

Neste artigo, você aprenderá:
- O que é o Microsoft TaskWeaver e o que o torna único.
- Por que estender o TaskWeaver com os serviços da Bright Data permite que você supere as limitações do LLM.
- Como integrar o Bright Data ao TaskWeaver por meio de um plug-in personalizado.
Vamos começar!
O que é o Microsoft TaskWeaver?
O Microsoft TaskWeaver é uma estrutura de agente de código aberto que transforma solicitações em linguagem natural em código Python executável. Seu objetivo final é alimentar agentes de IA que planejam e executam tarefas complexas de forma independente.
Essa tecnologia funciona pegando sua solicitação e dividindo-a em etapas acionáveis. Em seguida, ela seleciona os plug-ins apropriados para atingir o objetivo, gera código Python para executar o plano, executa o código em um ambiente seguro e retorna os resultados.
O TaskWeaver é de código aberto e recebeu mais de 6.000 estrelas no GitHub. Alguns dos principais recursos que o diferenciam incluem:
- Abordagem code-first: converte as solicitações do usuário em código Python, dando aos agentes a capacidade de gerar e executar soluções diretamente.
- Ecossistema de plug-ins: oferece suporte a tarefas especializadas por meio de plug-ins, tornando a estrutura altamente extensível.
- Manipulação rica de dados: funciona nativamente com estruturas de dados Python, como DataFrames, abrindo as portas para análises de dados avançadas.
- Adaptação de domínio: integra conhecimento específico do domínio para resultados mais precisos.
- Execução com estado e reflexiva: mantém o contexto e pode refletir sobre sua própria execução de código para se autocorrigir.
- Seguro e aberto: executa código em um ambiente seguro, oferecendo uma experiência de código aberto pronta para uso.
Saiba mais na documentação oficial.
Por que adicionar recursos de recuperação de dados da Web ao TaskWeaver
Os LLMs são inerentemente limitados pelos dados com os quais foram treinados. Embora possam gerar texto, código ou multimídia, a saída é sempre baseada em seu conhecimento desatualizado. Além disso, eles não podem interagir com páginas da web ao vivo como um usuário humano. Essas duas são as principais restrições dos modelos atuais de IA.
O TaskWeaver supera essas limitações, permitindo que os agentes se integrem a plug-ins personalizados. Você pode pensar nos plug-ins como ferramentas especializadas que o LLM pode usar para realizar tarefas além de seus recursos integrados, efetivamente ampliando seu escopo e utilidade prática.
Ao chamar esses plug-ins, o código gerado por um agente TaskWeaver pode interagir com ambientes externos e realizar operações complexas. Por exemplo, a Bright Data oferece uma variedade de ferramentas poderosas:
- API Web Unlocker: extraia qualquer site em uma única solicitação e receba HTML ou Markdown limpo, com tratamento automatizado de Proxies, desbloqueio, cabeçalhos e CAPTCHAs.
- API SERP: colete resultados de mecanismos de pesquisa do Google, Bing e outros em escala, sem se preocupar com bloqueios.
- Scraping de dados: recupere dados estruturados e parsed de sites conhecidos como Amazon, Instagram, LinkedIn, Yahoo Finance e muito mais.
- E outras soluções da Bright Data…
Com acesso a plug-ins que se conectam a esses serviços, um agente TaskWeaver pode pesquisar na web, extrair conteúdo e recuperar dados estruturados em tempo real de domínios populares. Isso permite que a IA lide com fluxos de trabalho complexos e prontos para uso corporativo que vão muito além do que um LLM padrão poderia realizar sozinho.
Como integrar a Bright Data ao TaskWeaver por meio de um plug-in personalizado
Nesta seção do tutorial, você aprenderá como integrar um agente TaskWeaver com o Bright Data para recuperação de dados da web.
Especificamente, você verá como estender um aplicativo TaskWeaver com uma ferramenta personalizada que se conecta à API Bright Data Web Unlocker. Isso permite que seu agente code-first busque dados de qualquer página da web na Internet e os processe de acordo com suas necessidades.
Observação: para uma abordagem semelhante, consulte nosso guia de integração com smoleagents, outro agente de IA com prioridade em código.
Siga as instruções abaixo cuidadosamente!
Pré-requisitos
Para acompanhar este tutorial, você precisa de:
- Python 3.10 ou superior instalado localmente: necessário para executar o TaskWeaver e seus plug-ins.
- Git instalado localmente: necessário para clonar o repositório TaskWeaver do GitHub.
- O daemon Docker em execução: deve estar em execução para evitar erros com o recurso de verificação de código (que é opcional).
- Uma chave API OpenAI (ou a chave API de qualquer outro LLM compatível).
Para trabalhar com a Bright Data, você também precisará de:
- Uma conta Bright Data com uma chave API.
- Uma zona Web Unlocker configurada em sua conta.
Não se preocupe em configurar o Bright Data ainda, pois isso será abordado em uma etapa dedicada.
Etapa nº 1: Crie um projeto Microsoft TaskWeaver
Comece criando uma pasta para o seu projeto TaskWeaver e navegue até ela no terminal:
mkdir taskweaver-bright-data-example
cd taskweaver-bright-data-exampleDentro da pasta do projeto, crie um ambiente virtual:
python -m venv .venvEm seguida, ative-o. No Linux/macOS, execute este comando:
source .venv/bin/activateOu, alternativamente, no Windows, execute:
.venvScriptsactivateAgora, instale o TaskWeaver através dos seguintes comandos:
git clone https://github.com/microsoft/TaskWeaver.git
cd TaskWeaver
pip install -r requirements.txtIsso clonará o TaskWeaver/ na pasta do seu projeto e instalará todas as dependências no ambiente virtual que você acabou de criar através do pip.
O TaskWeaver é executado como um processo e requer um diretório de projeto para armazenar plug-ins, arquivos de configuração e dados de sessão. O repositório que você acabou de clonar fornece um projeto de amostra no diretório TaskWeaver/project/: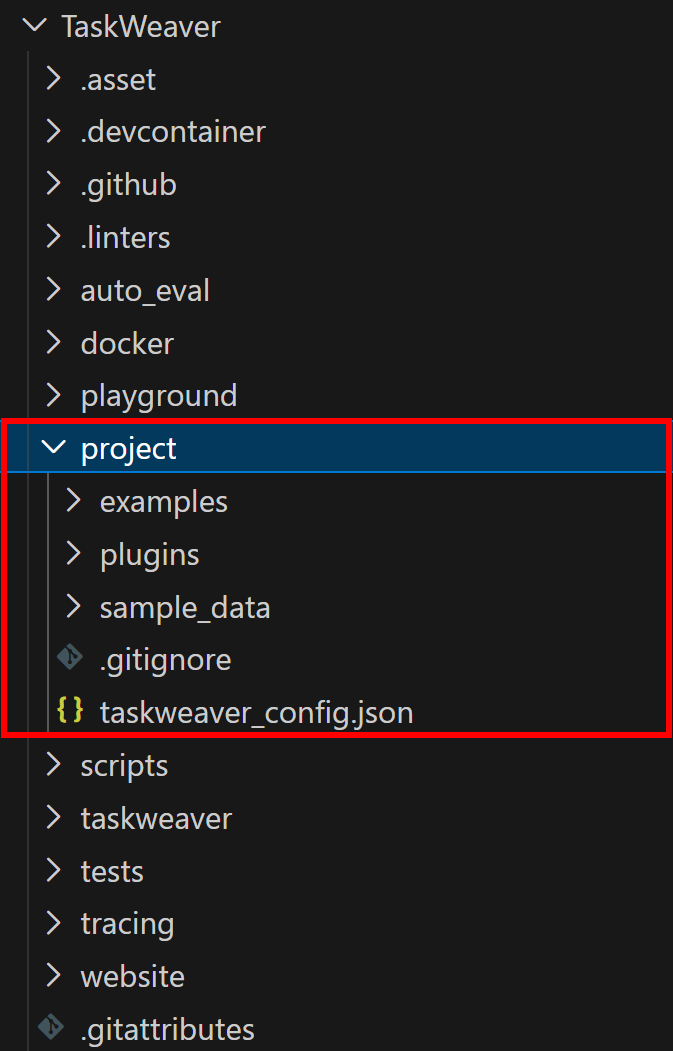
Copie o conteúdo da pasta do projeto para o seu espaço de trabalho. Depois disso, sua pasta taskweaver-bright-data-example/ deve ficar assim:
taskweaver-bright-data-example/
├─ .venv/
├─ TaskWeaver/
├─ plugins/ # Pasta para armazenar seus plug-ins
├─ examples/
│ ├─ planner_examples/ # Scripts de planejamento de exemplo
│ └─ code_generator_examples/ # Scripts de gerador de código de exemplo
├─ sample_data/ # Conjuntos de dados de amostra opcionais
├─ .gitignore
└─ taskweaver_config.json # Arquivo de configuração do projetoEm particular, um diretório típico de projeto do Microsoft TaskWeaver contém pastas e arquivos específicos, conforme descrito na documentação oficial.
Carregue taskweaver-bright-data-example/ em seu IDE Python favorito, como Visual Studio Code ou PyCharm.
Com seu ambiente virtual ativo, inicie o aplicativo enquanto ainda estiver dentro da pasta /TaskWeaver com:
python -m taskweaverIsso iniciará o processo TaskWeaver a partir da pasta /TaskWeaver, que carregará os arquivos e diretórios do projeto da pasta taskweaver-bright-data-example/.
Se tudo estiver funcionando, você deverá ver isso no seu terminal:
Sucesso! O Microsoft TaskWeaver está funcionando. Após executar o aplicativo pela primeira vez, as seguintes pastas serão criadas:
workspace/: Armazena os dados da sessão do seu projeto.logs/: Armazena os arquivos de log gerados pelo programa.
Observação: se você tentar inserir um prompt agora, ele falhará porque você ainda precisa configurar uma conexão com um LLM. Isso será abordado na próxima etapa.
Etapa 2: Configure o LLM no TaskWeaver
O TaskWeaver oferece suporte a uma ampla variedade de LLMs. Neste tutorial, integraremos um modelo OpenAI, mas você pode adaptar facilmente as instruções para qualquer outro provedor de LLM compatível.
Para configurar o modelo GPT-4.1 mini no TaskWeaver, certifique-se de que o arquivo taskweaver_config.json dentro de taskweaver-bright-data-example/ contenha o seguinte:
{
"llm.api_key": "<SUA_CHAVE_API_OPENAI>",
"llm.model": "gpt-4.1-mini"
}Substitua <SUA_CHAVE_API_OPENAI> pela sua chave API OpenAI real.
Observação: no momento da redação deste artigo, o TaskWeaver não oferece suporte a modelos GPT-5. Se você tentar configurar um modelo GPT-5, encontrará o erro abaixo:
{'error': {'message': "Parâmetro não suportado: 'max_tokens' não é compatível com este modelo. Use 'max_completion_tokens' em vez disso.", 'type': 'invalid_request_error', 'param': 'max_tokens', 'code': 'unsupported_parameter'}}Ótimo! Seu projeto TaskWeaver agora é alimentado pelo modelo mini OpenAI GPT-4.1 e está pronto para processar prompts.
Etapa 3: Configure uma zona da API Bright Data Web Unlocker
Para conectar seu agente TaskWeaver ao Bright Data para obter recursos de Scraping de dados, primeiro você precisa concluir algumas etapas preliminares. Mais especificamente, você precisa preparar sua conta Bright Data configurando uma zona Web Unlocker.
Se você ainda não tem uma conta, crie uma conta Bright Data. Caso contrário, basta fazer login. Uma vez na sua conta, navegue até a página “Proxies & Scraping”. Na seção “My Zones”, verifique se há uma linha chamada “Web Unlocker API” na tabela: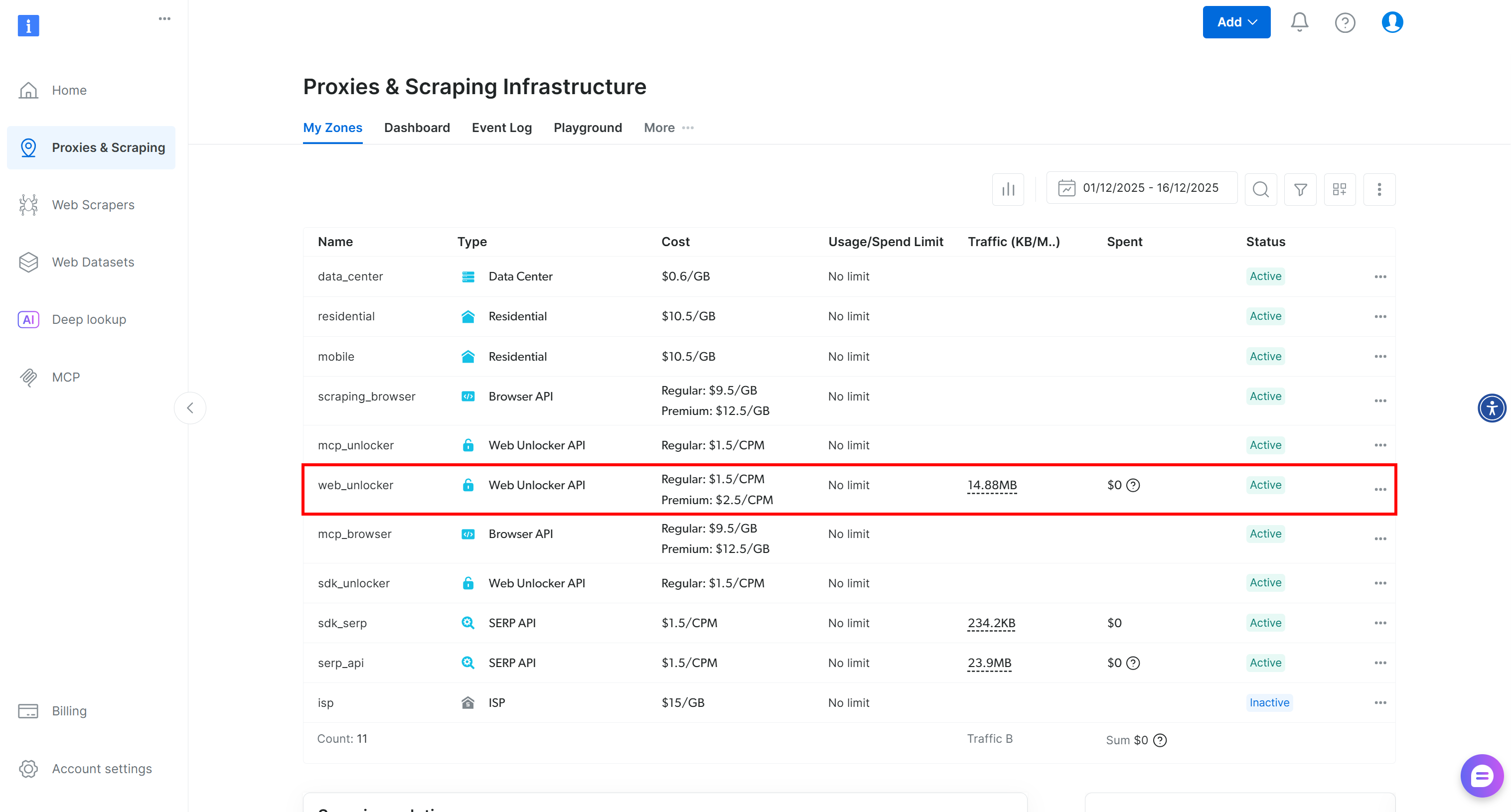
Se você não vir uma linha chamada “Web Unlocker API”, isso significa que essa zona ainda não foi configurada na sua conta Bright Data. Para criar uma, role para baixo até a seção “Unlocker API” e clique em “Create zone” para adicionar uma: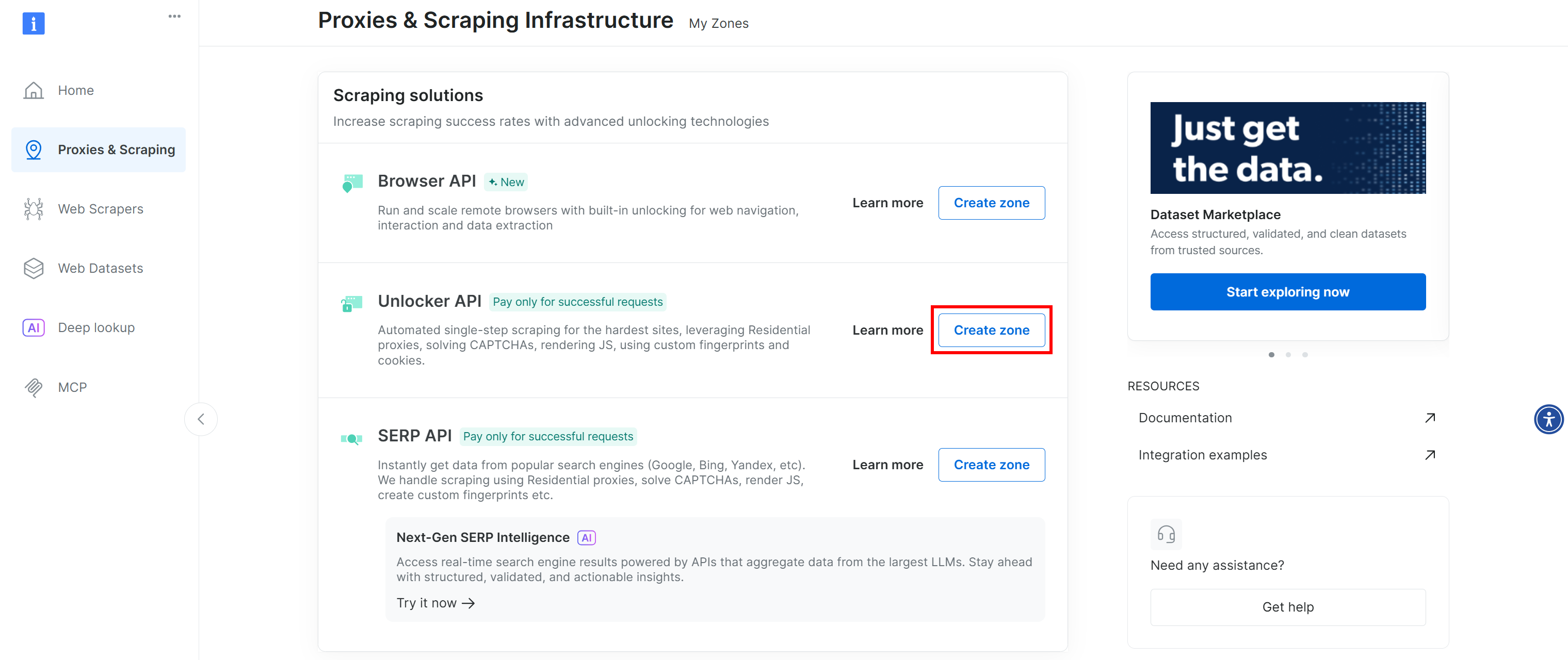
Crie uma zona Web Unlocker API e dê a ela um nome, como web_unlocker (ou qualquer nome de sua preferência). Lembre-se do nome da zona, pois você precisará dele para acessar o serviço por meio da API em um plugin personalizado.
Na página da zona Web Unlocker, certifique-se de que o botão esteja definido como “Ativo” para confirmar que a zona está habilitada.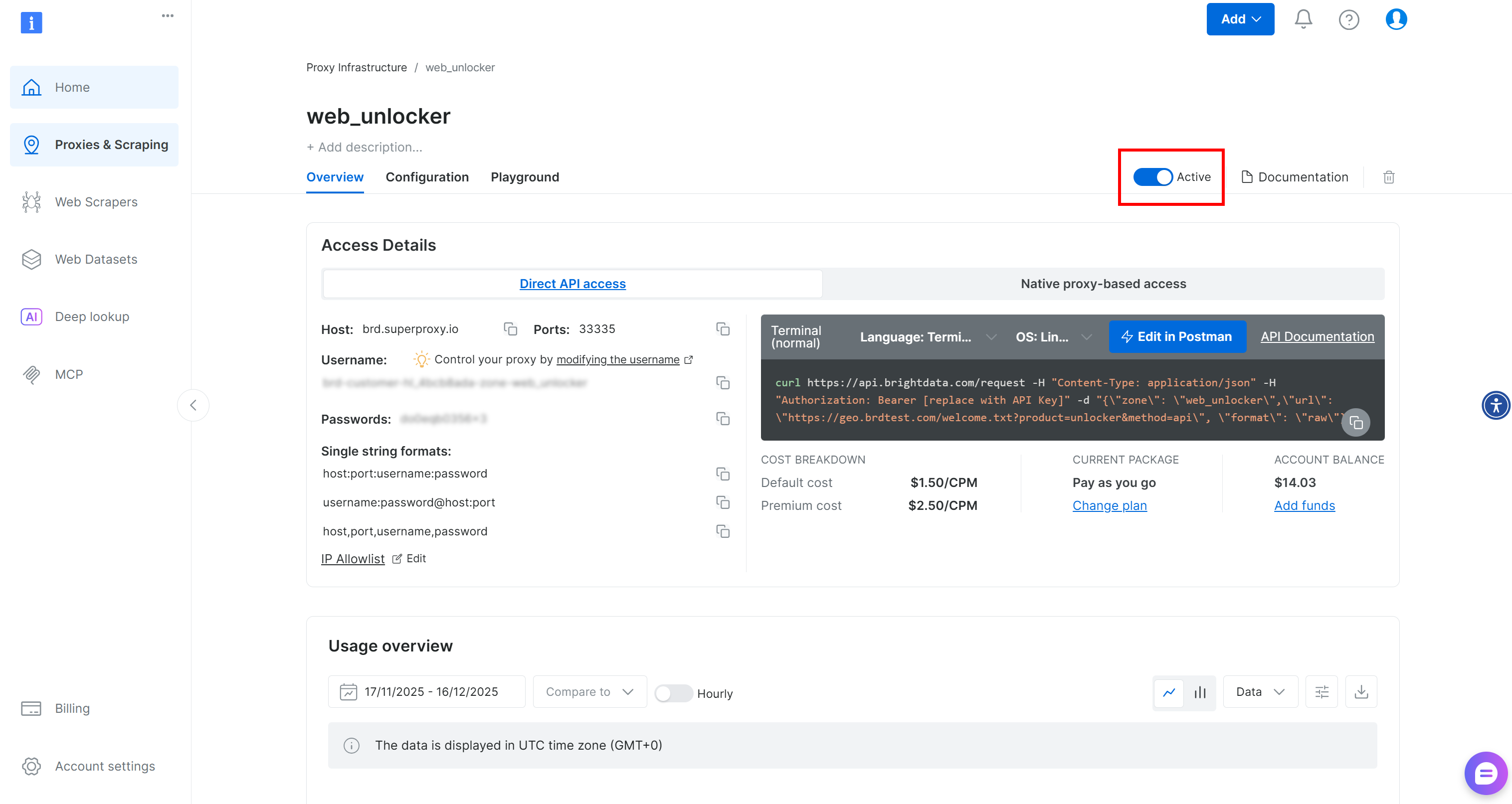
Por fim, siga o guia oficial para gerar sua chave API Bright Data. Armazene-a com segurança, pois você precisará dela em breve.
Ótimo! Agora você tem tudo configurado para usar o plugin da API Web Unlocker da Bright Data em seu aplicativo TaskWeaver.
Etapa 4: definir o plug-in TaskWeaver Web Unlocker para integração com a Bright Data
Plug-ins são unidades que podem ser orquestradas pelo interpretador de código do TaskWeaver. Mais especificamente, cada plug-in é uma função Python que pode ser chamada dentro do código gerado.
No TaskWeaver, um plugin envolve dois arquivos:
- Implementação do plugin: um arquivo Python que define o plugin.
- Esquema do plugin: um arquivo YAML que define as entradas, saídas e metadados do plugin.
Ambos os arquivos devem ser colocados na subpasta plugins/ dentro do seu projeto.
Nesse caso, você precisa adicionar um plugin que chame a API Bright Data Web Unlocker. Para obter mais informações sobre como chamar esse endpoint da API, consulte a documentação oficial.
No seu ambiente virtual ativo, primeiro instale um cliente HTTP Python como o Requests:
pip install requestsEm seguida, adicione um arquivo de plugin web_unlocker.py dentro da pasta plugins/. Defina-o da seguinte forma:
# taskweaver-bright-data-example/plugins/web_unlocker.py
import requests
from taskweaver.plugin import Plugin, register_plugin
@register_plugin
class WebUnlockerPlugin(Plugin):
def __call__(
self,
url: str,
data_format: str = None
):
# Leia os valores de configuração para a chamada da API
bright_data_api_key = self.config.get("api_key")
zone = self.config.get("zone", "web_unlocker")
default_format = self.config.get("data_format", "markdown")
# Cabeçalhos HTTP exigidos pela API Bright Data para autenticação
headers = {
"Authorization": f"Bearer {bright_data_api_key}",
"Content-Type": "application/json"
}
# Carga útil da solicitação enviada ao Bright Data Web Unlocker
payload = {
"zone": zone,
"url": url,
"format": "raw", # Para obter a resposta diretamente no corpo
"data_format": data_format ou default_format
}
# Enviar a solicitação para a API do Bright Data Web Unlocker
response = requests.post(
"https://api.brightdata.com/request",
json=payload,
headers=headers,)
# Gerar uma exceção para respostas HTTP que não sejam 2xx
response.raise_for_status()
# Extrair o conteúdo da resposta e o código de status HTTP
content = response.text
status = response.status_code
# Resumo em linguagem natural retornado ao LLM
description = (
f"Página buscada com sucesso usando o Bright Data Web Unlocker "
f"(HTTP {status}, {len(content)} caracteres)."
)
# Persistir a página buscada como um artefato na área de trabalho da sessão
self.ctx.add_artifact(
name="web_unlocker_page",
file_name="page_content.md",
type="txt",
val=content)
# Retornar o conteúdo bruto e uma descrição legível por humanos
return content, descriptionEste plug-in busca uma página da web por meio da API Bright Data Web Unlocker. Primeiro, ele lê os valores de configuração da seção de configurações YAML do plug-in (a ser definida em breve) usando self.config.get().
Em seguida, ele envia uma solicitação HTTP, verifica se há erros e salva a página obtida como um artefato na área de trabalho por meio de self.ctx.add_artifact(), permitindo que você revise o resultado durante e após a execução. Por fim, ele retorna o conteúdo bruto da página e um resumo legível por humanos para uso pelo LLM.
Observação: por padrão, a chamada da API Bright Data Web Unlocker foi configurada para retornar o conteúdo da página da web no formato Markdown, que é ideal para ingestão LLM. Esse é um recurso útil fornecido pela API Web Unlocker para oferecer suporte a integrações de IA e simplificar o processamento de conteúdo.
Incrível! Antes que o agente TaskWeaver possa usar este plugin, você também precisa especificar o arquivo de esquema YAML do plugin.
Etapa 5: Continue com a definição do esquema do plug-in
O esquema do plug-in especifica como o LLM no TaskWeaver entende e chama o plug-in. Isso deve ser escrito no formato YAML, portanto, crie um arquivo chamado web_unlocker.yaml dentro da pasta plugins/ da seguinte maneira:
# taskweaver-bright-data-example/plugins/web_unlocker.yaml
name: web_unlocker
enabled: true
plugin_only: true
description: >-
Busca e desbloqueia páginas da web usando a API Bright Data Web Unlocker,
contornando proteções anti-bot e retornando conteúdo de página limpo.
parameters:
- name: url
tipo: str
obrigatório: verdadeiro
descrição: A URL completa da página da web a ser recuperada.
- nome: formato_dos_dados
tipo: str
obrigatório: falso
descrição: Formato de saída do conteúdo da página ("markdown" ou HTML bruto, se omitido).
retorna:
- nome: conteúdo
tipo: str
descrição: O conteúdo da página desbloqueada.
- nome: descrição
tipo: str
descrição: Um resumo em linguagem natural da operação de busca.
configurações:
api_key: <SUA_CHAVE_API_BRIGHT_DATA> # Substitua pela sua chave API Bright Data
zona: web_unlocker # Substitua pelo nome da sua zona Web Unlocker
formato_dos_dados: markdownO arquivo YAML acima descreve as entradas e saídas da função __call__() na classe WebUnlockerPlugin definida anteriormente. Graças a esse esquema, o LLM do TaskWeaver entenderá como o plug-in web_unlocker.py funciona e como chamá-lo no código Python gerado.
Na seção de configurações, especifique sua chave API da Bright Data, o nome da zona do Web Unlocker e o formato de saída desejado. Substitua os campos api_key e zone pelos valores que você configurou na Etapa #3.
Pronto! Sua integração do TaskWeaver + Bright Data está concluída.
Observação: você pode usar a mesma abordagem para integrar outros serviços Bright Data via API, como a API SERP ou as APIs de Scraping de dados.
Etapa 6: teste o agente TaskWeaver
É hora de verificar se o agente code-first no TaskWeaver agora pode chamar o plug-in com tecnologia Bright Data. A ideia é que o código gerado invoque a função do plug-in e acesse os recursos de desbloqueio da web fornecidos pela API do Web Unlocker.
Para testar isso, tente um prompt como este:
Busque o changelog MCP mais recente em “https://modelcontextprotocol.io/specification/2025-11-25/changelog” e liste as alterações.Essa tarefa normalmente seria impossível para um LLM padrão, pois requer uma ferramenta personalizada para navegar até uma URL e extrair informações dela. No entanto, com o TaskWeaver + Bright Data, o agente pode lidar com isso!
Inicie o aplicativo TaskWeaver com:
python -m taskweaverCole o prompt e pressione Enter. Você deverá ver algo assim: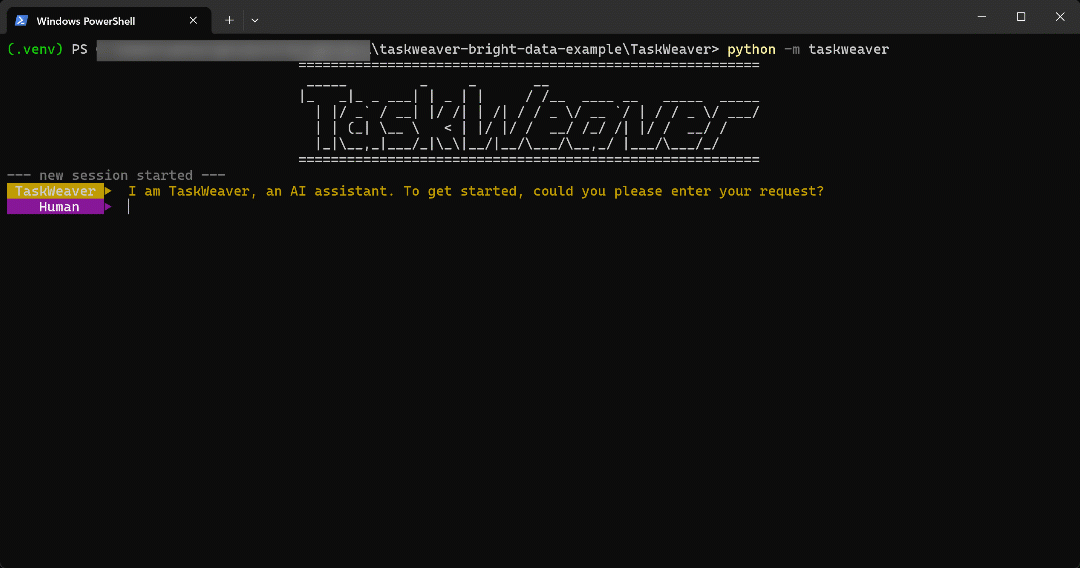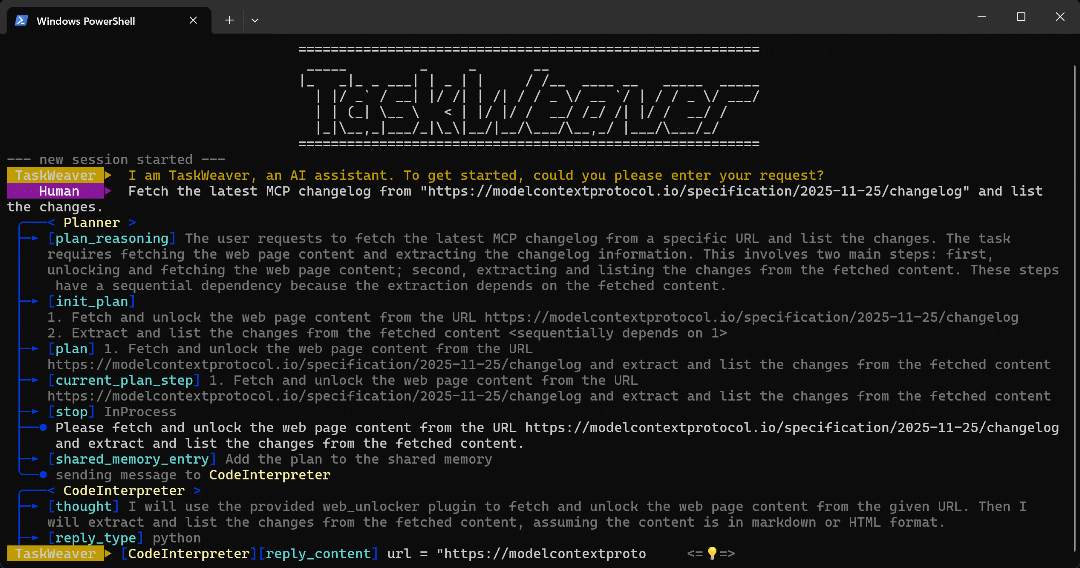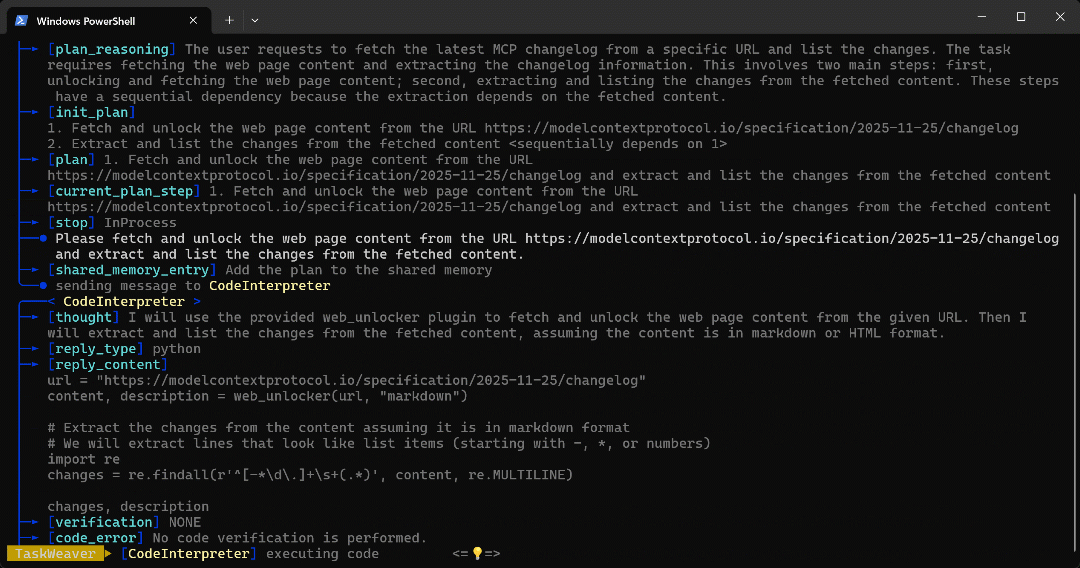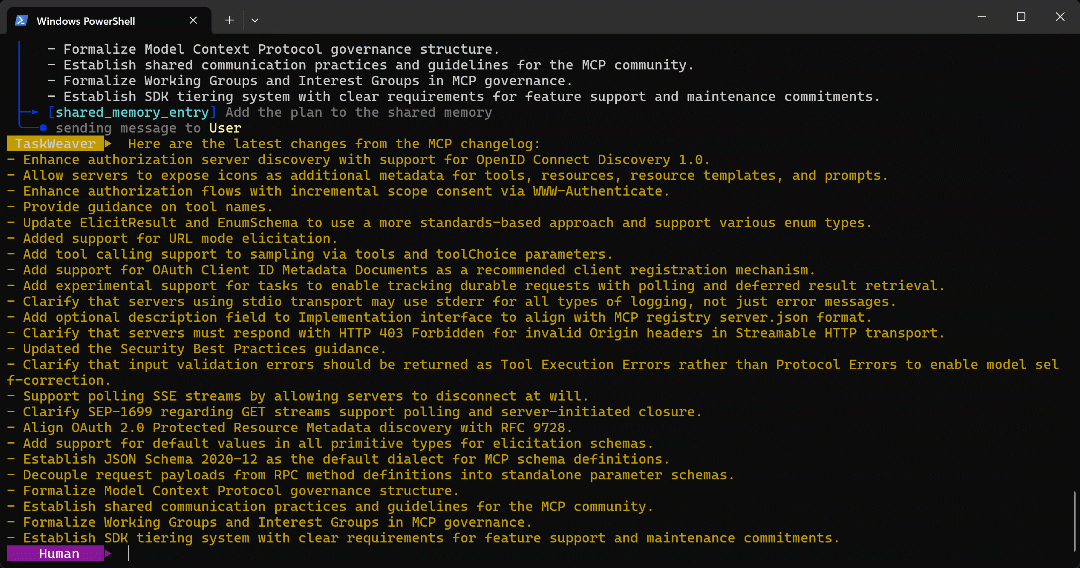
Como você pode ver, o agente:
- O TaskWeaver
Plannercomeça produzindo um plano para realizar a tarefa. - O plano é então enviado ao agente interno
CodeInterpreter, que gera código Python para atingir o objetivo. - O código Python chama o plug-in da API Web Unlocker e, em seguida, extrai todos os pontos do artigo usando uma expressão regular.
- O código é executado e os dados desejados são recuperados por meio da API Web Unlocker e armazenados na pasta da área de trabalho, conforme configurado com
self.ctx.add_artifact(). - Os dados Markdown retornados, contendo o conteúdo da página especificada pela URL, são enviados de volta ao
Planner, que continua com a próxima etapa. - A lista de pontos extraídos da página de destino é devolvida ao usuário conforme pretendido.
Ótimo! O agente TaskWeaver funciona perfeitamente. Vamos dedicar algum tempo para inspecionar o resultado produzido.
Etapa 7: Explore a saída
O resultado final da execução do agente é:
Como você pode verificar na página de destino, essa lista corresponde exatamente às informações encontradas no changelog do MCP: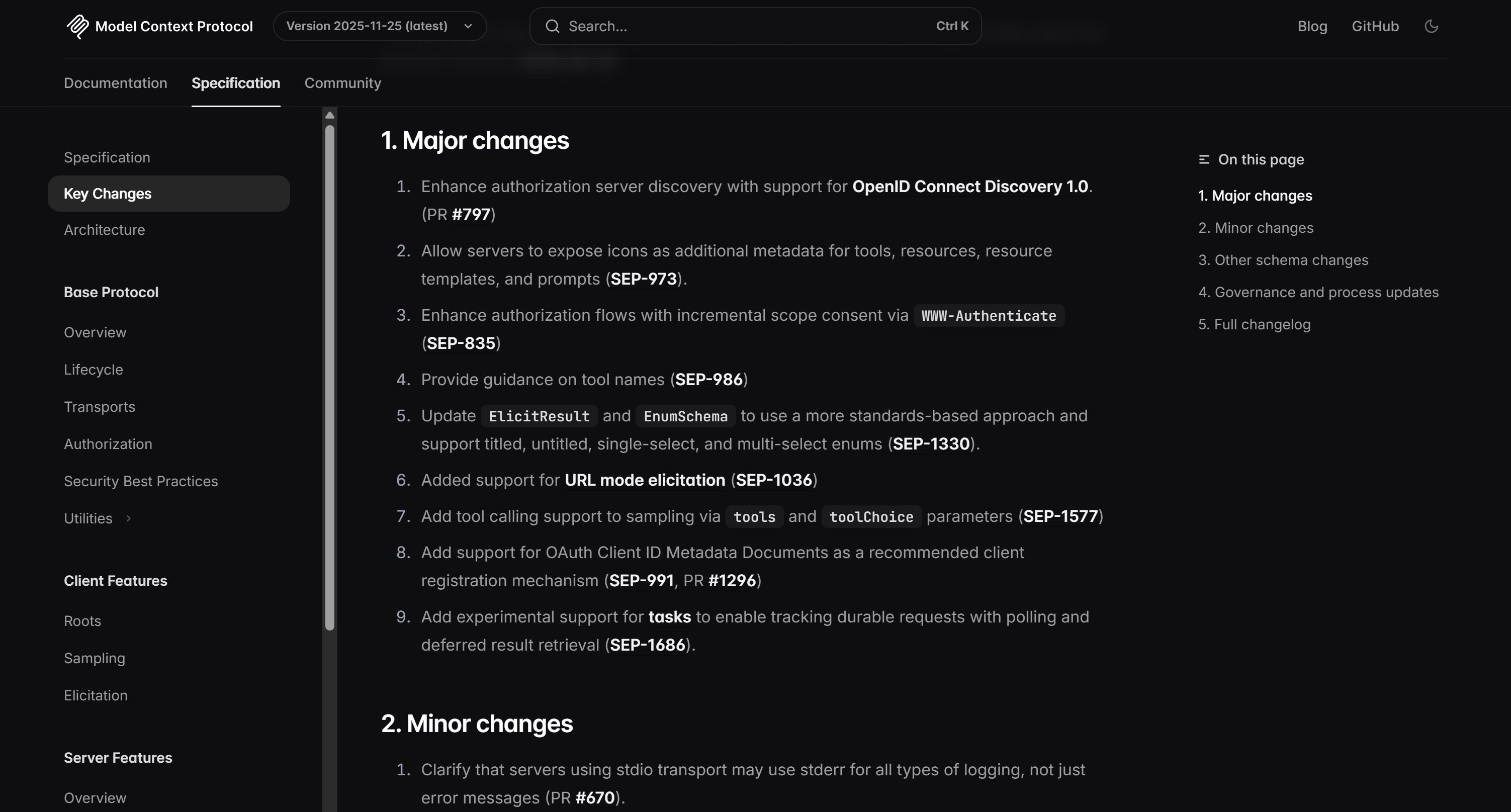
Em particular, o agente produziu o resultado por meio do seguinte código Python:
url = "https://modelcontextprotocol.io/specification/2025-11-25/changelog"
content, description = web_unlocker(url, "markdown")
# Extraia as alterações do conteúdo, presumindo que ele esteja no formato markdown.
# Extrairemos linhas que se parecem com itens de lista (começando com -, * ou números).
import re
changes = re.findall(r'^[-*d.]+s+(.*)', content, re.MULTILINE)
changes, descriptionObserve como o trecho gerado chama o plugin da função web_unlocker() para recuperar a página de entrada no formato Markdown. Em seguida, ele a processa usando uma expressão regular simples para extrair as informações relevantes.
Para verificar se a API do Web Unlocker retornou o conteúdo da página em Markdown, verifique os arquivos dentro da pasta workspace/. Cada execução do agente produz uma subpasta de sessão em workspace/sessions/, contendo uma subpasta para essa execução específica.
Na pasta cwd/, você encontrará o arquivo .md criado por meio da chamada self.ctx.add_artifact(). Abra-o para visualizar o conteúdo retornado da API do Web Unlocker: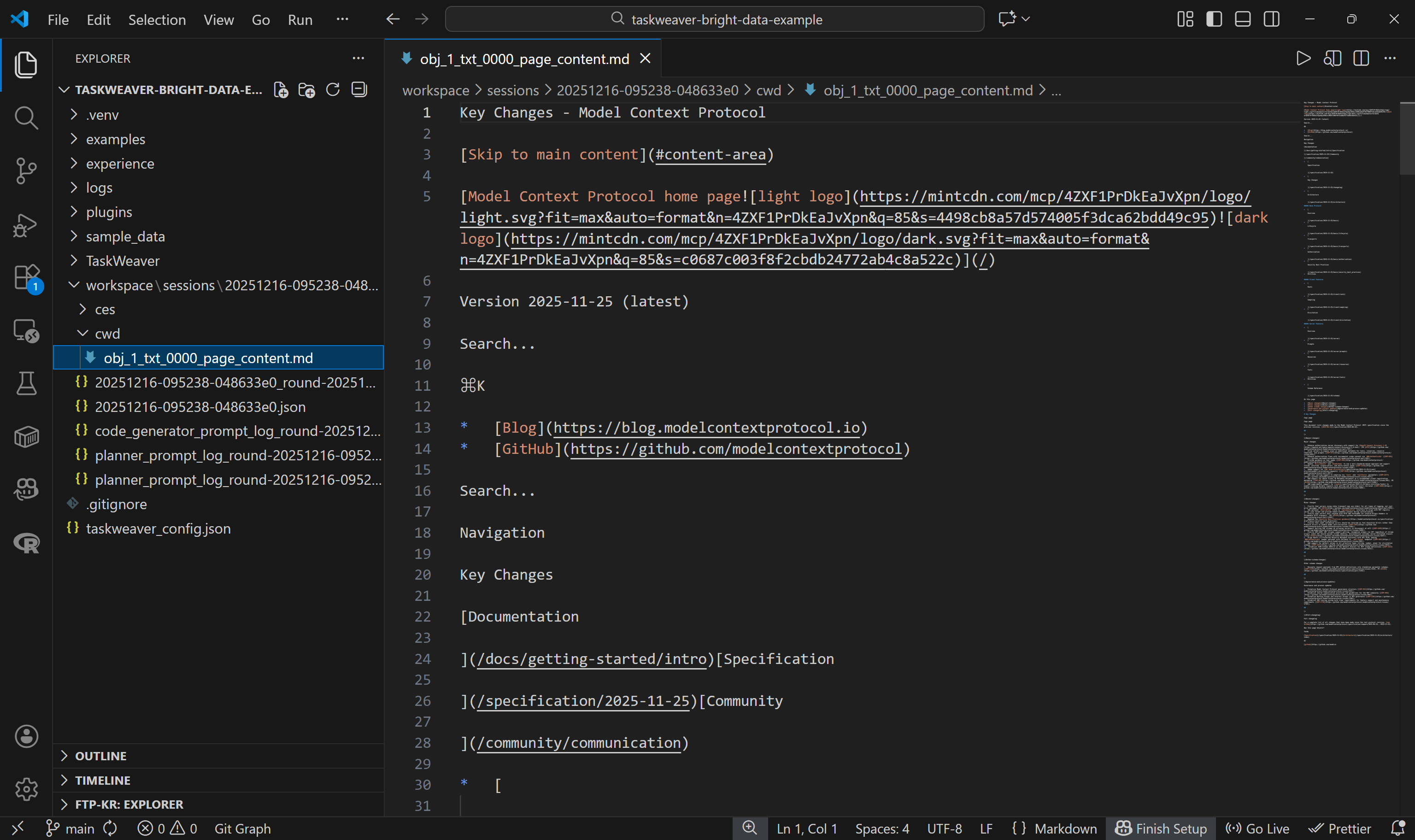
Isso corresponde exatamente à versão Markdown da página de destino, o que significa que a função da API Web Unlocker no código Python gerado funcionou perfeitamente. Uau!
Agora, leve seu agente ainda mais longe. Experimente diferentes prompts para lidar com cenários mais realistas e prontos para uso corporativo.
Et voilà! Você criou com sucesso um agente de IA code-first integrado ao Bright Data usando o TaskWeaver. Esse agente pode recuperar de forma confiável dados prontos para IA de qualquer página da web.
Próximos passos
A integração demonstrada aqui é um exemplo básico. Para levar seu agente TaskWeaver para o próximo nível e torná-lo pronto para produção, considere as seguintes melhorias:
- Integre soluções adicionais da Bright Data, como a API SERP, para dar ao agente a capacidade de pesquisar na web e coletar dados em tempo real.
- Configure a interface do usuário da web como um playground para simplificar o desenvolvimento, o teste e o monitoramento do seu agente.
- Habilite recursos avançados como compactação de prompt, seleção automática de plug-ins etelemetria/observabilidade para melhorar o desempenho, a escalabilidade e a manutenção.
Conclusão
Neste tutorial, você viu como integrar o Bright Data ao TaskWeaver por meio de plug-ins personalizados que se conectam a APIs externas.
Essa configuração permite pesquisas na web em tempo real, extração de dados estruturados, acesso a feeds da web em tempo real e interações automatizadas na web. Ao aproveitar o conjunto completo de serviços da Bright Data para IA, você libera todo o potencial de seus agentes de IA com prioridade em código!
Crie uma conta Bright Data gratuitamente hoje mesmo e tenha acesso às nossas soluções de dados da web prontas para IA.




