

Neste guia, você aprenderá:
- A definição de um conjunto de dados
- As melhores maneiras de criar Conjuntos de dados
- Como criar um conjunto de dados em Python
- Como criar um conjunto de dados em R
Vamos começar!
O que é um conjunto de dados?
Um conjunto de dados é uma coleção de dados associados a um tema, tópico ou setor específico. Os conjuntos de dados podem abranger vários tipos de informações, incluindo números, texto, imagens, vídeos e áudio, e podem ser armazenados em formatos como CSV, JSON, XLS, XLSX ou SQL.
Essencialmente, um conjunto de dados compreende dados estruturados voltados para um propósito específico.
As 5 principais estratégias para criar um Conjunto de dados
Explore as 5 melhores estratégias para criar Conjuntos de dados, analisando como eles funcionam e suas vantagens e desvantagens.
Estratégia nº 1: terceirizar a tarefa
Estabelecer e gerenciar uma unidade de negócios para a criação de Conjuntos de dados pode não ser viável ou prático. Isso é especialmente verdadeiro se você não tiver recursos internos ou tempo. Nesse cenário, uma estratégia eficaz para a criação de Conjuntos de dados é terceirizar a tarefa.
A terceirização envolve delegar o processo de criação dos Conjuntos de dados a especialistas externos ou agências especializadas, em vez de lidar com isso internamente. Essa abordagem permite que você aproveite as habilidades de profissionais ou organizações com experiência em coleta, limpeza e formatação de dados.
A quem você deve terceirizar a criação de Conjuntos de dados? Bem, muitas empresas oferecem Conjuntos de dados prontos para uso ou serviços personalizados de coleta de dados. Para obter mais detalhes, consulte nosso guia sobre os melhores sites de Conjuntos de dados.
Esses fornecedores utilizam técnicas avançadas para garantir que os dados recuperados sejam precisos e formatados de acordo com suas especificações. Embora a terceirização permita que você se concentre em outros aspectos importantes do seu negócio, é essencial selecionar um parceiro confiável que atenda às suas expectativas de qualidade.
Prós:
- Você não precisa se preocupar com nada
- Conjuntos de dados de qualquer site em qualquer formato
- Dados históricos ou recentes
Contras:
- Você não tem controle total sobre o processo de recuperação de dados
- Possíveis problemas de conformidade dos dados com o GDPR e a CCPA
- Pode não ser a solução mais econômica
Estratégia nº 2: recuperar dados de APIs públicas
Muitas plataformas, desde redes sociais até sites de comércio eletrônico, oferecem APIs públicas que expõem uma grande quantidade de dados. Por exemplo, a API do X dá acesso a informações sobre contas públicas, publicações e respostas.
A recuperação de dados de APIs públicas é uma técnica eficaz para criar Conjuntos de dados. O motivo é que esses pontos finais retornam dados em um formato estruturado, facilitando a geração de um conjunto de dados a partir de suas respostas. Não é surpresa que as APIs sejam uma das melhores estratégias para obtenção de dados.
Ao aproveitar essas APIs, você pode coletar rapidamente grandes volumes de dados confiáveis diretamente de plataformas estabelecidas. A principal desvantagem é que você precisa respeitar os limites de uso e os termos de serviço da API.
Prós:
- Acesso a dados oficiais
- Integração simples em qualquer linguagem de programação
- Obtenha dados estruturados diretamente da fonte
Contras:
- Nem todas as plataformas têm APIs públicas
- Você deve cumprir as limitações impostas pelo provedor da API
- Os dados retornados por essas APIs podem mudar com o tempo
Estratégia nº 3: procure dados abertos
Dados abertos referem-se a Conjuntos de dados que são compartilhados abertamente com o público de forma gratuita. Esses dados são utilizados principalmente em pesquisas e artigos científicos, mas também podem atender às necessidades comerciais, como análises de mercado.
Os dados abertos são confiáveis, pois são fornecidos por fontes respeitáveis, como governos, organizações sem fins lucrativos e instituições acadêmicas. Essas organizações oferecem repositórios de dados abertos que abrangem uma ampla variedade de tópicos, incluindo tendências sociais, estatísticas de saúde, indicadores econômicos, dados ambientais e muito mais.
Sites populares onde você pode recuperar dados abertos incluem:
- Data.gov: um repositório abrangente de dados federais dos EUA.
- Portal de Dados Abertos da União Europeia: oferece Conjuntos de dados de toda a Europa.
- Dados abertos do Banco Mundial: fornece dados econômicos e de desenvolvimento globais.
- UN Data: apresenta uma variedade de Conjuntos de dados sobre indicadores sociais e econômicos globais.
- Registro de Dados Abertos na AWS: uma plataforma para descobrir e compartilhar Conjuntos de dados disponíveis por meio dos recursos da AWS.
Os dados abertos são uma forma popular de criar Conjuntos de dados, pois eliminam a necessidade de coleta de dados ao fornecer dados disponíveis gratuitamente. Ainda assim, você deve verificar a qualidade, a integridade e os termos de licenciamento dos dados para garantir que eles atendam aos requisitos do seu projeto.
Prós:
- Dados gratuitos
- Conjuntos de dados prontos para uso, grandes e completos
- Conjuntos de dados respaldados por fontes confiáveis, como órgãos governamentais
Contras:
- Geralmente fornece acesso apenas a dados históricos
- Exigem algum trabalho para obter informações úteis para o seu negócio
- Talvez você não consiga encontrar os dados de seu interesse
Estratégia nº 4: baixe Conjuntos de dados do GitHub
O GitHub hospeda vários repositórios contendo Conjuntos de dados para diversos fins, desde aprendizado de máquina e ciência de dados até desenvolvimento de software e pesquisa. Esses Conjuntos de dados são compartilhados por indivíduos e organizações para receber feedback e contribuir com a comunidade.
Em alguns casos, esses repositórios do GitHub também incluem código para processar, analisar e explorar os dados.
Alguns repositórios notáveis para obter repositórios incluem:
- Awesome Public Datasets: uma coleção com curadoria de Conjuntos de dados de alta qualidade em vários domínios, incluindo finanças, clima e esportes. Serve como um hub para encontrar Conjuntos de dados relacionados a tópicos ou setores específicos.
- Conjuntos de dados Kaggle: o Kaggle, uma plataforma proeminente para competições de ciência de dados, hospeda alguns de seus conjuntos de dados no GitHub. Os usuários podem criar conjuntos de dados Kaggle a partir de repositórios GitHub com apenas alguns cliques.
- Outros repositórios de dados abertos: várias organizações e grupos de pesquisa usam o GitHub para hospedar Conjuntos de dados abertos.
Esses repositórios oferecem Conjuntos de dados pré-existentes que podem ser prontamente usados ou adaptados para atender às suas necessidades. Para acessá-los, basta um único comando git clone ou um clique no botão “Download”.
Prós:
- Conjuntos de datos prontos para uso
- Código para analisar e interagir com os dados
- Muitas categorias diferentes de dados para escolher
Contras:
- Possíveis problemas de licenciamento
- A maioria desses repositórios não está atualizada
- Dados genéricos, não adaptados às suas necessidades
Estratégia nº 5: crie seu próprio conjunto de dados com Scraping de dados
O scraping de dados é o processo de extrair dados de páginas da web e convertê-los em um formato utilizável.
Criar conjuntos de dados por meio do Scraping de dados é uma abordagem popular por vários motivos:
- Acesso a uma grande quantidade de dados: a Web é a maior fonte de dados do mundo. O scraping de dados permite que você aproveite esse recurso extenso, reunindo informações que podem não estar disponíveis por outros meios.
- Flexibilidade: você pode escolher quais dados recuperar, o formato em que os Conjuntos de dados serão produzidos e controlar a frequência de atualização dos dados.
- Personalização: adapte sua extração de dados para atender a necessidades específicas, como extrair dados de nichos de mercado ou tópicos especializados não cobertos por Conjuntos de dados públicos.
Veja como o Scraping de dados normalmente funciona:
- Identifique o site de destino
- Inspecione suas páginas da web para elaborar uma estratégia de extração de dados
- Crie um script para se conectar às páginas de destino.
- Parsing do conteúdo HTML das páginas
- Selecione os elementos DOM que contêm os dados de interesse
- Extraia os dados desses elementos
- Exporte os dados coletados para o formato desejado, como JSON, CSV ou XLSX
Observe que o script para fazer Scraping de dados pode ser escrito em praticamente qualquer linguagem de programação, como Python, JavaScript ou Ruby. Saiba mais em nosso artigo sobre as melhores linguagens para Scraping de dados. Além disso, confira as melhores ferramentas para Scraping de dados.
Como a maioria das empresas sabe o quanto seus dados são valiosos, mesmo que sejam acessíveis publicamente em seus sites, elas os protegem com tecnologias anti-bot. Essas soluções podem bloquear as solicitações automatizadas feitas por seus scripts. Veja como contornar essas medidas em nosso tutorial sobre como realizar Scraping de dados sem ser bloqueado.
Além disso, se você estiver curioso para saber como o Scraping de dados difere da obtenção de dados de APIs públicas, confira nosso artigo sobre Scraping de dados vs API.
Prós:
- Dados públicos de qualquer site
- Você tem controle sobre o processo de extração de dados
- Solução econômica que funciona com a maioria das linguagens de programação
Contras:
- Soluções anti-bot e anti-scraping podem impedir você
- Requer alguma manutenção
- Pode exigir lógica personalizada de agregação de dados
Como criar Conjuntos de dados em Python
Python é uma linguagem líder em ciência de dados e, portanto, uma escolha popular para a criação de Conjuntos de dados. Como você verá, criar um conjunto de dados em Python requer apenas algumas linhas de código.
Aqui, vamos nos concentrar em coletar informações sobre todos os Conjuntos de dados disponíveis no Bright Data Dataset Marketplace:
Siga o tutorial guiado para atingir o objetivo!
Para obter instruções mais detalhadas, explore nosso guia de Scraping de dados em Python.
Etapa 1: Instalação e configuração
Vamos supor que você tenha o Python 3+ instalado em sua máquina e que tenha um projeto Python configurado.
Primeiro, você precisa instalar as bibliotecas necessárias para este projeto:
- requests: para enviar solicitações HTTP e recuperar os documentos HTML associados às páginas da web.
- Beautiful Soup: para parsing de documentos HTML e XML e extrair dados de páginas da web.
- pandas: para manipular dados e exportá-los para Conjuntos de dados CSV.
Abra o terminal no ambiente virtual ativado na pasta do seu projeto e execute:
pip install requests beautifulsoup4 pandasDepois de instaladas, você pode importar essas bibliotecas para o seu script Python:
import requests
from bs4 import BeautifulSoup
import pandas as pdEtapa 2: Conecte-se ao site de destino
Recupere o HTML da página da qual deseja extrair os dados. Use a biblioteca requests para enviar uma solicitação HTTP ao site de destino e recuperar seu conteúdo HTML:
url = 'https://brightdata.com/products/Conjuntos de datos'
headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36' }
response = requests.get(url=url, headers=headers)Para obter mais detalhes, consulte nosso guia sobre como definir um agente de usuário em solicitações Python.
Etapa 3: Implemente a lógica de scraping
Com o conteúdo HTML em mãos, faça o Parsing usando o BeautifulSoup e extraia os dados necessários. Selecione os elementos HTML que contêm os dados de interesse e obtenha os dados deles:
# analisar o HTML recuperado
soup = BeautifulSoup(response.text, 'html.parser')
# onde armazenar os dados extraídos
data = []
# lógica de extração
dataset_elements = soup.select('.datasets__loop .datasets__item--wrapper')
para dataset_element em dataset_elements:
dataset_item = dataset_element.select_one('.datasets__item')
title = dataset_item.select_one('.datasets__item--title').text.strip()
url_item = dataset_item.select_one('.datasets__item--title a')
if (item_url não é None):
url = item_url['href']
else:
url = None
tipo = item_do_conjunto_de_dados.get('aria-label', 'regular').lower()
dados.append({
'título': título,
'url': url,
'tipo': tipo
})Etapa 4: Exportar para CSV
Use pandas para converter os dados coletados em um DataFrame e exportá-los para um arquivo CSV.
df = pd.DataFrame(data, columns=data[0].keys())
df.to_csv('dataset.csv', index=False)Etapa 5: Execute o script
Seu script Python final conterá estas linhas de código:
import requests
from bs4 import BeautifulSoup
import pandas as pd
# faça uma solicitação GET ao site de destino com um agente de usuário personalizado
url = 'https://brightdata.com/products/Conjuntos de datos'
headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36' }
response = requests.get(url=url, headers=headers)
# analisar o HTML recuperado
soup = BeautifulSoup(response.text, 'html.parser')
# onde armazenar os dados extraídos
data = []
# lógica de extração
dataset_elements = soup.select('.datasets__loop .datasets__item--wrapper')
para dataset_element em dataset_elements:
dataset_item = dataset_element.select_one('.datasets__item')
title = dataset_item.select_one('.datasets__item--title').text.strip()
url_item = dataset_item.select_one('.datasets__item--title a')
if (url_item is not None):
url = url_item['href']
else:
url = None
type = dataset_item.get('aria-label', 'regular').lower()
data.append({
'title': title,
'url': url,
'type': type
})
# exportar para CSV
df = pd.DataFrame(data, columns=data[0].keys())
df.to_csv('dataset.csv', index=False)Execute-o e o seguinte arquivo dataset.csv aparecerá na pasta do seu projeto:
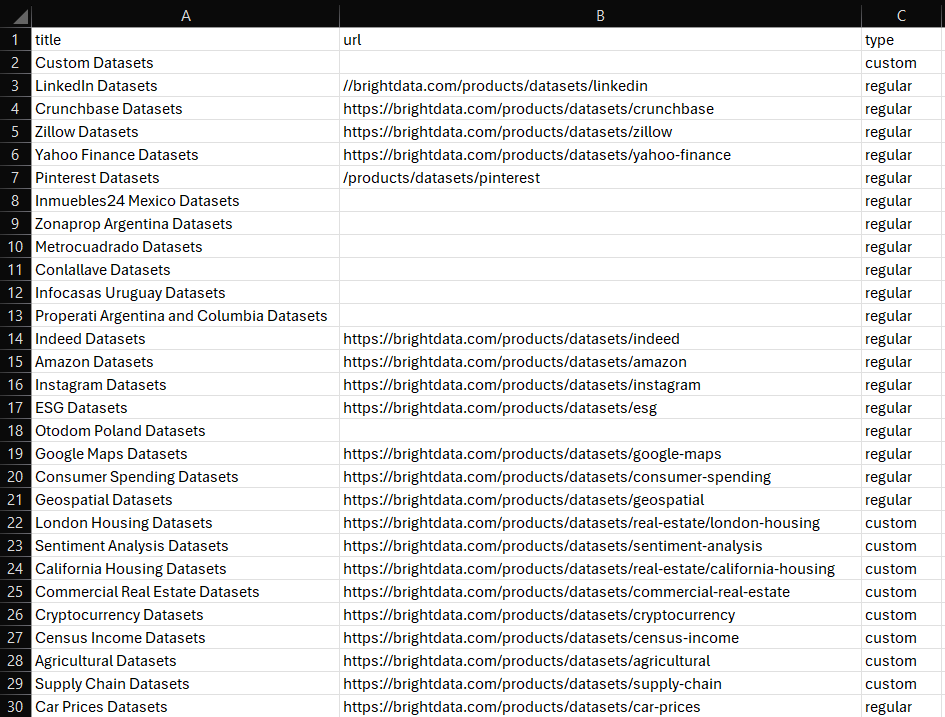
Et voilà! Agora você sabe como criar Conjuntos de dados em Python.
Como criar um Conjunto de dados em R
R é outra linguagem amplamente adotada por pesquisadores e cientistas de dados. Abaixo está o script equivalente — de acordo com o que vimos anteriormente em Python — para criar um Conjunto de dados em R:
library(httr)
library(rvest)
library(dplyr)
library(readr)
# faça uma solicitação GET ao site de destino com um agente de usuário personalizado
url <- "https://brightdata.com/products/Conjuntos de dados"
headers <- add_headers(`User-Agent` = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36")
response <- GET(url, headers)
# analisar o HTML recuperado
página <- ler_html(resposta)
# onde armazenar os dados extraídos
dados <- tibble()
# lógica de extração
elementos_do_conjunto_de_dados <- página %>%
html_nodes(".datasets__loop .datasets__item--wrapper")
for (dataset_element in dataset_elements) {
title <- dataset_element %>%
html_node(".datasets__item .datasets__item--title") %>%
html_text(trim = TRUE)
url_item <- dataset_element %>%
html_node(".datasets__item .datasets__item--title a")
url <- if (!is.null(url_item)) {
html_attr(url_item, "href")
} else {
""
}
type <- dataset_element %>%
html_attr("aria-label", "regular") %>%
tolower()
data <- bind_rows(data, tibble(
title = title,
url = url,
type = type
))
}
# exportar para CSV
write_csv(data, "dataset.csv")Para obter mais orientações, siga nosso tutorial sobre Scraping de dados com R.
Conclusão
Nesta postagem do blog, você aprendeu como criar Conjuntos de dados. Você entendeu o que é um Conjunto de dados e explorou diferentes estratégias para criá-lo. Você também viu como aplicar a estratégia de Scraping de dados em Python e R.
A Bright Data opera uma rede de Proxy grande, rápida e confiável, atendendo a muitas empresas da Fortune 500 e mais de 20.000 clientes. Ela é usada para recuperar dados da Web de forma ética e oferecê-los em um vasto mercado de Conjuntos de dados, que inclui:
- Conjuntos de dados comerciais: dados de fontes importantes como LinkedIn, CrunchBase, Owler e Indeed.
- Conjuntos de dados de comércio eletrônico: dados da Amazon, Walmart, Target, Zara, Zalando, Asos e muitos outros.
- Conjuntos de dados imobiliários: dados de sites como Zillow, MLS e outros.
- Conjuntos de dados de mídias sociais: dados do Facebook, Instagram, YouTube e Reddit.
- Conjuntos de dados financeiros: dados do Yahoo Finance, Market Watch, Investopedia e muito mais.
Se essas opções pré-definidas não atenderem às suas necessidades, considere nossos serviços personalizados de coleta de dados.
Além disso, a Bright Data oferece uma ampla gama de ferramentas poderosas de scraping, incluindo APIs de Scraping de dados e Navegador de scraping.
Inscreva-se agora e veja quais produtos e serviços da Bright Data melhor atendem às suas necessidades.




