

Neste guia, você aprenderá:
- O que é o Ferret e o que ele oferece como biblioteca declarativa de raspagem da Web
- Como configurá-lo para uso local em um ambiente Go
- Como usá-lo para coletar dados de um site estático
- Como usá-lo para extrair dados de um site dinâmico
- As principais limitações do Ferret e como contorná-las
Vamos mergulhar de cabeça!
Introdução ao Ferret para Web Scraping
Antes de vê-lo em ação, explore o que é o Ferret, como ele funciona, o que ele oferece e quando usá-lo.
O que é furão?
Ferret é uma biblioteca de raspagem da Web de código aberto escrita em Go. Seu objetivo é simplificar a extração de dados de páginas da Web usando uma abordagem declarativa. Especificamente, ela abstrai as complexidades técnicas de análise e extração usando sua própria linguagem declarativa personalizada: a Ferret Query Language (FQL).
Com quase 6 mil estrelas no GitHub, o Ferret é uma das bibliotecas de coleta de dados da Web mais populares para Go. Ela pode ser incorporada e é compatível com raspagem estática e dinâmica da Web.
FQL: A linguagem de consulta Ferret para raspagem declarativa da Web
A Ferret Query Language (FQL) é uma linguagem de consulta de uso geral, fortemente inspirada na AQL do ArangoDB. Embora seja capaz de fazer mais, a FQL é usada principalmente para extrair dados de páginas da Web.
A FQL segue uma abordagem declarativa, o que significa que ela se concentra nos dados a serem recuperados e não em como recuperá-los. Como o AQL, ele compartilha semelhanças com o SQL. Mas, ao contrário do AQL, o FQL é estritamente somente leitura. Observe que qualquer forma de manipulação de dados deve ser feita usando funções internas específicas.
Para obter mais informações sobre a sintaxe, as palavras-chave, as construções e os tipos de dados compatíveis do FQL, consulte a página de documentação do FQL.
Casos de uso
Conforme destacado na página oficial do GitHub, os principais casos de uso do Ferret incluem:
- Teste de interface do usuário: Automatize os testes em aplicativos da Web simulando as interações do navegador e validando se os elementos da página se comportam e são renderizados corretamente em diferentes cenários.
- Aprendizado de máquina: Extraia dados estruturados de páginas da Web e use-os para criar conjuntos de dados de alta qualidade. Eles podem ser usados para treinar ou validar modelos de aprendizado de máquina com mais eficiência. Veja como usar a raspagem da Web para aprendizado de máquina.
- Análises: Extraia e agregue dados da Web, como preços, avaliações ou atividade do usuário, para gerar insights, rastrear tendências ou alimentar painéis de controle.
Ao mesmo tempo, lembre-se de que os possíveis casos de uso de raspagem da Web vão muito além desses exemplos.
Introdução ao Ferret
Agora que você já sabe o que é o Ferret, está pronto para vê-lo em ação em páginas da Web estáticas e dinâmicas. Se você não estiver familiarizado com a diferença entre os dois, leia nosso guia sobre conteúdo estático e dinâmico na raspagem da Web.
Vamos configurar um ambiente para usar o Ferret para raspagem da Web!
Pré-requisitos
Certifique-se de ter os seguintes itens instalados em seu computador local:
- Ir
- Docker
Para verificar se o Golang está instalado e pronto, execute o seguinte comando no terminal:
go versionVocê deverá ver um resultado semelhante a este:
go version go1.24.3 windows/amd64Se ocorrer um erro, instale o Golang e configure-o para seu sistema operacional.
Da mesma forma, verifique se o Docker está instalado e configurado corretamente em seu sistema.
Criar o Projeto Furão
Agora, crie uma pasta para seu projeto de raspagem da Web do Ferret e navegue até ela:
mkdir ferret-web-scraping
cd ferret-web-scrapingFaça o download do Ferret CLI para seu sistema operacional e descompacte-o diretamente na pasta ferret-web-scraping/. Verifique se ele funciona executando:
./ferret helpO resultado deve ser:
Usage:
ferret [flags]
ferret [command]
Available Commands:
browser Manage Ferret browsers
config Manage Ferret configs
exec Execute a FQL script or launch REPL
help Help about any command
update
version Show the CLI version information
Flags:
-h, --help help for ferret
-l, --log-level string Set the logging level ("debug"|"info"|"warn"|"error"|"fatal") (default "info")
Use "ferret [command] --help" for more information about a command.Em seguida, abra a pasta do projeto em seu IDE favorito, como o Visual Studio Code. Dentro da pasta do projeto, crie um arquivo chamado scraper.fql:
ferret-web-scraping/
├── ferret
├── CHANGELOG.md
├── LICENSE
├── README.md
└── scraper.fql # <-- The FQL file for web scraping in Ferretscraper.fql conterá sua lógica declarativa FQL para raspagem da Web.
Configurar a instalação do Ferret Docker
Para usar todos os recursos do Ferret, você deve ter o Chrome ou o Chromium instalado localmente ou em execução no Docker. Os documentos oficiais recomendam a execução do Chrome/Chromium em um contêiner do Docker.
Você pode usar qualquer imagem sem cabeça baseada no Chromium, mas a imagem montferret/chromium é recomendada. Recupere-a com:
docker pull montferret/chromiumEm seguida, inicie essa imagem do Docker com este comando:
docker run -d -p 9222:9222 montferret/chromiumObservação: se quiser ver o que está acontecendo no navegador durante a execução de seus scripts FQL, inicie o Chrome no computador host com a depuração remota ativada com:
chrome.exe --remote-debugging-port=9222Extraia um site estático com o Ferret
Siga as etapas abaixo para saber como usar o Ferret para extrair um site estático. Neste exemplo, a página de destino será o site sandbox “Books to Scrape“:
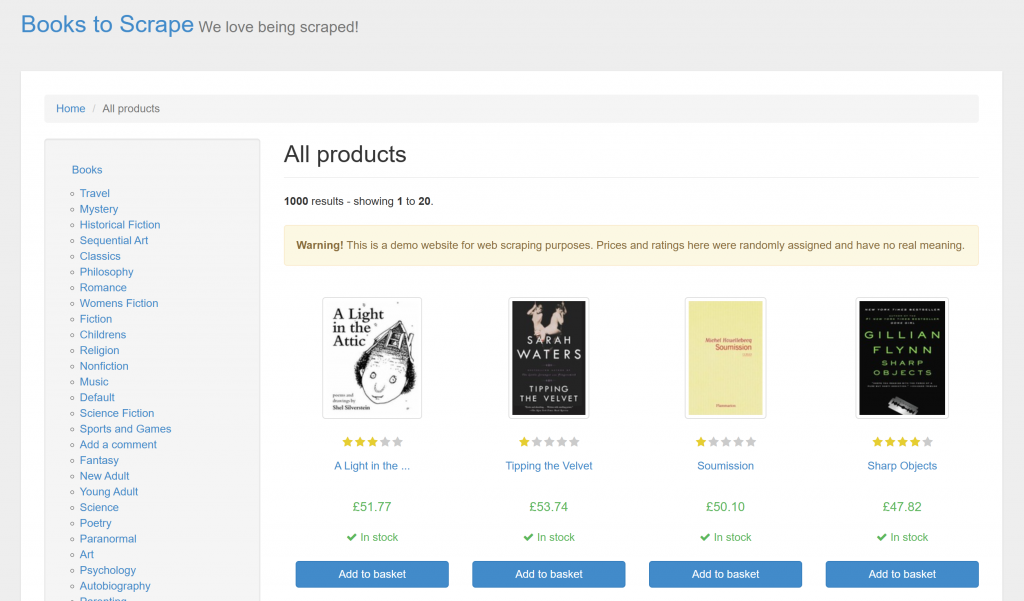
O objetivo é extrair informações importantes de cada livro na página usando a abordagem declarativa do Ferret por meio de FQL.
Etapa 1: conectar-se ao site de destino
No scraper.fql, use a função DOCUMENT para se conectar à página de destino:
LET doc = DOCUMENT("https://books.toscrape.com/")LET permite que você defina uma variável em FQL. Após essa instrução, doc conterá o HTML da página de destino.
Etapa 2: Selecione todos os elementos do livro
Primeiro, familiarize-se com a estrutura da página da Web de destino visitando-a em seu navegador e inspecionando-a. Em detalhes, clique com o botão direito do mouse em um elemento do livro e selecione a opção “Inspect” (Inspecionar) para abrir o DevTools:
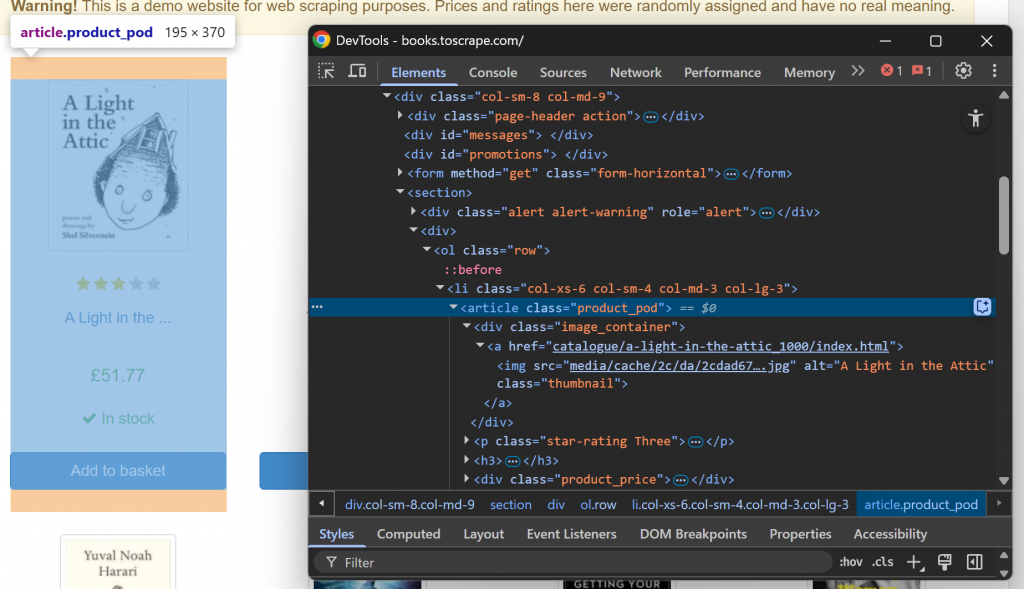
Observe que cada elemento do livro é um nó
. Selecione todos os elementos de livros com a função ELEMENTS():
LET book_elements = ELEMENTS(doc, "section article")ELEMENTS() aplica o seletor CSS passado como o segundo argumento ao documento. Em outras palavras, ele seleciona os elementos HTML desejados na página.
Itere sobre a lista de elementos selecionados e prepare-se para aplicar a lógica de raspagem a eles:
FOR book_element IN book_elements
// book scraping logic...Incrível! É hora de iterar sobre cada elemento do livro e extrair dados de cada um deles.
Etapa 3: Extrair dados de cada cotação
Agora, inspecione um único elemento de livro HTML:
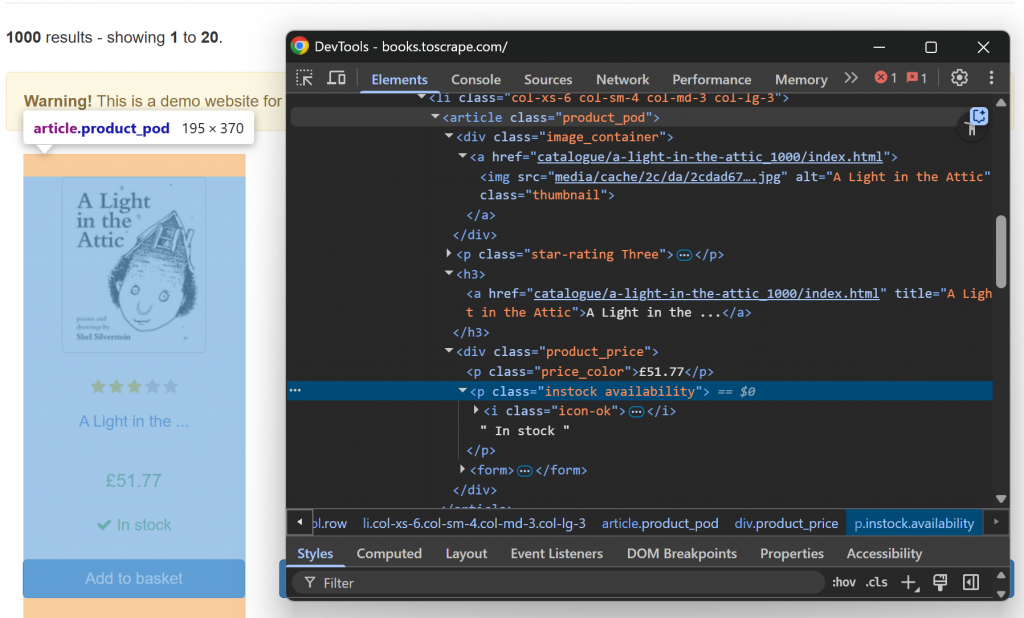
Observe que você pode raspar:
- O URL da imagem do atributo
srcdo elemento.image_container img. - O título do livro do atributo
titledo elementoh3 a. - O URL da página do livro do atributo
hrefdo nóh3 a. - O preço do livro do texto de
.price_color. - As informações de disponibilidade do texto do
.instock.
Implemente essa lógica de análise de dados com:
LET image_element = ELEMENT(book_element, ".image_container img")
LET title_element = ELEMENT(book_element, "h3 a")
LET price_element = ELEMENT(book_element, ".price_color")
LET availability_element = ELEMENT(book_element, ".instock")
RETURN {
image_url: base_url + image_element.attributes.src,
title: base_url+ title_element.attributes.title,
book_url: title_element.attributes.href,
price: TRIM(INNER_TEXT(price_element)),
availability: TRIM(INNER_TEXT(availability_element))
}Onde base_url é uma variável definida fora do loop for:
LET base_url = "https://books.toscrape.com/"No código acima:
ELEMENT()permite que você selecione um único elemento na página usando um seletor CSS.attributesé um atributo especial que todos os objetos retornados porELEMENT()têm. Ele contém os valores dos atributos HTML do elemento atual.INNER_TEXT()retorna o texto contido no elemento atual.TRIM()remove os espaços em branco à esquerda e à direita.
Fantástico! Lógica de raspagem estática concluída.
Etapa nº 4: Juntar tudo
Seu arquivo scraper.fql deve ter a seguinte aparência:
// connect to the target site
LET doc = DOCUMENT("https://books.toscrape.com/")
// select the book HTML elements
LET book_elements = ELEMENTS(doc, "section article")
// the base URL of the target site
LET base_url = "https://books.toscrape.com/"
// iterate over each book element and apply the scraping logic
FOR book_element IN book_elements
// select all info elements
LET image_element = ELEMENT(book_element, ".image_container img")
LET title_element = ELEMENT(book_element, "h3 a")
LET price_element = ELEMENT(book_element, ".price_color")
LET availability_element = ELEMENT(book_element, ".instock")
// scrape the data of interest
RETURN {
image_url: base_url + image_element.attributes.src,
title: base_url+ title_element.attributes.title,
book_url: title_element.attributes.href,
price: TRIM(INNER_TEXT(price_element)),
availability: TRIM(INNER_TEXT(availability_element))
}Como você pode ver, a lógica de raspagem se concentra mais em quais dados extrair do que em como extraí-los. Esse é o poder da raspagem declarativa da Web com o Ferret!
Etapa 5: Executar o script FQL
Execute seu script Ferret com:
./ferret exec scraper.fqlNo terminal, a saída será:
[{"availability":"In stock","book_url":"catalogue/a-light-in-the-attic_1000/index.html","image_url":"https://books.toscrape.com/media/cache/2c/da/2cdad67c44b002e7ead0cc35693c0e8b.jpg","price":"£51.77","title":"https://books.toscrape.com/A Light in the Attic"},{"availability":"In stock","book_url":"catalogue/tipping-the-velvet_999/index.html","image_url":"https://books.toscrape.com/media/cache/26/0c/260c6ae16bce31c8f8c95daddd9f4a1c.jpg","price":"£53.74","title":"https://books.toscrape.com/Tipping the Velvet"},
// omitted for brevity...
,{"availability":"In stock","book_url":"catalogue/its-only-the-himalayas_981/index.html","image_url":"https://books.toscrape.com/media/cache/27/a5/27a53d0bb95bdd88288eaf66c9230d7e.jpg","price":"£45.17","title":"https://books.toscrape.com/It's Only the Himalayas"}]Trata-se de uma cadeia de caracteres JSON que contém todos os dados do livro coletados da página da Web, conforme pretendido. Para uma abordagem não declarativa da análise de dados, dê uma olhada em nosso guia sobre raspagem da Web com Go.
Missão cumprida!
Extraia um site dinâmico com o Ferret
O Ferret também suporta a coleta de dados de sites dinâmicos que exigem a execução de JavaScript. Nesta seção do guia, o site de destino será a versão com atraso de JavaScript do site “Quotes to Scrape”:

A página usa JavaScript para injetar dinamicamente elementos de citação no DOM após um pequeno atraso. Esse cenário requer a execução de JavaScript – portanto, a necessidade de renderizar a página em um navegador. (Esse também é o motivo pelo qual configuramos anteriormente um contêiner do Chromium Docker).
Siga as etapas abaixo para saber como lidar com páginas da Web dinâmicas usando o Ferret!
Etapa 1: Conecte-se à página de destino no navegador
Use as linhas a seguir para se conectar à página de destino por meio de um navegador sem cabeça:
LET doc = DOCUMENT("https://quotes.toscrape.com/js-delayed/?delay=2000", {
driver: "cdp"
})Observe o uso do campo driver na função DOCUMENT(). Isso é o que diz ao Ferret para renderizar a página na instância do Chroumium sem cabeça configurada via Docker.
Etapa 2: Aguarde até que os elementos de destino estejam na página
Visite a página de destino em seu navegador, aguarde o carregamento dos elementos de citação e inspecione um deles:
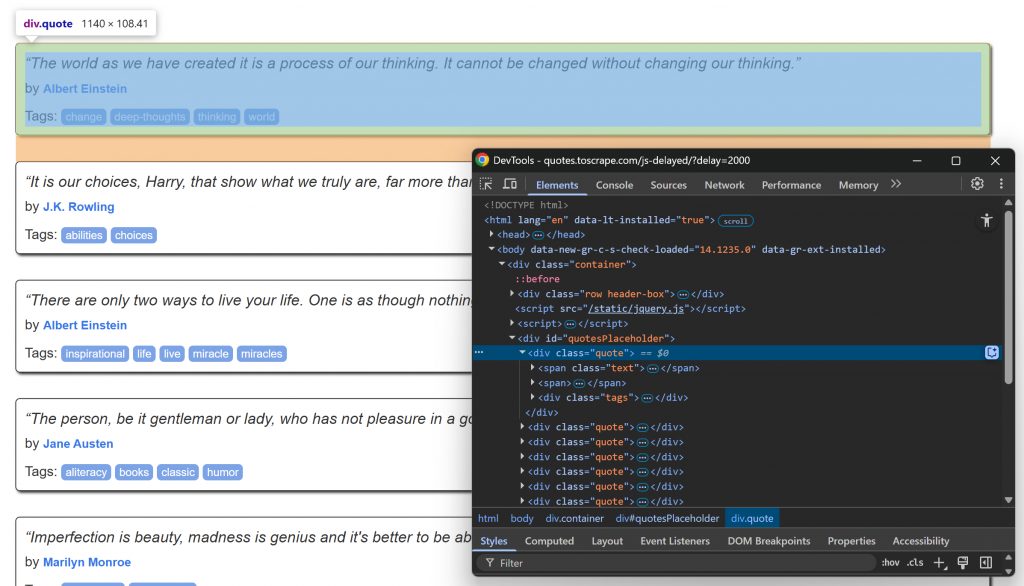
Observe como os elementos de citação podem ser selecionados usando o seletor .quote CSS. Esses elementos de citação serão renderizados via JavaScript após um pequeno atraso, portanto, você deve esperar por eles.
Use a função WAIT_ELEMENT() no Ferret para aguardar que os elementos de citação apareçam na página:
// wait up to 5 seconds for the quote elements to be on the page
WAIT_ELEMENT(doc, ".quote", 5000)Essa é uma construção essencial a ser usada ao raspar páginas dinâmicas da Web que dependem do JavaScript para renderizar o conteúdo.
Etapa nº 3: Aplicar a lógica de raspagem
Agora, concentre-se na estrutura HTML dos elementos de informação dentro de um nó .quote:
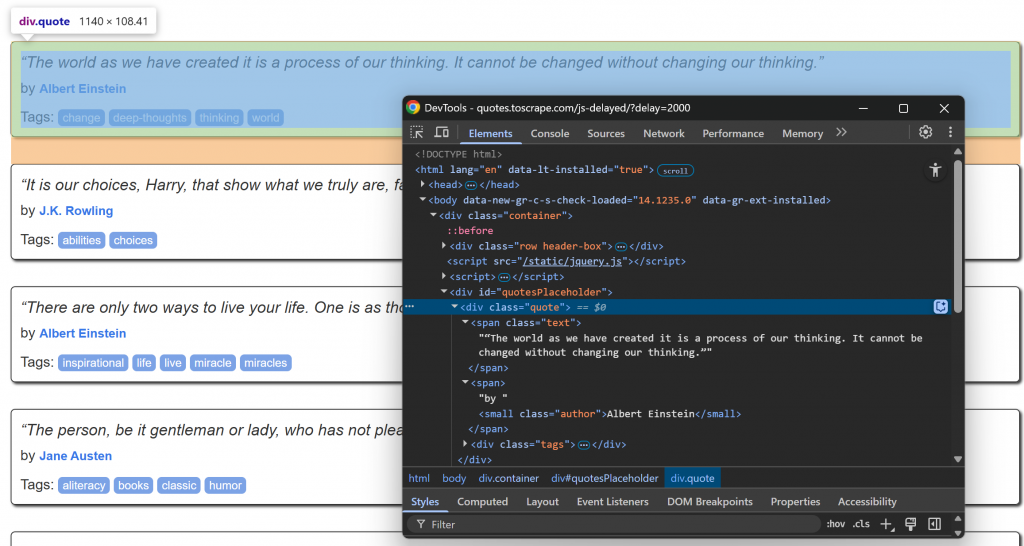
Observe que você pode raspar:
- O texto da citação de
.quote - O autor de
.author
Implemente a lógica de raspagem da Web do Ferret com:
// select the quote HTML elements
LET quote_elements = ELEMENTS(doc, ".quote")
// iterate over each quote element and apply the scraping logic
FOR quote_element IN quote_elements
// select all info elements
LET text_element = ELEMENT(quote_element, ".text")
LET author_element = ELEMENT(quote_element, ".author")
// scrape the data of interest
RETURN {
quote: TRIM(INNER_TEXT(text_element)),
author: TRIM(INNER_TEXT(author_element))
} Fantástico! Lógica de análise concluída.
Etapa 4: Montar tudo
O arquivo scraper.fql deve conter:
// connect to the target site via the Chromium headless instance
LET doc = DOCUMENT("https://quotes.toscrape.com/js-delayed/?delay=2000", {
driver: "cdp"
})
// wait up to 5 seconds for the quote elements to be on the page
WAIT_ELEMENT(doc, ".quote", 5000)
// select the quote HTML elements
LET quote_elements = ELEMENTS(doc, ".quote")
// iterate over each quote element and apply the scraping logic
FOR quote_element IN quote_elements
// select all info elements
LET text_element = ELEMENT(quote_element, ".text")
LET author_element = ELEMENT(quote_element, ".author")
// scrape the data of interest
RETURN {
quote: TRIM(INNER_TEXT(text_element)),
author: TRIM(INNER_TEXT(author_element))
}Como você pode ver, isso não é muito diferente do script de um site estático. Mais uma vez, o motivo é que o Ferret usa uma abordagem declarativa para raspagem da Web.
Etapa 5: Executar o código FQL
Execute seu script de raspagem do Ferret com:
./ferret exec scraper.fqlDessa vez, o resultado será:
[{"author":"Albert Einstein","quote":"“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”"},{"author":"J.K. Rowling","quote":"“It is our choices, Harry, that show what we truly are, far more than our abilities.”"},{"author":"Albert Einstein","quote":"“There are only two ways to live your life. One is as though nothing is a miracle. The other is as though everything is a miracle.”"},{"author":"Jane Austen","quote":"“The person, be it gentleman or lady, who has not pleasure in a good novel, must be intolerably stupid.”"},{"author":"Marilyn Monroe","quote":"“Imperfection is beauty, madness is genius and it's better to be absolutely ridiculous than absolutely boring.”"},{"author":"Albert Einstein","quote":"“Try not to become a man of success. Rather become a man of value.”"},{"author":"André Gide","quote":"“It is better to be hated for what you are than to be loved for what you are not.”"},{"author":"Thomas A. Edison","quote":"“I have not failed. I've just found 10,000 ways that won't work.”"},{"author":"Eleanor Roosevelt","quote":"“A woman is like a tea bag; you never know how strong it is until it's in hot water.”"},{"author":"Steve Martin","quote":"“A day without sunshine is like, you know, night.”"}]E pronto! Esse é exatamente o conteúdo estruturado recuperado da página renderizada em JavaScript.
Limitações da abordagem de raspagem declarativa da Web do Ferret
O Ferret é, sem dúvida, uma ferramenta poderosa e uma das poucas que adota uma abordagem declarativa para a raspagem da Web. No entanto, ela tem pelo menos três grandes desvantagens:
- Documentação deficiente e atualizações pouco frequentes: Embora a documentação oficial inclua textos úteis, ela não contém referências abrangentes à API. Isso dificulta a criação de scripts complexos. Além disso, o projeto não recebe atualizações regulares, o que significa que pode estar atrasado em relação às técnicas modernas de raspagem.
- Não há suporte para desvio anti-scraping: O Ferret não oferece mecanismos internos para lidar com CAPTCHAs, limites de taxa ou outras defesas avançadas contra raspagem. Isso o torna inadequado para raspagem de sites mais protegidos.
- Expressividade limitada: FQ, a Ferret Query Language, ainda está em desenvolvimento e não oferece o mesmo nível de flexibilidade ou controle que as ferramentas de raspagem mais modernas, como Playwright ou Puppeteer.
Essas limitações não podem ser facilmente resolvidas por meio de integrações simples. Além disso, não se esqueça de que o foco principal do Ferret é a recuperação de dados da Web. Portanto, a solução é considerar uma alternativa mais robusta.
A infraestrutura de IA da Bright Data inclui um conjunto de serviços avançados adaptados para extração confiável e inteligente de dados da Web. Isso permite que você recupere dados de qualquer site e em escala.
Conclusão
Neste tutorial, você aprendeu a usar o Ferret para raspagem declarativa da Web em Go. Conforme demonstrado, essa biblioteca permite que você extraia dados de páginas estáticas e dinâmicas, concentrando-se no que recuperar, em vez de como recuperar.
O problema é que o Ferret tem várias limitações, portanto, pode não ser a melhor solução disponível. Se estiver procurando uma maneira mais simplificada e dimensionável de recuperar dados da Web, considere adotar as APIs do Web Scraper –pontos de extremidade dedicadospara extrair dados da Web atualizados, estruturados e totalmente compatíveis de mais de 120 sites populares.
Inscreva-se hoje mesmo em uma conta gratuita da Bright Data e teste nossa poderosa infraestrutura de raspagem da Web!




