

Ao fazer Scraping de dados na web, o Parsing de HTML é vital, independentemente das ferramentas que você estiver usando.O Scraping de dados na web com Java não é exceção a essa regra. Em Python, usamos ferramentas comoRequestseBeautifulSoup. Com Java, podemos enviar nossas solicitações HTTP e analisar nosso HTML usandojsoup. Usaremoso Books to Scrapepara este tutorial.
Introdução
Neste tutorial, vamos usar o Maven para gerenciamento de dependências. Se você ainda não o tem, pode instalar o Mavenaqui.
Depois de instalar o Maven, você precisa criar um novo projeto Java. O comando abaixo cria um novo projeto, jsoup-scraper.
mvn archetype:generate -DgroupId=com.example -DartifactId=jsoup-scraper -DarchetypeArtifactId=maven-archetype-quickstart -DinteractiveMode=false
Em seguida, você precisará adicionar dependências relevantes. Substitua o código empom.xmlpelo código abaixo. Isso é semelhante ao gerenciamento de dependências noRustcom o Cargo.
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.example</groupId>
<ARTIFACTID>jsoup-scraper</ARTIFACTID>
<PACKAGING>jar</PACKAGING>
<VERSION>1.0-SNAPSHOT</VERSION>
<NAME>jsoup-scraper</NAME>
<URL>http://maven.apache.org</URL>
<DEPENDENCIES>
<dependência>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<versão>3.8.1</versão>
<escopo>teste</escopo>
</dependência>
<dependência>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<versão>1.16.1</versão>
</dependência>
</dependências>
<propriedades>
<maven.compiler.source>17</maven.compiler.source>
<maven.compiler.target>17</maven.compiler.target>
</propriedades>
</projeto>
Vá em frente e cole o seguinte código em App.java. Não é muito, mas este é o Scraper básico a partir do qual construiremos.
package com.example;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class App {
public static void main(String[] args) {
String url = "https://books.toscrape.com";
int pageCount = 1;
enquanto (pageCount <= 1) {
tente {
System.out.println("---------------------PÁGINA "+pageCount+"--------------------------");
//conecte-se a um site e obtenha seu HTML
Document doc = Jsoup.connect(url).get();
//imprima o título
System.out.println("Título da página: " + doc.title());
} catch (Exception e) {
e.printStackTrace();
}
}
System.out.println("Total de páginas coletadas: "+(pageCount-1));
}
}
Jsoup.connect("https://books.toscrape.com").get(): Esta linha busca a página e retorna um objetoDocumentque podemos manipular.doc.title()retorna o título no documento HTML, neste caso:Todos os produtos | Livros para extrair - Sandbox.
Usando métodos DOM com Jsoup
O jsoup contém uma variedade de métodos para localizar elementos no DOM (Document Object Model). Podemos usar qualquer um dos seguintes para localizar elementos da página facilmente.
getElementById(): Encontre um elemento usando seuid.getElementsByClass(): Encontre todos os elementos usando sua classe CSS.getElementsByTag(): Encontra todos os elementos usando sua tag HTML.getElementsByAttribute(): Encontra todos os elementos que contêm um determinado atributo.
getElementById
Em nosso site de destino, a barra lateral contém um div com um id de promotions_left. Você pode ver isso na imagem abaixo.
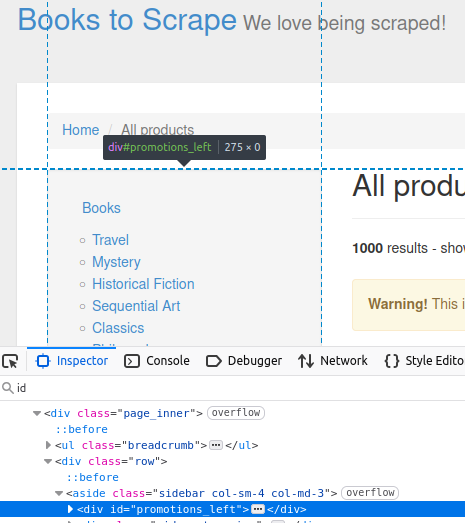
//obter por Id
Element sidebar = doc.getElementById("promotions_left");
System.out.println("Sidebar: " + sidebar);
Este código exibe o elemento HTML que você vê na página de inspeção.
Barra lateral: <div id="promotions_left">
</div>
getElementsByTag
getElementsByTag() nos permite encontrar todos os elementos na página com uma determinada tag. Vejamos os livros nesta página.
Cada livro está contido em uma tag de artigo exclusiva.
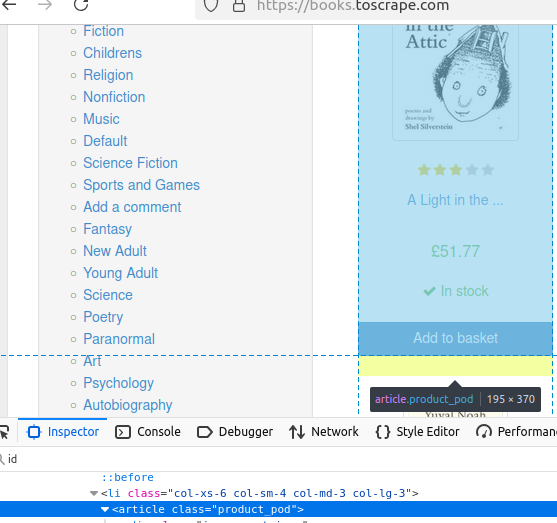
O código abaixo não imprimirá nada, mas retornará uma matriz de livros. Esses livros fornecerão a base para o restante dos nossos dados.
//obter por tag
Elementos livros = doc.getElementsByTag("article");
getElementsByClass
Vamos dar uma olhada no preço de um livro. Como você pode ver destacado, sua classe é price_color.
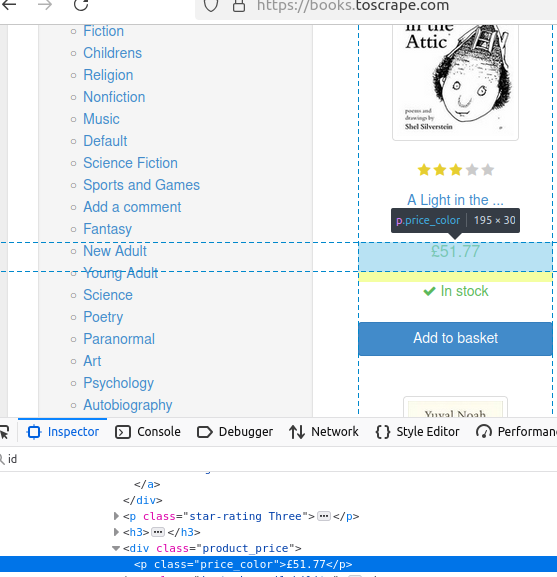
Neste trecho, encontramos todos os elementos da classe price_color. Em seguida, imprimimos o texto do primeiro usando .first().text().
System.out.println("Preço: " + livro.getElementsByClass("price_color").first().text());
getElementsByAttribute
Como você já deve saber, todos os elementos a exigem um atributo href. No código abaixo, usamos getElementsByAttribute("href") para encontrar todos os elementos com um href. Usamos .first().attr("href") para retornar seu href.
//obter por atributo
Elements hrefs = book.getElementsByAttribute("href");
System.out.println("Link: https://books.toscrape.com/" + hrefs.first().attr("href"));
Técnicas avançadas
Seletores CSS
Quando queremos usar vários critérios para encontrar elementos, podemos passar seletores CSSpara o métodoselect(). Esse método retorna uma matriz de todos os objetos que correspondem ao seletor. Abaixo, usamosli[class='next']para encontrar todos os itenslicom a classenext.
Elementos nextPage = doc.select("li[class='next']");
Tratamento da paginação
Para lidar com nossa paginação, usamos nextPage.first() para chamar getElementsByAttribute("href").attr("href") no primeiro elemento retornado da matriz e extrair seu href. Curiosamente, após a página 2, a palavra catálogo é removida dos links, então, se ela não estiver presente no href, nós a adicionamos de volta. Em seguida, combinamos esse link com nossa URL base e o usamos para obter o link para a próxima página.
if (!nextPage.isEmpty()) {
String nextUrl = nextPage.first().getElementsByAttribute("href").attr("href");
if (!nextUrl.contains("catalogue")) {
nextUrl = "catalogue/"+nextUrl;
}
url = "https://books.toscrape.com/" + nextUrl;
pageCount++;
}
Juntando tudo
Aqui está nosso código final. Se você deseja extrair mais de uma página, basta alterar o 1 em while (pageCount <= 1) para o valor desejado. Se você deseja extrair 4 páginas, use while (pageCount <= 4).
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class App {
public static void main(String[] args) {
String url = "https://books.toscrape.com";
int pageCount = 1;
enquanto (pageCount <= 1) {
tente {
System.out.println("---------------------PÁGINA "+pageCount+"--------------------------");
//conecte-se a um site e obtenha seu HTML
Document doc = Jsoup.connect(url).get();
//imprima o título
System.out.println("Título da página: " + doc.title());
//obtenha por Id
Element sidebar = doc.getElementById("promotions_left");
System.out.println("Barra lateral: " + barra lateral);
//obter por tag
Elements livros = doc.getElementsByTag("artigo");
for (Element livro : livros) {
System.out.println("------Livro------");
System.out.println("Título: " + livro.getElementsByTag("img").first().attr("alt"));
System.out.println("Preço: " + livro.getElementsByClass("price_color").first().text());
System.out.println("Disponibilidade: " + livro.obterElementosPorClasse("disponibilidade em estoque").primeiro().texto());
//obter por atributo
Elementos hrefs = livro.obterElementosPorAtributo("href");
System.out.println("Link: https://books.toscrape.com/" + hrefs.first().attr("href"));
}
//encontrar o próximo botão usando seu seletor CSS
Elements nextPage = doc.select("li[class='next']");
if (!nextPage.isEmpty()) {
String nextUrl = nextPage.first().getElementsByAttribute("href").attr("href");
if (!nextUrl.contains("catalogue")) {
nextUrl = "catalogue/"+nextUrl;
}
url = "https://books.toscrape.com/" + nextUrl;
pageCount++;
}
} catch (Exception e) {
e.printStackTrace();
}
}
System.out.println("Total de páginas coletadas: "+(pageCount-1));
}
}
Antes de executar o código, lembre-se de compilá-lo.
mvn package
Em seguida, execute-o com o seguinte comando.
mvn exec:java -Dexec.mainClass="com.example.App"
Aqui está a saída da primeira página.
---------------------PÁGINA 1--------------------------
Título da página: Todos os produtos | Livros para raspar - Sandbox
Barra lateral: <div id="promotions_left">
</div>
------Livro------
Título: A Light in the Attic
Preço: £51,77
Disponibilidade: Em estoque
Link: https://books.toscrape.com/catalogue/a-light-in-the-attic_1000/index.html
------Livro------
Título: Tipping the Velvet
Preço: £53,74
Disponibilidade: Em estoque
Link: https://books.toscrape.com/catalogue/tipping-the-velvet_999/index.html
------Livro------
Título: Soumission
Preço: £50,10
Disponibilidade: Em estoque
Link: https://books.toscrape.com/catalogue/soumission_998/index.html
------Livro------
Título: Sharp Objects
Preço: £47,82
Disponibilidade: Em estoque
Link: https://books.toscrape.com/catalogue/sharp-objects_997/index.html
------Livro------
Título: Sapiens: Uma Breve História da Humanidade
Preço: £54,23
Disponibilidade: Em estoque
Link: https://books.toscrape.com/catalogue/sapiens-a-brief-history-of-humankind_996/index.html
------Livro------
Título: The Requiem Red
Preço: £22,65
Disponibilidade: Em estoque
Link: https://books.toscrape.com/catalogue/the-requiem-red_995/index.html
------Livro------
Título: The Dirty Little Secrets of Getting Your Dream Job
Preço: £33,34
Disponibilidade: Em estoque
Link: https://books.toscrape.com/catalogue/the-dirty-little-secrets-of-getting-your-dream-job_994/index.html
------Livro------
Título: The Coming Woman: Um romance baseado na vida da famosa feminista Victoria Woodhull
Preço: £17,93
Disponibilidade: Em estoque
Link: https://books.toscrape.com/catalogue/the-coming-woman-a-novel-based-on-the-life-of-the-infamous-feminist-victoria-woodhull_993/index.html
------Livro------
Título: Os Rapazes no Barco: Nove Americanos e Sua Jornada Épica em Busca do Ouro nas Olimpíadas de Berlim de 1936
Preço: £22,60
Disponibilidade: Em estoque
Link: https://books.toscrape.com/catalogue/the-boys-in-the-boat-nine-americans-and-their-epic-quest-for-gold-at-the-1936-berlin-olympics_992/index.html
------Livro------
Título: The Black Maria
Preço: £52,15
Disponibilidade: Em estoque
Link: https://books.toscrape.com/catalogue/the-black-maria_991/index.html
------Livro------
Título: Starving Hearts (Trilogia Triangular Trade, n.º 1)
Preço: £13,99
Disponibilidade: Em stock
Link: https://books.toscrape.com/catalogue/starving-hearts-triangular-trade-trilogy-1_990/index.html
------Livro------
Título: Shakespeare's Sonnets (Sonetos de Shakespeare)
Preço: £20,66
Disponibilidade: Em estoque
Link: https://books.toscrape.com/catalogue/shakespeares-sonnets_989/index.html
------Livro------
Título: Liberte-me
Preço: £17,46
Disponibilidade: Em estoque
Link: https://books.toscrape.com/catalogue/set-me-free_988/index.html
------Livro------
Título: A Preciosa Vida de Scott Pilgrim (Scott Pilgrim #1)
Preço: £52,29
Disponibilidade: Em estoque
Link: https://books.toscrape.com/catalogue/scott-pilgrims-precious-little-life-scott-pilgrim-1_987/index.html
------Livro------
Título: Rip it Up and Start Again
Preço: £35,02
Disponibilidade: Em estoque
Link: https://books.toscrape.com/catalogue/rip-it-up-and-start-again_986/index.html
------Livro------
Título: Nossa banda pode ser sua vida: Cenas do underground indie americano, 1981-1991
Preço: £57,25
Disponibilidade: Em estoque
Link: https://books.toscrape.com/catalogue/our-band-could-be-your-life-scenes-from-the-american-indie-underground-1981-1991_985/index.html
------Livro------
Título: Olio
Preço: £23,88
Disponibilidade: Em estoque
Link: https://books.toscrape.com/catalogue/olio_984/index.html
------Livro------
Título: Mesaerion: As melhores histórias de ficção científica 1800-1849
Preço: £37,59
Disponibilidade: Em estoque
Link: https://books.toscrape.com/catalogue/mesaerion-the-best-science-fiction-stories-1800-1849_983/index.html
------Livro------
Título: Libertarianismo para Iniciantes
Preço: £51,33
Disponibilidade: Em estoque
Link: https://books.toscrape.com/catalogue/libertarianism-for-beginners_982/index.html
------Livro------
Título: It's Only the Himalayas (É só o Himalaia)
Preço: £45,17
Disponibilidade: Em estoque
Link: https://books.toscrape.com/catalogue/its-only-the-himalayas_981/index.html
Total de páginas coletadas: 1
Conclusão
Agora que você aprendeu a extrair dados HTML usando o jsoup, pode começar a criar Scrapers da web mais avançados. Seja para extrair listas de produtos, artigos de notícias ou dados de pesquisa, lidar com conteúdo dinâmico e evitar bloqueios são desafios importantes.
Para dimensionar seus esforços de scraping com eficiência, considere usar as ferramentas da Bright Data:
- Proxies residenciais – Evite bloqueios de IP e acesse conteúdo com restrições geográficas.
- Navegador de scraping – Renderize sites com muito JavaScript sem esforço.
- Conjuntos de dados prontos para uso – Pule a etapa de scraping e obtenha dados estruturados instantaneamente.
Ao combinar o jsoup com a infraestrutura certa, você pode extrair dados em escala, minimizando os riscos de detecção. Pronto para levar o Scraping de dados da web para o próximo nível? Inscreva-se agora e comece seu Teste grátis.





