

Neste guia sobre o ajuste fino do Llama 4 com dados da web, você aprenderá:
- O que é ajuste fino
- Como recuperar os Conjuntos de dados prontos para ajuste fino usando algumas APIs de scraping
- Como configurar a infraestrutura em nuvem para o processo de ajuste fino
- Como ajustar o Llama 4 com um tutorial passo a passo
Vamos começar!
O que é ajuste fino?
O ajuste fino, também conhecido como ajuste fino supervisionado (SFT), é um processo usado para melhorar conhecimentos ou habilidades específicos em um LLM pré-treinado. No contexto dos LLMs, o pré-treinamento se refere ao treinamento de um modelo de IA a partir do zero.
O SFT é usado porque um modelo imita seus dados de treinamento. No entanto, atualmente, os LLMs são principalmente modelos generalistas. Isso significa que, se você deseja que um modelo aprenda conhecimentos específicos, é necessário ajustá-lo.
Se você quiser saber mais sobre SFT, leia nosso guia sobre ajuste fino supervisionado em LLMs.
Raspando os dados para ajustar o LLama 4
Para ajustar um LLM, primeiro você precisa de um conjunto de dados de ajuste. Esta seção mostra como recuperar dados de um site usando as APIs Web Scraperda Bright Data — endpoints dedicados para mais de 100 domínios que coletam dados novos para você e os recuperam no formato desejado.
A página da web de destino será a página de produtos de escritório mais vendidos da Amazon:
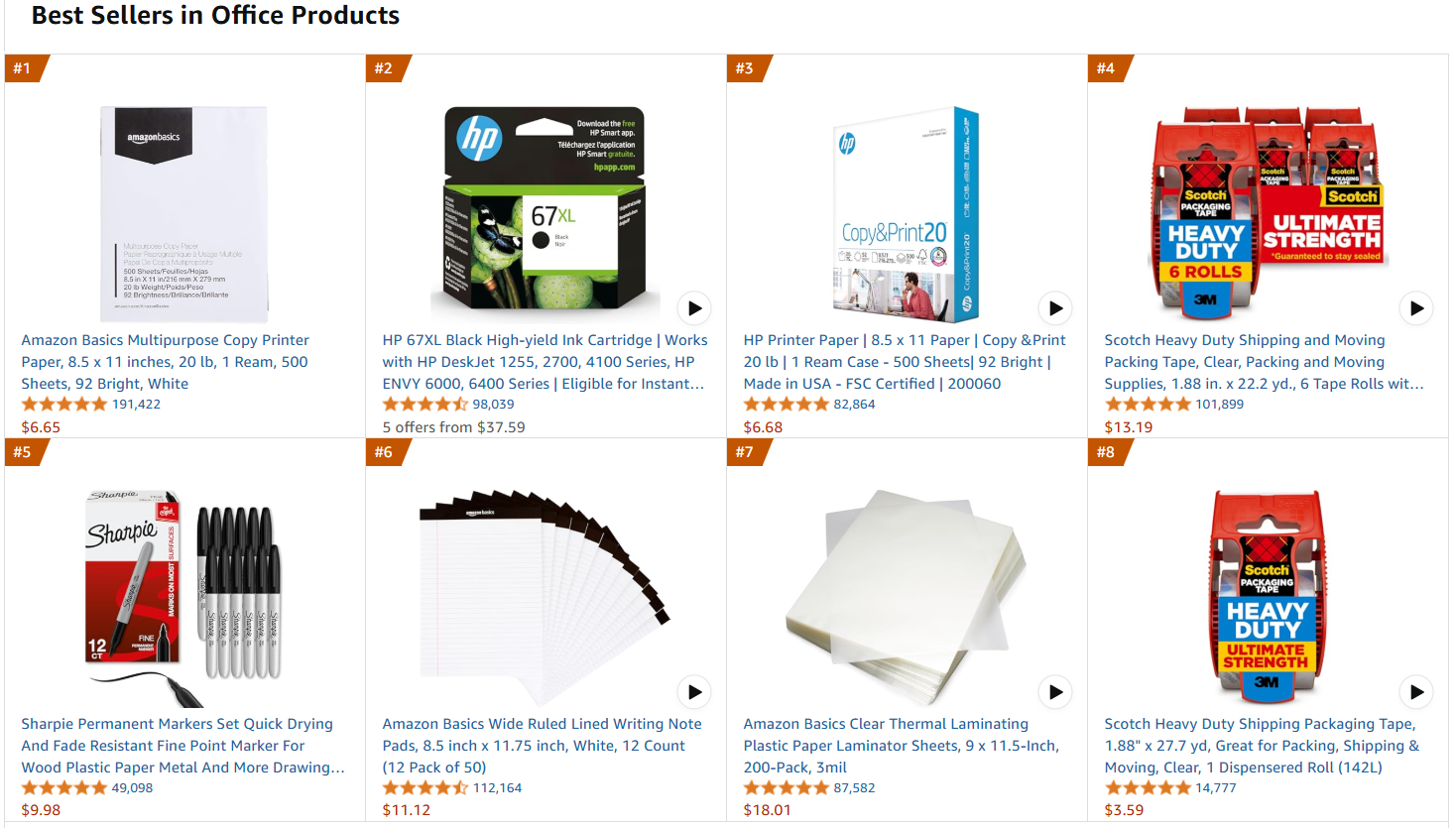
Siga as etapas abaixo para recuperar os dados de ajuste fino!
Requisitos
Para usar o código para recuperar os dados da Amazon, você precisa de:
- Python 3.10+ instalado em sua máquina.
- Uma chave API válida do Bright Data Scraper.
Siga a documentação da Bright Data para recuperar sua chave API.
Estrutura do projeto e dependências
Suponha que você chame a pasta principal do seu projeto de amazon_scraper/. Ao final desta etapa, a pasta terá a seguinte estrutura:
amazon_scraper/
├── scraper.py
└── venv/Onde:
scraper.pyé o arquivo Python que contém a lógica de codificação.venv/contém o ambiente virtual.
Você pode criar o diretório do ambiente virtual venv/ da seguinte maneira:
python -m venv venvPara ativá-lo, no Windows, execute:
venvScriptsactivateDe forma equivalente, no macOS e no Linux, execute:
source venv/bin/activateNo ambiente virtual ativado, instale as dependências com:
pip install requestsOnde requests é uma biblioteca para fazer solicitações HTTP na web.
Ótimo! Agora você está pronto para obter os dados de interesse usando as APIs Scraper da Bright Data.
Etapa 1: definir a lógica de scraping
O trecho a seguir define toda a lógica de scraping:
import requests
import json
import time
def trigger_amazon_products_scraping(api_key, urls):
# Endpoint para acionar a tarefa da API Web Scraper
url = "https://api.brightdata.com/datasets/v3/trigger"
params = {
"dataset_id": "gd_l7q7dkf244hwjntr0",
"include_errors": "true",
"type": "discover_new",
"discover_by": "best_sellers_url",
}
# Converta os dados de entrada no formato desejado para chamar a API
data = [{"category_url": url} for url in urls]
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json",
}
response = requests.post(url, headers=headers, params=params, json=data)
if response.status_code == 200:
snapshot_id = response.json()["snapshot_id"]
print(f"Solicitação bem-sucedida! Resposta: {snapshot_id}")
return response.json()["snapshot_id"]
else:
print(f"Solicitação falhou! Erro: {response.status_code}")
print(response.text)
def poll_and_retrieve_snapshot(api_key, snapshot_id, output_file, polling_timeout=20):
snapshot_url = f"https://api.brightdata.com/conjuntos_de_dados/v3/snapshot/{snapshot_id}?format=json"
headers = {
"Authorization": f"Bearer {api_key}"
}
print(f"Pesquisando snapshot para ID: {snapshot_id}...")
enquanto True:
response = requests.get(snapshot_url, headers=headers)
if response.status_code == 200:
print("Instantâneo pronto. Baixando...")
snapshot_data = response.json()
# Gravar o snapshot em um arquivo json de saída
with open(output_file, "w", encoding="utf-8") as file:
json.dump(snapshot_data, file, indent=4)
imprimir(f"Instantâneo salvo em {output_file}")
retornar
elif response.status_code == 202:
imprimir(F"O instantâneo ainda não está pronto. Repetindo em {polling_timeout} segundos...")
time.sleep(polling_timeout)
else:
imprimir(f"Falha na solicitação! Erro: {response.status_code}")
print(response.text)
break
if __name__ == "__main__":
BRIGHT_DATA_API_KEY = "<SUA chave API>" # Substitua por sua chave API do Web Scraper da Bright Data ou leia-a dos envs
# URLs dos produtos mais vendidos para recuperar dados
urls = [
"https://www.amazon.com/gp/bestsellers/office-products/ref=pd_zg_ts_office-products"
]
snapshot_id = trigger_amazon_products_scraping(BRIGHT_DATA_API_KEY, urls)
poll_and_retrieve_snapshot(BRIGHT_DATA_API_KEY, snapshot_id, "amazon-data.json")Este código:
- Cria a função
trigger_amazon_products_scraping()que inicia a tarefa de Scraping de dados por meio de:- Definir o endpoint da API do Scraper a ser acionado.
- Configurar os parâmetros para a atividade de scraping.
- Formatar as
URLsde entrada em uma estrutura JSON esperada pela API. - Enviando uma solicitação
POSTpara a API Bright Data Scraper com o endpoint, cabeçalhos, parâmetros e dados especificados. - Gerenciando o status da resposta.
- Cria uma função
poll_and_retrieve_snapshot()que verifica o status da tarefa de scraping (identificada porsnapshot_id) e recupera os dados assim que estiverem prontos.
Observe que a API de scraping foi chamada usando apenas um URL. Assim, o código acima recupera os dados apenas de uma página Amazon de destino. Isso é suficiente para o escopo deste tutorial, mas você pode adicionar quantos URLs Amazon desejar à lista.
Lembre-se de que quanto mais URLs você adicionar, maior será o tamanho do conjunto de dados. Um conjunto de dados maior, se bem organizado, significa um ajuste melhor. Por outro lado, quanto maior o conjunto de dados, maior será o tempo de computação necessário.
Perfeito! Sua lógica de scraping está bem definida e agora você está pronto para executar o script.
Etapa 2: execute o script
Para fazer o scraping da página da web de destino, execute o script com:
python Scraper.pyVocê obterá o seguinte resultado:
Solicitação bem-sucedida! Resposta: s_m9in0ojm4tu1v8h78
Polling snapshot para ID: s_m9in0ojm4tu1v8h78...
O instantâneo ainda não está pronto. Repetindo em 20 segundos...
# ...
O instantâneo ainda não está pronto. Repetindo em 20 segundos...
O instantâneo está pronto. Baixando...
Instantâneo salvo em amazon-data.jsonNo final do processo, a pasta do projeto conterá:
amazon_scraper/
├── scraper.py
├── amazon-data.json # <-- Observe o conjunto de dados de ajuste fino
└── venv/O processo criou automaticamente o amazon-data.json que contém os dados coletados. Abaixo está a estrutura esperada do arquivo JSON:
[
{
"title": "Papel para impressora multifuncional Amazon Basics, 8,5 x 11 polegadas, 20 lb, 1 resma, 500 folhas, 92 brilho, branco",
"seller_name": "Amazon.com",
"brand": "Amazon Basics",
"description": "Descrição do produto Papel multifuncional para impressora Amazon Basics, 8,5 x 11 polegadas, 20 lb - 1 resma (500 folhas), 92 GE branco brilhante do fabricante AmazonBasics",
"initial_price": 6,65,
"currency": "USD",
"availability": “Em estoque”,
“reviews_count”: 190989,
“categories”: [
“Produtos de escritório”,
“Material de escritório e escolar”,
“Papel”,
“Papel para cópia e impressão”,
“Papel para cópia e multifuncional”
],
...
// omitido por brevidade...
}Muito bem! Você conseguiu extrair dados da Amazon e salvá-los em um arquivo JSON. Esse arquivo JSON é o conjunto de dados de ajuste fino que você usará mais tarde no processo de ajuste fino.
Configurando o Hugging Face para usar o Llama 4
O modelo que você usará é o Llama-4-Scout-17B-16E-Instruct do Hugging Face.
Se você nunca usou o Hugging Face antes, ao clicar no link pela primeira vez, será solicitado que você crie uma conta:
Após criar a conta, se você nunca utilizou nenhum modelo Llama 4, precisará preencher o formulário de acordo. Clique em “Expandir para revisar e acessar” para ler e preencher o formulário:
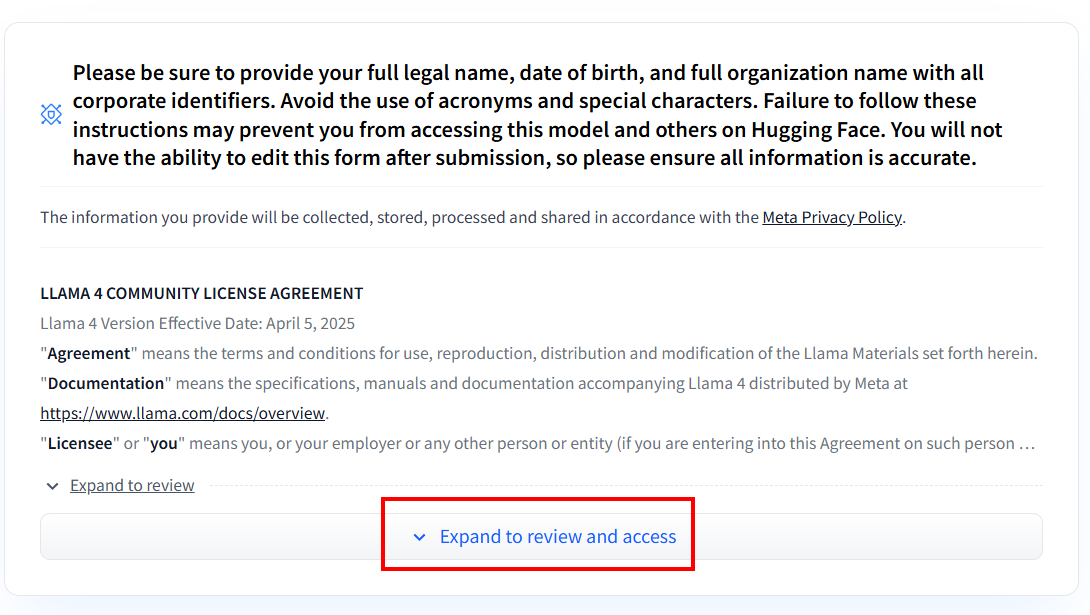
Após preencher o formulário, sua solicitação será analisada:
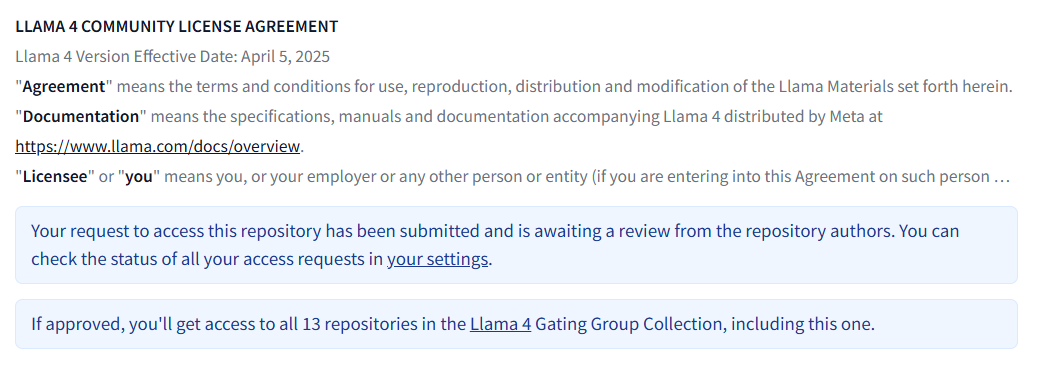
Verifique o status da sua solicitação na seção“Repositórios restritos”:
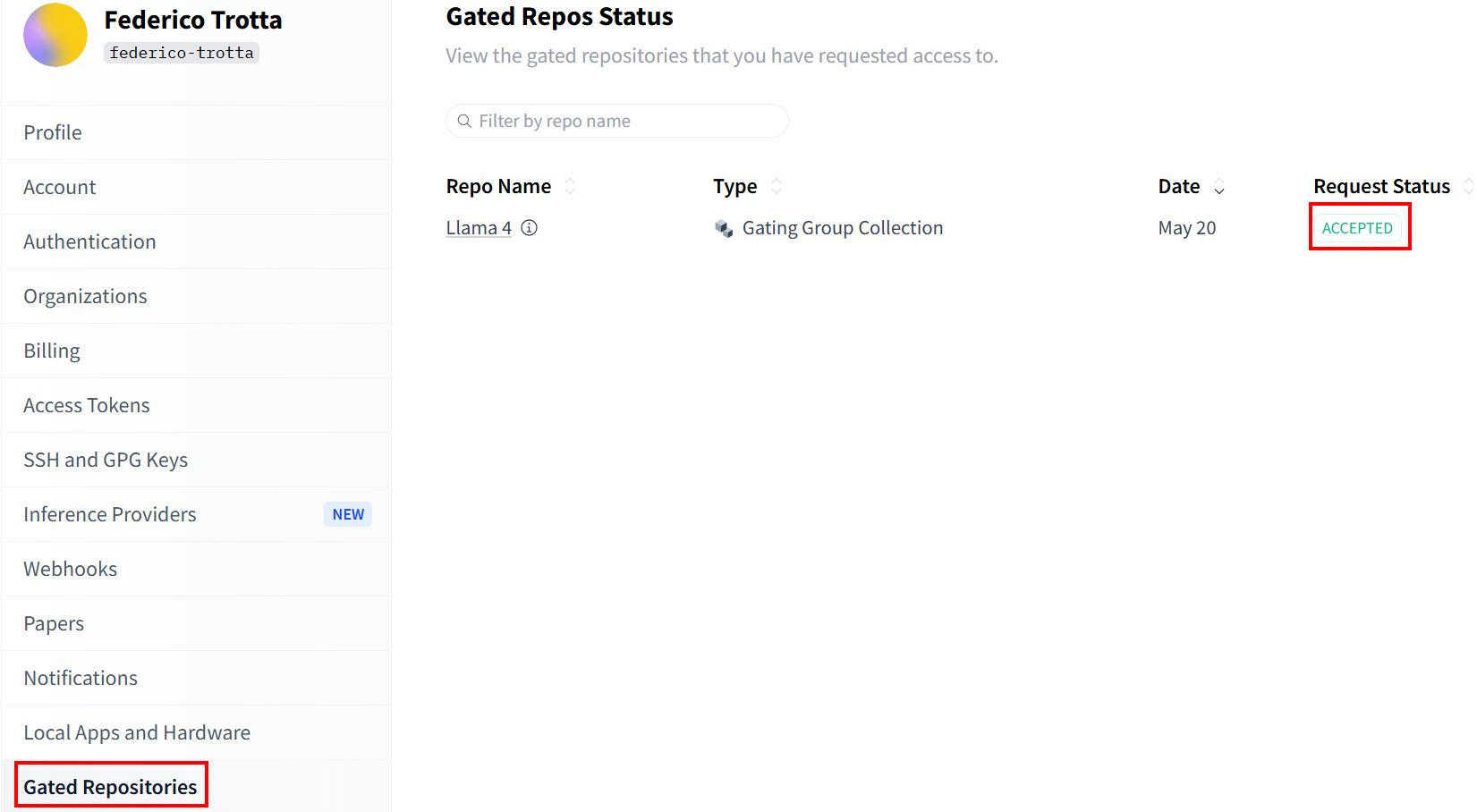
Assim que sua solicitação for aceita, você poderá criar um novo token. Vá para“Access Tokens” (Tokens de acesso) e crie um token com permissões de gravação. Em seguida, copie e salve-o em um local seguro para usá-lo posteriormente:
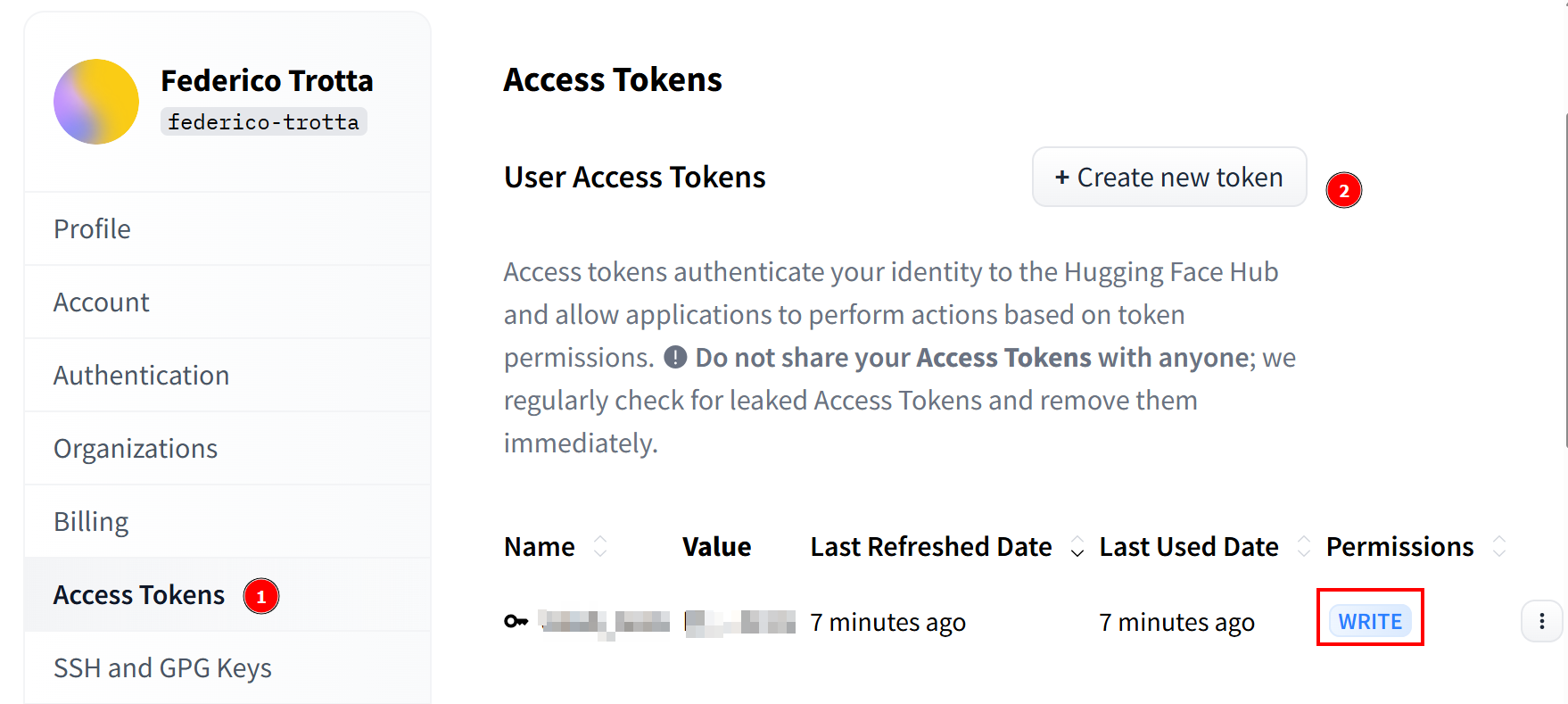
Parabéns! Você concluiu todas as etapas necessárias para usar um modelo Llama 4 com o Hugging Face.
Configurando a infraestrutura em nuvem para ajustar o Llama 4
Os modelos Llama 4 são muito grandes — e o nome deles ajuda a entender o quanto são grandes. Por exemplo, Llama-4-Scout-17B-16E-Instruct significa que ele tem 17 bilhões de parâmetros com 128 especialistas.
O processo de ajuste fino exige que você treine o modelo usando o conjunto de dados de ajuste fino que você recuperou anteriormente. Como o modelo tem 17 bilhões de parâmetros, você precisa de muito hardware para fazer isso. Especificamente, você precisa de mais de uma GPU. Por esse motivo, você usará um serviço em nuvem para realizar o processo de ajuste fino.
Para este tutorial, você usará o RunPod como serviço em nuvem. Acesse“RunPod”e crie uma conta. Em seguida, acesse o menu “Faturamento” e adicione US$ 25 usando o cartão de crédito:
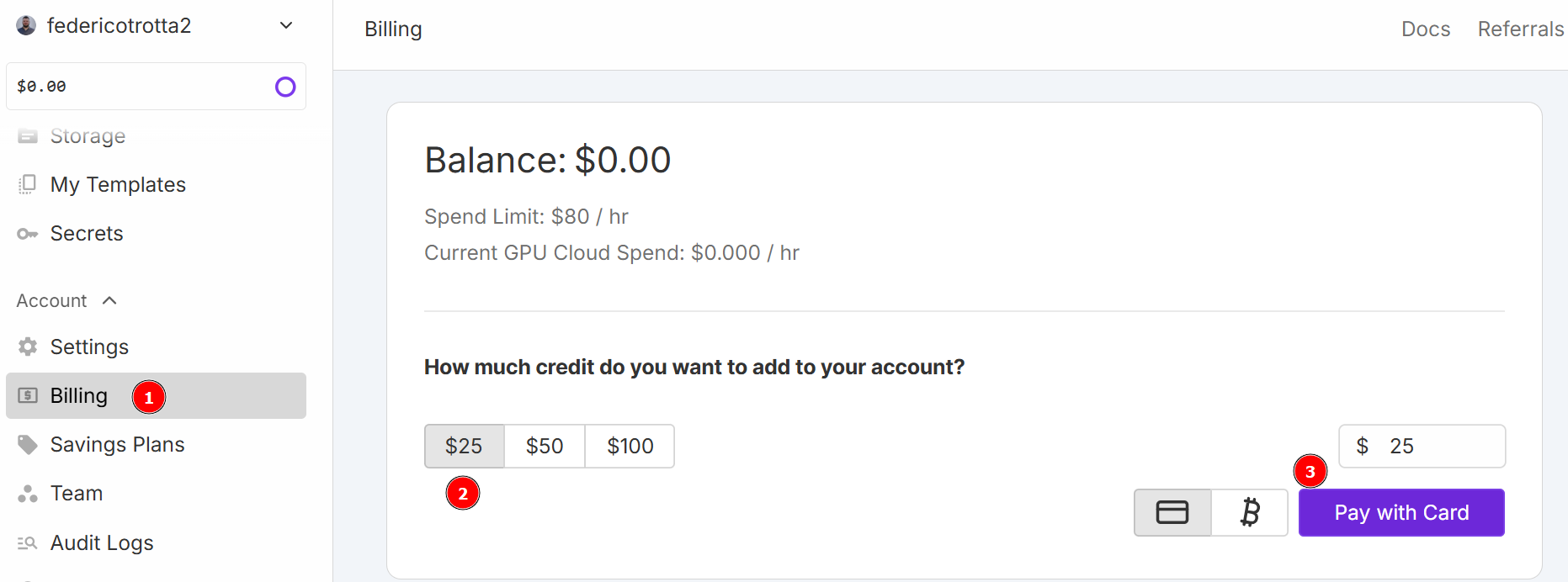
Observação: você pagará imediatamente US$ 25 e o RunPod adicionará o equivalente a US$ 25 em créditos à sua conta. Você consumirá créditos por hora, dependendo de quantas horas seu pod ficará ativo quando implantado. Portanto, implante-o somente quando tiver certeza de que poderá usá-lo. Caso contrário, você consumirá créditos sem realmente usá-los. O consumo real por hora depende do tipo e do número de GPUs que você escolherá nas próximas etapas.
Navegue até o menu “Pods” para começar a configurar seu pod. O pod funciona como um servidor virtual que fornece as CPUs, GPUs, memória e armazenamento necessários para suas tarefas. Clique no botão “Implantar”:
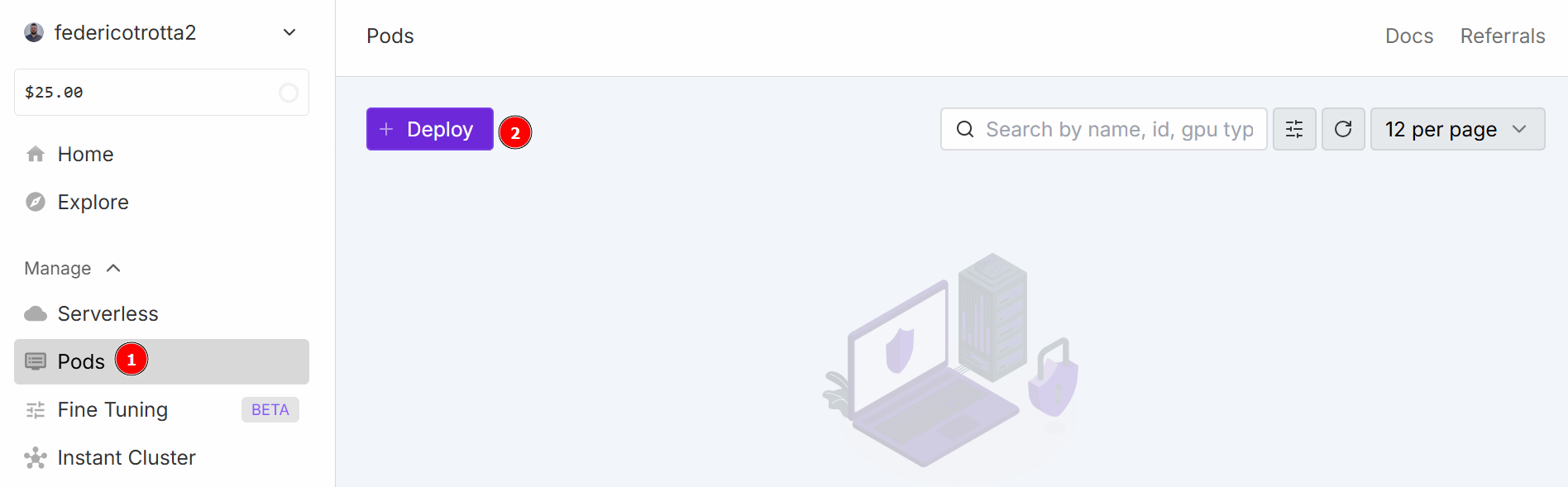
Você pode escolher entre diferentes configurações:
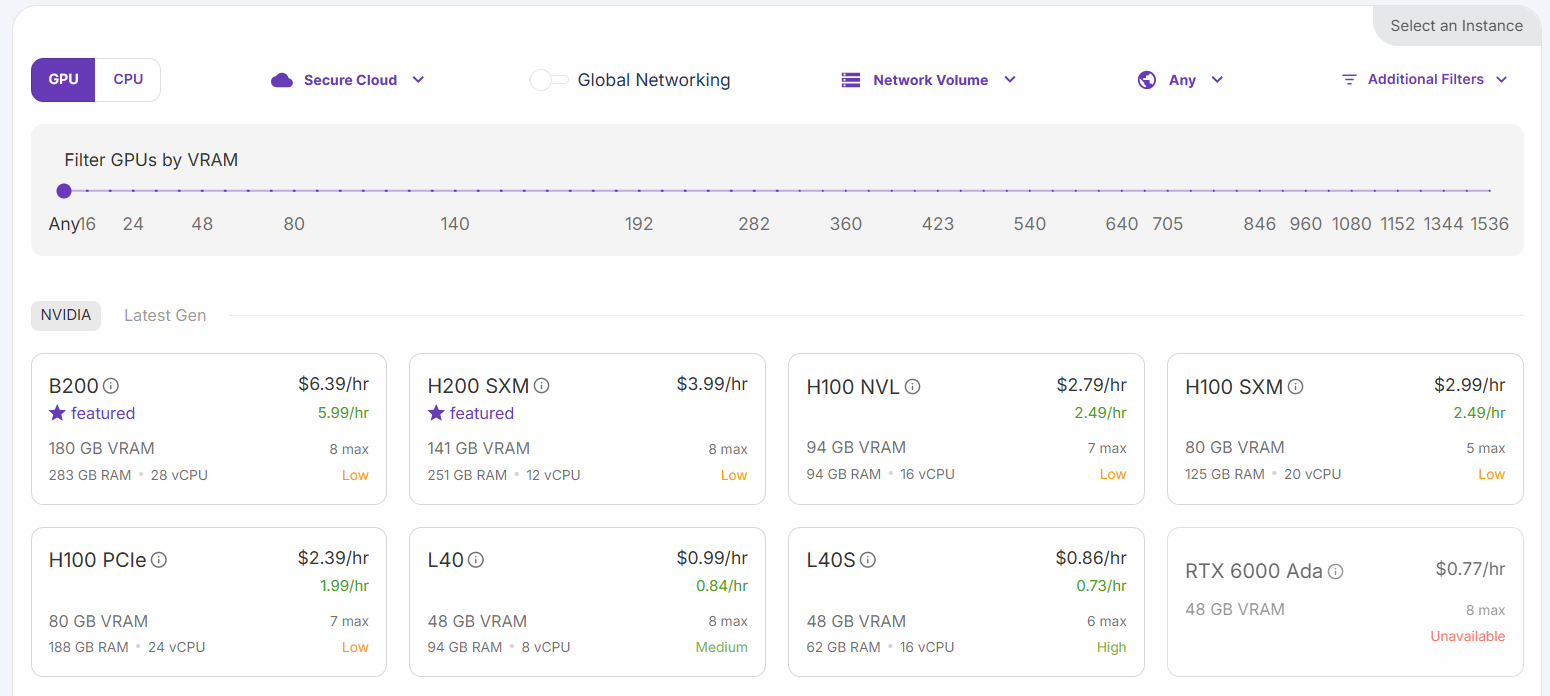
Selecione a opção “H200 SXM GPU”. Dê um nome ao pod e selecione o número de GPUs. Três GPUs são suficientes para este tutorial:
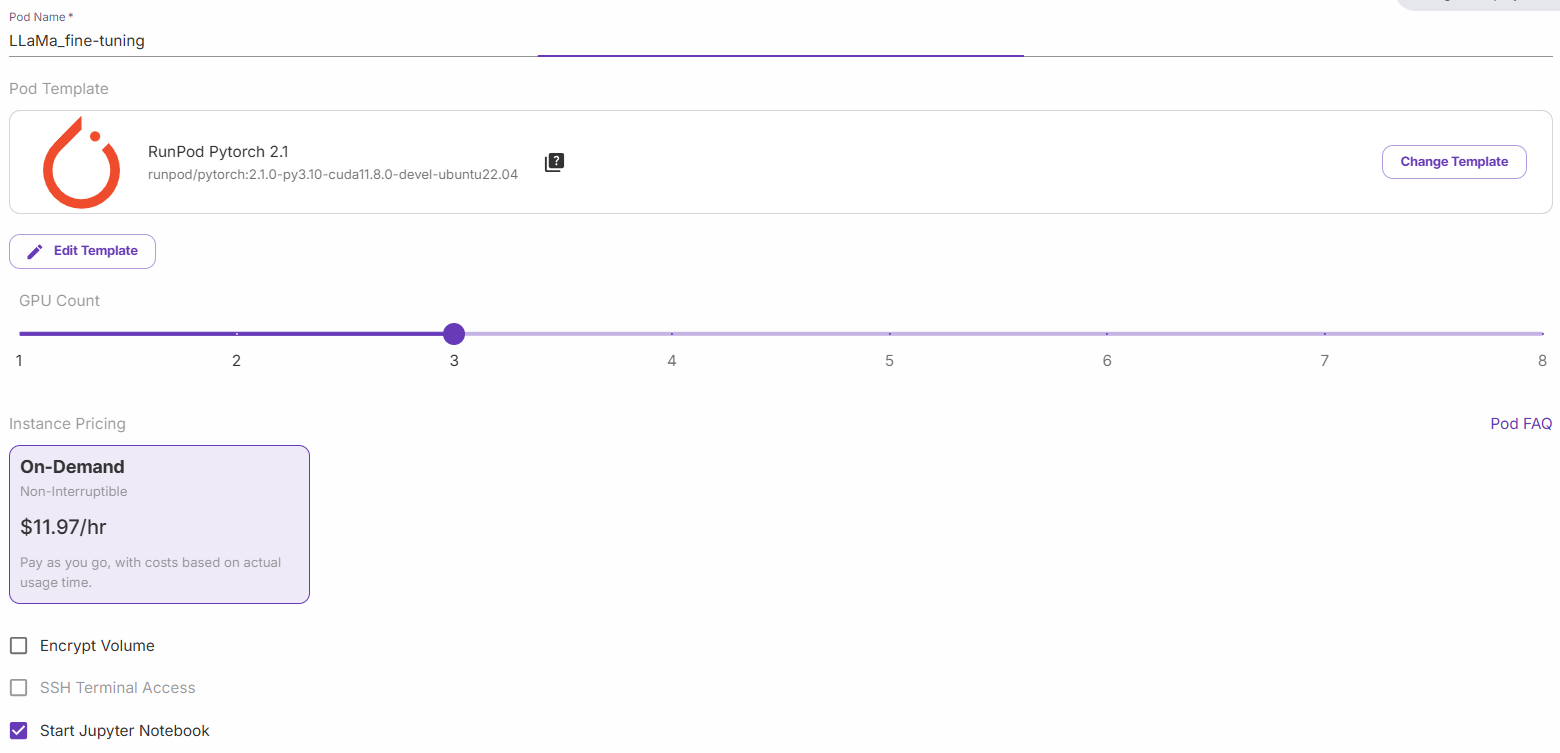
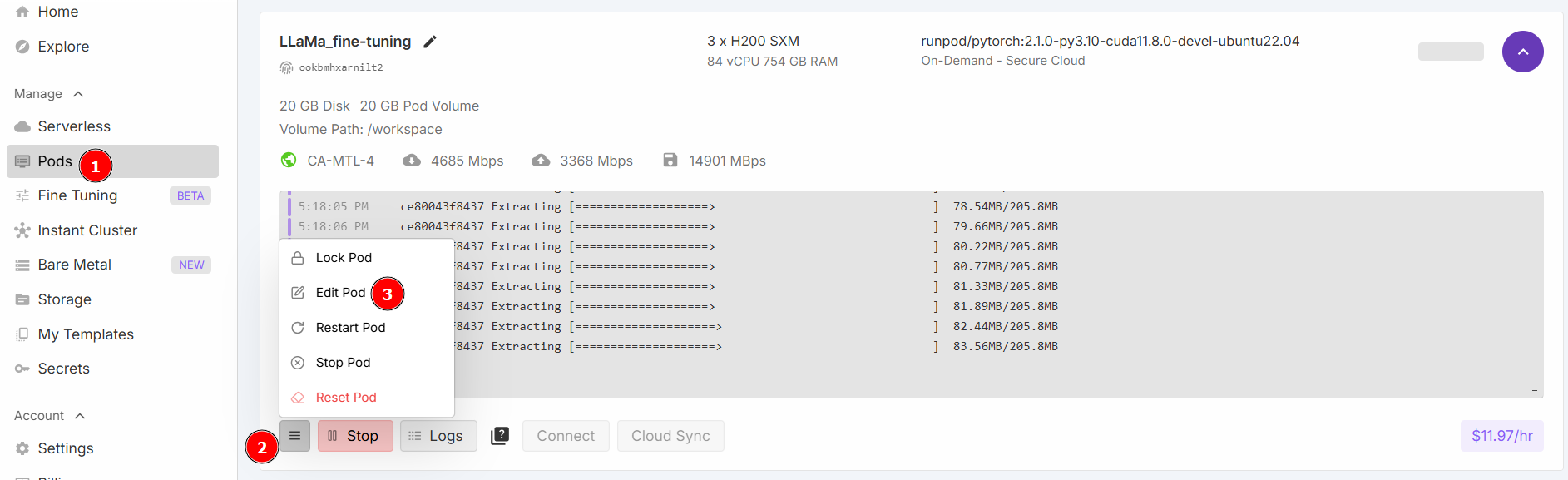
Selecione “Iniciar um Jupyter Notebook” e clique em “Implantar sob demanda”. Agora, vá para a seção “Pods” e edite seu pod:
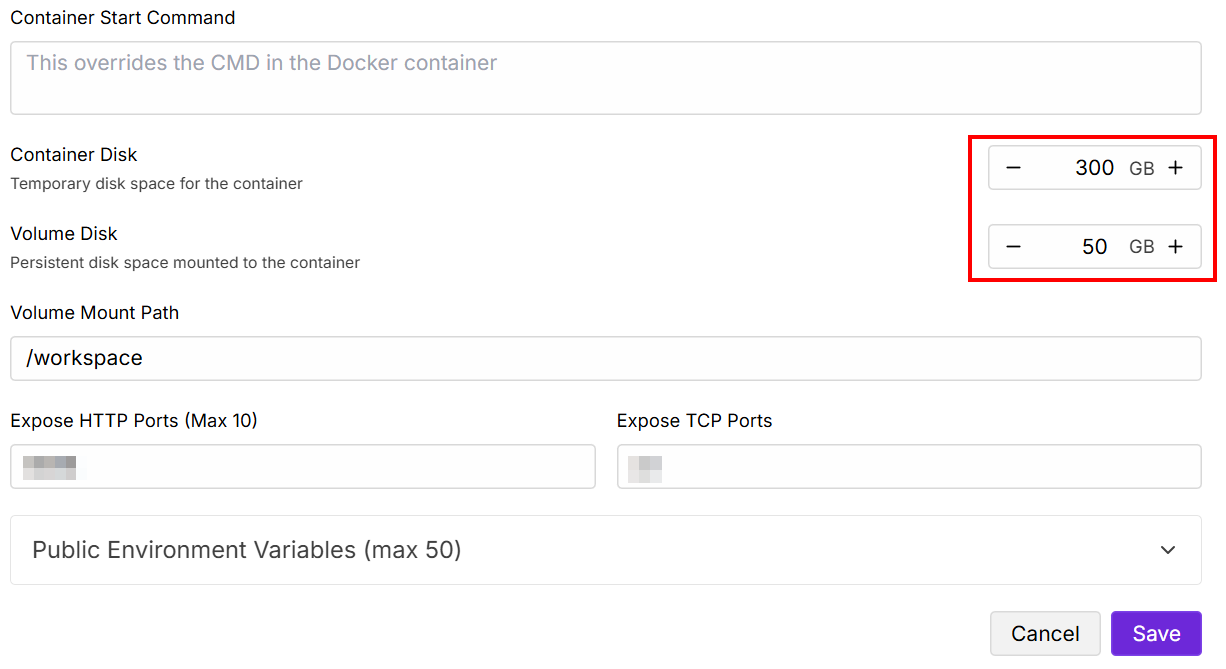
Altere os valores de “Disco contido” e “Disco de volume” conforme abaixo e salve:
Quando a configuração estiver concluída, clique no botão “Conectar”:
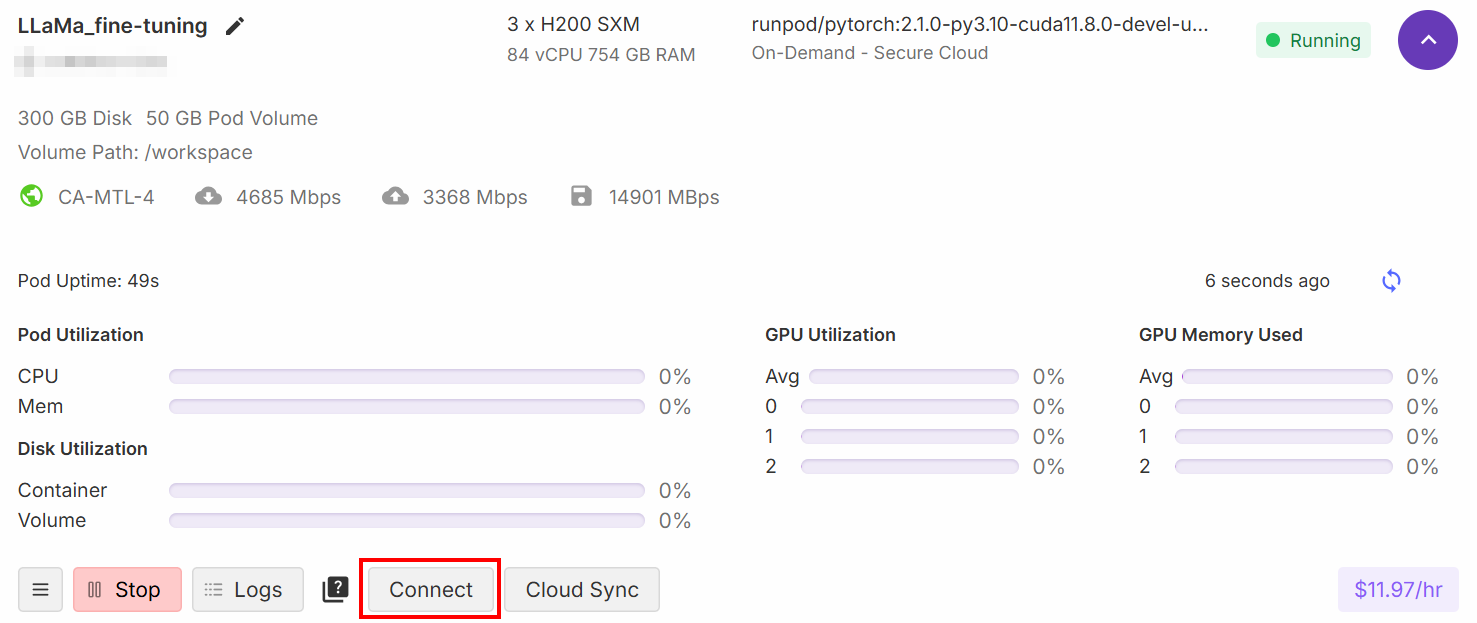
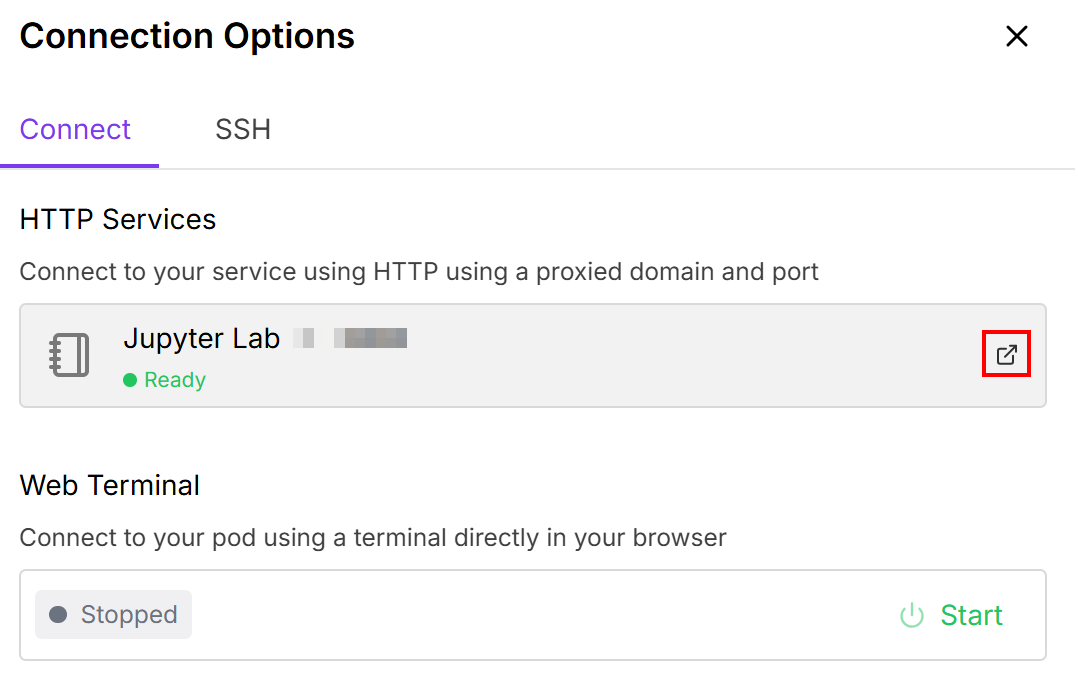
Isso permite que você conecte o Pod a um notebook Jupiter Lab:
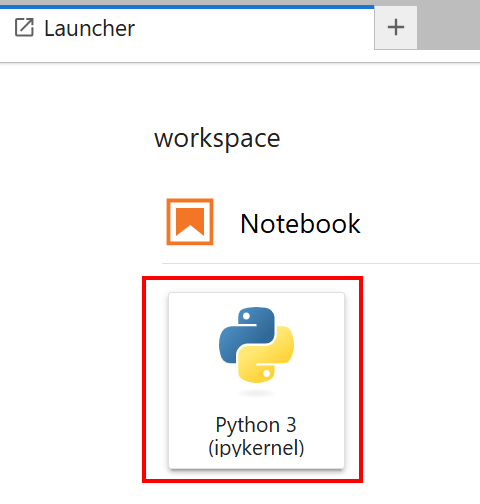
Selecione o Notebook com o cartão “Python 3 (ipykernel)”:
Muito bem! Agora você tem a infraestrutura certa para treinar o modelo Llama 4.
Ajustando o Llama 4 com os dados coletados
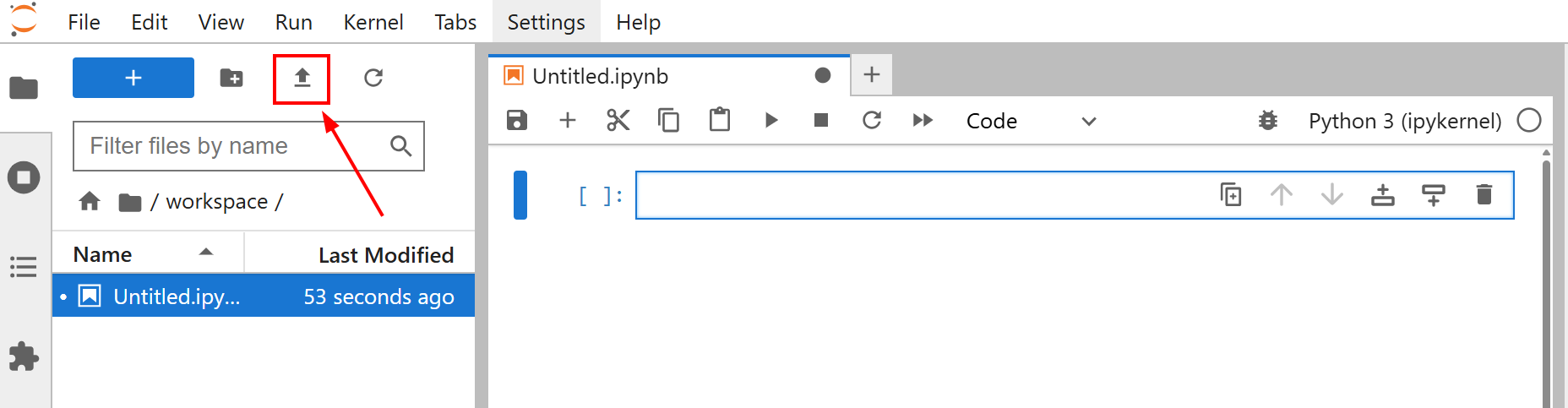
Antes de começar a ajustar seu modelo, carregue o arquivo amazon-data.json no seu notebook Jupyter Lab. Para fazer isso, clique no botão “Carregar arquivos”:
O objetivo do ajuste fino para este tutorial é treinar o Llama 4 usando o conjunto de dados amazon-data.json. Dessa forma, você ensina ao Llama 4 como criar descrições para objetos de escritório, considerando algumas características, como o nome do objeto e algumas funcionalidades.
Agora você está pronto para começar a treinar o modelo. Siga as etapas abaixo para ajustar o Llama 4 com novos dados da web!
Etapa 1: Instale as bibliotecas
Na primeira célula do seu notebook, instale as bibliotecas necessárias:
%%capture
!pip install transformers==4.51.0
%pip install -U Conjuntos de datos
%pip install -U accelerate
%pip install -U peft
%pip install -U trl
%pip install -U bitsandbytes
%pip install huggingface_hub[hf_xet]Essas bibliotecas são:
transformers: fornece milhares de modelos pré-treinados.Conjuntos de dados: oferece acesso a uma vasta coleção de conjuntos de dados e ferramentas eficientes de processamento de dados.accelerate: simplifica a execução de scripts de treinamento PyTorch em várias configurações distribuídas com alterações mínimas no código.peft: permite o ajuste fino de grandes modelos pré-treinados de forma mais eficiente, atualizando apenas um pequeno subconjunto de parâmetros.trl: Projetado para treinar modelos de linguagem transformadores usando técnicas de aprendizado por reforço.scipy: uma biblioteca para computação científica e técnica em Python.huggingface_hub: fornece uma interface Python para interagir com o Hugging Face Hub. Isso permite que você baixe e envie modelos, Conjuntos de dados e espaços.bitsandbytes: Oferece otimizadores de 8 bits e funções de quantização fáceis de usar, reduzindo o consumo de memória para treinamento e inferência de grandes modelos de deep learning.
Perfeito! Você instalou as bibliotecas necessárias para o processo de ajuste fino.
Etapa 2: Conecte-se ao Hugging Face
Na segunda célula do seu notebook, escreva:
from huggingface_hub import notebook_login, login
# Login interativo
notebook_login()
print("Célula de login executada. Se for bem-sucedido, você pode prosseguir.")Ao executá-lo, será exibido o seguinte:
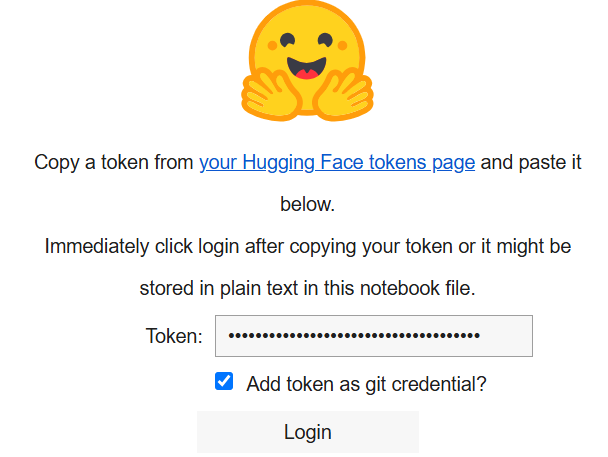
Na caixa “Token”, cole o token que você criou na sua conta Hugging Face.
Ótimo! Agora você pode recuperar o modelo Llama 4 do Hugging Face.
Etapa 3: Carregue o modelo Llama 4
Na terceira célula do seu notebook, escreva o seguinte código:
import os
import torch
import json
from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline, Llama4ForConditionalGeneration, BitsAndBytesConfig
from trl import SFTTrainer
# Carregar modelo
base_model_name = "meta-llama/Llama-4-Scout-17B-16E-Instruct"
# Configuração para quantização BitsAndBytes
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=False,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
)
# Carregar o modelo Llama4 com as configurações especificadas
model = Llama4ForConditionalGeneration.from_pre-trained(
base_model_name,
device_map="auto",
torch_dtype=torch.bfloat16,
quantization_config=bnb_config,
trust_remote_code=True,
)
# Desativar o cache para o modelo
model.config.use_cache = False
# Definir o paralelismo do tensor de pré-treinamento como 1
model.config.pre-training_tp = 1
# Caminho para o arquivo de dados JSON de ajuste fino.
fine_tuning_data_file_path = "amazon-data.json"
# Caminho para os resultados
output_model_dir = "results_llama_office_items_finetuned/"
final_model_adapter_path = os.path.join(output_model_dir, "final_adapter")
max_seq_length_for_tokenization = 1024
# Criar diretório de saída
os.makedirs(output_model_dir)O trecho acima:
- Define o nome do modelo a ser carregado com
base_model_name. - Configura os pesos do modelo com
bnb_configusando o métodoBitsAndBytesConfig(). - Carrega o modelo com o método
from_pre-trained()para treiná-lo. - Carrega o conjunto de dados de ajuste fino com
fine_tuning_data_file_path. - Define o caminho do diretório de saída para os resultados e o cria com o método
makedirs().
Quando a célula terminar de ser executada, você deverá ver um resultado como este:

Fantástico! Seu modelo Llama 4 está configurado e carregado no notebook.
Etapa 4: Prepare o conjunto de dados de ajuste fino para o processo de treinamento
Escreva o seguinte código na quarta célula do seu notebook para preparar o conjunto de dados de ajuste fino para o processo de treinamento:
from Conjuntos de dados import Dataset
# Abra o conjunto de dados de ajuste fino
with open(fine_tuning_data_file_path, "r") as f:
data_list = json.load(f)
# Converta a lista de itens de dados em um objeto Hugging Face Dataset
raw_fine_tuning_dataset = Dataset.from_list(data_list)
print(f"Dados JSON convertidos para Hugging Face Dataset. Número de exemplos: {len(raw_fine_tuning_dataset)}")
def format_fine_tuning_entry(data_item):
system_message = "Você é um redator especialista. Gere uma descrição concisa e atraente do produto com base nos detalhes fornecidos."
# AJUSTE AS LINHAS A SEGUIR ao seu arquivo de ajuste fino
item_title = data_item.get("title")
item_brand = data_item.get("brand")
item_category = data_item.get("categories")
item_name = data_item.get("name")
item_features_list = data_item.get("features")
item_features_str = ", ".join(item_features_list) if isinstance(item_features_list, list) else str(item_features_list)
target_description = data_item.get("description")
# Prompt de treinamento
prompt_do_usuário = (
f"Gere uma descrição do produto para o seguinte item:n"
f"Título: {item_title}nMarca: {item_brand}nCategoria: {item_category}n"
f"Nome: {item_name}nCaracterísticas: {item_features_str}nDescrição:"
)
# Formato de chat Llama
formatted_string = (
f"<|start_header_id|>system<|end_header_id|>nn{system_message}<|eot_id|>"
f"<|start_header_id|>user<|end_header_id|>nn{user_prompt}<|eot_id|>"
f"<|start_header_id|>assistente<|end_header_id|>nn{target_description}<|eot_id|>"
)
return {"text": string formatada}
# Aplique a função de formatação a cada entrada no conjunto de dados brutos para estruturá-lo para ajuste fino
conjunto_de_dados_formatado = conjunto_de_dados_brutos_ajuste_fino.map(format_fine_tuning_entry)
# Configuração do tokenizador
tokenizer = AutoTokenizer.from_pre-trained(base_model_name, trust_remote_code=True)
tokenizer.pad_token = tokenizer.eos_token
# Pré-tokenizar o conjunto de dados
def tokenize_function_for_sft(examples):
# Tokenizar o campo "texto" que contém a string completa formatada como chat
tokenized_output = tokenizer(
examples["text"],
truncation=True,
padding="max_length",
max_length=max_seq_length_for_tokenization,
)
return tokenized_output
# Aplicar a função de tokenização ao conjunto de dados formatado
tokenized_train_dataset = text_formatted_dataset.map(
tokenize_function_for_sft,
batched=True,
remove_columns=["text"]
)Esta célula do notebook:
- Abre o conjunto de dados de ajuste fino e o converte em um objeto Hugging Face
Datasetusando o métodoDataset.from_list(). - Define uma função
format_fine_tuning_entry(). Seu objetivo é pegar um único item de dados (os detalhes de um produto) e transformá-lo em um formato de texto estruturado adequado para o ajuste fino de instruções de um modelo de chat como o Llama. Observe que isso deve ser adaptado à estrutura do seu conjunto de dados de ajuste fino. - Tokeniza os conjuntos de dados e aplica a tokenização com o método
map(). Isso é feito porque os modelos de linguagem não entendem texto bruto. Eles operam em representações numéricas chamadas tokens.
Quando a célula termina de ser executada, o resultado esperado é o seguinte:

Observe que o valor de “Num examples” depende do seu conjunto de dados de ajuste fino.
Incrível! Seu conjunto de dados de ajuste fino está pronto para o processo de ajuste fino.
Etapa 5: Configure o ambiente e os parâmetros para o ajuste fino eficiente em termos de parâmetros (PEFT)
Em uma nova célula do seu notebook, escreva o seguinte código para definir o ambiente e os parâmetros para PEFT:
from transformers import BitsAndBytesConfig
from peft import LoraConfig
# Configuração QLoRA
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
bnb_4bit_use_double_quant=True,)
# Configuração LoRA
lora_config = LoraConfig(
r=16,
lora_alpha=32,
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
target_modules=["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj"],
)Este código:
- Define a configuração QLoRA para quantização com o método
BitsAndBytesConfig()para especificar como um modelo de linguagem pré-treinado deve ser quantizado quando carregado. A quantização é uma técnica para reduzir custos computacionais e de memória. - Define a configuração LoRA para configurar o modelo para um ajuste fino eficiente em termos de parâmetros com o método LoraConfig().
Muito bem! O ambiente está pronto para um ajuste fino eficiente.
Etapa 6: Inicializar o processo de treinamento
Em uma nova célula, escreva o seguinte código para inicializar o processo de treinamento:
from peft import get_peft_model, prepare_model_for_kbit_training
from transformers import TrainingArguments
# Prepare o modelo para o treinamento k-bit
model = prepare_model_for_kbit_training(
model,
gradient_checkpointing_kwargs={"use_reentrant": False}
)
# Aplicar a configuração PEFT (LoRA) ao modelo.
model = get_peft_model(model, lora_config)
# Desativar o cache na configuração do modelo.
model.config.use_cache = False
# Imprimir o número de parâmetros treináveis no modelo.
model.print_trainable_parameters()
# Definir argumentos de treinamento
training_args = TrainingArguments(
output_dir=output_model_dir,
num_train_epochs=3,
per_device_train_batch_size=1,
gradient_accumulation_steps=4,
learning_rate=2e-4,
logging_steps=25,
save_steps=50,
fp16=True,
optim="paged_adamw_8bit",
lr_scheduler_type="cosine",
warmup_ratio=0.03,
report_to="none",
max_grad_norm=0.3,
save_total_limit=2,)
# Inicializar SFTTrainer
trainer = SFTTrainer(
model=model,
args=training_args,
train_dataset=tokenized_train_dataset,
peft_config=lora_config,
)O código nesta célula:
- O método
prepare_model_for_kbit_training()prepara omodelopré-carregado para treinamento com quantização. - O método
get_peft_model()pega omodelobase quantizado e preparado e aplica olora_config. - Define os argumentos de treinamento chamando a classe
TrainingArguments(). - Inicializa o treinador com
SFTTrainer().
Abaixo está o resultado esperado:

Etapa 7: Treinar o modelo
O processo está finalmente pronto para treinar o modelo Llama 4 usando o método train():
# Treinar o modelo
treinador.train()
# Salvar o modelo ajustado
treinador.save_model(final_model_adapter_path) # Salva o adaptador LoRA
tokenizador.save_pre-trained(final_model_adapter_path) # Salvar o tokenizador com o adaptadorO resultado é o seguinte:

Observe que você pode obter números diferentes devido à natureza estocástica da IA.
Etapa 8: Prepare o modelo para inferência
Para preparar o modelo para inferência, escreva o seguinte código em uma nova célula:
# Carregue o modelo com quantização para inferência
base_model_for_inference = AutoModelForCausalLM.from_pre-trained(
base_model_name,
quantization_config=bnb_config,
device_map="auto",
trust_remote_code=True
)
# Carregue o adaptador LoRA ajustado e anexe-o ao modelo
fine_tuned_model_for_testing = PeftModel.from_pre-trained(
base_model_for_inference,
final_model_adapter_path
)
# Mesclar o adaptador LoRA no modelo base
fine_tuned_model_for_testing = fine_tuned_model_for_testing.merge_and_unload()
# Carregue o tokenizador
fine_tuned_tokenizer_for_testing = AutoTokenizer.from_pre-trained(
final_model_adapter_path,
trust_remote_code=True)
# Configure o tokenizador para inferência
fine_tuned_tokenizer_for_testing.pad_token = fine_tuned_tokenizer_for_testing.eos_token
fine_tuned_tokenizer_for_testing.padding_side = "left"
# Definir o modelo ajustado para o modo de avaliação
fine_tuned_model_for_testing.eval()O código nesta célula:
- Carrega o modelo com o método
from_pre-trained()para inferência. - Carrega, aplica e mescla o adaptador LoRA ao modelo base para inferência.
- Carrega o tokenizador ajustado e o configura para inferência.
- Define o modelo para o modo de avaliação com o método
eval(). Isso desativa comportamentos específicos do treinamento, garantindo resultados consistentes e determinísticos durante a inferência.
Pronto! Tudo está configurado para a inferência.
Etapa 9: Inferir o modelo
Nesta última etapa, você realizará a inferência. Anteriormente, você treinou o Llama 4 em produtos coletados da Amazon. Agora, com alguns dados que incluem o nome e as características de itens de escritório, você deseja ver se o modelo é capaz de gerar sua descrição.
O código a seguir permite que você gerencie o processo de inferência:
# Defina uma lista de itens de dados sintéticos de produtos para testar o modelo ajustado
synthetic_test_items = [
{
"title": "Cadeira ergonômica executiva para escritório", "brand": "ComfortLuxe", "category": "Cadeiras de escritório", "name": "ErgoPro-EL100",
"features": ["Design com encosto alto", "Apoio lombar ajustável", "Tecido de malha respirável", "Mecanismo de inclinação sincronizado", "Apoios de braços acolchoados", "Base de nylon resistente"]
},
{
"title": "Conversor de mesa ajustável", "brand": "FlexiDesk", "category": "Mesas e estações de trabalho", "name": "HeightRise-FD20",
“características”: [“Superfície espaçosa de dois níveis”, “Elevação suave por mola a gás”, “Alcance de altura ajustável de 15 a 43 cm”, “Suporta até 16 kg”, “Bandeja para teclado incluída”, “Pés de borracha antiderrapantes”]
},
{
“título”: “Conjunto de teclado e mouse sem fio”, “marca”: “TechGear”, “categoria”: “Periféricos de computador”, “nome”: “SilentType-KM850”,
"características": ["Teclado de tamanho normal com teclado numérico", "Teclas silenciosas", "Mouse ergonômico com DPI ajustável", "Conectividade sem fio de 2,4 GHz", "Bateria de longa duração", "Receptor USB plug-and-play"]
},
{
“título”: “Organizador de mesa com gavetas”, “marca”: “NeatOffice”, “categoria”: “Acessórios de mesa”, “nome”: “SpaceSaver-DO3”,
“características”: [“Design com vários compartimentos”, “Duas gavetas extraíveis”, “Construção em madeira resistente”, “Dimensões compactas”, “Ideal para canetas, notas e pequenos materiais”]
},
{
"title": "Lâmpada de mesa LED com porta de carregamento USB", "brand": "BrightSpark", "category": "Iluminação para escritório", "name": "LumiCharge-LS50",
"características": ["Níveis de brilho ajustáveis (5)", "Modos de temperatura de cor (3)", "Design flexível com pescoço de ganso", "Porta de carregamento USB integrada", "Luz sem cintilação, que protege os olhos", "LED com eficiência energética"]
},
]
# Mensagem do sistema e estrutura de prompt para inferência
system_message_inference = "Você é um redator especialista. Gere uma descrição concisa e atraente do produto com base nos detalhes fornecidos."
print("n--- Gerando descrições com modelo ajustado usando dados de teste sintéticos ---")
# Iterar por cada item na lista synthetic_test_items
para item_data em synthetic_test_items:
# Construir a parte do prompt do usuário com base na estrutura do item sintético
user_prompt_inference = (
f"Gere uma descrição do produto para o seguinte item de escritório:n"
f"Título: {item_data["title"]}n"
f"Marca: {item_data["brand"]}n"
f"Categoria: {item_data["category"]}n"
f"Nome: {item_data["name"]}n"
f"Características: {", ".join(item_data["features"])}n"
f"Descrição:" # O modelo irá gerar texto após isto.
)
full_prompt_for_inference = (
f"<|start_header_id|>system<|end_header_id|>nn{system_message_inference}<|eot_id|>"
f"<|start_header_id|>usuário<|end_header_id|>nn{user_prompt_inference}<|eot_id|>"
f"<|start_header_id|>assistente<|end_header_id|>nn"
)
print(f"nPROMPT para o item: {item_data["name"]}")
# Tokenize a string completa do prompt usando o tokenizador ajustado.
inputs = fine_tuned_tokenizer_for_testing(
full_prompt_for_inference,
return_tensors="pt",
padding=False,
truncation=True,
max_length=max_seq_length_for_tokenization - 150
).to(fine_tuned_model_for_testing.device)
# Realizar inferência
with torch.no_grad():
outputs = fine_tuned_model_for_testing.generate(
**inputs,
max_new_tokens=150,
num_return_sequences=1,
do_sample=True,
temperature=0.6,
top_k=50,
top_p=0.9,
pad_token_id=fine_tuned_tokenizer_for_testing.eos_token_id,
eos_token_id=[
fine_tuned_tokenizer_for_testing.eos_token_id,
fine_tuned_tokenizer_for_testing.convert_tokens_to_ids("<|eot_id|>")
]
)
# Decodifique os IDs de token gerados de volta para uma string de texto legível por humanos
texto_gerado_completo = tokenizador_ajustado_para_teste.decodificar(saídas[0], ignorar_tokens_especiais=False)
# Defina o marcador que indica o início da resposta do assistente no formato de chat Llama.
marcador_assistente = "<|start_header_id|>assistente<|end_header_id|>nn"
# Encontre a última ocorrência do marcador do assistente no texto gerado
assistant_response_start_index = generated_text_full.rfind(assistant_marker)
# Extraia a descrição real gerada da saída completa do modelo
if assistant_response_start_index != -1:
# Se o marcador do assistente for encontrado, extraia o texto que vem depois dele
descrição_gerada = texto_gerado_completo[índice_início_resposta_assistente + len(marcador_assistente):]
# Defina o token de fim de turno para Llama
token_eot = "<|eot_id|>"
# Verifique se a descrição extraída termina com o token de fim de turno Llama e remova-o.
if generated_description.endswith(eot_token):
generated_description = generated_description[:-len(eot_token)]
# Verifique também se termina com o token padrão de fim de sequência do tokenizador e remova-o.
if generated_description.endswith(fine_tuned_tokenizer_for_testing.eos_token):
descrição_gerada = descrição_gerada[:-len(fine_tuned_tokenizer_for_testing.eos_token)]
# Remova qualquer espaço em branco à esquerda ou à direita da descrição limpa
descrição_gerada = descrição_gerada.strip()
else:
# Fallback: Se o marcador assistente não for encontrado, tente extrair a parte gerada assumindo que é tudo após o prompt de entrada original.
input_prompt_decoded_len = len(fine_tuned_tokenizer_for_testing.decode(inputs["input_ids"][0], skip_special_tokens=False))
# Decodifique os tokens do prompt de entrada para obter seu comprimento como uma string.
descrição_gerada = texto_gerado_completo[input_prompt_decoded_len:].strip()
# Limpe qualquer token de fim de turno Llama desta extração de fallback.
if descrição_gerada.endswith("<|eot_id|>"):
descrição_gerada = descrição_gerada[:-len("<|eot_id|>")]
descrição_gerada = descrição_gerada.strip()
# Imprima a descrição gerada extraída e limpa
print(f"GERADO (Ajustado):n{descrição_gerada}")
# Imprima uma linha separadora para melhorar a legibilidade entre os itens.
print("-" * 50)Esta última célula do Jupyter Notebook gerencia o processo de inferência. Esse processo é útil para ver a qualidade do treinamento durante o processo de ajuste fino.
Em particular, o código acima:
- Define os dados de teste como uma lista chamada
synthetic_test_items. Cada elemento dessa lista é um dicionário que representa um produto, contendo detalhes como título, marca, categoria, nome e uma lista de recursos. Esses dados servem como entrada para o modelo e sua estrutura deve corresponder à do conjunto de dados de ajuste fino. - Configura sua estrutura de prompt de referência com
system_message_inference. Isso deve corresponder ao prompt usado durante o processo de treinamento. - O loop
for item_data em synthetic_test_itemscria um prompt de usuário para cadaitem_data. A estrutura de cadaitem_datadeve corresponder à usada no processo de treinamento. - Tokeniza e controla como o modelo produz o texto de saída. A inferência real é feita sob a instrução
with. Particularmente, graças ao métodogenerate(), que é a etapa central da inferência. - Decodifica a saída bruta do modelo (que é uma sequência de IDs de tokens) em uma string legível por humanos (
generated_text_full) usando o tokenizador. - Usa um bloco
if-elsepara limpar a saída bruta do modelo de linguagem para extrair apenas a descrição do produto gerada pelo assistente. A saída bruta (generated_text_full) normalmente inclui todo o prompt de entrada seguido pela resposta do modelo, tudo formatado com tokens de chat especiais do Llama. - Imprime os resultados.
Você pode esperar o seguinte resultado:
--- Gerando descrições com modelo ajustado usando dados de teste sintéticos ---
PROMPT para item: ErgoPro-EL100
GERADO (ajustado):
**Apresentando a ErgoPro-EL100: a melhor cadeira ergonômica executiva para escritório**
Experimente o auge do conforto e do apoio com a ComfortLuxe ErgoPro-EL100, projetada para elevar sua experiência de trabalho. Esta cadeira de escritório premium possui um design com encosto alto que envolve a parte superior do corpo, proporcionando um apoio lombar incomparável e promovendo uma postura saudável.
O tecido de malha respirável garante uma experiência de assento fresca e confortável, enquanto o mecanismo de inclinação sincronizado permite ajustes perfeitos para sua posição de trabalho preferida. Os apoios de braços acolchoados oferecem suporte e conforto adicionais, reduzindo a tensão nos ombros e pulsos.
Construída para durar, a ErgoPro-EL100 possui uma base de nylon resistente que garante estabilidade e durabilidade. Quer você trabalhe muitas horas ou simplesmente
--------------------------------------------------
PROMPT para o item: HeightRise-FD20
GERADO (ajustado):
**Aumente sua produtividade com o conversor de mesa ajustável HeightRise-FD20 da FlexiDesk**
Leve seu trabalho a novos patamares com o HeightRise-FD20 da FlexiDesk, o conversor de mesa ajustável definitivo. Projetado para revolucionar seu espaço de trabalho, este conversor inovador transforma qualquer mesa em uma estação de pé confortável e ergonômica.
**Experimente os benefícios de ficar em pé**
O HeightRise-FD20 possui uma superfície espaçosa de dois níveis, perfeita para acomodar seu laptop, monitor e outras ferramentas de trabalho essenciais. O elevador de mola a gás suave permite ajustes de altura sem esforço, variando de 15 a 43 cm, garantindo uma posição confortável em pé que atende às suas necessidades.
**Durável e confiável**
Com uma construção robusta e pés de borracha antiderrapantes
--------------------------------------------------Et voilà! Você ajustou o Llama 4 com um novo conjunto de dados recuperado usando as APIs do Bright Data Scraper.
Conclusão
Neste artigo, você aprendeu como ajustar o Llama 4 com um conjunto de dados extraído da Amazon usando as APIs do Bright Data Scraper. Você passou por todo o processo que consiste em:
- Recuperar os dados da web.
- Configurar uma conta Hugging Face com um token.
- Configurar a infraestrutura de nuvem necessária.
- Treinar e testar (inferência) o Llama 4.
O núcleo do processo de ajuste depende de Conjuntos de dados de alta qualidade. Felizmente, a Bright Data oferece vários serviços prontos para IA para aquisição ou criação de Conjuntos de dados:
- Navegador de scraping: um navegador compatível com Playwright, Selenium e Puppeter com recursos de desbloqueio integrados.
- Web Scraper APIs: APIs pré-configuradas para extrair dados estruturados de mais de 100 domínios importantes.
- Web Unlocker: uma API completa que lida com o desbloqueio de sites com proteções anti-bot.
- API SERP: uma API especializada que desbloqueia resultados de mecanismos de pesquisa e extrai dados SERP completos.
- Modelos básicos: acesse conjuntos de dados compatíveis e em escala da web para alimentar o pré-treinamento, a avaliação e o ajuste fino.
- Provedores de dados: conecte-se a provedores confiáveis para obter Conjuntos de dados de alta qualidade e prontos para IA em escala.
- Pacotes de dados: obtenha conjuntos de dados selecionados e prontos para uso — estruturados, enriquecidos e anotados.
Crie uma conta Bright Data gratuitamente para testar nossa infraestrutura de dados pronta para IA!





