resultado.avaliações_de_risco)}")
imprimir(f"Scripts de monitoramento: {len(resultado.scripts_de_monitoramento)}")
# Imprimir avaliações de risco
para avaliação em resultado.avaliações_de_risco:
imprimir(f"n{'─'*60}")
imprimir(f"[{avaliação.categoria.upper()}] Gravidade: {avaliação.gravidade.upper()}")
imprimir(f"{'─'*60}")
imprimir(f"Resumo: {avaliação.resumo}")
imprimir("nPrincipais conclusões:")
para conclusão em avaliação.principais_conclusões:
imprimir(f" • {descoberta}")
imprimir("nAções recomendadas:")
para ação em avaliação.ações_recomendadas:
imprimir(f" → {ação}")
# Imprimir informações do script de monitoramento
para script em resultado.scripts_de_monitoramento:
imprimir(f"n{'='*60}")
imprimir(f"Script de monitoramento gerado")
imprimir(f"{'='*60}")
imprimir(f"Caminho: {script.script_path}")
imprimir(f"Monitorando {len(script.urls_monitored)} URLs")
imprimir(f"Frequência: {script.check_frequency}")
# Imprimir erros, se houver
if result.errors:
print(f"n{'='*60}")
print("Erros:")
for error in result.errors:
print(f" ⚠️ {error}")
if __name__ == "__main__":
investigate_vendor()Execute o script de investigação em um novo terminal
# Ative seu ambiente virtual
source venv/bin/activate # No Windows: venvScriptsactivate
# Execute o script de investigação
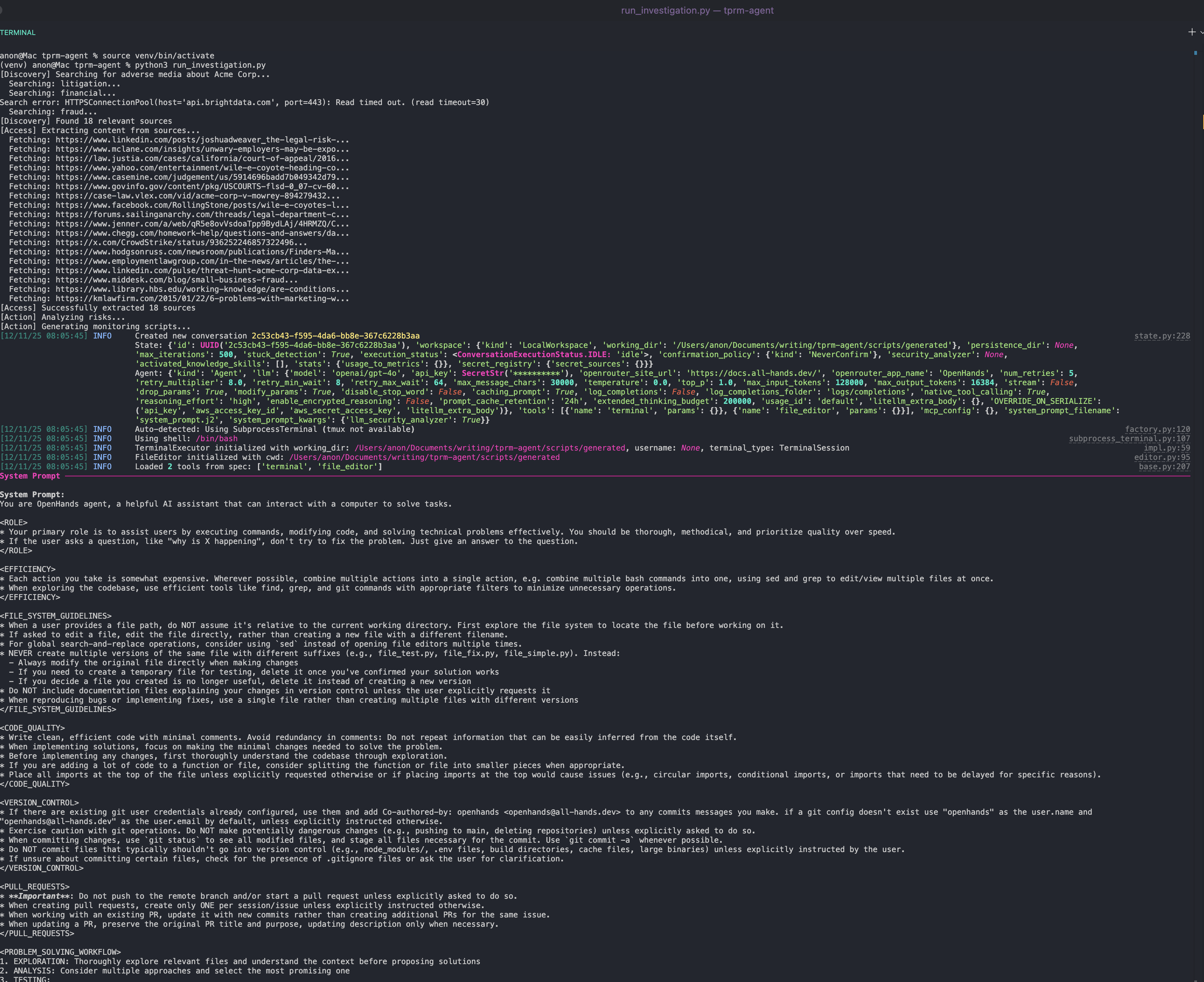
python run_investigation.pyO agente irá:
- Pesquisar no Google por mídia adversa usando a API SERP
- Acessar fontes usando o Web Unlocker
- Analisar o conteúdo quanto à gravidade do risco usando o OpenAI
- Gerar um script de monitoramento Python usando o OpenHands SDK que pode ser programado via cron
Executando o script de monitoramento gerado automaticamente
Após a conclusão da investigação, você encontrará um script de monitoramento na pasta scripts/generated:
cd scripts/generated
python monitor_acme_corp.pyO script de monitoramento usa a API Bright Data Web Unlocker para verificar todos os URLs monitorados e irá gerar: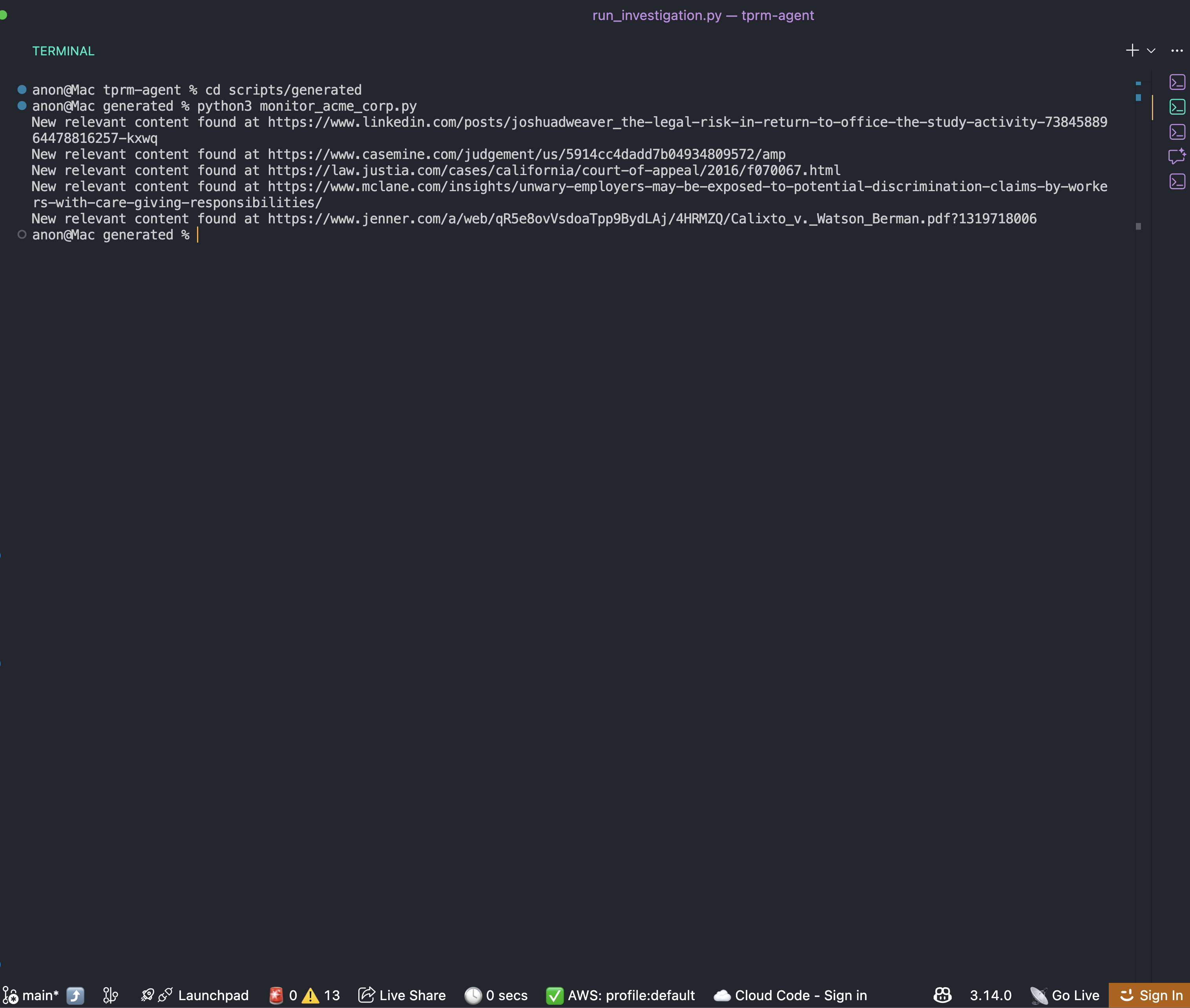
Agora você pode configurar uma programação cron para o script, conforme desejar, para obter sempre as informações corretas e atualizadas sobre o negócio.
Conclusão
Agora você tem uma estrutura completa para criar um agente TPRM empresarial que automatiza a investigação de mídia adversa do fornecedor. Este sistema:
- Descobre sinais de risco em várias categorias usando a API SERP da Bright Data
- Acessa o conteúdo usando o Bright Data Web Unlocker
- Analisa riscos usando OpenAI e gera scripts de monitoramento usando OpenHands SDK
- Aprimora os recursos com a API do navegador para cenários complexos
A arquitetura modular facilita a extensão:
- Adicione novas categorias de risco atualizando o dicionário
RISK_CATEGORIES - Integre com sua plataforma GRC ampliando a camada API
- Expanda para milhares de fornecedores usando filas de tarefas em segundo plano
- Adicione pesquisas no registro judicial usando o aprimoramento da API do navegador
Próximos passos
Para melhorar ainda mais este agente, considere:
- Integrar fontes de dados adicionais: registros da SEC, listas de sanções da OFAC, registros corporativos
- Adicionar persistência ao banco de dados: armazenar o histórico de investigações no PostgreSQL ou MongoDB
- Implementar notificações webhook: alertar o Slack ou o Teams quando fornecedores de alto risco forem detectados
- Criar um painel: crie um front-end React para visualizar as pontuações de risco dos fornecedores
- Agendar varreduras automatizadas: use Celery ou APScheduler para monitoramento periódico de fornecedores





