Neste tutorial, você entenderá por que o Go é uma das melhores linguagens para raspar a web de forma eficiente e aprenderá a construir um raspador de Go do zero.
Este artigo abordará:
É possível efetuar a raspagem da web com Go?
Melhores bibliotecas de Go para raspagem da web
Construir um raspador da web em Go
É possível efetuar a raspagem da web com Go?
Go, também conhecida como Golang, é uma linguagem de programação com tipagem estática criada pela Google. Foi concebida para ser eficiente, concorrente e fácil de escrever e manter. Estas características fizeram recentemente do Go uma escolha popular em várias aplicações, incluindo a raspagem da web.
Em pormenor, o Go fornece características poderosas que são úteis quando se trata de tarefas de raspagem da web. Estas incluem o seu modelo de concorrência incorporado, que suporta o processamento simultâneo de vários pedidos web. Isto faz de Go a linguagem ideal para extrair grandes quantidades de dados de vários sítios web de forma eficiente. Além disso, a biblioteca padrão do Go inclui pacotes de cliente HTTP e de análise HTML que podem ser usados para buscar páginas web, analisar HTML e extrair dados de sítios web.
Se estas capacidades e pacotes predefinidos não forem suficientes ou forem demasiado difíceis de utilizar, existem também várias bibliotecas de Go para raspagem da web. Vejamos as mais importantes:
Melhores bibliotecas de Go para raspagem da web
Aqui está uma lista de algumas das melhores bibliotecas de raspagem da web para Go:
Colly: Uma poderosa estrutura de raspagem e rastejamento da web para Go. Fornece uma API funcional para efetuar pedidos HTTP, gerir cabeçalhos e analisar o DOM. Colly também suporta raspagem paralela, limitação de taxa e tratamento automático de cookies.
Goquery: Uma biblioteca popular de análise de HTML em Go baseada numa sintaxe semelhante à do jQuery. Permite-lhe selecionar elementos HTML através de seletores CSS, manipular o DOM e extrair dados dos mesmos.
Selenium: Um cliente Go da estrutura de testes web mais popular. Permite-lhe automatizar os navegadores web para várias tarefas, incluindo a raspagem da web. Especificamente, o Selenium pode controlar um navegador web e dar-lhe instruções para interagir com as páginas como um usuário humano faria. Também é capaz de efetuar raspagem em páginas web que utilizam JavaScript para recuperação ou apresentação de dados.
Pré-requisitos
Antes de começar, é necessário instalar o Go no seu computador. Note que o procedimento de instalação muda com base no sistema operativo.
Abra o ficheiro descarregado e siga as instruções de instalação. O pacote instalará Go em /usr/local/go e adicionará /usr/local/go/bin à sua variável de ambiente PATH.
Inicie o ficheiro MSI que descarregou e siga o assistente de instalação. O instalador instalará Go em C:/Program Files ou C:/rogram Files (x86) e adicionará a pasta bin à variável de ambiente PATH.
Certifique-se de que o seu sistema não tem uma pasta /usr/local/go. Se existir, elimine-a com:
rm -rf /usr/local/go
Extraia o arquivo descarregado para /usr/local:
tar -C /usr/local -xzf goX.Y.Z.linux-amd64.tar.gz
Certifique-se de que substitui X.Y.Z pela versão do pacote Go que descarregou.
Adicione /usr/local/go/bin à variável de ambiente PATH:
export PATH=$PATH:/usr/local/go/bin
Recarregue o PC.
Independentemente do seu sistema operativo, verifique se o Go foi instalado com êxito com o comando abaixo:
go version
Isso retornará algo como:
go version go1.20.3
Muito bem! Agora está pronto para testar a raspagem da web com Go!
Construir um raspador da web em Go
Aqui, aprenderá a construir um raspador da web em Go. Este script automatizado será capaz de recuperar automaticamente os dados da página inicial da Bright Data. O objetivo do processo de raspagem da web com Go será selecionar alguns elementos HTML da página, extrair dados dos mesmos e converter os dados coletados num formato fácil de explorar.
No momento de escrever, é este o aspeto do sítio-alvo:
Siga o tutorial passo-a-passo e aprenda a efetuar a raspagem da web em Go!
Passo 1: Configurar um projeto com Go
É hora de inicializar seu projeto de raspador da web em Go. Abra o terminal e crie uma pasta go-web-scraper:
Isto irá inicializar um módulo web-scraper dentro da raiz do projeto.
O diretório go-web-scraper conterá agora o seguinte ficheiro go.mod:
module web-scraper
go 1.20
Note que a última linha muda dependendo da sua versão do Go.
Agora está pronto para começar a escrever alguma lógica de Go no seu IDE! Neste tutorial, vamos utilizar o Visual Studio Code. Uma vez que não suporta Go nativamente, é necessário instalar primeiro a extensão Go.
Inicie o VS Code, clique no ícone “Extensões” na barra esquerda e escreva “Go”.
Lembre-se de que a função main() representa o ponto de entrada de qualquer aplicação Go. É aqui que terá de colocar a sua lógica de raspagem da web de Golang.
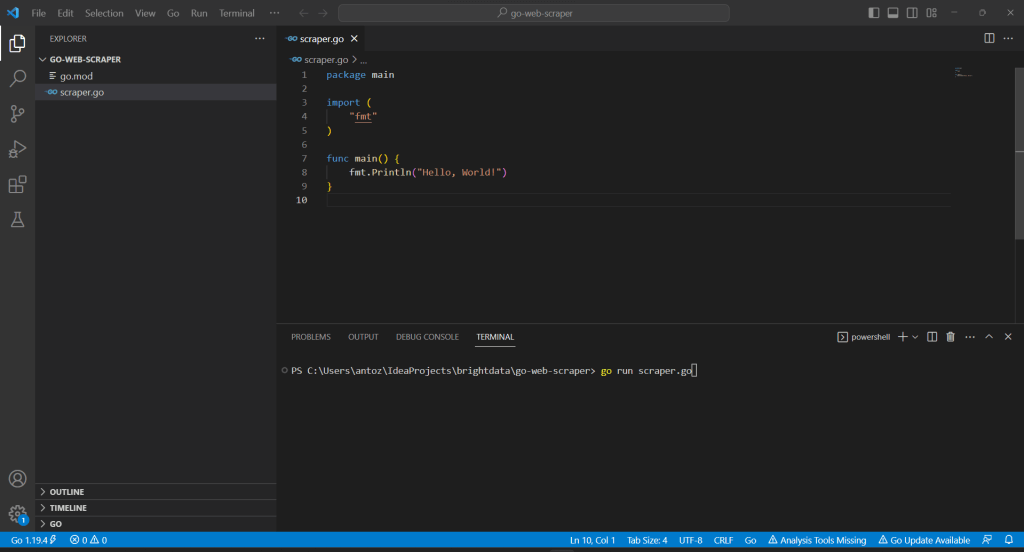
O Visual Studio Code solicitará que você instale alguns pacotes para concluir a integração com Go. Instale-os todos. Em seguida, execute o script Go lançando o comando abaixo no Terminal de VS:
go run scraper.go
Isso imprimirá:
Hello, World!
Passo 2: Começar a utilizar o Colly
Para construir um raspador web para o Go mais facilmente, deve utilizar um dos pacotes apresentados anteriormente. Mas primeiro, você precisa descobrir qual biblioteca de Golang para raspagem da web melhor se encaixa nos seus objetivos. Para o fazer, visite o sítio web alvo, clique com o botão direito do rato no fundo e selecione a opção “Inspecionar”. Isto abrirá as ferramentas de desenvolvimento do seu navegador. No separador “Rede”, dê uma vista de olhos à seção “Fetch/XHR”.
Note-se que o sítio de destino não efetua nenhuma chamada AJAX significativa.
Como se pode ver acima, a página web de destino efetua apenas alguns pedidos AJAX. Se explorar cada pedido XHR, verificará que não devolvem dados significativos. Por outras palavras, o documento HTML devolvido pelo servidor já contém todos os dados. É o que geralmente acontece com os sítios de conteúdo estático.
Isto mostra que o sítio de destino não depende do JavaScript para obter dados dinamicamente ou para fins de apresentação. Como resultado, não é necessária uma biblioteca com capacidades de navegador sem cabeça para obter dados da página web de destino. Pode ainda utilizar o Selenium, mas isso apenas introduziria uma sobrecarga de desempenho. Por este motivo, deve preferir um analisador HTML simples como o Colly.
Adicione o Colly às dependências do seu projeto com:
go get github.com/gocolly/colly
Este comando cria um ficheiro go.sum e atualiza o ficheiro go.mod em conformidade.
Antes de começar a utilizá-lo, é necessário aprofundar alguns conceitos-chave do Colly.
A principal entidade do Colly é o Coletor. Este objeto permite-lhe realizar pedidos HTTP e efetuar a raspagem da web através das seguintes chamadas de retorno:
OnRequest(): Chamado antes de efetuar qualquer pedido HTTP com Visit().
OnError(): Chamado se ocorrer um erro num pedido HTTP.
OnResponse(): Chamado depois de obter uma resposta do servidor.
OnHTML(): Chamado após OnResponse(), se o servidor devolveu um documento HTML válido.
OnScraped(): Chamado após todas as chamadas OnHTML() terem terminado.
Cada uma destas funções recebe um retorno de chamada como parâmetro. Quando o evento associado à função é ativado, Colly executa a chamada de retorno de entrada. Assim, para construir um raspador de dados em Colly, é necessário seguir uma abordagem funcional baseada em chamadas de retorno.
É possível inicializar um objeto Coletor com a função NewCollector():
c := colly.NewCollector()
Importe o Colly e crie um Coletor atualizando o scraper.go da seguinte forma:
Utilize Colly para se ligar à página de destino com:
c.Visit("https://brightdata.com/")
Nos bastidores, a função Visit() executa um pedido HTTP GET e recupera o documento HTML de destino do servidor. Em pormenor, dispara o evento onRequest e inicia o ciclo de vida funcional do Colly. Tenha em atenção que Visit() deve ser chamada depois de registar as outras chamadas de retorno do Colly.
Note-se que o pedido HTTP efetuado por Visit() pode falhar. Quando isso acontece, Colly gera o evento OnError. Os motivos da falha podem ser qualquer coisa, desde um servidor temporariamente indisponível até um URL inválido. Ao mesmo tempo, os “raspadores da web” geralmente falham quando o sítio alvo adota medidas antibot. Por exemplo, estas tecnologias filtram geralmente os pedidos que não têm um cabeçalho HTTP de Usuário-Agente válido. Consulte o nosso guia para saber mais sobre Usuários-Agentes para raspagem da web.
Por predefinição, o Colly define um Usuário-Agente de espaço reservado que não corresponde aos agentes utilizados pelos navegadores mais populares. Este fato torna os pedidos do Colly facilmente identificáveis pelas tecnologias antirraspagem. Para evitar ser bloqueado por causa disso, especifique um cabeçalho de Usuário-Agente válido no Colly, como abaixo:
c.UserAgent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36
Qualquer chamada Visit() irá agora efetuar um pedido com esse cabeçalho HTTP.
O seu ficheiro scraper.go deve agora ter o seguinte aspeto:
// scraper.go
package main
import (
// import Colly
"github.com/gocolly/colly"
)
func main() {
// initialize the Collector
c := colly.NewCollector()
// set a valid User-Agent header
c.UserAgent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36"
// connect to the target site
c.Visit("https://brightdata.com/")
// scraping logic...
}
Passo 4: Inspecionar a página HTML
Vamos analisar o DOM da página web de destino para definir uma estratégia eficaz de recuperação de dados.
Abra a página inicial da Bright Data no seu navegador. Se você der uma olhada, notará uma lista de cartões com as indústrias onde os serviços da Bright Data podem fornecer uma vantagem competitiva. Essa é uma informação interessante para raspar.
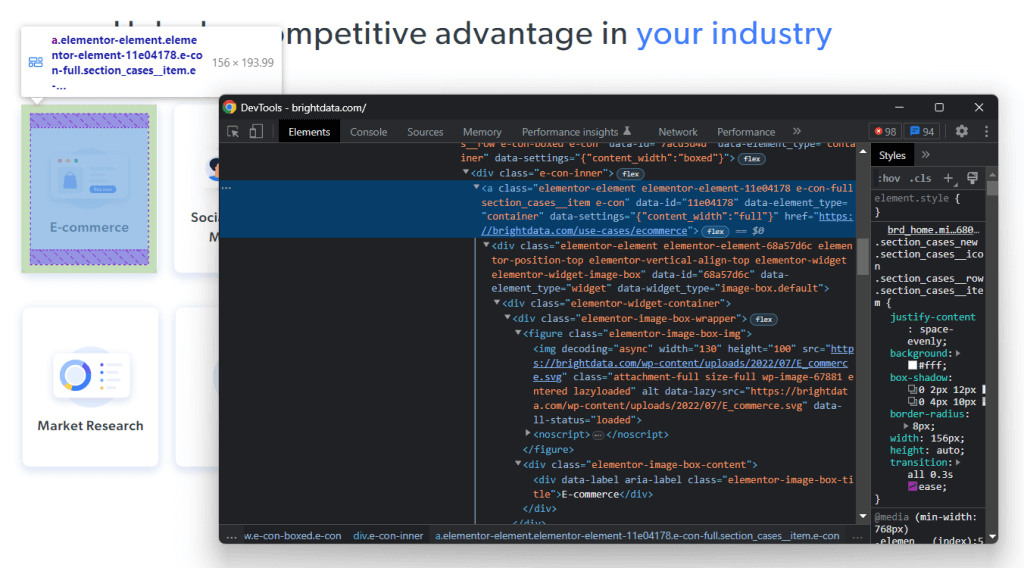
Clique com o botão direito do rato num destes cartões HTML e selecione “Inspecionar”:
Agora, concentre-se nas classes CSS utilizadas pelos elementos HTML de interesse e seus pais. Graças a eles, você será capaz de definir a estratégia de seletor CSS necessária para obter os elementos do DOM desejados.
Em pormenor, cada cartão é caraterizado pela classe section_cases__item e está contido no elemento .elementor-element-6b05593c <div>. Assim, pode obter todos os cartões da indústria com o seguinte seletor CSS:
.elementor-element-6b05593c .section_cases__item
Dado um cartão, pode então selecionar os seus <figure> e <div> filhos relevantes com:
O objetivo do raspador de Go é extrair o URL, a imagem e o nome da indústria de cada cartão.
Passo 5: Selecionar elementos HTML com Colly
You can apply a CSS or XPath selector in Colly as follows:
c.OnHTML(".your-css-selector", func(e *colly.HTMLElement) {
// data extraction logic...
})
O Colly chamará a função passada como parâmetro para cada elemento HTML que corresponda ao seletor CSS. Por outras palavras, itera automaticamente sobre todos os elementos selecionados.
Não se esqueça de que um Coletor pode ter várias chamadas de retorno OnHTML(). Estas serão executadas pela ordem em que as instruções onHTML() aparecem no código.
Passo 6: Extrair dados de uma página web com o Colly
Saiba como utilizar o Colly para extrair os dados pretendidos da página web HTML.
Antes de escrever a lógica de raspagem, são necessárias algumas estruturas de dados para armazenar os dados extraídos. Por exemplo, é possível utilizar um Struct para definir um tipo de dados da Indústria da seguinte forma:
type Industry struct {
Url, Image, Name string
}
Em Go, um Struct especifica um conjunto de campos tipados que podem ser instanciados como um objeto. Se estiver familiarizado com a programação orientada a objetos, pode pensar num Struct como uma espécie de classe.
Agora, pode utilizar a função OnHTML() para implementar a lógica de raspagem, como se indica a seguir:
// iterating over the list of industry card
// HTML elements
c.OnHTML(".elementor-element-6b05593c .section_cases__item", func(e *colly.HTMLElement) {
url := e.Attr("href")
image := e.ChildAttr(".elementor-image-box-img img", "data-lazy-src")
name := e.ChildText(".elementor-image-box-content .elementor-image-box-title")
// filter out unwanted data
if url!= "" || image != "" || name != "" {
// initialize a new Industry instance
industry := Industry{
Url: url,
Image: image,
Name: name,
}
// add the industry instance to the list
// of scraped industries
industries = append(industries, industry)
}
})
O trecho de raspagem da web do Go acima seleciona todos os cartões de indústria na página inicial da Bright Data e faz uma iteração sobre eles. Em seguida, preenche o URL, a imagem e o nome do setor associados a cada cartão. Por fim, instância um novo objeto Indústria e adiciona-o ao slice de indústrias.
Como pode ver, executar o raspagem no Colly é simples. Graças ao método Attr(), pode extrair um atributo HTML do elemento atual. Em vez disso, ChildAttr() e ChildText() permitem-lhe atribuir o valor e o texto de um filho HTML selecionado através de um seletor CSS.
Não se esqueça de que também pode coletar dados das páginas de pormenor do setor. Tudo o que tem de fazer é seguir as ligações descobertas na página atual e implementar uma nova lógica de exploração em conformidade. É para isso que servem o rastejamento e a raspagem da web!
Muito bem! Acabou de aprender como atingir os seus objetivos na raspagem da web utilizando Go!
Passo 7: Exportar os dados extraídos
Após a instrução OnHTML(), as indústrias conterão os dados extraídos em objetos Go. Para tornar os dados extraídos da web mais acessíveis, é necessário convertê-los para um formato diferente. Veja como exportar os dados extraídos para CSV e JSON.
Note que a biblioteca padrão do Go vem com recursos avançados de exportação de dados. Não precisa de nenhum pacote externo para converter os dados em CSV e JSON. Tudo o que precisa de fazer é certificar-se de que o seu script de Go contém as seguintes importações:
Para exportação a CSV:
import (
"encoding/csv"
"log"
"os"
)
Para exportação a JSON:
import (
"encoding/json"
"log"
"os"
)
É possível exportar o slice de indústrias para um ficheiro industries.csv em Go da seguinte forma:
// open the output CSV file
file, err := os.Create("industries.csv")
// if the file creation fails
if err != nil {
log.Fatalln("Failed to create the output CSV file", err)
}
// release the resource allocated to handle
// the file before ending the execution
defer file.Close()
// create a CSV file writer
writer := csv.NewWriter(file)
// release the resources associated with the
// file writer before ending the execution
defer writer.Flush()
// add the header row to the CSV
headers := []string{
"url",
"image",
"name",
}
writer.Write(headers)
// store each Industry product in the
// output CSV file
for _, industry := range industries {
// convert the Industry instance to
// a slice of strings
record := []string{
industry.Url,
industry.Image,
industry.Name,
}
// add a new CSV record
writer.Write(record)
}
O trecho acima cria um ficheiro CSV e o inicializa com a linha de cabeçalho. Em seguida, itera sobre o slice de objetos da Indústria, converte cada elemento num slice de cadeias de caracteres e anexa-o ao ficheiro de saída. O CSV Writer de Go converte automaticamente a lista de cadeias de caracteres para um novo registo no formato CSV.
Executar o script com:
go run scraper.go
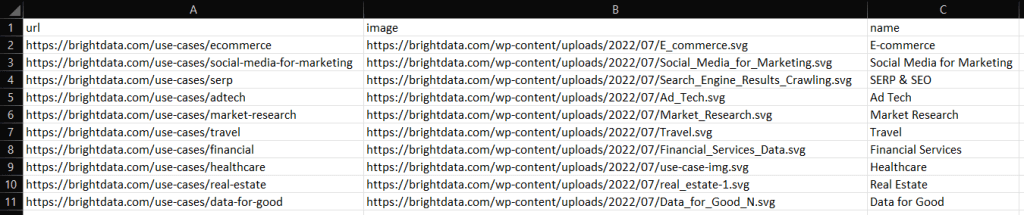
Após a sua execução, irá notar um ficheiro industries.csv na pasta raiz do seu projeto Go. Abra-o e você verá os seguintes dados:
Da mesma forma, pode exportar indústrias para industry.json como abaixo:
file, err:= os.Create("industries.json")
if err != nil {
log.Fatalln("Failed to create the output JSON file", err)
}
defer file.Close()
// convert industries to an indented JSON string
jsonString, _ := json.MarshalIndent(industries, " ", " ")
// write the JSON string to file
file.Write(jsonString)
This will produce the JSON file below:
[
{
"Url": "https://brightdata.com/use-cases/ecommerce",
"Image": "https://brightdata.com/wp-content/uploads/2022/07/E_commerce.svg",
"Name": "E-commerce"
},
// ...
{
"Url": "https://brightdata.com/use-cases/real-estate",
"Image": "https://brightdata.com/wp-content/uploads/2022/07/real_estate-1.svg",
"Name": "Real Estate"
},
{
"Url": "https://brightdata.com/use-cases/data-for-good",
"Image": "https://brightdata.com/wp-content/uploads/2022/07/Data_for_Good_N.svg",
"Name": "Data for Good"
}
]
E pronto! Agora já sabe como transferir os dados coletados para um formato mais útil!
Passo 8: Juntar tudo
Eis o aspeto do código completo do raspador de Golang:
// scraper.go
package main
import (
"encoding/csv"
"encoding/json"
"log"
"os"
// import Colly
"github.com/gocolly/colly"
)
// definr some data structures
// to store the scraped data
type Industry struct {
Url, Image, Name string
}
func main() {
// initialize the struct slices
var industries []Industry
// initialize the Collector
c := colly.NewCollector()
// set a valid User-Agent header
c.UserAgent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36"
// iterating over the list of industry card
// HTML elements
c.OnHTML(".elementor-element-6b05593c .section_cases__item", func(e *colly.HTMLElement) {
url := e.Attr("href")
image := e.ChildAttr(".elementor-image-box-img img", "data-lazy-src")
name := e.ChildText(".elementor-image-box-content .elementor-image-box-title")
// filter out unwanted data
if url != "" && image != "" && name != "" {
// initialize a new Industry instance
industry := Industry{
Url: url,
Image: image,
Name: name,
}
// add the industry instance to the list
// of scraped industries
industries = append(industries, industry)
}
})
// connect to the target site
c.Visit("https://brightdata.com/")
// --- export to CSV ---
// open the output CSV file
csvFile, csvErr := os.Create("industries.csv")
// if the file creation fails
if csvErr != nil {
log.Fatalln("Failed to create the output CSV file", csvErr)
}
// release the resource allocated to handle
// the file before ending the execution
defer csvFile.Close()
// create a CSV file writer
writer := csv.NewWriter(csvFile)
// release the resources associated with the
// file writer before ending the execution
defer writer.Flush()
// add the header row to the CSV
headers := []string{
"url",
"image",
"name",
}
writer.Write(headers)
// store each Industry product in the
// output CSV file
for _, industry := range industries {
// convert the Industry instance to
// a slice of strings
record := []string{
industry.Url,
industry.Image,
industry.Name,
}
// add a new CSV record
writer.Write(record)
}
// --- export to JSON ---
// open the output JSON file
jsonFile, jsonErr := os.Create("industries.json")
if jsonErr != nil {
log.Fatalln("Failed to create the output JSON file", jsonErr)
}
defer jsonFile.Close()
// convert industries to an indented JSON string
jsonString, _ := json.MarshalIndent(industries, " ", " ")
// write the JSON string to file
jsonFile.Write(jsonString)
}
Em menos de 100 linhas de código, é possível construir um raspador de dados em Go!
Conclusão
Neste tutorial, você viu por que Go é uma boa linguagem para raspagem da web. Além disso, percebeu quais são as melhores bibliotecas de Go para raspagem e o que elas oferecem. Em seguida, aprendeu a utilizar a biblioteca padrão do Go e Colly para criar uma aplicação de raspagem da web. O raspador de Go construído aqui pode raspar dados de um alvo do mundo real. Como você viu, a raspagem da web com Go leva apenas algumas linhas de código.
Ao mesmo tempo, não se esqueça de que há muitos desafios a ter em conta ao extrair dados da Internet. É por esta razão que muitos sítios web adotam soluções antirraspagem e antibot que podem detetar e bloquear o seu script de raspagem de Go. Felizmente, é possível criar um raspador da web capaz de contornar e evitar quaisquer bloqueios com o IDE para Raspador da Web de última geração da Bright Data.
Não quer lidar com a raspagem da web, mas está interessado em dados da web? Explore os nossos conjuntos de dados prontos a utilizar.