

O scraping de dados é o processo de extrair conteúdo e dados de sites usando scripts ou ferramentas de software automatizadas. As informações extraídas são então geralmente exportadas para um formato mais útil, como um arquivo bruto ou CSV, para facilitar o consumo.
Se você deseja simplificar seus fluxos de trabalho de Scraping de dados,o Google Sheetsé a solução. É uma ferramenta popular de gerenciamento de dados, ótima para extrair dados estruturados ou tabulares de sites e para analisar ou visualizar seus dados. Por exemplo, você pode usá-la para obter detalhes e preços de produtos em sites de comércio eletrônico ou informações de contato em diretórios comerciais. Também é útil para rastrear o engajamento nas redes sociais ou fazer análises de opinião pública para medir a eficácia de campanhas.
Neste tutorial, você aprenderá como configurar e usar o Google Sheets para Scraping de dados.
Configurando suas planilhas do Google
Para começar o Scraping de dados com o Google Sheets, você precisa criar uma nova planilha do Google Sheets navegando atéhttps://sheets.google.come clicando no botão+:
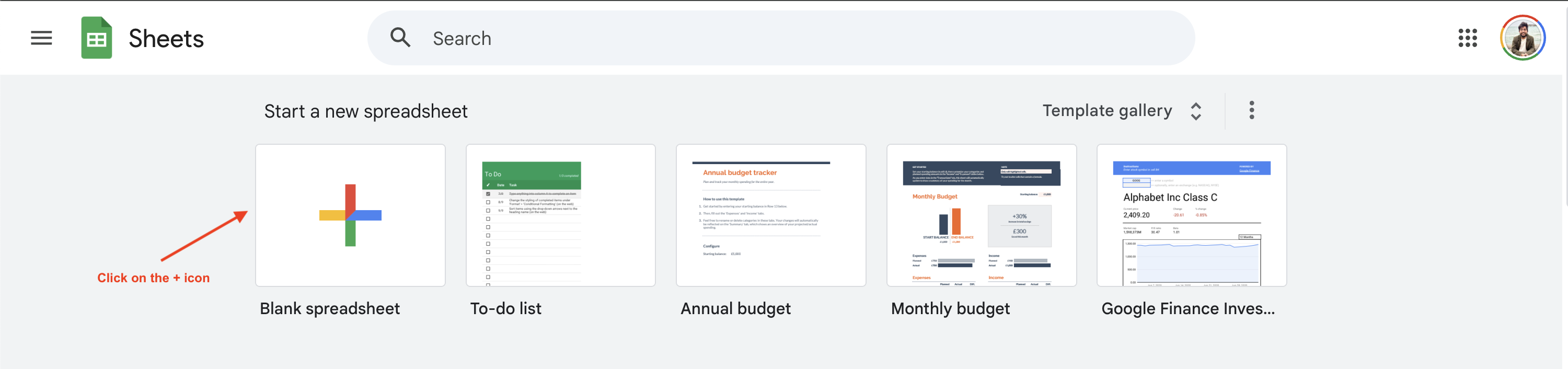
Este tutorial mostra como extrair informações sobre preços de livros dositeBooks to Scrape, mas você pode usar um site diferente modificando a URL e as consultas a seguir.
Entendendo as fórmulas do Google Sheets
O Google Sheets oferece suporte a váriasfórmulas de célulaque podem ser usadas para uma variedade de operações, incluindo Scraping de dados. Vamos dar uma olhada em como algumas dessas fórmulas funcionam.
IMPORTXML
A funçãoIMPORTXMLpermite consultar e importar dados estruturados para o Google Sheets. Ela suporta os formatos de arquivo XML, HTML, CSV e TSV. A sintaxe da função é a seguinte:
=IMPORTXML(url, xpath_query)
A função importa dados da URL da web especificada e usa o localizadorXPathpara encontrar o elemento relevante na página da web. Por exemplo, você pode obter o títuloH1do siteBooks to Scrapeadicionando a seguinte fórmula em uma célula do Google Sheets:
=IMPORTXML("https://books.toscrape.com/catalogue/category/books/default_15/index.html", "//h1")
Na primeira utilização, o Google Sheets solicita que você habilite o acesso antes de buscar dados de sites de terceiros:
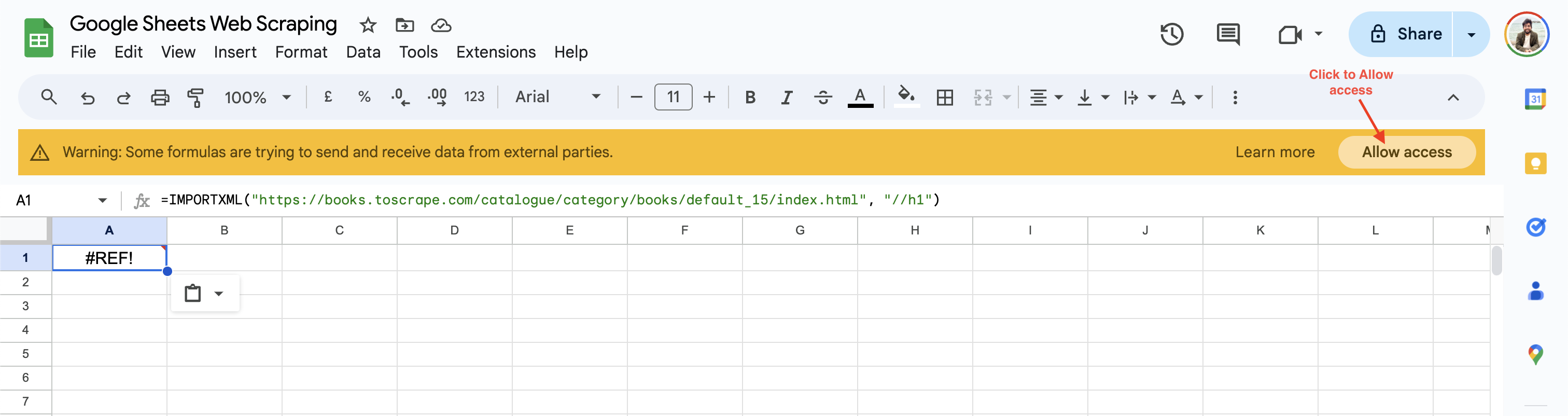
Depois de clicar em Permitir acesso, o Google Sheets resolve o valor da célula para o título H1 da página da web como Padrão.
IMPORTHTML
A função IMPORTHTML permite importar dados de uma tabela ou lista em uma página HTML. A sintaxe da função é a seguinte:
=IMPORTHTML(url, consulta, índice)
Essa função importa os dados da url para a planilha com base na consulta especificada. O atributo de consulta pode ser definido como uma lista ou tabela, dependendo do tipo de dados que você deseja importar. O índice começa em 1 e determina qual tabela ou lista deve ser importada. Por exemplo, você pode buscar a lista de livros do Books to Scrape usando esta fórmula:
=IMPORTHTML("https://books.toscrape.com/catalogue/category/books/default_15/index.html", "list", 2)
Essa fórmula gera a lista de livros na célula atual, conforme mostrado aqui:
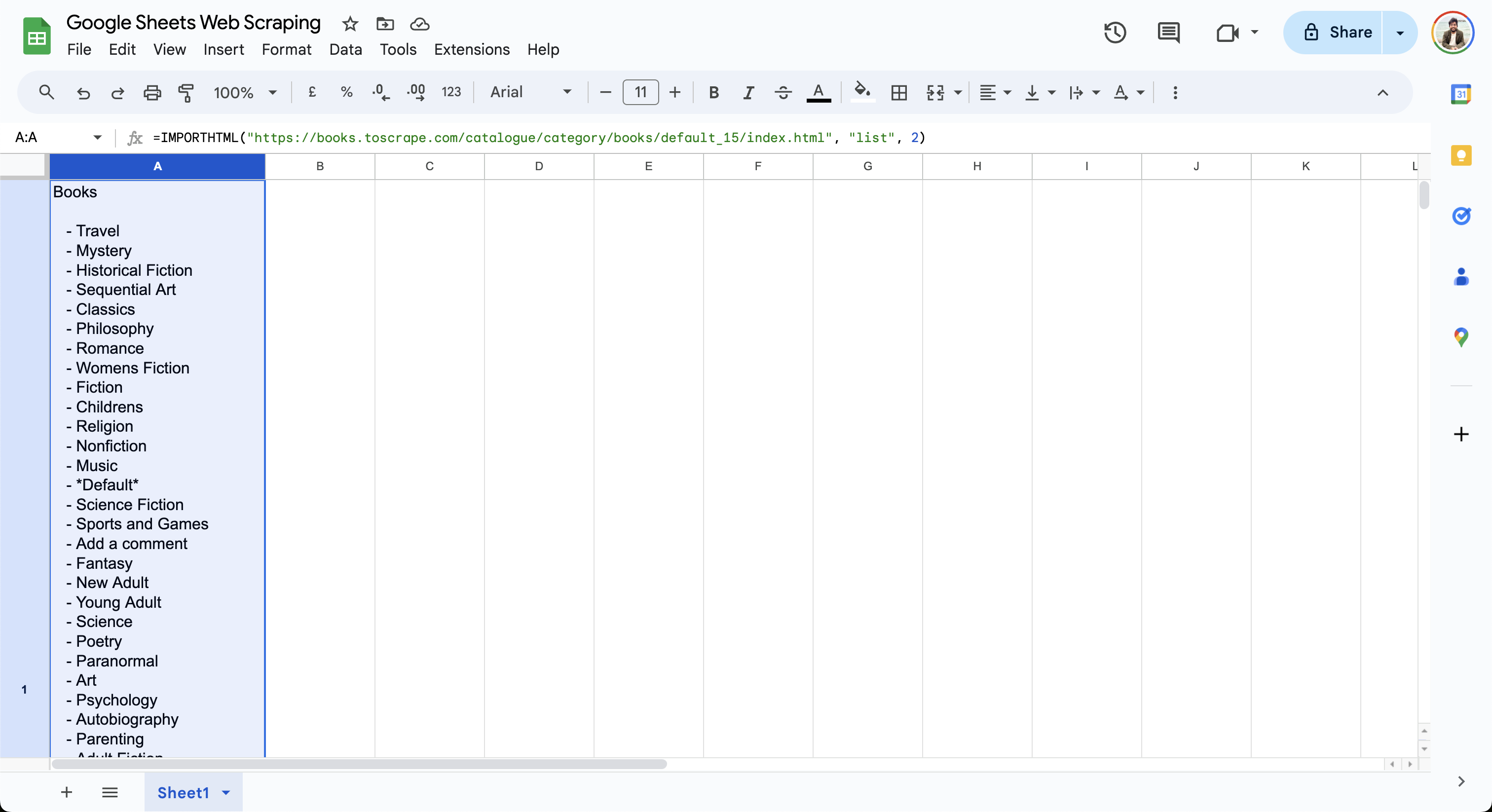
Como você pode ver, as fórmulasIMPORTXMLeIMPORTHTMLsão fáceis de usar e permitem que você comece a extrair dados de uma página da web usando consultas simples. Para casos de uso mais complexos, consulte este guia que explica como usar VBA e Selenium para Scraping de dados da web no Excel.
Extraindo dados usando IMPORTXML
Na seção anterior, você aprendeu o uso básico doIMPORTXMLpara buscar títulos de páginas especificando o atributo XPath relevante. O atributo XPath é bastante poderoso e permite que você percorra qualquer elemento em uma página da web, independentemente de sua hierarquia. Na seção a seguir, você usaráo IMPORTXMLpara buscar o título, o preço e a classificação de todos os livrosnestapágina da webBooks to Scrape.
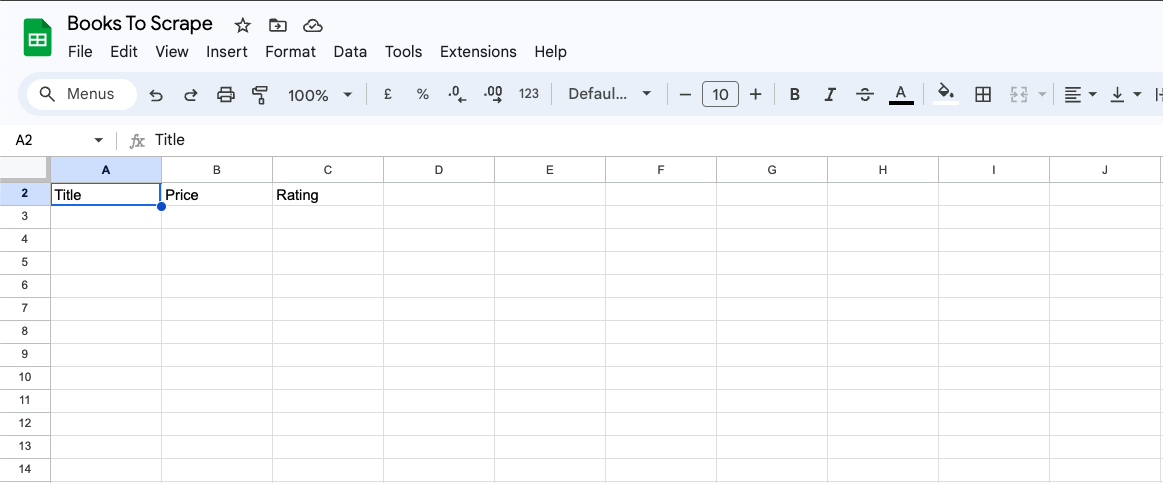
Para começar, adicione as colunas Título, Preço e Classificação no Google Sheets:
Para obter o título do livro em Books to Scrape, você precisa da localização XPath, que pode ser encontrada usando a ferramenta Inspecionar do navegador. Para encontrar o XPath do título do livro, clique com o botão direito do mouse no título do primeiro livro e clique em Inspecionar. Em seguida, clique em Copiar > XPath para copiar o localizador XPath:
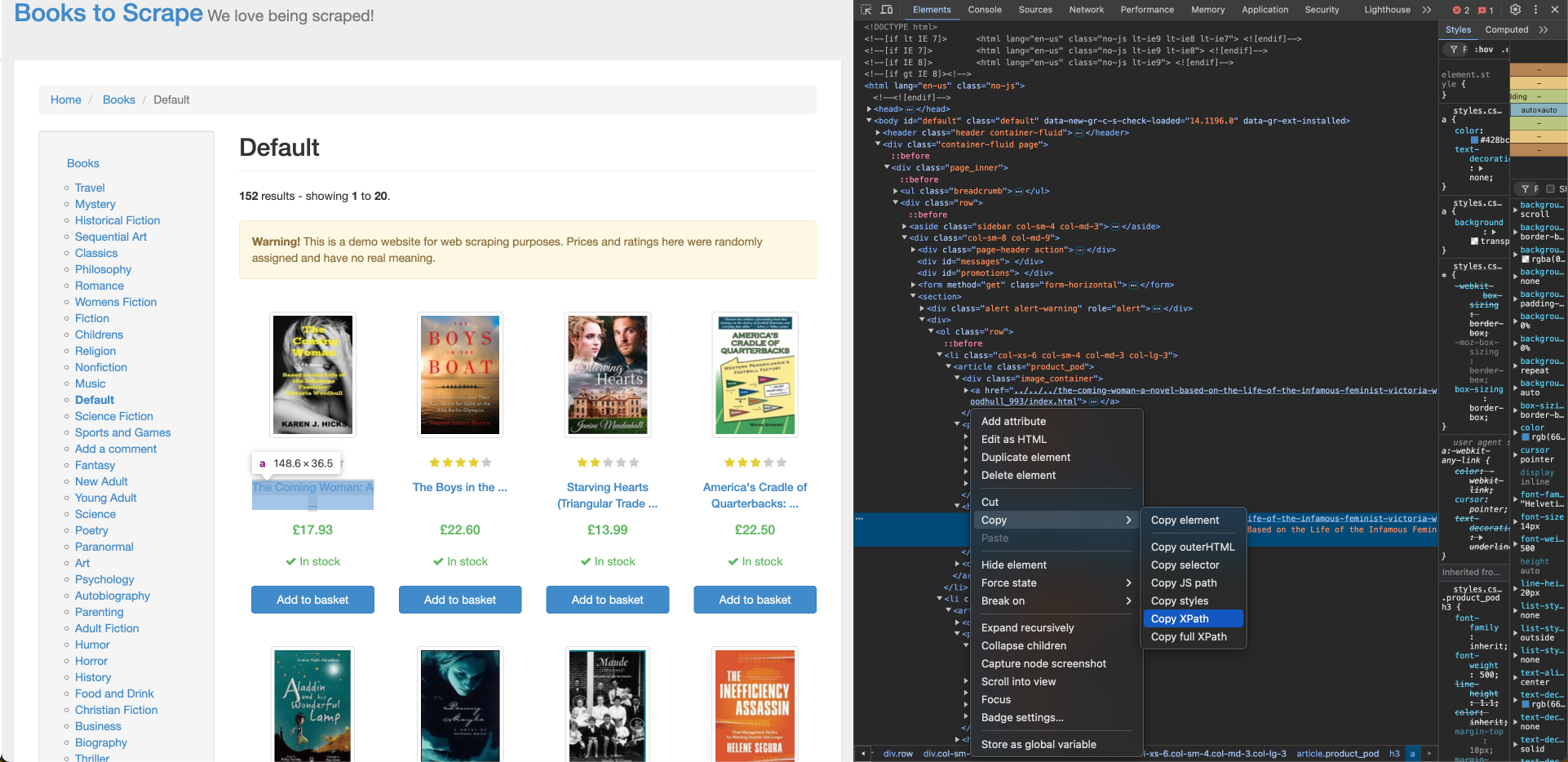
O XPath do título do primeiro livro corresponde a uma tag âncora (a) e se parece com isto:
//*[@id="default"]/div/div/div/div/section/div[2]/ol/li[1]/article/h3/a
Você precisa fazer alguns ajustes no XPath para garantir que o título do livro seja importado corretamente para todos os livros da lista:
- O XPath contém
li[1]no caminho, indicando que o primeiro livro está selecionado. Substitua-o porlipara recuperar todos os elementos. - O conteúdo interno da tag
acontém um título de livro truncado, mas a tagacontém um atributotitlecom o título completo do livro. Modifique oano XPath paraa/@titlepara usar o atributo title. - Substitua todas as aspas duplas no XPath por aspas simples para evitar problemas de escape na fórmula.
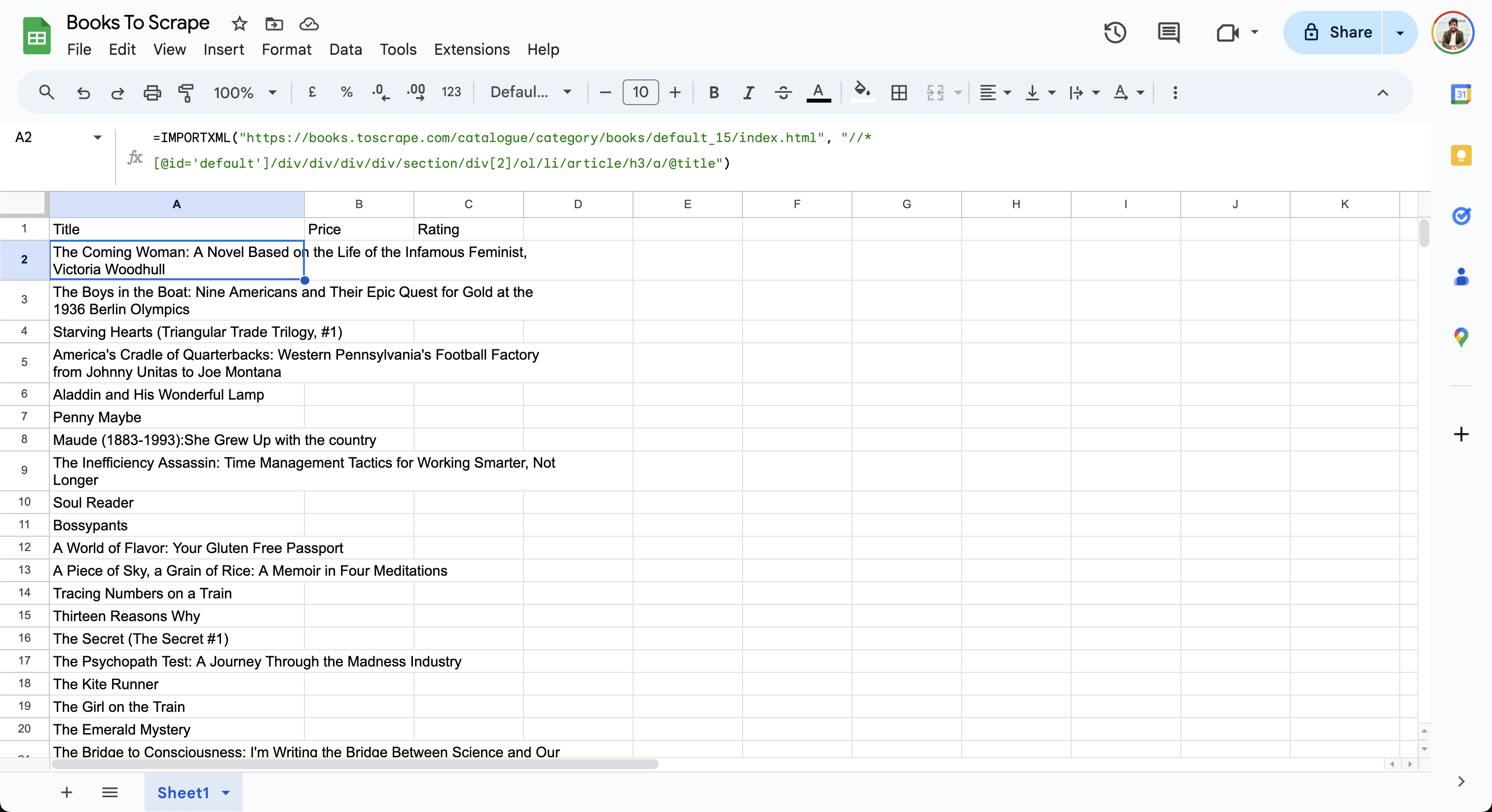
Depois de ajustar o XPath, adicione a seguinte fórmula com o XPath atualizado na célula A2 da sua planilha do Google:
=IMPORTXML("https://books.toscrape.com/catalogue/category/books/default_15/index.html", "//*[@id='default']/div/div/div/div/section/div[2]/ol/li/article/h3/a/@title")
A planilha importa os dados da página da web e atualiza as linhas da seguinte maneira:
Em seguida, construa o XPath para o preço e adicione-o à célula B2 na planilha do Google:
=IMPORTXML("https://books.toscrape.com/catalogue/category/books/default_15/index.html", "//*[@id='default']/div/div/div/div/section/div[2]/ol/li/article/div[2]/p[1]")
Por fim, encontre o XPath para a classificação e adicione-o à célula C2 na planilha do Google:
=IMPORTXML("https://books.toscrape.com/", "//*[@id='default']/div/div/div/div/section/div[2]/ol/li/article/p/@class")
Os dados finais na planilha ficam assim:
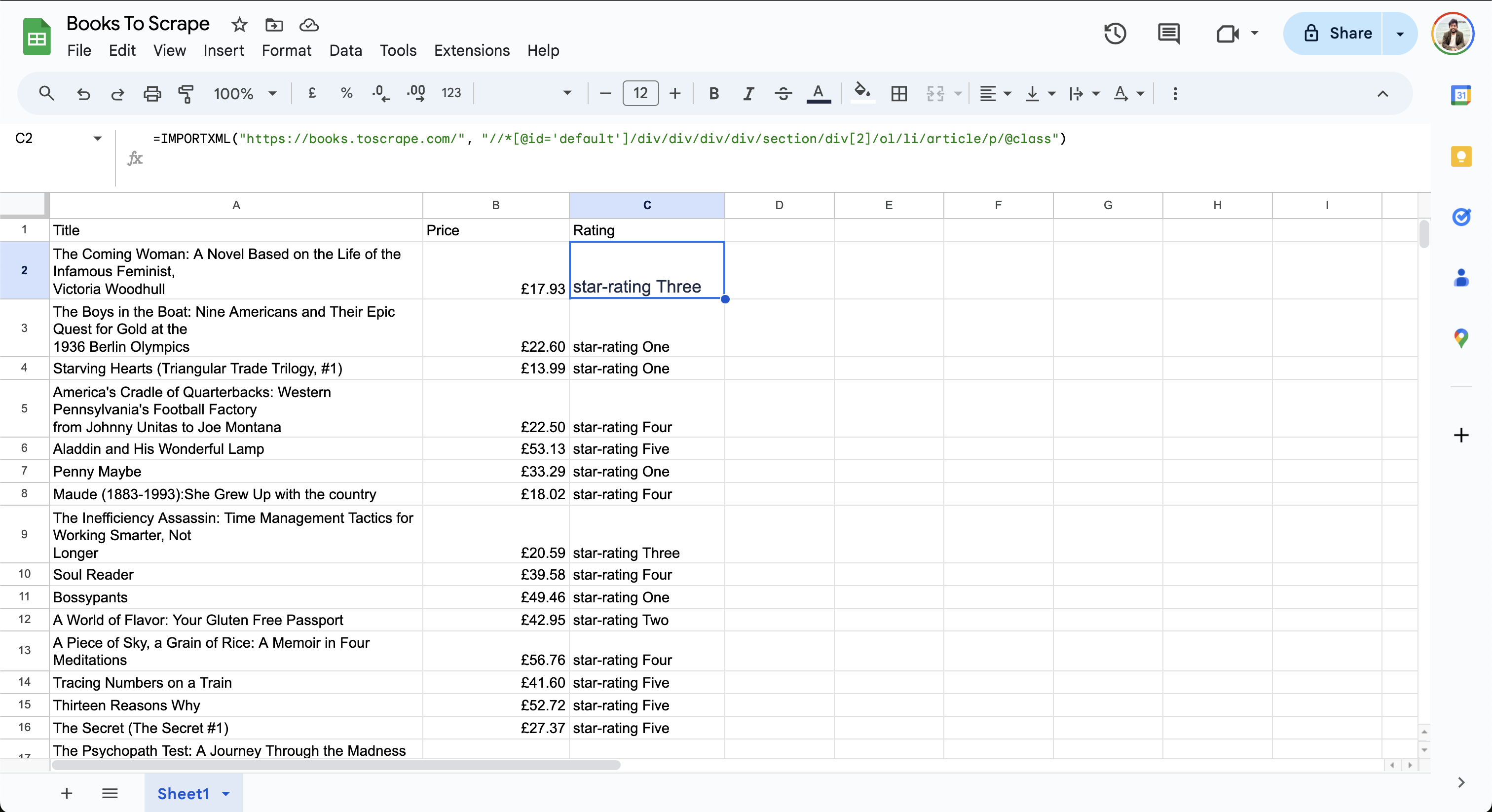
Observe que a colunaClassificaçãomostraa classificação por estrelas Trêsoua classificação por estrelas Quatro. Comoo XPath 2.0ainda não é compatível com o Google Sheets, você não pode manipular os dados para simplificar a saída.
Tratamento de páginas da Web complexas
Embora o Google Sheets seja adequado para tarefas simples de scraping de dados, o scraping pode se tornar um desafio se o site de destino contiver conteúdo dinâmico e paginação ou se exigir interações de clique. Por exemplo, se sua página da web carrega conteúdo de forma assíncrona usando JavaScript, as fórmulasIMPORTXMLeIMPORTHTMLdo Google Sheets não podem extrair dados dela, pois suportam apenas páginas da web estáticas. Da mesma forma, se o conteúdo depender de interações do usuário, como clicar, digitar ou rolar a tela, essas fórmulas não serão capazes de extrair os dados. Se você deseja extrair conteúdo dinâmico, pode escrever um script que use um navegador sem interface gráfica, como o Selenium.
O Google Sheets também não consegue lidar automaticamente com tarefas de extração paginadas. Embora você possa adicionar manualmente a fórmula IMPORTXML após a última linha com uma URL atualizada, esse método não é escalável, pois requer a repetição do processo para cada página.
Se você estiver procurando casos de uso mais avançados, como lidar com conteúdo dinâmico ou grandes volumes de dados, considere usar os produtos da Bright Data para uma extração de dados eficiente. A Bright Data fornece uma API unificada de Scraping de dados da Web para qualquer tarefa de extração de dados e lida com as complexidades de Proxies, CAPTCHAs e agentes de usuário nos bastidores. Sua API lida com solicitações em massa, Parsing e validação, permitindo que você implante e dimensione mais rapidamente. Além disso, ela fornece uma grande coleção de Conjuntos de dados pré-construídosde sites populares, comoLinkedIneZillow, que podem ser integrados aos seus fluxos de trabalho existentes, reduzindo o incômodo de manter os scripts de scraping.
Automatizando a atualização de dados no Google Sheets
Para algumas tarefas de scraping, como rastreamento de preços ou engajamento nas redes sociais, você precisa atualizar automaticamente os dados coletados em intervalos periódicos para garantir que tenha acesso a dados precisos para análise e tomada de decisões.
Para definir o intervalo de cálculo no Google Sheets, basta clicar em Arquivo > Configurações e navegar até a guia Cálculo:
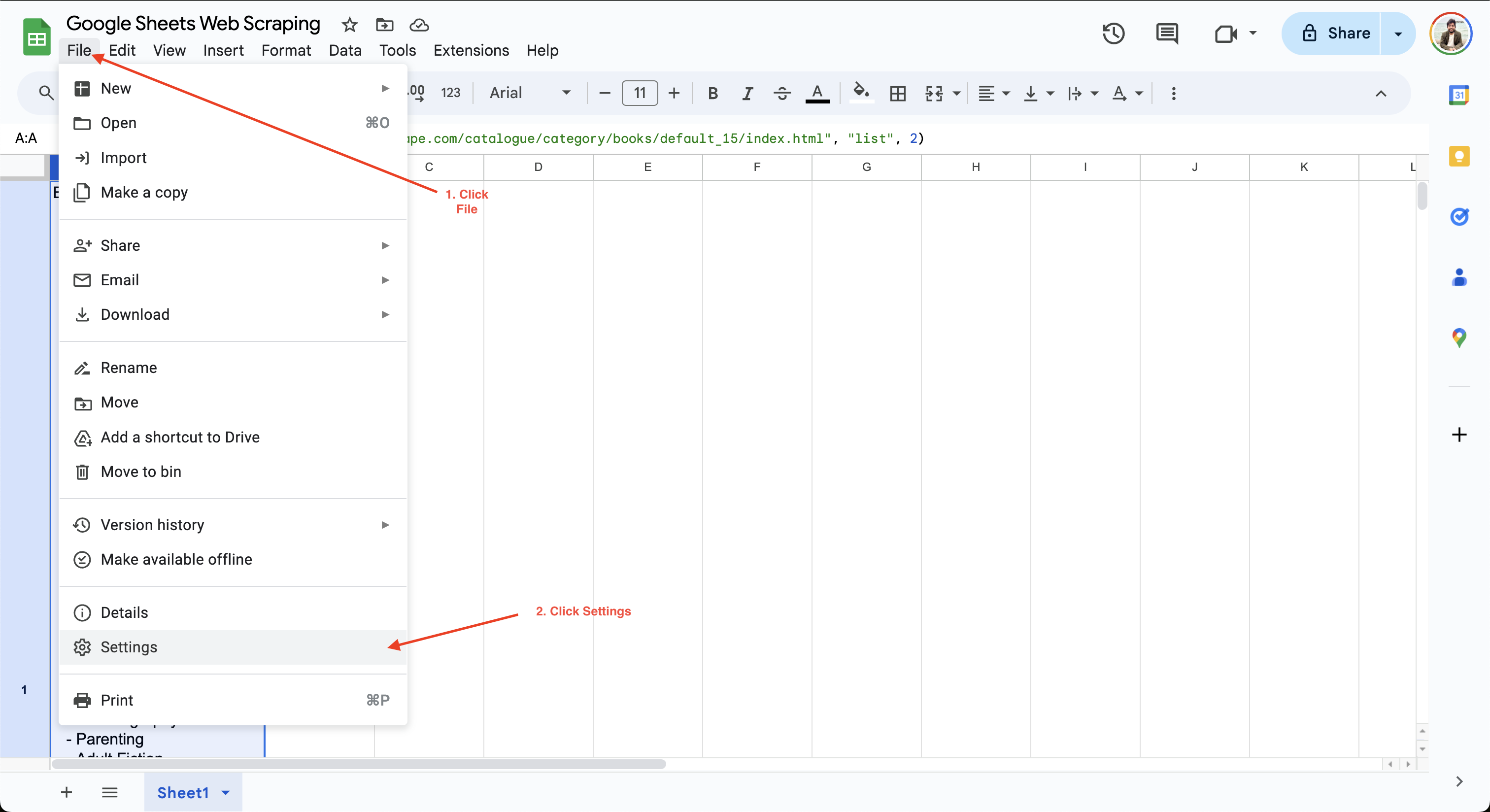
Em seguida, você pode atualizar o intervalo de cálculo para um minuto ou uma hora. Por exemplo, aqui, a configuração Recálculo é atualizada para Ao alterar e a cada minuto para garantir que os dados sejam atualizados automaticamente a cada minuto:
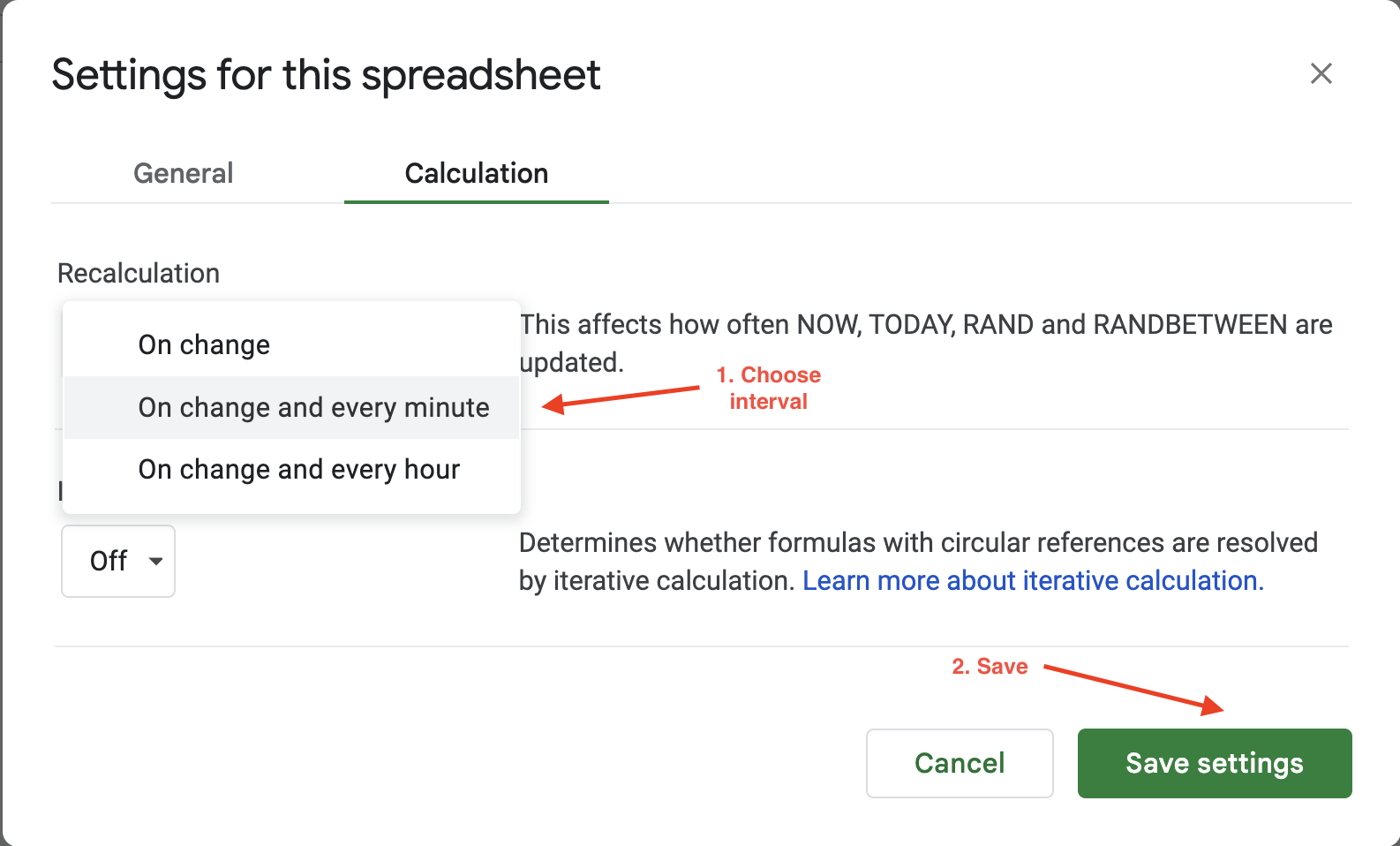
As opções de atualização automática do Google Sheets oferecem flexibilidade limitada para configurar a frequência ou os gatilhos de atualização, pois você só pode escolher entre dois valores: a cada hora ou a cada minuto. Se você procura mais flexibilidade, a Bright Data oferece conjuntos de dados limpos, validados e atualizados em vários formatos de arquivo, como JSON, CSV e Parquet. Portanto, é ideal para tarefas de coleta em grande escala que, de outra forma, exigiriam a manutenção de uma vasta infraestrutura de scraping.
Implementação das melhores práticas e solução de problemas
Se você deseja melhorar a eficiência da sua extração, certifique-se de ser seletivo quanto aos dados que extrai. Tentar extrair dados desnecessários pode retardar o seu processo e aumentar a carga no site de destino.
Se você deseja fazer scraping de grandes volumes de dados, adicione atrasos artificiais entre as solicitações e considere executar as tarefas fora do horário de pico para garantir que o site não fique sobrecarregado com tráfego inesperado. Altos volumes de tráfego podem levar a bloqueios de IP ou limitação de taxa, impedindo você de continuar sua tarefa de scraping. Saiba mais sobre como fazer scraping de sites sem ser bloqueado.
Além dos bloqueios de IP, apresentar aos usuários umdesafio CAPTCHAé outra técnica anti-bot comum usada por sites para restringir o acesso ao conteúdo até que o usuário verifique que é humano. Considere usar osProxies residenciais da Bright Datapara tarefas avançadas de extração que se beneficiariam da rotação de IP e solucionadores CAPTCHA automáticos.
Antes de fazer scraping de quaisquer dados, você também deve revisar os termos de serviço do site para garantir a conformidade. Seus scripts devem seguir as instruçõesdo robot.txtpara interagir com o site. Consulteeste guiapara saber mais sobre como usar as regrasdo robot.txtpara Scraping de dados.
Conclusão
O Google Sheets é adequado para extrair dados de sites estáticos que não envolvem conteúdo dinâmico, elementos ocultos ou paginação. Neste artigo, você aprendeu como automatizar facilmente tarefas de extração de dados usando as fórmulas IMPORTXML e IMPORTHTML sem experiência prévia em scripts.
Para tarefas complexas de scraping que envolvem conteúdo dinâmico ou grandes volumes de dados,a Bright Datafornece APIs fáceis de usar, flexíveis, escaláveis e de alto desempenho para scraping de dados da web em diferentes formatos, incluindo JSON, CSV ou NDJSON. Nos bastidores, ela lida com as complexidades do scraping, cuidando da rotação de IP e agente do usuário, CAPTCHAs e conteúdo dinâmico. Se você está pronto para levar o Scraping de dados da web para o próximo nível, considere experimentar a melhor API de Scraping de dados da web.
Inscreva-se hoje mesmo para um teste grátis e comece a otimizar seus fluxos de trabalho de dados!





