

O guia definitivo para Scraping de dados com Rust
Neste guia, você aprenderá:
- Se Rust é uma boa linguagem para Scraping de dados.
- Quais são as melhores bibliotecas de Scraping de dados em Rust.
- Como construir um Scraper em Rust
- Como manter sua operação de scraping ética e respeitosa.
Vamos começar!
Rust é uma boa linguagem para Scraping de dados?
Rust é uma linguagem de programação estaticamente tipada, conhecida por seu foco em segurança, desempenho e concorrência. Nos últimos anos, ela ganhou popularidade por sua alta eficiência. Isso a torna uma excelente escolha para uma variedade de aplicações, incluindo Scraping de dados.
Rust oferece recursos valiosos para iniciativas de scraping de dados online. Notavelmente, seu modelo de concorrência robusto facilita a execução simultânea de várias solicitações da web. Essa característica a posiciona como uma linguagem versátil, hábil em extrair com eficiência quantidades substanciais de dados de diversos sites.
Além disso, o ecossistema Rust abrange bibliotecas de Parsing de HTML e clientes HTTP para otimizar os processos de recuperação de páginas da web e extração de dados. Vamos ver algumas das melhores!
Melhores bibliotecas de Scraping de dados do Rust
As bibliotecas de Scraping de dados Rust mais populares e amplamente adotadas incluem:
- reqwest: um poderoso cliente HTTP para Rust, que permite solicitações e interações na web sem interrupções.
- Scraper: uma biblioteca flexível de Parsing HTML em Rust, que facilita a extração eficiente de dados de documentos HTML.
- rust-headless-chrome: oferece automação do navegador Chrome headless usando Rust, fornecendo uma solução robusta para Scraping de dados dinâmico.
- thirtyfour: ligações Rust para Selenium, permitindo testes automatizados e Scraping de dados através da interação com navegadores web.
Pré-requisitos
Siga as instruções abaixo e prepare-se para escrever algum código Rust.
Configurar o ambiente
Antes de começar, você deve ter o Rust instalado no seu computador. Para verificar se você já o tem, abra o terminal e digite o seguinte comando:
rustc --versionSe o resultado for semelhante ao abaixo, você está pronto para começar:
rustc 1.75.0 (82e1608df 2023-12-21)Atualize o Rust para a versão mais recente com:
rustup updateSe esse comando retornar um erro, você precisará instalar o Rust. Baixe o instalador do site oficial, execute-o e siga o assistente. Isso configurará:
- rustup: Um instalador e gerenciador de versões para a linguagem de programação Rust, permitindo fácil instalação e gerenciamento de diferentes cadeias de ferramentas.
- cargo: O gerenciador de pacotes oficial e ferramenta de compilação para Rust. Ele simplifica o processo de gerenciamento de dependências e compilação de projetos Rust.
Feche todas as janelas do terminal abertas e repita o comando no início desta seção. Desta vez, você obterá o resultado desejado.
Ótimo! Agora você tem o Rust instalado!
Crie um projeto Rust
Suponha que você queira criar um novo projeto Rust chamado simple_rust_web_scraper. Abra o terminal e execute o seguinte comando cargo new:
cargo new simple_rust_web_scraperSe tudo correr como planejado, você receberá a seguinte mensagem:
Pacote binário (aplicativo) `simple_rust_web_scraper` criadoEspecificamente, esse comando criará uma pasta simple_rust_web_scraper. Abra-a e observe que ela inclui:
- Cargo.toml: o arquivo manifesto para especificar as dependências do projeto.
- src/: A pasta onde você deve colocar seus arquivos Rust. Por padrão, ele inicializa um arquivo main.rs de amostra para você.
Abra simple_rust_web_scraper no seu IDE Rust. Por exemplo, o Visual Studio Code com a extensão Rust será perfeito:
Navegue dentro da pasta src/, abra o arquivo main.rs e você verá estas linhas:
fn main() {
println!("Hello, world!");
}Isso nada mais é do que um script Rust simples que imprime “Olá, mundo!” no terminal. Em particular, a função main() representa o ponto de entrada de qualquer aplicativo Rust e é onde você escreverá a lógica de scraping.
Incrível! Resta apenas verificar se o seu novo projeto Rust funciona!
Abra o terminal do seu IDE e execute este comando para compilar sua aplicação Rust:
cargo buildUma pasta target/ que armazena alguns arquivos binários aparecerá na pasta raiz do seu projeto.
Execute o executável binário compilado associado ao seu código com:
cargo runIsso deve ser exibido no terminal:
Concluído dev [não otimizado + debuginfo] alvo(s) em 0,05s
Executando `targetdebugsimple_rust_web_scraper.exe`
Olá, mundo!As duas primeiras linhas são apenas informações de log, portanto, você pode ignorá-las. Concentre-se na última linha e veja que o projeto produziu a mensagem “Olá, mundo!” como esperado.
Perfeito! Agora você tem um projeto Rust. É hora de escrever alguma lógica de Scraping de dados em Rust!
Como construir um Scraper em Rust
Nesta seção do tutorial passo a passo, você aprenderá como realizar Scraping de dados com Rust. Mais especificamente, você criará um Scraper em Rust que coleta automaticamente dados da sandbox Scrape This Site Country. Esta é a aparência da página de destino:
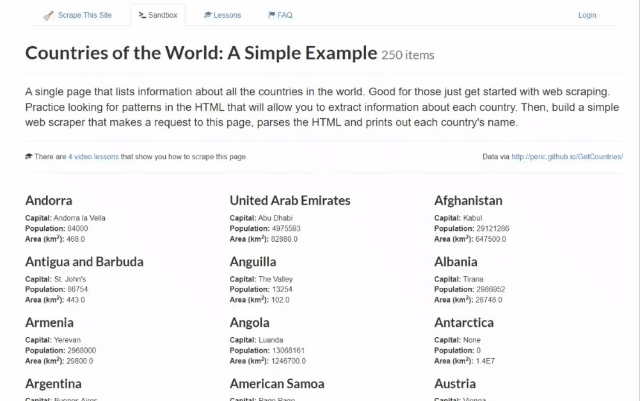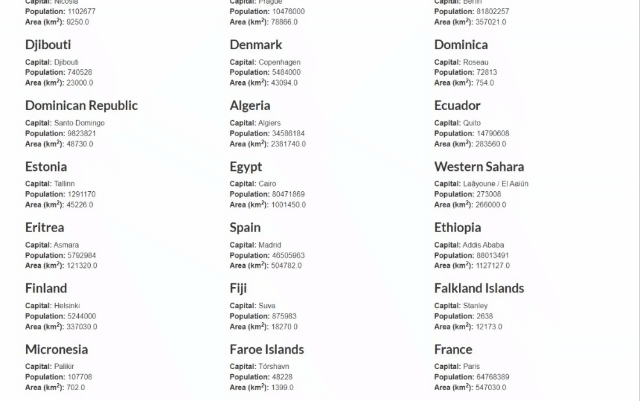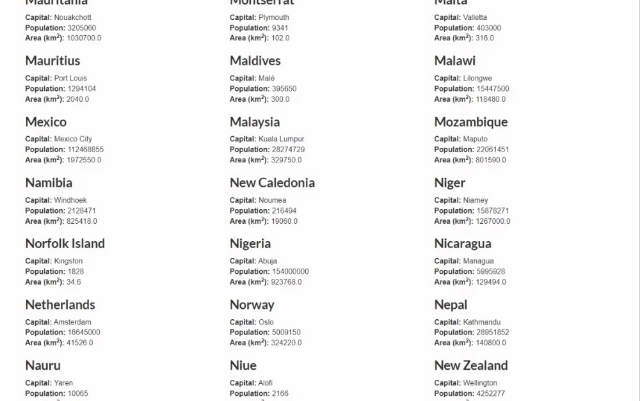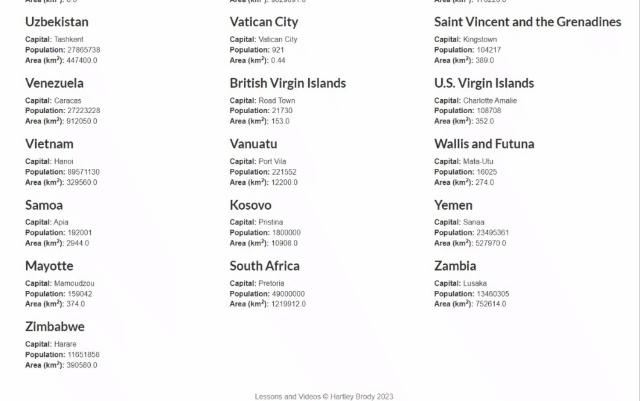
Como você pode ver, ela contém uma lista de todos os países do mundo e algumas informações interessantes sobre eles.
O que o script de Scraping de dados em Rust fará é:
- Conectar-se à página de destino e realizar o Parsing do seu HTML.
- Selecionar os elementos HTML dos países na página.
- Extrair os dados deles e armazená-los em uma estrutura de dados Rust.
- Transformar os dados coletados em um formato legível por humanos, como CSV.
Siga as etapas abaixo e alcance seu objetivo de scraping!
Etapa 1: inspecione o site de destino
Você precisará instalar algumas bibliotecas para fazer Scraping de dados em Rust, mas quais são as mais adequadas para o seu cenário específico? Para responder a essa pergunta, você precisa descobrir se o site de destino tem páginas de conteúdo estático ou dinâmico. Portanto, visite o site no seu navegador.
Navegue até a página de destino, clique com o botão direito do mouse em uma seção em branco e selecione a opção “Inspecionar” para abrir o DevTools. Acesse a guia “Rede” e recarregue a página. Concentre-se no que você vê na seção “Buscar/XHR”:
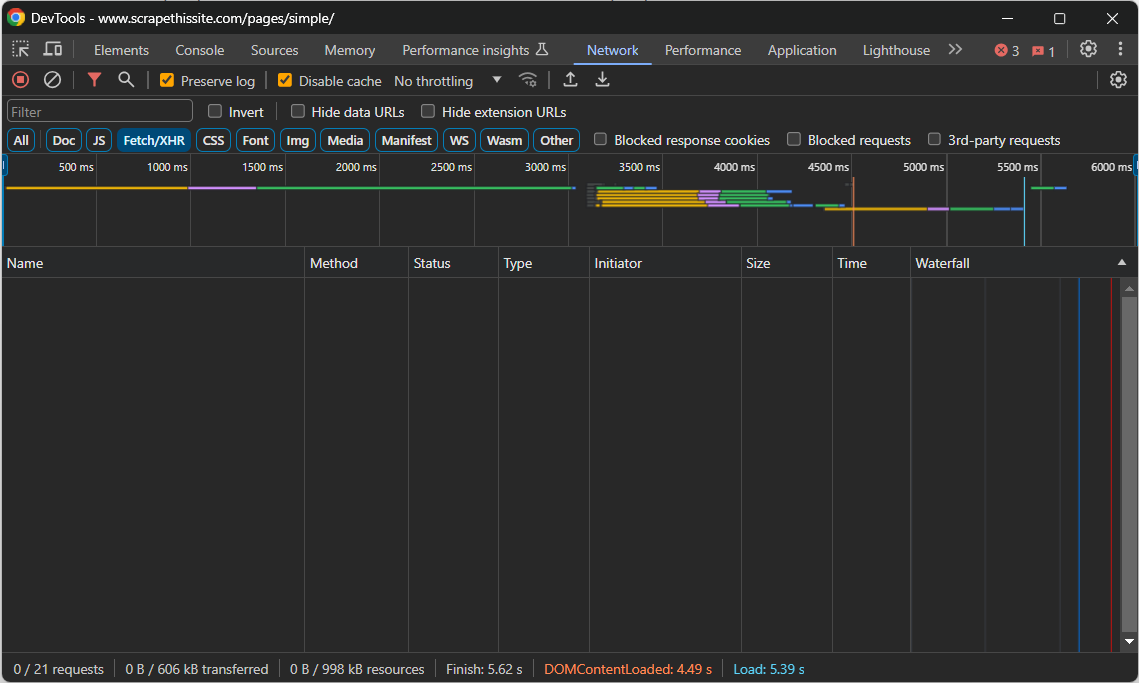
Enquanto a página estiver carregando e sendo renderizada, essa seção permanecerá vazia. Isso significa que a página da web não faz nenhuma solicitação AJAX. Em outras palavras, ela não recupera dados dinamicamente no cliente via JavaScript. Portanto, é uma página de conteúdo estático, cujo documento HTML já contém todos os dados de interesse.
Para confirmar, clique com o botão direito do mouse e selecione a opção “Exibir código-fonte da página”:

Explore o código e você perceberá que todos os dados da página estão incorporados no HTML retornado pelo servidor.
Em um site com várias páginas, repita esse procedimento em todas as páginas de interesse.
Como as páginas de destino não usam JavaScript, você não precisa de uma biblioteca de automação de navegador como o rust-headless-chrome. Você ainda pode usá-la, mas executar o Chrome leva tempo e recursos, então isso só introduziria uma sobrecarga de desempenho e nenhum benefício real.
Em vez disso, você deve empregar uma biblioteca cliente HTTP para recuperar o documento HTML associado a uma página e uma biblioteca analisadora HTML para extrair dados dela. Portanto, reqwest e Scraper são as duas bibliotecas Rust de Scraping de dados de que você precisa!
Etapa 2: Instale as bibliotecas de scraping
É hora de instalar o reqwest e o Scraper.
Abra um terminal na pasta raiz do seu projeto ou use o terminal do seu IDE. Execute o seguinte comando para adicionar reqwest e Scraper às dependências do seu projeto:
cargo add Scraper reqwest --features "reqwest/blocking"Observação: o recurso reqwest/blocking permite que o reqwest execute chamadas HTTP síncronas que bloqueiam o thread atual. Saiba mais na documentação.
O comando cargo add atualizará o arquivo Cargo.toml de acordo, garantindo que ele contenha:
[dependencies]
reqwest = { version = "0.11.23", features = ["blocking"] }
Scraper = "0.18.1"
Além disso, ele instalará as duas bibliotecas e todas as suas dependências.
Perfeito! Agora você tem tudo o que precisa para fazer Scraping de dados com Rust!
Etapa 3: conecte-se à página de destino
Use o método get() do reqwest::blocking para fazer uma solicitação GET para a URL fornecida e baixar o documento HTML associado:
let response = reqwest::blocking::get("https://www.scrapethissite.com/pages/simple/")?;Lembre-se de que essa instrução é síncrona, portanto, a execução do script será interrompida até que o servidor responda.
Depois de obter uma resposta, você pode acessar o código HTML da página de destino com:
let html = response.text()?;Escreva essas duas linhas na função main() do min.rs.:
fn main() -> Result<(), Box<dyn std::error::Error>> {
// conecte-se à página de destino
let response = reqwest::blocking::get("https://www.scrapethissite.com/pages/simple/")?;
// extrair o html bruto e imprimi-lo
let html = response.text()?;
println!("{html}");
Ok(())
}Se você está se perguntando o que é Result<(), Box<dyn std::error::Error>>, é porque vamos usar Residuals. Observe também a função println() no final, que registra o HTML recuperado.
Execute o script e ele será impresso no terminal:
<!doctype html>
<HTML lang="en">
<HEAD>
<META charset="utf-8">
<TITLE>Países do mundo: um exemplo simples | Scrape This Site | Uma área pública para aprender sobre Scraping de dados</TITLE>
<!-- omitido por brevidade... -->Muito bem! Esse é exatamente o HTML da página de destino!
Etapa 4: Parsing do documento HTML
Agora você tem o HTML de origem da página desejada armazenado em uma variável de string. Insira-o na função parse_document() do Scraper para analisá-lo:
let document = Scraper::Html::parse_document(&html);O objeto de documento retornado expõe a API de exploração DOM necessária para realizar o Scraping de dados da web usando Rust.
Esta é a aparência que seu arquivo main.rs deve ter até agora:
fn main() -> Result<(), Box<dyn std::error::Error>> {
// conecte-se à página de destino
let response = reqwest::blocking::get("https://www.scrapethissite.com/pages/simple/")?;
// extrair o html bruto e imprimi-lo
let html = response.text()?;
// analisar o documento HTML
let document = Scraper::Html::parse_document(&html);
Ok(())
}Você está pronto para escrever a lógica de Parsing de dados. Mas primeiro, você precisa estudar a estrutura da página de destino!
Etapa 5: inspecione a página
O scraping de dados envolve selecionar nós HTML em uma página e extrair dados deles. Os seletores CSS estão entre os métodos mais populares para selecionar nós HTML. Se você é um desenvolvedor web, provavelmente já está familiarizado com eles. Caso contrário, explore a documentação.
A única maneira de definir seletores CSS eficazes é inspecionar o HTML da página de destino. Portanto, abra a sandbox Scrape This Site Country no navegador, clique com o botão direito do mouse em um elemento de país e selecione “Inspect:”
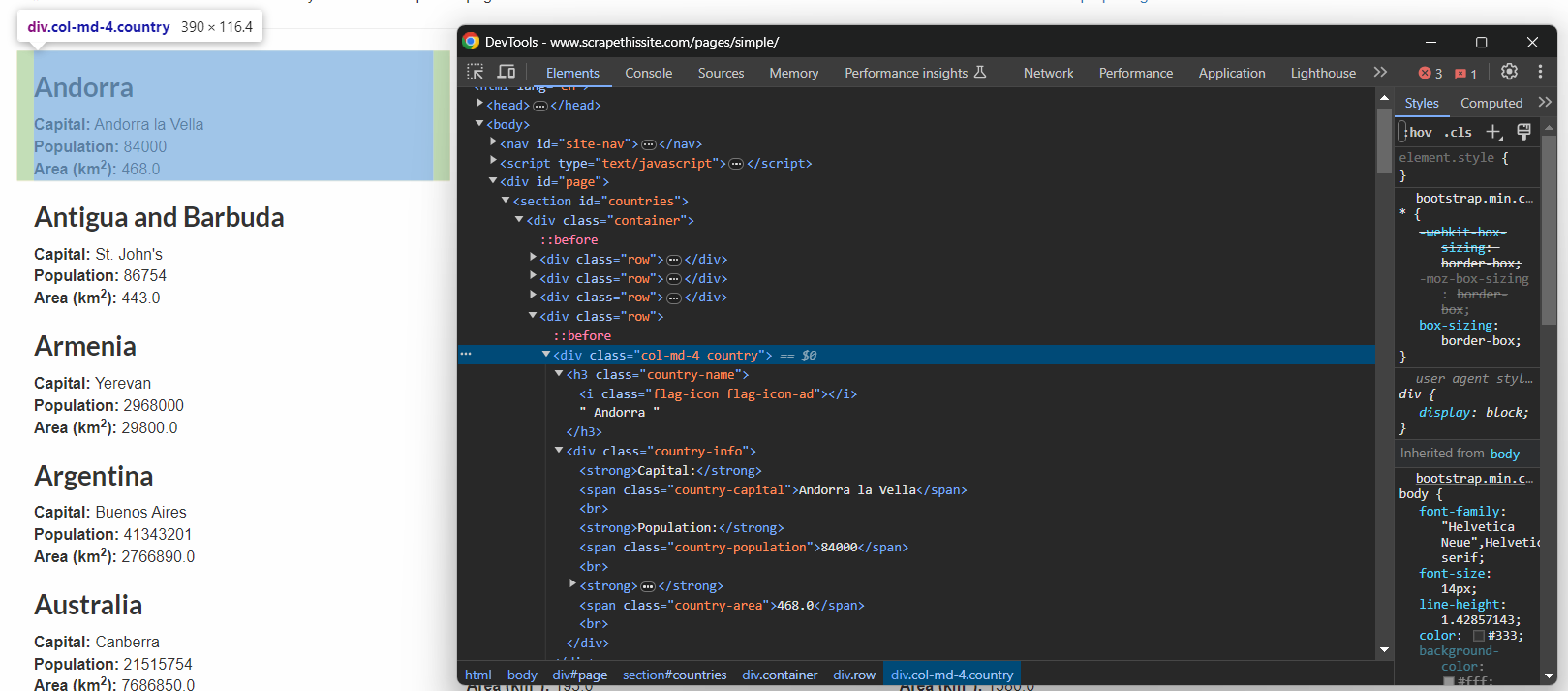
Lá, você pode ver que cada caixa de informações do país é um nó HTML .country que contém:
- O nome do país em um elemento .country-name.
- O nome da capital em um elemento .country-capital.
- As informações sobre a população em um elemento .country-population.
- A área em km² ocupada pelo país no elemento .country-area.
No parágrafo acima, estão todos os seletores CSS necessários para selecionar os nós HTML desejados. Teste os seletores em uma caixa de informações do país antes de aplicá-los a todos os elementos da página!
Etapa 6: Recuperar dados de um único elemento
A função parse() do Scraper::Selector aceita uma string que representa um seletor CSS e retorna um objeto seletor. Use-a conforme abaixo:
let html_country_info_box_selector = Scraper::Selector::parse(".country")?;Você pode então passar o seletor para o método select() exposto por document:
let html_country_info_box_element = document
.select(&html_country_info_box_selector)
.next()
.ok_or("Elemento da caixa de informações do país não encontrado!")?;Isso aplicará o seletor CSS na página e retornará o elemento HTML selecionado. Como select() sempre retorna um iterador, a chamada .next() é necessária para obter o primeiro nó da caixa de informações do país.
Observe que o objeto retornado por select() também expõe a função select(). Nesse caso, ele pesquisará nós apenas nos filhos do nó atual. Portanto, você pode implementar toda a lógica de Scraping de dados do Rust da seguinte maneira:
let country_name_selector = Scraper::Selector::parse(".country-name")?;
let name = html_country_info_box_element
.select(&country_name_selector)
.next()
.map(|element| element.text().collect::<STRING>().trim().to_owned())
.ok_or("Nome do país não encontrado")?;
let country_capital_selector = Scraper::Selector::parse(".country-capital")?;
let capital = html_country_info_box_element
.select(&country_capital_selector)
.next()
.map(|element| element.text().collect::<STRING>().trim().to_owned())
.ok_or("Capital do país não encontrada")?;
let country_population_selector = Scraper::Selector::parse(".country-population")?;
let population = html_country_info_box_element
.select(&country_population_selector)
.next()
.map(|element| element.text().collect::<STRING>().trim().to_owned())
.ok_or("População do país não encontrada")?;
let country_area_selector = Scraper::Selector::parse(".country-area")?;
let área = html_country_info_box_element
.select(&country_area_selector)
.next()
.map(|element| element.text().collect::<String>().trim().to_owned())
.ok_or("Área do país não encontrada")?;O método text() permite acessar o texto contido no nó HTML selecionado. Para outras abordagens de extração de dados, consulte a documentação. Como o texto extraído pode conter espaços indesejados, remova-os com trim().
Imprima os dados extraídos para verificar se a lógica de extração funciona conforme o esperado:
println!("Nome do país: {name}");
println!("Capital do país: {capital}");
println!("Nome do país: {population}");
println!("Área do país: {area}");
Isso produziria:
Nome do país: Andorra
Capital do país: Andorra la Vella
População do país: 84.000
Área do país: 468,0Sim! Você acabou de realizar o Scraping de dados em Rust!
Etapa 7: extrair todos os elementos da página
Desta vez, você ampliará o código visto acima para percorrer todos os nós da caixa de informações do país na página.
Primeiro, você precisa definir uma estrutura de dados personalizada para armazenar os dados coletados. Para especificar uma nova estrutura adaptada para isso, adicione as seguintes linhas no topo do seu arquivo main.rs:
struct Country {
name: String,
capital: String,
population: String,
area: String,
}Em segundo lugar, instancie um Vec de objetos Country em main():
let mut countries: Vec<Country> = Vec::new();Esse vetor conterá todos os seus dados coletados.
Em seguida, remova a chamada .next() para obter todas as caixas de informações do país, itere sobre elas e preencha os países:
// onde armazenar os dados coletados
let mut países: Vec<PAÍS> = Vec::new();
// selecionar os elementos HTML da caixa de informações do país
let html_country_info_box_selector = Scraper::Selector::parse(".country")?;
let html_country_info_box_elements = document.select(&html_country_info_box_selector);
// iterar sobre os elementos HTML do país
// e coletá-los todos
for html_country_info_box_element in html_country_info_box_elements {
// lógica de coleta para um único elemento HTML da caixa de informações do país...
// criar um novo objeto País e adicioná-lo ao vetor
let country = País {
nome,
capital,
população,
área,
};
países.push(country);
}Você pode então imprimir todos os países extraídos com:
// registrar os resultados
para país em países {
println!("Nome do país: {}", país.nome);
imprimir!("Capital do país: {}", país.capital);
println!("Nome do país: {}", país.população);
imprimir!("Área do país: {}", área do país);
imprimir!();
}
O novo arquivo main.rs Rust para Scraping de dados conterá:
// estrutura personalizada para armazenar os dados coletados
struct País {
nome: String,
capital: String,
população: String,
área: String,
}
fn main() -> Result<(), Box<dyn std::error::Error>> {
// conectar-se à página de destino
let response = reqwest::blocking::get("https://www.scrapethissite.com/pages/simple/")?;
// extrair o html bruto e imprimi-lo
let html = response.text()?;
// analisar o documento HTML
let document = Scraper::Html::parse_document(&html);
// onde armazenar os dados extraídos
let mut países: Vec<PAÍS> = Vec::new();
// selecionar os elementos HTML da caixa de informações do país
let html_country_info_box_selector = Scraper::Selector::parse(".country")?;
let html_country_info_box_elements = document.select(&html_country_info_box_selector);
// iterar sobre os elementos HTML do país
// e extraí-los todos
for html_country_info_box_element in html_country_info_box_elements {
// lógica de extração para um único elemento HTML da caixa de informações do país
let country_name_selector = Scraper::Selector::parse(".country-name")?;
let name = html_country_info_box_element
.select(&country_name_selector)
.next()
.map(|element| element.text().collect::<STRING>().trim().to_owned())
.ok_or("Nome do país não encontrado")?;
let country_capital_selector = Scraper::Selector::parse(".country-capital")?;
let capital = html_country_info_box_element
.select(&country_capital_selector)
.next()
.map(|element| element.text().collect::<STRING>().trim().to_owned())
.ok_or("Capital do país não encontrada")?;
let country_population_selector = Scraper::Selector::parse(".country-population")?;
let population = html_country_info_box_element
.select(&country_population_selector)
.next()
.map(|element| element.text().collect::<STRING>().trim().to_owned())
.ok_or("População do país não encontrada")?;
let country_area_selector = Scraper::Selector::parse(".country-area")?;
let área = html_country_info_box_element
.select(&country_area_selector)
.next()
.map(|element| element.text().collect::<String>().trim().to_owned())
.ok_or("Área do país não encontrada")?;
// crie um novo objeto País e adicione-o ao vetor
let país = País {
nome,
capital,
população,
área,
};
países.push(país);
}
// registrar os resultados
para país em países {
println!("Nome do país: {}", país.nome);
println!("Capital do país: {}", capital do país);
println!("Nome do país: {}", população do país);
println!("Área do país: {}", área do país);
println!();
}
Ok(())
}
Inicie-o e ele gerará esta saída:
Nome do país: Andorra
Capital do país: Andorra la Vella
População do país: 84000
Área do país: 468,0
# omitido por brevidade...
Nome do país: Zimbábue
Capital do país: Harare
Nome do país: 11651858
Área do país: 390580,0Missão cumprida! Você acabou de extrair todos os países da página de destino!
Etapa 8: Exportar os dados extraídos para CSV
Os dados coletados agora estão armazenados no vetor Rust, que não é o melhor formato se você quiser compartilhá-los com outras pessoas. É por isso que você precisa exportá-los para formatos fáceis de explorar, como CSV.
Para exportar os dados para um arquivo CSV, você deve usar a biblioteca csv. Instale-a com este comando:
cargo add csvVocê pode então usá-la para produzir um arquivo CSV de exportação com:
// inicialize o arquivo CSV de saída
let mut writer = csv::Writer::from_path("countries.csv")?;
// escreva o cabeçalho CSV
writer.write_record(&["name", "capital", "population", "area"])?;
// preencha o arquivo com cada país
for country in countries {
writer.write_record(&[
country.name,
country.capital,
country.population,
country.area,
])?;
}Este trecho cria um arquivo CSV, inicializa-o com a linha do cabeçalho e, finalmente, preenche-o iterando sobre o vetor de países.
Etapa 9: Junte tudo
Aqui está o código completo do seu script Rust de Scraping de dados:
// estrutura personalizada para armazenar os dados de scraping
pub struct Country {
name: String,
capital: String,
population: String,
area: String,
}
fn main() -> Result<(), Box<dyn std::error::Error>> {
// conecte-se à página de destino
let response = reqwest::blocking::get("https://www.scrapethissite.com/pages/simple/")?;
// extrair o html bruto e imprimi-lo
let html = response.text()?;
// analisar o documento HTML
let document = Scraper::Html::parse_document(&html);
// onde armazenar os dados extraídos
let mut countries: Vec<COUNTRY> = Vec::new();
// selecionar os elementos HTML da caixa de informações do país
let html_country_info_box_selector = Scraper::Selector::parse(".country")?;
let html_country_info_box_elements = document.select(&html_country_info_box_selector);
// iterar sobre os elementos HTML do país
// e extraí-los todos
para html_country_info_box_element em html_country_info_box_elements {
// lógica de extração para um único elemento HTML da caixa de informações do país
let country_name_selector = Scraper::Selector::parse(".country-name")?;
let name = html_country_info_box_element
.select(&country_name_selector)
.next()
.map(|element| element.text().collect::<STRING>().trim().to_owned())
.ok_or("Nome do país não encontrado")?;
let country_capital_selector = Scraper::Selector::parse(".country-capital")?;
let capital = html_country_info_box_element
.select(&country_capital_selector)
.next()
.map(|element| element.text().collect::<STRING>().trim().to_owned())
.ok_or("Capital do país não encontrada")?;
let country_population_selector = Scraper::Selector::parse(".country-population")?;
let population = html_country_info_box_element
.select(&country_population_selector)
.next()
.map(|element| element.text().collect::<String>().trim().to_owned())
.ok_or("População do país não encontrada")?;
let country_area_selector = Scraper::Selector::parse(".country-area")?;
let area = html_country_info_box_element
.select(&country_area_selector)
.next()
.map(|element| element.text().collect::<STRING>().trim().to_owned())
.ok_or("Área do país não encontrada")?;
// criar um novo objeto País e adicioná-lo ao vetor
let país = País {
nome,
capital,
população,
área,
};
países.push(país);
}
// inicializar o arquivo CSV de saída
let mut writer = csv::Writer::from_path("countries.csv")?;
// escrever o cabeçalho CSV
writer.write_record(&["name", "capital", "population", "area"])?;
// preencher o arquivo com cada país
para país em países {
writer.write_record(&[
país.nome,
país.capital,
país.população,
país.área,
])?;
}
Ok(())
}Dá para acreditar? Você pode criar um Scraper de dados Rust com menos de 100 linhas de código.
Compile o aplicativo com o comando abaixo:
cargo buildEm seguida, inicie-o com:
cargo runQuando o script terminar, um arquivo countries.csv aparecerá na pasta raiz do seu projeto. Abra-o e você verá os seguintes dados:
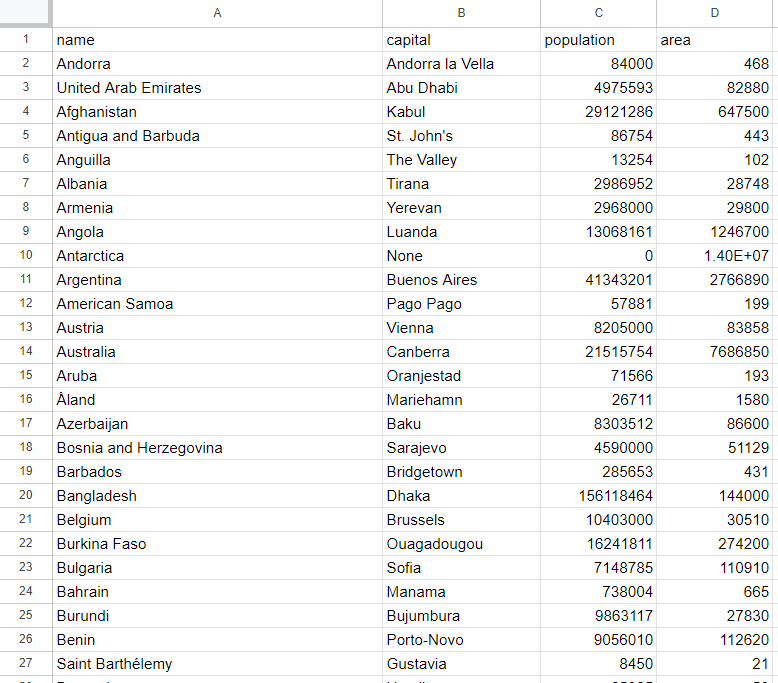
Et voilà! Agora você conhece os fundamentos do Scraping de dados da web com Rust!
Mantenha sua operação de Scraping de dados ética e respeitosa
Recuperar dados automaticamente da Internet é uma maneira eficaz de obter informações úteis. No entanto, você não quer prejudicar o site de destino ao fazer isso. Portanto, você deve abordar essa operação com as devidas precauções.
Para realizar um Scraping de dados responsável, considere estas dicas:
- Cumpra o arquivo robots.txt: todo site tem um arquivo robots.txt que especifica as regras sobre como os rastreadores automatizados devem acessar suas páginas. Para manter práticas éticas de scraping de dados, você deve seguir essas diretrizes. Saiba mais em nosso guia robots.txt para Scraping de dados.
- Limite a frequência de suas solicitações: fazer muitas solicitações em um curto período levará a uma sobrecarga do servidor, afetando o desempenho do site para todos os usuários. Isso também pode acionar medidas de limitação de taxa e fazer com que você seja bloqueado. Portanto, adicione atrasos aleatórios às suas solicitações para evitar sobrecarregar o servidor de destino.
- Verifique e respeite os Termos de Serviço do site: antes de fazer scraping em um site, revise e cumpra seus Termos de Serviço. Eles podem conter informações sobre direitos autorais, direitos de propriedade intelectual e diretrizes sobre como e quando usar seus dados.
- Extraia apenas informações disponíveis publicamente: concentre-se em extrair dados que sejam acessíveis publicamente no site e não protegidos por credenciais de login ou outras formas de autorização. Extrair dados privados ou confidenciais sem a devida permissão é antiético e pode levar a consequências legais.
- Confie em ferramentas de extração confiáveis e atualizadas: selecione fornecedores conceituados e opte por bibliotecas e ferramentas que sejam bem mantidas e atualizadas regularmente. Só assim você poderá garantir que elas estejam em conformidade com os princípios éticos e as melhores práticas mais recentes de Scraping de dados. Se tiver alguma dúvida, leia nosso artigo sobre como escolher o melhor serviço de Scraping de dados.
Conclusão
Neste tutorial, você viu por que o Rust é uma boa opção para o Scraping de dados e quais bibliotecas você deve usar para realizá-lo. Aqui, você aprendeu como usar o reqwest e o Scraper para construir um web scraper Rust que pode extrair dados de um site do mundo real. Isso leva apenas algumas linhas de código!
No entanto, tenha em mente que o Scraping de dados nem sempre é tão fácil. O motivo é que as soluções anti-scraping e anti-bot estão se tornando mais comuns. Essas tecnologias podem detectar a natureza autônoma do seu script e bloqueá-lo, representando um sério desafio para sua operação de scraping.
Evite essa dor de cabeça com a ferramenta de Scraping de dados avançada e de última geração fornecida pela Bright Data. Se você quiser saber mais sobre como evitar ser bloqueado, adote um Proxy da web de um dos vários serviços de Proxy disponíveis ou comece a usar o Web Unlocker avançado.
Não quer lidar com Scraping de dados? Explore nossos Conjuntos de dados.
Não sabe qual produto escolher? Inscreva-se agora e encontre a solução certa para o seu negócio.





