
Neste artigo, você aprenderá:
- Como criar um agente de IA pronto para produção que persiste conversas em bancos de dados
- Como implementar a extração inteligente de dados e o rastreamento de entidades
- Como criar um tratamento robusto de erros com recuperação automática
- Como aprimorar seu agente com dados da web em tempo real da Bright Data
Vamos começar!
O desafio das conversas de IA sem estado
Os agentes de IA atuais geralmente funcionam como sistemas sem estado. Eles tratam cada conversa como um evento separado. Essa falta de contexto histórico faz com que os usuários repitam informações. Como resultado, isso causa ineficiências operacionais e frustração do usuário. Além disso, as empresas perdem a oportunidade de usar dados de longo prazo para personalização ou melhoria do serviço.
A IA com persistência de dados resolve esse problema registrando todas as interações em um banco de dados estruturado. Ao manter um registro contínuo, esses sistemas podem lembrar o contexto histórico, rastrear entidades específicas ao longo do tempo e usar padrões de interação anteriores para fornecer uma experiência de usuário consistente e personalizada.
O que estamos construindo: sistema de agente de IA conectado a banco de dados
Criaremos um agente de IA pronto para produção que processa mensagens usando LangChain e GPT-4. Ele salva cada conversa no PostgreSQL. Ele extrai entidades e insights em tempo real. Ele mantém um histórico completo de conversas entre as sessões. Ele gerencia erros com sistemas de repetição automática. Ele oferece monitoramento com registro.
O sistema lidará com:
- Esquema de banco de dados com relações e índices adequados
- Agente LangChain com ferramentas de banco de dados personalizadas
- Persistência automática de conversas e extração de entidades
- Pipeline de processamento em segundo plano para coleta de dados
- Tratamento de erros com gerenciamento de transações
- Interface de consulta para recuperar dados históricos
- Integração RAG com Bright Data para inteligência web
Pré-requisitos
Configure seu ambiente de desenvolvimento com:
- Python 3.10 ou superior. Necessário para recursos assíncronos modernos e dicas de tipo
- PostgreSQL 14+ ou SQLite 3.35+. Banco de dados para persistência de dados
- Chave API OpenAI. Para acesso ao GPT-4. Obtenha-a na Plataforma OpenAI
- LangChain. Estrutura para a criação de agentes de IA. Consulte a documentação
- Ambiente virtual Python. Mantém as dependências isoladas. Consulte a documentação
venv
Configuração do ambiente
Crie o diretório do seu projeto e instale as dependências:
mkdir database-agent
cd database-agent
python -m venv venv
# macOS/Linux: source venv/bin/activate
# Windows: venv\Scripts\activate
pip install langchain langchain-openai sqlalchemy psycopg2-binary python-dotenv pydanticCrie um novo arquivo chamado agent.py e adicione as seguintes importações:
import os
import json
import logging
import time
from datetime import datetime, timedelta
from typing import List, Dict, Any, Optional
from queue import Queue
from threading import Thread
# Importações do SQLAlchemy
from sqlalchemy import create_engine, Column, Integer, String, Text, DateTime, Float, JSON, ForeignKey, text
from sqlalchemy.orm import sessionmaker, relationship, Session, declarative_base
from sqlalchemy.pool import QueuePool
from sqlalchemy.exc import SQLAlchemyError
# Importações LangChain
de langchain.agents import AgentExecutor, create_openai_functions_agent
de langchain.prompts import ChatPromptTemplate, MessagesPlaceholder
de langchain.tools import Tool
de langchain_openai import ChatOpenAI
de langchain.memory import ConversationBufferMemory
de langchain.schema import HumanMessage, AIMessage, SystemMessage
# Importações RAG
from langchain_community.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
import requests
# Configuração do ambiente
from dotenv import load_dotenv
load_dotenv()
# Configurar registro
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)Crie um arquivo .env com suas credenciais:
# Configuração do banco de dados
DATABASE_URL="postgresql://username:password@localhost:5432/agent_db"
# Ou para SQLite: DATABASE_URL="sqlite:///./agent_data.db"
# Chaves API
OPENAI_API_KEY="your-openai-api-key"
# Opcional: Bright Data (para a Etapa 7)
BRIGHT_DATA_API_KEY="sua-chave-API-bright-data"
# Configurações do aplicativo
AGENT_MODEL="gpt-4-turbo-preview"
CONNECTION_POOL_SIZE=5
MAX_RETRIES=3Você precisa de:
- URL do banco de dados: cadeia de conexão para PostgreSQL ou SQLite
- Chave da API OpenAI: para inteligência do agente via GPT-4
- Chave da API Bright Data: opcional, para dados da web em tempo real na Etapa 7
Criando seu agente de IA conectado ao banco de dados
Etapa 1: Projetando o esquema do banco de dados
Crie tabelas para usuários, conversas, mensagens e entidades extraídas. O esquema usa chaves estrangeiras e relações para manter a integridade dos dados.
Base = declarative_base()
class User(Base):
"""Tabela de perfil do usuário - armazena informações e preferências do usuário."""
__tablename__ = 'users'
id = Column(Integer, primary_key=True)
user_id = Column(String(255), unique=True, nullable=False, index=True)
name = Column(String(255))
email = Column(String(255))
preferences = Column(JSON, default={})
created_at = Column(DateTime, default=datetime.utcnow)
last_active = Column(DateTime, default=datetime.utcnow, onupdate=datetime.utcnow)
# Relações
conversations = relationship("Conversation", back_populates="user", cascade="all, delete-orphan")
def __repr__(self):
return f"<User(user_id='{self.user_id}', name='{self.name}')>"
class Conversation(Base):
"""Tabela de sessões de conversação - rastreia sessões de conversação individuais."""
__tablename__ = 'conversations'
id = Coluna(Integer, primary_key=True)
conversation_id = Coluna(String(255), unique=True, nullable=False, index=True)
user_id = Coluna(Integer, ForeignKey('users.id'), nullable=False)
title = Coluna(String(500))
summary = Coluna(Text)
status = Coluna(String(50), padrão='ativo') # ativo, arquivado, excluído
meta_data = Coluna(JSON, padrão={})
criado_em = Coluna(DateTime, padrão=datetime.utcnow)
atualizado_em = Coluna(DateTime, padrão=datetime.utcnow, onupdate=datetime.utcnow)
# Relações
usuário = relationship("User", back_populates="conversations")
mensagens = relationship("Message", back_populates="conversation", cascade="all, delete-orphan")
entidades = relationship("Entity", back_populates="conversation", cascade="all, delete-orphan")
def __repr__(self):
return f"<Conversation(id='{self.conversation_id}', user='{self.user_id}')>"
class Message(Base):
"""Tabela de mensagens individuais - armazena cada mensagem em uma conversa."""
__tablename__ = 'messages'
id = Coluna(Inteiro, chave_primária=Verdadeiro)
conversation_id = Coluna(Inteiro, Chave_estrangeira('conversations.id'), nulo=Falso, índice=Verdadeiro)
role = Coluna(String(50), nulo=Falso) # usuário, assistente, sistema
content = Coluna(Texto, nulo=Falso)
tokens = Coluna(Inteiro)
model = Coluna(String(100))
meta_data = Coluna(JSON, padrão={})
created_at = Coluna(DataHora, padrão=datetime.utcnow)
# Relações
conversation = relação("Conversation", back_populates="messages")
def __repr__(self):
return f"<Message(role='{self.role}', conversation='{self.conversation_id}')>"
class Entity(Base):
"""Tabela de entidades extraídas - armazena entidades nomeadas extraídas de conversas."""
__tablename__ = 'entities'
id = Coluna(Inteiro, primary_key=True)
conversation_id = Coluna(Inteiro, ForeignKey('conversations.id'), nullable=False, index=True)
entity_type = Coluna(String(100), nullable=False, index=True) # pessoa, organização, localização, etc.
entity_value = Coluna(String(500), nulo=False)
context = Coluna(Texto)
confidence = Coluna(Float, padrão=0.0)
meta_data = Coluna(JSON, padrão={})
extracted_at = Coluna(DateTime, padrão=datetime.utcnow)
# Relações
conversation = relationship("Conversation", back_populates="entities")
def __repr__(self):
return f"<Entity(type='{self.entity_type}', value='{self.entity_value}')>"
class AgentLog(Base):
"""Tabela de registros de operação do agente - armazena registros operacionais para monitoramento."""
__tablename__ = 'agent_logs'
id = Coluna(Integer, primary_key=True)
conversation_id = Coluna(String(255), index=True)
level = Coluna(String(50), nullable=False) # INFO, WARNING, ERROR
operation = Coluna(String(255), nullable=False)
message = Coluna(Texto, nullable=False)
error_details = Coluna(JSON)
execution_time = Coluna(Float) # em segundos
created_at = Coluna(DateTime, default=datetime.utcnow)
def __repr__(self):
return f"<AgentLog(level='{self.level}', operation='{self.operation}')>"O esquema define cinco tabelas principais. O usuário armazena perfis com preferências JSON para dados flexíveis. A conversa rastreia sessões com rastreamento de status. A mensagem mantém trocas individuais com indicadores de função para mensagens do usuário versus assistente. A entidade captura informações extraídas com pontuações de confiança. O AgentLog fornece rastreamento de operações para monitoramento. Chaves estrangeiras mantêm a integridade referencial. Índices em campos frequentemente consultados otimizam o desempenho. A configuração cascade="all, delete-orphan" limpa registros relacionados quando os registros pai são excluídos.
Etapa 2: Configurando a camada de conexão do banco de dados
Configure o gerenciador de conexão de banco de dados com o SQLAlchemy. O gerenciador lida com o pool de conexões, verificações de integridade e lógica de repetição automática para garantir a confiabilidade.
class DatabaseManager:
"""
Gerencia conexões e operações de banco de dados.
Recursos:
- Pool de conexões para uso eficiente de recursos
- Verificações de integridade para verificar a conectividade do banco de dados
- Criação automática de tabelas
"""
def __init__(self, database_url: str, pool_size: int = 5, max_retries: int = 3):
"""
Inicializa o gerenciador de banco de dados.
Argumentos:
database_url: String de conexão do banco de dados (por exemplo, 'sqlite:///./agent_data.db')
pool_size: Número de conexões a serem mantidas no pool
max_retries: Número máximo de tentativas de repetição para operações com falha
"""
self.database_url = database_url
self.max_retries = max_retries
# Cria o mecanismo com pool de conexões
self.engine = create_engine(
database_url,
poolclass=QueuePool,
pool_size=pool_size,
max_overflow=10,
pool_pre_ping=True, # Verifica as conexões antes de usar
echo=False # Defina como True para depuração SQL
)
# Crie uma fábrica de sessões
self.SessionLocal = sessionmaker(
bind=self.engine,
autocommit=False,
autoflush=False
)
logger.info(f"✓ Mecanismo de banco de dados criado com pool de conexões {pool_size}")
def initialize_database(self):
"""Criar todas as tabelas no banco de dados."""
try:
Base.metadata.create_all(bind=self.engine)
logger.info("✓ Tabelas do banco de dados criadas com sucesso")
except Exception as e:
logger.error(f"❌ Falha ao criar tabelas do banco de dados: {e}")
raise
def get_session(self) -> Session:
"""Obter uma nova sessão de banco de dados para realizar operações."""
return self.SessionLocal()
def health_check(self) -> bool:
"""
Verificar a conectividade do banco de dados.
Retorna:
bool: True se o banco de dados estiver saudável, False caso contrário
"""
tente:
com self.engine.connect() como conn:
conn.execute(text("SELECT 1"))
logger.info("✓ Verificação de integridade do banco de dados aprovada")
retorne Verdadeiro
exceto Exceção como e:
logger.error(f"❌ Falha na verificação de integridade do banco de dados: {e}")
retorne FalsoO DatabaseManager estabelece conexões usando o pool de conexões do SQLAlchemy. Definir pool_size=5 mantém cinco conexões persistentes para maior eficiência. A opção pool_pre_ping valida as conexões antes do uso. Isso evita erros de conexão obsoletas. O mecanismo de repetição tenta operações com falha até três vezes com backoff exponencial. Ele lida com problemas de rede transitórios.
Etapa 3: Construindo o núcleo do agente LangChain
Crie o agente de IA usando o LangChain com ferramentas personalizadas que interagem com o banco de dados. O agente usa chamadas de função para salvar informações e recuperar o histórico de conversas.
class DataPersistentAgent:
"""
Agente de IA com recursos de persistência de banco de dados.
Este agente:
- Lembra conversas entre sessões
- Salva e recupera informações do usuário
- Extrai e armazena entidades importantes
- Fornece respostas personalizadas com base no histórico
"""
def __init__(
self,
db_manager: DatabaseManager,
model_name: str = "gpt-4-turbo-preview",
temperature: float = 0.7
):
"""
Inicializa o agente persistente de dados.
Argumentos:
db_manager: Instância do gerenciador de banco de dados
model_name: Modelo LLM a ser usado (padrão: gpt-4-turbo-preview)
temperature: Temperatura do modelo para geração de respostas
"""
self.db_manager = db_manager
self.model_name = model_name
# Inicializar LLM
self.llm = ChatOpenAI(
model=model_name,
temperature=temperature,
openai_api_key=os.getenv("OPENAI_API_KEY")
)
# Criar ferramentas para o agente
self.tools = self._create_agent_tools()
# Criar prompt do agente
self.prompt = self._create_agent_prompt()
# Inicializar memória
self.memory = ConversationBufferMemory(
memory_key="chat_history",
return_messages=True
)
# Criar agente
self.agent = create_openai_functions_agent(
llm=self.llm,
tools=self.tools,
prompt=self.prompt
)
# Criar executor do agente
self.agent_executor = AgentExecutor(
agent=self.agent,
tools=self.tools,
memory=self.memory,
verbose=True,
handle_parsing_errors=True,
max_iterations=5
)
logger.info(f"✓ Agente persistente de dados inicializado com {model_name}")
def _create_agent_tools(self) -> List[Tool]:
"""Criar ferramentas personalizadas para operações de banco de dados."""
def salvar_informações_do_usuário(dados_do_usuário: str) -> str:
"""Salvar informações do usuário no banco de dados."""
tente:
dados = json.loads(dados_do_usuário)
sessão = self.db_manager.get_session()
user = session.query(User).filter_by(user_id=data['user_id']).first()
if not user:
user = User(**data)
session.add(user)
else:
for key, value in data.items():
setattr(user, key, value)
sessão.confirmar()
sessão.fechar()
retornar f"✓ Informações do usuário salvas com sucesso"
exceto Exceção como e:
logger.error(f"Falha ao salvar informações do usuário: {e}")
retornar f"❌ Erro ao salvar informações do usuário: {str(e)}"
def recuperar_histórico_do_usuário(id_do_usuário: str) -> str:
"""Recupera o histórico de conversas do usuário."""
tente:
sessão = self.db_manager.get_session()
usuário = sessão.query(User).filter_by(user_id=id_do_usuário).first()
se não houver usuário:
retorne "Nenhum usuário encontrado"
conversations = session.query(Conversation).filter_by(user_id=user.id).order_by(Conversation.created_at.desc()).limit(5).all()
history = []
for conv in conversations:
messages = session.query(Message).filter_by(conversation_id=conv.id).all()
histórico.append({
'id_da_conversa': conv.conversation_id,
'criado_em': conv.created_at.isoformat(),
'contagem_de_mensagens': len(mensagens),
'resumo': conv.summary
})
sessão.close()
retornar json.dumps(histórico, indent=2)
exceto Exception como e:
logger.error(f"Falha ao recuperar o histórico: {e}")
retornar f"❌ Erro ao recuperar o histórico: {str(e)}"
def extrair_entidades(texto: str) -> str:
"""Extrair entidades do texto e salvar no banco de dados."""
tentar:
entidades = []
# Extração simples de palavras-chave (substitua por NER adequado)
palavras-chave = ['importante', 'chave', 'crítico']
para palavra-chave em palavras-chave:
se palavra-chave em texto.lower():
entidades.append({
'entity_type': 'palavra-chave',
'entity_value': palavra-chave,
'confidence': 0.8
})
retornar json.dumps(entidades, indent=2)
exceto Exception como e:
logger.error(f"Falha ao extrair entidades: {e}")
retornar f"❌ Erro ao extrair entidades: {str(e)}"
tools = [
Tool(
name="SaveUserInfo",
func=save_user_info,
description="Salvar informações do usuário no banco de dados. A entrada deve ser uma string JSON com detalhes do usuário."
),
Tool(
name="RetrieveUserHistory",
func=retrieve_user_history,
description="Recupera o histórico de conversas de um usuário do banco de dados. A entrada deve ser o user_id."
),
Tool(
name="ExtractEntities",
func=extract_entities,
description="Extrair entidades importantes do texto e salvar no banco de dados. A entrada deve ser o texto a ser analisado."
)
]
retornar ferramentas
def _create_agent_prompt(self) -> ChatPromptTemplate:
"""Criar modelo de prompt do agente."""
system_message = """Você é um assistente de IA útil, com a capacidade de lembrar e aprender com as conversas.
Você tem acesso às seguintes ferramentas:
- SaveUserInfo: Salvar informações do usuário para lembrar em conversas futuras
- RetrieveUserHistory: Pesquisar conversas anteriores com um usuário
- ExtractEntities: Extrair e salvar informações importantes das conversas
Use essas ferramentas para fornecer respostas personalizadas e contextuais. Sempre verifique se você tem conversas anteriores com um usuário antes de responder.
Seja proativo em salvar informações importantes para conversas futuras."""
prompt = ChatPromptTemplate.from_messages([
("system", system_message),
MessagesPlaceholder(variable_name="chat_history"),
("human", "{input}"),
MessagesPlaceholder(variable_name="agent_scratchpad")
])
return prompt
def chat(self, user_id: str, message: str, conversation_id: Optional[str] = None) -> Dict[str, Any]:
"""
Processe uma mensagem de chat e persista no banco de dados.
Este método lida com:
1. Criação ou recuperação de conversas
2. Salvamento de mensagens do usuário no banco de dados
3. Geração de respostas do agente
4. Salvamento das respostas do agente no banco de dados
5. Registro de operações para monitoramento
Argumentos:
user_id: Identificador exclusivo do usuário
message: Texto da mensagem do usuário
conversation_id: ID opcional da conversa para continuar a conversa existente
Retorna:
dict: Contém conversation_id, response e execution_time
"""
start_time = datetime.utcnow()
try:
# Obter ou criar conversa
session = self.db_manager.get_session()
if conversation_id:
conversation = session.query(Conversation).filter_by(conversation_id=conversation_id).first()
else:
# Cria uma nova conversa
user = session.query(User).filter_by(user_id=user_id).first()
if not user:
usuário = Usuário(user_id=user_id, nome=user_id)
sessão.adicionar(usuário)
sessão.confirmar()
conversa = Conversa(
conversation_id=f"conv_{user_id}_{datetime.utcnow().timestamp()}",
user_id=user.id,
title=message[:100]
)
sessão.adicionar(conversa)
sessão.confirmar()
# Salvar mensagem do usuário
mensagem_do_usuário = Mensagem(
conversa_id=conversa.id,
função="usuário",
conteúdo=mensagem,
modelo=self.nome_do_modelo)
sessão.adicionar(mensagem_do_usuário)
sessão.confirmar()
# Obter resposta do agente
response = self.agent_executor.invoke({
"input": f"[ID do usuário: {user_id}] {message}"
})
# Salvar mensagem do assistente
assistant_message = Message(
conversation_id=conversation.id,
role="assistant",
content=response['output'],
model=self.model_name
)
session.add(assistant_message)
session.commit()
# Registrar operação
execution_time = (datetime.utcnow() - start_time).total_seconds()
log_entry = AgentLog(
conversation_id=conversation.conversation_id,
level="INFO",
operation="chat",
message="Chat processado com sucesso",
execution_time=execution_time
)
sessão.adicionar(entrada_de_registro)
sessão.confirmar()
# Extrair conversation_id antes de encerrar a sessão
resultado_conversation_id = conversation.conversation_id
sessão.encerrar()
logger.info(f"✓ Chat processado para o usuário {user_id} em {execution_time:.2f}s")
return {
'conversation_id': conversation_id_result,
'response': response['output'],
'execution_time': execution_time
}
except Exception as e:
logger.error(f"❌ Erro ao processar o chat: {e}")
# Registrar erro
sessão = self.db_manager.get_session()
error_log = AgentLog(
conversation_id=conversation_id ou "desconhecido",
level="ERROR",
operation="chat",
message=str(e),
error_details={'exception_type': type(e).__name__}
)
sessão.add(error_log)
sessão.commit()
sessão.close()
raiseO DataPersistentAgent envolve a função de chamada do agente do LangChain com ferramentas de banco de dados. A ferramenta SaveUserInfo mantém os dados do usuário criando ou atualizando registros de usuário. A ferramenta RetrieveHistory consulta conversas anteriores para fornecer contexto. O prompt do sistema instrui o agente a ser proativo quanto ao salvamento de informações e à verificação do histórico. O ConversationBufferMemory mantém o contexto de curto prazo dentro das sessões. O armazenamento em banco de dados fornece persistência de longo prazo entre as sessões.
Etapa 3.5: Criação do módulo de coleta de dados
Crie ferramentas para extrair e estruturar dados das conversas. O coletor gera resumos, extrai preferências e identifica entidades usando o LLM.
class DataCollector:
"""
Coleta e estrutura dados de conversas do agente.
Este módulo:
- Gera resumos de conversas
- Extrai preferências do usuário do histórico de conversas
- Identifica e salva entidades nomeadas
"""
def __init__(self, db_manager: DatabaseManager, llm: ChatOpenAI):
"""
Inicializa o coletor de dados.
Argumentos:
db_manager: Instância do gerenciador de banco de dados
llm: Modelo de linguagem para análise de texto
"""
self.db_manager = db_manager
self.llm = llm
logger.info("✓ Coletor de dados inicializado")
def extrair_resumo_da_conversa(self, id_da_conversa: str) -> str:
"""
Gera e salva o resumo da conversa usando LLM.
Argumentos:
id_da_conversa: ID da conversa a ser resumida
Retorna:
str: Texto do resumo gerado
"""
tente:
sessão = self.db_manager.get_session()
conversation = session.query(Conversation).filter_by(conversation_id=conversation_id).first()
if not conversation:
return "Conversation not found"
messages = session.query(Message).filter_by(conversation_id=conversation.id).all()
# Construir texto da conversa
conv_text = "n".join([
f"{msg.role}: {msg.content}" for msg in messages
])
# Gerar resumo usando LLM
summary_prompt = f"""Resuma a seguinte conversa em 2-3 frases, capturando os principais tópicos e resultados:
{conv_text}
Resumo:"""
summary_response = self.llm.invoke([HumanMessage(content=summary_prompt)])
summary = summary_response.content
# Atualizar conversa com resumo
conversation.summary = summary
session.commit()
session.close()
logger.info(f"✓ Resumo gerado para a conversa {conversation_id}")
return summary
except Exception as e:
logger.error(f"Falha ao gerar o resumo: {e}")
return ""
def extrair_preferências_do_usuário(self, user_id: str) -> Dict[str, Any]:
"""
Extrair e salvar as preferências do usuário do histórico de conversas.
Argumentos:
user_id: ID do usuário a ser analisado
Retorna:
dict: Preferências extraídas
"""
tente:
sessão = self.db_manager.get_session()
usuário = sessão.query(User).filter_by(user_id=user_id).first()
if not user:
return {}
# Obter conversas recentes
conversations = session.query(Conversation).filter_by(user_id=user.id).order_by(Conversation.created_at.desc()).limit(10).all()
all_messages = []
para conv em conversas:
mensagens = sessão.query(Mensagem).filter_by(conversation_id=conv.id).all()
todas_as_mensagens.extend([msg.content para msg em mensagens se msg.role == "usuário"])
se não todas_as_mensagens:
retornar {}
# Analisar preferências usando LLM
analysis_prompt = f"""Analise as seguintes mensagens de um usuário e extraia suas preferências, interesses e estilo de comunicação.
Mensagens:
{chr(10).join(all_messages[:20])}
Retorne um objeto JSON com a seguinte estrutura:
{{
"interests": ["interest1", "interest2"],
"communication_style": "description",
"preferred_topics": ["topic1", "topic2"],
"language_preference": "language"
}}"""
response = self.llm.invoke([HumanMessage(content=analysis_prompt)])
tente:
# Extrair JSON da resposta
content = response.content
if '```json' in content:
content = content.split('```json')[1].split('```')[0].strip()
elif '```' in content:
content = content.split('```')[1].split('```')[0].strip()
preferences = json.loads(conteúdo)
# Atualizar preferências do usuário
usuário.preferências = preferências
sessão.confirmar()
logger.info(f"✓ Preferências extraídas para o usuário {user_id}")
retornar preferências
exceto json.JSONDecodeError:
logger.warning("Falha ao analisar JSON das preferências")
retornar {}
finalmente:
session.close()
exceto Exception como e:
logger.error(f"Falha ao extrair preferências: {e}")
retornar {}
def extrair_entidades_com_llm(self, conversation_id: str) -> Lista[Dict[str, Any]]:
"""
Extrair entidades nomeadas usando LLM.
Argumentos:
conversation_id: ID da conversa a ser analisada
Retorna:
list: Lista de entidades extraídas
"""
tente:
session = self.db_manager.get_session()
conversation = session.query(Conversation).filter_by(conversation_id=conversation_id).first()
se não houver conversation:
retorne []
messages = session.query(Message).filter_by(conversation_id=conversation.id).all()
conv_text = "n".join([msg.content for msg in messages])
# Extrair entidades usando LLM
entity_prompt = f"""Extraia entidades nomeadas da seguinte conversa. Identifique:
- Pessoas (PESSOA)
- Organizações (ORG)
- Locais (LOC)
- Datas (DATE)
- Produtos (PRODUCT)
- Tecnologias (TECH)
Conversa:
{conv_text}
Retorne uma matriz JSON de entidades com o formato:
[
{{"type": "PERSON", "value": "John Doe", "context": "mencionado como líder da equipe"}},
{{"type": "ORG", "value": "Acme Corp", "context": "empresa cliente"}}
]"""
response = self.llm.invoke([HumanMessage(content=entity_prompt)])
try:
content = response.content
if '```json' in content:
content = content.split('```json')[1].split('```')[0].strip()
elif '```' in content:
content = content.split('```')[1].split('```')[0].strip()
entities_data = json.loads(content)
# Salvar entidades no banco de dados
saved_entities = []
para entity_data em entities_data:
entidade = Entidade(
conversation_id=conversation.id,
entity_type=entity_data['type'],
entity_value=entity_data['value'],
context=entity_data.get('context', ''),
confidence=0.9 # A extração LLM tem alta confiança
)
sessão.adicionar(entidade)
entidades_salvas.acrescentar(entidade_dados)
sessão.confirmar()
sessão.fechar()
logger.info(f"✓ Extraiu {len(entidades_salvas)} entidades da conversa {conversation_id}")
retornar entidades_salvas
exceto json.JSONDecodeError:
logger.warning("Falha no Parsing de JSON das entidades")
retornar []
exceto Exception como e:
logger.error(f"Falha ao extrair entidades: {e}")
retornar []O DataCollector usa o LLM para analisar conversas. O método extract_conversation_summary cria resumos concisos das conversas. O método extract_user_preferences analisa padrões de mensagens para identificar os interesses e estilos de comunicação dos usuários. O método extract_entities_with_llm usa prompts estruturados para extrair entidades nomeadas, como pessoas, organizações e tecnologias. Todos os dados extraídos são salvos no banco de dados para referência futura.
Etapa 4: Construindo o pipeline de processamento de dados inteligente
Implemente o processamento em segundo plano para lidar com a coleta de dados sem bloquear o agente. O pipeline usa threads de trabalho e filas para processar resumos e entidades.
class DataProcessingPipeline:
"""
Pipeline de processamento de dados assíncrono.
Este pipeline:
- Processa conversas em segundo plano
- Gera resumos
- Extrai entidades sem bloquear o fluxo principal
- Atualiza as preferências do usuário periodicamente
"""
def __init__(self, db_manager: DatabaseManager, collector: DataCollector, batch_size: int = 10):
"""
Inicializa o pipeline de processamento.
Argumentos:
db_manager: Instância do gerenciador de banco de dados
collector: Coletor de dados para operações de processamento
batch_size: Número de itens a serem processados em cada lote
"""
self.db_manager = db_manager
self.collector = collector
self.batch_size = batch_size
# Filas de processamento
self.summary_queue = Queue()
self.entity_queue = Queue()
self.preference_queue = Queue()
# Threads de trabalho
self.workers = []
self.running = False
logger.info("✓ Pipeline de processamento de dados inicializado")
def start(self):
"""Iniciar trabalhadores de processamento em segundo plano."""
self.running = True
# Criar threads de trabalho
summary_worker = Thread(target=self._process_summaries, daemon=True)
entity_worker = Thread(target=self._process_entities, daemon=True)
preference_worker = Thread(target=self._process_preferences, daemon=True)
summary_worker.start()
entity_worker.start()
preference_worker.start()
self.workers = [summary_worker, entity_worker, preference_worker]
logger.info("✓ Iniciados 3 trabalhadores de processamento em segundo plano")
def stop(self):
"""Interromper trabalhadores de processamento em segundo plano."""
self.running = False
for worker in self.workers:
worker.join(timeout=5)
logger.info("✓ Interrompidos trabalhadores de processamento em segundo plano")
def queue_conversation_for_processing(self, conversation_id: str, user_id: str):
"""
Adicionar conversa às filas de processamento.
Argumentos:
conversation_id: ID da conversa a ser processada
user_id: ID do usuário para extração de preferências
"""
self.summary_queue.put(conversation_id)
self.entity_queue.put(conversation_id)
self.preference_queue.put(user_id)
logger.info(f"✓ Conversa {conversation_id} na fila para processamento")
def _process_summaries(self):
"""Trabalhador para processamento de resumos de conversas."""
enquanto self.running:
tente:
se não self.summary_queue.empty():
conversation_id = self.summary_queue.get()
self.collector.extract_conversation_summary(conversation_id)
self.summary_queue.task_done()
caso contrário:
time.sleep(1)
exceto Exception como e:
logger.error(f"Erro no trabalhador de resumo: {e}")
def _process_entities(self):
"""Trabalhador para processamento de extração de entidades."""
enquanto self.running:
tente:
se não self.entity_queue.empty():
conversation_id = self.entity_queue.get()
self.collector.extract_entities_with_llm(conversation_id)
self.entity_queue.task_done()
else:
time.sleep(1)
except Exception as e:
logger.error(f"Erro no trabalhador de entidade: {e}")
def _process_preferences(self):
"""Trabalhador para processar as preferências do usuário."""
enquanto self.running:
tente:
se não self.preference_queue.empty():
user_id = self.preference_queue.get()
self.collector.extract_user_preferences(user_id)
self.preference_queue.task_done()
else:
time.sleep(1)
except Exception as e:
logger.error(f"Erro no trabalhador de preferências: {e}")
def get_queue_status(self) -> Dict[str, int]:
"""
Obter os tamanhos atuais das filas.
Retorna:
dict: Tamanhos das filas para cada tipo de processamento
"""
return {
'summary_queue': self.summary_queue.qsize(),
'entity_queue': self.entity_queue.qsize(),
'preference_queue': self.preference_queue.qsize()
}O ProcessingPipeline separa a coleta de dados do processamento de mensagens. Quando uma conversa é concluída, ela é adicionada às filas em vez de ser processada imediatamente. Threads de trabalho separadas extraem dessas filas e processam itens em segundo plano. Isso evita que a coleta de dados bloqueie as respostas do agente. A configuração daemon=True garante que os trabalhadores sejam encerrados quando o programa principal for fechado. O monitoramento do status da fila ajuda a rastrear atrasos no processamento.
Etapa 5: adicionar monitoramento e registro em tempo real
Crie um sistema de monitoramento para rastrear o desempenho do agente, detectar erros e gerar relatórios. O monitor analisa os registros para fornecer insights operacionais.
class AgentMonitor:
"""
Monitoramento em tempo real e coleta de métricas.
Este módulo:
- Rastreia métricas de desempenho
- Monitora a integridade do sistema
- Gera relatórios analíticos
"""
def __init__(self, db_manager: DatabaseManager):
"""
Inicializa o monitor do agente.
Args:
db_manager: Instância do gerenciador de banco de dados
"""
self.db_manager = db_manager
logger.info("✓ Monitor do agente inicializado")
def get_performance_metrics(self, hours: int = 24) -> Dict[str, Any]:
"""
Obtém métricas de desempenho para o período de tempo especificado.
Argumentos:
hours: Número de horas a serem analisadas
Retorna:
dict: Métricas de desempenho, incluindo contagens de operações e taxas de erro
"""
tente:
session = self.db_manager.get_session()
cutoff_time = datetime.utcnow() - timedelta(hours=hours)
# Consultar logs
logs = session.query(AgentLog).filter(
AgentLog.created_at >= cutoff_time
).all()
# Calcular métricas
total_operations = len(logs)
error_count = len([log for log in logs if log.level == "ERROR"])
avg_execution_time = sum([log.execution_time or 0 for log in logs]) / max(total_operations, 1)
# Obter contagens de conversas
conversations = session.query(Conversation).filter(
Conversation.created_at >= cutoff_time
).count()
messages = session.query(Message).join(Conversation).filter(
Message.created_at >= cutoff_time
).count()
session.close()
métricas = {
'período_horas': horas,
'total_operações': total_operações,
'contagem_erros': contagem_erros,
'taxa_erros': contagem_erros / max(total_operações, 1),
'avg_execution_time': avg_execution_time,
'conversations_created': conversations,
'messages_processed': messages
}
logger.info(f"✓ Métricas de desempenho geradas para as últimas {hours} horas")
return metrics
except Exception as e:
logger.error(f"Falha ao obter métricas de desempenho: {e}")
return {}
def health_check(self) -> Dict[str, Any]:
"""
Executar verificação de integridade.
Retorna:
dict: Status de integridade, incluindo conectividade do banco de dados e taxas de erro
"""
try:
# Verificar conectividade do banco de dados
db_healthy = self.db_manager.health_check()
# Verificar taxa de erros recentes
metrics = self.get_performance_metrics(hours=1)
recent_errors = metrics.get('error_count', 0)
# Determinar integridade geral
is_healthy = db_healthy and recent_errors < 10
health_status = {
'status': 'healthy' se is_healthy, caso contrário 'degraded',
'database_connected': db_healthy,
'recent_errors': recent_errors,
'timestamp': datetime.utcnow().isoformat()
}
logger.info(f"✓ Verificação de integridade: {health_status['status']}")
retornar health_status
exceto Exception como e:
logger.error(f"Falha na verificação de integridade: {e}")
retornar {
'status': 'unhealthy',
'error': str(e),
'timestamp': datetime.utcnow().isoformat()
}O AgentMonitor fornece observabilidade nas operações do sistema. Ele rastreia métricas como operações totais, taxas de erro e tempos médios de execução, consultando a tabela AgentLog. O método get_metrics calcula estatísticas em janelas de tempo configuráveis. O método get_error_report recupera informações detalhadas sobre erros para depuração. Esse monitoramento permite a detecção proativa de problemas. Altas taxas de erro acionam uma investigação antes que os usuários sejam afetados.
Etapa 6: Criação da interface de consulta
Crie recursos de consulta para recuperar e analisar dados armazenados. A interface fornece métodos para pesquisar conversas, rastrear entidades e gerar análises.
class DataQueryInterface:
"""
Interface para consultar dados armazenados do agente.
Este módulo fornece métodos para:
- Consultar análises do usuário
- Recuperar histórico de conversas
- Pesquisar informações específicas
"""
def __init__(self, db_manager: DatabaseManager):
"""
Inicializar a interface de consulta.
Args:
db_manager: Instância do gerenciador de banco de dados
"""
self.db_manager = db_manager
logger.info("✓ Interface de consulta inicializada")
def get_user_analytics(self, user_id: str) -> Dict[str, Any]:
"""
Obter análises para um usuário específico.
Argumentos:
user_id: ID do usuário a ser analisado
Retorna:
dict: Análises do usuário, incluindo contagens de conversas e preferências
"""
tente:
session = self.db_manager.get_session()
user = session.query(User).filter_by(user_id=user_id).first()
se não houver usuário:
retornar {}
# Obter contagem de conversas
conversation_count = session.query(Conversation).filter_by(user_id=user.id).count()
# Obter contagem de mensagens
message_count = session.query(Message).join(Conversation).filter(
Conversation.user_id == user.id
).count()
# Obter contagem de entidades
entity_count = session.query(Entity).join(Conversation).filter(
Conversation.user_id == user.id
).count()
# Obter intervalo de tempo
first_conversation = session.query(Conversation).filter_by(
user_id=user.id
).order_by(Conversation.created_at).first()
last_conversation = session.query(Conversation).filter_by(
user_id=user.id
).order_by(Conversation.created_at.desc()).first()
session.close()
analytics = {
'user_id': user_id,
'name': user.name,
'conversation_count': conversation_count,
'message_count': message_count,
'entity_count': entity_count,
'preferences': user.preferences,
'first_interaction': first_conversation.created_at.isoformat() se for a primeira conversa, caso contrário, None,
'last_interaction': last_conversation.created_at.isoformat() se for a última conversa, caso contrário, None,
'avg_messages_per_conversation': message_count / max(conversation_count, 1)
}
logger.info(f"✓ Análises geradas para o usuário {user_id}")
return analytics
except Exception as e:
logger.error(f"Falha ao obter as análises do usuário: {e}")
return {}O QueryInterface fornece métodos para acessar dados armazenados. O método get_user_conversations recupera o histórico completo da conversa com inclusão opcional de mensagens. O método search_conversations realiza uma pesquisa de texto completo no conteúdo da mensagem usando o operador ILIKE do SQL. O método get_entity_mentions encontra todas as conversas em que entidades específicas foram mencionadas. O método get_user_analytics gera estatísticas sobre a atividade do usuário. Essas consultas permitem a criação de painéis, a geração de relatórios e a criação de experiências personalizadas.
Etapa 7: Criação de um RAG com dados da web em tempo real da Bright Data
Aprimore seu agente conectado ao banco de dados com recursos RAG da inteligência da web em tempo real da Bright Data. Essa integração combina seu histórico de conversas com dados da web atualizados para respostas melhores.
class BrightDataRAGEnhancer:
"""
Aprimore o agente persistente de dados com a inteligência da web da Bright Data.
Este módulo:
- Busca dados da web em tempo real da Bright Data
- Ingere dados da web no armazenamento vetorial para RAG
- Aprimora o agente com conhecimento aumentado pela web
"""
def __init__(self, api_key: str, db_manager: DatabaseManager):
"""
Inicializa o aprimorador RAG com a Bright Data.
Args:
api_key: chave API da Bright Data
db_manager: instância do gerenciador de banco de dados
"""
self.api_key = api_key
self.db_manager = db_manager
self.base_url = "https://api.brightdata.com"
# Inicializar armazenamento de vetores para RAG
self.embeddings = OpenAIEmbeddings()
self.vector_store = Chroma(
embedding_function=self.embeddings,
persist_directory="./chroma_db"
)
self.text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200
)
logger.info("✓ Bright Data RAG enhancer inicializado")
def fetch_dataset_data(
self,
dataset_id: str,
filters: Optional[Dict[str, Any]] = None,
limit: int = 1000
) -> List[Dict[str, Any]]:
"""
Busca dados do Bright Data Dataset Marketplace.
Argumentos:
dataset_id: ID do conjunto de dados a ser buscado
filtros: Filtros opcionais para os dados
limite: Número máximo de registros a serem buscados
Retorna:
lista: Registros do conjunto de dados recuperados
"""
headers = {
"Autorização": f"Bearer {self.api_key}",
"Tipo de conteúdo": "application/json"
}
endpoint = f"{self.base_url}/Conjuntos de datos/v3/snapshot/{dataset_id}"
params = {
"format": "json",
"limit": limit
}
if filters:
params["filter"] = json.dumps(filters)
tente:
resposta = requests.get(endpoint, headers=headers, params=params)
resposta.raise_for_status()
dados = resposta.json()
logger.info(f"✓ Recuperados {len(dados)} registros do conjunto de dados Bright Data {dataset_id}")
retorne dados
exceto Exception como e:
logger.error(f"Falha ao buscar o conjunto de dados Bright Data: {e}")
return []
def ingest_web_data_to_rag(
self,
dataset_records: List[Dict[str, Any]],
text_fields: List[str],
metadata_fields: Optional[List[str]] = None
) -> int:
"""
Ingestão de dados da web no armazenamento vetorial RAG.
Argumentos:
dataset_records: Registros do Bright Data
text_fields: Campos a serem usados como conteúdo de texto
metadata_fields: Campos a serem incluídos nos metadados
Retorna:
int: Número de fragmentos de documentos inseridos
"""
tente:
documentos = []
para registro em registros_do_conjunto_de_dados:
# Combinar campos de texto
conteúdo_de_texto = " ".join([
str(registro.get(campo, ""))
para campo em campos_de_texto
se registro.get(campo)
])
if not text_content.strip():
continue
# Criar metadados
metadata = {
"source": "bright_data",
"record_id": record.get("id", "unknown"),
"timestamp": datetime.utcnow().isoformat()
}
if metadata_fields:
for field in metadata_fields:
if field in record:
metadata[field] = record[field]
# Dividir o texto em partes
chunks = self.text_splitter.split_text(text_content)
para chunk em chunks:
documentos.append({
"conteúdo": chunk,
"metadados": metadata
})
# Adicionar ao armazenamento vetorial
se documentos:
textos = [doc["conteúdo"] para doc em documentos]
metadados = [doc["metadados"] para doc em documentos]
self.vector_store.add_texts(
texts=texts,
metadatas=metadatas
)
logger.info(f"✓ Ingestão de {len(documents)} partes de documentos no RAG")
return len(documents)
exceto Exception como e:
logger.error(f"Falha ao inserir dados da web no RAG: {e}")
retornar 0
def create_rag_enhanced_agent(
self,
base_agent: DataPersistentAgent
) -> DataPersistentAgent:
"""
Aprimorar o agente existente com recursos RAG.
Argumentos:
base_agent: Agente base a ser aprimorado
Retorna:
DataPersistentAgent: Agente aprimorado com a ferramenta RAG
"""
def rag_search(query: str) -> str:
"""Pesquisar tanto o histórico de conversas quanto os dados da web."""
tente:
# Recuperar do histórico de conversas
sessão = self.db_manager.get_session()
mensagens = sessão.query(Mensagem).filter(
Mensagem.content.ilike(f'%{query}%')
).order_by(Mensagem.created_at.desc()).limit(5).all()
resultados = []
para msg em mensagens:
resultados.append({
'conteúdo': msg.content,
'fonte': 'histórico_de_conversas',
'relevância': 0.8
})
sessão.close()
# Recuperar do armazenamento vetorial (dados da web)
tente:
resultados_vetoriais = self.vector_store.similarity_search_with_score(query, k=5)
para doc, pontuação em resultados_vetoriais:
resultados.append({
'conteúdo': doc.page_content,
'fonte': 'web_data',
'relevância': 1 - pontuação
})
exceto Exception como e:
logger.error(f"Falha ao recuperar do armazenamento vetorial: {e}")
se não houver resultados:
retorne "Nenhuma informação relevante encontrada."
# Formatar contexto
context_text = "nn".join([
f"[{item['source']}] {item['content'][:200]}..."
para item em results[:5]
])
retornar f"Contexto recuperado:n{context_text}"
exceto Exception como e:
logger.error(f"Falha na pesquisa RAG: {e}")
return f"Erro ao realizar a pesquisa: {str(e)}"
# Adicionar ferramenta RAG ao agente
rag_tool = Tool(
name="SearchKnowledgeBase",
func=rag_search,
description="Pesquisar informações relevantes no histórico de conversas e nos dados da web em tempo real. A entrada deve ser uma consulta de pesquisa."
)
base_agent.tools.append(rag_tool)
# Recrie o agente com novas ferramentas
base_agent.agent = create_openai_functions_agent(
llm=base_agent.llm,
tools=base_agent.tools,
prompt=base_agent.prompt
)
base_agent.agent_executor = AgentExecutor(
agent=base_agent.agent,
tools=base_agent.tools,
memory=base_agent.memory,
verbose=True,
handle_parsing_errors=True,
max_iterations=5
)
logger.info("✓ Agente aprimorado com recursos RAG")
return base_agentO BrightDataEnhancer integra dados da web em tempo real ao seu agente. O método fetch_dataset recupera dados estruturados do marketplace da Bright Data. O método ingest_to_rag processa e divide esses dados. Ele os armazena em um banco de dados vetorial Chroma para pesquisa semântica. O método retrieve_context realiza uma recuperação híbrida. Ele combina o histórico do banco de dados com a pesquisa de similaridade vetorial. O método create_rag_tool empacota essa funcionalidade como uma ferramenta LangChain que o agente usa. O método enhance_agent adiciona esse recurso RAG ao seu agente existente. Ele permite que o agente responda a perguntas usando tanto o histórico de conversas internas quanto dados externos recentes.
Executando seu sistema completo de agente com persistência de dados
Reúna todos os componentes para criar um sistema funcional.
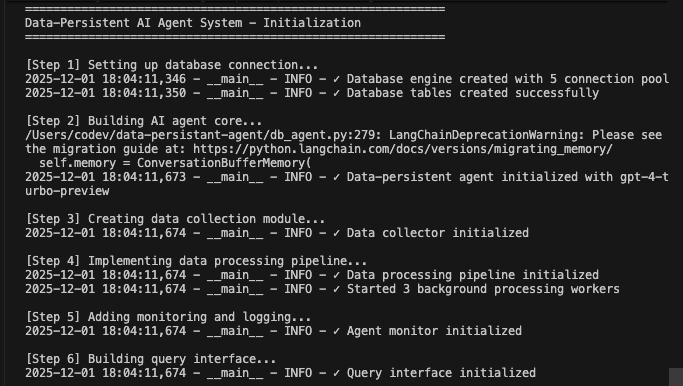
def main():
"""Fluxo de execução principal demonstrando todos os componentes trabalhando juntos."""
print("=" * 60)
print("Sistema de agente de IA com persistência de dados - Inicialização")
print("=" * 60)
# Etapa 1: Inicializar banco de dados
print("n[Etapa 1] Configurando conexão com banco de dados...")
db_manager = DatabaseManager(
database_url=os.getenv("DATABASE_URL"),
pool_size=5,
max_retries=3
)
db_manager.initialize_database()
# Etapa 2: Inicializar o agente principal
print("n[Etapa 2] Construindo o núcleo do agente de IA...")
agent = DataPersistentAgent(
db_manager=db_manager,
model_name=os.getenv("AGENT_MODEL", "gpt-4-turbo-preview")
)
# Passo 3: Inicializar coletor de dados
print("n[Passo 3] Criando módulo de coleta de dados...")
coletor = DataCollector(db_manager, agente.llm)
# Etapa 4: Inicializar pipeline de processamento
print("n[Etapa 4] Implementando pipeline de processamento de dados...")
pipeline = DataProcessingPipeline(db_manager, coletor)
pipeline.start()
# Passo 5: Inicializar o monitoramento
print("n[Passo 5] Adicionando monitoramento e registro...")
monitor = AgentMonitor(db_manager)
# Passo 6: Inicializar a interface de consulta
print("n[Passo 6] Construindo a interface de consulta...")
query_interface = DataQueryInterface(db_manager)
# Etapa 7: Aprimoramento opcional do Bright Data RAG
print("n[Etapa 7] Aprimoramento do RAG (opcional)...")
bright_data_key = os.getenv("BRIGHT_DATA_API_KEY")
if bright_data_key and bright_data_key != "your-bright-data-api-key":
print("Buscando dados da web em tempo real do Bright Data...")
enhancer = BrightDataRAGEnhancer(bright_data_key, db_manager)
# Exemplo: Buscar e ingestão de dados da web
web_data = enhancer.fetch_dataset_data(
dataset_id="example_dataset_id",
limit=100
)
if web_data:
enhancer.ingest_web_data_to_rag(
dataset_records=web_data,
text_fields=["title", "content", "description"],
metadata_fields=["url", "published_date"]
)
# Aprimorar o agente com RAG
agent = enhancer.create_rag_enhanced_agent(agent)
print("✓ Agente aprimorado com recursos RAG da Bright Data")
else:
print("⚠️ Chave API da Bright Data não encontrada - ignorando integração de dados da web")
print("n" + "=" * 60)
imprimir("Conversas de demonstração")
imprimir("=" * 60)
# Interações de usuário de demonstração
usuário_teste = "demo_user_001"
# Primeira conversa
imprimir("n📝 Conversa 1:")
resposta1 = agente.chat(
user_id=usuário_teste,
mensagem="Olá! Estou interessado em aprender sobre aprendizado de máquina.")
print(f"Agente: {response1['response']}n")
# Fila para processamento
pipeline.queue_conversation_for_processing(
response1['conversation_id'],
test_user
)
# Segunda conversa
print("📝 Conversa 2:")
response2 = agent.chat(
user_id=test_user,
message="Ajude-me a entender redes neurais?",
conversation_id=response1['conversation_id']
)
print(f"Agente: {response2['response']}n")
# Aguardar processamento em segundo plano
print("⏳ Processando dados em segundo plano...")
time.sleep(5)
print("n" + "=" * 60)
print("Análise e monitoramento")
print("=" * 60)
# Obter métricas de desempenho
metrics = monitor.get_performance_metrics(hours=1)
print(f"n📊 Métricas de desempenho:")
print(f" - Total de operações: {metrics.get('total_operations', 0)}")
print(f" - Taxa de erro: {metrics.get('error_rate', 0):.2%}")
print(f" - Tempo médio de execução: {metrics.get('avg_execution_time', 0):.2f}s")
print(f" - Conversas criadas: {metrics.get('conversations_created', 0)}")
imprimir(f" - Mensagens processadas: {metrics.get('messages_processed', 0)}")
# Obter análises do usuário
analytics = query_interface.get_user_analytics(test_user)
imprimir(f"n👤 Análises do usuário:")
imprimir(f" - Contagem de conversas: {analytics.get('conversation_count', 0)}")
imprimir(f" - Contagem de mensagens: {analytics.get('message_count', 0)}")
imprimir(f" - Contagem de entidades: {analytics.get('entity_count', 0)}")
imprimir(f" - Média de mensagens/conversa: {analytics.get('avg_messages_per_conversation', 0):.1f}")
# Verificação de integridade
integridade = monitor.health_check()
imprimir(f"n🏥 Integridade do sistema: {integridade['status']}")
# Status da fila
queue_status = pipeline.get_queue_status()
print(f"n📋 Filas de processamento:")
print(f" - Fila de resumo: {queue_status['summary_queue']}")
print(f" - Fila de entidades: {queue_status['entity_queue']}")
print(f" - Fila de preferências: {queue_status['preference_queue']}")
# Parar pipeline
pipeline.stop()
imprimir("n" + "=" * 60)
imprimir("Sistema de agente com persistência de dados - Concluído")
imprimir("=" * 60)
imprimir("n✓ Todos os dados persistentes no banco de dados")
imprimir("✓ Processamento em segundo plano concluído")
imprimir("✓ Sistema pronto para uso em produção")
if __name__ == "__main__":
try:
main()
except KeyboardInterrupt:
print("nn⚠️ Desligando normalmente...")
except Exception as e:
logger.error(f"Erro do sistema: {e}")
import traceback
traceback.print_exc()Execute seu sistema agente conectado ao banco de dados:
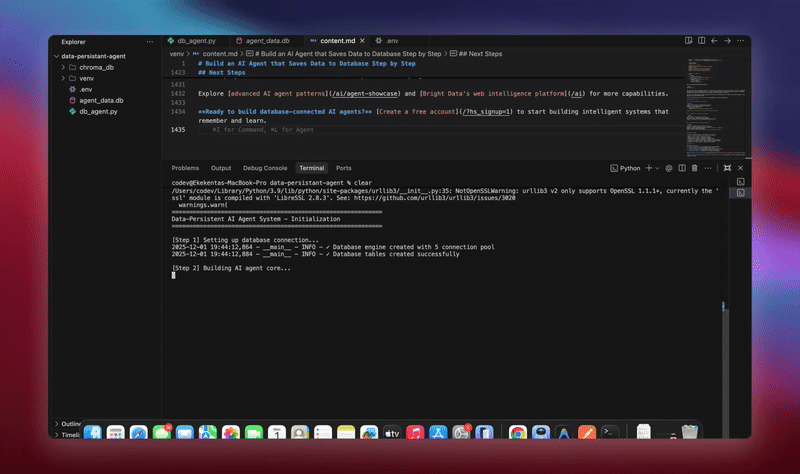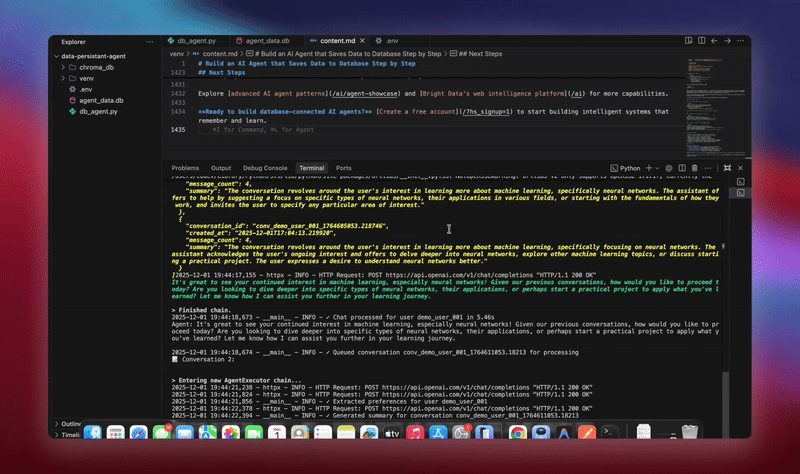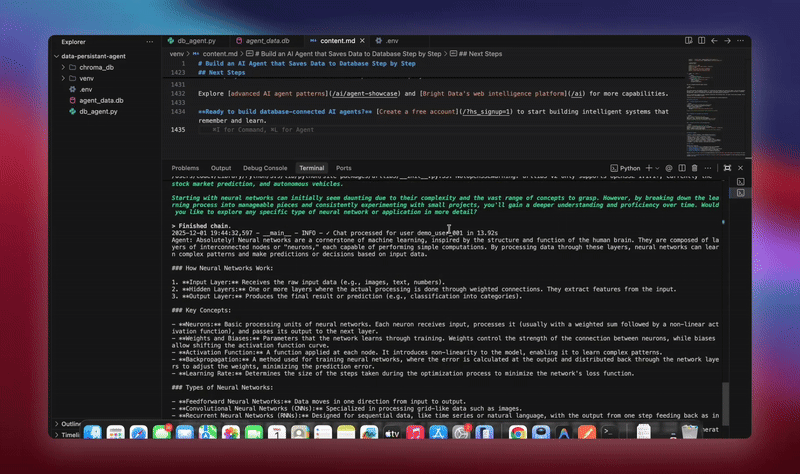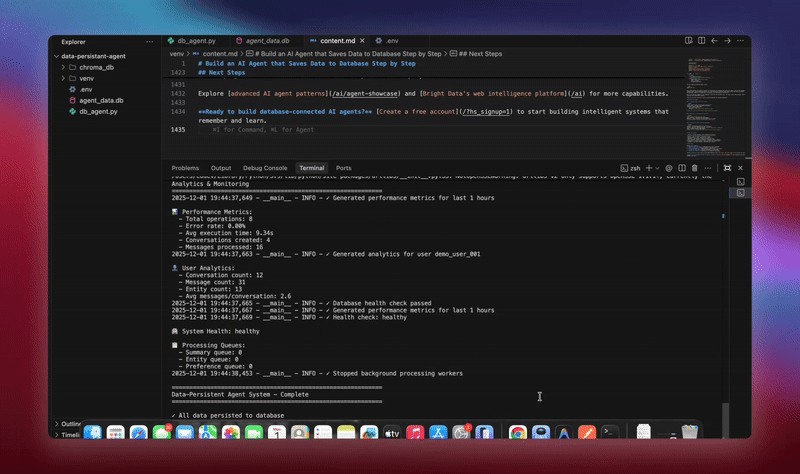
python agent.pyO sistema executa o fluxo de trabalho completo. Ele inicializa o banco de dados e cria todas as tabelas. Ele configura o agente LangChain com ferramentas de banco de dados. Ele inicia os trabalhadores em segundo plano para processamento. Ele processa conversas de demonstração e salva no banco de dados. Ele extrai entidades e gera resumos em segundo plano. Ele exibe análises e métricas em tempo real.
Você verá registros detalhados à medida que cada componente inicializa e processa os dados. O agente armazena todas as mensagens. Ele extrai insights. Ele mantém o contexto completo da conversa.
Casos de uso práticos
1. Suporte ao cliente com histórico completo
# O agente recupera interações anteriores
support_agent = DataPersistentAgent(db_manager)
response = support_agent.chat(
user_id="customer_123",
message="Ainda estou tendo esse problema de conexão")
# O agente vê conversas anteriores sobre problemas de conexão2. Assistente pessoal de IA com aprendizagem
# O agente aprende as preferências ao longo do tempo
query_interface = QueryInterface(db_manager)
analytics = query_interface.get_user_analytics("user_456")
# Mostra padrões de interação, preferências, tópicos comuns3. Assistente de pesquisa com base de conhecimento
# Combina o histórico de conversas com dados da web
enhancer = BrightDataEnhancer(api_key, db_manager)
enhancer.ingest_to_rag(research_data, ["title", "abstract", "content"])
agent = enhancer.enhance_agent(agent)
# O agente consulta discussões anteriores e pesquisas mais recentesResumo dos benefícios
| Recurso | Sem banco de dados | Com banco de dados Persistência |
|---|---|---|
| Memória | Perdida na reinicialização | Armazenamento permanente |
| Personalização | Nenhuma | Com base no histórico completo |
| Análise | Não é possível | Dados completos de interação |
| Recuperação de erros | Intervenção manual | Nova tentativa automática e registro |
| Escalabilidade | Instância única | Múltiplas instâncias com estado compartilhado |
| Insights | Perdido após a sessão | Extraídos e rastreados |
Conclusão
Agora você tem um sistema de agente de IA pronto para produção que mantém as conversas em bancos de dados. O sistema armazena todas as interações, extrai entidades e insights, mantém o histórico completo das conversas e fornece monitoramento com recuperação automática de erros.
Aprimore-o adicionando autenticação de usuário para acesso seguro, criando painéis para visualizar análises, implementando incorporações para pesquisa semântica, criando pontos de extremidade de API para integração ou implantando com Docker para escalabilidade. O design modular permite fácil personalização para suas necessidades específicas.
Explore padrões avançados de agentes de IA e a plataforma de inteligência da web da Bright Data para obter mais recursos.
Crie uma conta gratuita para começar a construir sistemas inteligentes que lembram e aprendem.





