

Neste tutorial, você explorará o Scraping de dados da web no Laravel e aprenderá:
- Por que o Laravel é uma ótima tecnologia para Scraping de dados
- Quais são as melhores bibliotecas de scraping do Laravel
- Como construir uma API de Scraping de dados Laravel do zero
Vamos começar!
É possível realizar Scraping de dados no Laravel?
TL;DR: Sim, o Laravel é uma tecnologia viável para Scraping de dados.
O Laravel é uma poderosa estrutura PHP conhecida por sua sintaxe elegante e expressiva. Em particular, ele permite que você crie APIs para scraping de dados da Web em tempo real. Isso é possível graças ao suporte de muitas bibliotecas de scraping, que simplificam o processo de obtenção de dados das páginas. Para obter mais orientações, consulte nosso artigo sobre Scraping de dados na Web em PHP.
O Laravel é uma excelente escolha para Scraping de dados devido à sua escalabilidade, fácil integração com outras ferramentas e amplo suporte da comunidade. Sua forte arquitetura MVC ajuda a manter sua lógica de scraping bem organizada e sustentável. Isso é útil ao construir projetos de Scraping de dados complexos ou em grande escala.
Melhores bibliotecas de Scraping de dados do Laravel
Estas são as melhores bibliotecas para fazer Scraping de dados com Laravel:
- BrowserKit: parte do framework Symfony, simula a API de um navegador da web para interagir com documentos HTML. Ele depende do
DomCrawlerpara navegar e fazer scraping de documentos HTML. Essa biblioteca é ideal para extrair dados de páginas estáticas em PHP. - HttpClient: Um componente Symfony para enviar solicitações HTTP. Ele se integra perfeitamente ao
BrowserKit. - Guzzle: Um cliente HTTP robusto para enviar solicitações da web aos servidores e lidar com respostas de maneira eficiente. É útil para recuperar os documentos HTML associados às páginas da web. Aprenda a configurar um Proxy no Guzzle.
- Panther: Um componente Symfony que fornece um navegador headless para o Scraping de dados. Ele permite que você interaja com sites dinâmicos que exigem JavaScript para renderização ou interação.
Pré-requisitos
Para seguir este tutorial de Scraping de dados no Laravel, você precisa atender aos seguintes pré-requisitos:
Também é recomendável um IDE para codificar em PHP. O Visual Studio Code com a extensão PHP ou o WebStorm são ótimas soluções.
Como criar uma API de Scraping de dados no Laravel
Nesta seção passo a passo, você verá como criar uma API de Scraping de dados no Laravel. O site de destino será o site de sandbox de Scraping de dados Quotes, e o endpoint de Scraping irá:
- Selecionar os elementos HTML da citação na página
- Extrair dados deles
- Retornar os dados coletados em JSON
Esta é a aparência do site de destino:

Siga as instruções abaixo e aprenda a realizar Scraping de dados no Laravel!
Etapa 1: Configure um projeto Laravel
Abra o terminal. Em seguida, execute o comando Composer create abaixo para inicializar seu aplicativo de Scraping de dados Laravel:
composer create-project laravel/laravel laravel-ScraperA pasta lavaral-Scraper agora conterá um projeto Laravel em branco. Carregue-o em seu IDE PHP favorito.
Esta é a estrutura de arquivos do seu backend atual:
Ótimo! Agora você tem um projeto Laravel pronto.
Etapa 2: inicialize sua API de scraping
Execute o comando Artisan abaixo no diretório do projeto para adicionar um novo controlador Laravel:
php artisan make:controller HelloWorldControllerIsso criará o seguinte arquivo ScrapingController.php no diretório /app/Http/Controllers:
<?php
namespace AppHttpControllers;
use IlluminateHttpRequest;
class ScrapingController extends Controller
{
//
}No arquivo ScrapingController, adicione o seguinte método scrapeQuotes():
public function scrapeQuotes(): JsonResponse
{
// lógica de scraping...
return response()->json('Hello, World!');
}Atualmente, o método retorna uma mensagem JSON de espaço reservado 'Hello, World!'. Em breve, ele conterá alguma lógica de scraping no Laravel.
Não se esqueça de adicionar a seguinte importação:
use IlluminateHttpJsonResponse;Associe o método scrapeQuotes() a um endpoint dedicado adicionando as seguintes linhas ao routes/api.php:
use AppHttpControllersScrapingController;
Route::get('/v1/scraping/scrape-quotes', [ScrapingController::class, 'scrapeQuotes']);Ótimo! É hora de verificar se a API de scraping do Laravel funciona como desejado. Lembre-se de que as APIs do Laravel estão disponíveis no caminho /api. Portanto, o endpoint completo da API é /api/v1/scraping/scrape-quotes.
Inicie seu aplicativo Laravel com o seguinte comando:
php artisan serveSeu servidor agora deve estar escutando localmente na porta 8000.
Use o cURL para fazer uma solicitação GET ao endpoint /api/v1/scraping/scrape-quotes:
curl -X GET 'http://localhost:8000/api/v1/scraping/scrape-quotes'Observação: no Windows, substitua curl por curl.exe. Saiba mais em nosso guia cURL para Scraping de dados.
Você deve obter a seguinte resposta:
“Olá, mundo!”Fantástico! A API de scraping de amostra funciona perfeitamente. É hora de definir alguma lógica de scraping com o Laravel.
Etapa 3: Instale as bibliotecas de scraping
Antes de instalar qualquer pacote, você precisa determinar quais bibliotecas de Scraping de dados do Laravel melhor atendem às suas necessidades. Para fazer isso, abra o site de destino no seu navegador. Clique com o botão direito do mouse na página e selecione “Inspecionar” para abrir as Ferramentas do desenvolvedor. Em seguida, vá para a guia “Rede”, recarregue a página e acesse a seção “Fetch/XHR”:
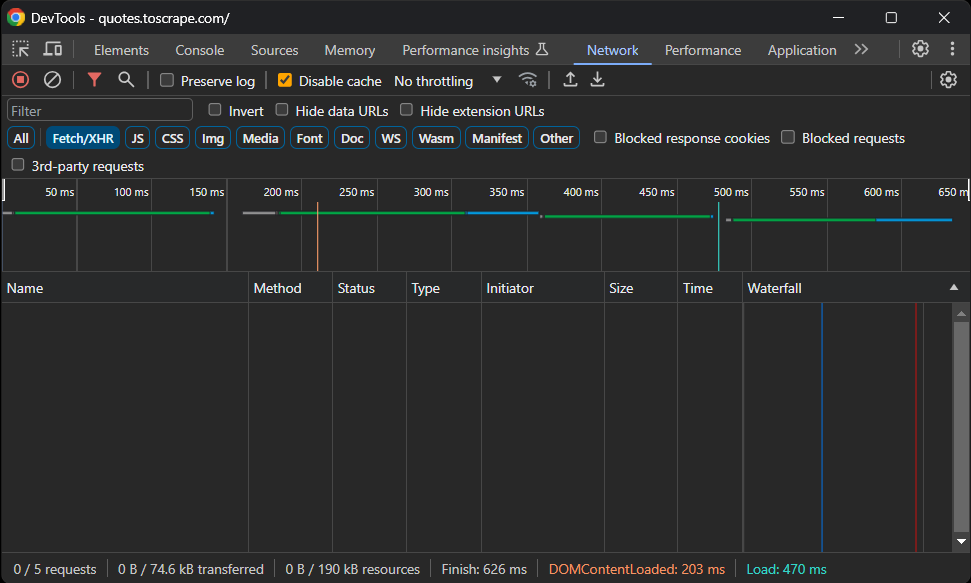
Como você pode ver, a página da web não realiza nenhuma solicitação AJAX. Isso significa que ela não carrega dados dinamicamente no lado do cliente. Portanto, é uma página estática com todos os dados incorporados nos documentos HTML.
Como a página é estática, você não precisa de uma biblioteca de navegador headless para extrair os dados. Embora você ainda possa usar uma ferramenta de automação de navegador, isso só introduziria uma sobrecarga desnecessária. A abordagem recomendada é usar os componentes BrowserKit e HttpClient do Symfony.
Adicione os componentes symfony/browser-kit e symfony/http-client às dependências do seu projeto com:
composer require symfony/browser-kit symfony/http-clientMuito bem! Agora você tem tudo o que precisa para realizar a extração de dados no Laravel.
Etapa 4: baixe a página de destino
Importe o BrowserKit e o HttpClient no ScrapingController:
use SymfonyComponentBrowserKitHttpBrowser;
use SymfonyComponentHttpClientHttpClient;Em scrapeQuotes(), inicialize um novo objeto HttpBrowser:
$browser = new HttpBrowser(HttpClient::create());Isso permite que você faça solicitações HTTP simulando o comportamento do navegador. Ao mesmo tempo, lembre-se de que ele não executa solicitações em um navegador real. O HttpBrowser apenas fornece recursos semelhantes aos de um navegador, como gerenciamento de cookies e sessões.
Use o método request() para realizar uma solicitação HTTP GET para a URL da página de destino:
$crawler = $browser->request('GET', 'https://quotes.toscrape.com/');O resultado será um objeto Crawler, que realiza o Parsing automático do documento HTML retornado pelo servidor. Essa classe também oferece recursos de seleção de nós e extração de dados.
Você pode verificar se a lógica acima funciona extraindo o HTML da página do crawler:
$html = $crawler->outerHtml();Para testar, faça com que sua API retorne esses dados.
Sua função scrapeQuotes() agora ficará assim:
função pública scrapeQuotes(): JsonResponse
{
// inicializar um cliente HTTP semelhante a um navegador
$browser = new HttpBrowser(HttpClient::create());
// baixar e analisar o HTML da página de destino
$crawler = $browser->request('GET', 'https://quotes.toscrape.com/');
// obter o HTML externo da página e retorná-lo
$html = $crawler->outerHtml();
return response()->json($html);
}Incrível! Agora, sua API retornará:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Citações para extrair</title>
<link rel="stylesheet" href="/static/bootstrap.min.css">
<link rel="stylesheet" href="/static/main.css">
</head>
<!-- omitido por brevidade ... -->Etapa 5: Inspecione o conteúdo da página
Para definir a lógica de extração de dados, é essencial examinar a estrutura HTML da página de destino.
Portanto, abra Citações para extrair no seu navegador. Em seguida, clique com o botão direito do mouse em um elemento HTML de citação e selecione a opção “Inspecionar”. No DevTools do seu navegador, expanda o HTML e comece a estudá-lo:
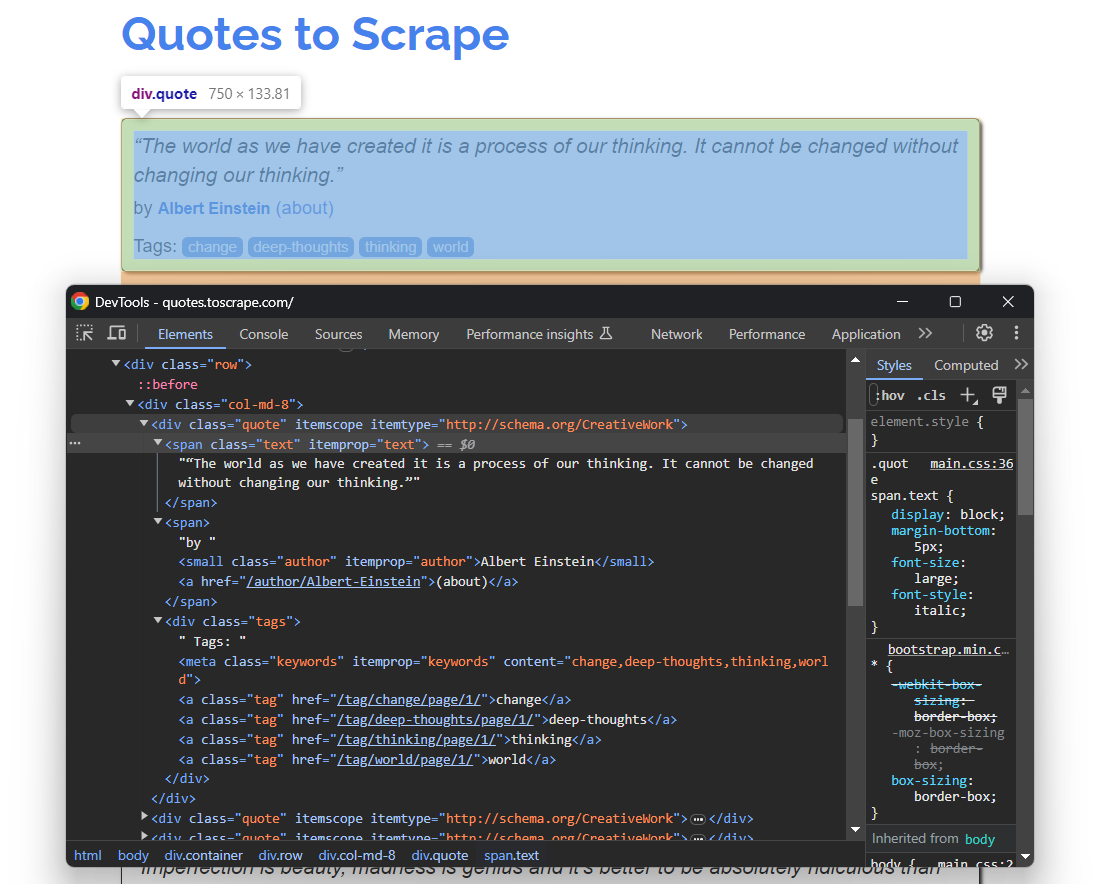
Aqui, observe que cada cartão de citação é um nó HTML .quote que contém:
- Um elemento
.textcom o texto da citação - Um nó
.authorcom o nome do autor - Muitos elementos
.tag, cada um exibindo uma única tag
Com os seletores CSS acima, você tem tudo o que precisa para realizar Scraping de dados no Laravel. Use esses seletores para direcionar os elementos DOM de interesse e extrair dados deles nas próximas etapas!
Etapa 6: Prepare-se para realizar o Scraping de dados
Como a página de destino contém várias citações, crie uma estrutura de dados onde armazenar os dados extraídos. Uma matriz será ideal:
citações = []Em seguida, use o método filter() da classe Crawler para selecionar todos os elementos de citação:
$quote_html_elements = $crawler->filter('.quote');Isso retorna todos os nós DOM na página que correspondem ao seletor CSS .quote especificado.
Em seguida, itere sobre eles e prepare-se para aplicar a lógica de extração de dados em cada um deles:
foreach ($quote_html_elements as $quote_html_element) {
// crie um novo rastreador de citações
$quote_crawler = new Crawler($quote_html_element);
// lógica de raspagem...
}Observe que os objetos DOMNode retornados por filter() não fornecem métodos para seleção de nós. Portanto, você precisa criar uma instância local do Crawler limitada ao seu elemento HTML quote específico.
Para que o código acima funcione, adicione a seguinte importação:
use SymfonyComponentDomCrawlerCrawler;Você não precisa instalar manualmente o pacote DomCrawler. Isso porque ele é uma dependência direta do componente BrowserKit.
Ótimo! Você está um passo mais perto de seu objetivo de Scraping de dados com Laravel.
Etapa 7: Implemente a extração de dados
Dentro do loop foreach:
- Extraia os dados de interesse dos elementos
.text,.authore.tag - Preencha um novo objeto
$quotecom eles - Adicione o novo objeto
$quotea$quotes
Primeiro, selecione o elemento .text dentro do elemento HTML quote. Em seguida, use o método text() para extrair o texto interno dele:
$text_html_element = $quote_crawler->filter('.text');
$raw_text = $text_html_element->text();Observe que cada citação é delimitada pelos caracteres especiais u201c e u201d. Você pode removê-los usando a função str_replace() do PHP da seguinte maneira:
$text = str_replace(["u{201c}", "u{201d}"], '', $raw_text);Da mesma forma, extraia as informações do autor com:
$author_html_element = $quote_crawler->filter('.author');
$author = $author_html_element->text();Extrair as tags pode ser um pouco mais desafiador. Como uma única citação pode ter várias tags, você precisa definir uma matriz e extrair cada tag individualmente:
$tag_html_elements = $quote_crawler->filter('.tag');
$tags = [];
foreach ($tag_html_elements as $tag_html_element) {
$tag = $tag_html_element->textContent;
$tags[] = $tag;
}Observe que os elementos DOMNode retornados por filter() não expõem o método text(). De forma equivalente, eles fornecem o atributo textContent.
Esta é a aparência de toda a lógica de extração de dados do Laravel:
// criar um novo rastreador de citações
$quote_crawler = new Crawler($quote_html_element);
// executar a lógica de extração de dados
$text_html_element = $quote_crawler->filter('.text');
$raw_text = $text_html_element->text();
// remova caracteres especiais das informações de texto bruto
$text = str_replace(["u{201c}", "u{201d}"], '', $raw_text);
$author_html_element = $quote_crawler->filter('.author');
$author = $author_html_element->text();
$tag_html_elements = $quote_crawler->filter('.tag');
$tags = [];
foreach ($tag_html_elements as $tag_html_element) {
$tag = $tag_html_element->textContent;
$tags[] = $tag;
}Pronto! Você está perto do objetivo final.
Etapa 8: Retorne os dados coletados
Crie um objeto $quote com os dados coletados e adicione-o a $quotes:
$quote = [
'text' => $text,
'author' => $author,
'tags' => $tags
];
$quotes[] = $quote;Em seguida, atualize os dados de resposta da API com a lista $quotes:
return response()->json(['quotes' => $quotes]);No final do loop de coleta, $quotes conterá:
array(10) {
[0]=>
array(3) {
["text"]=>
string(113) "O mundo como o criamos é um processo do nosso pensamento. Ele não pode ser mudado sem mudar nosso pensamento."
["author"]=>
string(15) "Albert Einstein"
["tags"]=>
array(4) {
[0]=>
string(6) "mudança"
[1]=>
string(13) "pensamentos profundos"
[2]=>
string(8) "pensamento"
[3]=>
string(5) "mundo"
}
}
// omitido por brevidade...
[9]=>
array(3) {
["text"]=>
string(48) "Um dia sem sol é como, você sabe, a noite."
["author"]=>
string(12) "Steve Martin"
["tags"]=>
array(3) {
[0]=>
string(5) "humor"
[1]=>
string(7) "óbvio"
[2]=>
string(6) "comparação"
}
}
}Ótimo! Esses dados serão então serializados em JSON e retornados pela API de scraping do Laravel.
Etapa 9: Junte tudo
Aqui está o código final do arquivo ScrapingController no Laravel:
<?php
namespace AppHttpControllers;
use IlluminateHttpRequest;
use IlluminateHttpJsonResponse;
use SymfonyComponentBrowserKitHttpBrowser;
use SymfonyComponentHttpClientHttpClient;
use SymfonyComponentDomCrawlerCrawler;
class ScrapingController extends Controller
{
função pública scrapeQuotes(): JsonResponse
{
// inicializar um cliente HTTP semelhante a um navegador
$browser = new HttpBrowser(HttpClient::create());
// baixar e analisar o HTML da página de destino
$crawler = $browser->request('GET', 'https://quotes.toscrape.com/');
// onde armazenar os dados coletados
$quotes = [];
// selecionar todos os elementos HTML de citação na página
$quote_html_elements = $crawler->filter('.quote');
// iterar sobre cada elemento HTML de citação e aplicar
// a lógica de coleta
foreach ($quote_html_elements as $quote_html_element) {
// criar um novo rastreador de citações
$quote_crawler = new Crawler($quote_html_element);
// executar a lógica de extração de dados
$text_html_element = $quote_crawler->filter('.text');
$raw_text = $text_html_element->text();
// remova caracteres especiais das informações de texto bruto
$text = str_replace(["u{201c}", "u{201d}"], '', $raw_text);
$author_html_element = $quote_crawler->filter('.author');
$author = $author_html_element->text();
$tag_html_elements = $quote_crawler->filter('.tag');
$tags = [];
foreach ($tag_html_elements as $tag_html_element) {
$tag = $tag_html_element->textContent;
$tags[] = $tag;
}
// criar um novo objeto de citação
// com os dados coletados
$citação = [
'text' => $text,
'author' => $author,
'tags' => $tags
];
// adicionar o objeto de citação à matriz de citações
$citações[] = $citação;
}
var_dump($citações);
return response()->json(['citações' => $citações]);
}
}Hora de testar!
Inicie seu servidor Laravel:
php artisan serveEm seguida, faça uma solicitação GET para o endpoint /api/v1/scraping/scrape-quotes:
curl -X GET 'http://localhost:8000/api/v1/scraping/scrape-quotes'Você obterá o seguinte resultado:
{
"quotes": [
{
"text": "O mundo como o criamos é um processo do nosso pensamento. Ele não pode ser mudado sem mudar nosso pensamento.",
"author": "Albert Einstein",
"tags": [
"change",
"deep-thoughts",
"thinking",
"world"
]
},
// omitido por brevidade...
{
"text": "Um dia sem sol é como, você sabe, a noite.",
"author": "Steve Martin",
"tags": [
"humor",
"óbvio",
"comparação"
]
}
]
}Et voilà! Em menos de 100 linhas de código, você acabou de realizar o Scraping de dados da web no Laravel.
Próximos passos
A API que você criou aqui é apenas um exemplo básico do que você pode fazer com o Laravel quando se trata de Scraping de dados. Para levar seu projeto ao próximo nível, considere as seguintes melhorias:
- Implemente o rastreamento da web: o site de destino contém várias citações espalhadas por várias páginas. Esse é um cenário comum que requer rastreamento da web para a recuperação completa dos dados. Leia nosso artigo sobre a definição de um rastreador da web.
- Programe sua tarefa de scraping: adicione um programador para chamar sua API em intervalos regulares, armazene os dados em um banco de dados e garanta que você sempre tenha dados atualizados.
- Integre um Proxy: fazer várias solicitações a partir do mesmo IP pode levar ao bloqueio por medidas anti-scraping. Para evitar isso, considere integrar Proxies residenciais ao seu Scraper PHP.
Mantenha sua operação de Scraping de dados Laravel ética e respeitosa
O scraping de dados é uma maneira eficaz de coletar dados valiosos para diversos fins. No entanto, o objetivo é recuperar dados de forma responsável, sem prejudicar o site de destino. Portanto, é importante abordar o scraping com as devidas precauções.
Siga estas dicas para garantir um Scraping de dados responsável com Kotlin:
- Verifique e cumpra os Termos de Serviço do site: antes de fazer scraping em um site, revise seus Termos de Serviço. Eles geralmente incluem informações sobre direitos autorais, direitos de propriedade intelectual e diretrizes para o uso de seus dados.
- Respeite o arquivo robots.txt: o arquivo robots.txt de um site define as regras de como os rastreadores automatizados devem acessar suas páginas. Para manter práticas éticas, siga essas diretrizes. Saiba mais em nosso guia robots.txt para Scraping de dados.
- Visar apenas informações disponíveis publicamente: concentre-se em dados que sejam acessíveis ao público. Evite fazer scraping de páginas protegidas por credenciais de login ou outras formas de autorização. Visar dados privados ou confidenciais sem a devida permissão é antiético e pode levar a consequências legais.
- Limite a frequência de suas solicitações: fazer muitas solicitações em um curto período pode sobrecarregar o servidor, afetando o desempenho do site para todos os usuários. Isso também pode acionar medidas de limitação de taxa e fazer com que você seja bloqueado. Evite sobrecarregar o servidor de destino adicionando atrasos aleatórios entre suas solicitações.
- Confie em ferramentas de scraping confiáveis e atualizadas: prefira fornecedores conceituados e opte por ferramentas que sejam bem mantidas e atualizadas regularmente. Isso garante que elas estejam alinhadas com as práticas éticas mais recentes de Scraping de dados do Laravel. Se você não tiver certeza, confira nosso artigo sobre como escolher o melhor serviço de Scraping de dados.
Conclusão
Neste guia, você viu por que o Laravel é uma boa estrutura para construir APIs de Scraping de dados da web. Você também teve a oportunidade de explorar algumas de suas melhores bibliotecas de Scraping de dados. Em seguida, você aprendeu como criar uma API de Scraping de dados da web Laravel que extrai dados de uma página de destino em tempo real. Como você viu, o Scraping de dados com Laravel é simples e requer apenas algumas linhas de código.
O problema é que a maioria dos sites protege seus dados com soluções anti-bot e anti-scraping. Essas tecnologias podem detectar e bloquear suas solicitações automatizadas. Felizmente, a Bright Data tem um conjunto de soluções para facilitar o scraping:
- Navegador de scraping: um navegador controlável baseado em nuvem que oferece recursos de renderização JavaScript enquanto lida com CAPTCHAs, impressão digital do navegador, tentativas automatizadas e muito mais para você. Ele se integra às bibliotecas de navegador de automação mais populares, como Playwright e Puppeteer.
- Web Unlocker: uma API de desbloqueio que pode retornar perfeitamente o HTML limpo de qualquer página, contornando quaisquer medidas anti-scraping.
- API de Scraping de dados: pontos finais para acesso programático a dados estruturados da web de dezenas de domínios populares.
Não quer lidar com Scraping de dados, mas ainda está interessado em dados online? Explore os Conjuntos de dados prontos para uso da Bright Data!
Inscreva-se agora e comece seu teste grátis.





