
Neste artigo, você aprenderá:
- O que é um rastreador de preços da Amazon e por que ele é útil
- Como construir um com um tutorial passo a passo em Python
- As limitações dessa abordagem e como superá-las
Vamos começar!
O que é um rastreador de preços da Amazon?
Um rastreador de preços da Amazon é uma ferramenta, serviço ou script para monitorar o preço de um ou mais produtos da Amazon ao longo do tempo. Ele fornece atualizações periódicas sobre mudanças de preço, permitindo que você identifique quedas, descontos ou flutuações de preço.
Por que rastrear o preço de um item da Amazon?
Acompanhar os preços da Amazon ajuda você a:
- Economizar dinheiro comprando produtos pelos preços mais baixos
- Programar compras durante liquidações ou promoções
- Definir preços competitivos para seus produtos, se você for um vendedor
Além disso, acompanhar os preços da Amazon é essencial para monitorar tendências sazonais e entender a dinâmica do mercado.
Criando um rastreador de preços da Amazon: guia passo a passo
Nesta seção do tutorial, você aprenderá como criar um rastreador de preços da Amazon usando Python. Siga as etapas abaixo para criar um bot de scraping que:
- Se conecta às páginas da Amazon de produtos específicos
- Rastreia dados de preços dessas páginas
- Acompanha as mudanças de preço ao longo do tempo
Se você também estiver interessado em outros dados, consulte nosso guia sobre como coletar dados de produtos da Amazon.
Hora de implementar um script de rastreamento de preços da Amazon!
Etapa 1: Configuração do projeto
Antes de começar, certifique-se de que você tem o Python 3+ instalado em seu computador. Caso contrário, baixe-o do site oficial e siga as instruções de instalação.
Em seguida, crie um diretório para o seu projeto de rastreamento de preços da Amazon com este comando:
mkdir amazon-price-tracker
Navegue até esse diretório e configure um ambiente virtual dentro dele:
cd amazon-price-tracker
python -m venv venv
Abra a pasta do projeto no seu IDE Python preferido. O Visual Studio Code com a extensão Python ou o PyCharm Community Edition são boas opções.
Crie um arquivo scraper.py na pasta do projeto, que agora deve conter esta estrutura de arquivos:
O Scraper.py conterá a lógica de rastreamento de preços da Amazon.
No terminal do seu IDE, ative o ambiente virtual. No Linux ou macOS, use:
./venv/bin/activate
De forma equivalente, no Windows, execute:
venv/Scripts/activate
Ótimo! Agora você está configurado e pronto para começar.
Etapa 2: Configure as bibliotecas de scraping
Conforme discutido em nosso guia sobre scraping de sites de comércio eletrônico, o scraping da Amazon requer uma ferramenta de automação de navegador. Isso não se deve ao fato de o site ser particularmente dinâmico, mas porque a Amazon emprega medidas anti-bot para detectar e bloquear solicitações automatizadas.
Em termos simples, você precisa de uma ferramenta de automação de navegador como o Selenium para recuperar dados da Amazon. Para começar, instale o Selenium da seguinte maneira:
pip install selenium
Se você não estiver familiarizado com essa biblioteca, consulte nosso tutorial sobre Scraping de dados com Selenium.
Importe a biblioteca Selenium para o seu script scraper.py:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
Em seguida, crie um objeto ChromeDriver para controlar uma instância do navegador Chrome:
# Inicialize o WebDriver para controlar o Chrome
driver = webdriver.Chrome(service=Service())
# Lógica de scraping...
# Libere os recursos do driver
driver.quit()
O driver será usado para interagir com a página de produtos da Amazon para rastreamento de preços.
Lembre-se de que a Amazon adota medidas anti-scraping, que podem bloquear navegadores headless. Para evitar problemas, mantenha seu navegador controlado pelo Selenium no modo headed.
Ótimo! É hora de automatizar sua lógica de scraping da Amazon.
Etapa 3: conecte-se à página de destino
Suponha que você queira rastrear o preço do PS5 na Amazon:
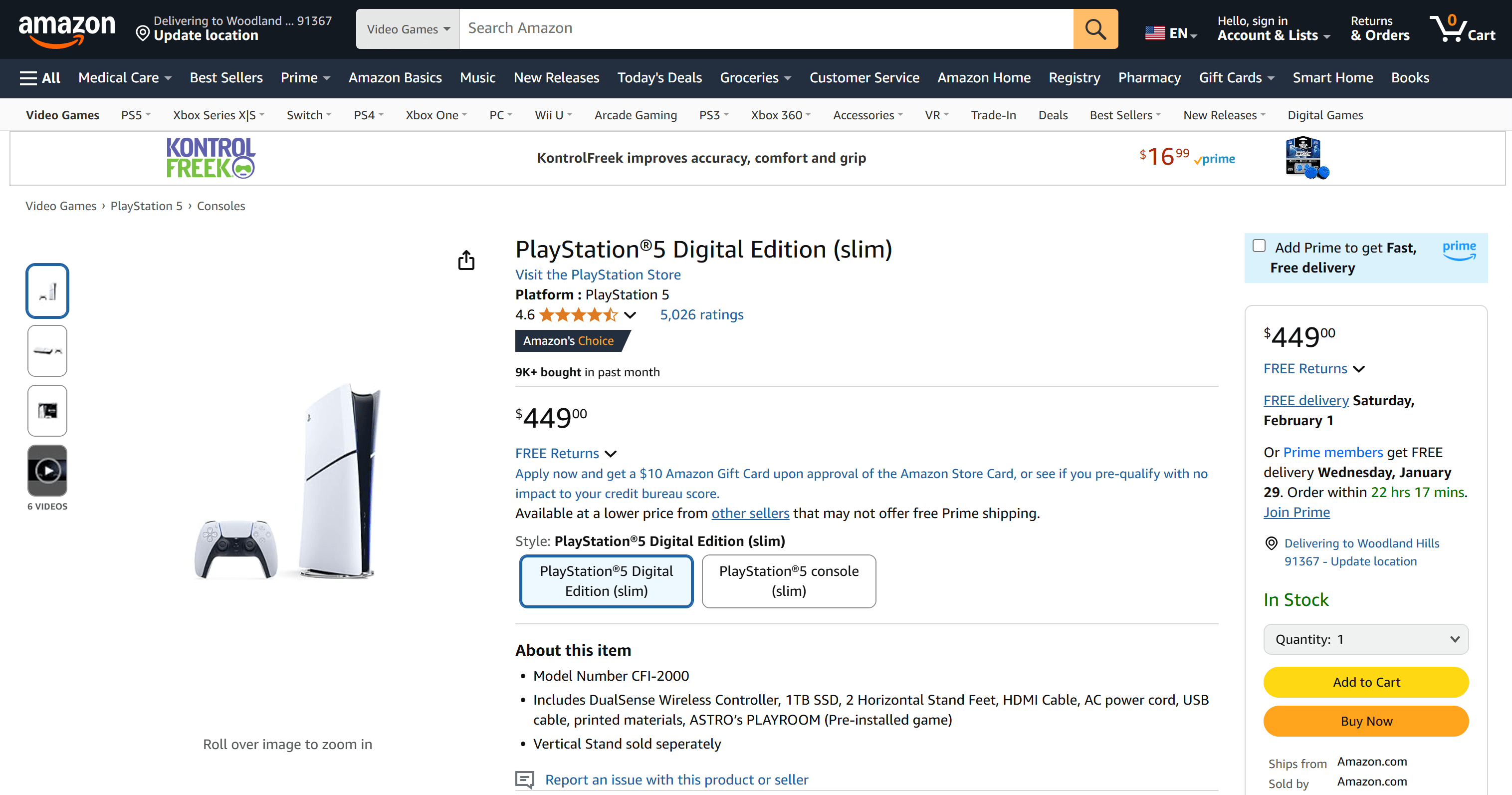
Aqui está a URL da página do produto:
https://www.amazon.com/PlayStation%C2%AE5-Digital-slim-PlayStation-5/dp/B0CL5KNB9M/
A parte após amazon.com é apenas um slug para facilitar a leitura, mas a parte importante é o código após /dp/. Esse código é chamado de ASIN da Amazon, um identificador exclusivo para produtos da Amazon.
Em outras palavras, você pode acessar a mesma página do produto usando o ASIN diretamente no seguinte formato:
https://www.amazon.com/product/dp/<AMAZON_ASIN>
Para este exemplo, o ASIN do PS5 é B0CL5KNB9M. Armazene este ASIN em uma variável e use-o para gerar a URL do produto da Amazon:
amazon_asin = "B0CL5KNB9M"
amazon_url = f"https://www.amazon.com/product/dp/{amazon_asin}"
Em seguida, use o método get() do Selenium para instruir o navegador a navegar até a página de destino:
driver.get(amazon_url)
Defina um ponto de interrupção antes da instrução driver.quit() e execute o script. Agora você deverá ver a página do produto da Amazon carregada no navegador:
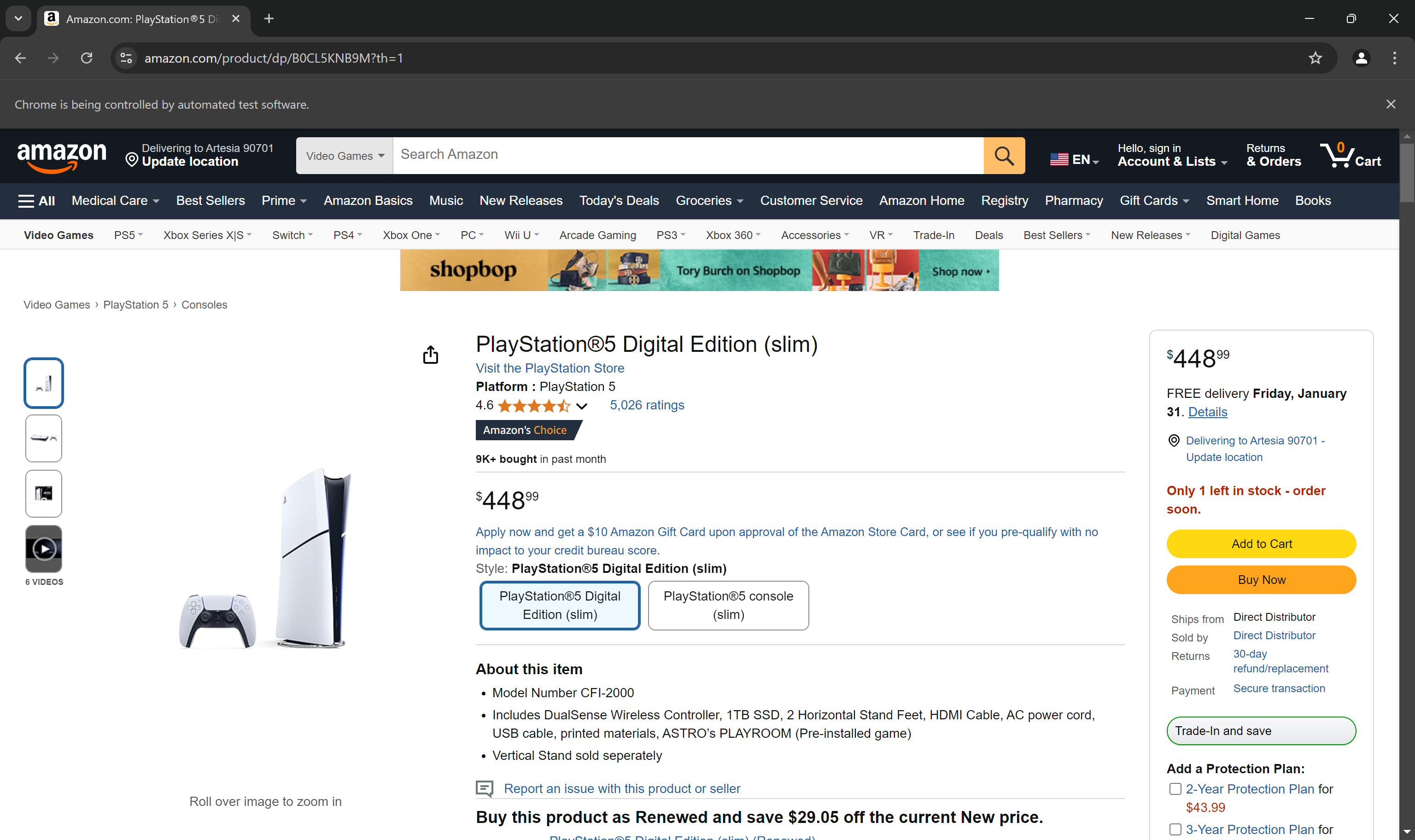
A mensagem “O Chrome está sendo controlado por um software automatizado” prova que o Selenium está operando no navegador conforme desejado.
Lembre-se de que a Amazon usa medidas anti-bot, o que pode resultar em desafios CAPTCHA ou solicitações bloqueadas. Não se preocupe, pois discutiremos estratégias para lidar com essas questões mais adiante neste artigo.
Saiba mais sobre o Amazon ASIN Scraper da Bright Data aqui.
Etapa 4: extraia as informações de preço
Abra a página do produto desejado no modo de navegação anônima do seu navegador. Em seguida, clique com o botão direito do mouse no preço exibido na página e selecione a opção “Inspecionar”:
Na seção DevTools, dê uma olhada no HTML do elemento de preço. Observe que o preço está dentro de um elemento .a-price.
Selecione o elemento com um seletor CSS e extraia os dados dele:
price_element = driver.find_element(By.CLASS_NAME, "a-price")
price = price_element.text.replace("n", ".")
A função replace() é usada para limpar o preço dos caracteres de nova linha.
Não se esqueça de importar By:
from selenium.webdriver.common.by import By
Ótimo! Você implementou com sucesso o recurso principal do seu Amazon Price Tracker: extrair o preço.
Etapa 5: armazenar os preços
O recurso mais importante de um rastreador de preços da Amazon é a capacidade de rastrear o histórico de preços, para que você possa avaliar as mudanças e flutuações ao longo do tempo. Para isso, você precisa armazenar os dados de preços em algum lugar, como um banco de dados ou um arquivo.
Para simplificar, usaremos um arquivo JSON como banco de dados. O arquivo armazenará o ASIN do produto e uma lista de preços históricos.
Primeiro, certifique-se de que o arquivo JSON exista com a seguinte estrutura:
{
"asin": "<AMAZON_ASIN>",
"prices": []
}
Veja como inicializar esse arquivo em Python, caso ele não exista:
# Nome do arquivo JSON db e dados iniciais
file_name = "price_history.json"
initial_data = {
"asin": amazon_asin,
"prices": []
}
# Grave o arquivo JSON db se ele não existir
if not os.path.exists(file_name):
with open(file_name, "w") as file:
json.dump(initial_data, file, indent=4)
# Lógica Selenium...
Para funcionar, o trecho acima requer as duas importações a seguir:
import os
import json
Antes da lógica de scraping, carregue o arquivo JSON para acessar seus dados atuais:
# Abra o arquivo JSON para leitura e gravação
com open(nome_do_arquivo, "r+") como arquivo:
# Carregue os dados de preço atuais
dados_de_preço = json.load(arquivo)
# Lógica de scraping...
Após extrair o preço, adicione o novo preço junto com um carimbo de data/hora à lista de preços:
price = price_element.text.replace("n", "")
# Carimbo de data/hora atual
timestamp = datetime.now().isoformat()
# Adicione um novo ponto de informação de preço
price_data["prices"].append({
"price": price,
"timestamp": timestamp
})
Adicione a seguinte importação:
from datetime import datetime
Por fim, atualize o arquivo JSON:
# Mova o ponteiro do arquivo para o início
file.seek(0)
# Substitua os dados coletados
json.dump(price_data, file, indent=4)
# Trunque o arquivo para que, se o novo conteúdo for mais curto que o original, os dados extras sejam apagados
file.truncate()
Fantástico! A lógica de rastreamento de preços foi implementada.
Etapa 6: programe a lógica de rastreamento de preços
Atualmente, você precisa executar manualmente o script sempre que quiser coletar e rastrear os preços da Amazon. Isso pode funcionar para uso ocasional. Ainda assim, automatizar o script para ser executado em intervalos regulares o torna muito mais eficaz.
Consiga isso usando a biblioteca de programação Python. Ela fornece uma API intuitiva para agendar tarefas em Python.
Instale a biblioteca executando o seguinte comando em seu ambiente virtual ativado:
pip install schedule
Em seguida, encapsule toda a sua lógica de rastreamento de preços da Amazon em uma função que aceite o ASIN como parâmetro:
def track_price(amazon_asin):
# Toda a lógica de rastreamento de preços da Amazon...
Agora você tem uma tarefa Python que pode ser agendada para ser executada a cada 12 horas:
# Executar imediatamente
amazon_asin="B0CL5KNB9M"
track_price(amazon_asin)
# Em seguida, agende a tarefa para ser executada a cada 12 horas
schedule.every(12).hours.do(track_price, amazon_asin=amazon_asin)
while True:
schedule.run_pending()
time.sleep(1)
O loop while garante que o script permaneça ativo para processar as tarefas agendadas.
Não se esqueça das duas importações a seguir:
import schedule
import time
Perfeito! Você acabou de automatizar todo o processo, transformando seu script em um rastreador de preços da Amazon que funciona sem intervenção manual.
Etapa 7: Junte tudo
Agora, seu rastreador de preços da Amazon em Python deve estar assim:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
import json
import os
from datetime import datetime
import schedule
import time
def track_price(amazon_asin):
# Inicialize o WebDriver para controlar o Chrome
driver = webdriver.Chrome(service=Service())
# Geração da URL do produto Amazon
amazon_url = f"https://www.amazon.com/product/dp/{amazon_asin}"
# Nome do arquivo JSON db e dados iniciais
file_name = "price_history.json"
initial_data = {
"asin": amazon_asin,
"prices": []
}
# Gravar o arquivo JSON db se ele não existir
if not os.path.exists(file_name):
with open(file_name, "w") as file:
json.dump(initial_data, file, indent=4)
# Abrir o arquivo JSON para leitura e gravação
com open(nome_do_arquivo, "r+") como arquivo:
# Carregue os dados de preço atuais
dados_de_preço = json.load(arquivo)
# Navegue até a página de destino
driver.get(url_amazon)
# Extraia o preço
elemento_de_preço = driver.find_element(By.CSS_SELECTOR, ".a-price")
preço = preço_element.text.replace("n", ".")
# Carimbo de data/hora atual
timestamp = datetime.now().isoformat()
# Adicionar um novo ponto de informação de preço
preço_data["prices"].append({
"price": preço,
"timestamp": timestamp
})
# Mova o ponteiro do arquivo para o início
file.seek(0)
# Substitua os dados coletados
json.dump(price_data, file, indent=4)
# Trunque o arquivo para que, se o novo conteúdo for mais curto que o original, os dados extras sejam apagados
file.truncate()
# Libere os recursos do driver
driver.quit()
# Execute imediatamente
amazon_asin="B0CL5KNB9M"
track_price(amazon_asin)
# Em seguida, programe a tarefa para ser executada a cada 12 horas
schedule.every(12).hours.do(track_price, amazon_asin=amazon_asin)
while True:
schedule.run_pending()
time.sleep(1)
Inicie conforme abaixo:
python3 Scraper.py
Ou, no Windows:
python Scraper.py
Deixe o script rodar por várias horas. O script vai gerar um arquivo price_history.json parecido com o seguinte:
{
"asin": "B0CL5KNB9M",
"prices": [
{
"price": "$449.00",
"timestamp": "2026-01-27T08:02:20.333369"
},
{
"price": "$449.00",
"timestamp": "2026-01-27T20:02:20.935339"
},
{
"preço": "$449,00",
"timestamp": "2026-01-28T08:02:21.109284"
},
{
"preço": "$449,00",
"timestamp": "2026-01-28T20:02:21.385681"
},
{
"preço": "$449,00",
"timestamp": "2026-01-29T08:02:22.123612"
}
]
}
Observe como cada entrada na matriz de preços é registrada exatamente 12 horas após a anterior.
Missão cumprida!
Etapa 8: Próximas etapas
Você acabou de criar um rastreador de preços da Amazon funcional, mas há espaço para melhorias para levá-lo ao próximo nível. As melhorias possíveis são:
- Adicionar registro: como qualquer processo autônomo, é fundamental entender o que está acontecendo. Para isso, adicione alguns registros para rastrear as ações do script.
- Use um banco de dados: substitua o arquivo JSON por um banco de dados para armazenar dados. Isso facilita o compartilhamento e o acesso ao histórico de preços em vários dispositivos ou aplicativos.
- Implemente o tratamento de erros: adicione um tratamento de erros robusto para gerenciar medidas anti-bot, tempos limite de rede e falhas inesperadas. Certifique-se de que o script tente novamente ou pule graciosamente quando ocorrerem erros.
- Leia as opções da CLI: permita que o script aceite entradas da linha de comando, como ASIN e opções de programação. Isso o tornará mais flexível.
- Sistema de notificação: integre alertas por e-mail ou aplicativos de mensagens para notificá-lo sobre mudanças significativas de preço.
Limitações dessa abordagem e como superá-las
O script de rastreamento de preços da Amazon criado no capítulo anterior é apenas um exemplo básico. Você não pode confiar em um script tão simples para uso a longo prazo, a menos que implemente as próximas etapas. Embora essas etapas aprimorem o script, elas também o tornarão mais complexo e difícil de gerenciar.
No entanto, não importa o quão sofisticado seu script se torne, a Amazon ainda pode bloqueá-lo com CAPTCHAs:
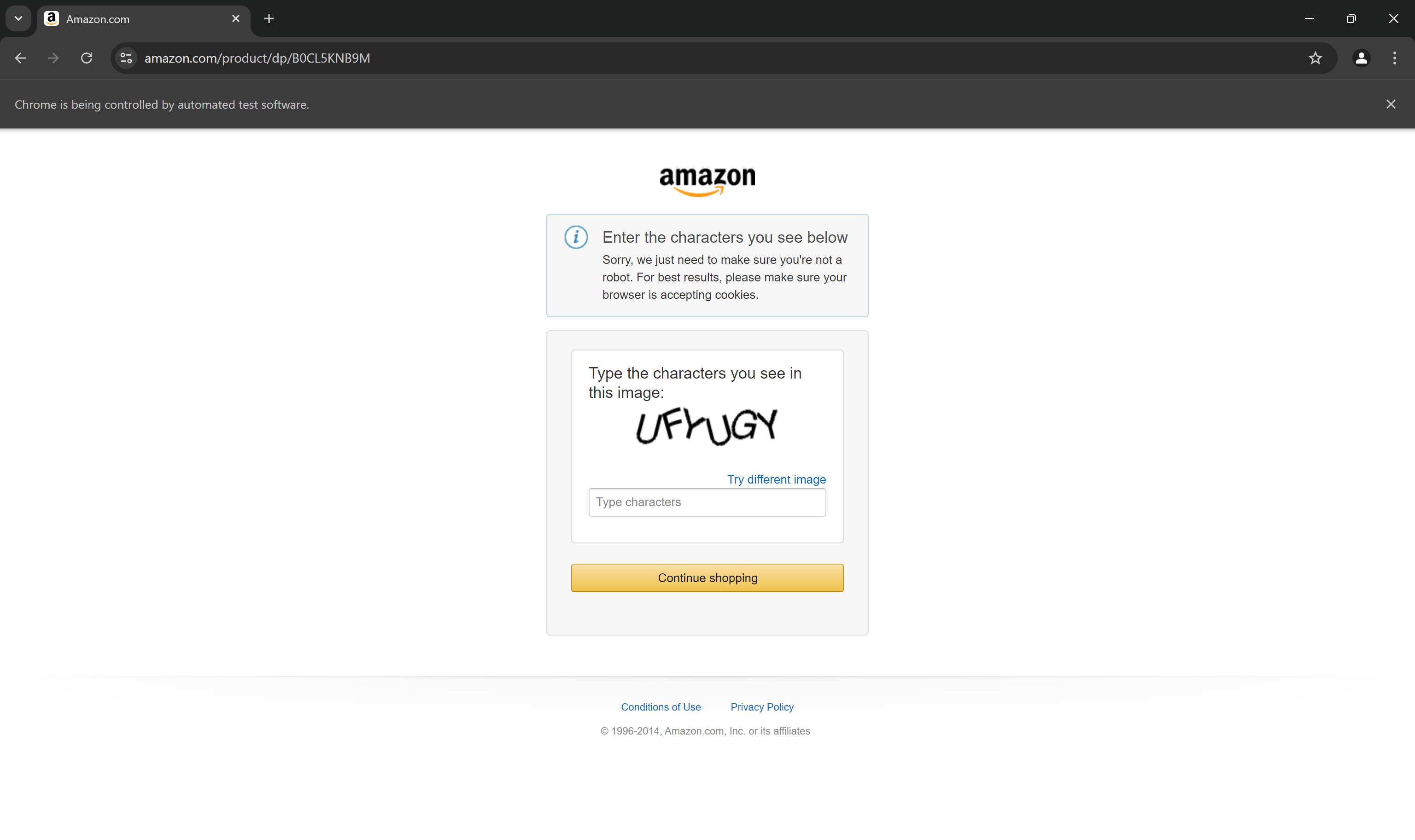
Na verdade, é provável que seu script de scraping da Amazon baseado em Selenium já esteja sendo bloqueado por CAPTCHAs. Como primeira etapa, considere seguir nosso guia sobre como contornar CAPTCHAs em Python.
Ainda assim, você pode enfrentar erros 429 Too Many Requests devido à limitação rigorosa de taxa. Nesses casos, integrar um Proxy ao Selenium para alternar seu IP de saída é uma boa estratégia.
Esses desafios destacam como sites de scraping como a Amazon podem se tornar frustrantes sem as ferramentas certas. Além disso, não poder usar ferramentas de automação do navegador torna seu script lento e consome muitos recursos.
Então, você deve desistir? De forma alguma! A solução real é contar com um serviço como o Bright Insights, que fornece insights de comércio eletrônico acionáveis e baseados em IA para ajudá-lo a:
- Economizar receitas perdidas: identifique e resolva a perda de receita devido à retirada de listagem, eventos de falta de estoque ou problemas de visibilidade.
- Acompanhar as vendas e a participação no mercado: descubra oportunidades em áreas inexploradas, acompanhe as vendas dos concorrentes e identifique tendências antecipadamente.
- Otimizar preços: monitore os preços dos concorrentes em tempo real para se manter competitivo.
- Maximizar a mídia de varejo: use análises para otimizar a publicidade, maximizar o ROI e garantir resultados crescentes.
- Otimizar a variedade de produtos: melhore sua variedade de produtos acompanhando os concorrentes e maximizando a receita.
- Otimização multicanal: aproveite a inteligência multicanal para gerenciar as vendas de produtos e obter sucesso em todas as plataformas.
O Bright Insights fornece todos os dados de comércio eletrônico de que você precisa, incluindo recursos de acompanhamento de preços da Amazon.
Conclusão
Nesta postagem do blog, você aprendeu o que é um rastreador de preços da Amazon e as vantagens que ele oferece. Você também viu como criar um usando Python e Selenium para Scraping de dados.
O desafio é que a Amazon emprega medidas anti-bot rigorosas, como CAPTCHAs, impressão digital do navegador e bloqueios de IP, para bloquear scripts automatizados. Mas com nosso rastreador de preços da Amazon, você pode esquecer esses desafios e obter os preços da Amazon.
Se você gosta de Scraping de dados e está interessado em diferentes tipos de dados da Amazon, considere também nossa API Amazon Scraper!
Crie uma conta gratuita na Bright Data hoje mesmo e explore nossos serviços.




