

Por que extrair dados de detalhes de produtos da Zalando?
A Zalando é uma das plataformas de varejo de roupas online mais populares da Europa. Com mais de 50 milhões de usuários ativos, é o site líder em comércio eletrônico de moda na Europa. Oferece uma vasta gama de produtos, incluindo calçados, roupas e acessórios de marcas bem estabelecidas e designers emergentes.
As três principais razões para coletar dados de detalhes de produtos da Zalando são:
- Pesquisa de mercado: obtenha informações valiosas sobre as tendências atuais da moda. Essas informações ajudam as empresas a tomar decisões informadas, permanecer competitivas e adaptar suas ofertas para atender às demandas dos clientes de maneira eficaz.
- Monitoramento de preços: acompanhe as flutuações de preços para aproveitar ótimas ofertas e estudar o mercado.
- Popularidade da marca: concentre-se nos produtos populares na Zalando para ver quais marcas são atualmente mais populares entre os clientes e estudar sua estratégia.
Em resumo, a extração de dados da Zalando abre um mundo de possibilidades e é excelente tanto para empresas quanto para usuários.
Bibliotecas e ferramentas para scraping do Zalando
Para entender qual das muitas ferramentas de scraping disponíveis é a melhor para fazer scraping no Zalando, abra-o no seu navegador. Inspecione o DOM e compare-o com o código-fonte bruto. Você notará que a estrutura do DOM é ligeiramente diferente do documento HTML produzido pelo servidor. Isso significa que o site depende do JavaScript para renderização. Para fazer scraping em um site de conteúdo dinâmico, você precisa de uma ferramenta que possa executar JavaScript, como o Selenium!
Agora é a vez da linguagem de programação. Quando se trata de Scraping de dados, a mais popular é Python. Sua sintaxe fácil e seu rico ecossistema de bibliotecas a tornam perfeita para nossos objetivos. Então, vamos usar Python
Antes de começar, confira estes dois guias:
- Scraping de dados com Python – Guia passo a passo
- Raspagem de sites dinâmicos com Python
O Selenium renderiza sites em um navegador da web controlável, que você pode instruir a realizar operações específicas. Ao usá-lo em Python, você poderá criar um Scraper Zalando eficaz. Hora de ver como!
Raspagem de dados de produtos do Zalando com Selenium
Siga este tutorial passo a passo e aprenda a criar um Scraper Zalando em Python.
Etapa 1: Configure um projeto Python
Antes de começar a fazer Scraping de dados, certifique-se de que você atende aos seguintes pré-requisitos:
- Python 3+ instalado em sua máquina: baixe o instalador, clique duas vezes nele e siga o assistente de instalação.
- Um IDE Python de sua escolha: PyCharm Community Edition ou Visual Studio Code com a extensão Python são adequados.
Agora você tem tudo o que precisa para configurar um projeto Python e escrever alguns códigos!
Inicie o terminal e execute os comandos abaixo para:
- Criar uma pasta zalando-scraper.
- Entrar nela.
- Inicialize-a com um ambiente virtual Python.
mkdir zalando-scraper
cd zalando-scraper
python -m venv envNo Linux ou macOS, execute o comando abaixo para ativar o ambiente:
./env/bin/activateNo Windows, execute:envScriptsactivate.ps1
Em seguida, crie um arquivo scraper.py na pasta do projeto e adicione a seguinte linha a ele:
print("Olá, mundo!")Este é o script Python mais fácil que você pode escrever. No momento, ele apenas imprime “Olá, mundo!”, mas em breve conterá a lógica de scraping da Zalando.
Inicie-o para verificar se funciona com:
python Scraper.pyEle deve imprimir esta mensagem no terminal:
Olá, mundo!Agora que você tem certeza de que o script funciona como esperado, abra a pasta do projeto no seu IDE Python.
Ótimo! Prepare-se para escrever as primeiras linhas do seu Scraper.
Etapa 2: Instale as bibliotecas de raspagem
Como mencionado anteriormente, o Selenium é a ferramenta escolhida para construir um Scraper Zalando. No ambiente virtual Python ativado, execute o comando abaixo para adicioná-lo às dependências do projeto:
pip install seleniumO processo de instalação pode demorar um pouco, então seja paciente.
Observe que este tutorial se refere ao Selenium 4.13.x, que vem com a funcionalidade de detecção automática de drivers. Se você tiver uma versão mais antiga do Selenium em sua máquina, atualize-a com:
pip install selenium -URemova todo o conteúdo de scraper.py e inicialize um Scraper Selenium com:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# configure uma instância controlável do Chrome
service = Service()
options = webdriver.ChromeOptions()
# suas opções de navegador...
driver = webdriver.Chrome(
service=service,
options=options
)
# maximize a janela para evitar a renderização responsiva
driver.maximize_window()
# lógica de raspagem...
# feche o navegador e libere seus recursos
driver.quit()O script acima importa o Selenium e o utiliza para instanciar um objeto WebDriver. Isso permite controlar programaticamente uma instância do navegador Chrome.
Por padrão, a janela do navegador será aberta e você poderá monitorar as ações realizadas na página. Isso é útil no desenvolvimento.
Para abrir o Chrome no modo headless sem GUI, configure as opções abaixo:
options.add_argument('--headless=new')
user_agent = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36'
options.add_argument(f'user-agent={user_agent}')Observe que a opção extra user-agent é necessária, pois o Zalando bloqueia solicitações de navegadores headless sem esse cabeçalho. Essa configuração é mais comum em produção.
Ótimo! É hora de criar seu Scraper Python para Scraping de dados da Zalando.
Etapa 3: Abra a página de destino
Neste guia, você verá como extrair dados detalhados de um produto de calçados da Zalando UK. Ao direcionar um tipo de produto diferente, você terá que fazer pequenas alterações no script que está prestes a criar. O motivo é que cada produto pode ter estruturas de página específicas com informações diferentes.
No momento da redação deste artigo, esta é a aparência da página de destino:
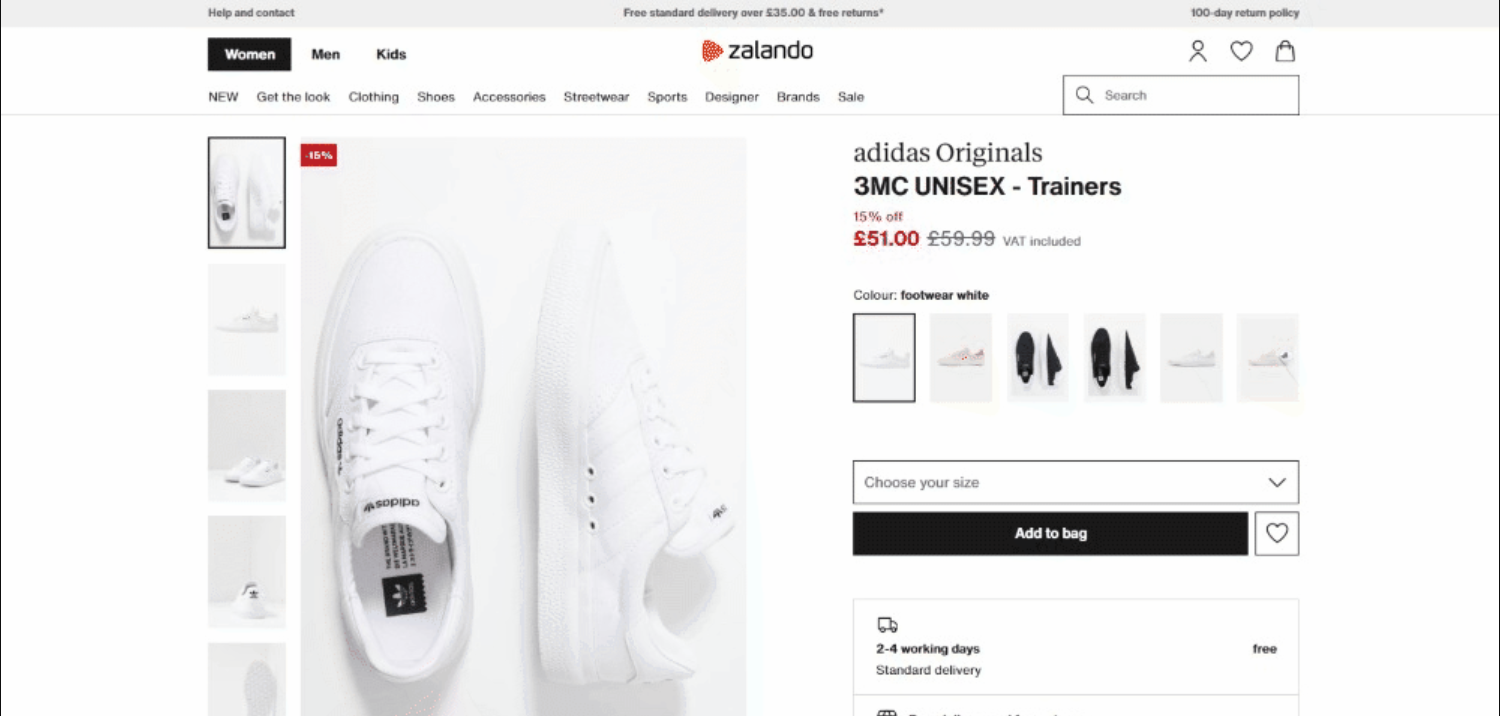
Em detalhes, esta é a URL da página de destino:
Conecte-se à página de destino no Selenium com:
driver.get('https://www.zalando.co.uk/adidas-originals-3mc-trainers-footwear-whitegold-metallic-ad115o0da-a11.html')get() instrui o navegador a visitar a página especificada pela URL passada como parâmetro.
Este é o script de scraping da Zalando até agora:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
service = Service()
# configure a instância do Chrome
options = webdriver.ChromeOptions()
# suas opções de navegador...
driver = webdriver.Chrome(
service=service,
options=options
)
# maximizar a janela para evitar a renderização responsiva
driver.maximize_window()
# visitar a página de destino no navegador controlado
driver.get('https://www.zalando.co.uk/adidas-originals-3mc-trainers-footwear-whitegold-metallic-ad115o0da-a11.html')
# lógica de scraping...
# fechar o navegador e liberar seus recursos
driver.quit()Execute o aplicativo. Ele abrirá a janela abaixo por menos de um segundo antes de encerrar:
A mensagem “O Chrome está sendo controlado por um software automatizado” garante que o Selenium está funcionando conforme o esperado.
Etapa 4: familiarize-se com a estrutura da página
Para escrever uma lógica de scraping eficaz, você precisa dedicar algum tempo ao estudo da estrutura DOM da página de destino. Isso ajudará você a entender como selecionar elementos HTML e extrair dados deles.
Abra seu navegador no modo de navegação anônima e visite a página do produto Zalando escolhido. Clique com o botão direito do mouse e selecione a opção “Inspecionar” para abrir as DevTools do seu navegador:
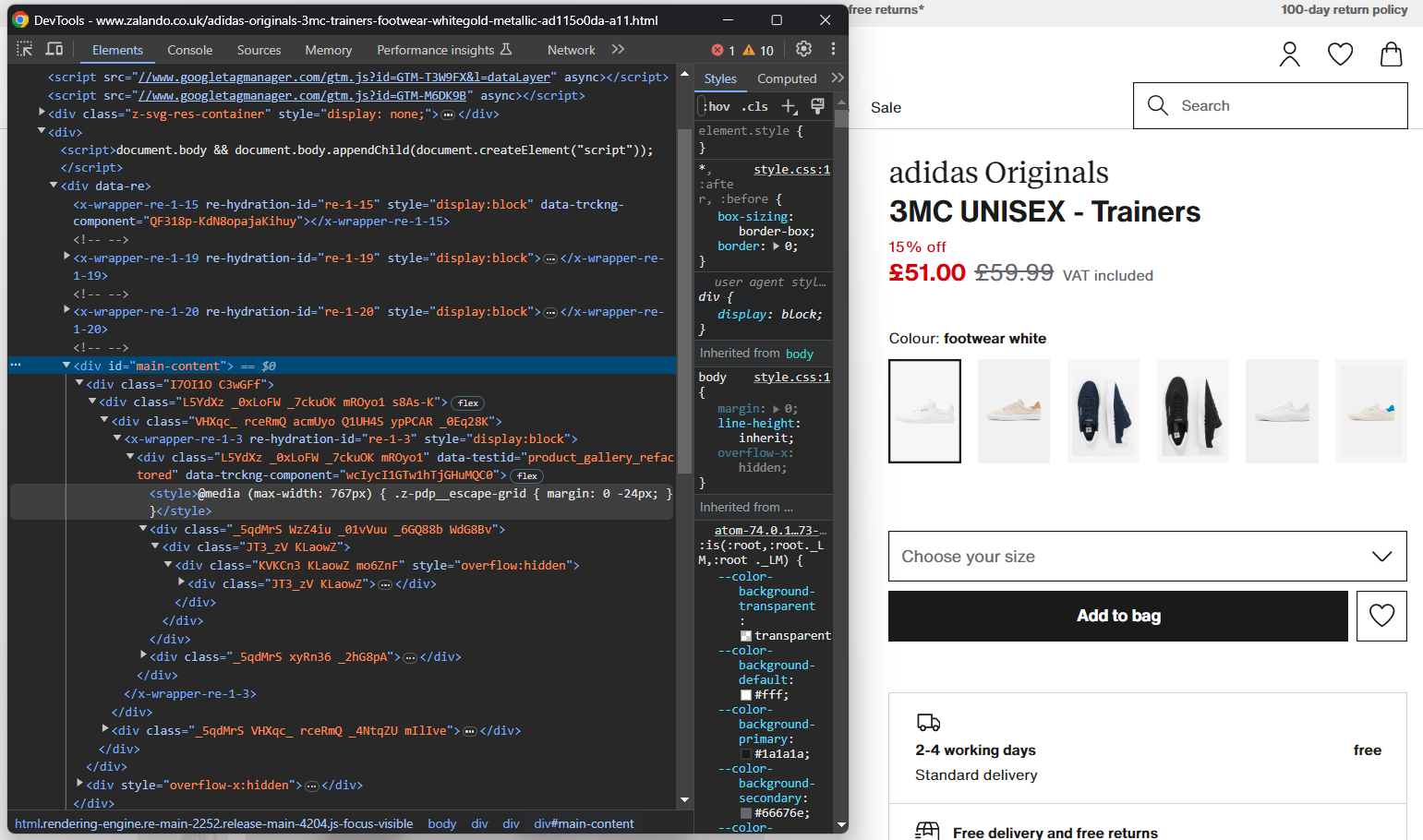
Aqui, você certamente notará que a maioria das classes CSS parece ser gerada aleatoriamente no momento da compilação. Em outras palavras, você não deve basear sua estratégia de seleção nelas, pois elas mudarão a cada implantação. Ao mesmo tempo, alguns elementos têm atributos HTML incomuns, como data-testid. Isso ajudará você a definir seletores eficazes.
Interaja com a página para estudar como o DOM muda após clicar em elementos específicos, como os acordeões. Você perceberá que alguns dados são adicionados dinamicamente ao DOM com base nas ações do usuário.
Continue inspecionando a página de destino e familiarize-se com sua estrutura HTML até se sentir pronto para prosseguir.
Etapa 5: Comece a extrair os dados do produto
Primeiro, inicialize uma estrutura de dados onde você poderá acompanhar os dados coletados. Um dicionário Python será perfeito:
produto = {}Comece a selecionar elementos na página e extraia os dados deles!
Inspecione o elemento HTML que contém a marca do sapato:
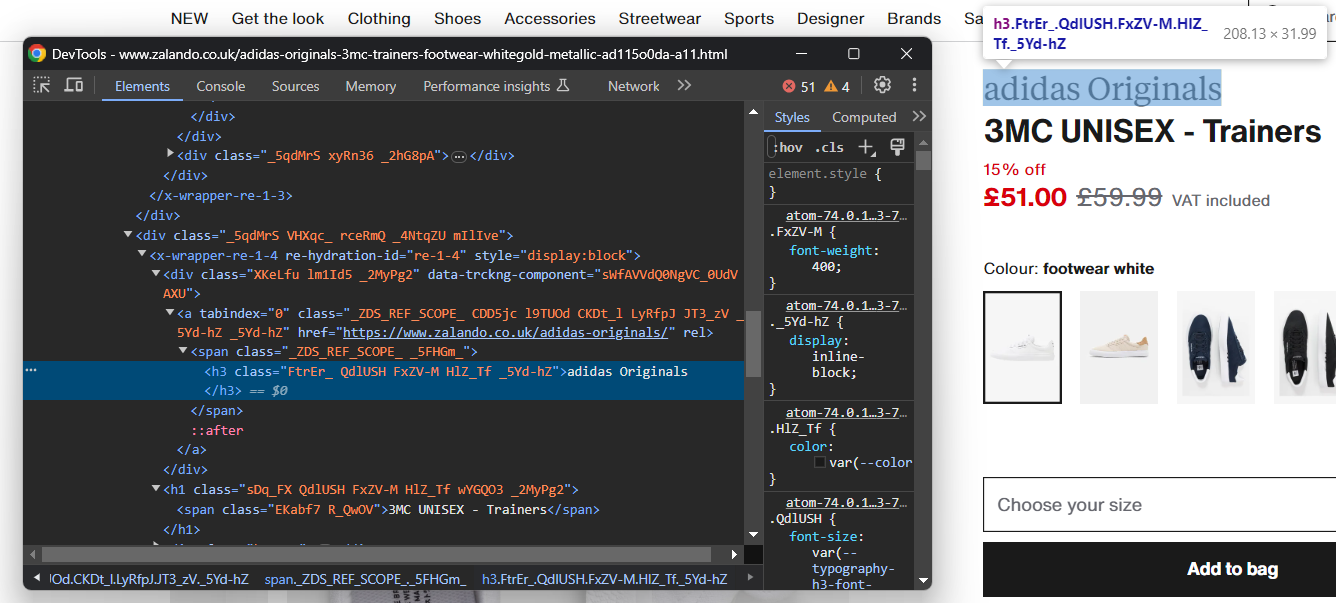
Observe que a marca é um <h3> e o nome do produto é um <h1>. Colete esses dados com:
brand_element = driver.find_element(By.CSS_SELECTOR, 'h3')
brand = brand_element.text
name_element = driver.find_element(By.CSS_SELECTOR, 'h1')
name = name_element.textfind_element() é um método do Selenium que retorna o primeiro elemento que corresponde à estratégia de seleção passada como parâmetro. Em particular, By.CSS_SELECTOR instrui o driver a usar uma estratégia de seletor CSS. O Selenium também suporta:
- By.TAG_NAME: para pesquisar elementos com base em sua tag HTML.
- By.XPATH: Para pesquisar elementos por meio de uma expressão XPath.
Da mesma forma, também existe find_elements(), que retorna a lista de todos os nós que correspondem à consulta de seleção.
Lembre-se de importar By com:
from selenium.webdriver.common.by import ByDado um elemento HTML, você pode acessar seu conteúdo de texto com o atributo text. Quando necessário, use o método Python replace() para limpar as cadeias de texto.
Extrair informações de preço é um pouco mais complicado. Como você pode ver na imagem abaixo, não há uma maneira fácil de selecionar esses elementos:
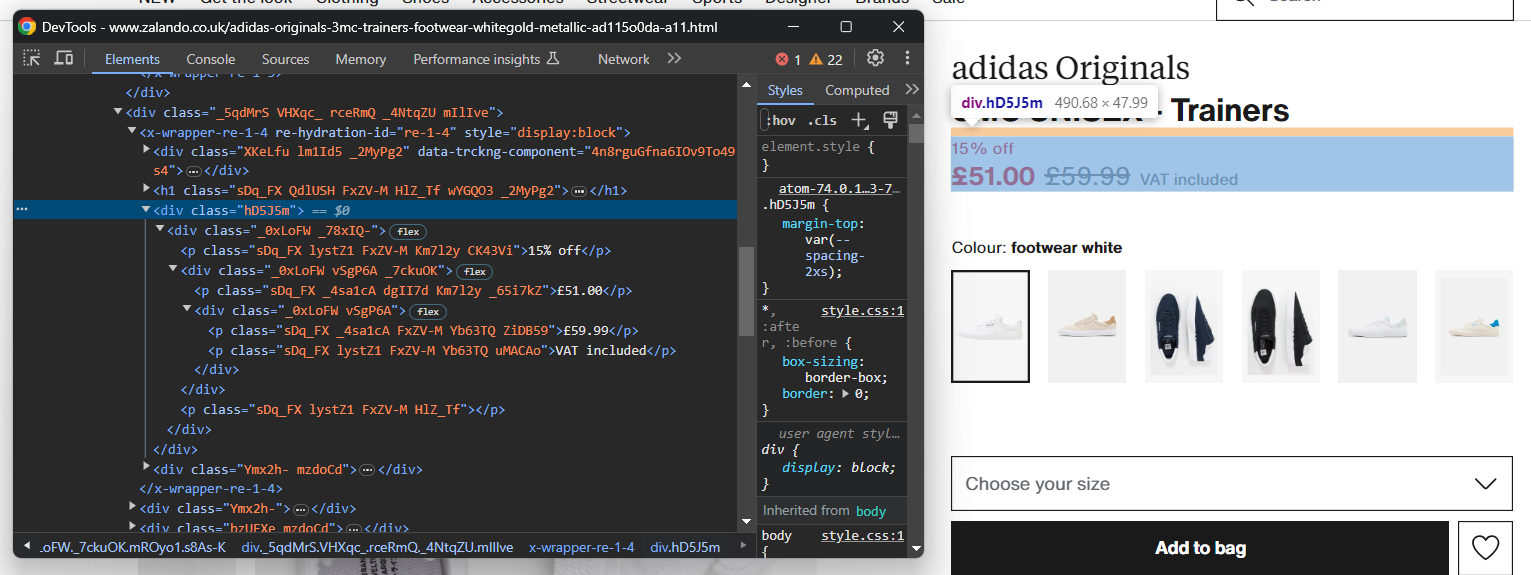
O que você pode fazer é:
- Acessar o preço <div> como o primeiro irmão do elemento <h1> name.
- Obter todos os nós <p> dentro dele.
Faça isso com:
price_elements = name_element
.find_element(By.XPATH, 'following-sibling::*[1]')
.find_elements(By.TAG_NAME, "p")Lembre-se de que o Selenium não oferece um método utilitário para acessar os irmãos de um nó. É por isso que você precisa usar a expressão Xpath following-sibling::* em vez disso.
Você pode então obter os dados do preço do produto com:
desconto = Nenhum
preço = Nenhum
preço_original = Nenhum
se len(elementos_de_preço) >= 3:
desconto = elementos_de_preço[0].texto.substituir('off', '')
preço = elementos_de_preço[1].texto
preço_original = elementos_de_preço[2].textoAgora concentre-se na galeria de imagens do produto:
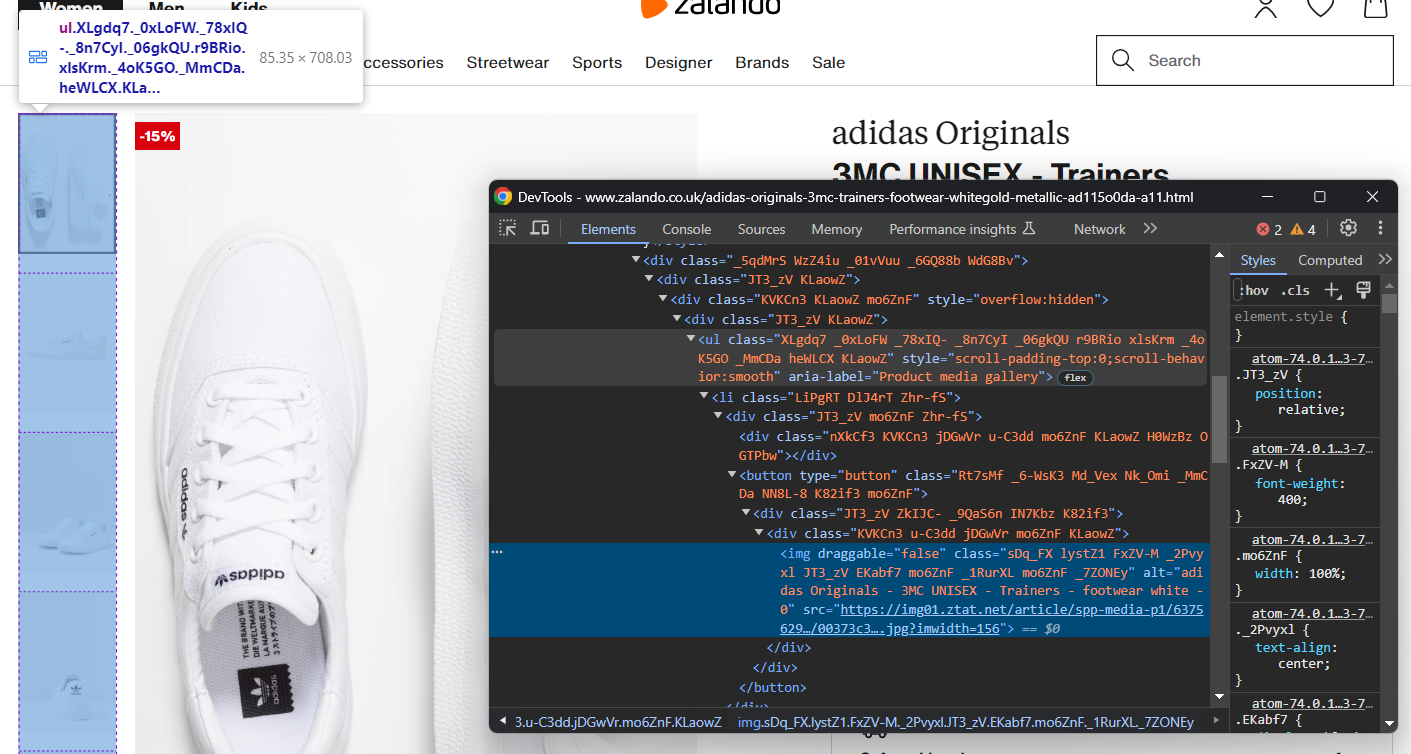
Ela contém várias imagens, portanto, inicialize uma matriz para armazená-las todas:
imagens = []Novamente, selecionar o <img> não é fácil, mas você pode fazer isso direcionando os elementos <li> dentro do <ul> “Galeria de mídia do produto”:
image_elements = driver.find_elements(By.CSS_SELECTOR, '[aria-label="Galeria de mídia do produto"] li')para image_element em image_elements:
image = image_element.find_element(By.TAG_NAME, 'img').get_attribute('src')
images.append(image)Da mesma forma, você pode coletar as opções de cores dos sapatos:
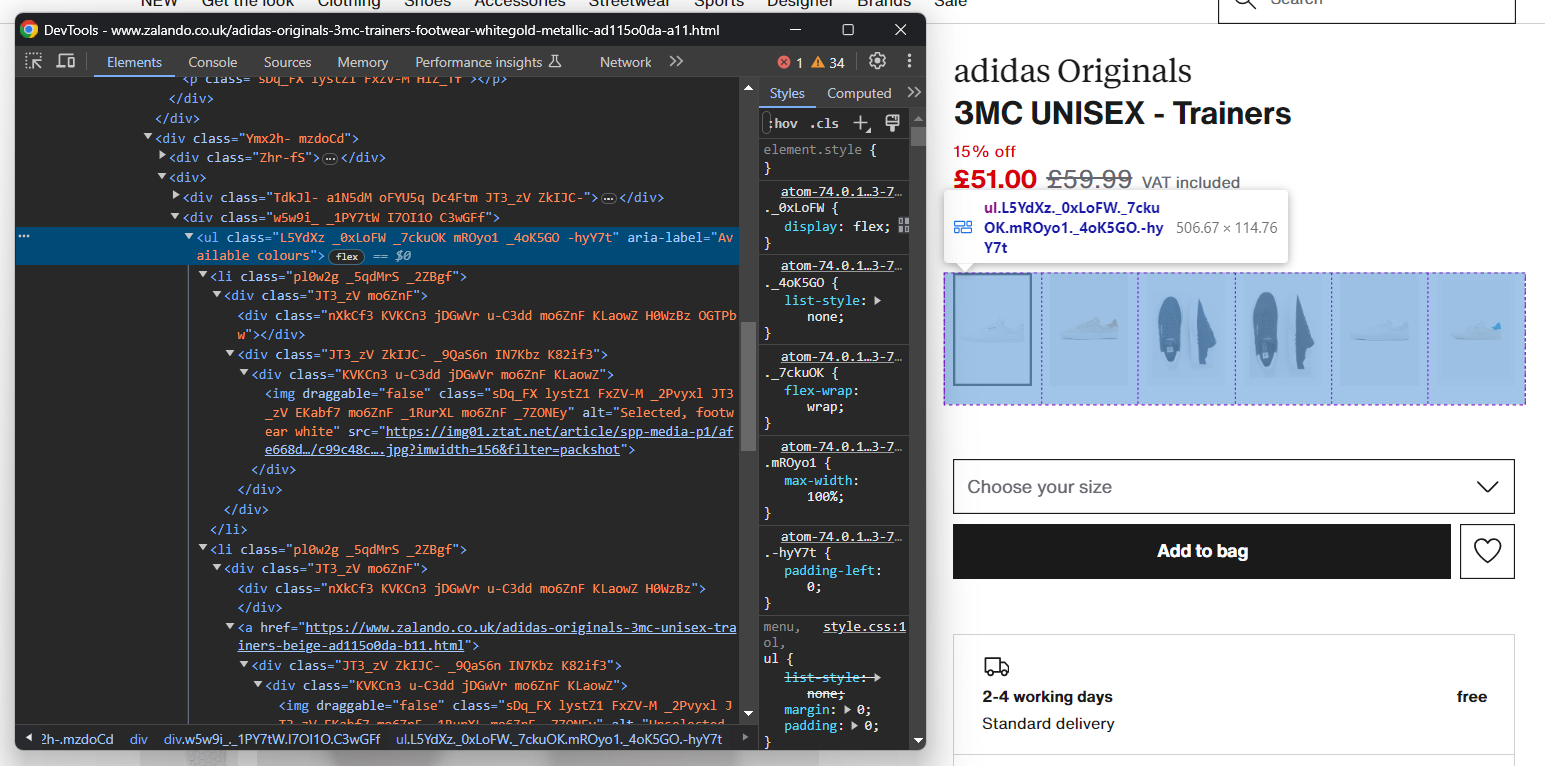
Assim como antes, cada elemento de cor é <li>. Em detalhes, cada seção de cor tem:
- Um link opcional.
- Uma imagem.
- Um nome, armazenado no atributo alt do elemento de imagem.
Extraia todas as cores com:
colors = []
color_elements = driver.find_elements(By.CSS_SELECTOR, '[aria-label="Cores disponíveis"] li')
for color_element in color_elements:
# inicialize um novo objeto de cor
color = {
'color': None,
'image': None,
'link': None
}
# verificar se o link da cor está presente e extrair sua URL
link_elements = color_element.find_elements(By.TAG_NAME, 'a')
if len(link_elements) > 0:
cor['link'] = link_elements[0].get_attribute('href')
# verificar se a imagem da cor está presente e extrair seus dados
image_elements = color_element.find_elements(By.TAG_NAME, 'img')
if len(image_elements) > 0:
color['image'] = image_elements[0].get_attribute('src')
color['color'] = image_elements[0].get_attribute('alt')
.replace('Selected, ', '')
.replace('Unselected, ','')
.strip()
colors.append(color)Perfeito! Você acabou de implementar uma lógica de scraping, mas ainda há mais dados para recuperar.
Etapa 6: extraia os dados dos detalhes do produto
Os detalhes do produto estão armazenados em cartões colocados sob o elemento de seleção de cor:
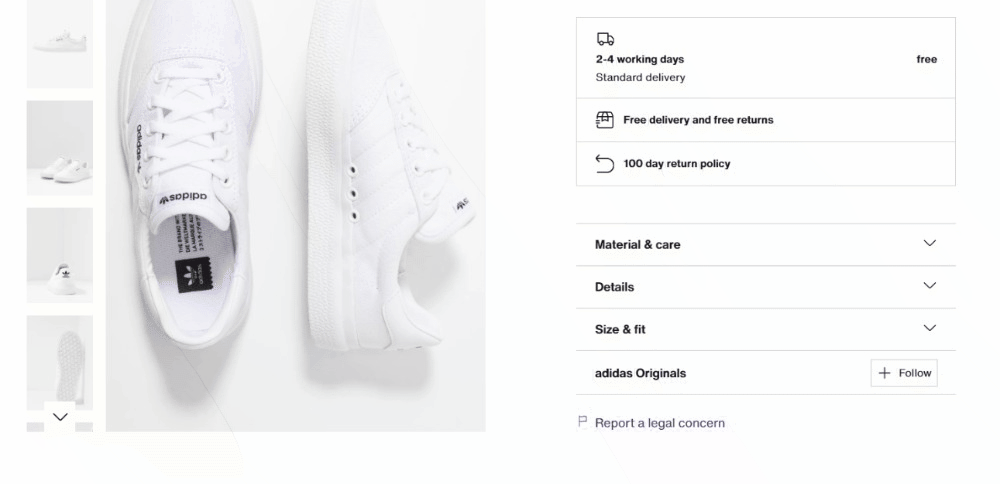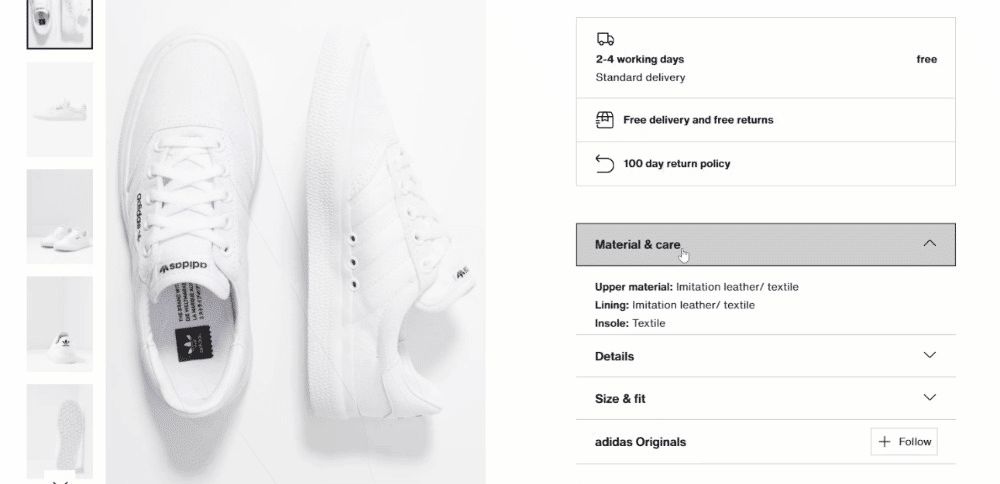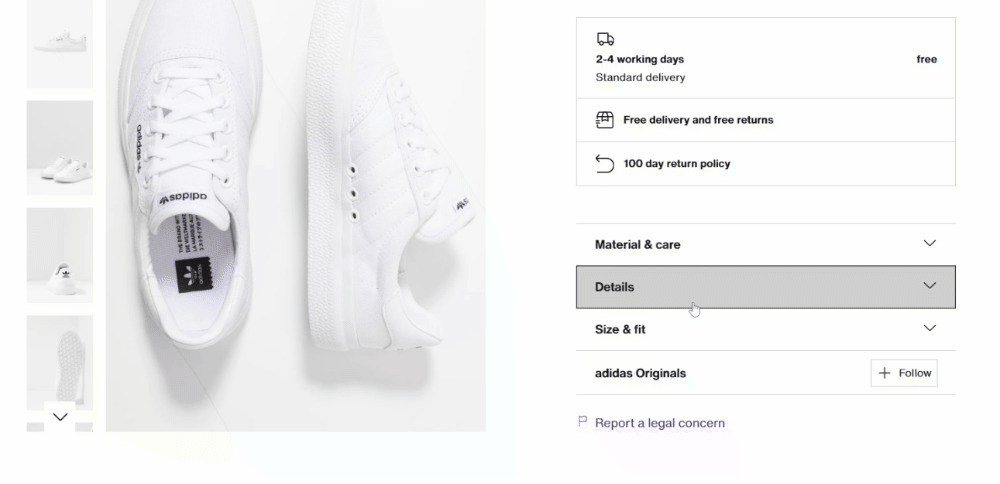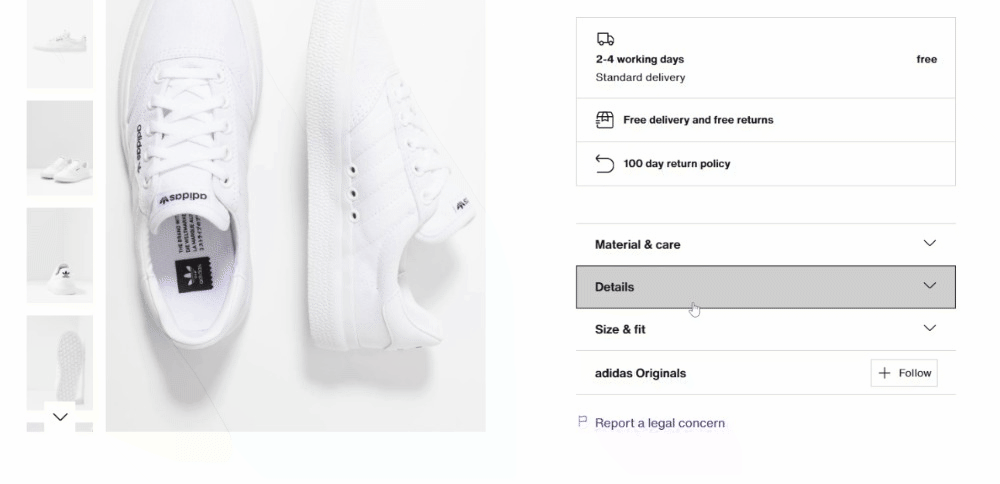
Primeiro, concentre-se nas informações de entrega:
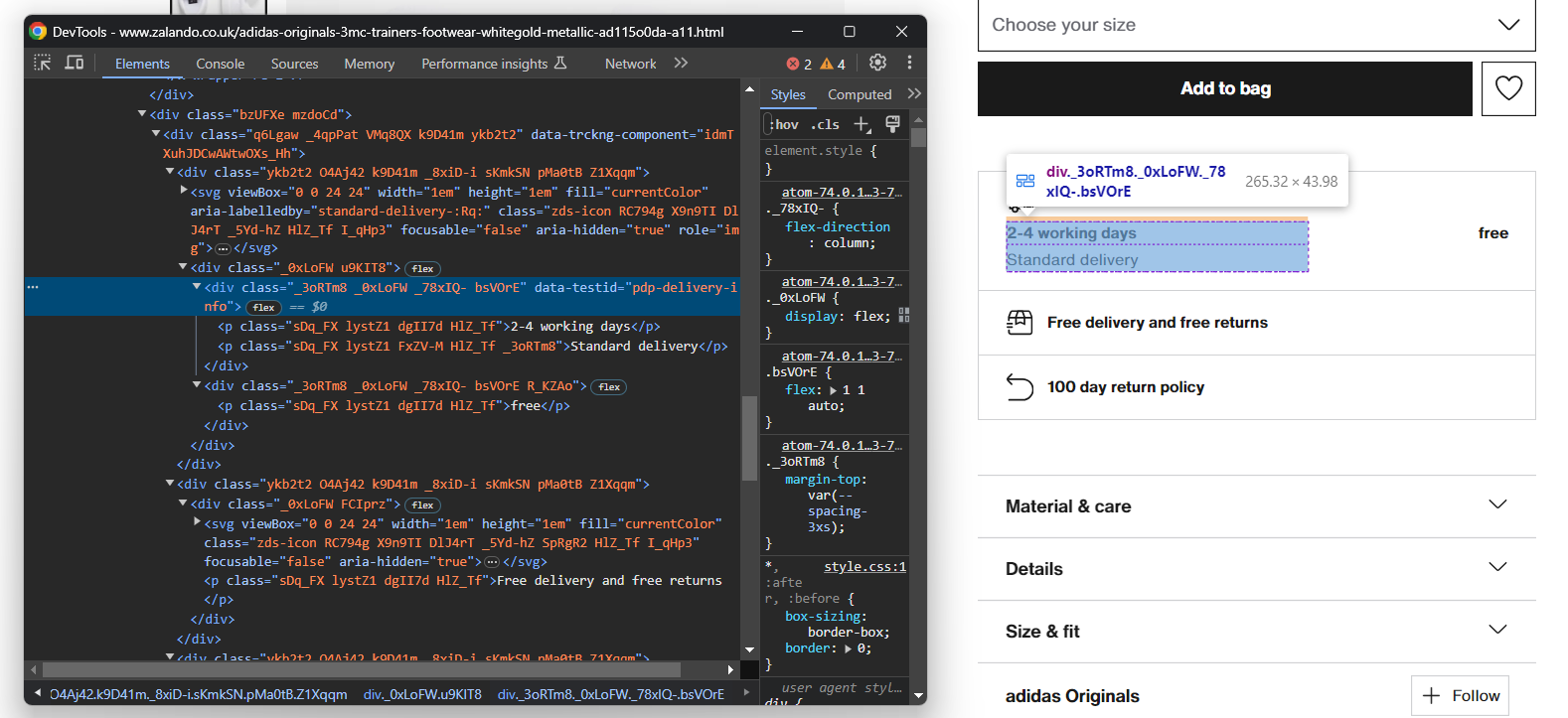
Isso consiste em três campos de dados, então inicialize um dicionário de entrega como abaixo:
delivery = {
'time': None,
'type': None,
'cost': None,
}Novamente, não há um seletor fácil para selecionar esses três elementos. O que você pode fazer é:
- Selecionar o nó cujo atributo data-testid é “pdp-delivery-info”.
- Vá para o seu pai.
- Obtenha todos os elementos <p> descendentes.
Implemente essa lógica e extraia os dados de entrega com:
delivery_elements = driver
.find_element(By.CSS_SELECTOR, '[data-testid="pdp-delivery-info"]')
.find_element(By.XPATH, 'parent::*[1]')
.find_elements(By.TAG_NAME, 'p')
if len(delivery_elements) == 3:
delivery['time'] = delivery_elements[0].text
delivery['type'] = delivery_elements[1].text
delivery['cost'] = delivery_elements[2].textComo o Selenium não expõe uma maneira de acessar o pai de um nó, você precisa usar a expressão parent::* Xpath.
Em seguida, concentre sua atenção nos acordeões de detalhes do produto:
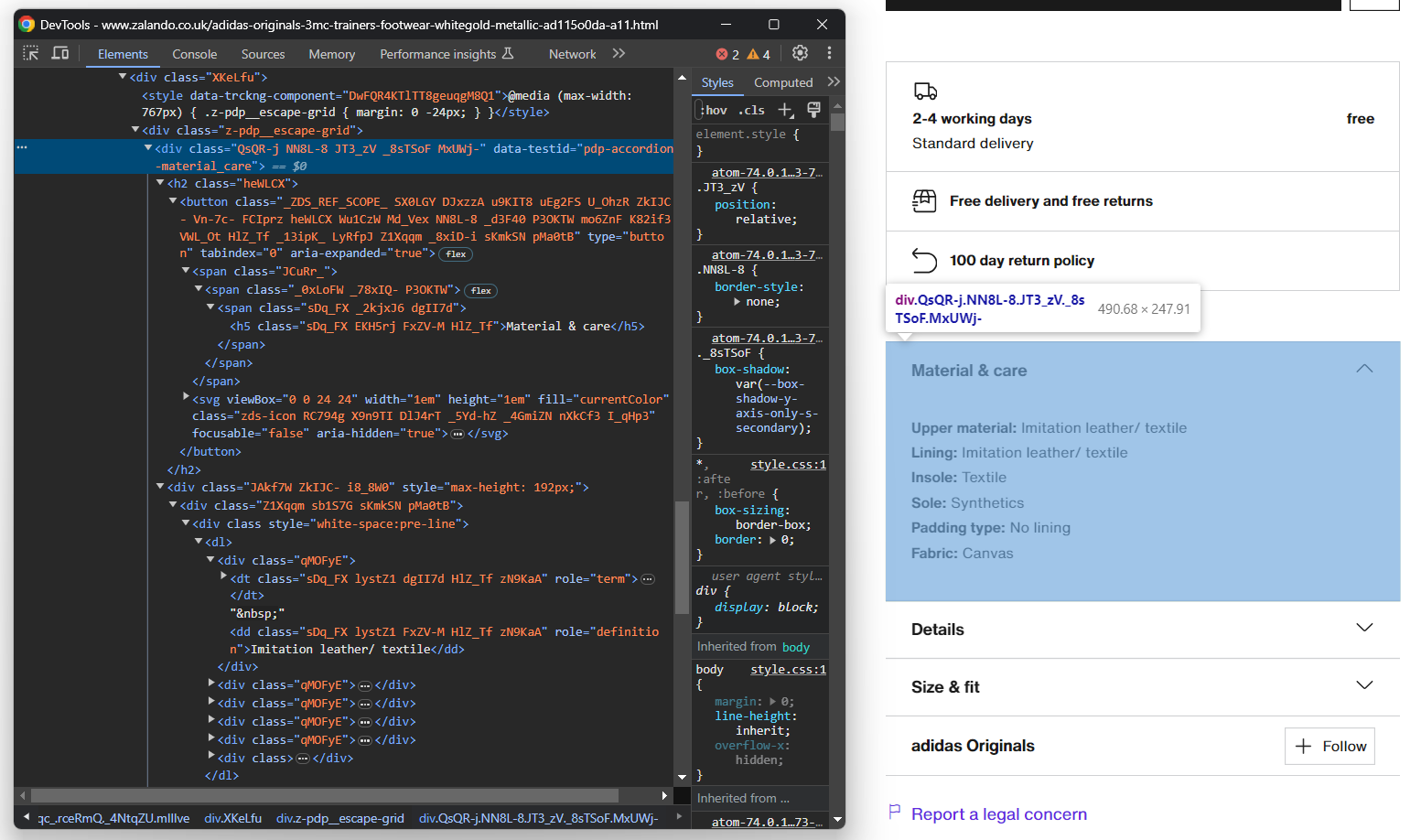
Desta vez, você pode obter todos os elementos do acordeão direcionando os nós cujo atributo data-testid começa com “pdp-accordion-”. Faça isso com o seguinte seletor CSS:
[data-testid^="pdp-accordion-"]Essa seção contém vários campos, então você precisa criar um dicionário para acompanhá-los:
info = {}Em seguida, aplique o seletor CSS mencionado acima para selecionar os acordeões de detalhes do produto:
info_elements = driver.find_elements(By.CSS_SELECTOR, '[data-testid^="pdp-accordion-"]')[:2]O elemento “Tamanho e ajuste” não contém dados relevantes, portanto, você pode ignorá-lo. [:2] reduzirá a lista aos dois primeiros elementos, conforme desejado.
Esses elementos HTML são dinâmicos e seu conteúdo é adicionado ao DOM somente quando abertos. Portanto, você precisa simular a interação do clique com o método click():
para info_element em info_elements:
info_element.click()
// lógica de scraping...
Em seguida, preencha programaticamente o objeto info com:
info_section_name = info_element.find_element(By.CSS_SELECTOR, 'h5').text
info[info_section_name] = {}
para dt_element em info_element.find_elements(By.CSS_SELECTOR, 'dt'):
info_section_detail_name = dt_element.text.replace(':', '')
info[info_section_name][info_section_detail_name] = dt_element.find_element(By.XPATH, 'following-sibling::dd').textA lógica acima extrai dinamicamente as informações dos acordeões e as organiza por nome.
Para entender melhor como esse código funciona, tente imprimir info. Você verá:
{'Material e cuidados': {'Material superior': 'Imitação de couro/tecido', 'Forro': 'Imitação de couro/tecido', 'Palmilha': 'Tecido', 'Sola': 'Sintética', 'Tipo de acolchoamento': 'Sem forro', 'Tecido': 'Lona'}, 'Detalhes': {'Biqueira': 'Redonda', 'Tipo de salto': 'Plano', 'Fecho': 'Atacadores', 'Fecho do sapato': 'Atacadores', 'Padrão': 'Liso', 'Número do artigo': 'AD115O0DA-A11'}}Fantástico! Detalhes do produto Zalando extraídos!
Etapa 7: Preencha o objeto do produto
Resta apenas preencher o dicionário do produto com os dados coletados:
# atribuir os dados extraídos ao dicionário
produto['marca'] = marca
produto['nome'] = nome
produto['preço'] = preço
produto['preço_original'] = preço_original
produto['desconto'] = desconto
produto['imagens'] = imagens
produto['cores'] = cores
produto['entrega'] = entrega
produto['informações'] = informaçõesVocê também pode adicionar uma instrução de log para verificar se o Scraper Zalando funciona conforme o esperado:
imprimir(trabalho)
Execute o script:
python Scraper.pyIsso produzirá uma saída semelhante a:
{'brand': 'adidas Originals', 'name': '3MC UNISEX - Trainers', 'price': '£51.00', 'original_price': '£59.99', 'discount': '15%', ... }Et voilà! Você acabou de aprender como extrair dados de produtos da Zalando.
Etapa 8: Exporte os dados extraídos para JSON
No momento, os dados extraídos estão armazenados em um dicionário Python. Exporte-os para JSON para facilitar o compartilhamento e a leitura:
with open('product.json', 'w', encoding='utf-8') as file:
json.dump(product, file, indent=4, ensure_ascii=False)O trecho acima cria um arquivo de saída product.json com open() e o preenche com dados JSON via json.dump(). Consulte nosso guia para saber mais sobre como realizar Parsing e serializar dados para JSON em Python.
Lembre-se de adicionar a importação json:
import jsonEste pacote vem da Biblioteca Padrão do Python, então você nem precisa instalá-lo manualmente.
Incrível! Você começou com dados brutos de produtos contidos em uma página da web e agora tem dados JSON semiestruturados. Você está pronto para conferir o Scraper completo da Zalando.
Etapa 8: Junte tudo
Aqui está o código completo do arquivo scraper.py:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
import json
service = Service()
# configure a instância do Chrome
options = webdriver.ChromeOptions()
# suas opções de navegador...
driver = webdriver.Chrome(
service=service,
options=options)
# maximizar a janela para evitar a renderização responsiva
driver.maximize_window()
# visitar a página de destino no navegador controlado
driver.get('https://www.zalando.co.uk/adidas-originals-3mc-trainers-footwear-whitegold-metallic-ad115o0da-a11.html')
# instanciar o objeto que conterá os dados extraídos
produto = {}
# lógica de extração
elemento_marca = driver.find_element(By.CSS_SELECTOR, 'h3')
marca = elemento_marca.text
elemento_nome = driver.find_element(By.CSS_SELECTOR, 'h1')
nome = elemento_nome.text
price_elements = name_element
.find_element(By.XPATH, 'following-sibling::*[1]')
.find_elements(By.TAG_NAME, "p")
discount = None
price = None
original_price = None
if len(price_elements) >= 3:
desconto = price_elements[0].text.replace(' off', '')
preço = price_elements[1].text
preço_original = price_elements[2].text
imagens = []
image_elements = driver.find_elements(By.CSS_SELECTOR, '[aria-label="Galeria de mídia do produto"] li')
para image_element em image_elements:
image = image_element.find_element(By.TAG_NAME, 'img').get_attribute('src')
images.append(image)
colors = []
color_elements = driver.find_elements(By.CSS_SELECTOR, '[aria-label="Cores disponíveis"] li')
para color_element em color_elements:
color = {
'color': None,
'image': None,
'link': None
}
link_elements = color_element.find_elements(By.TAG_NAME, 'a')
if len(link_elements) > 0:
color['link'] = link_elements[0].get_attribute('href')
image_elements = color_element.find_elements(By.TAG_NAME, 'img')
if len(image_elements) > 0:
color['image'] = image_elements[0].get_attribute('src')
color['color'] = image_elements[0].get_attribute('alt')
.replace('Selected, ', '')
.replace('Unselected, ','')
.strip()
colors.append(color)
delivery = {
'time': None,
'type': None,
'cost': None,
}
delivery_elements = driver
.find_element(By.CSS_SELECTOR, '[data-testid="pdp-delivery-info"]')
.find_element(By.XPATH, 'parent::*[1]')
.find_elements(By.TAG_NAME, 'p')
if len(delivery_elements) == 3:
delivery['time'] = delivery_elements[0].text
delivery['type'] = delivery_elements[1].text
delivery['cost'] = delivery_elements[2].text
info = {}
info_elements = driver.find_elements(By.CSS_SELECTOR, '[data-testid^="pdp-accordion-"]')[:2]
para info_element em info_elements:
info_element.click()
info_section_name = info_element.find_element(By.CSS_SELECTOR, 'h5').text
info[info_section_name] = {}
para dt_element em info_element.find_elements(By.CSS_SELECTOR, 'dt'):
info_section_detail_name = dt_element.text.replace(':', '')
info[info_section_name][info_section_detail_name] = dt_element.find_element(By.XPATH, 'following-sibling::dd').text
# fechar o navegador e liberar seus recursos
driver.quit()
# atribuir os dados extraídos ao dicionário
product['brand'] = brand
product['name'] = name
product['price'] = price
product['original_price'] = original_price
product['discount'] = discount
product['images'] = images
product['colors'] = colors
product['delivery'] = delivery
product['info'] = info
print(produto)
# exportar os dados coletados para um arquivo JSON
com open('produto.json', 'w', encoding='utf-8') como arquivo:
json.dump(produto, arquivo, indent=4, ensure_ascii=False)Em pouco mais de 100 linhas de código, você acabou de criar um Scraper da Zalando com todos os recursos para recuperar dados detalhados dos produtos.
Execute-o com:
python Scraper.pyAguarde alguns segundos até que o script seja concluído.
No final do processo de scraping, um arquivo product.json aparecerá na pasta raiz do seu projeto. Abra-o e você verá:
{
"brand": "adidas Originals",
"name": "3MC UNISEX - Trainers",
"price": "£51.00",
"original_price": "£59.99",
"discount": "15%",
"images": [
“https://img01.ztat.net/article/spp-media-p1/637562911a7e36c28ce77c9db69b4cef/00373c35a7f94b4b84a4e070879289a2.jpg?imwidth=156”,
// omitido por brevidade...
“https://img01.ztat.net/article/spp-media-p1/7d4856f0e4803b759145755d10e8e6b6/521545d1286c478695901d26fcd9ed3a.jpg?imwidth=156”
],
"colors": [
{
"color": "footwear white",
"image": "https://img01.ztat.net/article/spp-media-p1/afe668d0109a3de0a5175a1b966bf0c9/c99c48c977ff429f8748f961446f79f5.jpg?imwidth=156&filter=packshot",
"link": null
},
// omitido por brevidade...
{
"color": "white",
"image": "https://img01.ztat.net/article/spp-media-p1/87e6a1f18ce44e3cbd14da8f10f52dfd/bb1c3a8c409544a085c977d6b4bef937.jpg?imwidth=156&filter=packshot",
"link": "https://www.zalando.co.uk/adidas-originals-3mc-unisex-trainers-white-ad115o0da-a16.html"
}
],
"delivery": {
"time": "2-4 dias úteis",
"tipo": "Entrega padrão",
"custo": "grátis"
},
"informações": {
"Material e cuidados": {
"Material superior": "Imitação de couro/tecido",
"Forro": "Imitação de couro/tecido",
"Palmilha": "Têxtil",
"Sola": "Sintética",
"Tipo de acolchoamento": "Sem forro",
"Tecido": "Lona"
},
"Detalhes": {
"Biqueira": "Redonda",
“Tipo de salto”: “Plano”,
“Fecho”: “Atacadores”,
“Fecho do sapato”: “Atacadores”,
“Padrão”: “Liso”,
“Número do artigo”: “AD115O0DA-A11”
}
}
}Parabéns! Você acabou de aprender a fazer scraping no Zalando em Python!
Conclusão
Neste tutorial, você entendeu por que o Zalando é um ótimo site de comércio eletrônico para fazer scraping e como extrair dados dele. Aqui, você viu como construir um Scraper do Zalando que recupera automaticamente os dados de uma página de produto.
Como mostrado aqui, fazer scraping no Zalando não é uma tarefa fácil por pelo menos três motivos:
- O site implementa algumas medidas anti-scraping que podem bloquear seu script.
- As páginas da web contêm classes CSS aleatórias.
- Cada página de produto tem uma estrutura específica e pode envolver informações diferentes.
Para evitar o primeiro problema e não se preocupar com bloqueios, experimente nossa nova solução! O Navegador de scraping é um navegador controlável que lida automaticamente com CAPTCHAs, impressões digitais, novas tentativas automatizadas e muito mais para você. No entanto, você ainda precisará escrever o código e mantê-lo. Resolva os dois problemas restantes com uma solução pronta para uso, confira nosso scraper Zalando!
Observação: este guia foi exaustivamente testado por nossa equipe no momento da redação, mas como os sites atualizam frequentemente seu código e estrutura, algumas etapas podem não funcionar mais como esperado.




