

À medida que a quantidade de dados na internet continua a crescer, o rastreamento da web, o processo de navegar e extrair informações automaticamente de sites, torna-se uma habilidade cada vez mais importante para os desenvolvedores aprenderem. Isso é feito enviando solicitações HTTP para servidores web e realizando o Parsing da resposta HTML para extrair os dados desejados.
O processo de rastreamento da web pode ser complexo e demorado; no entanto, as ferramentas e técnicas certas podem ajudar. Com sua flexibilidade e facilidade de uso, o Python emergiu como uma linguagem popular para a construção de rastreadores da web, permitindo que os desenvolvedores escrevam rapidamente scripts para automatizar o processo de extração de dados.
Neste artigo, você aprenderá tudo sobre rastreamento da web com Python usando a biblioteca Scrapy.
Por que você precisa do rastreamento da web
Antes de mergulharmos no tutorial, é importante reconhecer a diferença entre Scraping de dados e rastreamento da web. Embora semelhantes, o Scraping de dados extrai dados específicos de páginas da web, enquanto o rastreamento da web navega pelas páginas da web para indexação e coleta informações para mecanismos de pesquisa.
O rastreamento da web é útil em todos os tipos de cenários, incluindo os seguintes:
- Extração de dados: o rastreamento da web pode ser usado para extrair dados específicos de sites, que podem ser usados para análise ou pesquisa.
- Indexação de sites: os mecanismos de pesquisa costumam usar o rastreamento da web para indexar sites e torná-los pesquisáveis para os usuários.
- Monitoramento: o rastreamento da web pode ser usado para monitorar sites em busca de alterações ou atualizações. Essas informações costumam ser úteis para rastrear concorrentes.
- Agregação de conteúdo: o rastreamento da web pode ser usado para coletar conteúdo de vários sites e agregá-lo em um único local para facilitar o acesso.
- Testes de segurança: o rastreamento da web pode ser usado para testes de segurança para identificar vulnerabilidades ou pontos fracos em sites e aplicativos da web.
Rastreamento da web com Python
Python é uma escolha popular para rastreamento da web devido à sua facilidade de uso na codificação e sintaxe intuitiva. Além disso, o Scrapy, uma das estruturas de rastreamento da web mais populares, é construído em Python. Essa estrutura poderosa e flexível facilita a extração de dados de sites, o acompanhamento de links e o armazenamento dos resultados.
O Scrapy foi projetado para lidar com grandes quantidades de dados e pode ser usado para uma ampla gama de tarefas de Scraping de dados. As ferramentas incluídas no Scrapy, como o downloader HTTP, o spider para rastrear sites, o agendador para gerenciar a frequência de rastreamento e o pipeline de itens para processar dados rastreados, tornam-no adequado para várias tarefas de rastreamento da web.
Para começar a rastrear a web usando Python, você precisa instalar a estrutura Scrapy no seu sistema.
Abra seu terminal e execute o seguinte comando:
pip install scrapyn
Após executar este comando, você terá o Scrapy instalado em seu sistema. O Scrapy fornece classes chamadas spiders que definem como realizar uma tarefa de rastreamento da web. Esses spiders são responsáveis por navegar no site, enviar solicitações e extrair dados do HTML do site.
Criando um projeto Scrapy
Neste artigo, você rastreará um site chamado Books to Scrape e salvará o nome, a categoria e o preço de cada livro em um arquivo CSV. Este site foi criado para funcionar como uma área restrita para projetos de scraping.
Depois de instalar o Scrapy, você precisa criar uma nova estrutura de projeto usando o seguinte comando:
scrapy startproject bookcrawlern
(observação: se você receber uma mensagem de erro “comando não encontrado”, reinicie seu terminal)
A estrutura de diretórios padrão fornece uma estrutura clara e organizada, com arquivos e diretórios separados para cada componente do processo de Scraping de dados. Isso facilita a escrita, o teste e a manutenção do seu código spider, bem como o processamento e o armazenamento dos dados extraídos da maneira que você preferir. Esta é a aparência da sua estrutura de diretórios:
bookcrawlernâ scrapy.cfgnânââââbookcrawlern â items.pyn â middlewares.pyn â pipelines.pyn â settings.pyn â __init__.pyn ân ââââspidersn __init__.pynn
Para iniciar o processo de rastreamento em seu projeto Scrapy, é essencial criar um novo arquivo spider no diretório bookcrawler/spiders, pois esse é o diretório padrão onde o Scrapy procura por spiders para executar o código. Para fazer isso, navegue até o diretório bookcrawler/spiders e crie um novo arquivo chamado bookspider.py. Em seguida, escreva o seguinte código no arquivo para definir seu spider e especificar seu comportamento:
from scrapy.spiders import CrawlSpider, Rulenfrom scrapy.linkextractors import LinkExtractornnclass BookCrawler(CrawlSpider):n name = 'bookspider'n start_urls = [n 'https://books.toscrape.com/',n ]n rules = (n Rule(LinkExtractor(allow='/catalogue/category/books/')),n )nn
Este código define um BookCrawler, que é uma subclasse do CrawlSpider integrado, e fornece uma maneira conveniente de definir regras para seguir links e extrair dados. O atributo start_urls especifica uma lista de URLs para iniciar o rastreamento. Neste caso, ele contém apenas um URL, que é a página inicial do site.
O atributo rules especifica um conjunto de regras para determinar quais links o spider deve seguir. Neste caso, há apenas uma regra definida, criada usando a classe Rule do módulo scrapy.spiders. A regra é definida com uma instância LinkExtractor que especifica o padrão de links que o spider deve seguir. O parâmetro allow do LinkExtractor é definido como /catalogue/category/books/, o que significa que o spider deve seguir apenas links que contenham essa string em sua URL.
Para executar o spider, abra seu terminal e execute o seguinte comando:
scrapy crawl bookspidern
Assim que você executar isso, o Scrapy inicializa a classe spider BookCrawler, cria uma solicitação para cada URL no atributo start_urls e as envia para o agendador do Scrapy. Quando o agendador recebe uma solicitação, ele verifica se a solicitação é permitida pelo atributo allowed_domains (se especificado) do spider. Se o domínio for permitido, a solicitação é então passada para o downloader, que faz uma solicitação HTTP ao servidor e recupera a resposta.
Nesse ponto, você deve conseguir ver todas as URLs que seu spider rastreou na janela do console:
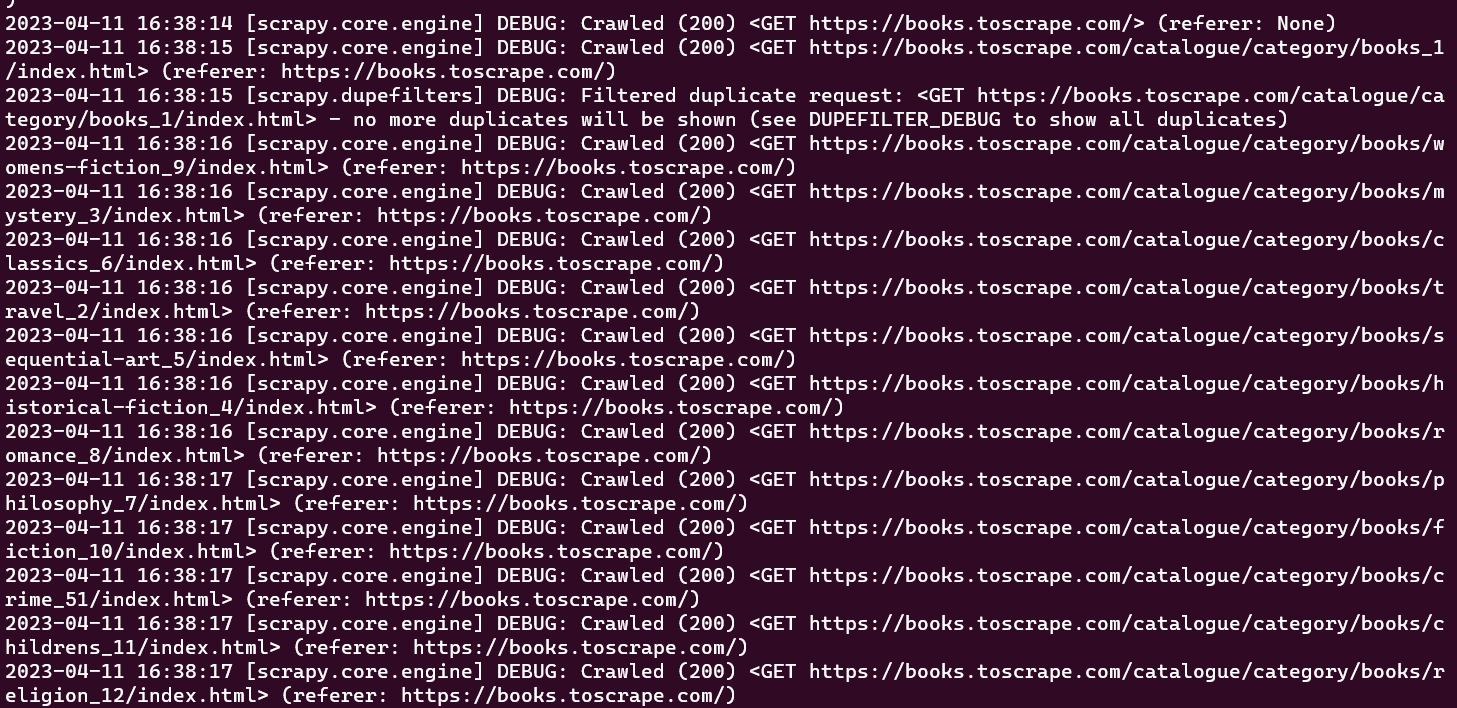
O rastreador inicial que foi criado apenas executa a tarefa de rastrear um conjunto predefinido de URLs sem extrair nenhuma informação. Para recuperar dados durante o processo de rastreamento, você precisa definir uma função parse_item dentro da classe do rastreador. A função parse_item tem a tarefa de receber a resposta de cada solicitação feita pelo rastreador e retornar os dados relevantes obtidos da resposta.
Observação: a função
parse_itemsó funciona após definir o atributocallbackno seuLinkExtractor.
Para extrair dados da resposta obtida ao rastrear páginas da web no Scrapy, você precisa usar seletores CSS. A próxima seção fornece uma breve introdução aos seletores CSS.
Um pouco sobre seletores CSS
Os seletores CSS são uma forma de extrair dados da página da web especificando tags, classes e atributos. Por exemplo, aqui está uma sessão do shell do Scrapy que foi inicializada usando scrapy shell books.toscrape.com:
# check if the response was successfulnu003eu003eu003e responsenu003c200 http://books.toscrape.comu003enn#extract the title tagnu003eu003eu003e response.css('title')n[u003cSelector xpath='descendant-or-self::title' data='u003ctitleu003en All products | Books to S...'u003e]n
Nesta sessão, a função css recebe uma tag (ou seja, título) e retorna o objeto Selector. Para obter o texto dentro da tag título, você deve escrever a seguinte consulta:
u003eu003eu003e print(response.css('title::text').get())n All products | Books to Scrape - Sandboxn
Neste trecho, o pseudo-seletor de texto é usado para remover a tag title que o envolve e retorna apenas o texto interno. O método get é usado para exibir apenas o valor dos dados.
Para obter as classes dos elementos, você precisa visualizar o código-fonte da página clicando com o botão direito do mouse e selecionando Inspecionar:
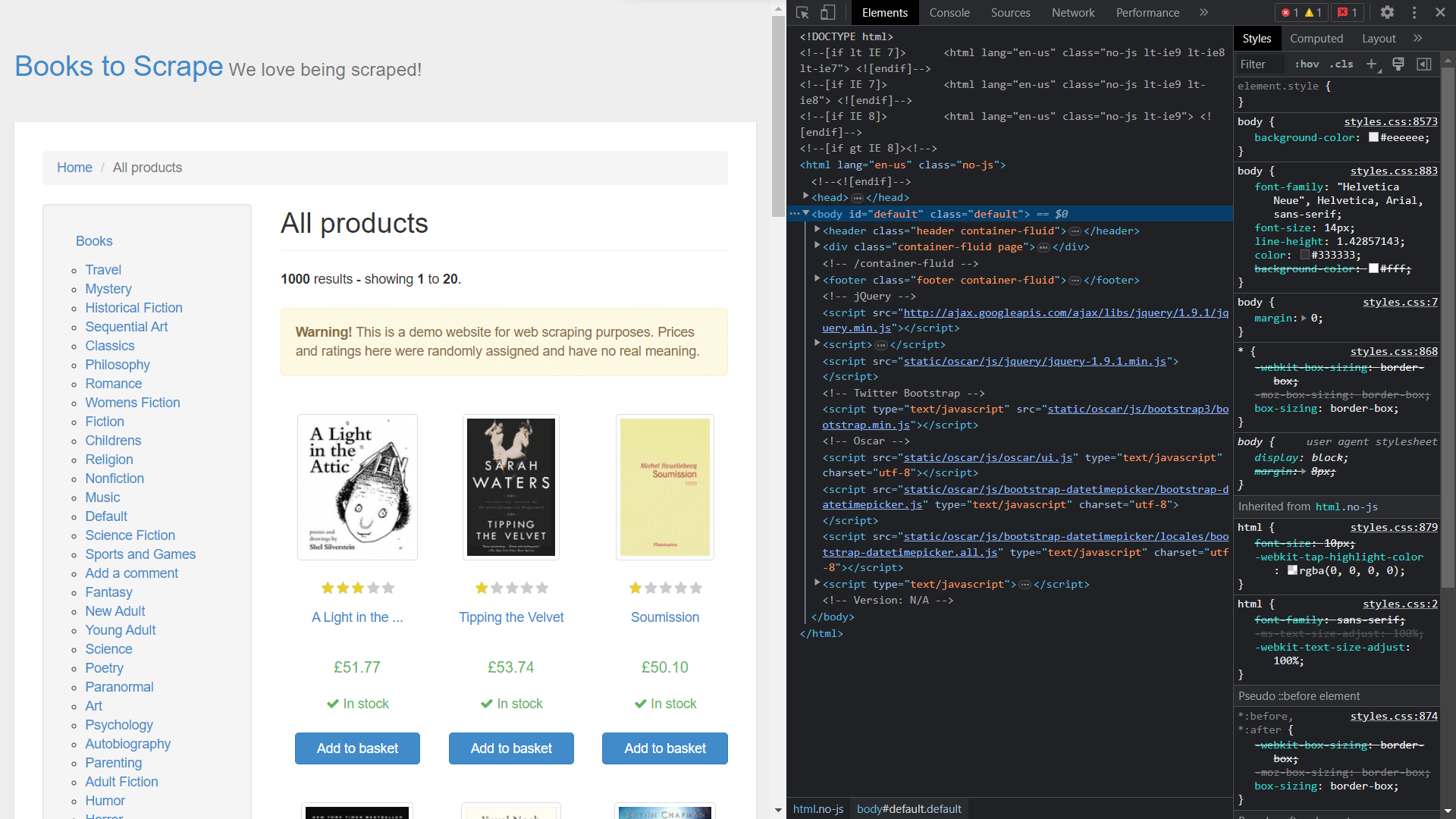
Extraindo dados usando o Scrapy
Para extrair elementos do objeto de resposta, você precisa definir uma função de retorno de chamada e atribuí-la como um atributo na classe Rule.
Abra bookspider.py e execute o seguinte código:
from scrapy.spiders import CrawlSpider, Rulenfrom scrapy.linkextractors import LinkExtractornnclass BookCrawler(CrawlSpider):n name = 'bookspider'n start_urls = [n 'https://books.toscrape.com/',n ]nnn rules = (n Rule(LinkExtractor(allow='/catalogue/category/books/'), callback=u0022parse_itemu0022), n n )n def parse_item(self, response):n category = response.css('h1::text').get()n book_titles = response.css('article.product_pod').css('h3').css('a::text').getall()n book_prices = response.css('article.product_pod').css('p.price_color::text').getall()n yield {n u0022categoryu0022: category,n u0022booksu0022:list(zip(book_titles,book_prices))n }nn
A função parse_item na classe BookCrawler contém a lógica para os dados a serem extraídos e os envia para o console. O uso de yield permite que o Scrapy processe os dados na forma de itens, que podem então ser passados por pipelines de itens para processamento ou armazenamento posterior.
O processo de seleção da categoria é uma tarefa simples, pois está codificado dentro de uma tag <h1> simples. No entanto, a seleção de book_titles é realizada por meio de um processo de seleção multinível, em que a primeira etapa envolve a seleção da tag <article> com a classe product_pod. Em seguida, o processo de travessia continua para identificar a tag <a> aninhada dentro da tag <h3>. A mesma abordagem é adotada ao selecionar book_prices, permitindo a recuperação das informações necessárias da página da web.
Neste ponto, você criou um spider que rastreia um site e recupera dados. Para executar o spider, abra o terminal e execute o seguinte comando:
scrapy crawl bookspider -o books.jsonn
Quando executado, as páginas da web rastreadas pelo rastreador e seus dados correspondentes são exibidos no console. O uso do sinalizador -o instrui o Scrapy a armazenar todos os dados recuperados em um arquivo chamado books.json. Após a conclusão do script, um novo arquivo chamado books.json é criado no diretório do projeto. Esse arquivo contém todos os dados relacionados a livros recuperados pelo rastreador:
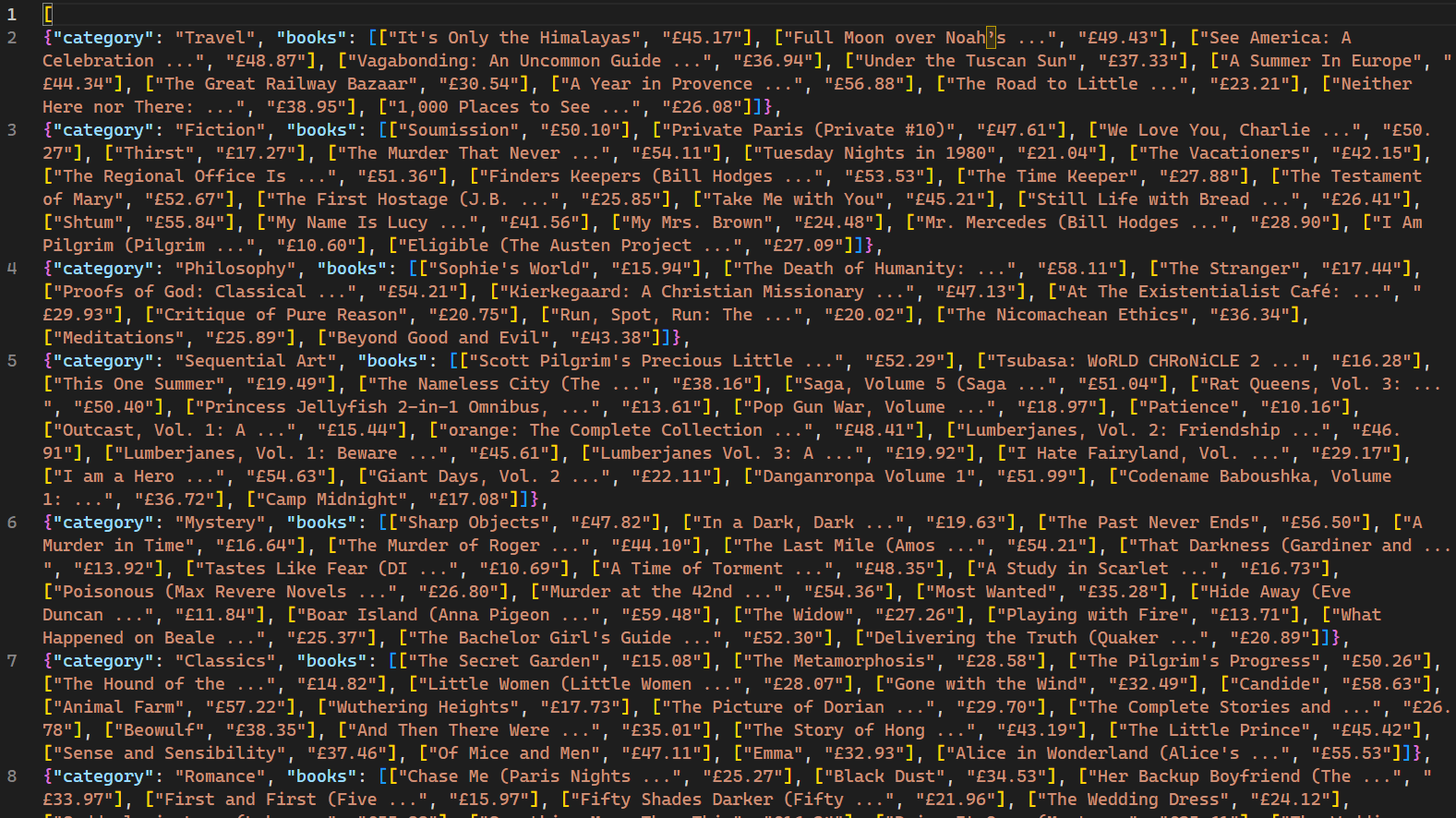
É importante observar que esse rastreador da web só é eficaz para sites que não empregam mecanismos de bloqueio de IP em resposta a várias solicitações. Para sites menos receptivos a bots e rastreadores da web, um serviço de Proxy como o Bright Data é necessário para extrair dados em escala. Os serviços da Bright Data permitem que os usuários coletem dados da web de várias fontes, evitando bloqueios e detecção de IP.
Conclusão
O rastreamento da web, integrado ao Scraping de dados, é uma habilidade altamente valiosa para a coleta de dados e a ciência de dados. O Scrapy, uma estrutura projetada para rastreamento da web, simplifica o processo ao oferecer rastreadores e Scrapers integrados.
Este artigo mostrou como construir um rastreador da web e, em seguida, extrair dados usando a estrutura Scrapy. Você aprendeu a usar o CrawlSpider para rastreamento fácil da web e conheceu conceitos como Rule e LinkExtractor para rastrear padrões específicos de URLs. Além disso, você abordou os conceitos de seleção de elementos HTML usando seletores CSS. Ao dominar essas habilidades, você estará bem equipado para enfrentar os desafios do rastreamento e Scraping de dados na ciência de dados e além.





